
Remote core locking (rcl)
25
Presented by Chinthaka Henadeera Seminar- SFT ws12/13 Remote Core Locking (RCL)
-
Upload
chinthaka-henadeera -
Category
Technology
-
view
100 -
download
0
Transcript of Remote core locking (rcl)

Presented by Chinthaka Henadeera
Seminar- SFT ws12/13
Remote Core Locking (RCL)

Presentation Outline 1. Introduction
2. Motivation
3. RCL
3.1 Core algorithm
3.2 Profiling
3.3 Re-engineering
3.4 RCL runtime implenetation
4. Evaluation
4.1 Comparison with other locks
4.2 Comparison of app. Performance
4.3 Locality analysis
5. Related work
6. References

1. Introduction
The lock algorithm in a multithreaded application
is a key factor to scaling up the performance in
multicore world.
Remote Core Locking (RCL) is a newly invented
locking techinque to reduce cache misses and to
reduce access contention simultaniously.

2. Motivation
2 main issues while the critical section(cs)
execution.
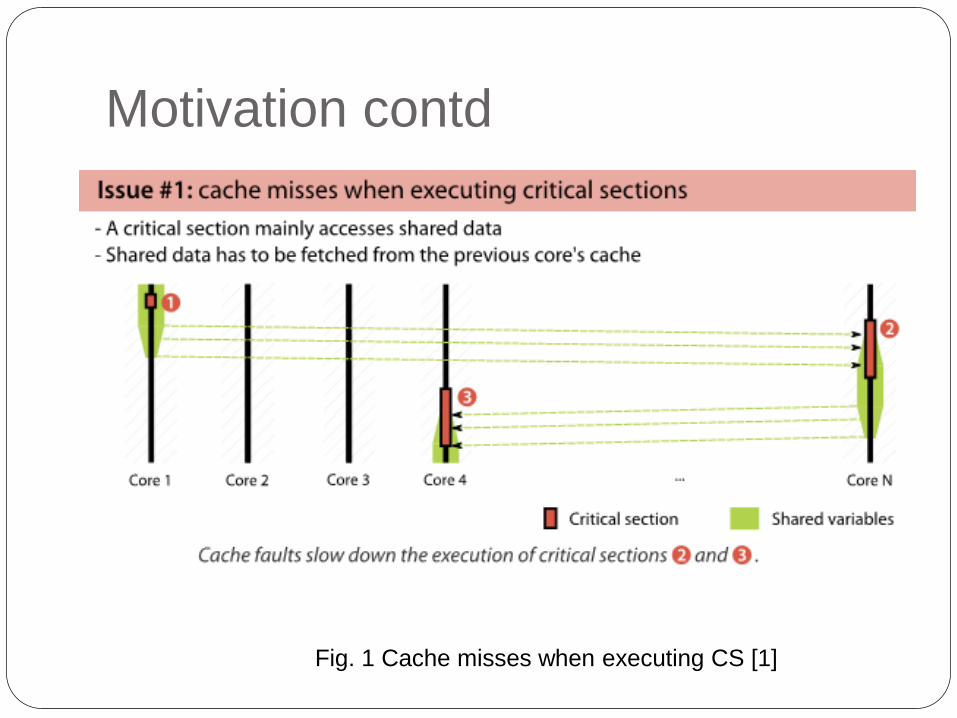
Motivation contd
Fig. 1 Cache misses when executing CS [1]
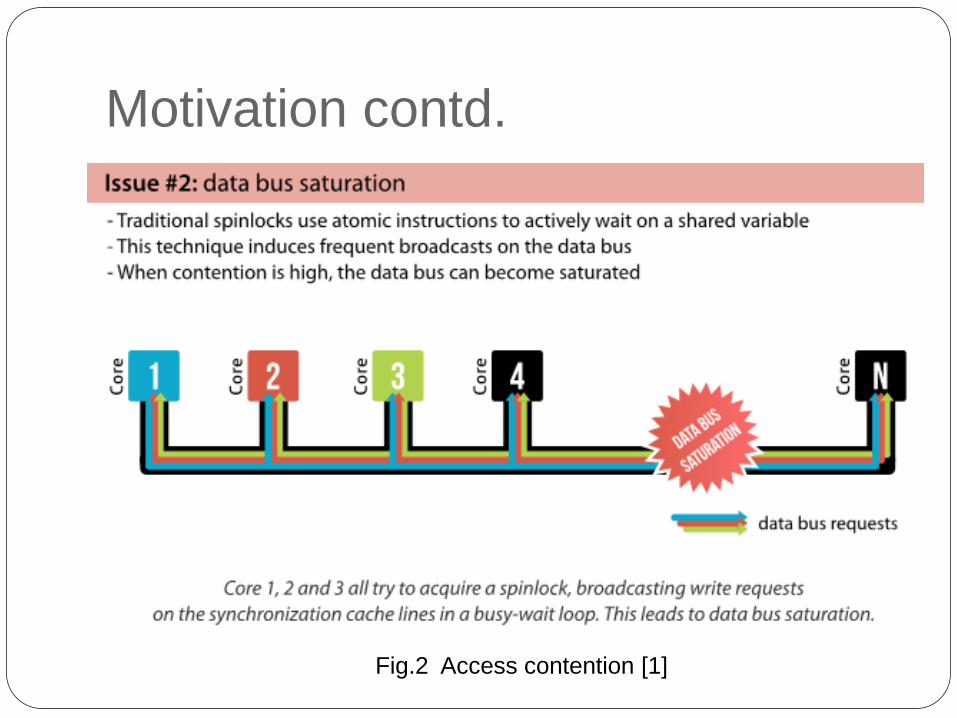
Motivation contd.
Fig.2 Access contention [1]

Motivation contd.
RCL is introduced to address both issues
simultaniously.

3. RCL
Main idea of RCL is,
- Requests of the client cores are entered into a
request array.
- Remote server core executes CS and returns the
results to the client core.

RCL contd..
RCL consists 3 phases.
1) Profiling
2) Re-engineering
3) RCL runtime implenetation
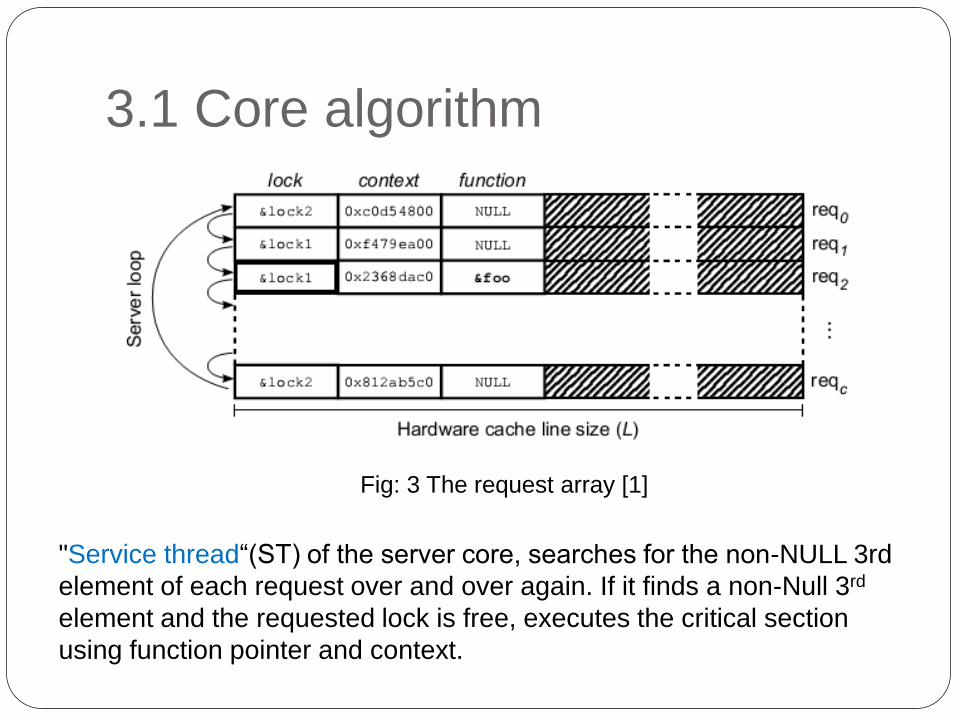
3.1 Core algorithm
Fig: 3 The request array [1]
"Service thread“(ST) of the server core, searches for the non-NULL 3rd
element of each request over and over again. If it finds a non-Null 3rd
element and the requested lock is free, executes the critical section
using function pointer and context.

3.2 Profiling
Profiler is a tool which dynamically loads a library
and intercepts the applications.
Extracts the information( involving POSIX locks,
condition variables and threads etc.) about
application
Determines that which locks can be improved by
using RCL.

3.3 Re-engineering
Reengineering tool takes out the critical section
code into a separate function.
Such a function receives the values of the
variables and returns the updated values of the
variables.

3.4 RCL runtime implenetation
It is difficult to ensure the liveness and the
responsiveness using only a server thread
because ,
(i) Blocked by the operating system
(ii) Spin in the cases of acquiring a spin lock or
nested RCL or implements some form of ad
hoc synchronization.
(iii) Thread can be pre-empted by the operating
system if the time-slice of the thread is run
out or due to a page fault.
t

In RCL runtime, there is a "management thread“ (MT) which responsible to keep liveness of RCL by managing the ST pool.
MT is activated and is expired in a given frequency. When it is activated it runs at highest priority.
MT checks a global flag which indicates the ST is progressing since last activation of the MT.
If the flag is not updated, the MT considers that the ST is waiting or is blocked and it adds a free ST to service thread pool.

4 strategies to improve the responsiveness.
i) RCL runtime uses POSIX FIFO scheduling policy
to prevent the thread pre-emption from the OS
scheduler.
ii) RCL runtime minimizes the number of STs before
an unblocked servicing thread is rescheduled in
order to reduce the delay.

iii) When servicing threads are blocked by the
OS, RCL runtime uses a low prioritized (than ST)
backup thread to clear the global flag and to wake
up the MT.
iv) When nested RCL is handled by the same
core, sometimes the lock may already owned by
another servicing thread. In this case the
servicing thread yields without delay, in order to
owner of the lock to release the lock.

Using FIFO policy introduces another two problems.
1) FIFO scheduling can course to priority mismatches. Ex: between BT and ST and between ST and MT. This problem can be solved by only using lock-free algorithms in RCL runtime.
2) When a ST mumbles in an active wait loop, it will not be pre-empted. There for unable to elect a free thread. In this case MT detects no progression of the servicing thread and it decreases the priority of the particular ST and then increase the priorities of all STs.

4. Evaluation
Comparison with other locks using a custom
microbenchmark
Comparison of the application performance
Locality analysis
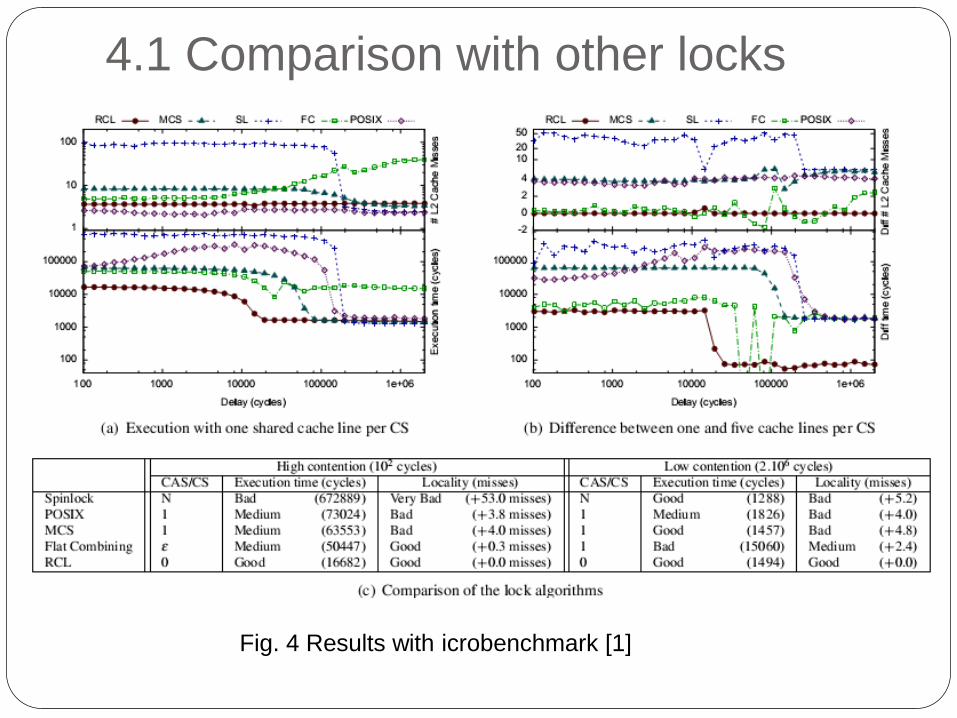
4.1 Comparison with other locks
Fig. 4 Results with icrobenchmark [1]
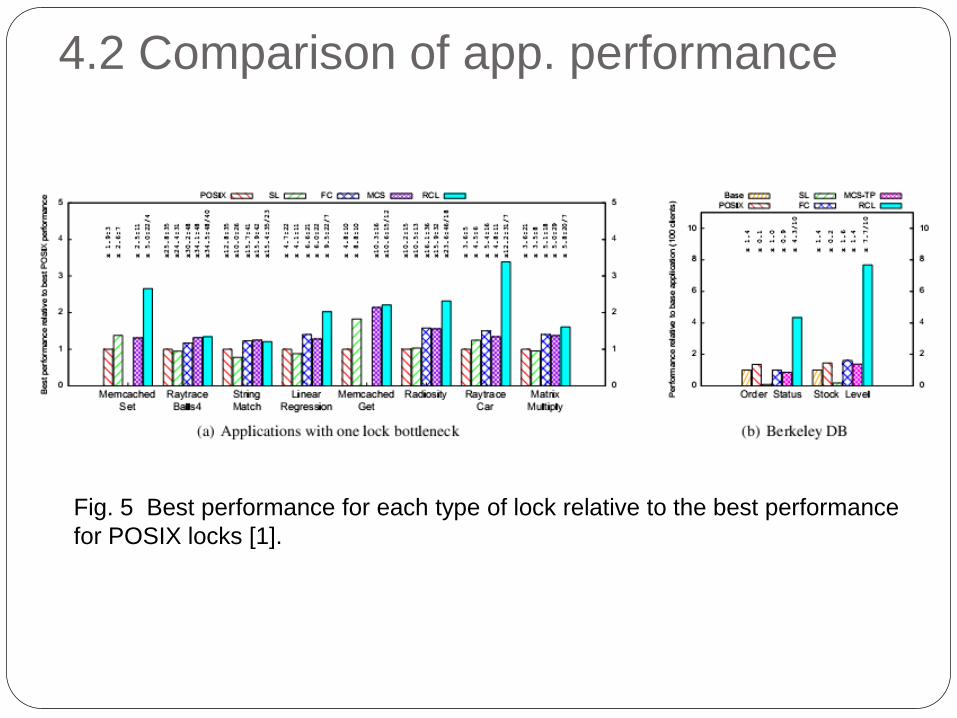
4.2 Comparison of app. performance
Fig. 5 Best performance for each type of lock relative to the best performance
for POSIX locks [1].

4.3 Locality analysis
Table 1. Number of L2 cache misses per CS[1]

5. Related work
Attaluri at. al. Proposed a control concurrency
with lock pre-emption and restoration in 1995 [2].
Abellan at. al. have proposed the concept of G-
locks [3]
Suleman et al. have proposed to critical sections
are executed in a special fast core in an ACMP by
introducing new instructions to handover the
control [4].

Related work contd..
Handler et al. have suggested software only
solution called "Flat combining" based on coarse
gained locking [5].

6. References [1] Jean-Pierre Lozi, Florian David, Gael Thomas, Julia Lawall, and Filles
Muller. Re-mote core locking: Migrating critical-section execution to improve the performance of multithreaded applications. IBM Systems Journal,2012 USENIX Annual Technical Conference BOSTON MA, 47(2):221{236, April 2008.
[2] J. Slonim G. K. Attaluri and P. Larson. Concurrency control with lock preemtion and restoration. CASCON ' 95, 1995.
[3] J. Fernndez J. L. Abelln and M. E. Acacio. Glocks: Efficient support for highly-contended locks in many-core cmps. In 25th IPDPS, 2011.
[4] M.K. Qureshi M. A. Suleman, O. Mutlu and Y. N. Patt. Accelerating critical section execution with asynchronous multi-core architecture. ASPLOS, pages 253-264, 2009.
[5] N. Shavit D. Hendler, I. Incze and M. Tzafrir. Flat combining and the synchronization-parallelism tradeo. SPAA' 10, pages 355-354, 2010.

Thank you


















