
Recent Advances in Machine Learningml.typepad.com/Talks/iwfhr.pdfConstructing Algorithms Choosing...
88
Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion Recent Advances in Machine Learning Olivier Bousquet, Pertinence IWFHR, La Baule, 2006 Olivier Bousquet, Pertinence Recent Advances in Machine Learning
Transcript of Recent Advances in Machine Learningml.typepad.com/Talks/iwfhr.pdfConstructing Algorithms Choosing...

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Recent Advances in Machine Learning
Olivier Bousquet, Pertinence
IWFHR, La Baule, 2006
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Goal of this talk
Demystifying some of the recent learning algorithms
Forget about how they were originally derivedForget about how they are ”marketed”Rebuild them from scratch
Give hints at how to choose between them
Show how to integrate prior knowledge
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Goal of this talk
Demystifying some of the recent learning algorithms
Forget about how they were originally derivedForget about how they are ”marketed”Rebuild them from scratch
Give hints at how to choose between them
Show how to integrate prior knowledge
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Goal of this talk
Demystifying some of the recent learning algorithms
Forget about how they were originally derivedForget about how they are ”marketed”Rebuild them from scratch
Give hints at how to choose between them
Show how to integrate prior knowledge
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Outline
1 Constructing AlgorithmsStarting From Similarity IStarting From Similarity IIStarting From Features
2 Choosing the Appropriate AlgorithmUnified view via RegularizationHow to choose?
3 Wrap-up and Conclusion
Olivier Bousquet, Pertinence Recent Advances in Machine Learning
Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Outline
1 Constructing AlgorithmsStarting From Similarity IStarting From Similarity IIStarting From Features
2 Choosing the Appropriate AlgorithmUnified view via RegularizationHow to choose?
3 Wrap-up and Conclusion
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Scratch
Assume we are engineers who want to build a good binaryclassification algorithm
Assume we have not heard about recent advances in MachineLearning
Standard notation
Training examples (x1, y1), . . . , (xn, yn)xi arbitrary object in X (e.g. image)yi binary label +1,−1f : X → R classification function (decision corresponds tosgn f (x))
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Scratch
Assume we are engineers who want to build a good binaryclassification algorithm
Assume we have not heard about recent advances in MachineLearning
Standard notation
Training examples (x1, y1), . . . , (xn, yn)xi arbitrary object in X (e.g. image)yi binary label +1,−1f : X → R classification function (decision corresponds tosgn f (x))
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Scratch
Assume we are engineers who want to build a good binaryclassification algorithm
Assume we have not heard about recent advances in MachineLearning
Standard notation
Training examples (x1, y1), . . . , (xn, yn)xi arbitrary object in X (e.g. image)yi binary label +1,−1f : X → R classification function (decision corresponds tosgn f (x))
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Starting From Similarity
Assume some colleague of yours gives you a similarity measureon images and tells you that whenever the similarity is high,the images are likely to correspond to the same character
Similarity function: s : X × X → RAssume further that for any x ,
s(x , x) ≥ 0
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Starting From Similarity
Assume some colleague of yours gives you a similarity measureon images and tells you that whenever the similarity is high,the images are likely to correspond to the same character
Similarity function: s : X × X → RAssume further that for any x ,
s(x , x) ≥ 0
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Starting From Similarity
Assume some colleague of yours gives you a similarity measureon images and tells you that whenever the similarity is high,the images are likely to correspond to the same character
Similarity function: s : X × X → RAssume further that for any x ,
s(x , x) ≥ 0
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Simplistic Approach
Compute similarity of a new example to all training examples
Compare average similarity to positives and average similarityto negatives
f (x) =1
n+
∑i :yi=+1
s(xi , x)− 1
n−
∑i :yi=−1
s(xi , x)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Simplistic Approach
Compute similarity of a new example to all training examples
Compare average similarity to positives and average similarityto negatives
f (x) =1
n+
∑i :yi=+1
s(xi , x)− 1
n−
∑i :yi=−1
s(xi , x)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Refined Approach
Not fully satisfactory: some training examples are misclassified
Try to modify the weights, look for a function
f (x) =n∑
i=1
αiyi s(xi , x)
With the following constraints on the weights
∀i , αi ≥ 0,∑
yiαi = 0,∑
αi = 2
which is equivalent to
∀i , αi ≥ 0,∑
i :yi=+1
αi =∑
i :yi=−1
αi = 1
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Refined Approach
Not fully satisfactory: some training examples are misclassified
Try to modify the weights, look for a function
f (x) =n∑
i=1
αiyi s(xi , x)
With the following constraints on the weights
∀i , αi ≥ 0,∑
yiαi = 0,∑
αi = 2
which is equivalent to
∀i , αi ≥ 0,∑
i :yi=+1
αi =∑
i :yi=−1
αi = 1
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Refined Approach
Not fully satisfactory: some training examples are misclassified
Try to modify the weights, look for a function
f (x) =n∑
i=1
αiyi s(xi , x)
With the following constraints on the weights
∀i , αi ≥ 0,∑
yiαi = 0,∑
αi = 2
which is equivalent to
∀i , αi ≥ 0,∑
i :yi=+1
αi =∑
i :yi=−1
αi = 1
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Tuning the weights
When xi is misclassified, yi f (xi ) ≤ 0
yi f (xi ) = αi s(xi , xi ) +∑j 6=i
yiyjs(xi , xj)
In order to increase yi f (xi ), we need to increase αi , i.e.decrease αiyi f (xi )
Let us do it simultaneously for all examples
minα
n∑i=1
αiyi f (xi )
but f itself depends on the αi so that replacing we get
minα
∑i ,j
αiαjyiyjs(xi , xj)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Tuning the weights
When xi is misclassified, yi f (xi ) ≤ 0
yi f (xi ) = αi s(xi , xi ) +∑j 6=i
yiyjs(xi , xj)
In order to increase yi f (xi ), we need to increase αi , i.e.decrease αiyi f (xi )
Let us do it simultaneously for all examples
minα
n∑i=1
αiyi f (xi )
but f itself depends on the αi so that replacing we get
minα
∑i ,j
αiαjyiyjs(xi , xj)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Tuning the weights
When xi is misclassified, yi f (xi ) ≤ 0
yi f (xi ) = αi s(xi , xi ) +∑j 6=i
yiyjs(xi , xj)
In order to increase yi f (xi ), we need to increase αi , i.e.decrease αiyi f (xi )
Let us do it simultaneously for all examples
minα
n∑i=1
αiyi f (xi )
but f itself depends on the αi so that replacing we get
minα
∑i ,j
αiαjyiyjs(xi , xj)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Illustration
Evolving weights
Olivier Bousquet, Pertinence Recent Advances in Machine Learning
Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
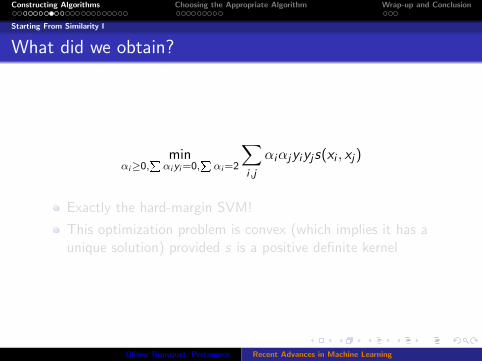
What did we obtain?
minαi≥0,
Pαiyi=0,
Pαi=2
∑i ,j
αiαjyiyjs(xi , xj)
Exactly the hard-margin SVM!
This optimization problem is convex (which implies it has aunique solution) provided s is a positive definite kernel
Olivier Bousquet, Pertinence Recent Advances in Machine Learning
Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
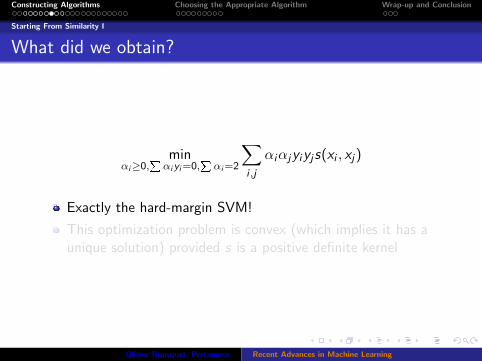
What did we obtain?
minαi≥0,
Pαiyi=0,
Pαi=2
∑i ,j
αiαjyiyjs(xi , xj)
Exactly the hard-margin SVM!
This optimization problem is convex (which implies it has aunique solution) provided s is a positive definite kernel
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
What did we obtain?
minαi≥0,
Pαiyi=0,
Pαi=2
∑i ,j
αiαjyiyjs(xi , xj)
Exactly the hard-margin SVM!
This optimization problem is convex (which implies it has aunique solution) provided s is a positive definite kernel
Olivier Bousquet, Pertinence Recent Advances in Machine Learning
Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
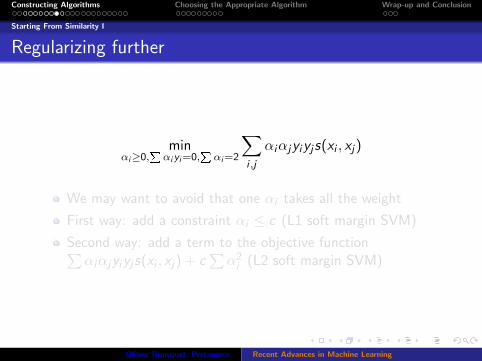
Regularizing further
minαi≥0,
Pαiyi=0,
Pαi=2
∑i ,j
αiαjyiyjs(xi , xj)
We may want to avoid that one αi takes all the weight
First way: add a constraint αi ≤ c (L1 soft margin SVM)
Second way: add a term to the objective function∑αiαjyiyjs(xi , xj) + c
∑α2
i (L2 soft margin SVM)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Regularizing further
minαi≥0,
Pαiyi=0,
Pαi=2
∑i ,j
αiαjyiyjs(xi , xj)
We may want to avoid that one αi takes all the weight
First way: add a constraint αi ≤ c (L1 soft margin SVM)
Second way: add a term to the objective function∑αiαjyiyjs(xi , xj) + c
∑α2
i (L2 soft margin SVM)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Regularizing further
minαi≥0,
Pαiyi=0,
Pαi=2
∑i ,j
αiαjyiyjs(xi , xj)
We may want to avoid that one αi takes all the weight
First way: add a constraint αi ≤ c (L1 soft margin SVM)
Second way: add a term to the objective function∑αiαjyiyjs(xi , xj) + c
∑α2
i (L2 soft margin SVM)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Regularizing further
minαi≥0,
Pαiyi=0,
Pαi=2
∑i ,j
αiαjyiyjs(xi , xj)
We may want to avoid that one αi takes all the weight
First way: add a constraint αi ≤ c (L1 soft margin SVM)
Second way: add a term to the objective function∑αiαjyiyjs(xi , xj) + c
∑α2
i (L2 soft margin SVM)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Wrap-up
Convex combination of similarities to examples
Increase the weights of misclassified examples till convergence
Possibly add a regularization term or a constraint on theweights
Forget about margin, high dimensional feature space, linearseparators... kernels are used to make the optimizationtractable
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Wrap-up
Convex combination of similarities to examples
Increase the weights of misclassified examples till convergence
Possibly add a regularization term or a constraint on theweights
Forget about margin, high dimensional feature space, linearseparators... kernels are used to make the optimizationtractable
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Wrap-up
Convex combination of similarities to examples
Increase the weights of misclassified examples till convergence
Possibly add a regularization term or a constraint on theweights
Forget about margin, high dimensional feature space, linearseparators... kernels are used to make the optimizationtractable
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity I
Wrap-up
Convex combination of similarities to examples
Increase the weights of misclassified examples till convergence
Possibly add a regularization term or a constraint on theweights
Forget about margin, high dimensional feature space, linearseparators... kernels are used to make the optimizationtractable
Olivier Bousquet, Pertinence Recent Advances in Machine Learning
Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
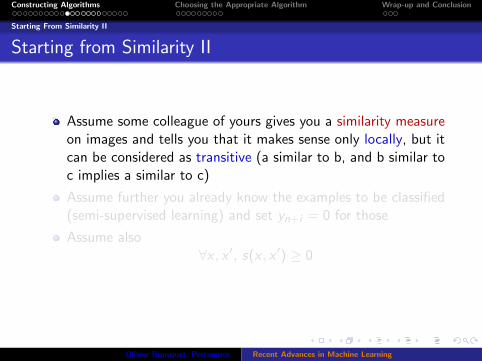
Starting From Similarity II
Starting from Similarity II
Assume some colleague of yours gives you a similarity measureon images and tells you that it makes sense only locally, but itcan be considered as transitive (a similar to b, and b similar toc implies a similar to c)
Assume further you already know the examples to be classified(semi-supervised learning) and set yn+i = 0 for those
Assume also∀x , x ′, s(x , x ′) ≥ 0
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity II
Starting from Similarity II
Assume some colleague of yours gives you a similarity measureon images and tells you that it makes sense only locally, but itcan be considered as transitive (a similar to b, and b similar toc implies a similar to c)
Assume further you already know the examples to be classified(semi-supervised learning) and set yn+i = 0 for those
Assume also∀x , x ′, s(x , x ′) ≥ 0
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity II
Starting from Similarity II
Assume some colleague of yours gives you a similarity measureon images and tells you that it makes sense only locally, but itcan be considered as transitive (a similar to b, and b similar toc implies a similar to c)
Assume further you already know the examples to be classified(semi-supervised learning) and set yn+i = 0 for those
Assume also∀x , x ′, s(x , x ′) ≥ 0
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity II
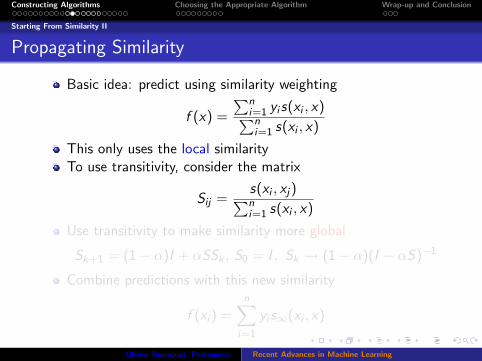
Propagating Similarity
Basic idea: predict using similarity weighting
f (x) =
∑ni=1 yi s(xi , x)∑ni=1 s(xi , x)
This only uses the local similarityTo use transitivity, consider the matrix
Sij =s(xi , xj)∑ni=1 s(xi , x)
Use transitivity to make similarity more global
Sk+1 = (1− α)I + αSSk , S0 = I , Sk → (1− α)(I − αS)−1
Combine predictions with this new similarity
f (xi ) =n∑
i=1
yi s∞(xi , x)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity II
Propagating Similarity
Basic idea: predict using similarity weighting
f (x) =
∑ni=1 yi s(xi , x)∑ni=1 s(xi , x)
This only uses the local similarityTo use transitivity, consider the matrix
Sij =s(xi , xj)∑ni=1 s(xi , x)
Use transitivity to make similarity more global
Sk+1 = (1− α)I + αSSk , S0 = I , Sk → (1− α)(I − αS)−1
Combine predictions with this new similarity
f (xi ) =n∑
i=1
yi s∞(xi , x)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning
Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity II
Propagating Similarity
Basic idea: predict using similarity weighting
f (x) =
∑ni=1 yi s(xi , x)∑ni=1 s(xi , x)
This only uses the local similarityTo use transitivity, consider the matrix
Sij =s(xi , xj)∑ni=1 s(xi , x)
Use transitivity to make similarity more global
Sk+1 = (1− α)I + αSSk , S0 = I , Sk → (1− α)(I − αS)−1
Combine predictions with this new similarity
f (xi ) =n∑
i=1
yi s∞(xi , x)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity II
Propagating Similarity
Basic idea: predict using similarity weighting
f (x) =
∑ni=1 yi s(xi , x)∑ni=1 s(xi , x)
This only uses the local similarityTo use transitivity, consider the matrix
Sij =s(xi , xj)∑ni=1 s(xi , x)
Use transitivity to make similarity more global
Sk+1 = (1− α)I + αSSk , S0 = I , Sk → (1− α)(I − αS)−1
Combine predictions with this new similarity
f (xi ) =n∑
i=1
yi s∞(xi , x)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity II
Propagating Similarity
Basic idea: predict using similarity weighting
f (x) =
∑ni=1 yi s(xi , x)∑ni=1 s(xi , x)
This only uses the local similarityTo use transitivity, consider the matrix
Sij =s(xi , xj)∑ni=1 s(xi , x)
Use transitivity to make similarity more global
Sk+1 = (1− α)I + αSSk , S0 = I , Sk → (1− α)(I − αS)−1
Combine predictions with this new similarity
f (xi ) =n∑
i=1
yi s∞(xi , x)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity II
−1.5 −1 −0.5 0 0.5 1 1.5 2 2.5−1
−0.5
0
0.5
1
1.5
Olivier Bousquet, Pertinence Recent Advances in Machine Learning
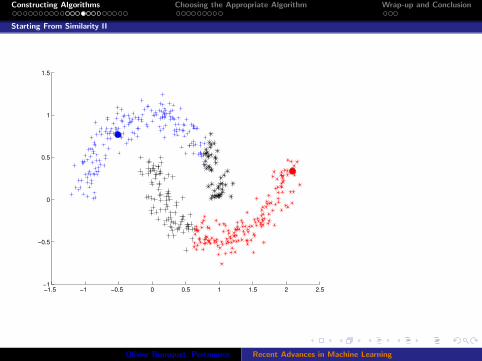
Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity II
−1.5 −1 −0.5 0 0.5 1 1.5 2 2.5−1
−0.5
0
0.5
1
1.5
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity II
−1.5 −1 −0.5 0 0.5 1 1.5 2 2.5−1
−0.5
0
0.5
1
1.5
Olivier Bousquet, Pertinence Recent Advances in Machine Learning
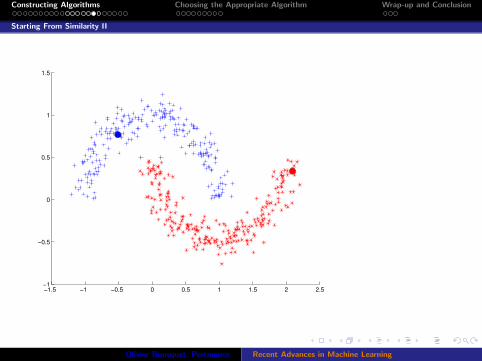
Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity II
−1.5 −1 −0.5 0 0.5 1 1.5 2 2.5−1
−0.5
0
0.5
1
1.5
Olivier Bousquet, Pertinence Recent Advances in Machine Learning
Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity II
Wrap-up
Propagate similarity to make it more global (i.e. add all paths)
Predict by summing all labels with similarity weight
Forget about manifolds, spectrum of Laplacian...
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity II
Wrap-up
Propagate similarity to make it more global (i.e. add all paths)
Predict by summing all labels with similarity weight
Forget about manifolds, spectrum of Laplacian...
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Similarity II
Wrap-up
Propagate similarity to make it more global (i.e. add all paths)
Predict by summing all labels with similarity weight
Forget about manifolds, spectrum of Laplacian...
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Features
Starting from Features
Assume some colleague of yours gives you a large set of binaryfeatures and tells you that he believes that a small number ofthem will allow to classify the images
Set of features H possibly infinite, h(x) ∈ −1, 1 (can begeneralized to [−1, 1])
Goal: construct a linear combination
Olivier Bousquet, Pertinence Recent Advances in Machine Learning
Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Features
Starting from Features
Assume some colleague of yours gives you a large set of binaryfeatures and tells you that he believes that a small number ofthem will allow to classify the images
Set of features H possibly infinite, h(x) ∈ −1, 1 (can begeneralized to [−1, 1])
Goal: construct a linear combination
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Features
Starting from Features
Assume some colleague of yours gives you a large set of binaryfeatures and tells you that he believes that a small number ofthem will allow to classify the images
Set of features H possibly infinite, h(x) ∈ −1, 1 (can begeneralized to [−1, 1])
Goal: construct a linear combination
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Features
Building a linear combination I
Idea: let us be greedy
Pick the most accurate feature:
maxh
n∑i=1
yih(xi )
Add it to the linear combination: f (x) = h(x)
Update (compute error differently)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Features
Building a linear combination I
Idea: let us be greedy
Pick the most accurate feature:
maxh
n∑i=1
yih(xi )
Add it to the linear combination: f (x) = h(x)
Update (compute error differently)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Features
Building a linear combination I
Idea: let us be greedy
Pick the most accurate feature:
maxh
n∑i=1
yih(xi )
Add it to the linear combination: f (x) = h(x)
Update (compute error differently)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Features
Building a linear combination I
Idea: let us be greedy
Pick the most accurate feature:
maxh
n∑i=1
yih(xi )
Add it to the linear combination: f (x) = h(x)
Update (compute error differently)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning
Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Features
Building a linear combination II
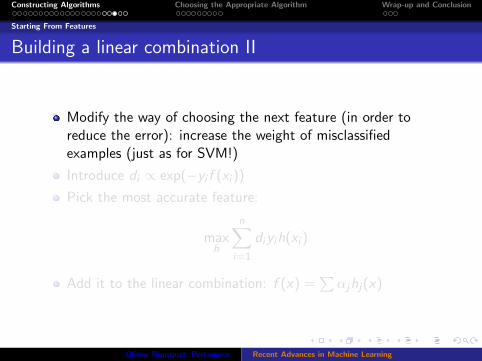
Modify the way of choosing the next feature (in order toreduce the error): increase the weight of misclassifiedexamples (just as for SVM!)
Introduce di ∝ exp(−yi f (xi ))
Pick the most accurate feature:
maxh
n∑i=1
diyih(xi )
Add it to the linear combination: f (x) =∑
αjhj(x)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Features
Building a linear combination II
Modify the way of choosing the next feature (in order toreduce the error): increase the weight of misclassifiedexamples (just as for SVM!)
Introduce di ∝ exp(−yi f (xi ))
Pick the most accurate feature:
maxh
n∑i=1
diyih(xi )
Add it to the linear combination: f (x) =∑
αjhj(x)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Features
Building a linear combination II
Modify the way of choosing the next feature (in order toreduce the error): increase the weight of misclassifiedexamples (just as for SVM!)
Introduce di ∝ exp(−yi f (xi ))
Pick the most accurate feature:
maxh
n∑i=1
diyih(xi )
Add it to the linear combination: f (x) =∑
αjhj(x)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Features
Building a linear combination II
Modify the way of choosing the next feature (in order toreduce the error): increase the weight of misclassifiedexamples (just as for SVM!)
Introduce di ∝ exp(−yi f (xi ))
Pick the most accurate feature:
maxh
n∑i=1
diyih(xi )
Add it to the linear combination: f (x) =∑
αjhj(x)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Features
What do we end up with?
Choice of the best feature at a given step is called weaklearning
Many variants of Boosting (including Adaboost) work in thisway (with various ways of choosing the αi )
Also similar to iterative regression (e.g. LAR)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Features
What do we end up with?
Choice of the best feature at a given step is called weaklearning
Many variants of Boosting (including Adaboost) work in thisway (with various ways of choosing the αi )
Also similar to iterative regression (e.g. LAR)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Features
What do we end up with?
Choice of the best feature at a given step is called weaklearning
Many variants of Boosting (including Adaboost) work in thisway (with various ways of choosing the αi )
Also similar to iterative regression (e.g. LAR)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Features
Wrap-up
Create linear combination of a few features
Choose most discriminative feature, and update weights onexample
Forget about weak and strong learning, margin, ensembles...
Olivier Bousquet, Pertinence Recent Advances in Machine Learning
Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Features
Wrap-up
Create linear combination of a few features
Choose most discriminative feature, and update weights onexample
Forget about weak and strong learning, margin, ensembles...
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Starting From Features
Wrap-up
Create linear combination of a few features
Choose most discriminative feature, and update weights onexample
Forget about weak and strong learning, margin, ensembles...
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Outline
1 Constructing AlgorithmsStarting From Similarity IStarting From Similarity IIStarting From Features
2 Choosing the Appropriate AlgorithmUnified view via RegularizationHow to choose?
3 Wrap-up and Conclusion
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Unified view via Regularization
The functional viewpoint
All approaches boil down to a regularized functional viewpoint
minf ∈F
∑`(f (xi ), yi ) + λΩf
Key ingredients
Convex loss functionConvex regularizer (ensure smoothness of the function)Convex search space (e.g. linear combinations)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Unified view via Regularization
The functional viewpoint
All approaches boil down to a regularized functional viewpoint
minf ∈F
∑`(f (xi ), yi ) + λΩf
Key ingredients
Convex loss functionConvex regularizer (ensure smoothness of the function)Convex search space (e.g. linear combinations)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning
Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Unified view via Regularization
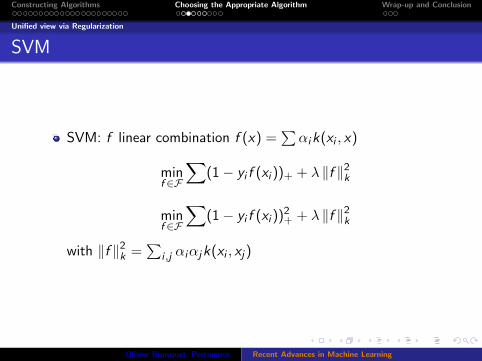
SVM
SVM: f linear combination f (x) =∑
αik(xi , x)
minf ∈F
∑(1− yi f (xi ))+ + λ ‖f ‖2
k
minf ∈F
∑(1− yi f (xi ))
2+ + λ ‖f ‖2
k
with ‖f ‖2k =
∑i ,j αiαjk(xi , xj)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Unified view via Regularization
Manifold
Manifold
minf
n∑i=1
(f (xi )− yi )2 + λf t∆f
with f t∆f =∑
s(xi , xj)(f (xi )− f (xj))2
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Unified view via Regularization
Boosting
Boosting: f linear combination f (x) =∑
αjhj(x)
minf
n∑i=1
e−yi f (xi ) + λ ‖f ‖1
with ‖f ‖1 =∑|αj |
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Unified view via Regularization
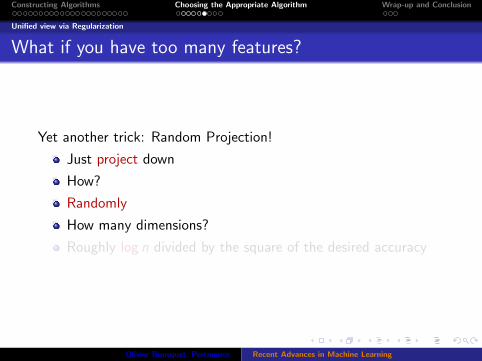
What if you have too many features?
Yet another trick: Random Projection!
Just project down
How?
Randomly
How many dimensions?
Roughly log n divided by the square of the desired accuracy
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Unified view via Regularization
What if you have too many features?
Yet another trick: Random Projection!
Just project down
How?
Randomly
How many dimensions?
Roughly log n divided by the square of the desired accuracy
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Unified view via Regularization
What if you have too many features?
Yet another trick: Random Projection!
Just project down
How?
Randomly
How many dimensions?
Roughly log n divided by the square of the desired accuracy
Olivier Bousquet, Pertinence Recent Advances in Machine Learning
Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Unified view via Regularization
What if you have too many features?
Yet another trick: Random Projection!
Just project down
How?
Randomly
How many dimensions?
Roughly log n divided by the square of the desired accuracy
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Unified view via Regularization
What if you have too many features?
Yet another trick: Random Projection!
Just project down
How?
Randomly
How many dimensions?
Roughly log n divided by the square of the desired accuracy
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
How to choose?
Criteria
The main criteria for choosing the appropriate algorithm
Knowledge you have about the problem
Computational constraints
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
How to choose?
Criteria
The main criteria for choosing the appropriate algorithm
Knowledge you have about the problem
Computational constraints
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
How to choose?
Decision List
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
How to choose?
More Knowledge
Similarity: build sophisticated kernels
Incremental approach: use known kernels and combine them invarious ways (algebra +, ∗, lim, convolution, exp), e.g.sequencesInvariances (e.g. tangent distance)Structured objects (sets, probability distributions, graphs,trees, sequences...)
Features: use sophisticated features (i.e. classifiers)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
How to choose?
More Knowledge
Similarity: build sophisticated kernels
Incremental approach: use known kernels and combine them invarious ways (algebra +, ∗, lim, convolution, exp), e.g.sequencesInvariances (e.g. tangent distance)Structured objects (sets, probability distributions, graphs,trees, sequences...)
Features: use sophisticated features (i.e. classifiers)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Outline
1 Constructing AlgorithmsStarting From Similarity IStarting From Similarity IIStarting From Features
2 Choosing the Appropriate AlgorithmUnified view via RegularizationHow to choose?
3 Wrap-up and Conclusion
Olivier Bousquet, Pertinence Recent Advances in Machine Learning
Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Wrap-up
Various tools
Need to understand what each brings
Can combine those basic tools to build the desired system
Trends
Do not refrain from using complex representationsBut avoid overfittingAnd remain tractableMany tools and tricks for doing both
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Wrap-up
Various tools
Need to understand what each brings
Can combine those basic tools to build the desired system
Trends
Do not refrain from using complex representationsBut avoid overfittingAnd remain tractableMany tools and tricks for doing both
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Wrap-up
Various tools
Need to understand what each brings
Can combine those basic tools to build the desired system
Trends
Do not refrain from using complex representationsBut avoid overfittingAnd remain tractableMany tools and tricks for doing both
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Wrap-up
Various tools
Need to understand what each brings
Can combine those basic tools to build the desired system
Trends
Do not refrain from using complex representationsBut avoid overfittingAnd remain tractableMany tools and tricks for doing both
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Conclusion
Forget about fancy ideas (SVM margin, implicit featuremapping, manifolds, boosting the margin...)
Only relevant: regularization. Works if you have the goodfeatures/similarity and if you have the appropriateregularization mechanism!
Future directions: multiclass made easy, more kernel buildingtools, more modularity (easy to combine several algorithms)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Conclusion
Forget about fancy ideas (SVM margin, implicit featuremapping, manifolds, boosting the margin...)
Only relevant: regularization. Works if you have the goodfeatures/similarity and if you have the appropriateregularization mechanism!
Future directions: multiclass made easy, more kernel buildingtools, more modularity (easy to combine several algorithms)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning

Constructing Algorithms Choosing the Appropriate Algorithm Wrap-up and Conclusion
Conclusion
Forget about fancy ideas (SVM margin, implicit featuremapping, manifolds, boosting the margin...)
Only relevant: regularization. Works if you have the goodfeatures/similarity and if you have the appropriateregularization mechanism!
Future directions: multiclass made easy, more kernel buildingtools, more modularity (easy to combine several algorithms)
Olivier Bousquet, Pertinence Recent Advances in Machine Learning


















