Realtime Search Infrastructure at Craigslist (OpenWest 2014)
24
Realtime Search Infrastructure sphinx at craigslist Jeremy Zawodny @jzawodn https://github.com/jzawodn http://blog.zawodny.com / [email protected]
-
Upload
jeremy-zawodny -
Category
Engineering
-
view
7.154 -
download
3
description
A brief history of search infrastructure at craigslist with an emphasis on our recent transition to using realtime (RT) indexing in Sphinx.
Transcript of Realtime Search Infrastructure at Craigslist (OpenWest 2014)

Realtime Search Infrastructure
sphinx at craigslist !
Jeremy Zawodny @jzawodn
https://github.com/jzawodn http://blog.zawodny.com/

About Me
at craigslist since mid-2008!
first major project: “fix search”!
Perl, search, MySQL, redis, MongoDB, data, backend services!
previously: Yahoo! and Marathon Oil!
wrote 1st edition of High Performance MySQL

About craigslistengineering culture!
no product managers or marketing!
< 50 employees!
self-hosted infrastructure we own & manage!
no “cloud” or virtualization!
multi-datacenter!
driven by user needs and feedback
Search

Outline
challenges!
history of search at craigslist!
lessons!
questions?

Challengesindexing rate (incoming volume)!
thousands of postings per minute!
churn and half-life!
traffic (always increasing)!
peak over 4,000 queries/second!
query multipliers (new features)!
spreading the load!
sharding and partitioning

History
search 1.0: Perl + DBM (2000-2002)!
search 2.0: MySQL Full-Text (2002-2008)!
search 3.0: sphinx master/slave (2008-2011)!
search 4.0: autonomous sphinx (2011-2013)!
search 5.0: realtime sphinx (2013 - today)

Evolutionneeds and desires are changing!
sphinx is improving!
hardware is more capable!
learn from previous mistakes!
it’s fun to do new things :-)!
searching > browsing

MySQL Full-Text

MySQL Full-Textused up until late 2008!
manual sharding!
performance was poor (easy to DoS)!
often fell off a cliff!
limited query syntax!
MyISAM corruption

Sphinx

Sphinx
awesome!
speaks MySQL protocol!
amazingly fast indexing!
very fast queries!
easy to understand!
programmer friendly!
open source!
great support!
stable

Sphinx Tools
searchd: the sphinx server process!
multi-threaded or pre-forking!
indexer: build batch indexes off-line!
indextool: check indexes and get details!
search: diagnostic tool for simple searches

Master/Slave Sphinxone index per city!
growth by sharding into 2 then 3 clusters!
masters build indexes every 10 minutes!
used indexer and perl scripts to generate XML!
build versioning and rollback mechanism!
slaves pull indexes via rsync and reload!
used pre-forking config!
hardware was dual proc, dual core AMD Opterons with 32GB RAM
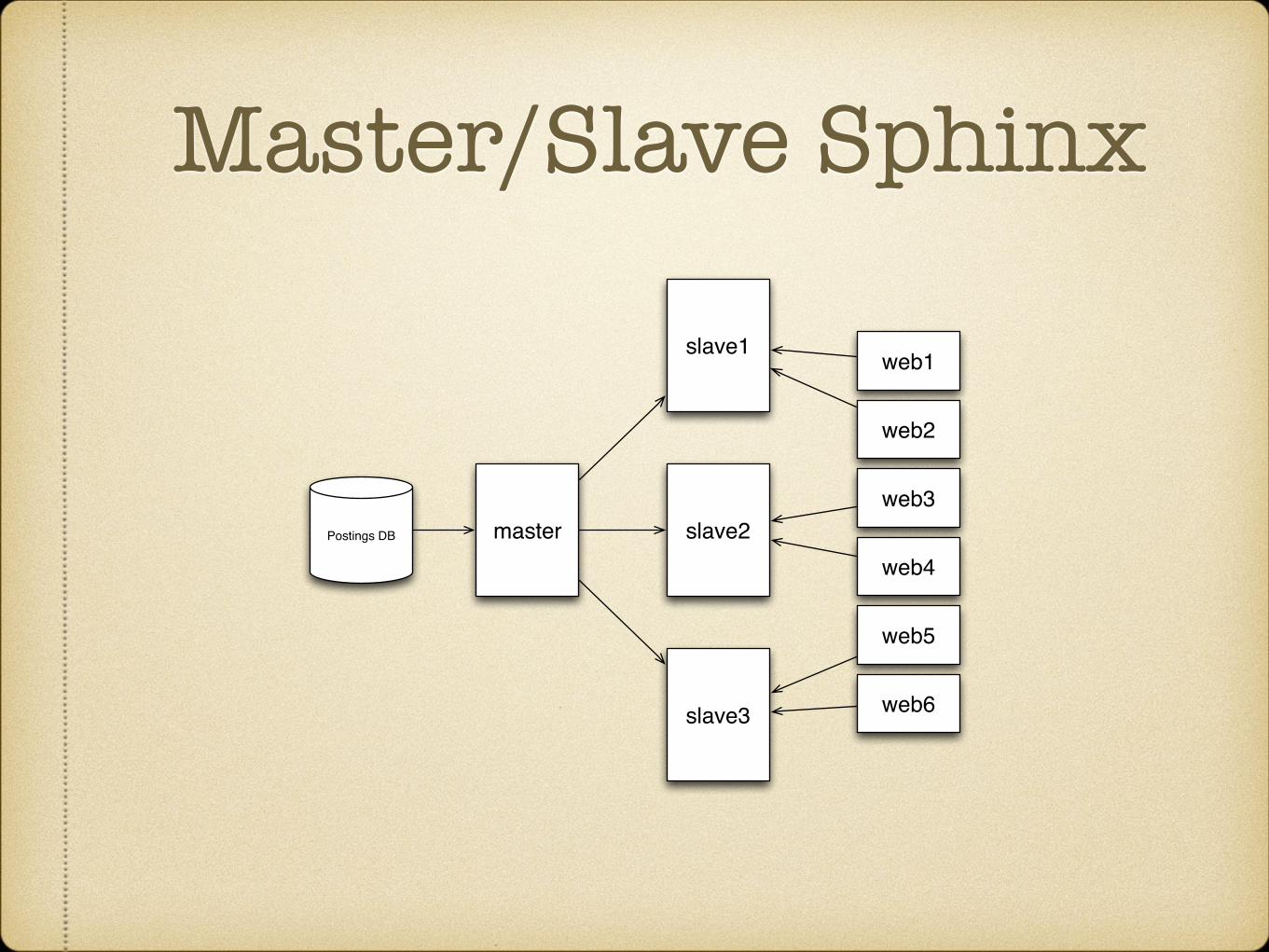
Master/Slave Sphinx
master slave2
slave1
slave3
Postings DB
web1
web2
web3
web4
web5
web6

Hardware Upgrade!

Autonomous Sphinx24 cores, 72GB RAM, 300GB SSD!
combine master and slave onto single node!
eliminate SPOF!
no replication delay!
simplify codebase!
better utilization of hardware

Autonomous Sphinx
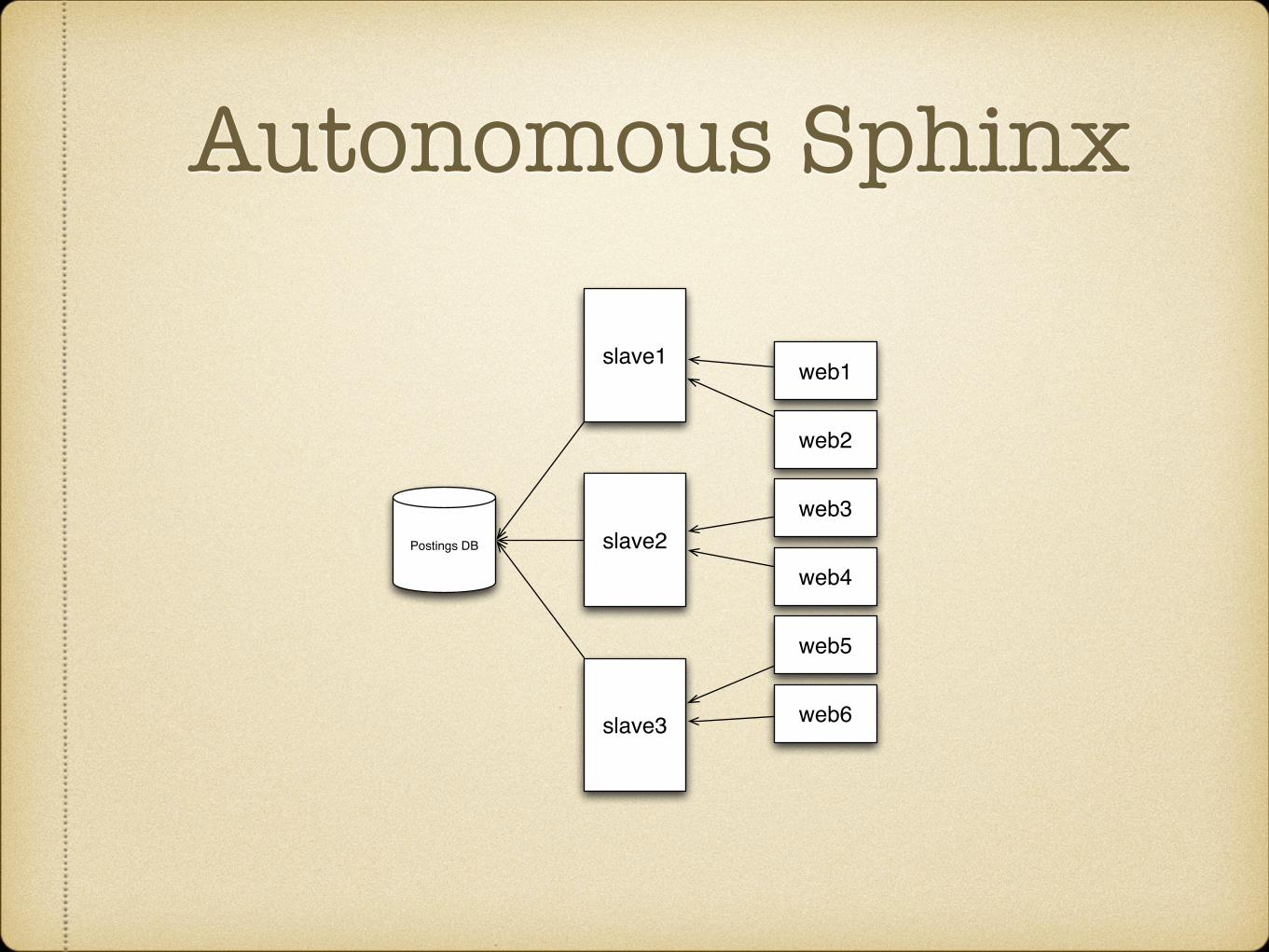
Autonomous Sphinx
slave2
slave1
slave3
Postings DB
web1
web2
web3
web4
web5
web6

Real-Time SphinxRT indexes in sphinx have matured!
reduce overhead from the searchd restart!
reduce time to search from posting going live!
goal < 10 seconds!
eliminate XML generation code!
use MySQL protocol

Sphinx ClustersLive: what you use!
highest traffic, volume, churn!
Team: what we use!
lowest traffic, lots of extra data!
Forums: yes, we have threaded discussions!
low volume, low traffic!
Archive: posting more than a few months old!
terabytes of indexes, constantly growing

Ram & Disk ChunksIndexes begin as “ram chunks”!
rt_mem_limit caps their size!
once too large, they become “disk chunks”!
obviously, disk is slower than RAM!
the more chunks, the more docs to check!
query times fall, CPU use rises...

Lessonsstopwords: google has spoiled users!
MONITOR ALL THE THINGS!!1!!
Mind your rt_mem_limit!
Keep it all in RAM!
Make re-indexing easy!
Automate cloning

Questions?While you ask, keeping in mind...!
craigslist is hiring!
front-end developers!
systems and network admins!
back-end developers!
send me your resume: [email protected]!
https://www.craigslist.org/about/craigslist_is_hiring