Scala and Spark: Coevolving Ecosystems for Big Data
36
Scala and Spark: Coevolving Ecosystems for Big Data John Nestor 47 Degrees Datapalooza Seattle February 10-11, 2016 www.47deg.com 1 47deg.com
-
Upload
john-nestor -
Category
Data & Analytics
-
view
905 -
download
2
Transcript of Scala and Spark: Coevolving Ecosystems for Big Data

Scala and Spark:Coevolving Ecosystems
for Big Data
John Nestor47 Degrees
Datapalooza SeattleFebruary 10-11, 2016
www.47deg.com
147deg.com

47deg.com
Outline
• Scala
• Spark
• Scala Impact on Spark
• Spark Impact on Scala
• Summary
• Questions
2

Scala
3

47deg.com
Scala History
• Scala created by Martin Odersky, EFPL Switzerland
• wrote javac, the compiler for Java
• designed Java generics
• 2004 Scala announced
• 2006 Scala 2.0
• 2011 Typesafe started, Scala 2.9
• 2012 Scala 2.10
• 2014 Scala 2.11
• 2015 Scala 2.12-RC1
• 2016 Scala now 12 years old and quite mature4

47deg.com
Why Scala?
• Open Source
• Strong typing
• Concise elegant syntax
• Runs on JVM (Java Virtual Machine)
• Supports both object-oriented and functional
• Small simple programs (REPL) through very large multi-server systems
• Easy to cleanly extend with new libraries and DSL’s
• Ideal for parallel and distributed systems
5

47deg.com
Scala: Strong Typing and Concise Syntax
• Strong typing like Java.
• Compile time checks
• Better modularity via strongly typed interfaces
• Easier maintenance: types make code easier to understand
• Concise syntax like Python.
• Type inference. Compiler infers most types that had to be explicit in Java.
• Powerful syntax that avoid much of the boilerplate of Java code (see next slide).
• Best of both worlds: safety of strong typing with conciseness (like Python).
6

47deg.com
Scala Case Class
• Java version class User { private String name; private Int age; public User(String name, Int age) { this.name = name; this.age = age; } public getAge() { return age; } public setAge(Int age) { this.age = age;} } User joe = new User(“Joe”, 30);
• Scala versioncase class User(name:String, var age:Int) val joe = User(“Joe”, 30)
7

47deg.com
Key Scala Features
• Immutable Collections
• Seq, Set, Map
• Functional Programming
• (i:Int) => i + 1
• Functions can be parameters and results
• For collections: map, filter, flatMap, groupBy, …
• Case Classes
• case class Person(name:String, age:Int)
• Define Domain Specific Languages (DSLs)
• Akka, SBT, Spray, ScalaTest and now Spark8

Spark
10

47deg.com
Spark History
• 2009 Mesos developed at UC Berkeley AmpLab
• 2009 Matei Zaharia starts Spark as a test case for Mesos
• 2012 Spark 0.5
• 2014 Spark 1.0, Top Level Apache Project
• 2014 Databricks started
• 2016 Spark 1.6
11

47deg.com
Why Spark?
• Support for not only batch but also (near) real-time
• Fast - keeps data in memory as much as possible
• Often 10X to 100X Hadoop speed
• A clean easy-to-use API
• A richer set of functional operations than just map and reduce
• A foundation for a wide set of integrated data applications
• Can recover from failures - recompute or (optional) replication
• Scalable for very large data sets and reduced time
12

47deg.com
Spark Components
• Spark Core
• Scalable multi-node cluster
• Failure detection and recovery
• RDDs, Dataframes and functional operations
• MLLib - for machine learning
• linear regression, SVMs, clustering, collaborative filtering, dimension reduction
• more on the way!
• GraphX - for graph computation
• Streaming - for near real-time
13

47deg.com
Spark RDDs
• RDD[T] - resilient distributed data set
• typed
• immutable
• ordered
• can be processed in parallel
• lazy evaluation - permits more global optimizations
• Rich set of functional operations ( a small sample)
• map, flatMap, reduce, …
• filter, groupBy, sortBy, take, drop, …
14

47deg.com
Spark Data Frames
• Similar to SQL tables
• can be transformed using SQL
• Focus of much of the work on Spark performance optimization
• Unlike RDD’s, optimized knows about fields
• Dynamically typed
• Not a natural fit for Scala (more on this later)
15

47deg.com
View Sample Spark Code - Data Frames
• Tweet language count using Data Frames written in Scala
17

Scala Impact on Spark
18

47deg.com
Spark Impact on Scala
• Written in Scala
• Scala is primary API
• Must use Scala to extend
• Source code as documentation: Scala code
• Design from Scala
• functional programming
• immutable collections
• Spark is a Scala DSL
19

47deg.com
Spark Application Language Choices - 1
• 71% Scala, 58% Python
• Code length similar
• Scala faster for RDDs (no need to move serialized data between JVM and Python)
• Scala is generally faster
• Scala provides strong typing
• Compile time checks
• Code is easier to understand
• Types help when writing and maintaining code
20

47deg.com
Spark Application Language Choices- 2
• In addition to Scala and Python also supports Java and R
• If you want to build scalable high performance production code based on Spark
• R by itself is too specialized
• Python is too slow
• Java is tedious to write and maintain
• Scala is “just right”
21

47deg.com
Transformations: Parallel versus Serial
• Scala has operations that traverse sequence elements in serial order: foldLeft, scanLeft
• Spark RDDs can only process sequence elements in parallel
• Enables full use of multiple works with multiple cores
• Serial operations like foldLeft would be slow compared to current parallel operations
• But there are cases where foldLeft or scanLeft is really needed
• Example: time series where early event can affect later event
• Example: Sherlock, word count by story
• So should Spark add foldLeft or similar operators?
22

47deg.com
Sample Spark Internal Code
• Lets examine the internal code in Spark
• Spark Context
• RDD
23

Spark Impact on Scala
24
47deg.com
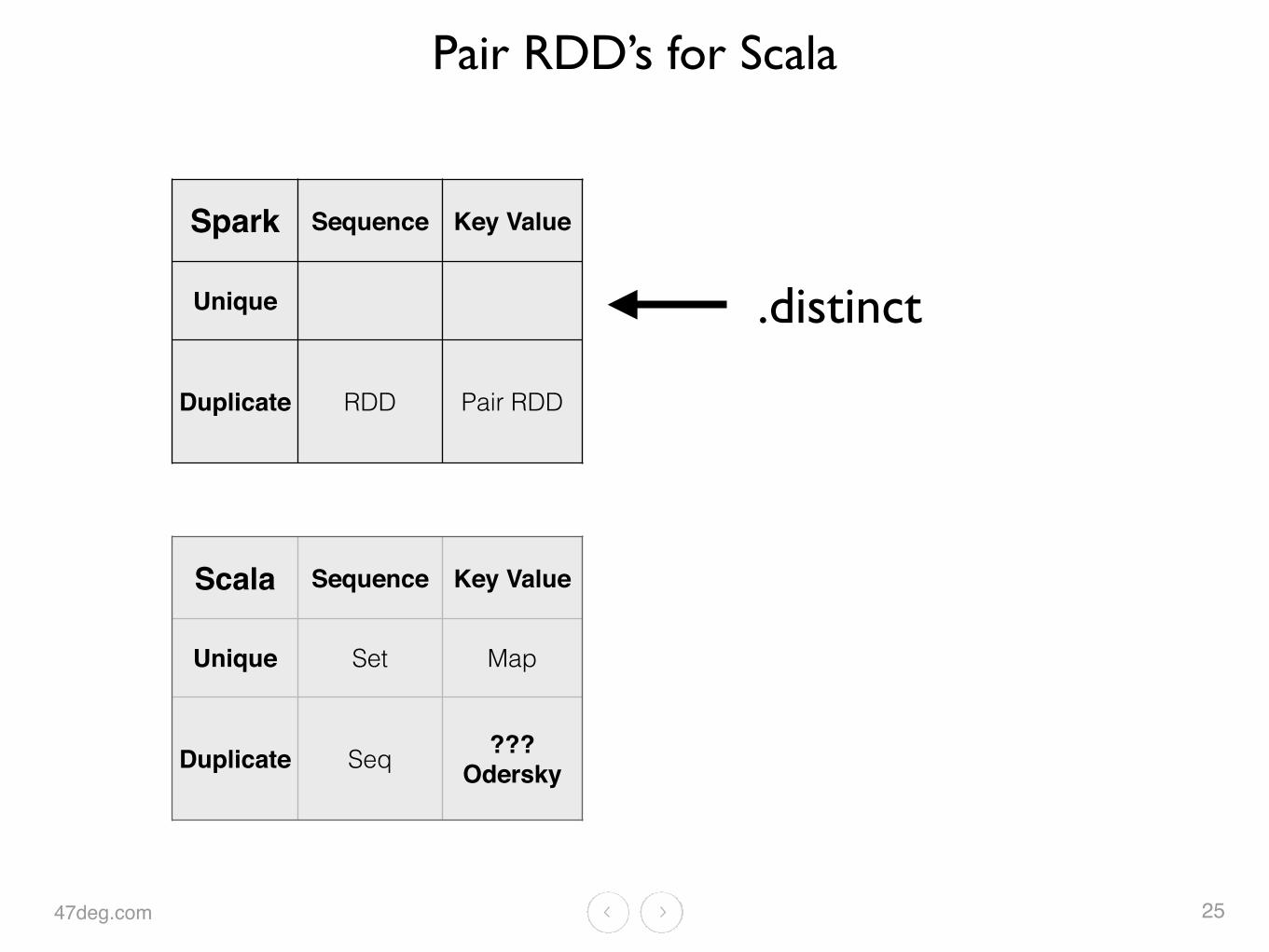
Pair RDD’s for Scala
25
Scala Sequence Key Value
Unique Set Map
Duplicate Seq ???Odersky
Spark Sequence Key Value
Unique
Duplicate RDD Pair RDD
.distinct

47deg.com
Lazy Evaluation
• Strict evaluation (Scala)
• Each transformation is evaluated as it is seen
• Easy to understand and debug
• Lazy evaluation (Spark)
• Transformations are collected into a linage graph
• Evaluated only when a final action is applied
• Allows cross transformation optimization
26

47deg.com
Lazy Evaluation in Scala
• Scala has Stream (a kind of sequence)
• Elements are evaluated in order as needed
• Allows infinite collections
• But no cross transform optimization
• Lazy Spark evaluation does all elements at once
• Enables parallelism
• Scala may add lazy versions of its collections that are more like Spark (Odersky)
27
47deg.com © Copyright 2015 47 Degrees
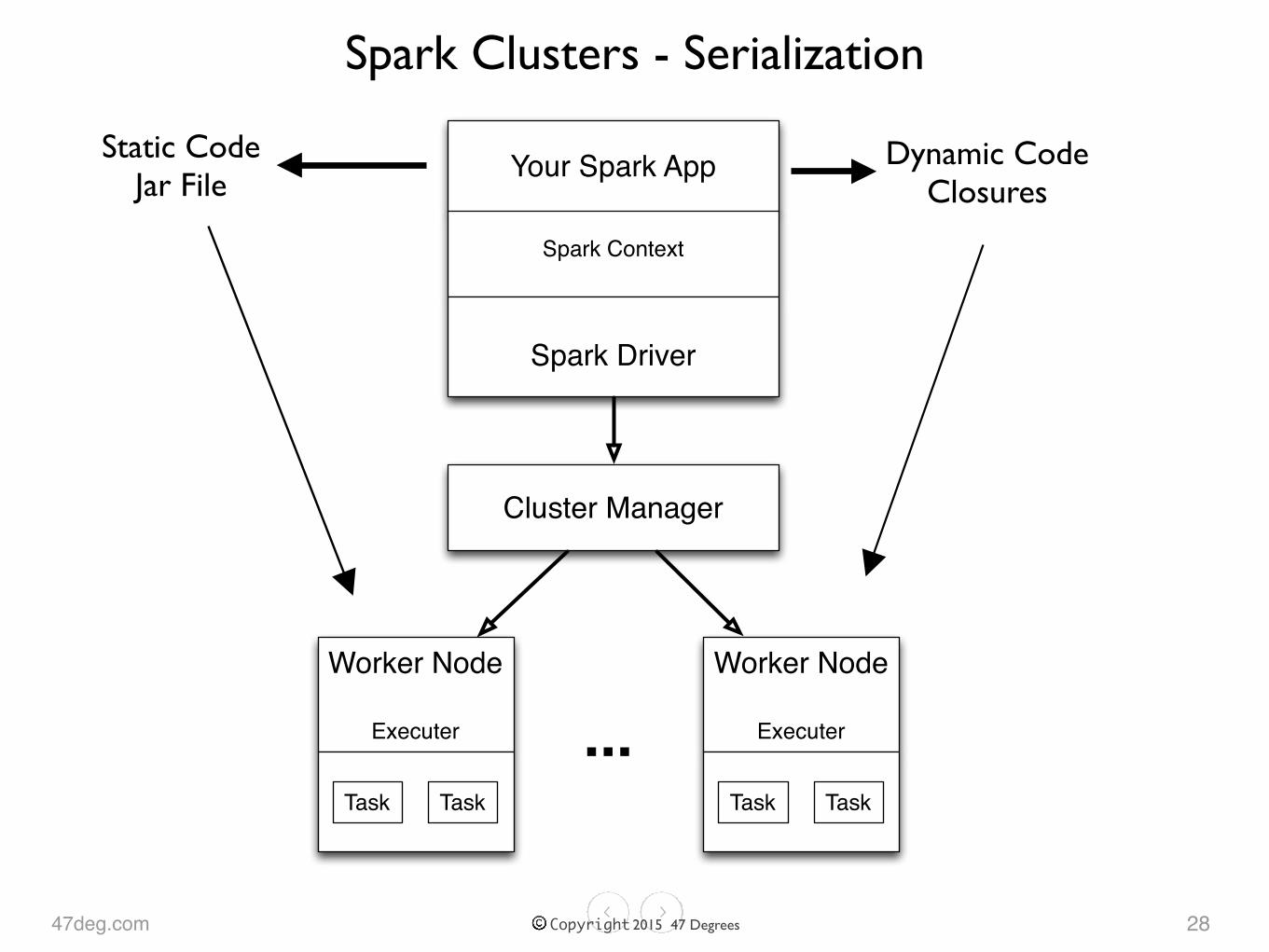
Spark Clusters - Serialization
28
Your Spark App
Spark Context
Cluster Manager
Worker Node
Executer
Task Task
Spark Driver
Worker Node
Executer
Task Task
...
Static CodeJar File
Dynamic CodeClosures

47deg.com
Dynamic Code Serialization
• Depends on values known at run-time
• Often a function passed to Spark transformations such as map, filter, and flatMap
• Sent from driver to workers
• Serialized on driver to byte array
• Deserialized on each work
29

47deg.com
Serialization of Closures
• Often include more than needed (or expected)
• Demo
• Scala may become smarter about including less in closure serialization (Odersky)
30

47deg.com
Datasets
• DataFrames are becoming the focus of Spark optimization
• DataFrames are dynamically typed
• Scala API would be nicer if there was static typing
• Datasets (new experimental in Spark 1.6) attempt to solve this
• Sample Code
• It would be nice if DataBricks and Typesafe could work together to produce a better solution
31

Scala and Spark in Seattle
32

47deg.com
Scala and Spark in Seattle
• Seattle Meetups
• Scala at the Sea Meetup (over 1000 members)http://www.meetup.com/Seattle-Scala-User-Group/
• Seattle Spark Meetup (over 1400 members)http://www.meetup.com/Seattle-Spark-Meetup/
• 47 DegreesTraining (Seattle and Worldwide) http://www.47deg.com/events#training
• Typesafe Scala Training: Scala, Akka
• Spark Training: Programming Spark with Scala
• UW Scala Professional Certificate Program http://www.pce.uw.edu/certificates/scala-functional-reactive-programming.html
33

Summary
34

47deg.com
Summary
• Scala and Spark are great technologies for big data applications
• Both are functional
• Both have immutable Data
• Both can be used to build very large systems
• Typesafe and Databricks evolving relationship
• Databricks is a consumer of Typesafe components
• Typesafe now supports Spark in addition to the Scala compiler and other Scala components
• They are working together to evolve toward ever more coordinated and integrated ecosystem for big data
• Martin Odersky - Spark — The Ultimate Scala Collections
35

Questions
36