
系統樹・系統仮説の可視化 と系統仮説間の統計的比較 · 系統樹・系統仮説の可視化 と系統仮説間の統計的比較 田辺晶史 実習編. 演習
Upload
corpuslingCategory
view
1.335download
5
小林雄一郎
1

Agenda
• 1. はじめに―言語統計の基礎
• 2. 仮説検定―データ間の差を検証する • 3. 相関分析―データの関連を見る
• 4. おわりにー統計的言語研究を行う際の注意点 • 5. 統計的言語研究の参考文献
• 6. 練習問題
2

1. はじめに―言語統計の基礎
• 言語と統計 • おそらく30年前であれば、かなり縁遠い関係
• そもそも言語研究に統計処理が必要であるという意識すら希薄
• 言語学の本流は、質的で定性的なもの? • 20世紀の言語学に大きな影響を及ぼした生成文法では、母語話者の内省や直感により、言語の深層構造を把握することが強調
↓
• コーパス言語学の登場 • 1990年代以降、コンピュータとインターネットが発達
• 従来は想像もできなかった大量の量的データが入手可能に
→ 言語研究における統計の重要性
3

• 言語研究における統計 • 言語資料を収集し、数量的に記述する実証的アプローチ
→ 人間が関わる現象を扱う諸科学がとる研究方法と共通の方向性
• そもそも統計って何? • 統計学は、「科学の文法」(grammar of science) と呼ばれる • 文法とは、それに依拠して多様な表現を算出し得るもので、逆に産出された多様な表現に人々が共通の理解を持つための礎を与える
• 統計学は、言語データに基づく実証的研究に対して、まさに文法としての役割を果たす
↓
• 数学が得意ではない人にとって、統計は敬遠したくなるもの?
• しかし、統計学の方法は特殊な論理を使っているものではない • 考え方の基礎を理解すれば、誰でも同じ理解が可能になる
4

• 統計的言語研究の例をいくつか
• シェイクスピアは誰か • シェイクスピア別人説の根拠 • シェイクスピアの個人史には所々大きな空白部分がある • シェイクスピア自身によって書かれた手紙が存在しない • 詳細に書かれたシェイクスピアの遺言書が現存するが、そこには本や戯曲や詩、その他いかなる書き物についても言及されていない
• 自分の芸術に関する持論を1つも著していない • 署名が4通りもあり、どれ1つとして似た書体ではない
• シェイクスピアの人となりについてはほとんど何も知られていない
5
◆村上征勝 (2004). 『シェイクスピアは誰ですか?―計量文献学の世界』 東京: 文春新書. ◆「シェイクスピア別人説」(融合のときをもとめて・・・) http://blogs.yahoo.co.jp/igproj_fusion/archive/2011/03/01

• 「シェイクスピア=ベーコン」説 • 1890年頃、アメリカの物理学者メンデンホール(T. C. Mendenhall)は「シェイクスピア=ベーコン説」批判を展開
• シェイクスピアの文章の40万語、ベーコンの文章の20万語を比較 • シェイクスピアが4文字の単語を最も多く使用しているのに対し、ベーコンは3文字の単語を最も多く使用していることを発見
6
http://blogs.yahoo.co.jp/igproj_fusion/archive/2011/03/01
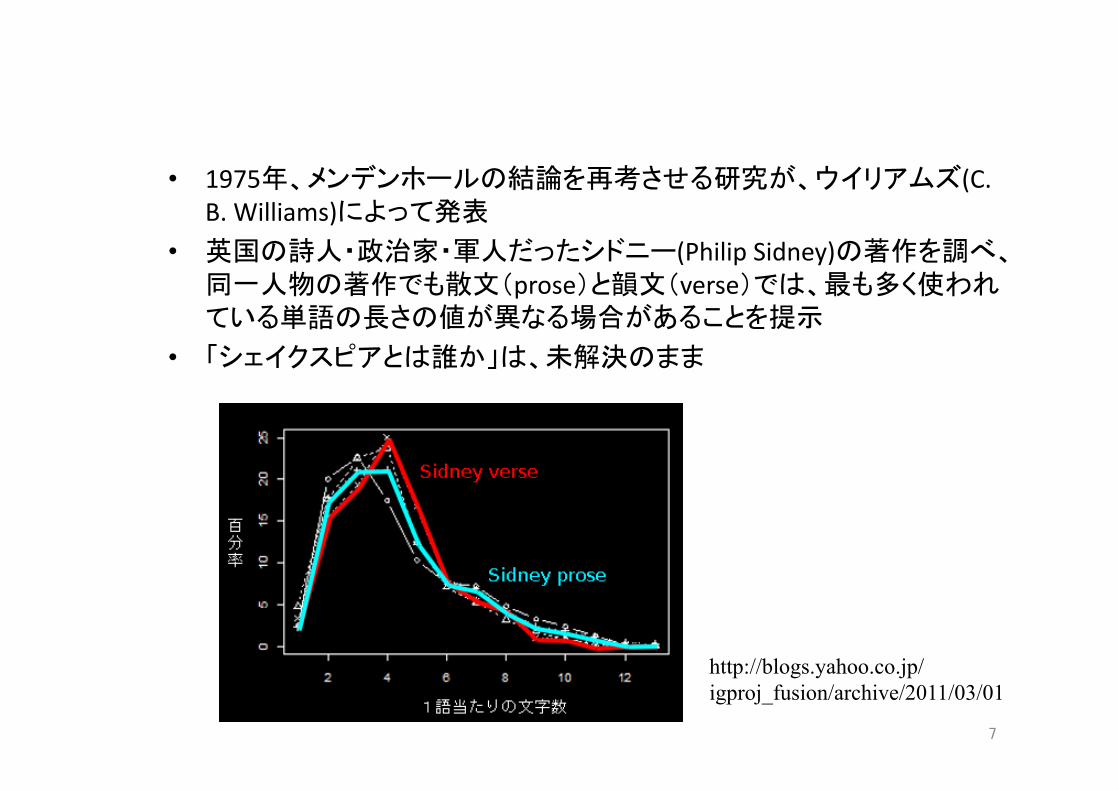
• 1975年、メンデンホールの結論を再考させる研究が、ウイリアムズ(C. B. Williams)によって発表
• 英国の詩人・政治家・軍人だったシドニー(Philip Sidney)の著作を調べ、同一人物の著作でも散文(prose)と韻文(verse)では、最も多く使われている単語の長さの値が異なる場合があることを提示
• 「シェイクスピアとは誰か」は、未解決のまま
7
http://blogs.yahoo.co.jp/igproj_fusion/archive/2011/03/01

• 読点に注目した著者推定 • 他の言語に比べて、日本語は読点の位置に関する厳密なルールがないため、そこに文章の書き手の癖が表れるのではないか
• 中島敦、三島由紀夫、谷崎潤一郎、井上靖の作品を読点の位置で分類
8 ◆金明哲 (1996). 「読点から現代作家のクセを検証する」 『統計数理』44(1), 121-125.
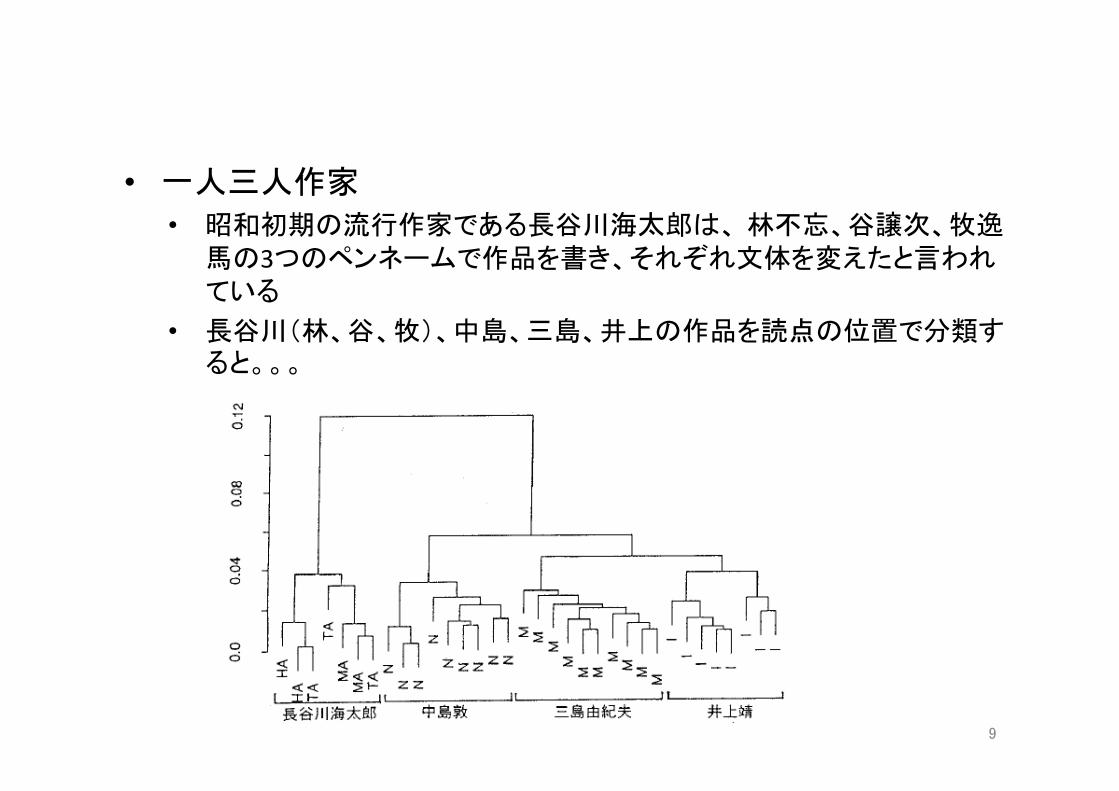
• 一人三人作家 • 昭和初期の流行作家である長谷川海太郎は、 林不忘、谷譲次、牧逸馬の3つのペンネームで作品を書き、それぞれ文体を変えたと言われている
• 長谷川(林、谷、牧)、中島、三島、井上の作品を読点の位置で分類すると。。。
9

• その他の研究(主に、著者推定) • プラトンの『第七書簡』は贋作か? • 南北戦争の体験談『Q. C. レター』はマーク・トウェインの著作か? • ショーロホフの『静かなるドン』は盗作か? • 『紅楼夢』は1人の作家が書いたものか?
• 『旧約聖書』の「イザヤ記」の著者は誰か? • 『源氏物語』の著者は、本当に紫式部か? • 日蓮遺文の著者は、本当に日蓮か? • 英国内閣を攻撃した投書『ジュニアス・レター』は誰が書いたか? • パトリシア・ハースト誘拐事件の声明文は誰が書いたか? (詳しくは、前掲の村上 2004などを参照)
↓
• これら著者推定の技術は、ジャンル判別、言語能力測定、スパム判別、ゲノム解析など、様々な分野に応用
10
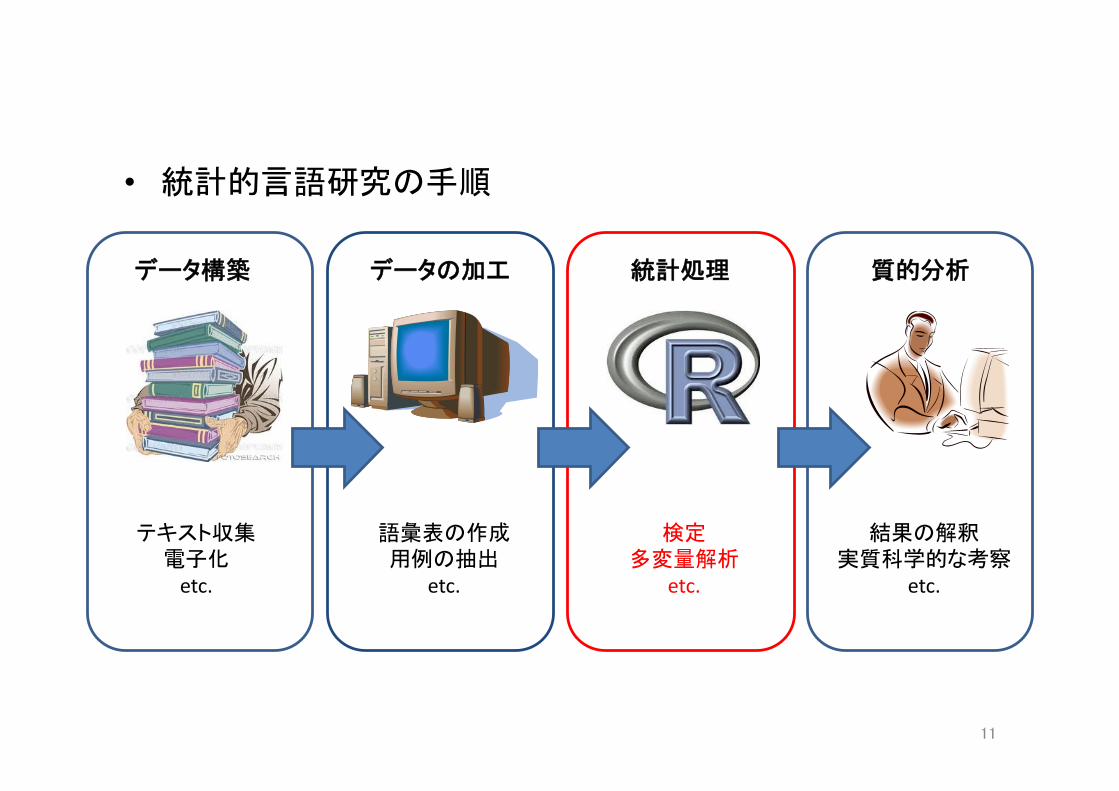
• 統計的言語研究の手順
11
データ構築 データの加工 統計処理 質的分析
テキスト収集 電子化 etc.
語彙表の作成 用例の抽出
etc.
検定 多変量解析
etc.
結果の解釈 実質科学的な考察
etc.

• 資料のデータ化 • 生起した現象を資料として正確に記録(測定) • しかし、資料はそのままでは、分析に適さないことが多い → 数値や文字列の並びに変換(加工)
• 言語データの加工 • 形態素解析(分かち書き) • 構文解析(係り受け解析) etc.
↓
• ケースと変数 • ケース = 分析の対象となるもの(例:書き手、テキスト、コーパス) • 変数 = ケースの性質を何らかの観点から記述するための項目 (単語、品詞、文法項目の頻度など)
12
変数 1 変数 2 … 変数 n
ケース1 12 3 … 8
ケース2 7 9 … 11
… … … … …
ケースn 15 6 … 5

• 粗頻度と相対頻度 • 粗頻度 = 個々のテキストやコーパスの中で実際に使われた回数
• 相対頻度 = テキストやコーパスの総語数を考慮して、粗頻度を調整 ↓
• 2つ以上のコーパスの頻度を比較する場合、通常は相対頻度を使う
• ただし、統計手法(カイ2乗検定など)によっては、粗頻度を使わなければならない
• 量的変数と質的変数 • 量的変数 = 頻度など • 質的変数 = 性別、学年など(註:性別は順序なし、学年は順序あり)
13

• 記述統計学 • 「手元のデータ」の分布の様子を数値で表現
• その際、「手元のデータ」の由来については特に考えない • 平均、分散、標準偏差 etc.
• 推測統計学 • サンプル(=手元のデータ)の情報を使って、その背後にある母集団についての情報を推測
• 例えば、「日本人英語学習者コーパス」というサンプルを使って、その背後にある日本人英語学習者の実情を推測
↓
• 文学研究(例えば、夏目漱石の研究)を分析する場合、「漱石の特徴を明らかにすること」が研究目的ならば、漱石の作品は母集団
• 漱石という作家を例に「日本文学における特徴を明らかにすること」が研究目的ならば、漱石の作品はサンプル 14

• 様々な統計手法
【基礎編】 • データ間の差を調べたい → 仮説検定
• データ間の関連を調べたい → 相関分析
• あるデータを他のデータを使って説明したい → 回帰分析
【発展編】 • データの識別ルールを発見したい → 判別分析
• データをいくつかの群にグルーピングしたい → クラスター分析
• データを合成して新しい指標を作り出したい → 主成分分析
• データを分解して隠れた要因を探り出したい → 因子分析
• データ間の構造を整理したい → コレスポンデンス分析 etc. etc.
15
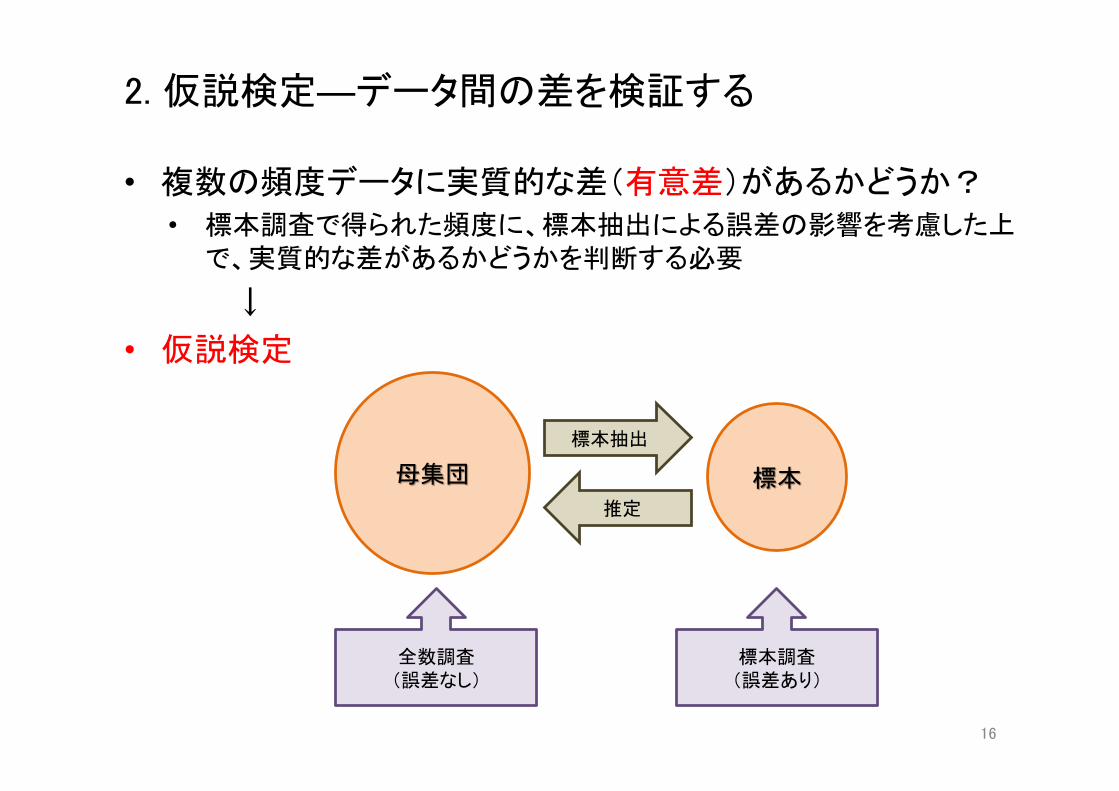
2. 仮説検定―データ間の差を検証する
• 複数の頻度データに実質的な差(有意差)があるかどうか? • 標本調査で得られた頻度に、標本抽出による誤差の影響を考慮した上で、実質的な差があるかどうかを判断する必要
↓ • 仮説検定
16
標本抽出
推定
全数調査 (誤差なし)
標本調査 (誤差あり)
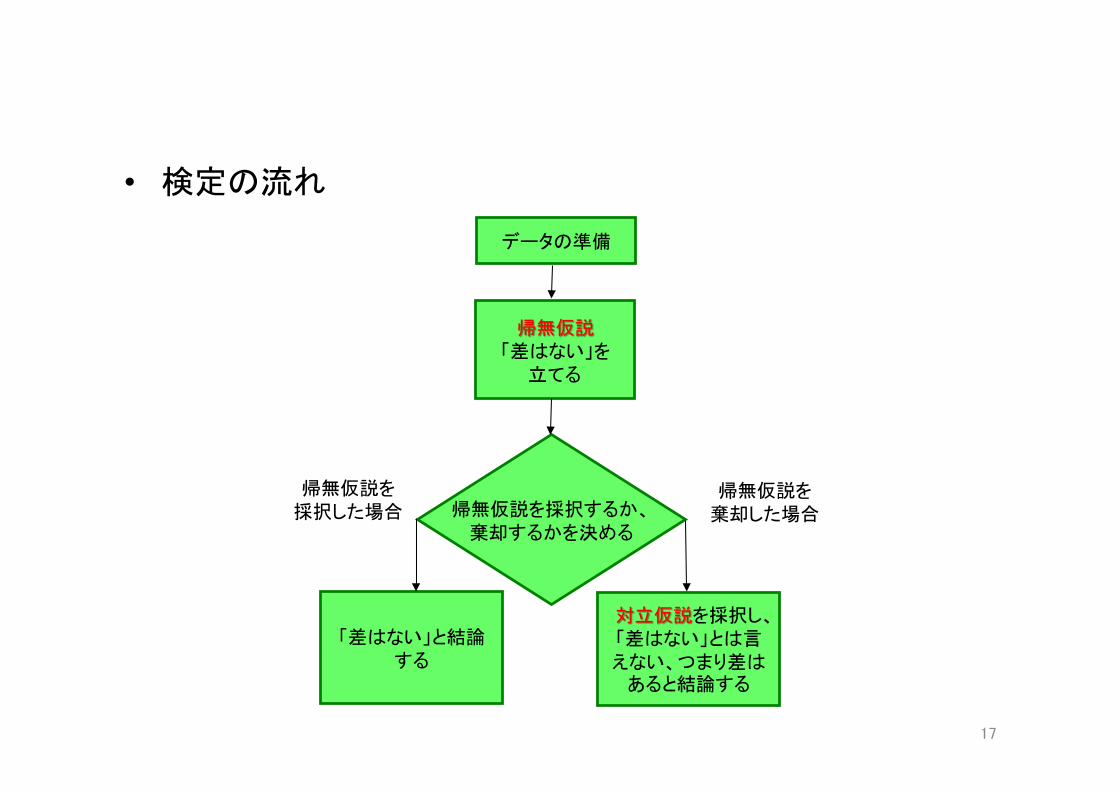
• 検定の流れ
17
データの準備
帰無仮説を採択するか、 棄却するかを決める
「差はない」と結論する
帰無仮説を 採択した場合
帰無仮説を 棄却した場合

• 検定は万能ではない • 100%確実な推定は不可能
• 仮説検定は、「~%の確からしさで~と言える」というもの
• 第1種の誤り (Type 1 Error) • 本当は差がないのに差があると結論してしまう誤り
• 第2種の誤り (Type 2 Error) • 本当は差があるのに差がないと結論してしまう誤り
• 有意水準(危険率) • 「有意差ありという判定が間違っている可能性」として許容できる確率
• 5%、1%、0.1%が一般的
18
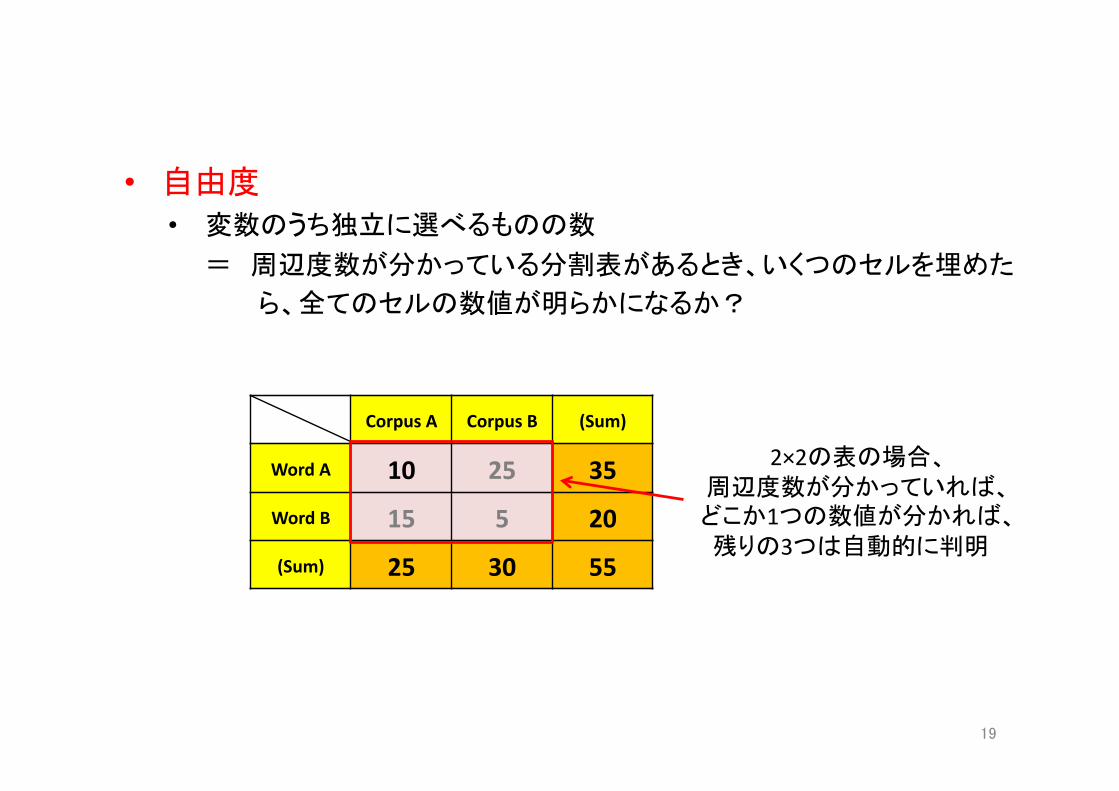
• 自由度 • 変数のうち独立に選べるものの数
= 周辺度数が分かっている分割表があるとき、いくつのセルを埋めた ら、全てのセルの数値が明らかになるか?
19
Corpus A Corpus B (Sum)
Word A 10 25 35
Word B 15 5 20
(Sum) 25 30 55
2×2の表の場合、 周辺度数が分かっていれば、 どこか1つの数値が分かれば、 残りの3つは自動的に判明

• カイ2乗検定 • 頻度差の検定(の1つ)
• 解析事例 • 夏目漱石の初期作品『吾輩は猫である』(1905-‐1906) と、絶筆となった『明暗』(1916) に関して、思考動詞「思う」と「考える」の頻度に差はあるのか?
20
吾輩は猫である 明暗
思う 503 430
考える 127 217

• Rで解析
21
# データの読み込み > dat001 <-‐ matrix(c(503, 127, 430, 217), nrow=2, byrow=F) > dat001 [,1] [,2] [1,] 503 430 [2,] 127 217
# カイ2乗検定 > chisq.test(dat001, correct=F)
Pearson's Chi-‐squared test
data: dat001 X-‐squared = 29.037, df = 1, p-‐value = 7.101e-‐08
カイ2乗統計量、自由度、p値
イェーツの補正(後述)は しない

• カイ2乗検定における留意点 • 「~語あたり」のような相対頻度ではなく、粗頻度を使用
• 低頻度(一般的には、期待値や実測値が5以下)の値を含むデータでは、結果が不正確になる可能性
→ イェーツの補正、フィッシャーの正確検定など(次頁)
• 同じデータに対して、組み合わせを変えて、2回、3回…と検定を繰り返すと、「5%の危険性」が累積し、全体としての危険率が許容できるレベルを超過(=検定の多重性)
→ 有意水準を繰り返し回数nで割るボンフェローニの補正など
(詳細は割愛)
22

23
# イェーツの補正をしたカイ2乗検定 > chisq.test(dat001, correct=T)
Pearson's Chi-‐squared test with Yates' conanuity correcaon
data: dat001 X-‐squared = 28.3611, df = 1, p-‐value = 1.007e-‐07
# フィッシャーの正確検定 > fisher.test(dat001)
Fisher's Exact Test for Count Data
data: dat001 p-‐value = 7.46e-‐08 alternaave hypothesis: true odds raao is not equal to 1 95 percent confidence interval: 1.538908 2.600169 sample esamates: odds raao 1.997669

• 発展研究のヒント • 著者Aと著者Bの使用語彙の違い(文体研究)
• 母語話者の頻度と非母語話者の頻度の違い(習得研究) • 書き言葉における頻度と話し言葉における頻度の違い(レジスター研究)
• 文学作品における頻度と新聞における頻度の違い(レジスター研究) • 19世紀における頻度と21世紀における頻度の違い(通時的研究)
etc.
• 何を変数にするか(=どこに注目するか)が大切 • 単語?
• 品詞? • N-‐gram?
• それ以外? 24

3. 相関分析―データの関連を見る
• 複数の変数がどの程度で相互に関係しているか? = 一方が変化したら、他方もそれにつれて変化するという直線的な
関係がどの程度の強さで見られるか? → -‐1から1の間の数値で表現
• 正の相関 • 一方が増えれば、他方も増える • 一方が減れば、他方も減る
• 負の相関 • 一方が増えれば、他方は減る • 一方が減れば、他方が増える
25

• 相関の強さ • 絶対的な基準はないが。。。
– 0.7以上 = 強い相関 – 0.4以上 = 中程度の相関
– 0.2以上 = 弱い相関
• 説明力 • 相関係数を2乗したもの
= データの分散のうち相関係数で説明できる割合
• 例えば、2変数に関する相関変数が0.9の場合、相関係数によって説明できるのは、2変数が持っている情報の81%
26
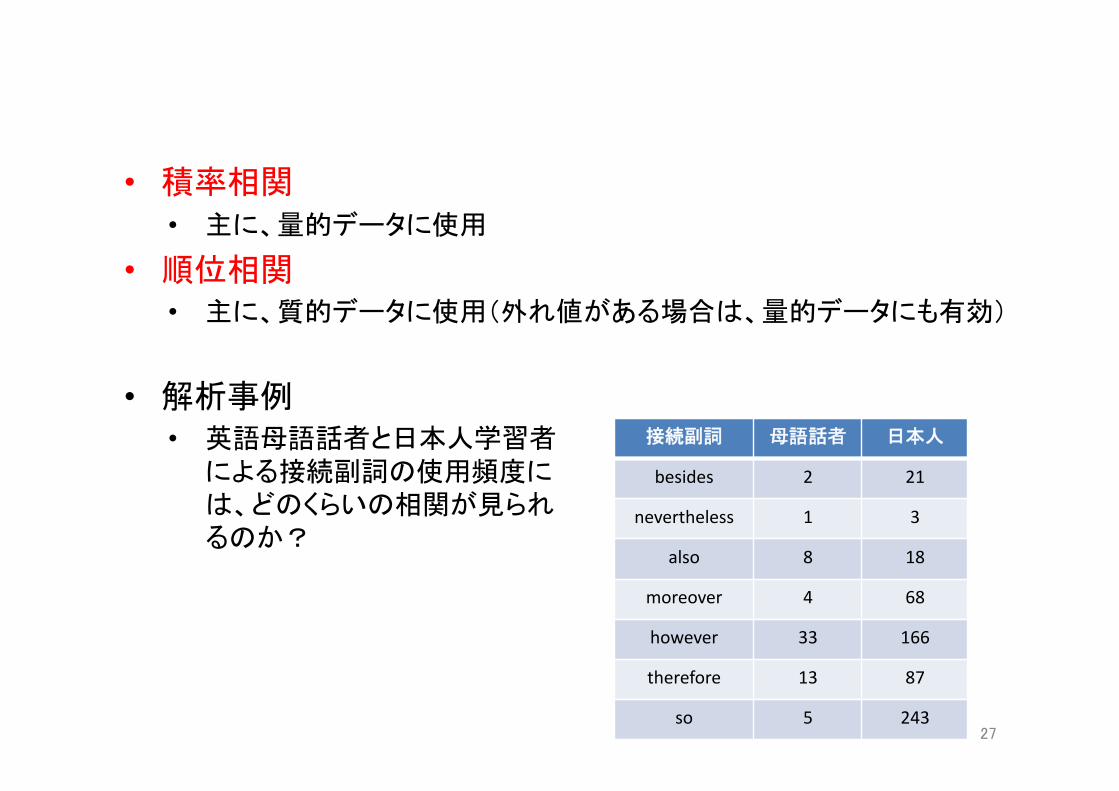
• 積率相関 • 主に、量的データに使用
• 順位相関 • 主に、質的データに使用(外れ値がある場合は、量的データにも有効)
• 解析事例 • 英語母語話者と日本人学習者 による接続副詞の使用頻度に は、どのくらいの相関が見られ るのか?
27
接続副詞 母語話者 日本人
besides 2 21
nevertheless 1 3
also 8 18
moreover 4 68
however 33 166
therefore 13 87
so 5 243

28
• Rで解析 # データの読み込み > dat002 <-‐ matrix(c(2, 1, 8, 4, 33, 13, 5, > 21, 3, 18, 68, 166, 87, 243), > nrow=7, byrow=F)
# Pearsonの積率相関係数 > cor(dat002, method="pearson") [,1] [,2] [1,] 1.0000000 0.4338193 [2,] 0.4338193 1.0000000
# Spearmanの順位相関係数 > cor(dat002, method="spearman") [,1] [,2] [1,] 1.0000000 0.6071429 [2,] 0.6071429 1.0000000
[, 1]が母語話者で、 [, 2]が日本人

• 相関分析の留意点 • 相関係数の大きさで有意性を判断することがあるが、特に統計的な裏付けがある訳ではない
• サンプルサイズが小さい場合、相関係数が高くなる傾向 • 積率相関係数の場合、外れ値が結果に大きく影響
29
# 無相関検定(無相関であるか否かを検定) > cor.test(dat002[, 1], dat002[, 2], method="pearson")
Pearson's product-‐moment correlaaon
data: dat002[, 1] and dat002[, 2] t = 1.0766, df = 5, p-‐value = 0.3308 alternaave hypothesis: true correlaaon is not equal to 0 95 percent confidence interval: -‐0.4741343 0.8946147 sample esamates: cor 0.4338193

• 発展研究のヒント • 複数人の書き手の文章における文末表現の頻度を調べて、相関係数を求める(文体研究)
• いくつかの語に関して、1970年代、1980年代、1990年代、2000年代の頻度を調べて、相関係数を求める(通時的研究)
• いくつかの文法項目に関して、中学1年、中学2年、中学3年、高校1年、高校2年、高校3年の英作文における頻度を調べて、相関係数を求める(習得研究)
etc.
• やはり、何を変数にするか(=どこに注目するか)が大切
30

4. 統計的言語研究を行う際の注意点
• データや目的にあった手法を使う • 必ずしも統計の数学的原理を理解する必要はないが、「こういうときにはこの手法を使う」、あるいは「こういうときにこの手法を使ってはいけない」という最低限の知識は必要
• できるだけシンプルな手法で解く • 無理に高度な手法を使う必要はない • 「何で解くか」ではなく、「何を解くか」
• 統計は万能ではない • 統計を使ったからといって、「新しいこと」が分かるとは限らない • 統計的な有意差が言語学的な有意差を意味するとは限らない • 一番大切なものは、データを正しく解釈する能力
31

5. 統計的言語研究の参考文献
• 洋書
Oakes, M. (1998). Sta%s%cs for corpus linguis%cs. Edinburgh: Edinburgh University Press.
Johnson, K. (2008). Quan%ta%ve methods in linguis%cs. Oxford: Blackwell.
Gries, S. Th. (2009). Sta%s%cs for linguis%cs with R. Berlin: Mouton.

• 和書
33
金明哲 (2009). 『テキストデータの統計科学入門』 東京: 岩波書店.
村上征勝 (1994). 『真贋の科学―計量文献学入門』 東京: 朝倉書店.
石川慎一郎・前田忠彦・山崎誠 (編) (2010). 『言語研究のための統計入門』 東京: くろしお出版.

6. 練習問題
• 1)夏目漱石の『吾輩は猫である』(1905-‐1906) と『三四郎』(1908) に関して、思考動詞「思う」と「考える」の頻度に差はあるのか?
↓
• カイ2乗検定(補正なし)を実行し、カイ2乗統計量と自由度とp値を答えなさい
34
吾輩は猫である 三四郎
思う 503 247
考える 127 87

• 2)英語母語話者と中国人学習者による接続副詞の使用頻度には、どのくらいの相関が見られるのか?
↓ • Pearsonの積率相関係数、そして、無相関検定のp値を答えなさい
35
接続副詞 母語話者 中国人
besides 2 5
nevertheless 1 1
also 8 5
moreover 4 8
however 33 18
therefore 13 7
so 5 9

36
![GoogleMapsを用いた地理統計データの可視化統計数理(2007) 第55 巻第1 号101–112 2007c 統計数理研究所 特集「統計データの可視化」 [研究ノート]](https://static.fdocuments.net/doc/165x107/5e41afd326f6522d866653ff/googlemapscoecceffeoe-ceci2007i-c55.jpg)
















![[XLS] · Web view統計表9 統計表8 統計表7 統計表6 統計表5 統計表4 統計表3 統計表2 統計表1-3 統計表1-2 統計表1-1 総 数 (単位:千人) 傷 病](https://static.fdocuments.net/doc/165x107/5b0d33387f8b9af65e8d497a/xls-view9-8-7-6-5-4-3.jpg)
