
Sarah Guido @sarah_guido Reonomy OSCON 2014 ANALYZING DATA WITH PYTHON.
48
Sarah Guido @sarah_gui do Reonomy OSCON 2014 ANALYZING DATA WITH PYTHON
-
Upload
tyler-barry-cooper -
Category
Documents
-
view
220 -
download
0
Transcript of Sarah Guido @sarah_guido Reonomy OSCON 2014 ANALYZING DATA WITH PYTHON.

Sarah Guido@sarah_guidoReonomyOSCON 2014
ANALYZING DATA WITH PYTHON

Data scientist at ReonomyUniversity of Michigan graduateNYC Python organizerPyGotham organizer
ABOUT ME

Bird’s-eye overview: not comprehensive explanation of these tools!
Take data from start-to-finishPreprocessing: PandasAnalysis: scikit-learnAnalysis: nltkData pipeline: MRjobVisualization: matplotlib
What next?
ABOUT THIS TALK

So many toolsPreprocessing, analysis, statistics, machine learning, natural language processing, network analysis, visualization, scalability
Community support“Easy” language to learnBoth a scripting and production-ready
language
WHY PYTHON?

How to find the best tool(s)?The 90/10 ruleSimple is better than complex
FROM POINT A TO POINT…X?

Available resourcesDocumentation, tutorials, books, videos
Ease of use (with a grain of salt)Community support and continuous
developmentWidely used
WHY I CHOSE THESE TOOLS

The importance of data preprocessingAKA wrangling, munging, manipulating, and so on
Preprocessing is also getting to know your dataMissing values? Categorical/continuous? Distribution?
PREPROCESSING

Data analysis and modelingSimilar to R and ExcelEasy-to-use data structures
DataFrameData wrangling tools
Merging, pivoting, etc
PANDAS

Keep everything in PythonCommunity support/resourcesUse for preprocessing
File I/0, cleaning, manipulation, etcCombinable with other modules
NumPy, SciPy, statsmodel, matplotlib
PANDAS

File I/O
PANDAS
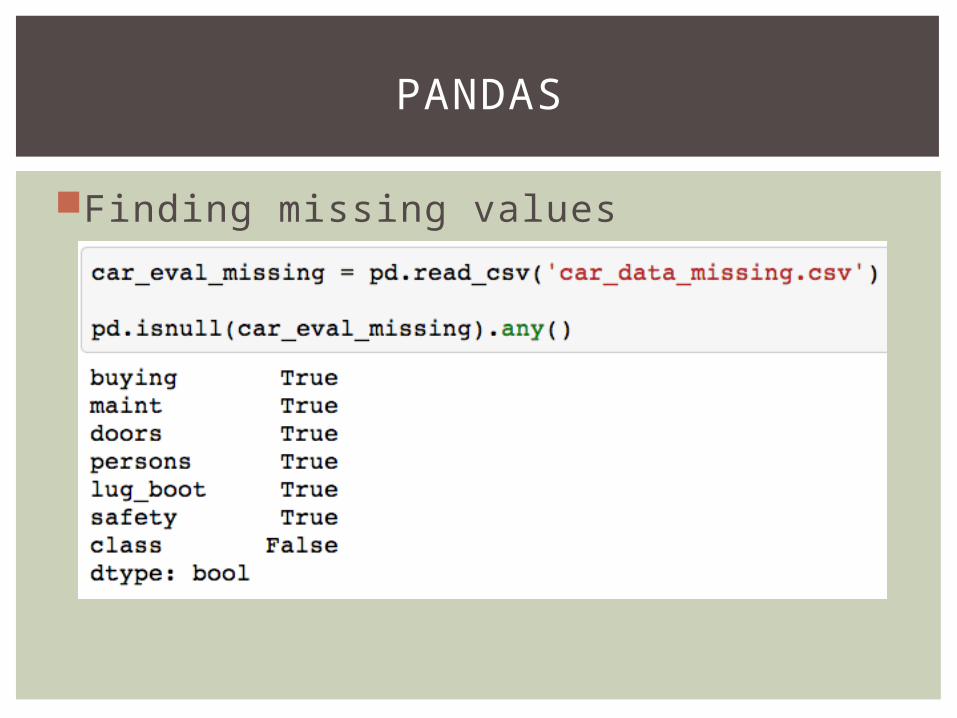
Finding missing values
PANDAS

Removing missing values
PANDAS

Pivoting
PANDAS

Other thingsStatistical methodsMerge/join like SQLTime seriesHas some visualization functionality
PANDAS

Application of algorithms that learn from examples
Representation and generalizationUseful in everyday lifeEspecially useful in data analysis
MACHINE LEARNING

Supervised learningClassification and regression
Unsupervised learningClustering and dimensionality reduction
MACHINE LEARNING

Machine learning moduleOpen-sourceBuilt-in datasetsGood resources for learning
SCIKIT-LEARN

Scikit-learn: your data has to be continuous
Here’s what one observation/label looks like:
SCIKIT-LEARN

Transform categorical values/labels
SCIKIT-LEARN

Classification
SCIKIT-LEARN

Classification
SCIKIT-LEARN

Other thingsVery comprehensive of machine learning algorithms
Preprocessing toolsMethods for testing the accuracy of your model
SCIKIT-LEARN

Concerned with interactions between computers and human languages
Derive meaning from textMany NLP algorithms are based on
machine learning
NATURAL LANGUAGE PROCESSING

Natural Language ToolKitAccess to over 50 corpora
Corpus: body of textNLP tools
Stemming, tokenizing, etcResources for learning
NLTK

Stopword removal
NLTK

Stopword removal
NLTK

Stemming
NLTK

Other thingsLemmatizing, tokenization, tagging, parse trees
ClassificationChunkingSentence structure
NLTK

Data that takes too long to process on your machineNot “big data” but larger data
Solution: MapReduce!Processing large datasets with a parallel, distributed algorithm
Map stepReduce step
PROCESSING LARGE DATA

Map stepTakes series of key/value pairs Ex. Word counts: break line into words, return word and count within line
Reduce stepOnce for each unique key: iterates through values associated with that key
Ex. Word counts: returns word and sum of all counts
PROCESSING LARGE DATA

Write MapReduce jobs in PythonTest code locally without installing
HadoopLots of thorough documentationA few things to know
Keep everything in one classMRJob program in a separate fileOutput to new file if doing something like word counts
MRJOB

Stemmed file
Line 1: (‘miss’, 2), (‘taylor’, 1)Line 2: (‘taylor’, 1), (‘first’, 1), (‘wed’,
1)And so on…
MRJOB

MapLine 1: (‘miss’, 2),
(‘taylor’, 1)Line 2: (‘taylor’, 1),
(‘first’, 1), (‘wed’, 1)Line 3: (‘first’, 1),
(‘wed’, 1)Line 4: (‘father’, 1)Line 5: (‘father’, 1)
Reduce(‘miss’, 2)(‘taylor’, 2)(‘first’, 2)(‘wed’, 2)(‘father’, 2)
MRJOB

Let’s count all words in the Gutenberg file
Map step
MRJOB

Reduce (and run) step
MRJOB

ResultsMapped counts reducedKey/val pairs
MRJOB

Other thingsRun on Hadoop clustersCan write highly complex jobsWorks with Elasticsearch
MRJOB

The “final step”Conveying your results in a meaningful
wayLiterally see what’s going on
DATA VISUALIZATION

2D visualization libraryVery VERY widely usedWide variety of plotsEasy to feed in results from other
modules (like Pandas, scikit-learn, NumPy, SciPy, etc)
MATPLOTLIB

Remember this?
MATPLOTLIB
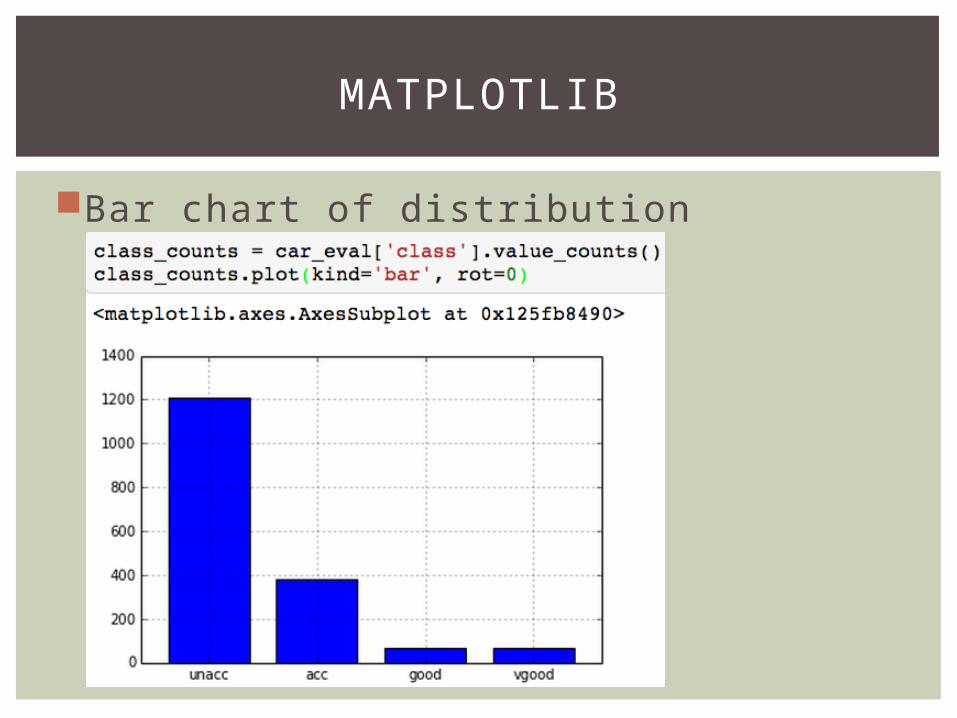
Bar chart of distribution
MATPLOTLIB

Let’s graph our word count frequencies(Hint: It’s a power law distribution!)
MATPLOTLIB

High frequency of low numbers, low frequency of high numbers
MATPLOTLIB

Other thingsMany different kinds of graphsCustomizableTime series
MATPLOTLIB

Phew!Which tool to choose depends on your
needsWorkflow:
PreprocessAnalyzeVisualize
WHAT NEXT?

Pandashttp://pandas.pydata.org/
scikit-learnhttp://scikit-learn.org/
NLTKhttp://www.nltk.org/
MRJobhttp://mrjob.readthedocs.org/
matplotlibhttp://matplotlib.org/
RESOURCES

Twitter@sarah_guido
LinkedInhttps://www.linkedin.com/in/sarahguido
NYC Pythonhttp://www.meetup.com/nycpython/
CONTACT ME!

Questions?
THE END!


















