
SAN DIEGO SUPERCOMPUTER CENTER Niches, Long Tails, and Condos Effectively Supporting Modest-Scale...
18
SAN DIEGO SUPERCOMPUTER CENTER Niches, Long Tails, and Condos Effectively Supporting Modest-Scale HPC Users 21st High Performance Computing Symposia (HPC'13) Rick Wagner High Performance System Manager San Diego Supercomputer Center April 10, 2013
-
Upload
travis-eyres -
Category
Documents
-
view
215 -
download
0
Transcript of SAN DIEGO SUPERCOMPUTER CENTER Niches, Long Tails, and Condos Effectively Supporting Modest-Scale...

SAN DIEGO SUPERCOMPUTER CENTER
Niches, Long Tails, and Condos
Effectively Supporting Modest-Scale HPC Users
21st High Performance Computing Symposia (HPC'13)
Rick WagnerHigh Performance System ManagerSan Diego Supercomputer Center
April 10, 2013

SAN DIEGO SUPERCOMPUTER CENTER
What trends are driving HPC in the SDSC machine room?
Niches:Specialized hardware
for specialized applications
Long tail of science:Broadening the HPC user base
Condos:Leveraging our facility
to support campus users

SAN DIEGO SUPERCOMPUTER CENTER
SDSC Clusters
UCSD System:Triton Shared Compute Cluster
GordonTrestles
XSEDE Systemshttps://www.xsede.org/
Overview:http://bit.ly/14Xj0Dm

SAN DIEGO SUPERCOMPUTER CENTER
SDSC Clusters
Gordon
Niches:Specialized hardware
for specialized applications

SAN DIEGO SUPERCOMPUTER CENTER
Gordon – An Innovative Data Intensive Supercomputer
• Designed to accelerate access to massive amounts of data in areas of genomics, earth science, engineering, medicine, and others
• Emphasizes memory and IO over FLOPS.• Appro integrated 1,024 node Sandy Bridge
cluster• 300 TB of high performance Intel flash• Large memory supernodes via vSMP
Foundation from ScaleMP• 3D torus interconnect from Mellanox• In production operation since February 2012• Funded by the NSF and available through the
NSF Extreme Science and Engineering Discovery Environment program (XSEDE)

SAN DIEGO SUPERCOMPUTER CENTER
Gordon Design: Two Driving Ideas
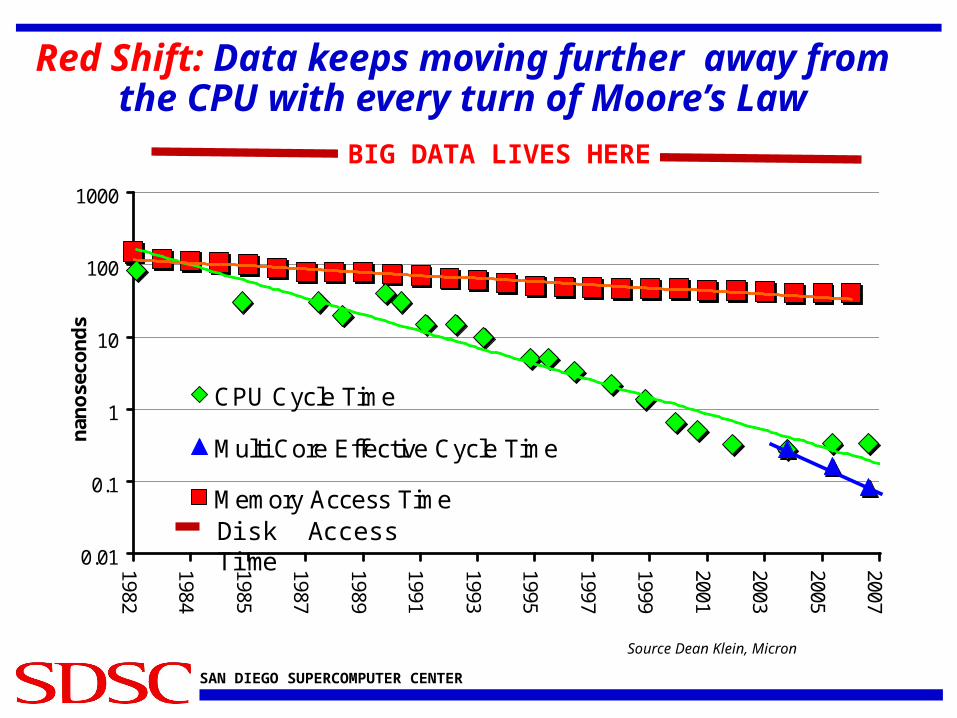
• Observation #1: Data keeps getting further away from processor cores (“red shift”)• Do we need a new level in the memory hierarchy?
• Observation #2: Many data-intensive applications are serial and difficult to parallelize • Would a large, shared memory machine be better from the
standpoint of researcher productivity for some of these?• Rapid prototyping of new approaches to data analysis
SAN DIEGO SUPERCOMPUTER CENTER
Red Shift: Data keeps moving further away from the CPU with every turn of Moore’s Law
0.01
0.1
1
10
100
1000
1982
1984
1985
1987
1989
1991
1993
1995
1997
1999
2001
2003
2005
2007n
ano
seco
nd
s
CPU Cycle Time
Multi Core Effective Cycle Time
Memory Access Time
Source Dean Klein, Micron
Disk Access Time
BIG DATA LIVES HERE

SAN DIEGO SUPERCOMPUTER CENTER
Gordon Design Highlights
• 3D Torus• Dual rail QDR
• 64, 2S Westmere I/O nodes
• 12 core, 48 GB/node• 4 LSI controllers• 16 SSDs• Dual 10GbE• SuperMicro mobo• PCI Gen2
• 300 GB Intel 710 eMLC SSDs
• 300 TB aggregate
• 1,024 2S Xeon E5 (Sandy Bridge) nodes
• 16 cores, 64 GB/node• Intel Jefferson Pass
mobo• PCI Gen3
• Large Memory vSMP Supernodes
• 2TB DRAM• 10 TB Flash
“Data Oasis”Lustre PFS100 GB/sec, 4 PB

SAN DIEGO SUPERCOMPUTER CENTER
SDSC Clusters
Trestles
Long tail of science:Broadening the HPC user base
SAN DIEGO SUPERCOMPUTER CENTER
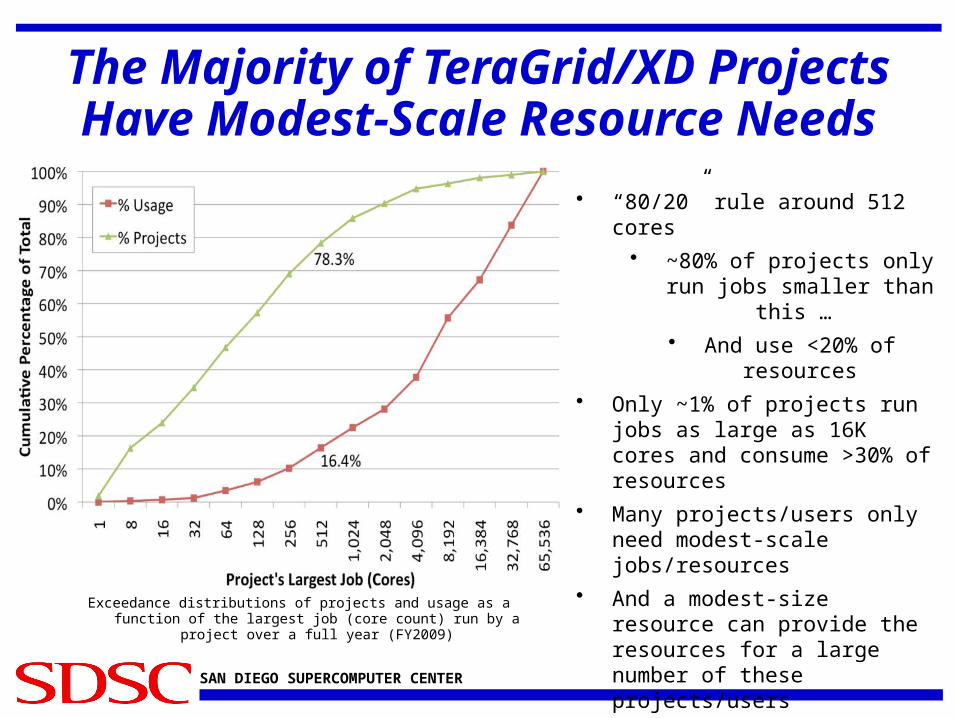
The Majority of TeraGrid/XD Projects Have Modest-Scale Resource Needs
• “80/20” rule around 512 cores
• ~80% of projects only run jobs smaller than this …
• And use <20% of resources
• Only ~1% of projects run jobs as large as 16K cores and consume >30% of resources
• Many projects/users only need modest-scale jobs/resources
• And a modest-size resource can provide the resources for a large number of these projects/users
Exceedance distributions of projects and usage as a function of the largest job (core count) run by a project over a full year (FY2009)
SAN DIEGO SUPERCOMPUTER CENTER
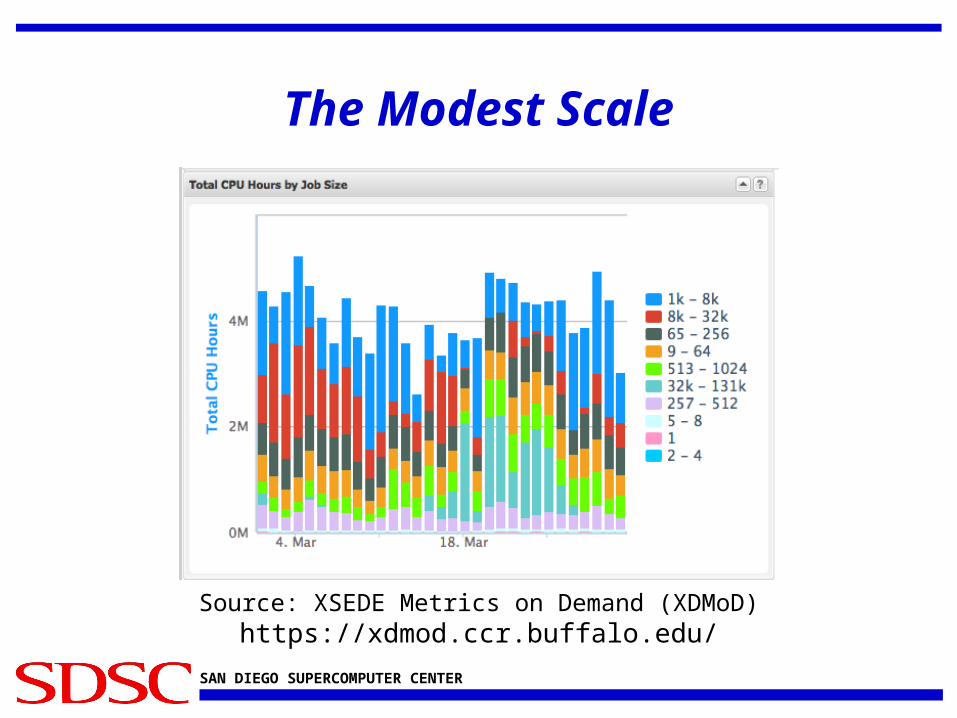
The Modest Scale
Source: XSEDE Metrics on Demand (XDMoD)https://xdmod.ccr.buffalo.edu/

SAN DIEGO SUPERCOMPUTER CENTER
Trestles Focuses on Productivity of its Users Rather than System Utilization
• We manage the system with a different focus than has been typical of TeraGrid/XD systems
• Short queue waits are key to productivity• Primary system metric is expansion factor = 1 + (wait time/run time)
• Long-running job queues (48 hours std, up to 2 weeks)• Shared nodes for interactive, accessible computing• User-settable advance reservations• Automatic on-demand access for urgent applications• Robust suite of applications software• Once expectations for system are established, say yes to
user requests whenever possible …

SAN DIEGO SUPERCOMPUTER CENTER
Trestles is a 100TF system with 324 nodes(Each node 4 socket*8-core/64GB DRAM/120GB flash, AMD Magny-Cours)
System Component ConfigurationAMD MAGNY-COURS COMPUTE NODE
Sockets 4Cores 32Clock Speed 2.4 GHzFlop Speed 307 Gflop/sMemory capacity 64 GBMemory bandwidth 171 GB/sSTREAM Triad bandwidth 100 GB/sFlash memory (SSD) 120 GB
FULL SYSTEMTotal compute nodes 324Total compute cores 10,368Peak performance 100 Tflop/sTotal memory 20.7 TBTotal memory bandwidth 55.4 TB/sTotal flash memory 39 TB
QDR INFINIBAND INTERCONNECTTopology Fat treeLink bandwidth 8 GB/s (bidrectional)Peak bisection bandwidth 5.2 TB/s (bidirectional)MPI latency 1.3 us
DISK I/O SUBSYSTEMFile systems NFS, LustreStorage capacity (usable) 150 TB: Dec 2010
2PB : August 20114PB: July 2012
I/O bandwidth 50 GB/s

SAN DIEGO SUPERCOMPUTER CENTER
SDSC Clusters
UCSD System:Triton Shared Compute Cluster
Condos:Leveraging our facility
to support campus users

SAN DIEGO SUPERCOMPUTER CENTER
Competitive Edge
Source:http://ovpitnews.iu.edu/news/page/normal/23265.html

SAN DIEGO SUPERCOMPUTER CENTER
Condo Model(for those who can’t afford Crays)
• Central facility (space, power, network, management)• Researchers purchase compute nodes on grants• Some campus subsidy for operation• Small selection of nodes (Model T or Model A)• Benefits
• Sustainability• Efficiency from scale• Harvest idle cycles
• Adopters: Purdue, LBNL, UCLA, Clemson, …

SAN DIEGO SUPERCOMPUTER CENTER
Triton Shared Compute Cluster
Performance TBD
Compute Nodes ~100 Intel XEON E5 2.6 GHz dual socket;16 cores/node; 64 GB RAM
GPU Nodes ~4 Intel XEON E5 2.3 GHz dual socket;16 cores/node; 32 GB RAM4 NVIDIA GeForce GTX680
Interconnects 10GbEQDR, Fat Tree Islands (Opt)

SAN DIEGO SUPERCOMPUTER CENTER
Conclusion: Supporting Evidence
Source:http://www.nsf.gov/funding/pgm_summ.jsp?pims_id=503148


















