
SALINI M T - Cochin University of Science and...
31
Word Sense Disambiguation SEMINAR REPORT 2009-2011 In partial fulfillment of Requirements in Degree of Master of Technology In COMPUTER & INFORMATION SCIENCE SUBMITTED BY SALINI M T DEPARTMENT OF COMPUTER SCIENCE COCHIN UNIVERSITY OF SCIENCE AND TECHNOLOGY KOCHI – 682 022
Transcript of SALINI M T - Cochin University of Science and...

WWoorrdd SSeennssee DDiissaammbbiigguuaattiioonn
SEMINAR REPORT2009-2011
In partial fulfillment of Requirements inDegree of Master of Technology
InCOMPUTER & INFORMATION SCIENCE
SUBMITTED BY
SALINI M T
DEPARTMENT OF COMPUTER SCIENCECOCHIN UNIVERSITY OF SCIENCE AND TECHNOLOGY
KOCHI – 682 022

COCHIN UNIVERSITY OF SCIENCE AND TECHNOLOGYKOCHI – 682 022
DEPARTMENT OF COMPUTER SCIENCE
CCEERRTTIIFFIICCAATTEE
This is to certify that the seminar report entitled “WWoorrdd SSeennssee DDiissaammbbiigguuaattiioonn ((WWSSDD))””
is being submitted by SSaalliinnii MM TT in partial fulfillment of the requirements for the award
of M.Tech in Computer & Information Science is a bonafide record of the seminar
presented by her during the academic year 2010.
Mr. G.Santhosh Kumar Prof. Dr.K.Poulose JacobLecturer DirectorDept. of Computer Science Dept. of Computer Science

AACCKKNNOOWWLLEEDDGGEEMMEENNTT
First of all let me thank our Director Prof: Dr. K. Poulose Jacob, Dept. of
Computer Science, CUSAT who provided with the necessary facilities and advice. I am
also thankful to Mr. G.Santhosh Kumar, Lecturer, Dept of Computer Science,
CUSAT for his valuable suggestions and support for the completion of this seminar.
With great pleasure I remember Dr. Sumam Mary Idicula, Reader, Dept. of Computer
Science, CUSAT for her sincere guidance. Also I am thankful to all of my teaching and
non-teaching staff in the department and my friends for extending their warm kindness
and help.
I would like to thank my parents without their blessings and support I would not
have been able to accomplish my goal. I also extend my thanks to all my well wishers.
Finally, I thank the almighty for giving the guidance and blessings.

ABSTRACT
Words have different meanings based on the context of the word usage in a
sentence. Word sense is one of the meanings of a word. Human language is ambiguous,
so that many words can be interpreted in multiple ways depending on the context in
which they occur. Word sense disambiguation (WSD) is the ability to identify the
meaning of words in context in a computational manner. WSD is considered an AI-
complete problem, that is, a task whose solution is at least as hard as the most difficult
problems in artificial intelligence.
WSD can be viewed as a classification task: word senses are the classes, and an
automatic classification method is used to assign each occurrence of a word to one or
more classes based on the evidence from the context and from external knowledge
sources. WSD heavily relies on knowledge. Knowledge sources provide data which are
essential to associate senses with words.
The assessment of WSD systems is discussed in the context of the
Senseval/Semeval campaigns, aiming at the objective evaluation of systems participating
in several different disambiguation tasks. Here, some of the knowledge sources used in
WSD, different approaches for WSD (supervised, unsupervised and Knowledge-based )
and evaluation of WSD systems are discussed. The applications of WSD are also seen.
Key words: Word Sense Disambiguation, Word Sense Discrimination, Context, Lexical
ambiguity, Knowlege source, Sense Inventory , Sense annotation.

TABLE OF CONTENTS
1 Introduction 1
2 Brief historical overview 2
3 WSD task Description 3
4 Elements of WSD 4
4.1 Selection of Word Senses 5
4.2 External Knowledge Sources 6
4.2.1 WordNet 8
4.4.2 SemCor 12
4.3 Representation of Context 12
4.4 Choice of classification method 15
4.4.1 Knowledge based disambiguation 16
4.4.2 Supervised disambiguation 18
4.4.3 Un-supervised disambiguation 20
5 Comparison of WSD approaches 21
6 Evaluation of WSD systems 22
7 Applications 23
8 Conclusion 25
9 References 26

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 1
1. Introduction
One of the first problems that any natural language processing (NLP) system encounters
is lexical ambiguity, syntactic or semantic. The resolution of a word’s syntactic ambiguity has
been solved in language processing by part-of-speech taggers with high levels of accuracy. The
problem of resolving semantic ambiguity is generally known as word sense disambiguation
(WSD) and has been proved to be more difficult than syntactic disambiguation.
Human language is ambiguous, so that many words can be interpreted in multiple ways
depending on the context in which they occur the identification of the specific meaning that a
word assumes in context is only apparently simple. Unfortunately, the identification of the
specific meaning that a word assumes in context is only apparently simple. While most of the
time humans do not even think about the ambiguities of language, machines need to process
unstructured textual information and transform them into data structures which must be analyzed
in order to determine the underlying meaning. The computational identification of meaning for
words in context is called word sense disambiguation (WSD).
Words have multiple meaning based on the context of the word usage in a sentence.
Word Sense is one of the meanings of a word .Word Sense Disambiguation (WSD) is the ability
to identify the meaning of words in context in a computational manner. WSD is considered as an
AI-complete problem, that is, a problem which can be solved only by first resolving all the
difficult problems in Artificial Intelligence such as Turing Test. Consider the following two
sentences,
(a) I can hear bass sounds.
(b) They like grilled bass.
The occurrences of the word bass in the two sentences clearly denote different meanings: low-
frequency tones and a type of fish, respectively. Here, the process WSD assigns correct
meaning to the word bass in the above two sentences as
(a) I can hear bass / low frequency tone sounds.
(b) (b) They like grilled bass / fish.

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 2
WSD is one of the central challenges in Natural Language Processing(NLP). Many tasks
in NLP require diambiguation. Word Sense Disambiguation is needed in Machine Translation,
Information Retrieval , Information Extraction etc. WSD is typically configured as an
intermediate task, either as a stand-alone module or properly integrated into an application (thus
performing disambiguation implicitly).
2. Brief historical overview
The task of WSD is a historical one in the field of Natural Language Processing
(NLP).WSD was first formulated as a distinct computational task during the early days of
machine translation in the 1940s, making it one of the oldest problems in computational
linguistics. Warren Weaver in 1949 first introduced WSD problem in a computational context.
In 1960 Bar-Hillel posed the following :
Little John was looking for his toy box. Finally, he found it. The box was in the pen. John was
very happy. Is “pen” a writing instrument or an enclosure where children play? And he declared
it as unsolvable. That is, WSD could not be solved by "electronic computer" because of the need
in general to model all world knowledge.

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 3
Bar-Hillel
In the 1970s, WSD was a subtask of semantic interpretation systems developed within the
field of artificial intelligence, but since WSD systems were largely rule-based and hand-coded
they were prone to a knowledge acquisition bottleneck.
By the 1980s large-scale lexical resources, such as the Oxford Advanced Learner's
Dictionary of Current English (OALD), became available: hand-coding was replaced with
knowledge automatically extracted from these resources, but disambiguation was still
knowledge-based or dictionary-based. In the 1990s, the statistical revolution swept through
computational linguistics, and WSD became a paradigm problem on which to apply supervised
machine learning techniques. The 2000s saw supervised techniques reach a plateau in accuracy,
and so attention has shifted to semi-supervised, unsupervised corpus-based systems and
combinations of different methods. Still, supervised systems continue to perform best.
3. WSD task descriptionWord sense disambiguation is the ability to computationally determine which sense of a
word is activated by its use in a particular context. WSD is usually performed on one or more
texts .If we disregard the punctuation, we can view a text T as a sequence of words (w1, w2, . . . ,
wn), and we can formally describe WSD as the task of assigning the appropriate senses to all or
some of the words in T. That is, WSD identifies a mapping A from words to senses, such that
A(i) ⊆ SensesD(wi) where SensesD(wi) is the set of senses encoded in the dictionary D for word
wi. and A(i) is that subset of the senses of wi which are appropriate in the context T. The

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 4
mapping A can assign more than one sense to each word wi ∈ T, although typically only the
most appropriate sense is selected, that is, | A(i) |= 1.
WSD can be viewed as a classification task where word senses are the classes, and an
automatic classification method is used to assign each occurrence of a word to one or more
classes based on the evidence from the context and from external knowledge sources. The task of
WSD involves two steps: (1) the determination of all the different senses for every word in the text
and (2) the assignment of each occurrence of a word to the appropriate sense. The assignment is
done by relying on two major sources of information, the context of the ambiguous word and
external knowledge sources.
There are two varients of generic WSD Task.
1) Lexical Sample, where a system is required to disambiguate a restricted set of target
words usually occurring one per sentence.Supervised systems are typically employed
in this setting, as they can be trained using a number of hand-labeled instances
(training set) and then applied to classify a set of unlabeled examples (test set)
2) All words WSD, where the systems are expected to disambiguate all open –class
words in a text (ie, nouns , verbs, adjectives etc). This task requires wide-coverage
systems. Consequently, purely supervised systems can potentially suffer from the
problem of data sparseness, as it is unlikely that a training set of adequate size is
available which covers the full lexicon of the language of interest. On the other
hand,other approaches, such as knowledge-lean systems, rely on full-coverage
knowledge resources, whose availability must be assured.
4. Elements of WSD
There are mainly four elements for performing WSD. They are
1) Selection of word senses
2) Use of external knowledge sources
3) Representation of context
4) Selection of an automatic classification method

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 5
4.1 Selection of word senses
Since WSD is the process of assigning correct sense or meaning of a word in a
computational manner, first of all we have to identify the possible meaning for the target word.
The predefined set of possibilities for a word is known as sense inventory. A sense inventory
partitions the range of meaning of a word in to its senses and a word sense is commonly accepted
meaning of a word. For example, consider the following two sentences
o She chopped the vegetables with a chef’s knife.
o A man was beaten and cut with a knife.
The word knife is used in the above sentences with two different senses; in the first
sentence it is used as cutting tool and in the second sentence it is used as a weapon. The two
senses are clearly related, as they possibly refer to the same object; however the object’s
intended uses are different. Word senses cannot be easily discretized, that is, reduced to a finite
discrete set of entries, each encoding a distinct meaning. Determining the sense inventory is a
key problem in WSD.
One approach for representing senses in sense inventory is called enumerative approach.
Here senses must be enumerated in sense inventory. While ambiguity does not usually affect the
human understanding of language, WSD aims at making explicit the meaning underlying words
in context in a computational manner. Therefore it is generally agreed that, in order to enable an
objective evaluation and comparison of WSD systems, senses must be enumerated in a sense
inventory. All traditional paper-based and machine-readable dictionaries adopt the enumerative
approach.
As an example the word knife can be enumerated in sense inventory as,
knife (n)
1. a cutting tool composed of a blade with a sharp point and a handle.
2. an instrument with a handle and blade with a sharp point used as a weapon.
The association of discrete sense distinctions with words encoded in the dictionary can be written
as a function SensesD : L × POS → 2C, where,

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 6
L is the lexicon(the set of words encoded in the dictionary) , POS is the set of open-class parts of
speech(noun, adjective, verb, adverb), C is the full set of concepts labels in dictionary D and 2C
denotes the power set of its concepts.Hence SensesD (wp) encodes all the distinct senses of the
word wp where the suffix ‘p’ denote the part of speech tag for the word w. In practice, the need for a
sense inventory has driven WSD research.
In practice, the need for a sense inventory has driven WSD research. In the common
conception, a sense inventory is an exhaustive and fixed list of the senses of every word of
concern in an application. The nature of the sense inventory depends on the application, and the
nature of the disambiguation task depends on the inventory. The three Cs of sense inventories are
clarity, consistency, and complete coverage of the range of meaning distinctions that matter.
Sense granularity is actually a key consideration:too coarse and some critical senses may be
missed, too fine and unnecessary errors may occur. For example, the ambiguity of mouse (animal
or device) is not relevant in English-Basque machine translation, where saguis the only
translation, but is relevant in (English and Basque) information retrieval.
A word (wp) is monosemous when it can convey only one meaning, that is,
| SensesD(wp) | = 1. For instance, well-beingn is a monosemous word, as it denotes a single sense
of being comfortable. Conversely, wp is polysemous if it can convey more meanings (e.g., racen
as a competition, as a contest of speed, as a taxonomic group, etc.). Senses of a word wp which
can convey unrelated meanings are homonymous (e.g., racen as a contest vs. racen as a
taxonomic group). We denote the ith word sense of a word w with part of speech p as wip .
4.2 External knowledge sources
Knowledge is a fundamental component of WSD. Knowledge sources provide data which
are essential to associate senses with words. They can vary from corpora of texts, either
unlabeled or annotated with word senses, to machine-readable dictionaries, thesauri, glossaries,
ontologies, etc . Two main two catagories of knowledge sources available are structured
resources and un-structured resources.

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 7
Structured resources :—Thesauri, which provide information about relationships between words, like
synonymy (e.g., car is a synonym of motorcar), antonymy (representing opposite
meanings, e.g., ugly is an antonym of beautiful) and, possibly, further relations. The
most widely used thesaurus in the field of WSD is Roget’s International Thesaurus.
— Machine-readable dictionaries (MRDs), which have become a popular source of
knowledge for natural language processing since the 1980s. Collins English Dictionary,
the Oxford Advanced Learner’s Dictionary of Current English,the Oxford Dictionary of
English , and the Longman Dictionary of Contemporary English are the famous MRDs.
—Ontologies, which are specifications of conceptualizations of specific domains of
interest ,usually including a taxonomy and a set of semantic relations.In this respect,
WordNet and its extensions can be considered as ontologies.
Unstructured resources:
—Corpora, that is, collections of texts used for learning language models. Corpora can
be sense-annotated or raw (i.e., unlabeled). Both kinds of resources are used in WSD, and
are most useful in supervised and unsupervised approaches, respectively. Examples of
Raw corpora are the Brown Corpus , the British National Corpus (BNC), the Wall
Street Journal (WSJ) Corpus etc. Example of Sense-Annotated Corpora is SemCor ,the
largest and most used sense-tagged corpus, which includes 352 texts tagged with around
234,000 sense Annotations.
—Collocation resources, which register the tendency for words to occur regularly with
others: examples include theWord Sketch Engine.
Among these resources, the most widely used resources are WordNet and SemCor.

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 8
4.2.1 WordNet
WordNet is a computational lexicon of English created and maintained at Princeton
University. It combines the features of many of the other resources commonly exploited in
disambiguation work: it includes definitions for individual senses of words within it, as in a
dictionary; it defines "synsets" of synonymous words representing a single lexical concept, and
organizes them into a conceptual hierarchy and it includes other links among words according to
several semantic relations, including hyponymy/hyperonymy, antonymy, and meronymy. As
such, it currently provides the broadest set of lexical information in a single resource. So
WordNet encodes concepts in terms of sets of synonyms (called synsets).The term Synset means
the set of word senses, all expressing (approximately) the same meaning. For example, the
concept of automobile is expressed with the following synset :-
We can use WordNet 2.1 software for finding the synsets as shown in Figure1.
Figure 1

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 9
Similarly the concept of car is expressed with the following synset :-
Here five different synset are available for the word car.
We can find this synset using WordNet 2.1 as shown in figure2 .
Figure 2
For each synset, WordNet provides the following information:
A gloss, a textual definition of the synset possibly with a set of usage examples (e.g.,
the gloss of car1n is “a 4-wheeled motor vehicle; usually propelled by an internal
combustion engine; ‘he needs a car to get to work’ ”).

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 10
Lexical and semantic relations, which connect pairs of word senses and synsets,
respectively:
Some of the relations in WordNet are:
Antonymy: X is an antonym of Y if it expresses the opposite concept.
Nominalization: a noun X nominalizes a verb Y (e.g., service nominalizes the verb serve)
Hypernymy (also called kind-of or is-a): Y is a hypernym of X if every X is a Y (Eg: motor
vehicle is a hypernym of car).
Hyponymy: is the inverse relation of Hypernym.
Meronymy (also called part-of): Y is a meronym of X if Y is a part of X. (Eg: chapter is a part
of text, so chapter is a Meronym of text).
Holonymy: Y is a holonym of X if X is a part of Y (the inverse of meronymy).
Similarity: Specifies similar relations (e.g., beautiful is similar to pretty).
Attribute: a noun X is an attribute for which an adjective Y expresses a value (e.g., hot is a
value of temperature).
We can find out these relations using WordNet2.1 .Figure3 shows a sample instance.
Figure 3

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 11
The following figure shows an example of the WordNet semantic network containing the carsynset.
Figure 4
Given its widespread diffusion within the research community, WordNet can be considered a de
facto standard for English WSD. Following its success, WordNets for several languages have
been developed and linked to the original Princeton WordNet. An association, namely, the
Global WordNet Association has been founded to share and link WordNets for all languages in
the world. These projects make not only WSD possible in other languages, but can potentially
enable the application of WSD to machine translation. Among enumerative lexicons, WordNet is
at present the best-known and the most utilized resource for word sense disambiguation in
English. Its latest version, WordNet 3.0, contains about 155,000 words organized in over
117,000 synsets

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 12
4.2.2 SemCor
SemCor is a subset of the Brown Corpus whose content words has been manually
annotated with part-of speech tags, word senses etc from the WordNet inventory. It is composed
of 352 texts. In 186 texts, all the open-class words (nouns, verbs, adjectives, and adverbs) are
annotated with the above information .In 166 texts only verbs are semantically annotated with
word senses constitute the largest sense-tagged corpus for training sense classifiers in supervised
disambiguation technique.
4.3 Representation of context
As text is an unstructured source of information, to make it a suitable input to an
automatic method it is usually transformed into a structured format. To this end, a preprocessing
of the input text is usually performed, which typically (but not necessarily) includes the
following steps:
Tokenization a normalization step, which splits up the text into a set of tokens
(usually words).
Part-of-speech tagging consisting in the assignment of a grammatical category to each
word (e.g. in the sentence ,the bar was crowded ,“the/DT bar/NN
was/VBD crowded/JJ,” where DT, NN, VBD and JJ are tags for
determiners, nouns, verbs, and adjectives, respectively)
Lemmatization the reduction of morphological variants to their base forms
. (e.g. was → be, bars → bar);
Chunking which consists of dividing a text in syntactically correlated parts
(e.g., [the bar]NP [was crowded]VP, respectively the noun phrase
and the verb phrase for the sentence “ the bar was crowded”).
Parsing aim is to identify the syntactic structure of a sentence.

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 13
An example of preprocessing of the text “the bar was crowded” is shown below.
Figure 5
As a result of the preprocessing phase of a portion of text (e.g., a sentence, a paragraph, a
full document,etc.), each word can be represented as a vector of features of different kinds or in
more structured ways, for example, as a tree or a graph of the relations between words.The
representation of a word in context is the main support, together with additional knowledge
resources, for allowing automatic methods to choose the appropriate sense from a reference
inventory.

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 14
After preprocessing a set of features is chosen to represent the context. These include
information resulting from the above-mentioned preprocessing steps, such as partof-speech tags,
grammatical relations, lemmas, etc. We can group these features as follows:
—local features, which represent the local context of a word usage, that is, features of a small
number of words surrounding the target word, including part-of-speech tags, word forms,
positions with respect to the target word, etc.;
—topical features, which in contrast to local features define the general topic of a text or
discourse, thus representing more general contexts (e.g., a window of words,a sentence, a phrase,
a paragraph, etc.), usually as bags of words;
—syntactic features, representing syntactic cues and argument-head relations between the target
word and other words within the same sentence (note that these words might be outside the local
context);
—semantic features, representing semantic information, such as previously established
senses of words in context, domain indicators, etc.
Based on this set of features, each word occurrence (usually within a sentence) can be converted
to a feature vector. For example consider the two sentences,
(1) The bank cashed my cheque.
(2) We sat along the bank of the Tevere river.
Here the target word is bank and the two contexts/ sentences can be represented as the followingFeature vectors:
Sentence W-2 W-1 W+1 W+2 SENSE TAG
1) - Deteminer Verb Adj FINANCE
2) Preposition Deteminer Preposition Deteminer RIVER
These vectors include four local features for the part-of-speech tags of the two words on the left
and on the right of bank and a sense classification tag (either FINANCE or SHORE). Different
context sizes can be used for feature vector. Sizes range from n-grams (i.e., a sequence of n

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 15
words including the target word), specifically unigrams (n = 1), bigrams (n = 2), and trigrams
(n = 3), to a full sentence or paragraph containing the target word.
More structured representations, such as trees or graphs, can be employed to represent word
contexts, which can potentially span an entire text.Flat representations, such as context vectors,
are more suitable for supervised disambiguation methods, as training instances are usually
(though not always) in this form. In contrast, structured representations are more useful in
unsupervised and knowledge-based methods, as they can fully exploit the lexical and semantic
interrelationships between concepts encoded in semantic networks and computational lexicons.
Choosing the appropriate size of context is an important factor in the development of a WSD
algorithm.
4.4 Choice of classification method
The final step is the choice of a classification method. After representing the
context containing the target word, we have to use some classification methods to assign
appropriate sense to the target word. We can broadly distinguish the main three approaches to
WSD as
1) Knowledge-Based Disambiguation:- This method use external lexical resources such
as dictionaries and thesauri .

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 16
2) Supervised Disambiguation :- This method is based on a labelled training set .Here
the learning system has a training set of feature-encoded inputs and their appropriate
sense label (category).
3) Unsupervised Disambiguation: - This method is based on unlabeled corpora. Here the
learning system has a training set of feature-encoded inputs but not their appropriate
sense label (category)
4.4.1 Knowledge based disambiguation
Objective of knowledge-based or dictionary-based WSD is to exploit knowledge
resources (such as dictionaries, thesauri, ontology etc) to infer the senses of words in context.
Overlap of sense definitions is one of the important knowledge based disambiguation
technique. It is also called Lesk Algorithm .This algorithm identify the senses of words in
context using definition overlap (the number of words in the sense definitions that are in
common).
The steps for performing disambiguation are,
Retrieve from Machine Readable Dictionaries (MRD), all sense definitions of the
target word and context words.
Determine the definition overlap for all possible sense combinations.
Choose senses that lead to highest overlap.
Given a two-word context (w1, w2), the senses of the target words whose
definitions have the highest overlap are assumed to be the correct ones. Formally given two
words w1 and w2 the following score is computed for each pair of word senses S1 ∈ Senses(w1)
and S2 ∈ Senses(w2):
Score Lesk (S1, S2) = │gloss (S1) ∩ gloss (S2)│

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 17
where gloss(Si) is the bag of words in the textual definition of sense Si of wi . The senses which
maximize the above formula are assigned to the respective words. However, this requires the
calculation of | Senses(w1) | · | Senses(w2) | gloss overlaps.
Example for disambiguating the word cone in the context pine cone.
Sense definitions of the word pine are
1. kinds of evergreen tree with needle-shaped leaves
2. waste away through sorrow or illness
Sense definitions of the word pine are Cone
1. solid body which narrows to a point
2. something of this shape whether solid or hollow
3. fruit of certain evergreen trees
The possible combinations of sense definition are:
Here sense definition 1 of pine and sense definition2 of cone yields highest overlap.
Hence sense3 of the word cone is assigned to the target word cone.
Given the exponential number of steps required, a variant of the Lesk algorithm is
currently employed which identifies the sense of a word w whose textual definition has the
highest overlap with the words in the context of w. Formally, given a target word w, the
following score is computed for each sense S of w:
scoreLeskVar (S) =| context(w) ∩ gloss(S) |,
where context(w) is the bag of all content words in a context window around the target word w.

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 18
Example: disambiguate the word key in the text “I inserted the key and locked the door”. The
following table shows the sense definitions of the target word key from WordNet dictionary.
Here we have to find out the word overlaps between these definitions and the context (I
inserted the key and locked the door) .Sense 1 of key has 3 overlaps, whereas the other two
senses have zero. These words are marked as italic in the table. So the first sense is selected for
the word key.
Banerjee and Pedersen introduced a measure of extended gloss overlap, which expands
the glosses through explicit relations in the dictionary (e.g., hypernymy, meronymy, pertainymy,
in WordNet)
where gloss(S’ ) is the bag of words in the textual definition of a sense S’ which is either S itself
or related to S through a relation rel . Unfortunately, Lesk’s approach is very sensitive to the
exact wording of definitions, so the absence of a certain word can radically change the results.
4.4.2 Supervised disambiguation
Supervised WSD uses machine-learning techniques for inducing a classifier from
manually sense-annotated data sets. In machine learning, systems are trained to perform
disambiguation. Usually, the classifier (often called word expert) is concerned with a single word
and performs a classification task in order to assign the appropriate sense to each instance of that
word. A training set used to learn the classifier typically contains a set of examples in which a
given target word is manually tagged with a sense from the sense inventory of a reference
dictionary. Here the input to be tested is the target word and its context. This input has to be

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 19
preprocessed first to select the appropriate features for target word and form a feature vector.
Then apply this feature vector to a classifier. Classifier selects the appropriate sense.
The most popular machine learning method in the field of WSD is Decision List.
A decision list is an ordered set of rules for categorizing test instances, That is, in WSD
decision list is used for assigning appropriate sense to a target word. It can be seen as a list of
weighted “if-then-else” rules. A training set is used for inducing a set of features. Based on this
features compute the score of the sense of a word as,
Here the score of sense Si is calculated as the maximum among the feature scores, where
the score of a feature f is computed as the logarithm of the probability of sense Si given feature f
divided by the sum of the probabilities of the other senses given feature f. Now rules of the kind
(feature-value, sense, score) are created. The ordering of these rules, based on their decreasing
score, constitutes the decision list.
Now given a word occurrence w and its representation as a feature vector (test set), the
decision list is checked, and the feature with highest score that matches the input vector selects
the word sense to be assigned. The feature with highest score can be computed as ,
A simplified example of a decision list is reported in following table. The first rule in the
example applies to the financial sense of bank and expects account with as a left context, the
third applies to bank as a supply (e.g., a bank of blood, a bank of food), and so on (notice that
more rules can predict a given sense of a word).
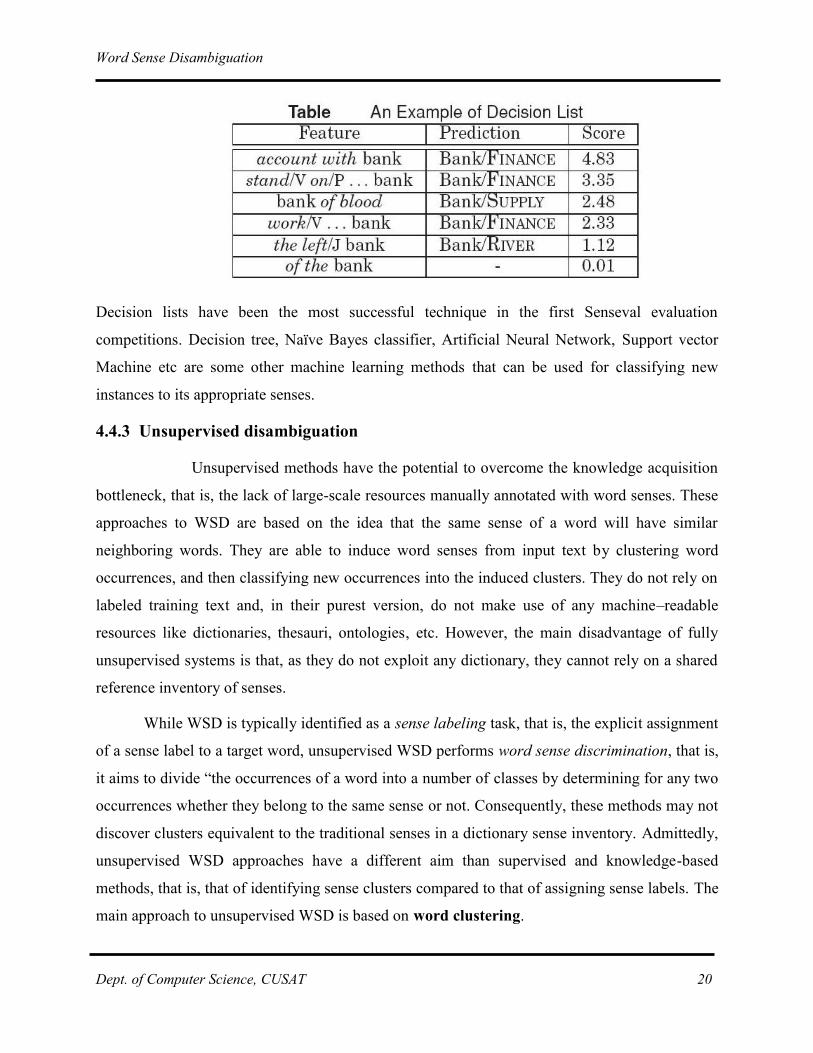
Word Sense Disambiguation
Dept. of Computer Science, CUSAT 20
Decision lists have been the most successful technique in the first Senseval evaluation
competitions. Decision tree, Naïve Bayes classifier, Artificial Neural Network, Support vector
Machine etc are some other machine learning methods that can be used for classifying new
instances to its appropriate senses.
4.4.3 Unsupervised disambiguation
Unsupervised methods have the potential to overcome the knowledge acquisition
bottleneck, that is, the lack of large-scale resources manually annotated with word senses. These
approaches to WSD are based on the idea that the same sense of a word will have similar
neighboring words. They are able to induce word senses from input text by clustering word
occurrences, and then classifying new occurrences into the induced clusters. They do not rely on
labeled training text and, in their purest version, do not make use of any machine–readable
resources like dictionaries, thesauri, ontologies, etc. However, the main disadvantage of fully
unsupervised systems is that, as they do not exploit any dictionary, they cannot rely on a shared
reference inventory of senses.
While WSD is typically identified as a sense labeling task, that is, the explicit assignment
of a sense label to a target word, unsupervised WSD performs word sense discrimination, that is,
it aims to divide “the occurrences of a word into a number of classes by determining for any two
occurrences whether they belong to the same sense or not. Consequently, these methods may not
discover clusters equivalent to the traditional senses in a dictionary sense inventory. Admittedly,
unsupervised WSD approaches have a different aim than supervised and knowledge-based
methods, that is, that of identifying sense clusters compared to that of assigning sense labels. The
main approach to unsupervised WSD is based on word clustering.

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 21
Word Clustering aims at clustering words which are semantically similar and thus convey
specific meaning. A well-known approach to word clustering consists of the identification of
word W = (w1, . . . , wk) similar to a target word w0. The similarity between w0 and wi is
determined based on the information content of their single features such as subject-verb, verb-
object, adjective-noun, etc. which occur in the corpus. Let W be the list of similar words ordered
by degree of similarity to w0. A similarity tree T is initially created which consists of a single
node w0. Next, for each i ∈ {1, . . . , k}, wi ∈ W is added as a child of wj in the tree T such that wj
is the most similar word to w0 among { w0., . . . , wi-1}. After a pruning step, each subtree rooted
at w0 is considered as a distinct sense of w0. Now new instances can be classified. In supervised
learning, a set of a priori potential classes (senses in the case of WSD) are established before the
learning process, while unsupervised learning means that the set of senses for a word are
inferred a posteriori from text.
5. Comparison of WSD approaches Supervised WSD methods uses labeled training set for classifying new instances and this
method yield best performance. But training data is expensive to generate doesn't work
for words not in training data. Another disadvantage is the knowledge acquisition
bottleneck, that is, the lack of large-scale resources manually annotated with word senses.
Unsupervised WSD methods just uses unlabelled training set for classifying new
instances and thus these methods will overcome the knowledge acquisition bottleneck.
But as they do not exploit any dictionary, senses assigned to a word may not be the
correct one.
Knowledge based method exploit knowledge resources (such as dictionaries, thesauri,
ontologies, collocations, etc.) to infer the senses of words in context. These methods
usually have lower performance than their supervised alternatives since the dictionary
entries for the target word may not provide sufficient material to assign the correct sense
for the target word. But they have the advantage of a wider coverage.

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 22
6. Evaluation of WSD systems
The main measures for evaluating the performance of WSD systems are precision and
recall. Precision means percentage of words that are tagged correctly, out of the words
addressed by the system and Recall means percentage of words that are tagged correctly, out of
all words in the test set. As an example consider ,our test set consists of 100 words. System
attempts 75 words for assigning sense labels and out of which 50 words were correctly sense
tagged by the system. Then,
Precision = 50 / 75 = 0.66
Recall = 50 / 100 = 0.50.
Comparing and evaluating different WSD systems is extremely difficult, because of the
different test sets, sense inventories, and knowledge resources adopted. Senseval (now renamed
Semeval) is an international word sense disambiguation competition, held every three years since
1998. The objective of the competition is to perform a comparative evaluation of WSD systems
in several kinds of tasks, including all-words and lexical sample WSD for different languages.
The systems submitted for evaluation to these competitions usually integrate different techniques
and often combine supervised and knowledge-based methods.
The first edition of Senseval took place in 1998 at Herstmonceux Castle, Sussex. The
importance of this edition is given by the fact that WSD researchers joined their efforts and
discussed several issues concerning the lexicon to be adopted, the annotation of training and test
sets, the evaluation procedure, etc.Senseval-1 consisted of a lexical-sample task for three
languages: English, French,and Italian. A total of 25 systems from 23 research groups
participated in the competition. Decision lists with the addition of some hierarchical structure
were the most successful approach in the first edition of the Senseval competition.
Senseval-2 took place in Toulouse (France) in 2001. Two main tasks were organized in
12 different languages: all-words and lexical sample WSD . Overall, 93 systems from 34
research groups participated in the competition. WordNet 1.7 sense inventory was adopted for
English. The performance was generally lower than in Senseval-1, probably due the fine
granularity of the adopted sense inventory.

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 23
The third edition of the Senseval (Senseval-3) competition took place in Barcelona in
2004. It consisted of 14 tasks, and, overall, 160 systems from 55 teams participated in the tasks.
These included lexical sample and all-words tasks for seven languages as well as new tasks such
as gloss disambiguation, semantic role labeling, multilingual annotations etc. In this WordNet
1.7.1 was adopted as a sense inventory for nouns and adjectives, and WordSmyth for verbs.Most
of the systems were supervised.
The fourth edition of Senseval, held in 2007, has been renamed Semeval-2007 given the
presence of tasks of semantic analysis not necessarily related to word sense disambiguation.
More than 100 research teams and 123 systems were participated in this competition. WordNet
2.1 and coarse-grained inventories are used as dictionaries for WSD.
SemEval-2010 will be the 5th workshop on semantic evaluation. The first three
workshops, Senseval-1 through Senseval-3, were focused on word sense disambiguation, each
time growing in the number of languages offered in the tasks and in the number of participating
teams. In the 4th workshop, SemEval-2007, the nature of the tasks evolved to include semantic
analysis tasks outside of word sense disambiguation.
7. Applications
Machine translation is the original and most obvious application for WSD but
disambiguation has been considered in almost every NLP application,and is becoming
increasingly important in recent areas such as bioinformatics and the Semantic Web.
Machine translation (MT). WSD is required for lexical choice in MT for words that
have different translations for different senses and that are potentially ambiguous within a
given domain . For example, in an English-French financial news translator, the English
noun change could translate to either changement (‘transformation’) or monnaie (‘pocket
money’). In MT, the senses are often represented directly as words in the target
language.However, most MT models do not use explicit WSD. Either the lexicon is pre-
disambiguated for a given domain, hand-crafted rules are devised, or WSD is folded into
a statistical translation model .

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 24
Information retrieval (IR). Search engines can use explicit semantics to prune out
documents irrelevant to a user query.Ambiguity has to be resolved in some queries. For
instance, given the query “depression” should the system return documents about illness,
weather systems, or economics? Current IR systems do not use explicit WSD, and rely on
the user typing enough contexts in the query to only retrieve documents relevant to the
intended sense (e.g., “tropical depression”). Early experiments suggested that reliable IR
would require at least 90% disambiguation accuracy for explicit WSD to be of benefit.
Information extraction (IE) . Information retrieval is a type of information retrieval
whose goal is to automatically extract structured information, from unstructured
machine-readable documents. WSD is required for the accurate analysis of text in many
applications. For instance, an intelligence gathering system might require the flagging of,
say, all the references to illegal drugs, rather than medical drugs. Named-entity
classification, co-reference determination, and acronym expansion (MG as magnesium or
milligram) can also be cast as WSD problems for proper names. WSD is only beginning
to be applied in these areas.
Content Analysis: The analysis of the general content of a text in terms of its ideas,
themes, etc., can certainly benefit from the application of sense disambiguation.
Word Processing: Word processing is a relevant application of natural language
processing, whose importance has been recognized for a long time. Word sense
disambiguation can aid in correcting the spelling of a word, for case change, or to
determine when diacritics should be inserted etc.
Lexicography: WSD and lexicography (i.e., the professional writing of dictionaries) can
certainly benefit from each other: WSD can help provide empirical sense groupings and
statistically significant indicators of context for new or existing senses. Moreover, WSD
can help to create semantic networks out of machine-readable dictionaries .On the other
side, a lexicographer can provide better sense inventories and sense annotated corpora
which can benefit WSD.

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 25
8. Conclusions
Word Sense Disambiguation (WSD) is a hard task as it deals with the full complexities of
language and aims at identifying a semantic structure from apparently unstructured sources of
text. The hardness of WSD strictly depends on the granularity of the sense distinctions taken into
account. The problem gets much harder when it comes to a more general notion of polysemy,
where sense granularity makes the difference both in the performance of disambiguation systems
and in the agreement between human annotators.
WSD is the ability to identify the meaning of words in context in a computational manner
and it heavily relies on knowledge .A rich variety of techniques have been researched such as
knowledge based, supervised, unsupervised etc. Supervised methods undoubtedly perform better
than other approaches.To obtain a high-accuracy wide-coverage disambiguation system, we
probably need a corpus of about 3.2 million sense-tagged words.
Comparing and evaluating different WSD systems is extremely difficult, because of the
different test sets, sense inventories, and knowledge resources adopted .WSD is problematic in
part because of the inherent difficulty of determining or even defining word sense, and this is not
an issue that is likely to be solved in the near future. Machine translation is the original and most
obvious application for WSD but disambiguation has been considered in almost every NLP
application,and is becoming increasingly important in recent areas such as bioinformatics and the
Semantic Web. Although different works and proposals have been published on WSD,
application oriented evaluation of WSD is an open research area.

Word Sense Disambiguation
Dept. of Computer Science, CUSAT 26
9. References
[1]. Roberto Navigli .Word Sense Disambiguation: A Survey. ACM Computing Surveys, Vol. 4,
Article 10. Publishing date: February 2009.
[2] .Agirre Encko and Edmonds Philip . Word Sense Disambiguation : Algorithms and
Applications 1-28 Springer 2006.
[3]. Nancy Ide, Jean Véronis. Word Sense Disambiguation: The State of Art. Association for
Computational Linguistics, Vol.24, No.1, March 1998.
[4]. Daniel Jurafsky and James H. Martin, Speech and Language Processing,An Introduction to
Natural Language Processing, Computational Linguistics and Speech Recognition Second
Edition.
[5]. www.senseval.org


















