
Reviving and Improving Recurrent Back Propagationrjliao/papers/rbp_slides.pdf · Overview 1...
39
Reviving and Improving Recurrent Back Propagation Renjie Liao 1,2,3 , Yuwen Xiong 1 , Ethan Fetaya 1,3 , Lisa Zhang 1,3 , KiJung Yoon 4,5 , Xaq Pitkow 4,5 , Raquel Urtasun 1,2,3 , Richard Zemel 1,3,6 1 University of Toronto, 2 Uber ATG Toronto, 3 Vector Institute, 4 Rice University, 5 Baylor College of Medicine, 6 Canadian Institute for Advanced Research [email protected] July 12, 2018 Renjie Liao (UofT) RBP July 12, 2018 1 / 39
Transcript of Reviving and Improving Recurrent Back Propagationrjliao/papers/rbp_slides.pdf · Overview 1...

Reviving and Improving Recurrent Back Propagation
Renjie Liao1,2,3, Yuwen Xiong1, Ethan Fetaya1,3, Lisa Zhang1,3,KiJung Yoon4,5, Xaq Pitkow4,5, Raquel Urtasun1,2,3, Richard Zemel1,3,6
1University of Toronto, 2Uber ATG Toronto, 3Vector Institute,4Rice University, 5Baylor College of Medicine, 6Canadian Institute for Advanced Research
July 12, 2018
Renjie Liao (UofT) RBP July 12, 2018 1 / 39

Overview
1 Motivations & Backgrounds
2 Algorithms
3 Experiments
Renjie Liao (UofT) RBP July 12, 2018 2 / 39

Motivations
Recurrent Back-Propagation (RBP), a.k.a., Almeida-Pineda algorithm, isindependently proposed by following papers:
Almeida, L.B., 1987. A learning rule for asynchronous perceptrons withfeedback in a combinatorial environment. IEEE International Conference onNeural Networks, 609-618.
Pineda, F.J., 1987. Generalization of back-propagation to recurrent neuralnetworks. Physical Review Letters, 59(19), p.2229.
Renjie Liao (UofT) RBP July 12, 2018 3 / 39

Motivations
Recurrent Back-Propagation (RBP), a.k.a., Almeida-Pineda algorithm, isindependently proposed by following papers:
Almeida, L.B., 1987. A learning rule for asynchronous perceptrons withfeedback in a combinatorial environment. IEEE International Conference onNeural Networks, 609-618.
Pineda, F.J., 1987. Generalization of back-propagation to recurrent neuralnetworks. Physical Review Letters, 59(19), p.2229.
Property
It exploits implicit function theorem to compute the gradient withoutback-propagating through time
Renjie Liao (UofT) RBP July 12, 2018 4 / 39

Motivations
Recurrent Back-Propagation (RBP), a.k.a., Almeida-Pineda algorithm, isindependently proposed by following papers:
Almeida, L.B., 1987. A learning rule for asynchronous perceptrons withfeedback in a combinatorial environment. IEEE International Conference onNeural Networks, 609-618.
Pineda, F.J., 1987. Generalization of back-propagation to recurrent neuralnetworks. Physical Review Letters, 59(19), p.2229.
Property
It exploits implicit function theorem to compute the gradient withoutback-propagating through time
It is efficient with memory and computation
Renjie Liao (UofT) RBP July 12, 2018 5 / 39

Motivations
Recurrent Back-Propagation (RBP), a.k.a., Almeida-Pineda algorithm, isindependently proposed by following papers:
Almeida, L.B., 1987. A learning rule for asynchronous perceptrons withfeedback in a combinatorial environment. IEEE International Conference onNeural Networks, 609-618.
Pineda, F.J., 1987. Generalization of back-propagation to recurrent neuralnetworks. Physical Review Letters, 59(19), p.2229.
Property
It exploits implicit function theorem to compute the gradient withoutback-propagating through time
It is efficient with memory and computation
It is successful for limited cases, e.g., Hopfield Networks
Renjie Liao (UofT) RBP July 12, 2018 6 / 39

Motivations
Recurrent Back-Propagation (RBP), a.k.a., Almeida-Pineda algorithm, isindependently proposed by following papers:
Almeida, L.B., 1987. A learning rule for asynchronous perceptrons withfeedback in a combinatorial environment. IEEE International Conference onNeural Networks, 609-618.
Pineda, F.J., 1987. Generalization of back-propagation to recurrent neuralnetworks. Physical Review Letters, 59(19), p.2229.
Property
It exploits implicit function theorem to compute the gradient withoutback-propagating through time
It is efficient with memory and computation
It is successful for limited cases, e.g., Hopfield Networks
Similar technique (implicit differentiation) was rediscovered later in PGMs!
Renjie Liao (UofT) RBP July 12, 2018 7 / 39

Background
Convergent Recurrent Neural Networks
Dynamics:
ht+1 = F (x ,w , ht)
where x , w and ht are data, weight and hidden state.
Steady/Stationary/Equilibrium State:
h∗ = F (x ,w , h∗)
Special Instances
Jacobi method
Gauss–Seidel method
Fixed-point iteration method
Renjie Liao (UofT) RBP July 12, 2018 8 / 39

Back-Propagation Through Time
Forward Pass:
x
F Fh1 h2 F
x x
w w w
F
w
x
hThT-1 Lh0
Renjie Liao (UofT) RBP July 12, 2018 9 / 39

Back-Propagation Through Time
Forward Pass:
x
F Fh1 h2 F
x x
w w w
F
w
x
hThT-1 Lh0
Renjie Liao (UofT) RBP July 12, 2018 10 / 39

Back-Propagation Through Time
Forward Pass:
x
F Fh1 h2 F
x x
w w w
F
w
x
hThT-1 Lh0
Renjie Liao (UofT) RBP July 12, 2018 11 / 39

Back-Propagation Through Time
Forward Pass:
x
F Fh1 h2 F
x x
w w w
F
w
x
hThT-1 Lh0
Renjie Liao (UofT) RBP July 12, 2018 12 / 39

Back-Propagation Through Time
Backward Pass:
x
F Fh1 h2 F
x x
w w w
F
w
x
hThT-1 Lh0
Renjie Liao (UofT) RBP July 12, 2018 13 / 39

Back-Propagation Through Time
Backward Pass:
x
F Fh1 h2 F
x x
w w w
F
w
x
hThT-1 Lh0
Renjie Liao (UofT) RBP July 12, 2018 14 / 39

Back-Propagation Through Time
Backward Pass:
x
F Fh1 h2 F
x x
w w w
F
w
x
hThT-1 Lh0
Renjie Liao (UofT) RBP July 12, 2018 15 / 39

Back-Propagation Through Time
Backward Pass:
x
F Fh1 h2 F
x x
w w w
F
w
x
hThT-1 Lh0
Renjie Liao (UofT) RBP July 12, 2018 16 / 39

Back-Propagation Through Time
Backward Pass:
x
F Fh1 h2 F
x x
w w w
F
w
x
hThT-1 Lh0
BPTT
∂L
∂w=
∂L
∂hT
(∂hT
∂w+
∂hT
∂hT−1
∂hT−1
∂w+ . . .
)=
∂L
∂hT
T∑k=1
(T−1∏
i=T−k+1
JF ,hi
)∂F (x ,w , hT−k)
∂w
Renjie Liao (UofT) RBP July 12, 2018 17 / 39

Truncated Back-Propagation Through Time
Backward Pass:
x
F Fh1 h2 F
x x
w w w
F
w
x
hThT-1 Lh0
TBPTT
Truncated at K -th step:
∂L
∂w=
∂L
∂hT
(∂hT
∂w+
∂hT
∂hT−1
∂hT−1
∂w+ . . .
)=
∂L
∂hT
K∑k=1
(T−1∏
i=T−k+1
JF ,hi
)∂F (x ,w , hT−k)
∂w
Renjie Liao (UofT) RBP July 12, 2018 18 / 39

Recurrent Back-Propagation
x
F Fh1 h2 F
x x
w w w
F
w
x
hThT-1 Lh0
Implicit Function Theorem
Let Ψ(x ,w , h) = h − F (x ,w , h), at steady state h∗, we haveΨ(x ,w , h∗) = 0Implicit Function Theorem is applicable if two conditions hold:
Ψ is continuously differentiable
I − JF ,h∗ is invertible
Renjie Liao (UofT) RBP July 12, 2018 19 / 39

Recurrent Back-Propagation
x
F Fh1 h2 F
x x
w w w
F
w
x
hThT-1 Lh0
Implicit Function Theorem
Let Ψ(x ,w , h) = h − F (x ,w , h), at steady state h∗, we haveΨ(x ,w , h∗) = 0Implicit Function Theorem is applicable if two conditions hold:
Ψ is continuously differentiable (LSTM, GRU)
I − JF ,h∗ is invertible
Renjie Liao (UofT) RBP July 12, 2018 20 / 39

Recurrent Back-Propagation
Contraction Mapping on Banach Space
F is a contraction mapping on Banach (completed and normed) space B,iff there exists some 0 ≤ µ < 1 such that ∀x , y ∈ B
‖F (x)− F (y)‖ ≤ µ‖x − y‖
One Sufficient Condition
Contraction Mapping =⇒ σmax(JF ,h∗) ≤ µ < 1
We then have,
|det(I − JF ,h∗)| =∏i
|σi (I − JF ,h∗)|
≥ [1− σmax(JF ,h∗)]d > 0
I − JF ,h∗ is invertible
Renjie Liao (UofT) RBP July 12, 2018 21 / 39

Recurrent Back-Propagation
x
F Fh1 h2 F
x x
w w w
F
w
x
hThT-1 Lh0
Implicit Function Theorem
∂Ψ(x ,w , h∗)
∂w=∂h∗
∂w− ∇F (x ,w , h∗)
∇w
= (I − JF ,h∗)∂h∗
∂w− ∂F (x ,w , h∗)
∂w= 0 (1)
The desired gradient is:
∂L
∂w=
∂L
∂h∗(I − JF ,h∗)
−1 ∂F (x ,w , h∗)
∂w
Renjie Liao (UofT) RBP July 12, 2018 22 / 39

Recurrent Back-Propagation
Derivation of Original RBP
Gradient:
∂L
∂w=
∂L
∂h∗(I − JF ,h∗)
−1∂F (x ,w , h∗)
∂w
Introduce z> = ∂L∂h∗ (I − JF ,h∗)
−1 which defines an adjoint linearsystem, (
I − J>F ,h∗)z =
(∂L
∂h∗
)>(2)
Original RBP uses fixed-point iteration method,
z = J>F ,h∗z +
(∂L
∂h∗
)>= f (z) (3)
Renjie Liao (UofT) RBP July 12, 2018 23 / 39

Recurrent Back-Propagation
Algorithm 1: : Original RBP
1: Initialization: initial guess z0, e.g., draw uniformly from[0, 1], i = 0, threshold ε
2: repeat3: i = i + 14: zi = J>F ,h∗zi−1 +
(∂L∂h∗
)>5: until ‖zi − zi−1‖ < ε
6: Return ∂L∂w
= z>i∂F (x,w,h∗)
∂w
Pros & Cons
Memory cost scales constantly w.r.t. # time steps whereas BPTTscales linearly
It is often faster than BPTT for many-step RNNs
It may converge slowly and sometimes numerically unstable
Renjie Liao (UofT) RBP July 12, 2018 24 / 39

Conjugate Gradient based RBP
Observations
Our core problem is(I − J>F ,h∗
)z =
(∂L∂h∗
)>, simplified as Az = b
CG is better than fixed-point iteration if A is PSD
A is often asymmetric for RNNs
Conjugate Gradient on the Normal Equations (CGNE)
Multiple (I − JF ,h∗) on both sides,
(I − JF ,h∗)(I − J>F ,h∗
)z = (I − JF ,h∗)
(∂L
∂h∗
)>Apply CG to solve z
Caveat: the condition number of the new system is squared!
Renjie Liao (UofT) RBP July 12, 2018 25 / 39

Neumann Series based RBP
Neumann Series
It’s a mathematical series of the form∑∞
t=0 At where A is an
operator, a.k.a., matrix geometric series in matrix terminology
A convergent Neumann series has the property:
(I − A)−1 =∞∑k=0
Ak
Neumann-RBP
Recall auxiliary variable z in RBP:
z =(I − J>F ,h∗
)−1(∂L
∂h∗
)>Replace A with J>F ,h∗ and truncate it at K -th power
Renjie Liao (UofT) RBP July 12, 2018 26 / 39

Neumann-RBP
Algorithm 2: : Neumann-RBP
1: Initialization: v0 = g0 =(
∂L∂h∗
)>2: for t = 1, 2, . . . ,K do3: vt = J>F ,h∗vt−1
4: gt = gt−1 + vt5: end for6: Return ∂L
∂w= (gK )> ∂F (x,w,h∗)
∂w
We show Neumann-RBP is related to BPTT and TBPTT:
Proposition 1Assume that we have a convergent RNN which satisfies the implicit function theoremconditions. If the Neumann series
∑∞t=0 J
tF ,h∗ converges, then the full Neumann-RBP is
equivalent to BPTT.
Proposition 2For the above RNN, let us denote its convergent sequence of hidden states ash0, h1, . . . , hT where h∗ = hT is the steady state. If we further assume that there existssome step K where 0 < K ≤ T such that h∗ = hT = hT−1 = · · · = hT−K , then K -stepNeumann-RBP is equivalent to K -step TBPTT.
Renjie Liao (UofT) RBP July 12, 2018 27 / 39

Neumann-RBP
Proposition 3
If the Neumann series∑∞
t=0 JtF ,h∗ converges, then the error between
K -step and full Neumann series is as follows,∥∥∥∥∥K∑t=0
JtF ,h∗ −∞∑t=0
JtF ,h∗
∥∥∥∥∥ ≤ ∥∥(I − JF ,h∗)−1∥∥ ‖JF ,h∗‖K+1
Pros & Cons
CG-RBP requires fewer # updates but may be slower in run time andis sometimes problematic due to the squared condition number
Neumann-RBP is stable and has same time & memory complexity
Renjie Liao (UofT) RBP July 12, 2018 28 / 39

Continuous Hopfield Networks
h1 h2
h3
h4h5
h6
Model
Inference:
d
dthi (t) = −hi (t)
a+
N∑j=1
wijφ(b · hj(t)) + Ii ,
Learning: minw1|I|∑
i∈I ‖φ(b · hi )− Ii‖1
Renjie Liao (UofT) RBP July 12, 2018 29 / 39

Continuous Hopfield Networks
0 2000 4000 6000 8000 10000train epoch
0.8
0.6
0.4
0.2
0.0
0.2
0.4
0.6
0.8
log
L1 lo
ss
BPTTTBPTTNeumann-RBPRBPCG-RBP
0 2000 4000 6000 8000 10000train epoch
1.0
0.9
0.8
0.7
0.6
0.5
0.4
log
L1 lo
ss
BPTTTBPTTNeumann-RBPRBPCG-RBP
Truncation Step 10 20 30
TBPTT 100% 100% 100%RBP 1% 4% 99%
CG-RBP 100% 100% 100%Neumann-RBP 100% 100% 100%
Table: Success (final loss
≤ 50% initial loss) rate.
(a) (b) (c) (d) (e) (f) (a) (b) (c) (d) (e) (f)
Figure: Visualization of associative memory. (a) Corrupted input image; (b)-(f) are retrievedimages by BPTT, TBPTT, RBP, CG-RBP, Neumann-RBP respectively.
Renjie Liao (UofT) RBP July 12, 2018 30 / 39

Gated Graph Neural Networks
GRU GRU
… …
…
Input
Hidden Layer Hidden Layer
Output
Renjie Liao (UofT) RBP July 12, 2018 31 / 39
Gated Graph Neural Networks
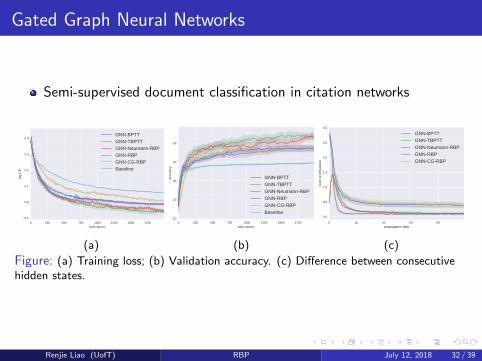
Semi-supervised document classification in citation networks
0 250 500 750 1000 1250 1500 1750train epoch
0.1
0.0
0.1
0.2
0.3
0.4
log
CE
GNNBPTTGNNTBPTTGNNNeumannRBPGNNRBPGNNCGRBPBaseline
0 250 500 750 1000 1250 1500 1750train epoch
10
20
30
40
50
accu
racy
GNNBPTTGNNTBPTTGNNNeumannRBPGNNRBPGNNCGRBPBaseline
0 20 40 60 80propagation step
0.0
0.5
1.0
1.5
2.0
2.5
3.0
norm
of d
iffer
ence
GNNBPTTGNNTBPTTGNNNeumannRBPGNNRBPGNNCGRBP
(a) (b) (c)
Figure: (a) Training loss; (b) Validation accuracy. (c) Difference between consecutivehidden states.
Renjie Liao (UofT) RBP July 12, 2018 32 / 39

Hyperparameter Optimization
data
MLP + SGD
lr, wd, etc.
w1
data
MLP + SGD
lr, wd, etc.
w2
data
MLP + SGD
lr, wd, etc.
wT
data
MLP Lw0
Renjie Liao (UofT) RBP July 12, 2018 33 / 39

Hyperparameter Optimization
Optimize 100 steps, truncate 50 steps:
0 20 40 60 80unroll step
0.8
0.6
0.4
0.2
0.0
0.2
0.4
Log
CE
NeumannRBPRBPBPTTTBPTTInit
0 20 40 60 80meta step
0.7
0.6
0.5
0.4
0.3
Log
CE
NeumannRBPRBPBPTTTBPTT
(a) (b)Figure: (a) Training loss at last meta step; (b) Meta training loss.
Renjie Liao (UofT) RBP July 12, 2018 34 / 39

Hyperparameter Optimization
Optimize 1500 steps, truncate 50 steps:
0 200 400 600 800 1000 1200 1400unroll step
3.0
2.5
2.0
1.5
1.0
0.5
0.0
0.5
Log
CE
NeumannRBPRBPBPTTTBPTTInit
0 20 40 60 80meta step
3.0
2.5
2.0
1.5
1.0
Log
CE
NeumannRBPRBPBPTTTBPTT
(a) (b)Figure: (a) Training loss at last meta step; (b) Meta training loss.
Renjie Liao (UofT) RBP July 12, 2018 35 / 39

Hyperparameter Optimization
TBPTT
Neumann-RBP
Train Step
TBPTT
Neumann-RBP
Train Step
(a) Meta step 20 (b) Meta step 40.
Truncation Step 10 50 100 10 50 100
Run Time ×3.02 ×2.87 ×2.68 Memory ×4.35 ×4.25 ×4.11
Table: Run time and memory comparison. We show the ratio of BPTT’s cost divided by
Neumann-RBP’s.
Renjie Liao (UofT) RBP July 12, 2018 36 / 39

Source Code
Our code is released at https://github.com/lrjconan/RBP
Renjie Liao (UofT) RBP July 12, 2018 37 / 39

Take Home Messages
RBP is very efficient for learning convergent RNNs
Neumann-RBP is stable, often faster than BPTT and takes constantmemory
Neumann-RBP is simple to implement
Welcome to our poster #178 tonight!
Renjie Liao (UofT) RBP July 12, 2018 38 / 39

Thank You
Renjie Liao (UofT) RBP July 12, 2018 39 / 39


















