
Why developers should care about database devops. DevOps Days 4-2013
Upload
francois-garillotCategory
view
176download
3
Ramping(up(your(devops1fu(for(Big(Data(Developers
1

Francois)Garillot
Typesafe
@huitseeker
2
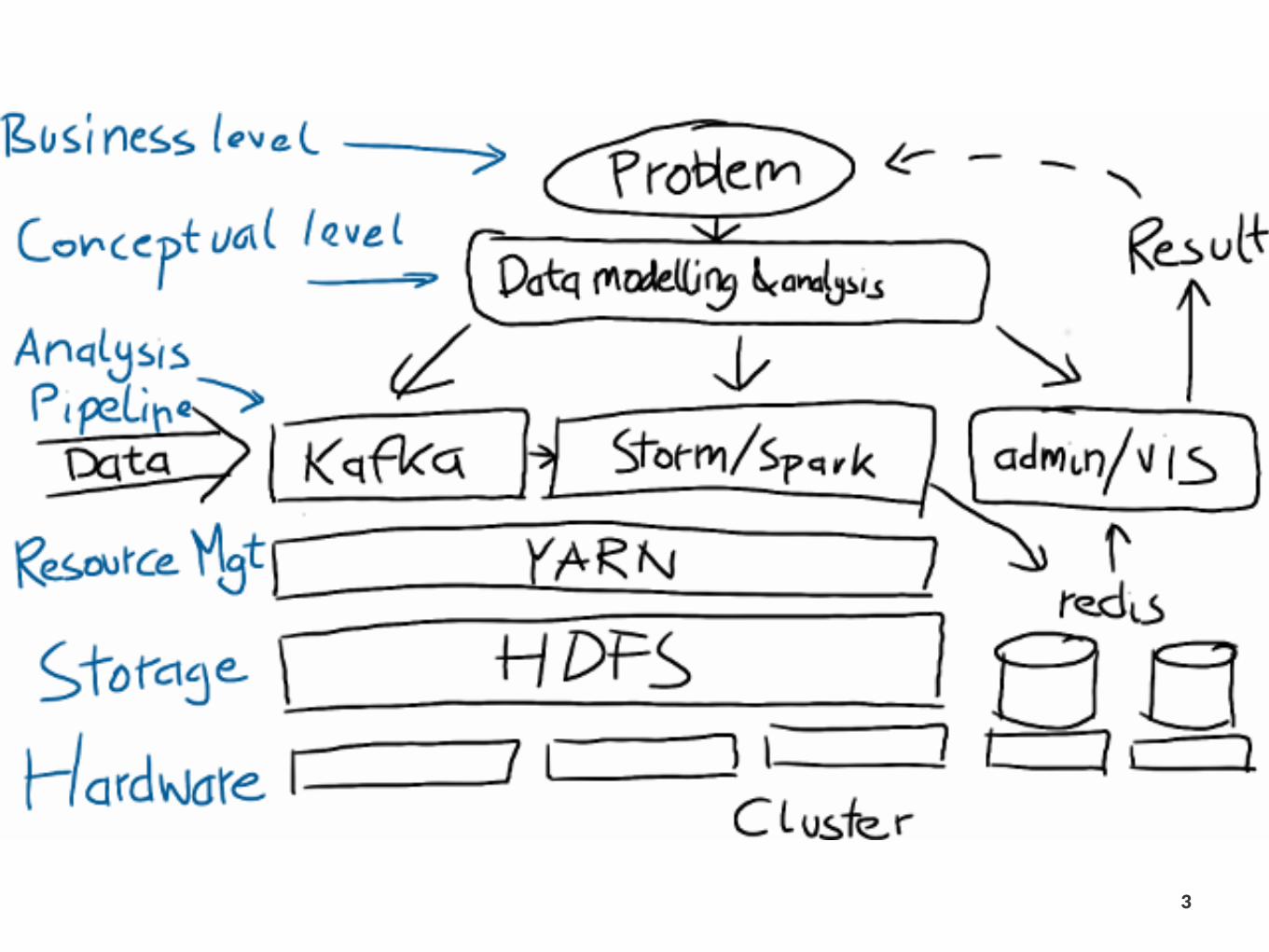
3

4

Apache'Mesos• top%level)Apache)project)since)July)2013
• framework)agnos?c
• a)cluster)manager)&)resource)manager
• developed)by)TwiDer)&)Mesosphere,)among)others
• "The)data)center's)opera?ng)system"
5

Mesos%PrinciplesMesos%=%cluster%+%cgroups%+%LXC
6

7

8

Mesos%internals
9

10

11

Mesos%topology
12

13

So,$why$do$we$care$?
• mul%&processes
• mul%&roles
• mul%&versions
• legacy3use3cases
14

Spark
"To$validate$our$hypothesis$[...],$we$have%also%built%a%new%framework%on%top%of%Mesos%called%Spark,$
op7mized$for$itera7ve$jobs$where$a$dataset$is$reused$in$many$parallel$operand$shown$that$Spark$can$outperform$Hadoop$by$10x$in$itera7ve$machine$
learning$workloads.
—"Hindman"&"al."2011
15

Spark• top%level)Apache)Project)since)February)2014
• also,)growth
16

Spark&expressivityval textFile = spark.textFile("hdfs://...")val counts = textFile.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _)counts.saveAsTextFile("hdfs://...")
17

Java$word$countpackage org.myorg;
import java.io.IOException;import java.util.*;
import org.apache.hadoop.fs.Path;import org.apache.hadoop.conf.*;import org.apache.hadoop.io.*;import org.apache.hadoop.mapreduce.*;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCount {
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, one); } } }
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } }
public static void main(String[] args) throws Exception { Configuration conf = new Configuration();
Job job = new Job(conf, "wordcount");
job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class); job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true); }
}
18

Spark&advantages• Fast&!&...
• Because&no&dump&to&disk&between&every&opera9on
• Combiners&(map<side&reduce)&automa9cally&applied&...
• ...&and&easy&to&define
• clever&map&pipeline
19

Spark&advantages• flexible(I/O(:(interfaces(to(DBs,(Streaming,(S3,(local(filesystem(and(HDFS
• faultAtolerance(for(executor(&(master
• SparkSQL
• MLLib,(GraphX
20

Spark&Streaming
21

Spark&advantagesMomentum(!!
• Sparkling+Water+=+H2O+++Spark
• Apache+Mahout+rewrite+since+March+2014
• DeepLearning4jBScaleout+=+Deeplearning4j+on+ND4J+++Spark
• 'Lingua+Franca'+of+distributed+data+analysis
22

Spark&clustering&modes• local
• standalone
• Mesos
• YARN
23
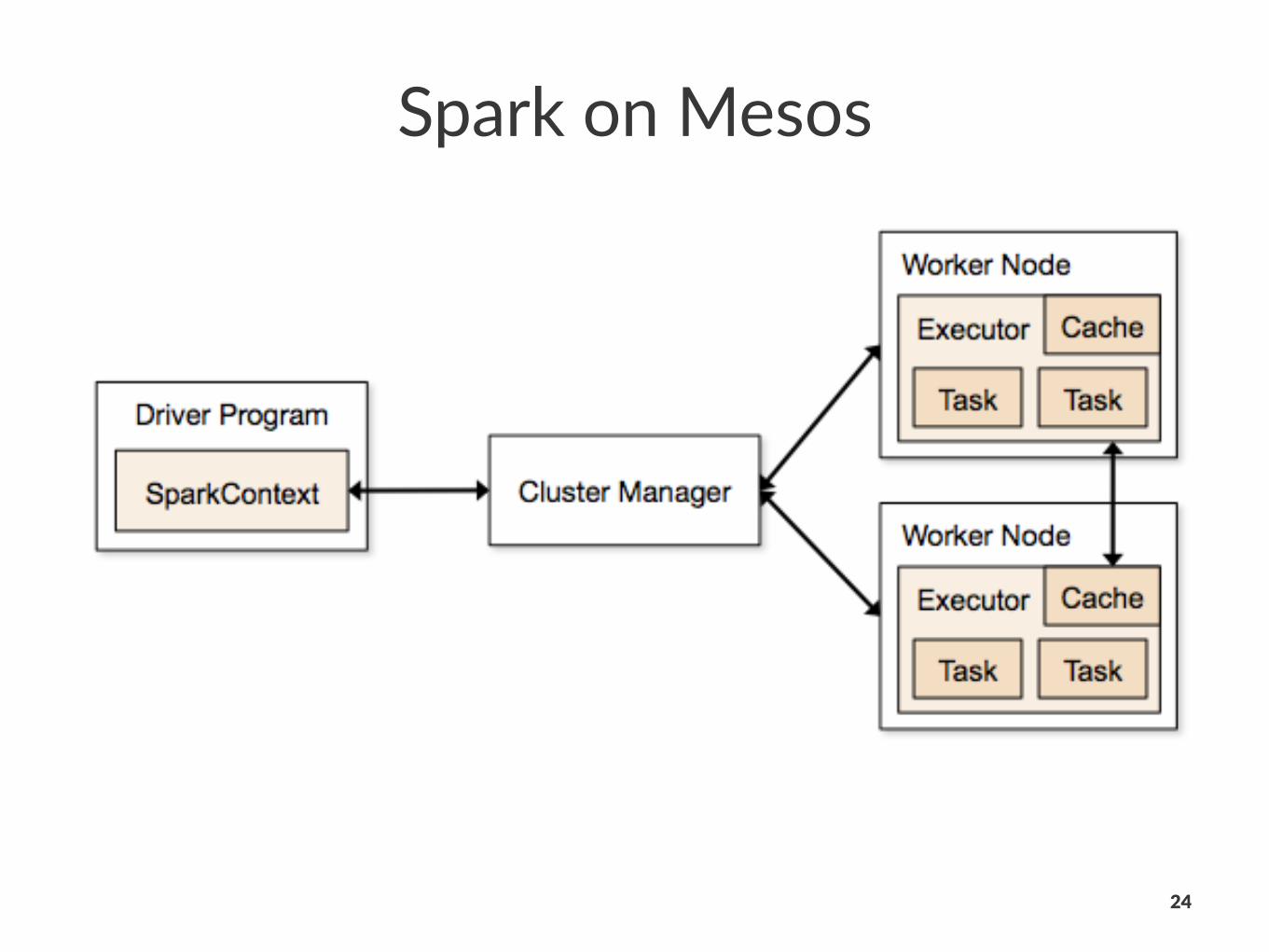
Spark&on&Mesos
24

25

Fine%grained*mode• “fine&grained”-mode-(default):-each-Spark-task-runs-as-a-separate-Mesos-task.
• each-applica?on-gets-more-or-fewer-machines-as-it-ramps-up-and-down,
• but-overhead-in-launching-each-task.
26

Coarse'grained,mode• “coarse)grained”/mode/:/only/one/long)running/Spark/task/on/each/Mesosmachine,
• and/dynamically/schedule/its/own/“mini)tasks”/within/it.
• much/lower/startup/overhead,
• but/reserving/the/Mesos/resources/for/the/duraAon
27

Deployment
28

Automa'on
29

Ansible
• pilots(through(ssh
• no(dependencies(on(slaves
• YAML(scrip7ng,(but(can(drop(down(to(Python
• integrated(modules(for(EC2,(apt(...
30

Ansible
...- name: download spark sources git: repo: "{{ spark_repo }}" dest: "{{ spark_dir }}" version: "{{ spark_ref }}" force: yes- name: prepare sources for {{ scala_major_version }} command: dev/change-version-to-{{scala_major_version}}.sh args: chdir: "{{spark_dir}}"- name: build spark command: ./make-distribution.sh -Pyarn -Phadoop-{{hadoop_major_version}} args: chdir: "{{ spark_dir }}" environment: java_env...
31
Packer
• hybrid(virtual(image(genera2on
• provision(on(VirtualBox
• provision(on(Amazon(AWS
• Vagrant(an(interes2ng(target(as(well
32

Tinc
• VPN
• simple+file-based+configura7on+(BSD-style)
• automa7c+mesh+rou7ng+in+1+config+line:AutoConnect = yes
• mul7ple+opera7ng+systems
33

Tinc%and%Spark• Spark'binds'using'naming'only'(see'SPARK9624)
• Tinc'name'resolu@on'only'works'reliably'in'some'configura@ons
• use'avahi9daemon'or'your'own'DNS
• more'simply,'set'hostnames'and'write'to'/etc/hosts'everywhere
• avoid'non9ascii'in'both'@nc'network'and'machine'names
34

So#Far• deployment+of+Mesos,+HDFS,+Spark
• fully+automated,+from+any+commit+of+Mesos+/+Spark+git+repositories
• ...+or+our+forks
• stress=tes>ng,+in+collab.+Mesosphere+&+DataBricks
• partnership+for+huge+prototype+deployment
35

Ongoing&steps
36

Mesos%and%Spark%integra0on• dynamic)alloca,on)for)coarse1grained)mode)&)external)shuffle)service)
• co1tes,ng)w/DB,)Mesosphere)
• cluster)mode)
37

Docker':'your'favorite'containerizer
38

39

40


















