
Python twitter data_150709
34
Pythonによるネットワーク分析 ~Twitterデータの取得~ 株式会社ブレインパッド 2015年7月9日 Data Analytics for Sustainability
-
Upload
brainpad-inc -
Category
Data & Analytics
-
view
625 -
download
1
Transcript of Python twitter data_150709

Pythonによるネットワーク分析~Twitterデータの取得~
株式会社ブレインパッド
2015年7月9日
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.1
目次
1. はじめに
2. TwitterAPIの使い方
3. データの取得
4. おわりに
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.2
1.はじめに
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.3
本資料の位置づけ
目的はPythonによるネットワーク分析を行うこと
ネットワーク分析を行う際、頻繁に用いられるSNSのデータを利用する
SNSデータの中で、「Twitter」データをAPIを用いて取得する
以下のフローで分析を進める
1. Twitterデータの取得 ← 本資料ではここが対象
2. igraphを用いたネットワーク分析
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.4
TwitterAPIとは
インターネットを経由してTwitterの機能を利用することができるTwitter社が提
供しているサービスのこと
Twitter DevelopersでDocumentationを公開している
https://dev.twitter.com/overview/documentation
※2013年6月11日にTwitterAPI v1.1にバージョンが更新された
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.5
収集するデータ
TwitterAPIから取得でき、分析によく用いられるデータは以下4つなどがある
また、データの種類によって、データ量・期間などの取得制限がある
⇒ ネットワーク分析をするため「フォロー、フォロワーリスト」のデータを取得する
データの種類 取得制限
ユーザプロフィール -
ユーザのタイムライン 最新3,200タイムライン
ツイート検索 最新1週間
フォロー、フォロワーリスト -
※鍵付アカウントは取得できない
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.6
Pythonライブラリ
Pythonには、以下のようなTwitterAPIのラッパーライブラリが多く存在する
• python-twitter
• tweepy
• twython
ライブラリは便利だが、以下のような問題点がある
• APIの仕様変更の際、作成者の更新に依存する
• 取得できない情報が存在する
⇒ 今回はライブラリを利用せず直接APIを呼び出す
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.7
事前準備
TwitterAPIにアクセスする前に以下項目を登録する必要がある
1. Twitterアカウントの登録
2. アプリケーションの登録
登録を済ませると4つの鍵が発行され、これがAPIにアクセスする際必要となる
• Consumer Key
• Consumer Secret
• Access Token
• Access Token Secret
※こちらの登録方法はWEBにわかりやすい記事がいくつも存在するため割愛する
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.8
2.TwitterAPIの使い方
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.9
対象となるアカウントを取得する
follower (フォロワー)を取得する際、対象アカウント識別情報が必要となる
アカウント識別情報
• screen name
• user id
image
名前
screen name
アカウントページ
class="account-summary account-summary-small js-nav“data-nav="view_profile"><div class="content"><div class="account-group js-mini-current-user" data-user-id=“***"
HTMLソース
※Web上に記載はされておらず、ソースから取得する必要がある
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.10
followerを取得できるエンドポイント
followerを取得できるエンドポイントは2つある
エンドポイントによって取得時間、取得データの種類が異なる
※大量のフォロワーを取得する際は、「GET followers/ids」が良い
エンドポイント 取得時間 取得データの種類
GET followers/ids あまり時間がかからない アカウントIDのみ
GET followers/list 時間がかかる 豊富
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.11
APIのリクエスト制限
TwitterAPIには時間あたりのリクエスト制限がある
エンドポイントによってリクエスト制限は異なる
1リクエストあたり取得件数に大きな差がある
エンドポイント 15分内リクエスト数 1リクエストあたり取得件数
GET followers/ids 15 5,000
GET followers/list 15 200
Data Analytics for Sustainability
©BrainPad Inc. 2015, All rights reserved.12
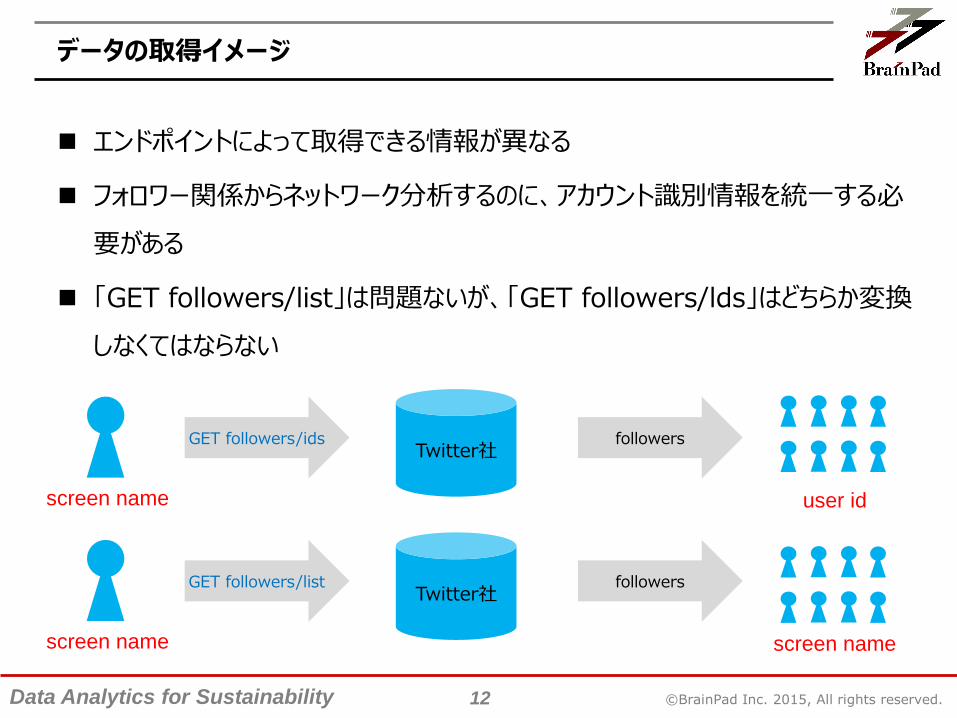
データの取得イメージ
エンドポイントによって取得できる情報が異なる
フォロワー関係からネットワーク分析するのに、アカウント識別情報を統一する必
要がある
「GET followers/list」は問題ないが、「GET followers/lds」はどちらか変換
しなくてはならない
screen name
GET followers/idsTwitter社
followers
user id
screen name
GET followers/listTwitter社
followers
screen name
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.13
アカウント識別情報を変換する方法
アカウント識別情報を変換するには「users/lookup」を利用する
対象アカウントを変換する方法と、フォロワーを変換する方法がある
対象アカウントを変換する方がリクエスト制限にかかりにくい
• GET users/lookup
• 180 × 100 = 18,000
• GET followers/ids
• 15 × 5,000 = 75,000
※フォロワーを変換する場合、最大で75,000変換することになるが、変換できる最大は18,000
エンドポイント 15分内リクエスト数 1リクエストあたり取得件数
GET users/lookup 180 100
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.14
取得可能なユーザ情報
取得可能なユーザ情報として以下などがある
key 名称
created_at 登録日
id ユーザID
screen_name ユーザ名
description 自己紹介
statuses_count ツイート数
followers_count フォロワー数
friends_count フォロイー数
favourites_count お気に入り数
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.15
3.データの取得
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.16
利用するエンドポイント
フォロワーの取得
– GET followers/ids
アカウントの変換
– GET users/lookup
※対象アカウントを「screen name」から「user id」に変換する
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.17
データ取得の流れ
データ取得の流れは以下の通り
① 日本語文字を扱う処理
② OAuth認証
③ リクエスト(アカウントの変換)
④ レスポンス内容取得
⑤ リクエスト(フォロワー)
⑥ レスポンス内容取得
⑦ ページング処理
⑧ リクエスト制限による待機
(参考) 応用
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.18
①日本語を扱う
日本語を扱う際に文字化けを防ぐため、以下の処理を行う
#!/usr/bin/python# -*- coding: utf-8 -*-
import sysreload(sys)sys.setdefaultencoding('utf-8')
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.19
②OAuth認証
OAuth認証する際、「requests_oauthlib」というライブラリを利用する
作成した鍵を利用してOAuth認証をする
# インストールpip install requests_oauthlib# または easy_install requests_oauthlib
# 読み込みfrom requests_oauthlib import OAuth1Session
CONSUMER_KEY = '****************'CONSUMER_SECRET = '****************'ACCESS_TOKEN = '****************'ACCESS_SECRET = '****************'
api = OAuth1Session(CONSUMER_KEY, CONSUMER_SECRET, ACCESS_TOKEN, ACCESS_SECRET)
©BrainPad Inc. 2015, All rights reserved.20
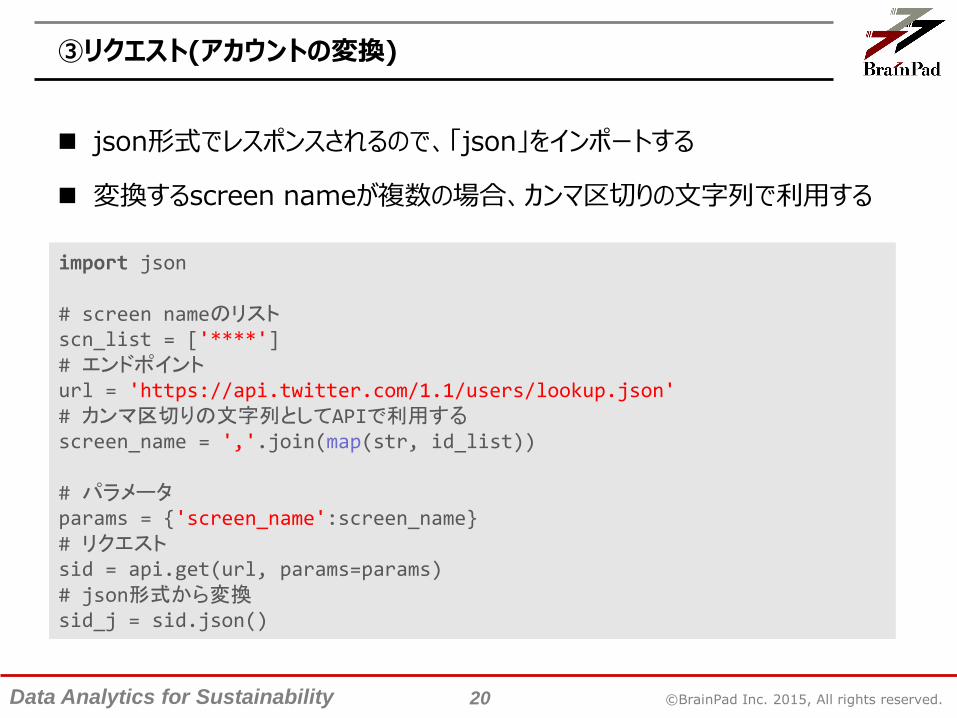
③リクエスト(アカウントの変換)
json形式でレスポンスされるので、「json」をインポートする
変換するscreen nameが複数の場合、カンマ区切りの文字列で利用する
import json
# screen nameのリストscn_list = ['****']# エンドポイントurl = 'https://api.twitter.com/1.1/users/lookup.json'# カンマ区切りの文字列としてAPIで利用するscreen_name = ','.join(map(str, id_list))
# パラメータparams = {'screen_name':screen_name}# リクエストsid = api.get(url, params=params)# json形式から変換sid_j = sid.json()
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.21
④レスポンス内容取得
リスト型の中に辞書型が入った形で返ってくる
辞書型にはユーザ情報が入っている
>>> # screen nameの繰り返し>>> for sid_list in sid_j:・・・ print sid_list・・・{'scree_name':'*****', 'id':*******, ・・・}>>> >>> for sid_list in sid_j:・・・ print sid_list['id']*******
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.22
⑤リクエスト(フォロワー)
json形式でレスポンスされるので、「json」をインポートする
取得件数にあたる「count」は最大の5,000を指定
import json
# エンドポイントurl = 'https://api.twitter.com/1.1/followers/ids.json'# user idsid = '***********'# ページング処理の際の初期値cursor = -1
# パラメータparams = {'screen_name':sid, 'cursor':cursor, 'count':5000}# リクエストfollowers = api.get(url, params=params)# json形式から変換followers_j = followers.json()
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.23
⑥レスポンス内容取得
辞書型で返ってくる
valueにアカウントIDがリスト型で入っている
>> print followers_j{'ids':[******,******,*****,*****]}>>>> print followers_j['ids'][******,******,*****,*****]
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.24
⑦ページング処理
レスポンスのkeyに「next_cursor」があり次のリクエストの際この値を指定する
取得が完了したら、 レスポンスのstatus_code が200以外の値を返す
# ページング処理while cursor != 0:
# パラメータparams = {'screen_name':sid, 'cursor':cursor, 'count':5000}# リクエストfollowers = api.get(url, params=params)# json形式から変換followers_j = followers.json()# エラーの場合処理を終わらせるif followers.status_code != 200:
break# 次のカーソルを指定cursor = followers_j['next_cursor']
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.25
⑧リクエスト制限による待機
現状のリクエスト制限を確認する方法は2つある
① リクエスト制限確認用のエンドポイント
② レスポンス
※初回リクエストでは①を使い、それ以降は②を使うと効率的
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.26
⑧リクエスト制限による待機
現在のリクエスト制限を確認する方法は2つある
① リクエスト制限確認用のエンドポイント
② レスポンス
import json
url = 'https://api.twitter.com/1.1/application/rate_limit_status.json'rate = api.get(url)rate_j = rate.json()# 残りリクエスト数remaining = rate_j['resources']['users']['/followers/ids']['remaining']# 最大リクエスト数limit = rate_j['resources']['users']['/followers/ids']['limit']
ここに確認したいエンドポイントを入力する※確認方法: print rate_j['resources']
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.27
⑧リクエスト制限による待機
現在のリクエスト制限を確認する方法は2つある
① リクエスト制限確認用のエンドポイント
② レスポンス
# 残りリクエスト数remaining = int(followers.headers['x-rate-limit-remaining']) if 'x-rate-limit-remaining' in followers.headers else 0# 最大リクエスト数limit = int(followers.headers['X-Rate-Limit-Limit']) if 'X-Rate-Limit-Limit' in followers.headers else 0
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.28
⑧リクエスト制限による待機
「remaining=0」の時に処理を待機させる
15分でリクエスト制限が解除されるが念のため、1分多めに待機
import time
# リクエスト上限に達したら、待機if remaining == 0:
# 待機(16分)time.sleep(16*60)
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.29
(参考) 応用
フォローしているユーザに関しても同様の処理で取得可能
エンドポイントは、「https://api.twitter.com/1.1/friends/ids.json」
フォロワー用に書いたスクリプトの「followers」を「friends」に置換するだけで取
得することができる
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.30
4.おわりに
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.31
まとめ
アカウントのフォロー、フォロワーのリストを取得する方法は2つあり、利用目的に応
じて、使い分ける
大量にフォロー、フォロワーを取得する場合、アカウントを変換する必要がある
紹介したプログラムを利用することで、アカウントのフォロー、フォロワーのリストを取
得することができる
また、アカウントが大量のフォロー、フォロワーがいたとしても、リクエスト制限内で待
機しながら取得することできる
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.32
今後の進め方
取得したデータを用いて、ネットワーク分析を行う
「python igraph」のパッケージを利用し、使い方、分析例を紹介する
igraphでの分析例
Data Analytics for Sustainability

©BrainPad Inc. 2015, All rights reserved.33
参考文献、参考リンク
Twitter Developers
https://dev.twitter.com/overview/documentation
Python で Twitter API にアクセス
http://qiita.com/yubais/items/dd143fe608ccad8e9f85
スタバのTwitterデータをpythonで大量に取得し、データ分析を試みる その1
http://qiita.com/kenmatsu4/items/23768cbe32fe381d54a2
Python で Twitter から情報収集 (Twitter API 編)
http://qiita.com/Salinger/items/020b670466a9835c94bb
Pythonを用いてTwitterの検索を行う
http://qiita.com/mima_ita/items/ba59a18440790b12d97e
python-twitterで100人以上のフォロイーを取得
http://pika-shi.hatenablog.com/entry/20111210/1323534823
実験ぶろぐ(仮)試供品
http://needtec.exblog.jp/21581492/
Data Analytics for Sustainability


















