RWF-2000: An Open Large Scale Video Database for Violence ... · clips from 18 selected Hollywood...
8
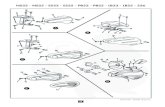
RWF-2000: An Open Large Scale Video Database for Violence Detection Ming Cheng Duke Kunshan University Kunshan, China [email protected] Kunjing Cai Sun Yat-sen Universit Guangzhou, China [email protected] Ming Li Duke Kunshan University Kunshan, China [email protected] Abstract—In recent years, surveillance cameras are widely deployed in public places, and the general crime rate has been reduced significantly due to these ubiquitous devices. Usually, these cameras provide cues and evidence after crimes were conducted, while they are rarely used to prevent or stop criminal activities in time. It is both time and labor consuming to manually monitor a large amount of video data from surveillance cameras. Therefore, automatically recognizing violent behaviors from video signals becomes essential. In this paper, we summarize several existing video datasets for violence detection and propose a new video dataset with 2,000 videos all captured by surveillance cameras in real-world scenes. Also, we present a new method that utilizes both the merits of 3D-CNNs and optical flow, namely Flow Gated Network. The proposed approach obtains an accuracy of 87.25% on the test set of our proposed RWF-2000 database. The proposed database and source codes of this paper are currently open to access 1 . I. I NTRODUCTION Recently, video-based violent behavior detection has at- tracted more and more attention. There is an increasing number of surveillance cameras in public places, which could collect evidence and deter potential criminals. However, it is too expensive to monitor a large amount of video data in real-time manually. Thus, automatically recognizing criminal scenes from videos becomes essential and challenging. Generally, the concept of video-based violence detection is defined as detecting violent behaviors in video data. It can be viewed as a subset of human action recognition that aims at recognizing general human actions. Compared to still images, video data has additional temporal sequences. A set of consecutive frames can represent a continuous motion, and neighboring frames contain much redundant information due to high inter-frame correlation. Thus, many researchers devote to fuse both spatial and temporal information properly. Some earlier methods rely on detecting the presences of highly relevant objects (e.g., gun shooting, blaze, blood, blast), rather than directly recognizing the violent events [1], [2], [3]. In 2011, Nievas et al. [4], [5] firstly released two video datasets for violence detection, namely the Hockey Fight dataset and the Movies Fight dataset. Moreover, in 2012, Hassner et al. [6] also proposed the Crowd Violence dataset. Since then, most 1 https://github.com/mchengny/RWF2000-Video-Database-for-Violence-D etection Figure 1. Gallery of the RWF-2000 database works focus on developing methods that directly recognize violence in videos. To directly recognize human action from videos as well as violence detection, there are mainly two categories of methods in these algorithms, namely the traditional feature extraction with shallow classifiers and the end-to-end deep learning framework. For the conventional feature extraction methods, researchers try to build a powerful set of video descriptors and feed them to a linear classifier (e.g., SVM). Based on this principle, many classical methods were presented: ViF [6], STIPs [7], SCOF [8], iDT [9], etc. While in recent years, many end-to-end deep learning based methods have been proposed, e.g. two-stream method [10], ConvLSTM [11], C3D [12], TSN [13], ECO [14]. Currently, most state-of-the-art results are obtained through deep learning based methods. Although there are some existing video datasets for violence detection, they still have the drawbacks of small scale, reduced diversity, and low imaging resolution. Moreover, some of the violence datasets with high imaging quality are extracted from movies, which are not close enough to real-world scenes. In order to solve the problem of insufficient high-quality data arXiv:1911.05913v2 [cs.CV] 17 Apr 2020
Transcript of RWF-2000: An Open Large Scale Video Database for Violence ... · clips from 18 selected Hollywood...

RWF-2000: An Open Large Scale Video Databasefor Violence Detection
Ming ChengDuke Kunshan University
Kunshan, [email protected]
Kunjing CaiSun Yat-sen Universit
Guangzhou, [email protected]
Ming LiDuke Kunshan University
Kunshan, [email protected]
Abstract—In recent years, surveillance cameras are widelydeployed in public places, and the general crime rate has beenreduced significantly due to these ubiquitous devices. Usually,these cameras provide cues and evidence after crimes wereconducted, while they are rarely used to prevent or stop criminalactivities in time. It is both time and labor consuming tomanually monitor a large amount of video data from surveillancecameras. Therefore, automatically recognizing violent behaviorsfrom video signals becomes essential. In this paper, we summarizeseveral existing video datasets for violence detection and proposea new video dataset with 2,000 videos all captured by surveillancecameras in real-world scenes. Also, we present a new method thatutilizes both the merits of 3D-CNNs and optical flow, namely FlowGated Network. The proposed approach obtains an accuracy of87.25% on the test set of our proposed RWF-2000 database. Theproposed database and source codes of this paper are currentlyopen to access 1.
I. INTRODUCTION
Recently, video-based violent behavior detection has at-tracted more and more attention. There is an increasingnumber of surveillance cameras in public places, which couldcollect evidence and deter potential criminals. However, it istoo expensive to monitor a large amount of video data inreal-time manually. Thus, automatically recognizing criminalscenes from videos becomes essential and challenging.
Generally, the concept of video-based violence detectionis defined as detecting violent behaviors in video data. Itcan be viewed as a subset of human action recognition thataims at recognizing general human actions. Compared to stillimages, video data has additional temporal sequences. A setof consecutive frames can represent a continuous motion, andneighboring frames contain much redundant information dueto high inter-frame correlation. Thus, many researchers devoteto fuse both spatial and temporal information properly.
Some earlier methods rely on detecting the presences ofhighly relevant objects (e.g., gun shooting, blaze, blood, blast),rather than directly recognizing the violent events [1], [2], [3].In 2011, Nievas et al. [4], [5] firstly released two video datasetsfor violence detection, namely the Hockey Fight dataset andthe Movies Fight dataset. Moreover, in 2012, Hassner et al. [6]also proposed the Crowd Violence dataset. Since then, most
1https://github.com/mchengny/RWF2000-Video-Database-for-Violence-Detection
Figure 1. Gallery of the RWF-2000 database
works focus on developing methods that directly recognizeviolence in videos.
To directly recognize human action from videos as well asviolence detection, there are mainly two categories of methodsin these algorithms, namely the traditional feature extractionwith shallow classifiers and the end-to-end deep learningframework. For the conventional feature extraction methods,researchers try to build a powerful set of video descriptorsand feed them to a linear classifier (e.g., SVM). Based onthis principle, many classical methods were presented: ViF [6],STIPs [7], SCOF [8], iDT [9], etc. While in recent years, manyend-to-end deep learning based methods have been proposed,e.g. two-stream method [10], ConvLSTM [11], C3D [12], TSN[13], ECO [14]. Currently, most state-of-the-art results areobtained through deep learning based methods.
Although there are some existing video datasets for violencedetection, they still have the drawbacks of small scale, reduceddiversity, and low imaging resolution. Moreover, some of theviolence datasets with high imaging quality are extracted frommovies, which are not close enough to real-world scenes. Inorder to solve the problem of insufficient high-quality data
arX
iv:1
911.
0591
3v2
[cs
.CV
] 1
7 A
pr 2
020

Table ICOMPARISONS OF THE RWF-2000 WITH PREVIOUS DATASETS. THE ’NATURAL’ REPRESENTS THAT VIDEOS ARE FROM REALISTIC SCENES, BUT
RECORDED BY HYBRID TYPES OF DEVICES (E.G., MOBILE CAMERAS, CAR-MOUNTED CAMERAS).
Authors Dataset Data Scale Length/Clip (sec) Resolution Annotation ScenarioBlunsden et al. [15] BEHAVE 4 Videos (171 Clips) 0.24-61.92 640×480 Frame-Level Acted Fights
Rota et al. [16] RE-DID 30 Videos 20-240 1280×720 Frame-Level NaturalDemarty et al.[17] VSD 18 Movies (1,317 Clips) 55.3-829.4 Variable Frame-Level MoviePerez et al. [18] CCTV-Fights 1,000 clips 5-720 Variable Frame-Level NaturalNievas et al. [4] Hockey Fight 1,000 Clips 1.6-1.96 360×288 Video-Level Hockey GamesNievas et al. [5] Movies Fight 200 Clips 1.6-2 720×480 Video-Level MovieHassner et al. [6] Crowd Violence 246 Clips 1.04-6.52 Variable Video-Level Natural
Yun et al. [19] SBU Kinect Interaction 264 Clips 0.67-3 640×480 Video-Level Acted FightsSultani et al. [20] UCF-Crime 1,900 Clips 60-600 Variable Video-Level Surveillance
Ours RWF-2000 2,000 Clips 5 Variable Video-Level Surveillance
from real violence activities, we collect a new video dataset(RWF-2000) and freely release it to the research community.This dataset has a large scale with 2,000 clips extracted fromsurveillance videos. Besides, we present a novel model witha self-learned pooling mechanism, which could adopt bothappearance features and temporal features well.
II. RELATED WORK
A. Previous Datasets
According to the annotation method, there are mainlytrimmed and untrimmed video datasets for violence detection.The videos in trimmed datasets are cut into short clips witha length of several seconds, and each one of them has avideo-level annotation. While the videos in untrimmed datasetsusually have a longer duration. Furthermore, the start time andend time of violent activities are labeled at a frame-level. TableI shows the comparison of our proposed RWF-2000 datasetwith previous others.
Blunsden et al. [15] proposed the BEHAVE dataset formulti-person behavior classification in 2010. This datasetconsists of 2 to 5 people as one or two interacting groups.There are 171 clips extracted from four surveillance videoswith a long duration. Moreover, ten categories of group behav-iors were labeled (InGroup, Approach, WalkTogether, Meet,Split, Ignore, Chase, Fight, RunTogether, Following). All theinteracting activities were recorded from the performance ofinvited actors.
Nievas et al. presented two video datasets for violencedetection in 2011, namely the Movies Fight [5] and the HockeyFight [4]. The Movies Fight dataset has 200 clips extractedfrom short movies. The number of video samples is insufficientnowadays. In the Hockey Fight dataset, there are 1,000 clipscaptured in hockey games of the National Hockey League.One of its disadvantages is the lack of diversity because all thevideos are taken in a single scene. Both of these two datasetsare labeled at the video-level.
Hassner et al. [6] collected 246 videos with or withoutviolent behaviors in 2012, namely the Crow Violence dataset.It is dedicated to recognizing violence in crowded scenes.Videos in this dataset are ranged from 1.04 seconds to 6.53
seconds. The characteristic of this dataset is its crowdedscenes, but deficient imaging quality.
Compared to recognize violence by only RGB data, Yunet al. [19] presented the first violence dataset in the formof RGB-D data in 2012. Actors act eight interactions (ap-proaching, departing, pushing, kicking, punching, exchangingobjects, hugging, and shaking hands). Using the MicrosoftKinect sensor, 21 pairs of two-actor interactions performed byseven participants are recorded. Also, not only the video-levelannotations are provided, but also the joints data are given.
Rota et al. [16] presented the RE-DID (Real-Life Events-Dyadic Interactions) dataset in 2015. This dataset is composedof 30 videos with high-quality resolution up to 1280×720.Twenty-five of them are captured using car-mounted cameras,and the rest are taken by other types of devices (e.g., mo-bile phone). Moreover, the bounding boxes of participatinginstances with relative ID, the position of the interpersonalspaces are both provided at frame-level, which is useful forin-depth analysis.
Demarty et al. [17] defined the violent contents in moviesas Blood, Fights, Fire, Guns, Cold weapons, Car chases,Gory scenes, Gunshots, Explosions, Screams. In 2015, theycontributed to building the VSD dataset consisting of 1,317clips from 18 selected Hollywood movies (e.g., Kill Bill, FightClub), and annotated each frame as violence or non-violence.
Those above datasets are mainly composed of videos cap-tured in a single scene, performed by actors, or extracted fromedited movies. Only a few parts of them are from realisticevents. To make the trained model more practical, Sultani etal. [20] presented a model named UCF-Crime, which contains1,900 videos recorded by real-world surveillance cameras.This video dataset is preliminarily designed to detect 13realistic anomalies, including abuse, arrest, arson, assault, acci-dent, burglary, explosion, fighting, robbery, shooting, stealing,shoplifting, and vandalism. While there are still some limits init, videos in this dataset usually have a long duration rangedfrom 1 to 10 minutes, while they are annotated at just video-level. Hence, detecting violent activities from a long video isvery tough.
The latest large-scale video dataset for violence detection

was presented by Perez et al [18] in 2019. It consists of 1,000videos containing violent activities, and each violent activityis annotated with the start and end time. 280 of them are fromreal-world surveillance cameras, and 720 of them are taken byother types of devices, including mobile cameras, car cameras,drones, or helicopters. Only a small part of these videos comesfrom the shooting perspective of real surveillance cameras.
Summarizing these proposed datasets, each of them has atleast one or more of the following limits:
• Low imaging quality;• Lack of sufficient data amount;• Videos with long duration but crude annotations;• Hybrid source of videos that is not close enough to
realistic violence.To cope with the above issues, we collect a new RWF-2000 (Real-World Fighting) dataset from the YouTube website,which consists of 2,000 trimmed video clips captured bysurveillance cameras in the real-world scenes. Figure 1 demon-strates some video samples from the RWF-2000 dataset. Thedetailed description of this proposed dataset will be introducedin Section III-A.
B. Previous Methods
In the earlier period, many researchers explored to extractfeatures from videos by identifying the spatial-temporal in-terest points and build traditional machine learning classi-fiers based on the extracted patterns. Some classical methodsinvolve space-time interest points (STIP) [7], Harris cornerdetector [21], improved dense trajectory (iDT) [9], motionscale-invariant feature transform (MoSIFT) [22].
Chen et al. [2] explored the way to detect violence fromcompressed video data. They utilized the encoded motion vec-tor from the MPEG-1 video data as extracted features, whichrepresent the data component with high motion intensity. Bythis data format, they built a classifier to detect the presenceof blood as violence.
Hassner et al. [6] presented the violent flows (ViF) de-scriptors for violence detection, which is the magnitude seriesof optical flow over time. Later, Gao et al. [23] improvedthis method by introducing the orientation of the violent flowfeatures into the ViF descriptor, namely the oriented violentflows (OViF).
Not limited to the filed of violence recognition, the im-proved dense trajectory (iDT) [9] features has made a sig-nificant performance in generic human action recognition.Bilinski et al. [24] adopted the iDT features into the violencerecognition. Besides, they presented an improve Fisher en-coding method that is powerful to encode the spatial-temporalinformation in a video.
With the fast development of deep learning in recentyears, currently the methods based on convolutional neuralnetworks have become the mainstream in video-based actionrecognition (e.g., TSN [13], ECO [14], C3D [12]). Manyresearcher attempted to address the violence recognition taskby introducing deep learning based methods [25], [26], [27],[28], [29].
Figure 2. Pipeline of data collection
Dong et al. [28] presented a multi-stream deep neuralnetwork for inter-person violence detection from videos. Theraw videos, optical flows, and acceleration flow maps extractedfrom a given video are regarded as three input branches.Followed by the Long Short Term Memory (LSTM) network,a score-level fusion was employed to adopt the three streamsto predict a final result for violence detection.
Sudhakaran et al. [29] combined the advantages of bothconvolutional neural networks and recurrent neural networks todo violence detection. They modified the ConvLSTM network[30] to adopt the difference of adjacent frames as input, insteadof to give a sequence of raw frames. The convolutional neuralnetwork was deployed to extract spatial features at the frame-level, and the following LSTM network was used to modelthe temporal relationships.
Zhou et al. [26] also built a FightNet to discover the violentactivities in videos from multiple channels (e.g., RGB images,optical flow images, and acceleration images). They firstly pre-trained the proposed model on a generic action recognitiondataset named UCF101 [31], and then fine-tuned it on theCrowd Violence dataset [6] while they found that it is quiteeasy to fall into an over-fitting problem because of the highmodel complexity under insufficient violence data.
To summarize those methods above, deep learning basedapproaches usually outperformed the traditional feature extrac-tion based models. Most of the state-of-the-art results utilizemulti-channel inputs (e.g., raw RGB images, optical flows,acceleration maps). While complex models are not very robustagainst over-fitting. In this paper, we only adopt RGB imagesand optical flows to build the neural network, which is able

to process the spatial and temporal information. Furthermore,our proposed Flow-Gated architecture can reduce temporalchannels of input videos by self-learning, instead of traditionalpooling strategies. More details of the architecture will bedescribed in Section III-B.
III. RWF-2000 DATABASE AND PROPOSED METHOD
A. Data Collection
To make violence detection more practical in realistic appli-cation, we collect a new Real-World Fighting (RWF) datasetfrom YouTube, which consists of 2,000 video clips capturedby surveillance cameras in real-world scenes (shown in Figure1).
Figure 2 illustrates the pipeline of data collection. Firstlywe search on the YouTube website by specifying a set ofkeywords related to violence (e.g., real fights, violence undersurveillance, violent events), and obtain a list of URLs. Then,we employ a program to download videos from the obtainedlinks automatically, and roughly check each video to removethe irrelevant ones. To exhaustively extend the diversity ofour dataset, we repeat the above procedures by changing thelanguage of keywords to various types, including English, Chi-nese, German, French, Japanese, Russian, etc. Our selectioncriteria do not limit the type of violence, including any form ofsubjectively identified violent activities (e.g., fighting, robbery,explosion, shooting, blood, assault). After these, we obtain alot of raw videos and cut each video into a 5-second clip with30 FPS. In the end, we elaborately delete the noisy clips whichcontain unrealistic and non-monitoring scenes and annotateeach clip as Violent or Non-Violent.
Furthermore, as the total 2,000 video clips are extractedfrom around 1,000 raw surveillance videos with extendedfootage, we take a set of means to avoid data leakage insplitting ’train/test’ partitions. First, we employ a dictionary torecord the ID of source surveillance video for each extractedclip. Second, a python script is used to allocate clips to thetraining set and test set randomly, meanwhile it guarantees thatclips from the same source will not be assigned to the samecollection by checking records in the dictionary. Besides, wecalculate the color histogram of each clip as a feature vectorto compute the mutual cosine similarity between clips in thesame collection. Based on the similarity ranking from high tolow, we manually recheck the top 30% of the data to makesure the reliability of dataset partition.
The proposed dataset has a total of 2,000 video clips, whichare split into two parts: the training set (80%) and the test set(%20). Half of the videos include violent behaviors, whileothers belong to non-violent activities. Table I thoroughlycompares our RWF-2000 dataset with others. Our highlightis that all videos in this dataset are captured from the perspec-tive of surveillance cameras; none of them are modified bymultimedia technologies. Therefore, they are close to realisticviolent events. Besides, the number of videos also exceeds theprevious datasets.
Figure 3 demonstrates the distribution of video quality in theRWF-2000 dataset. As the normal settings of cameras, videos
Figure 3. Resolution Distribution of the RWF-2000 Database
are usually captured by a series of resolution standards (e.g.,720P, 1080P, 2K, 4K). Many data points in the distributionmap will overlap. Therefore, we add a few random jitters tothe original resolution data to obtain a better visualization. It isshown that several significant clusters are around the standardformats of 240P, 320P, 720P, and 1080P, respectively. Further-more, the proportion of violent videos is almost uniform atdifferent scales.
B. Flow Gated Network
In previous methods, most of them were trying to extractappearance features of the individual frame, then fuse themfor modeling temporal information. Ng et al. [32] summarizedvarious architectures for temporal feature pooling, while mostof them were human-designed and tested one by one. Asthe utilization of motion information may be limited due tothe coarse pooling mechanism, we try to design a temporalpooling mechanism that is achieved by network self-learning.
Figure 4 shows the structure of our proposed model withfour parts: the RGB channel, the Optical Flow channel,the Merging Block, and the Fully Connected Layer. RGBchannel and Optical Flow channel are made of cascading 3DCNNs, and they have consistent structures so that their outputcould be fused. Merging Block is also composed of basic3D CNNs, which is used to process information after self-learned temporal pooling. Moreover, the fully-connected layersgenerate output. Moreover, we adopt the concept of depth-wise separable convolutions from MobileNet [33] and Pseudo-3D Residual Networks [34], to modify the 3D convolutionallayers in our model, which can significantly reduce the modelparameters without significant performance loss.
The highlight of this model is to utilize a branch of theoptical flow channel to help build a pooling mechanism. Reluactivation is adopted at the end of the RGB channel, whilethe sigmoid function is placed at the end of the OpticalFlow channel. Then, outputs from RGB and Optical Flowchannels are multiplied together and processed by a temporalmax-pooling. Since the output of the sigmoid function isbetween 0 and 1, it is a scaling factor to adjust the outputof the RGB channel. Meanwhile, as max-pooling just reservelocal maximum, the output of RGB channel multiplied byone will have a larger probability to be retained, and the

Figure 4. The structure of the Flow Gated Network
Figure 5. Cropping strategy using dense optical flow
value multiplied by zero is more natural to be dropped. Thismechanism is a kind of self-learned pooling mechanism, whichutilizes a branch of optical flow as a gate to determine whatinformation the model should preserve or drop. The detailedparameters of the model structure are described in Table II.
IV. EXPERIMENTS
A. Basic Settings
It is known that consecutive frames in a video are highlycorrelated, and the region of interest for recognizing humanactivity is usually a small area, we implement both croppingand sampling strategies to reduce the amount of input videodata.
Firstly, we employ Gunner Farneback’s method [35] to com-pute the dense optical flow between neighboring frames. Thecomputed dense optical flow is a field of the 2-D displacementvector. Thus we calculate the norm of each vector to obtaina heat map for indicating the motion intensity. We use thesum of all the heat maps to be a final motion intensity map,then the region of interest is extracted from the location withthe most significant motion intensity (shown in Figure 5).Secondly, we implement a sparse sampling strategy. For eachinput video, we sparsely sample frames from the video bya uniform interval, then generate a fix-length video clip. Byadopting both cropping and sampling, the amount of input
Table IIPARAMETERS OF THE MODEL ARCHITECTURE (THE t REPRESENTS THE
NUMBER OF REPEATS)
Block Name Type Filter Shape tConv3d 1×3×3@16Conv3d 3×1×1@16 2
RGB/Flow MaxPool3d 1×2×2Channels Conv3d 1×3×3@32
Conv3d 3×1×1@32 2MaxPool3d 1×2×2
Fusion and Multiply None 1Pooling MaxPool3d 8×1×1 1
Conv3d 1×3×3@64Conv3d 3×1×1@64 2
Merging MaxPool3d 2×2×2Block Conv3d 1×3×3@128
Conv3d 3×1×1@128 1MaxPool3d 2×2×2
Fully-connected FC layer 128 2Layers Softmax 2 1
data is significantly reduced. In this project, the target lengthof the video clip is set to 64, and the size of the croppedregion is 224 × 224. After sampling and cropping processes,the input data has a shape of 64 × 224 × 224 × 5. The lastdimension has five channels containing three RGB channelsand two optical flow channels (a horizontal component and avertical component, respectively).
In the training process, we implement the SGD optimizerwith momentum (0.9) and the learning rate decay (1e-6).Also, we introduce the brightness transformation and randomrotation as a set of tricks for data augmentation, which helpmitigate the over-fitting problem by simulating various lightingconditions and camera perspectives in real-world scenes.
B. Ablation Experiments
In this part, we present detailed ablation studies to evaluateour model performance on the proposed RWF-2000 dataset.Table III shows the experimental results of four different cases.
The RGB Only represents the situation of removing theoptical flow channel while only keeping the RGB channel as

Table IIIEVALUATION OF THE PROPOSED FLOW GATED NETWORK ON THE
RWF-2000 DATASET
Method Train Accuracy(%) Test Accuracy(%) ParamsRGB Only 89.50 84.50 248,402OPT Only 82.31 75.50 248,258
Fusion (P3D) 88.44 87.25 272,690Fusion (C3D) 96.50 85.75 507,154
input. On the other hand, the OPT Only shows the case ofremoving the RGB channel and only keeping the optical flowchannel. Subsequently, the Fusion (P3D) proves that the fusedversion of our proposed method can achieve the best accuracyof 87.25%.
To compare the trade-off of computation amount betweendepth-wise separable 3D convolutions and traditional 3D con-volutions, we also test the fused version of our proposedmethod without adopting the concept from P3D-Net [34].The Fusion (C3D) shows the case of utilizing traditional 3Dconvolutions, instead of depth-wise separable 3D convolutions.This model achieves an accuracy of 85.75%, with nearlydouble the amount of model parameters. This result showsthat modifying the standard 3D convolutions to the depth-wise separable 3D convolutions could greatly reduce the modelparameters with increasing the classification performance.
C. Comparisons
Although we have listed a series of datasets for violencerecognition in Section II-A, it is still difficult to evaluate amethod on all of them due to their heterogeneity, includingdata format, annotation type, etc. Therefore, we only test ourproposed method on the Hockey Fight, the Movies Fight, andthe Crowd Violence datasets, which are all consistent withthe RWF-2000 dataset in data format, annotation type, andclose video footage. Table IV shows the comparisons of theFlow Gated Network and other previous methods. The authorsreport the performances of the first eight methods (from ViFto 3D ConvNet) in their published papers, and the last sixmethods are implemented and trained by ourselves due to thelack of existing experiments on these datasets. Generally, deeplearning based approaches significantly outperform the modelswhich depend on hand-crafted features.
Two experimental results can be observed in Table IV. First,the deep learning based methods are all over-fitted on theMovies Fight dataset. Hence, it is no longer suitable to beused in the current situation. Second, The performance of mostmethods carrying optical flow information has a significantdrop in the Crowd Violence dataset. The reason for thisphenomenon is due to the computing error of optical flow.The premise assumptions of the optical flow method include:the brightness between adjacent frames is constant; the timebetween the adjacent frames is continuous, or the motionchange is small; the pixels in the same sub-image have thesame motion. While in terms of camera movements, stablelighting conditions, and low imaging quality, videos in the
Table IVCOMPARISONS OF THE PROPOSED METHOD AND OTHERS ON THE
PREVIOUS DATASETS
Type Method Movies Hockey Crowd
Hand-CraftedFeatures
ViF [6] - 82.90% 81.30%LHOG+LOF [36] - 95.10% 94.31%HOF+HIK [37] 59.0% 88.60% -HOG+HIK [37] 49.0% 91.70% -
MoWLD+BoW [38] - 91.90% 82.56%MoSIFT+HIK [37] 89.5% 90.90% -
Deep-LearningBased
FightNet [26] 100% 97.00% -3D ConvNet [39] 99.97% 99.62% 94.30%ConvLSTM [29] 100% 97.10% 94.57.
C3D [12] 100% 96.50% 84.44%I3D(RGB only) [40] 100% 98.50% 86.67%I3D(Flow only) [40] 100% 84.00% 88.89%
I3D(Fusion) [40] 100% 97.50% 88.89%Ours 100% 98.00% 88.87%
Table VCOMPARISONS OF THE PROPOSED METHOD AND OTHERS ON THE
RWF-2000 DATASET
Method Accuracy(%) Params (M)ConvLSTM [29] 77.00 47.4C3D [12] 82.75 94.8I3D (RGB only) [40] 85.75 12.3I3D (Flow only) [40] 75.50 12.3I3D (TwoStream) [40] 81.50 24.6Ours (best version) 87.25 0.27
Crowd Violence dataset are far from the requirements. FigureIV-C shows two bad cases of computing the optical flow inthe Crowd Violence dataset, which visualize the reason whyflow-based methods perform poorly in this situation.
Also, compared to the generic human action recognition,the essence of video-based violence detection is actually adata-driven problem. Hence, we not only compare with othermethods presented for violence detection but also test someclassical models for generic action recognition on differentviolence datasets. The benchmarks of the RWF-2000 datasetare illustrated in Table V. Our proposed method achieves anaccurate result for violence recognition. Meanwhile, it hasfewer trainable model parameters.
V. CONCLUSION
This paper presents both a novel dataset and a method forviolence detection in surveillance videos. The proposed RWF-2000 dataset is the currently largest surveillance video datasetused for violence detection in realistic scenes. Moreover, aspecial pooling mechanism is employed by optical flow, whichcould implement temporal feature pooling instead of human-designed strategies. In the future, we will explore methodswithout the optical flow channel. Also, to train a more robustand reliable model, the size of the dataset needs to be furtherexpanded in the future.

(a) Example 1 (b) Example 2
Figure 6. Bad cases of computing optical flow in the Crowd Violence dataset
ACKNOWLEDGMENT
This research is funded in part by the National NaturalScience Foundation of China (61773413), Key Research andDevelopment Program of Jiangsu Province (BE2019054), Sixtalent peaks project in Jiangsu Province (JY-074), GuangzhouMunicipal People’s Livelihood Science and Technology Plan(201903010040).
REFERENCES
[1] C. Clarin, J. Dionisio, M. Echavez, and P. Naval, “Dove: Detectionof movie violence using motion intensity analysis on skin and blood,”PCSC, vol. 6, pp. 150–156, 2005.
[2] L.-H. Chen, H.-W. Hsu, L.-Y. Wang, and C.-W. Su, “Violence detectionin movies,” in 2011 Eighth International Conference Computer Graph-ics, Imaging and Visualization. IEEE, 2011, pp. 119–124.
[3] W.-H. Cheng, W.-T. Chu, and J.-L. Wu, “Semantic context detectionbased on hierarchical audio models,” in Proceedings of the 5th ACMSIGMM international workshop on Multimedia information retrieval,2003, pp. 109–115.
[4] E. B. Nievas, O. D. Suarez, G. B. Garcia, and R. Sukthankar, “Hockeyfight detection dataset,” in Computer Analysis of Images and Patterns.Springer, 2011, pp. 332–339.
[5] ——, “Movies fight detection dataset,” in Computer Analysis of Imagesand Patterns. Springer, 2011, pp. 332–339.
[6] T. Hassner, Y. Itcher, and O. Kliper-Gross, “Violent flows: Real-timedetection of violent crowd behavior,” in 2012 IEEE Computer SocietyConference on Computer Vision and Pattern Recognition Workshops.IEEE, 2012, pp. 1–6.
[7] F. D. De Souza, G. C. Chavez, E. A. do Valle Jr, and A. d. A. Araujo,“Violence detection in video using spatio-temporal features,” in 201023rd SIBGRAPI Conference on Graphics, Patterns and Images. IEEE,2010, pp. 224–230.
[8] J.-F. Huang and S.-L. Chen, “Detection of violent crowd behaviorbased on statistical characteristics of the optical flow,” in 2014 11thInternational Conference on Fuzzy Systems and Knowledge Discovery(FSKD). IEEE, 2014, pp. 565–569.
[9] H. Wang and C. Schmid, “Action recognition with improved trajecto-ries,” in Proceedings of the IEEE international conference on computervision, 2013, pp. 3551–3558.
[10] K. Simonyan and A. Zisserman, “Two-stream convolutional networksfor action recognition in videos,” in Advances in neural informationprocessing systems, 2014, pp. 568–576.
[11] J. Donahue, L. Anne Hendricks, S. Guadarrama, M. Rohrbach, S. Venu-gopalan, K. Saenko, and T. Darrell, “Long-term recurrent convolutionalnetworks for visual recognition and description,” in Proceedings of theIEEE conference on computer vision and pattern recognition, 2015, pp.2625–2634.
[12] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learningspatiotemporal features with 3d convolutional networks,” in Proceedingsof the IEEE international conference on computer vision, 2015, pp.4489–4497.
[13] L. Wang, Y. Xiong, Z. Wang, Y. Qiao, D. Lin, X. Tang, and L. Van Gool,“Temporal segment networks: Towards good practices for deep actionrecognition,” in European conference on computer vision. Springer,2016, pp. 20–36.
[14] M. Zolfaghari, K. Singh, and T. Brox, “Eco: Efficient convolutionalnetwork for online video understanding,” in Proceedings of the EuropeanConference on Computer Vision (ECCV), 2018, pp. 695–712.
[15] S. Blunsden and R. Fisher, “The behave video dataset: ground truthedvideo for multi-person behavior classification,” Annals of the BMVA,vol. 4, no. 1-12, p. 4, 2010.
[16] P. Rota, N. Conci, N. Sebe, and J. M. Rehg, “Real-life violent socialinteraction detection,” in 2015 IEEE International Conference on ImageProcessing (ICIP). IEEE, 2015, pp. 3456–3460.
[17] C.-H. Demarty, C. Penet, M. Soleymani, and G. Gravier, “Vsd, a publicdataset for the detection of violent scenes in movies: design, annotation,analysis and evaluation,” Multimedia Tools and Applications, vol. 74,no. 17, pp. 7379–7404, 2015.
[18] M. Perez, A. C. Kot, and A. Rocha, “Detection of real-world fights insurveillance videos,” in ICASSP 2019-2019 IEEE International Confer-ence on Acoustics, Speech and Signal Processing (ICASSP). IEEE,2019, pp. 2662–2666.
[19] K. Yun, J. Honorio, D. Chattopadhyay, T. L. Berg, and D. Samaras,“Two-person interaction detection using body-pose features and multipleinstance learning,” in 2012 IEEE Computer Society Conference onComputer Vision and Pattern Recognition Workshops. IEEE, 2012,pp. 28–35.
[20] W. Sultani, C. Chen, and M. Shah, “Real-world anomaly detectionin surveillance videos,” in Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition, 2018, pp. 6479–6488.
[21] D. Chen, H. Wactlar, M.-y. Chen, C. Gao, A. Bharucha, and A. Haupt-mann, “Recognition of aggressive human behavior using binary localmotion descriptors,” in 2008 30th Annual International Conference ofthe IEEE Engineering in Medicine and Biology Society. IEEE, 2008,pp. 5238–5241.
[22] L. Xu, C. Gong, J. Yang, Q. Wu, and L. Yao, “Violent video detectionbased on mosift feature and sparse coding,” in 2014 IEEE InternationalConference on Acoustics, Speech and Signal Processing (ICASSP).IEEE, 2014, pp. 3538–3542.
[23] Y. Gao, H. Liu, X. Sun, C. Wang, and Y. Liu, “Violence detection usingoriented violent flows,” Image and vision computing, vol. 48, pp. 37–41,2016.
[24] P. Bilinski and F. Bremond, “Human violence recognition and detectionin surveillance videos,” in 2016 13th IEEE International Conference onAdvanced Video and Signal Based Surveillance (AVSS). IEEE, 2016,pp. 30–36.
[25] Z. Fang, F. Fei, Y. Fang, C. Lee, N. Xiong, L. Shu, and S. Chen,“Abnormal event detection in crowded scenes based on deep learning,”Multimedia Tools and Applications, vol. 75, no. 22, pp. 14 617–14 639,2016.
[26] P. Zhou, Q. Ding, H. Luo, and X. Hou, “Violent interaction detection invideo based on deep learning,” in Journal of physics: conference series,vol. 844, no. 1. IOP Publishing, 2017, p. 012044.
[27] D. Xu, E. Ricci, Y. Yan, J. Song, and N. Sebe, “Learning deep represen-tations of appearance and motion for anomalous event detection,” arXivpreprint arXiv:1510.01553, 2015.
[28] Z. Dong, J. Qin, and Y. Wang, “Multi-stream deep networks for person toperson violence detection in videos,” in Chinese Conference on PatternRecognition. Springer, 2016, pp. 517–531.
[29] S. Sudhakaran and O. Lanz, “Learning to detect violent videos usingconvolutional long short-term memory,” in Advanced Video and SignalBased Surveillance (AVSS), 2017 14th IEEE International Conferenceon. IEEE, 2017, pp. 1–6.
[30] S. Xingjian, Z. Chen, H. Wang, D.-Y. Yeung, W.-K. Wong, and W.-c. Woo, “Convolutional lstm network: A machine learning approach forprecipitation nowcasting,” in Advances in neural information processingsystems, 2015, pp. 802–810.
[31] K. Soomro, A. R. Zamir, and M. Shah, “Ucf101: A dataset of 101 humanactions classes from videos in the wild,” arXiv preprint arXiv:1212.0402,2012.

[32] J. Yue-Hei Ng, M. Hausknecht, S. Vijayanarasimhan, O. Vinyals,R. Monga, and G. Toderici, “Beyond short snippets: Deep networks forvideo classification,” in Proceedings of the IEEE conference on computervision and pattern recognition, 2015, pp. 4694–4702.
[33] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang,T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convo-lutional neural networks for mobile vision applications,” arXiv preprintarXiv:1704.04861, 2017.
[34] Z. Qiu, T. Yao, and T. Mei, “Learning spatio-temporal representationwith pseudo-3d residual networks,” in proceedings of the IEEE Interna-tional Conference on Computer Vision, 2017, pp. 5533–5541.
[35] G. Farneback, “Two-frame motion estimation based on polynomialexpansion,” in SCIA. Springer, 2003, pp. 363–370.
[36] P. Zhou, Q. Ding, H. Luo, and X. Hou, “Violence detection in surveil-lance video using low-level features,” PLoS one, vol. 13, no. 10, 2018.
[37] E. B. Nievas, O. D. Suarez, G. B. Garcıa, and R. Sukthankar, “Violencedetection in video using computer vision techniques,” in Internationalconference on Computer analysis of images and patterns. Springer,2011, pp. 332–339.
[38] T. Zhang, W. Jia, B. Yang, J. Yang, X. He, and Z. Zheng, “Mowld:a robust motion image descriptor for violence detection,” MultimediaTools and Applications, vol. 76, no. 1, pp. 1419–1438, 2017.
[39] W. Song, D. Zhang, X. Zhao, J. Yu, R. Zheng, and A. Wang, “A novelviolent video detection scheme based on modified 3d convolutionalneural networks,” IEEE Access, vol. 7, pp. 39 172–39 179, 2019.
[40] J. Carreira and A. Zisserman, “Quo vadis, action recognition? a newmodel and the kinetics dataset,” in proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition, 2017, pp. 6299–6308.