
Reference-Based Indexing of Sequence Databases (VLDB ’ 06) Jayendra Venkateswaran Deepak Lachwani...
26
Indexing of Sequence Databases (VLDB ’06) Jayendra Venkateswaran Deepak Lachwani Tamer Kahveci Christopher Jermaine Presented by Angela Siu
-
Upload
alvin-nelson -
Category
Documents
-
view
224 -
download
2
Transcript of Reference-Based Indexing of Sequence Databases (VLDB ’ 06) Jayendra Venkateswaran Deepak Lachwani...

Reference-Based Indexing of Sequence Databases
(VLDB ’06)
Jayendra VenkateswaranDeepak Lachwani
Tamer KahveciChristopher Jermaine
Presented by Angela Siu

Content Introduction Related work Reference-Based Methodology Selection of References Mapping of References Search Algorithm Experimental evaluation Conclusion

Introduction Many and/or very long sequences Similarity search
Genomics, proteomics, dictionary search Edit distance metric Dynamic programming (Expensive)
Reference-based indexing Reduce number of comparisons Choice of references

Related work Index structures
k-gram indexing Exact matches of k-gram Extend to find longer alignments with errors Eg. FASTA, BLAST Performance deteriorates quickly as the size of the database increases
Suffix tree Manage mismatches ineficiently Excessive memory usage: 10 – 37 bytes per letter
Vector space indexing SST, frequency vector, … Store the occurrence of each letter in sequence Lower bound of actual distance Performs poorly as the query range increases
Reference-based indexing A variation of vector space indexing VP-tree, MVP-Tree, iDistance, Omni, M-Tree, Slim-Tree, DBM-Tree, DF-Tre
e

Reference-Based indexing A seqeunce database S A set of reference sequences V Pre-compute edit distances ED
{ED(si, vj)|(∀si ∈ S) ∧ (∀vj ∈ V )} Similarity Search
Distance Threshold ε Triangle inequality
Prune sequences that are too close or too far away from a reference LB = max( ⋁ vj∈V |ED(q, vj) − ED(vj, s)|) UB = min( ⋁ vj∈V |ED(q, vj) + ED(vj, s)|) If ε < LB, add si to the pruned set If ε > UB, add si to the result set If LB ≤ ε ≤ UB, add si to the candidate set
si in candidate set are compared with queries using dynamic programming

Cost Analysis Memory
Main memory: B bytes Number of sequences: N Number of references assigned: k Average size of a sequence: z bytes Sequence-reference mapping of sequence s and reference vi: [i, ED(s, vi)] B = <storage of reference> + <storage of pre-computed edit distances> B = 8kN + zk
Time Query Set: Q Time taken for one sequence comparison: t Average size of candidate set: cavg Total query time = <Query-Reference comparison> + <Candidate-Query comparision> = tk|Q| + tCavg|Q|

Selection of references Omni method
Existing approach References near the convex
hull of the database Sequences near the hull
pruned by multiple, redundant references
Sequences far away from the hull cannot be pruned
Poor pruning rates

Proposed methods Goal: choose references that represent all part
s of the database Two novel strategies
Maximum Variance (MV) Maximize the spread of database around the references
Maximum Pruning (MP) Optimizes pruning based on a set of sample queries

Maximum Variance If q is close to reference v
Prune sequences far away from v Accept sequences close to v
If q is far away from v Prune sequences close to v
Select references with high variance of distances
Assume queries follow the same distribution as the database sequences
New reference prunes some part of the database not pruned by existing set of references

Maximum Variance Measure closeness of sequences
L: the length of the longest sequence in S μi: mean of distances of si
σi: variance of distances of si
w: a cut-off distance w = L.perc, where 0 < perc < 1 sj is close to si if ED(si, sj) < (μi − w) sj is far away from si if ED(si, sj) > (μi + w) Choose perc = 0.15, derived from experiment

Maximum VarianceS1
S2
S3
S4
S5
S6
σ1
σ2
σ3
σ4
σ5
σ6
Sequencedatabase
S1
S2
S4
S6
Randomsubset
+Calculate
S2
S5
S3
S1
S6
S4
Variance
Sort
CandidateReference
Set
Remove sequences close to or far away from the reference

Maximum Variance Algorithm Time complexity
Step 2: O(N|S’|L2) Step 4: O(N logN) Step 5: O(mN) Overall time:
O(NL2|S| + N logN + mN)

Maximum Pruning Combinatorially tries to compute the best reference s
ets for a given query distribution Greedy approach
Start with an initial reference set Consider each sequence in the database as a candidate Iteratively, replace an existing reference with a new one if pru
ning is improved Gain – the amount of improvement in pruning Stop if no further improvement
Sampling-based optimization

Maximum Pruning
S1
S2
S3
S4
S5
S6
G1
G2
G3
G4
G5
G6
CandidateReference
V1
V2
V3
CurrentReference
Set
Replace
Q1
Q2
Q3
Gain
Get
SampleQuery
Set
S1
G1
MaxV1
S3
V3
S1 S2 S3 S4 S5 S6
Sequence Database
S1

Maximum Pruning Algorithm Time complexity
Sequence Distances: O(N2) PRUNE(): O(N|Q|) Step 2:
Number of sequences: O(N2) Compute gain: O(m|Q|) Time: O(N2m|Q|)
Overall worst case N iterations O(N3m|Q|)

Maximum Pruning Sampling-Based Optimization
Estimation of gain Reduce the number of sequences, use subset of database Determine accuracy of gain estimate based on Central Limit Theorem Iteratively randomly select a sequence to calculate the gain of a candidate until
desired accuracy is reached Time complexity: O(N2fm|Q|), f is the sample size
Estimation of largest gain Reduce the number of candidate references Ensure the largest gain is at least τG[e] with ψ probability, where 0 ≤ τ , ψ ≤ 1,
G[e] has the largest gain Use Extreme Value Distribution to estimate G[e] From the sample set of candidates, find mean and standard deviation Best reference sequence has the expected gain of
where
Sample size:
Time complexity: O(Nfhm|Q|)

Mapping of references Each sequence has its own set of best
references Based on a sample query set Q Assign references that prune the sequence for most
queries in Q Avoid redundant references
Keep a reference only if it can prune a total of more than |Q| sequences
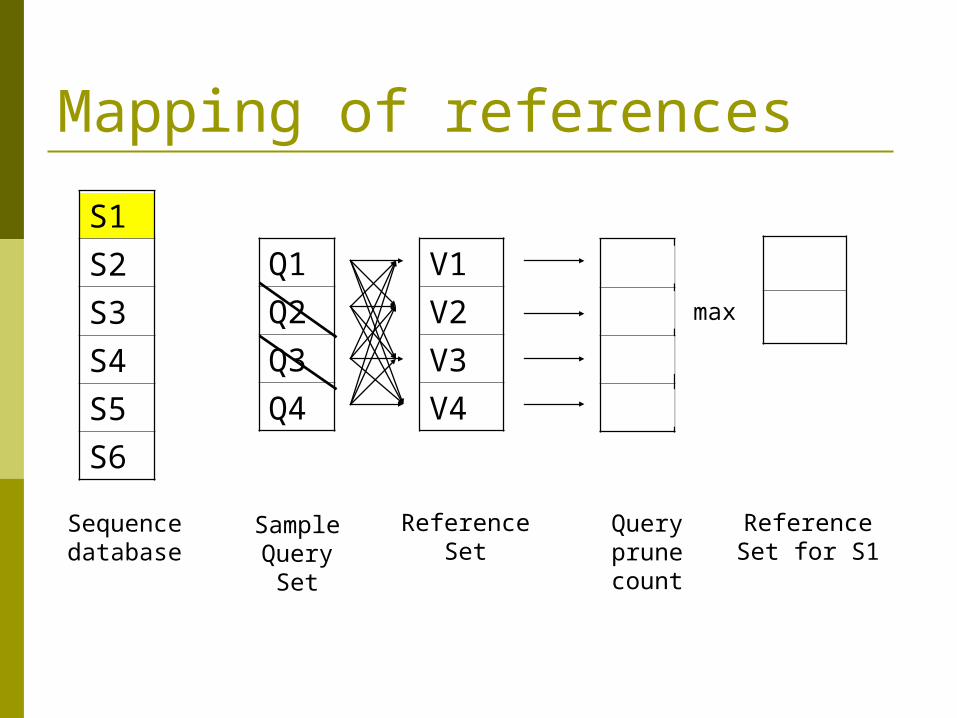
Mapping of references
V1
V2
V3
V4
ReferenceSet
S1
S2
S3
S4
S5
S6
Sequencedatabase
Q1
Q2
Q3
Q4
SampleQuery
Set
C1
C2
C3
C4
Queryprunecount
V2
ReferenceSet for S1
max

Mapping of references Algorithm Time complexity
Distance computation: O(tm|Q|), sequence comparison takes t time
Pruning amount calculation: O(m|Q|)
Overall time: O(Nmk|Q|)

Search Algorithm Calculate edit distances between queries and every reference Compute lower bound LB and upper bound UB ε: query range By triangle inequality,
If LB > ε, prune sequence If UB < ε, accept sequence Otherwise, perform actual sequence comparison
Memory complexity z: average sequence size [i, ED(s, vi)]: Sequence-Reference mapping N: number of database sequences m: number of references k: number of reference per database sequence Overall memory: (8Nk + mz) bytes
Time complexity Q: query set L: average sequence length Cm: average candidate set size for Q using m references Overall time: O((m + Cm)|Q|L2 + Nk|Q|)

Experimental evaluation Size of reference set: 200 Datasets
Text: alphabet size of 36 and 8000 sequences of length 100 DNA: alphabet size of 4 and 20000 sequences Protein: alphabet size of 20 and 4000 sequences of length 500
Comparisons of the selection strategies MV-S, MV-D: Maximum variance with same and different
reference sets MP-S, MP-D: Maximum pruning with same and different
reference sets Comparisons with existing methods
Omni, FV, M-Tree, DBM-Tree, Slim-Tree, DF-Tree

Comparison of selection strategies Impact of query range
Impact of number of reference per sequence

Comparisons with existing methods
Number of sequence comparisons IC: index contruction time ss: second ms: minute QR: query range MP-D is sampling-based optimized
Impact of query range

Comparison with existing methods Impact of input queries
Number of sequence comparisons Sample query set in reference selection: E.Coli Actual query set
HM: a butterfly species MM: a mouse speciecs DR: a zebrafish species
QR: query range

Comparison with existing methods Scalability of database size and sequence length

Conclusion Similarity search over a large database
Edit distance as the similarity measure Selection of references
Maximum variance Maximize spread of database around the database
Maximum pruning Optimize pruning based on a set of sample queries Sampling-based optimization
Mapping of references Each sequence has a different set of references
Experimental evaluation Outperform existing strategies including Omni and frequency
vectors MP-D, Maximum pruning with dynamic assignment of reference
sequences, performs the best


















