
Radial Basis Function Network for Multitask Pattern Recognition
17
Neural Process Lett (2011) 33:283–299 DOI 10.1007/s11063-011-9178-9 Radial Basis Function Network for Multitask Pattern Recognition Hitoshi Nishikawa · Seiichi Ozawa Published online: 7 May 2011 © Springer Science+Business Media, LLC. 2011 Abstract In this paper, a novel type of radial basis function network is proposed for multi- task pattern recognition. We assume that recognition tasks are switched sequentially without notice to a learner and they have relatedness to some extent. We further assume that training data are given to learn one by one and they are discarded after learning. To learn a recogni- tion system incrementally in such a multitask environment, we propose Resource Allocating Network for Multi-Task Pattern Recognition (RAN-MTPR). There are five distinguished functions in RAN-MTPR: one-pass incremental learning, task change detection, task cate- gorization, knowledge consolidation, and knowledge transfer. The first three functions enable RAN-MTPR not only to acquire and accumulate knowledge of tasks stably but also to allocate classes to appropriate tasks unless task labels are not explicitly given. The fourth function enables RAN-MTPR to recover the failure in task categorization by minimizing the conflict in class allocation to tasks. The fifth function, knowledge transfer from one task to another, is realized by sharing the internal representation of a hidden layer with different tasks and by transferring class information of the most related task to a new task. The experimental results show that the recognition performance of RAN-MTPR is enhanced by introducing the two types of knowledge transfer and the consolidation works well to reduce the failure in task change detection and task categorization if the RBF width is properly set. Keywords Radial basis function network · Multitask learning · Incremental learning · Pattern recognition · Knowledge transfer 1 Introduction In the real world, we human confront numerous learning tasks on an ongoing basis such as classification, diagnosis, prediction, etc. Tasks are given sequentially and/or in parallel, and some tasks might be known in the past and some others might be totally unknown. Thinking H. Nishikawa · S. Ozawa (B ) Graduate School of Engineering, Kobe University, 1-1 Rokko-Dai, Kobe 657-8501, Japan e-mail: [email protected] 123
-
Upload
hitoshi-nishikawa -
Category
Documents
-
view
215 -
download
3
Transcript of Radial Basis Function Network for Multitask Pattern Recognition

Neural Process Lett (2011) 33:283–299DOI 10.1007/s11063-011-9178-9
Radial Basis Function Network for Multitask PatternRecognition
Hitoshi Nishikawa · Seiichi Ozawa
Published online: 7 May 2011© Springer Science+Business Media, LLC. 2011
Abstract In this paper, a novel type of radial basis function network is proposed for multi-task pattern recognition. We assume that recognition tasks are switched sequentially withoutnotice to a learner and they have relatedness to some extent. We further assume that trainingdata are given to learn one by one and they are discarded after learning. To learn a recogni-tion system incrementally in such a multitask environment, we propose Resource AllocatingNetwork for Multi-Task Pattern Recognition (RAN-MTPR). There are five distinguishedfunctions in RAN-MTPR: one-pass incremental learning, task change detection, task cate-gorization, knowledge consolidation, and knowledge transfer. The first three functions enableRAN-MTPR not only to acquire and accumulate knowledge of tasks stably but also to allocateclasses to appropriate tasks unless task labels are not explicitly given. The fourth functionenables RAN-MTPR to recover the failure in task categorization by minimizing the conflictin class allocation to tasks. The fifth function, knowledge transfer from one task to another,is realized by sharing the internal representation of a hidden layer with different tasks andby transferring class information of the most related task to a new task. The experimentalresults show that the recognition performance of RAN-MTPR is enhanced by introducingthe two types of knowledge transfer and the consolidation works well to reduce the failurein task change detection and task categorization if the RBF width is properly set.
Keywords Radial basis function network ·Multitask learning · Incremental learning ·Pattern recognition · Knowledge transfer
1 Introduction
In the real world, we human confront numerous learning tasks on an ongoing basis such asclassification, diagnosis, prediction, etc. Tasks are given sequentially and/or in parallel, andsome tasks might be known in the past and some others might be totally unknown. Thinking
H. Nishikawa · S. Ozawa (B)Graduate School of Engineering, Kobe University, 1-1 Rokko-Dai, Kobe 657-8501, Japane-mail: [email protected]
123

284 H. Nishikawa, S. Ozawa
about face recognition, there exist various different but related tasks. For example, whenseeing a human face, we might be required to answer the gender, but in some cases, we mighthave to answer the name, age, or health condition. Tasks to be solved can vary depending onsituations, and they are generally related to some extent. Therefore, it is unrealistic to assumethat such related tasks are learned independently, because this would cause the explosion incomputational resources under life-long learning environments. To avoid this, we need a newlearning framework that enables a system to acquire shared knowledge with different tasksand to utilize it for learning a new task. This type of learning is called multitask learning(MTL), and the main issue is to extract shared knowledge called inductive bias and to utilizethe bias for learning a new task in an efficient way [3,24].
Caruana [5] proposed an MTL model using a backprobagation network for multitaskpattern recognition (MTPR) problems where source and target recognition tasks are pre-sented to learn in parallel. According to the definition by Pratt and Jennings [20], this typeof knowledge transfer is called functional transfer. In the Caruana’s MTL model, an induc-tive bias corresponds to the internal representation of a hidden layer, and the knowledgetransfer is mainly actualized by sharing hidden units with different tasks. Therefore, thenetwork weights for previous tasks are used for learning a new task as the initial weights.In this sense, the Caruana’s MTL model is also categorized into literal transfer. Silver andMercer [23] extended the Caruana’s MTL model such that recognition tasks are stably learnedunder a situation where tasks are given sequentially. Although the knowledge transfer in theSilver’s MTL model is also categorized into the functional and literal transfer, one big differ-ence is that the knowledge transfer from one task to another is effectively conducted withoutbeing incurred by so-called catastrophic forgetting [4]. Ghosn and Bengio [8] have proposedanother approach to acquiring an inductive bias based on the functional and literal transfer.In the Ghosn’s MTL model, the hidden layers in learned networks are not shared; instead,the weights are constrained such that they are on an Affine manifold in a parameter space.Finding a hypothesis on such a manifold results in natural introduction of inductive bias inlearning. Other than the above models, there have been proposed various MTL models forMTPR problems [9,21] and recently they are applied to practical problems [6,12].
In many MTL models, however, it is assumed that tasks and training data are given ina batch and the task category is explicitly given to a learner. Considering our daily life,such assumptions are not always hold; that is, both tasks and training data of a task mightbe provided sequentially and the change of tasks might not always be explicitly informed.The difficulty of learning tasks in such a situation is to detect task changes on its own evenwhen the task category is not given. In addition, the knowledge on the previous tasks can beforgotten by learning a new task (i.e., catastrophic forgetting). To prevent the catastrophicforgetting, several incremental learning algorithms have been proposed [1,2,7,10,11,27];however, most of them assume single-task learning.
The above discussion suggests us an interesting direction for an MTL model which learnsmultiple tasks stably and efficiently based on knowledge transfer even when tasks andtraining data are presented to a learner as a sequence. For such sequential MTPR prob-lems, Ozawa et al. [17] proposed an MTL model by extending an incremental learningmodel called Resource Allocating Network with Long-Term Memory (RAN-LTM) [14], inwhich a resource allocating network (RAN) [19] is learned not only with training databut also with several representative training data in long-term memory (LTM) to suppressthe catastrophic forgetting. In this MTL model, incremental learning is stably conductedeven if training data are thrown away after learning. We call this property one-pass incre-mental learning [13]. In addition, this model can detect the change of different taskson its own, allocate classes to appropriate recognition tasks, utilize the knowledge of
123

Radial Basis Function Network 285
previous tasks for learning a new task, and recover the failure in task categorization auton-omously. These abilities in the MTL model are called task change detection, task cate-gorization, knowledge transfer, and knowledge consolidation, respectively. In this MTLmodel, it is assumed that a target task is presented after learning source tasks and a dif-ferent task is separately learned by a single RAN without sharing weights and RBFs.Therefore, according to the definition by Pratt and Jennings [20], the knowledge trans-fer in this MTL model is categorized into representational and non-literal transfer. Onthe other hand, there still remain open problems to be solved in this model. One prob-lem is that a RAN classifier is increased whenever a new task appears. Since radial basisfunctions (RBFs) in all RAN classifiers cover the same input domain, keeping all theRBFs is insufficient in terms of memory use. Another problem is that the knowledgeis transferred only from the task right before the current task; thus, the task relatednessis not considered in knowledge transfer. In general, shared knowledge to be transferredincreases if two tasks are more related. Therefore, if a related task is properly selectedas a source task, it is expected that the knowledge transfer works more effectively inlearning.
In this paper, against the above problems, we proposed a new MTL model called ResourceAllocating Network for Multi-Task Pattern Recognition (RAN-MTPR) which also possessesthe five abilities mentioned above. The primary difference is that all tasks are learned bya single RAN classifier. In the RAN classifier, the outputs are automatically grouped intooutput sections, each of which is responsible for a certain task. In such network architecture,all the output sections are shared with the same RBFs; therefore, the internal representationof RBFs learned in one task works as a bias when learning a new task. This leads to a nat-ural implementation of literal transfer which has been introduced in various MTL models[5,23]. Another benefit to learn with a single RAN is that the relatedness of two tasks canbe measured by calculating the similarity between the weight vectors of two output sections.Based on this task relatedness, the non-literal transfer in [17] is also introduced; that is, theinformation on a class region of one task is transferred to a new task. Therefore, one cansay that the knowledge transfer in the proposed model is categorized into representationaltransfer; in addition, it belongs to both literal and non-literal transfer.
The paper is organized as follows. In Sect. 2, first we define MTPR problems assumed inthis paper. Section 3 explains how the abilities of one-pass incremental learning, task changedetection, task categorization, knowledge consolidation, and knowledge transfer are imple-mented. In Sect. 4, the performance of RAN-MTPR is evaluated for eight MTPR problemswhich are redefined from the original datasets in the UCI machine learning repository [26].Section 5 gives conclusions of this paper and states future work.
2 Multitask Pattern Recognition
In this paper, we focus on pattern recognition problems under multitask learning environ-ments (i.e., MTPR problems). An MTPR problem defined here consists of several multi-classrecognition tasks. We assume that recognition tasks are given one after another to a learnerin random order during a learning session. Figure 1 shows an example of MTPR problemwhich consists of 3 recognition tasks. In this example, Task 1 is given as the first task inthe learning session, and Task 2 is provided next, then Task 1 comes again; thus, the sametasks can appear recurrently. It is assumed that training data of a task are also given oneafter another in random order. Here, we assume one-pass incremental learning environments
123
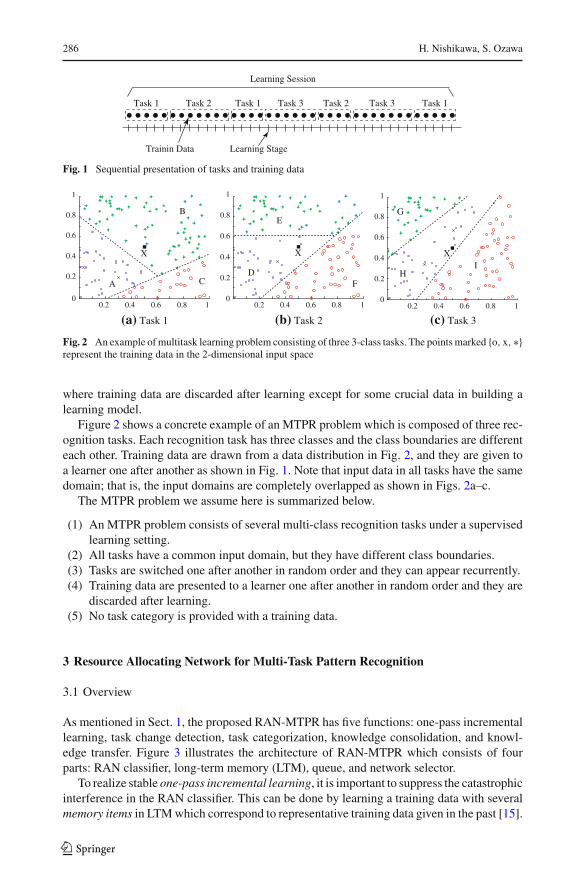
286 H. Nishikawa, S. Ozawa
Learning Stage
Task 1 Task 2 Task 1 Task 3 Task 2 Task 3 Task 1
Learning Session
Trainin Data
Fig. 1 Sequential presentation of tasks and training data
(a) Task 1
0.2 0.4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
A C
B
0.2 0.4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
(b) Task 2
F
E
D
0.2 0.4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
(c) Task 3
I
G
H
X XX
Fig. 2 An example of multitask learning problem consisting of three 3-class tasks. The points marked {o, x, ∗}represent the training data in the 2-dimensional input space
where training data are discarded after learning except for some crucial data in building alearning model.
Figure 2 shows a concrete example of an MTPR problem which is composed of three rec-ognition tasks. Each recognition task has three classes and the class boundaries are differenteach other. Training data are drawn from a data distribution in Fig. 2, and they are given toa learner one after another as shown in Fig. 1. Note that input data in all tasks have the samedomain; that is, the input domains are completely overlapped as shown in Figs. 2a–c.
The MTPR problem we assume here is summarized below.
(1) An MTPR problem consists of several multi-class recognition tasks under a supervisedlearning setting.
(2) All tasks have a common input domain, but they have different class boundaries.(3) Tasks are switched one after another in random order and they can appear recurrently.(4) Training data are presented to a learner one after another in random order and they are
discarded after learning.(5) No task category is provided with a training data.
3 Resource Allocating Network for Multi-Task Pattern Recognition
3.1 Overview
As mentioned in Sect. 1, the proposed RAN-MTPR has five functions: one-pass incrementallearning, task change detection, task categorization, knowledge consolidation, and knowl-edge transfer. Figure 3 illustrates the architecture of RAN-MTPR which consists of fourparts: RAN classifier, long-term memory (LTM), queue, and network selector.
To realize stable one-pass incremental learning, it is important to suppress the catastrophicinterference in the RAN classifier. This can be done by learning a training data with severalmemory items in LTM which correspond to representative training data given in the past [15].
123

Radial Basis Function Network 287
Create & Store
Recall & Learn
NetworkSelector
Long-Term Memory(LTM)
(x , d , ..., d )1(1)1 1
(M)~ ~ ~
(x , d , ..., d )L(1)
L L(M)~ ~ ~
Stack
Queue
(x , d )t t
(x , d )t-q+1 t-q+1
Queued Training Data
Matched Network
(x , d ) :Training Datat t
RAN Classifier
Queued Training Data
Error
Det
ect T
ask
Cha
nge Select
Target
Select Output Section
cJ
(1)z1(1)zK
(m)z1(m)zK
(M)z1(M)zK
(1)z (m)z (M)z
c1 c2 cJ-1
y1
yJ
xt1 xt2 xtI
w11(1) wJK
(M)
Section 1 Section m Section M
Input
RBF
Fig. 3 Architecture of RAN-MTPR
In MTPR problems, multiple class labels are associated with an input; thus, each memoryitem also includes multiple class labels and a target class should be chosen depending onwhat task is currently learned.
The task change detection is carried out by monitoring the conflict in the classifier pre-diction. The conflict is measured by calculating the training error, and several training dataare temporally stacked in the queue while the conflict is detected. When the queue is full,RAN-MTPR confirms there is a task change. Then, the queued training data are forwardedto the network selector, and the errors at all output sections in RAN are calculated for thequeued data. If an output section with low error is found, the network selector switches to theoutput section and selects the target class of memory items in LTM (see Fig. 3). Otherwise,it indicates that a new task is given; then, a new output section is created in RAN. Note thatdata in the queue are learned by RAN in both cases after the selection or creation of an outputsection. If the task change detection works well and an output section is properly selected,training data of a certain task are always learned at the same output section, resulting insuccessful task categorization.
The knowledge consolidation is performed in the RAN classifier and LTM to recover thefailure in task categorization. This process is evoked right after a task change is detected,and the classifier outputs are calculated for all the queued training data. The conflict in taskcategorization is detected by checking whether more than two outputs are simultaneouslyactive in the same output section. If a conflict is found, misallocated outputs in RAN aremoved to an appropriate section, and the class labels of memory items are also modified.
In RAN-MTPR, two types of knowledge transfer are implemented (1) by sharing RBFswith all tasks and (2) by transferring the information on class subregions. The first knowledgetransfer is based on the following heuristics: RBFs that span class regions in one task are alsouseful for spanning class regions in another if two tasks are related. The second knowledgetransfer is performed in LTM by setting the class of a training data to the target class ofmemory items which exist in the neighbor of the training data. Although the neighbor isdefined as a hypersphere with a certain radius, the class information is transferred to not all
123

288 H. Nishikawa, S. Ozawa
the memory items in it; precisely, it is transferred to the memory items which belong to theclass of the training data in the most related task. Therefore, we can say that the informationon a class subregion in the previous task is transferred as knowledge in this type of knowledgetransfer.
Further details on the above functions are described below.
3.2 One-Pass Incremental Learning
Assume that a pair of an input xt = {xt1, . . . , xt I }T and the class dt is given to RAN-MTPRas a training data. Then, the RBF outputs y j are calculated by
y j = exp
(−‖x j − c j‖2
2σ 2j
)( j = 1, . . . , J ) (1)
where J is the number of RBFs, c j = {c j1, . . . , c j I }T and σ j are the center and the widthof the j th RBF, respectively.
Assume that M tasks have been trained so far and the current training data at time tbelongs to task m. Then, the RAN classifier has M output sections, and the mth output sec-tion is selected by the network selector (see Fig. 3). The outputs z(m) = {z(m)
1 , . . . , z(m)K }T
are calculated by
z(m)k =
J∑j=1
w(m)k j y j + ξ
(m)k (k = 1, . . . , K (m)) (2)
where K (m) is the number of classes allocated in task m, w(m)k j is the connection weight from
the j th RBF to the kth output in the mth section, and ξ(m)k is the bias of the kth output.
Although the RAN classifier is trained based on the learning algorithm of RAN-LTM [15],RBF centers c j are not updated once they are created. Since RBFs are shared with differentoutput sections, the change of RBF centers affects all the predictions in output sections; thus,if RBF centers are learned only with a training data of the current task, it would cause thecatastrophic interference. The classifier learning is conducted in either of the two operations:(1) creating a new RBF or (2) modifying connection weights. When a training data (xt , dt )
is given to RAN, the following squared error is first calculated in the mth output section:
E (m) = 1
K (m)‖d(m)
t − z(m)(xt )‖2 (3)
where d(m)t = {d(m)
t1 , . . . , d(m)t K }T is a target vector for the mth output section that encodes
the class dt based on the binary coding scheme.If the squared error E (m) is larger than a threshold ε and the input xt is far enough to the
closest RBF center c∗ (i.e., ‖xt − c∗‖ > δ where δ is a threshold), then a new RBF is createdand the number of RBFs J is incremented by 1. And the RBF center c
(m)J and the connection
weights w(m′)J = {w(m′)
1J , . . . , w(m′)K J }T are set as follows:
cJi = xti (i = 1, . . . , I ) (4)
w(m′)k J =
{d(m)
tk − z(m)k (m′ = m)
0 (otherwise)(m′ = 1, . . . , M; k = 1, . . . , K (m′)). (5)
123

Radial Basis Function Network 289
Algorithm 1 Learn RAN-MTPRInput: Training data (xt , dt ) and the current output section m.1: Calculate the outputs z(m) for xt using Eqs. 1, 2.2: Calculate the squared error E(m) in Eq. 3.3: if E(m) > ε and min j ‖xt − c j‖ > δ then
4: Add a hidden unit (i.e., J ← J + 1) and set the RBF center cJ and the weights w(m)J based on Eqs. 4, 5.
5: Create a new memory item based on Eq. 6 and L ← L + 1.6: else7: Recall the memory items from LTM and define the index set �(x) of the memory items.8: Calculate the outputs z(m)(xl ) for all memory items in �(x).
9: Calculate the error e(m)k (k = 1 · · · , K (m)) in Eq. 10.
10: Update weights w(m)k j and biases ξ
(m)k using Eqs. 8, 9.
11: Calculate the squared error E(m) in Eq. 3 again.12: if E(m) > ε then13: Create a hidden unit and a memory item based on Eqs. 4–6.14: end if15: end if
In addition to creating an RBF, the training data (xt , dt ) is stored in LTM as a memoryitem. Assume that there have been created L memory items and the mth output section isselected. Then, a new memory item ML+1 is created as follows:
ML+1 : (xL+1, d(1)L+1, . . . , d(m)
L+1 . . . , d(M)L+1) = (xt , 0, . . . , dt , . . . , 0). (6)
On the other hand, if the above condition is not satisfied, the connection weights w(m)k j are
modified such that not only the error E (m) in Eq. 3 but also the following error E (m) formemory items (xl , d(m)
l ) is minimized in order to avoid the catastrophic forgetting:
E (m) = 1
K (m)|�|∑
l∈�(x t )
‖d(m)
l − z(m)(xl)‖2 (7)
where �(xt ) is an index set of memory items Ml that exist in the neighborhood of xt , |�|is the size of �(xt ), and d
(m)
l = {d(m)l1 , . . . , d(m)
l K } is the target vector encoding class d(m)l .
To minimize the sum of E (m) and E (m), the following update equations are derived based onthe steepest descent method:
w(m)N EWkj = w
(m)O L Dkj + αe(m)
k y j (8)
ξ(m)N EWk = ξ
(m)O L Dk + αe(m)
k (9)
where
e(m)k = (d(m)
k − z(m)k (xt ))+
∑l∈�(x t )
(d(m)lk − z(m)
k (xl)). (10)
After updating weights and biases, the squared error for the training data is calculatedagain. If the error is not getting smaller than ε, a new RBF is created to ensure the mini-mization of the training error E (m). The incremental learning algorithm of RAN-MTPR issummarized in Algorithm 1.
123

290 H. Nishikawa, S. Ozawa
3.3 Task Change Detection
We assume that incoming training data have class information but no task information. Thus,RAN-MTPR has to judge task changes only from class labels. In addition, after detecting atask change, RAN-MTPR has to identify whether the next task is known or unknown. Forthis purpose, we have proposed a heuristic algorithm [17,25] based on the prediction error.
Assume that a certain number of training data of a task were learned and a training data(xt , dt ) of a new task is now given without notice to RAN-MTPR. Then, the RAN classifierwould predict a class of the previous task with confidence, but the given label should becompletely different from the prediction. In general, an output value of RAN reflects theconfidence in prediction. Here, let us define that the classifier predicts with confidence whenthe output is larger than a threshold θ . In the above case, the squared error should be largerthan 1+ θ2; thus, such a large error can signal a potential task change to RAN-MTPR.
The prediction error on a particular data happens to be large due to overlapping clas-ses within a task and not due to task change. To avoid the potential error in detection,RAN-MTPR looks for some more evidence for a task change. That is to say, when atraining data signals the potential for a task change (large prediction error coupled witha new class not seen before), the learning of RAN is suspended and the current trainingdata is temporally stored in the queue whose maximum size is defined as q . Then, theprediction errors and the class labels are tracked for the next (q − 1) data. If the averageerror for the queued data becomes less than the threshold (1 − θ)2 or a known class isgiven before the queue becomes full, RAN-MTPR infers that there is no task change. Evenwhen the queue reaches its size limit, no task change is detected if the average error onthe q stored data is less than 1 + θ2. In both cases, the queued training data are learnedby RAN, and the queue is emptied. On the other hand, if the queue becomes full andthe average error exceeds the threshold 1 + θ2, it infers that a task change has indeedoccurred.
After detecting a task change, RAN-MTPR has to identify whether the next task is knownor unknown. This is done by evaluating the errors in all output sections. When a task changeis detected, RAN-MTPR first tries to find an output section whose average error is less than1 + θ2. If such an output section is found, the network selector switches to this section forthe next task and the target classes of memory items in LTM are also changed according tothis selection. Otherwise, a new output section is created in RAN for the new task.
3.4 Knowledge Consolidation
Since the task change detection is based on a heuristic, there is no guarantee that RAN-MTPRalways detects task changes correctly. Misdetection of task changes results in misallocationof classes to appropriate output sections (i.e., tasks). Thus, a backup process called consoli-dation is introduced to compensate for such failures, and it should be carried out before thelearning of the next task is started.
Since every class should be allocated to either of existing tasks, the failure in task categori-zation can be found by checking whether more than two classes are simultaneously predictedin the same output section. Considering that RAN-MTPR holds q training data in the queuewhen a task change is detected, the queued data are used for finding such a conflict in taskcategorization. Let (xt− j , dt− j ) ( j = 0, . . . , q − 1) be the q training data in the queue. For
every queued data, the classifier outputs z(m)k (xt− j ) (k = 1, . . . , K (m);m = 1, . . . , M) are
calculated in all output sections. If more than two outputs are larger than a threshold θ inthe same section, RAN-MTPR recognizes that the misallocation of classes occurs. Then,
123

Radial Basis Function Network 291
RAN-MTPR tries to find suitable allocation for those classes. Let C (m) be a set of classlabels for such active outputs with conflict in the mth section. In order to find a proper sec-tion for every class dt− j ∈ C (m), all the memory items (xl , d(m)
l ) whose class is dt− j (i.e.,
d(m)l = dt− j ) are recalled from LTM; then, the classifier outputs in all sections z(m′)(xl)
(m′ = 1, . . . , M) are calculated and the average errors E (m′) are checked.Assume that the output section where minm′ E (m′) < (1− θ)2 is found and let m∗ be that
output section. Then, the output unit for class dt− j in the mth section should be integratedinto the m∗th section; that is, the connection weights and the biases in the m∗th section aretrained with the recalled memory items, and those in the mth section are deleted. In addition,the class labels of the recalled memory items are modified as follows:
d(m)l = 0, d(m∗)
l = dt− j . (11)
On the other hand, if no output section satisfying the above condition is found, RAN-MTPR recognizes that class dt− j belongs to a new task. Then, dt− j is associated with the
first output z(M+1)1 in the (M+1)th section, and the class label of the recalled memory items
are set to as follows:
d(M+1)l = dt− j . (12)
Algorithm 2 Do Knowledge ConsolidationInput: Training data in the queue: {(xt− j , dt− j ) | j = 0, . . . , q − 1} and the current output section m.1: for j = 0 to q − 1 do2: Calculate outputs z(m)(xt− j ) = {z(m)
1 , . . . , z(m)K }T in the mth output section.
3: Find active outputs z(m)k > θ .
4: if there exist more than two active outputs then5: Put the corresponding classes in a set C(m).6: end if7: end for8: for class d in C(m) do9: Recall all memory items of class d: {(xl , d(m)
l ) | d(m)l = d}.
10: for m′ = 1 to M do11: Calculate average squared error E(m′) for the recalled memory items.12: end for13: m∗ = arg minm′ E(m′).14: if E(m∗) < (1− θ)2 then15: Modify class labels of recalled memory items based on Eq. 11.
16: Update w(m∗)k j (k = 1, . . . , K (m∗); j = 1, · · · , J ) and ξ
(m∗)k (k = 1, . . . , K (m∗)) based on
Eqs. 8, 9.17: else18: Create a new output section M + 1 and a new output for class d in RAN.19: Define the (M + 1)th labels in the recalled memory items based on Eq. 12.
20: Update w(M+1)1, j ( j = 1, . . . , J ) and ξ
(M+1)1 based on Eqs. 8, 9.
21: M ← M + 1.22: end if23: if m∗ �= m then24: Delete w
(m)
k′ j ( j = 1, . . . , J ) and biases ξ(m)
k′ where k′ is the index of the class d output in the mth
section.25: end if26: end for
123

292 H. Nishikawa, S. Ozawa
And the connection weights and the biases in the mth section should also be deleted. Theknowledge consolidation process is summarized in Algorithm 2.
3.5 Knowledge Transfer
As mentioned in Sect. 3.1, two types of knowledge transfer are implemented in RAN-MTPR.The one is the knowledge transfer by sharing RBFs with all output sections, each of whichis responsible for a certain task. This type of knowledge transfer has been adopted in variousmultitask learning models, and the knowledge to be transferred is RBFs themselves whichspan class regions. Since we assume that there is some relatedness between tasks, the classregions in different tasks should have some overlaps each other (see Fig. 2 for example).Therefore, the RBFs which were originally created to span class regions of a certain task canhelp to span similar regions of a related task.
The other is the knowledge transfer by presetting the class labels of memory items inLTM. Although the basic idea has already been proposed in our previous work [17], a notice-able difference is that the source knowledge to be transferred is selected based on the taskrelatedness. The proposed method is based on the following heuristics: if two data belong tothe same class in a task, it is likely that these also belong to the same class in another relatedtask.
Let us take an example in Fig. 4 to explain how the proposed method works.Consider a situation where the task is changed from Task 1 to Task 2 and a training data
X is given. At this moment, no class label of Task 2 is defined for all memory items denotedby dots. The dotted lines in Fig. 4b are true class boundaries in Task 2, but they are unknownto RAN-MTPR. On the other hand, since Task 1 was already learned, the memory itemshave class labels denoted by (*, +, o) and the classifier learns the class boundaries (solidlines) in Fig. 4a. The knowledge on Task 1 is transferred to Task 2 as follows. First, theneighborhood of X is defined as a transfer region (dotted circle in Fig. 4b), and the memoryitems within the region are recalled from LTM. For the seven recalled memory items, thosewhose class labels in Task 1 are the same as the label of the closest memory item to X (fivesquares in Fig. 4a) are selected. Then, the class labels of the selected memory items in Task2 (five squares in Fig. 4b) are set to the label of X , and the knowledge transfer is completed.Considering that the selected five memory items cover a class subregion in Task 1, we cansay that the knowledge on the class subregion in Task 1 is transferred to Task 2 by giving
Class 6Class 5
(b) Task 2
X
0.2 0.4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
Class 4
0.2 0.4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
Class 1Class 2
Class 3
(a) Task 1
X
Fig. 4 Basic idea of knowledge transfer by presetting class labels of memory items
123

Radial Basis Function Network 293
the class information. In this case, such knowledge transfer should be helpful in learningbecause two subregions in Tasks 1 and 2 are completely overlapped the number of trainingdata increases from one to six (original training data plus five memory items of Class 5).However, the effectiveness of this type of knowledge transfer depends on how properly thetransfer region is defined. Actually, some transferred class labels might mislead the classifierlearning if they are different from the true classes. However, such mislead class labels areupdated correctly when the true classes are given later.
The last thing to be mentioned on knowledge transfer is how to measure the relatedness ofrecognition tasks. This can be done by calculating the similarity of class boundaries. SinceRBFs are shared with all output sections, a class boundary in a certain task is determinedonly by the connection weights. Therefore, the similarity Rkk′(m, m′) between the kth classof the mth task and the k′th class of the m′th task can be defined by the following directioncosine:
Rkk′(m, m′) = w(m)k w
(m′)k′
‖w(m)k ‖‖w(m′)
k′ ‖(13)
where w(m)k = {w(m)
k1 , . . . , w(m)k J }T represents the connection weights from RBFs to the kth
output in the mth output section.The algorithm of the knowledge transfer and the main algorithm of RAN-MTPR are
summarized in Algorithms 3 and 4, respectively.
Algorithm 3 Do Knowledge TransferInput: Training data (xt , dt ) and the current output section m.
1: Find the memory item Ml : (xl∗ , d(1)l∗ , · · · , d(M)
l∗ ) which is closest to xt .
2: if xl∗ � xt and d(m)l∗ �= dt then
3: d(m)l∗ = dt . // Mislead class is modified.
4: end if5: m∗ = arg maxm′ �=m
{maxk′ Rkk′ (m, m′)
}where Rkk′ (m, m′) is given by Eq. 13.
6: Recall memory items Ml within the neighborhood of xt and put them into the set �(xt ).7: for Ml ∈ �(xt ) do
8: if d(m∗)l = d(m∗)
l∗ then
9: Set the class dt of training data to the mth target class of Ml (i.e., d(m)l = dt ).
10: end if11: end for
4 Performance Evaluation
4.1 Experimental Setup
The performance of RAN-MTPR is evaluated for the eight MTPR problems which are rede-fined from the four UCI datasets [26]. The information of original datasets is summarized inTable 1. We define two MTPR problems per UCI data, each of which consists of three tasks.Table 2 shows the correspondence between the labels of the original Vehicle data and thedefined tasks. As seen in Table 2a, Class 5 of Task 2 corresponds to Classes 1 and 2 in theoriginal dataset; hence, the training data whose original classes are either Class 1 or 2 are
123

294 H. Nishikawa, S. Ozawa
Algorithm 4 Main Learning Algorithm1: Initialize the number of output sections and the current section in RAN by M = 1 and m = 1.2: Define an empty queue Q with the maximum size of q.3: loop // Do forever.4: Input: training data (xt , dt ).5: if dt is an unknown class label then6: Add a new output for class dt in the mth output section, and K (m) ← K (m) + 1.7: end if8: Calculate the outputs z(m)(xt ) using Eqs. 1,2 and store (xt , dt ) in Q.
9: Calculate the average squared error E(m)Q .
10: if E(m)Q < (1− θ)2 or dt is a known class then
11: No task change is detected and go to Line 24.12: else if Q is not full then13: A task change is suspected and go back to Line 4 to check another data.14: end if15: A task change is detected and perform Do Knowledge Consolidation.16: for m′ = 1 to M ; m′ �= m do17: Calculate the outputs z(m′) in the m′th section for all training data in Q.
18: Calculate the average squared error E(m′)Q .
19: if E(m′)Q < 1+ θ2 then
20: Switch the current output section m to m′ and go to Line 24.21: end if22: end for23: Create a new output section in RAN, M ← M + 1, and set m = M .24: for training data in Q do25: Perform Do Knowledge Transfer.26: Perform Learn RAN-MTPR.27: end for28: Clear the queue Q.29: end loop
Table 1 Original datasets forevaluation
# Attrib. # Classes # Training # Test
Segmentation 19 7 210 2100
Thyroid 21 3 3772 3428
Vehicle 18 4 188 658
Vowel-context 10 11 528 462
relabeled as Class 5 in Task 2. We define MTPR problems for the other datasets in a similarmanner. However, due to space limitations, the label correspondence tables are omitted forthe other MTPR problems. Please see [17] for the details.
As mentioned in Sect. 2, we assume that learning tasks are presented one after anotherduring a learning session and the same task could appear again several times (see Fig. 1).The period to learn each task is called epoch, and training data are given one by one duringan epoch. In our experiments, the number of training data per epoch is fixed at 40, and alearning session is composed of 18 epochs. Therefore, 720 training data of three tasks in totalare learned incrementally. Since the performance is generally influenced by the presentationorder of tasks and training data, we generate 25 different sequences of tasks and training datafor each MTPR problem, and the average performance for 50 sequences is evaluated.
123

Radial Basis Function Network 295
Table 2 Two MTPR problemsdefined from the original Vehicledata
The correspondence between thelabels of the original data and thedefined three tasks is shown
Original Task 1 Task 2 Task 3
(a) Problem 1
1 1 5 7
2 2 5 8
3 3 6 7
4 4 6 8
(b) Problem 2
1 1 3 5
2 2 3 6
3 2 4 5
4 1 4 6
The most critical parameter in RAN-MTPR is the RBF width σ 2. In general, it is noteasy to determine a proper σ 2 under incremental learning settings because different σ 2sare often selected depending on training sequences even if a cross-validation method isadopted. In the following experiments, we adopt two strategies to select σ 2. One is to use apreselected σ 2 (we use σ 2 = 2 that is obtained from our preliminary experiments), and theother is to perform the leave-one-out cross-validation under the assumption that 40 trainingdata in the first epoch are given in a batch. In the leave-one-out cross-validation, an optimal σ 2
is searched from 0.5 in increments of 0.5, the search is stopped when the maximum accuracyis obtained. At each validation round, a classifier model is trained with the 39 training databased on Algorithm 1, and then the remaining one is used for evaluation. Other parametersin RAN-MTPR are fixed as follows: δ = σ, ε = 0.05, θ = 0.5, and q = 5.
4.2 Effect of Knowledge Transfer
The final recognition performance of RAN-MTPR is evaluated for the following three mod-els. The first one is the conventional single-task learning model in which multiple RAN-LTMs learn given tasks individually. Task changes are explicitly informed and the classifier(RAN-LTM) is switched by a supervisor because this model has no task change detectionmechanism. In the test mode, the recognition in RAN-LTMs is judged correct if one of theRAN-LTMs predicts the true class. Since no knowledge transfer is introduced in RAN-LTMs,we can study the effectiveness of introducing two types of knowledge transfer in RAN-MTPRthrough this comparison. The second one is our previous MTL model [17] which consists ofmultiple RAN-LTM classifiers. This MTL model also has the functions of one-pass incre-mental learning, task change detection, task categorization, knowledge consolidation, andknowledge transfer. However, the knowledge transfer by sharing RBFs is not introduced andthe task relatedness is not considered in knowledge transfer. Therefore, the effect of introduc-ing such knowledge transfer mechanisms is evaluated through this comparison. The third oneis a variant of RAN-MTPR in which the knowledge transfer is implemented only by sharingRBFs. This variant model is adopted to see the effectiveness of transferring class informationof memory items. For notational convenience, the above three models are abbreviated toRAN-LTMs, pre-MTL, and RAN-MTPR(IR), respectively.
Table 3 a, b respectively show the average recognition accuracies at the final learn-ing stage when the parameter σ 2 is fixed at 2 over the 50 sequences of training data andwhen σ 2 is automatically selected by the leave-one-out cross-validation. Since the same
123

296 H. Nishikawa, S. Ozawa
Table 3 Final recognition accuracies [%] (a) when σ 2 = 2 is used for all cases and (b) when σ 2 is selectedby the leave-one-out cross-validation
RAN-LTMs pre-MTL RAN-MTPR(IR) RAN-MTPR σ 2
(a)
Segmentation 85.0± 1.8 84.5± 2.0 84.9± 2.1 85.3± 2.3 2
Thyroid 81.7± 0.5∗ 82.8± 1.1∗ 85.7± 6.7 86.9± 1.8 2
Vehicle 78.2± 1.3∗ 78.7± 1.5∗ 77.1± 1.6∗ 79.7± 1.4 2
Vowel-context 58.7± 3.0∗ 58.6± 2.9∗ 60.1± 5.4∗ 62.2± 3.5 2
RAN-LTMs pre-MTL RAN-MTPR(IR) RAN-MTPR σ 2
(b)
Segmentation 83.0± 2.9 83.2± 3.3 83.8± 3.2 84.0± 2.8 2.2
Thyroid 83.5± 2.9∗ 85.6± 3.1∗ 90.0± 1.5 90.2± 1.3 2.9
Vehicle 75.9± 1.6 75.3± 1.8 75.2± 2.4 75.9± 1.8 2.6
Vowel-context 56.2± 5.1∗ 56.6± 3.6∗ 58.3± 4.0 59.6± 3.4 2.5
The two values in each cell are the average accuracy and the standard deviation. The accuracy with an asteriskmeans that the difference from the accuracy of RAN-MTPR is statistically significant
training sequence is given to all models, the same σ 2 is selected by the leave-one-out cross-validation. If stable incremental learning is carried out and the knowledge of the previoustasks is successfully transferred, it is expected that the generalization performance is improvedbecause transferred inductive bias leads to increasing training data virtually.
As seen in Table 3a, RAN-MTPR outperforms the other three models in recognition per-formance for Thyroid, Vehicle, and Vowel-context when the RBF width σ 2 is fixed at 2, andthe differences in average recognition accuracy are statistically significant in eight cases.Since the performances of pre-MTL and RAN-MTPR(IR) are not always higher than that ofRAN-LTMs, the results in Table 3(a) suggest that the introduction of two types of knowledgetransfer is crucial for the performance improvement in RAN-MTPR. Although the recogni-tion accuracy of the proposed RAN-MTPR is always higher than that of RAN-LTMs, theperformances of pre-MTL and RAN-MTPR(IR) are sometimes lower than that of RAN-LTMs. One reason is that pre-MTL and RAN-MTPR(IR) have to detect task changes on theirown and sometimes miss the changes. Once the misdetection occurs, training data of the nexttask are learned by the current classifier and this results in degrading its recognition accuracy.
On the other hand, as seen in Table 3b, the overall recognition accuracies are droppedexcept for Thyroid when σ 2 is selected by the leave-one-out cross-validation. Althoughthe proposed RAN-MTPR still has the highest accuracies, there are only four cases that theimprovement in recognition accuracy is statistically significant. The reason is that a relativelylarge σ 2 is selected on average by the leave-one-out cross-validation (see σ 2 in Table 3b)and such a large σ 2 can cause unexpected interference between existing RBFs and a newlyallocated RBF during incremental learning. The above results suggest that the performanceenhancement by knowledge transfer could be reduced unless σ 2 is properly selected and theleave-one-out cross-validation method might not work well in the selection of σ 2 dependingon training sequences.
4.3 Effect of Knowledge Consolidation
Here, the effect of introducing the knowledge consolidation mechanism in RAN-MTPR isstudied for Thyroid data. If the consolidation works well, all the class labels in a certain
123

Radial Basis Function Network 297
Table 4 The effect of the number of training data per epoch on the performances of RAN-MTPR with andwithout consolidation.
P = 20 P = 30 P = 40
(a) Task categorization accuracy [%]
RAN-MTPR 92 96 100
RAN-MTPR(NC) 88 88 96
(b) Final recognition accuracy [%]
RAN-MTPR 85.0± 6.4 85.1± 7.0 86.9± 1.8
RAN-MTPR(NC) 82.9± 10 84.0± 9.0 85.8± 6.6
The RBF width σ 2 is fixed at 2 in all cases
task are allocated to the corresponding output section. Therefore, the effect of knowledgeconsolidation can be measured by examining how many output sections give proper taskcategorization at the final stage. Let us call this performance measure task categorizationaccuracy. Another performance measure is the final recognition accuracy. Since the taskchange detection relies on the classifier prediction, the misdetection of task changes andthe miscategorization of tasks tend to happen at early learning stages. If the consolidationworks well, the misdetection and the miscategorization would be recovered at early learningstages; then, more training data would be learned by appropriate classifiers. This will lead toenhancing the final recognition accuracy.
In order to evaluate the effectiveness of consolidation, we evaluate the performance ofRAN-MTPR without the consolidation mechanism. Let us call this model RAN-MTPR(NC).Here, we evaluate the performance for different numbers of training data per epochP: P = 20, 30, 40. If sufficient training data are provided in every epoch, it is expectedthat RAN-MTPR can construct a classifier with good prediction performance and the misde-tection of task changes would be reduced. In contrast, if only a small number of training dataare provided, a task change appears before the classifier has good prediction; this results indegrading the performance of task change detection and task categorization. Thus, it becomesdifficult for RAN-MTPR to work properly when P is small. In this experiment, the RBF widthσ 2 is fixed at 2 in all cases.
Table 4 shows the task categorization accuracy and the average recognition accuracy over50 different sequence of tasks and training data. As seen in Table 4, the knowledge consoli-dation obviously contributes to improving the task categorization accuracy and the averagerecognition accuracy in all cases. In addition, the standard deviations of recognition accu-racy are reduced by introducing the knowledge consolidation. From the above results, weconclude that the consolidation mechanism in RAN-MTPR works well even under difficultlearning conditions.
5 Conclusions and Future Work
In this paper, we propose a new radial basis function network called RAN-MTPR for mul-titask pattern recognition problems in which different but related recognition problems aregiven sequentially. The proposed RAN-MTPR has the following functions: one-pass incre-mental learning, task change detection, task categorization, knowledge consolidation, andknowledge transfer. Although the above functions have already been implemented in our
123

298 H. Nishikawa, S. Ozawa
previous multitask learning model [17], there is an important difference in network architec-ture. In the previous model, every task should be individually learned by a single resourceallocating network (RAN); thus, a RAN classifier is created whenever a new task appears.On the other hand, in RAN-MTPR, all tasks are learned by a single RAN whose radial basisfunctions (RBFs) are shared with different tasks. This enables RAN-MTPR to implement theknowledge transfer naturally by sharing internal representation of RBFs. Another differencefrom the previous model is that the source of knowledge transfer is selected based on thetask relatedness which is measured by the similarity between two weight vectors for differenttasks. Such a selective mechanism helps to increase the effectiveness of knowledge transfer.
In the experiments, the performance of RAN-MTPR is evaluated for the four datasets inorder to study the effect of knowledge transfer and knowledge consolidation. The experi-mental results demonstrate that the recognition accuracy of RAN-MTPR at the final learningstage is significantly improved for three out of the four datasets if an RBF width σ 2 is fixedat 2. Obviously, this improvement results from introducing the two types of knowledge trans-fer. In addition, we show that the knowledge consolidation contributes to enhancing the taskcategorization accuracy. On the other hand, when σ 2 is selected by the leave-one-out cross-validation, the overall recognition accuracies are dropped except for a dataset. Although wecan still recognize the contribution of knowledge transfer, the performance enhancement islimited compared with the case of σ 2 = 2. The main reason of this performance degradationis that a relatively large σ 2 tends to be selected by the leave-one-out cross-validation andsuch a large σ 2 sometimes leads to unexpected interference between existing RBFs and anewly allocated RBF during incremental learning. In order to select a proper σ 2 by a cross-validation method, a sufficient training data should be given before incremental learningstarts. However, this is not always ensured in practice. Therefore, we should devise a dynamicselection method for σ 2 such that an optimal σ 2 can always be searched during incrementallearning [22].
There still remain several open problems in the current model that have to be addressedas future work. In general, the performance of RAN-MTPR is influenced by how tasks arerelated because the transferred knowledge depends on the similarity of class boundaries andthe size of overlapped class regions between two tasks. Therefore, further experiments areneeded to discuss the influence of task relatedness to the performance. Although the misallo-cation of classes could be resolved through consolidation, there is no guarantee to work wellfor any biased cases. This problem is also left as future work. Finally, pattern recognitionsystems need feature extraction especially when inputs have large dimensions. Therefore, forpractical purposes, the proposed RAN-MTPR should also have the ability to extract featureson an ongoing basis. This can be done with online feature extraction algorithms such as incre-mental principal component analysis [15,16] and incremental linear discriminant analysis[18].
References
1. Attar V, Sinha P, Wankhade K (2010) A fast and light classifier for data streams. Evol Syst 1:199–2072. Ban SW, Lee M (2007) Autonomous incremental visual environment perception based on visual selec-
tive attention. Proceedings of IEEE/INNS International Joint Conference on Neural Network. IJCNN,Budapest pp 1411–1416
3. Baxter J (1997) A Bayesian/information theoretic model of learning to learn via multiple task sampling.Mach Learn 28:7–39
4. Carpenter GA, Grossberg S (1998) The ART of adaptive pattern recognition by a self-organizing neuralnetwork. IEEE Comput 21:77–88
123

Radial Basis Function Network 299
5. Caruana R (1997) Multitask learning. Mach Learn 28:41–756. Caruana R, O’Sullivan J (1998) Multitask pattern recognition for autonomous robots. Proc IEEE/RSJ Int
Conf on Intell Robotic Syst 1:13–187. Chen S, He H (2011) Towards incremental learning of nonstationary imbalanced data stream: a multiple
selectively recursive approach. Evol Syst 2:35–508. Ghosn J, Bengio Y (2003) Bias learning, knowledge sharing. IEEE Trans on Neural Netw 14:748–7659. Hisada M, Ozawa S, Zhang K, Kasabov N (2010) Incremental linear discriminant analysis for evolving
feature spaces in multitask pattern recognition problems. Evol Syst 1:17–2710. Huang GB, Saratchandran P, Sundararajan N (2005) A generalized growing and pruning RBF (GGAP-
RBF) neural network for function approximation. IEEE Trans on Neural Netw 16:57–6711. Iglesias JA, Angelov P, Ledezma A, Sanchis A (2010) Evolving classification of agents’ behaviors: a
general approach. Evol Syst 1:161–17112. Jin F, Sun S (2008) A multitask learning approach to face recognition based on neural networks.
In: Intelligent data engineering and automated Learning. Springer, Berlin, pp 24–3113. Kasabov N (2002) Evolving connectionist systems: methods and applications in bioinformatics, brain
study and intelligent machines. Springer, London14. Okamoto K, Ozawa S, Abe S (2003) A fast incremental learning algorithm of RBF networks with long-
term memory. Proceedings of IEEE/INNS International Joint Conference on Neural Network. IJCNN,Budapest, pp 102–107
15. Ozawa S, Toh SL, Abe S, Pang S, Kasabov N (2005) Incremental learning of feature space and classifierfor face recognition. Neural Netw 18:575–584
16. Ozawa S, Pang S, Kasabov N (2008) Incremental learning of chunk data for on-line pattern classificationsystems. IEEE Trans on Neural Netw 19:1061–1074
17. Ozawa S, Roy A, Roussinov D (2009) A multitask learning model for online pattern recognition. IEEETrans on Neural Netw 20:430–445
18. Pang S, Ozawa S, Kasabov N (2005) Incremental linear discriminant analysis for classification of datastreams. IEEE Trans on Syst Man and Cyber B 35:905–914
19. Platt J (1991) A resource allocating network for function interpolation. Neural Comput 3:213–22520. Pratt L and Jennings B (1998) A survey of connectionist network reuse through transfer. In: Learning to
learn. Kluwer Academic Publications, Boston, pp 19-4321. Puchala E (2004) A Bayes algorithm for the multitask pattern recognition problem? direct and decom-
posed independent approaches. In: Computational science and its applications. LNCS 3046, springeer,Heidelberg, pp 39–45
22. Rubio JJ, Vazquez DM, Pacheco J (2010) Backpropagation to train an evolving radial basis functionneural network. Evol Syst 1:173–180
23. Silver D and Mercer R (2001) Selective functional transfer: inductive bias from related tasks. Proceedingsof IASTED International Conference on Artificial Intelligence and Soft Computing, pp 182–189
24. Thrun S, Pratt L (1998) Learning to learn. Kluwer Academic Publications, Boston25. Tsumori K, Ozawa S (2003) Incremental learning in dynamic environments using neural network with
long-term memory. Proceedings IEEE/INNS International Joint Conference on Neural Network. IJCNN,Budapest, pp 2583–2588
26. Blake C, Keogh E, Merz C (1998) UCI repository of machine learning databases. www.ics.uci.edu/mlearn/MLRepository.html
27. Yamauchi K, Yamaguchi N, Ishii N (1999) Incremental learning methods with retrieving of interferedpatterns. IEEE Trans on Neural Netw 10:1351–1365
123


















