
Python* はネイティブコードと同じくらい速いのか · py36_intel_15、OpenMP*...
67
Python* はネイティブコードと同じくらい速いのか? インテル® Distribution for Python* によりハイパフォーマンス・アプリケーションを最適化し、ネイティブコードと同じくらい高速に実行する方法 1 インテル コーポレーション テクニカル・コンサルティング・エンジニア Nathan Greeneltch
Transcript of Python* はネイティブコードと同じくらい速いのか · py36_intel_15、OpenMP*...

Python* はネイティブコードと同じくらい速いのか? インテル® Distribution for Python* によりハイパフォーマンス・アプリケーションを最適化し、ネイティブコードと同じくらい高速に実行する方法
1
インテルコーポレーションテクニカル・コンサルティング・エンジニアNathan Greeneltch

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
内容Python* とパフォーマンスについて
Python* コードを高速化する 3 ステップのアプローチ
関連ライブラリー
デモと関連情報
2

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
Python* パフォーマンスと歴史的なスピードの欠如Python* の作成者による Python* の目的は...
「高速」であることではない表現力豊かで素早くプロトタイプを生成できること
初心者にとって「ダックタイピング」と英語のような構文の Python* は取っ付きやすい
数値、科学、工学の分野において Python* の使用が急速に拡大しているポピュラーな商用科学言語を置き換えるオープンソース言語
3

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
Python* パフォーマンスについて一般的な Python* の動作 (Cpython)Cpython は Python* バイトコード (.pyc) からコマンドを実行するインタープリターを提供コンパイルは x86 命令を生成しないPython* インタープリターコンパイル済みバイトコード Python* 仮想マシン非常に柔軟なバイトコードが可能で、Python* インタープリターが重要な役割を果たすCpython と PyPy にはグローバル・インタープリター・ロック (GIL) がある
スレッド w1
スレッド w2
スレッド w3
解放/取得GIL
解放/取得GIL
解放/取得GIL
Cpython のグローバル・インタープリター・ロック
実行
実行
実行
4
© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
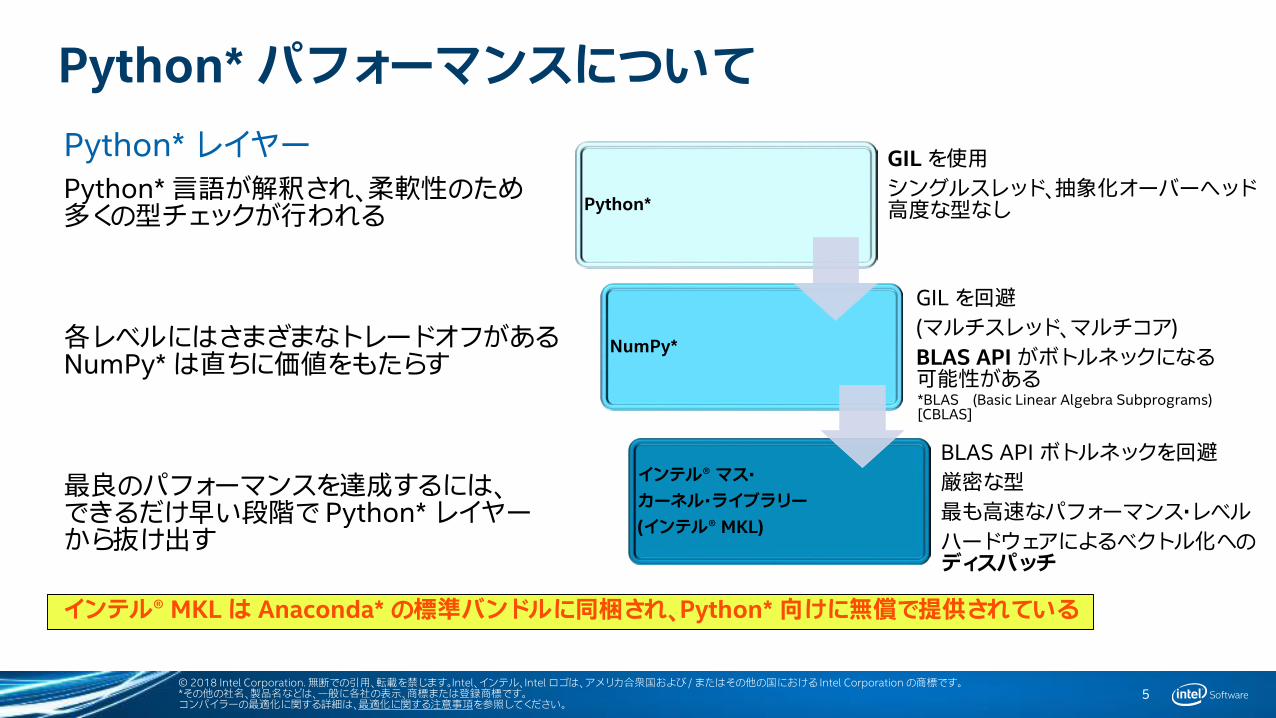
Python* パフォーマンスについてPython* レイヤーPython* 言語が解釈され、柔軟性のため多くの型チェックが行われる
各レベルにはさまざまなトレードオフがあるNumPy* は直ちに価値をもたらす
最良のパフォーマンスを達成するには、できるだけ早い段階で Python* レイヤーから抜け出す
Python*
NumPy*
インテル® マス・カーネル・ライブラリー(インテル® MKL)
GIL を使用シングルスレッド、抽象化オーバーヘッド高度な型なし
GIL を回避(マルチスレッド、マルチコア)BLAS API がボトルネックになる可能性がある
BLAS API ボトルネックを回避厳密な型最も高速なパフォーマンス・レベルハードウェアによるベクトル化へのディスパッチ
*BLAS (Basic Linear Algebra Subprograms)[CBLAS]
インテル® MKL は Anaconda* の標準バンドルに同梱され、Python* 向けに無償で提供されている
5

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
ループ(行 1)
ループ(行 2)
ループ(... 行 n)
ループ(行 1) 計算 アペンド
ループ(行 2) 計算 アペンド
ループ(... 行 n) 計算 アペンド
ループ呼び出し
ループ呼び出し
Python* レベルのみ (シングルスレッド)
Python* と NumPy* ディスパッチ
Python* パフォーマンスについてなぜ重要なのか? (Python* レイヤー)配列ループの例GIL によりループはシングルスレッドでの実行を強制されるNumPy* ディスパッチは C 関数の使用によりシングルスレッドを回避C 関数はプロセッサーによるベクトル化を呼び出し可能
パフォーマンスを向上するには、Python* レイヤーを抜け出すことが重要
6
© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
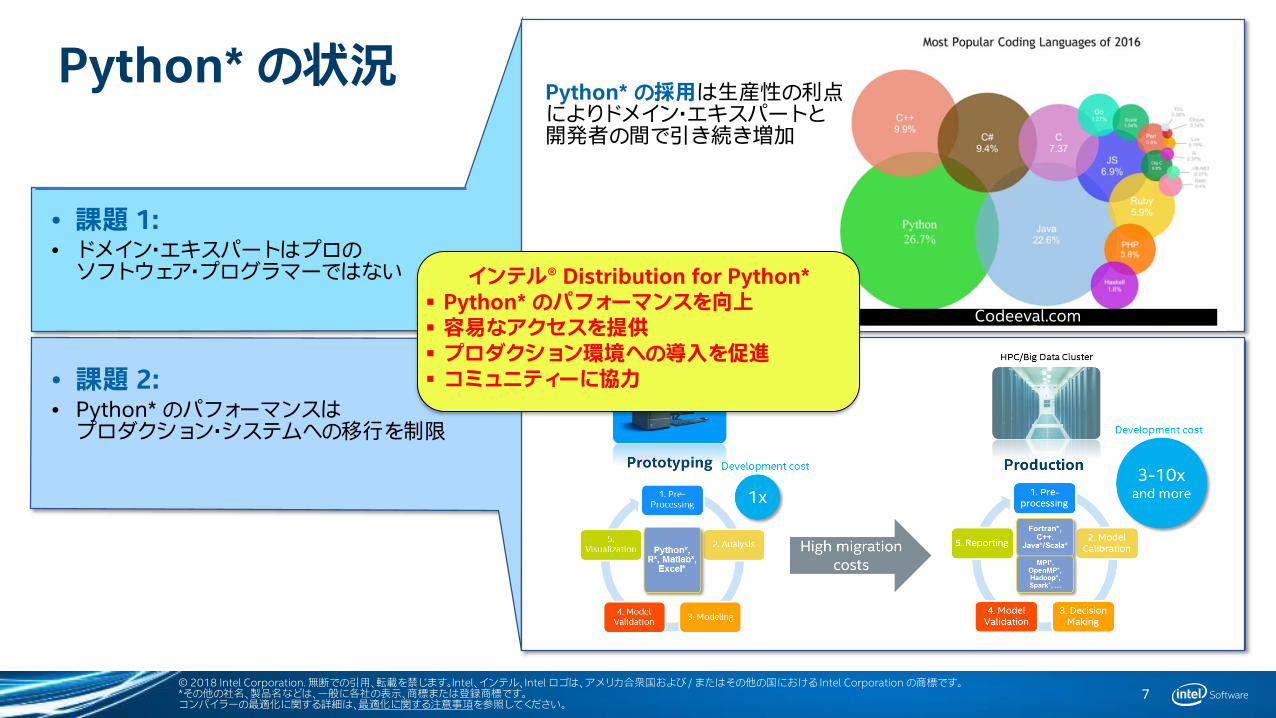
Python* の状況
• 課題 1: • ドメイン・エキスパートはプロのソフトウェア・プログラマーではない
• 課題 2: • Python* のパフォーマンスはプロダクション・システムへの移行を制限
Codeeval.com
インテル® Distribution for Python* Python* のパフォーマンスを向上 容易なアクセスを提供 プロダクション環境への導入を促進 コミュニティーに協力
7
Python* の採用は生産性の利点によりドメイン・エキスパートと開発者の間で引き続き増加

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
内容Python* とパフォーマンスについて
Python* コードを高速化する 3 ステップのアプローチ- Python* ライブラリーの高速化- パフォーマンスのためのコードのチューニング- 計算処理の分散
関連ライブラリー
デモと関連情報
8

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
エコシステムの互換性優れた生産性高速なパフォーマンス
事前ビルドの高速化されたパッケージ Python* 2.7 & 3.6、Conda*、pip をサポート
オペレーティング・システム: Windows*、Linux*、macOS*3
インテル® アーキテクチャー・ベースのプラットフォーム
パフォーマンス・ライブラリー、並列化、マルチスレッド化、言語拡張
インテル® MKL1 とインテル® DAAL2 によりNumPy*/SciPy*/scikit-learn を高速化
scikit-learn、pyDAAL によるデータ解析、マシンラーニング、ディープラーニング
Numba と Cython によるスケーリング
最適化された mpi4py、Dask & PySpark で動作
最新のインテル® アーキテクチャー向けに最適化
数値計算、マシンラーニング/ディープラーニング、HPC、データ解析向けの事前ビルドの最適化されたパッケージ
既存の Python* から簡単に移行可能通常コード変更不要Jupyter* Notebook、Matplotlib を含む
Conda* ビルドレシピをパッケージに同梱
商用開発を含むすべてのユーザーに無償で提供
Anaconda* との互換性、Conda* と pip をサポートディストリビューションと個々の最適化されたパッケージは conda と Anaconda.org、yum/apt、Docker* イメージ (Docker* Hub) からも利用可能最適化はメインの Python* トランクに反映されるインテル® Parallel Studio XE を通して商用サポートが受けられる
1インテル® マス・カーネル・ライブラリー2インテル® データ・アナリティクス・アクセラレーション・ライブラリー3インテル® Parallel Studio XE Composer Edition でのみ利用可能
インテル® Distribution for Python* でライブラリーを高速化科学計算、データ解析、マシンラーニング向けのハイパフォーマンスな Python*
既存の Python* から簡単に移行可能通常コード変更は不要
9

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
性能に関するテストに使用されるソフトウェアとワークロードは、性能がインテル® マイクロプロセッサー用に最適化されていることがあります。SYSmark* やMobileMark* などの性能テストは、特定のコンピューター・システム、コンポーネント、ソフトウェア、操作、機能に基づいて行ったものです。結果はこれらの要因によって異なります。製品の購入を検討される場合は、他の製品と組み合わせた場合の本製品の性能など、ほかの情報や性能テストも参考にして、パフォーマンスを総合的に評価することをお勧めします。* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。ベンチマークの出典: インテルコーポレーションel.com/performance.
インテル® Xeon® プロセッサー
インテル® Xeon Phi™ プロセッサー
インテル® Core™ i7 プロセッサー
最大 37 倍のスピードアップ
3,000 倍を超えるスピードアップ
ハードウェア: インテル® Core™ i7-7567U プロセッサー @3.50GHz (1 ソケット、ソケットごとに 2 コア、コアごとに 2 スレッド)、32GB DDR4 @2133MHz。インテル® Xeon® プロセッサー E5-2699 v4 @2.20GHz (2 ソケット、ソケットごとに 22 コア、コアごとに 1 スレッド、HT 無効)、256GB DDR4 @2400MHz。インテル® Xeon Phi™ プロセッサー 7250 @1.40GHz (1 ソケット、ソケットごとに 68 コア、コアごとに 4 スレッド)、192GB DDR4 @1200MHz、16GB MCDRAM @7200MHz キャッシュモードソフトウェア: CentOS* 7.3.1611 (Core)、Python* 3.6.2、pip 9.0.1、NumPy* 1.13.1、SciPy* 0.19.1、scikit-learn 0.19.0。インテル® Distribution for Python* 2018 Gold パッケージ: インテル® MKL 2018.0.0、intel_4、インテル® DAAL 2018.0.0.20170814、NumPy* 1.13.1、py36_intel_15、OpenMP* 2018.0.0、intel_7、SciPy* 0.19.1、np113py36_intel_11、scikit-learn 0.18.2、np113py36_intel_3。
最大 440 倍のスピードアップ
インテル® Xeon® プロセッサー
3,000 倍を超えるスピードアップ
インテル® Xeon Phi™ プロセッサー
マルチコア、メモリー管理を利用するUMath の最適化とベクトル化
最適化に関する注意事項: インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミングSIMD 拡張命令 3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。注意事項の改訂 #20110804
10

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
IDP による最適化のさらにその先
最適化された Python* 以外の Python*/C/C++ アプリケーション・コードの効率は?
パフォーマンス低下の原因が明らかでないものはないか?
パフォーマンス解析により解明できる
11

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
パフォーマンス向上のための Python* + ネイティブコードのチューニングインテル® VTune™ Amplifier によるパフォーマンス解析 (インテル® Parallel Studio XE に含まれる)
スクリーンショットを挿入
ソリューションPython*/C/C++ 混在コードと拡張を自動検出パフォーマンス hotspot を行レベルで正確に識別低オーバーヘッド、実行中のアプリケーションへのアタッチ/デタッチパフォーマンスへの影響が大きい個所をチューニング
インテル® VTune™ Amplifier とインテル® Parallel Studio XE で利用可能
課題Python* とネイティブコードが混在するアプリケーションを 1 つのツールでプロファイル非効率的なランタイム実行を検出
Python* とネイティブ関数の自動検出およびパフォーマンス解析
12

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
パフォーマンスが最適化されたネイティブ・ライブラリーを利用既存の Python* から簡単に移行可能 - コード変更不要マルチコアと最新のインテル® プロセッサー向けに最適化
ステップ 1: インテル® Distribution for Python* と高速なライブラリーを使用
アプリケーション全体の実行プロファイルの詳細なサマリーを取得Python*/C/C++ 混在コードと拡張を低オーバーヘッドで自動検出してプロファイルホットスポットを正確に検出 - 行レベルの解析により迅速に賢く最適化!インテル® Parallel Studio XE Professional Edition & Cluster Edition で利用可能
ステップ 2: インテル® VTune™ Amplifier でプロファイルとチューニング
Python* パフォーマンスを高速化する 3 ステップのアプローチハイパフォーマンスな Python* ディストリビューション + パフォーマンス・プロファイル
mpi4py のエンジンとしてインテル® MPI ライブラリーを使用
ステップ 3: メッセージ・パッシング・インターフェイスで計算処理を分散
13

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
2.7 & 3.6
Linux*Windows*
macOS*
インテル® Distribution for Python* 2018 のインストール
スタンドアロン・インストーラー
Anaconda.orgAnaconda.org/intel channel
YUM/APT
Docker* Hub
フル・インストーラーをダウンロード:https://www.isus.jp/python-distribution/
> conda config --add channels intel> conda install intelpython3_full> conda install intelpython3_core
docker pull intelpython/intelpython3_full
yum/apt の入手方法: https://software.intel.com/en-us/articles/installing-intel-free-libs-and-python (英語)
14

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
内容Python* とパフォーマンスについて
Python* コードを高速化する 3 ステップのアプローチ
関連ライブラリー- Python* ライブラリーの高速化 (インテル® MKL、インテル® DAAL、インテル® TBB)- パフォーマンスのためのコードのチューニング (インテル® VTune™ Amplifier)- 計算処理の分散 (インテル® MPI ライブラリー)
デモと関連情報
15

インテル® マス・カーネル・ライブラリー(インテル® MKL)インテル® Parallel Studio XE、インテル® System Studio、インテル® Distribution for Python* で利用可能
無償のスタンドアロン・バージョン (プライオリティー・サポートを含まない) でも利用可能

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
ハイパフォーマンスなマス・カーネル・ライブラリー各プロセッサー・ファミリーでパフォーマンスを最大限に引き出すように高度に最適化、スレッド化、ベクトル化された数学関数
業界標準の C および Fortran API を利用して、よく使用される BLAS、LAPACK、FFTW 関数との互換性を実現 — コード変更は不要
コードを分岐せずに各プロセッサー向けに最適化されたコードを自動ディスパッチ
インテル® MKL 2018 の新機能GEMM と LAPACK で小行列の乗算のパフォーマンスを向上
分散型計算の ScaLAPACK パフォーマンスを向上
24 の新しいベクトル演算関数
導入および再配布しやすい簡易ライセンス
yum、apt-get、Conda* リポジトリーでも配布詳細: isus.jp/intel-mkl/
インテル® MKL による高速でスケーラブルなコード
17

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
インテル® MKL のコンポーネントHPC、エンタープライズ、IoT、クラウド・アプリケーションを高速化
オペレーティング・システム: Windows*、Linux*、macOS*1
インテル® アーキテクチャー・ベースのプラットフォーム
線形代数• BLAS• LAPACK• ScaLAPACK• スパース BLAS• 反復法スパースソルバー• PARDISO • クラスター・スパース・ソ
ルバー
ベクトル RNG• 線形合同法• Wichmann-Hill• Mersenne Twister• Sobol• Neiderreiter• 非決定的
FFT• 多次元• FFTW インターフェイス• クラスター FFT
サマリー統計• 尖度• 変化係数• 順序統計量• 最小/最大• 分散/共分散
ベクトル演算• 三角関数• 双曲線• 指数• 対数• 累乗• 累乗根
その他• スプライン• 補間• 信頼領域• 高速ポアソンソルバー
ニューラル・ネットワーク• 畳み込み• プーリング• 正規化• ReLU• 内積
18
1インテル® Parallel Studio XE Composer Edition でのみ利用可能

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
Python* の使用インテル® MKL はインテル® Distribution of Python* に含まれる
そのままで高速な NumPy*
コード変更は不要
Python* でインテル® MKL を使用する利点
シングルコア: ベクトル化、プリフェッチ、キャッシュ効率
インテル® AVX-5121 ISA 向けの SIMD サポート
マルチ/メニーコア (プロセッサー/ソケット) レベルの並列化
OpenMP* とインテル® TBB をサポート
マルチソケット (ノード) レベルの並列化とクラスター・スケーリング
インテル® MKL: Python* との統合
Python* コードの変更は不要
19
1インテル® アドバンスト・ベクトル・エクステンション 512

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
性能に関するテストに使用されるソフトウェアとワークロードは、性能がインテル® マイクロプロセッサー用に最適化されていることがあります。SYSmark* やMobileMark* などの性能テストは、特定のコンピューター・システム、コンポーネント、ソフトウェア、操作、機能に基づいて行ったものです。結果はこれらの要因によって異なります。製品の購入を検討される場合は、他の製品と組み合わせた場合の本製品の性能など、ほかの情報や性能テストも参考にして、パフォーマンスを総合的に評価することをお勧めします。* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。ベンチマークの出典: インテルコーポレーションwww.intel.com/performance.
インテル® Core™ i7 プロセッサー
インテル® Xeon® プロセッサー
インテル® Xeon Phi™ プロセッサー
ハードウェア: インテル® Core™ i7-7567U プロセッサー @3.50GHz (1 ソケット、ソケットごとに 2 コア、コアごとに 2 スレッド)、32GB DDR4 @2133MHz。インテル® Xeon® プロセッサー E5-2699 v4 @2.20GHz (2 ソケット、ソケットごとに 22 コア、コアごとに 1 スレッド、HT 無効)、256GB DDR4 @2400MHz。インテル® Xeon Phi™ 7250プロセッサー @1.40GHz (1 ソケット、ソケットごとに 68 コア、コアごとに 4 スレッド)、192GB DDR4 @1200MHz、16GB MCDRAM @7200MHz キャッシュモードソフトウェア: CentOS* 7.3.1611 (Core)、Python* 3.6.2、pip 9.0.1、NumPy* 1.13.1、SciPy* 0.19.1、scikit-learn 0.19.0。インテル® Distribution for Python* 2018 Gold パッケージ: インテル® MKL 2018.0.0、intel_4、インテル® DAAL 2018.0.0.20170814、NumPy* 1.13.1、py36_intel_15、OpenMP* 2018.0.0、intel_7、SciPy* 0.19.1、np113py36_intel_11、scikit-learn 0.18.2、np113py36_intel_3。
Python* パフォーマンスの向上NumPy* とインテル® MKL を利用したブラック・ショールズ・アルゴリズム
最適化に関する注意事項: インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミングSIMD 拡張命令 3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。注意事項の改訂 #20110804
20

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
0x
1x
2x
3x
4x
5x
6x
7x
8x
9x
近似近傍 高速化 K 平均法 GLM GLM Net LASSO Lasso パス 最小角回帰
OpenMP*
非負値行列因子
分解
SGD 回帰 非復元抽出 SVD
インテル® Distribution for Python* と Python* & NumPy*/scikit-learn システムの比較
システム構成: 32x インテル® Xeon® プロセッサー E5-2698 v3 @ 2.30GHz、HT 無効、64GB RAM。インテル® Distribution for Python* 2017 Gold、インテル® MKL 2017.0.0、Ubuntu* 14.04.4 LTS、NumPy* 1.11.1、scikit-learn 0.17.1。最適化に関する注意事項を参照。
スピードアップ
性能に関するテストに使用されるソフトウェアとワークロードは、性能がインテル® マイクロプロセッサー用に最適化されていることがあります。SYSmark* や MobileMark* などの性能テストは、特定のコンピューター・システム、コンポーネント、ソフトウェア、操作、機能に基づいて行ったものです。結果はこれらの要因によって異なります。製品の購入を検討される場合は、他の製品と組み合わせた場合の本製品の性能など、ほかの情報や性能テストも参考にして、パフォーマンスを総合的に評価することをお勧めします。* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。ベンチマークの出典: インテルコーポレーションhttp://www.intel.com/performance. 最適化に関する注意事項: インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。注意事項の改訂 #20110804
Python* パフォーマンスの向上sci-kit learn とインテル® MKL を利用したブラック・ショールズ・アルゴリズム
21

インテル® データ・アナリティクス・アクセラレーション・ライブラリー (インテル® DAAL)インテル® Parallel Studio XE およびインテル® Distribution for Python* で利用可能
スタンドアロン・バージョン (プライオリティー・サポートを含む) でも利用可能

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
前処理 変換 解析 モデリング 意思決定
展開、フィルタリング、正規化
集計、次元縮小
サマリー統計、クラスタリングなど
マシンラーニング (訓練)、パラメーター推定、シミュレーション
予測、決定木など
科学
/工学
Web
/SN
S
ビジネス
計算 (サーバー、デスクトップ、…) クライアント・エッジデータ・ソース・エッジ
検証
仮説検証、モデルエラー
…
観測 n時間
メモリー
容量
カテゴリカル空白/不足
数値
特徴
p
ビッグデータの特性 計算ソリューション
異なるデバイスに分散 •通信を回避するアルゴリズムによる分散処理
デバイスメモリーに収まらない大きなデータサイズ •分散処理•ストリーミング・アルゴリズム
データがタイミングよく到着する •データバッファーと非同期計算•ストリーミング・アルゴリズム
非同次データ •カテゴリカル→数値 (カウンター、ヒストグラムなど)•同次数値データカーネル
• 変換、インデックス、再パック
疎/不足/ノイズの多いデータ •疎データ・アルゴリズム•リカバリー処理 (ブートストラップ、外れ値補正)外れ値
インテル® DAAL: 多用途のデータ解析 素早く簡単に分散可能な解析
23

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
データセットの基礎統計
低次モーメント
分散共分散行列
補正と依存性
コサイン距離
相関距離
行列の因数分解
SVD
QR
コレスキー
次元縮小
PCA
外れ値検出
相関ルールマイニング(アプリオリ)
単変量
多変量
バッチ、オンライン、分散処理をサポートするアルゴリズム
分位数
順序統計量最適化ソルバー
(SGD、AdaGrad、lBFGS)
数学関数(exp、log、…)
バッチ処理をサポートするアルゴリズム
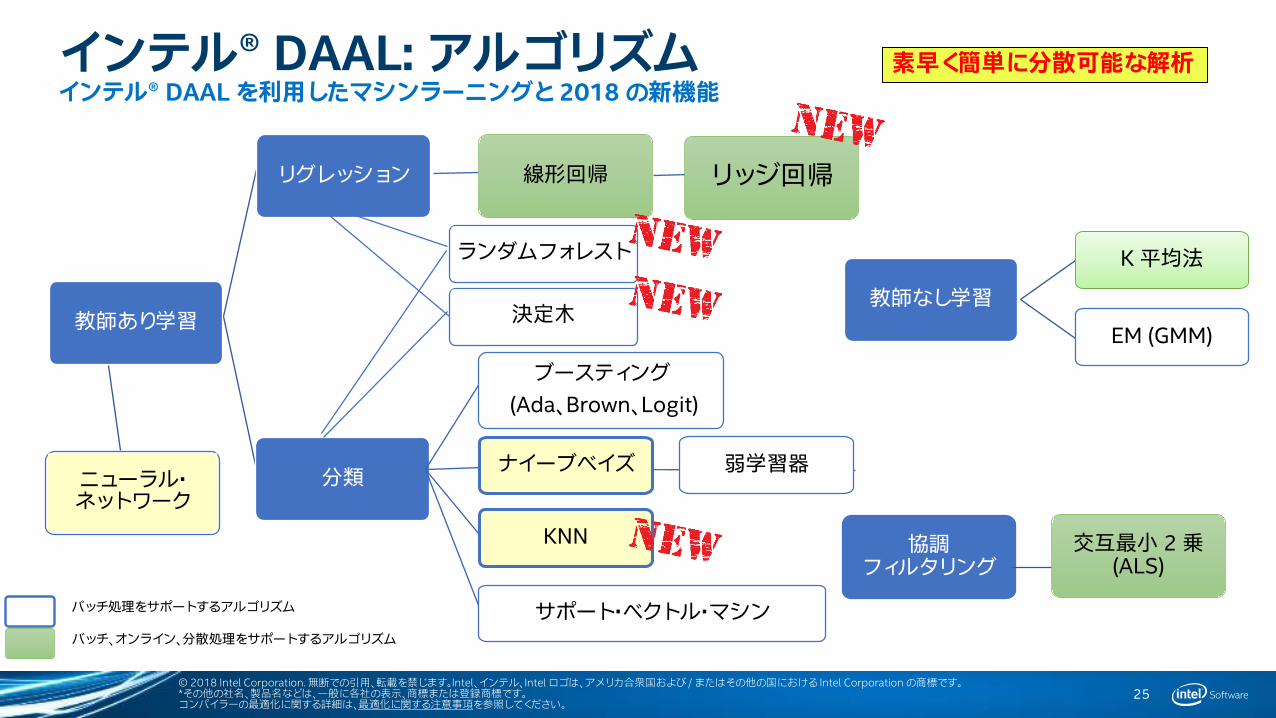
インテル® DAAL: アルゴリズムインテル® DAAL のデータ変換と解析
素早く簡単に分散可能な解析
24
© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
バッチ、オンライン、分散処理をサポートするアルゴリズム
バッチ処理をサポートするアルゴリズム
インテル® DAAL: アルゴリズムインテル® DAAL を利用したマシンラーニングと 2018 の新機能
素早く簡単に分散可能な解析
25
教師あり学習
リグレッション 線形回帰
分類 弱学習器
ブースティング(Ada、Brown、Logit)
ナイーブベイズ
KNN
サポート・ベクトル・マシン
教師なし学習
K 平均法
EM (GMM)
協調フィルタリング
交互最小 2 乗(ALS)
ランダムフォレスト
ニューラル・ネットワーク
決定木
リッジ回帰

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
インテル® DAAL: Python* および NumPy* との統合NumPy* 配列を利用してNumPy* およびその他の
パッケージと連携
"Gentle Introduction" シリーズで pandas との統合と
ヘルパー関数を利用可能
完全な Python* API (PyDAAL)
26

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
インテル® DAAL: Python* および NumPy* との統合NumPy* 配列を利用してNumPy* およびその他の
パッケージと連携
"Gentle Introduction" シリーズで pandas との統合と
ヘルパー関数を利用可能
完全な Python* API (PyDAAL)
software.intel.com (英語) にアクセスして"Gentle Introduction to PyDAAL" を検索
27

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
4X
6X 6X7X 7X
0
2
4
6
8
1M x 200 1M x 400 1M x 600 1M x 800 1M x 1000
スピードアップ
テーブルサイズ
インテル® Xeon® プロセッサー E5-2697 v3 ベースの 8 ノードのHadoop* クラスターにおける PCA (相関法)
システム構成: インテル® Data Analytics Acceleration Library 2016、CDH v5.3.1、Apache Spark* v1.2.0。ハードウェア: インテル® Xeon® プロセッサー E5-2699 v3、2 x 18 コア CPU (45MB LLC、2.3GHz)、1 ノードあたり128GB RAM。オペレーティング・システム: CentOS* 6.6 x86_64。
性能に関するテストに使用されるソフトウェアとワークロードは、性能がインテル® マイクロプロセッサー用に最適化されていることがあります。SYSmark* や MobileMark* などの性能テストは、特定のコンピューター・システム、コンポーネント、ソフトウェア、操作、機能に基づいて行ったものです。結果はこれらの要因によって異なります。製品の購入を検討される場合は、他の製品と組み合わせた場合の本製品の性能など、ほかの情報や性能テストも参考にして、パフォーマンスを総合的に評価することをお勧めします。* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。ベンチマークの出典: インテルコーポレーション
最適化に関する注意事項: インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。注意事項の改訂 #20110804
インテル® DAAL と Spark* MLLib を使用した PCA 計算
28

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
インテル® DAAL による主要なマシンラーニング・アルゴリズムの高速化距離、K 平均法、線形/リッジ回帰、PCAインテル® MKL による最適化からさらに最大 160 倍スピードアップ
158.91
2.56
157.94
39.65
5.39 1.570.00
20.00
40.00
60.00
80.00
100.00
120.00
140.00
160.00
180.00
1Kx150K 1Kx150K 100Kx50, 10 clusters 10Mx25, training 10Mx25, training 1Mx50, 3 components
Correlation Distance Cosine Distance K-means Linear Regression Ridge Regression PCA
Scikit-Learn OptimizationsDue to Intel(R) DAAL
Intel Python 2017 U2 vs. U1
スピードアップ
インテル® DAAL による scikit-learn のさらなる最適化scikit-learn ベンチマークのスピードアップ
システム構成: インテル® Data Analytics Acceleration Library 2016、CDH v5.3.1、Apache Spark* v1.2.0。ハードウェア: インテル® Xeon® プロセッサー E5-2699 v3、2 x 18 コア CPU (45MB LLC、2.3GHz)、1 ノードあたり128GB RAM。オペレーティング・システム: CentOS* 6.6 x86_64。
性能に関するテストに使用されるソフトウェアとワークロードは、性能がインテル® マイクロプロセッサー用に最適化されていることがあります。SYSmark* や MobileMark* などの性能テストは、特定のコンピューター・システム、コンポーネント、ソフトウェア、操作、機能に基づいて行ったものです。結果はこれらの要因によって異なります。製品の購入を検討される場合は、他の製品と組み合わせた場合の本製品の性能など、ほかの情報や性能テストも参考にして、パフォーマンスを総合的に評価することをお勧めします。* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。ベンチマークの出典: インテルコーポレーション
最適化に関する注意事項: インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。注意事項の改訂 #20110804
29

インテル® スレッディング・ビルディング・ブロック(インテル® TBB)インテル® Parallel Studio XE、インテル® System Studio、インテル® Distribution for Python* で利用可能
オープンソースのスタンドアロン・バージョン (プライオリティー・サポートを含まない) でも利用可能

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
インテル® TBB によりマルチスレッド化とヘテロジニアス・コンピューティングを容易にスレッドの管理を行い、開発者が実証済みの並列処理パターンに専念できるようにするC++ ランタイム・ライブラリー利用可能なハードウェア・スレッド数に応じてスケーリング入れ子の並列処理をサポート
最適なサイズのスレッドプール、タスク粒度、パフォーマンス重視のスケジュールを提供するランタイム・ライブラリータスクスチールによる自動ロードバランスキャッシュ効率とメモリー再利用
コミットメントコンパイラー非依存性プロセッサー非依存性OS 非依存性
GNU* GPL v2 ライセンスおよび無償の商用ライセンスhttp://opentbb.org (英語)
31

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
スレッド化する理由とPython* との統合スレッド化の問題は 1990 年代に解決済みでは?その通り! しかし...作業を分割する方法は? キャッシュをホットな状態で保持する方法は?スレッド間のロードバランスをとる方法は? 入れ子の並列処理 (コールチェーン) は?
Python* との統合インテル® MKL (と OpenMP*) をサポートインテル® DAAL (& PyDAAL) を使用
グローバル・インタープリター・ロックは?C の呼び出し時に解放できるネイティブコードは Python* を実行しない限り並列に実行できるアムダールの法則による効率の制限
> python -m tbb script.py
コマンドラインから Python* インタープリター命令で呼び出されるその他のコード変更は不要
32

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
[Data, Data+N)
[Data, Data+N/2)[Data+N/2, Data+N)
[Data, Data+N/k)
[Data, Data+GrainSize)
スチール可能なタスク
範囲を分割...
.. 再帰的に分割...
... GrainSize 以下になるまで
ほかのワーカースレッドは幅優先で古い大きなチャンクのワークをスチールする
スレッドは深さ優先で実行するため、局所性が得られる
インテル® TBB が再帰並列処理を使用する場合のスケジュール例
33

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
インテル® TBB ランタイム
インテル® MKL
NumPy* SciPy*
インテル® DAAL
pyDAAL
Python* 向けのインテル® TBB モジュール
Joblib Daskスレッドプール
Numba
ApplicationComponent 1
Component N
Subcomponent 1
Subcomponent 2
Subcomponent K
Subcomponent 1
Subcomponent M
Subcomponent 1
Subcomponent 1
Subcomponent 1
Subcomponent 1
Subcomponent 1
Subcomponent 1
Subcomponent 1
Subcomponent 1
ソフトウェア・コンポーネントはサブコンポーネント群により構成される各コンポーネントをスレッド化したら大変!インテル® TBB は、動的にスレッドのロードバランスを調整し、効率良くオーバーサブスクリプションを管理
インテル® TBB と Python* による並列処理
> python -m tbb script.py
34

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
Numpy*
1.00x
Numpy*
0.22x
Numpy*
0.47x
Dask
0.61x
Dask
0.89x
Dask
1.46x
-0.1x
0.1x
0.3x
0.5x
0.7x
0.9x
1.1x
1.3x
1.5x
インテル® MKL デフォルト インテル® MKL シリアル インテル® TBBシステム構成: 32x インテル® Xeon® プロセッサー E5-2698 v3 @ 2.30GHz、HT 無効、64GB RAM。
インテル® MKL 2017.0 Beta Update 1。インテル® 64 アーキテクチャー、インテル® AVX2。
インテル® TBB 4.4.4。Ubuntu* 14.04.4 LTS。Dask 0.10.0。Numpy* 1.11.0。
インテル® MKL Numpy* との比較
> python -m tbb script.py
例: インテル® TBB を利用した Python* の入れ子の並列処理
35

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
内容Python* とパフォーマンスについて
Python* コードを高速化する 3 ステップのアプローチ
関連ライブラリー- Python* ライブラリーの高速化 (インテル® MKL、インテル® DAAL、インテル® TBB)- パフォーマンスのためのコードのチューニング (インテル® VTune™ Amplifier)- 計算処理の分散 (インテル® MPI ライブラリー)
デモと関連情報
36

インテル® VTune™ Amplifierインテル® Parallel Studio XE Professional Edition & Cluster Edition、インテル® System Studio、インテル® Media Server Studio で利用可能
すべてのバージョンにプライオリティー・サポートが含まれる

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
インテル® VTune™ Amplifier パフォーマンス・プロファイラーアプリケーション・パフォーマンスとスケーラビリティーの解析とチューニング
高速でスケーラブルなコードを迅速に開発C、C++、Fortran、Python*、Go*、Java* に加えて、これらの言語が混在したコードを正確にプロファイルCPU/GPU、スレッド、メモリー、キャッシュ、MPI、ストレージなどを最適化時間を節約: 詳細な解析により洞察が得られるプライオリティー・サポートの利用
- インテルのエンジニアに技術的な質問を直接問い合わせ可能 (有償バージョン)
2018 の新機能 (一部抜粋)メモリー解析で Python* をサポートスレッドのロックと待機解析で Python* をサポートクロス OS 解析 – Windows* や macOS* から Linux* を解析コンテナー内部もプロファイル
38

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
さまざまな分野に対応した豊富なプロファイル機能インテル® VTune™ Amplifier パフォーマンス・プロファイラー
メモリーを効率良く使用データ構造と NUMA のチューニング高速ストレージ向けに最適化I/O と計算のインバランス容易な OpenCL* & GPU 解析サマリー + 拡張カウンターインテル® Media SDK との統合有用なメディア・スタック・メトリック低オーバーヘッドの Java*、Python*、Go*マネージド + ネイティブコードコンテナーDocker*、Mesos*、LXC
基本プロファイルhotspot
スレッド解析コンカレンシー、ロックと待機OpenMP*、インテル® TBB
マイクロアーキテクチャー解析キャッシュ、分岐予測、…
ベクトル化 (+ インテル® Advisor)FLOPS 推定
MPI (+ インテル® Trace Analyzer & Collector)スケーラビリティー、インバランス、オーバーヘッド
39OpenCL および OpenCL ロゴは、Apple Inc. の商標であり、Khronos の使用許諾を受けて使用しています。

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
機能 cProfile Line_profiler インテル® VTune™ Amplifierプロファイル方法 イベント インストルメンテーション サンプリング、ハードウェア・イベント
解析の粒度 関数レベル 行レベル 行レベル、コールスタック、タイムライン・ウィンドウ、ハードウェア・イベント
干渉レベル 中 (1.3-5 倍) 高 (4-10 倍) 低 (1.05-1.3 倍)
言語が混在したプログラム Python* Python* Python*、Cython、C++、Fortran
ハイパフォーマンス・アプリケーションをすべてのレベルでプロファイルできるツール関数レベル/行レベルの hotspot 解析、逆アセンブル
コールスタック解析
低オーバーヘッド
言語が混在したマルチスレッド・アプリケーションの解析
キャッシュミス、分岐予測ミスなどが分かる、ネイティブコード (Cython、C++、Fortran) の高度なハードウェア・イベント解析
インテル® VTune™ Amplifier とその他の Python* プロファイラーの比較
40

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
インテル® VTune™ Amplifier でコードの問題を素早く正確に診断
Python* からネイティブ関数への呼び出しの詳細
ボトルネックのコード行を正確に特定
41

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
インテル® VTune™ Amplifier: 詳細な解析により詳しい情報を提供
Python* とネイティブコードのコールスタックのリスト
詳細なタイムライン解析Python* はシングルスレッド
スレッド化されたプログラムの例
42

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
内容Python* とパフォーマンスについて
Python* コードを高速化する 3 ステップのアプローチ
関連ライブラリー- Python* ライブラリーの高速化 (インテル® MKL、インテル® DAAL、インテル® TBB)- パフォーマンスのためのコードのチューニング (インテル® VTune™ Amplifier)- 計算処理の分散 (インテル® MPI ライブラリー)
デモと関連情報
43

インテル® MPI ライブラリー (impi)インテル® Parallel Studio XE Cluster Edition およびインテル® Distribution for Python* で利用可能
スタンドアロン・バージョン (プライオリティー・サポートを含む) でも利用可能

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
インテル® MPI ライブラリーの概要最適化された MPI アプリケーション・パフォーマンスアプリケーション固有のチューニング自動チューニングインテル® Xeon Phi™ プロセッサーをサポートNew! – インテル® Omni-Path ファブリック
低レイテンシーおよび複数のベンダーとの互換性業界トップレベルのレイテンシーOpenFabrics* インターフェイス (OFI) により、ファブリック向けに最適化されたパフォーマンスをサポート
高速な MPI 通信最適化された集合操作
持続性のあるスケーラビリティー (最大 34 万コアまで)ネイティブ InfiniBand* インターフェイス・サポートにより、低レイテンシー、高帯域幅、メモリー使用量の軽減を実現
安定性に優れた MPI アプリケーションインテル® Trace Analyzer & Collector とシームレスに連携
最適化された MPI パフォーマンス
インテル® Omni-Path ファブリック
TCP/IP InfiniBand* iWarp 共有メモリー
…その他のネットワーク
インテル® MPI ライブラリー
ファブリック
アプリケーション
クラッシュCFD 気候 OCD BIO その他...
1 つのファブリック向けにアプリケーションを開発
実行時にインターコネクト・ファブリックを選択
クラスター
インテル® MPI ライブラリー – 1 つの MPI ライブラリーで複数のファブリック向けの
開発、保守、テストが可能
45

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
インテル® MPI ライブラリーと Python* (mpi4py)Conda* とインテル® Distribution of Python* とともに簡単に使用できる環境変数の設定が不要"mpirun" が Conda* の環境パスに含まれているmpi4py コードの構文は変更不要
高速な MPI 通信最適化された集合操作
持続性のあるスケーラビリティー (最大 34 万コアまで)ネイティブ InfiniBand* インターフェイス・サポートにより、低レイテンシー、高帯域幅、メモリー使用量の軽減を実現
安定性に優れた MPI アプリケーションインテル® Trace Analyzer & Collector とシームレスに連携
> conda activate idp> mpirun –n 16 python -m tbb script.py
コマンドラインから Python* インタープリター命令で呼び出されるその他のコード変更は不要
46

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
内容Python* とパフォーマンスについて
Python* コードを高速化する 3 ステップのアプローチ
関連ライブラリー
デモと関連情報
47

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
共分散行列のデモ
http://stattrek.com/matrix-algebra/covariance-matrix.aspx (英語)
メモリー: 4GB (x72、ECC、SR) 288 ピン DDR4 RDIMMOS: Ubuntu* 16.04
48

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
共分散行列のデモ
49

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
共分散行列のデモ: 基本 hotspots サマリー
50

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
共分散行列のデモ: 基本 hotspots ボトムアップ
51

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
共分散行列のデモ: 基本 hotspots ソースコード
52

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
共分散行列のデモ: 基本 hotspots ソースコードインテル® VTune™ Amplifier により検出された hotspot
オープンソースの code.py
NumPy* を使用してベクトル化
53
© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
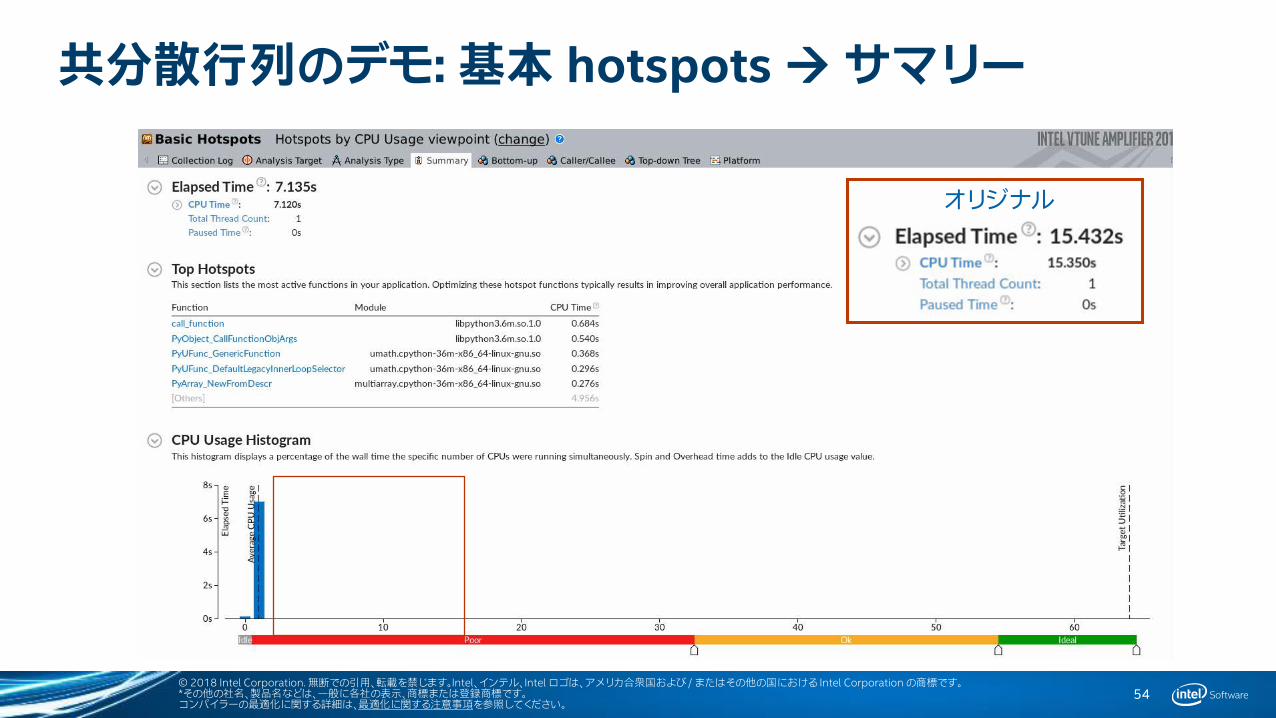
共分散行列のデモ: 基本 hotspots サマリー
オリジナル
54

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
共分散行列のデモ: 基本 hotspots トップダウン
55

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
共分散行列のデモ: 基本 hotspots ソースコード
56

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
共分散行列のデモ: 基本 hotspots ソースコードインテル® VTune™ Amplifier により検出された hotspot
オープンソースの code.py
NumPy* を使用してベクトル化
57

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
共分散行列のデモ: 基本 hotspots サマリー
オリジナル
ベクトル化適用後
58

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
共分散行列のデモ: NumPy* と PyDAAL 大きなデータセット4000 万要素の行列
デフォルトのスレッド化を使用
NumPy* コード
PyDAAL コード
NumPy* の結果 PyDAAL の結果
59

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
共分散行列のデモ: NumPy* と PyDAAL 大きなデータセット4000 万要素の行列
デフォルトのスレッド化を使用NumPy* のスレッド化の結果
PyDAAL のスレッド化の結果
60

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
1
10
100
1000
10000
100000
1000000
一部をベクトル化 さらにベクトル化 Numpy* PyDAAL
オリジナルのループに対するスピードアップ (対数)
100 万要素 250 万要素 500 万要素 750 万要素 1000 万要素 2500 万要素
前述の手法で共分散を特定
さまざまなデータセット・サイズ
オリジナルのループとの比較 (対数)
メモリー: 4GB (x72、ECC、SR) 288 ピン DDR4 RDIMMOS: Ubuntu* 16.04
61
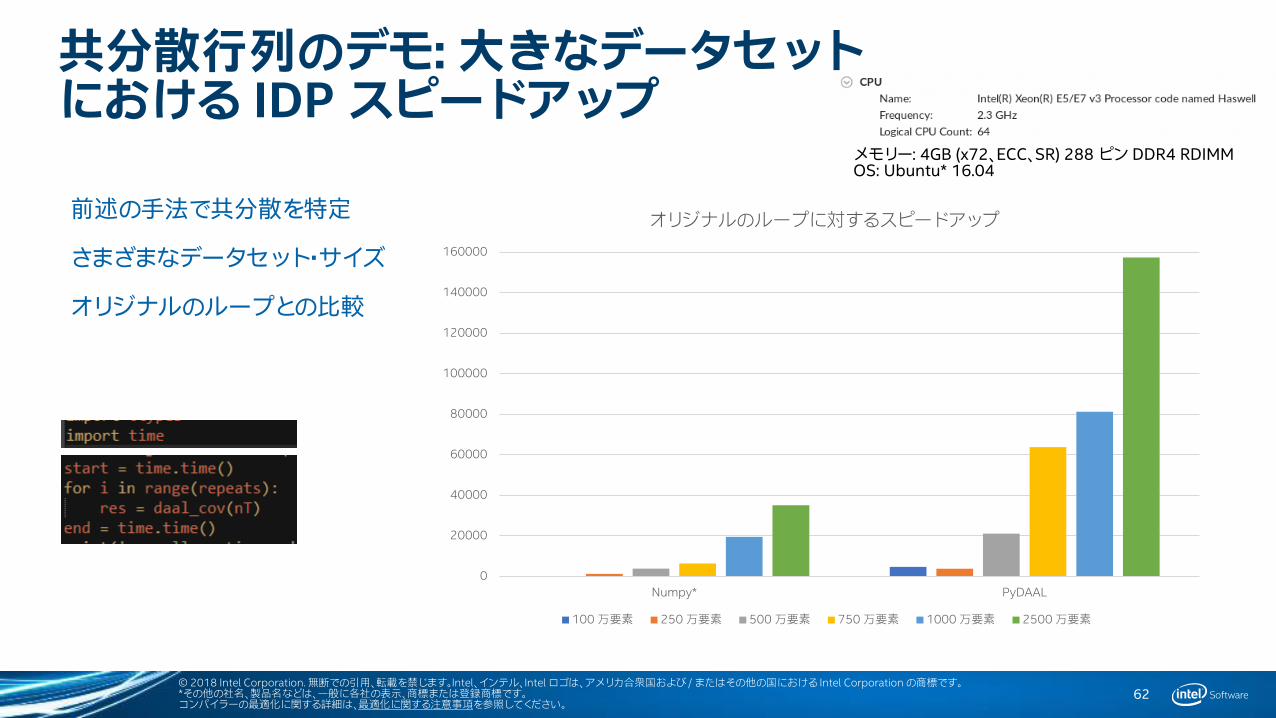
共分散行列のデモ: 大きなデータセットにおける IDP スピードアップ
© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
共分散行列のデモ: 大きなデータセットにおける IDP スピードアップ
0
20000
40000
60000
80000
100000
120000
140000
160000
Numpy* PyDAAL
オリジナルのループに対するスピードアップ
100 万要素 250 万要素 500 万要素 750 万要素 1000 万要素 2500 万要素
62
前述の手法で共分散を特定
さまざまなデータセット・サイズ
オリジナルのループとの比較
メモリー: 4GB (x72、ECC、SR) 288 ピン DDR4 RDIMMOS: Ubuntu* 16.04

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
共分散行列のデモ: impi
ローカルおよびマスター PyDAAL 関数を定義 Python* で実行ルーチンを記述
メモリー: 4GB (x72、ECC、SR) 288 ピン DDR4 RDIMMOS: Ubuntu* 16.04
63

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
共分散行列のデモ: impi
MPI_Procs PyDAAL 実行時間 (秒)1 0.3082 0.254 0.149
16 0.08332 0.04664 0.089
128 0.31
メモリー: 4GB (x72、ECC、SR) 288 ピン DDR4 RDIMMOS: Ubuntu* 16.04
64

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
インテル® Distribution for Python* のダウンロードインテル® VTune™ Amplifier のダウンロードパフォーマンスの高速化を体験してくださいsoftware.intel.com (英語) からチュートリアルとサンプルコードを入手可能
インテル® Distribution for Python*https://www.isus.jp/python-distribution/
インテル® VTune™ Amplifierhttps://www.isus.jp/intel-vtune-amplifier-xe/
関連情報
65

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
法務上の注意書きと最適化に関する注意事項本資料の情報は、現状のまま提供され、本資料は、明示されているか否かにかかわらず、また禁反言によるとよらずにかかわらず、いかなる知的財産権のライセンスも許諾するものではありません。製品に付属の売買契約書『Intel's Terms and Conditions of Sale』に規定されている場合を除き、インテルはいかなる責任を負うものではなく、またインテル製品の販売や使用に関する明示または黙示の保証 (特定目的への適合性、商品性に関する保証、第三者の特許権、著作権、その他、知的財産権の侵害への保証を含む) をするものではありません。
性能に関するテストに使用されるソフトウェアとワークロードは、性能がインテル® マイクロプロセッサー用に最適化されていることがあります。SYSmark* や MobileMark* などの性能テストは、特定のコンピューター・システム、コンポーネント、ソフトウェア、操作、機能に基づいて行ったものです。結果はこれらの要因によって異なります。製品の購入を検討される場合は、他の製品と組み合わせた場合の本製品の性能など、ほかの情報や性能テストも参考にして、パフォーマンスを総合的に評価することをお勧めします。
© 2018 Intel Corporation. 無断での引用、転載を禁じます。Intel、インテル、Intel ロゴ、Intel Inside、Intel Inside ロゴ、Intel Atom、Intel Core、Xeon、Intel Xeon Phi、VTune は、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。
最適化に関する注意事項
インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。
注意事項の改訂 #20110804
66

© 2018 Intel Corporation.無断での引用、転載を禁じます。Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。*その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。


















