Publish-subscribe Message Framework with Apache Kafka and...
157
Publish-subscribe Message Framework with Apache Kafka and Kinesis Presented by:- Prince Kumar Aashish Ranjan Raghavendra Tiwari Joel joy
Transcript of Publish-subscribe Message Framework with Apache Kafka and...

Publish-subscribe Message Framework withApache Kafka and Kinesis
Presented by:-
Prince Kumar
Aashish Ranjan
Raghavendra Tiwari
Joel joy

CONTENT
Introduction of Messaging Framework
Pub-sub model
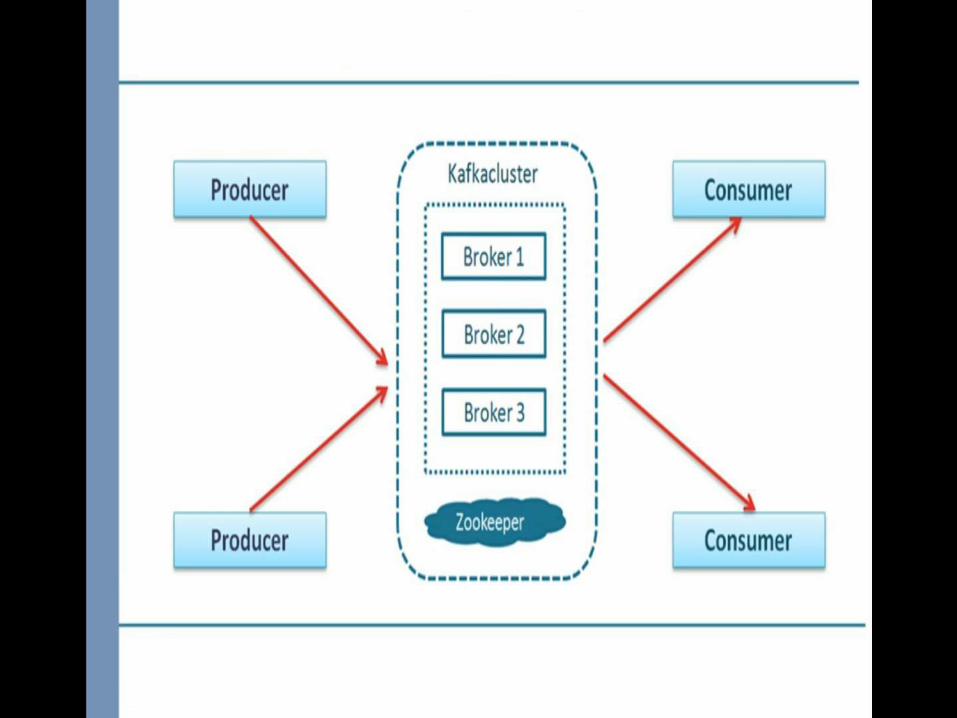
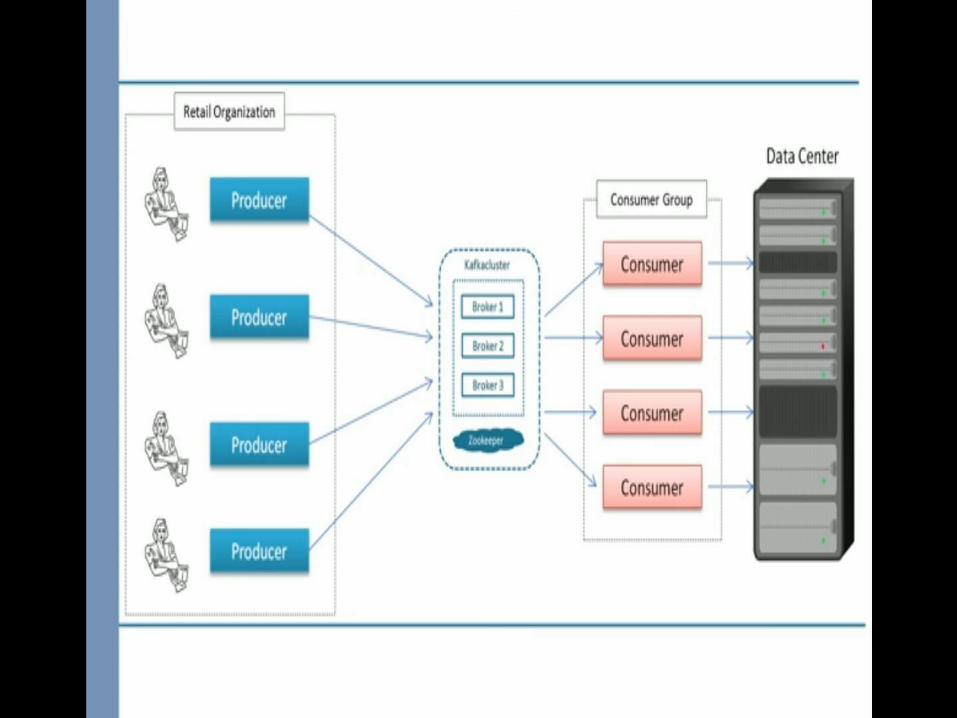
Publish subscribe Messaging Framework architecture
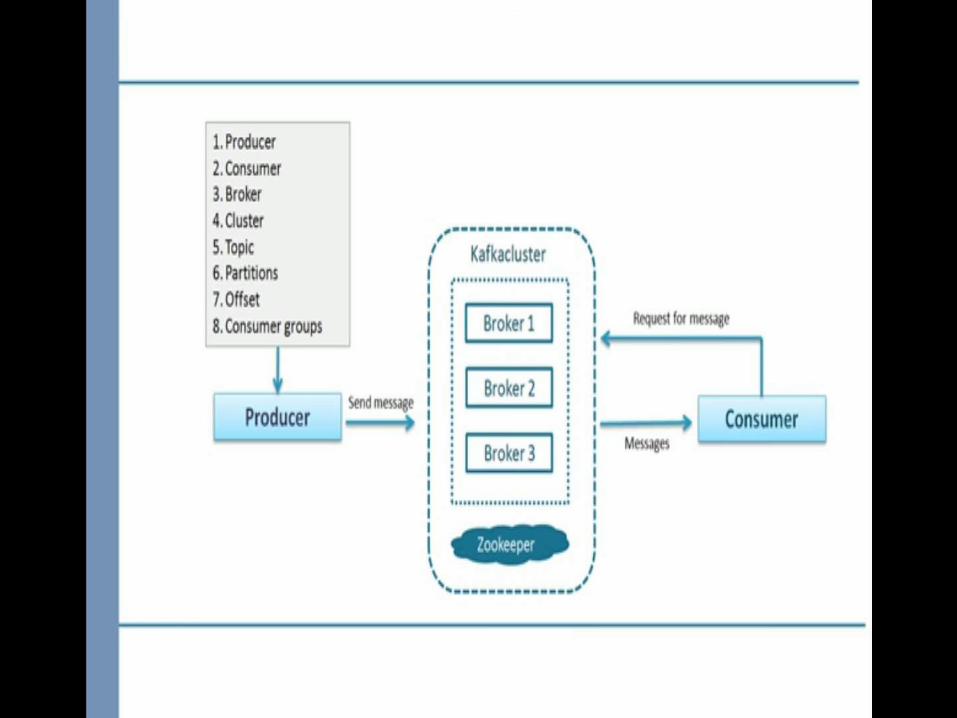
Introduction of zookeeper
Zookeeper core concepts
Zookeeper architecture
Introduction of Kafka
Kafka elementary concepts
Kafka architecture
How Kafka works in the messaging Framework
Introduction of Firehouse and Kinesis Analytics
Key concepts of kinesis
Uses of Amazon kinesis analytics
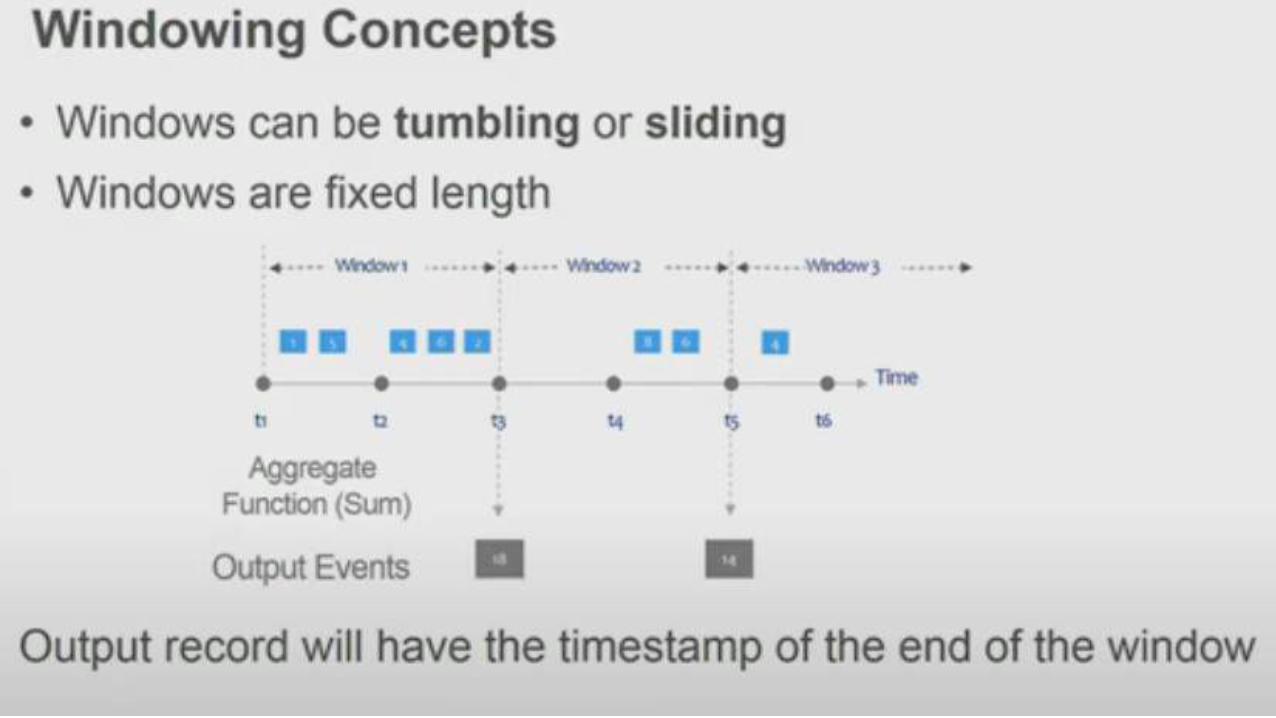
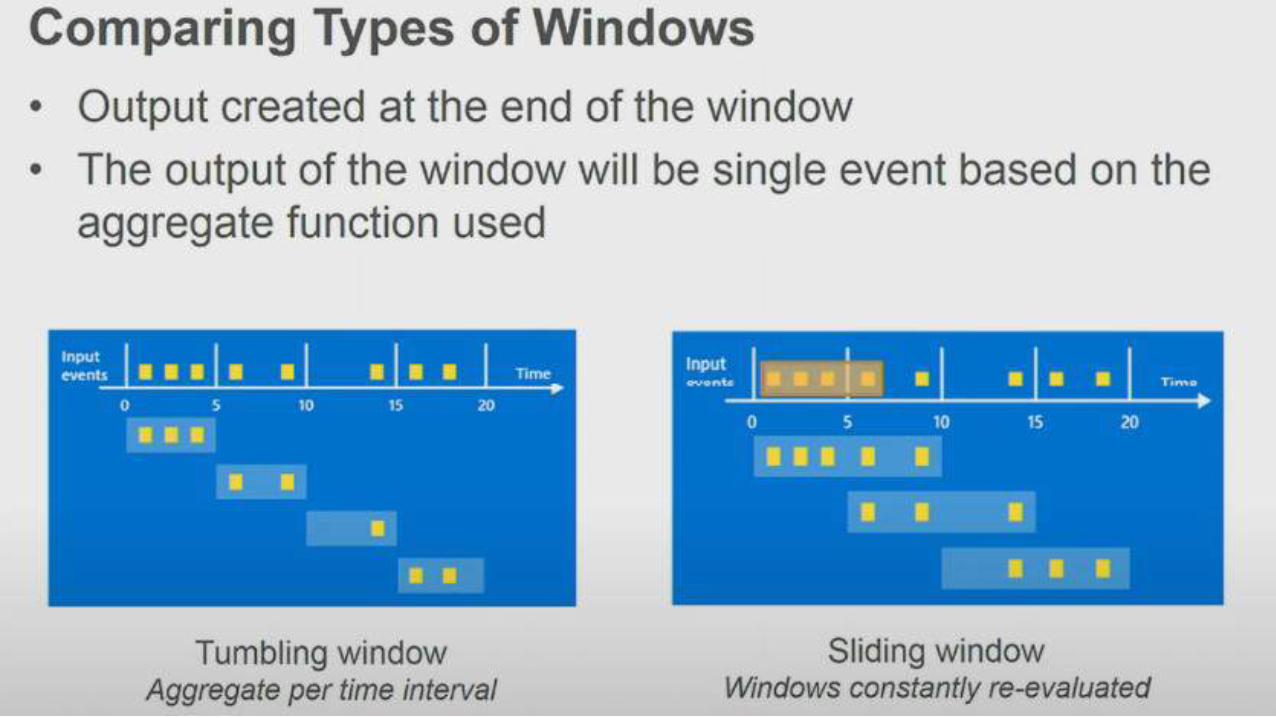
Windowing concepts

Publish-subscribe
Message Framework
with Apache Kafka
and Kinesis

Lets discuss first about Publish-Subscribe messaging framework

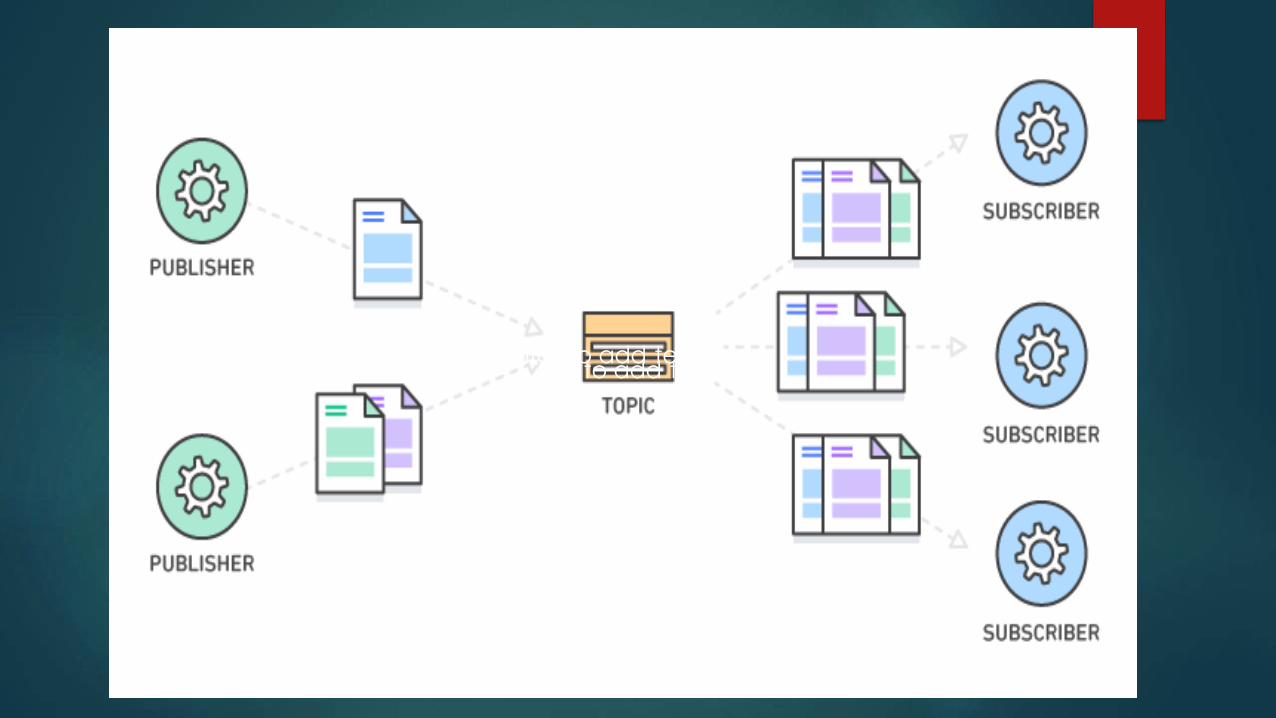
The Publish/Subscribe pattern, also known as Pub/Sub, is an architectural design pattern
that provides a framework for exchanging messages between publishers and subscribers. This pattern
involves the publisher and the subscriber relying on a message broker that relays messages from the publisher to the subscribers. The host (publisher)
publishes messages (events) to a channel that subscribers can then sign up to.

• Four core concepts make up the pub/sub model:• Topic – An intermediary channel that maintains a list
of subscribers to relay messages to that are
received from publishers
• Message – Serialized messages sent to a topic by a
publisher which has no knowledge of thesubscribers
• Publisher – The application that publishes a
message to a topic
• Subscriber – An application that registers itself with
the desired topic in order to receive the appropriatemessages

In topic-based system, messages are published to "topics" or named logical channels. Subscribers in a topic-based system
will receive all messages published to the topics to which
they subscribe. The publisher is responsible for defining the
topics to which subscribers can subscribe.
The process of selecting messages for reception and processing is
called filtering. There are two common forms of filtering: topic-based and content-based.
In a content-based system, messages are only delivered to a subscriber if the attributes or content of those
messages matches constraints defined by the subscriber.
The subscriber is responsible for classifying the messages.1.

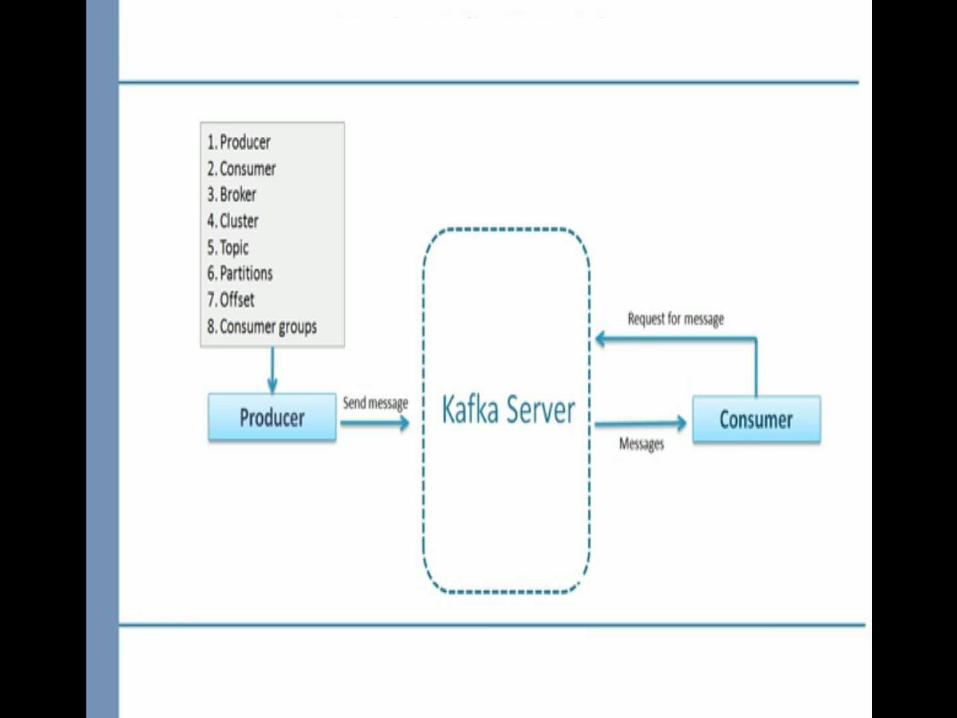
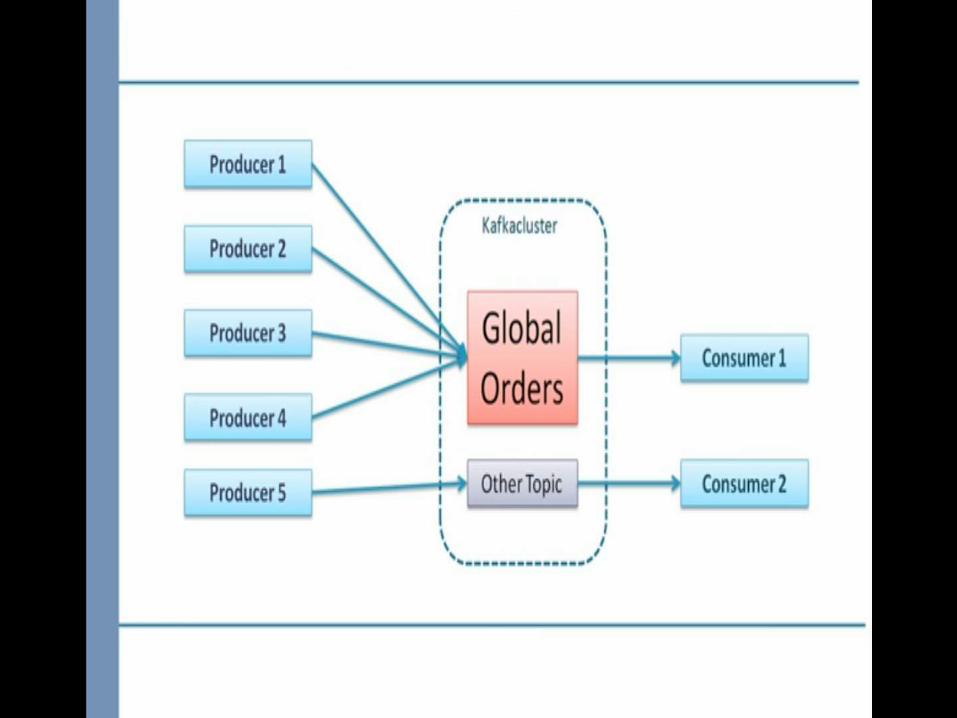
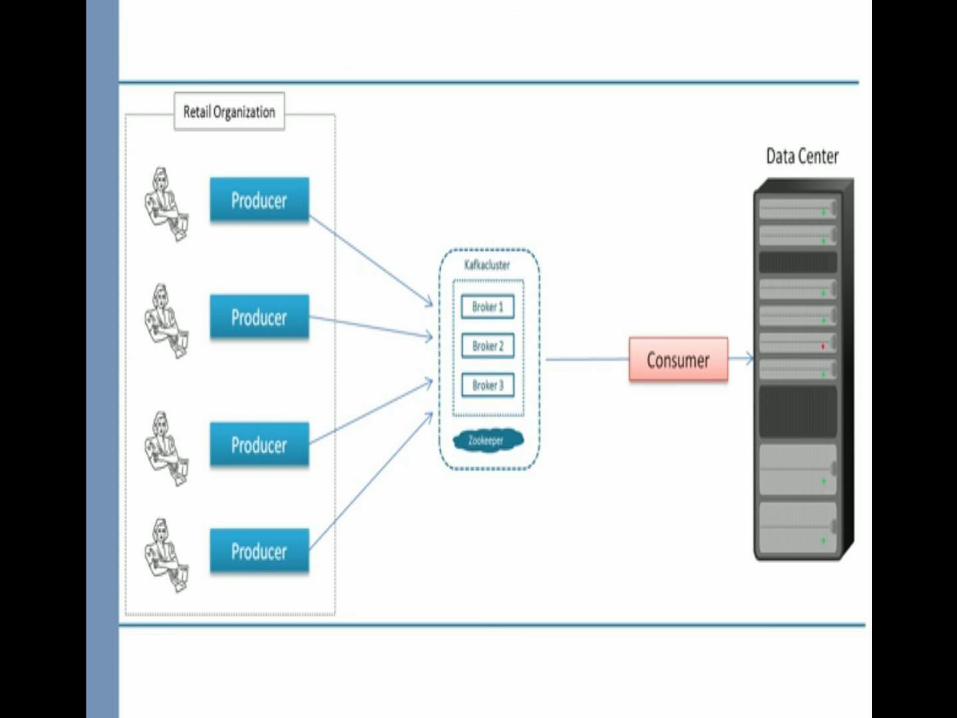
Publish-Subscribe Message Framework architecture
Click to add textClick to add text

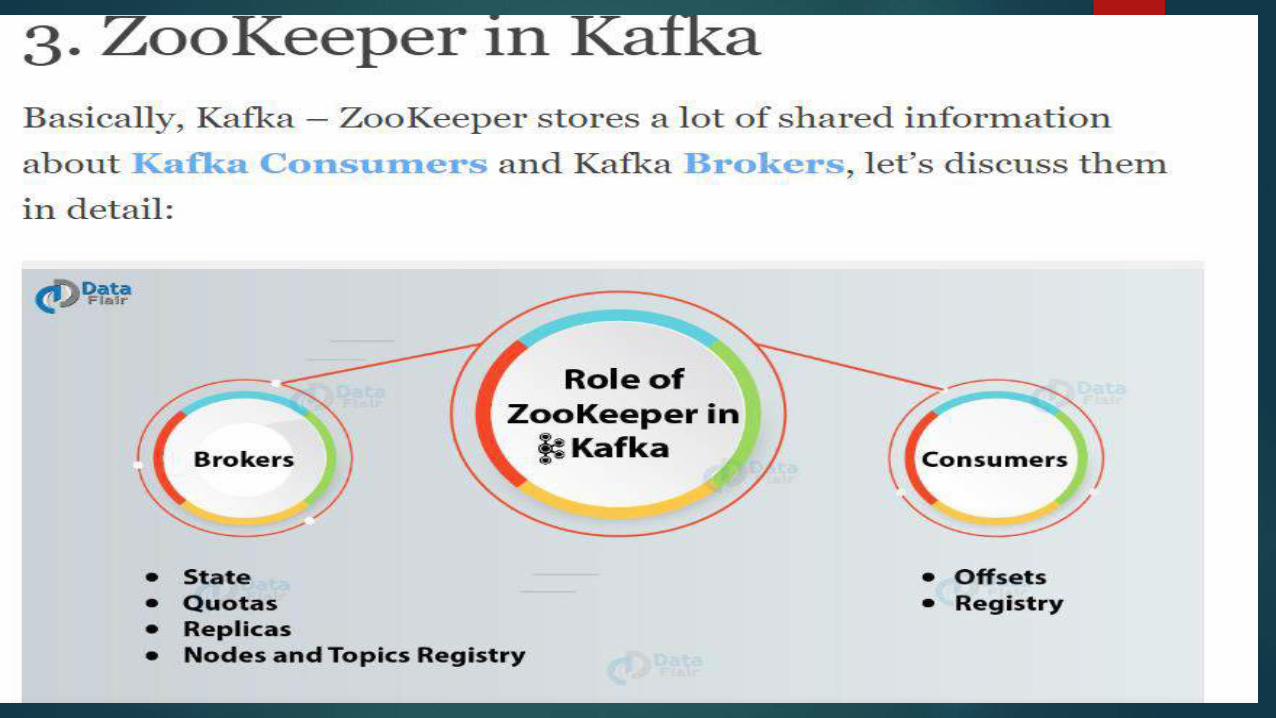
Lets discuss about zookeeper.
It is one of the essential part of kafka so we should understand it clearly.


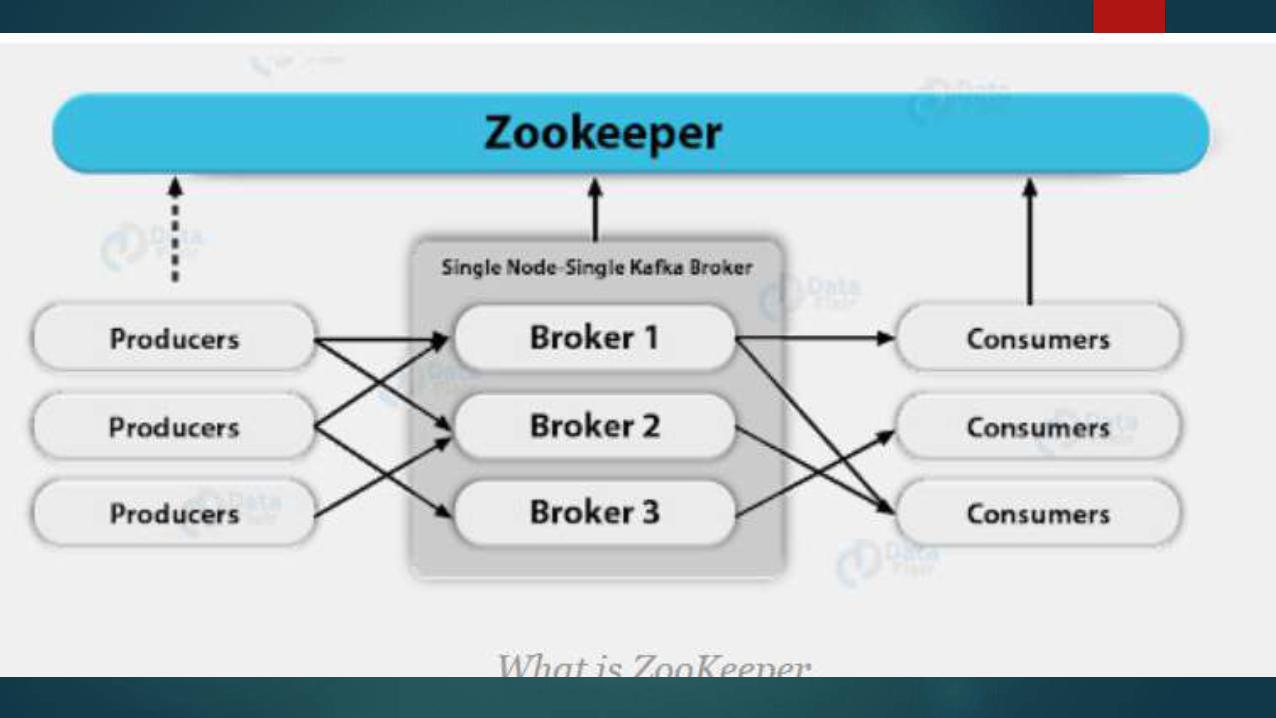

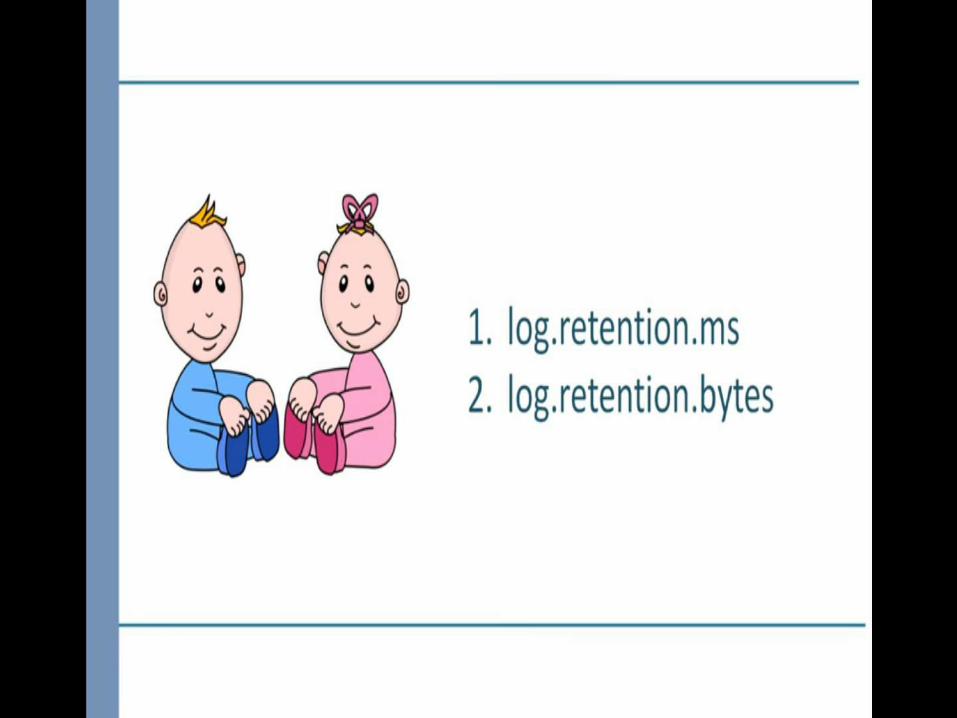
Zookeeper properties


Producer


• Small or medium piece of data
• For kafka, an array of bytes


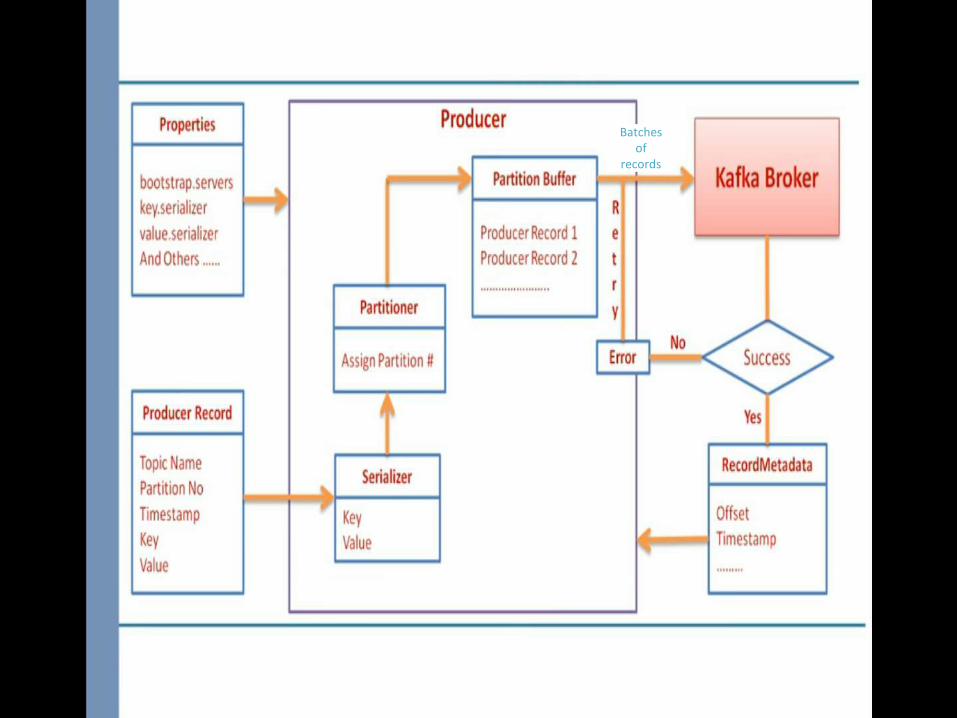
Batches of
records

Ways of sending messages

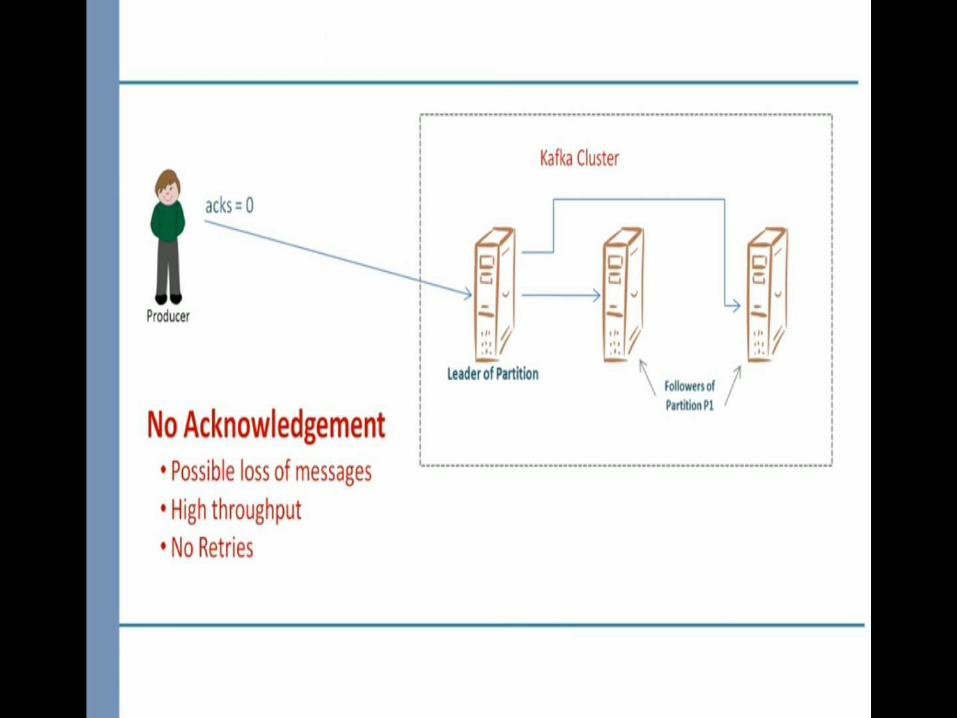
Send the Message and Forget it

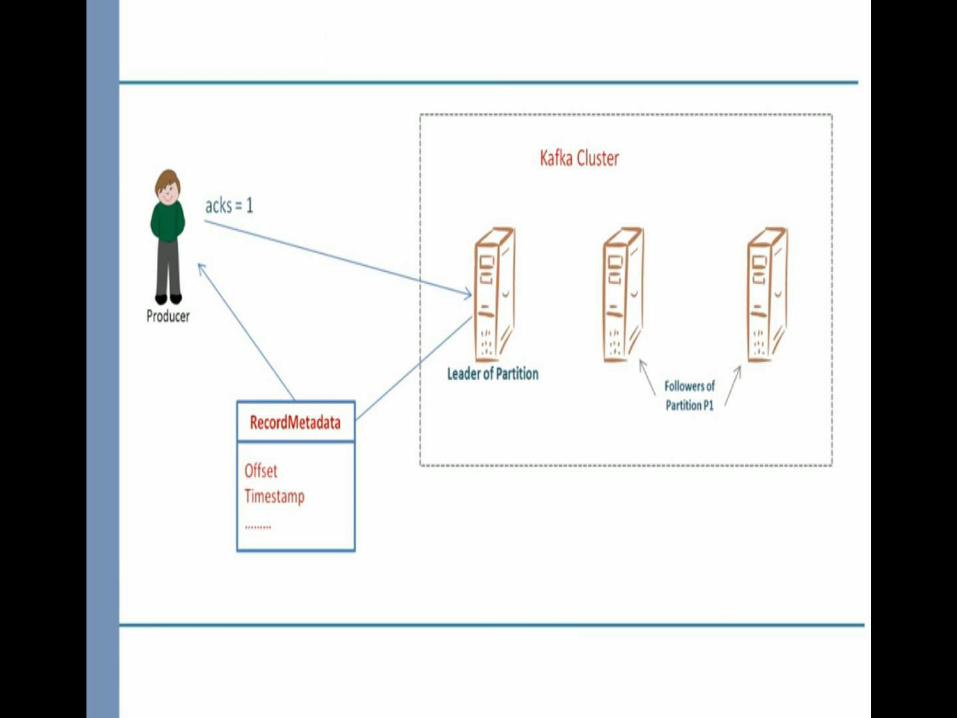
Send the message and wait for acknowledgment

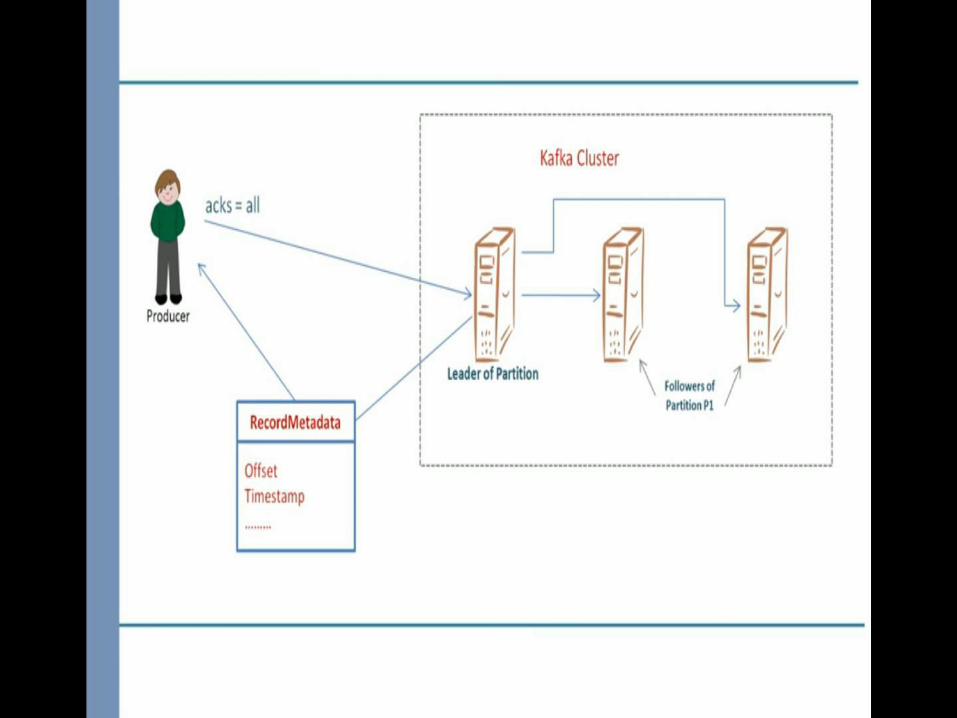
Send the message and use call back function for acknowledgment


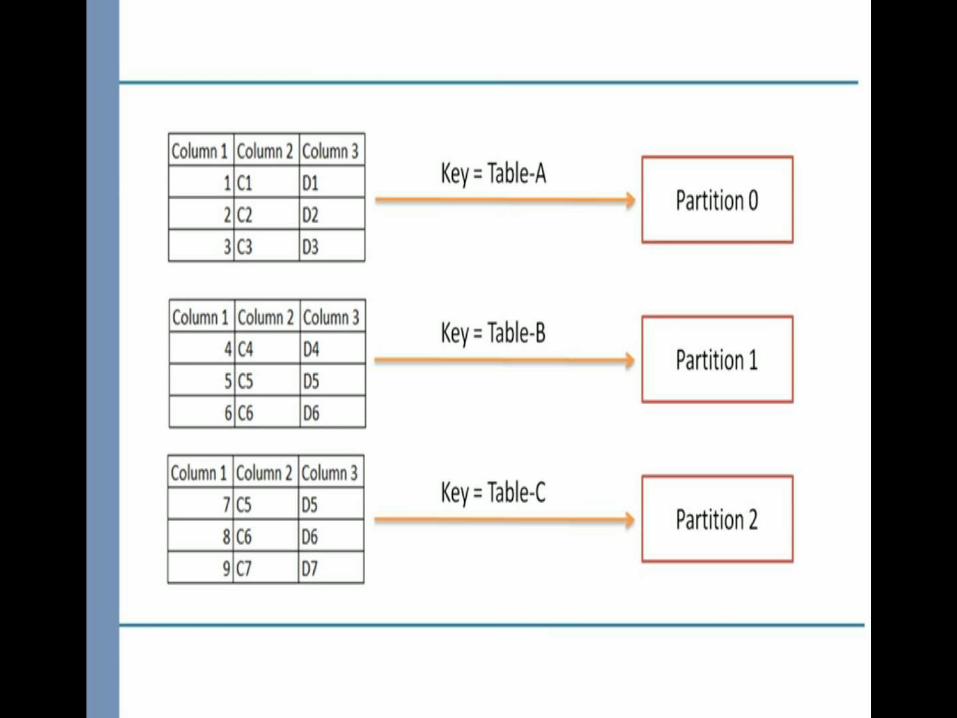
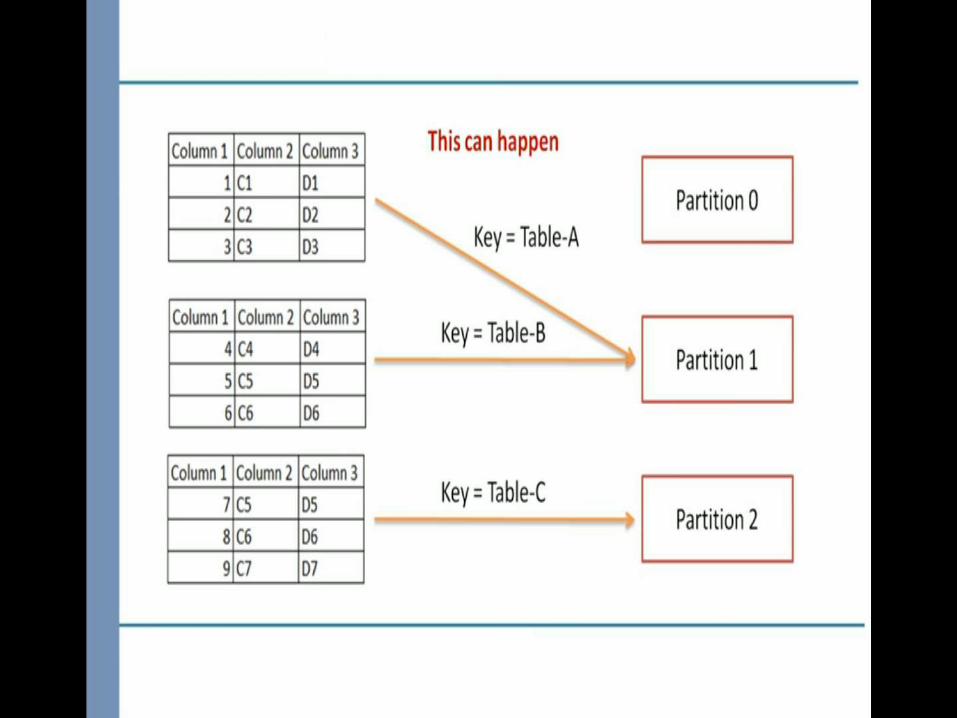
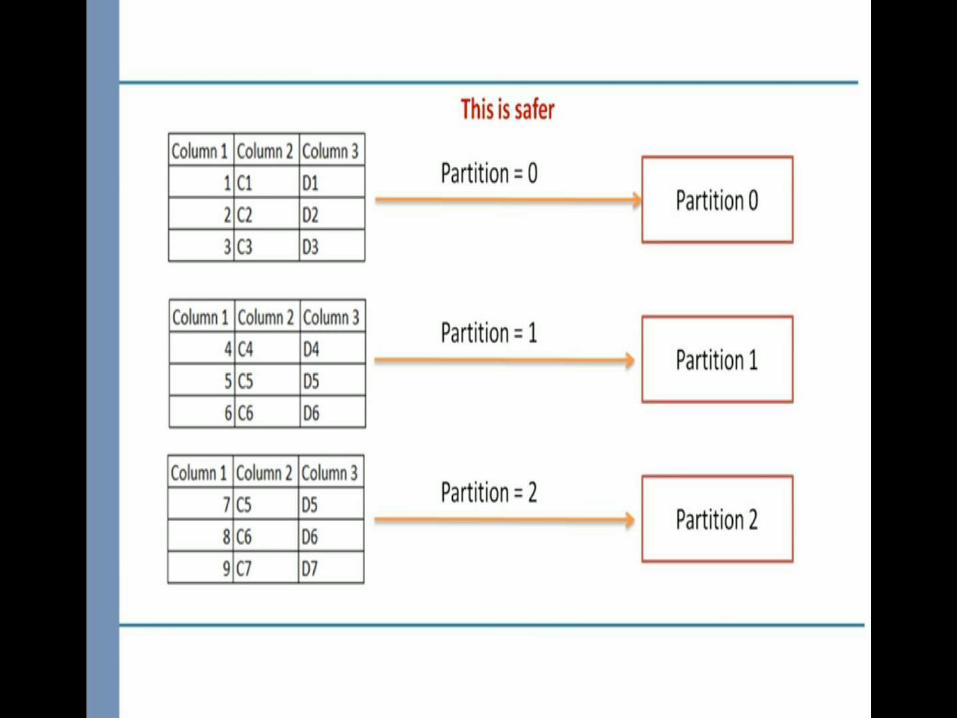

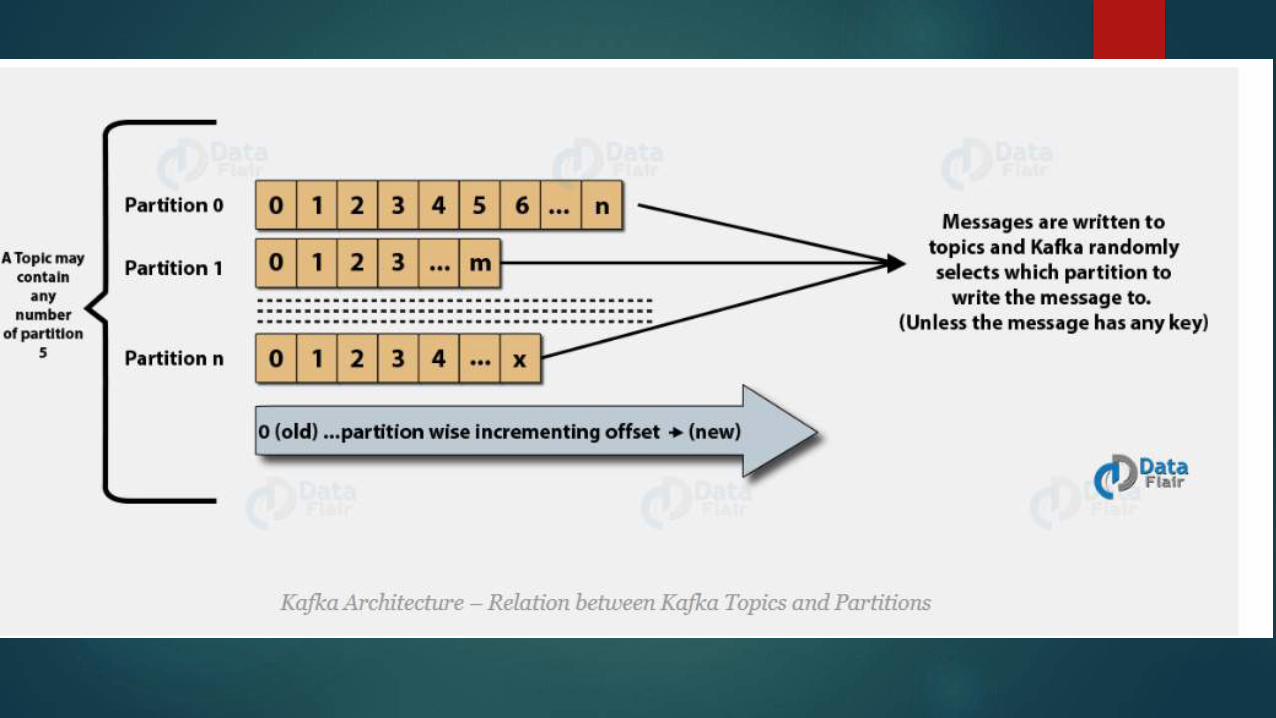
Since partition number is decided on the basis of mod of hash value of key and total number of partition . So, partition number
will change for a key as we increase the number of partition

Automatic Partition
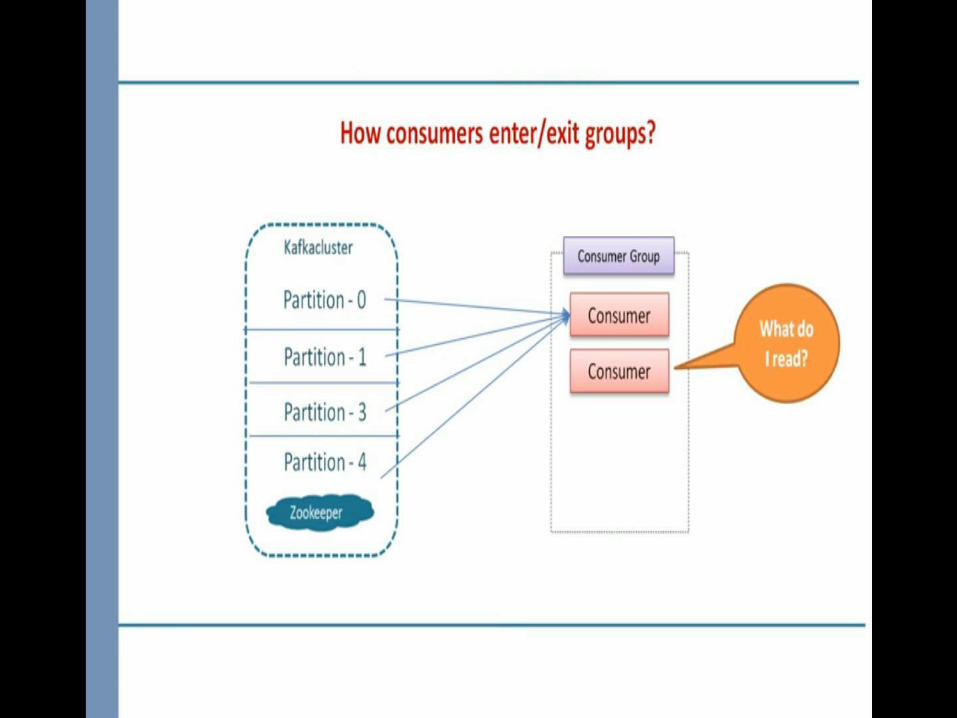
We don’t which partition goes to which consumer
Use Round Robin Strategy

Custom Partitioner
• Allow to decide partition number for different kinds of messages
• Allow to process messages coming from certain number of partition



retries
Allow to access the number of retry and time between two retries
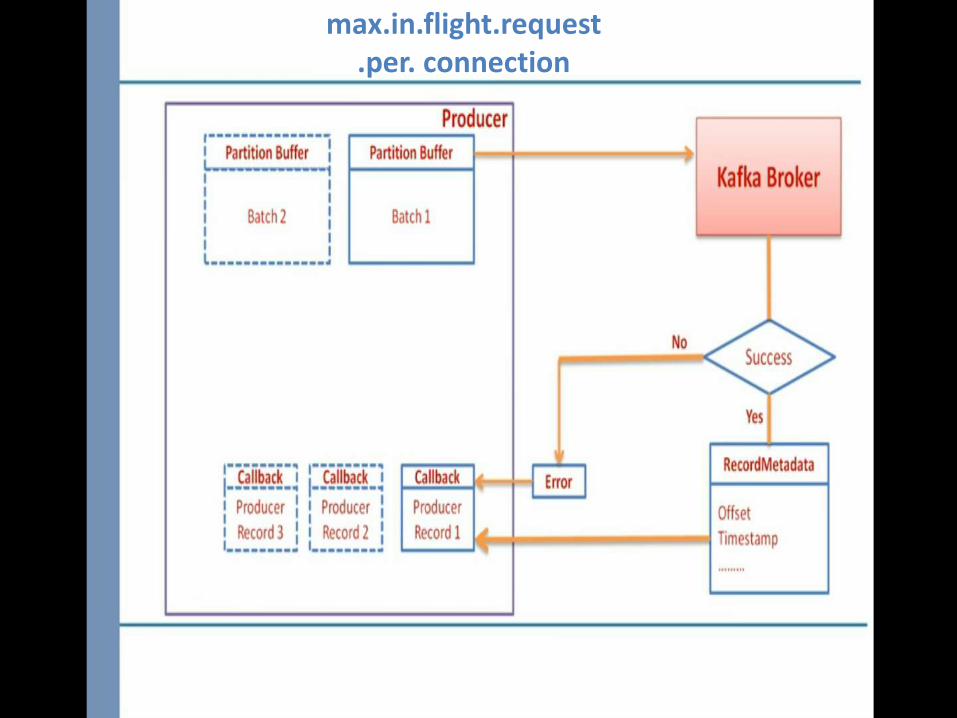
max.in.flight.request.per. connection
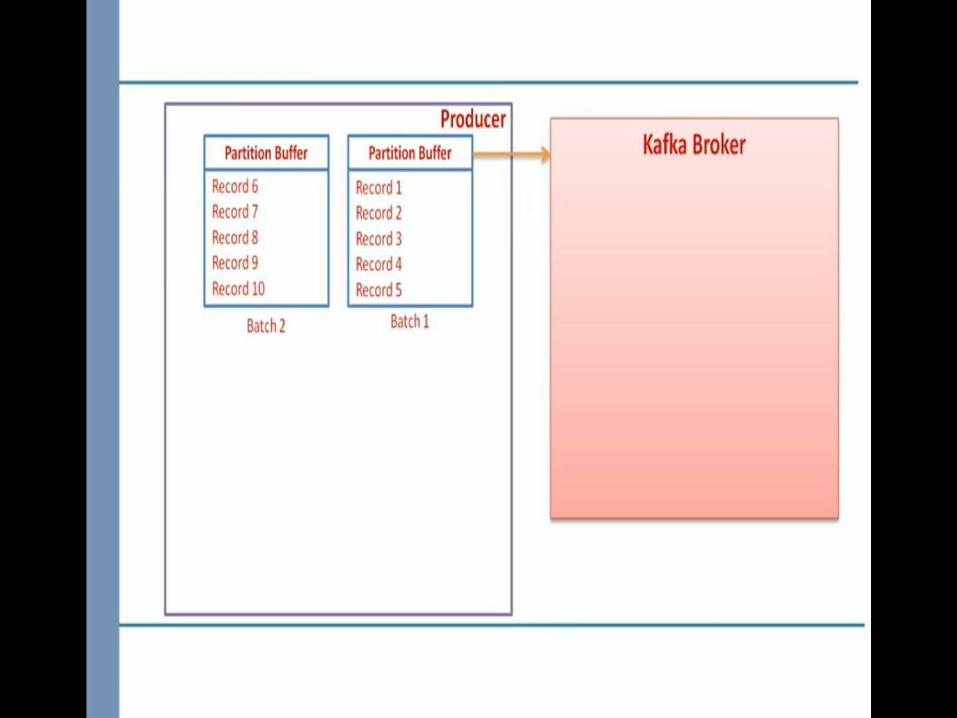
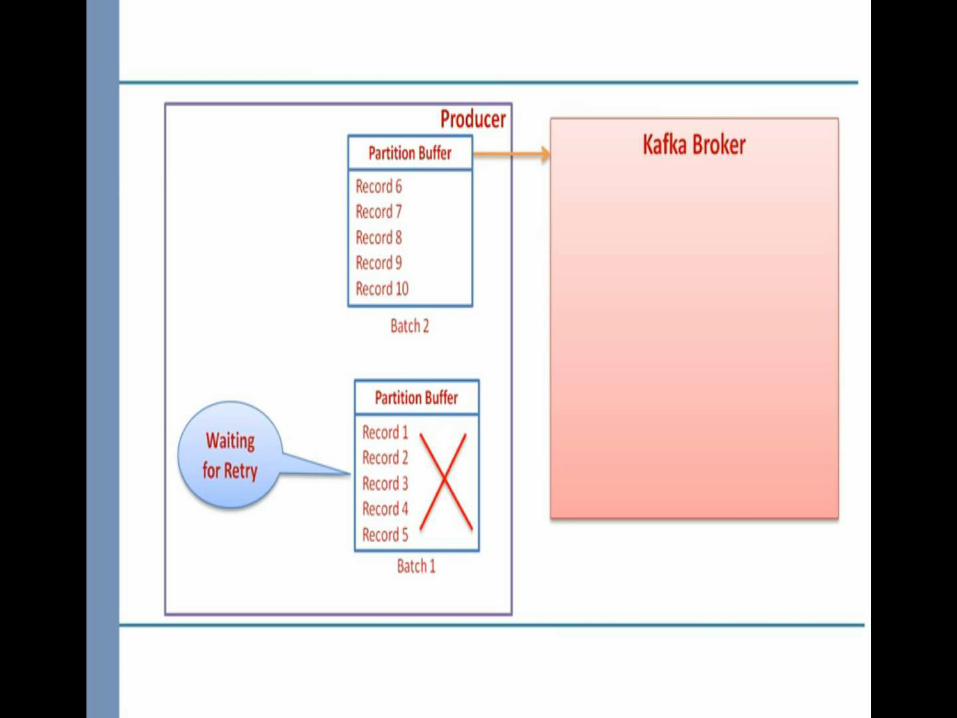
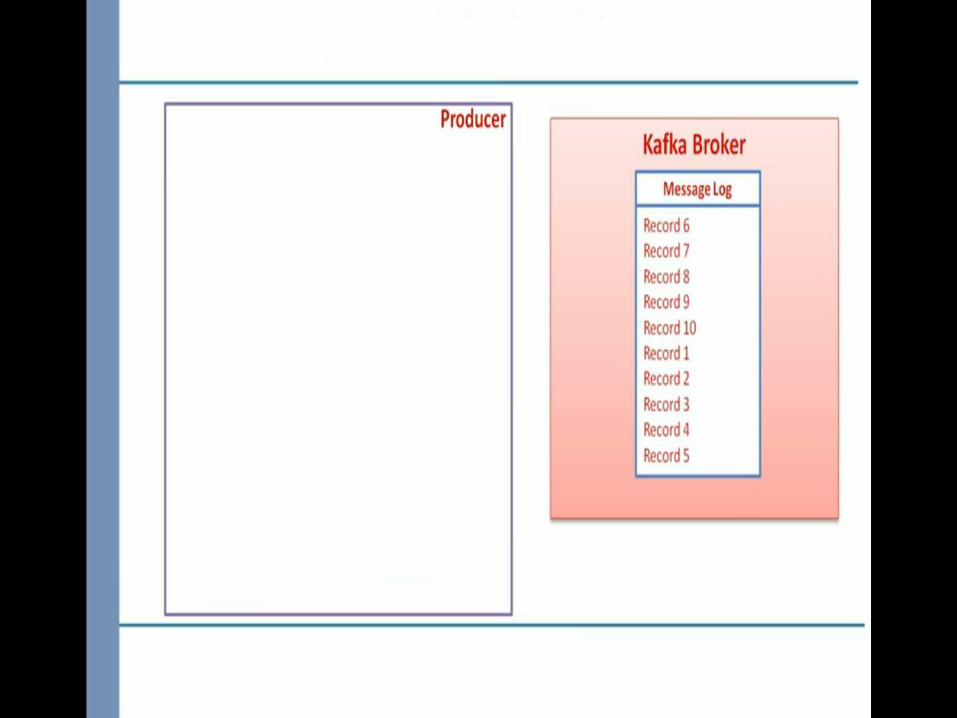


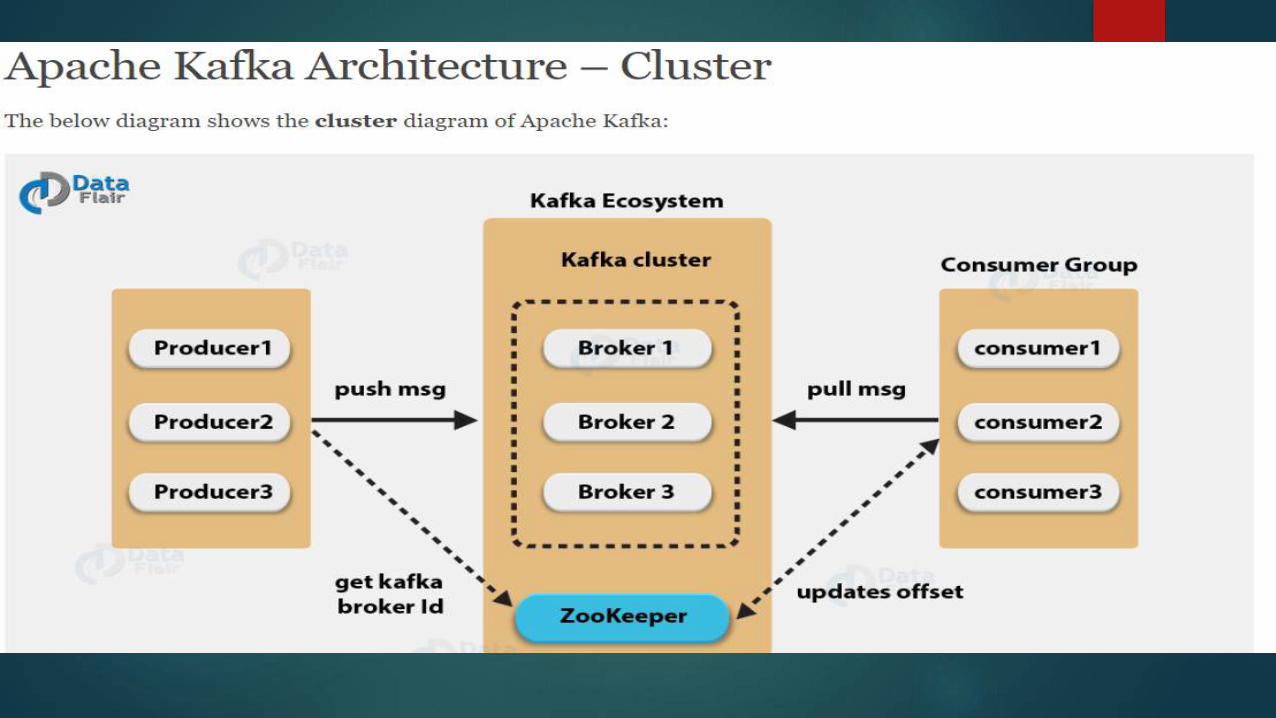
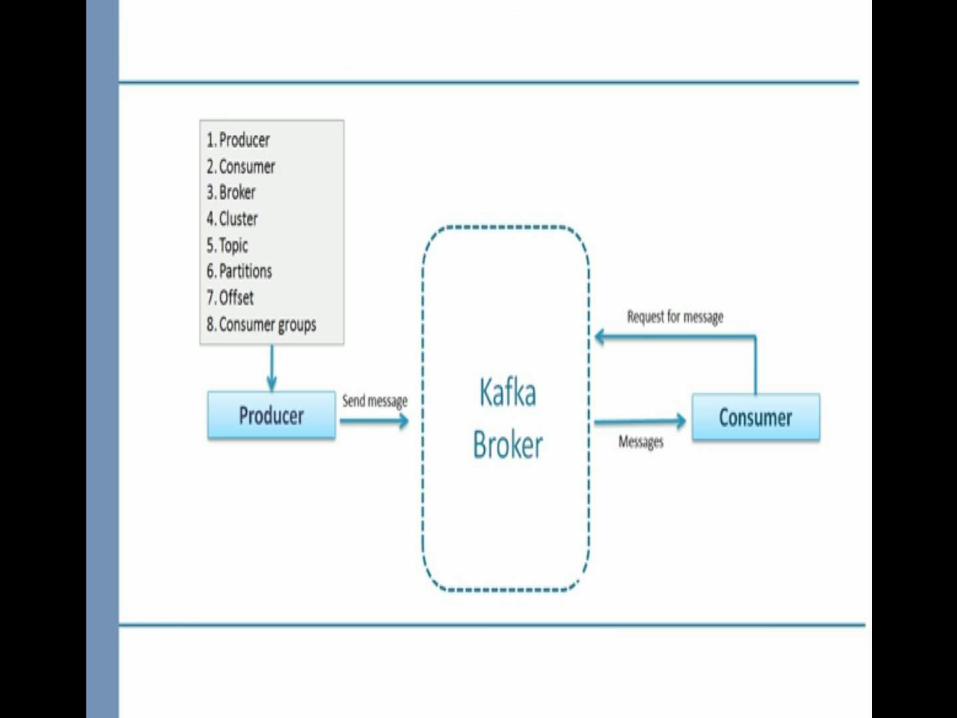
Broker

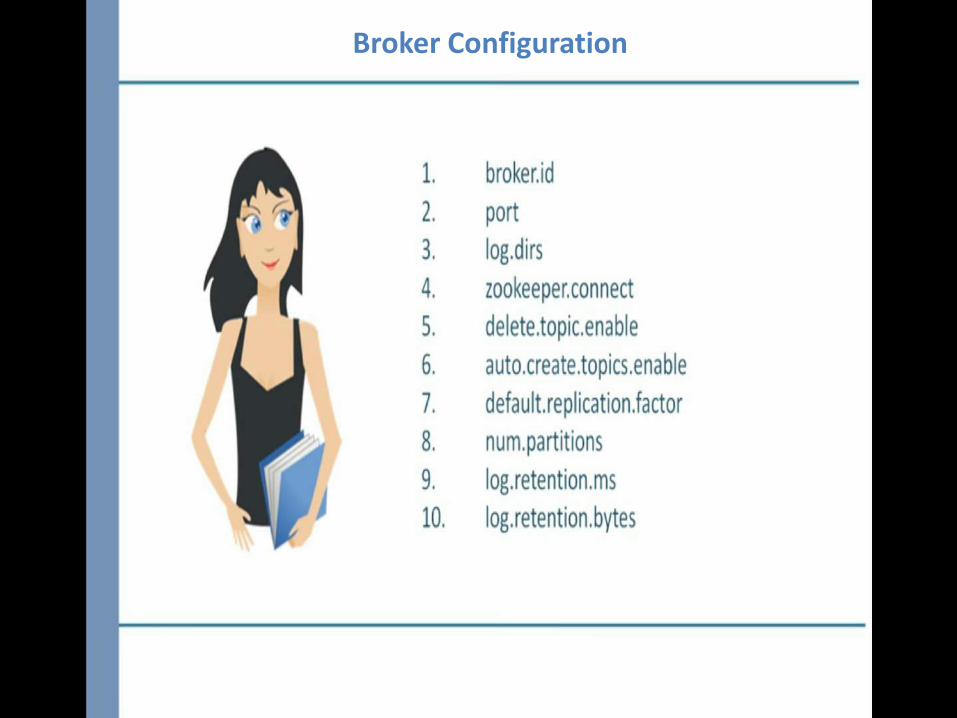
Broker Configuration

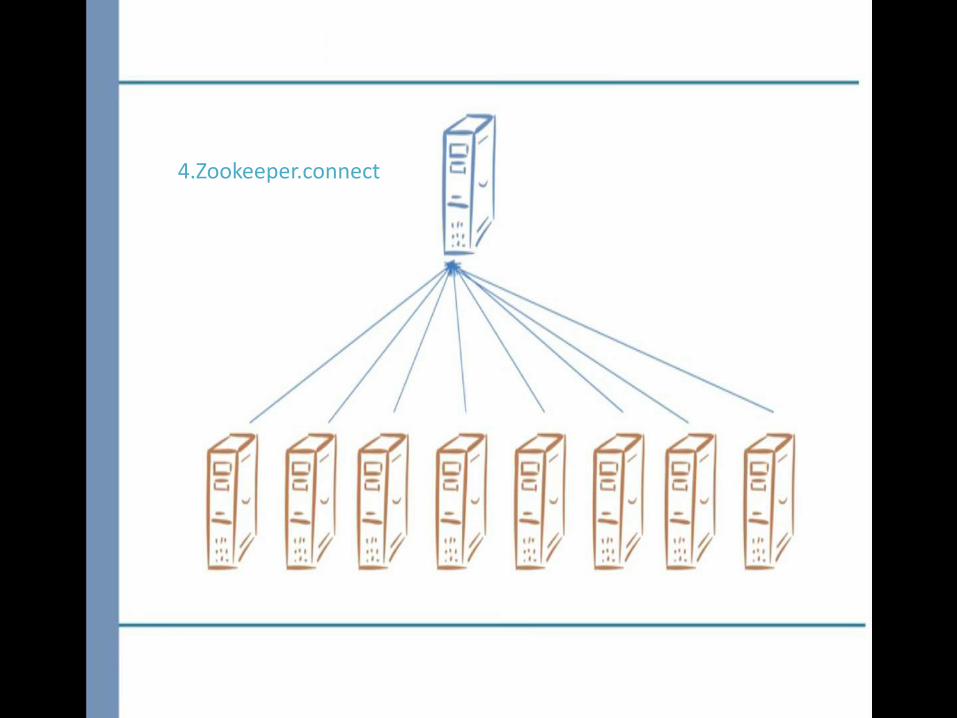
4.Zookeeper.connect



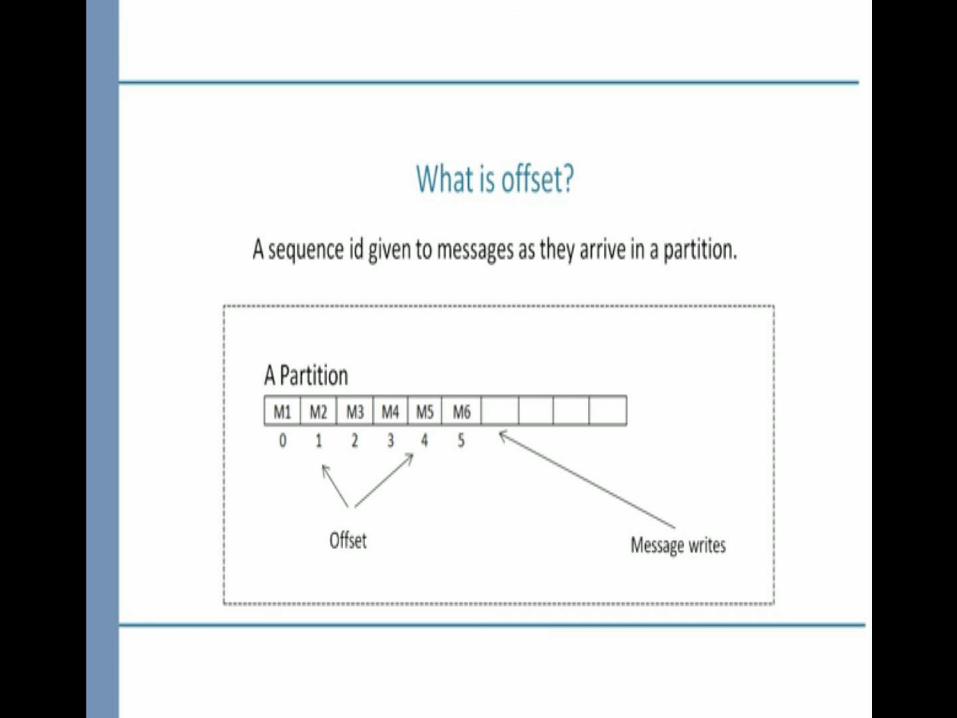


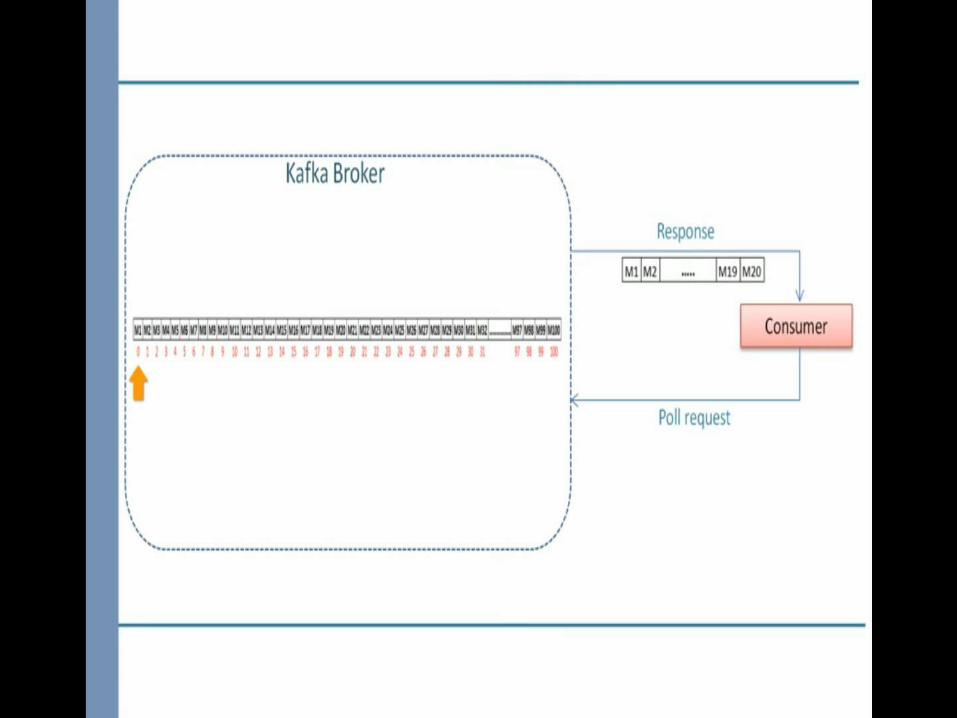
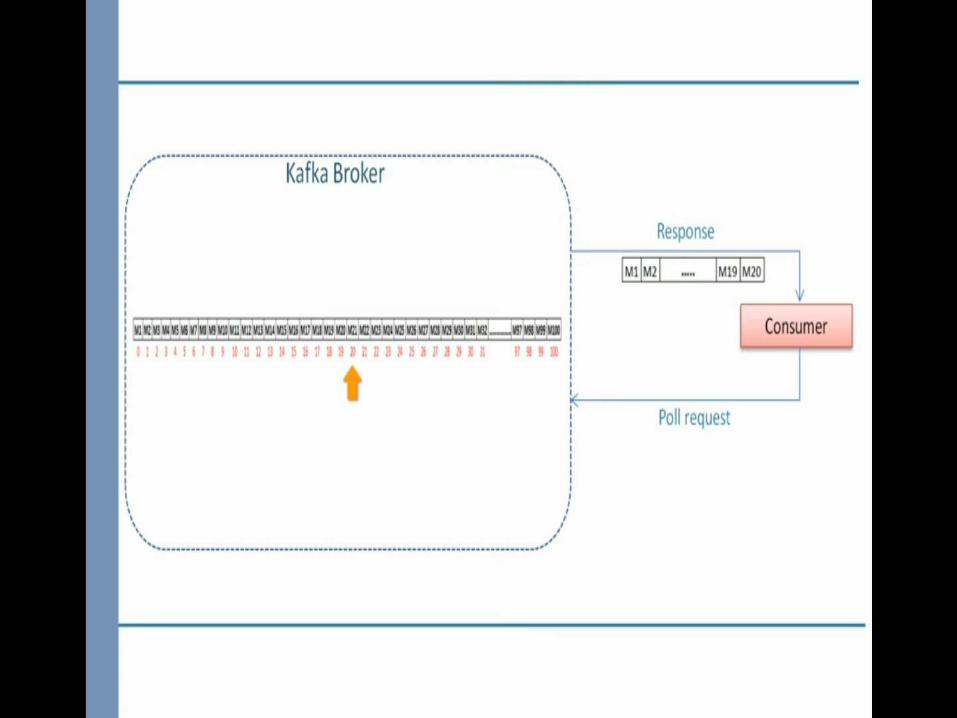
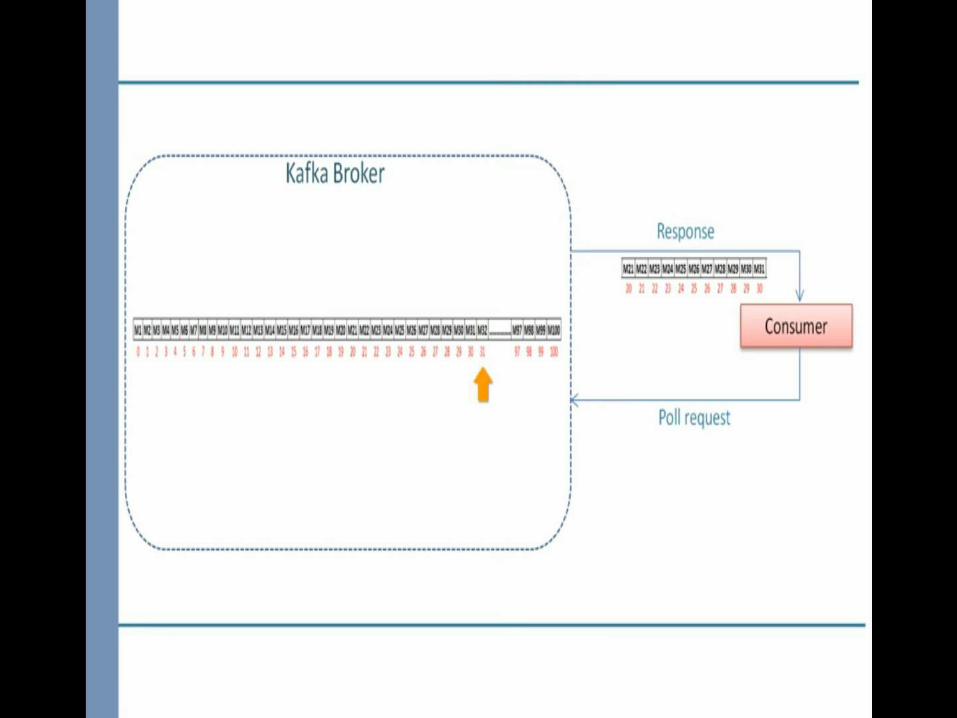

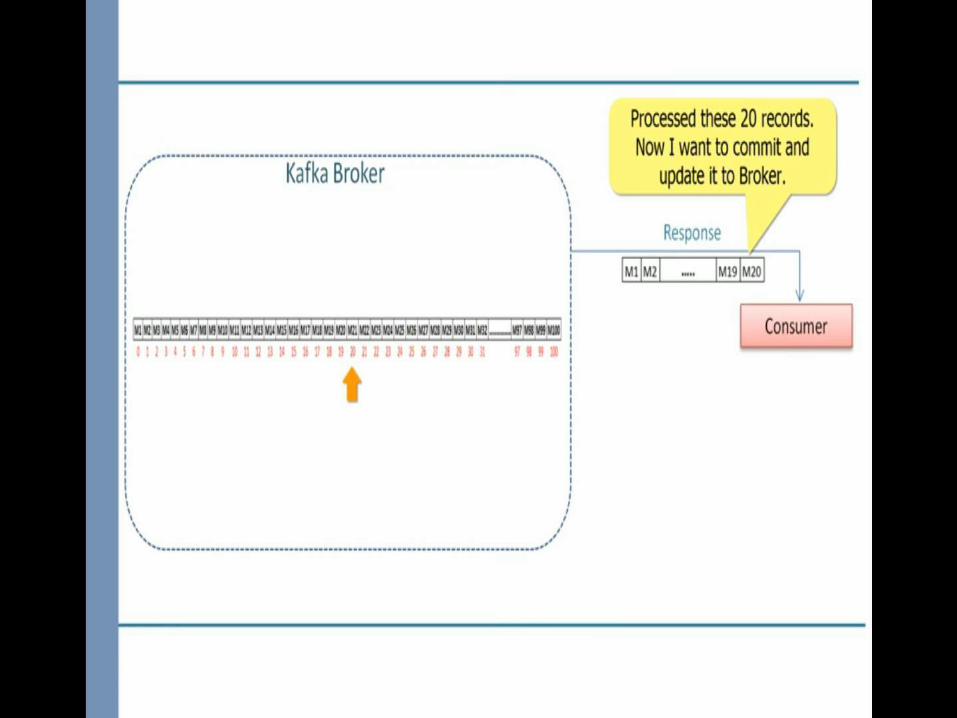
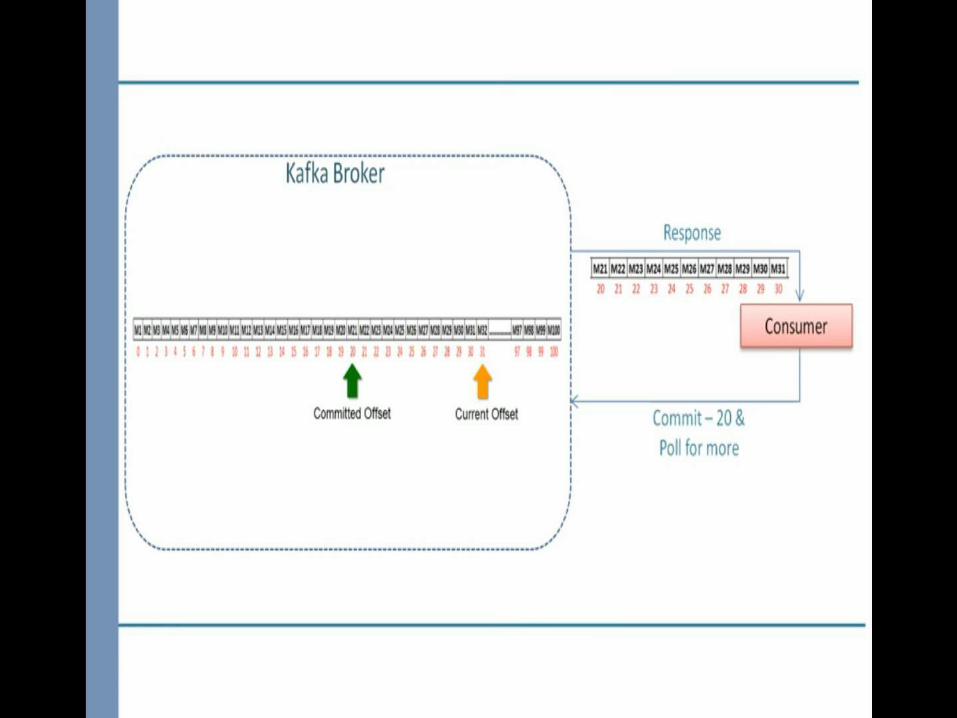



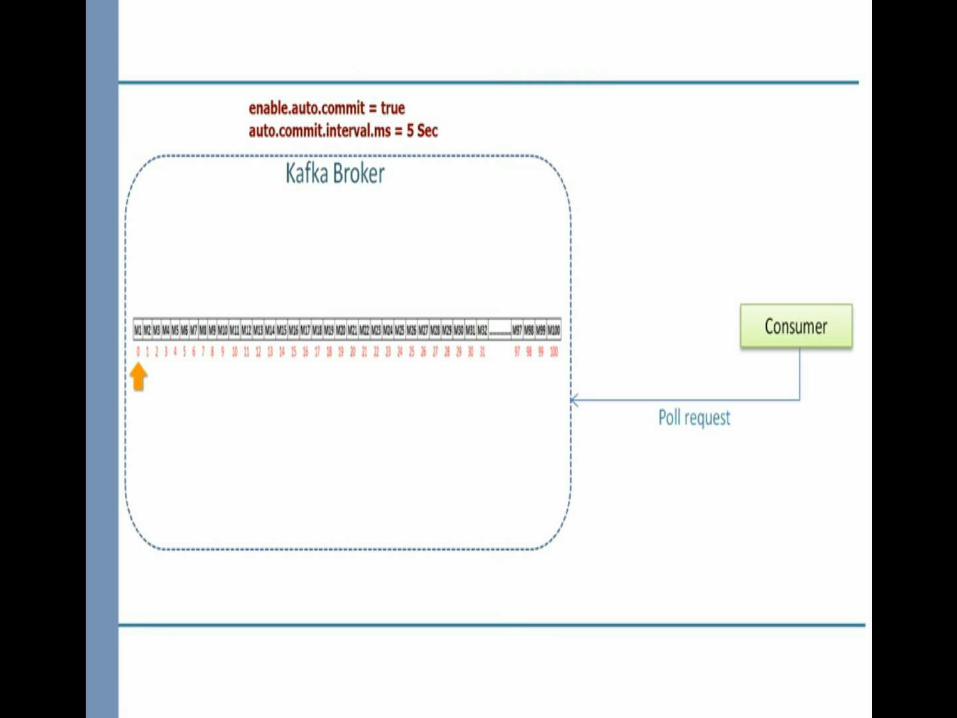

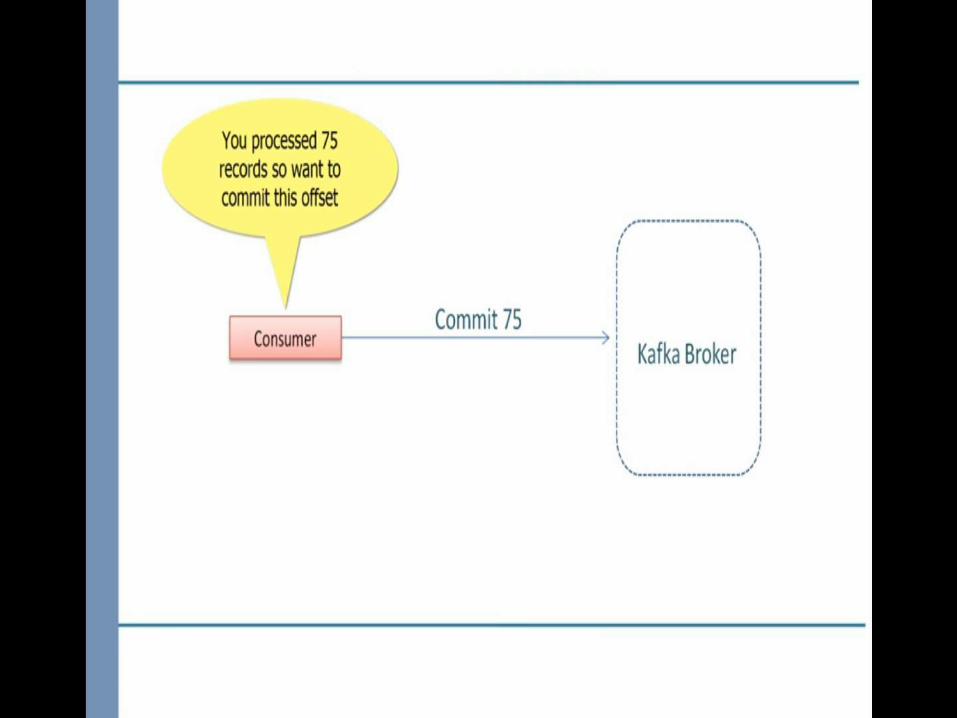
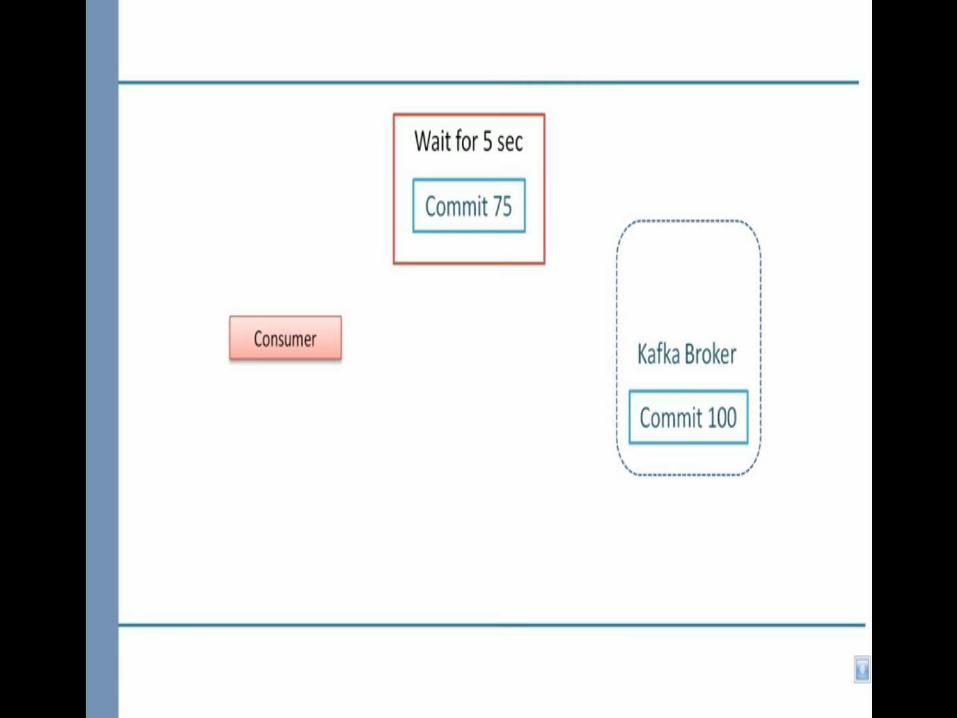




1.Maintain a list of offsets that are processed and ready to be committed.2.Commit the offsets when partition are going away which is notify by one of the configuration rebalance listener called onPartitionsRevoked

Consumer


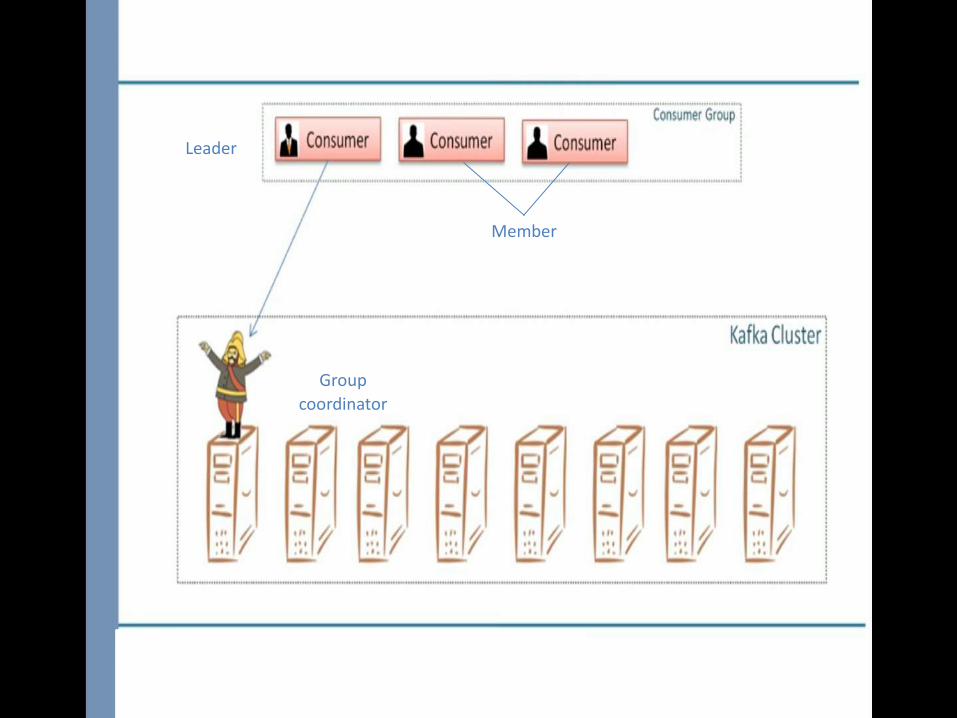
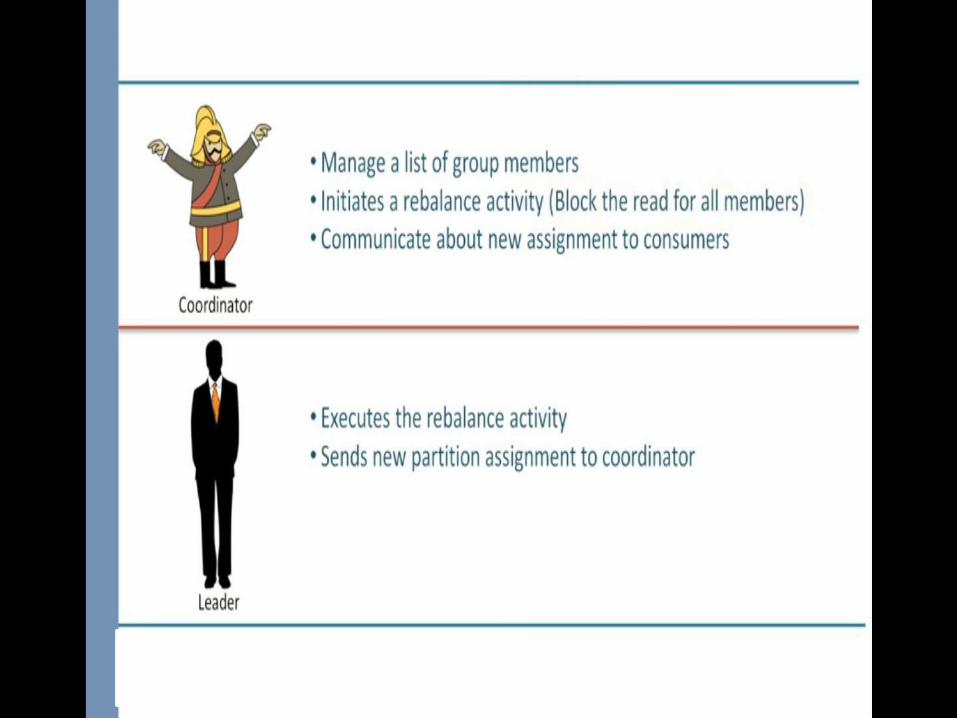
Group
coordinator
Leader
Member

Consumer Configuration
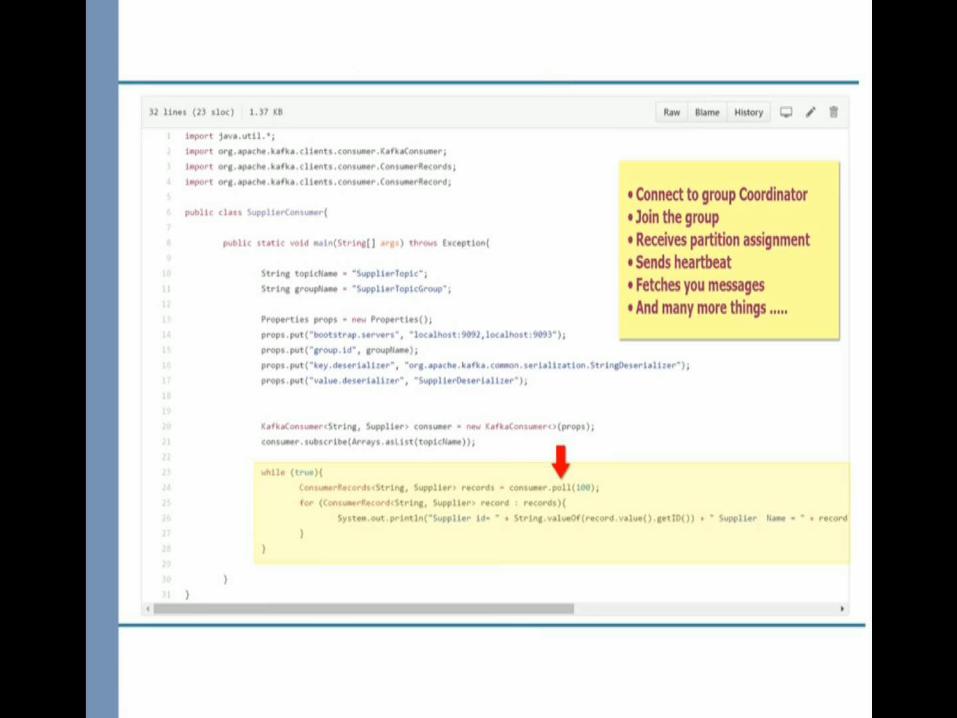

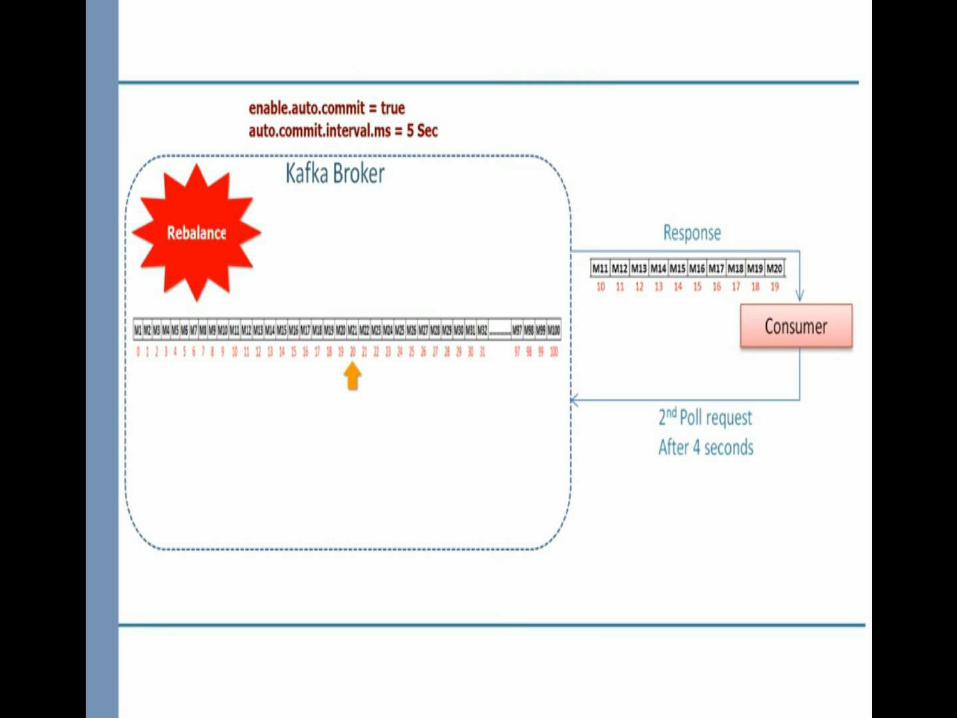
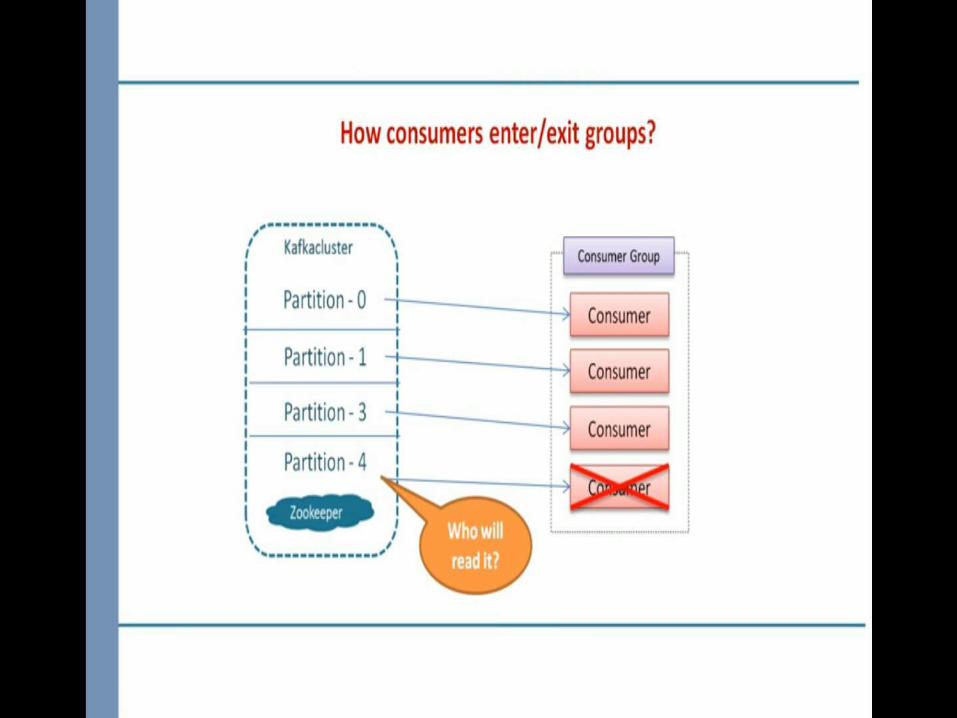
• Default iteration time is less than 3 seconds.• Set heartbeat.interval and session.timeout.ms if we can’t poll every
3 seconds.• Otherwise Rebalancing occur
poll


© Stephane Maarek
● *Amazon Kinesis is a fully managed, scalable, cloud-based service.
● Allows real-time processing of streaming large amount of data.
● takes in any amount of data from several sources, scaling up and down that can be run on *EC2 instances.
Key capabilities:
● Kinesis Firehose – to easily load streaming data into AWS.
● Kinesis Analytics – to easily process and analyze streaming data with standard SQL.
● Kinesis Streams – to build custom applications that process and analyze data.
Kinesis Overview
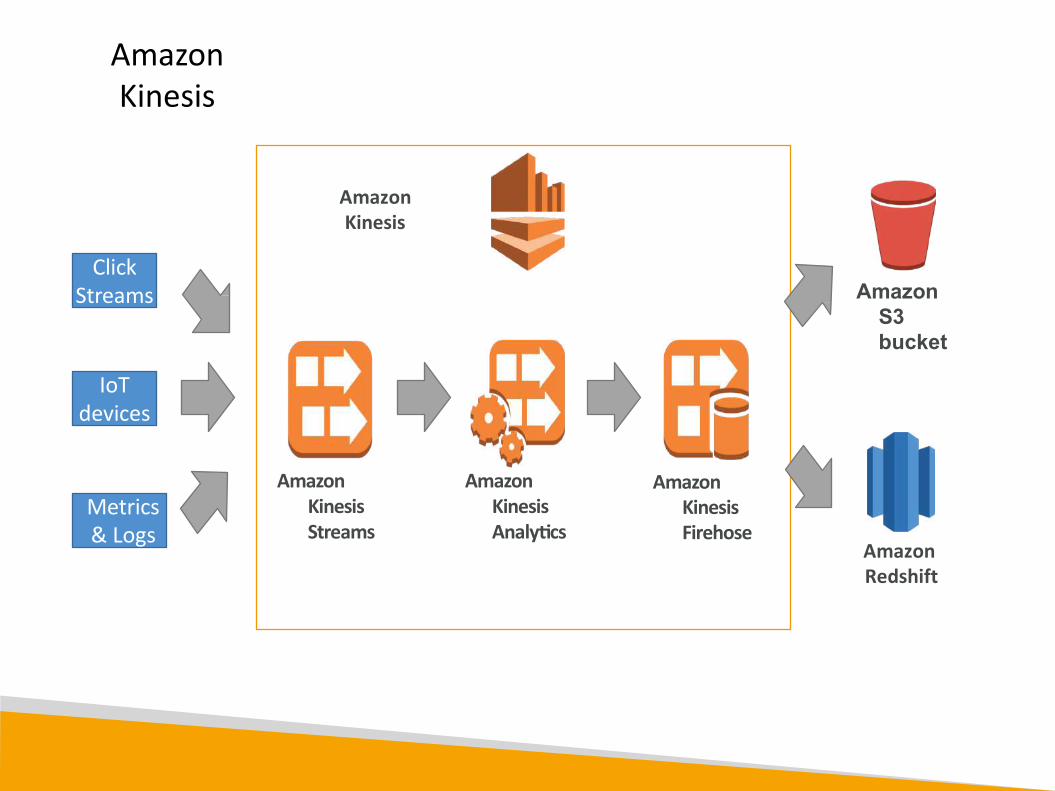
Amazon Kinesis
Amazon Kinesis Streams
Amazon Kinesis Firehose
Amazon Kinesis Analytics
ClickStreams
IoTdevices
Metrics& Logs
Amazon S3 bucket
Amazon Redshift
Amazon Kinesis
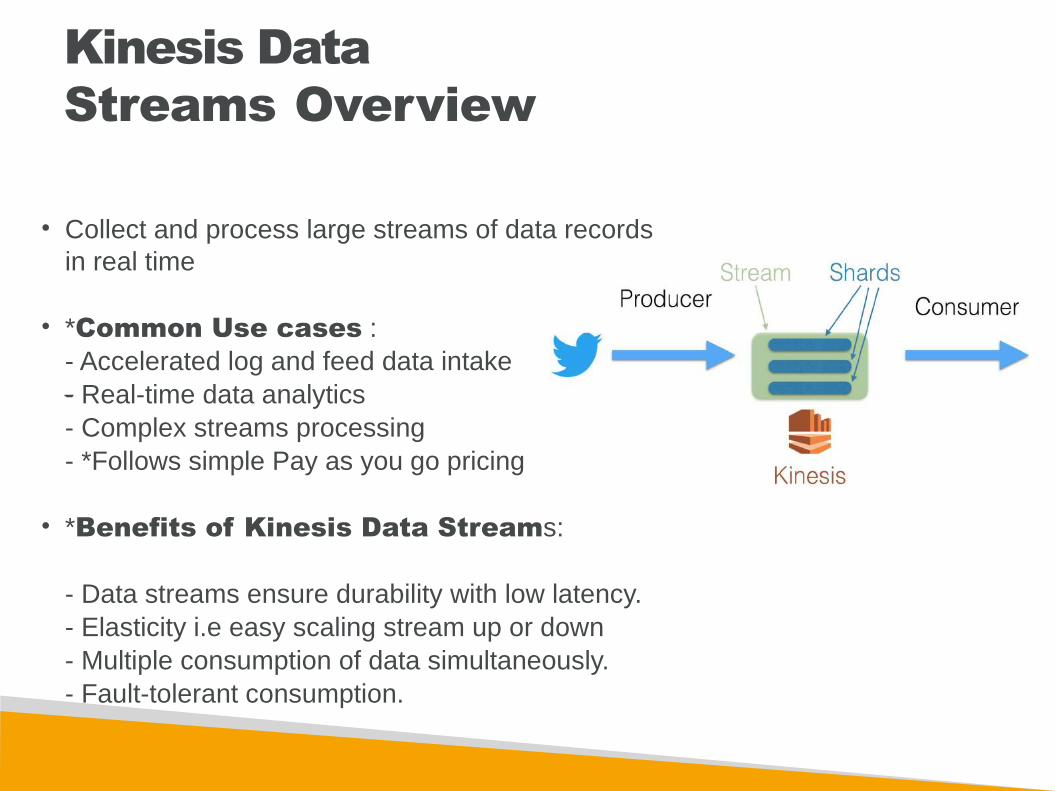
• Collect and process large streams of data records in real time
• *Common Use cases : - Accelerated log and feed data intake - Real-time data analytics- Complex streams processing- *Follows simple Pay as you go pricing
• *Benefits of Kinesis Data Streams:
- Data streams ensure durability with low latency.- Elasticity i.e easy scaling stream up or down- Multiple consumption of data simultaneously.- Fault-tolerant consumption.
Kinesis Data Streams Overview

Terminlogy and concepts Overview :
Kinesis Data Stream : -Set of Shards- Unlimited streams in an AWS account.
Shard : -Uniquely identified set of data records in a stream. - Unlimited number of shards in a stream. - Max. Ingest capacity : 1 MB(including partition keys)/s or 1000 records/s - Max. Read-rate : 2 MB/s per shard - Max. Read-transactions: 5/s per shard - *Each shard has a hash key range.
Account Charged per-shard basis.
Data record : unit of data stored. Composed of : Sequence number,Partition Key, data blobs. Data blob can be any type of data; a segment from a log file,
geographic/location data, website clickstream data, and so on- Max. Size : 1 MB
Partition Key: - Unicode strings, maximum length: 256 characters - hashed to 128-bit integer values(using MD5 hash function) - ExplicitHashKey to explicitly determine the shard to be sent a record. - *Map associated data records to shards using hash-key ranges.
Sequence number : - Unique number per partition-key assigned to each data record by KDS after writing to stream.
- Increases over time.

Total capacity of Stream : sum of capacities of shards.
No. of Shards to be specified before creating Data Stream. Dynamic scaling possible.
* Factors for initial size : Avg. data record size,Data read/write rate, No. of consumers,incoming/outgoing write/read bandwith
Producer : ● Puts data records into Amazon Kinesis Data Streams.
● To put data, specify name, partition key and data blob.
● No. Of partition keys >> No. Of shards
Kinesis Data Stream Application/Consumers:
● Read and process data records from stream.
● Runs on fleet of *EC2 instances.
● Multiple applications for one stream ; consume data independently and concurrently.
Server side encryption : Data streams automatically encrypt sensitive data as producer enters AWS KMS master key

Retention Period : Length of time that data records are accessible after they are added to the stream.Default : 24 hrs. After creation. Max : 168 hrs.Additional charges for setting retention period > 24 hrs.
Tagging:
● Tag : Key-value pairs to define a stream.● Categorize streams by purpose,owner, environment etc.● Custom set of categories for specific needs
Eg- Project: Project Name Owner : NamePurpose : Load TestingEnvironment : Production

Resharding :
● Adjust the number of shards in a stream to adapt to changes in data flow rate.● Performed by administrative application different from producer and consumer.
● Types of Resharding: Splitting Merging
Splitting:
● Data records with same partition key have same hash value.● Selectively split the “hot shards” into two “child” shards ● While splitting, a value in the hash key range specified:
- hash key values higher than that value(inclusive) distributed to one child shard- hash key values lower than that value distributed to another child shard.
● Splitting causes..- increased stream capacity.- increased cost.- wastage of resources if child shards not used
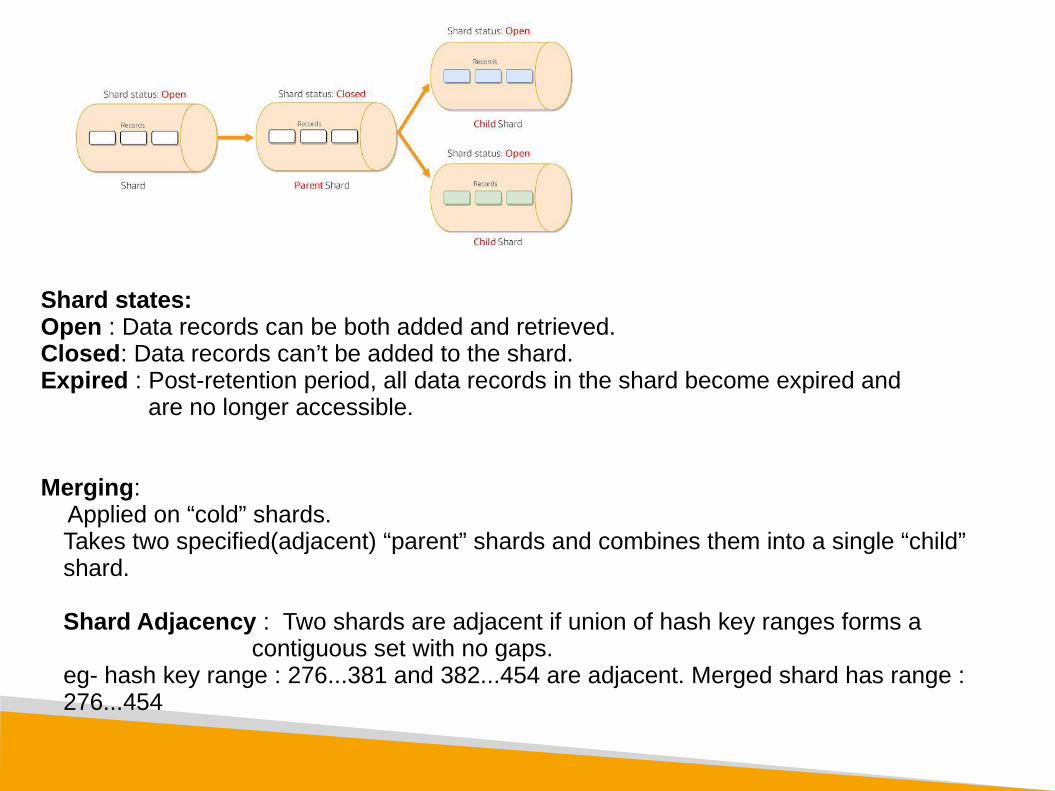
Shard states:Open : Data records can be both added and retrieved.Closed: Data records can’t be added to the shard.Expired : Post-retention period, all data records in the shard become expired and
are no longer accessible.
Merging: Applied on “cold” shards.
Takes two specified(adjacent) “parent” shards and combines them into a single “child” shard.
Shard Adjacency : Two shards are adjacent if union of hash key ranges forms a contiguous set with no gaps.
eg- hash key range : 276...381 and 382...454 are adjacent. Merged shard has range : 276...454

Changing Data retention :
● Increase data retention period upto 168 hrs using IncreaseStreamRetentionPeriod .
● *Records stop becoming inaccessible (at old retention period) within several minutes after increasing .
● *Records older than new retention period immediately become inaccessible after decreasing retention period.
● Additional charges apply for streams with data retention set above 24 hrs.
After Resharding :
● After calling a reshard operation, wait for stream to become active.● After reshard, data records to parent shard are re-routed to child shard.● Data records in parent shards before reshard persist i.e remain accessible until
retention period.● Data from parent shards is not transferred to child shards after splitting.● After stream becomes Active, data can be read from child shards.● KCL ensures data is read in order even if reshard occurs.

Producer
● Application that writes data to Kinesis Data Streams.● Build producers using :
● AWS SDK for Java ● Kinesis Producer Library● Kinesis agent
Kinesis Producer Library (KPL)
● Easy to use, highly configurable library.● Interface between producer application code and KDS API actions.
● Primary Tasks:● Write to one/more stream with automatic/configurable retry.● Collects records & uses PutRecords ; multiplle records to multiple shards per
request.● Aggregates user records,implement complicated logics like batching,retry
mechanisms,consumer de-aggregation etc.● Integrates seamlessly with Kinesis Client Library and other consumer side APIs.● Submits Amazon CloudWatch metrics to track producer performance;
configurable to monitor at stream,shard or producer level.● *Asynchronous architecture : Buffers records before sending to KDS.
Does not block caller application. creates “Future” object containing result of sending
records to Data Streams.
Note: KPL is different from KDS API.

KPL Key concepts
Batching : Performing single action on multiple items instead of repeatedly performing the same action multiple times.
KPL supports two types of batching:
● Aggregation● Collection
Note: both coexist and can be turned on or off independently.
Collection :
● Batching multiple KDS records and sending them in a single HTTP request using “PutRecords” instead of sending individualy.
● Increased throughput .
KPL user record : blob of data that has particular meaning to the user. Eg- JSON blob
KDS user record : instance of “Record” data structure defined by KDS API. contains : partition key,sequence number and data blob.
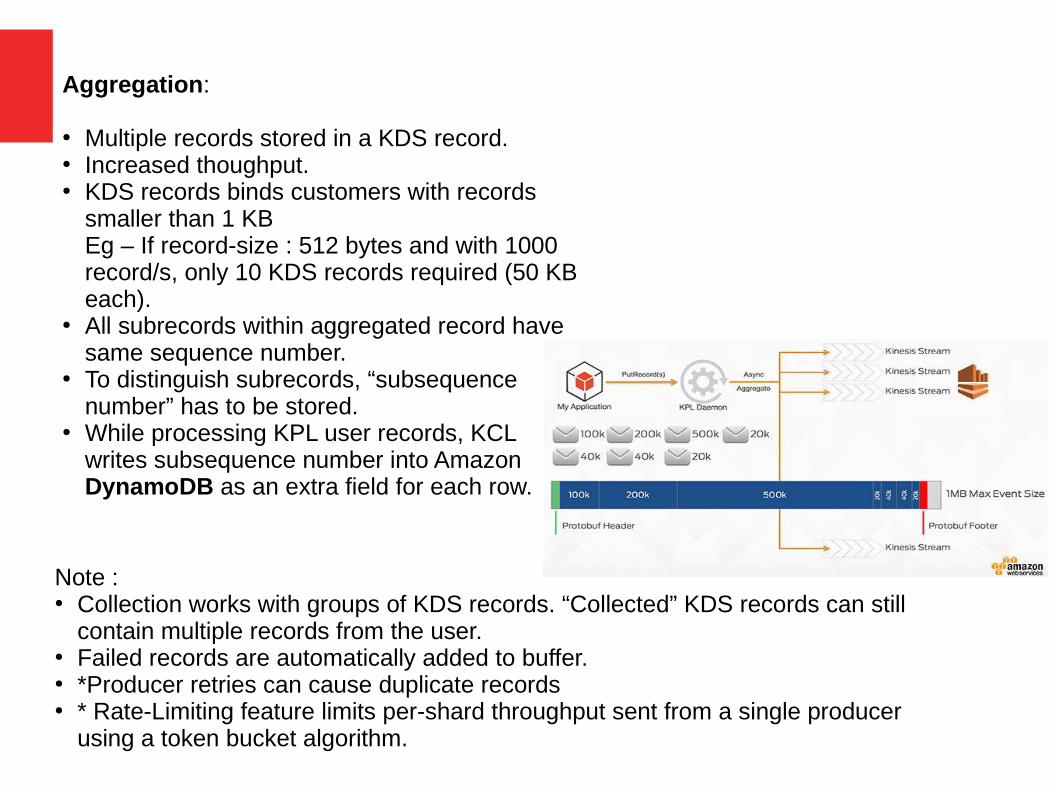
Note : ● Collection works with groups of KDS records. “Collected” KDS records can still
contain multiple records from the user.● Failed records are automatically added to buffer.● *Producer retries can cause duplicate records● * Rate-Limiting feature limits per-shard throughput sent from a single producer
using a token bucket algorithm.
Aggregation:
● Multiple records stored in a KDS record.● Increased thoughput.● KDS records binds customers with records
smaller than 1 KBEg – If record-size : 512 bytes and with 1000 record/s, only 10 KDS records required (50 KB each).
● All subrecords within aggregated record have same sequence number.
● To distinguish subrecords, “subsequence number” has to be stored.
● While processing KPL user records, KCL writes subsequence number into Amazon DynamoDB as an extra field for each row.

Using Data Streams API with AWS SDK for Java
Two operations in KDS API to add data to a stream:● PutRecords● PutRecord
PutRecords : Sends multiple records to stream with single HTTP request.
- Provides higher throughput- Each request can support upto 500 records. Each record can be as large as 1 MB upto 5 MB for the entire request(including partition keys)- Processes all records in the natural order of request.- Sequence number is assigned by KDS streams after call to “putRecords”.- Scope of a request is a stream; each request may include any combination of partition keys - Response includes an array of response “Records” consisting of successfully and unsuccessfully processed records.- By default, failure of individual records within a request does not stop processing of subsequent records.- Successful records include SequenceNumber and ShardID values.- Unsuccessful records include ErrorCode and ErrorMessage values.- Unsuccessfully processed records should be detected and sent in subsequent call.

PutRecord - Operates on a single record.
- Low throughput.
-Sequence number assigned by KinesisDataStreams.
- Sequence number increases over time for a given partition key.
- * Successive calls do not ensure increasing Sequence numbers.
- “SequenceNumberForOrdering” parameter ensures strictly increasing ordering for same partition key
- records received through “GetRecords” call are strictly ordered by sequence numbers.
Note : - KPL is an abstraction built on AWS SDK.
-* KPL provides asynchronous architecture but SDK does not.
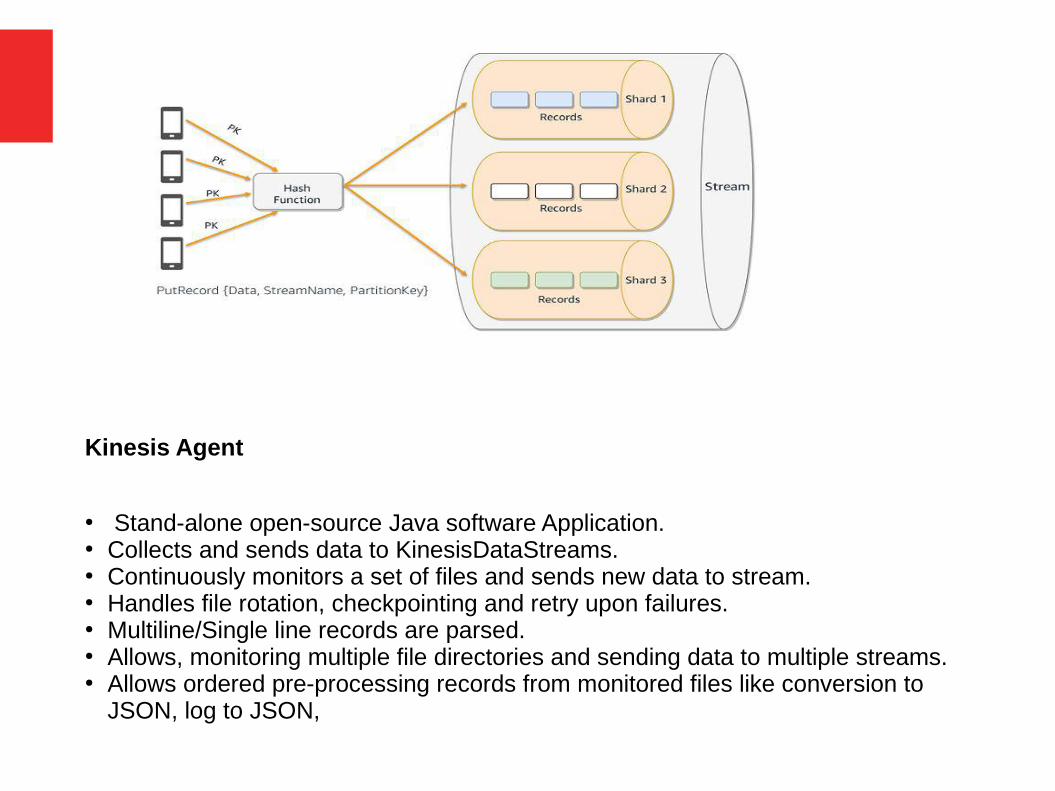
Kinesis Agent
● Stand-alone open-source Java software Application.● Collects and sends data to KinesisDataStreams.● Continuously monitors a set of files and sends new data to stream.● Handles file rotation, checkpointing and retry upon failures.● Multiline/Single line records are parsed.● Allows, monitoring multiple file directories and sending data to multiple streams.● Allows ordered pre-processing records from monitored files like conversion to
JSON, log to JSON,

Consumers
Application that processes data from Kinesis Data Stteam.
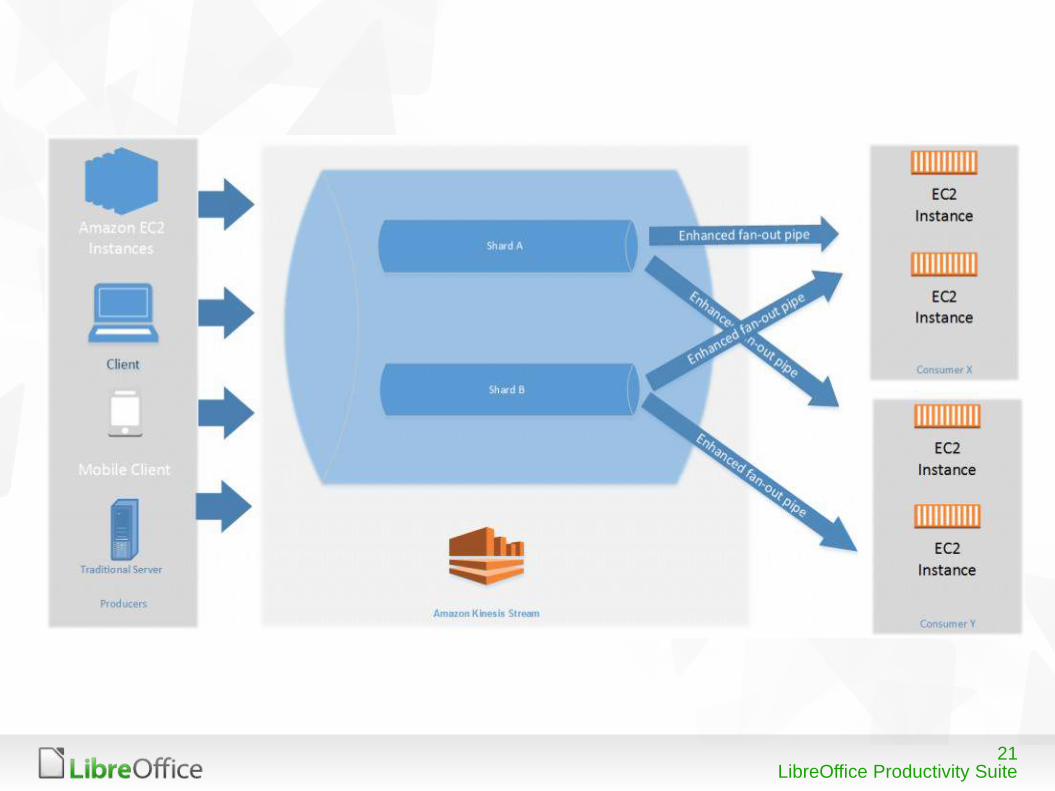
● Shared consumersRead throughput( 2 MB/s) of a shard shared across all consumers reading from the shard.
● Enhanced Fan-out consumerEach consumer reading from a shard gets its own allotment of read throughput.
Shared vs Enhanced :
● Read throughput in shared depends on contending consumers whereas in enhanced it is fixed.
● *Message Propagation delay in shared higher than enhanced on average.● Shared is default and has no cost. Enhanced has a data retrieval cost and a
consumer shard-hour cost.● *Shared follows Pull model over HTTP using “GetRecords” whereas Kinesis Data
Streams pushes the records over HTTP using “SubscribeToShard”.
We can develop custom consumers using Kinesis Client Library or AWS SDK.

Kinesis Client Library
● Helps consume and process data from data stream.● Interface between record processing logic and Kinesis Data Streams.● Takes care of complex tasks like – load balancing across multiple instances,responding
to instance failures, checkpointing processed records and reacting to resharding.● Enables focus on writing record-processing logic.● *A Java Library; but provides support for languages other than Java using multi-
language interface called MultiLangDaemon.● *At runtime, KCL instantiates a worker with configuration information and then uses
record processor to process the data.● Each shard is processed by exactly one KCL worker and one corresponding record
processor. ● *A worker can process any number of shards.
Primary tasks : ➔ Connects to the stream.
➔ Enumerates the shards.
➔ Calls “initialise” method when record processor is istantiated, passing a specific ShardId.
➔ Calls “processRecords” method with a list of data records from “initialise” method for the record processor to processrecord data according to semantics specified by consumer.
➔ *Tracks record processing in a shard by passing a checkpointer to mark progress.

19LibreOffice Productivity Suite
● If worker fails, checkpoint used to restart the processing.
● *Handles processing exception by skipping over the records passed before the exception.
●
● *Creates a DynamoDB table for each consumer application which maintains state information such as worker-shard mapping,checkpoints etc. Each application has its own DynamoDB table.
● *Tracks and distributes shards in a stream using DynamoDB table.
● *Preserves order of records even after resharding for a particular partition key.
● *Calls shutdown when processing ends or worker is no longer responding.
● If stream is “terminated”, then record processor finishes processing remaining data records.
● Implements enhanced fan-out retrieval by automatically subscribing consumer to all shards.
Note:● *Kinesis Data streams has “at least once “ semantics.

20LibreOffice Productivity Suite
Custom consumers using Data Streams API with AWS SDK for Java
● “GetShardIterator” and “getRecords” are used to retrieve data from stream.● *KCL support can be used to retrieve data.● *For each shard, and for each batch of records of that shard, a shard iterator is obtained.● Iterator types - TRIM_HORIZON,AT SEQUENCE_NUMBER etc. ● A shard iterator is valid for 5 minutes.● Records are retrieved using “getRecords” by specifying the shard iterator.● Provision to set the limit on number of records returned by “getRecords”.
● *Implement enhanced fan-out consumer by subscribing to the required shards individually using ARN(Amazon Resource Name).
● Deregister a fan-out consumer using “DeregisterStream-Consumer”.
Consumer retries can result in duplicate records.
● Record processors restart when – worker terminates, resharding,scaling worker instances,application is deployed.
● *Duplication occurs when shard processors migrate from one instance to another.● Duplicate records can be handled at the final destination or by overwriting.
● Throttling : *If an application or group of applications(on the same stream) attempts to get data from a shard at a *faster rate, data streams “throttles” the corresponding get operations.
21LibreOffice Productivity Suite

22LibreOffice Productivity Suite
DynamoDB table
Unique table created by KCL to track application state for each application
Each row represents a shard that is being processed by the consumer appplication
Hash key is leasekey which is basically the shard ID.
*Stores data such as : checkpoint, checkpointSubSequenceNumber, leaseKey, leaseOwnerownerSwitchesSinceCheckpoint , parentShardId etc.
Scaling
To scale up processing in your application, we can apply a combination of the folllowing
• *Increasing the instance size • Increasing the number of instances up to the maximum number of open shards • Increasing the number of shards

23LibreOffice Productivity Suite
Auto Scaling :
Automatically scale consumer instances based on appropriate metrics
Create collections of EC2 called auto scaling groups.
Allows to specify the minimum, maximum or desired size of group which is a collection of EC2 instances.
*Based on CloudWatch Alarm for a specific metric ,notifies the Application Auto Scaling policy.
Auto scaling provides:
● *Better fault tolerance. Amazon EC2 Auto Scaling can detect when an instance is unhealthy, terminate it, and launch an instance to replace it.
● Better availability
● Better cost management.

Monitoring Data Streams:
● With Cloudwatch:
● *Data Streams and Amazon CloudWatch are integrated.● Basic( stream level): Stream level data sent every minute with no charge like – number
of records retrieved, no. Of successful stream over a time period, latency etc.
● Enhanced(Shard – Level) : Shard level data is sent every minute for an additional cost like – number of bytes successfully put/retrieved to the shard, number of records throttled etc.
● All available statistics are filtered by stream name.● Kinesis agent health can also be tracked.● KCL provides metrics per shard, worker and KCL application like – no. of successful
record processor initializations,successful final checkpoints, shard leases owned by worker, time taken for renewing all leases etc.
● KPL provides metrics per shard, per worker and KPL application like – no. Of successful put records, retries performed per user per second, time taken to perform putRecords etc.
● With CloudTrail :
● CloudTrail captures all API calls by Kinesis Data Streams as events.● Can determine the request made to Kinesis Data Streams, the IP address etc.● Supports logging activities like – Merge/split shards, stream encryption etc.

Firehouse and KinesisAnalytcs
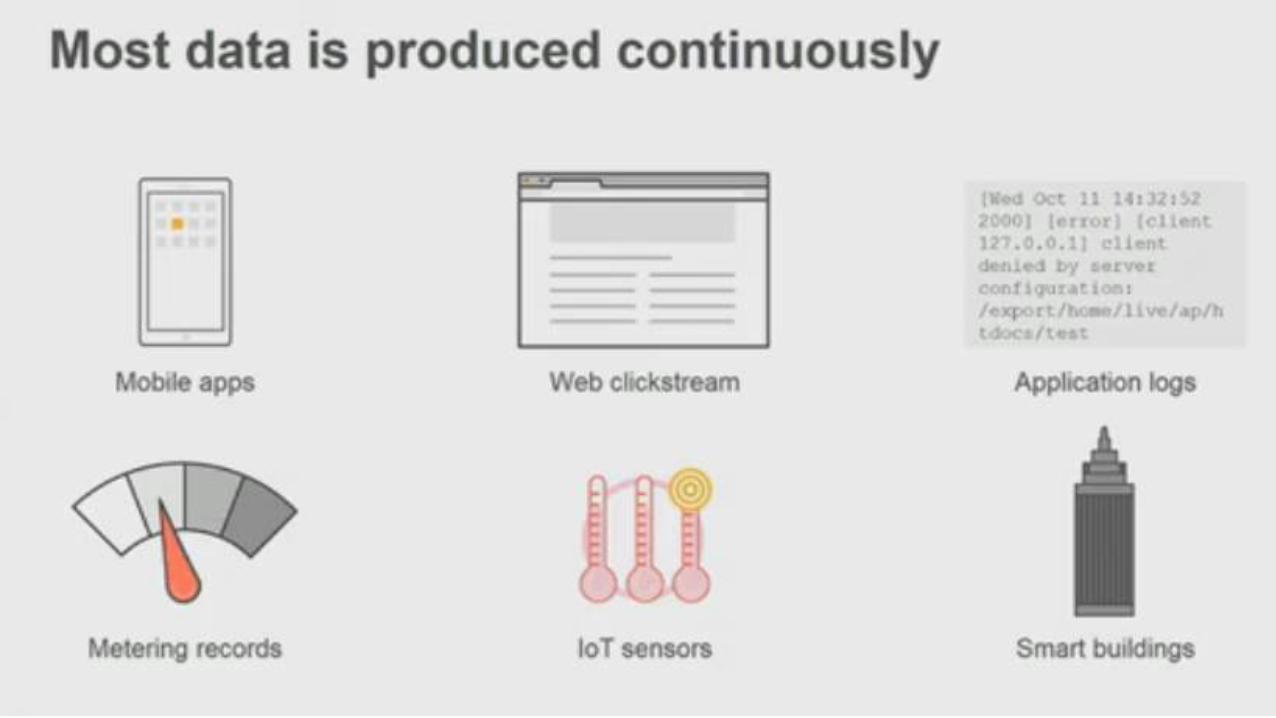

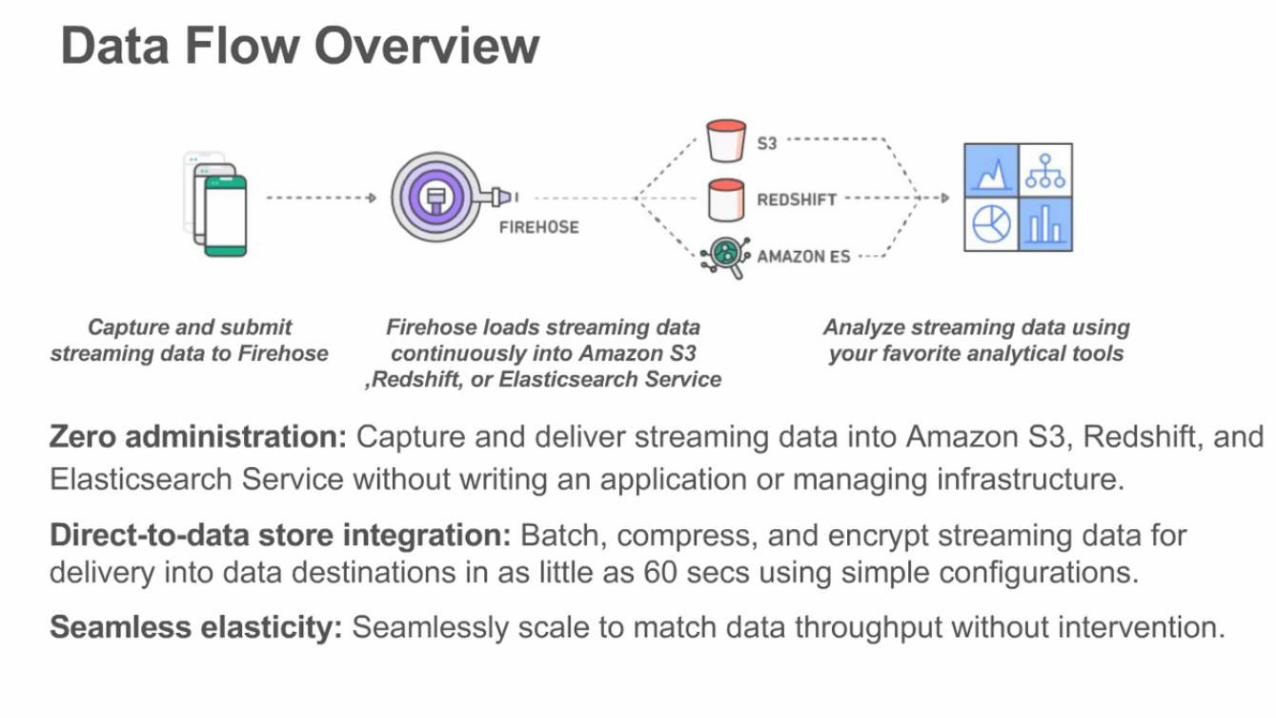


What more can we do ?
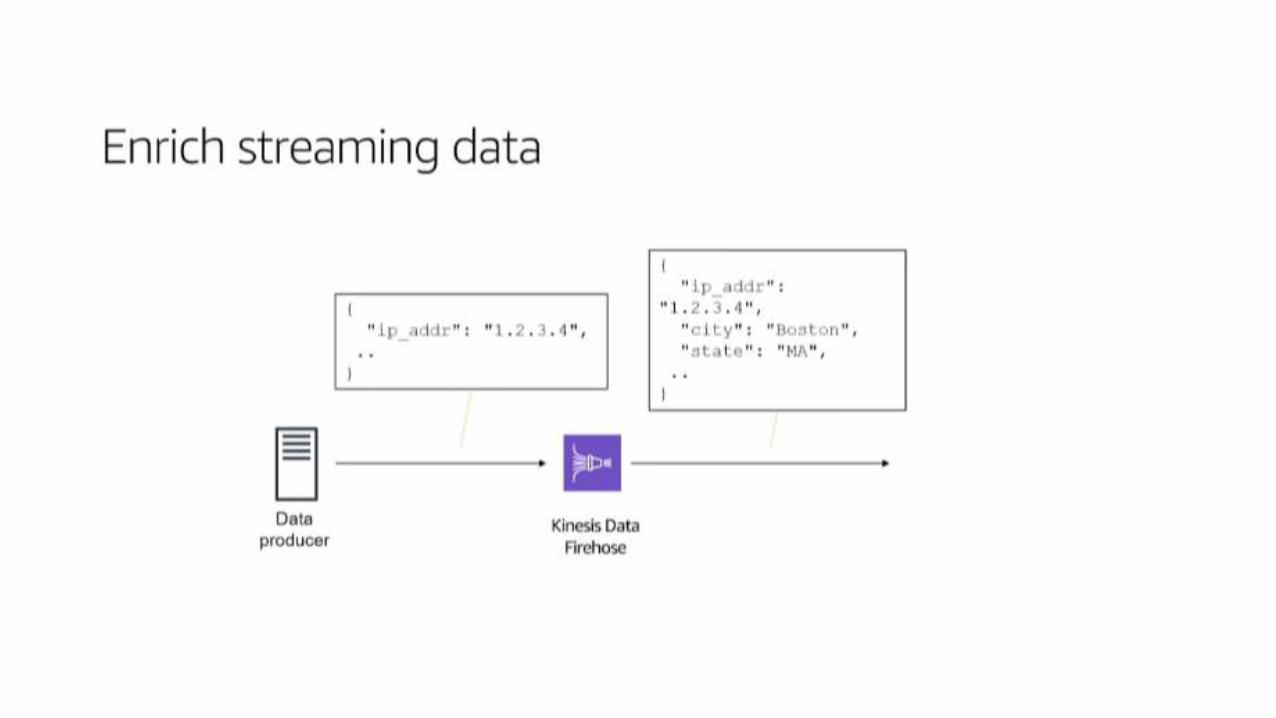
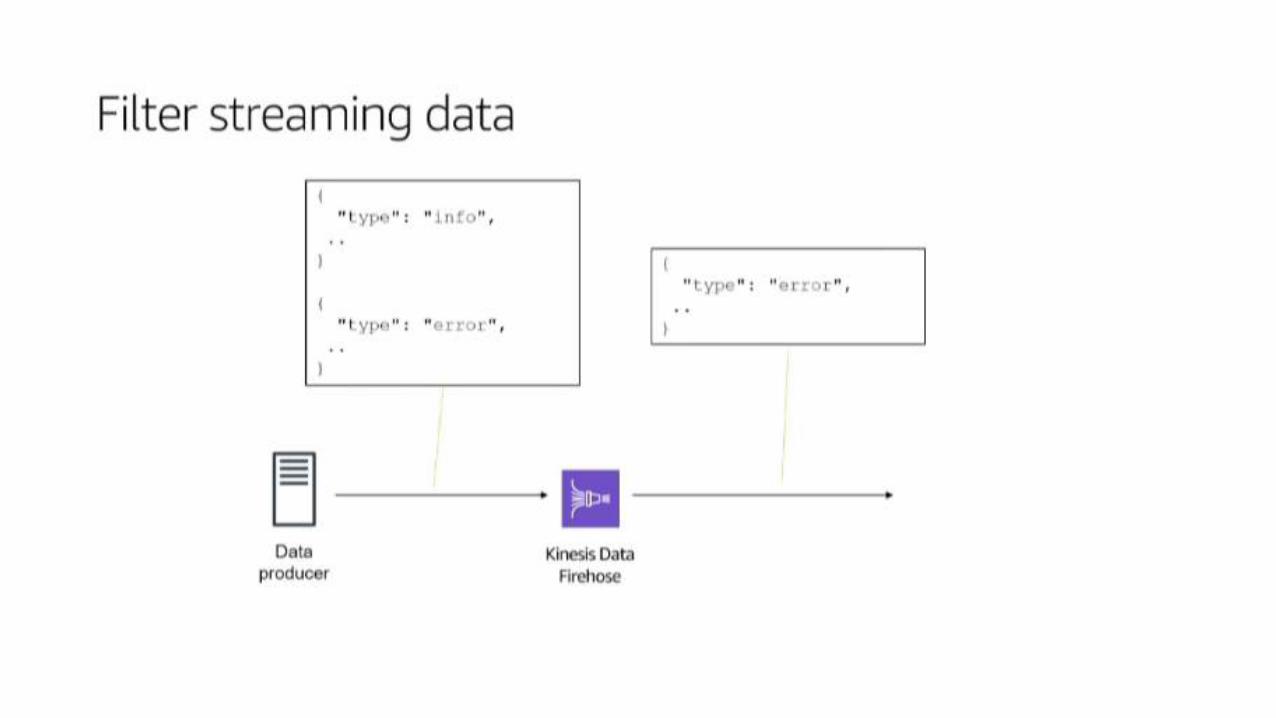
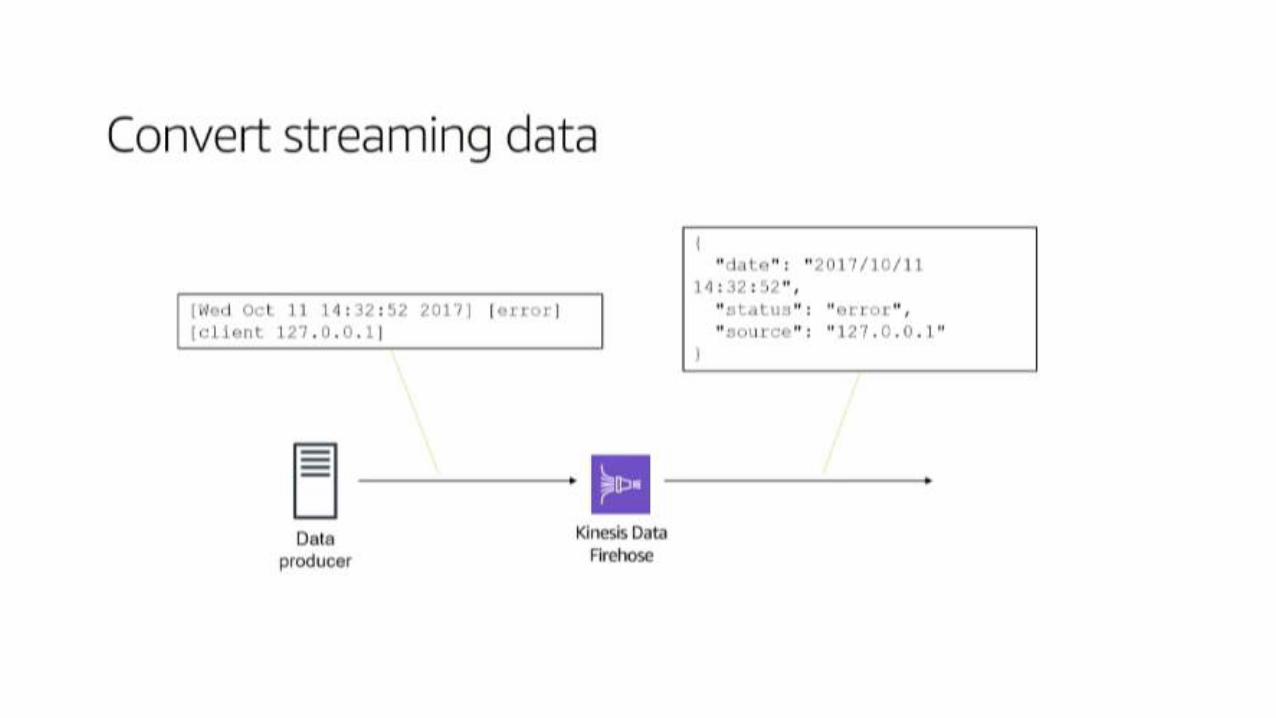

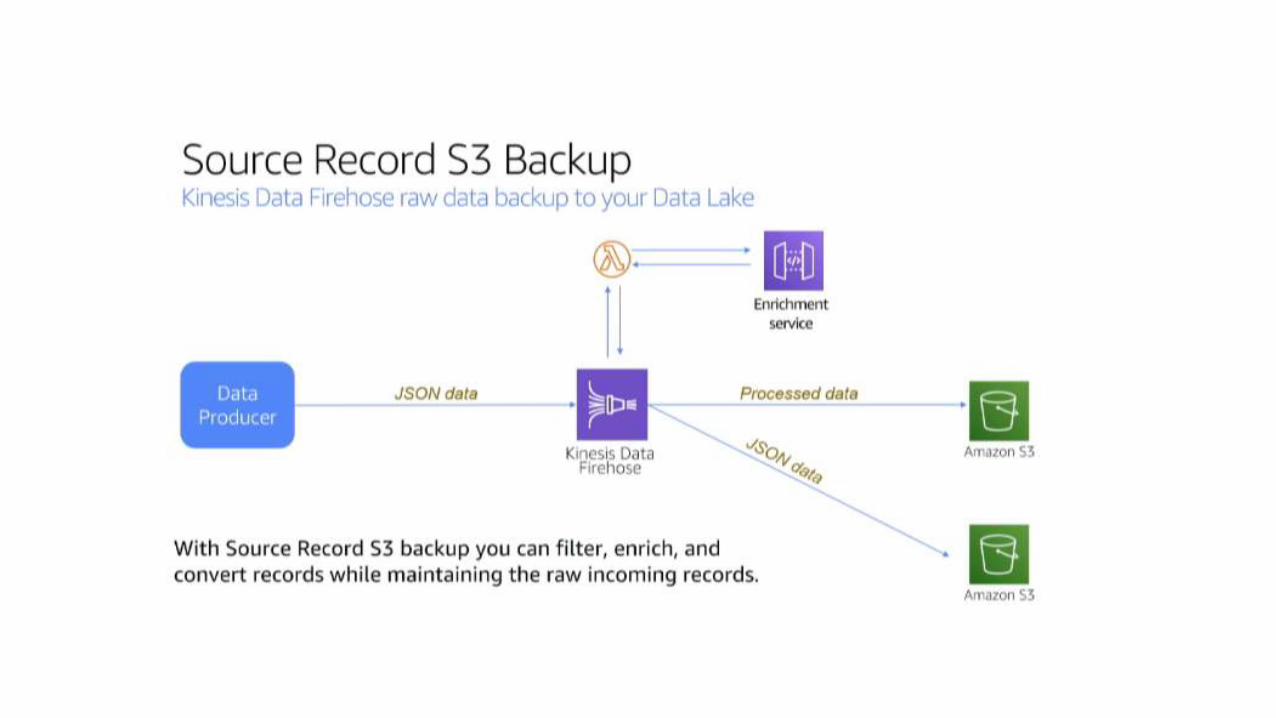

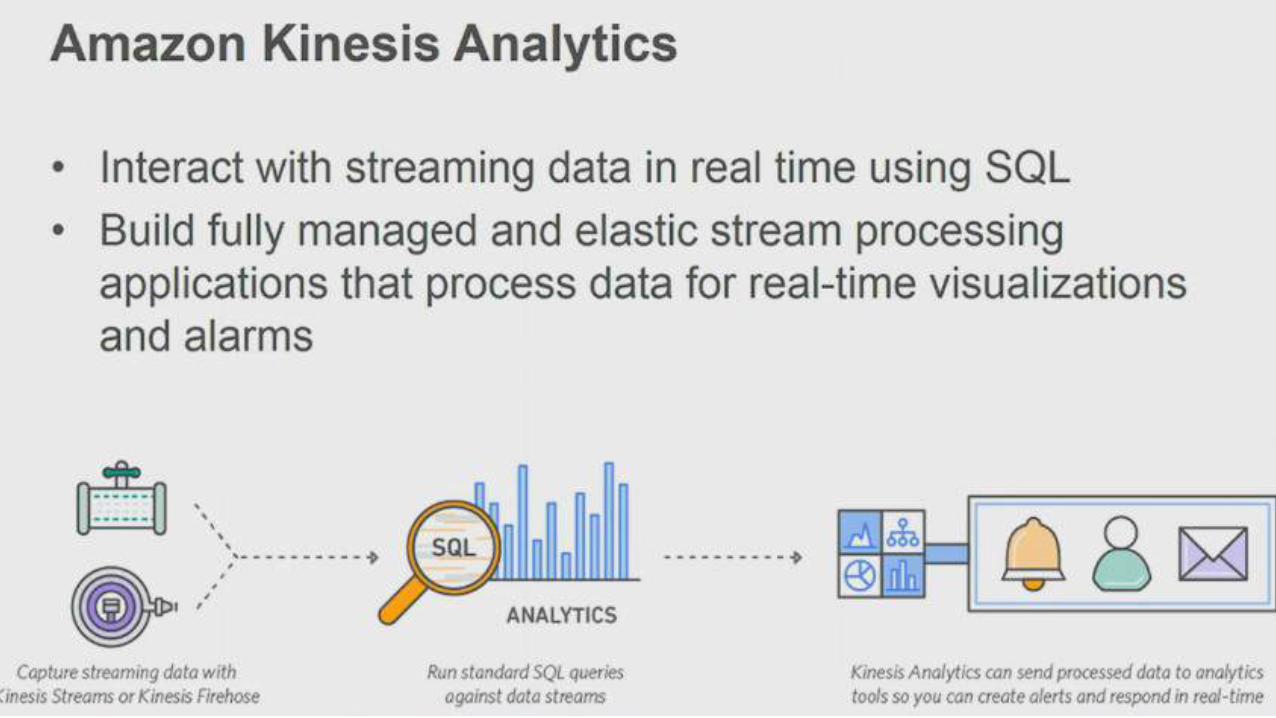
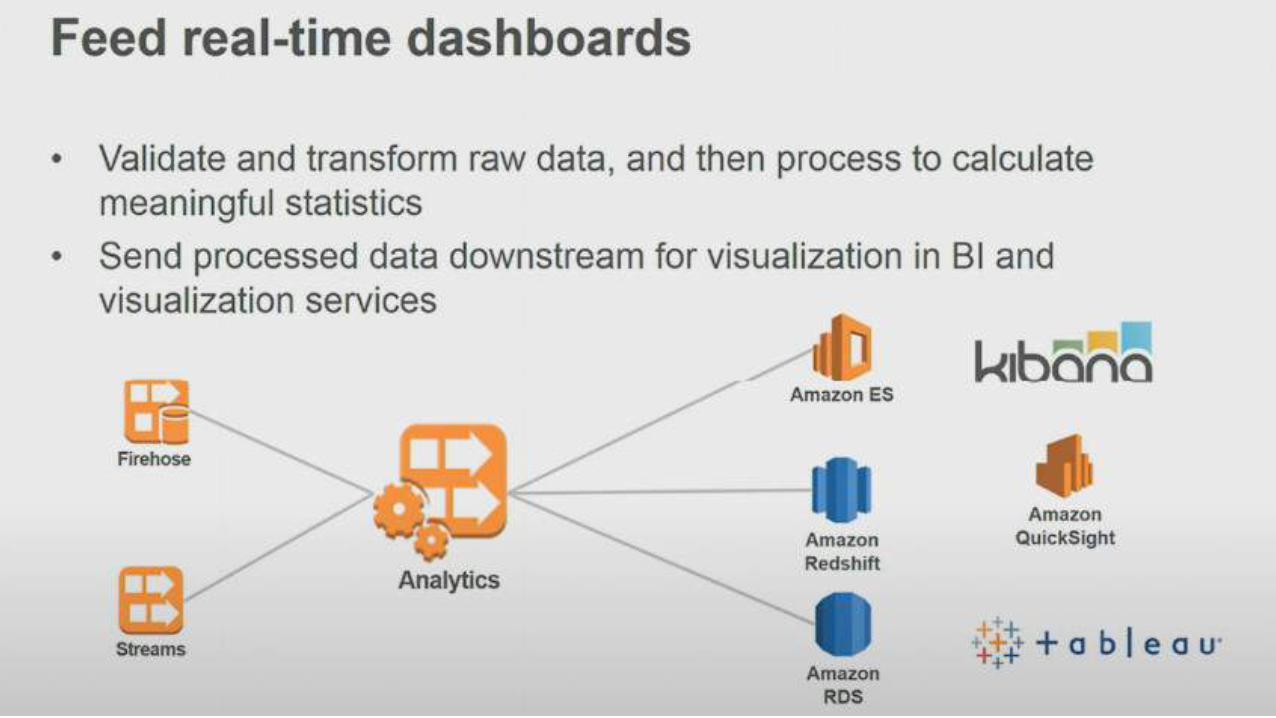
Kinesis Analytcs













Thankyou!