

PyCon UA 2016
57
What is the best full text search engine for Python? Andrii Soldatenko 23-24 April 2016 @a_soldatenko
-
Upload
andrii-soldatenko -
Category
Internet
-
view
1.500 -
download
4
Transcript of PyCon UA 2016

What is the best full text search engine
for Python?Andrii Soldatenko 23-24 April 2016 @a_soldatenko

Agenda:• Who am I?
• What is full text search?
• PostgreSQL FTS / Elastic / Whoosh
• Pros and Cons
• What’s next?

Andrii Soldatenko
• Backend Python Developer at
• CTO in Persollo.com
• Speaker at many PyCons and Python meetups
• blogger at https://asoldatenko.com

Preface

Text Search
➜ cpython time ack OrderedDict
ack OrderedDict 2.53s user 0.22s system 94% cpu 2.915 total
➜ cpython time pt OrderedDict
pt OrderedDict 0.14s user 0.12s system 406% cpu 0.064 total
➜ cpython time pss OrderedDict
pss OrderedDict 1.08s user 0.14s system 88% cpu 1.370 total
➜ cpython time grep -r -i 'OrderedDict' .
grep -r -i 'OrderedDict' 2.70s user 0.13s system 94% cpu 2.998 total

Full text search

Search index

Simple sentences
1. The quick brown fox jumped over the lazy dog
2. Quick brown foxes leap over lazy dogs in summer

Inverted index

Inverted index
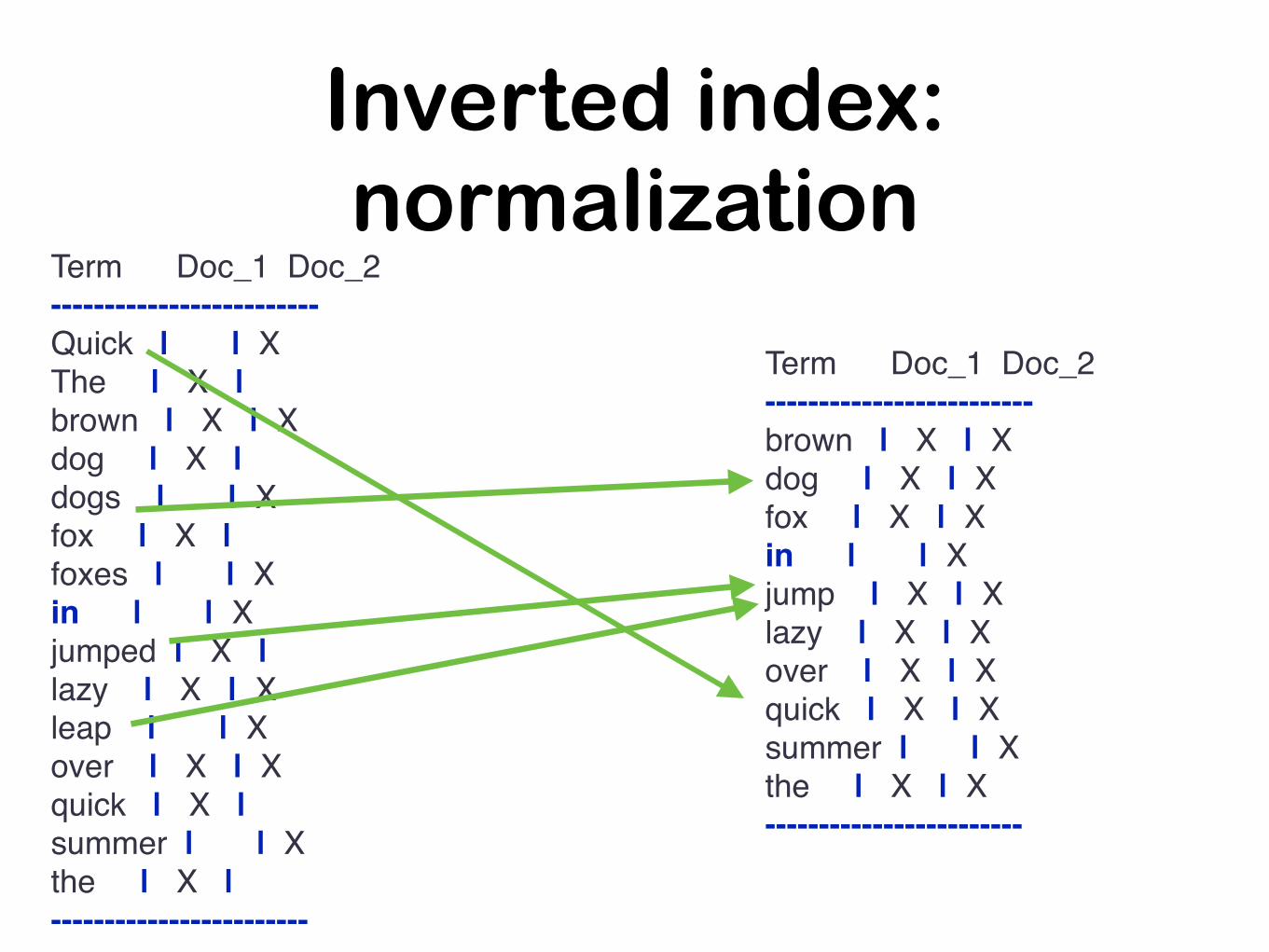
Inverted index: normalization
Term Doc_1 Doc_2-------------------------brown | X | Xdog | X | Xfox | X | Xin | | Xjump | X | Xlazy | X | Xover | X | Xquick | X | Xsummer | | Xthe | X | X------------------------
Term Doc_1 Doc_2-------------------------Quick | | XThe | X |brown | X | Xdog | X |dogs | | Xfox | X |foxes | | Xin | | Xjumped | X |lazy | X | Xleap | | Xover | X | Xquick | X |summer | | Xthe | X |------------------------

Search Engines

PostgreSQL Full Text Search
support from version 8.3

PostgreSQL Full Text Search
SELECT to_tsvector('text') @@ to_tsquery('query');
Simple is better than complex. - by import this

SELECT 'python conference ukraine 2016'::tsvector @@
'python & ukraine'::tsquery;
?column?
----------
t
(1 row)
Do PostgreSQL FTS without index

Do PostgreSQL FTS with index
CREATE INDEX name ON table USING GIN (column);
CREATE INDEX name ON table USING GIST (column);

PostgreSQL FTS: Ranking Search Results
ts_rank() -> float4 - based on the frequency of their matching lexemes
ts_rank_cd() -> float4 - cover density ranking for the given document vector and query

PostgresSQL FTS Highlighting Results
SELECT ts_headline('english', 'python conference ukraine 2016', to_tsquery('python & 2016'));
ts_headline---------------------------------------------- <b>python</b> conference ukraine <b>2016</b>

Stop Words
postgresql/9.5.2/share/postgresql/tsearch_data/english.stop

PostgresSQL FTS Stop Words
SELECT to_tsvector('in the list of stop words');
to_tsvector---------------------------- 'list':3 'stop':5 'word':6

PG FTSand Python
• Django 1.10 django.contrib.postgres.search
(36 hours ago)
• djorm-ext-pgfulltext
• sqlalchemy

PostgreSQL FTS integration with django orm
https://github.com/linuxlewis/djorm-ext-pgfulltext
from djorm_pgfulltext.models import SearchManagerfrom djorm_pgfulltext.fields import VectorFieldfrom django.db import models
class Page(models.Model): name = models.CharField(max_length=200) description = models.TextField()
search_index = VectorField()
objects = SearchManager( fields = ('name', 'description'), config = 'pg_catalog.english', # this is default search_field = 'search_index', # this is default auto_update_search_field = True )
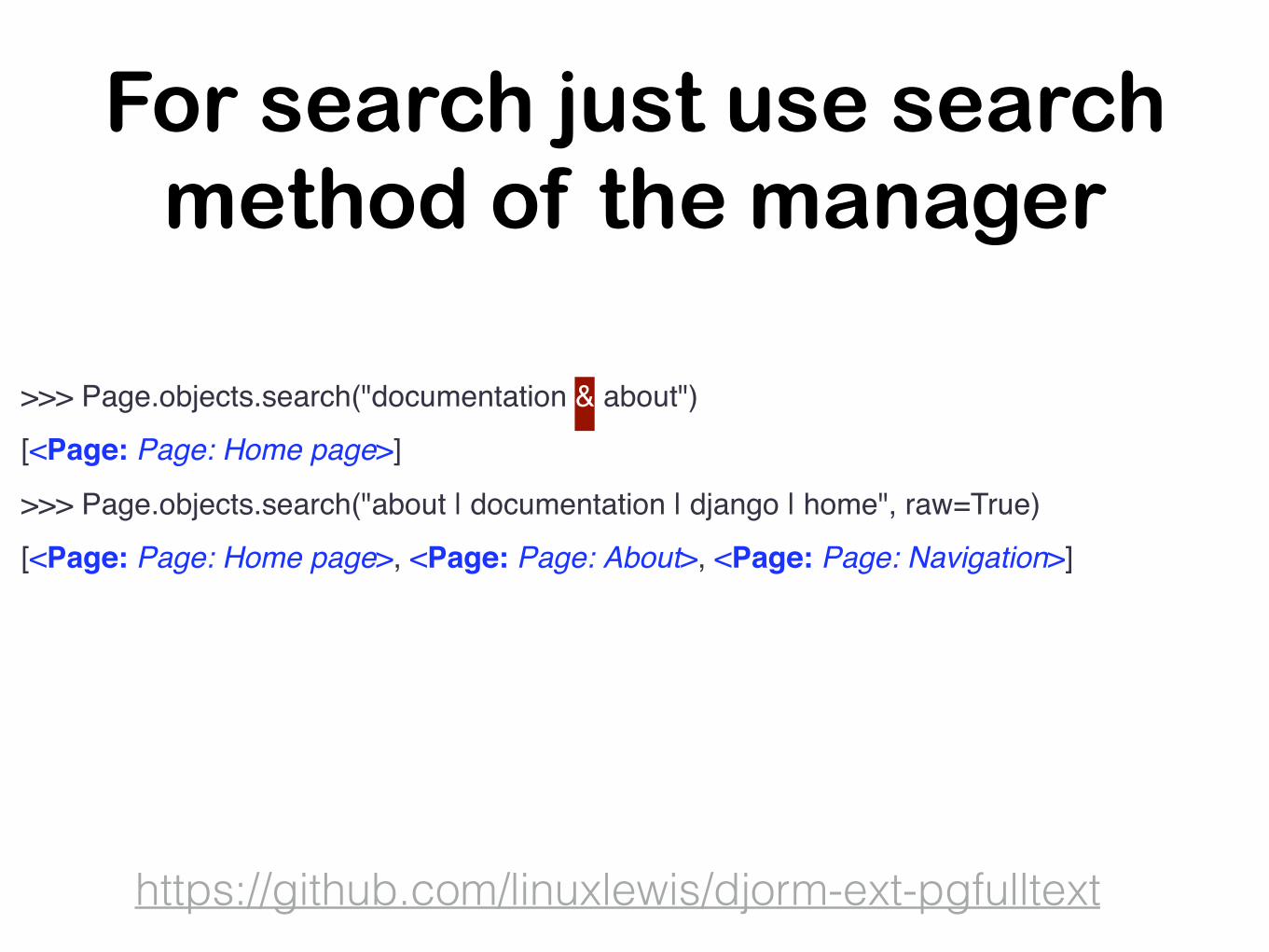
For search just use search method of the manager
https://github.com/linuxlewis/djorm-ext-pgfulltext
>>> Page.objects.search("documentation & about")[<Page: Page: Home page>]
>>> Page.objects.search("about | documentation | django | home", raw=True)[<Page: Page: Home page>, <Page: Page: About>, <Page: Page: Navigation>]

Django 1.10>>> Entry.objects.filter(body_text__search='recipe') [<Entry: Cheese on Toast recipes>, <Entry: Pizza recipes>]
>>> Entry.objects.annotate( ... search=SearchVector('blog__tagline', 'body_text'), ... ).filter(search='cheese') [ <Entry: Cheese on Toast recipes>, <Entry: Pizza Recipes>, <Entry: Dairy farming in Argentina>, ]
https://github.com/django/django/commit/2d877da

Pros and ConsPros:
• Quick implementation • No dependency
Cons:
• Need manually manage indexes • depend on PostgreSQL • no analytics data • no DSL only `&` and `|` queries • difficult to manage stop words

ElasticSearch

Who uses ElasticSearch?
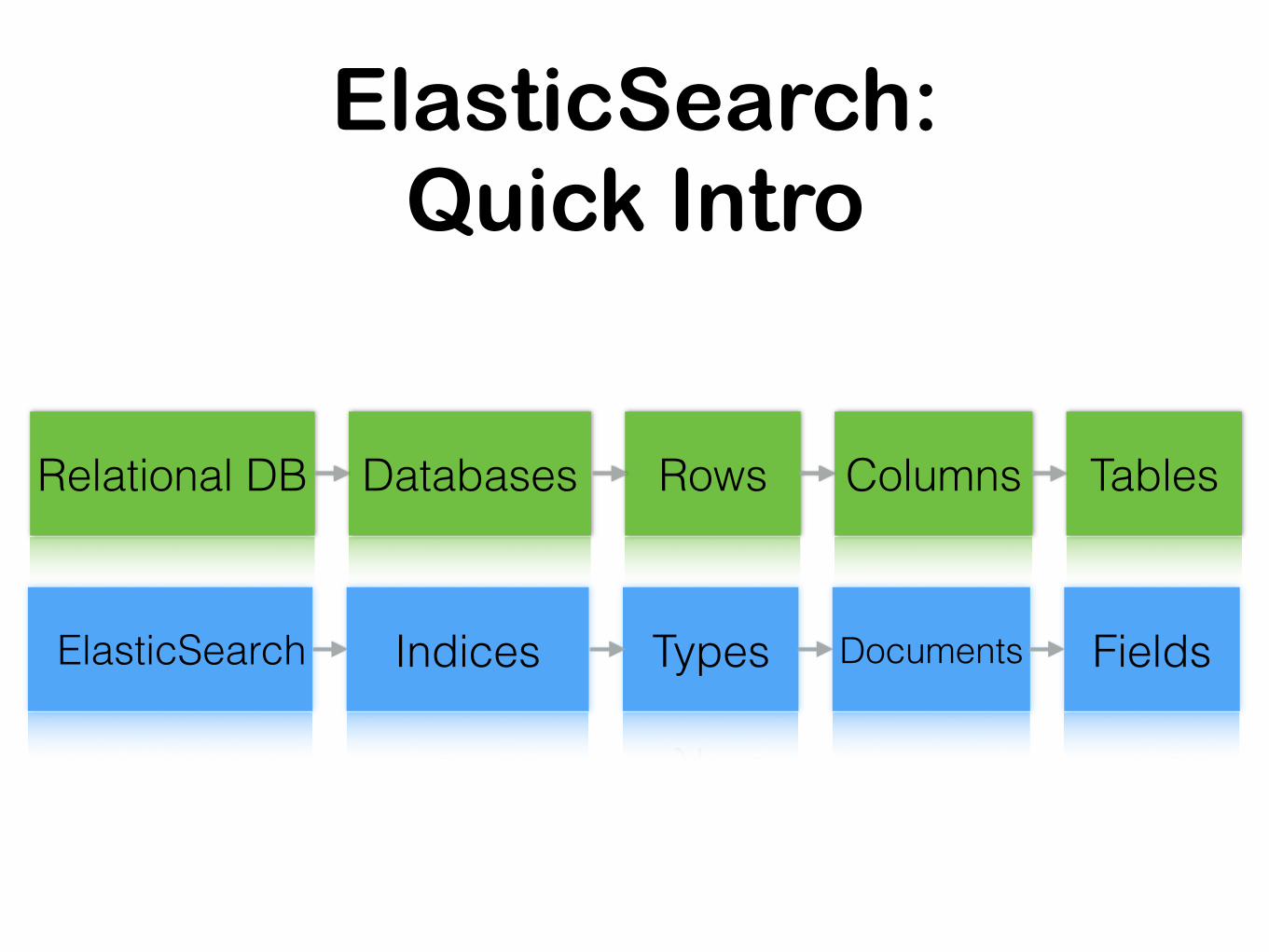
ElasticSearch: Quick Intro
Relational DB Databases TablesRows Columns
ElasticSearch Indices FieldsTypes Documents

ElasticSearch: Locks
•Pessimistic concurrency control
•Optimistic concurrency control

ElasticSearch and Python
• elasticsearch-py
• elasticsearch-dsl-py by Honza Kral
• elasticsearch-py-async by Honza Kral

ElasticSearch: FTS
$ curl -XGET 'http://localhost:9200/pyconua/talk/_search' -d '{ "query": { "match": { "user": "Andrii" } }}'

ES: Create Index$ curl -XPUT 'http://localhost:9200/twitter/' -d '{ "settings" : { "index" : { "number_of_shards" : 3, "number_of_replicas" : 2 } }}'

ES: Add json to Index
$ curl -XPUT 'http://localhost:9200/pyconua/talk/1' -d '{ "user" : "andrii", "description" : "Full text search"}'

ES: Stopwords$ curl -XPUT 'http://localhost:9200/pyconua' -d '{ "settings": { "analysis": { "analyzer": { "my_english": { "type": "english", "stopwords_path": "stopwords/english.txt" } } } }}'

ES: Highlight
$ curl -XGET 'http://localhost:9200/pyconua/talk/_search' -d '{ "query" : {...}, "highlight" : { "pre_tags" : ["<tag1>"], "post_tags" : ["</tag1>"], "fields" : { "_all" : {} } }}'

ES: Relevance
$ curl -XGET 'http://localhost:9200/_search?explain -d '{ "query" : { "match" : { "user" : "andrii" }}}'
"_explanation": { "description": "weight(tweet:honeymoon in 0) [PerFieldSimilarity], result of:", "value": 0.076713204, "details": [...]}

Whoosh
• Pure-Python
• Whoosh was created by Matt Chaput.
• Pluggable scoring algorithm (including BM25F)
• more info at video from PyCon US 2013

Whoosh: Stop wordsimport os.pathimport textwrap
names = os.listdir("stopwords")for name in names: f = open("stopwords/" + name) wordls = [line.strip() for line in f] words = " ".join(wordls) print '"%s": frozenset(u"""' % name print textwrap.fill(words, 72) print '""".split())'
http://anoncvs.postgresql.org/cvsweb.cgi/pgsql/src/backend/snowball/stopwords/

Whoosh: Highlight
results = pycon.search(myquery)for hit in results: print(hit["title"]) # Assume "content" field is stored print(hit.highlights("content"))

Whoosh: Ranking search results
• Pluggable scoring algorithm
• including BM25F

Haystack

Adding search functionality to Simple Model
$ cat myapp/models.py
from django.db import modelsfrom django.contrib.auth.models import User
class Page(models.Model): user = models.ForeignKey(User) name = models.CharField(max_length=200) description = models.TextField()
def __unicode__(self): return self.name

Haystack: Installation$ pip install django-haystack
$ cat settings.py
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.sites',
# Added. 'haystack',
# Then your usual apps... 'blog',]

Haystack: Installation
$ pip install elasticsearch
$ cat settings.py...HAYSTACK_CONNECTIONS = { 'default': { 'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine', 'URL': 'http://127.0.0.1:9200/', 'INDEX_NAME': 'haystack', },}...

Haystack: Creating SearchIndexes
$ cat myapp/search_indexes.py
import datetimefrom haystack import indexesfrom myapp.models import Note
class PageIndex(indexes.SearchIndex, indexes.Indexable): text = indexes.CharField(document=True, use_template=True) author = indexes.CharField(model_attr='user') pub_date = indexes.DateTimeField(model_attr='pub_date')
def get_model(self): return Note
def index_queryset(self, using=None): """Used when the entire index for model is updated.""" return self.get_model().objects. \ filter(pub_date__lte=datetime.datetime.now())

Haystack: SearchQuerySet API
from haystack.query import SearchQuerySetfrom haystack.inputs import Raw
all_results = SearchQuerySet().all()
hello_results = SearchQuerySet().filter(content='hello')
unfriendly_results = SearchQuerySet().\ exclude(content=‘hello’).\ filter(content=‘world’)
# To send unescaped data:sqs = SearchQuerySet().filter(title=Raw(trusted_query))

Keeping data in sync# Update everything../manage.py update_index --settings=settings.prod
# Update everything with lots of information about what's going on../manage.py update_index --settings=settings.prod --verbosity=2
# Update everything, cleaning up after deleted models../manage.py update_index --remove --settings=settings.prod
# Update everything changed in the last 2 hours../manage.py update_index --age=2 --settings=settings.prod
# Update everything between Dec. 1, 2011 & Dec 31, 2011./manage.py update_index --start='2011-12-01T00:00:00' --end='2011-12-31T23:59:59' --settings=settings.prod

Signalsclass RealtimeSignalProcessor(BaseSignalProcessor): """ Allows for observing when saves/deletes fire & automatically updates the search engine appropriately. """ def setup(self): # Naive (listen to all model saves). models.signals.post_save.connect(self.handle_save) models.signals.post_delete.connect(self.handle_delete) # Efficient would be going through all backends & collecting all models # being used, then hooking up signals only for those.
def teardown(self): # Naive (listen to all model saves). models.signals.post_save.disconnect(self.handle_save) models.signals.post_delete.disconnect(self.handle_delete) # Efficient would be going through all backends & collecting all models # being used, then disconnecting signals only for those.

Haystack: Pros and Cons
Pros:
• easy to setup • looks like Django ORM but for searches • search engine independent • support 4 engines (Elastic, Solr, Xapian, Whoosh)
Cons:
• poor SearchQuerySet API • difficult to manage stop words • loose performance, because extra layer • Model - based

ResultsPython clients Python 3 Django
support
elasticsearch-pyelasticsearch-dsl-
pyelasticsearch-py-
async
YES haystack +elasticstack
psycopg2 YES
djorm-ext-pgfulltext
django.contrib.postgres
Whoosh YES support using haystack

ResultsIndexes Without indexes
PUT /index/ No support
GIN/GIST to_tsvector()
index folder No support
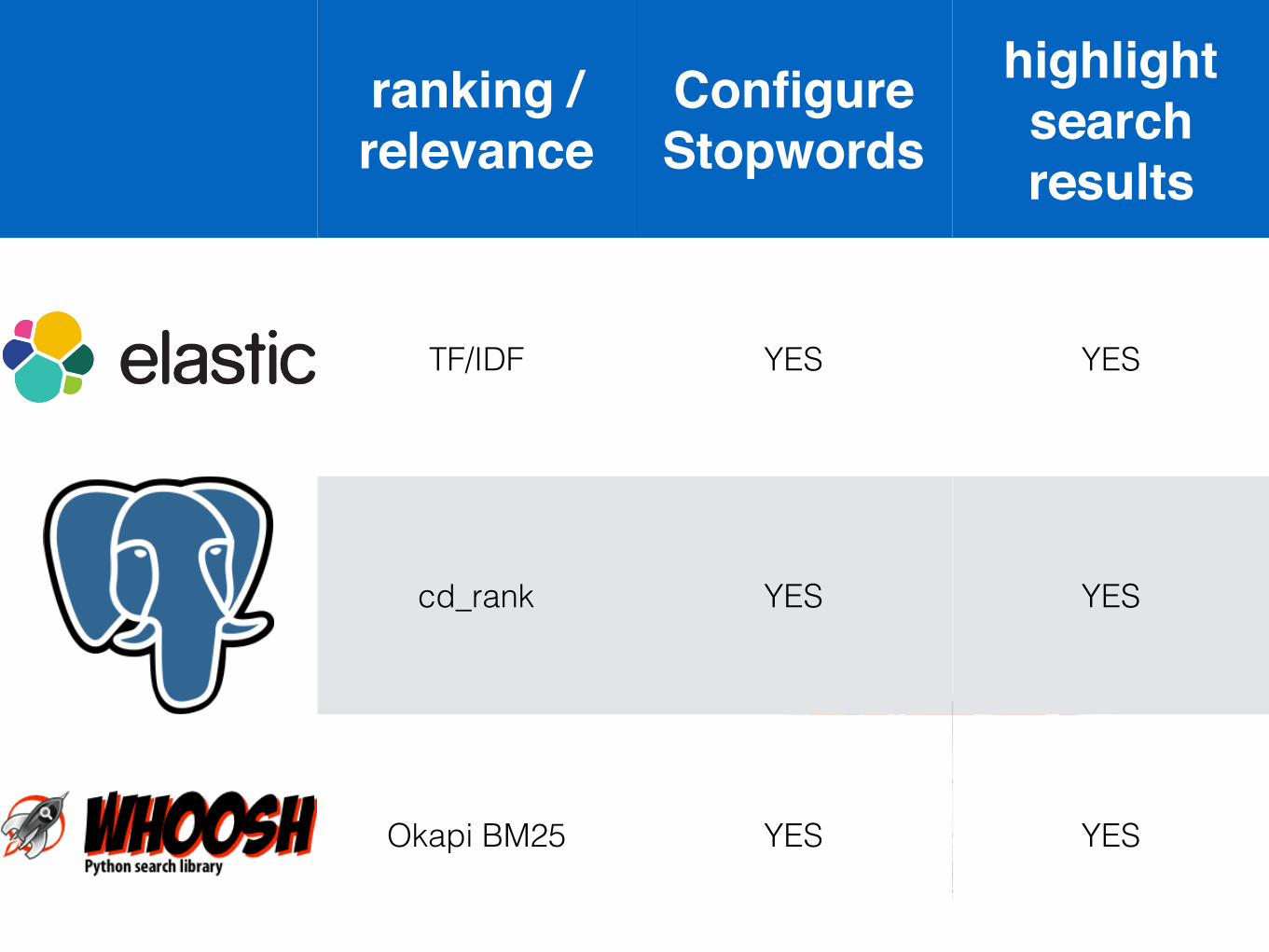
Resultsranking / relevance
Configure Stopwords
highlight search results
TF/IDF YES YES
cd_rank YES YES
Okapi BM25 YES YES

ResultsSynonyms Scale
YES YES
NO SUPPORT I’m not sure
NO SUPPORT NO

Final Thoughts

Questions
?

We are hiring
https://www.toptal.com/#connect-fantastic-computer-engineers













![PyCon APAC 2016 Regular Expression[A-Z]+](https://static.fdocuments.net/doc/165x107/58f9ad5a760da3da068b9760/pycon-apac-2016-regular-expressiona-z.jpg)




