
Robert Liao Tracy Wang CS252 Spring 2007. Overview Traditional GPU Architecture The NVIDIA G80...
24
Robert Liao Tracy Wang CS252 Spring 2007
-
Upload
leon-conley -
Category
Documents
-
view
219 -
download
0
Transcript of Robert Liao Tracy Wang CS252 Spring 2007. Overview Traditional GPU Architecture The NVIDIA G80...

Robert LiaoTracy Wang
CS252 Spring 2007

OverviewTraditional GPU ArchitectureThe NVIDIA G80 ProcessorCUDA (Compute Unified Device Architecture)LAPACKPerformance and Issues

A Quick Note on Naming“G80” is the codename for the GPU found in
the following graphics cards.NVIDIA GeForce 8 Series Graphics CardsNVIDIA Quadro FX 4600NVIDIA Quadro FX 5600

Traditional GPUs
From Intel Corporation

Traditional GPUsGPUs talk Polygons
Vertex Processor
FromCPU
Pixel Fragmenti
ngCreation
Merge Output
ProcessFragment
sDisplay

Traditional GPUsOpenGL and DirectX abstract this away.
Vertex Processor
FromCPU
Pixel Fragmenti
ngCreation
Merge Output
ProcessFragment
sDisplay
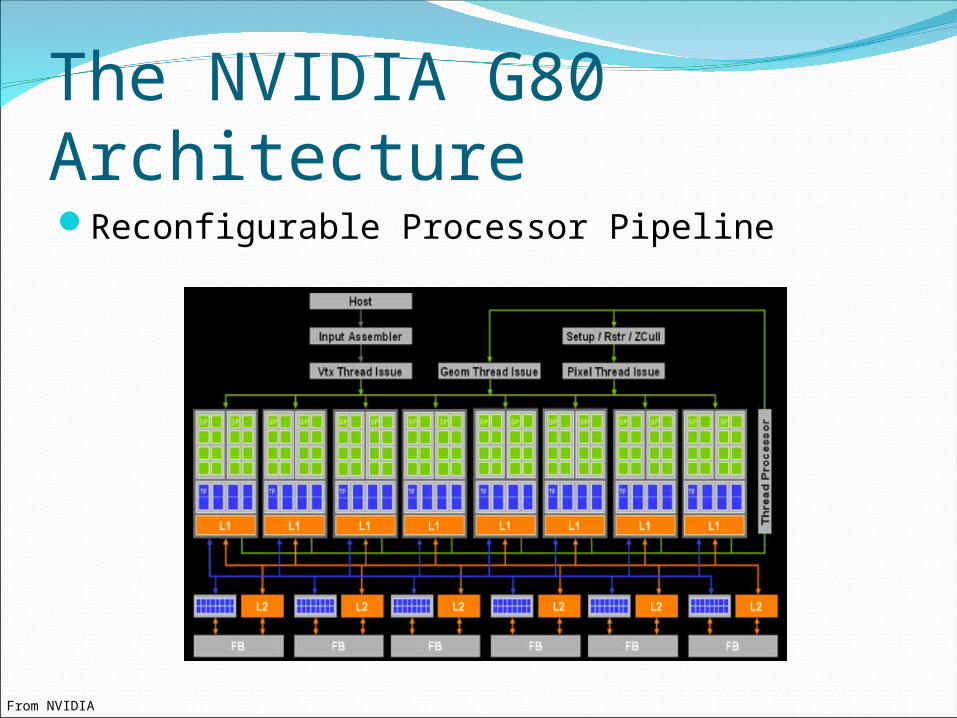
The NVIDIA G80 ArchitectureReconfigurable Processor Pipeline
From NVIDIA

G80 History and SpecificationsProject Started in Summer of 2002.128 Compute Cores
1.35 GHz in the GeForce 8800Floating Point Ops
Stream Processor ArchitectureOne Computing Unit Streams into another
Computing Unit

The CUDA Interface to the G80Compute Unified Device ArchitectureC Interface for Performing Operations on the
NVIDIA ProcessorContains traditional C memory semantics
with the context of a GPU

Working with CUDACustom compiler provided to compile C code
that the GPU can understand.The API functions provide a whole host of
ways to interface with the GPU.CUDA Libraries are provided for common
tasks.CUDA Runtime helps management of
memory
No DirectX or OpenGL knowledge needed!

Working with CUDARunning C on the CPU Running C on the GPUmallocfreeCPU Code
cudaMalloccudaFreeGPU Code
Pointers on one side stay on one side.This will create issues for existing applications

LAPACKLinear Algebra PACKageImplemented in Fortran 77Interfaces with BLAS
(Basic Linear Algebra Subprograms)Professor James Demmel involved in Project

CLAPACKAn F2C’ed version of LAPACK.Very ugly! s_rsle(&io___8); do_lio(&c__3, &c__1, (char *)&nm, (ftnlen)sizeof(integer)); e_rsle(); if (nm < 1) {
s_wsfe(&io___10);do_fio(&c__1, " NM ", (ftnlen)4);do_fio(&c__1, (char *)&nm, (ftnlen)sizeof(integer));do_fio(&c__1, (char *)&c__1, (ftnlen)sizeof(integer));e_wsfe();nm = 0;fatal = TRUE_;
} else if (nm > 12) {s_wsfe(&io___11);do_fio(&c__1, " NM ", (ftnlen)4);do_fio(&c__1, (char *)&nm, (ftnlen)sizeof(integer));do_fio(&c__1, (char *)&c__12, (ftnlen)sizeof(integer));e_wsfe();nm = 0;

CUBLASNVIDIA’s CUDA Based Implementation of
BLASMany functions are similar, but argument
signatures are slightly differentAdds some other functions as well
cublasAlloccublasFree
CUBLAS lives in the GPU world

CLAPACK and CUBLASPutting them together is not as easy as just
linking CLAPACK to CUBLAS.Matrices and data structures must be moved
into GPU memory space.CLAPACK executes on the CPU.CUBLAS executes on the GPU.
CLAPACK Function
CUBLASMemory
copy CPU->GPU
Memory copy GPU->CPU

CLAPACK ConcentrationGeneral Solve
sgesvComputes solution to linear system of equations
A × X = BTo Solve, A is factored into three matrices, P, L,
and U. P = Permutation Matrix L = Lower Triangular U = Upper Triangular
Currently, our results cover the triangular factoring step

Performance Results

Performance Results

Performance IssuesMuch copying must be done from the CPU to
GPU and GPU to CPU to communicate results.
Why not convert all pointers into GPU pointers?Requires CLAPACK to run in GPU memory.Could be someone’s research paper…

Other IssuesFloating Point Behaves Differently
Section 5.2 of the CUDA Programming Guide Discusses Deviations from IEEE-754
No support for denormalized numbersUnderflowed numbers are flushed to zero
We noticed some results appearing as 0.0001 instead of 0, for example

Current StateInvestigating some interesting memory issues
on the GPU side.Allocations Mysteriously Fail.

Conclusions To DateSmall data sets are better left off on the CPU.GPU calculations may not be appropriate for
scientific computing depending on needs.

Future DirectionsMoving all of LAPACK into GPUResolving the copying issue
Perhaps resolved by unifying the CPU and GPU?
Want to give it a try?Can’t find Quadro FX 5600 on Market (MSRP
$2,999)GeForce 8 Series have the G80 Processor
GeForce 8500GT ($99.99) GeForce 8800GTX ($939.99)



















