Reseaux de Neurones´ - clement.chatelain.free.frclement.chatelain.free.fr/enseignements/rdn.pdf ·...
60
M2 STIM - Identification & aide ` a la d ´ ecision R´ eseaux de Neurones [email protected] 21 janvier 2016 [email protected] R´ eseaux de Neurones 21 janvier 2016 1 / 60
Transcript of Reseaux de Neurones´ - clement.chatelain.free.frclement.chatelain.free.fr/enseignements/rdn.pdf ·...

M2 STIM - � Identification & aide a la decision �
Reseaux de Neurones
21 janvier 2016
[email protected] Reseaux de Neurones 21 janvier 2016 1 / 60

Sommaire1 Introduction2 Principes generaux
Neurone formelTopologies
3 Apprentissage(s)Posons le problemeReseau lineaire a une coucheReseau non lineaire a une coucheReseaux multicouches
4 Autres architecturesArchitectures profondesReseaux recurrentsReseaux convolutionnelsLegos
5 Reseaux de neurones dans la pratiqueParametrisationMise en œuvre
[email protected] Reseaux de Neurones 21 janvier 2016 2 / 60

Introduction
Introduction
AvantageFonctionne ∀ le nombre d’entrees, ∀ le nombre de sortiesModele pas forcement lineaire par rapport aux parametresEt surtout ... ca marche tres bien !
InconvenientsLe critere doit etre derivableLe parametrage et l’apprentissage demandent un peu d’experience ...
[email protected] Reseaux de Neurones 21 janvier 2016 3 / 60

Introduction
Introduction
Les reseaux de neurones permettent d’estimer une fonction f :
f : x → y
avec xT = [x1, x2, . . . , xE ] ∈ RE
Si y ∈ RS, on parle de regressionSi y ∈ {C1,C2, . . . ,CS}, on parle de classificationDans ce cas, autant de neurones de sortie que de classe→ Sorties desirees de la forme : yd T
= [0,0, . . . ,1, . . . ,0]
Estimation de f :Apprentissage des poids de connexion entre neuronesSur une base etiquetee de N couples({x(1), y(1)}, . . . , {x(n), y(n)}, . . . , {x(N), y(N)})
[email protected] Reseaux de Neurones 21 janvier 2016 4 / 60

Principes generaux
Principes generauxIdee generale des Reseaux de neurones :
combiner de nombreuses fonctions elementaires pour former desfonctions complexes.Apprendre les liens entre ces fonctions simples a partir d’exemplesetiquetes
Analogie (un peu commerciale) avec le cerveau :Fonctions elementaires = neuronesConnexion = synapseApprentissage des connexions = la connaissance
[email protected] Reseaux de Neurones 21 janvier 2016 5 / 60

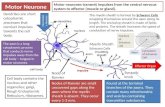
Principes generaux Neurone formel
Le neurone formel [McCulloch et Pitts, 1943]Unite elementaire : neurone formel
E entrees xe, sortie ySomme des entrees xe ponderee par des poids we :
α =E∑
e=1
wexe + b =E∑
e=0
wexe avec x0 = 1
Une fonction d’activation ϕ, lineaire ou non :y = ϕ (α) = ϕ
(∑Ee=0 wexe
)ϕ lineaire : hyperplan separateur ; ϕ non lineaire : hyperbole dimension E
[email protected] Reseaux de Neurones 21 janvier 2016 6 / 60

Principes generaux Neurone formel
Le neurone formel [McCulloch et Pitts, 1943]
Differentes fonctions d’activationElles introduisent un intervalle sur lequel le neurone est active
fonction identiteheaviside : ϕ(x) = 0 si x < 0, 1 sinonsigmoıde : ϕ(x) = 1
1+e−x
tanh : ϕ(x) = ex−e−x
ex +e−x = e2x−1e2x +1
fonction noyau (gaussienne)
heaviside - sigmoıde - tanh - gaussienne
[email protected] Reseaux de Neurones 21 janvier 2016 7 / 60

Principes generaux Topologies
Topologies
Il existe de nombreuses maniere d’organiser les neurones enreseau :
Reseau en couches (adaline, perceptron, perceptron multicouches,RBF)Reseau totalement interconnecte (Hopfield, Boltzmann)Reseau recurrent (LSTM)Reseau a convolution (TDNN, SDNN)Reseau avec beaucoup de couches ! (architectures profondes)
[email protected] Reseaux de Neurones 21 janvier 2016 8 / 60

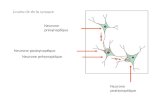
Principes generaux Topologies
Reseaux en couches (1)
Chaque neurone d’une couche est connecte a tous les neurones descouches precedentes et suivantesReseaux dits � feedforward � : propagation des entrees de couches encouches vers la sortie
Structure la plus repandueAlgorithmes d’apprentissage des poids efficaces
[email protected] Reseaux de Neurones 21 janvier 2016 9 / 60

Principes generaux Topologies
Reseaux en couches (2)
VariantesUne couche, fonction d’activationheaviside, une sortie : perceptron[Rosenblatt 1957]Si plus d’une couche : couches dites� cachees �, perceptron multicouchesSi beaucoup de couches : architecturesprofondes
[email protected] Reseaux de Neurones 21 janvier 2016 10 / 60

Principes generaux Topologies
Reseaux totalement interconnectes
Reseaux de Hopfield, Machines de BoltzmannTous les neurones sont connectes entre euxDifficile a entrainerN’a jamais vraiment prouve son utilite sur des problemes reels→ interet essentiellement theorique
[email protected] Reseaux de Neurones 21 janvier 2016 11 / 60

Principes generaux Topologies
Reseaux recurrents
Adapte aux sequencesPermet de prendre en compte lecontexteOn calcule y(n) a partir de :
I x(n) les entrees courantesI y(n − 1) les sorties de l’exemple
precedent(provenant d’une meme sequence)
Hypothese ' Markovienne
[email protected] Reseaux de Neurones 21 janvier 2016 12 / 60

Principes generaux Topologies
Reseaux convolutionnels
Poids partages, connexions localesApprentissage de configurations particulieres
[email protected] Reseaux de Neurones 21 janvier 2016 13 / 60

Apprentissage(s) Posons le probleme
Plan1 Introduction2 Principes generaux
Neurone formelTopologies
3 Apprentissage(s)Posons le problemeReseau lineaire a une coucheReseau non lineaire a une coucheReseaux multicouches
4 Autres architecturesArchitectures profondesReseaux recurrentsReseaux convolutionnelsLegos
5 Reseaux de neurones dans la pratiqueParametrisationMise en œuvre
[email protected] Reseaux de Neurones 21 janvier 2016 14 / 60

Apprentissage(s) Posons le probleme
Notations (1)
Les donneesOn dispose d’une base etiquetee de N couples {x(n), yd (n)}X ∈ RE×N , Yd ∈ RS×N
X = {x(n)} =
x1(n)
...xE (n)
=
x1(1) . . . . . . x1(N)...
. . . xe(n)...
xE (1) . . . . . . xE (N)
Yd = {yd (n)} =
yd
1 (n)...
ydE (n)
=
yd1 (1) . . . . . . yd
1 (N)...
. . . yds (n)
...yd
S (1) . . . . . . ydS (N)
[email protected] Reseaux de Neurones 21 janvier 2016 15 / 60

Apprentissage(s) Posons le probleme
Notations(2)
Le reseau (en couche)E entree, S sortiesLe reseau comporte Λ couchesWλ matrice des poids entre couches λ− 1 et λOn appelera yd (n) la sortie desiree pourl’exemple n
Si :- la couche λ− 1 contient ni neurones- la couche λ nj neurones,alors :
Wλ = {wji} =
w11 . . . w1i . . . w1ni
wj1... wji
... wjni
wnj 1 . . . wnj i . . . wnj ni
x ∈ RE
◦ ◦ ◦ ◦ ◦ ◦ ◦
◦ ◦ ◦ ◦ ◦ ◦ ◦ ◦ ◦
◦ ◦ ◦ ◦ ◦◦
◦ ◦ ◦ ◦ ◦
y ∈ RS
W1
W2
W3
WΛ−1
WΛ
layer 1
layer 2
layer Λ− 1
layer Λ
[email protected] Reseaux de Neurones 21 janvier 2016 16 / 60

Apprentissage(s) Posons le probleme
Le probleme
Rappel : on souhaite estimer f :Apprentissage sur la base des poids de connexion entre neurones W
→ CritereCritere des moindres carres (derivable) :
J (W ) =N∑
n=1
e(n)T e(n) avec e(n) =(
y(n)− yd (n))
Qu’on peut reecrire en sommant sur les sorties :
J (W ) =S∑
s=1
N∑n=1
(es(n))2 =S∑
s=1
J (Ws) (1)
Avec es(n) =(ys(n)− yd
s (n))
[email protected] Reseaux de Neurones 21 janvier 2016 17 / 60

Apprentissage(s) Reseau lineaire a une couche
Plan1 Introduction2 Principes generaux
Neurone formelTopologies
3 Apprentissage(s)Posons le problemeReseau lineaire a une coucheReseau non lineaire a une coucheReseaux multicouches
4 Autres architecturesArchitectures profondesReseaux recurrentsReseaux convolutionnelsLegos
5 Reseaux de neurones dans la pratiqueParametrisationMise en œuvre
[email protected] Reseaux de Neurones 21 janvier 2016 18 / 60

Apprentissage(s) Reseau lineaire a une couche
Reseau lineaire a une couche (1)
Une couche de neurones avec une fonction d’activation ϕ = identite
poids : W = {wse} =
W T1...
W TS
=
w11 . . . w1E... wse
...wS1 . . . wSE
Propagation 1 ex. sur une sortie : ys(n) = W T
s x(n)
[ys
]=[
ws1 . . . wsE]×
x1...
xE
Propagation 1 ex. sur toutes les sorties : y(n) = Wx(n)y1...
yS
=
w11 . . . w1E
.
.
. wse
.
.
.wS1 . . . wSE
×
x1...
xE
Propagation N ex. sur S sortie : Y = WXyd1 (1) . . . . . . yd
1 (N)
.
.
.. . . yd
s (n)
.
.
.ydS (1) . . . . . . yd
S (N)
=
w11 . . . w1E
.
.
. wse
.
.
.wS1 . . . wSE
×
x1(1) . . . . . . x1(N)
.
.
.. . . xe(n)
.
.
.xE (1) . . . . . . xE (N)
[email protected] Reseaux de Neurones 21 janvier 2016 19 / 60

Apprentissage(s) Reseau lineaire a une couche
Reseau lineaire a une couche (2)
Calcul de l’erreurErreur sur une sortie pour 1 exemple :
es(n) = yds (n)−W T
s x(n)
Critere :
J (W ) =S∑
s=1
N∑n=1
(yd
s (n)−W Ts x(n)
)2
Apprentissage des poids ?On a donc un probleme lineaire par rapport aux parametres Y = WXavec un critere des moindres carres→ solution des moindres carres !Rappel :Si Y = XΘ et que X T X est inversible, alors ΘMC = (X T X )−1X T Y
Attention : formulation legerement differente
[email protected] Reseaux de Neurones 21 janvier 2016 20 / 60

Apprentissage(s) Reseau lineaire a une couche
Reseau lineaire a une couche (3)
Si Y = WX, alors YT = XT WT ...... qui est de la forme Y = XΘ, en remplacant X et Y par leurtransposees, et Θ par WT
En appliquant les MC, on obtient WTMC = (XX T )−1XY T
D’ou WMC = YX T (X T X )−1
ConclusionApprentissage OK avec les MC, mais :
Pas de non linearite = pas terribleUne seule couche = pas terrible(X T X ) a inverser : potentiellement tres lourd (mais MC recursifspossibles)
Introduction d’une fonction ϕ non lineaire
[email protected] Reseaux de Neurones 21 janvier 2016 21 / 60

Apprentissage(s) Reseau non lineaire a une couche
Plan1 Introduction2 Principes generaux
Neurone formelTopologies
3 Apprentissage(s)Posons le problemeReseau lineaire a une coucheReseau non lineaire a une coucheReseaux multicouches
4 Autres architecturesArchitectures profondesReseaux recurrentsReseaux convolutionnelsLegos
5 Reseaux de neurones dans la pratiqueParametrisationMise en œuvre
[email protected] Reseaux de Neurones 21 janvier 2016 22 / 60

Apprentissage(s) Reseau non lineaire a une couche
Reseau non lineaire a une couche (1)Introduction d’une fonction ϕ non lineaire
On a donc Y = ϕ(WX), et les MC ne sont plus applicablesOn va appliquer une methode de descente de gradient→ rappels !
Algorithme iteratif :On choisit un Wt=0 aleatoireBonne direction = celle ou le criterebaisseAvancer un peu, mais pas trop
Wt+1 ←Wt − ηdJ (W)
dW
∣∣∣∣Wt
avec :W les parametres ; η : le pas ; dJ (W)
dW
∣∣∣Wt
: la � bonne �direction
[email protected] Reseaux de Neurones 21 janvier 2016 23 / 60

Apprentissage(s) Reseau non lineaire a une couche
Reseau non lineaire a une couche (2)Critere
Pour un reseau a une couche contenant une FNL ϕ : y(n) = ϕ (Wx(n))
Le critere s’ecrit donc :
J (W ) =N∑
n=1
(yd (n)− ϕ (Wx(n))
)2
On derive pour appliquer le gradient : Wt+1 ←Wt − η dJ (W)dW
∣∣∣Wt
dJ (W)
dW= −2
N∑n=1
(yd (n)− ϕ (Wx(n))
)× dϕ (Wx(n))
dW
= −2N∑
n=1
(yd (n)− ϕ (Wx(n))
)× ϕ′ (Wx(n)) x(n)
[email protected] Reseaux de Neurones 21 janvier 2016 24 / 60

Apprentissage(s) Reseau non lineaire a une couche
Reseau non lineaire a une couche (3)Application du gradient
dJ (W)
dW= −2
N∑n=1
(yd (n)− ϕ (Wx(n))
)× ϕ′ (Wx(n))x(n)
Deux cas de figure :
Si ϕ n’est pas derivable (ex. heaviside) : ca ne marche pas !Approximation lineaire de la derivee : algo adaline [Widrow & Hoff 1960]
dJ (W)
dW= −2
N∑n=1
(yd (n)− ϕ (Wx(n))
)× x(n)
Si ϕ est derivable (ex. sigmoıde, tanh) : ca marche !Dans ce cas on applique la descente de gradientRemarque : dans le cas d’une fonction identite, ϕ′ = 1 : ca marche
OK pour une couche, et pour plusieurs [email protected] Reseaux de Neurones 21 janvier 2016 25 / 60

Apprentissage(s) Reseaux multicouches
Plan1 Introduction2 Principes generaux
Neurone formelTopologies
3 Apprentissage(s)Posons le problemeReseau lineaire a une coucheReseau non lineaire a une coucheReseaux multicouches
4 Autres architecturesArchitectures profondesReseaux recurrentsReseaux convolutionnelsLegos
5 Reseaux de neurones dans la pratiqueParametrisationMise en œuvre
[email protected] Reseaux de Neurones 21 janvier 2016 26 / 60

Apprentissage(s) Reseaux multicouches
Reseaux multicouches (1)C’est le perceptron multicouches (PMC ou MLP)→ Couches dites cacheesFNL ϕ, peuvent etre 6= suivant les couches
Exemple d’un reseau a deux couchesE entree, S sorties, J neurones en couchecacheeW1 ∈ RJ×E poids entre les x et la couche 1W2 ∈ RS×J poids entre les couches 1 et 2z(n) ∈ RJ : variable intermediaireϕ1 : sigmoıde ; ϕ2 : softmax x(n) ∈ RE
◦ ◦ ◦ ◦ ◦ ◦ ◦
◦ ◦ ◦ ◦ ◦
y(n) ∈ RS
z(n)J = 7
S = 5
W1 = {wje}
W2 = {wsj}
W1 = {wje} =
w11 . . . w1E
wj1. . . wjE
wJ1 . . . wJE
W2 = {wsj} =
w11 . . . w1J
ws1. . . wsJ
wS1 . . . wSJ
[email protected] Reseaux de Neurones 21 janvier 2016 27 / 60

Apprentissage(s) Reseaux multicouches
Reseaux multicouches (2)
Propagation d’un exemple :
couche 1 : somme ponderee α1j =
∑e wjexe, puis zj = ϕ1
(α1
j ))
couche 2 : somme ponderee α2s =
∑j wsjzj , puis ys = ϕ2
(α2
s))
Apprentissage : Retropropagation du gradient [Rumelhart 86]
Initialiser les Wλ au hasard1 Propager un exemple x(n) pour calculer y(n)
2 Calculer l’erreur (yd (n)− y(n))
3 Retropropager le critere J = (yd (n)− y(n))2 a travers W2 ...4 ... puis a travers W1
On passe tous les exemples de la base, et on itere tant qu’on n’est passatisfait
[email protected] Reseaux de Neurones 21 janvier 2016 28 / 60

Apprentissage(s) Reseaux multicouches
Reseaux multicouches (3)
Chaque sortie s’ecrit :
ys = ϕ2
∑j
wsjϕ1
(∑e
wjexe
)Donc le critere J = 1/2
∑s(yd
s − ys)2 depend de (wje, ϕ1,wsj , ϕ
2).
Apprentissage de wje et wsj :Descente de gradient :
wjet+1 ← wjet − η∂J∂wje
∣∣∣∣wje t
et wsj t+1 ← wsj t − η∂J∂wsj
∣∣∣∣wsj t
Probleme : comment calculer les derivees partielles du critere ?
[email protected] Reseaux de Neurones 21 janvier 2016 29 / 60

Apprentissage(s) Reseaux multicouches
Reseaux multicouches (3)
On commence par le calcul de : ∂J∂wsj= ∂J
∂ys× ∂ys
∂α2s× ∂α2
s∂wsj
∂J∂ys
=∂
∂ys
12
S∑s=1
(yds − ys)2 = −(yd
s − ys)
∂ys
∂α2s
=∂
∂α2sϕ2(α2
s) = ϕ2′(α2s)
∂α2s
∂wsj=
∂
∂wsj
J∑j=1
wsjzj = zj
Finalement : ∂J∂wsj
= −(yds − ys)× ϕ2′(α2
s)× zj = Erreurszj
Cette quantite represente l’erreur sur la sortie s due au neurone j
[email protected] Reseaux de Neurones 21 janvier 2016 30 / 60

Apprentissage(s) Reseaux multicouches
Reseaux multicouches (4)
On enchaine avec le calcul de : ∂J∂wje= ∂J
∂zj× ∂zj
∂α1j× ∂α1
j
∂wje
∂J∂zj
=∑
s
[∂J∂α2
s× ∂α2
s
∂zj
]1er terme : rouge*vert du slide precedent
=∑
s
−(yds − ys)× ϕ2′(α2
s)× ∂
∂zj
∑j
wsjzj
= −∑
s
(yds − ys)× ϕ2′(α2
s)× wsj
∂zj
∂α1j
=∂
∂α1jϕ1(α1
j ) = ϕ1′(α1j )
∂α1j
∂wje=
∂
∂wje
∑e
wjexe = xe
Finalement :∂J∂wje
= −∑
s(yds − ys)× ϕ2′(α2
s)× wsj × ϕ1′(α1j )× xe = Erreurjxe
Cette quantite represente l’erreur sur le neurone j due a l’entree e
[email protected] Reseaux de Neurones 21 janvier 2016 31 / 60

Apprentissage(s) Reseaux multicouches
Reseaux multicouches (5)
On recapitule :
Algorithm 1 Backpropagation algorithmη ← 0.001W1← rand(J,E)W2← rand(S,J)while (erreurApp ≤ ε) do
for n = 1→ N dopropagate x(n) : compute z(n) and y(n)compute ErrorSW2 ←W2 − η ∗ ErrorS ∗ z(n)compute ErreurJW1 ←W1 − η ∗ ErrorJ ∗ x(n)
end forend while
[email protected] Reseaux de Neurones 21 janvier 2016 32 / 60

Apprentissage(s) Reseaux multicouches
Reseaux multicouches (5’)
On recapitule, en matlab :Function grad = retropropag(x,yd,W1,W2)...a1 = [x ones(n,1)]*W1 ; x1 = tanh(a1) ;a2 = [x1 ones(n,1)]*W2 ; y = a2 ;errorS = -(yd-y).*(1-y.*y) ;GradW2 = [x1 ones(n,1)]’* errorS ;errorJ = (w2(1 :n2-1, :)*errorS’)’.*(1-x1.*x1) ;GradW1 = [x ones(n,1)]’* errorJ ;w1 = w1 - pas1 .* GradW1 ;w2 = w2 - pas2 .* GradW2 ;
[email protected] Reseaux de Neurones 21 janvier 2016 33 / 60

Apprentissage(s) Reseaux multicouches
Reseaux multicouches (6)
Remarques :On peut sommer les erreurs sur toute la base et retropropager uneseule fois :→ mode Batch (plus rapide)Question du pas ... 2eme ordre ? Cf. cours gradientQuand stopper l’algorithme ? Attention au surapprentissage
[email protected] Reseaux de Neurones 21 janvier 2016 34 / 60

Apprentissage(s) Reseaux multicouches
Reseaux multicouches (7)
DimensionnementCombien de neurones par couches / Combien de couches ?Une seul couche suffit pour estimer n’importe quelle fonction f ,pourvu que : J →∞ et N →∞ [Lippman 87]
Solution : rajoutons des couches !,Backprop generalisable avec plusieurs couches cachees,Frontieres de decision plus complexes,Representation de haut niveau des donnees/Mais l’energie de l’erreur est trop faible pour modifier les couches basses
→ Deep learning !
[email protected] Reseaux de Neurones 21 janvier 2016 35 / 60

Autres architectures Architectures profondes
Plan1 Introduction2 Principes generaux
Neurone formelTopologies
3 Apprentissage(s)Posons le problemeReseau lineaire a une coucheReseau non lineaire a une coucheReseaux multicouches
4 Autres architecturesArchitectures profondesReseaux recurrentsReseaux convolutionnelsLegos
5 Reseaux de neurones dans la pratiqueParametrisationMise en œuvre
[email protected] Reseaux de Neurones 21 janvier 2016 36 / 60

Autres architectures Architectures profondes
SVM vs. Architectures profondes1985 - 1995 : l’essor des reseaux de neurones
Emergence de nombreuses applications industrielles :Reconnaissance d’ecriture, de la parole, etc.
1995 - 2005 : La supprematie des Support Vector MachinesClassifieurs aux bases theoriques fortesExcellentes capacites de generalisation, perf. a l’etat de l’artReseaux de neurones = has been . . .
2006 - 20 ? ? : Le retour des reseaux de neuronesHinton, G. E., Osindero, S. and Teh, Y. A fast learning algorithm for deepbelief nets. Neural Computation, 18, pp 1527-1554 (2006)
Reseaux de neurones profondsArchitectures connues, nouveaux algo d’apprentissagePerformances permettant d’envisager de nouvelles applications
[email protected] Reseaux de Neurones 21 janvier 2016 37 / 60

Autres architectures Architectures profondes
Architectures profondes (1)
PrincipeReseau feedforward comportant Λ couches,avec Λ > 2Wλ matrice des poids entre couches λ− 1 et λbackprop insuffisante→ comment faire ?
Apprentissage en deux tempsApprentissage des couches dites basses, ennon supervise
I Utilisation des autoencodeursI Couches dites de modeles
Apprentissage des dernieres couches ensupervise
I BackpropagationI Couches dites de decision
x ∈ RE
◦ ◦ ◦ ◦ ◦ ◦ ◦
◦ ◦ ◦ ◦ ◦ ◦ ◦ ◦ ◦
◦ ◦ ◦ ◦ ◦◦
◦ ◦ ◦ ◦ ◦
y ∈ RS
W1
W2
W3
WΛ−1
WΛ
layer 1
layer 2
layer Λ− 1
layer Λ
[email protected] Reseaux de Neurones 21 janvier 2016 38 / 60

Autres architectures Architectures profondes
Architectures profondes (2)
Auto Associateurs (AA)Un AA cherche a apprendre ses propres entrees : on veut yd = xApprentissage d’un encodeur e(x) et d’un decodeur d((e(x))
Reseau a une couche cachee e et une couche de sortie dCritere : J = (x − x)2 = (d(e(x))− x)2
Si le nombre de neurones de e est< E :Compression, representationparcimonieuse de x
x
◦ ◦ ◦ ◦ ◦
◦ ◦ ◦ ◦ ◦◦
x = d(e(x))
e
d
[email protected] Reseaux de Neurones 21 janvier 2016 39 / 60

Autres architectures Architectures profondes
Architectures profondes (3) : Apprentissage� pre-training �
Apprendre un AA sur x .Garder e1(x) = H1, jeter d1(e1(x))
Apprendre un nouvel AA sur e1(x)
Garder e2(e1(x)) = H2, jeter d2
etc.
� fine-tuning �
deverrouiller tous les Hλ
rajouter une ouplusieurs couchesbackpropagation surl’ensemble du reseau
[email protected] Reseaux de Neurones 21 janvier 2016 40 / 60

Autres architectures Architectures profondes
Architectures profondes (4) : Exemple d’application
Apprentissage en trois etapes [4, 5] :1 Preapprentissage des entrees = representation des donnees2 Preapprentissage des sorties = app. des connaissances a priori3 Fine tuning = apprentissage classique du lien entre entrees et sorties
[email protected] Reseaux de Neurones 21 janvier 2016 41 / 60

Autres architectures Reseaux recurrents
Plan1 Introduction2 Principes generaux
Neurone formelTopologies
3 Apprentissage(s)Posons le problemeReseau lineaire a une coucheReseau non lineaire a une coucheReseaux multicouches
4 Autres architecturesArchitectures profondesReseaux recurrentsReseaux convolutionnelsLegos
5 Reseaux de neurones dans la pratiqueParametrisationMise en œuvre
[email protected] Reseaux de Neurones 21 janvier 2016 42 / 60

Autres architectures Reseaux recurrents
Reseaux de neurones et sequences
Comment traiter des Sequences avec des reseaux deneurones ?
Parole, ecriture, cours de la bourse, image (2D), etc.Signaux de taille variable→ necessite de classifieurs dynamiques
1ere solution : reseaux de neurones / classifieur dynamiqueReseaux de neurones / Hidden Markov Model= classification locale / modelisation de sequence
[email protected] Reseaux de Neurones 21 janvier 2016 43 / 60

Autres architectures Reseaux recurrents
2eme solution : Reseaux recurrents (1)
Connexions recurrentesPermet de prendre en compte le contexteOn calcule y(n) a partir de x(n) et y(n − 1) les sorties de l’observationprecedente
Question :Comment apprendre les poids desconnexions recurrentes ?
1 BackProp Through Time (BPTT)2 Real Time Recurrent Learning (RTRL)
[email protected] Reseaux de Neurones 21 janvier 2016 44 / 60

Autres architectures Reseaux recurrents
Reseaux recurrents (2)Backpropagation Through Time (BPTT)
Idee : deplier le reseau R pour l’approximer par un reseau nonrecurrent R∗
Structure temporelle→ structure spatiale sur k pasLes poids des connexions recurrentes sont copies et attribues a desconnexions non recurrentes de R∗.Les copies des connexions possedent toutes la meme ponderation.Les premiers neurones rouges et bleus sont initialises au hasard
[email protected] Reseaux de Neurones 21 janvier 2016 45 / 60

Autres architectures Reseaux recurrents
Reseaux recurrents (3)
Backpropagation Through Time (BPTT), suiteUne fois deplie, on applique une backprop classique→ k limite = contexte limite ...
[email protected] Reseaux de Neurones 21 janvier 2016 46 / 60

Autres architectures Reseaux recurrents
Reseaux recurrents (4)
Real Time Recurrent Learning (RTRL) [Williams 1989]La sortie du neurone j recoit :
tous les x(t) de la couche precedente ponderes par wje
tous les y(t − 1) de sa couche ponderes par des wjj′
yj (t) = ϕ
E∑e=0
wjexe(t) +J∑
j′=0
wjj′yj′(t − 1)
RTRL : apprentissage
Critere J = (ydj − yj )
2
Calcul des ∂J∂wsj
, ∂J∂wje
et ∂J∂wjj′
pour appliquer le gradient � classique �
deuxieme ordre possibleComplexite importante O(N4)
[email protected] Reseaux de Neurones 21 janvier 2016 47 / 60

Autres architectures Reseaux recurrents
BLSTM
Bidirectionnal Long Short Term MemoryA. Graves and J. Schmidhuber. Offline handwriting recognition withmultidimensional recurrent neural networks. NIPS, 2009
Modelisation des dependences a court/long termeNeurone formel complexe, avec un mecanisme de gateApprentissage par BPTTEx. de Perf HWR : 83%→ 91% WER
[email protected] Reseaux de Neurones 21 janvier 2016 48 / 60

Autres architectures Reseaux recurrents
BLSTM (2)
Utilisation en generationDemo http://www.cs.toronto.edu/˜graves/handwriting.html
[email protected] Reseaux de Neurones 21 janvier 2016 49 / 60

Autres architectures Reseaux convolutionnels
Plan1 Introduction2 Principes generaux
Neurone formelTopologies
3 Apprentissage(s)Posons le problemeReseau lineaire a une coucheReseau non lineaire a une coucheReseaux multicouches
4 Autres architecturesArchitectures profondesReseaux recurrentsReseaux convolutionnelsLegos
5 Reseaux de neurones dans la pratiqueParametrisationMise en œuvre
[email protected] Reseaux de Neurones 21 janvier 2016 50 / 60

Autres architectures Reseaux convolutionnels
Convolutionnal neural network (1)
Reseaux de neurones convolutionnelsDestine a traiter les imagesMecanisme de poids partages→ moins de parametres, meilleuregeneralisationApprentissage de filtres par backprop classique
[email protected] Reseaux de Neurones 21 janvier 2016 51 / 60

Autres architectures Reseaux convolutionnels
Convolutionnal neural network (2)
[email protected] Reseaux de Neurones 21 janvier 2016 52 / 60

Autres architectures Legos
Plan1 Introduction2 Principes generaux
Neurone formelTopologies
3 Apprentissage(s)Posons le problemeReseau lineaire a une coucheReseau non lineaire a une coucheReseaux multicouches
4 Autres architecturesArchitectures profondesReseaux recurrentsReseaux convolutionnelsLegos
5 Reseaux de neurones dans la pratiqueParametrisationMise en œuvre
[email protected] Reseaux de Neurones 21 janvier 2016 53 / 60

Bibliographie
Combinaison d’architectures
[email protected] Reseaux de Neurones 21 janvier 2016 54 / 60

Reseaux de neurones dans la pratique
Plan
1 Introduction
2 Principes generaux
3 Apprentissage(s)
4 Autres architectures
5 Reseaux de neurones dans la pratiqueParametrisationMise en œuvre
[email protected] Reseaux de Neurones 21 janvier 2016 55 / 60

Reseaux de neurones dans la pratique
Avantages et Inconvenients
AvantagesUn RdN approxime des probabilites a posteriori p(Ci/x)
Tres rapide en decisionSupporte tres bien les grandes dimensions (E > qq centaines)Performances : architectures profondes a l’etat de l’art sur plusieursproblemes
InconvenientsParametrisationApprentissage long et parfois difficile a controler (minimum locaux)Necessite bcp de donnees
[email protected] Reseaux de Neurones 21 janvier 2016 56 / 60

Reseaux de neurones dans la pratique Parametrisation
Parametrisation/choix du reseau
Nombre de couchesAvec des caracteristiques : MLP avec 1 ou 2 couchesSinon : Architecture profonde : Pas de caracteristiques a extraire ,,mais plus d’hyperparametres /
Si besoin de rejet de distance : Radial Basis Function : neurones =gaussiennesSi sequence : reseau recurrent ou MLP couple a classifieur dynamique
Nombre de neurones couches cacheesClassique : moyenne geometrique ou arithmetique de (E ,S)Avec des deep : + difficile, premiere couche + grande que E
Fonction d’activation ϕfonction non lineaire, tanh, sigmoıde, ca ne change pas grand chose ...
[email protected] Reseaux de Neurones 21 janvier 2016 57 / 60

Reseaux de neurones dans la pratique Parametrisation
Parametrisation/choix du reseau
Reglage du pas (voir cours Gradient)pas fixe : petit ( 10−2, 10−3, 10−4, ...)pas adaptatif : diminue avec les iterationsline search : calcul du pas ”ideal” a chaque iterationMethode du deuxieme ordre (gradient conjugue), + de calculs
Les donneesCentrees reduites : c’est mieuxTaille de la base d’app : au moins E2 elements par classeAttention aux bases non balancees. Solutions :
I Compenser les proba a posteriori p(Ci/x) par 1/p(Ci ) avec p(Ci )probabilite a priori de la la classe Ci : Marche pas
I Echantillonner les donnees des classes sur-representeesI Dupliquer les echantillons sous-representeI Pendant l’apprentissage, ponderer les erreurs des exemples par 1/p(Ci )
[email protected] Reseaux de Neurones 21 janvier 2016 58 / 60

Reseaux de neurones dans la pratique Mise en œuvre
Mise en œuvre∃ de nombreuses librairies :
Torch3 (C++) / Torch5 (lua) (NEC) http://www.torch.ch/,http://torch5.sourceforge.net/
pybrain (python, TUM Munich) http://pybrain.org/Theano (python, Montreal)http://deeplearning.net/software/theano/
Caffe (Berkeley) http://caffe.berkeleyvision.org/TensorFlow (Google) https://www.tensorflow.org/versions/master/get_started/index.html
Exercice :Coder en matlab/octave un MLP a 1 couche cachee, sans librairieTester les hyperparametres : η ; nb d’iteration, nb de neurones dans lacouche cachee, etc.Base ? MNIST
[email protected] Reseaux de Neurones 21 janvier 2016 59 / 60

Reseaux de neurones dans la pratique Mise en œuvre
Bibliographie
F. Rosenblatt. Principles of Neurodynamics. New York : Spartan, 1962.
C.M. Bishop. Neural networks for pattern recognition, Oxford : OxfordUniversity Press, 1995.
D.E. Rumelhart, G.E. Hinton and R.J. Williams. Learning internalrepresentations by error propagation. Parallel Distributed ProcessingExplorations in the Microstructure of Cognition. MIT Press, BradfordBooks, vol. 1, pp. 318-362, 1986.
J. Lerouge, R. Herault, C. Chatelain, F. Jardin, and R. Modzelewski,”Ioda : an input output deep architecture for image labeling”, Patternrecognition, vol. 48, iss. 9, p. 2847-2858, 2015.
Soufiane Belharbi, Clement Chatelain, Romain Herault, SebastienAdam : Input/Output Deep Architecture for Structured Output Problems.CoRR abs/1504.07550 (2015)
[email protected] Reseaux de Neurones 21 janvier 2016 60 / 60