
Rim Moussa University Paris 9 Dauphine Experimental Performance Analysis of LH* RS Parity Management...
30
Rim Moussa Rim Moussa University Paris 9 University Paris 9 Dauphine Dauphine Experimental Experimental Performance Analysis of Performance Analysis of LH* LH* RS RS Parity Management Parity Management Workshop on Distributed Data Structures: WDAS 2002
-
Upload
dominique-stirton -
Category
Documents
-
view
212 -
download
0
Transcript of Rim Moussa University Paris 9 Dauphine Experimental Performance Analysis of LH* RS Parity Management...

Rim MoussaRim Moussa
University Paris 9 University Paris 9
DauphineDauphine
Experimental Performance Experimental Performance Analysis of LH*Analysis of LH*RSRS Parity Parity
ManagementManagement
Workshop on Distributed Data Structures: WDAS 2002

2
1.1. Contribute towards improving effictiveness Contribute towards improving effictiveness of the 1st prototype [of the 1st prototype [M. LjungströmM. Ljungström] :] :
Data Bucket Split
2.2. Proposal of ScenariosProposal of Scenarios
High Availability
Bucket Recovery
ObjectivesObjectives

3
OverviewOverview
1.1. Why SDDS ?Why SDDS ?
2.2. LH*LH*RSRS Data Structure Data Structure
3.3. File CreationFile Creation
4.4. High AvailabilityHigh Availability
5.5. RecoveryRecovery
6.6. Conclusion & Future WorkConclusion & Future Work

4
MotivationMotivation
Information Volume of 30% / yearInformation Volume of 30% / year Bottleneck of disk access and CPUsBottleneck of disk access and CPUs Failures Are frequentFailures Are frequent
ScalabilityScalability
High PerformanceHigh Performance
High AvailabilityHigh Availability

5
Hardware architectureHardware architecture
Modular Architecture Modular Architecture Best cost/ Performance ratioBest cost/ Performance ratio
NeedNeed
Network-based Network-based Storage SystemsStorage Systems
SDDSSDDS
Multicomputers
6
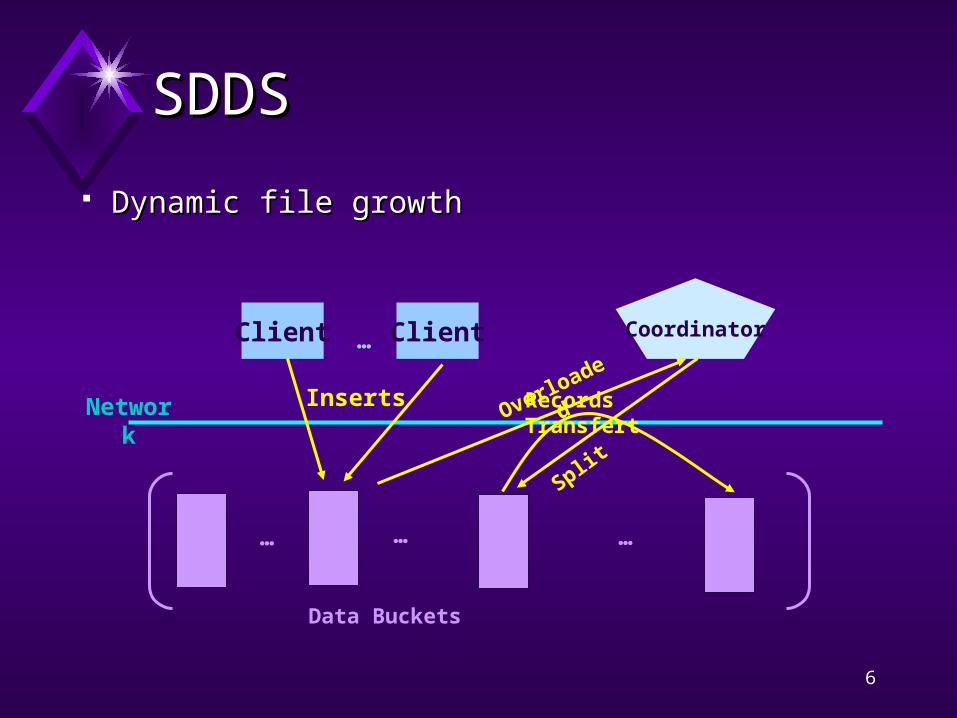
SDDSSDDS
Dynamic file growthDynamic file growth
Client
Network
Client…
Data Buckets
Inserts
……
Coordinator
…
Overloaded
Split
Records Transfert

7
SDDS SDDS (ctnd.)(ctnd.)
No Centralized directory accessNo Centralized directory access
Client
NetworkQuery IAM
…… … …
Data Buckets
Query

8
High Availability ?High Availability ?
DistributionDistribution Nodes’ Nodes’ FailureFailure
Parity Calculus
High storage costHigh storage cost
Data ReplicationData Replication

9
LH*LH*RS RS in a few wordsin a few words
SDDSSDDS
Distribution –Hashing Function
Parity Calculus –Reed Salomon Codes

10
LH*LH*RSRS – File Structure – File Structure
r [ e -1 … -1 ] P
Insert Rank
2
1
0
er
4 Data Buckets
Key Data Field
Rank Key list Parity Field

11
LH*LH*RSRS : Split Scenario : Split Scenario
Splitting Data Bucket
New Data Bucket
er
Delete e of rank r
r* e
Insert e in rank r*
er*
Insert e in rank r*
Delete e of rank r

12
Why the use of TCP/IP ?Why the use of TCP/IP ?
Flow ControlFlow Control No more loss of messages No more loss of messages
even if parity sites are overloaded even if parity sites are overloaded In opposition to UDP – Ljungström thesisIn opposition to UDP – Ljungström thesis
Parity Buckets coherenceParity Buckets coherence SSerialize Communicationerialize Communication at PBs at PBs
Critical sectionsCritical sections

13
Hardware TestbedHardware Testbed
6 Pentium III, 730 MHz, 128 Mb Machines6 Pentium III, 730 MHz, 128 Mb Machines Ethernet network: max bandwidth of 100 Ethernet network: max bandwidth of 100
Mbps Mbps 1 entity: (bucket, client)/ Machine1 entity: (bucket, client)/ Machine Configuration tested:Configuration tested:
1 Client1 Client A group of 4 Data BucketsA group of 4 Data Buckets K K Parity Buckets, k Parity Buckets, k {0, 1, 2} {0, 1, 2}

14
File Creation PerformancesFile Creation Performances
Ack k = 0 k = 1 k = 2
Key Total time (sec) /record (ms) Total time (sec) /record (ms) Total time (sec) /record (ms)
500 0,211 0,422 0,221 0,442 0,230 0,460
10000 4,046 0,400 4,537 0,440 4,746 0,480
10500 5,198 2,304 7,351 5,628 7,781 6,070
11000 5,398 0,400 7,571 0,440 8,011 0,460
20000 8,903 0,380 11,607 0,440 12,237 0,460
20500 11,046 4,286 15,473 7,732 16,794 9,114
21000 11,236 0,380 15,693 0,440 17,024 0,460
24500 12,628 0,400 17,285 0,440 18,677 0,482
25000 12,829 0,402 17,516 0,462 18,917 0,480
0,40 ms0,40 ms 0,44 ms0,44 ms 0,48 0,48 msms
Insert Time/ Insert Time/ recordrecord
+10%+10%4,9ms4,9ms 6,5 ms6,5 ms 8 ms8 msAck KeyAck Key1000110001

15
File SizeFile Size
High AvailabiltyHigh Availabilty
Degradation of the Degradation of the High availability of High availability of the filethe file
SolutionSolution
Add a Parity Bucket/ GroupAdd a Parity Bucket/ Group
16
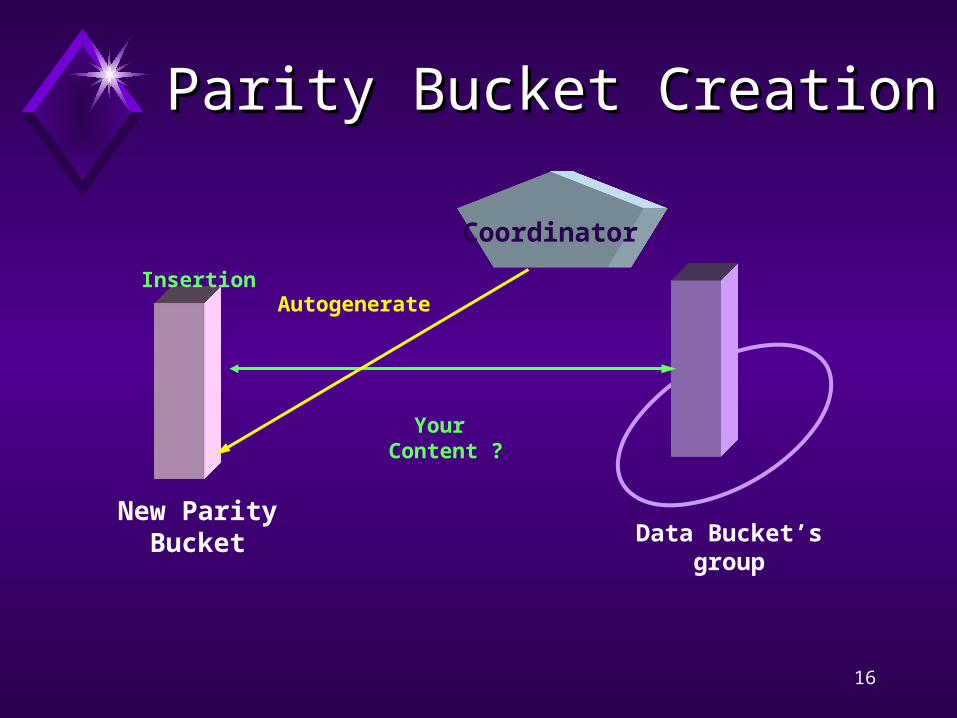
Parity Bucket CreationParity Bucket Creation
New Parity Bucket
Coordinator
Data Bucket’s group
Insertion
Your Content ?
Autogenerate

17
Parity Bucket Creation Parity Bucket Creation Perf.Perf.
Bucket Size Connection Time(s) Process Time (s) Total (sec)
5000 2,211 0,302 2,523
10000 2,433 0,611 3,044
25000 3,185 1,652 4,847
50000 4,667 3,395 8,062
87.63%87.63%
79.93%79.93%
65.71%65.71%
57.89%57.89%
Connection Time/ Connection Time/ Total TimeTotal Time

18
Data Bucket RecoveryData Bucket Recovery
UDPUDP TCPTCP/IP/IP
2 Scenarios2 Scenarios

19
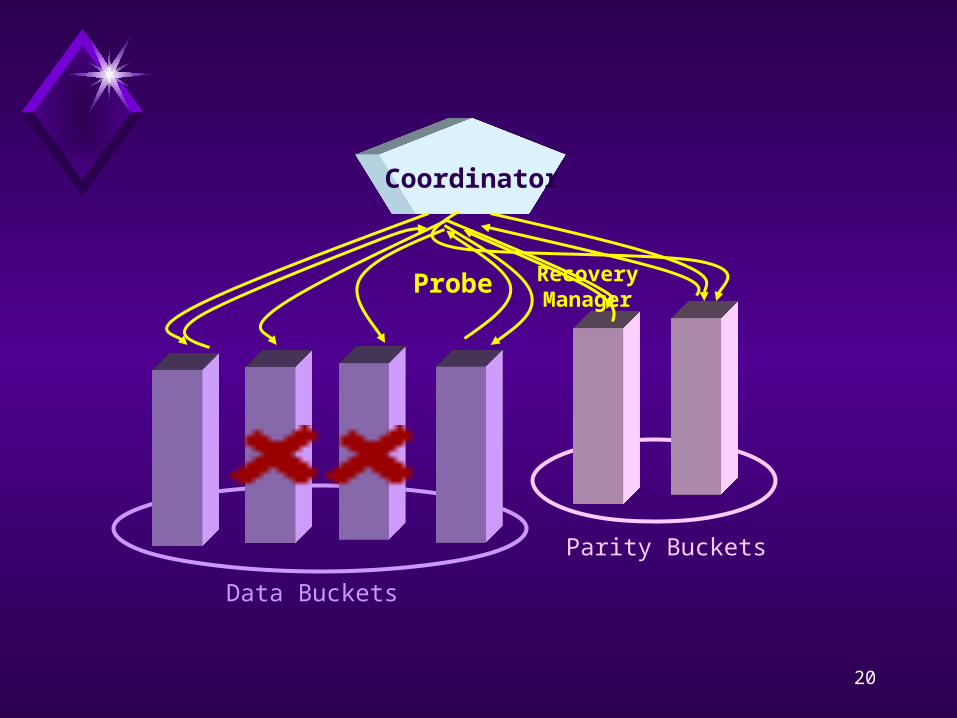
RecoveryRecovery
Client
Group g of Data Buckets
Coordinator
QueryGroup g
Failure !
20
Coordinator
Probe
Data Buckets
Parity Buckets
Recovery Manager
21
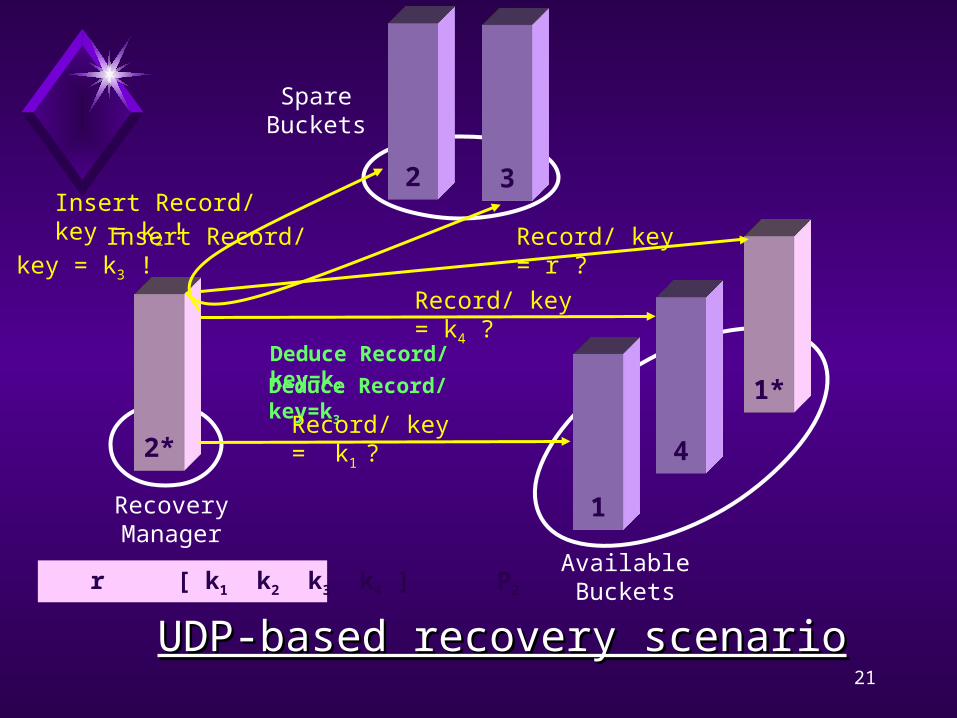
1
42*
Recovery Manager
Available Buckets r [ k1 k2 k3 k4 ] P2
1*
2
Spare Buckets
Deduce Record/ key=k3
Deduce Record/ key=k2
Insert Record/ key = k2 !
Insert Record/ key = k3 !
3
Record/ key = k1 ?
Record/ key = k4 ?
Record/ key = r ?
UDP-based recovery scenarioUDP-based recovery scenario

22
UDP-based Recovery UDP-based Recovery ScenarioScenario
Recovery of 1 Data Bucket
Bucket Size Nbr of records/ Bucket Recov, Time (sec) Time/ iter (ms) Time/record (ms)
5000 3125 1,742 0,557440 0,557440
10000 6250 3,465 0,554400 0,554400
25000 15625 8,662 0,554368 0,554368
50000 31250 17,375 0,556000 0,556000 Recovery of 2 Data Buckets
Bucket Size Nbr of records/ Bucket Recov, Time (sec) Time/ iter (ms) Time/record (ms)
5000 3125 2,043 0,653760 0,326880
10000 6250 4,076 0,652160 0,326080
25000 15625 10,185 0,651840 0,325920
50000 31250 20,349 0,651168 0,325584 Recovery of 3 Data Buckets
Bucket Size Nbr of records/ Bucket Recov, Time (sec) Time/ iter (ms) Time/record (ms)
5000 3125 2,564 0,820480 0,273493
10000 6250 4,797 0,767520 0,255840
25000 15625 11,928 0,763392 0,254464
50000 31250 23,895 0,764640 0,254880
0.55 0.55 msms
0.65 0.65 msms
0.76 0.76 msms
Just Just 0.1ms0.1ms to compute a record/ iteration to compute a record/ iteration
23
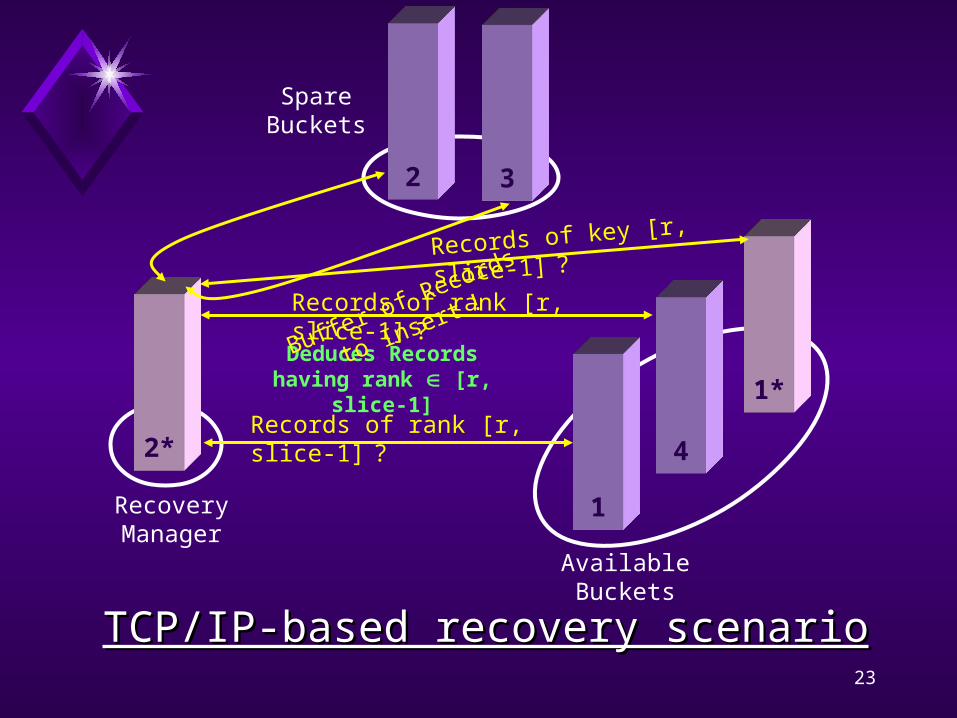
1
42*
Recovery Manager
Available Buckets
1*
2
Spare Buckets
Deduces Records having rank [r, slice-1]
3
Buffer of Records to
Insert !
Records of rank [r, slice-1] ?
Records of rank [r, slice-1] ?
Records of key [r, slice-1] ?
TCP/IP-based recovery scenarioTCP/IP-based recovery scenario

24
TCP/IP-based Recovery ScenarioTCP/IP-based Recovery Scenario
Recovery of 1 DB
Slice Total Time (sec) Communication Time (sec) Process Time (ms)
1250 50,352 46,968 1,161
3125 23,073 20,008 1,052
6250 13,650 10,523 1,043
15625 8,292 4,986 1,042
31250 6,700 3,134 1,042 Recovery of 2 DBs Slice Total Time (sec) Communication Time (sec) Process Time (ms)
1250 62,620 57,083 2,495
3125 29,893 24,081 2,403
6250 19,529 14,243 2,402 15625 14,510 8,556 2,364
31250 12,718 7,580 2,354 Recovery of 3 DBs Slice Total Time (sec) Communication Time (sec) Process Time (ms)
1250 82,619 74,227 3,996 3125 38,645 30,824 3,815
6250 26,028 18,387 3,775 15625 19,638 11,436 3,756
31250 17,825 9,233 3,735
CommunicatioCommunication Time >> n Time >>
Process Time.Process Time.Slice increases Slice increases
implies better implies better performance performance
results.results.
b = 50000 b = 50000 recordsrecords file of 125000 file of 125000 recsrecs 31250 records/B 31250 records/B

25
Discussion TCP/IP vs UDPDiscussion TCP/IP vs UDP
ReliabilityReliability Performance gainPerformance gain
Best improvements when slice = entire Best improvements when slice = entire bucket content (31250 recs). bucket content (31250 recs).
Indeed,Indeed,
UDPUDP TCP/IPTCP/IP GainGain
1 DB1 DB 17.375 s17.375 s 6.7 s 6.7 s 160%160%

26
ConclusionConclusion
Implementation of a new split algorithm Implementation of a new split algorithm Use TCP/IP instead of UDP Use TCP/IP instead of UDP Use Critical section to manage the Use Critical section to manage the
concurrent requests of updates at the level concurrent requests of updates at the level of Parity Bucketsof Parity Buckets
Parity Buckets ManagementParity Buckets Management Efficient Data Buckets RecoveryEfficient Data Buckets Recovery

27
Future WorkFuture Work
More performance Measurements More performance Measurements
Variation of Parity CalculusVariation of Parity Calculus

ReferencesReferences
[LS00] http://ceria.dauphine.fr
[Ljungström, 2000] CERIA & U. Linkoping
[Rizzo] http://www.iet.unipi.it/~luigi
[Luby] http://icsi.berkeley.edu/~luby
[XB99] http://paradise.caltech.edu

Demo of the PrototypeDemo of the Prototype
Friday – Poster SessionFriday – Poster SessionCERIA Lab.CERIA Lab.
B017B017

EndEnd
Thank you for Thank you for your Attentionyour Attention


















