
Scalable Process Discovery and Conformance Checkingwvdaalst/publications/z7.pdf · Scalable Process...
42
Scalable Process Discovery and Conformance Checking Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst Eindhoven University of Technology, the Netherlands {s.j.j.leemans, d.fahland, w.m.p.v.d.aalst}@tue.nl Abstract Considerable amounts of data, including process event data, are collected and stored by organisations nowadays. Discovering a process model from recorded process event data and verification of the quality of discovered models are important steps in process mining. Many discovery techniques have been proposed, but none combines scalability with qual- ity guarantees. We would like such techniques to handle billions of events or thousands of activities, to produce sound models (without deadlocks and other anomalies), and to guarantee that the underlying process can be rediscovered when sufficient information is available. In this paper, we introduce a framework for process discovery that ensures these properties while passing over the log only once and we introduce three algorithms using the framework. To measure the quality of discovered models on these large logs, we introduce a model-model and model-log comparison framework that applies a divide-and-conquer strategy to measure recall, fitness and precision. We experimentally show that these discovery and measuring techniques sacrifice little compared to other algorithms, while gaining the ability to cope with event logs of 100,000,000 traces and processes of 10,000 activities. Keywords: big data, scalable process mining, block-structured process discov- ery, directly-follows graphs, algorithm evaluation, rediscoverability, conformance checking 1 Introduction Considerable amounts of data are collected and stored by organisations nowadays. For instance, ERP systems log business transaction events, high tech systems such as X-ray machines record software and hardware events, and web servers log page visits. Typically, each action of a user executed with the system, e.g. a customer filling in a form or a machine being switched on, can be recorded by the system as an event; all events related to the same process execution, e.g. a customer order or an X-Ray diagnosis, are grouped in a trace (ordered by their time); an event log contains all recorded traces of the system. Process mining aims to extract information from such event logs, for instance social networks, business process models, compliance to rules and regulations, and performance information (e.g. bottlenecks) [6].
Transcript of Scalable Process Discovery and Conformance Checkingwvdaalst/publications/z7.pdf · Scalable Process...

Scalable Process Discovery and ConformanceChecking
Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
Eindhoven University of Technology, the Netherlands{s.j.j.leemans, d.fahland, w.m.p.v.d.aalst}@tue.nl
Abstract Considerable amounts of data, including process event data,are collected and stored by organisations nowadays. Discovering a processmodel from recorded process event data and verification of the quality ofdiscovered models are important steps in process mining. Many discoverytechniques have been proposed, but none combines scalability with qual-ity guarantees. We would like such techniques to handle billions of eventsor thousands of activities, to produce sound models (without deadlocksand other anomalies), and to guarantee that the underlying process canbe rediscovered when sufficient information is available. In this paper, weintroduce a framework for process discovery that ensures these propertieswhile passing over the log only once and we introduce three algorithmsusing the framework. To measure the quality of discovered models onthese large logs, we introduce a model-model and model-log comparisonframework that applies a divide-and-conquer strategy to measure recall,fitness and precision. We experimentally show that these discovery andmeasuring techniques sacrifice little compared to other algorithms, whilegaining the ability to cope with event logs of 100,000,000 traces andprocesses of 10,000 activities.
Keywords: big data, scalable process mining, block-structured process discov-ery, directly-follows graphs, algorithm evaluation, rediscoverability, conformancechecking
1 Introduction
Considerable amounts of data are collected and stored by organisations nowadays.For instance, ERP systems log business transaction events, high tech systemssuch as X-ray machines record software and hardware events, and web serverslog page visits. Typically, each action of a user executed with the system, e.g. acustomer filling in a form or a machine being switched on, can be recorded bythe system as an event; all events related to the same process execution, e.g. acustomer order or an X-Ray diagnosis, are grouped in a trace (ordered by theirtime); an event log contains all recorded traces of the system. Process miningaims to extract information from such event logs, for instance social networks,business process models, compliance to rules and regulations, and performanceinformation (e.g. bottlenecks) [6].

2 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
system
system-model
log model
implemented by
executes discover
log-conformance
model-conformance
Figure 1: Process discovery and conformance checking in their context. The boxcontains a typical process mining project’s scope.
In this paper, we focus on two challenges of process mining: process discoveryand conformance checking. Figure 1 shows the context of these two challenges:a real-life business process (a system) is running, and the executed process stepsare recorded in an event log. In process discovery, one assumes that the innerworkings of the system are unknown to the analyst and cannot be obtainedotherwise. Therefore, process discovery aims to learn a process model from anevent log, which describes the system as it actually happened (in contrast to whatis assumed has happened) [2]. Two main challenges exist in process discovery:first, one would like to learn an easy to understand model that captures theactual behaviour. Second, the model should have a proper formal interpretation,i.e. have well-defined behavioural semantics and be free of deadlocks and otheranomalies (be sound) [43]. In Section 2, we explore these challenges in moredetail and explore how they are realised in existing algorithms and settings. Fewexisting algorithms solve both challenges together.
In contrast, conformance checking studies the differences between a processmodel and reality. We distinguish two types of conformance checking. First, themodel can be compared with a log. Such log-conformance checking can provideinsight into the real behaviour of an organisation, by highlighting which tracesdeviate from the model, and where in the model deviations occur [2]. Second,the model can be compared with a model of the system (if that is available).Model-conformance checking can be used to highlight differences between dif-ferent snapshots of a process, or to verify that a process model conforms to adesign made earlier [27]. Moreover, model-conformance checking can be used toevaluate discovery algorithms by choosing a system-model and quantifying thesimilarity between this chosen model and the models discovered by a discoveryalgorithms. In Section 2 we discuss both log and model conformance checking inmore detail.
Large Event Logs. Current process discovery and conformance checking tech-niques work reasonably well on smaller event logs, but might have difficultieshandling larger event logs. For instance, discovery techniques typically requirethe event log to fit in main memory and require the log to be rather complete,i.e. most of the possible behaviour must be present. Reducing the log size to fitin memory, e.g. through sampling, may yield incomplete event logs, which for

Scalable Process Discovery and Conformance Checking 3
discovery may lead to over-fitting models (showing only the behaviour of thesample but not of the system) or under-fitting models (showing arbitrary beha-viour beyond the sample log) (for discovery). For conformance checking, suchlogs may lead to skewed measurements [2].
Event logs might be larger on two dimensions: the number of events or thenumber of activities (i.e. the different process steps). From our experiments (Sec-tion 6), we identified relevant gradations for these dimensions: for the numberof activities we identified complex logs, i.e. containing hundreds of activities,and more complex logs, i.e. containing thousands of activities. For the numberof events we identified medium logs, i.e. containing tens of thousands of events,large logs, i.e. containing millions of events, and larger logs, i.e. containingbillions of events. In contrast, event logs typically considered in process miningare medium and simple, i.e. containing tens of activities, e.g. [29].
# of activities
# of
eve
nts 101
103
105
107
109
101 102 103 104100
α
HM
IMd (this paper)
IMBPIC11
SL
CSco
mpl
ex
mor
eco
mpl
ex
large
largerLHC
medium
Figure 2: dots: maximum number of eventsseveral discovery algorithms could handle(Section 6). (connected for readability, al-gorithms see Section 2); Circles: logs.
In our experiments we ob-served that existing process dis-covery algorithms with strongquality guarantees, e.g. sound-ness, can handle medium logs (seeIM in Figure 2; the algorithmswill be introduced later). al-gorithms not providing such guar-antees (α, HM) can handle largelogs, but fail on larger logs.In the dimension of the num-ber of different activities, ex-periments showed that most al-gorithms could not handle com-plex processes. Current conform-ance checking techniques in ourexperiments and [50] seem tobe unable to handle medium orcomplex event logs.
Such numbers of events andactivities might seem large for acomplaint-handling process in anairline, however processes of muchlarger complexity exist. For in-stance, even simple software toolscontains hundreds or thousandsof different methods. To studyor reverse engineer such software,studies [39] have recorded methodcalls in event logs (at variouslevels of granularity), and processmining and software mining techniques have been used on small examples to

4 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
perform the analyses [51,39]; we obtained a large and complex log (SL). com-plex logs can for instance be found in hospitals: the BPI Challenge log of 2011(BPIC11) [28] was recorded in the emergency department of a Dutch hospitaland contains over 600 activities [28]. Even though this log is just complex andmedium, current discovery techniques have difficulties with this log (we will useit in the evaluation). Other areas in which more complex logs appear are click-stream data from web-sites, such as the web-site of a dot-com start-up, whichproduced an event log containing 3300 activities (CL) [37]. Even more difficultlogs could be extracted from large machines, such as the Large Hadron Collider,in which over 25,000 distributed communicating components form just a part ofthe control systems [36], resulting in complicated behaviour that could be ana-lysed using scalable process mining techniques. In the future, we aim to extractsuch logs and apply our techniques to it, but currently, we would only discover amodel buy not be able to process the discovered model further (no conformancechecking and no visualisation on that scale). Nevertheless, we will show in ourevaluation that our discovery techniques are able to handle such logs.
Problem Definition and Contribution. In this paper, we address two problems:applying process discovery to larger and more complex logs, and conform-ance checking to medium and complex logs. We introduce two scalable frame-works: one for process discovery, the Inductive Miner - directly-follows framework(IMd framework), and one for conformance checking: the projected conformancechecking framework (pcc framework). We instantiate these frameworks to ob-tain several algorithms, each with their specific purposes. For discovery, we showhow to adapt an existing family of algorithms that offers several quality guaran-tees (the Inductive Miner framework (IM framework) [40]), such that is scalesbetter and works on larger and more complex logs. We show that the recur-sion on event logs used by the IM framework can be replaced by recursion onan abstraction (i.e. the so-called directly-follows graph [40]), which can be com-puted in a single pass over the event log. We show that this principle can also beapplied to incomplete event logs (when a discovery technique has to infer miss-ing information) and logs with infrequent behaviour or noise (when a discoveryalgorithm has to identify and filter the events that would degrade model qual-ity); we present corresponding algorithms. Incompleteness and infrequency/noisepose opposing challenges to discovery algorithms, i.e. not enough and too muchinformation. For these purposes, we introduce different algorithms. For conform-ance checking, we introduce the configurable divide-and-conquer pcc frameworkto compare logs to models and models to models. Instead of comparing the com-plete behaviour over all activities, we decompose the problem into comparingbehaviour for subsets of activities. For each such subset, a recall, fitness or pre-cision measure is computed. The average over these subsets provides the finalmeasure, while the subsets with low values give information about the locationin the model/log/system-model where deviations occur.
Results. We conducted a series of experiments in which we tested how well al-gorithms handle large logs and complex processes, in which we found that the

Scalable Process Discovery and Conformance Checking 5
IMd framework provides the scalability to handle all kinds of logs up to largerand more complex logs (see Figure 2). In a second series of experiments weinvestigated the ability of several discovery algorithms to rediscover the originalsystem-model: we experimented to analyse the influence of log sizes, i.e. com-pleteness of the logs, to analyse the influence of noise, i.e. randomly appearingor missing events in process executions, and to assess the influence of infrequentbehaviour, i.e. structural deviations from the system-model during execution.We found that the new discovery algorithms perform comparable to existingalgorithms, while providing much better scalability. In a third experiment, weexplored how the new discovery algorithms handle large and complex real-lifelogs.
In all these experiments, the new pcc framework was applied to assess thequality of the discovered models with respect to the log and where applicable thesystem, as existing conformance checking techniques could not handle mediumor complex logs and systems. We compared the new conformance checkingtechniques to existing techniques, and the results suggest that the new techniquesmight be able to replace existing less-scalable techniques. In particular, modelquality with respect to a log can now be assessed in situations where existingtechniques fail, up to large and complex logs.
Relation to earlier papers. This paper extends the work presented in [41]. Wepresent the new pcc framework, which is able to cope with medium and com-plex logs and models. This allows us to analyse and compare the quality of theIMd framework to other algorithms on such event logs in detail.
Outline. First, process mining is discussed in more detail in Section 2. Second,process trees, directly-follows graphs and cuts are introduced in Section 3. InSection 4, the IMd framework and three algorithms using it are introduced.We introduce the pcc framework in Section 5. The algorithms are evaluated inSection 6 using this pcc framework. Section 7 concludes the paper.
2 Process Mining
In this section, we discuss conformance checking and process discovery in moredetail.
2.1 Conformance Checking
The aim of conformance checking is to verify a process model against reality.As shown in Figure 1, two types of conformance checking exist: log-model con-formance checking and model-model conformance checking. In log-model con-formance checking, reality is assumed to be represented by an event log, while inmodel-model conformance checking, a representation of the system is assumedto be present and to represent reality. Such a system is usually given as anotherprocess model, to which we refer to as system-model.

6 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
Log-Model Conformance Checking. To compare a process model to anevent log, several quality measures have been proposed [9]. For instance, fitnessexpresses the part of the event log that is represented by the model, log-precisionexpresses the behaviour in the model that is present in the event log, general-isation expresses the likelihood that future behaviour will be representible bythe model, and simplicity expresses the absence of complexity in a model [9] torepresent its behaviour.
Several techniques and measures have been proposed to measure fitness andprecision, such as token-based replay [54], alignments [9,10] and many more:for an overview, see [56]. Some techniques that were proposed earlier, such astoken-based replay [54], cannot handle non-determinism well, i.e. silent activ-ities (τ) and duplicate activities. Later techniques, such as alignments [9], canhandle non-determinism by exhaustively searching for the model trace that hasthe least deviations from a given log trace (according to some cost function).However, even optimised implementations of these techniques cannot deal withmedium or complex event logs and models [50]. To alleviate this problem, de-composition techniques have been proposed, for instance using passages [3,4]or single-entry-single-exit decompositions [50]. The pcc framework presented inthis paper can be seen as a generalisation of these techniques, that takes thecontext of decomposed nets into account.
Model-Model Conformance Checking. For a more elaborate overview ofthis field, we refer to [27] and [14].
Typically, the quality of a process discovery algorithm is measured usinglog-conformance checking, i.e. a discovered model is compared to an event log.Alternatively, discovered model and system-model could be compared directly.Ideally, both would be compared on branching bisimilarity or even strongernotions of equivalence [33], thereby taking the moments of choice into account.However, as an event log describes a language and does not contain informationabout choices, the discovered model will lack this information as well and weconsider comparison based on languages (trace equivalence, a language is the setof traces of a log, or the set of traces that a model can produce).
One such technique is [12]. This approach translates the models into partially-ordered runs annotated with exclusive relationships (event structures), whichcan be generated from process models as well [12]. However, event structureshave difficulties supporting loops by their acyclic nature and constructing themrequires a full state-space exploration.
As noted in [27], many model-model comparison techniques suffer from ex-ponential complexity due to concurrency and loops in the models. To overcomethis problem, several techniques apply an abstraction, for instance using causalfootprints [30], weak order relations [65] or behavioural profiles [58,38]. Anothertechnique to reduce the state space is decompose the model in pieces and performthe computations on these pieces individually [38]. Our approach (pcc frame-work, which applies to both log-model and model-model conformance checking)applies an abstraction using a different angle: we project on subsets of activ-

Scalable Process Discovery and Conformance Checking 7
ities, thereby generalising over many of these abstractions, i.e. many relationsbetween the projected activities are captured. Moreover, our approach handlesany formalism of which the executable semantics can be described by Determin-istic Finite Automata, which includes labelled Petri nets, i.e. duplicate activities,silent transitions, and even some unsound models.
2.2 Process Discovery
Process discovery aims at discovering a process model from an event log (seeFigure 1). We first sketch some challenges that discovery algorithms face, afterwhich we discuss existing discovery approaches.
Challenges. Several factors challenge process discovery algorithms. One suchchallenge is that the resulting process model should have well-defined behavi-oural semantics and be sound [2]. Even though an unsound process model or amodel without a language, i.e. without a definition of traces the model expresses,might be useful for manual analysis, conformance checking and other automatedtechniques can obviously not provide accurate measures on such models [55,43].The IMd framework uses its representational bias to provide a language andto guarantee soundness: it discovers an abstract hierarchical view on workflownets [2], process trees, that is guaranteed to be sound [20].
Another challenge of process discovery is that for many event logs the meas-ures fitness, log-precision, generalisation and simplicity are competing, i.e. theremight not exist a model that scores well on all criteria [21]. Thus, discoveryalgorithms have to balance these measures, and this balance might depend onthe use case at hand, e.g. auditing questions are best answered using a modelwith high fitness, optimisations are best performed on a model with high log-precision, implementations might require a model with high generalisation, andhuman interpretation is eased by a simple model [21].
A desirable property of discovery algorithms is having the ability to redis-cover the language of the system (rediscoverability); we assume the system andthe system-model to have the same behaviour for rediscoverability. Rediscov-erability is usually proven using assumptions on both system and event log:the system typically must be of a certain class, and the event log must containenough correct information to describe the system well [40]. Therefore, threemore challenges of process discovery algorithms are to handle 1) noise in theevent log, i.e. random absence or presence of events [19], 2) infrequent beha-viour, i.e. behaviour that occurs less frequent than ‘normal’ behaviour, i.e. theexceptional cases. For instance, most complaints sent to an airline are handledaccording to a model, but a few complaints are so complicated that they requiread-hoc solutions. This behaviour could be of interest or not, which depends onthe goal of the analysis [2]. 3) incompleteness, i.e. the event log does not con-tain “enough” information. The notion of what “enough” means depends on thediscovery algorithm [13,40]. Even though rediscoverability is desirable, it is aformal property, and it is not easy to compare algorithms using it. However, the

8 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
pcc framework allows to perform experiments to quantify how rediscoverabilityis influenced by noise, infrequent behaviour and incompleteness.
A last challenge arises from the main focus of this paper, i.e. highly scal-able environments. Ideally, a discovery technique should linearly pass over theevent log once, which removes the need to keep the event log in memory. In theremainder of this section, we discuss related process discovery techniques andtheir application in scalable environments.
Sound Process Discovery Algorithms. Process discovery techniques such as theEvolutionary Tree Miner (ETM) [20], the Constructs Competition Miner (CCM)[52], Maximal Pattern Mining (MPM) [46] and Inductive Miner (IM) [40] provideseveral quality guarantees, in particular soundness and some offer rediscoverab-ility, but do not manage to discover a model in a single pass. ETM applies agenetic strategy, i.e. generates an initial population, and then applies randomcrossover steps, selects the ‘best’ individuals from the population and repeats.While ETM is very flexible towards the desired log-measures to which respectthe model should be ‘best’ and guarantees soundness, it requires multiple passesover the event log and does not provide rediscoverability.
CCM and IM use a divide-and-conquer strategy on event logs. In the In-ductive Miner IM framework, first an appropriate cut of the process activitiesis selected; second, that cut is used to split the event log into sub logs; third,these sub logs are recursed on, until a base case is encountered. If no appropri-ate cut can be found, a fall-through (‘anything can happen’) is returned. CCMworks similarly by having several process constructs compete with one another.While both CCM and the IM framework guarantee soundness and IM guaran-tees rediscoverability (for the class of models described in [42, Appendix A]),both require multiple passes through the event log (the event log is being splitand recursed on).
MPM first constructs a prefix-tree of the event log. Second, it folds leaves toobtain a process model, thereby applying local generalisations to detect concur-rency. The MPM technique guarantees soundness and fitness, allows for noisefiltering and can reach high precision, but it does so at the cost of simplicity: typ-ically, lots of activities are duplicated. Inherently, the MPM technique requiresrandom access to the event log and a single pass does not suffice.
Other Process Discovery Algorithms. Other process discovery techniques arefor instance the α-algorithm (α) and its derivatives [7,61,62], the HeuristicsMiner [59] (HM), the Integer Linear Programming miner [63] (ILP) and sev-eral commercial tools, such as Fluxicon Disco (FD) [34] and Perceptive ProcessMining (two versions: PM1 and PM2).
Some of these guarantee soundness, but do not support explicit concurrency(FD, PM1) [45]. The ILP miner guarantees fitness and can guarantee that themodel is empty after completion, but only for the traces seen in the event log,i.e. the models produced by ILP are usually not sound. However, most of thesealgorithms (α, HM, ILP, PM2) do not guarantee soundness or even providea final marking, which makes it difficult to determine their language (see [42,

Scalable Process Discovery and Conformance Checking 9
Appendix E]), thus their models are difficult to analyse automatically (though,such unsound models can still be useful for manual analysis).
Several techniques (α, HM) satisfy the single-pass requirement. These al-gorithms first obtain an abstraction from the log, which denotes what activitiesdirectly follow one another; in HM, this abstraction is filtered. Second, from thisabstraction a process model is constructed. Both α and HM have been demon-strated to be applicable in highly-scalable environments: event logs of 5 milliontraces have been processed using map-reduce techniques [31]. Moreover, α guar-antees rediscoverability, but neither α nor HM guarantees soundness. We showthat our approach offers the same scalability as HM and α, but provides bothsoundness and rediscoverability.
Some commercial tools such as FD and PM1 offer high scalability, but donot support explicit concurrency [45]. Other discovery techniques, such as thelanguage-based region miner [17,18] or the state-based region miner [25] guar-antee fitness but neither soundness nor rediscoverability nor work in single pass.
Software Mining. In the field of software mining, similar techniques have beenused to discover formal specifications of software. For instance, in [51] and [11],execution sequences of software runs (i.e. traces) are recorded in an event log,from which techniques extract e.g. valid execution sequences on the methods ofan api. Such valid execution sequences can then be used to generate document-ation. Process discovery differs from software mining in focus and challenges:Process discovery aims to find process models with soundness and concurrencyand is challenged e.g. by deviations from the model (noise, infrequent behaviour)and readability requirements of the discovered models, while for software miningtechniques, the system is fixed and challenges arise from e.g. nesting levels [51],programmed exceptions [64] and collaborating components [32].
Streams. Another set of approaches that aims to handle even bigger logs assumesthat the event log is an unbounded stream of events. Some approaches such as[26,35] work on click-stream data, i.e. the sequence of web pages users visit, toextract for instance clusters of similar users or web pages. However, we aim toextract end-to-end process models, in particular containing parallelism. HM, αand CCM have been shown to be applicable in streaming environments [23,53].While streaming algorithms could handle event logs containing billions of eventsby feeding them as streams, these algorithms assume the log can never be ex-amined completely and, as of the unbounded stream, eventually cannot storeinformation for an event without throwing away information about an earlierseen event. In this paper, we assume the log is bounded and we investigate howfar we can get using all information in it.
3 Preliminaries
To overcome the limitations of process discovery on large event logs, we will com-bine the single-pass property of directly-follows graphs with a divide-and-conquer

10 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
strategy. This section recalls these existing concepts. The new algorithms are in-troduced in Section 4.
3.1 Basic Notions
Event Logs. An event log is a multiset of traces that denote process executions.For instance, the event log [〈a, b, c〉, 〈b, d〉2] denotes the event log in which thetrace consisting of the activity a followed by the activity b followed by the activityc was executed once, and the trace consisting of b followed by d was executedtwice.
Process Trees. A process tree is an abstract representation of a block-structuredhierarchical process model, in which the leaves represent the activities, i.e. thebasic process steps, and the operators describe how their children are to be com-bined [20]. τ denotes the activity whose execution is not visible in the event log.We consider four operators: ×, →, ∧ and . × describes the exclusive choicebetween its children, → the sequential composition and ∧ the parallel composi-tion. The first child of a loop is the body of the loop, all other children are redochildren. First, the body must be executed, followed by zero or more iterationsof a redo child and the body. A formal definition is given in [42, Appendix A]; wegive an example here: Figure 3 shows the Petri net corresponding to the processtree →(×(∧(a, b), c),×((→(d, e), f), g)). Process trees are inherently sound.
b
c
d e
f
g
a
Figure 3: A block-structured hierarchical workflow net; the block-structure isdenoted by filled regions (image taken from [44]).
Directly-Follows Graphs. A directly-follows graph can be derived from a log anddescribes what activities follow one another directly, and with which activitiesa trace starts or ends. In a directly-follows graph, there is an edge from anactivity a to an activity b if a is followed directly by b. The weight of an edgedenotes how often that happened. For instance, the directly-follows graph of ourexample log [〈a, b, c〉, 〈b, d〉2] is shown in Figure 4. Note that the multiset of startactivities is [a, b2] and the multiset of end activities is [c, d2]. A directly-followsgraph can be obtained in a single pass over the event log with minimal memoryrequirements [31].

Scalable Process Discovery and Conformance Checking 11
a b
c
d1 2
2
1
1
1
2
Figure 4: Example of a directly-follows graph.
Cuts, Characteristics and the Inductive Miner framework. A partition is a non-overlapping division of the activities of a directly-follows graph. For instance,({a, b}, {c, d}) is a binary partition of the directly-follows graph in Figure 4. A cutis a partition combined with a process tree operator, for instance (→, {a, b}, {c, d}).In the IM framework, finding a cut is an essential step: its operator becomes theroot of the process tree, and its partition determines how the log is split.
The IM framework [40] discovers the main cut, and projects the given logonto the activity partition. In case of loops, each iteration becomes a new tracein the projected sub-log. Subsequently, for each sub-log its main cut is detectedand recursion continues until reaching partitions with singleton elements; thesebecome the leaves of the process tree. If no cut can be found, a generalising fall-through is returned that allows for any behaviour (a “flower model”). By theuse of process trees, the IM framework guarantees sound models, and makes iteasy to guarantee fitness. The IM framework is formalised in [42, Appendix A].
Suppose that the log is produced by a process which can be represented by aprocess tree T . Then, the root of T leaves certain characteristics in the log andin the directly-follows graph. The most basic algorithm that uses the IM frame-work, i.e. IM [40], searches for a cut that matches these characteristics perfectly.Other algorithms using the IM framework are the infrequent-behaviour-filteringInductive Miner - infrequent (IMf) [43] and the incompleteness-handling In-ductive Miner - incompleteness (IMc) [44].
3.2 Cut Detection
Cut definitions are given [42, Appendix A]. Here we describe how the cut de-tection works. Each of the four process tree operators ×, →, ∧ and leaves adifferent characteristic footprint in the directly-follows graph. Figure 5 visual-ises these characteristics: for exclusive choice, the activities of one sub-tree willnever occur in the same trace as activities of another sub-tree. Hence, activitiesof the different sub-trees form clusters that are not connected by edges in thedirectly-follows graph. Thus, the × cut is computed by taking the connectedcomponents of the directly-follows graph.
If two sub-trees are sequentially ordered, all activities of the first sub-treestrictly precede all activists of the second sub-tree; in the directly-follows graphwe expect to see a chain of clusters without edges going back. The procedure to

12 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
...
sequence:
...
exclusive choice:
...
parallel:
...
loop:
Figure 5: Cut characteristics.
discover a sequence cut is as follows: each activity starts as a singleton set. First,the strongly connected components of the directly-follows graph are computedand merged. By definition, two activities are in a strongly connected componentif they are pairwise reachable, and therefore they cannot sequential. Second,pairwise unreachable sets are merged, as if there is no way to reach two nodes inthe same trace, they cannot be sequential. Finally, the remaining sets are sortedbased on reachability.
The activities of two parallel subtrees can occur in any intertwined order; weexpect all possible connections to be present between the child-clusters in thedirectly-follows graph. To detect parallelism, the graph is negated: the negatedgraph gets no edge between two activities if both directly-follows edges betweenthese activities are present. If either edge is missing, the negated graph willcontain an edge between these two activities. In this negated graph, the partitionof the parallel cut is the set of connected components.
In a loop, the directly-follows graph must contain a clear set of start and endactivities; all connections between clusters must go through these activities. Todetect a loop cut, first the connected components of the directly-follows graphare computed, while excluding the start and end activities. Please note that startand end activities by definition belong to the body of the loop. Second, for eachcomponent reachability is used to determine whether it is directed from a startactivity to an end activity (body part), or directed the other way round (a redo).
4 Process Discovery Using a Directly-Follows Graph
Algorithms using the IM framework guarantee soundness, and some even redis-coverability, but do not satisfy the single-pass property, as the log is traversedand even copied during each recursive step. Therefore, we introduce an adaptedframework: Inductive Miner - directly-follows (IMd framework) that recurseson the directly-follows graph instead of the event log. In this section, we first

Scalable Process Discovery and Conformance Checking 13
a
b
c
e
i
d
h
g
f
9
3
3
3
3
33
1 11
1
1
1
1 1
6
16
3
3
63
3
9
Figure 6: Directly-follows graph D1 of L. In a next step, the partition({a}, {b, c, d, e}, {f, g, h}, {i}), denoted by the dashed lines, will be used.
introduce the IMd framework and a basic algorithm using it. Second, we intro-duce two more algorithms: one to handle infrequent behaviour; another one thathandles incompleteness.
4.1 Inductive Miner - directly-follows
As a first algorithm that uses the framework, we introduce Inductive Miner -directly-follows (IMd). We explain the stages of IMd in more detail by meansof an example: Let L be [〈a, b, c, f, g, h, i〉, 〈a, b, c, g, h, f, i〉, 〈a, b, c, h, f, g, i〉,〈a, c, b, f, g, h, i〉, 〈a, c, b, g, h, f, i〉, 〈a, c, b, h, f, g, i〉, 〈a, d, f, g, h, i〉,〈a, d, e, d, g, h, f, i〉, 〈a, d, e, d, e, d, h, f, g, i〉]. The directly-follows graph D1 of Lis shown in Figure 6.
Cut Detection. IMd searches for a cut that perfectly matches the characteristicsmentioned in Section 3. As explained, cut detection has been implemented usingstandard graph algorithms (connected components, strongly connected compon-ents), which run in polynomial time, given the number of activities (O(n)) anddirectly-follows edges (O(n2)) in the graph.
In our example, the cut (→, {a}, {b, c, d, e}, {f, g, h}, {i}) is selected: as shownin Figure 5, every edge crosses the cut lines from left to right. Therefore, itperfectly matches the sequence cut characteristic. Using this cut, the sequenceis recorded and the directly-follows graph can be split.
Directly-Follows Graph Splitting. Given a cut, the IMd framework splits thedirectly-follows-graph in disjoint subgraphs. The idea is to keep the internalstructure of each of the clusters of the cut by simply projecting a graph onthe cluster. Figure 7 gives an example of how D1 (Figure 6) is split using the

14 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
sequence cut that was discovered in our example. If the operator of the cut is→or , the start and end activities of a child might be different from the start andend activities of its parent. Therefore, every edge that enters a cluster is countedas a start activity, and an edge leaving a cluster is counted as an end activity. Inour example, the start activities of cluster {f, g, h} are those having an incomingedge not starting in {f, g, h}, and correspondingly for end activities. The resultis shown in Figure 7a. In case of ×, no edges leave any cluster and hence the startand end activities remain unchanged. In case of ∧, removed edges express thearbitrary interleaving of activities in parallel clusters; removing this interleavinginformation does not change with which activities a cluster may start or end,thus start and end activities remain unchanged.
The choices for a sequence cut and the split directly-follows graphs are re-corded in an intermediate tree: →((D2), (D3), (D4), (D5)), denoting a sequenceoperator with 4 unknown sub-trees that are to be derived from 4 directly-followsgraphs.
a 99
(a) D2 of {a}
b
c
e
d
3
33
33
3
3
33
3
(b) D3 of {b, c, d, e}
h
g
f
6
33
3 3
33
6
6
(c) D4 of {f, g, h}
i9 9
(d) D5 of {i}
Figure 7: Split directly-follows graphs of D1. The dashed line is used in a nextstep and denotes another partition.
Recursion. Next, IMd recurses on each of the new directly-follows graphs (findcut, split, . . . ) until a base case (see below) is reached or no perfectly matchingcut can be found. Each of these recursions returns a process tree, which in turncan be inserted as a child of an operator identified in an earlier recursion step.
Base Case. Directly-follows graphs D2 (Figure 7a) and D5 (Figure 7d) containbase cases: in both graphs, only a single activity is left. The algorithm turnsthese into leaves of the process tree and inserts them at the respective spot ofthe parent operator. In our example, detecting the base cases of D2 and D5
yields the intermediate tree →(a, (D3), (D4), i), in which D3 and D4 indicatedirectly-follows graphs that are not base cases and will be recursed on later.
Fall-Through. Consider D4 as, shown in Figure 7c. D4 does not contain uncon-nected parts, so does not contain an exclusive choice cut. There is no sequence

Scalable Process Discovery and Conformance Checking 15
cut possible, as f , g and h form a strongly connected component. There is noparallel cut as there are no dually connected parts, and no loop cut as all activit-ies are start and end activities. Thus, IMd selects a fall-through, being a processtree that allows for any behaviour consisting of f , g and h (a flower model(τ, f, g, h), having the language (f |g|h)∗). The intermediate tree of our ex-ample up till now becomes →(a, (D3),(τ, f, g, h), i) (remember that τ denotesthe activity of which the execution is invisible).
Example Continued. InD3, shown in Figure 7b, a cut is present: (×, {b, c}, {d, e}):no edge in D3 crosses this cut. The directly-follows graphs D6 and D7, shown inFigures 8a and 8b, result after splitting D3. The tree of our example up till nowbecomes →(a,×((D6), (D7)),(τ, f, g, h), i).
In D6, shown in Figure 8a, a parallel cut is present, as all possible edges crossthe cut, i.e. the dashed line, in both ways. The dashed line in D7 (Figure 8b)denotes a loop cut, as all connections between {d} and {e} go via the set of startand end activities {d}. Four more base cases give us the complete process tree→(a,×(∧(b, c),(d, e)),(τ, f, g, h), i).
b
c
3
33
3
33
(a) D6 of {b, c} in D3
e
d33
3 3
(b) D7 of {d, e} in D3
Figure 8: Split directly-follows graphs. Dashed lines denote cuts, which are usedin the next steps.
To summarise: IMd selects a cut, splits the directly-follows graph and re-curses until a base case is encountered or a fall-through is necessary. As eachrecursion removes at least one activity from the graph and cut detection is O(n2),IMd runs in O(n3), in which n is the number of activities in the directly-followsgraph.
By the nature of process trees, the returned model is sound. By reasoningsimilar to IM [40], IMd guarantees rediscoverability on the same class of models(see [42, Appendix A]), i.e. assuming that the model is representable by a processtree without using duplicate activities, and it is not possible to start loops withan activity they can also end with [40]. This makes IMd the first single-passalgorithm to offer these guarantees.
4.2 Handling Infrequency and Incompleteness
The basic algorithm IMd guarantees rediscoverability, but, as will be shown inthis section, is sensitive to both infrequent and incomplete behaviour. To solvethis, we introduce two more algorithms using the IMd framework.

16 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
Infrequent Behaviour. Infrequent behaviour in an event log is behaviour thatoccurs less frequent than ‘normal’ behaviour, i.e. the exceptional cases. For in-stance, most complaints sent to an airline are handled according to a model, buta few complaints are so complicated that they require ad-hoc solutions. Thisbehaviour could be of interest or not, which depends on the goal of the analysis.
Consider again directly-follows graph D3, shown in Figure 7b, and sup-pose that there is a single directly-follows edge added, from c to d. Then,(×, {b, c}, {d, e}) is not a perfectly matching cut, as with the addition of thisedge the two parts {b, c} and {d, e} became connected. Nevertheless, as 9 tracesshowed exclusive-choice behaviour and only one did not, this single trace isprobably an outlier and in most cases, a model ignoring this trace would bepreferable.
To handle these infrequent cases, we apply a strategy similar to IMf [43]and use the IMd framework to define another discovery algorithm: InductiveMiner - infrequent - directly-follows (IMfD). Infrequent behaviour introducesedges in the directly-follows graph that violate cut requirements. As a result, asingle edge makes it impossible to detect an otherwise very strong cut. To handlethis, IMfD first searches for existing cuts as described in Section 4.1. If none isfound (when IMd would select a fall through), the graph is filtered by removingedges which are infrequent with respect to their neighbours. Technically, for aparameter 0 ≤ h ≤ 1, for an activity a we keep the outgoing edges that occurmore than h times the most occurring outgoing edge of a (a formal definition isgiven in [42, Appendix A]). Start and end activities are filtered similarly.
a b
c d
3
211
3
2 3
23
2
11
1
Figure 9: An incomplete directly-follows graph.
Incompleteness. A log in a “big-data setting” can be assumed to contain lots ofbehaviour. However, we only see example behaviour and we cannot assume tohave seen all possible traces, even if we use the rather weak notion of directly-follows completeness [44] as we do here. Moreover, sometimes smaller subsetsof the log are considered, for instance when performing slicing and dicing inthe context of process cubes [5]. For instance, an airline might be interested incomparing the complaint handling process for several groups of customers, togain insight in how the process relates to age, city and frequent-flyer level ofthe customer. Then, there might be combinations of age, city and frequent-flyer

Scalable Process Discovery and Conformance Checking 17
level that rarely occur and the log for these customers might contain too littleinformation.
If the log contains little information, edges might be missing from the directly-follows graph and the underlying real process might not be rediscovered. Fig-ure 9 shows an example: the cut ({a, b}, {c, d}) is not a parallel cut as the edge(c, b) is missing. As the event log only provides example behaviour, it could bethat this edge is possible in the process, but has not been seen yet. Given thisdirectly-follows graph, IMd can only give up and return a fall-through flowermodel, which yields a very imprecise model. However, choosing the parallel cut({a, b}, {c, d}) would obviously be a better choice here, providing a better preci-sion.
To handle incompleteness, we introduce Inductive Miner - incompleteness -directly-follows (IMcD), which adopts ideas of IMc [44] into the IMd frame-work. IMcD first applies the cut detection of IMd and searches for a cut thatperfectly matches a characteristic. If that fails, instead of a perfectly matchingcut, IMcD searches for the most probable cut of the directly-follows graph athand.
IMcD does so by first estimating the most probable behavioural relationbetween any two activities in the directly-follows graph. In Figure 9, the activitiesa and b are most likely in a sequential relation as there is an edge from a to b.a and c are most likely in parallel as there are edges in both directions. Loopsand choices have similar local characteristics. For each pair of activities x and ythe probability Pr(x, y) that x and y are in relation R is determined. The bestcut is then a partition into sets of activities X and Y such that the averageprobabilities that x ∈ X and y ∈ Y are in relation R is maximal. For a formaldefinition, please refer to [44].
In our example, the probability of cut (∧, {a, b}, {c, d}) is the average prob-ability that (a, c), (a, d), (b, c) and (b, d) are parallel. IMcD chooses the cut withhighest probability, using optimisation techniques. This approach gives IMcD arun time exponential in the number of activities, but still requires a single passover the event log.
4.3 Limitations
The IMd framework imposes some limitations on process discovery. We dis-cuss limiting factors on the challenges identified in Section 2: rediscoverability,handling incompleteness, handling noise and handling infrequent behaviour, andbalancing fitness, precision, generalisation and simplicity.
Limitations on rediscoverability of the IMd framework are similar to the IMframework: the system must be a process tree and adhere to some restrictions,and the log must be directly-follows complete (as discussed before). If the sys-tem does not adhere to the restrictions, then IMd framework will not give upbut rather try to discover as much process-tree like behaviour as possible. Forinstance, if a part of the process is sequential, then IMd framework might beable to discover this, even though the other parts of the process are not block-structured. Therefore, in practice, such models can be useful [22,16]. To formally

18 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
investigate what happens on non-block structured models would be an interest-ing subject of further study. For the remaining non-block structured parts, theflexibility of IMd framework easily allows for future customisations, e.g. [48].
If the log is incomplete, in some cases log-based discovery techniques mighthandle this incompleteness better. For instance, take the process tree P1 =∧(a, b, c) and an event log L = {〈a, b, c〉, 〈c, b, a〉, 〈b, a, c〉, 〈a, c, b〉}. Figure 10ashows the directly-follows graph of L. Log L is not directly-follows completewith respect to P1, as the edge (c, a) is missing. Both IM and IMd will firstdetect a concurrent cut (∧, {a, c}, {b}). The sub-logs after splitting by IM are{〈a, c〉, 〈c, a〉} and {〈b〉}, in which the missing directly-follows edge a, c pops upand enables the rediscovery of P1. In IMd, however, the directly-follows graphis split, resulting in the directly-follows graph for a, c shown in Figure 10b, fromwhich P1 cannot be rediscovered. In Section 6, we will illustrate that the effectof this limitation is limited on larger examples.
a
b
c
(a) directly-follows graph ofL.
a c
(b) after splitting by IMd.
a
c
b
(c) the directly-follows graphof both P2 and L2.
Figure 10: A directly-follows graph that does not suffice to discover concurrencywhere the log does (a, b) and an ambiguous directly-follows graph (c).
If the log contains noise and/or infrequent behaviour, then the IMd frame-work might choose a wrong cut at some point (as discussed in Section 4.2),possibly preventing rediscovery of the system. The noise handling abilities of log-based and directly-follows based algorithms differ in details; in both, noise andinfrequent behaviour manifest as superfluous edges in a directly-follows graph.On one hand, in IM, such wrong edges might pop up during recursion by reas-oning similar to the incompleteness case (which could be harmful), while usingthe same reasoning, log-based algorithms might have more information availableto filter such edges again (which could be beneficial). In the evaluation, we willinvestigate this difference further.
Given an event log, both types of algorithms have to balance fitness, precision,generalisation and simplicity. For directly-follows based algorithms, this balancemight be different.
For instance, a desirable property of discovery algorithms is the ability to pre-serve fitness, i.e. to discover a model that is guaranteed to include all behaviour

Scalable Process Discovery and Conformance Checking 19
seen in the event log. For directly-follows based algorithms, this is challenging.For instance, Figure 10c shows a complete directly-follows graph of the pro-cess tree P2 = ∧(→(a, b), c). However, it is also the directly-follows graph ofthe event log L2 = {〈a, c, b, c, a, b〉, 〈c〉}. Hence, if a fitness-preserving directly-follows based discovery algorithm would be applied to the directly-follows graphin Figure 10c, this algorithm could not return P2 and has to seriously under-fit/generalise to preserve fitness since the behaviour of both needs to be included.Hence, P2 could never be returned. Therefore, we chose the IMd framework tonot guarantee fitness, while the IM framework by its log splitting indirectly takessuch concurrency dependencies into account. Please note that this holds for anypure directly-follows based process discovery algorithm (see the limitations ofthe α-algorithm). Generalisation, i.e. the likelihood that future behaviour willbe representable by the model, is similarly influenced.
Algorithms of the IM framework can achieve a high log-precision if it canavoid fall-throughs such as the flower model [43]. Thus, IM framework achievesthe highest log-precision if it can find a cut. The same holds for IMd framework,and therefore we expect log-precision to largely depend on the cut selection. Inthe evaluation, we will investigate log-precision further.
The influence of directly-follows based algorithms on simplicity highly de-pends on the chosen simplicity measure: both IM framework and IMd frameworkreturn models in which each activity appears once.
5 Comparing Models to Logs and Models
We want to evaluate and compare our algorithm to other algorithms regardingseveral criteria.
– First, we want to compare algorithms based on the size of event logs theycan handle, as well as the quality of the produced models. In particular bothrecall/fitness and precision (with respect to the given system-model or log)need to be compared, as trivial models exist that achieve either perfect recallor perfect precision, but not both.
– Second, we want to assess under which conditions the new algorithms achieverediscoverability, i.e. under which conditions the partial or incorrect inform-ation in the event log allows to obtain a model that has exactly the samebehaviour as the original system that produced the event log. More formally,under which conditions (and up to which sizes of systems) has the discoveredmodel the same language as the original system.
Measuring model quality is crucial in typical process mining workflows asshown in the introduction. However, as discussed in Section 2, existing tech-niques for measuring model quality (on log or model) cannot handle large andcomplex logs and processes. Our technique has to overcome two difficulties: (1)it has to compute precision and recall of very large, possibly infinite languages;and (2) it should allow a fine-grained measurement of precision and recall allow-ing to identify particular activities or behavioural relations where the the modeland the log/other model differ.

20 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
We first introduce this technique for measuring recall and precision of twomodels - with the aim of analysing rediscoverability of process mining algorithms(Section 5.1). Second, we adopt this technique to also compare a discoveredmodel to a (possibly very large) event log (Section 5.2). We use the techniquesin our evaluation in Section 6.
5.1 Model-Model Comparison
The recall of a model S and a model M describes the part of the behaviour ofS that is captured by M (compare to the conventional fitness notion in processmining), while precision captures the part of the behaviour of M that is alsopossible in S.
For a complex model S and a complex model M , direct language-based com-parison of the two models by constructing and comparing their state spaces mightsuffer from the state explosion problem, and hence be prohibitively expensive.Therefore, the framework approximates recall and precision by measuring themon subsets of activities, i.e. we avoid the state explosion problem by consideringsmall submodels, and averaging over all such subsets. The framework is applic-able to any process model formalism and process discovery algorithm, as long asthe languages of the models used can be described as deterministic finite auto-mata (DFAs). We first introduce the general idea of the framework, after whichwe describe its steps in more detail.
process model
project on a1 ... akproject on a1 ... ak
DFA DFA
recallprecision
process model
Figure 11: Evaluation framework for process discovery algorithms.
Framework Figure 11 gives an overview of the model-model evaluation frame-work; formally, the framework takes as input a model S, a model M and aninteger k. S and M must be process models, but can be represented using anyformalism with executable semantics.
To measure recall and precision of S and M , we introduce a parameterisedtechnique in which k defines the size of the subsets of activities for which recall

Scalable Process Discovery and Conformance Checking 21
and precision shall be computed. Take a subset of activities A = {a1 . . . ak},such that A ⊆ Σ(M) ∪ Σ(S), and |A| = k. Then, S and M are projected ontoA, yielding S|A and M |A (we will show how the projection is performed below).From these projected S|A and M |A, deterministic finite automata (DFAs) aregenerated, which are compared to quantify recall and precision. These steps arerepeated for all such subsets A, and the average recall and precision over allsubsets is reported.
As we aim to apply this method to test rediscoverability, a desirable propertyis that precision and recall should be 1 if and only if L(S) = L(M). Theorem 1,given later, states that this is the case for the class of process trees used in thispaper.
As a running example, we will compare two models, being a process tree anda Petri net. Both are shown in Figure 12.
×(∧(a, b),(c, d))
(a) Process tree S.
a
c
b
(b) Petri net M .
Figure 12: Example models S and M .
In the remainder of this section, we describe the steps of the framework inmore detail after which we give an example and prove Theorem 1.
Projection Many process formalisms allow for projection on subsets of activ-ities; we give a definition for process trees here and sketch projection for Petrinets in [42, Appendix E].
A process tree can be projected on a set of activities A = {a1 . . . ak} byreplacing every leaf that is not in A with τ : (in which ⊕ is any process treeoperator)
a|A = if a ∈ A then a else τ
τ |A = τ
⊕(M1 . . .Mn)|A = ⊕(M1|A . . .Mn|A)
After projection, a major problem reduction (and speedup) can be achieved byapplying structural language-preserving reduction rules to the process tree, suchas the rules described in [42, Appendix B].
In principle, any further language preserving state-space reduction rules canbe applied; we will not explore further options in this paper.
If we project our example process tree and Petri net onto activities a and b,we obtain the models as shown in Figure 13.

22 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
×(∧(a, b),(τ, τ))
(a) S|a,b.
×(∧(a, b), τ)
(b) S|a,b reduced.
a
b
(c) M |a,b.
Figure 13: Example models S and M projected/reduced.
Process Model to Deterministic Finite Automaton An automaton de-scribes a language based on an alphabet Σ. The automaton starts in its initialstate; from each state, transitions labelled with activities from Σ denote the pos-sible steps that can be taken from that state. A state can be an accepting state,which denotes that a trace which execution ends in that state is accepted bythe automaton. An automaton with a finite set of states is a non-deterministicfinite automaton (NFA). In case that the automaton does not contain a statefrom which two transitions with the same activity leave, the automaton is adeterministic finite automaton (DFA). Each NFA can be translated into a DFAand a language for which a DFA exist is a regular language; for each DFA, thereexists a reduced unique minimal version [47].
Process tree are defined using regular expressions in [42, Appendix A], whichcan be transformed straightforwardly into an NFA (we used the implementa-tion [49], which provides a shuffle-operator). Secondly, a simple procedure trans-forms the NFA into a DFA [47].
The translation of our example S|{a,b} and M |{a,b} to DFAs results in theautomata shown in figures 14a and 14b.
s1 s2
s3s4
a
bb
a
(a) DFA(S|{a,b}).
m1 m2
m3
a
bb
(b) DFA(M |{a,b}).
s1m1 s2m2
s3m3
a
b
(c) DFAc(S,M, {a, b}).
Figure 14: DFAs for S and M projected to {a, b} and reduced, and their con-junction.
Comparing Deterministic Finite Automata Precision is defined as thepart of behaviour in M |A that is also in S|A. Therefore, first the conjunction

Scalable Process Discovery and Conformance Checking 23
Table 1: Outgoing edge counting of our running example.recall for activity subset {a, b}
state in DFA(S|{a,b}) outgoing edges state in DFAc(S,M, {a, b}) outgoing edges
s1 3 s1m1 1s2 1 s2m2 1s3 1 s3m3 1s4 1 - 0
precision for activity subset {a, b}state in DFA(M |{a,b}) outgoing edges state in DFAc(S,M, {a, b}) outgoing edges
m1 2 s1m1 1m2 1 s2m2 1m3 1 s3m3 1
DFA(S|A)∩DFA(M |A) (which we abbreviate to DFAc(S,M,A)) of these DFAs isconstructed, which accepts the traces accepted by both S|A and M |A. Figure 14cshows the conjunctive DFA of our running example. Then, precision is measuredsimilarly to several existing precision metrics, such as [8]: we count the outgoingedges of all states in DFA(M |A), and compare that to the outgoing edges of thecorresponding states (s,m) in DFAc(S,M,A) (for ease of notation, we consideran automaton as a set of states here):
precision(S,M,A) =∑m∈DFA(M |A)
∑(s,m)∈DFAc(S,M,A) outgoing edges of (s,m) in DFAc(S,M,A)∑
m∈DFA(M |A)
∑(s,m)∈DFAc(S,M,A) outgoing edges of m in DFA(M |A)
If DFA(M |A) has no edges at all (i.e. describes the empty language), we define
precision(S,M,A) =
{0 if DFAc(S,M,A) has edges
1 if DFAc(S,M,A) has no edges
Please note that we count acceptance as an outgoing edge, and that states maybe counted multiple times if they are used multiple times in DFAc. Recall isdefined as the part of behaviour in S|A that is not in M |A, i.e. recall(S,M,A) =precision(M,S,A). In our example (see Table 1), recall for (a, b) is 1+1+1
3+1+1+1 =
0.5; precision is 1+1+12+1+1 = 0.75.
Over all activities For an alphabet Σ, finally the previous steps are repeatedfor each set of activities {a1 . . . ak} ⊆ Σ of size k and the results are averaged:
recall(S,M, k) =
∑A⊆Σ(S)∪Σ(M)∧|A|=k recall(S,M, a1 . . . ak)
|{A ⊆ Σ(S) ∪Σ(M) ∧ |A| = k}|
precision(S,M, k) = recall(M,S, k)

24 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
Note that we assume a closed-world here, i.e. the alphabet Σ is assumed tobe the same for S and M . If an activity is missing from M , we therefore considerM to express that the activity can never happen.
Framework Guarantees Using these definitions, we prove that the frameworkis able to detect language equivalence between process trees of the class that canbe rediscovered by IM and IMd. This theorem will be useful in later evaluations,where from recall and precision being 1, we can conclude that the system wasrediscovered.
Theorem 1. Let S and M be process trees without duplicate activities andwithout τs. Then, recall(S,M, 2) = 1∧precision(S,M, 2) = 1⇔ L(S) = L(M).
The proof strategy is to prove the two directions of the implication separ-ately, using that for such trees, there exists a language-unique normal form [40,Corollary 15]. For a detailed proof, see [42, Appendix C]. As for sound free-choiceunlabeled workflow nets without short loops the directly-follows graph defines aunique language [57], Theorem 1 applies to these nets as well.
Corollary 2. Let S and M be sound free-choice unlabelled workflow nets withoutshort loops. Then, recall(S,M, 2) = 1∧precision(S,M, 2) = 1⇔ L(S) = L(M).
Unfortunately, this theorem does not hold for general process trees. For in-stance, take S = ×(a, b, c, τ) and M = ×(a, b, c). For k = 2, the framework willconsider the subtrees ×(a, b, τ), ×(a, c, τ) and ×(b, c, τ) for both S and M , thuswill not spot any difference: recall = 1 and precision = 1, even though thelanguages of S and M are clearly different. Only for k = 3, the framework willdetect the difference.
In Section 6, we use the algorithm framework to test incompleteness, noiseand infrequent behaviour on large models. Before that, we first show that theideas of the framework can also be used to compare models to event logs.
5.2 Log-Model Comparison
In order to evaluate models with respect to event logs, the framework in Sec-tion 5.1 is adapted as follows: Figure 15 shows an overview: the frameworkstarts from an event log L and a model M (in a process mining setting, Mwould have been discovered from L). First, L and M are projected on a setof activities A. A log is projected by removing the non-projected events, e.g.{〈a, b, c〉, 〈c, d〉}|{a,b} = {〈a, b〉, 〈 〉}. Second, from both projections a DFA is con-structed. Precision is computed as in Section 5.2, i.e. by comparing DFA(L|A)and DFA(M |A). For fitness, it is desirable that the frequencies of traces are takeninto account, such that a trace that appears 10,000 times in L contributes moreto the fitness value than a trace that appears just once. Therefore, we computefitness as the fraction of traces of L|A that can be replayed on DFA(M |A):
fitness(L,M,A) =|[t ∈ L|A|t ∈ DFA(M |A)]|
|L|A|

Scalable Process Discovery and Conformance Checking 25
event log process model
project on a1 ... akproject on a1 ... ak
DFA
�tnessprecision
DFA
Figure 15: Evaluation approach for logs vs models.
If the log contains no traces, we define fitness to be 1.Note that L is a multiset: if a trace appears multiple times in L, it contrib-
utes multiple times as well. This is repeated for all subsets of activities A of acertain length k, similarly to the model-model comparison. Note that besides afitness/precision number, the subsets A also provide clues where deviations inthe log and model occur.
6 Evaluation
To understand the impact of “big data” event logs on process discovery andquality assessment, we conducted a series of experiments to answer the followingresearch questions:
RQ1 What is the largest event log (number of events/traces or number of activ-ities) that process discovery algorithms can handle?
RQ2 Are single-pass algorithms such as the algorithms of the IMd frameworkable to rediscover the system? How large do event logs have to be in orderto enable this rediscovery? How do these algorithms compare to classicalalgorithms?
RQ3 Can the system also be rediscovered if an event log contains unstructurednoise or structured infrequent behaviour? How does model quality of thenewly introduced algorithms suffer compared to other algorithms?
RQ4 Can pcc framework handle logs that existing measures cannot handle? Howdo both sets of measures compare on smaller logs?

26 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
To answer the first three questions, we conducted four similar experiments, asshown in Figure 16: we choose a system, generate an event log and discover aprocess model, after which we measure how well the discovered model representsthe system using log-precision and recall. Of these experiments, one focuseson scalability, i.e. the ability in handling big event logs and complex systems(Section 6.1); handling incompleteness (Section 6.2), handling noise (Section 6.3)and handling infrequent behaviour (Section 6.4).
event log process modelsystem
discovergenerate
recalllog-precision
Figure 16: Set-up of our evaluation.
To answer RQ4, we conducted another experiment: we use real-life logs, applydiscovery algorithms and measure fitness and log-precision, using both the pccframework and existing measures (Section 6.5). All algorithms of the IMd frame-work and pcc framework are implemented as plug-ins of the ProM framework1,taking as input a directly-follows graph. Directly-follows graphs were generatedusing an external Python script. For more details on the set-up, please refer to[42, Appendix D].
6.1 Scalability of IMd vs Other Discovery Algorithms
First, we compare the IMd algorithms with several other discovery algorithmsin their ability to handle big event logs and complex systems using limited mainmemory.
Set-up. All algorithms were tested on the same set of XES event logs, whichhave been created randomly from three process trees, of (A) 40 activities, (B)1,000 activities and (C) 10,000 activities. The three trees have been generatedrandomly.
For each tree, we first generate a random log of t traces, starting t at 1.Second, we test whether an algorithm returns a model for that log when allocated2GB of main memory, i.e. the algorithm terminates with a result and does notcrash. If successful, we multiply t by 10 and repeat the procedure. The maximumt is recorded for each algorithm and process tree A, B and C.
1 Available for download at http://promtools.org

Scalable Process Discovery and Conformance Checking 27
Besides the new algorithms introduced in this paper, the following algorithmswere included in the experiment:
α-algorithm (α) [7] ProM 6.5.1aHeuristics Miner (HM) [60] ProM 6.5.1aInteger Linear Programming (ILP) [63] ProM 6.5.1aimmediately follows cnet from log (P-IF) [24] PMLABpn from ts (P-PT) [24] PMLABInductive Miner (IM) [40] ProM 6.5.1aInductive Miner - infrequent (IMf) [43] ProM 6.5.1aInductive Miner - incompleteness (IMc) [44] ProM 6.5.1aIM - directly-follows (IMd) this paper ProM 6.5.1aIM - infrequent - directly-follows (IMfD) this paper ProM 6.5.1aIM - incompleteness - directly-follows (IMcD) this paper ProM 6.5.1a
The soundness-guaranteeing algorithms ETM, CCM and MPM were not in-cluded, as ETM is a non-deterministic algorithm and there is no implementationavailable for CCM and MPM. It would be interesting to test these as well.
Event Logs. The complexities of the event logs are shown in Table 2; they weregenerated randomly from trees A, B or C. From this table, we can deduce thatthe average trace length in (A) is 37 events, in (B) 109 and in (C) 764; [42,Appendix F] shows additional statistics. Thus, the average trace length increaseswith the number of activities.
The largest log we could generate for A was 217GB (108 traces), limited bydisk space. For the trees B and C, the largest logs we could generated were 106
and 105 traces, limited by RAM. For the bigger logs, the traces were directlytransformed into a directly-follows graph and the log itself was not stored. InTable 2, these logs are marked with *.
Compared with [41], tree B was added and the logs of trees A and C wereregenerated. Therefore, the log generated for these trees are slightly differentfrom [41]. However, the conclusions were not influenced by this.
Results. Table 3 shows the results. Results that could not be obtained are markedwith * (for instance, IMc and IMcD ran for over a week without returning aresult).
This experiment clearly shows the scalability of the IMd framework, whichhandles larger and more complex logs easily (IMd and IMfD handle 108
traces, 7 ∗ 1010 events and 104 activities). Moreover, it shows the inability of ex-isting approaches to handle larger and complex logs: the most scalable otheralgorithms were IM and IMf, that both handled only 1,000 traces. Furthermore,it shows the limited use sampling would have on such logs (logs manageable forother algorithms, i.e. 1,000 traces for tree C, do not contain all activities yet).We discuss the results in detail in [42, Appendix G].
Time. Timewise, it took a day to obtain a directly-follows graph from the log of108 traces of tree A, (using the pre-processing Python script) after that discover-ing a process model was a matter of seconds for IMd and IMfD. For the largest

28 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
Table 2: log complexity (* denotes that a directly-follows graph was generated).A: 40 activities B: 1,000 activities C: 10,000 activities
complex more complextraces events activities events activities events activities
1 21 21 190 52 81 6610 309 40 922 359 8,796 1,932
102 3,567 40 9,577 802 77,664 7,195103 37,415 40 112,821 973 780,535 9,589104 370,687 40 1,106,495 999 7,641,398 9,991105 3,697,424 40 10,908,461 1,000 76,663,981 10,000106 36,970,718 40 109,147,057 1,000 764,585,193 *10,000107 369,999,523 40 1,090,802,965 *1,000 7,644,466,866 *10,000108 3,700,046,394 40 10,908,051,834 *1,000 76,477,175,661 *10,000
Table 3: scalability: maximum number of traces an algorithm could handle.A: 40 activities B: 1,000 activities C: 10,000 activities
traces traces traces
α 10,000 100 1HM 1,000,000 1,000,000 1ILP 1,000 100 1P-IF 10,000 *0 *1P-PT 10,000 *0 *1IM 100,000 100,000 1,000IMd 100,000,000 100,000,000 100,000,000IMf 100,000 100,000 1,000IMfD 100,000,000 100,000,000 100,000,000IMc † 100,000 1 *10IMcD † 100,000,000 1 *10
logs they could handle, P-IF, α, HM, IM, IMf and IMc took a few minutes;P-PT took days, ILP a few hours. In comparison, on the logs that ILP couldhandle, creating a directly-follows graph took a few seconds, just as applyingIMd.
6.2 The Influence of Incompleteness on Rediscoverability
To answer RQ2, i.e. whether single-pass algorithms are able to rediscover thesystem, how large logs need to be in order to enable rediscovery, and how thesealgorithms compare to classical algorithms, we performed a second experiment.In complex processes, such as B and C, information can be missing from logsif the logs are not large enough: Table 2 shows that in our example, 105 traceswere necessary for B to have all activities appear in the log.
Set-up. For each model generated in the scalability experiment, we measurerecall and precision with respect to tree A, B or C using the pcc framework.

Scalable Process Discovery and Conformance Checking 29
Given the results of the scalability experiment, we include the algorithms IM,IMf, IMc, HM, IMd, IMfD, IMcD, and a baseline model allowing for anybehaviour (a flower model).
As HM does not guarantee to return a sound model, nor provides a finalmarking, we obtain a final marking using the method described in [42, Ap-pendix E]. However, even with this method we were unable to determine thelanguages of the models returned by HM, thus these were excluded.
Results. Figure 17 shows that for model A (40 activities) both IM and IMdrediscover the language of A (a model that has 1.0 model-precision and recallwith respect to A) on a log of 104 traces. IMd could rediscover the language of Bat 108 traces, IM did not succeed as the largest log it could handle (105 traces)did not contain enough information to rediscover the language of B. The largestlog we generated for tree C, i.e. containing 108 traces, did not contain enoughinformation to rediscover the language of C: IMfD discovered a model with arecall of running. . . and a model-precision of running. . . . Corresponding resultshave been obtained for IMf/IMfD and IMc/IMcD; see [42, Appendix H] forall details. The flower model provided the baseline for precision: it achieved recall1.0 at 101 (A) and 102 (B) traces, and achieves a model-precision of 0.8.
100 102 104 1060
0.2
0.4
0.6
0.8
1
number of traces
reca
ll/pre
cisi
on
IM
100 102 104 1060
0.2
0.4
0.6
0.8
1
number of traces
IMd
recall; precision
Figure 17: Incompleteness results for process tree A (40 activities).
We conclude that algorithms of the IMd framework are capable of rediscov-ering the original system, even in case of very large systems (trees B and C), andthat these algorithms do not require larger logs than other algorithms to do so:IM and IMd rediscovered the models on logs of the same sizes; for smaller logsIMd performed slightly better than IMfD. Overall, IMd and IMfD have a sim-ilar robustness to incomplete event logs as their IM counterparts, which makesthem more robust than other algorithms as well [44]. We discuss the results indetail in [42, Appendix G].
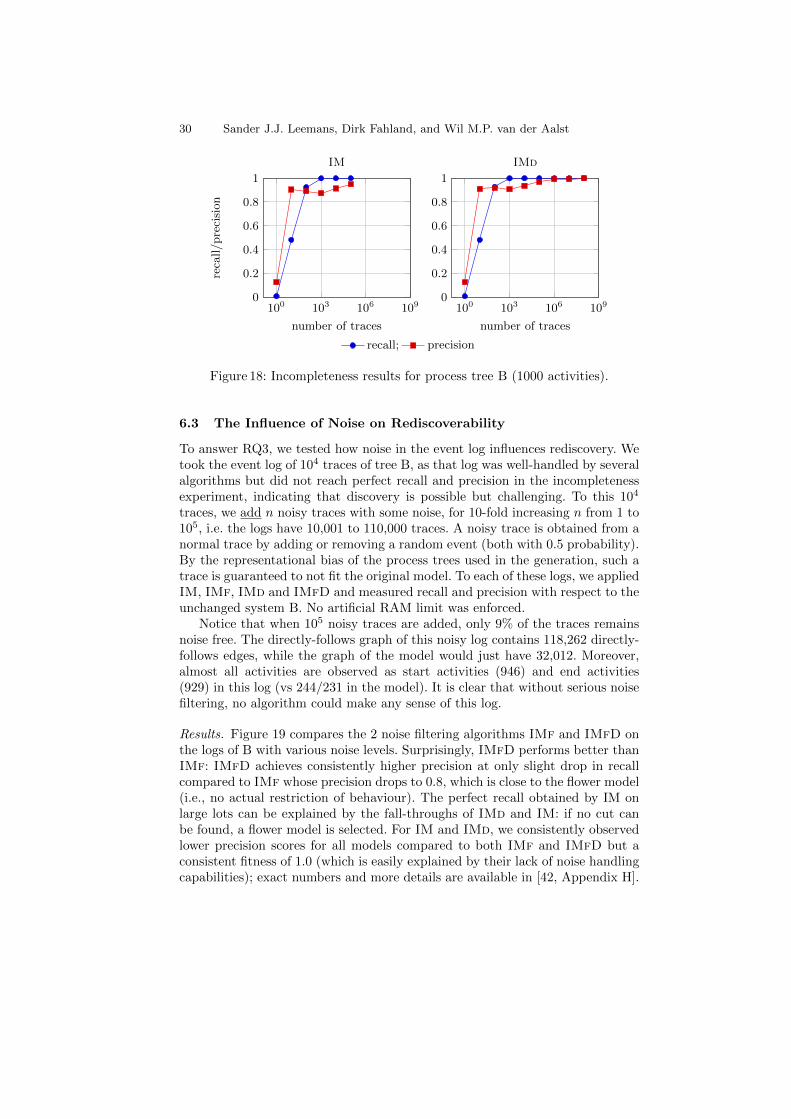
30 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
100 103 106 1090
0.2
0.4
0.6
0.8
1
number of traces
reca
ll/pre
cisi
on
IM
100 103 106 1090
0.2
0.4
0.6
0.8
1
number of traces
IMd
recall; precision
Figure 18: Incompleteness results for process tree B (1000 activities).
6.3 The Influence of Noise on Rediscoverability
To answer RQ3, we tested how noise in the event log influences rediscovery. Wetook the event log of 104 traces of tree B, as that log was well-handled by severalalgorithms but did not reach perfect recall and precision in the incompletenessexperiment, indicating that discovery is possible but challenging. To this 104
traces, we add n noisy traces with some noise, for 10-fold increasing n from 1 to105, i.e. the logs have 10,001 to 110,000 traces. A noisy trace is obtained from anormal trace by adding or removing a random event (both with 0.5 probability).By the representational bias of the process trees used in the generation, such atrace is guaranteed to not fit the original model. To each of these logs, we appliedIM, IMf, IMd and IMfD and measured recall and precision with respect to theunchanged system B. No artificial RAM limit was enforced.
Notice that when 105 noisy traces are added, only 9% of the traces remainsnoise free. The directly-follows graph of this noisy log contains 118,262 directly-follows edges, while the graph of the model would just have 32,012. Moreover,almost all activities are observed as start activities (946) and end activities(929) in this log (vs 244/231 in the model). It is clear that without serious noisefiltering, no algorithm could make any sense of this log.
Results. Figure 19 compares the 2 noise filtering algorithms IMf and IMfD onthe logs of B with various noise levels. Surprisingly, IMfD performs better thanIMf: IMfD achieves consistently higher precision at only slight drop in recallcompared to IMf whose precision drops to 0.8, which is close to the flower model(i.e., no actual restriction of behaviour). The perfect recall obtained by IM onlarge lots can be explained by the fall-throughs of IMd and IM: if no cut canbe found, a flower model is selected. For IM and IMd, we consistently observedlower precision scores for all models compared to both IMf and IMfD but aconsistent fitness of 1.0 (which is easily explained by their lack of noise handlingcapabilities); exact numbers and more details are available in [42, Appendix H].

Scalable Process Discovery and Conformance Checking 31
100 101 102 103 104 1050
0.2
0.4
0.6
0.8
1
noisy traces added
reca
ll/pre
cisi
on
IMf 0.2
100 101 102 103 104 1050
0.2
0.4
0.6
0.8
1
noisy traces added
IMfD 0.2
recall; precision
Figure 19: Algorithms applied to logs with noisy traces (tree B (1,000 activities)).
A manual inspection of the models returned shows that all models still giveinformation on the overall structure of the system, while for larger parts of themodel no structure could be discovered and a flower sub-model was discovered.In this limited experiment, IMfD is the clear winner: it keeps precision highestin return for a little drop in recall. We suspect that this is due to IMfD usingless information than IMf and therefore the introduced noise has a larger impact(see Section 4.3). More experiments need to evaluate this hypothesis.
6.4 The Influence of Infrequent Behaviour on Rediscoverability
To answer the second part of RQ3 we investigated how infrequent behaviour,i.e. structured deviations from the system, influences rediscovery. The set-up ofthis experiment is similar to the noise experiment, i.e. t deviating traces areadded. Each deviating trace contains one structural deviation from the model,e.g. for an ×, two children are executed. For more details, please refer to [42,Appendix D].
Similar to the noise experiment, the log with 105 added infrequent traceshas a lot of wrong behaviour: without infrequent behaviour, its directly-followsgraph would contain 32, 012 edges, 244 start activities and 231 end activities,but the deviating log contained 118, 262 edges, 946 start activities and 929 endactivities. That means that if one would randomly pick an edge from the log,there would be only 27% chance that the chosen edge would be according to themodel. Exact numbers and more details are available in [42, Appendix H].
Results. Figure 20 shows the results of IMf and IMfD on logs of process treeB with various levels of added infrequent behaviour. Similar to the noise exper-iments, IMfD compared to IMf trades recall (0.95 vs 0.99) for log-precision(0.95 vs 0.90). Of the non-filtering versions IM and IMd, both got a recall of0.99, IM a model-precision of around 0.90, and IMd 0.92, thus IMd performs abit better in this experiment.

32 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
100 101 102 103 104 1050
0.2
0.4
0.6
0.8
1
infrequent traces added
reca
ll/pre
cisi
on
IMf 0.2
100 101 102 103 104 1050
0.2
0.4
0.6
0.8
1
infrequent traces added
IMfD 0.2
recall; precision
Figure 20: Infrequent behaviour results of process tree B (1000 activities).
We suspect that two of the inserted types of infrequent behaviour might beof influence here: skipping a child of a→ or ∧ has no troublesome impact on thedirectly-follows graph for the IM framework, but log splitting will introduce a(false) empty trace for the IM framework; IM framework algorithms must decideto ignore this empty trace in later recursions, while IMd framework algorithmssimply don’t see it. Altogether, IMfD performs remarkably well and stable inthis typical case of process discovery where an event log contains structureddeviations from the system.
6.5 Real-Life Model-Log Evaluation
To test real-life performance of the new algorithms and to answer RQ4, i.e.whether the newly introduced fitness and precision measures can handle largerlogs and how they compare to existing measures, we performed a fourth experi-ment.
Experimental Set-up. In this experiment, we take four real-life event logs.To these event logs, we apply the algorithms α, HM, IM, IMf, IMd and IMfDand analyse the resulting models manually. The algorithms CCM and MPM arenot publicly available and were excluded.
Secondly, in order to evaluate the pcc framework, we apply the pcc frame-work and existing fitness [1] and log-precision [10] measures to the discoveredmodels. The models by HM and α were unsound and had to be excluded (ourunsoundness-handling tricks in [42, Appendix E] brought no avail). Furthermore,IM and IMd do not apply noise filtering and therefore their models are oftenflower models, so these were excluded as well.
To provide a baseline for log-precision, we add a flower model to the com-parison: a flower model allows for all behaviour, so intuitively has the worst

Scalable Process Discovery and Conformance Checking 33
precision. Therefore, we scale (normalised) the log-precision according to thisbaseline:
scaled log-precision = 1− 1− log-precision of model
1− log-precision of flower model
Intuitively, scaled precision denotes the linear precision gain with respect to aflower model, i.e. 0 for the flower model itself and 1 for perfect precision. The pccframework-fitness measure and the existing fitness measure [1] are conceptuallysimilar, so they are not scaled.
Logs. We analysed four real-life logs. The first log (BPIC11) originates fromthe emergency department of a Dutch hospital [28]. BPIC11 describes a fairlyunstructured process, and contains 624 activities, 1,143 traces (patients) and150,291 events. In our classification, it is a complex and medium log. Thesecond log (BPIC12) originates from a Dutch financial institution, and describesa mortgage application process [29]. It contains 23 activities, 13,087 traces (cli-ents) and 164,506 events, and is therefore a medium log. BPIC12 was filtered toonly contain events having the “complete” life cycle transition, i.e. “schedule”and “start” events were removed. The resulting log was included, as well as threeactivity-subsets: activities prefixed by respectively A, O or W (BPIC|A, BPIC|Oand BPIC|W ). The third log (SL) originates from the repeated execution of soft-ware: SL was obtained by recording method calls executed by RapidMiner, using5 operators, each corresponding to plug-ins of RapidProM. The recording wasperformed using the Kieker tool (see http://kieker-monitoring.net), and re-peated 25 times with different input event logs. In total, the event log (SL) has25 traces, 5,869,492 events and 271 activities, which makes it a large. Its tracesare particularly long: up to 1,151,788 events per trace. The fourth log (CS) ori-ginates from a web-site of a dot-com start-up, and represents click-stream data,i.e. every web-site visitor is a trace, and each page visited is an events [37]. CScontains 77,513 traces, 358,278 events and 3,300 activities, which makes it morecomplex and medium. As described in the introduction, much bigger event logsexist. We were able to run IMd and IMfD on larger and more complex logs,but we were unable to compute metrics or even visualise the resulting models.Therefore, we do not report on such logs in this evaluation.
Results for Process Discovery. The first step in this experiment was to applyseveral process discovery algorithms.
On BPIC11, IM, IMf, IMd and IMfD produced a model.On BPIC12, all the algorithms produced a model. We illustrate the results
of the experiments on BPIC12, filtered for activities starting with A (BPIC|A):Figure 21 shows the model returned by IMf; Figure 22 the model by IMfD.This illustrates the different trade-offs made between IM and IMd: these modelsare very similar, except that for IMf, three activities can be skipped. Operatingon the directly-follows abstraction of the log, IMfD was unable to decide to

34 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
make these activities skippable, which lowers fitness a bit (0.816 vs 0.995) butincreases precision (1 vs 0.606).
Figure 21: IMf applied to BPIC12|A (without activity names).
Figure 22: IMfD applied to BPIC12|A (without activity names).
On the SL log, HM, IM, IMf, IMd and IMfD produced a model, and α couldnot proceed beyond passing over the event log. The models discovered by HM,IMf and IMfD are shown in Figure 23 (we uploaded these models to http://
www.processmining.org/blogs/pub2015/scalable_process_discovery_and_
evaluation; these can be drag-and-dropped onto ProM to be visualised). Themodel discovered by HM has 2 unconnected parts, of which one is not containedin the initial marking. Hence it is not a workflow model, thus not sound and, asdiscussed before, difficult to be analysed automatically. In the models discoveredIMf and IMfD, the several RapidProM operators are easily recognisable. How-ever, the models are too complex to be analysed in detail by hand2 Therefore,in further analysis steps, problematic parts of the models by IMf and IMfDcould be identified, the log filtered for them, and the analysis repeated.
On the CS log, IM, IMf, IMd and IMfD produced a model. IMd and IMfDreturned a model in less than 30 seconds using less than 1GB of RAM, whileIM and IMf took more than an hour and used 30GB of RAM. As CS has fivetimes more activities than SL, we could not visualise it. This illustrates thatscalable process discovery is a first step in scalable process mining: the modelswe obtained are suitable for automatic processing, but human analysis withoutfurther visualisation techniques is very challenging.
Results for Log-Conformance Checking. Table 4 shows the results, exten-ded with the approximate running time of the techniques.
2 Anecdotically: the vector-images of these models were too large to be displayed byAdobe Illustrator or Adobe Acrobat.
Scalable Process Discovery and Conformance Checking 35
(a) Impression of the model discovered by HM.
(b) Impression of the model discovered by IMf.
(c) Impression of the model discovered by IMfD.
Figure 23: Models discovered from a software execution log.
Fitness scores according to the pcc framework differ from the fitness scoresby [1] by at most 0.05 (except for BPIC12|A IMfD). Thus, this experimentsuggests that the new fitness measurement could replace the alignment-basedfitness [1] metric, while being generally faster on both smaller and larger logs,though additional experiments may be required to verify this hypothesis. Moreimportantly, the pcc framework could handle logs (BPIC11, SL, CS) that theexisting measure could not handle.
Comparing the scaled precision measures, the pcc framework and the exist-ing approach agree on the relative order of IMf and IMfD for BPIC12|A andBPIC12|O, disagree on BPIC12 and are incomparable on BPIC11, SL and CS dueto failure of the existing measure. For BPIC12|W , IMfD performed worse thanthe flower model according to [10] but better according to our measure. Thismodel, shown in Figure 24, is certainly more restrictive than a flower model,which is correctly reflected by our new precision measure. Therefore, likely theapproach of [10] encounters an inaccuracy when computing the precision score.For BPIC12, precision [10] ranks IMf higher than IMfD, whereas our preci-sion ranks IMfD higher than IMf. Inspecting the models, we found that IMfmisses one activity from the log while IMfD has all activities. Apparently, ournew measure penalises more for a missing activity, while the alignment-basedexisting measure penalises more for a missing structure.
A similar effect is visible for SL: IMf achieves a lower precision than theflower model. Further analysis revealed that several activities were missing from
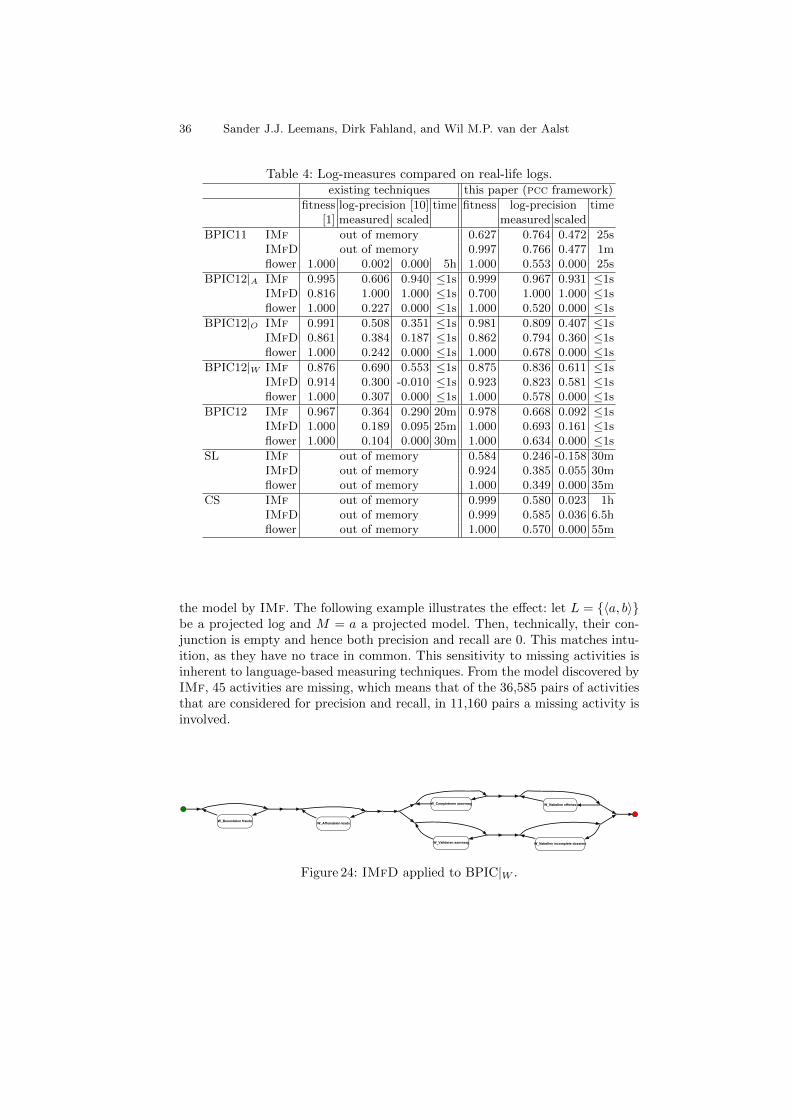
36 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
Table 4: Log-measures compared on real-life logs.existing techniques this paper (pcc framework)
fitness log-precision [10] time fitness log-precision time[1] measured scaled measured scaled
BPIC11 IMf out of memory 0.627 0.764 0.472 25sIMfD out of memory 0.997 0.766 0.477 1mflower 1.000 0.002 0.000 5h 1.000 0.553 0.000 25s
BPIC12|A IMf 0.995 0.606 0.940 ≤1s 0.999 0.967 0.931 ≤1sIMfD 0.816 1.000 1.000 ≤1s 0.700 1.000 1.000 ≤1sflower 1.000 0.227 0.000 ≤1s 1.000 0.520 0.000 ≤1s
BPIC12|O IMf 0.991 0.508 0.351 ≤1s 0.981 0.809 0.407 ≤1sIMfD 0.861 0.384 0.187 ≤1s 0.862 0.794 0.360 ≤1sflower 1.000 0.242 0.000 ≤1s 1.000 0.678 0.000 ≤1s
BPIC12|W IMf 0.876 0.690 0.553 ≤1s 0.875 0.836 0.611 ≤1sIMfD 0.914 0.300 -0.010 ≤1s 0.923 0.823 0.581 ≤1sflower 1.000 0.307 0.000 ≤1s 1.000 0.578 0.000 ≤1s
BPIC12 IMf 0.967 0.364 0.290 20m 0.978 0.668 0.092 ≤1sIMfD 1.000 0.189 0.095 25m 1.000 0.693 0.161 ≤1sflower 1.000 0.104 0.000 30m 1.000 0.634 0.000 ≤1s
SL IMf out of memory 0.584 0.246 -0.158 30mIMfD out of memory 0.924 0.385 0.055 30mflower out of memory 1.000 0.349 0.000 35m
CS IMf out of memory 0.999 0.580 0.023 1hIMfD out of memory 0.999 0.585 0.036 6.5hflower out of memory 1.000 0.570 0.000 55m
the model by IMf. The following example illustrates the effect: let L = {〈a, b〉}be a projected log and M = a a projected model. Then, technically, their con-junction is empty and hence both precision and recall are 0. This matches intu-ition, as they have no trace in common. This sensitivity to missing activities isinherent to language-based measuring techniques. From the model discovered byIMf, 45 activities are missing, which means that of the 36,585 pairs of activitiesthat are considered for precision and recall, in 11,160 pairs a missing activity isinvolved.
Figure 24: IMfD applied to BPIC|W .

Scalable Process Discovery and Conformance Checking 37
This experiment does not suggest that our new measure can directly replacethe existing measure, but precision seems to be able to provide a categorisation,such as good/mediocre/bad precision, compared to the flower model.
Altogether we showed that our new fitness and precision metrics are usefulto quickly assess the quality of a discovered model and decide whether to con-tinue analyses with it or not, in particular on event logs that are too large forcurrent techniques. In addition to simply providing an aggregated fitness andprecision value, both existing and our new technique allow for more fine-graineddiagnostics of where in the model and event log fitness and precision are lost.For instance, by looking at the subsets a1 . . . ak of activities with a low fitness orprecision score, one can identify the activities that are not accurately representedby the model, and then refine the analysis of the event log accordingly.
On most of the event logs, IMfD seems to perform comparably to IMf.However, please notice that by the nature of fitness and log-precision, for eachevent log there exists a trivial model that scores perfectly on both, i.e. the modelconsisting of a choice between all traces. As such a model provides neither anynew information nor insight, generalisation and simplicity have to be taken intoaccount as well. As future work, we would like to adapt generalisation metricsto be applicable to large event logs and complex processes as well.
7 Conclusion
Process discovery aims to obtain process models from event logs, while conform-ance checking aims to obtain information from the differences between a modeland either an event log or a system-model. Currently, there is no process discov-ery technique that works on larger and more complex logs, i.e. containingbillions of events or thousands of activities, and that guarantees both soundnessand rediscoverability. Moreover, current log-conformance checking techniquescannot handle medium and complex logs, and as current process discoveryevaluation techniques are based on log-conformance checking, algorithms can-not be evaluated for medium and complex logs. In this paper, we pushed theboundary on what can be done with larger and more complex logs.
For process discovery, we introduced the Inductive Miner - directly-follows(IMd) framework and three algorithms using it. The input of the frameworkis a directly-follows graph, which can be obtained from any event log in lin-ear time, even using highly-scalable techniques such as Map-Reduce. The IMframework uses a divide-and-conquer strategy that recursively builds a processmodel by splitting the directly-follows graph and recursing on the sub-graphsuntil encountering a base case.
We showed that the memory usage of algorithms of the IMd framework isindependent of the number of traces in the event log considered. In our experi-ments, the scalability was only limited by the logs we could generate. The IMdframework managed to handle over 70 billion events, while using only 2GB ofRAM; some other techniques required the event log to be in main memory andtherefore could handle at most 1 - 10 million events. Besides scalability, we also

38 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
investigated how the new algorithms compare qualitatively to existing techniquesthat use more knowledge, but also have higher memory requirements. The newalgorithms handled systems of 10,000 activities in polynomial time, and were ro-bust to incompleteness, noise and infrequent behaviour. Moreover, they alwaysreturn sound models and suffered little loss in quality compared to multi-passalgorithms; in some cases we even observed quality improvements.
For conformance checking, we introduced the projected conformance checkingframework (pcc framework), that is applicable to both log-model and model-model conformance checking. The pcc framework measures recall/fitness andprecision, by projecting both system and system-model/log onto subsets of activ-ities to determine their recall/fitness and precision. Using this framework, onecan measure recall/fitness and precision of arbitrary models with a boundedstate space of (almost) arbitrary size.
The pcc framework’s model-model capabilities enable a novel way to evaluatediscovery techniques that scales well and provides new insights. We applied thisto test robustness of various algorithms to incompleteness, noise and infrequentbehaviour. Moreover, we showed that the log-model version of the pcc frameworkallows to measure fitness and precision of a model with respect to an event log,even in cases where classical techniques fail, and can give detailed insights intothe location of deviations in both log and model.
Altogether, we have presented the first steps of process mining workflows onvery large data sets: discovering a model and assessing its quality. However, aswe encountered in our evaluation, we envision further steps in the processingand visualisation of large models, such as using natural language based tech-niques [12]. To ease the analyses in contexts of big data, our algorithm evalu-ation framework could be combined with the approach in [15], by having ourframework detecting the problematic sets of activities, and the approach in [15]focusing on these sub-models.
Furthermore, it would be interesting to study the influence of k on the pccframework, both practically and theoretically. As shown in Section 5.1, thereexist cases for which the language equivalence can only be guaranteed if k is atleast the number of nodes minus one. However, besides for the classes for whichTheorem 1 or Corollary 2 holds, there might be other classes of models for whicha smaller k suffices.
References
1. van der Aalst, W., Adriansyah, A., van Dongen, B.: Replaying history on processmodels for conformance checking and performance analysis. Wiley InterdisciplinaryReviews: Data Mining and Knowledge Discovery 2(2), 182–192 (2012)
2. van der Aalst, W.M.P.: Process Mining - Discovery, Conformance and En-hancement of Business Processes. Springer (2011), http://dx.doi.org/10.1007/978-3-642-19345-3
3. van der Aalst, W.M.P.: Decomposing process mining problems using pas-sages. In: Petri Nets 2012. pp. 72–91 (2012), http://dx.doi.org/10.1007/
978-3-642-31131-4_5

Scalable Process Discovery and Conformance Checking 39
4. van der Aalst, W.M.P.: Decomposing Petri nets for process mining: A genericapproach. Distributed and Parallel Databases 31(4), 471–507 (2013), http://dx.doi.org/10.1007/s10619-013-7127-5
5. van der Aalst, W.M.P.: Process cubes: Slicing, dicing, rolling up and drilling downevent data for process mining. In: AP-BPM 2013. pp. 1–22 (2013), http://dx.
doi.org/10.1007/978-3-319-02922-1_1
6. van der Aalst, W.M.P., et al.: Process mining manifesto. In: Business ProcessManagement Workshops 2011. pp. 169–194 (2011), http://dx.doi.org/10.1007/978-3-642-28108-2_19
7. van der Aalst, W., Weijters, A., Maruster, L.: Workflow mining: Discovering pro-cess models from event logs. IEEE Trans. Knowl. Data Eng. 16(9), 1128–1142(2004)
8. Adriansyah, A.: Aligning Observed and Modeled Behavior. Ph.D. thesis, EindhovenUniversity of Technology (2014)
9. Adriansyah, A., van Dongen, B.F., van der Aalst, W.M.P.: Conformance checkingusing cost-based fitness analysis. In: IEEE EDOC 2011. pp. 55–64 (2011), http://dx.doi.org/10.1109/EDOC.2011.12
10. Adriansyah, A., Munoz-Gama, J., Carmona, J., van Dongen, B.F., van derAalst, W.M.P.: Alignment based precision checking. In: Business Process Man-agement Workshops 2012. pp. 137–149 (2012), http://dx.doi.org/10.1007/
978-3-642-36285-9_15
11. Ammons, G., Bodık, R., Larus, J.R.: Mining specifications. In: POPL SIGPLAN-SIGACT 2002. pp. 4–16 (2002), http://doi.acm.org/10.1145/503272.503275
12. Armas-Cervantes, A., Baldan, P., Dumas, M., Garcıa-Banuelos, L.: Beha-vioral comparison of process models based on canonically reduced eventstructures. In: BPM 2014. pp. 267–282 (2014), http://dx.doi.org/10.1007/
978-3-319-10172-9_17
13. Badouel, E.: On the α-reconstructibility of workflow nets. In: Petri Nets’12. LNCS,vol. 7347, pp. 128–147. Springer (2012)
14. Becker, M., Laue, R.: A comparative survey of business process similarity measures.Computers in Industry 63(2), 148–167 (2012), http://dx.doi.org/10.1016/j.
compind.2011.11.003
15. van Beest, N.R.T.P., Dumas, M., Garcıa-Banuelos, L., Rosa, M.L.: Log delta ana-lysis: Interpretable differencing of business process event logs. In: BPM 2015. pp.386–405 (2015), http://dx.doi.org/10.1007/978-3-319-23063-4_26
16. Benner-Wickner, M., Bruckmann, T., Gruhn, V., Book, M.: Process mining forknowledge-intensive business processes. In: I-KNOW 2015. pp. 4:1–4:8 (2015),http://doi.acm.org/10.1145/2809563.2809580
17. Bergenthum, R., Desel, J., Lorenz, R., Mauser, S.: Process mining based on regionsof languages. Business Process Management pp. 375–383 (2007)
18. Bergenthum, R., Desel, J., Mauser, S., Lorenz, R.: Synthesis of Petri nets fromterm based representations of infinite partial languages. Fundam. Inform. 95(1),187–217 (2009)
19. Buijs, J.C.A.M.: Flexible Evolutionary Algorithms for Mining Structured ProcessModels. Ph.D. thesis, Eindhoven University of Technology (2014)
20. Buijs, J., van Dongen, B., van der Aalst, W.: A genetic algorithm for discoveringprocess trees. In: IEEE Congress on Evolutionary Computation. pp. 1–8 (2012)
21. Buijs, J.C.A.M., van Dongen, B.F., van der Aalst, W.M.P.: On the role of fitness,precision, generalization and simplicity in process discovery. In: OTM. LNCS, vol.7565, pp. 305–322 (2012), http://dx.doi.org/10.1007/978-3-642-33606-5_19

40 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
22. Burattin, A.: PLG2: multiperspective processes randomization and simulation foronline and offline settings. CoRR abs/1506.08415 (2015), http://arxiv.org/abs/1506.08415
23. Burattin, A., Sperduti, A., van der Aalst, W.M.P.: Control-flow discovery fromevent streams. In: IEEE Congress on Evolutionary Computation. pp. 2420–2427(2014), http://dx.doi.org/10.1109/CEC.2014.6900341
24. Carmona, J., Sole, M.: PMLAB: an scripting environment for process mining. In:BPM Demos. CEUR-WP, vol. 1295, p. 16 (2014)
25. Cortadella, J., Kishinevsky, M., Lavagno, L., Yakovlev, A.: Deriving Petri netsfrom finite transition systems. Computers, IEEE Transactions on 47(8), 859–882(1998)
26. Datta, S., Bhaduri, K., Giannella, C., Wolff, R., Kargupta, H.: Distributed datamining in peer-to-peer networks. IEEE Internet Computing 10(4), 18–26 (2006),http://doi.ieeecomputersociety.org/10.1109/MIC.2006.74
27. Dijkman, R.M., van Dongen, B.F., Dumas, M., Garcıa-Banuelos, L., Kunze, M.,Leopold, H., Mendling, J., Uba, R., Weidlich, M., Weske, M., Yan, Z.: A shortsurvey on process model similarity. In: Seminal Contributions to Information Sys-tems Engineering, 25 Years of CAiSE, pp. 421–427 (2013), http://dx.doi.org/10.1007/978-3-642-36926-1_34
28. van Dongen, B.: BPI Challenge 2011 Dataset (2011), http://dx.doi.org/10.
4121/uuid:d9769f3d-0ab0-4fb8-803b-0d1120ffcf54
29. van Dongen, B.: BPI Challenge 2012 Dataset (2012), http://dx.doi.org/10.
4121/uuid:3926db30-f712-4394-aebc-75976070e91f
30. van Dongen, B.F., Dijkman, R.M., Mendling, J.: Measuring similarity betweenbusiness process models. In: Seminal Contributions to Information Systems En-gineering, 25 Years of CAiSE, pp. 405–419 (2013), http://dx.doi.org/10.1007/978-3-642-36926-1_33
31. Evermann, J.: Scalable process discovery using map-reduce. In: IEEE Transactionson Services Computing. vol. to appear (2014)
32. Gabel, M., Su, Z.: Javert: fully automatic mining of general temporal propertiesfrom dynamic traces. In: ACM SIGSOFT 2008. pp. 339–349 (2008), http://doi.acm.org/10.1145/1453101.1453150
33. van Glabbeek, R.J., Weijland, W.P.: Branching time and abstraction in bisimu-lation semantics. J. ACM 43(3), 555–600 (1996), http://doi.acm.org/10.1145/233551.233556
34. Gunther, C., Rozinat, A.: Disco: Discover your processes. In: BPM (Demos). pp.40–44 (2012)
35. Hay, B., Wets, G., Vanhoof, K.: Mining navigation patterns using a sequence align-ment method. Knowl. Inf. Syst. 6(2), 150–163 (2004)
36. Hwong, Y., Keiren, J.J.A., Kusters, V.J.J., Leemans, S.J.J., Willemse, T.A.C.:Formalising and analysing the control software of the compact muon solenoid ex-periment at the large hadron collider. Sci. Comput. Program. 78(12), 2435–2452(2013), http://dx.doi.org/10.1016/j.scico.2012.11.009
37. Kohavi, R., Brodley, C.E., Frasca, B., Mason, L., Zheng, Z.: Kdd-cup 2000 or-ganizers’ report: Peeling the onion. SIGKDD Explorations 2(2), 86–98 (2000),http://doi.acm.org/10.1145/380995.381033
38. Kunze, M., Weidlich, M., Weske, M.: Querying process models by behavior in-clusion. Software and System Modeling 14(3), 1105–1125 (2015), http://dx.doi.org/10.1007/s10270-013-0389-6

Scalable Process Discovery and Conformance Checking 41
39. Leemans, M., van der Aalst, W.: Process mining in software systems. ACM/IEEEInternational Conference on Model Driven Engineering Languages and Systems p.to appear (2015)
40. Leemans, S.J.J., Fahland, D., van der Aalst, W.M.P.: Discovering block-structuredprocess models from event logs - A constructive approach. In: Petri Nets 2013. pp.311–329 (2013), http://dx.doi.org/10.1007/978-3-642-38697-8_17
41. Leemans, S.J.J., Fahland, D., van der Aalst, W.M.P.: Scalable process discoverywith guarantees. In: BPMDS 2015. pp. 85–101 (2015), http://dx.doi.org/10.
1007/978-3-319-19237-6_642. Leemans, S.J.J., Fahland, D., van der Aalst, W.M.P.: Scalable process discov-
ery and conformance checking. BPM Center Report BPM-16-03, BPMcenter.org(2016)
43. Leemans, S., Fahland, D., van der Aalst, W.: Discovering block-structured pro-cess models from event logs containing infrequent behaviour. In: Business ProcessManagement Workshops. pp. 66–78 (2013)
44. Leemans, S., Fahland, D., van der Aalst, W.: Discovering block-structured processmodels from incomplete event logs. In: Petri nets 2014. vol. 8489, pp. 91–110 (2014),http://dx.doi.org/10.1007/978-3-319-07734-5_6
45. Leemans, S., Fahland, D., van der Aalst, W.: Exploring processes and deviations.In: Business Process Management Workshops. p. to appear (2014)
46. Liesaputra, V., Yongchareon, S., Chaisiri, S.: Efficient process model discoveryusing maximal pattern mining. In: BPM 2015. pp. 441–456 (2015), http://dx.
doi.org/10.1007/978-3-319-23063-4_2947. Linz, P.: An introduction to formal languages and automata. Jones & Bartlett
Learning (2011)48. Lu, X., Fahland, D., van den Biggelaar, F.J., van der Aalst, W.M.: Label refinement
for handling duplicated tasks in process discovery. In: BPM. p. submitted (2016)49. Møller, A.: dk.brics.automaton – finite-state automata and regular expressions for
Java (2010), http://www.brics.dk/automaton/50. Munoz-Gama, J., Carmona, J., van der Aalst, W.M.P.: Single-entry single-exit
decomposed conformance checking. Inf. Syst. 46, 102–122 (2014), http://dx.doi.org/10.1016/j.is.2014.04.003
51. Pradel, M., Gross, T.R.: Automatic generation of object usage specifications fromlarge method traces. In: ASE 2009. pp. 371–382. IEEE Computer Society (2009),http://dx.doi.org/10.1109/ASE.2009.60
52. Redlich, D., Molka, T., Gilani, W., Blair, G.S., Rashid, A.: Constructs com-petition miner: Process control-flow discovery of bp-domain constructs. In:BPM 2014. LNCS, vol. 8659, pp. 134–150 (2014), http://dx.doi.org/10.1007/978-3-319-10172-9_9
53. Redlich, D., Molka, T., Gilani, W., Blair, G.S., Rashid, A.: Scalable dynamic busi-ness process discovery with the constructs competition miner. In: SIMPDA 2014.CEUR-WP, vol. 1293, pp. 91–107 (2014)
54. Rozinat, A., van der Aalst, W.M.P.: Conformance checking of processes based onmonitoring real behavior. Inf. Syst. 33(1), 64–95 (2008), http://dx.doi.org/10.1016/j.is.2007.07.001
55. Vanhatalo, J., Volzer, H., Leymann, F.: Faster and more focused control-flow ana-lysis for business process models through SESE decomposition. In: ICSOC 2007.pp. 43–55 (2007), http://dx.doi.org/10.1007/978-3-540-74974-5_4
56. Weerdt, J.D., Backer, M.D., Vanthienen, J., Baesens, B.: A multi-dimensional qual-ity assessment of state-of-the-art process discovery algorithms using real-life eventlogs. Inf. Syst. 37(7), 654–676 (2012)

42 Sander J.J. Leemans, Dirk Fahland, and Wil M.P. van der Aalst
57. Weidlich, M., van der Werf, J.: On profiles and footprints - relational semanticsfor Petri nets. In: Petri Nets. pp. 148–167 (2012)
58. Weidlich, M., Polyvyanyy, A., Mendling, J., Weske, M.: Causal behavioural profiles- efficient computation, applications, and evaluation. Fundam. Inform. 113(3-4),399–435 (2011)
59. Weijters, A., van der Aalst, W., de Medeiros, A.: Process mining with the heur-istics miner-algorithm. BETA Working Paper series 166, Eindhoven University ofTechnology (2006)
60. Weijters, A., Ribeiro, J.: Flexible Heuristics Miner. In: CIDM. pp. 310–317 (2011)61. Wen, L., van der Aalst, W., Wang, J., Sun, J.: Mining process models with non-free-
choice constructs. Data Mining and Knowledge Discovery 15(2), 145–180 (2007)62. Wen, L., Wang, J., Sun, J.: Mining invisible tasks from event logs. Advances in
Data and Web Management pp. 358–365 (2007)63. van der Werf, J., van Dongen, B., Hurkens, C., Serebrenik, A.: Process discovery
using integer linear programming. Fundam. Inform. 94(3-4), 387–412 (2009)64. Yang, J., Evans, D., Bhardwaj, D., Bhat, T., Das, M.: Perracotta: mining temporal
API rules from imperfect traces. In: ICSE 2006. pp. 282–291 (2006), http://doi.acm.org/10.1145/1134325
65. Zha, H., Wang, J., Wen, L., Wang, C., Sun, J.: A workflow net similarity measurebased on transition adjacency relations. Computers in Industry 61(5), 463–471(2010), http://dx.doi.org/10.1016/j.compind.2010.01.001


















