
Så används statistiska metoder i jordbruksförsök Svenska statistikfrämjandets vårkonferens den...
37
Så används statistiska metoder i jordbruksförsök Svenska statistikfrämjandets vårkonferens den 23 mars 2012 i Alnarp Johannes Forkman, Fältforsk, SLU
-
Upload
colin-brooks -
Category
Documents
-
view
215 -
download
1
Transcript of Så används statistiska metoder i jordbruksförsök Svenska statistikfrämjandets vårkonferens den...

Så används statistiska metoder i jordbruksförsökSvenska statistikfrämjandets vårkonferens den 23 mars 2012 i Alnarp
Johannes Forkman, Fältforsk, SLU

Agricultural field experiments
Experimental treatments
• Varieties
• Weed control treatments
• Plant protection treatments
• Tillage methods
• Fertilizers

Experimental design
Allocate Treatments A and B to eight plots...
A A A A B B B B
A B A B A B A B
A B B A A B B A
Option 1:
Option 2:
Option 3:

Systematic error
• The plots differ...
• The treatments are not compared on equal terms.
• There will be a systematic error in the comparison of A and B.

Randomise the treatments. This procedure transforms the systematic error into a random error.
R. A. Fisher

ExampleTreatment Yield (kg/ha) Mean (kg/ha)
A 8165
A 7792
A 8397
A 7764 8029.3
B 8483
B 8602
B 8641
B 8783 8627.2
Th
e d
iffere
nce
is 59
8

Randomisation test
• The observed difference is 598 kg/ha.
• There are 8!/(4! 4!) = 70 possible random arrangements.
• The two most extreme differences are 598 and -598.
• P-value = 2/70 = 0.029

t-test
6339164
598
4
15298
4
93438
598.
.t
Compare with a t-distribution with 6 degrees of freedom
P-value = 0.011

The randomisation model
is the number of available plots.

The approximate model
When is infinitely large
.
For statistical tests, we assume further that
𝐲=𝐗𝛃+𝐞 , E (𝐲 )=𝐗𝛃

A crucial assumption
Unit-Treatment additivity:
• Variances and covariances do not depend on treatment

Heterogeneity
A B

Inference about what??• Randomisation model: The average if the
treatment was given to all plots of the experiment.
• The approximate model: The average if the treatment was given to infinitely many plots?
Sample Population

Variance in a difference
When then
.
When then
.

Independent errors• Randomisation gives approximately independent
error terms
• Information about plot position was ignored
• This information can be utilized
B A B A A B B A

Tobler’s law of geography
“Everything is related to everything else, but near things are more related than distant things.”
Waldo Tobler

Random fieldsThe random function Z(s) is a
• stochastic process if the plots belong to a space in one dimension
• random field, if the plots belong to a space in two or more dimensions

Semivariogram
|| h ||
(|
| h
||)
practical range
95%sill

Spatial modelling• Can improve precision.
• Still rare in analysis of agricultural field experiments.
• There are many possible spatial models and methods.
• Can be used whether or not the treatments were randomized...
• Which is the best design for spatial analysis?

G H D E F B C A
A C G B D E H F
E F C D G A H B
I
II
III
Gradient
Randomised block design
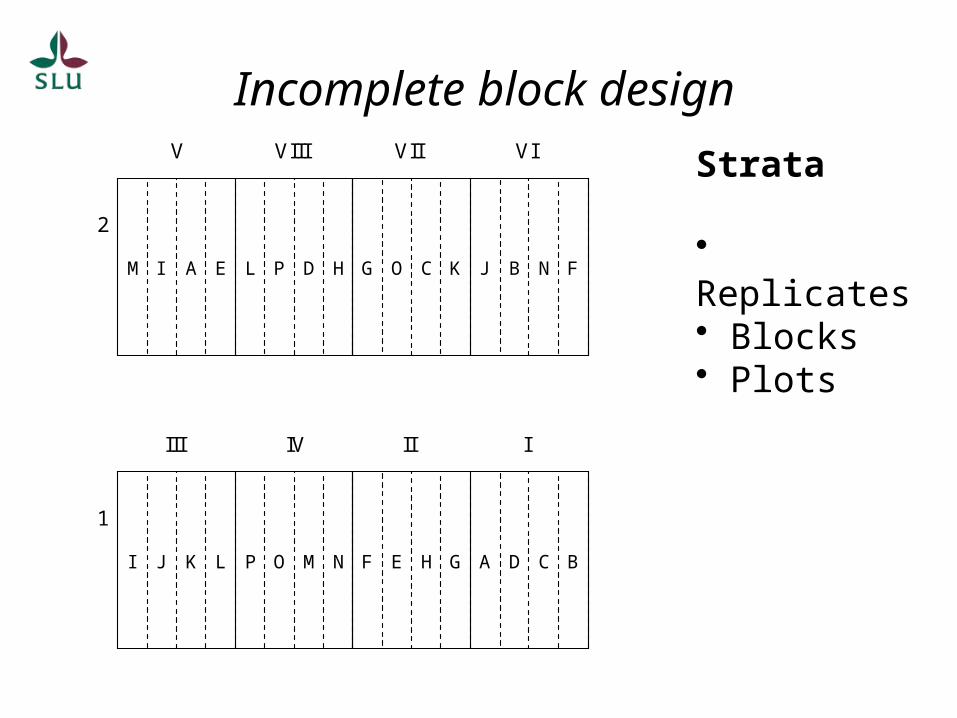
Incomplete block design
1
2
III IV II I
I J K L P O M N F E H G A D C B
V VIII VII VI
M I A E L P D H G O C K J B N F
Strata
• Replicates• Blocks• Plots

Ofullständiga block

D A C B B C A D C B D A B D C A C B A D B C A D
1 3 2 2 1 3
Replicate I Replicate II
Strata• Replicates• Plots• Subplots
Split-plot design

D A C B B C A D C B D A B D C A C B A D B C A D
1 3 2 2 1 3
Replicate I Replicate II
D A C B B C A D C B D A B D C A C B A D B C A D
D A C B B C A D C B D A B D C A C B A D B C A D
D A C B B C A D C B D A B D C A C B A D B C A D
D A C B B C A D C B D A B D C A C B A D B C A D
1a
1b
2a
2b
3
Comparison

sown conventionally sown with no tillage
cultivar 2cultivar 1cultivar 3
Mo applied Mo applied
Each replicate:
A design with several strata
Bailey, R. A. (2008). Design of comparative experiments. Cambridge University Press.


The linear mixed model
y = Xb + Zu + e
X: design matrix for fixed effects (treatments)
Z: design matrix for random effects (strata)
u is N(0, G) e is N(0, R)

Bates about error strata“Those who long ago took courses in "analysis of variance" or "experimental design" that concentrated on designs for agricultural experiments would have learned methods for estimating variance components based on observed and expected mean squares and methods of testing based on "error strata". (If you weren't forced to learn this, consider yourself lucky.) It is therefore natural to expect that the F statistics created from an lmer model (and also those created by SAS PROC MIXED) are based on error strata but that is not the case.”

Approximate t and F-tests
The number of degrees of freedom is an issue.SAS: the Satterthwaite or the Kenward & Roger method.
𝑡= 𝑳 ��
√v a r (𝑳 ��)when L is one-dimensional, and
otherwise.𝐹=(𝐋 �� ) ′ ( var (𝐋 �� ))−1 (𝐋 �� )
rank ( var (𝐋 �� ))

Likelihood ratio test
Full model (FM): p parameters
Reduced model (RM): q parameters
is asymptotically c2 with p – q degrees of freedom.
)(
)(log
y
y
|L
|L
RM
FM
2

Bayesian analysis
y = Xb + Zu + e
u is N(0, G) e is N(0, R)
G is diag(Φ) R is diag(σ2)
Independent priori distributions: p(b), p(Φ)
Sampling from the posterior distribution: p( ,b Φ | y)

P-values in agricultural research
• Only discuss statistically significant results
• Do not discuss biologically insignificant results (although they are statistically significant).
• “Limit statements about significance to those which have a direct bearing on the aims of the research”. (Onofri et al., Weed Science, 2009)

Shrinkage estimators
Galwey (2006). Introduction to mixed modelling. Wiley.

Fixed or random varieties?
Fixed varieties (BLUE)• Few varieties • Estimation of differences
Random varieties (BLUP)• Many varieties
• Ranking of varieties

Conclusions based on a simulation study
i. Modelling treatment as random is efficient for small block experiments.
ii. A model with normally distributed random effects performs well, even if the effects are not normally distributed.
iii. Bayesian methods can be recommended for inference about treatment differences.

Summary• Fisher’s ideas about randomisation and blocking
are still predominant.
• Strong focus on p-values.
• Linear mixed models are used extensively.
• Spatial and Bayesian methods are used less often.
• The question is what is random and fixed, and how to calculate p-values.

Tack för uppmärksamheten!


















