
Logical Systems and Knowledge Representation Fuzzy Logical Systems 1.

Airo National Research Journal December, 2017 Volume XII, ISSN: 2321-3914
1
QUALITATIVE ANALYSIS OF MULTI-OBJECT CLASSIFICATION
USING DEEP LEARNING PROBABILISTIC MODELS EXECUTION
ON INFORMATIONAL INDEXES
Scholar Name Gonuguntla Sreenivasulu Having Enrollment No: SSSCSE1514 under the faculty of PhD
CSE SSSUTMS -Sehore, MP. Academic Session 2016-17. Working under the supervision of R.P Singh
ABSTRACT
Deep learning has demonstrated state-of-art classification execution on informational
indexes, for example, Image Net, which contain a solitary object in each picture. Be that as it
may, multi-object classification is much additionally difficult. We show a bound together
structure which uses the qualities of multiple machine learning methods, viz deep learning,
probabilistic models and kernel methods to acquire state-of-art execution on Microsoft
COCO, comprising of non-notorious pictures. We join logical data in normal pictures
through a contingent inactive tree probabilistic model (CLTM), where the object co-events
are adapted on the separated fc7 highlights from pre-prepared Image net CNN as input. We
take in the CLTM tree structure utilizing contingent pair wise probabilities for object co-
events, evaluated through kernel methods, and we take in its hub and edge possibilities via
training another 3-layer neural network, which takes fc7 includes as input. Object
classification is completed by means of derivation on the learnt restrictive tree model, and we
acquire huge pick up in exactness review and F-measures on MS-COCO, particularly for
troublesome object classifications. In addition, the dormant factors in the CLTM catch scene
data: the pictures with top enactments for an inactive hub have normal subjects, along these
lines; we show a brought together structure for multi-object classification and unsupervised
scene understanding. Scene parsing, or perceiving and portioning objects and stuff in a
picture, is one of the key issues in computer vision. Notwithstanding the group's endeavors in
information collection, there are as yet few picture datasets covering an extensive variety of
scenes and object classes with thick and point by point comments for scene parsing.
INTRODUCTION
Deep learning has altered execution on an
assortment of computer vision
assignments, for example, object
classification and limitation, scene
parsing, human stance estimation, et
cetera. However, most deep learning
works concentrate on basic classifiers at
the yield, and prepare on datasets, for
example, Image Net which comprise of
single object classifications. Then again,
Multi-object classification is a
significantly all the more difficult issue.
At present numerous structures for multi-
object classification utilize basic
Methodologies: the multi-class setting,
which predicts one classification out of an
arrangement of fundamentally unrelated
classes (e.g. ILSVRC), or binary
classification, which settles on binary
choices f or each name freely (e.g.
PASCAL VOC). The two models, be that

Airo National Research Journal December, 2017 Volume XII, ISSN: 2321-3914
2
as it may, don't catch the intricacy of
names in natural images. The names are
not fundamentally unrelated, as expected
in the multi-class setting. Autonomous
binary classifiers, then again, overlook the
connections amongst marks and miss the
chance to exchange and offer information
among various name classifications amid
learning. More complex classification
techniques in light of organized forecast
are being investigated, yet all in all, they
are computationally more costly and not
adaptable to huge datasets (see related
works for a dialog).
In this paper, we propose a proficient
multi-object classification system by
fusing con-literary information in images.
The setting in natural images catches
connections between different object
classifications, for example, co-event of
objects inside a scene or relative places of
objects regarding a foundation scene.
Joining such logical information can
limitlessly enhance discovery execution,
dispense with false positives, and give a
lucid scene elucidation.
We introduce a productive and a brought
together way to deal with learn logical
information through probabilistic inert
variable models, and join it with pre-
prepared deep learning highlights to
acquire state-of-art multi-object
classification framework. It is realized that
deep learning produces transferable
highlights, which can be utilized to learn
new errands, which vary from
undertakings on which the neural networks
were prepared. Here, we show that the
transferability of pre-prepared deep
learning highlights can be additionally
improved by catching the relevant
information in images.
We display the relevant conditions
utilizing a contingent idle tree demonstrate
(CLTM), where we condition on the pre-
prepared deep learning highlights as input.
This enables us to consolidate the joint
impacts of both the pre-prepared
highlights and the setting for object
classification. Note that a hierarchical tree
structure is natural for catching the
groupings of different object classes in
images; the idle or concealed factors catch
the "group" names of objects. Dissimilar
to past works, we don't force a settled tree
structure, or even a settled number of
inactive variables, however gain an
adaptable structure productively from
information. In addition, since we make
these "group" factors inert, there is no
need access to group marks amid training,
and we take in the object groups or scene
classes in an unsupervised way. Along
these lines, notwithstanding proficient
multi-object classification, we additionally
learn inactive factors that catch semantic
information about the scene in an
unsupervised way.
RELATED WORK
Correlations between labels have been
investigated for identifying multiple object
classes before learn contextual relations
between co-happening objects utilizing a
tree structure graphical model to catch
conditions among various objects. In this
model, they consolidate conditions
between object classes, and yields of
nearby detectors into one probabilistic
structure. In any case, utilizing
straightforward pre-prepared object
detectors are ordinarily uproarious and
prompt execution debasement.
Interestingly, we utilize pre-prepared deep
learning highlights as input, and consider a

Airo National Research Journal December, 2017 Volume XII, ISSN: 2321-3914
3
restrictive model for setting, given the
highlights. This enables us to consolidate
both deep learning highlights and setting
into our structure.
In numerous settings, the hierarchical
structure speaking to the contextual
relations between various objects is settled
and depends on semantic closeness, or
may depend on content, notwithstanding
picture information. Conversely, we take
in the tree structure from information
effectively, and therefore, the edge work
can be adjusted to settings where such a
tree may not be accessible, and regardless
of the possibility that accessible, may not
give the best classification execution for
multi-object classification.
Utilizing pre-prepared Image Net
highlights for other computer vision
errands have been famous in various
works as of late, e.g. term this as
administered pre-training and utilize them
to prepare local convolution neural
networks (R-CNN) for object limitation.
We take note of that our system can be
reached out to limitation and we intend to
seek after it in future. While utilize free
SVM classifiers for each class, we trust
that consolidating our probabilistic casing
work for multi-object confinement can
fundamentally enhance execution. As of
late, propose enhancing object recognition
utilizing Bayesian optimization for fine
grained seek and a structured misfortune
work that goes for both classification and
limitation. We trust that joining
probabilistic contextual models can
additionally enhance execution in these
settings.
Late papers additionally fuse deep learning
for scene classification. Present the spots
dataset and utilize CNNs for scene
classification. In this structure, scene
labels are accessible amid training, while
we don't accept access to these labels amid
our training procedure. We exhibit how
presenting inactive factors can
consequently catch semantic information
about the scenes, without the requirement
for marked information.
Scene understanding is an extremely rich
and a dynamic region of computer vision
and comprises of an assortment of
undertakings, for example, object
restriction, pixel marking, and division et
cetera, notwithstanding classification
assignments. Propose a hierarchical
generative model that plays out multiple
assignments in a reasonable way. Likewise
consider the utilization of setting by
considering the spatial area of the areas of
intrigue. While there is an expansive
collection of such works which utilize
contextual information (see for example),
they generally don't fuse dormant factors
in their displaying. In future, we intend to
broaden our system for these different
scene understanding assignments and
expect huge change over existing
techniques.
There have been some current endeavors
to consolidate neural networks with
probabilistic models. For instance, propose
to join CRF and auto-encoder systems for
unsupervised learning. Markov irregular
fields are utilized for posture estimation to
encode the spatial connections between
joint areas propose a joint system for deep
learning and probabilistic models. They
learn deep highlights which consider
conditions between yield factors. While
they prepare a 8-layer deep network
starting with no outside help to take in the

Airo National Research Journal December, 2017 Volume XII, ISSN: 2321-3914
4
potential elements of a MRF, we show
how a less complex network can be
utilized on the off chance that we utilize
pre-prepared highlights as an input to the
contingent model. In addition, we fuse
inactive factors that enable us to utilize a
basic tree display, prompting quicker
training and induction. At last, while many
works have utilized MS-COCO for
subtitling and joint picture content related
assignments, there have been no endeavors
to enhance multi-object classification over
standard deep learning techniques,
utilizing images alone on MS-COCO and
not the content information, to the best of
our insight.
OVERVIEW OF THE MODEL AND
ALGORITHM
We consider pre-prepared Image Net as a
settled component extractor by
considering the fc7 layer (4096-D vector)
as the element vector for a given input
picture. We signify this extricated include
as xi for ith picture. It is likewise shown
that such component vectors can be
successfully utilized for various
assignments with various labels. The
objective here is to learn models which
can mark a picture to multiple-object
class’s display in a given picture. Our
model predicts a structured yield y ∈ {0,
1} L. To accomplish this objective, we
utilize a reliance structure that relates
diverse object labels. Such reliance
structure should ready to catch combine
shrewd probabilities of object labels
adapted on input highlights. We show this
reliance structure utilizing an inert tree.
Initially, these kinds of structures take into
consideration more intricate structures of
reliance contrasted with a completely
watched tree. Besides, derivation on it is
tractable.

Airo National Research Journal December, 2017 Volume XII, ISSN: 2321-3914
5
Figure 1: Our Model takes input as fc7 features and generates node potentials at the
output layer of a given neural network. Using these node potentials, our model outputs
MAP configuration and marginal probabilities of observed and latent nodes
We assess probabilities of object co-events
molded on input fc7 highlights. We at that
point utilize separate based calculation to
recuperate the structure utilizing evaluated
remove lattice. When we recoup the
structure, we display the dissemination of
watched labels and dormant nodes for a
given input covariates as a discriminative
model. We utilize contingent inactive Tree
Model, a class of CRF that has a place
with exponential group of appropriations
to display dispersion of output variables
given an input. In-stead of limiting the
potentials (factors) to linear functions of
covariates, we sum up potentials as
functions spoke to by outputs of a neural
network. For a given engineering of neural
net-work which takes X as input, we learn
weights W by back propagating the angle
of minimized log-probability of output
binary variables. When we prepare the
given neural network, we consider the
outputs of neural network as potentials for
evaluating peripheral node convictions
adapted on input covariates X. Our model
additionally brings about MAP setup for a
given input covariates X. Algo.1 gives
review of our structure.
Utilization of non-parametric methods for
end-end errands on substantial datasets is
computationally costly. Along these lines,
we confine utilizing kernel methods to just
assess pair wise restrictive probabilities,
and here, we can utilize randomized lattice
methods to proficiently scale the
calculations. The tree structure is
evaluated through CL grouping
calculation. In spite of the fact that the
strategy is serial, we take note of that as of
late there have been parallel renditions of
this technique. At long last, we prepare
neural networks to output node and edge
potentials for CLTM. At long last,
identification is done by means of
derivation on the tree show through
message passing calculations. Along these
lines, we have a productive system for
multi-object identification in images.
We mean given marked training set as D =
{(x1, y1), •, (xn, yn)} and xi ∈ R4096, yi ∈
{0, 1} L ∀ I ∈ (1, 2, •, n). We mean
separated tree by T = (Z, E) where Z
shows the arrangement of watched and
inactive nodes and E signifies edge set.
When we recuperate the structure, we
utilize contingent idle tree model to

Airo National Research Journal December, 2017 Volume XII, ISSN: 2321-3914
6
display P (Z|X). Molded on input X, we
show dissemination of Z utilizing as a part
of the underneath Eqn.
Where A(X, θ) is the term that
standardizes the circulation, otherwise
called the log partition work φk(X, θ) and
φ(k,t)(X, θ) show the node and edge
potentials of the exponential family
dissemination, individually. Rather than
confining the potentials to linear functions
of covariates, we sum up potentials as
functions spoke to by outputs of a neural
network. Sec.4 clarifies how we take in the
weights of such a neural network.
We take in the reliance structure among
object labels from an arrangement of
completely named images. Customary
separation based methods utilize just exact
co-events of objects to take in the
structure. Learning a structure that
includes solid combine insightful relations
among objects requires training images to
contain many occasions of various object
classifications. In this area, we propose
another structure recuperation technique
without the need of such training sets. This
technique includes both observational co-
events and the appropriation of fc7
highlights to compute separates between
labels.
Kernel Embedding of Conditional
Distribution
The kernel conditional embedding
framework, depicted gives us methods for
displaying conditional and joint
appropriations. These methods are
successful in high-dimensional settings
with multi-modal parts, for example, the
present setting.
In the general setting, given changes φ(X)
and Ψ(Y ) on X,Y to the RKHS utilizing
kernel functions K(x, .), K′ (y, .), the
above framework gives us the
accompanying experimental administrators
to implant joint circulations into the
imitating kernel Hilbert space (RKHS).
Define
And Cˆ Y |X := Cˆ Y XCˆ−1 XX . We
have following results that can be used to
evaluate Eˆ YiYj |X[yi ⊗ yj|x] for a given
data-set.
(1)
We employ Gaussian RBF kernels and use
the estimated conditional pair wise
probabilities for learning the latent tree
structure.

Airo National Research Journal December, 2017 Volume XII, ISSN: 2321-3914
7
Learning Latent Tree Structure
A lot of work has been done on learning
inactive tree models. Among the
accessible methodologies for inert tree
learning, we utilize the information
distance based calculation CL Grouping
which has provable computational
effectiveness ensures. These algorithms
depend on a measure of factual added
substance tree distance. For our
conditional setting, we utilize the
accompanying type of the distance work:
where Sk,k := | det(Eˆ[Yk ⊗ Yk|X = x i ])|,
and similarly for St,t, for observed nodes
k, t using N samples. We employ the CL
grouping to learn the tree structure from
the estimated distances.
Training Energy Based Models using
Neural Networks
Training an energy based model (EBM)
comprises of finding an energy work that
delivers the best Y for any X. The look for
the best energy work is performed inside a
group of energy functions ordered by a
parameter W. The design of the EBM is
the inward structure of the parameterized
energy work E (W, Y, X). On account of
neural networks the group of energy
functions is the arrangement of neural net
structures and weight esteems.
For a given neural network engineering,
weights are found out by back propagating
the slope through some misfortune work.
On account of structures including idle
variables h, we utilize negative minimal
log-probability misfortune for training.
(2)
And the gradient is evaluated using below
Eqn.
LEARNING CLTM USING NEURAL
NETWORKS
Energy-based learning gives a bound
together framework to various
probabilistic and non-probabilistic
approaches to manage structured output
endeavors, particularly for non-
Airo National Research Journal December, 2017 Volume XII, ISSN: 2321-3914
8
probabilistic training of graphical models
and other structured models. In addition,
the nonattendance of the
institutionalization condition considers
more noteworthy flexibility in the design
of learning machines. Most probabilistic
models can be viewed as remarkable sorts
of energy-based models in which the
energy work satisfies certain
normalizability conditions, and in which
the disaster work, enhanced by learning,
has a particular edge.
Inference Consider watched variable X
and output variable Y. Characterize an
energy work E(X, Y) that is limited when
X and Y are good. The most perfect Y ∗
given a watched X can be communicated
as
The energy limit can be conveyed as a
factor chart, i.e. a whole of energy
functions (node and edge potentials) that
depend upon input covariates x. viable
inference techniques for factor graphs can
be used to find the perfect design Y ∗. In
the underneath Eqn. we describe the
energy work which is used to show
hardship work.
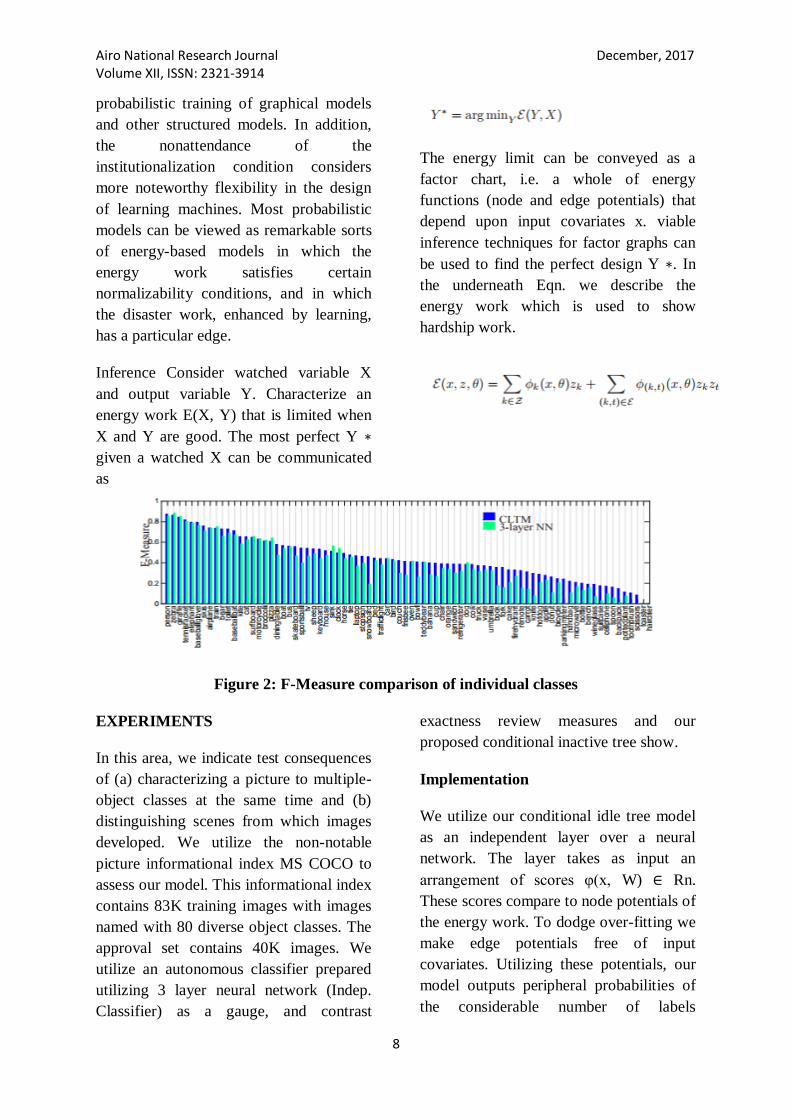
Figure 2: F-Measure comparison of individual classes
EXPERIMENTS
In this area, we indicate test consequences
of (a) characterizing a picture to multiple-
object classes at the same time and (b)
distinguishing scenes from which images
developed. We utilize the non-notable
picture informational index MS COCO to
assess our model. This informational index
contains 83K training images with images
named with 80 diverse object classes. The
approval set contains 40K images. We
utilize an autonomous classifier prepared
utilizing 3 layer neural network (Indep.
Classifier) as a gauge, and contrast
exactness review measures and our
proposed conditional inactive tree show.
Implementation
We utilize our conditional idle tree model
as an independent layer over a neural
network. The layer takes as input an
arrangement of scores φ(x, W) ∈ Rn.
These scores compare to node potentials of
the energy work. To dodge over-fitting we
make edge potentials free of input
covariates. Utilizing these potentials, our
model outputs peripheral probabilities of
the considerable number of labels
Airo National Research Journal December, 2017 Volume XII, ISSN: 2321-3914
9
alongside the MAP design. Amid learning,
we utilize stochastic gradient plunge and
figure ∂∂φL , where L is misfortune work
characterized in Eqn.( 2). This subsidiary
is then back engendered to the past layers
spoke to by φ(x; w). Utilizing a small
bunch size of 250 and dropout, we prepare
the model. We utilize the Viterbi message
passing calculation for correct inference on
conditional inert tree model.
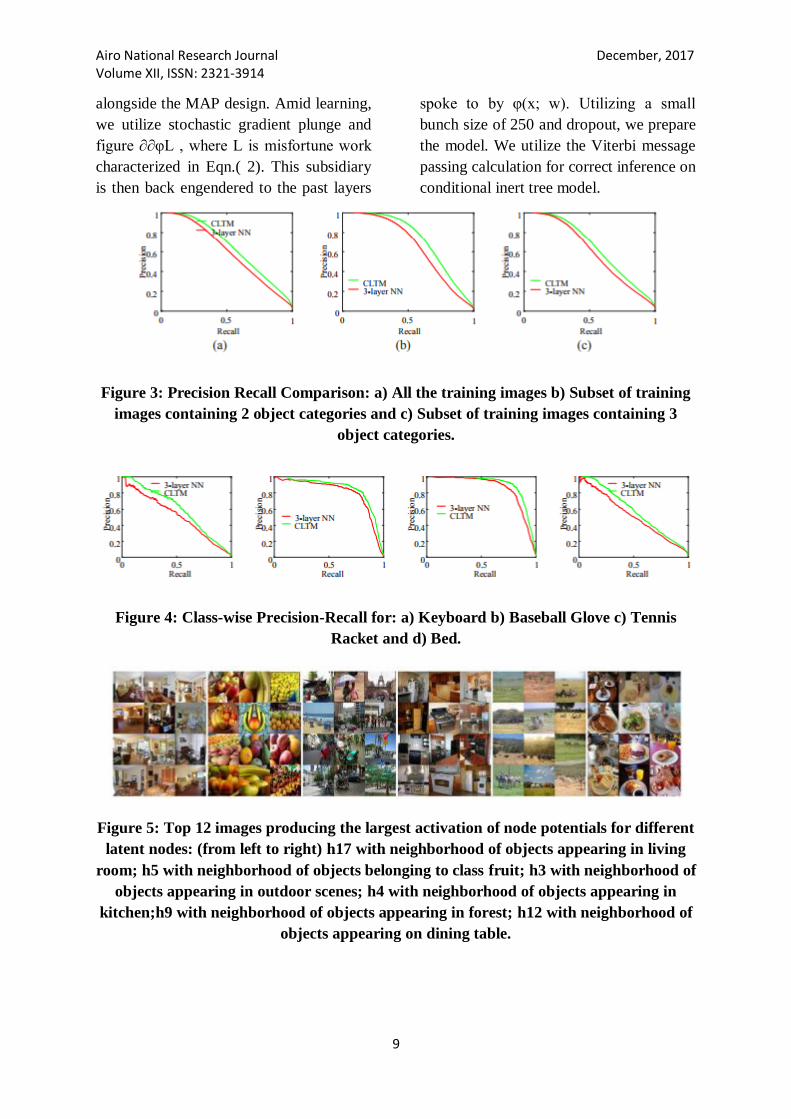
Figure 3: Precision Recall Comparison: a) All the training images b) Subset of training
images containing 2 object categories and c) Subset of training images containing 3
object categories.
Figure 4: Class-wise Precision-Recall for: a) Keyboard b) Baseball Glove c) Tennis
Racket and d) Bed.
Figure 5: Top 12 images producing the largest activation of node potentials for different
latent nodes: (from left to right) h17 with neighborhood of objects appearing in living
room; h5 with neighborhood of objects belonging to class fruit; h3 with neighborhood of
objects appearing in outdoor scenes; h4 with neighborhood of objects appearing in
kitchen;h9 with neighborhood of objects appearing in forest; h12 with neighborhood of
objects appearing on dining table.
Airo National Research Journal December, 2017 Volume XII, ISSN: 2321-3914
10
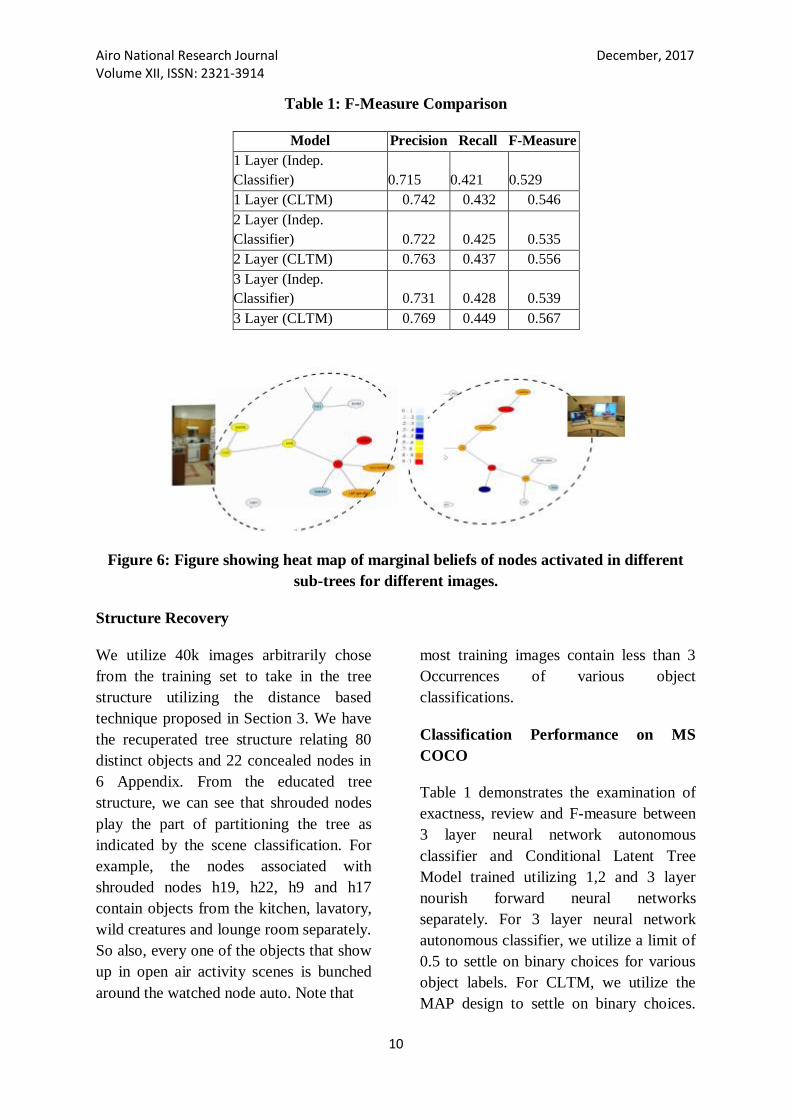
Table 1: F-Measure Comparison
Model Precision Recall F-Measure
1 Layer (Indep.
Classifier) 0.715 0.421 0.529
1 Layer (CLTM) 0.742 0.432 0.546
2 Layer (Indep.
Classifier) 0.722 0.425 0.535
2 Layer (CLTM) 0.763 0.437 0.556
3 Layer (Indep.
Classifier) 0.731 0.428 0.539
3 Layer (CLTM) 0.769 0.449 0.567
Figure 6: Figure showing heat map of marginal beliefs of nodes activated in different
sub-trees for different images.
Structure Recovery
We utilize 40k images arbitrarily chose
from the training set to take in the tree
structure utilizing the distance based
technique proposed in Section 3. We have
the recuperated tree structure relating 80
distinct objects and 22 concealed nodes in
6 Appendix. From the educated tree
structure, we can see that shrouded nodes
play the part of partitioning the tree as
indicated by the scene classification. For
example, the nodes associated with
shrouded nodes h19, h22, h9 and h17
contain objects from the kitchen, lavatory,
wild creatures and lounge room separately.
So also, every one of the objects that show
up in open air activity scenes is bunched
around the watched node auto. Note that
most training images contain less than 3
Occurrences of various object
classifications.
Classification Performance on MS
COCO
Table 1 demonstrates the examination of
exactness, review and F-measure between
3 layer neural network autonomous
classifier and Conditional Latent Tree
Model trained utilizing 1,2 and 3 layer
nourish forward neural networks
separately. For 3 layer neural network
autonomous classifier, we utilize a limit of
0.5 to settle on binary choices for various
object labels. For CLTM, we utilize the
MAP design to settle on binary choices.

Airo National Research Journal December, 2017 Volume XII, ISSN: 2321-3914
11
Note that CLTM enhances F-measure
fundamentally. Fig. 2 demonstrates the
correlation of F-measure for each object
class amongst gauge and CLTM prepared
utilizing a 3 layer neural network.
Generally speaking the pickup in F-
measure utilizing our model is 7-percent
contrasted with 3 Layer neural networks.
Note that F-measure pick up for indoor
objects is more noteworthy. For
troublesome objects like skateboard,
console, tablet, bowl, container and wine-
glass, F-measure pick up is 19-percent, 20-
percent, 27-percent, 56-percent, 50-percent
and 171-percent separately. Fig. 3
demonstrates the accuracy review bends
for a) whole test picture set b) a subset of
test images that contain 2 diverse object
classes c) a subset of test images that
contain 3 distinctive object classifications.
We consider minor probabilities of each
watched class that our model delivered to
gauge exactness review bends for differing
limit esteems. Fig.4 demonstrates
correlation of plots of exactness review
bends of a subset of object classes: tennis
racket, bed, and console and baseball
glove.
Qualitative Analysis
In this area, we examine the class of
images that activated most astounding
initiation of node potentials for various
inert nodes. Fig. 5 demonstrates the main
12 images from test set that brought about
the most elevated enactment of various
inert nodes. It is watched that distinctive
dormant nodes successfully catch diverse
semantic information regular to images
containing neighboring object classes. For
example, the main 12 images of inert
nodes h9, h12, h4, h21, h3 and h5 brought
about a class of images showing up in
scenes of woods, feasting table, kitchen,
lounge room, movement and having a
place with natural product classification.
Scene Classification on MIT-Indoor
Dataset
The concealed nodes in CLTM model
catch scene pertinent information which
can be utilized to perform scene
classification undertakings. In this
segment, we exhibit scene classification
abilities of CLTM model. We utilize 529
images from MIT-Indoor informational
index having a place with 4 unique scenes:
Kitchen, Bathroom, Living Room and
Bedroom. We perform k-implies on
outputs of CLTM model and 3 layer neural
network autonomous classifier to bunch
images. We at that point ideally coordinate
these clusters to scenes to assess
misclassification rate. Note that we never
prepared our model utilizing scene labels
and we simply utilize them for approving
the execution. In our investigations, we
utilize minor probabilities of watched and
shrouded nodes of CLTM, peripheral
probabilities of concealed nodes of CLTM
and probabilities of individual classes
came about because of 3 layer neural
network molded on input highlights. Table
2 indicates misclassification rates of
various input highlights used for
clustering. Without the need of object
nearness information, clustering on
negligible probabilities of shrouded nodes
alone brought about the slightest
misclassification rate.

Airo National Research Journal December, 2017 Volume XII, ISSN: 2321-3914
12
Table 2: Misclassification Rate
Model k=4 k=6
Observed + Hidden 0.326 0.242
3 layer neural
network 0.390 0.301
Hidden 0.314 0.238
CONCLUSION AND FUTURE WORK
Taking everything into account, with the
proposed structure recuperation strategy
we could recoup the structure of dormant
tree. This tree has natural progressive
system of related objects set by their co-
appearance in changed scenes. We utilize
neural networks of various structures to
prepare conditional inert tree models. We
assess CLTM on MS COCO informational
index and there is a huge pick up in
exactness, review and F-measure
contrasted with 3 layer neural network free
classifier. Dormant nodes caught
distinctive semantic information to
recognize abnormal state class information
of images. Such information is utilized for
scene naming assignment in an
unsupervised way. In future, we plan to
model both spatial and co-event
information and apply the model to object
restriction undertakings utilizing CNN
(like RCNN).
REFERENCES
1. R. Ahuja, T. Magnanti, and J.
Orlin. Network flows. In
Optimization, pages 211–369.
Elsevier North-Holland, Inc., 1989.
2. W. Ammar, C. Dyer, and N. A.
Smith. Conditional random field
auto encoders for unsupervised
structured prediction. In Advances
in Neural Information Processing
Systems, pages 3311–3319, 2014.
3. L.-C. Chen, A. G. Schwing, A. L.
Yuille, and R. Urtasun. Learning
deep structured models. arXiv
preprint arXiv:1407.2538, 2014.
4. M. J. Choi, V. Y. F. Tan, A. Anand
kumar, and A. S. Willsky. Learning
latent tree graphical models. J.
Mach. Learn. Res., 12:1771–1812,
July 2011.
5. M. J. Choi, A. Torralba, and A. S.
Willsky. Context models and out-
of-context objects. Pattern
Recognition Letters, 33(7):853 –
862, 2012. Special Issue on
Awards from {ICPR} 2010. 3
6. M. J. Choi, A. Torralba, and A. S.
Willsky. A tree-based context
model for object recognition. IEEE
Trans. Pattern Anal. Mach. Intell.,
34(2):240–252, 2012
7. P. Drineas and M. W. Mahoney.
On the nyströ m method for
approximating a gram matrix for
improved kernel-based learning. J.

Airo National Research Journal December, 2017 Volume XII, ISSN: 2321-3914
13
Mach. Learn. Res., 6:2153–2175,
Dec. 2005.
8. M. Everingham, L. Gool, C. K.
Williams, J. Winn, and A.
Zisserman. The pascal visual object
classes (voc) challenge. Int. J.
Comput. Vision, 88(2):303–338,
June 2010.
9. R. Girshick, J. Donahue, T. Darrell,
and J. Malik. Rich feature
hierarchies for accurate object
detection and semantic
segmentation. In Computer Vision
and Pattern Recognition (CVPR),
2014 IEEE Conference on, pages
580–587, 2014.
10. K. Grauman, F. Sha, and S. J.
Hwang. Learning a tree of metrics
with disjoint visual features. In
Advances in Neural Information
Processing Systems, pages 621–
629, 2011.
11. F. Huang, N. U. N, and A. Anand
kumar. Integrated structure and
parameters learning in latent tree
graphical models. ArXiv
1406.4566, 2014.
12. Y. Jia, E. Shelhamer, J. Donahue,
S. Karayev, J. Long, R. Girshick,
S. Guadarrama, and T. Darrell.
Caffe: Convolutional architecture
for fast feature embedding. arXiv
preprint arXiv:1408.5093, 2014.


















