
reinforcement learning part2 - Cornell Universitydkm/tutorials/reinforcement_learning_part2.pdf ·...
37
Reinforcement Learning Part 2 Dipendra Misra Cornell University [email protected] https://dipendramisra.wordpress.com/
Transcript of reinforcement learning part2 - Cornell Universitydkm/tutorials/reinforcement_learning_part2.pdf ·...

Reinforcement Learning Part 2
Dipendra Misra Cornell University
https://dipendramisra.wordpress.com/

From previous tutorial
Reinforcement Learning
Agent-Reward-EnvironmentNo supervisionExploration
MDPPolicy
Consistency Equation Optimal Policy Optimality Condition
Bellman Backup Operator Iterative Solution

Interaction with the environment
reward +
new environment
action
Setup from Lenz et. al. 2014
Scalar reward

Rollout
Setup from Lenz et. al. 2014
.
.
.
a1
a2
an
r1
r2
rn
hs1, a1, r1, s2, a2, r2, s3, · · · an, rn, sni

Setup
st ! st+1
atrt
e.g.,1$
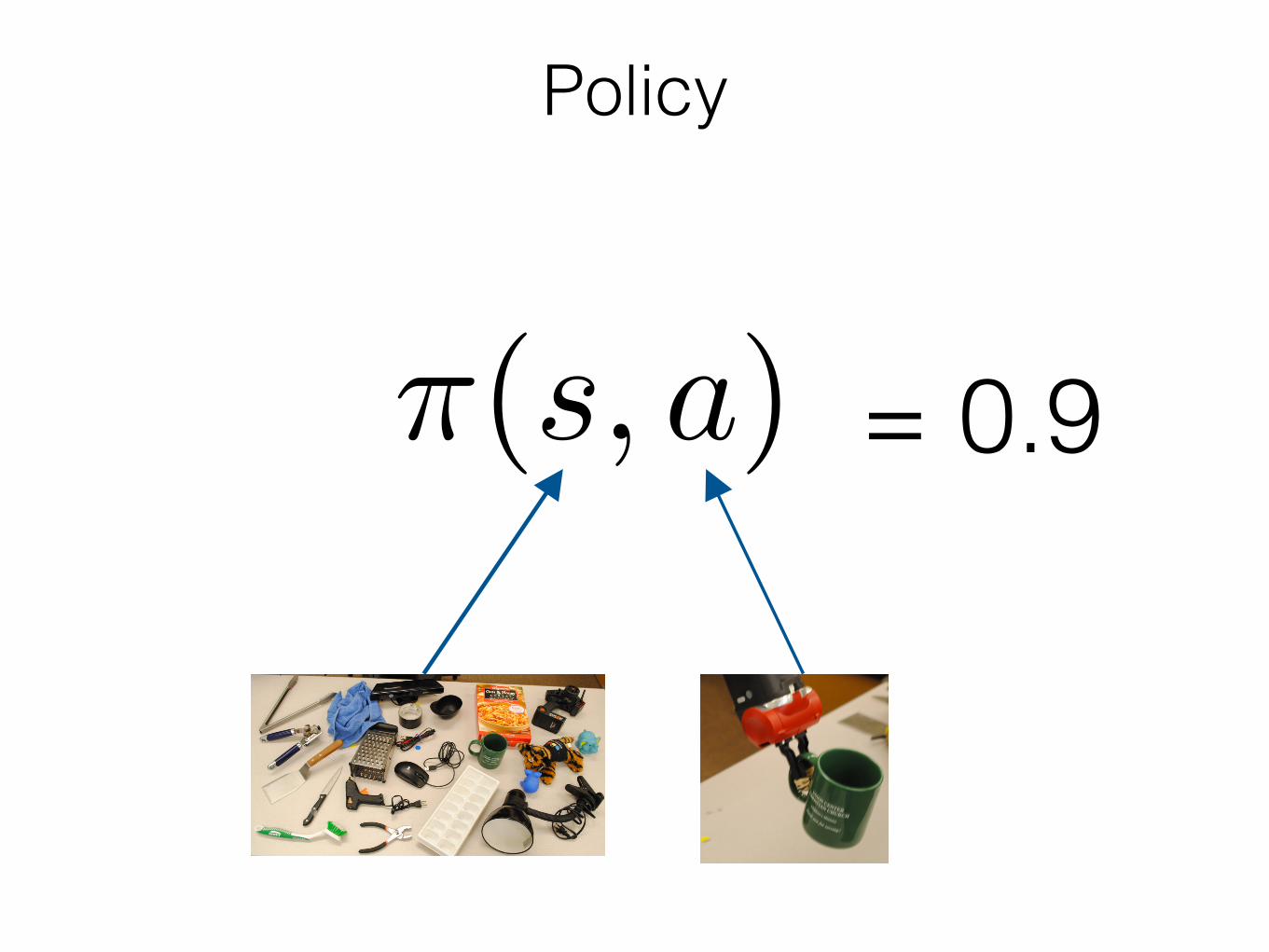
Policy
⇡(s, a) = 0.9

From previous tutorial
V ⇤(s) = max
a
X
s0
P as,s0{Ra
s,s0 + �V ⇤(s0)}
V ⇡(s) =X
a
⇡(s, a)X
s0
P as,s0
�Ra
s,s0 + �V ⇡(s0)
Bellman’s optimality condition
Bellman’s self-consistency equation
An optimal policy exists such that:⇡⇤
V ⇡⇤(s) � V ⇡(s) 8s 2 S,⇡

Solving MDP
To solve an MDP (or RL problem) is to find an optimal policy

Dynamic Programming Solution
Initialize randomlyV 0
do
until kV t+1 � V tk1 > ✏
V t+1 = TV t
return V t+1
T : V ! V
(TV )(s) = max
a
X
s0
P as,s0{Ra
s,s0 + �V (s0)}

From previous tutorial
Reinforcement Learning
Agent-Reward-EnvironmentNo supervisionExploration
MDPPolicy
Consistency Equation Optimal Policy Optimality Condition
Bellman Backup Operator Iterative Solution

Dynamic Programming Solution
Initialize randomlyV 0
do
until kV t+1 � V tk1 > ✏
V t+1 = TV t
return V t+1
Problem?
T : V ! V
(TV )(s) = max
a
X
s0
P as,s0{Ra
s,s0 + �V (s0)}
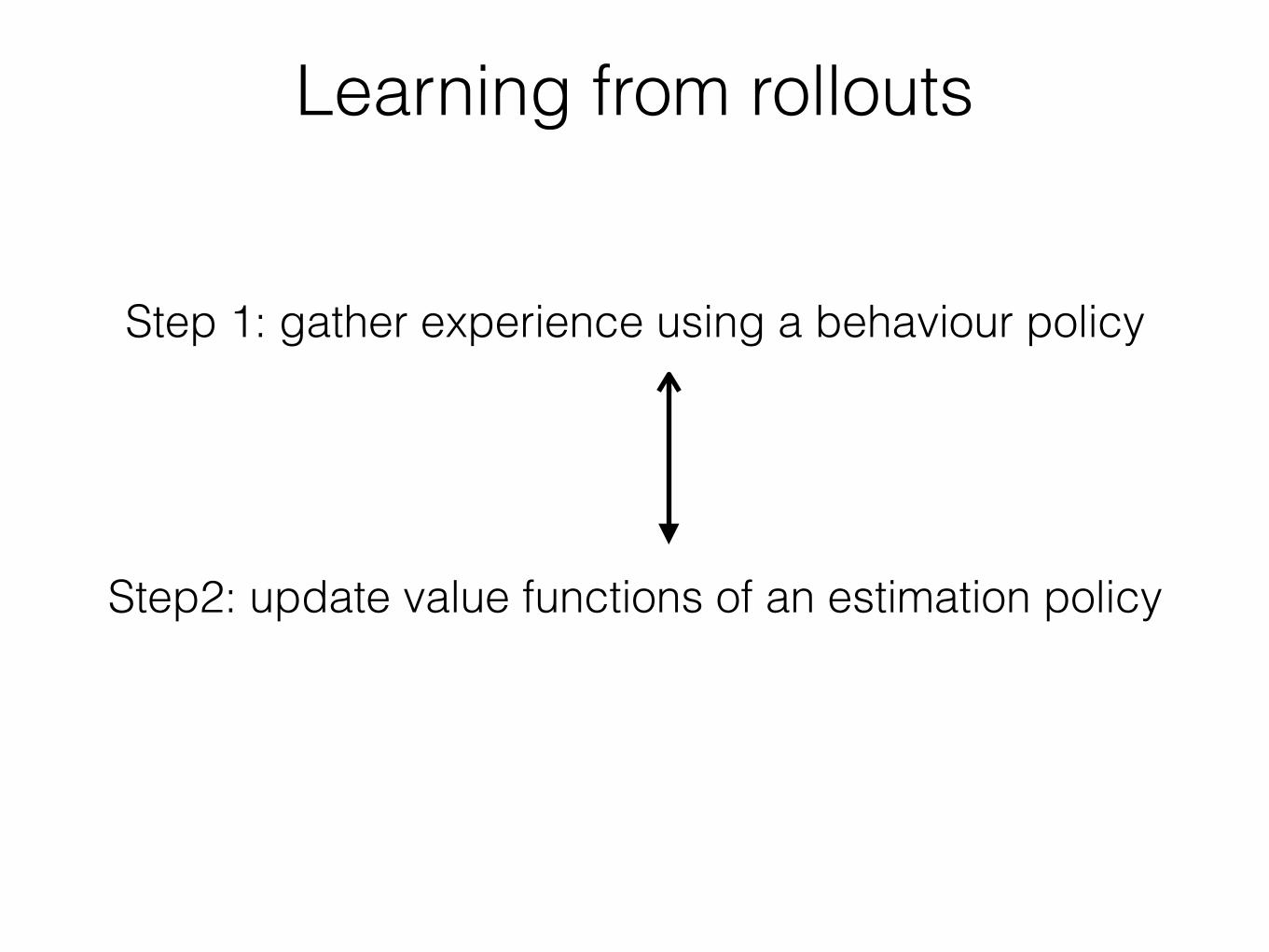
Learning from rollouts
Step 1: gather experience using a behaviour policy
Step2: update value functions of an estimation policy

On-Policy and Off-Policy
On policy methods
behaviour and estimation policy are same
Off policy methods
behaviour and estimation policy can be different
Advantage?

Behaviour Policy
• Encourage exploration of search space
• Epsilon-greedy policy
⇡✏(s, a) =1� ✏+
✏
|A(s)|
✏
|A(s)|
{ a = argmax
a0Q(s, a0)
otherwise

Temporal Difference Method
Q⇡(s, a) = E⇡
2
4X
t�0
�trt+1|s1 = s, a1 = a
3
5
= E⇡
2
4r1 + �
0
@X
t�0
�trt+2
1
A |s1 = s, a1 = a
3
5
= E⇡ [r1 + �Q⇡(s2, a2) |s1 = s, a1 = a]
Q⇡(s, a) = (1� ↵)Q⇡(s, a) + ↵(r1 + �Q⇡(s2, a2))
combination of monte carlo and dynamic programming

SARSA
Converges w.p.1 to an optimal policy as long as all state-action pairs are visited infinitely many times and epsilon eventually decays to 0 i.e. policy becomes greedy.
On or off?

Q-Learning
On or off?For proof of convergence see: http://users.isr.ist.utl.pt/~mtjspaan/readingGroup/ProofQlearning.pdf
Q⇤(s, a) =
X
s0
P as,s0{Ra
s,s0 + �max
a0Q⇤
(s0, a0)}
Resemblance to Bellman optimality condition

Summary
• SARSA and Q-Learning
• On vs Off policy. Epsilon greedy policy.
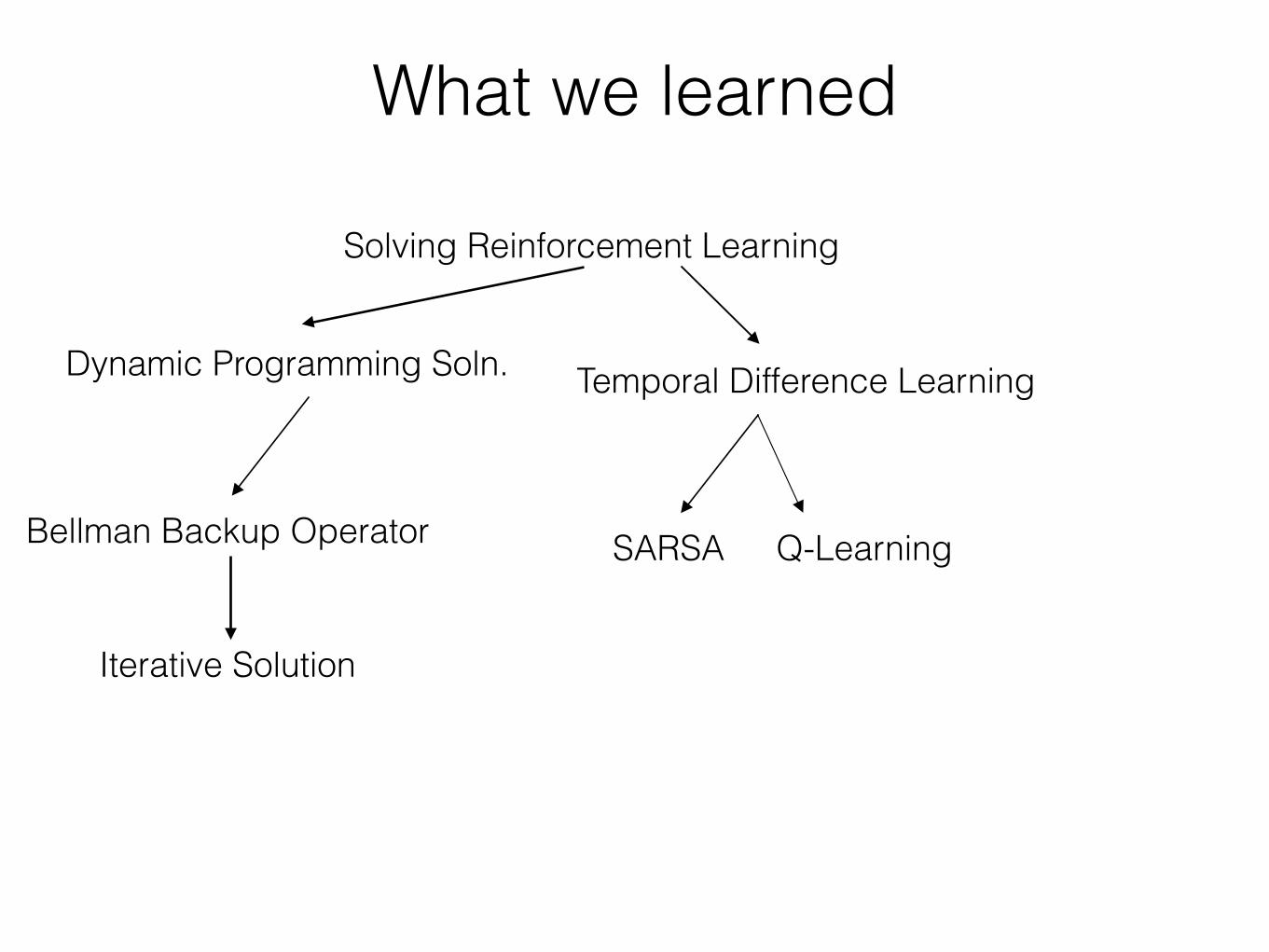
What we learned
Solving Reinforcement Learning
Dynamic Programming Soln.
Bellman Backup Operator
Iterative Solution
SARSA Q-Learning
Temporal Difference Learning

Another Approach
• So far policy is implicitly defined using value functions
• Can’t we directly work with policies

Policy Gradient Methods
• Parameterized policy ⇡✓(s, a)
• Gradient descent. Smoothly evolving policy.
• Obtaining gradient estimator?
• Optimization where max
✓J(✓) J(✓) = E⇡✓(s,a)
"X
t
�trt+1
#
On or off?

Finite Difference Method
@J(✓)
@✓i⇡ J(✓ + ✏ei)� J(✓ � ✏ei)
2✏
✓t+1i ✓ti + ↵
@J(✓t)
@✓ti
• Easy to implement and works for all policies.
Problem?

Likelihood Ratio Trick
r✓J(✓) =X
t
R(t)r✓p✓(t)
=
X
t
R(t)p✓(t)r✓ log p✓(t)
= Et⇠p✓(t0)[R(t)r✓ log p✓(t)]
max
✓J(✓)
J(✓) = Et⇠p✓(t0)[R(t)] =X
t
R(t)p✓(t)
= Et⇠p✓(t0)[(R(t)� b)r✓ log p✓(t)] 8 b

Reinforce (Multi Step)
r✓J(✓) = E⇡✓(s,a)[r✓ log ⇡✓(s, a)Q⇡✓(s,a)
(s, a)]
Policy gradient theorem:
initialize ✓
for each episode hs1, a1, r1, s2, a2, r2, s3, · · · an, rn, sni⇠ ⇡✓(s1, a1)
for t 2 {1, n}
✓ ✓ + ↵r✓ log ⇡✓(st, at)vt
vt ⇠ Q⇡✓ (st, at)
return ✓content from David Silver

Summary
• SARSA and Q-Learning
• Policy Gradient Methods
• On vs Off policy. Epsilon greedy policy.

What we learned
Solving Reinforcement Learning
Dynamic Programming Soln.
Bellman Backup Operator
Iterative Solution
SARSA Q-Learning
Temporal Difference Learning
Policy Gradient Methods
Finite difference method Reinforce

What we did not cover
• Generalized policy iteration
• Simple monte carlo solution
• TD( ) algorithm�
• Convergence of Q-learning, SARSA
• Actor-critic method
· · ·

Application

Playing Atari game with Deep RL
State is given by raw images.
Learn a good policy for a given game.

Playing Atari game with Deep RL
Q(s, a, ✓) ⇡ Q⇤(s, a)
Q⇤(s, a) =
X
s0
P as,s0{Ra
s,s0 + �max
a0Q⇤
(s0, a0)}
= Ras,s0 + �max
a0Q⇤
(s0, a0)
Q(s, a, ✓)
conv + reluconv + reluFC + relu
FC

Playing Atari game with Deep RLQ⇤
(s, a) = Ras,s0 + �max
a0Q⇤
(s0, a0)
Q(s, a, ✓) ! Ras,s0 + �max
a0Q(s0, a0, ✓)
Q(s, a, ✓)
conv + reluconv + reluFC + relu
FC
min(Q(s, a, ✓t)�Ras,s0 � �max
a0Q(s0, a0, ✓t�1
))
2
nothing deep about their RL

Playing Atari game with Deep RL

Playing Atari game with Deep RL
break correlation between consecutive datapointswhy replay memory?

Playing Atari game with Deep RL

Why Deep RL is hard
Q⇤(s, a) =
X
s0
P as,s0{Ra
s,s0 + �max
a0Q⇤
(s0, a0)}
• Recursive equation blows as difference between is smalls, s0
• Too many iterations required for convergence. 10 million frames for Atari game.
• It may take too long to see a high reward action.
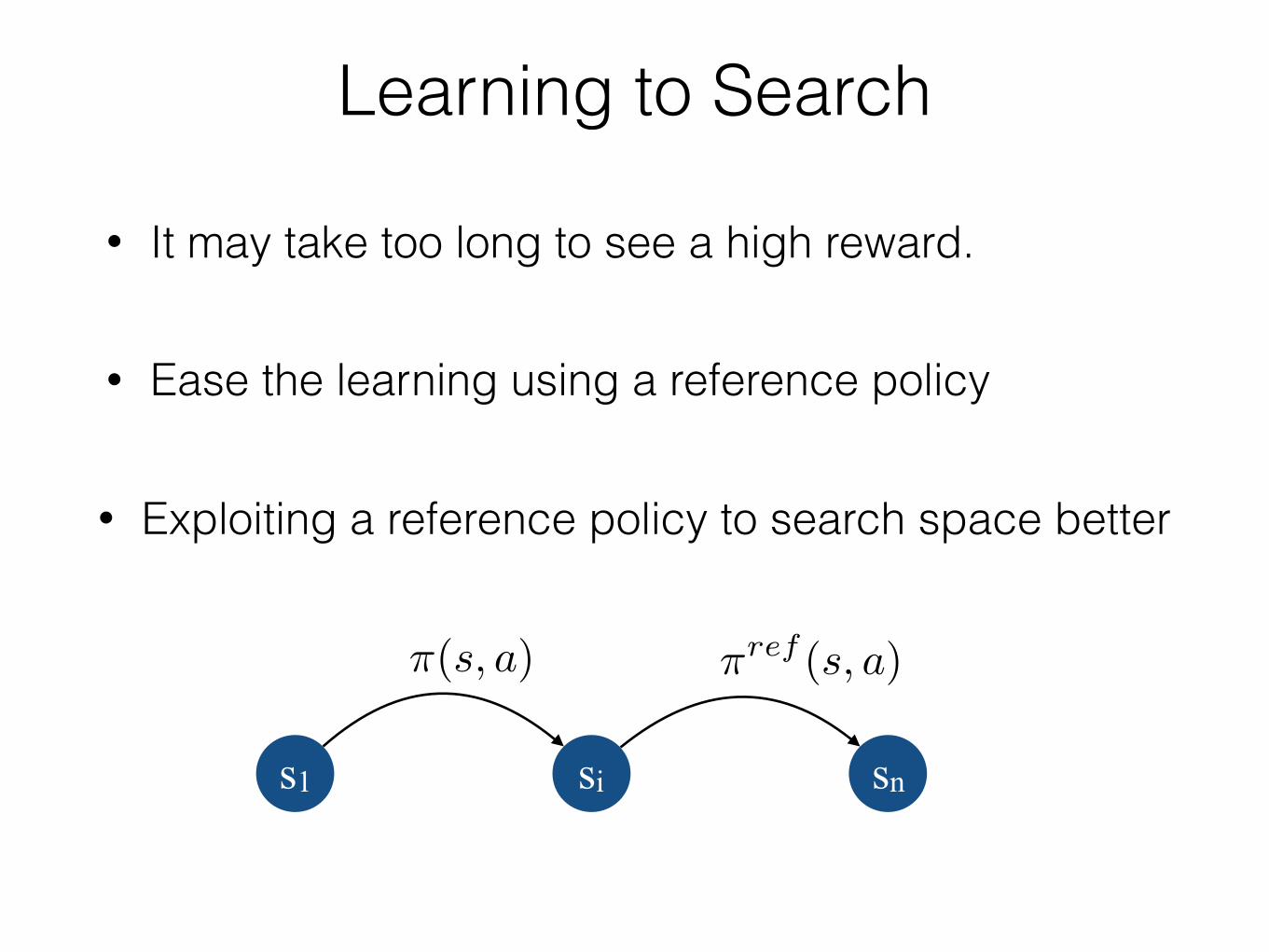
Learning to Search
• It may take too long to see a high reward.
• Ease the learning using a reference policy
• Exploiting a reference policy to search space better
s1 si sn
⇡(s, a) ⇡ref (s, a)

Summary
• SARSA and Q-Learning
• Policy Gradient Methods
• Playing Atari game using deep reinforcement learning
• On vs Off policy. Epsilon greedy policy.
• Why deep RL is hard. Learning to search.








![)( CORNELL REPORTS - [email protected] - Cornell University](https://static.fdocuments.net/doc/165x107/6206299f8c2f7b17300506a0/-cornell-reports-emailprotected-cornell-university.jpg)









