
Scotland Data Science Meetup Oct 13, 2015: Spark SQL, DataFrames, Catalyst, DataSources API, Spark...
56
IBM | spark.tc Scotland Data Science Meetup Spark SQL + DataFrames + Catalyst + Data Sources API Chris Fregly, Principal Data Solutions Engineer IBM Spark Technology Center Oct 13, 2015 Power of data. Simplicity of design. Speed of innovation.
-
Upload
chris-fregly -
Category
Software
-
view
931 -
download
0
Transcript of Scotland Data Science Meetup Oct 13, 2015: Spark SQL, DataFrames, Catalyst, DataSources API, Spark...

IBM | spark.tc
Scotland Data Science Meetup Spark SQL + DataFrames + Catalyst + Data Sources API
Chris Fregly, Principal Data Solutions Engineer IBM Spark Technology Center
Oct 13, 2015
Power of data. Simplicity of design. Speed of innovation.

IBM | spark.tc
Announcements
Thanks to !TechCube Incubator!!!
!Georgia Boyle!
Organizer, London Spark Meetup!!

IBM | spark.tc
Who am I?!!
Streaming Data Engineer!Netflix Open Source Committer!
!Data Solutions Engineer!
Apache Contributor!!
Principal Data Solutions Engineer!IBM Technology Center!
Meetup Organizer!Advanced Apache Meetup!
Book Author!Advanced Spark (2016)!

IBM | spark.tc
meetup.com/Advanced-Apache-Spark-Meetup/!Total Spark Experts: 1200+ in only 3 mos!!#5 most active Spark Meetup in the world!!!Goals!
Dig deep into the Spark & extended-Spark codebase!!
Study integrations such as Cassandra, ElasticSearch,!Tachyon, S3, BlinkDB, Mesos, YARN, Kafka, R, etc!
!Surface and share the patterns and idioms of these !
well-designed, distributed, big data components!!

IBM | spark.tc
Recent Events Cassandra Summit 2015!
Real-time Advanced Analytics w/ Spark & Cassandra!!!!
Strata NYC 2015!Practical Data Science w/ Spark: Recommender Systems!
!
All Slides Available on !Slideshare!
http://slideshare.net/cfregly!!

IBM | spark.tc
Upcoming Advanced Apache Spark Meetups!Project Tungsten Data Structs/Algos for CPU/Memory Optimization!
Nov 12th, 2015!
Text-based Advanced Analytics and Machine Learning!Jan 14th, 2016!
ElasticSearch-Spark Connector w/ Costin Leau (Elastic.co) & Me!Feb 16th, 2016!
Spark Internals Deep Dive!Mar 24th, 2016!
Spark SQL Catalyst Optimizer Deep Dive !Apr 21st, 2016!

IBM | spark.tc
Freg-a-palooza Upcoming World Tour London Spark Meetup (Oct 12th)! Scotland Data Science Meetup (Oct 13th)! Dublin Spark Meetup (Oct 15th)! Barcelona Spark Meetup (Oct 20th)! Madrid Spark/Big Data Meetup (Oct 22nd)! Paris Spark Meetup (Oct 26th)! Amsterdam Spark Summit (Oct 27th – Oct 29th)! Delft Dutch Data Science Meetup (Oct 29th) ! Brussels Spark Meetup (Oct 30th)! Zurich Big Data Developers Meetup (Nov 2nd)!
High probability!I’ll end up in jail!
or married!!
IBM | spark.tc
Slides and Videos
Slides!Links posted in Meetup directly!
!
Videos!Most talks are live streamed and/or video recorded!Links posted in Meetup directly!
!All Slides Available on Slideshare!
http://slideshare.net/cfregly!!

IBM | spark.tc
Last Meetup (Spark Wins 100 TB Daytona GraySort) On-disk only, in-memory caching disabled!!sortbenchmark.org/ApacheSpark2014.pdf!

Spark SQL + DataFrames
Catalyst + Data Sources API

IBM | spark.tc
Topics of this Talk! DataFrames! Catalyst Optimizer and Query Plans! Data Sources API! Creating and Contributing Custom Data Source!
! Partitions, Pruning, Pushdowns!
! Native + Third-Party Data Source Impls!
! Spark SQL Performance Tuning!

IBM | spark.tc
DataFrames!Inspired by R and Pandas DataFrames!Cross language support!
SQL, Python, Scala, Java, R!Levels performance of Python, Scala, Java, and R!
Generates JVM bytecode vs serialize/pickle objects to Python!DataFrame is Container for Logical Plan!
Transformations are lazy and represented as a tree!Catalyst Optimizer creates physical plan!
DataFrame.rdd returns the underlying RDD if needed!Custom UDF using registerFunction() New, experimental UDAF support!!
Use DataFrames !instead of RDDs!!!

IBM | spark.tc
Catalyst Optimizer!Converts logical plan to physical plan!Manipulate & optimize DataFrame transformation tree!
Subquery elimination – use aliases to collapse subqueries!Constant folding – replace expression with constant!Simplify filters – remove unnecessary filters!Predicate/filter pushdowns – avoid unnecessary data load!Projection collapsing – avoid unnecessary projections!
Hooks for custom rules!Rules = Scala Case Classes!
val newPlan = MyFilterRule(analyzedPlan)
!
Implements!oas.sql.catalyst.rules.Rule!
Apply to any !plan stage!
IBM | spark.tc
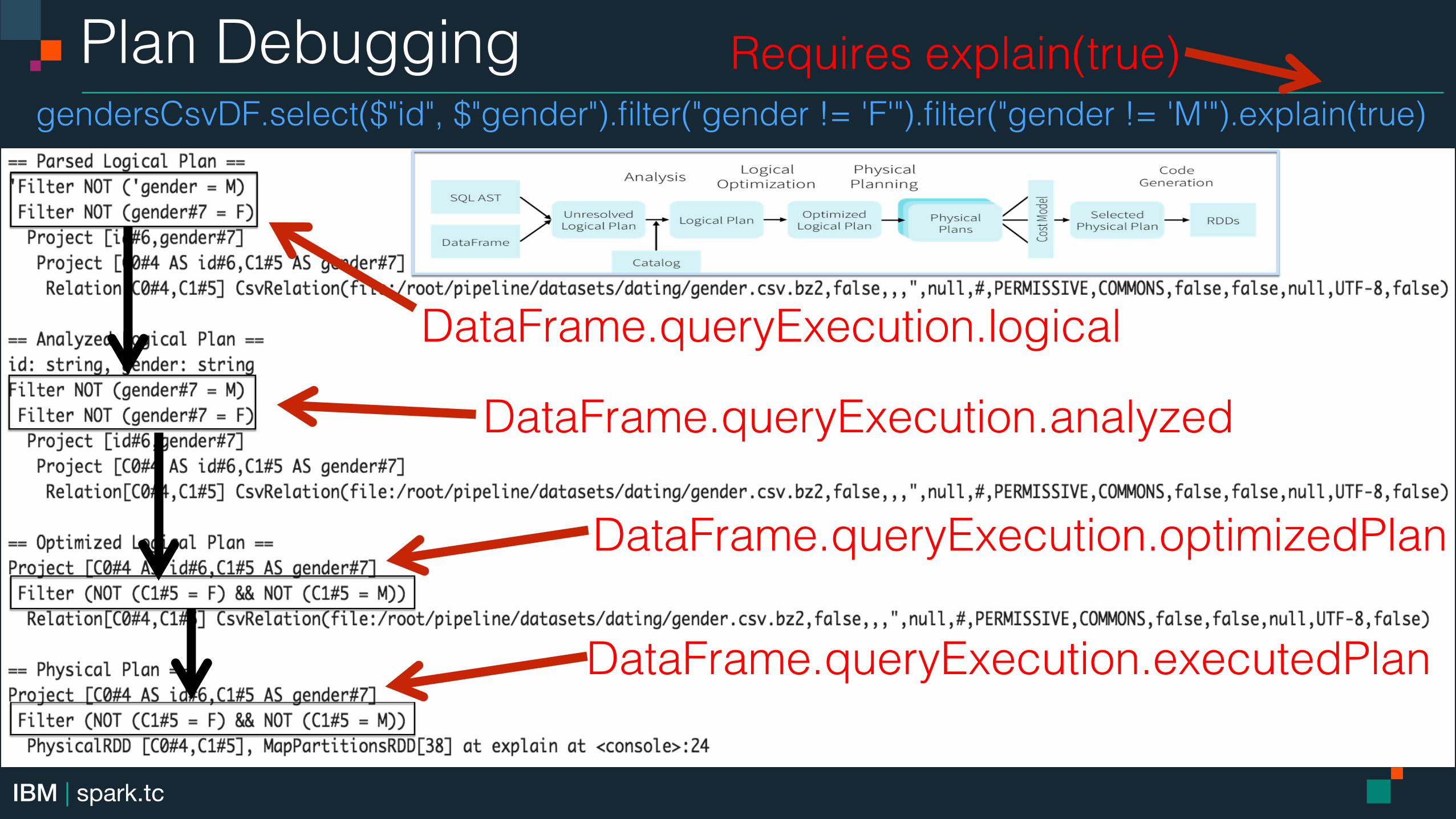
Plan Debugging!gendersCsvDF.select($"id", $"gender").filter("gender != 'F'").filter("gender != 'M'").explain(true)!
Requires explain(true)!
DataFrame.queryExecution.logical!
DataFrame.queryExecution.analyzed!
DataFrame.queryExecution.optimizedPlan!
DataFrame.queryExecution.executedPlan!
IBM | spark.tc
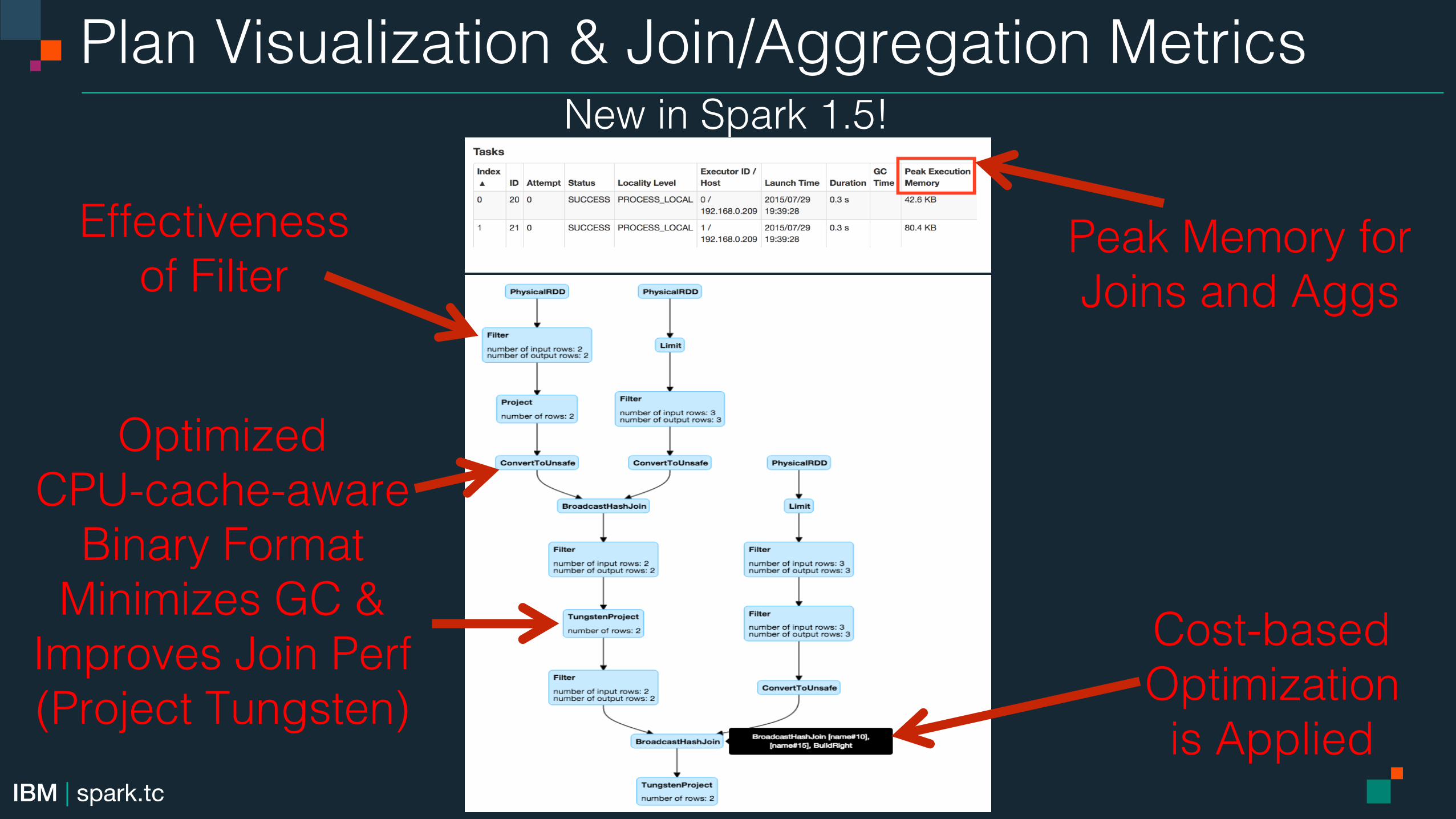
Plan Visualization & Join/Aggregation Metrics!
Effectiveness !of Filter!
Cost-based !Optimization!is Applied!
Peak Memory for!Joins and Aggs!
Optimized !CPU-cache-aware!
Binary Format!Minimizes GC &!
Improves Join Perf!(Project Tungsten)!
New in Spark 1.5!!

IBM | spark.tc
Data Sources API!Relations (o.a.s.sql.sources.interfaces.scala)!
BaseRelation (abstract class): Provides schema of data!TableScan (impl): Read all data from source, construct rows !PrunedFilteredScan (impl): Read with column pruning & predicate pushdowns!InsertableRelation (impl): Insert or overwrite data based on SaveMode enum!
RelationProvider (trait/interface): Handles user options, creates BaseRelation!Execution (o.a.s.sql.execution.commands.scala)!
RunnableCommand (trait/interface)!ExplainCommand(impl: case class)!CacheTableCommand(impl: case class)!
Filters (o.a.s.sql.sources.filters.scala)!Filter (abstract class for all filter pushdowns for this data source)!
EqualTo (impl)!GreaterThan (impl)!StringStartsWith (impl)!

IBM | spark.tc
Creating a Custom Data Source!Study Existing Native and Third-Party Data Source Impls!!
Native: JDBC (o.a.s.sql.execution.datasources.jdbc)! class JDBCRelation extends BaseRelation with PrunedFilteredScan with InsertableRelation
!Third-Party: Cassandra (o.a.s.sql.cassandra)! class CassandraSourceRelation extends BaseRelation with PrunedFilteredScan with InsertableRelation!
!!
IBM | spark.tc
Contributing a Custom Data Source!spark-packages.org!
Managed by!Contains links to externally-managed github projects!Ratings and comments!Spark version requirements of each package!
Examples!https://github.com/databricks/spark-csv!https://github.com/databricks/spark-avro!https://github.com/databricks/spark-redshift!!!

Partitions, Pruning, Pushdowns
IBM | spark.tc
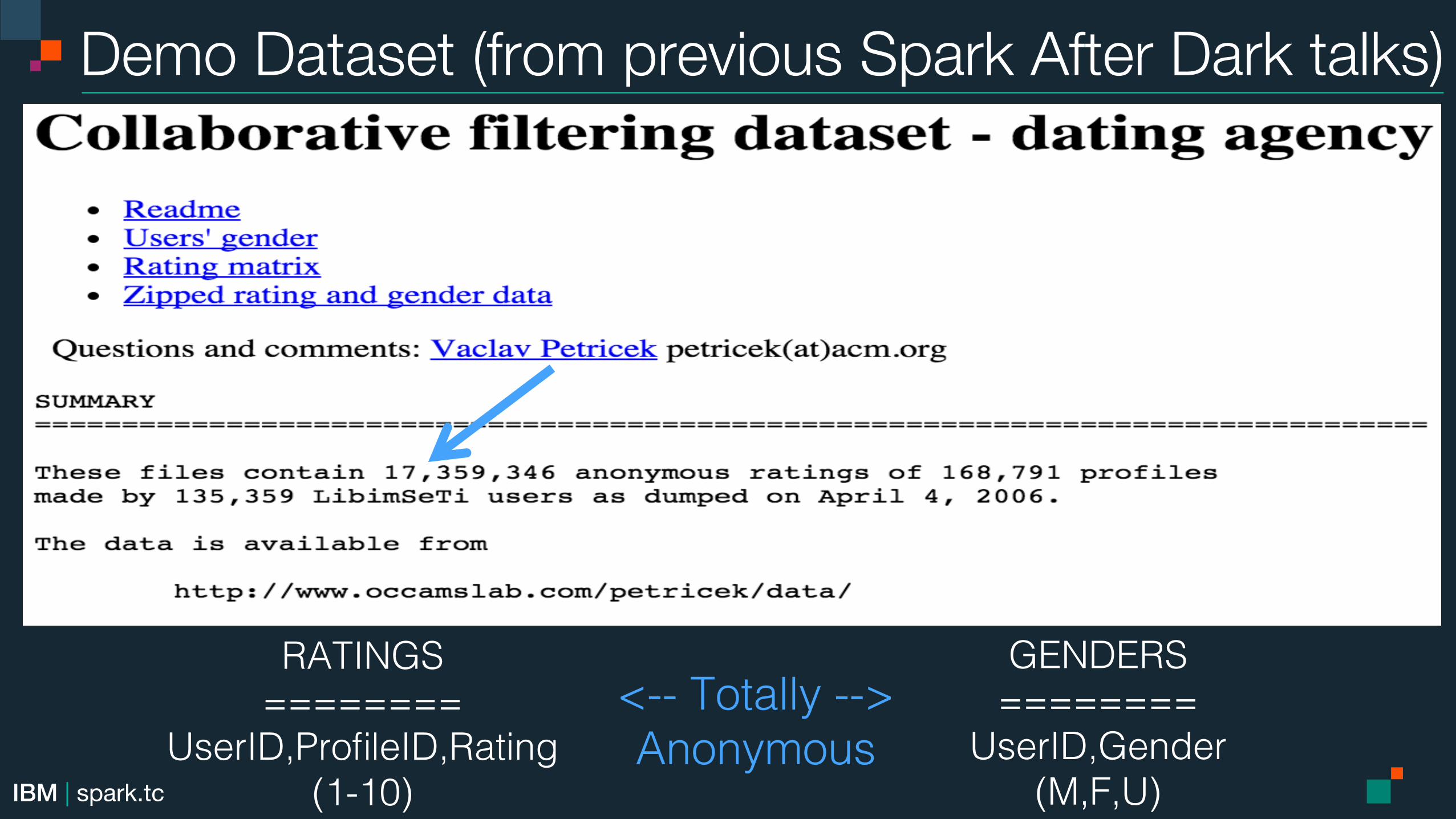
Demo Dataset (from previous Spark After Dark talks)!
RATINGS !========!
UserID,ProfileID,Rating !(1-10)!
GENDERS!========!
UserID,Gender !(M,F,U)!
<-- Totally -->!Anonymous !

IBM | spark.tc
Partitions!Partition based on data usage patterns!
/genders.parquet/gender=M/… /gender=F/… <-- Use case: access users by gender /gender=U/…
Partition Discovery!On read, infer partitions from organization of data (ie. gender=F)!
Dynamic Partitions!Upon insert, dynamically create partitions!Specify field to use for each partition (ie. gender)! SQL: INSERT TABLE genders PARTITION (gender) SELECT … DF: gendersDF.write.format(”parquet").partitionBy(”gender”).save(…)
IBM | spark.tc
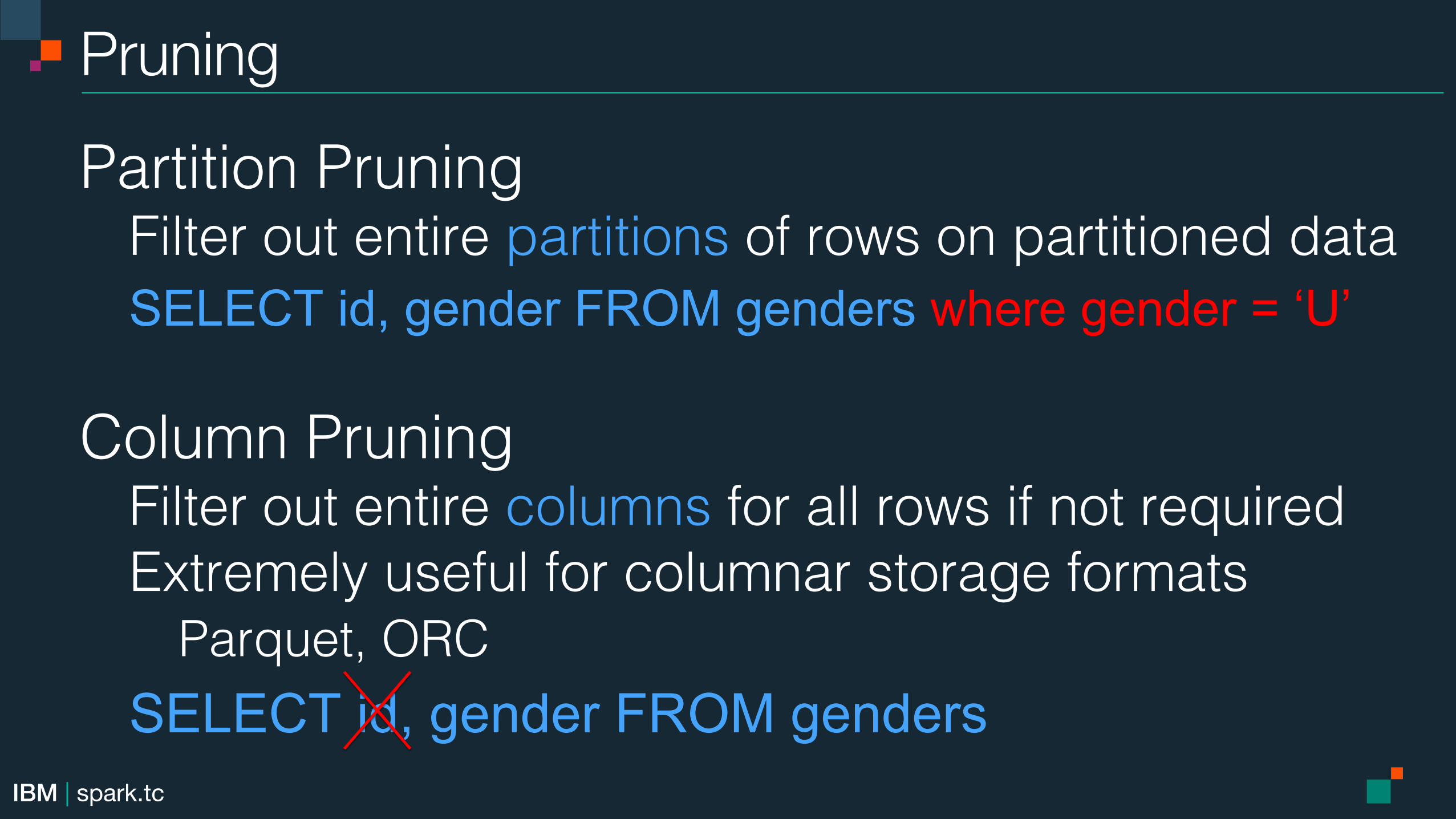
Pruning!
Partition Pruning!Filter out entire partitions of rows on partitioned data SELECT id, gender FROM genders where gender = ‘U’
Column Pruning!
Filter out entire columns for all rows if not required!Extremely useful for columnar storage formats!
Parquet, ORC! SELECT id, gender FROM genders
!

IBM | spark.tc
Pushdowns!Predicate (aka Filter) Pushdowns!
Predicate returns {true, false} for a given function/condition!Filters rows as deep into the data source as possible!
Data Source must implement PrunedFilteredScan!

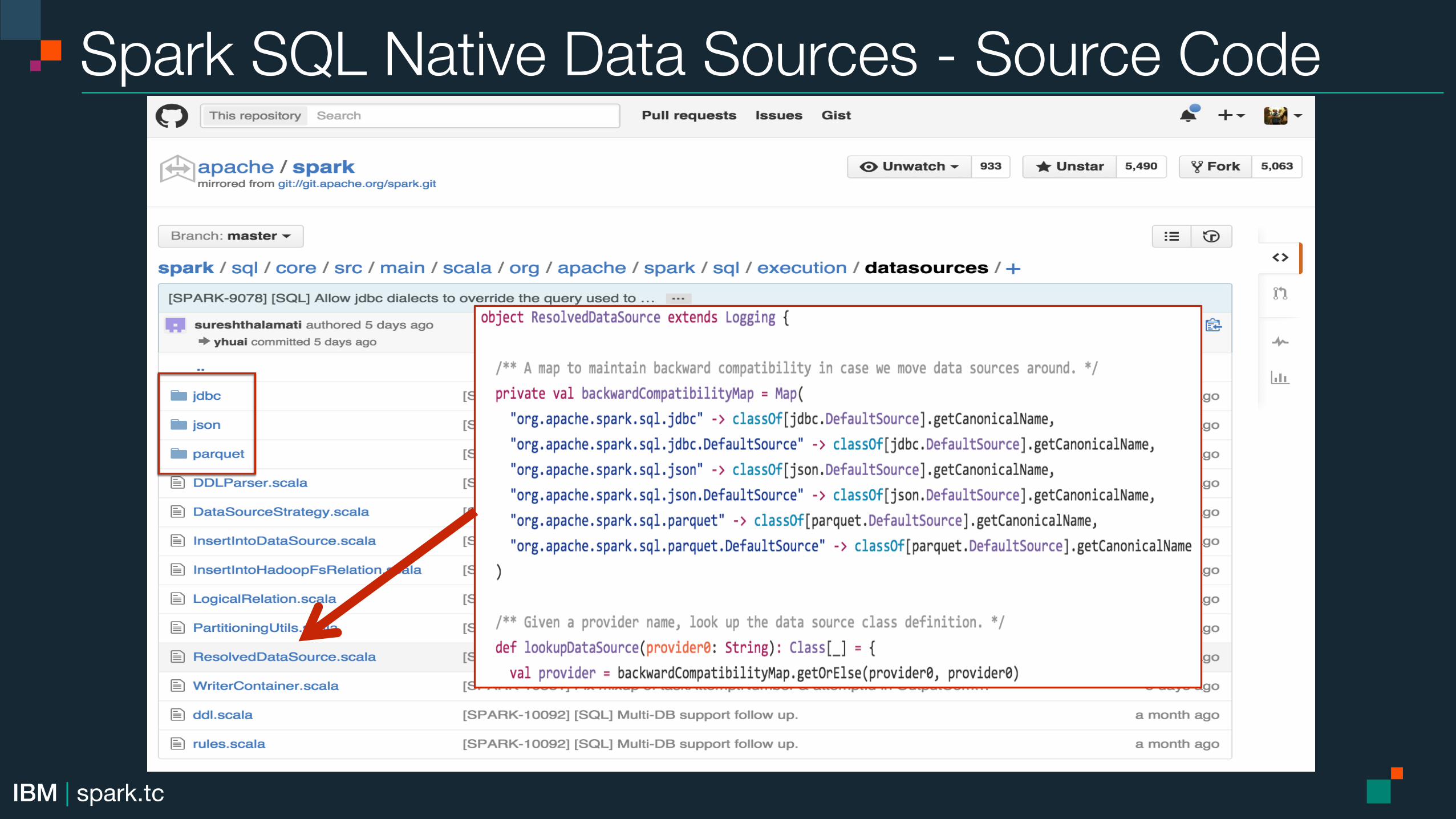
Native Spark SQL Data Sources
IBM | spark.tc
Spark SQL Native Data Sources - Source Code!
IBM | spark.tc
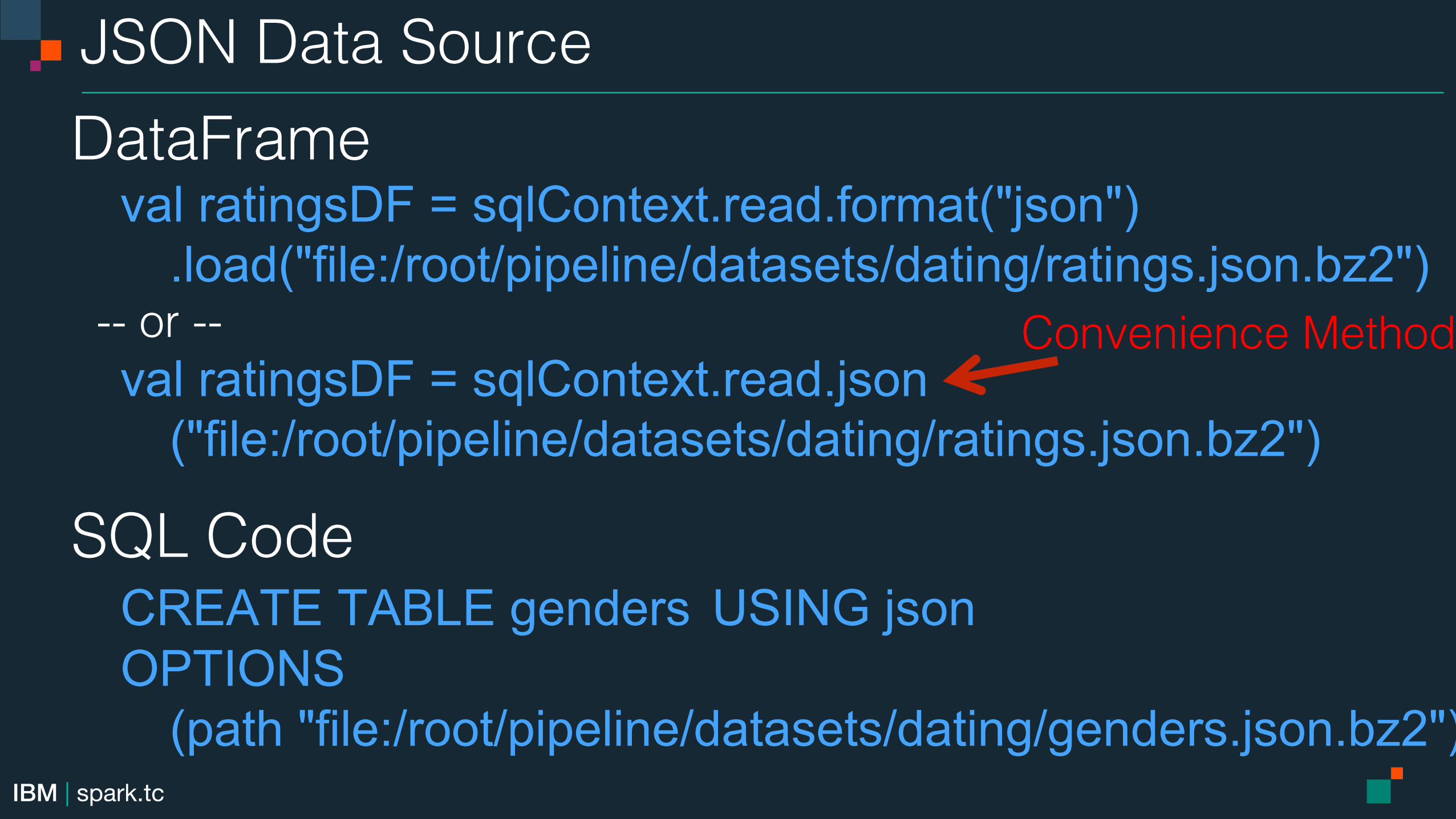
JSON Data Source!DataFrame!
val ratingsDF = sqlContext.read.format("json") .load("file:/root/pipeline/datasets/dating/ratings.json.bz2")
-- or --! val ratingsDF = sqlContext.read.json ("file:/root/pipeline/datasets/dating/ratings.json.bz2")
SQL Code! CREATE TABLE genders USING json OPTIONS (path "file:/root/pipeline/datasets/dating/genders.json.bz2")
Convenience Method!

IBM | spark.tc
JDBC Data Source!Add Driver to Spark JVM System Classpath!
$ export SPARK_CLASSPATH=<jdbc-driver.jar>
DataFrame! val jdbcConfig = Map("driver" -> "org.postgresql.Driver", "url" -> "jdbc:postgresql:hostname:port/database", "dbtable" -> ”schema.tablename")
df.read.format("jdbc").options(jdbcConfig).load()
SQL! CREATE TABLE genders USING jdbc OPTIONS (url, dbtable, driver, …)
IBM | spark.tc
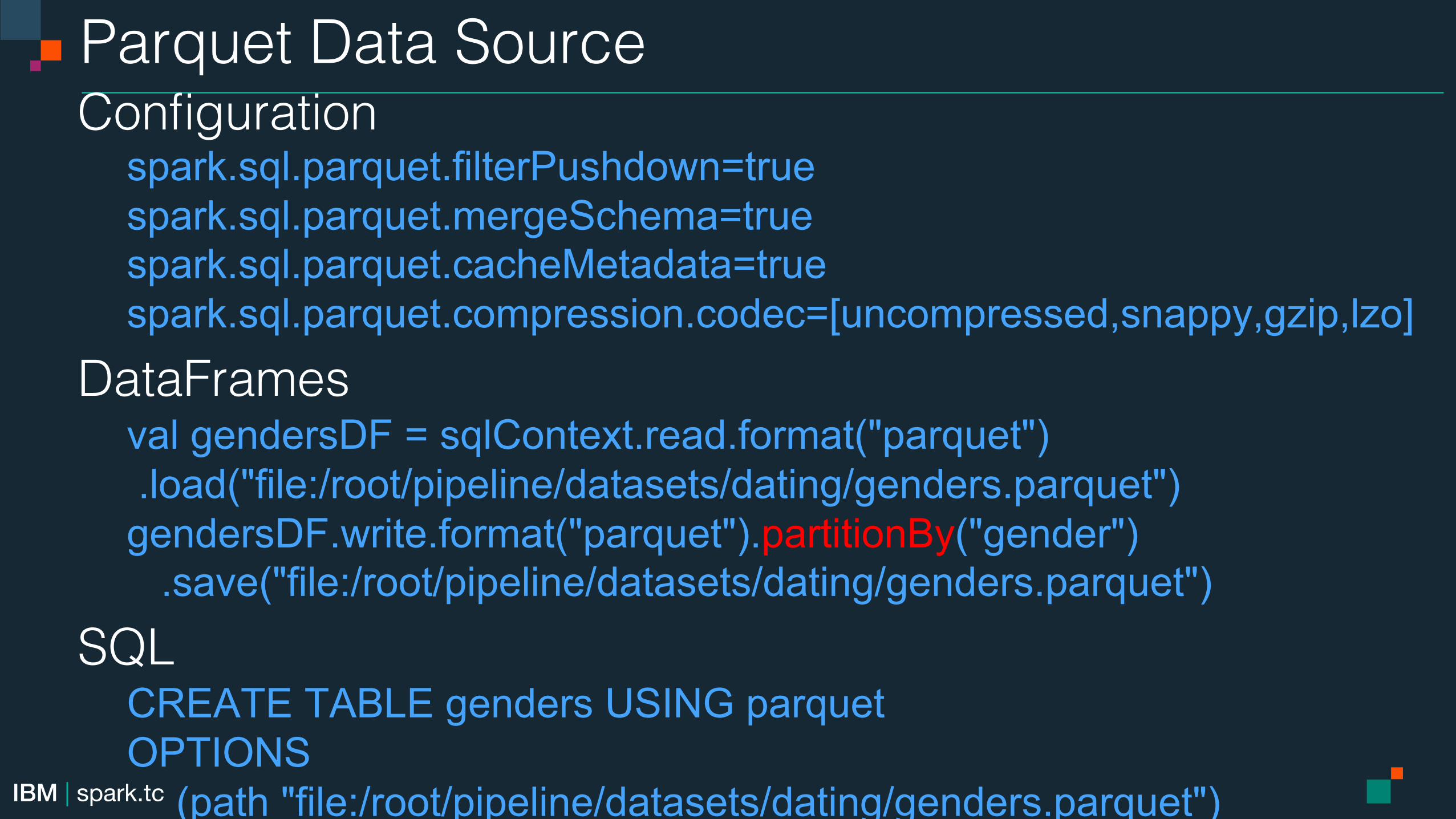
Parquet Data Source!Configuration!
spark.sql.parquet.filterPushdown=true ! spark.sql.parquet.mergeSchema=true spark.sql.parquet.cacheMetadata=true ! spark.sql.parquet.compression.codec=[uncompressed,snappy,gzip,lzo]
DataFrames! val gendersDF = sqlContext.read.format("parquet") .load("file:/root/pipeline/datasets/dating/genders.parquet")! gendersDF.write.format("parquet").partitionBy("gender") .save("file:/root/pipeline/datasets/dating/genders.parquet")
SQL! CREATE TABLE genders USING parquet OPTIONS (path "file:/root/pipeline/datasets/dating/genders.parquet")
IBM | spark.tc
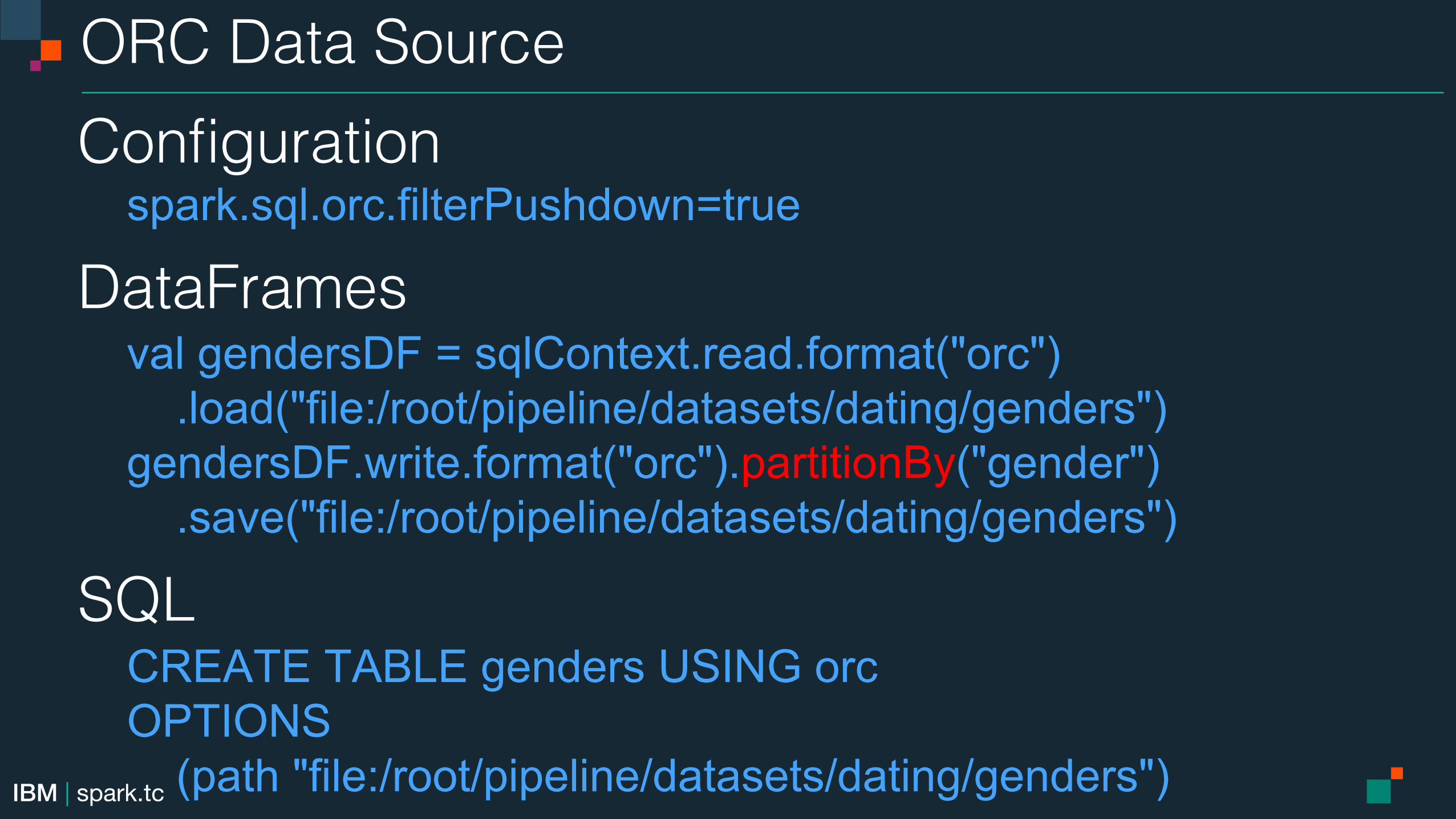
ORC Data Source!Configuration!
spark.sql.orc.filterPushdown=true
DataFrames! val gendersDF = sqlContext.read.format("orc") .load("file:/root/pipeline/datasets/dating/genders")! gendersDF.write.format("orc").partitionBy("gender") .save("file:/root/pipeline/datasets/dating/genders")
SQL! CREATE TABLE genders USING orc OPTIONS (path "file:/root/pipeline/datasets/dating/genders")

Third-Party Data Sources
spark-packages.org
IBM | spark.tc
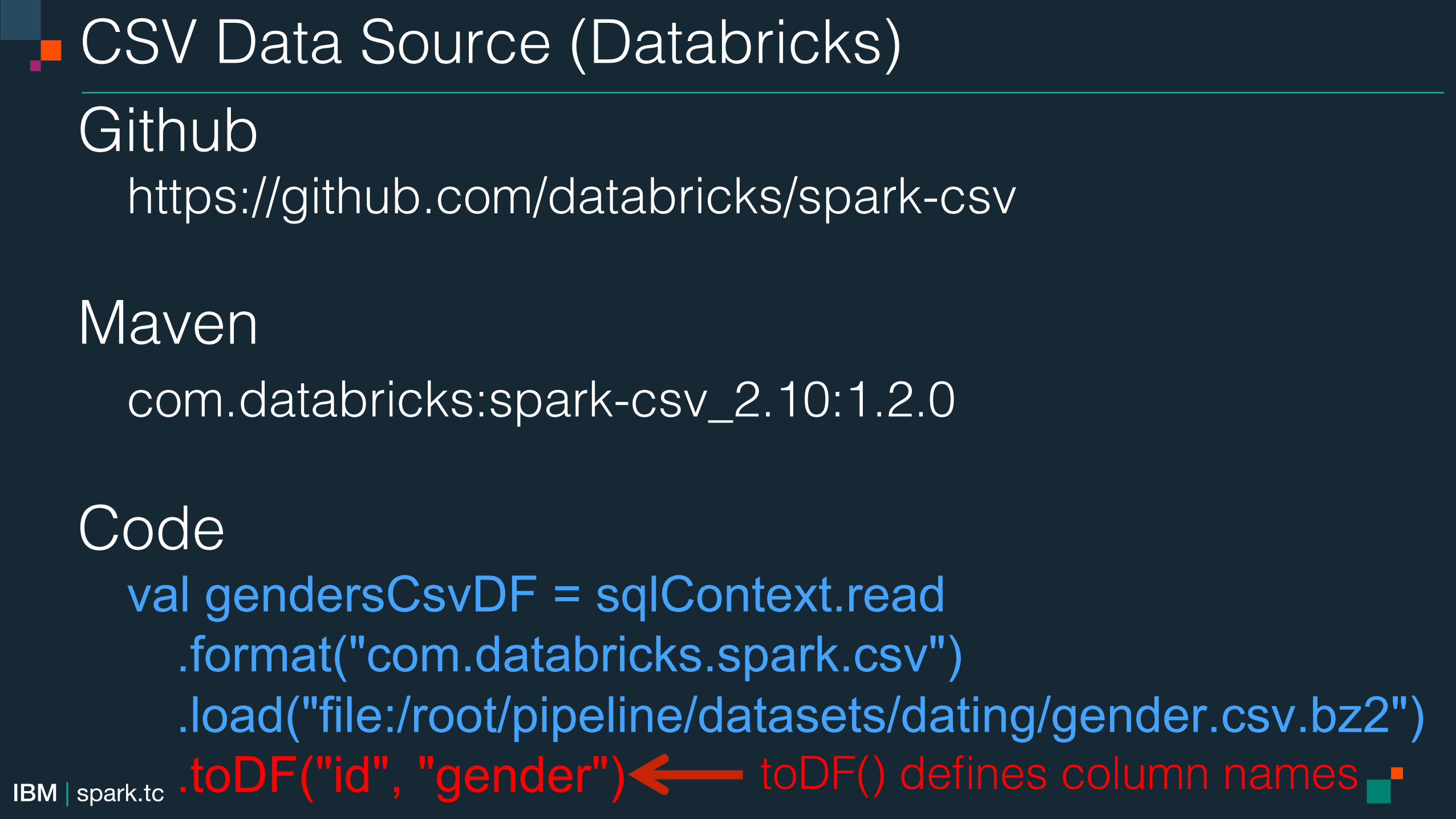
CSV Data Source (Databricks)!Github!
https://github.com/databricks/spark-csv!!Maven!
com.databricks:spark-csv_2.10:1.2.0!!Code!
val gendersCsvDF = sqlContext.read .format("com.databricks.spark.csv") .load("file:/root/pipeline/datasets/dating/gender.csv.bz2") .toDF("id", "gender") toDF() defines column names!
IBM | spark.tc
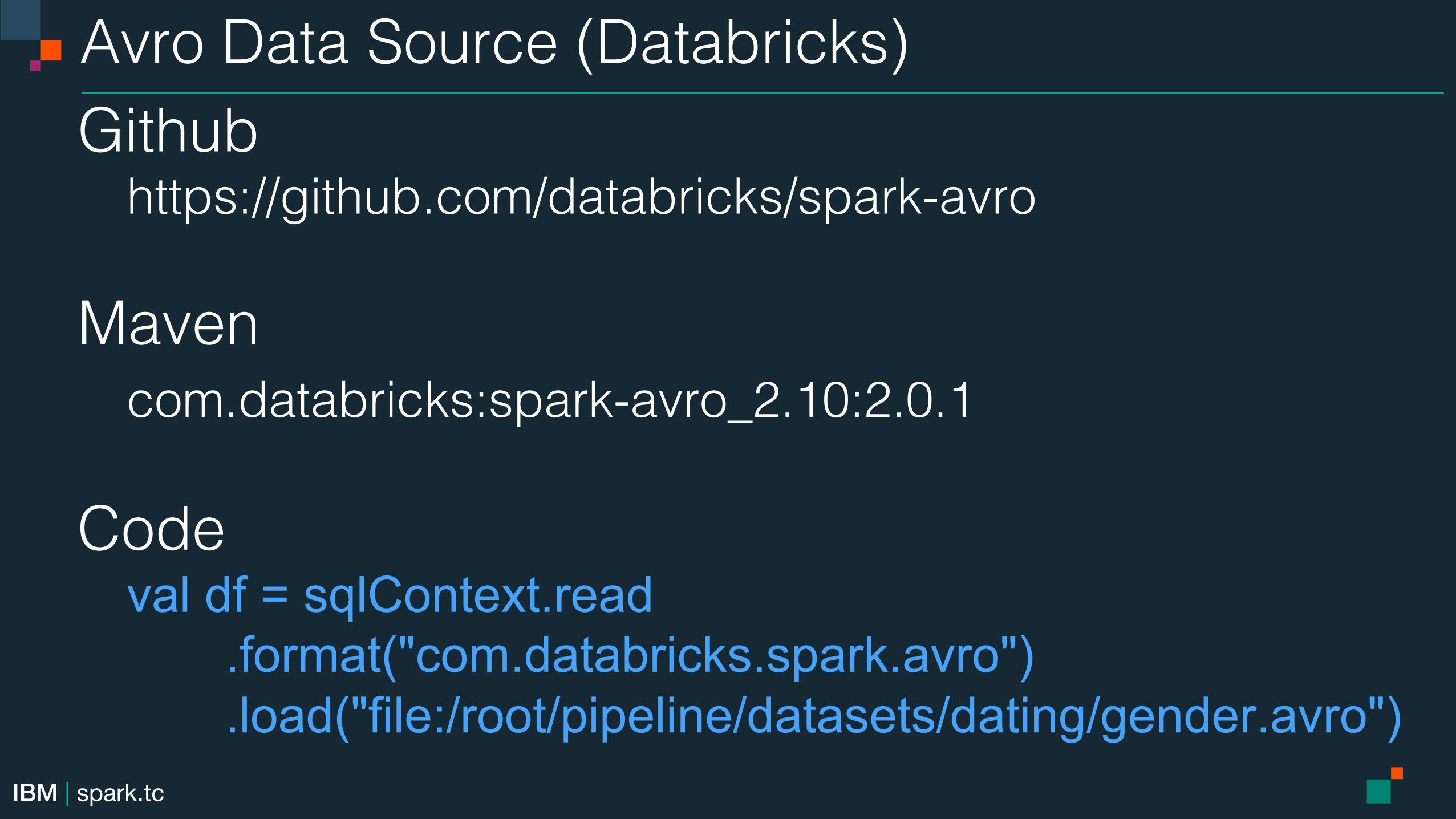
Avro Data Source (Databricks)!Github!
https://github.com/databricks/spark-avro!!Maven!
com.databricks:spark-avro_2.10:2.0.1!!Code!
val df = sqlContext.read .format("com.databricks.spark.avro") .load("file:/root/pipeline/datasets/dating/gender.avro") !
IBM | spark.tc
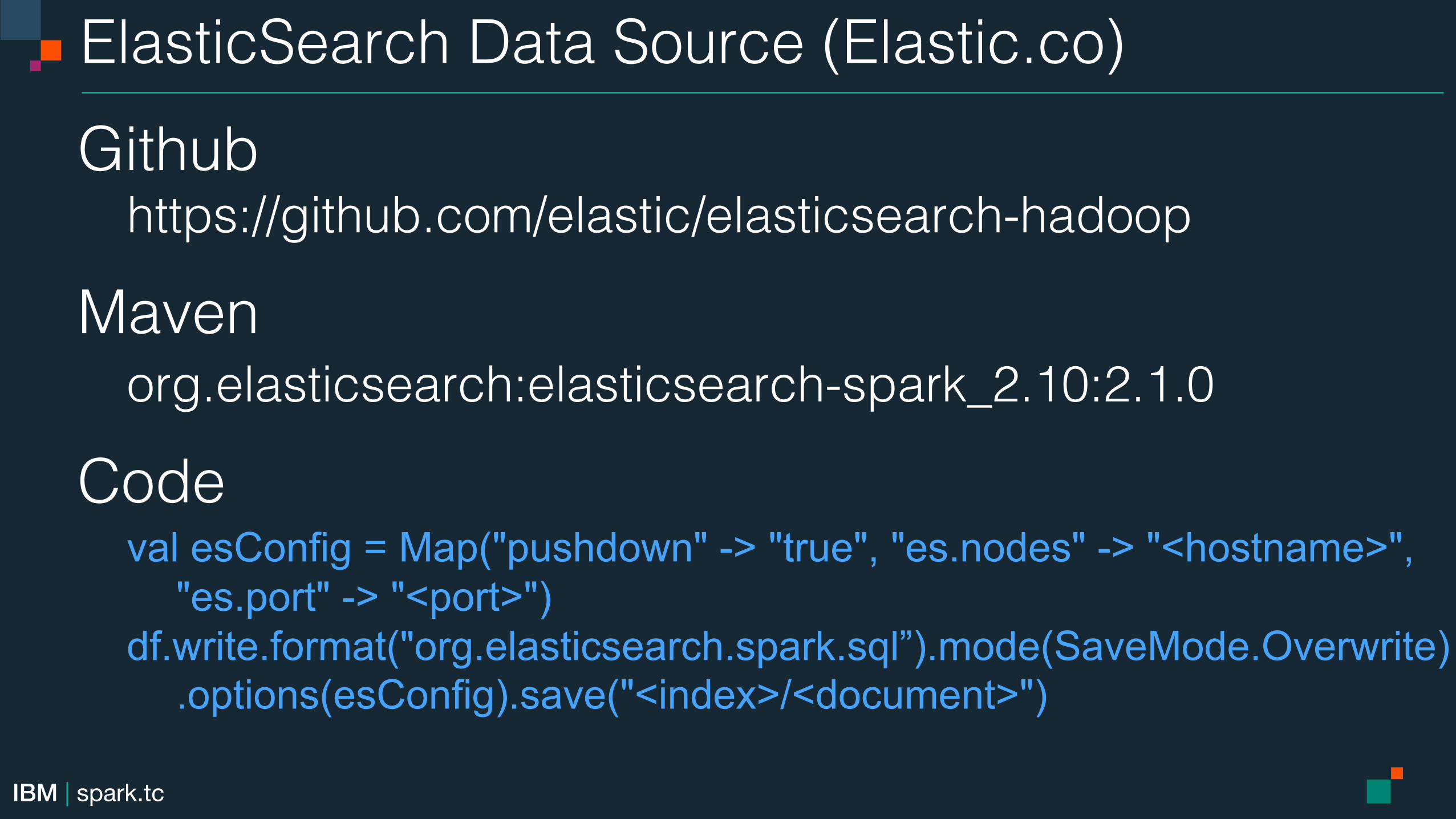
ElasticSearch Data Source (Elastic.co)!Github!
https://github.com/elastic/elasticsearch-hadoop!
Maven!org.elasticsearch:elasticsearch-spark_2.10:2.1.0!
Code! val esConfig = Map("pushdown" -> "true", "es.nodes" -> "<hostname>", "es.port" -> "<port>") df.write.format("org.elasticsearch.spark.sql”).mode(SaveMode.Overwrite) .options(esConfig).save("<index>/<document>")
IBM | spark.tc
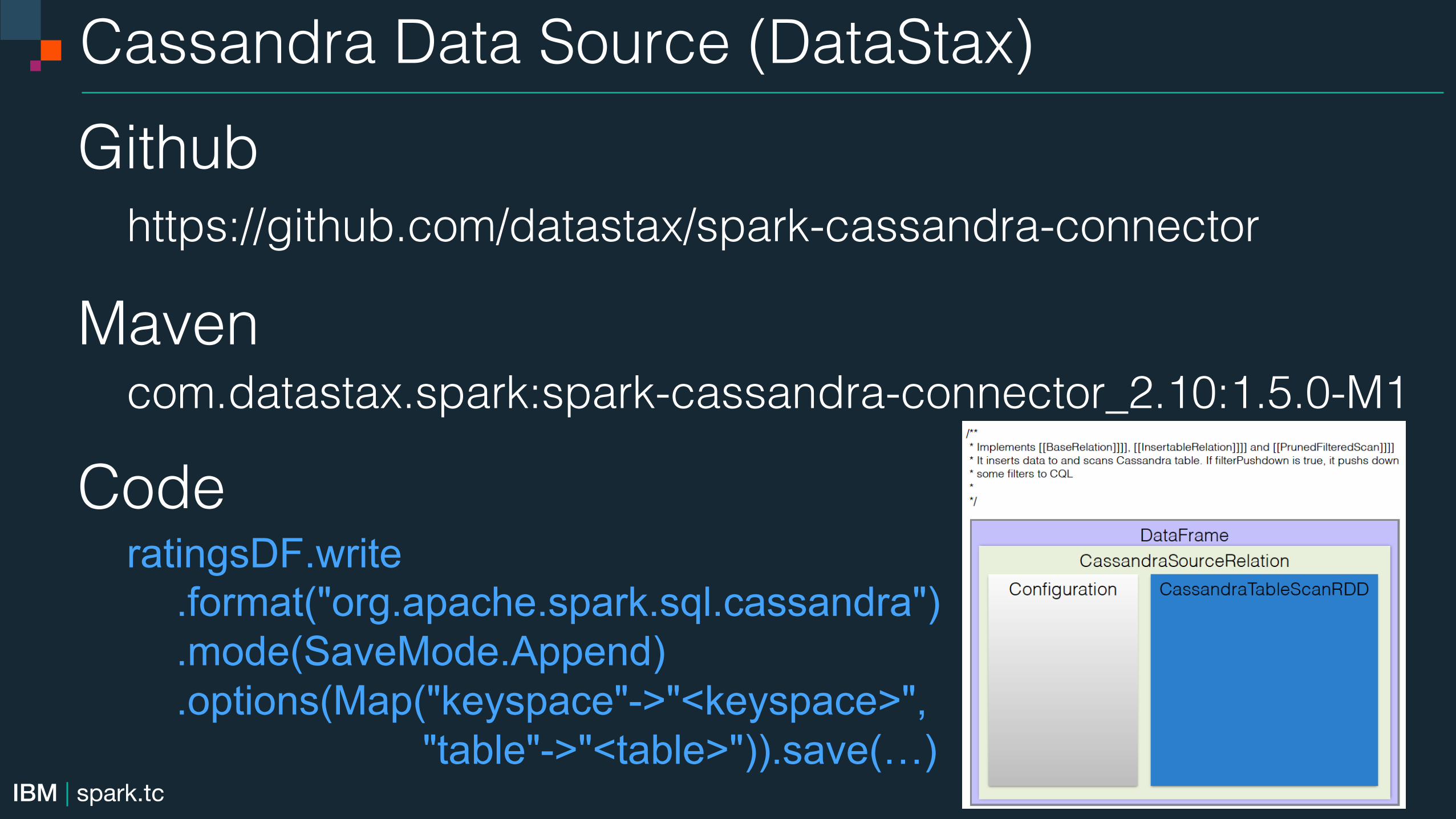
Cassandra Data Source (DataStax)!Github!
https://github.com/datastax/spark-cassandra-connector!Maven!
com.datastax.spark:spark-cassandra-connector_2.10:1.5.0-M1
Code! ratingsDF.write .format("org.apache.spark.sql.cassandra") .mode(SaveMode.Append) .options(Map("keyspace"->"<keyspace>", "table"->"<table>")).save(…)
IBM | spark.tc
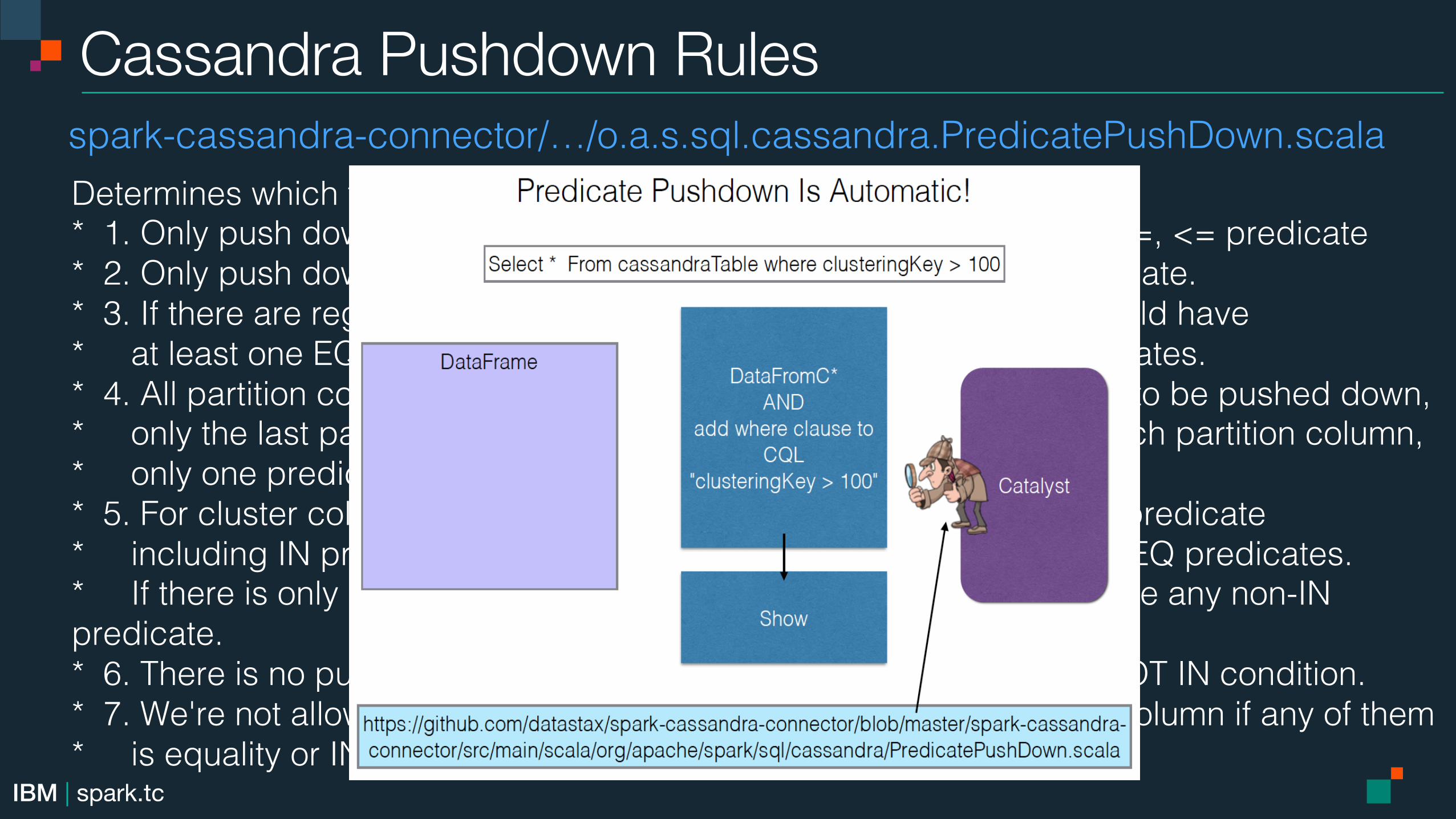
Cassandra Pushdown Rules!
Determines which filter predicates can be pushed down to Cassandra.!* 1. Only push down no-partition key column predicates with =, >, <, >=, <= predicate!* 2. Only push down primary key column predicates with = or IN predicate.!* 3. If there are regular columns in the pushdown predicates, they should have!* at least one EQ expression on an indexed column and no IN predicates.!* 4. All partition column predicates must be included in the predicates to be pushed down,!* only the last part of the partition key can be an IN predicate. For each partition column,!* only one predicate is allowed.!* 5. For cluster column predicates, only last predicate can be non-EQ predicate!* including IN predicate, and preceding column predicates must be EQ predicates.!* If there is only one cluster column predicate, the predicates could be any non-IN predicate.!* 6. There is no pushdown predicates if there is any OR condition or NOT IN condition.!* 7. We're not allowed to push down multiple predicates for the same column if any of them!* is equality or IN predicate.!
spark-cassandra-connector/…/o.a.s.sql.cassandra.PredicatePushDown.scala!
IBM | spark.tc
Special Thanks to DataStax!!!!
Russel Spitzer!@RussSpitzer!
(He created the following few slides)!
(These guys built a lot of the connector.)!
IBM | spark.tc
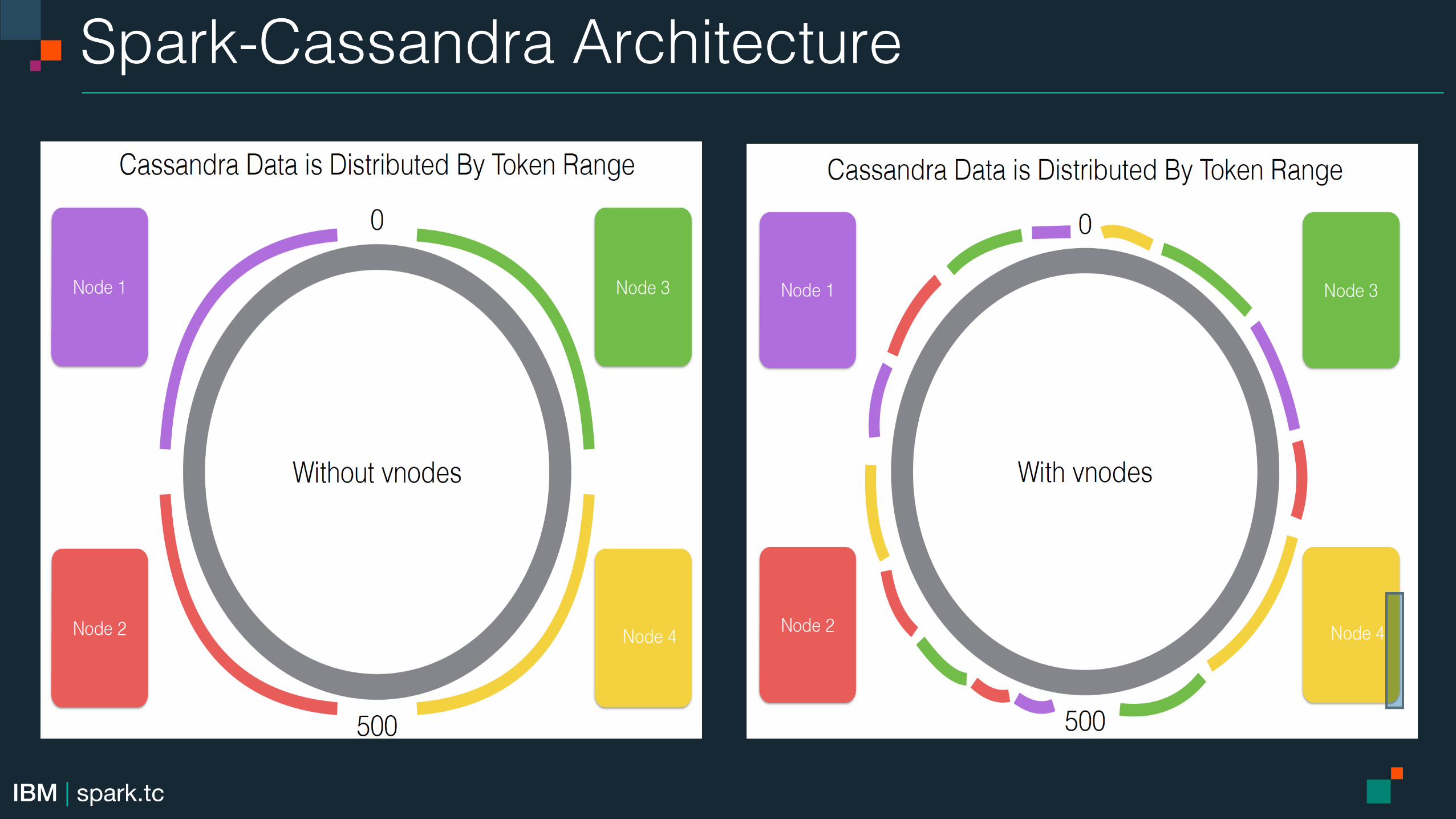
Spark-Cassandra Architecture!
IBM | spark.tc
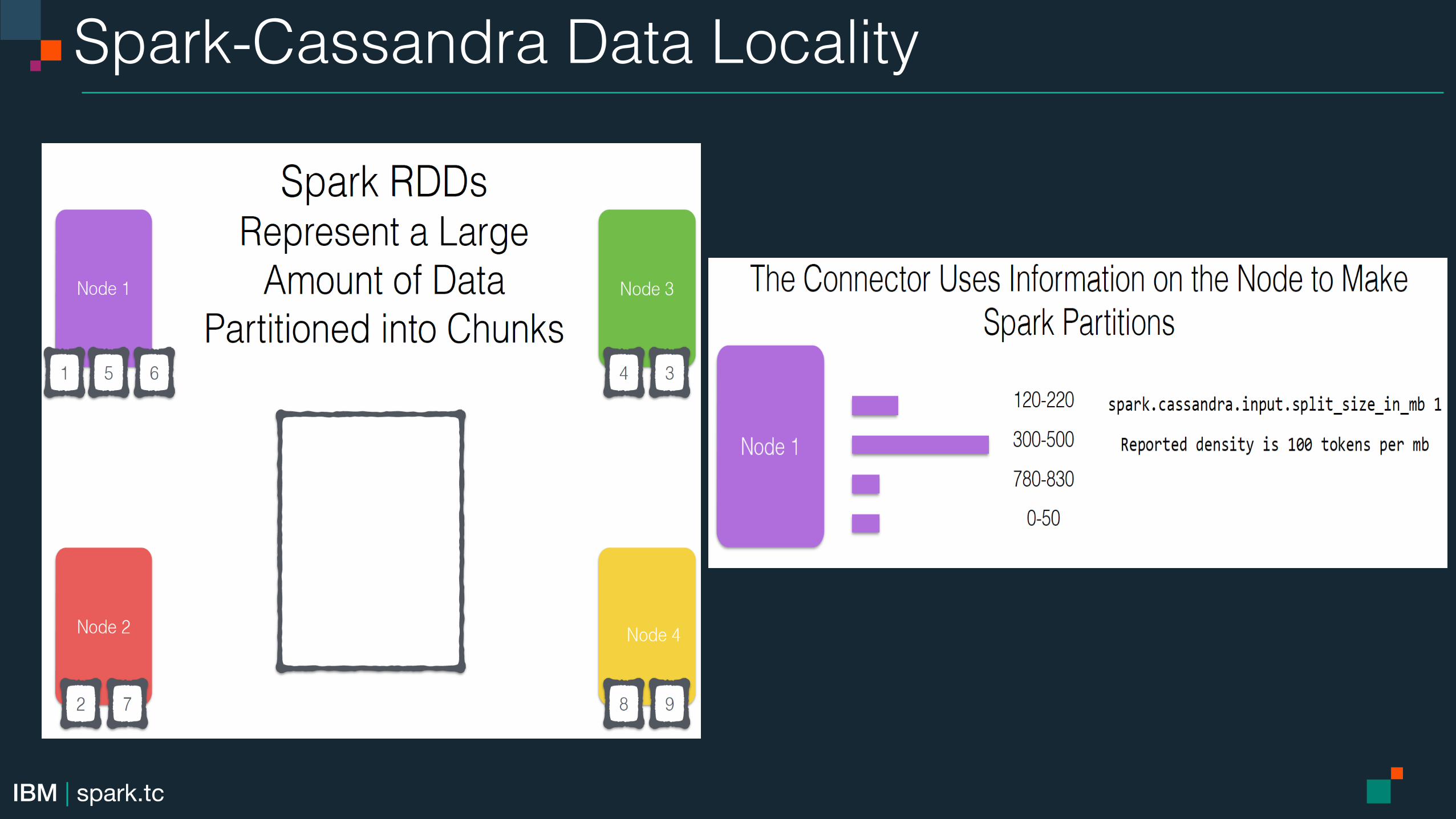
Spark-Cassandra Data Locality!
IBM | spark.tc
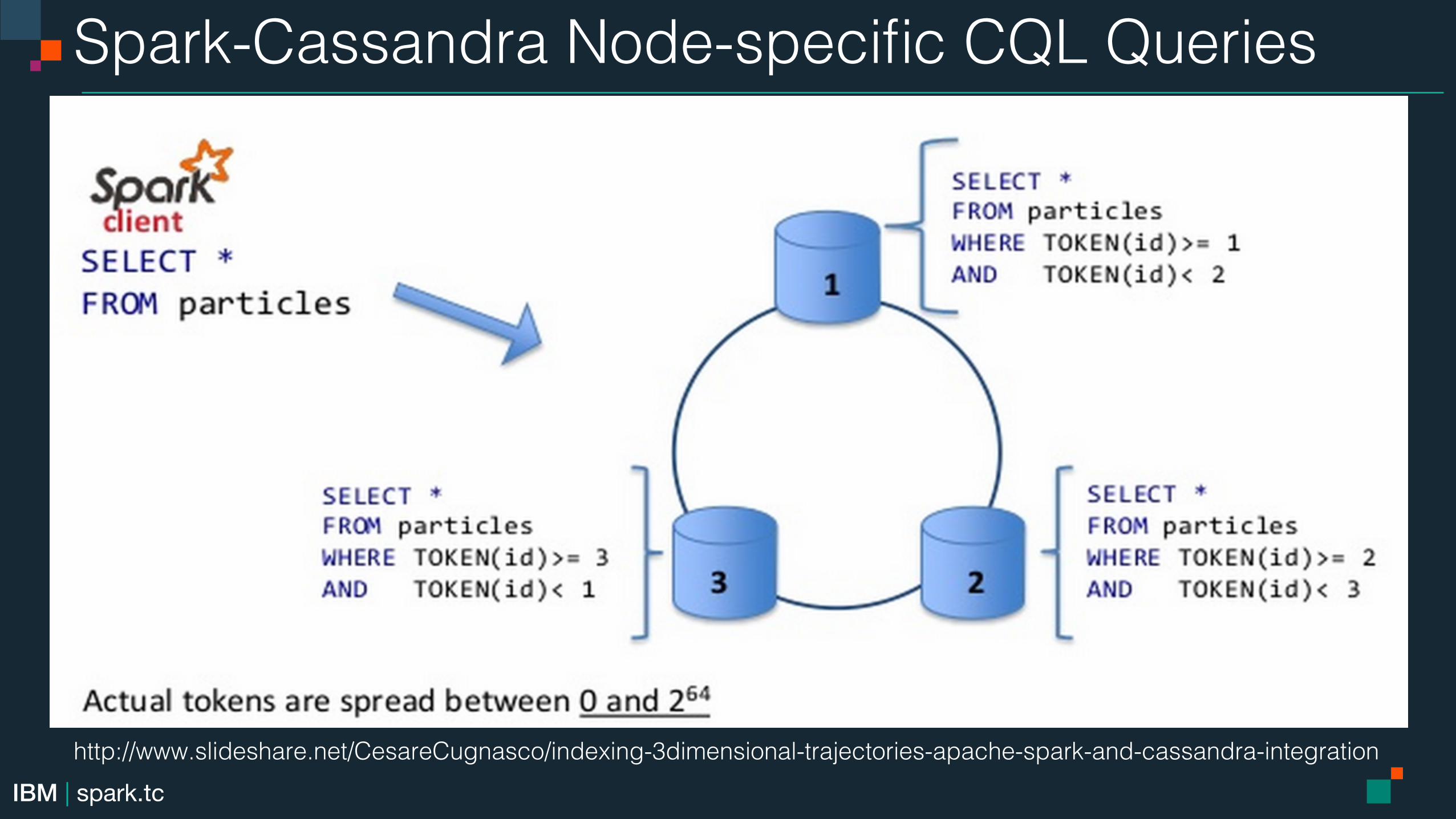
Spark-Cassandra Node-specific CQL Queries!
http://www.slideshare.net/CesareCugnasco/indexing-3dimensional-trajectories-apache-spark-and-cassandra-integration!

IBM | spark.tc
Spark-Cassandra Configuration:input.page.row.size!
IBM | spark.tc
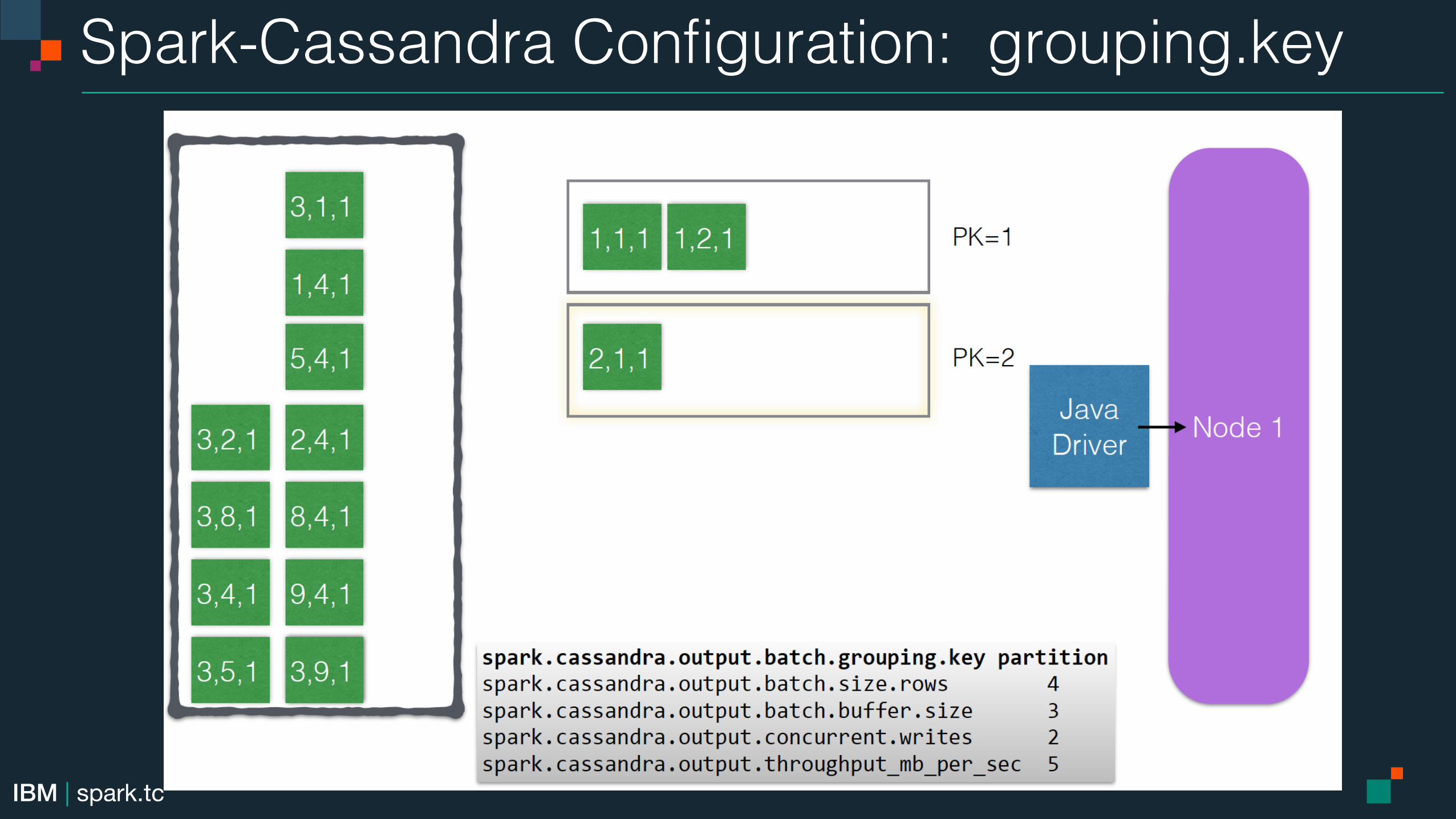
Spark-Cassandra Configuration: grouping.key!
IBM | spark.tc
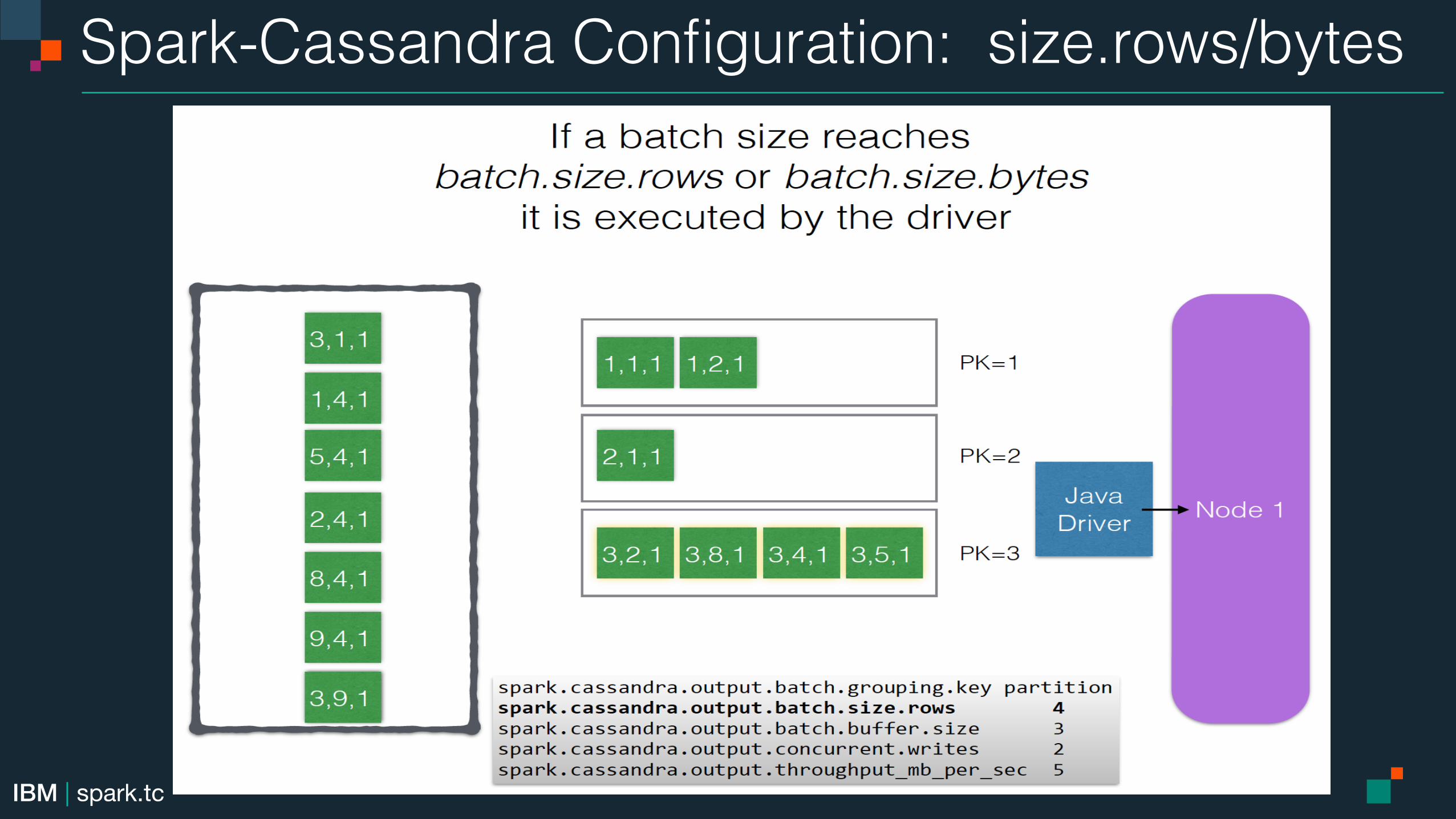
Spark-Cassandra Configuration: size.rows/bytes!

IBM | spark.tc
Spark-Cassandra Configuration: batch.buffer.size!
IBM | spark.tc
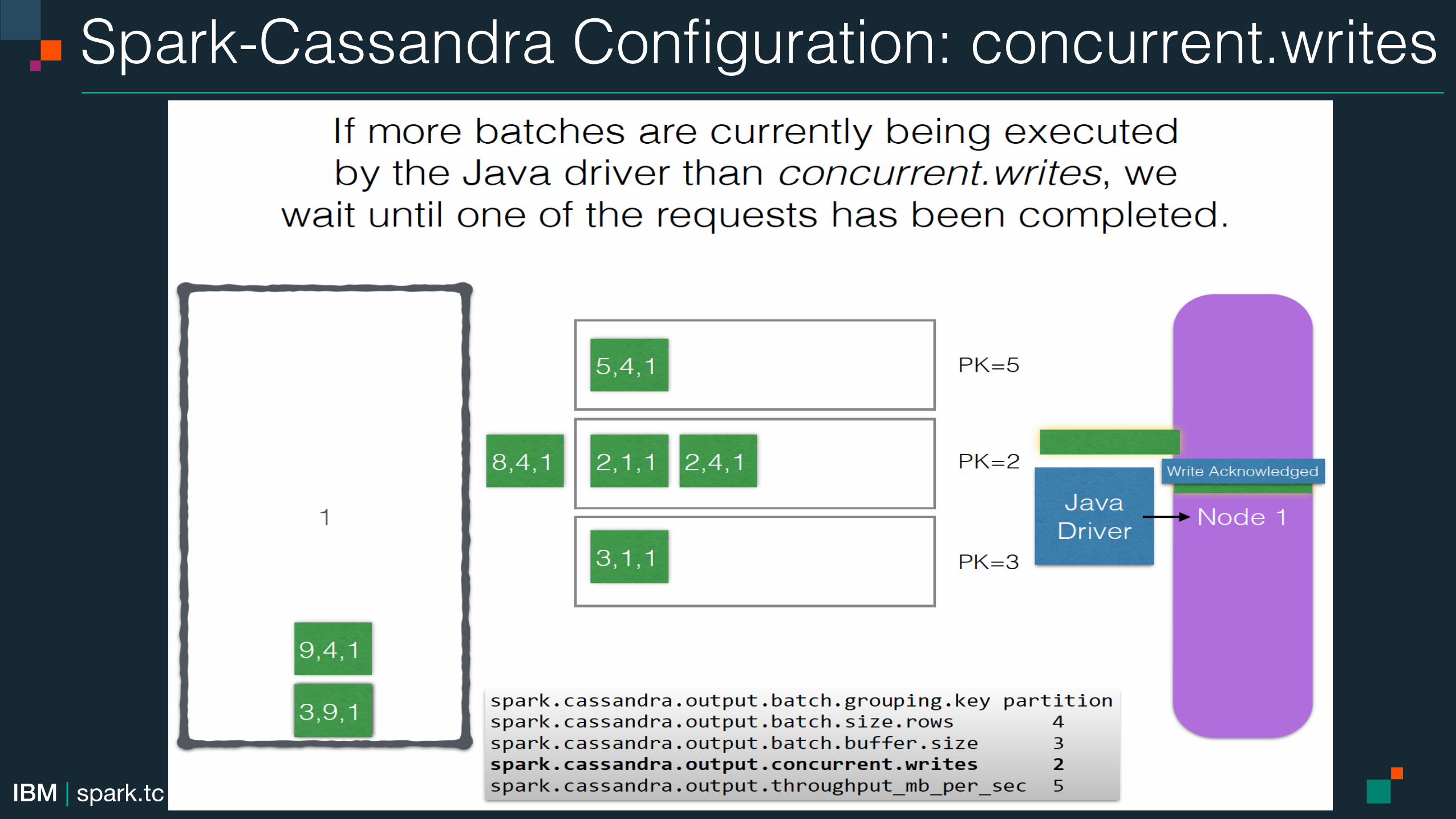
Spark-Cassandra Configuration: concurrent.writes!
IBM | spark.tc
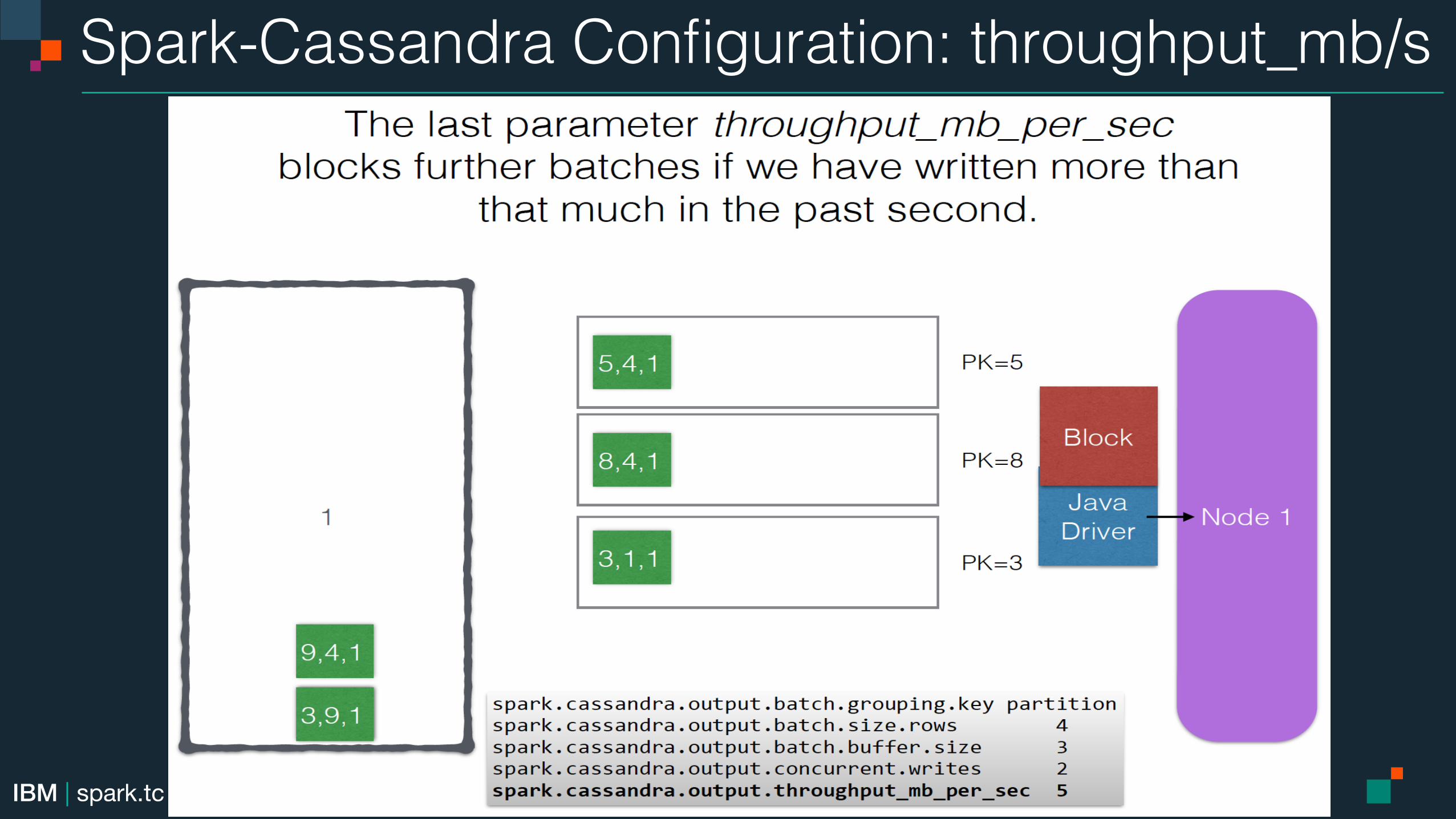
Spark-Cassandra Configuration: throughput_mb/s!

IBM | spark.tc
Spark-Cassandra Optimizatins and Next Steps!
By-pass CQL front door!
Bulk read/write directly to SSTables!
Rumored to be in existence!
DataStax Enterprise only?!
Closed Source Alert!!
IBM | spark.tc
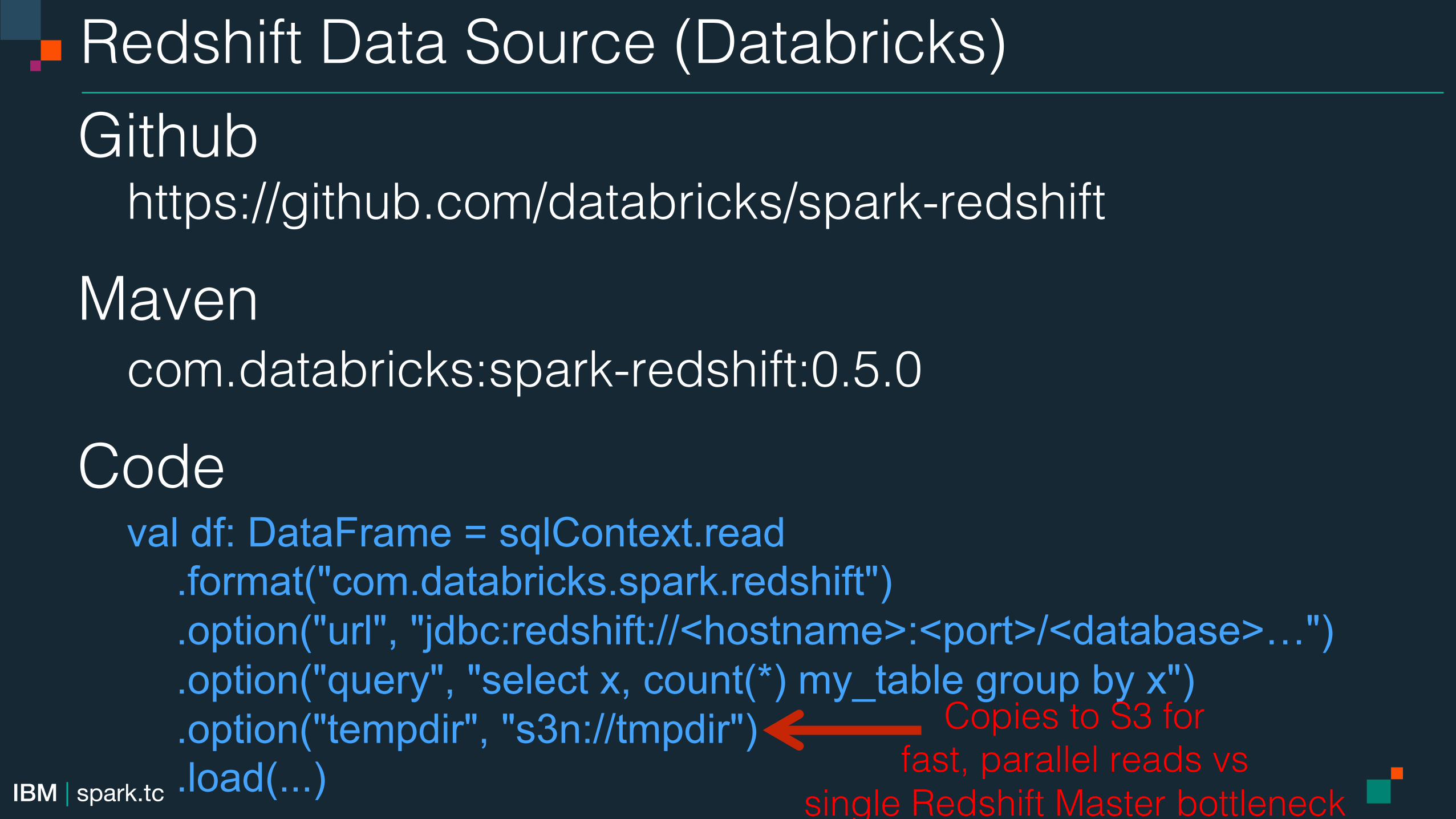
Redshift Data Source (Databricks)!Github!
https://github.com/databricks/spark-redshift!
Maven!com.databricks:spark-redshift:0.5.0!
Code! val df: DataFrame = sqlContext.read
.format("com.databricks.spark.redshift") .option("url", "jdbc:redshift://<hostname>:<port>/<database>…") .option("query", "select x, count(*) my_table group by x") .option("tempdir", "s3n://tmpdir") .load(...) !
Copies to S3 for !fast, parallel reads vs !
single Redshift Master bottleneck!

IBM | spark.tc
Cloudant Data Source (IBM)!Github!
http://spark-packages.org/package/cloudant/spark-cloudant!
Maven!com.datastax.spark:spark-cassandra-connector_2.10:1.5.0-M1
Code! ratingsDF.write.format("com.cloudant.spark") .mode(SaveMode.Append) .options(Map("cloudant.host"->"<account>.cloudant.com", "cloudant.username"->"<username>", "cloudant.password"->"<password>")) .save("<filename>")
!

IBM | spark.tc
DB2 and BigSQL Data Sources (IBM)!
Coming Soon!!!!!
https://github.com/SparkTC/spark-db2!https://github.com/SparkTC/spark-bigsql!
!

IBM | spark.tc
REST Data Source (Databricks)!
Coming Soon!!https://github.com/databricks/spark-rest?!
Michael Armbrust!Spark SQL Lead @ Databricks!

IBM | spark.tc
Simple Data Source (Me and You Guys)!
Coming Right Now!!!
Me!

IBM | spark.tc
SparkSQL Performance Tuning (oas.sql.SQLConf)!spark.sql.inMemoryColumnarStorage.compressed=true!
Automatically selects column codec based on data!spark.sql.inMemoryColumnarStorage.batchSize!
Increase as much as possible without OOM – improves compression and GC!spark.sql.inMemoryPartitionPruning=true!
Enable partition pruning for in-memory partitions!spark.sql.tungsten.enabled=true!
Code Gen for CPU and Memory Optimizations (Tungsten aka Unsafe Mode)!spark.sql.shuffle.partitions!
Increase from default 200 for large joins and aggregations!spark.sql.autoBroadcastJoinThreshold!
Increase to tune this cost-based, physical plan optimization!spark.sql.hive.metastorePartitionPruning!
Predicate pushdown into the metastore to prune partitions early!spark.sql.planner.sortMergeJoin!
Prefer sort-merge (vs. hash join) for large joins !spark.sql.sources.partitionDiscovery.enabled ! & spark.sql.sources.parallelPartitionDiscovery.threshold!
Enable automatic partition discovery when loading data!!
IBM | spark.tc
Related Links!
https://github.com/datastax/spark-cassandra-connector!
http://blog.madhukaraphatak.com/anatomy-of-spark-dataframe-api/!
https://github.com/phatak-dev/anatomy_of_spark_dataframe_api!
https://databricks.com/blog/!
https://www.youtube.com/watch?v=uxuLRiNoDio!
http://www.slideshare.net/RussellSpitzer!

IBM | spark.tc
Freg-a-palooza Upcoming World Tour London Spark Meetup (Oct 12th)! Scotland Data Science Meetup (Oct 13th)! Dublin Spark Meetup (Oct 15th)! Barcelona Spark Meetup (Oct 20th)! Madrid Spark/Big Data Meetup (Oct 22nd)! Paris Spark Meetup (Oct 26th)! Amsterdam Spark Summit (Oct 27th – Oct 29th)! Delft Dutch Data Science Meetup (Oct 29th) ! Brussels Spark Meetup (Oct 30th)! Zurich Big Data Developers Meetup (Nov 2nd)!
High probability!I’ll end up in jail!
or married!!

http://spark.tc/datapalooza IBM Spark Tech Center is Hiring! "JOnly Fun, Collaborative People!! J
IBM | spark.tc
Sign up for our newsletter at
Thank You!
Power of data. Simplicity of design. Speed of innovation.
Coming to Your City!!!!

Power of data. Simplicity of design. Speed of innovation.
IBM Spark


















