
Psychological Review - Indiana University Cognitive...
67
Psychological Review VOLUME 91 NUMBER 1 JANUARY 1984 A Retrieval Model for Both Recognition and Recall Gary Gillund and Richard M. Shiffrin Indiana University The Search of Associative Memory (SAM) model for recall (Raaijmakers & Shiffrin, 1981b) is extended by assuming that a familiarity process is used for recognition. The recall model posits cue-dependent probabilistic sampling and recovery from an associative network. Our recognition model is closely related to the recall model because the total episodic activation due to the context and item cues is used in recall as a basis for sampling and in recognition to make a decision. The model, formalized in a computer simulation program, correctly predicts a number of findings in the literature as well as the results from a new experiment on the word- frequency effect. "A critical problem of long standing in psy- chological study of memory is concerned with the relation between recall and recognition. In what sense are they the same, and in what sense are they different?" (Tulving & Watkins, 1973, p. 739). This article is a preliminary attempt to for- mulate a theory that describes in detail the relationship between recall and recognition. The relationship is realized in a computer simulation model, and the model's predictions are checked against existing data as well as data generated in our laboratory. The model for recognition is related mathematically and logically to the Search of Associative Memory (SAM) theory of memory retrieval that has This work was supported by Public Health Service Grant MH12717 and the Indiana University Waterman Research Award to Richard Shiftrin. We would like to thank Lloyd Peterson, Margaret Intons- Peterson, Linda Smith, Maynard Thompson, Jim Neely, Michael Humphreys, Jeroen Raaijmakers, Roger Ratcliff, and Steven Smith for their thoughtful comments on earlier drafts. Short annotated versions of the SAM simulation pro- grams for recall and recognition, in PASCAL or FORTRAN, are available from the authors on request. Requests for reprints should be sent to Richard M. Shiffrin, Psychology Department, Indiana University, Bloomington, Indiana 47405. Gary Gillund is now at the Center for Research in Human Learning, 204 Elliott Hall, University of Minnesota, Minneapolis, Minnesota 55455. been used previously to fit recall data (Gillund & Shiffrin, 1981; Raaijmakers & Shiffrin, 1980, 1981a, 1981b). We begin with a brief overview of theoretical treatments in the area of recognition (addi- tional models are discussed in Section 5). Sev- eral studies carried out to test one class of models are then reported and evaluated. The introduction ends with a listing of some of the major findings in recall and recognition that the model is intended to explicate. A rough classification of models for recall and recognition is given in Table 1. The com- ponent processes assumed to operate in recall and recognition are indicated by the symbols S, D s , D c , and /. S indicates an extended search, with the basic characteristic that it op- erates slowly and uncertainly. The speed and certainty of the search are defined empirically by results from tasks like free recall in which several seconds often elapse between successive recalls and in which many more than half the presented items may not be recalled even after many minutes of testing. Models with this property often assume serial sampling of im- ages from memory, with or without resam- pling. D indicates direct access in which all the relevant information in memory is ob- tained in one step. D s is a simplified form of direct access in which only the image of the tested item is contacted, so that searchlike ef- Copyright 1984 by the American Psychological Association, Inc.
Transcript of Psychological Review - Indiana University Cognitive...

Psychological ReviewV O L U M E 91 N U M B E R 1 J A N U A R Y 1984
A Retrieval Model for Both Recognition and Recall
Gary Gillund and Richard M. ShiffrinIndiana University
The Search of Associative Memory (SAM) model for recall (Raaijmakers & Shiffrin,1981b) is extended by assuming that a familiarity process is used for recognition.The recall model posits cue-dependent probabilistic sampling and recovery froman associative network. Our recognition model is closely related to the recall modelbecause the total episodic activation due to the context and item cues is used inrecall as a basis for sampling and in recognition to make a decision. The model,formalized in a computer simulation program, correctly predicts a number offindings in the literature as well as the results from a new experiment on the word-frequency effect.
"A critical problem of long standing in psy-chological study of memory is concerned withthe relation between recall and recognition.In what sense are they the same, and in whatsense are they different?" (Tulving & Watkins,1973, p. 739).
This article is a preliminary attempt to for-mulate a theory that describes in detail therelationship between recall and recognition.The relationship is realized in a computersimulation model, and the model's predictionsare checked against existing data as well asdata generated in our laboratory. The modelfor recognition is related mathematically andlogically to the Search of Associative Memory(SAM) theory of memory retrieval that has
This work was supported by Public Health Service GrantMH12717 and the Indiana University Waterman ResearchAward to Richard Shiftrin.
We would like to thank Lloyd Peterson, Margaret Intons-Peterson, Linda Smith, Maynard Thompson, Jim Neely,Michael Humphreys, Jeroen Raaijmakers, Roger Ratcliff,and Steven Smith for their thoughtful comments on earlierdrafts.
Short annotated versions of the SAM simulation pro-grams for recall and recognition, in PASCAL or FORTRAN,are available from the authors on request.
Requests for reprints should be sent to Richard M.Shiffrin, Psychology Department, Indiana University,Bloomington, Indiana 47405. Gary Gillund is now at theCenter for Research in Human Learning, 204 Elliott Hall,University of Minnesota, Minneapolis, Minnesota 55455.
been used previously to fit recall data (Gillund& Shiffrin, 1981; Raaijmakers & Shiffrin,1980, 1981a, 1981b).
We begin with a brief overview of theoreticaltreatments in the area of recognition (addi-tional models are discussed in Section 5). Sev-eral studies carried out to test one class ofmodels are then reported and evaluated. Theintroduction ends with a listing of some of themajor findings in recall and recognition thatthe model is intended to explicate.
A rough classification of models for recalland recognition is given in Table 1. The com-ponent processes assumed to operate in recalland recognition are indicated by the symbolsS, Ds, Dc, and /. S indicates an extendedsearch, with the basic characteristic that it op-erates slowly and uncertainly. The speed andcertainty of the search are defined empiricallyby results from tasks like free recall in whichseveral seconds often elapse between successiverecalls and in which many more than half thepresented items may not be recalled even aftermany minutes of testing. Models with thisproperty often assume serial sampling of im-ages from memory, with or without resam-pling. D indicates direct access in which allthe relevant information in memory is ob-tained in one step. Ds is a simplified form ofdirect access in which only the image of thetested item is contacted, so that searchlike ef-
Copyright 1984 by the American Psychological Association, Inc.

GARY OH,LUND AND RICHARD M. SHIFFRIN
Table 1Models for Recall and Recognition
Model Recall
S - \ D5
S I- (J)S H- (/)S f (/)s - i - (/)
Recognition
A,V + (/)S + Ds
»cS + D,
Note. S — extended search; Ds — simple direct accessprocess; /)c = complex direct access process; / -- implicitrecognitionlike process.
fects, such as list length and fan effects, cannotbe predicted. Dc indicates a complex directaccess process in which many memory imagesare contacted together, leaving open the pos-sibility of predicting searchlike effects. / is arecognitionlike process that allows the subjectto decide that a name recovered from a sam-pled image is appropriate to recall. / is placedin parentheses because it is often an implicit,rather than an explicit, component of a recallmodel.
Model 1 may be termed an embedded two-process model because the recognition mech-anism is embedded in the recall mechanism.Examples of such models include Kintsch(1970, 1974) and J. R. Anderson and Bower(1972, 1974). In typical models of this type,recall is a function of two sequential stages.The first is a generate stage, whereby long-term store (LTS) is searched and possible wordcandidates are output to the recognize stage.In the recognize stage, a word's familiarity(Kintsch, 1970) or contextual associations(J. R. Anderson & Bower, 1972) are evaluatedto determine if the generated word had beenpresented on the study list. During a recog-nition test, only the second stage is employed,and it is applied to the test word only. Directaccess is presumably gained to the appropriatestored memory representation (possibly anepisodic image), and the decision process thenproceeds just as it does for each word generatedin the recall process.
Embedded two-process models have diffi-culty explaining why recognition exhibitsmany of the same properties as recall, prop-erties that seem to imply that recognition in-volves a memory search. Examples includework on organizational effects (Mandler, 1972;Mandler & Boeck, 1974; Mandler, Pearlstone,
& Koopmans, 1969), test and lag effects (Mur-dock, 1974; Murdock & Anderson, 1975),repetition effects (Atkinson & Juola, 1973,1974), and the list-length effect (e.g., Strong,1912).
Perhaps the simplest alternative to Model1 is a model proposing common mechanismsfor recall and recognition. One such approachis seen in the work of Tulving (e.g., 1976). Heproposed that recognition and recall both in-volve cue-dependent retrieval processes (Tulv-ing, 1974), in which performance is dependenton the degree to which the cues available atthe time of test (including the test itself inrecognition) match the cues during presen-tation (Tulving, 1968, 1976; Tulving & Thom-son, 1973).
A particular type of cue-dependency theoryholds that recognition can be explained by thesame search mechanisms typically used tomodel recall (e.g., the SAM model of Raaij-makers & Shiffrin, 198Ib). This is indicatedby Model 2 in Table 1. However, these modelshave a serious problem: Subjects can quickly,accurately, and with high confidence classifyat least some distractors correctly (Atkinson& Juola, 1974; Fischler & Juola, 1971;Herrmann, Frisina, &Conti, 1978; Murdock,1974; Murdock & Anderson, 1975; see alsoGlucksberg & McCloskey, 1981). Even alengthy search may miss targets present inmemory; therefore only a weak inference canbe made that a nonlocated item is not inmemory. Thus search models may possibly beable to explain accurate negative recognitionresponses to distractors, but only if a long anddifficult search fails; conversely, fast negativerecognition responses can be generated bysearch models but only at a considerable costin accuracy.
It is of course possible to posit search modelsfor recall, but assume that recognition operatesdifferently, with direct and certain access tothe image of the tested item. Model 1 had thisproperty but had problems because the simplerecognition component could not producesearchlike effects. One way out of this difficultyinvolves retaining a simple direct-access com-ponent for recognition but adding a searchcomponent as well, as indicated by Model 3in Table 1. In two-phase models like Model3, recognition can occur either on the basis ofa simple fa miliarity process (i.e., £>s) or on the
RETRIEVAL MODEL FOR RECOGNITION AND RECALL
basis of a search (a slower process, on the av-erage, than familiarity). These phases can oc-cur sequentially or in parallel.
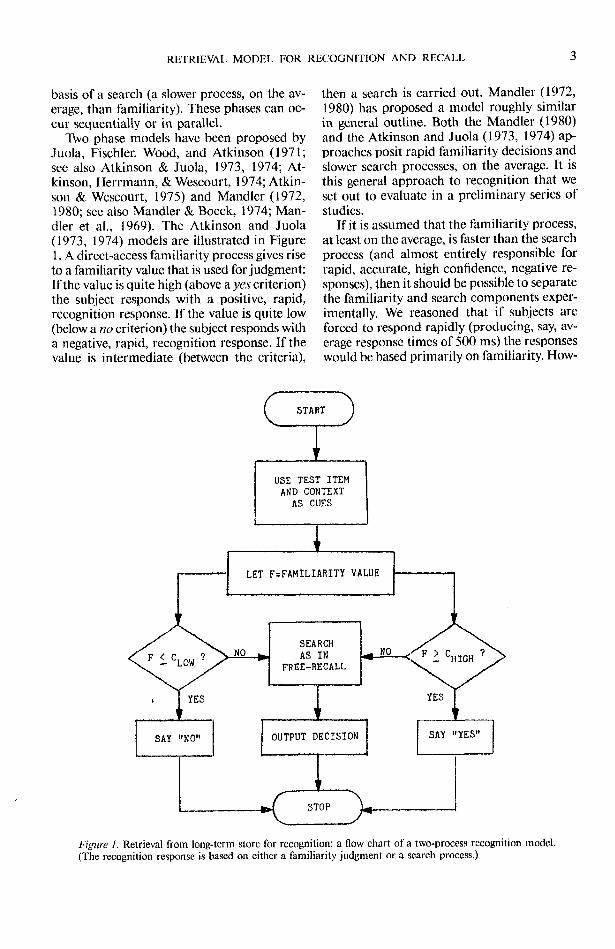
Two phase models have been proposed byJuola, Fischler, Wood, and Atkinson (1971;see also Atkinson & Juola, 1973, 1974; At-kinson, Herrmann, & Wescourt, 1974; Atkin-son & Wescourt, 1975) and Mandler (1972,1980; see also Mandler & Boeck, 1974; Man-dler et al., 1969). The Atkinson and Juola(1973, 1974) models are illustrated in Figure1. A direct-access familiarity process gives riseto a familiarity value that is used for judgment:If the value is quite high (above a yes criterion)the subject responds with a positive, rapid,recognition response. If the value is quite low(below a no criterion) the subject responds witha negative, rapid, recognition response. If thevalue is intermediate (between the criteria),
then a search is carried out. Mandler (1972,1980) has proposed a model roughly similarin general outline. Both the Mandler (1980)and the Atkinson and Juola (1973, 1974) ap-proaches posit rapid familiarity decisions andslower search processes, on the average. It isthis general approach to recognition that weset out to evaluate in a preliminary series ofstudies.
If it is assumed that the familiarity process,at least on the average, is faster than the searchprocess (and almost entirely responsible forrapid, accurate, high confidence, negative re-sponses), then it should be possible to separatethe familiarity and search components exper-imentally. We reasoned that if subjects areforced to respond rapidly (producing, say, av-erage response times of 500 ms) the responseswould be based primarily on familiarity. How-
( START J
USE TEST ITEMAND CONTEXTAS CUES
r
LET F=FAMILIARITY VALUE
\
Figure 1. Retrieval from long-term store for recognition: a flow chart of a two-process recognition model.(The recognition response is based on either a familiarity judgment or a search process.)

GARY GILLUND AND RICHARD M. SHIFFRIN
SHORT LIST LONG LIST.a
LLJ
<: -8
OC
5 .7EC
< 6
W .5
•? .4
UJ
< '3DC
b -2
1
' ' ̂ ^Ar^SLOW
>/^'•G
p-'" FAST-
d'
-
-
-
I I I
I I I
-
-
/ SLOW
- yO- —- 0
/ FAST/
/
d-
i i i
.a
.8
.7
.6
.5
.4
.3
.2
1
NUMBER OF PRESENTATIONS
figure 2. Recognition performance as a function of list length (36 or 96), number of presentations, andslow or fast recognition tests.
ever, if subjects are encouraged to take theirtime and are not even allowed to respond be-fore I (or 1.5) s, then a larger proportion ofresponses should be based on search processes.
The experiments involved visual, sequential,presentations of words in lists. Following eachlist a yes-no recognition test was given: Thelist words were mixed with an equal numberof distractor words and were tested one at atime. In fast tests, the items were presentedevery second, and subjects were required torespond to each item in under 900 ms. In slowtests, responses were not allowed before I (or1.5) s had elapsed, and 3 (or 4) s were givenbetween tests. In the fast test, subjects' latenciesaveraged about 500 ms, and in the slow test,the latencies averaged about 2.5 to 3 s (whichcompares with average latencies in uncon-strained settings of about 800 to 1500 ms).Different lists were tested with slow and fasttest techniques, with subjects practiced on therespective techniques and warned in advanceof each test (but not each study) concerningthe upcoming test speed. The results of threeexperiments that employed this procedure canbe seen in Figures 2, 3, and 4.
The first experiment varied list length andnumber of presentations. The second exper-iment varied depth of encoding (pleasantnessvs. pronounceability ratings) and number ofpresentations. In the third experiment, the type
of distractor was manipulated.' In all situa-tions, the variables had effects that were ex-pected based on prior findings in the literature:Subjects were better on repeated items thanon items presented only once (e.g., Atkinson& Juola, 1973; Ratcliff & Murdock, 1976).Performance was better on words rated forpleasantness than on words rated for pro-nounceability, although this factor did notquite reach statistical significance, F(l, 71) =3.21, p = .078 (e.g., Jacoby & Dallas, 1981).Accuracy was higher for words from the shortlist than for words from the long list (e.g., At-kinson & Juola, 1973; Ratcliff & Murdock,1976).
In the third experiment, the distractors oneach list were of four types. Control distractorswere not related in any systematic fashion tothe list items. Other distractors were synonymsof particular list items, were similar graphe-mically to particular list items, or were similarboth graphemically and phonemically to par-ticular list items. (Also, the fast vs. slow testvariable was a between-groups measure in thisexperiment.) Subjects made more errors (falsealarms) on distractors that were related gra-
1 The experiment on different types of distractors wascompleted with Tim Feustel. We gratefully acknowledgehis contribution in all stages of the experiment.

RETRIEVAL MODEL FOR RECOGNITION AND RECALL
PLEASANTNESS PRONOUNCEABILITY
cc3LU
LU
DC
X
I.U
.9
.8
.7
.6
•5
A
\ 1
SLOW
x^^
0""~~~FAST
-
-
i i
i i
SLOW
tS^
--oO--"~" FAST
-
-
i i
I.U
.9
.8
.7
.6
.5
A
1 3 1 3
NUMBER OF PRESENTATIONS
Figure 3. Recognition as a function of orienting task (pleasantness or pronounceability ratings), number ofpresentations, and slow or fast recognition tests.
phemically and phonemically to target itemsthan to control items or synonyms. Such re-sults have been found before (e.g., Cramer &Eagle, 1972; see also Eagle & Ortof, 1967;Nelson & Davis, 1972).2
In all three studies, performance was higherfor slow tests than for fast tests—a result thatis in accord with much work on speed-ac-curacy trade-offs—and research using the sig-nal-to-respond technique (e.g., Dosher, 1981;Pachella, 1974; Reed, 1973; Wickelgren &Corbett, 1977).
Most important for present purposes, therewere no significant interactions between thetype of test (fast vs. slow) and any of the othervariables in any of the three experiments.3
Thus these variables responded similarly inthe fast and in the slow test conditions. If searchhad occurred more often in the slow test con-ditions, and if search and familiarity responddifferently to these variables, then an inter-action would have been expected.4 At the least,doubt is cast on Model 3 of Table 1. The find-ings therefore suggest either that search is notbeing utilized in these studies (Model 4 of Ta-ble 1) or that both search and familiarity pro-cesses are being utilized but that they respondto these types of variables in similar ways(Model 5 of Table I).5 Note that Model 4 iscompletely embedded in Model 5 and there-fore cannot predict the data better than does
Model 5. It is our plan in this article to explorea version of Model 4 because we do not wishto propose a more complex model unless thesimpler version can be shown to fail. Fur-thermore, even if Model 4 can be shown tofail, its study could prove highly instructive.
Note that the direct-access component (Dcor D$ in Table 1) is often denoted familiarity.
2 It may appear surprising that no more false alarmswere made to synonyms than to control words in view ofthe large number of studies that have found higher falsealarms for synonyms than for control words (for examples,see Anisfeld & Knapp, 1968; Grossman & Eagle, 1970).However, we have replicated this finding several times inour laboratory (see also Cramer & Eagle, 1972). One pos-sible explanation is that the types of errors reflect the biasin encoding, and our subjects were emphasizing low-levelfeatures (acoustic or physical) rather than semantic featuresof the words. Some support for this notion can be foundin the literature (e.g., Cermak, Schnorr, Buschke, & At-kinson, 1970; Davies & Cubbage, 1976; Elias & Perfetti,1973). Other explanations are discussed later in this article.
3 Although the larger advantage for physical similarityunder fast testing in Figure 4 did not reach significance,the result, if reliable, may suggest that fast tests are moresensitive to low-level similarity features.
4 The use of different methods of measuring performancein our studies, such as utilization of d' measures, did notchange our findings or our conclusions.
5 There is a possibility that no interactions occurredbecause familiarity is not faster than search; this is anunattractive alternative because the puzzle of rapid, ac-curate, negative recognition responses is difficult to explain.

GARY GILLUND AND RICHARD M. SHIFFRIN
This terminology seems appropriate for mostlaboratory recognition studies because thetasks are episodic and the decision is usuallyone of discriminating a recently presented itemfrom preexperimentally known items. We usethe terms familiarity and direct access inter-changeably in this article.
We have assumed and defined the famil-iarity component to be faster on the averagethan the search process, because the searchprocess must predict interresponse times infree recall that are many seconds in length,whereas the familiarity process must allow ac-curate negative recognition responses to bemade in under a second (on many trials). Ofcourse it is possible that the Dc or Ds processis a sequential one, similar to the search pro-cess but far more rapid (and efficient). Thedifficulty of distinguishing serial and parallelprocesses in general is well known (see Town-send, 1971), and we shall not try to do so here.For present purposes, it suffices to note thatDc (or Ds) cannot be a search process withtemporal characteristics close to those neededfor search in free recall.
We conclude this introduction by indicatingthe scope of the present article and the typesof data we try to explain. Our present versionof the SAM model is meant to deal with allof the recall phenomena mentioned in our
earlier papers; these phenomena lie largely inthe domain of episodic memory (see Raaij-makers & Shiffrin, 1980). The extension ofthe model to recognition is meant to applyprimarily to situations in which long-termmemory is being accessed (i.e., in which nocontamination of recognition from short-termstore [STS] occurs) and to situations in whichsubjects are asked to make episodic judgmentsthat some item has occurred recently (whenthe distractors have not been presented re-cently and hence are unfamiliar).
The phenomena we wish our model to ex-plain include the following: (a) the large num-ber of factors that influence recall and rec-ognition performance similarly, such as theamount of time given for study (Ratcliff &Murdock, 1976; Roberts, 1972), list length(e.g., Murdock, 1962; Roberts, 1972; Strong,1912; see also Figure 2), test delay (e.g., Shep-ard, 1967; Strong, 1913; Underwood, 1957),and test position effects (e.g., RatclifF& Mur-dock, 1976; Raaijmakers & Shiffrin, 1981a);(b) the factors that influence recall and rec-ognition differently, such as word frequency(e.g., Gregg, 1976), types of encoding (e.g.,Tversky, 1973), types of rehearsal (e.g., Wood-ward, Bjork, & Jongeward, 1973), and the ef-fects of context shifts (e.g., Smith, Glenberg,& Bjork, 1978); and (c) the types of data that
.40
g.30
DC
5DC< .20
LU
2 -1°
.00
SLOW
CONTROL SYNONYM GRAPHEME PHONEME
DISTRACTOR TYPE
Figure 4. False alarm rate as a function of distractor similarity: control = not related; synonym = semanticallyrelated; grapheme = one letter in word altered, no rhyme; phoneme = one letter in word altered, and rhyme.

RETRIEVAL MODEL FOR RECOGNITION AND RECALL
have been thought to indicate searchlike pro-cesses in recognition (e.g., Murdock, 1974;Tulving & Thomson, 1973).
1. A Model for Recall and Recognition
In Section 1, we present a model to predictthe phenomena of both recall and recognition:We include (a) general features of the modelthat apply to both recognition and recall, (b)the recognition part of the model, (c) a sum-mary of the model as it applies to recall (therecall model and applications have been ex-plicated in detail in previous publications:Gillund & Shiffrin, 1981; Raaijmakers & Shif-frin, 1980, 1981a, 1981b), (d) a simple nu-merical example illustrating the quantitativefeatures of the approach, and (e) certain im-portant assumptions regarding storage andvariability.
General Features of the SAM Model
Long-term store (LTS) is assumed to becomposed of closely interconnected, relativelyunitized, permanent sets of features called im-ages. Episodic images contain many types ofinformation, including the following: (a) con-textual elements that can be used to identifythe contextual-temporal setting in which anitem occurs, (b) item information that can beused to name and identify the item encodedin the image, and (c) interitem informationthat links one image to others.
The process of retrieval is assumed to becue dependent (Tulving, 1974). Access to LTSoccurs when probe cues called a probe set areassembled in STS and are used to activate anassociated set of information in LTS. The ac-tivated set consists of a large set of imagesactivated to differing degrees. In recognition,some sort of integration across the entire ac-tivated set is used to generate a decision. Inrecall, one image is sampled from the activatedset during each cycle of the memory search.
The quantitative details of the retrieval pro-cess are based on a retrieval structure (see theleft-hand matrix in Figure 8). The retrievalstructure is a matrix of retrieval strengths re-lating all possible cues to all possible images.All of these strengths are greater than zero,although many are of negligible magnitude.In theory, all cues and all images are contained
in the structure, but in practice only the non-negligible cues and images are considered. Theretrieval strengths represent the relative ten-dency for a given cue to activate a given imageand are related to the strength of the associativeconnections between that cue and that image.
In an episodic task, the entries in the re-trieval structure are determined by two mainfactors. The first factor is the coding and re-hearsal process used at the time of study (andany additional learning that occurs during thecourse of retrieval). The second factor is thematch of the cue used at test to the nominallyidentical cue used at study: These might differdue to encoding variability and other factors.Particularly important cues in an episodic taskare (a) context cues, which through similarityto the storage context give the subject accessto recently presented items; (b) item cues,which have high strengths to the image con-taining the cue item itself and to the imagescontaining items rehearsed with the cue item;(c) category cues, which have high (preexper-imental) strengths to the images containingitems from the cue category.
For computational simplicity, the retrievalstructure is assumed to contain images of allpresented items (rather than all images inmemory). The context cue has strengths toeach image in proportion to the time spentrehearsing that item. Each list item, as well asnew items that are not from the list, can bea cue. If the cue item has not been rehearsedwith the item in a given image, then thestrength from item cue to image is set to asmall residual value based on preexperimentalfactors; otherwise the strength is proportionalto the time that both items had been rehearsedtogether. A category cue is given a high strengthto images of items from that category and asmaller residual strength to images of itemsfrom other categories.
The SAM Model for Recognition
As indicated in the introduction, we are in-terested in considering Models 4 and 5 of Table1. We present a version of the simpler model,Model 4, in spite of the fact that the basiclogic of the SAM model requires that subjectsshould be able to carry out a memory searchduring recognition testing, if they choose todo so. Thus, for the purposes of the devel-

GARY GTLLUND AND RICHARD M. SHIFFRIN
opment, we adopt the working assumption thatthe subjects choose not to carry out a memorysearch during recognition.
Model 4 of Table 1 assumes that recognitionis determined by a direct-access familiarityprocess, a process complex enough to producecharacteristics that normally are the result ofa search process. The model we propose doesthis in a very simple way. It is assumed thatin a yes-no recognition test the subject probesmemory with two cues: the context cue andthe tested item. The total activation of LTSin response to this probe set is taken to be thevalue of familiarity on which a response isbased. Thus when a target is tested, the acti-vation is based not only on the activation ofthe image of that target, but also on the ac-tivations of all other images in memory. Forthis reason, we refer to the approach as a globalmodel of familiarity. Searchlike effects arepredicted because images of items other than
the tested item are included in the activationon which a decision is based. The simplicityof the model is illustrated in Figure 5. In re-sponse to a test item, a value of familiarity isgenerated, and the subject responds yes or nodepending on whether the familiarity value isabove or below a criterion value chosen by thesubject.
The quantitative details are captured inEquation 1. This equation gives the generalexpression for the total LTS activation whencues Qi, Q2, .. ., QM are used together toprobe memory and when there are N imagesin LTS. The W/ are weighting factors associatedwith each cue, possibly reflecting the amountof attention allotted to each cue. (In previouswork with the SAM model these weights hadalways been set to 1.0.) The term representedby the product gives the activation contributedby any given image, I/c. Thus the activation ofa given image is just the product of the separate
f START J
USE TEST ITEMAND CONTEXT
AS CUES
LET F=DENOMINATOROF SAMPLING RULE
Figure 5. A flow chart for the basic SAM recognition process.

RETRIEVAL MODEL FOR RECOGNITION AND RECALL
activations of that image by each of the cues,the individual activation being the strength inthe retrieval structure, S(Q;, y. The total ac-tivation is just the sum of the activations foreach of the images.
N M
P(Qi, Ch, . . • , QA/) = 2 E S(Q;, yw'. (1)k=\ ;=i
In a yes-no recognition test for the presenceof single items on a recently presented list, weassume that just two cues are used to probememory: the context cue, C, and the testeditem, lj. In this case, Equation 1 simplifies toEquation 2, and when the weights are set to1.0, simplifies even further, as indicated inEquation 3. (For a numerical illustration ofEquation 3, see the first three matrices alongthe top of Figure 8.)
*\c, ij) = 2 s(c, yw<sd;, ywj. &)
F(c, ij) = 2 s(c, ysa,, y. (3)fc-i
The familiarity values indicated in Equa-tions 1,2, or 3 can produce higher than chancerecognition judgments because a few com-ponents of the sum making up the total ac-tivation will generally be higher for targets thandistractors. In particular, the strength of a tar-get to its own image, 8(1,, I;), will usually behigher than the strength of a distractor to thatsame image, S(L/, I,-). Furthermore, the inter-item strengths are sometimes higher for targets,S(lj, y, k + j, than for distractors, S(Id, y,d + k; this will usually be the case when thetest item, lj, had been rehearsed during listpresentation with item lk.
In applications to episodic tasks, the fa-miliarity value is calculated under the sim-plifying assumption that only the strengths forlist items contribute nonnegligible activations(i.e., the sum in Equations 1, 2, or 3 is takenonly over the N list items). This assumptionleads to what may seem an unusual featureof the model: When a distractor is tested, itsown image does not contribute to its famil-iarity; a distractor is familiar only to the degreethat it activates the list items.
Equations 1, 2, and 3 specify the values offamiliarity that are produced by tests of targets
and distractors. As indicated in Figure 5, adecision is made only after a criterion is chosenby the subject. Positive recognition judgmentsare made when the familiarity value is higherthan the criterion. Therefore the recognitionmodel is fully specified by Equations 1, 2, and3, and by a set of assumptions governing thechoice of criterion (see Sections 2 and 5).
The SAM Model for Recall
The SAM recall model is quite a bit morecomplicated than the model for recognition,because recall is assumed to require a memorysearch. The search consists of a sequence ofsampling and recovery operations, each cyclein the sequence containing a sample of animage from LTS and an evaluation of the in-formation recovered from the sampled image.
We begin our discussion of the recall modelby considering the basis for sampling an imagefrom LTS. During a given cycle of the searchof memory, assume that cues, Q l s Q2, .. .,QM are used together as a probe set. ThenEquation 4 gives the probability of samplingimage I,:
M
S(Q;
2. (4)
l S(Q,,
The denominator of this equation is ofcourse just the total activation of LTS, in re-sponse to the cues, that was the value of fa-miliarity used to make a recognition decision.The terms are defined similarly. Equation 4stipulates that sampling obeys a ratio rule(Luce, 1959) in which an image's chance ofbeing sampled is proportional to its netstrength to the probe cues. That is, the nu-merator is just the activation of a given image,whereas the denominator is the summed ac-tivation across all images.
The justification for the product rule bywhich individual cue strengths are combinedinto a single activation for a given image iseasy to see in the sampling equation. The useof a product rule ensures that the sampledimage tends to be an item strongly connectedto all cues rather than to just one. In other

10 GARY GILLUND AND RICHARD M. SHIFFRIN
words, the sampled image tends to come fromthe most dense region of the intersection ofthe associative fields of the separate cues. Thusthe product rule allows the subject to use mul-tiple cues to focus the search.
Equation 4 is somewhat easier to follow inthe case that has been used in simulations ofsimple free-recall in previous work (Raaij-makers & Shiffrin, 1980, 1981b). In these casesthe W,- were all set to 1.0, and only two typesof probe sets were allowed: the context cuealone or the context cue plus one item cue. Ifthe context cue alone is used, Equation 4 be-comes Equation 5 (see the top row of the sec-ond, third, and fourth matrices along the topof Figure 8):
/W/IQ = S(C, I,)(5)
2 s(c,
If the context cue and an item I, are usedas cues then Equation 4 becomes Equation 6(see rows 2 through 7 in the second, third, andfourth matrices in Figure 8):
SIT Tisn 11D n \r< T ^ - 5^' lt)^(\j, I,) (6)
s(C,
Once an item has been sampled, the subjectattempts to recover the information containedtherein and utilize it to succeed at the giventask. In the case when recall is required, thenthe name encoded in the image is desired; inthis case the probability of recovering the en-coded name has been specified in earlier workand is given in Equation 7:
M
j, i.)}.
In this equation, the weights do not nec-essarily have to be identical to those used inEquation 4. In applications to free recall, how-ever, the weights were set to 1 .0 also. Whencontext alone is the cue, we get Equation 8(see the top row of the lower matrices in Figure8):
FR(I,|C) = 1 - exp{-S(C, I,)}. (8)
When context and an item I/ are cues, we getEquation 9 (see rows 2 through 7 in the lowermatrices of Figure 8):
/mlC, I,)
= 1 - exp{-S(C, I,) - SdJ} I,)}. (9)
Equations 7, 8, and 9 are not quite as ar-bitrary as they look at first glance. Let 1 -exp{-W,S(Qj, I;)} be the probability of cor-rectly identifying the item in the sampled im-age, for some particular cue, Q;, used alone.Then Equations 7, 8, and 9 give the generalexpressions for correct recovery under the as-sumption that each different cue has an in-dependent chance of producing such recovery.
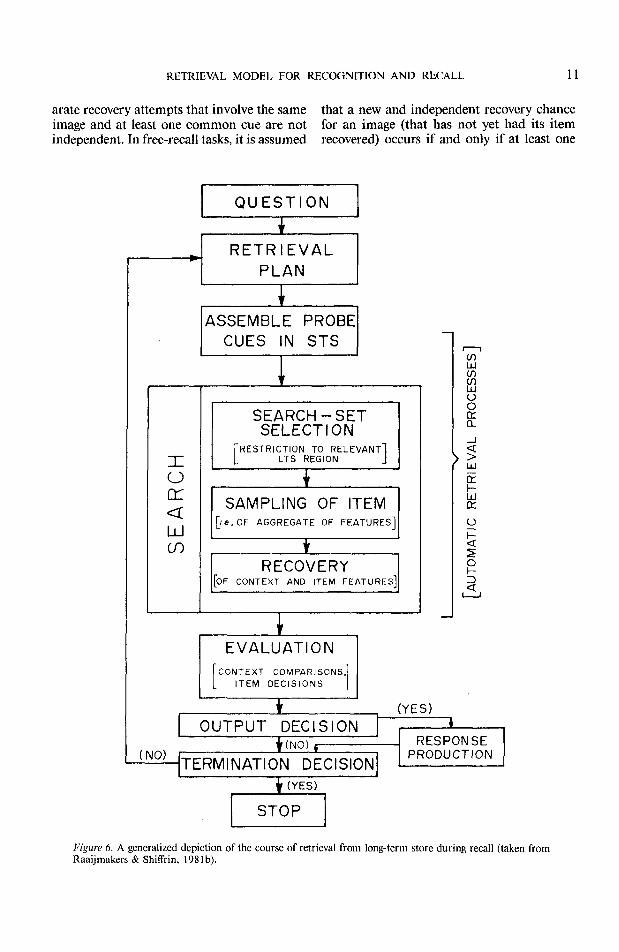
Equations 4-9 describe what happens on agiven cycle of the search. The whole course ofretrieval consists of a series of such cycles.Figure 6 depicts the course of the retrievalprocess. On each cycle the subject choosesprobe cues according to a retrieval plan thattakes into account both prior knowledge andthe outcome of the retrieval process to date.The overall plan may involve strategies suchas alphabetic search or temporally orderedsearch or instead may involve a strategy basedon the momentary outcome at each stage ofsearch. After probe cues are selected, the rel-atively automatic sampling and recoveryphases occur. Then the subject evaluates theoutcome and decides whether to terminate orto continue search. In free-recall tasks, thetermination decision is presumably based onthe number or proportion of search cycles thatate failures (these are cycles on which no newitem is successfully recovered). If the searchcontinues, then the cycle begins anew with thechoice of probe cues.
To predict certain changes that take placeduring the course of retrieval, it is necessaryto assume that some learning occurs duringretrieval (such learning was termed incre-menting in previous publications, in defianceof grammatical rules). In free recall, for ex-ample, each successful recovery is assumed tobe followed by an increase in the strengthsrelating the cues in that probe to the imagesampled (see Rundus, 1973).
Our brief review of the SAM model for recallmay be completed by pointing out that sep-
RETRIEVAL MODEL FOR RECOGNITION AND RECALL 11
arate recovery attempts that involve the sameimage and at least one common cue are notindependent. In free-recall tasks, it is assumed
that a new and independent recovery chancefor an image (that has not yet had its itemrecovered) occurs if and only if at least one
QUESTION
iRETRIEVAL
PLAN
Iotr<LUCO
ASSEMBLE PROBECUES IN STS
i t
SEARCH -SETSELECTION
[RESTRICTION TO RELEVANT![ LTS REGION J
*SAMPLING OF ITEM[ /a. OF AGGREGATE OF FEATURES]
tRECOVERY
[OF CONTEXT AND ITEM FEATURES]
EVALUATION[CONTEXT COMPARISONS][ ITEM DECISIONS j
OUTPUT DECISION(YES)
"L
LUin<s>LUooo:O.
cc.LUa:o
(NO)TERMINATION DECISION
RESPONSEPRODUCTION
(YES)
Figure 6. A generalized depiction of the course of retrieval from long-term store during recall (taken fromRaaijmakers & Shiffrin, 1981b).

12 GARY GILLUND AND RICHARD M. SHIFFRIN
new cue (that has not been tried yet for thepresent image) is in the probe set.6
The manner in which the process of retrieval 'is implemented for a particular task is illus-trated by the case of free recall. The flow chartfor retrieval used by Raaij makers and Shiffrin(1980) for this task is depicted in Figure 7.The retrieval structure is first filled accordingto a buffer-rehearsal process. Retrieval beginswith the output of all items currently in STS(unless an arithmetic or other task is used toempty the words from STS before recall be-gins).
The course of LTS retrieval is indicated inthe flow chart. Recall begins with the contextcue alone. This cue continues to be used onsuccessive search cycles until a word is recalled.Then an increment is given and the next probeset consists of the context cue plus the itemjust recalled. This probe set is used either untila new item is recalled or until Lmax failuresin a row occur; in the case of Lmax failures,the item cue is dropped and the subject revertsto the context cue alone. Whenever a new itemis recalled the probe cues to image strengthsare given an increment, and the next probeset consists of context plus the just recalleditem. Recall terminates whenever a total ofKmax failures accumulate. Although strategiesare surely idiosyncratic and variable, the free-recall strategy outlined here (and in Figure 7)seems to us a reasonable approximation thatis fairly rational and simple to apply.
Note that cued-recall tasks are also easy tohandle within the same framework. If an itemis presented as a cue, and some other item isrequired as a response, it is natural to assumethat the subject uses as a probe set the contextcue along with the presented item. This probeset can be repeated until the response is foundor the search is terminated.
Finally, note that the SAM recall model in-corporates several processes in the recoveryphase, implicitly. For example, in cued recallthe recovery probability incorporates a deci-sion process by which the subject decides asampled item that can be named is in fact theresponse to the stimulus. More important forpresent purposes, the recovery process in freerecall incorporates an implicit decision processby which the subject decides that a nameablesampled item was in fact on the recently pre-
sented list. This is the process denoted / inTable 1.
A Numerical Example
To help readers who are unfamiliar with theSAM model understand the implications ofthe equations and assumptions, we give a nu-merical example. The example is illustratedin Figure 8. The retrieval structure is indicatedin the left-hand matrix. This gives the retrievalstrengths linking cues to memory images. Inthis example it is assumed that four items arepresented to the subject for study, resulting inan interconnected storage network containingfour images corresponding to the four pre-sented items. The images are denoted by I*and the possible cues that might be used toprobe memory are given along the left-handmargin of the matrix. The cue labeled C isthe context cue (which effectively restricts thesearch to the just-presented list). The items ofthe list are possible cues and are denoted I,.The items as cues are distinguished from thememory images of those same items becausethese are never identical (and sometimes canbe quite different if, say, the encoding contextshifts between study and test). The remainingcues denoted D, are items that were not onthe study list (and might be distractors in arecognition test).
The retrieval strengths in the matrix areassumed to result from the operation of re-hearsal and coding processes during the studyof the list. Note that all of the cues are con-nected by nonzero strengths to all of the im-ages, even if they were not rehearsed together(as must have been the case for the D, cues).The high strength connecting the context cueto I* probably means that \* had been re-hearsed extensively, and the high strength re-lating I3 to I* (the self-strength) probably re-
6 Because our recovery rule is consistent with an hy-pothesis that each cue has an independent chance of leadingto recovery, it is perhaps more reasonable to assume thatthe recovery probability is based only on the strengthsassociated with the new cues and not on the strengthsassociated with the old cues that failed earlier. However,we have utilized the old assumption in the present articleto be consistent with the earlier SAM papers. We doubtthat important differences would result for the predictionsin the present article if the other assumption is adopted.

YES
( START J
K=0
sample item iusing context-cue
YES
NO
increase associationto context
sample item j using item iand context as cues
( STOP )
JfES
use item j asnew cue
Tincrease association tocontext and to item i
pi
ODw
370
O
HO
>za
r
Figure 7. A flow chart of the SAM retrieval process for free-recall (taken from Raaijmakers & Shiffrin, 19801.

RETRIEVAL STRENGTH TO SUM OF PROBABILITY OFSTRUCTURE PROBE SET STRENGTHS SAMPLING AN
" IMAGE WITH03 THE PROBE SET
C
Ii
12
uu3 u
Di
D2
Memory Images* * * *
Ii I2 Is Ii»
.5
. 3
.3
.4
.1
.1
.2
.3
.3
.4
.2
.1
.03
.1
.8
.4
.1
.7
.2
.1
.3
.4
.1
.1
.3
.4
.1
.1
ca0-§c.
c
01 !
OI2
01 3
OD,
OD2
* * * *Ii I2 la U
.5
.15
.15
.20
.05
.05
.10
.3
.09
.12
.06
.03
.013
.03
.8
.32
.08
.56
.16
.08
.24
.4
.04
.04
.12
.16
.04
.04
Sum of Strengths
Familiarityof
Probe Set
(2.0)
.60
.39
.94
.40
.185
.41
* * *Ii I2 Is
.25
.25
.39
.21
.13
.27
.24
.15
.15
.31
.06
.08
.08
.07
.40
.53
.20
.60
.40
.43
.59
RecoveryProbabilities
c
01 !
OI2
OI3
OB2
.5
.&
.8
.9
.6
.6
.7
.3
.6
.7
.5
.4
.35
.4
.8
1.2
.9
1.5
1.0
.9
1.1
.4
.5
.5
.7
.8
.5
.5
I2 I3
.39
.55
.55
.59
.45
.45
.50
.26
.45
.50
.39
.33
.30
.33
.55
.70
.59
.78
.63
.59
.67
.33
.39
.39
.50
.55
.39
.39
oIoF
za
n
Os
2z

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 15
fleets the same factor. The interitem strengthsare not very high, but the value of 0.4 for I3to If may reflect some extra joint rehearsal ofthese two items. The residual values con-necting the distractor D) to the list-item imagesare quite low, as is usually the case. However,the residual values for item D2 are somewhathigher, possibly indicating a higher similarityof this distractor to (some of) the list itemsthan was true for item D,. Finally, note thateven in cases where rehearsal and coding arenot factors (e.g., the rows of strengths for thedistractor cues), the strengths are somewhatvariable. This variability is quite important;as we see, without variability, recognition per-formance would generally be perfect.
According to the SAM model, the contextcue is always used to probe memory in episodictasks but sometimes is combined with othercues, in this case the item cues. The possibleprobe sets size of 1 or 2 are given on the left-hand margin of the second matrix. The nu-merator of Equation 6 specifies that thestrength when cues are combined is the prod-uct of the individual cue strengths. Theseproducts are given in the second matrix (exceptfor the first row, for the context cue alone,which is determined by the numerator ofEquation 5). Thus the strength connectingprobe set (C + Ij) to I* is given by the productof the strength connecting C to If (i.e., 0.5)and the strength connecting I] to If (i.e., 0.3)for a result of 0.15.
For a given probe set the sum of thestrengths to all the images is the familiarityvalue of Equations 1, 2, or 3 and also thedenominator of Equations 4, 5, or 6. We treatthis value as the total LTS activation engen-dered by the probe set, and the results aregiven in the column vector of Figure 8. If thesubject were carrying out a recognition testwith targets ^-Lt and distractors DI and D2,a criterion would be chosen and responsesmade accordingly. Because the familiarityvalue of D2 is higher than that of the two listitems, I2 and I4, errors occur wherever thecriterion is placed. Thus if the criterion were
set at 0.402, a false alarm would be given toD2 and a miss would be given to I2 and L».
Equations 4, 5, or 6 determine the samplingprobabilities for each image for a given probeset, for each cycle of the search process. Theprobabilities are simply the numbers in therows of the second matrix in Figure 8 dividedby the row sums given in the column vector.The resulting sampling probabilities are givenin the right-upper matrix of Figure 8. Notethat the absolute values of the strengths in thefirst two matrices along any row are not im-portant for sampling; sampling is based onlyon the relative strengths along any row of thesecond matrix. If learning takes place duringretrieval, then some of the strengths in theretrieval structure increase and, consequently,some of the sampling probabilities changeduring the course of retrieval.
Once an image is sampled, there is no cer-tainty that a recovery of the information inthat image will be complete enough that thename of the item embedded in that image willbe recallable. The probability of recovery isgiven by Equations 7, 8, or 9 and is based onan exponential function of the sum of strengthsfor the cues in the probe set. The sums ofstrengths are given in the lower left-hand ma-trix of Figure 8, and the corresponding re-covery probabilities from Equations 8 and 9are given in the lower right-hand matrix. Theseprobabilities apply whenever an image is sam-pled by a probe set that has not previouslybeen used to sample that image.
Storage and Variability Assumptions
The values in the retrieval structure are theresult of (a) rehearsal and coding processesthat take place during the study of the list, (b)preexperimental associations, and (c) thematch of the cue encodings at study and test.Storage assumptions based on a rehearsalbuffer have been used in previous applicationsof SAM to free and cued recall. However, theseprevious storage assumptions cannot be usedwithout modification in applications to rec-
I'igure 8. A numerical illustration of a possible retrieval structure for a four-item list with context, item,and distractor cues. (The remaining matrices give quantities that are used during the application of SAMto recognition and recall.)

16 GARY GILLUND AND RICHARD M. SHIFFRIN
ognition. The previous storage assumptionsallowed variability in the strengths placed inthe retrieval structure only to the degree thatthe amount of rehearsal (or coding) varied.Thus the residual values placed in the structure(when two items were not rehearsed together)were set to a fixed value. Because the residualvalue was low, and less than the self-strengthfor any list item, every list item would have ahigher familiarity value than every distractor.This is evident from inspection of Equation3: Both targets and distractors share the valuesof the context strengths, S(C, lk); for the dis-tractors, each interitem strength, 8(1,, lk),would attain a constant, small, residual value;for list items, some of the interitem strengthswould be higher than the residual value dueto rehearsal of an item I,. The result of theseassumptions is the prediction that recognitionperformance would be perfect.
Obviously what is needed for realistic rec-ognition predictions is variability of thestrengths placed in the retrieval structure. Fa-miliarity distributions for targets and distrac-tors would then have the possibility of over-lapping. Because items obviously differ (as domany other factors besides rehearsal time),variability is a very reasonable assumption.Variability was not assumed in previous pub-lications concerning free recall because it wasnot needed, but now that we introduce it forrecognition, we also use the assumption forrecall, and generate predictions accordingly.
Introduction of variability opens many de-grees of freedom for the model. We decidedto adopt a very simple approach, at least atthe outset: After the retrieval structure is filledin the usual fashion, each entry is replaced bya random sample from a 3-point distribution.In particular, if the starting value is x, thenthe final stored value, y, is chosen accordingto Equation 10.
(1 - v)x, P = 1/3
y= x, p= 1/3. (10)
(1 +v)x, p= 1/3
This discrete distribution is sufficient for ourpurposes because the familiarity value resultsfrom a sum across the list items; the law oflarge numbers assures that the distribution ofthe sum approaches a continuous distributionas the list length becomes large (actually ap-
proaching a normal distribution for the dis-tractor tests).
Although the choice of Equation 10 is fairlyarbitrary, it has a property that we regard asdesirable: The standard deviation associatedwith a value in the retrieval structure is a fixedmultiple (uV2/3) of that value. Such an as-sumption is not compatible with a hypothesisthat the variance associated with a strengthbased on a storage episode of time 2t is thesum of variances associated with the two suc-cessive storage episodes of time t for the sameitem (because storage is linear with time inour model). This independence assumptionwould lead to a linear growth of variance,rather than standard deviation, with strength.Our present variability assumption is com-patible with a dependence hypothesis in whichthe random deviation associated with thestrength for any subinterval of time for anitem is in the same direction as the deviationassociated with any other subinterval. Thisvariability assumption has what we regard asanother desirable property: Multiplication ofall the values in the retrieval matrix by anyconstant (before noise is added) leaves un-changed the shapes and overlap of the famil-iarity distributions for targets and distractors.7
Other assumptions concerning variability areobviously possible but are not explored in thisarticle.
SummaryOur model for recognition and recall is of
the type labeled Model 4 in Table 1. Recall iscarried out with a search process (containingan implicit episodic identification processembedded in the recovery phase of the searchcycle). Recognition is carried out with a direct-access familiarity process that is of the globaltype because familiarity is a sum of familiarityvalues for the images of each list item. Recalland recognition are linked quantitatively be-
7 Because overall level of strength has an effect on re-covery but not on sampling (see Equations 4 and 7), andbecause recognition performance is not dependent onoverall level of strength, the strength level may be used toadjust the relative performance level of recall versus rec-ognition. For this reason, it is possible to choose a valueofu fairly arbitrarily, within certain limits, and adjust theother parameters to fit the combined recognition-recalldata.

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 17
cause the familiarity value used in recognitionfor item and context cues is the denominatorof the sampling ratio used during searchwhen that item and context cue make up theprobe set.
2. The Simulation Model andQualitative Predictions
In Section 2 we first describe a particularlysimple simulation model, its parameters, andthe choices of parameter values. The modelis then used to produce qualitative predictionsfor a number of findings in the recall and rec-ognition domains.
The Simulation Model
The model's predictions are all generatedwith a computer simulation because analyticderivations are in most cases not feasible. Thebasic situation to be modeled assumes pre-sentation of a list of items followed by a rec-ognition or a recall test. The storage and re-trieval assumptions follow.
Storage
A buffer rehearsal process is assumed (At-kinson & Shiffrin, 1968). In this version a par-ticularly simple buffer is assumed. The buffercontains a maximum of r items. When thebuffer is full, each new item replaces the oldestitem in the buffer.8 Based on earlier work, rwas set equal to 4 (see Raaijmakers & Shiffrin,1980).
We assume that the items in the buffer sharerehearsal time—when n items are present, eachgets \/n of the available rehearsal time. (Thusprimacy is predicted because the first item isalone and several items are needed to fill thebuffer.) In particular, a mean of a* units ofstrength are stored between an item and thecontext cue for each second of rehearsal; amean of c* units of strength are stored betweenan item when used as a cue and its own mem-ory image, for each second of rehearsal; a meanof b* units of strength are stored between twodifferent items, for each second of individualrehearsal for one of the items that takes placeduring the period that both items are rehearsedtogether; and a mean of d units of strengthare present in the retrieval structure between
any two items that have never been rehearsedtogether. For studies using random word lists,the value of d is assumed to be small relativeto b* and represents preexperimental associ-ations between the items. Note that a distractoras a cue is given mean interitem strength valuesof d, like a list-item cue that has not beenrehearsed with any other list items.
Retrieval During Free Recall
The flow chart shown in Figure 7 is usedto govern retrieval, but for simplicity no in-crements are utilized (that is, the incrementparameters are set to 0). The two retrievalparameters that govern cessation of search arechosen fairly arbitrarily, although with pre-vious fits in mind, and are as follows: KmaK =30, Lmm = 8.
Retrieval During Recognition
The value of familiarity is calculated usingEquation 8. A criterion, Cr, is chosen. If thefamiliarity value is higher than the criterion,then a yes recognition response is given, oth-erwise a no response is given. Sensible criterionchoices are generally very near the point wherethe distributions of familiarity for targets anddistractors cross. An example is given in Fig-ure 9.
How the subject learns where to place thecriterion is an interesting question that is dis-cussed later. For present purposes it is simplyassumed that the criterion is fixed in valuefrom the start of the recognition test until theend. In every simulation in this section weassume that the criterion is placed at a point0.455 times the mean value of the distractordistribution plus the mean value of the targetdistribution; that is, Cr = 0.455 (Md + Mt).This criterion choice was used because for thepresent parameters it places the criterion
8 An assumption of oldest item deletion predicts a re-cency effect of size r, which surely doesn't match the knowndata when r = 4. However, because in this article we predictonly long-term performance (say, in situations where STSis cleared before test), our buffer assumption makes verylittle difference, and we use oldest item deletion for easeof calculation.

18 GARY GILLUND AND RICHARD M. SHIFFRIN
somewhere close to the crossing points of thetarget and distractor distributions.
Strengths in the Retrieval Structure
A given strength in the retrieval structurebetween a cue arid an image depends not onlyon coding processes that take place at the timeof study but also on the match of the encodinggiven to the cue at test to the encoding giventhat cue during storage. F'or example, increas-ing the delay of test usually causes the contextcue at test to differ more from the context cueused at study. As another example, a changein the item preceding the test item could causedifferent meanings of the item to be chosenat test and study.
We can capture this factor in the model bysetting the strength in the retrieval structureequal to the originally stored strength times afactor indicating the degree of match betweenthe two encodings of the cue: S(Q,, 1̂ ) =m(Q,)S*(Q;, I;), where S* represents the orig-inally stored strength and m(Q/) represents thedegree of match of the encodings of the cueat test and study. Our storage assumption letsus produce the strength values by setting a -=m(C)<z*, b = m(\)b*, and c = m(l)c*, and let-
ting the retrieval strengths equal a, b, and ctimes the appropriate number of seconds ofrehearsal (C is the context cue and I is anitem cue).
It is convenient to couch the predictions ofthe model in terms of a, h, and c. When ex-perimental manipulations are used that shouldshift the degree of match (e.g., delay of test orbiased encoding), these can be described asshifts in a, b, or c rather than in the m pa-rameters. This approach keeps the presenttreatment identical to that used in earlier pa-pers on the SAM model.
Simulation Procedures
For the set of qualitative simulations, anarbitrary parameter set was chosen, roughlyin accord with previous simulations of free-recall data. The values were a =• 0.25, b =•0.2, c = 0.15, and d = 0.075. In addition, thevariability parameter, v, was set equal to 0.5.The patterns of predictions that result are notdependent on the exact values chosen (al-though, of course, quantitative performancelevels do depend on these values).
For a given application, simulated data isgenerated for 500 lists for both recall and rec-
.200
.175
3-125Oiu£.100
.000
«-RESPOND"NO-
DISTRACTORS
•* RESPOND "YES" *-
CRITERION
TARGETS
1.0 1.5 2.0
FAMILIARITY VALUE
Figure 9. A target and distractor distribution. (If the value is greater [to the right of the criterion] a yesresponse is made. If the value is to the left of the criterion, a no response is made. The distributions aregenerated from the model applied to a 20-item list at 2 s per item. A buffer size of 4 is assumed, with oldestitem deletion. Parameter values are a = 0.25, b = 0.20, c=0.l5,cl= 0.075, and v = 0.5.)

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 19
ognition (using different randomizations eachtime). These pseudodata are averaged and theresults are plotted as the predictions of themodel. Because we are not trying to producequantitative predictions, we do not plot actualdata. Instead the literature is reviewed and thequalitative patterns that are observed in theliterature are described. Recall predictions aregiven in terms of probability of correct recalland recognition predictions in terms of d'?(Additional information is provided in Ap-pendix A.)
Roles of the Parameters
The roles played by the various parametersbecome clear in the following parts of this ar-ticle, where applications to various paradigmsare discussed. It is useful nevertheless to sum-marize briefly the main functions of the pa-rameters. To demonstrate the actions of theparameters most clearly, predictions were de-rived for a standard set of parameter values,and then each value was varied in turn, whileholding the other values constant. The resultsarc given in Figure 10 for recognition (d'), andin Figure 11 for free recall.
Parameter v. For recognition paradigms,decreases in the variability parameter, v, de-crease the variability of the entries in the re-trieval structure and hence decrease the vari-abilities of the target and distractor distribu-tions, without changing the mean difference.Performance therefore improves, as indicatedin the right-hand panel of Figure 10.
In free recall, changes in the v parameterhave an effect on the recovery process. Becauserecovery probability is an exponential functionof strength, moving from a smaller to a largervariance (increases in v) produces a loweringof the average recovery probability. The resultsare shown in the right-hand panel of Fig-ure 11.
Parameter a. The context parameter, a,acts as a scale factor in recognition and doesnot affect performance. (For example, mul-tiplying the value of a by a factor k causes allthe entries in the top row of the retrieval struc-ture of Figure 8 to be multiplied by k. In turn,this causes all entries in the adjacent matrixin Figure 8 to be multiplied by k and, hence,all the familiarity values to rise by a factor of
k. Obviously the ordering of magnitudes oftargets and distractors are not affected by mul-tiplication by a constant.) The results areshown in the left-hand panel of Figure 10.
In recall tasks, increases in the a parametercause increases in recovery probabilities (andno effects on sampling probabilities) and,hence, produce increases in recall, as shownin the first panel of Figure 11.
Parameter b. Increases in the i nteritem pa-rameter, b, improve recognition performanceby raising familiarity of the target distribution,but not the distractor distribution. Thus onlythe rows labeled / in the retrieval structure ofFigure 8 are altered by changes in b. The resultsare shown in the second panel of Figure 10.
Increases in b also improve free recall byimproving recovery and by altering samplingin subtle ways (e.g., decreasing self-samplingwhen an item cue is used—see next para-graph). The results are indicated in the secondpanel of Figure 11.
Parameter c. Increases in the self-codingparameter, c, improve recognition for similarreasons as in the case of the /; parameter: Onlythe target distribution is raised (one of theentries in each of the rows labeled / in theretrieval structure of Figure 8 are raised). Onthe other hand, increases in the c parameterharm free recall by increasing self-sampling(self-sampling is the tendency for an item usedas a cue to sample its own image). The op-posing results are shown in the third panel ofFigures 10 and 11.
Parameter d. Increases of the residual pa-rameter, J, reduce recognition by increasingthe familiarity of the distractors much morethan the familiarity of targets (e.g., all the en-tries in the lower two rows of the retrievalstructure of Figure 8 are increased, but onlya few entries in the rows labeled / are in-creased) and by increasing the variance of bothdistributions. Increases in the d parameter im-
9 Because the theoretical target and distractor familiaritydistributions arc of unequal variance, and because thetarget distribution is skewed, it is technically incorrect toanalyze the data in terms of d'. Nevertheless, because mostactual data are analyzed this way, we have converted thehit and the false alarm rates into d' scores. The patternsof predictions are unaltered by alternative measures ofdiscriminability.

LUO
DCOLLDCLU0.
ocjLUoc
6.0
5.0
4.0
3.0
Q 2.0
1.0
0.0.20 .25 .30
a.10 .20 .30
b.10 .15 .20
C
.050 .075.100
d.25 .50 .75
Figure 10. Changes in predicted recognition performance (d') for a 20-item list caused by changes in thea, b, c, d, and v parameters. (Unless otherwise indicated, t = 2 s ; r = 4;a = 0.25; b = 0.20; c = 0.15;d = 0.075; v = 0.5.)
O
I
O
CzD>
O
O
>73D
en

.65
< .60OLUocLU -55LLICC
fe .50
>
5 .45OQ
miQ.
.40f
.20 .25 .30a
.10 .20 .30b
.10 .15 .20C
.050 .075 .100d
.25 .50 .75
Figure 11. Changes in predicted recall performance for a 20-item list caused by changes in the a, b, c, d,and v parameters. (Unless otherwise indicated, t = 2 s; r = 4, a = 0.25, b = 0.20, c = 0.15, d = 0.075,«; = 0.5; K^ = 30, L^ = 8.)
2B
oa
potd
8o
o
>za

22 GARY GILLUND AND RICHARD M. SHIFFRIN
prove free recall mainly by increasing recoveryprobabilities and also through subtle effectson sampling (e.g., decreasing self-sampling).The predictions are shown in the fourth panelsof Figures 10 and 11.
Kmax and Lmax. These parameters applyonly to free recall, and only Km.M has largeeffects: Increases in Kmm are equivalent to ex-tending the length of search and produce betterfree recall. We do not vary Km.M in any of theapplications in this article.
Applications of the Recall andRecognition Model
We illustrate the workings of the new modelby applying it to a variety of results from theliterature. In most of the cases we contrast thepredictions of the model for a recall task withthe predictions of the model with the sameparameters and assumptions for a comparablerecognition task. We are not interested in exactquantitative fits of data; rather we show thatthe model (usually with a standard parameterset) fits the qualitative patterns that are ob-served in the data. (Detailed quantitative fitsare carried out in Section 3 of this article.)The figures plot recognition performance interms of d'. The means of the target and dis-tractor distributions and the hit and false alarmrates for each point are given in Appendix A.
The List-Length Effect
It is well known that the probability of re-calling or recognizing a particular item froma list decreases as the list length increases. Thisis true for recall (e.g., Murdock, 1962; Roberts,1972) as well as for recognition (e.g., Strong,1912; see also Figure 2).
Figure 12 gives the results of the model'spredictions for lists of words presented for 2s each. Recall and recognition are plotted to-gether, but we do not wish to imply that d'and the probability of recall are in any waydirectly comparable. We show the results inthis fashion simply to demonstrate that per-formance decreases for both measures.
The list-length effect occurs in free recall asa result of the sampling rules. The probabilityof sampling a given item on a given searchdecreases as the list length increases. Even
though more total samples are made for longerlists before the stopping criterion is reached(because the probability of resampling a pre-viously sampled item goes down with listlength), the sampling effect is the more pow-erful and recall per item decreases with listlength.
In recognition, quite a different mechanismis responsible for the list-length effect. Themean difference in familiarity for targets anddistractors remains constant as list length in-creases. This is so because only a few itemsare jointly rehearsed with any target item, re-gardless of list length (beyond some mini-mum). Therefore, adding list items plays thesame role for target and distractor tests—ineach case images are added to memory thatare only residually associated to the test item.Why then does performance decrease? Theanswer is simple: The variance of the distri-butions increases with increasing list length(because each additional item in the list addsan independent variance component). As aresult, there is more overlap of the target anddistractor distributions for the longer lists andd' is decreased.
Presentation Time
Increasing the presentation time per itemimproves both recall and recognition perfor-mance (e.g., Ratcliff & Murdock, 1976; Rob-erts, 1972; Shiffrin, 1970). In SAM, increasingpresentation time increases the strengths ofassociations built up during rehearsal: Context,interitem, and self-strengths all get larger. Inrecall these increases improve the probabilityof recovery (the ratio rule for sampling doesnot change with presentation time).
In recognition, the increase in d' arises be-cause the self-strength and interitem strengthsrise with presentation time. These increasescause only the target distribution to increase(the rise in mean far outweighs the concom-itant rise in variance), thereby improving per-formance. Note that the increase in contextstrength does not affect d'—the increase incontext strength acts like a scale factor in-creasing both mean familiarity and variancesso that no net change in d' results (see thediscussion of the a parameter). The results ofthe model's predictions for presentation time

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 23
oUJDC
LULUCC
.70
.60
.50
=! .40CQ
COoccQ.
—i 1 rQ RECOGNITION
RECALL
10 20 30 40
LIST LENGTH
4.0
3.5
3.0
73
LUO
CCOLI-CCUJQ.
2.5 1
CDOOLUCC
Figure 12. The model's predictions for recall and recognition as a function of list length, (t = 2 s; r = 4,a = 0.25, i = 0.20, c = 0.15, d = 0.075, « = 0.5; *„,„„ - 30, Lmax = 8.)
for a list of 30 words can be seen in Fig- the effects of item-specific, or maintenance,ure 13. rehearsal. Woodward, Bjork, and Jongeward
(1973) presented a series of words, each ofwhich was followed by 0, 4, or 12 s of delay.After the delay there was a cue to remember
A large literature exists on the effects of or to forget the word. It was assumed that thedifferent types of encoding operations on recall delay would be used for maintenance rehearsaland recognition performance. Consider first until the cue was given. At that time subjects
Encoding Effects
<O
ccLL
CO<CDOCCQ.
.60
.50
.40
.30
.20
RECALL
C5 RECOGNITION
5.0
4.0
3.0
2.0
1.0
T3
LUO
CC
errLUa.
ooLUCC
1 2 3
PRESENTATION TIME (SEC/ITEM)
figure 13. The model's predictions for increasing amounts of presentation time per word. (List length =30; r = 4, a = 0.25, b - 0.20, c = 0.15, af = 0.075, v = 0.5; Kmm = 30, Lmax = 8.)

24 GARY GILLUND AND RICHARD M. SHIFFRIN
could either quit processing the word or giveit more elaborate processing. Subjects werethen given a test for the to-be-rememberedwords only. In a surprise end-of-session free-recall or recognition test for all words, Wood-ward et al. (1973) found no advantage of extramaintenance rehearsal for recall performancebut a significant advantage for recognition (secGlenberg & Adams, 1978; Glenberg, Smith,& Green, 1977).
We assume that the effect of maintenancerehearsal is to cause repetitions of the featuresrelated to the physical aspects of the item, soself-coding, c, should increase with the amountof rehearsal. We also assume that extra contextand interitem coding due to increased mainte-nance rehearsal are reduced to a minimum.These assumptions are quantified by beginningwith the standard parameter set of the pre-ceding figures and then modeling changes inmaintenance rehearsal by changes in the c pa-rameter. The results are depicted in the thirdpanel of Figures 10 and 11, for the parametervalues c = 0.10, 0.15, and 0.20, from left toright, respectively.
Figure 11 shows recall to fall with increasesin c because self-sampling is increased: Whenan item is recalled and used as a cue it tends
to sample its own image, reducing the chancesof sampling something as yet unrecalled. Per-haps context coding does increase slightly withmaintenance rehearsal, canceling this drop.The predictions when the c values are 0.10,0.15, and 0.20, as before, but a = 0.23, 0.25,and 0.27, from left to right, are given in Fig-ure 14.
An interesting result by Nairne (1983) seemssuperficially at odds with the predictions justgiven. He found in several conditions of hisstudy that increasing amounts of maintenancerehearsal of pairs of items did not improverecognition performance on a later surprisetest. The answer lies in the nature of the dis-tractors used: The distractors consisted of twolist items, one from each of two different stud-ied pairs. In such a case, it turns out that theb parameter, rather than the c parameter, isthe crucial determinant of performance. Be-cause the b parameter is not assumed to risein this type of study, little effect is predicted.The reasons underlying the predictions forthese special types of stimuli and distractorsare covered in greater detail in Section 4.
Consider next the experiments on inten-tionality of encoding and test expectancy.These paradigms may produce variations in
o
UJUJDC
m
oDC
.55
.50
.45
-40
RECOGNITION
RECALL
3.5
3.0
2.5
2.0
2UJO
DCOu.CCUJ0.
z:(3OO
LOW MEDIUM HIGH
AMOUNT OF MAINTENANCE REHEARSAL
Figure 14. Predictions from the model for increasing amounts of maintenance rehearsal. (Increasing mainte-nance rehearsal is assumed to increase slightly context coding [a increases from 0.23 to 0.25 to 0.27, fromleft to right] and to increase substantially self-coding [c increases from 0.10 to 0.15 to 0.20, from left toright], whereas interitem encoding remains constant [r = 4, b = 0.2, d = 0.075, v - 0.5; Kmm = 30, Lmax =8; 20-word list at ?. s/item].)

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 25
OLLJtrUJLUa:
CO<CDO(£.Q.
.60
.55
.50
.45
.40
RECOGNITIONO-
RECALL
LOW MEDIUM HIGH
4.0
3.5
3.0
2.5
2.0
O
DCOLUQCLUQ.
2C3OOLUtr
RATIO OF INTERITEM TO SELF CODING
Figure 15. Predicted recall and recognition performance as interitem coding increases (b increases) andself-coding decreases (c decreases). (From left to right, b = 0.1, 0.15, and 0.2; and c = 0.51, 0.33, and 0.15.r = 4, a = 0.25, d = 0.075, v = 0.5; Km, = 30; LmM = 8; 20-word list at 2 s/item.)
the amount of interitem rehearsal, (a) Increas-ing interitem processing by instructional setresults in increased recall performance but lit-tle change in recognition performance (e.g.,Estes & DaPolito, 1967). (b) Changing fromincidental to intentional instructions increasesrecall performance but may slightly lower rec-ognition performance (e.g., Eagle & Leiter,1964). (c) Varying the test expectancy fromrecognition to recall generally increases bothrecall and recognition performance (e.g., Bal-ota & Neely, 1980; Neely & Balota, 1981; Hall,Grossman, & Elwood, 1976).
We suggest that increased intentionality, orincreased expectancy of recall, leads to in-creased interitem coding, possibly at the ex-pense of decreased self-coding, that is, in-creased b and possibly decreased c.I0 The sec-ond panel of Figures 10 and 11 show thepredictions of the model when the b parametertakes on the values 0.10, 0.20, and 0.30, andthe other parameters are unchanged. In thiscase, both recall and recognition performanceare predicted to rise as a result of increasedinteritem coding.
Figure 15 shows predictions of the modelwhen the b parameter increases from 0.10 to0.15 to 0.20, but in addition, the c parameterdecreases: c = 0.51, 0.33, and 0.15, from left
to right. In this case recall increases but rec-ognition remains relatively constant becausesubjects arc trading interitem coding for self-coding.
Why does the model predict the patternsseen in Figure 15? For recall, predictions areclearcut: Both increases in the b parameterand decreases in the c parameter improve re-call. Increases in b improve both sampling andrecovery and decreases in c reduce self-sam-pling. For recognition, the situation is morecomplicated: Increases in b improve recog-nition performance (due to increased associ-ations to items rehearsed with the test item)but decreases in c harm recognition (due tolower associations of the image of the test item
10 Neely and Balota (1981) came to the opposite con-clusion, that interitem coding was not affected, becausethe test-expectancy effect (better performance for recallexpectancy) did not interact with the semantic organizationeffect (better performance for related words). Their ar-gument was predicated on an assumption derived fromthe theory of J. R. Anderson (1972) and of J. R. Andersonand Bower (1972) that interitem coding should not onlybe higher under recall expectancy but should be differ-entially higher for related words. We see no basis for sucha prediction in our theory and, hence, we do not agreewith the conclusion. Furthermore, we think our theorycould handle the Neely and Balota (1981) results, althoughwe have not yet attempted to fit the findings.

26 GARY GILLUND AND RICHARD M. SHIFFRIN
itself). In this case, the precise nature of thetrade-off in rehearsal is crucial to the predictedoutcome. Just such a sensitivity to trade-offsmay explain the variability of observed results.
Match Between Encodings at Study and Test
There is a well-tested principle stating thatmemory improves to the degree that codingsat storage and test match (e.g., the encoding-specificity principle; Tulving & Thomson,1973). For example, a number of studies showthat words recognized in one semantic contextmay not be recognized in another. Light andCartcr-Sobell (1970) presented subjects withhomographic nouns to study. Each was pre-sented with an adjective to bias a specificmeaning of the word (e.g., traffic-jam). Subjectswere then tested for recognition of the ho-mographic nouns in the presence of the sameor a different biasing adjective (e.g., strawberry-jam). Recognition performance was higher inthe same-adjective tests (see also Tulving &Thomson, 1971; Winograd & Conn, 1971).
The present model handles such coding ef-fects through the match parameters, m, whichdetermine the relationship between encodingof a cue at study and test. Changes in m arecaptured in our present simulation by changesin a, b, and c as appropriate." This encodingvariability approach makes it easy to predicta variety of semantic context effects. The rea-soning is similar to that put forth by Tulvingand Thomson (1973) and Reder, Anderson,and Bjork (1974), among others. By the samereasoning, when a word has one meaning (e.g.,rhinoceros) effects of semantic context shouldbe lowered (Reder et al., 1974; Muter, in press).
It may be asked, how does the biasing itemor context affect the encoding of a study ortest item? Because a variety of subject con-trolled coding and rehearsal processes occurduring most study settings, the effects of se-mantic context are easy to incorporate. Onthe other hand, the initial encoding of a testitem is generally thought to be a relativelyautomatic process (e.g., Shiffrin & Schneider,1977). However, even though the initial en-coding may be automatic, it is determined bythe general stimulus environment, not just bythe nominal word itself. Therefore, contextdetermines encoding at both study and test,and the possible different encodings then pro-duce the cited effects of semantic context.
There is a variety of ways to demonstrateencoding match effects in our present simu-lation. Perhaps simplest is the assumption thatthe match of encoding at test to that at storageis lowered, thereby lowering the values of band c. The resulting predictions (for recog-nition only) are given in Figure 16. Decreasesin the b and c parameters each cause perfor-mance to drop as shown.
Although changes in meaning are undoubt-edly responsible for many semantic contexteffects, another factor may also contribute.When the test consists of both a critical wordand a word used to produce a bias, both wordsmay be used in the probe set, along with con-text. As we discuss in Section 4 the biasingword affects the resulting familiarity value.These changes in familiarity may produce se-mantic context effects similar to those ob-served, even if the coding of the critical wordis assumed to be the same in all contexts. Forexample, if biasing items at study and test aredifferent, recognition of the critical item isharmed: An identical bias item is morestrongly linked to both the test item (due torehearsal) and itself (due to identity) than isa shifted bias item, so the familiarity of thepair of items is higher in the identical case. Ifthe bias item is present only at test, it producesmore familiarity when it matches the domi-nant meaning, because the dominant meaningwas more likely coded at study and the residualassociation to the image of the test item ishigher in such a case. These examples makeit clear that the SAM model has two comple-mentary mechanisms that can help explaincontext effects in recognition, one based onthe coding of the test item and the other basedon the familiarity of a test pair.
Related results concerning encodingmatches have been found in a slightly differentparadigm. The paradigm consists of three basicphases: (a) the study of A-B pairs of words,of which the B members are the critical words;(b) a recognition test for the B members. Therecognition test is given in the absence of the
" An alternative treatment consistent with the SAMmodel would involve treating each new and different en-coding of a nominally identical item (whether presentedat study or at test) as a new item with appropriate interitemstrengths. This approach would probably be difficult todistinguish from the approach suggested in the text.
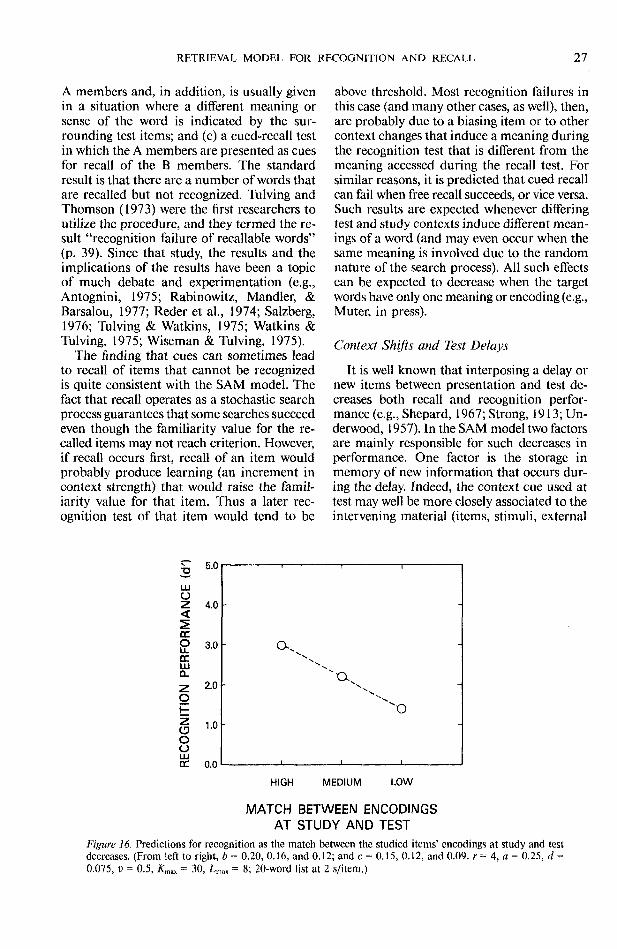
RETRIEVAL MODEL FOR RECOGNITION AND RECALL 27
A members and, in addition, is usually givenin a situation where a different meaning orsense of the word is indicated by the sur-rounding test items; and (c) a cued-recall testin which the A members are presented as cuesfor recall of the B members. The standardresult is that there are a number of words thatare recalled but not recognized. Tulving andThomson (1973) were the first researchers toutilize the procedure, and they termed the re-sult "recognition failure of recallable words"(p. 39). Since that study, the results and theimplications of the results have been a topicof much debate and experimentation (e.g.,Antognini, 1975; Rabinowitz, Mandler, &Barsalou, 1977; Reder et al., 1974; Salzberg,1976; Tulving & Watkins, 1975; Watkins &Tulving, 1975; Wiseman & Tulving, 1975).
The finding that cues can sometimes leadto recall of items that cannot be recognizedis quite consistent with the SAM model. Thefact that recall operates as a stochastic searchprocess guarantees that some searches succeedeven though the familiarity value for the re-called items may not reach criterion. However,if recall occurs first, recall of an item wouldprobably produce learning (an increment incontext strength) that would raise the famil-iarity value for that item. Thus a later rec-ognition test of that item would tend to be
above threshold. Most recognition failures inthis case (and many other cases, as well), then,are probably due to a biasing item or to othercontext changes that induce a meaning duringthe recognition test that is different from themeaning accessed during the recall test. Forsimilar reasons, it is predicted that cued recallcan fail when free recall succeeds, or vice versa.Such results are expected whenever differingtest and study contexts induce different mean-ings of a word (and may even occur when thesame meaning is involved due to the randomnature of the search process). All such effectscan be expected to decrease when the targetwords have only one meaning or encoding (e.g.,Muter, in press).
Context Shifts and Test Delays
It is well known that interposing a delay ornew items between presentation and test de-creases both recall and recognition perfor-mance (e.g., Shepard, 1967; Strong, 1913; Un-derwood, 1957). In the SAM model two factorsare mainly responsible for such decreases inperformance. One factor is the storage inmemory of new information that occurs dur-ing the delay. Indeed, the context cue used attest may well be more closely associated to theintervening material (items, stimuli, external
0
cc2ccLU0_
O
5.0
4.0
3.0
2.0
1.0
OOLUDC 0.0
a,
HIGH MEDIUM LOW
MATCH BETWEEN ENCODINGSAT STUDY AND TEST
Figure 16. Predictions for recognition as the match between the studied items' encodings at study and testdecreases. (From left to right, b = 0.20, 0.16, and 0.12; and c = 0.15, 0.12, and 0.09. r = 4, a = 0.25, d =0.075, v = 0.5, KmM = 30, Lmax = 8; 20-word list at 2 s/item.)

28 GARY GILLUND AND RICHARD M. SHIFFRIN
events, thoughts, etc.) than to the list itemsthemselves, because of the closer temporalproximity of the test setting to the interveningmaterial than to the list. On the other hand,the context cue surely includes some sort oflist cue that tends to access only the list items,thereby offsetting the factor of temporal prox-imity. Regardless of the balance of effects, thereis some tendency at test to sample informationstored during the delay, and the tendency in-creases with delay duration. The effect of thisfactor is much the same as that of increasedlist length-—performance drops for both recalland recognition for the reasons discussed inconnection with the list-length effect.
The second factor contributing to the delayeffect is the change in context from storage totest (see Bower, 1972). Normally the test con-text is increasingly changed from the storagecontext, as delay increases. Remember thatthe a parameter combines both a storage pa-rameter and a degree of cue matching; thusit represents the degree of context similaritybetween study and test. As a result, the effectof context shift can be captured simply bylowering the value of a. Lowering a lowersrecall directly, because recovery probabilitiesare less. However, lowering a has no effect onrecognition, because a acts as a scale factor.
In an experiment varying delay, these twofactors operate jointly, and respective effectsare difficult to disentangle. However, somestudies have altered context while holding delayconstant. For example, Smith et al., (1978)presented words for study in a particular room(context). Subjects were tested for the wordsby recall or recognition in either the same con-text or in another room that was very differentin setting than the first. The results showeddecrements in recall with context change butno change in recognition performance (see alsoGodden & Baddeley, 1975, 1980). Similarfindings have sometimes been been reportedin the state-dependent learning literature (seeEich, 1980; but see also Birnbaum & Parker,1977). In a typical state-dependent learningtask, subjects learn some material under theinfluence of a drug (e.g., caffeine, alcohol) andthen are tested later either under the same ordifferent drug state. It is sometimes found thatperformance decreases with state changeswhen measured by recall but remains relativelyconstant when measured by recognition tests.
We model the context-shift paradigm (withfixed delay) by letting the a parameter decreasewith context shift. The results for no delay,given in Figure 17, show the expected pat-tern—recall drops but recognition is unaf-fected.
We model the delay situation by retainingthe assumption that the a parameter dropswith delay but by adding the assumption thatnew information is added to memory. In par-ticular, the retrieval structure is increased insize through the addition of several columnsin the matrix that are meant to represent newinformation that has been stored. We refer tothis new information as junk. Item-to-junkstrengths are assigned a value of j\ and context-to-junk strengths are assigned a value jc. In-creases in delay are modeled by increases inthe number of such junk items (i.e., columnsin the matrix).
Figure 18 shows predictions derived by let-ting a = 0.25, 0.20, and 0.15 and letting thenumber of junk columns be 0, 10, or 20, fromleft to right, respectively. The junk parameterswerej'c = 0.1125 and j{ = 0.375. Both thedecrease in the a parameter and the increasein the number of junk columns cause recallto decrease. Only the increase in the numberof junk columns causes recognition to de-crease.
Each of the patterns in Figures 17 and 18is of course consistent with the results in theliterature. The notion of junk information isactually worth a deeper analysis. In all appli-cations of SAM thus far, it has been assumedthat the context cue is sufficiently precise tolimit search to the list just presented (or atleast it has been assumed that the contributionsof nonlist information is negligibly small). Forrecall, such assumptions do not seem to becrucial, failing mainly because intrusions ofnonlist items are not predicted. We have ex-amined the standard recall predictions (inprevious papers as well as in this article) withthe added assumption that several junk col-umns exist in the retrieval matrix (possiblyrepresenting events that occurred prior to thelist). Recall is always lowered by this alteration,but the patterns of recall are unchanged. Infact, an adjustment of parameter values canbe made to reinstate the original predictionswith little change.
For recognition, the presence of junk col-

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 29
oUJDC
LULJJDCLU
LLO
CO<CQOccCL
.60
.50
.40
.30
.20
RECALL
o- o-RECOGNITION
5.0 r-
4.0
3.0
2.0
1.0
SMALL MEDIUM LARGE
UJO
CC
2DC
ooLUcc
CONTEXT SHIFTFigure 17. Predictions for context shifts between presentation and test, with delay held small and constant.(From left to right, a = 0.25, 0.20, and 0.15. r = 4, b = 0.2, c = 0.15, d = 0.075, v = 0.5; Kmm = 30, Lmax =8; 20-item list at 2 s/item.)
umns (whether due to information occurringduring a study-test delay or to informationpreceding the list) can make an important dif-ference. For example, the lack of effect of con-text shift shown in Figure 17 (in the absenceof substantial delay) no longer obtains if junk
columns are assumed; this is shown in Figure19. Figure 19 indicates that the absence of aneffect (due to context shift) occurs only whenno junk is present; as the junk increases, theeffect appears and gets larger. By this logic, itcan be weakly argued in the context of the
<(J
CO<COOcco_
.60
.50
LU£ .40
.30
.20
RECALL
a.RECOGNITION
5.0
4.0
3.0
2.0
1.0
SMALL MEDIUM LARGE
CONTEXT SHIFT AND DELAY
2LUO
cc2ccLUQ_
OOLUCC
Figure 18. Predictions for increasing amounts of delay in conjunction with increasing amounts of contextshift. (From left to right, a = 0.25, 0.2, and 0.15; and number of junk items = 0, 10, and 20. r = 4, b =0.2, c=0.\5,d= 0.075, v = 0.5; jc = 0.1125,;, = 0.375; 20-word list at 2 s/item.)

30 GARY GILLUND AND RICHARD M. SHIFFRIN
PANEL A PANEL B
1<£
O C0LU ltju
CC
UJLUK .40
O
> .30h-_JCO< .20COODC
I 1 i
CONTEXT SHIFT
SMALL A_^^^^-^^
MEDIUM (X^ ""~~--TV^^^ ~- — -
LARGE D-̂ ~"~~O-^_ "̂^"--- ~ --^^
~~""I U ~~°~^ ^~ —
-
SMALL MEDIUM LARGE
AMOUNT OF EXTRA-LIST INFORMATION(DELAY!
TJ a'°
UJ<J^ 4.0
SEC0 3.0DCUJ
^ 2.0O
g 1.0oLU
. i i
1 CONTEXTSHIFT
e*>ss?==^\^^-y\
^^^^^~~-A- SMALL•̂ ~~--̂ ^p»IVlEDIUM -
'-'-LARGE
-
i iSMALL MEDIUM LARGE
DELAY(AMOUNT OF EXTRA-LIST INFORMATION)
Figure 19, The model's predictions for different amounts of context shift as a function of the amount ofextra-list information (delay) present at test. Panel A shows the results for recall. Panel B shows the resultsfor recognition. (All parameters in each case are identical to Figure 18, except number of junk items = 0,10, and 20 from left to right; and a = 0.25, 0.20, and 0.15 from top to bottom.)
present model that only a small amount ofjunk exists in certain types of list experiments,because the observed effect of context shift onrecognition is so small (where small amountrefers either to few junk items or to weak junkstrengths).
Test Position Effects
In previous recall applications we have as-sumed that learning can take place during thetesting procedure. Specifically, we have as-sumed that any time a probe set successfullyrecovers an item from memory, the strengthof association from the cues in the probe setto the recovered item is given an increment.The result of strengthening is to reduce theprobability of recall of a new item as the num-ber of items previously recalled increases. Thisoccurs because self-sampling is increased: Ifany of the cues that have been given an in-crement are used again, they are more to likelysample an old (previously recovered) item, andthus fewer new items are recalled (see Raaij-makers & Shiffrin, 198la, 1981b, for a moredetailed discussion of learning during recall).
The justification for learning during recallis straightforward: Learning occurs when itemsare together in STS, and is especially strongif those items are attended, coded, or re-hearsed. If an image is recovered in the pres-ence of a set of cues, then that image and those
cues are together in STS, probably under at-tended conditions. The situation in recognitionis quite different. In this case we have assumedthat a specific image is not recovered; instead,access is gained to the accumulated activationof all images. It might be possible to imaginethat the cue strengths to all images are slightlyincreased, but we think that this is an im-plausible assumption and is likely to have neg-ligible effects on performance in any event.
Instead, we propose that learning in rec-ognition testing takes a slightly differentform—each item tested produces a new imagein the retrieval structure with some new self-strength and some new context strength. (It ispossible that these strengths could differ foritems given positive and negative responses,because they might receive differential atten-tion; see Rabinowitz, Mandler, & Patterson,1977. However, as an initial simplification thestrength for positives and negatives is assumedequal.) The effect of this assumption is quitesimple: Recognition testing produces an in-crease in the effective list length that appliesfor subsequent test items. The effect is muchthe same as that seen when list length increases(Figure 12), or when junk items are added toa list due to delay of test (Figure 18). Perfor-mance is predicted to decrease across test po-sitions.
Simulation predictions are shown in Figure20. Self-strength is not relevant when items

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 31
are not retested. Therefore only one parameteris needed; The context strength for the newimages of tested items was set to 0.5. Thechanges in d' across quadrants of the test list(all 20 targets plus 20 distractors, mixed) iscalculated by comparing hit rates and falsealarm rates for items in similar test positions,with the results shown in the Figure 20.
Do such predictions correspond to the ob-served data? It is difficult to answer this ques-tion on the basis of previous research. Manystudies report decreasing performance with testposition (usually confounded with lag effectsfor targets), but the situations are ones in whichshort-term memory contributions to perfor-mance are not controlled or eliminated (e.g.,Murdock & Anderson, 1975; Ratcliff& Mur-dock, 1976). It seems sensible that an itemstill in STS when tested will give rise to anextremely rapid and accurate yes response.Because the probability of this event decreaseswith test position, exaggerated position effectsare to be expected. (Furthermore, the commonpractice of restricting consideration to highconfidence responses only accentuates thisproblem.) We obtained test position effectsfrom an experiment in which interveningarithmetic was used to clear STS before testing.
LUO2
CC
£CCLUQ.
OOLUCC
3.5
3.0
2.5
OUTPUT POSITION BY BLOCKS
Figure 20. Predictions for recognition performance in a20-item list (40-item test list) as a function of test position(blocked in groups of 10 items) when each test causesstorage of a new image with total context strength (incre-ment) = 0.5, and residual interitem strengths (d) of 0.075.(v = 0.5, r = 4, a = 0.25, b = 0.20, c = 0.15, d = 0.075;2 s/item.)
LUCO•z. 1.00oQ.COLUOC .90
uLUQCOCOO
LLo
00<00oDCQ.
.80
.70
.60
^SHORT CR
SHORT HIT
LONG CR
HIT
1 2 3 4
TEST POSITION BY BLOCK
Figure 21. Probability of correct rejections and hits for24-item (short) lists and 240-item (long) lists, averagedacross quarters of the 48- or 480-item test lists. (Arithmeticintervened between presentation and test.)
The probability of hits, and of correct rejec-tions, averaged over quarters of the test list, isshown in Figure 21, for both long (240 items)and short (24 items) lists.
Obviously the effects are not very large, ap-pearing only in the case of hits for the longlist, and showing only about a 9% falloff inthat case. (Other partitions of test positionsgave rise to similar results.) It seems likely thatan effect of this magnitude could be handledby assuming that a small amount of learningtakes place during testing, primarily for pos-itive responses.12
Distractor Type and Similarity
It is well known that the choice of distractoraffects recognition performance (e.g., Anisfeld
12 Todres and Watkins (1981) found a small decrementin recognition performance for categorized items whensubjects were given additional exposure to some of thepresented or nonpresented items before test (as comparedto subjects not receiving such experience). Neely, Schmidt,and Roediger (1983) showed that six successive test itemsfrom a category slowed reaction time to another test itemfrom that category (compared to two successive test itemsbefore the critical item). In both of these cases, learningduring retrieval or during an intervening task could accountfor the findings, although a quantitative demonstration ofthis claim would require a simulation of the particularprocedures in these studies.

32 GARY GILLUND AND RICHARD M. SHIFFRIN
& Knapp, 1968; Hall, 1979; Underwood &Freund, 1968; Walter, 1977). The point seemsclear: If a distractor is highly confusable withthe list items, discriminations arc difficult. Aninteresting question concerns the nature of therelationship necessary to produce such an ef-fect: Must the distractor be similar to many(or all) of the list items, or may the distractorbe similar to just one list item? Our modelsuggests that a very large decrement occurswhen the distractor is similar to a large pro-portion of the list items, because familiarityis a sum of familiarity values over all of thelist items. For example, if a study list consistedof flower names and the test list consisted ofall flower names (targets mixed with distrac-tors), surely performance would be lower thanin the case where all of the distractors wereanimal names. Evidence that this actually oc-curs is difficult to find, perhaps because ex-perimenters believe the outcome is so obviousthat experiments have not been done. Thereis evidence from reaction time studies thatnoncategory distractors are rejected faster thancategory distractors (distractors from the samecategory as the presented items; Herrmann,McLaughlin, & Nelson, 1975; Homa, 1973;Okada & Burrows, 1973).
Of greater interest for some purposes is theeffect of familiarity of a distractor to a single,matched list item (see Anisfeld & Knapp 1968;Underwood & Freund, 1968). Our model pre-dicts an effect of distractor similarity on thefollowing basis: The residual interitem strengthbetween the similar distractor and the imageof the matched list item will be higher thanthe usual residual value. If this value is calledd&, then we suggest that ds is greater than d tothe degree that the similarity between the itemsis high. Let us suppose, moreover, that thesimilarity of a distractor to a list item doesnot cause that distractor to share in the as-sociative linkages that had been formed duringstudy between the similar list item and otherjointly rehearsed list items. That is, ds for thedistractor would apply only to the single, sim-ilar list item. The predictions under these as-sumptions are depicted in Figure 22.
The lower curve in Figure 22 shows a sharpperformance drop when similarity of the dis-tractors to all of the list items is increased. Inthis case the value of d is increased from leftto right (d = 0.075, 0.1, and 0.125), but oth-
erwise the parameters remain the same in theprevious model applications. The upper curveshows a much smaller decrease when distractorsimilarity to a single list item is increased. Inthis case, all parameters remain the same asfor previous applications, but for just a singlelist item, the value of ds is increased from leftto right (d, = 0.75, 0.1, and 0.125). For thesepredictions, d' is calculated from hit rates forthe list item with the similar distractor, andfalse alarm rates for the similar distractor.
Data concerning similarity effects aresomewhat mixed. Some studies report thatsimilarity to a matched list item reduces per-formance (e.g., Anisfeld & Knapp, 1968; Un-derwood & Freund, 1968), but others do not(at least not for some related distractors orunder some encoding instructions—Buschke& Lenon, 1969; Cramer & Eagle, 1972; Elias&Perfetti, 1973; Underwood & Freund, 1968).Furthermore, it is often the case that physicalsimilarity (phonemic or graphemic) producesmore false alarms (and lower performance)than does semantic similarity (Cramer & Ea-gle, 1972; see also Davies & Cubbage, 1976;Eagle & Ortof, 1967; Juola et al., 1971). Wehave carried out several studies of our own onthis subject, with mixed results. Although onestudy showed associative similarity to increasefalse alarms, the others did not. A typical resultis shown in Figure 4: Synonyms did not leadto increased false alarms, although phonemicand graphemic similarity did. A similar resultwas obtained in another study for associativerelatedness that was not based on synonyms.
These results are generally consistent withthe model's predictions that distractor simi-larity to a single list item should produce smallperformance decrements. Nevertheless, it isnot easy for the model to predict that semanticsimilarity produces smaller effects than phys-ical similarity or that semantic similaritysometimes produces no increase in falsealarms at all. A possible explanation for suchfindings is discussed in Section 5.
3. Word-Frequency Effects
The predictions in Section 2 make it clearthat our model for recognition and recall hasthe potential to predict many of the observedfindings in the literature that involve accuracyof performance. In the present section we ad-
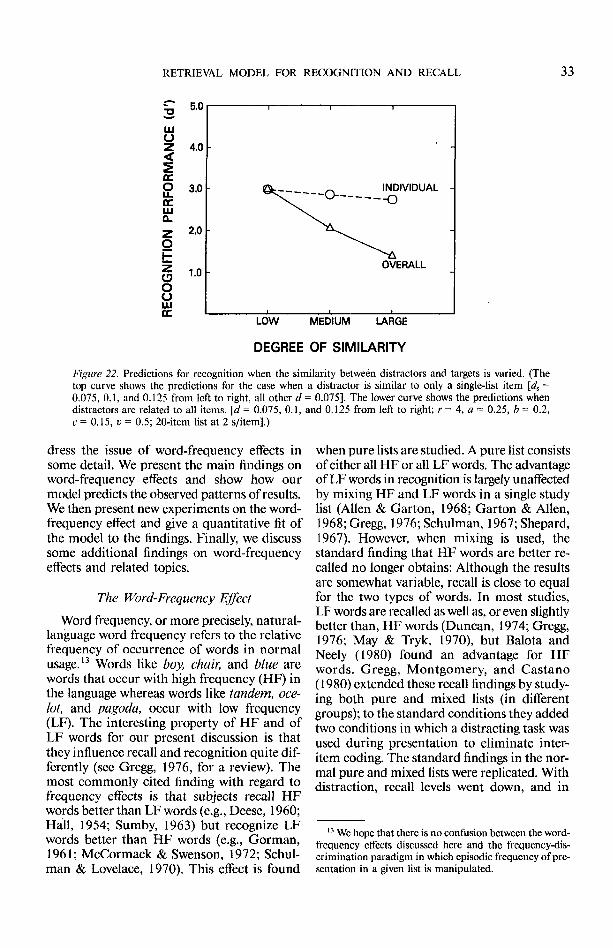
RETRIEVAL MODEL FOR RECOGNITION AND RECALL 33
OZ<
DCODCHICL
8LJUDC
5.0
4.0
3.0
2.0
1.0
_-—o INDIVIDUAL -
OVERALL
LOW MEDIUM LARGE
DEGREE OF SIMILARITY
Figure 22. Predictions for recognition when the similarity between distractors and targets is varied. (Thetop curve shows the predictions for the case when a distractor is similar to only a single-list item [d, =0.075, 0.1, and 0.125 from left to right, all other d - 0.075]. The lower curve shows the predictions whendistractors are related to all items, [d = 0.075, 0.1, and 0.125 from left to right; r = 4, a ~ 0.25, b = 0.2,c = 0.15, v = 0.5; 20-item list at 2 s/item].)
dress the issue of word-frequency effects insome detail. We present the main findings onword-frequency effects and show how ourmodel predicts the observed patterns of results.We then present new experiments on the word-frequency effect and give a quantitative fit ofthe model to the findings. Finally, we discusssome additional findings on word-frequencyeffects and related topics.
The Word-Frequency Effect
Word frequency, or more precisely, natural-language word frequency refers to the relativefrequency of occurrence of words in normalusage.13 Words like boy, chair, and blue arewords that occur with high frequency (HF) inthe language whereas words like tandem, oce-lot, and pagoda, occur with low frequency(LF). The interesting property of HF and ofLF words for our present discussion is thatthey influence recall and recognition quite dif-ferently (see Gregg, 1976, for a review). Themost commonly cited finding with regard tofrequency effects is that subjects recall HFwords better than LF words (e.g., Deese, 1960;Hall, 1954; Sumby, 1963) but recognize LFwords better than HF words (e.g., Gorman,1961; McCormack & Swenson, 1972; Schul-man & Lovelace, 1970). This effect is found
when pure lists are studied. A pure list consistsof either all HF or all LF words. The advantageof LF words in recognition is largely unaffectedby mixing HF and LF words in a single studylist (Allen & Carton, 1968; Carton & Allen,1968; Gregg, 1976;Schulman, 1967;Shepard,1967). However, when mixing is used, thestandard finding that HF words are better re-called no longer obtains: Although the resultsare somewhat variable, recall is close to equalfor the two types of words. In most studies,LF words are recalled as well as, or even slightlybetter than, HF words (Duncan, 1974; Gregg,1976; May & Tryk, 1970), but Balota andNeely (1980) found an advantage for HFwords. Gregg, Montgomery, and Castano(1980) extended these recall findings by study-ing both pure and mixed lists (in differentgroups); to the standard conditions they addedtwo conditions in which a distracting task wasused during presentation to eliminate inter-item coding. The standard findings in the nor-mal pure and mixed lists were replicated. Withdistraction, recall levels went down, and in
13 We hope that there is no confusion between the word-frequency effects discussed here and the frequency-dis-crimination paradigm in which episodic frequency of pre-sentation in a given list is manipulated.

34 GARY GILLUND AND RICHARD M. SHIFFRIN
pure lists the advantage of HF words was re-duced.
When considering the word-frequency effectfor recognition, we note that subjects show afrequency effect for distractors as well as fortargets. The correct-rejection rate for LF dis-tractors is higher than the correct-rejection ratefor HF distractors (McCormack & Swcnson,1972). Even when distractors are not used,however, frequency effects are found. Wallace,Sawyer, and Robertson (1978) presented sub-jects with cither HF or LF words and thengave a recognition test that contained no dis-tractors (only the target items were tested).Subjects were informed of this fact and weredirected to respond positively to words thatthey actually remembered seeing on the list.Subjects showed better recognition for LFwords than for HF words.
Predictions for the Word-Frequency Effect
The model we use to deal with frequencyeffects is identical with that presented in Sec-tions 1 and 2, with one slight addition to takeword frequency into account. We assume thatthe tendency for HF items to access imagesin memory is larger than that for LF items.That is, the retrieval strength between a HFcue and any image is higher than that betweena LF cue and any image. This assumption isinstantiated in two ways: First, the residualassociation between any two items not re-hearsed together, or between any distractor andany list item, is made frequency dependent.Thus when a HF word is a cue, the value ofthe d parameter is set equal to dH; when a LFitem is a cue, d = dL; du > dL. (The frequencyof the image in memory is not taken into ac-count in this approach.) Similarly, for wordsthat are rehearsed together, it is assumed thatHF cues are stronger than LF cues. Thus weset b - bu for a HF word and b = bL for aLF word; £H > bL. In short, HF words areassumed to be stronger cues than are LF words.
In our approach to word frequency, we makethe assumption that the a and c parametersare not frequency dependent. Thus thestrengths to context and to a word's self-strength (tendency to sample a word's ownimage) are assumed equal for HF and LFwords. These assumptions can be justified bythe reasoning that context coding is based on
the time for episodic coding and rehearsal,and self-coding is based on time for rehearsalof interitem features, whereas interitem andresidual interitem strengths are based, at leastin part, on extraexperimental semantic factorsthat are sensitive to word frequency.
We assume that two criteria are selected bythe subject, one for HF words and one for LFwords. This assumption is sensible for purelists, but we assume it holds for mixed listsand mixed tests, as well. Such an assumptioncould be justified on the basis that subjectscan ascertain the word frequency of the testedword and can use this knowledge to set a cri-terion.
The predictions of the simulation model areshown in Figures 23 and 24. The bn and dHparameters were set equal to the b and d pa-rameters used in earlier simulations (6H
= 0-2;t/n = 0.075). For LF words we set bL equal to0.1 and t/L equal to 0.035. The remaining pa-rameters, a, c, r, and v are assumed to beconstant for both HF and LF words and wereset equal to the same values used in earliersimulations (a = 0.25; c = 0.15; r = 4; v =0.5). The HF criterion was set to 1.3 and theLF criterion to 0.66. Figure 23 shows themodel's predictions for uniform frequencylists. Recognition performance is higher forLF words, whereas recall performance is higherfor HF words. Figure 24 shows the results formixed lists. It is assumed that the test list con-tains both HF and LF targets and HF and LFdistractors. We follow the usual procedure insuch cases by calculating d' from a comparisonof HF hits to HF false alarms or from a com-parison of LF hits to LF false alarms. Rec-ognition performance shows the same patternseen in the pure lists: LF words show betterrecognition than do HF words. Note that recallin mixed lists is predicted to be equal for LFand HF words.
The model predicts a pure-list HF advantagefor recall for two reasons. First, a given word(of any frequency) has a higher probability ofrecovery if it is sampled by a HF word as acue than if it is sampled by a LF word, due,to the higher strength values. In a pure HFlist, only HF words are used as cues, of ne-cessity, so recall is superior to that in a pureLF list, where all cues are LF items, of ne-cessity. Second, equal c values for HF and LFwords cause more self-sampling for pure lists

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 35
o
>
5<COoCCDL
.45
.40
UJ
SE -35
.30
.25
P RECOGNITION -
RECALL
3.5
3.0
2.5
2.0
HIGH LOW
LLJO
CCoLLCCLUa.
Oh-
OO
WORD FREQUENCY
Figure 23. The model's predictions for recall and recognition as a function of word frequency for uniformfrequency lists (30 words total), (r = 4, a = 0.25, b,, = 0.2, />L = 0.1, c = 0.15, dH = 0.075, rfL = 0.035, v =5; /Cm,* = 30, Lmm - 8; 2 s/item.)
of LF words because the interitem strengthsare lower for LF cues. Self-sampling reducesrecall because sampling the cue itself, whichhas just been recalled, is of no use and reducesthe opportunities for recovering a new word.
In mixed lists, however, a HF word is justas likely to sample a LF word as a HF wordand then either type is equally likely to be
recovered. Similarly, when a LF word is usedas a cue, it is equally likely to sample eithera HF or a LF word, and they have the sameprobability of recovery (although this is lowerthan the probability of recovery when a HFword is used as a cue). As a result HF and LFwords are sampled and recovered equally oftenand, hence, used as cues equally often, pro-
o-40
UJUJoc ,KU_ .35
O
> .30
CO
oDCQ.
.25
RECOGNITION -
RECALL
4.0
3.5
3.0
2.5
2.0
HIGH LOW
WORD FREQUENCYFigure 24. The model's predictions for recall and recognition as a function of word frequency, for mixed-frequency lists (15 high frequency and 15 low-frequency words), (r = 4, a = 0.25, blt = 0.2, bi = 0.1, c =0.15, da - 0.075, rfL = 0.035, v = 0.5; Kmm = 30, Z.max = 8; 2 s/item).

36 GARY GILLUND AND RICHARD M. SHIFFRIN
RE
CA
LLP
RO
BA
BIL
ITY
OF
FR
EE
.ou
.48
.46
.44
.42
AC\
— - " ' |
20 A
1C A
19 A
— O A
A A_
# HF WORDS
i
A A
A 19
A 20
# LF WORDS
i i
WORD FREQUENCY
Figure 25. Predictions for free recall of a 20-item list as the composition of the list changes from being oneof all high-frequency words to one of all low-frequency words. (Parameters are equal to those in Figures23 and 24).
ducing equal recall. (Due to self-sampling,more failures take place whenever LF wordsare cues, but this does not cause any differ-ential recall of HF and LF items).
These somewhat mysterious recall predic-tions may be clarified by considering how recallprobability changes with the proportion of HFwords in a list. Figure 25 gives the relevantpredictions, as the number of HF items in a20-item list is varied from 0 to 20. In any list,recall probability is equal for HF and LFwords, but the proportion of HF words de-termines the level of recall for both types.
The model predicts recognition superiorityfor LF words because the self-strength param-eter, c, is equal for HF and LF items. Becausethe residual interitem parameters are lowerfor LF items, the increase from distractor totarget distributions is larger for LF items, rel-ative to the corresponding variances of thedistributions. (Higher values of/JH than bL ac-tually help the HF items more than the LFitems, but for most reasonable combinationsof parameter values, the net effect of the bparameters is outweighed by the other factorsthat cause LF superiority.)14 Note that the pre-dictions are identical for mixed lists and forpure lists, because the distribution shapes andplacements are determined by the frequencyof the test item rather than the frequency com-position of the list.
An Experiment on Word Frequencyand Test Type
Most of the experiments we have discussedon word frequency have examined recall orrecognition, but not both (although see, e.g.,Balota & Neely, 1980; Neely & Balota, 1981).It is thus possible that some of the differencesthat exist between recall performance and rec-ognition performance are due to encoding dif-ferences for recall and recognition. It may bethat subjects who study for recall tests tend tointerrelate items and that subjects who studyfor recognition attend to structural features ofthe word as Tversky (1973) and Mandler(1980), among others, have suggested. To drawproper comparisons between recall and rec-ognition, therefore, it seems important to holdback knowledge concerning whether a recallor a recognition test is given until after listpresentation. This is especially important incases where the data are to be fit by a quan-
14 All of the predictions in this paper concerning wordfrequency would be obtained qualitatively if only the dparameter (and not b) varied with frequency. When wefit such a model quantitatively, we found that in order topredict a large enough pure list recall effect, so large adifference between dv and rfL was needed that recognitionpredictions were seriously in error (and vice versa). How-ever, we are reluctant to conclude that the difference be-tween bH and bi. is essential, without additional analysisand research.

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 37
titative model. In the present experiment sub-jects received several different types of tests(both recall and recognition) but were not in-formed prior to the test which type they wouldreceive. Presumably, subjects studied all listsin the same fashion. This presumption has theuseful property that all encoding parametersin our simulations may be held equal for recalland recognition tests. This provides a goodtest for our retrieval assumptions and for themodel's ability to handle recall and recognitiontogether.
In the present experiment, we wished toextend the word-frequency findings to differenttypes of presentation modes and to differenttypes of tests than are normally used in fre-quency experiments. Specifically, in each list,we presented subjects with 16 pairs of wordsto study. The pairs consisted of either HF-HF, HF-LF, LF-HF, or LF-LF word pairs.Subjects were told to associate the words of apair together. We hoped that such a procedureand instructions would give us better controlof the encoding operations used by the subjects.Each list was followed by an arithmetic taskto clear short-term memory.
Five different types of memory tests weregiven: (a) a single-recognition test where oneitem of each pair was tested as a target alongwith an equal number of never-presented dis-tractors, (b) a pair-recognition test in whichtargets consisted of both members of a pre-sented pair (tested in the order they were pre-sented) and in which distractors consisted oftwo items never presented, (c) a cued-recog-nition test where one member of each pairwas presented as a cue (and so indicated) alongwith either its original member or a never-presented distractor, (d) a free-recall test, and(e) a cued-recall test where subjects were givenone member of each pair as a cue and wereasked to recall the corresponding members.
We hoped that such a rich array of test typescarried out within subjects would provide apowerful-enough data base to allow us to fitour model quantitatively and to provide a fairtest of the model's ability to handle both recalland recognition. The details of the experi-mental procedures are given in Appendix B.
Results and DiscussionThere was no difference in performance for
items presented as the first member of a pair
or for items presented as the second item ofa pair. This is usually the case when neitherword is designated as the cue during study andwhen, in cued tests, either member may serveas the cue (see Raaijmaker & Shiffrin, 198 la).Therefore, all analyses were completed bysumming over position within pair.
The primary results can be seen in Figure26. The probability of correct recall is plottedfor the cued data and for the free-recall data.The hit rate minus the false alarm rate is plot-ted for the recognition tests. This measure wasused because it takes into account the hit rateand the false alarm rate simultaneously, muchlike d'. However, d' is sensitive to the as-sumptions of normality and homogeneity ofvariances (and cannot be computed when ei-ther the hit rate is 1 or the false alarm rate is0). We have analyzed the recognition data forhit rates minus false alarm rates, for hit ratesand false alarm rates separately, and for d'.The patterns of the data are the same for allmethods of analysis. In fact the model is fitto the hit rates and to the false alarm ratesseparately, as can be seen in the upcomingfigures.
The main findings are as follows. Cued-re-call performance is higher than free-recall per-formance, but in neither case is there a sizeableeffect of frequency on performance. In the rec-ognition results the most obvious findings showthat performance is higher for LF than for HFwords and that paired recognition is superiorto single recognition, which is superior to cuedrecognition. The details of the statistical anal-yses are given in Appendix C.
In general, the results accord well with theexisting data. Recall performance showed littleeffect of frequency, which is consistent withthe finding that in mixed lists the advantageof HF words over LF words is greatly reducedor eliminated (Duncan, 1974; Gregg et al.,1980; May & Tryk, 1970). The findings of LFadvantages in recognition are certainly con-sistent with the literature, as is discussed atthe start of Section 3.
A Quantitative Model for Frequency Effectsfor Different Test Types
The model, with a few exceptions, is iden-tical to the model outlined before in this sec-tion. However, some special assumptions aremade for the different presentation lists and

38 GARY GILLUND AND RICHARD M. SHIFFRIN
RECALL RECOGNITION.HU
|
< .35OUJ°- .30h-0LU OKtr -/s
QC
8 .20ULLO .15
£H -10
m< .05CQ0QC .00
, ! ! , ,
f-
<5>\ CUE^^v\
"o^-o^-o _X^--^^-^X
FREE
- _,
i i i i
A
/TC fi.'/ / " ^/ ' x
/ '' SINGLE -/ i
. . A 1 i ^"yn
/ / CUE/ /
/ '1 i
- H //^"\-<5/
\ /
b-i i i i
H-H H-L L-H L-L H-H H-L L-H L-L
.ouLU
.75 <
.70 SDC
65 ^.00 ^
LU.60 U3
_l
.55 "-
LU.50 H
DC.45 ,
1—I
.40
FREQUENCY OF WORDS IN PAIRS
Figure 26. Data from the five test conditions of the experiment reported in Section 3. (The left panel givesthe recall results and the right panel gives the recognition results, both as a function of word frequency. Inmixed pairs, the underlined letter designates whether performance is being measured for the high-frequency(H) or the low-frequency (L) member.)
the different types of tests. Specifically, we as-sume that subjects only rehearse items thatare presented as pairs at any one time—theynever rehearse items from different pairs to-gether. Thus the buffer-storage assumption isgone (as is the r parameter). We simply assumethat each presentation of a pair produces atotal context strength a, for each item in thepair and a total self-strength c, for each itemin the pair. We assume that the strength ofassociation of a HF word to its paired member(whether it be a HF word or a LF word) is bHand from a LF word to its paired member is&L. We assume that the residual associationsbetween items that are not presented togetheras pairs follow the usual assumption, givingparameters dw and d^. Finally, we assume thatthe context and self-strengths are not onlyequal to each other but are equal for HF andLF words (a = c, equal for both HF and LFwords).
Free recall is modeled in the same manneras was discussed earlier. The subject is assumedto begin search with context alone as a cue,and if an item is recovered then the item andcontext cues are combined and used until anew item is recovered or until Lmax failuresaccrue. The entire process continues until Kmmtotal failures are counted. Kmm was set to 30as it has been in all simulations and in many
of the previous applications (Raaij makers &Shiffrin, 1980; 1981b).
For cued recall the subject is assumed alwaysto use both context and the cue given by theexperimenter to probe memory. The subjectis assumed to use the cue until Afmax failuresaccumulate. There are no other stopping rulesin the cued-recall model. (Once the pairedmember is recovered, it is assumed that thesubject correctly realizes that that item hadbeen paired with the cue. Furthermore, in oursimple model, no provision for intrusions ismade. Natural and very minor extensions ofthe model could be made that would deal withintrusions, but we prefer to keep the assump-tions as simple as possible.)
The recognition models we propose are verysimilar to those used to generate predictionsearlier in this section. However, for the paired-and cued-recognition conditions some as-sumptions must be made concerning how thetwo words available at test are combined toform a familiarity value. One might assumethat the two words at test are independent andthus both could be used with context as athree-cue probe. Unfortunately, for any pa-rameter values that fit the other conditions,such a model results in predicted paired-rec-ognition performance that is far higher thanthat actually observed. The problem lies in

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 39
the fact that two items that make up a pairhave a strong interitem strength, b, as well asstrong self-strengths, c, and context strengths,a. When the two items of the pair are usedtogether as cues, the cross product terms be-tween the two items increase familiarity dis-proportionately.
The solution we suggest to this problem in-volves fractional weights assigned to multiplecues. In the present case, we decided to pre-serve a special role for the context cue andassign it always a weight of 1.0. We then de-cided to limit the total weights, and attentionalcapacity, by letting all the remaining cues sharea weight of 1.0. That is, the weights assignedto all cues other than context were made tosum to 1.0.
Under these assumptions, the modified rec-ognition model is straightforward. Single-itemrecognition is handled just as in the simulation.Paired recognition is handled by assuming thatthe subject probes memory with three cues,context with a weight of 1.0, and the two items,each with weights of 0.5. Cued recognition ishandled by assuming that the subject weightsthe test item very heavily and the cue itemless heavily. In particular, the cue weight isrepresented by a parameter, Wc, and then theitem weight is 1.0 — Wc.
Note that the recall and single-recognitionmodels need not be modified at all by theseweighting assumptions. Because at most twocues are used in any probe during free or cuedrecall or during single recognition, the weightswill still be 1.0 even under the new assump-tions.
The model was fit to the hit rates and thefalse alarm rates in the various recognitionconditions, and to the recall probabilities, bychoosing parameter values that minimized thesum of squared deviations between the ob-served and predicted values. Actually, the timeneeded to produce predictions by Monte Carlomethods was too large to carry out a completesearch of the parameter space, so certain sim-plifications were adopted. First, we arbitrarilyset v = 0.5, to match the value used in theprevious simulations. (Actually, the modelseems fairly insensitive to the value of the vparameter over small ranges because fits aboutas good were obtained with v = 0.25 and v =0.75, although other parameter values, ofcourse, had to be adjusted accordingly.) The
recall-stopping parameters were set to valuesestimated in previous research (Raaijmakers& Shiffrin, 1980, 1981): KmM = 30; Lmax =3. Also, following previous work, we set a =c. The remaining parameters were estimated,with the following results: a = 0.16, ba = 0.27,bL = 0.19, dH = 0.053, dL = 0.0262; Mmax =10; and Wc = 0.1. The recognition criteriawere set individually for each condition andthe values are given in the figure legends.
The number of parameters may seem ex-cessive, even considering the different tasksand variety of conditions that are being pre-dicted, but we do not feel that this is a properassessment. First of all, the parameters usedhere are essentially the parameters already usedby Raaijmakers and Shiffrin (1980) to predicta wide variety of recall data. A few additionalparameters are needed to handle the differenttasks and conditions, but the additions arequite natural: high and low values of the band d parameters to take word frequency intoaccount; Mmax to replace KmeM and Lmax forthe stopping rule for cued recall; and Wc togovern the weighting of the cue in cued rec-ognition. Second, the values of the estimatedparameters are close to the estimates obtainedin previous fits to recall data and are aboutwhat one might expect given the new stimuliand tasks in the present study.
The predictions of the model for the pa-rameter values indicated above are given alongwith the observed data in Figures 27, 28, 29,and 30. A few words of explanation are neededto explain the genesis of the predicted effects.
For free recall, for reasons similar to thosediscussed earlier, not much effect of frequencyis predicted—this is typical of predictions formixed lists. Actually, there are some slight pre-dicted differences that result from trade-offsbetween sampling and recovery probabilitieswhen one member of a pair has been recoveredand is being used as a cue. In such a case,slight differences in recallability of the pairedmember occurs depending on the frequencyof the cue.
For cued recall, the frequency differencesare somewhat magnified because all samplesfrom memory are made with the cue of spec-ified frequency. Even here, however, the dif-ferences are small. Thus for mixed lists of pairsof items varying in frequency composition,only very small differences are predicted in

40 GARY GILLUND AND RICHARD M. SHIFFRIN
FREE - RECALL CUED - RECALL_j .40
O .35LUCC,_ .30OLJJCC .25CC
O .20Li-0 .15
13 .10mCO .050ccn nn
1 1 r 1
-O OBSERVED--K PREDICTED
: :-_ v^S^*^* _
— i — i — i — ;
" K-*L "^^^S .
_
I ' l l
_J
.35 oLUCC
.30 |_O
.25 DCCCO
.20 OLU
.15 °
h-.10 IJ
CD
.05 COODCnn n
FREQUENCY OF ITEMS IN PAIRS
Figure 27. Predictions and data for cued and free recall from the experiment of Section 3. (a = 0.16, b,,0.27, b,. = 0.19, c = 0.16, du = 0.053, d,. = 0.0262, v = 0.5; Kmm = 30, Lmm = 3, MmaK = 10.)
both free and cued recall. Such predictionsconform quite well to the findings.
For single recognition, substantial effects offrequency are predicted. It is interesting thatthe frequency of the tested item, rather thanthe frequency of the paired member, deter-mines performance. This is not surprisingwhen one realizes that the tested item is thecue used to probe memory, so that its fre-quency is the determining factor according to
the model. LF items give superior performancefor essentially the reasons mentioned earlierin this section: The self-strength is higher rel-ative to the residuals for LF items, becausethe c parameter does not change with fre-quency, but dH > dL (this effect being muchlarger than an opposing factor; because bH >Z?L, a HF test item gains some strength due toits extra interitem strength to its pairedmember).
1.0LU
< 0.9CC
^ 0.8
0.7
LU
< 0.3CC
SINGLE ITEM RECOGNITION
CC
LL
0.2
0.0
—O OBSERVED
--K PREDICTED
H-H H-L L-H L-L
FREQUENCY OF ITEMS IN PAIRS
Figure 28. Predictions for the single-item recognition test. (Parameters are equal to those in Figure 27. Thecriterion for high-frequency (HF) items is 0.295 and for low-frequency (LF) items is 0.150.)

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 41
PAIR RECOGNITION |W=.5II.U
P 0.9
GCH 0.8
I
0.7
LLJ
< °'3
CC
;=» 0.2CC
1 f\ «— ; U. 1
111rn n n
1 1
—O OBSERVED~-X PREDICTED „ Q— — ̂ "̂
^**~"^ 5t-~ -V-*^^"^^^ ^-^ ^
x-'"-
„
-
^^^ ^•*~*t i= w~^= — __~ Q
1 1 1 1
LL FREQUENCY OF ITEMS IN PAIRS
Figure 29. Predictions for the paired-recognition test using a shared-weight model for multiple cues. (Theweights for the two test items are W — 0.5. Other parameters are equal to those in Figure 27. The criterionfor HF-HF pairs is 0.285, for HF-LF or LF-HF pairs is 0.205, and for LF-LF pairs is 0.146. HF = highfrequency; LF = low frequency.)
For pair recognition, the predicted effectsare slightly different, because the strengths foreach cue member, at their respective frequen-cies, are combined multiplicatively and thenare summed. In effect, this produces an averageof two different frequency effects in mixed-frequency pairs. Paired performance is pre-
dicted to be somewhat higher than single per-formance because the product rule for the twocues increases the signal-to-noise ratio, due tothe interitem strength between members of astudied pair. In fact, the predicted improve-ment would be far larger were it not for theweights of 0.5 assigned to the two item cues.
1.0
£ 0.9
,_ 0.8
X0.7
LUh- 0.3<CC.5 0.2CC
^°-1LU(/) 0.0
CUED RECOGNITION (WCUE = .1, \A/TEST = .9
—O OBSERVED--X PREDICTED
H-H H-L L-H L-L
FREQUENCY OF ITEMS IN PAIRS
Figure 30. Predictions for the cued-recognition test, using a shared-weight model for multiple cues. (Theweights are Wcue =0.1, WKS{ = 0.9. The other parameters are equal to those in Figure 27. The criterionfor the pairs as indicated from left to right are 0.292, 0.270, 0.160, and 0.150.)

42 GARY GILLUND AND RICHARD M. SHIFFRIN
It should be noted that quite different predic-tions would result if the distractor pairs con-tained either one or two items that had beenpresented on the list. Then performance wouldbe lowered. This can be seen, in part, by ex-amining the predictions for the cued-recog-nition case.
For cued recognition, the cued member isalways from the list, whether a distractor or atarget is tested. Therefore, its cue effect is com-mon to both targets and distractors, so thatdiscrimination of targets from distractors isnot helped. In fact, the effect is to add noiseto both target and distractor distributions,thereby reducing cued-recognition perfor-mance relative to the single-recognition case.
One might ask why subjects would assignany weight at all to the cue if this would lowerperformance. There are three plausible an-swers. First, the subjects are instructed thatthe cue item is present as a potential aid. Sec-ond, they may not realize that assigning anyattention to the cue will harm performance.Third, the process by which the cue is assignedattention (and weight) may be automatic, oc-curring without conscious choice by the sub-ject, simply as a byproduct of the subject'sattempt to utilize the cue in some fashion.
Note that the predictions are not as closeto the cued and paired data as to the single-recognition data. It may be that our methodof weighting cues does not correspond exactlyto the manner in which subjects assign theirattention.
Discussion
Cue Weights
The paired-recognition condition providesthe first evidence pointing to the need for shar-ing of cue weights. If weights are set equal to1.0, then the use of context plus both test itemsas cues produces predictions of performancelevels that are much too high. In particular,for parameter values that allow the single-rec-ognition data to be predicted, paired-recog-nition predictions are essentially at ceiling. Weare not arguing that the present results providedefinitive empirical evidence in favor of sharedcue weights. It is clear that models exist thatcan predict the paired- and cued-recognitiondata even if weights are all 1.0. For example,
we have been able to show this to be the casefor a model in which separate familiarity val-ues are calculated for each of the test itemsand then are added together before a decisionis made. This model and others like it, however,do not really resolve the basic problem: If cueweights are 1.0 then subjects can always im-prove their paired-recognition performance toceiling by utilizing both test items as cues inthe probe set. Because this option would alwaysbe available according to the logic of the SAMmodel, and because the expected results arenot found, it seems reasonable to concludethat the model is wrong and that sharedweights are used for multiple item cues.
Such reasoning is made even more plausiblewhen generalized for multiple cues in recog-nition. Imagine a list of single items followedby a typical yes-no test. The model assumesthat the subject probes memory with the testitem and context as cues. Suppose, however,that the subject adds extra cues to the probeset, cues that are closely related to the testitem. For example, if "table" is the test item,the subject might choose a probe set consistingof "context," "table," "food," "eating," "fur-niture," "chair," and so forth. Each of theserelated cues is only residually associated to listitems other than "table," but is more stronglyassociated to "table" than to these other items.Thus the product rule for multiple cues insuresthat the discriminability increases with thenumber of these added cues. In effect, the fa-miliarity assigned to "table" by the productrule, assuming "table" is on the list, becomesincreasingly independent of the other items onthe list, and performance continues to increaseto ceiling, as the number of related cues in-creases.
A general solution to problems of this sortinvolves limits on cue usage that are producedby appropriate choices of weights. One pos-sibility is a limit on the number of cues thatcan be utilized (perhaps due to a capacity limiton short-term memory). In this case, whenthe limit is exceeded, all cue weights for ad-ditional cues would be zero. A second possi-bility is to assign cue weights to new cues inaccord with the new information they providethat is not already encapsulated in previouscues. In this case, the weights assigned to newcues continues to decrease as related cues areadded. A final possibility is an attention limit

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 43
on cue utilization. In this approach, all cueweights sum to no more than some constant(1.0 in a pure attention sharing approach). Ifthe cue weights sum to 1.0, then adding cuesgenerally does not help and will hurt if theadded cues are less strongly associated to thetarget image than the target name itself, whichis usually the case. In fact, in a model of thistype, it is best to use just the cues that aremost strongly associated to the target and leaststrongly linked to other list items. Usually thebest cue is the test item itself.
This line of reasoning and the results of thepresent experiment convince us that some ap-propriate cue-weighting scheme is needed.Note that none of the qualitative predictionsshown in Section 2 are altered by the use offractional cue weights. Thus, although the useof fractional weights seems highly desirable,it was not necessary to adopt such an approachuntil the experimental results of the presentsection were encountered. Finally, although itseems clear that a shared-weight assumptionis needed to handle the experimental results,it is probably the case that a variety of sharingrules could handle the present findings quitewell, so that additional research is needed be-fore firm conclusions can be reached.
Frequency-Dependent Cue Strengths
The SAM model explicates many resultsconcerning word frequency by positing highercue strengths to other LTS images for HFwords than for LF words; in other words, theb and d parameters are higher for HF wordsthan for LF words, although the a and c pa-rameters do not vary with word frequency.This approach to word-frequency effects is farfrom novel; similar approaches, albeit statedin somewhat different terms, have been sug-gested or mentioned by Deese (1960), Gregg(1976), Sumby (1963), and Earhard (1982),to name just a few.
The Earhard (1982) results are particularlyinteresting. He set out to test the notion thatHF words have more meanings available atstudy and test, so the chances of identical en-coding at these two times would be lower;without identical encoding, performancewould be worse. Although this hypothesisseems compelling, in the sense that differentencodings would surely reduce performance,
and in the sense that HF words surely havemore meanings, the degree to which differentencodings actually occur may be fairly small,unless specific attempts are made to changethe context and bias different meanings (seeSection 2). In fact, when Earhard insuredidentical encodings at study and test, the word-frequency effect was not reduced in size, whichsuggests that the encodings at study and testare normally similar.
In a final experiment, Earhard tested thehypothesis that both HF and LF items causeimplicit rehearsal of (largely) HF items duringstudy. If so, false alarms to these rehearsedHF items would tend to occur during test,lowering performance. Indeed, a study phasein which subjects were forced to generate threefree-associates to each study item did producea sizeable word-frequency effect, and errorson the forced-choice test often consisted ofchoices of previously generated words (mostlyHF words). Unfortunately, the word-frequencyeffect was, if anything, even larger for the con-trol condition in which the study word wasjust repeated three times. Although subjectsmay have implicitly generated even more as-sociates in the repeat condition than they wereinstructed to produce overtly in the experi-mental condition, it seems to us more likelythat a different but related explanation iscalled for.
In our model, it is not necessary that animplicit or an explicit HF associate be gen-erated at the time of study. After all, the resultof such a generation in Earhard's (1982) modelis to make the generated item more familiarat test. In our model, such items would bemore familiar when tested anyway, becausethey have higher residual strengths to the studyitems. These higher residuals not only producethe extra familiarity of the generated items (asneeded in Earhard's model), but also the higherfamiliarity accruing to HF distractors whenthese are not rehearsed at study time (thusexplaining why the repetition condition alsoproduces a large word-frequency effect).
Although our explanation of the word-fre-quency effect is quite powerful, there is un-doubtedly more to the story, considering themany ways that HF and LF items differ (otherthan frequency). Furthermore, subjects aregenerally capable of assessing the frequencyof presented items and may vary their rehearsal

44 GARY GILLUND AND RICHARD M. SHIFFRIN
and coding operations accordingly (see May& Tryk, 1970).
Directional Retrieval Strengths
Previous articles on the SAM model allowedfor the possibility of asymmetrical retrievalstrengths between two items (one a cue, onean image), but in practice always adopted asymmetry assumption. It certainly seemsplausible that asymmetrical strengths shouldexist. Examples like air-port and port-air pro-vide illustrations. Within the frequency do-main, illustrations are not so obvious andsometimes seem to go in the direction oppositeto our frequency assumption: for example,stirrup-horse and horse-stirrup.
This example and others like it are some-what misleading for the following reasons.First, one's intuitions about strengths areprobably based on free association results—undoubtedly horse is a more likely responseto stirrup than the reverse. However there areprobably only a limited number of such in-stances. In general, there are at most a fewhigh likelihood HF responses to a given LFcue, and these responses are unlikely to havebeen included on the presentation list or testlist. In typical studies, virtually all the itemson the list are unrelated to a given LF item,in which case it seems quite plausible that theresidual strengths should have the relationshipbH > bL.
The second reason why a higher free-as-sociation probability for a HF response to aLF cue should not cause problems for ourmodel involves the absolute levels of strength.If one extends the SAM model to the semanticdomain and substitutes a semantic cue for acontext cue, the response probabilities do notdirectly reflect absolute levels of strength. Theyreflect relative strength values as well, becausethese determine sampling. Thus stirrup maycause sampling of horse, not because that con-nection is strong but because the other com-peting associations (like stirrup-table) are soweak. Horse could have a stronger connectionto stirrup than the reverse, yet produce sam-pling of stirrup less often because horse hasstrong connections to so many other words aswell.
In the SAM model for episodic recall,Equations 7, 8, and 9 give the recovery prob-
abilities that follow sampling; these do dependon the absolute levels of strength. If applieddirectly to the semantic situation, these equa-tions predict the counterintuitive result thata LF response to a HF cue, once sampled,would be recovered with a higher probabilitythan the reverse. It is possible that these equa-tions do not apply in their present form tothe semantic recall case or in any situationinvolving asymmetrical retrieval strengths.Perhaps the retrieval strength from the re-sponse to the cue should determine recoveryin such cases, or perhaps recovery should de-pend on other factors not yet incorporated inEquations 7, 8, and 9.
Very Low Frequency Words and Nonwords
Pronounceable nonwords may be equivalentto very low frequency (VLF) words, words thatare probably unknown to the subjects andtherefore are functional nonwords. Theseitems are recalled worse than HF or LF words.The situation in recognition is more complex:Performance is worse for VLF words than forLF words and may be as poor or poorer thanHF words (e.g., Mandler, Goodman, & Wilkes-Gibbs, 1982; Rao, 1983; Schulman, 1976;Zechmeister, Curt, & Sebastian, 1978). Thedifficulty of forming interitem associationsbetween VLF words is certainly one reasonfor their low recallability (e.g., it might not beeasy to associate abbatial and Jluviatile in ameaningful sentence or image). The recoveryprocess might also be exceptionally poor whenthe image sampled does not incorporate aunitized lexical entity.
How could our model deal with recognitionof VLF words or of nonwords? It is probablypremature to speculate considering the paucityof relevant data. On the surface, it seems likelythat for items without semantic or lexical rep-resentations, orthographic and phonologicalcodes and similarities would take on primaryimportance. On the other hand, it might notbe difficult to encode many VLF items interms of a word that is suggested by the VLFitem (probably a HF word). This would lendto semantic encoding in terms of the suggestedword. Thus it is not difficult to come up withpatterns of relationships among the parametersb, c, and d that would give rise to intermediaterecognition performance, but it is difficult to

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 45
select a hypothesis with any confidence, with-out further data.
Perhaps the simplest hypothesis holds thatthe b and d parameters are low for VLF items,but so is the c parameter. This pattern of pa-rameter values would be especially likely ifsubjects were told to code for meaning (e.g.,Mandler et al., 1982), because a self-codingfor meaning would not be easy for VLF words.However, if subjects were to attend to ortho-graphic features of the stimuli, then a higherc value might result, and recognition perfor-mance for VLF items would improve (e.g.,Rao, 1983).
Forced-Choice Recognition
Several interesting studies concerning wordfrequency have utilized forced-choice ratherthan yes-no testing. Before considering thesestudies, the SAM model must be extended toforced-choice settings. The simplest model forforced-choice performance would have thesubject compute separate familiarity values forthe two (or more) alternatives and choose theitem with the highest value. However, the itemsbeing compared might consist of classes thatdiffer widely in familiarity values. One way tohandle cases of this kind involves selecting acriterion for each item type, forming an es-timate of the standard deviation of the dis-tractor distribution for each item type, andconstructing a standard score for each item ofthat type. The standard score would be thedifference from the criterion divided by thestandard deviation estimate; the largest stan-dard score could mark the subject's choice.(Such a scheme could also be used to generateconfidence ratings; these could be determinedby cutoffs on the standard score dimension.Also, it is possible that some automatic processcarries out the standardization by, say, shrink-ing or expanding the different familiarity scoresto a common scale before a criterion is chosen.)
Interactions of the Word-Frequency EffectWith Distractor Similarity
An interesting word-frequency study usingforced choices has been carried out by Hall(1979). He was interested in demonstratingthat recognition performance is crucially de-pendent on choice of distractor, a point about
which we are in full agreement. He used twogroups of subjects. One group replicated theusual word-frequency effect: After a list ofmixed HF and LF items, forced-choice testswere given comparing HF targets with HFdistractors chosen from the same populations,and LF targets with LF distractors. As usual,recognition was superior for the LF items. Asecond group received mixed lists of HF andLF items but were given forced-choice testswith distractors chosen for orthographic sim-ilarity. The HF targets were paired with HFdistractors that differed in one letter position.The LF targets were paired with nonwordsthat differed in one letter position (the LFwords were low enough in frequency that theymay well have been functional nonwords—inany event lexicality could not have been ofmuch help in making a decision in light ofthe results). In this group, HF tests were su-perior to LF tests; in addition HF performancewas higher than in the control group, and LFperformance was worse. The results were rep-licated in a subsequent study.
We offer the following somewhat speculativehypothesis to explain these data. Suppose thata forced-choice test with an orthographicallymatched distractor leads the subject to encodethe test items in a way that deemphasizes or-thographic features. This might be done be-cause such features are common to bothchoices and therefore might be felt to be ofno help in making a discrimination (in thesame way that the common cue in our word-frequency study was no help and may evenhave harmed recognition performance). Theresult of deemphasis of orthographic encodingmight be improved HF performance, if se-mantic coding is thereby emphasized, and ifsemantic coding is the best discriminator forHF items (highest c to d ratio). On the otherhand, elimination of orthographic encodingmight harm LF performance because theseitems are not well discriminated by semanticfeatures (and would not have been easy to codesemantically at study).
This hypothesis requires a deeper analysisto justify the stipulated discrimination differ-ences. An item cue can be encoded in termsof a variety of features, containing two im-portant subclasses, orthographic (O) and se-mantic (S). The overall strength relating anitem cue to an image can be viewed as an

46 GARY GILLUND AND RICHARD M. SHIFFRIN
appropriate combination of the individualstrengths for O, S, and any other classes offeatures. At the time of study it seems rea-sonable that LF items are coded less in termsof S and more in terms of O because theseitems are harder to code semantically and, inaddition, tend to be more orthographicallydistinct. The result would be a higher c to dratio for the O component than for the S com-ponent. Just the reverse reasoning should applyto HF items, so that a higher c to d ratio wouldbe expected for the S component. For eitheritem type, then, it would be most helpful forrecognition performance to encode the itemat test only in terms of the component that isthe best discriminator. Subjects may not dothis most efficiently unless they are led to doso by fairly obvious test manipulations likeorthographically matched forced choices. (Alsonote that this analysis suggests that it is notnecessarily optimal to match the study en-coding at test because the d values are inde-pendent of study encoding, and it is the c (andb) to d ratio that determines recognition per-formance).
Forced Choices Between Two Distractors orBetween Two Targets
Another very interesting set of findings onword-frequency effects were collected byGlanzer and Bowles (1976). Subjects weregiven mixed lists of LF and HF items. Sixdifferent types of forced-choice tests were givenas follows: (a) HF target-HF dislractor, (b) LFtarget-HF distractor, (c) HF target-LF dis-tractor, (d) LF target-LF distractor, (e) LF tar-get-HF target, and (f) LF dislractor-HF dis-tractor. Subjects were not told that the last two"trick" choices would be used and, presum-ably, chose the item that they were more surewas on the list. The probabilities of correctchoices for the first four conditions were 0.71,0.82, 0.83, and 0.91, respectively. In addition,a HF distractor was chosen over a LF distractorwith probability 0.65, and a LF' target waschosen over a HF target with probability 0.64.
Our model can be applied to this situationdirectly, assuming that scaled familiarity dis-tances from a criterion are used to make forcedchoices. In particular, assume that an evalu-
ation of the familiarity of each of the forced-choice test items is carried out independently.Two criteria are chosen, one for HF items andone for LF items. The subject assesses the fre-quency of a test word, chooses the appropriatecriterion, subtracts the criterion from the fa-miliarity value attained, and then scales theresulting difference by dividing by an estimateof the standard deviation of the distractor dis-tribution for that frequency item. After thisprocess is carried out for each test item, thesubject compares the scaled values and choosesthe item with the highest value to be the target.
The essentials of this situation can begraphed as follows: We take the familiaritydistributions for HF targets and distractors (thesame distributions that underlie the predictionsin Figure 9) and scale them by dividing bythe standard deviation of the distractor dis-tribution; an analogous scaling is carried outfor the LF items. These two sets of distributionsare then aligned so that the respective criteriaare in the same location. The result is the fourdistributions graphed in Figure 31. From leftto right these distributions are for LF distrac-tors, HF distractors, HF targets, and LF targets.If we now make the mandated assumptionthat in a forced choice of items from any twoof these distributions the subject will choosethe higher (scaled) value, then it is easy to seethat the findings of Glanzer and Bowles (1976)will be predicted in qualitative fashion. (Forquantitative fits of the data, we would need toestimate parameters).
We can hardly claim much insight for theapproach shown in Figure 31 because this isexactly the framework proposed by Glanzerand Bowles (1976). Glanzer and Bowles pro-posed a particular model according to whichthe various distributions were generated—andthat underlying model had few similarities toours—but the general approach is identical.We report these findings because our modeldoes predict the ordering of the four distri-butions necessary to produce the correct pre-dictions.
We should note finally that a number ofresearchers have obtained results that are con-sistent with those obtained by Glanzer andBowles (e.g., Shepard, 1967). Our model wouldhandle these findings in a manner analogousto that described above.

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 47
14 21 28
FAMILIARITY VALUES35 42
Figure 31. Scaled distributions for high-frequency (HF) and low-frequency (LF) words. (The distributionsare the ones that give rise to the predictions in Figures 23 and 24.)
Final Remarks
The quantitative applications of the modelpresented in Section 3 amplify considerablythe qualitative applications of the Section 2.It seems clear that the model can predict agreat deal of data from recognition and recallstudies that measure levels of accuracy, in-cluding studies manipulating word frequency.
Although there are a fairly large number ofparameters in the model, the essentials of thepredictions are due to four working parame-ters, a, b, c, and d, with a, b, and c reflectingcoding at study and the match of coding attest to that at study, and d reflecting preex-perimental factors and coding at test. Each ofthese parameters has a well-defined role, isquite distinct in its effects, and should respondappropriately to experimental manipulations.The context strength is the a parameter, theinteritem strength is the b parameter, the self-strength is the c parameter, and the residualstrength (based on preexperimental factors) isthe d parameter. We have seen in Sections 2and 3 that the results of experimental manip-ulations can usually be handled in the modelby making natural and appropriate adjust-ments in the values of the parameters as re-quired by the changes in the experimental de-signs. Nevertheless, the progress thus far mustbe considered very preliminary. At the least,
quantitative applications to many of the par-adigms are required. Beyond this point, it isessential that the model be extended and/ormodified to deal with reaction time and con-fidence-rating data. We consider this possibilityand other extensions in the Section 4 of thisarticle.
4. Extensions
In Section 4 we briefly discuss possible ex-tensions of the SAM model of recognition toother types of paradigms and response mea-sures.
Effect of Number and Spacing ofTarget Presentations
Increasing the number of target presenta-tions causes both recall and recognition per-formance to rise (e.g., Atkinson & Juola, 1973;Murdock, 1962; Ratcliff and Murdock, 1976).Increasing the spacing of such presentationsalso causes recall and recognition performanceto rise (e.g., Hintzman, 1974; Hintzman,Block, & Summers, 1973; Madigan, 1969).
The simplest case occurs when presentationsare massed. In this case it seems plausible totreat « successive presentations each of timet as equivalent to one presentation of time «t.When this is done, the predictions for increas-

48 GARY GILLUND AND RICHARD M. SHIFFRIN
ing numbers of presentations are identical tothose shown in Figure 13 for increasing pre-sentation time (at least for the case when allof the list items are repeated n times in massedfashion).
When presentations are spaced, the situationis much more complex—so much so that adetailed treatment is not possible in this article.Nevertheless, a tentative conclusion can bereached. It must be realized that the equiva-lence assumption made in the case of massedpresentations does not hold. It seems morelikely that n spaced presentations would giverise to n separate images, each with a (some-what) independent variability contribution andeach with differing interitem strengths to dif-ferent items. For recognition, all of thesechanges produce a performance increase com-pared to the massed presentation case.
Frequency Discrimination
It ought to be possible to apply our modelto the paradigm of frequency discrimination,in which the subject attempts to discriminatebetween an item presented m times and someother item presented n times. This can beviewed as a generalization of recognition (forwhich m = 0 and n = 1). For m and n thatare both greater than 0, both test types arefamiliar, but more presentations should resultin greater familiarity on the average, other fac-tors being equal.
The considerations mentioned above duringthe discussion of multiple presentations alsocome into play when predicting frequency dis-crimination. Matters are especially difficultbecause most studies utilize a spaced presen-tation method. For a few reasonable sets ofassumptions we have looked at, performancein discriminating n occurrences from (n + 1)occurrences is a decreasing function of n. Thisprediction matches the findings in the litera-ture (e.g., Hintzman, 1974; Rao, 1983). Otherinteresting issues in this area, such as (a) theautomatism of frequency knowledge (withwhich the model seems to be consistent: Themodel predicts that the frequency discrimi-nations should take place under incidental in-structions, as shown by Zacks, Hasher, & Sanft,1982), (b) spacing effects (which may be duein part to differential coding at storage; seeHintzman, 1974), and (c) variations in pre-
sentation time for items of different frequency(the model may predict a choice of the LFitem if the times for this item are longer) arebeyond the scope of this article.
Multiple Test Items
In the experiment we reported, two itemswere presented for test in the paired and inthe cued conditions. In the paired condition,both items were relevant, but the decisioncould have been made on the basis of eitheritem alone, because distractor pairs consistedof two new items. In many studies, this pos-sibility is eliminated by using distractor pairsconsisting of one new and one old item or twoold items from different study pairs. Manyexperiments of this type involve sentencememory, with distractor sentences consistingof studied words in new arrangements (e.g.,J. R. Anderson, 1976). What is relevant forpresent purposes is the fact that the SAM rec-ognition model produces a familiarity valuefor an intact group of items that is higher onthe average than the familiarity value for arearranged group of items. This fact providesa basis for discriminating intact pairs fromrearranged pairs in recognition tests, a featthat subjects are quite capable of accomplish-ing (e.g., Humphreys, 1976, 1978).
The basis for the extra familiarity is thehigh interitem strength between members ofa studied pair; the interitem strength betweenmembers of a rearranged test pair is usuallylower and often at the residual value. It is eas-iest to follow the argument by way of an ex-ample, as indicated in Table 2.
Assume for the example that the study listcontains just two pairs, A-B and D-E. Rec-ognition tests of pairs could be of four types:A-B (intact), A-D (rearranged), A-F (old-new), and F-G (new-new). Table 2 gives pos-sible retrieval structures for this case undertwo assumptions: Structure 1 assumes that theb parameter for the items studied in a pair isgreater than the residual value, whereas Struc-ture 2 assumes that b = d. The familiarity forthe different types of test pairs is indicated atthe bottom of the table. Note that for b > d,all types are discriminable (Structure 1), butfor b = d, intact and rearranged pairs are notdiscriminable. Thus the interitem parameter,b, controls this type of discrimination. These

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 49
Table 2Retrieval Structures and Pair Familiarity for a List of Two Word Pairs, A-B and D-E
Structure 1: Interitem strength, b.within pair is higher than residual
Image
CABDEFG
A
101010
1111
B
101010
1111
D
1011
1010
11
E
1011
1010
11
FamiliarityF(AB)F(AD)F(AF)F(FG)
= 2020= 400= 220= 40
(intact)(rearranged)
Structure 2: Interitem
Image
CABDEFG
within
A
1010
11111
strength, b,pair equals residual value
B
101
101111
D
1011
10111
E
10111
1011
FamiliarityF(AB)F(AD)F(AF)F(FG)
= 220= 220= 130= 40
qualitative conclusions hold true even if frac-tional weights are assigned to the cues, a pointthat is important in light of the results ofSection 3.
In his work on this topic, Humphreys (1976,1978) contrasted item information, usedmainly to discriminate old from new items,and relational information, used mainly todiscriminate intact from rearranged pairs. Thiscontrast is captured in our model by the con-trast between the c and b parameters. To thisdegree our model is consonant with Hum-phreys's, although our detailed assumptionscertainly do not match his, and we do not yetknow whether our model can fit his data inquantitative fashion.15
We conclude Section 4 by mentioning oneother factor in our model that can lead todiscrimination of intact from rearranged pairs.This factor is the match of the encoding of agiven item at study to the encoding of thatitem at test. The paired member also presentedin these two cases can be viewed as an encodingcontext (see Section 2). When an intact pairis tested, the encoding of both items mightmatch the study encoding better than woulda rearranged pair. This would be reflected inhigher values of both the c and b parameters.Note that this encoding factor would be espe-cially important if either the test or the studypairs were chosen to lead to an unusual codingfor an item. In cases with random word pair-ings, the dominant encoding might tend to
occur at both study and test for both the intactand the rearranged cases, and therefore thematch of encodings might not play an im-portant role.
Recognition of Items FromCategorized Lists
Consider a paradigm in which items from« categories are presented on a list, followedby a yes-no recognition test for both list itemsand abstractors from each of those categories(e.g., Rabinowitz, 1978). This situation is notdifficult to model: Assume that an item haswithin-category residual strengths that arehigher than residual strengths to items in othercategories (Le., within-category strengths = rfw;between-category residual strengths = (/b;dw > db). Assume also that when category sizevaries, different criteria are chosen for the dif-ferent categories. Ignoring for the moment the
15 Mandler (1980) has suggested that an analogy can bedrawn between Humphreys's item information and thefamiliarity phase of recognition, and Humphreys's rela-tional information and the search phase of recognition.Obviously, our familiarity model can predict the basicphenomena in question with a familiarity approach alone.Note also that whereas we share Humphreys's emphasison the distinction between relational and item information,and his emphasis on cuing effects, the present model doesnot incorporate a search phase in cued-item recognition,a key component in Humphreys's model (see Humphreys& Bain, in press).

50 GARY GILLUND AND RICHARD M. SHIFFRIN
possibility of using a category cue in additionto item and context cues, predictions are rel-atively straightforward.
Category size effects are seen for reasonssimilar to those that explain list-length effects,although the relative size of the decrement ascategory size increases is reduced in a multiple-category list compared to a one-category list.For example, the decrease from a 5-flower listto a 10-flower list is lessened if 40 words fromother categories are added to each of theselists. The reason is simple: 4> is not zero, soadded items in other categories make eachcategory appear to have extra items, the num-ber extra depending on the ratio of afw to <4;the added number does not depend on initialcategory size. If the total list length is heldconstant, and the categories making up thelist are varied in size, as in Rabinowitz (1978),then performance is still predicted to drop ascategory size increases (because Jw is largerthan rfh), though at a somewhat different rate.These predictions are confirmed by reanalysisof Rabinowitz's data.
An interesting question arises if one com-pares performance for a list of n items all fromone category with a list of n unrelated items(each tested with distractors similar to the listitems). Because residuals between the categoryitems are larger, performance should be lowerin this case. Although we do not know of adirect test of this point, Kintsch (1968) com-pared recognition of a random 30-word listwith a list composed of six 5-word categories.These gave roughly equal performance, pos-sibly because the improvement due to usinga category size of 5 (rather than 30) offset theharm caused by extra-high within-categoryresidual strengths. (By way of comparison, notethat our recall model predicts recall of n wordsfrom one category to be superior to recall ofn random words, for several different reasons—see Raaijmakers & Shiffrin, 1980).
What would be the effect of adding a cat-egory cue to the probe set in addition to theitem and context cues? Because the categorycue would have higher strengths to images ofitems in that category than to images of otheritems, and because this effect would multiplythe same effect caused by item cue strengths,the noncategory images would contribute pro-portionally less familiarity. Although a relatedeffect occurrs for distractors, it is much smaller,
so that performance would increase for thecategory in question. In addition, categoryperformance would depend more on the sizeof the tested category and less on the size ofthe whole list. (Note that fractional cue weightsmight reduce or eliminate the effect of addinga category cue to the probe set).
When all list items and distractors are fromone category, a good case can be made foreliminating a category cue, because it increasesfamiliarity for both targets and distractors,perhaps in a fashion that would reduce per-formance. It could even be argued that it iswise to encode an item cue in such a case sothat category information would be de-em-phasized as much as possible. The residualsand the match parameters, m(b) and m(c),could both be reduced by such a de-emphasis,perhaps leading to an overall improvement.Such a possibility depends on a subject's abilityto exercise control over encoding of" items andcues. In any event, performance on a list anda test composed all of items from one categorymight well be improved by de-emphasis ofcategory information, so that comparisons toperformance levels for unrelated-item listsmight be closer than otherwise expected.
Continuous Recognition Paradigms
Virtually all of the discussion in this articleis directed toward study-test paradigms. Wehave done this because the previous recall work(Raaijmakers & Shiffrin, 1980) suggested thatcontext changes during the course of a givenlist either do not occur or may be assumed tohave negligible impact. A very different situ-ation obtains when a continuous recognitionparadigm is used: Words are presented in acontinuous sequence and tests are alternatedwith presentations throughout. In this para-digm we must assume that context is changingthroughout the experimental session, so thatas study-test lag increases, study context differsmore from test context and performance de-creases (e.g., see Hockley, 1982, for a contin-uous recognition paradigm and Shiffrin, 1970,for a continuous recall paradigm).
We do not analyze continuous recognitionparadigms in this article, but one importantpoint can be made. Most of the effects thatare seen as a function of study-test lag can beexplained by a change in context. This would

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 51
be handled in the model by changes in theparameter m(a), which can be instantiated inthe simulation by decreases in the value of thecontext strength in the retrieval structure, asa function of increasing lags. The familiaritywould be based on a sum over all of the imagesof items up to that point in the session. As atarget is tested at increasing delays, it con-tributes less and less of the total familiaritydespite large self-strength, because the self-strength is multiplied by decreasing contextstrength.
Short-Term Recognition
In the applications of the model to our dataand to the results from the literature, care hasbeen taken to exclude possible contributionsto performance that might be due to tests ofitems in STS. It seems likely that an item stillin STS (say, undergoing rehearsal) at the timeof a recognition test is given a very rapid andaccurate response, regardless of long-term fac-tors that would produce other results. For ex-ample, if the last item presented in a long listhad been the first tested, it is very likely thatboth the accuracy and latency would be welloff the distribution expected for other itemsin such a long list.
How might short-term recognition be in-corporated in the model? For recall, we havemade the simple assumption that the short-term rehearsal buffer is dumped. For recog-nition accuracy, a related assumption couldbe made that a correct response would be givenif a tested item is currently in STS.
It is interesting that a number of theoristshave put forth models to handle recognitionin both the long-term and short-term spheres(e.g., Murdock, 1974; Ratcliff, 1978). The de-bate between those who prefer two (or more)systems and those who prefer one has beenhighly active for 20 years without any definitiveresolution. It is even conceivable that our fa-miliarity model could be extended to short-term data with good success. Nevertheless, weprefer to retain a two-store system so as tomaintain the correspondence with the recallpart of the model.
Response Times
A great deal of the modern research intorecognition memory involves reaction time
measures (e.g., Atkinson & Juola, 1973;Hockley, 1982; McNicol & Stewart, 1980;Murdock & Dufty, 1972; RatclifT& Murdock,1976). The present model remains incompleteuntil a mechanism for the production of re-sponse times is included.
A Descriptive Approach to Response Times
Within the context of the present model,the simplest way to generate predictions forresponse time involves assignment of times inaccord with the distance from the criterion.It seems reasonable that familiarity values farfrom the criterion should be associated withfast reactions and low variability; values closeto the criterion should be associated with slowand variable reaction times.
For the reasons discussed in Section 3, it isnot sufficient to use only the distance fromthe criterion; because the variances can differgreatly with item type, the distance must bescaled. Perhaps it is simplest to divide the dis-tance from the criterion by the standard de-viation of the distractor distribution. The re-sulting scaled distance may be called D. Thena model for reaction times might propose thata reaction time distribution be associated witheach value of D, with mean ii(D) and varianceff\D). Most likely, we should set n(D) = /,(£>)and ff\D) - J2(D), where both j\ and f2 aremonotonically decreasing functions of the ab-solute value of D.
A model of just this sort was fit quantita-tively to the reaction time results of our ex-periment reported in Section 3. The meansand variances of the correct response timeswere fit quite accurately, as were the patternsof the error-response times (though the ab-solute values of the means and the variancesof the error-response times were overpre-dicted). We do not present these results andpredictions because the model is purely de-scriptive. Although the approach fit the datareasonably well, all that this demonstrates isa regular and lawful relationship betweenscaled criterion distance and response time,and hence a regular relationship between ac-curacy and latency measures.
Toward a Process Model of Response Times
A descriptive model of the type proposedin Section 3 has many drawbacks and limi-

52 GARY GILLUND AND RICHARD M. SHIFFRIN
tations. To give just one example, there is noobvious way to treat data concerning trade-offs between speed and accuracy (e.g., Corbett,1977; Dosher, 1981; Pachella, 1974; Reed,1973, 1976; Wickelgren, 1977; Wickelgren &Corbett, 1977).
We have not yet developed a process modelfor response time generation, but a randomwalk model of the type proposed by Link(1975) seems a reasonable candidate. One wayto implement such a model follows: A scaledfamiliarity value is obtained for any test item,as in the present model. This scaled value isused to generate a drift rate (and distribution)for a random walk that takes place until eithera positive response barrier or a negative re-sponse barrier is reached. The barrier reacheddetermines the response accuracy, and the re-sponse time is determined by the number ofsteps needed to reach the barrier.
Note that this model is not equivalent tothe model put forth in earlier sections of thisarticle. It is possible to have a positive scaledvalue of familiarity (which in the model of theearlier sections always produced a positive re-sponse) and yet have the random walk proceedto the negative response barrier (and viceversa). The closer the barriers, the more oftensuch errors occur, and the faster are the re-sponse times. In fact, it is in just this fashionthat speed-accuracy trade-off results are dealtwith in a random walk approach—barriersare moved in to speed response time and loweraccuracy or moved out to slow response timeand improve accuracy. We suspect that an ap-propriate choice of barriers and drift rateswould allow the random walk model to mimicclosely the accuracy predictions of the presentmodel. Whether the accuracy and latency datacould be fit simultaneously by a random walkmodel is a question that must be left for futurework.
Criticisms of Criterion Models forResponse Times
Although we have not extended the SAMmodel to predict response times, we feel con-fident that such an extension is possible, alongthe lines suggested above. Even if the randomwalk version of the model is excluded fromconsideration, the descriptive version can
handle most of the results. Our suggested de-scriptive version is similar to a number ofstrength models that have postulated that re-action time is determined by distance from acriterion (e.g., Norman & Wickelgren, 1969).This approach has usually been used to predictshort-term recognition data. It has been dis-missed as a viable candidate to explicate long-term recognition because it (a) predicts errorvariances to be smaller than correct variances,when the reverse is actually found (Murdock& Dufty, 1972); (b) is not a dynamic theory;that is, there is nothing than can change inthe model as variables change (such as testposition—Ratcliff& Murdock, 1976); and (c)makes no provision for response bias (Pike,1973). None of these criticisms hold for anextension of the SAM model to the reactiontime domain.
Confidence Ratings
Many of the same concerns that were dis-cussed with respect to response times applyto confidence ratings as well. Descriptively,one could suppose that subjects utilize a num-ber of criteria along the familiarity dimension,assigning confidence ratings in accord with thecriteria between which a given observation offamiliarity falls. Alternatively, in a randomwalk model, the confidence ratings could bemade a function either of the drift rate, thenumber of steps to reach a barrier, the place-ment of the barrier, or some combination ofall three (see Ratcliff, 1978).
5. Assessment and Generalization
Comparisons of the SAM Model toOther Theories
Our model postulates a deep-rooted rela-tionship between recall and recognition. Bothprocesses make use of the same types of in-formation during retrieval and both are cue-dependent retrieval processes. In fact, the samequantitative expression serves as the basis forthe recall and recognition models. The differ-ence between the two paradigms lies in howthe information is used. In recognition, thestrength of the total amount of informationactivated is used to make a familiarity decision.In recall that same information is used to de-

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 53
termine sampling and recovery during an ex-tended search.
The relationship we have specified is quitedifferent from the relationship specified byembedded two-process theories (Anderson &Bower, 1972; Kintsch, 1970), and two-phasetheories (Atkinson & Juola, 1973, 1974;Man-dler, 1980), as discussed in the introduction.
Moreover, even the familiarity componentof such two-phase models (Model 3 of Table1) differs significantly from our model of fa-miliarity. Atkinson and Juola (see also Atkin-son & Wescourt, 1975) postulate that the fa-miliarity process is based on the level of ac-tivation of the word (that was directly accessed)in the lexicon (i.e., semantic memory)—thedecision is thus context independent. Mandler(1980) also argues that the familiarity processis context independent, being based on in-traitem aspects of the stored word rather thanintetitem connections (which are used pri-marily in search). Our conceptualization of afamiliarity process is diametrically opposed,because the decision is based on a sum of fa-miliarity values across all the episodic imagesin the list and is not based on the familiarityvalue of a particular item. Whereas it is truethat intraitem factors have an important rolein our model, because the self-coding of targetsis one of the two crucial factors in raising thefamiliarity value for targets above that of dis-tractors, such intraitem effects are embeddedin a general interitem episodic sum (see Equa-tions 7 and 8). In fact the activation by a dis-tractor of its own semantic image does noteven enter into the familiarity value on whicha decision is based.
Our conceptualization of the familiarityprocess is closer to that used in models thatpropose simultaneous access to multiplememory images or to a single, holistic memorystore. In such models the memory decision isbased on an activation of many items ratherthan on direct access to a specific memoryimage. Such models have been proposed forperceptual tasks (Pike, 1973), short-termmemory tasks (Anderson, 1973; Cavanagh,1976; Pike, Dalgleish, & Wright, 1977), freerecall (Metcalfe & Murdock, 1981; Murdock,1982), paired-associate learning and forgetting(Eich, 1982), and recognition memory (Rat-cliff, 1978).16 Ratcliff's model, although it em-
phasizes latencies and is restricted to recog-nition, comes closest to predicting the typesof data in which we are interested, and is wortha closer examination.
Ratcliff assumes that multiple searches oc-cur in parallel. A test probe activates eachimage in memory and causes it to begin arandom walk between a yes barrier and a nobarrier. If any of the walks reaches the yesboundary before all reach the no boundarythen a positive response is given; otherwise anegative response is given. Negative responsescan be rapid because the negative boundaryis much closer than the positive one, althoughthe positive drift rate (if a target is tested) maybe faster than all of the negative drift rates.Drift rates are determined by similarity of thetest item to each image in memory.
The model is similar to ours in that rec-ognition does not involve direct access to oneimage but rather involves the activation of alarge portion of memory. The details of themodels differ quite a bit because Ratcliff'smodel is a process model of activation in realtime, whereas we have been more interestedin asymptotic familiarity. (Furthermore, Rat-cliff makes no distinction between short- andlong-term memory and applies his model toresults in both domains.) We do not necessarilyregard Ratcliff's approach as inconsistent withours in a global sense. In fact, as we discussedin Section 4, a real time-process version ofour model may well be conceptualized as arandom walk. (We prefer a random walk modelwith one rather than multiple walks becausewe are not enamored of a model in whichnegative responses must wait until all of somevery large but unspecified number of randomwalks reach a negative barrier.)
Next consider the work of Tulving (1974,1976; Tulving & Watkins, 1973), who sug-gested that recall and recognition involve thesame cue-dependent processes and informa-tion. All that distinguishes them is the amountand the type of information available at test
16 The Glanzer and Bowles (1976) model is, in effect,a model of this type. Although only the test item's featuresare contacted, all the other list items have an effect becausethey caused tagging of some of the features of the test itemwhen they were first presented.

54 GARY GILLUND AND RICHARD M. SHIFFRIN
that serve as cues. Our model is like Tulving'sin that we also posit cue-dependent retrievalsystems and place a great deal of importanceon the types of cues available at test. We agreewith Tulving that recall and recognition makeuse of basically the same types of information.However, we differ in that we postulate quitea different process for recall and recognition,whereas Tulving does not.17
Strengths and Weaknesses of the SAMModel for Recognition
We are reasonably satisfied with the pre-dictions for accuracy measures in recall andrecognition. The model has been able to fit awide variety of data in the domain of episodicmemory, in the paradigms of recall and rec-ognition, with a common set of assumptionsand parameters and with sensible values of theparameters. That is, when experimental ma-nipulations are carried out that ought tochange the values of certain parameters, thechanges in those parameter values actually dopredict the new data.
Another strength is the relative simplicityof the model. We have tried not to encumberthe model with all sorts of special processesdesigned to handle particular, troublesome re-sults. It is also gratifying that the model hasproduced a number of accurate predictionsthat we did not anticipate prior to carryingout the simulations. Perhaps the greateststrength of the present model is the tight linkbetween recall and recognition processes thatis produced by the use of the denominator ofthe sampling equation as the decision variablefor recognition judgments. Even though thefamiliarity mechanism for recognition is verydifferent from the search process for recall,there is a common basis that underlies bothprocesses. It is this fact that allows us to pro-duce joint predictions for recall and recog-nition with the same model using the sameparameters.
The weakest part of the present model isits preliminary nature: Predictions for responsetimes and confidence ratings have not yet beenproduced. Of the applications in the accuracydomain, the main weakness is the lack of amodel for choosing criteria. Another potentialproblem is the failure to include a search com-
ponent during recognition. We consider theseproblems in the following sections.
Criterion Placement
In the simulations of Section 2 an arbitraryrule was used to choose criteria; in each casea fixed point was chosen between the meansof the target and distractor distributions. Thisrule was used only as a demonstration device;in fact, the subject is assumed to choose acriterion appropriate for each test setting, aswas assumed in the quantitative simulationsof Section 3. The question then arises: Howis an appropriate criterion chosen? This issueis an important one that cannot be addressedin detail in the present work, but we have somesuggestions.
First, it is clear that a subject with someknowledge of the expected proportions of tar-gets and distractors can adjust the criterionduring the course of testing until a reasonablesetting is reached. This solution has severalproblems. First, the setting of the criterion onthe initial test trials is likely to be very im-precise. Second, subjects can produce sensiblerecognition results when tested with targetsonly, and no distractors whatever. In this case,it is possible that a criterion could be chosen(over test trials) to produce some arbitrary levelof misses, but it is difficult to see why anyparticular level should be chosen.
These considerations suggest a second so-lution, which may appear more plausible.During the list presentation, the subject isconstantly being presented with new items (ineffect, distractors) for each of which a famil-iarity value can be calculated. Although thesefamiliarity values change during the course ofthe presentations, the subject can neverthelessuse the last several presentations of the list toform an idea of the mean and variance of thedistractor distribution. (It may also be possibleto get an idea of the characteristics of the targetdistribution through recall of earlier items inLhe list). Given this knowledge of the famil-
17 Note that Tulving has recently modified his view ofthe relation between recall and recognition to allow differentprocesses to occur in recall and recognition (Tulving, 1982a,1982b).

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 55
iarity distribution for distractors, it should befairly easy to choose a sensible guess for acriterion setting, a setting that could be finetuned as needed during the test sequence.
A somewhat different problem concerns theplacement of criteria for different item typesas was needed for HF and LF items in Section3. One problem involves memory load—ifmany item types are used in a list, how canall the criteria be kept in memory and usedappropriately? A second problem concernsspeed of response—when a test item is pre-sented how can the item type be ascertained,and the appropriate criteria retrieved, rapidlyenough to allow fast recognition responses tobe given? An answer to both of these questionsmight involve an automatic adjustmentmechanism that utilizes nonepisodic charac-teristics of the test item to scale the values offamiliarity accordingly. Such a solution is at-tractive (although not yet implemented) butwould not work if the need for different criteriais episodically induced. For example, a listmade up of differing numbers of members ofdifferent categories requires different criteriafor each category. The basis for the choice,however, would not be inherent in the categorybut instead would be the experimenter's as-signment of presentation numbers to cate-gories. In this case, an automatic mechanismseems unlikely, and an appropriate adjustmentin criterion would have to be made by thesubject as the category membership of eachtest item is ascertained.
Is There a Search Componentto Recognition?
Several types of data tend to suggest thepresence of search processes and hence theinsufficiency of the familiarity-only model(Model 4 of Table 1). One source of evidenceconcerns false alarms to distractors that aresimilar to list items. A similar distractor wouldhave a higher than normal familiarity andhence should give rise to increased false alarmrates. However, this is not always the case. Ifenhanced false alarms are not seen, then itmay well be that information recovery fromthe image of the associated list item is occur-ring. The recovered information might thenbe used to inhibit a false alarm. Perhaps such
a process explains the failure to find excessfalse alarms to synonyms in the study withresults shown in Figure 4: Locating the listimage paired with the synonym could al-low the subject to discount the familiarity ofthe cue.
A different example of this kind is foundin a study by Tulving (1982a). After presen-tation of a list of items, a test list was presentedconsisting of 25% list items as targets, 25%control distractors (random), 25% rhyme dis-tractors, and 25% associated distractors. Group1 subjects performed a yes-no recognitionjudgment. Group 2 used the test items as cuesand wrote down next to each a list word thatthe cue suggested (including the cue itself, ifit was a target). An analysis showed that dis-tractors that were better cues for Group 2 (theyled to more recalls of their matched-list mem-bers) were given fewer false alarms by subjectsin Group 1. Such a result is hard to explainby a familiarity model alone. It seems likelythat good cues used as distractors for Group1 led on occasion to recovery of the list itemmatched to that cue; having found a similarlist item, the subject might then be able todecide that the cue was a distractor, despiteits level of familiarity.
These results suggest that sampling of animage may sometimes occur and, thus, inhibitfalse alarms, but other results suggest that suchsampling of the relevant image occurs onlyoccasionally. For example, in a continuous-recognition experiment, false alarms to similardistractors are a nonmonotonic function oflag, with the peak somewhere between oneand five intervening items. (MacLeod & Nel-son, 1976, tested lags of zero, five, and highernumbers and found a peak at five. In a similarstudy, we found a maximum false alarm rateat a lag of one). Presumably at zero lag, theitem is not given many false alarms becausethe relevant list item is still in STS at test. Atlarger lags, though, the increased familiaritycaused by a test at a short lag apparently over-comes whatever tendency there is for thematched-list item to be sampled by the similardistractor and apparently overcomes residualcontamination from STS retrieval.
Results like those obtained by Tulving sug-gest that a search component is at least some-times used during recognition. Whether the

56 GARY GILLUND AND RICHARD M. SHIFFRIN
search component occurs only when famil-iarity does not give a clear answer, as in Figure1, or whether the image-recovery process oc-curs quickly (on some trials) and precludes useof the familiarity system altogether, is an openquestion.
Evidence of a somewhat different kind ha'sbeen reported by Mandler et al., (1969). Aftersorting a list of words into n categories, a sub-ject attempts either recall or recognition, eitherimmediately or after a delay. Larger values ofn (up to about 7) lead to better recall at alltest delays, but recognition does not dependon n until long delays occur. Mandler arguesthat search is utilized relatively more and fa-miliarity relatively less as recognition-test delayincreases, thereby explaining the result if twoadditional assumptions are true: (a) Search isbetter after sorting into more categories, and(b) familiarity judgment is unaffected by sort-ing into more categories. This sort of argumentis a bit indirect but may provide evidence forsearch processes in recognition. Whereas dataconcerning a lessening of false alarm rates forsimilar distractors or for good recall cues seemto suggest automatic sampling and recoveryoccuring in parallel with the familiarity pro-cess, Mandler et al.'s (1969) data seem morecompatible with a search carried out after thefamiliarity process fails.
There may be other data that indicate thepresence of search during recognition, but theappropriate analyses have not yet been carriedout. One paradigm of this kind is that of mul-tiple-item recognition. Both Humphreys(1978; Humphreys & Bain, in press) andMandler (1980; Mandler, Rabinowitz, & Si-mon, 1981) have analyzed multiple-item rec-ognition by collecting data on the recognition,the cuing ability, and the recall recoverabilityof each individual item being tested. Throughappropriate analysis, it may be possible to ar-gue that joint recognizability is a function ofboth familiarity and search in combination.We must reserve judgment on this issue untilquantitative fits of our model to such data areundertaken, because it is possible that ourmodel could fit the same data, although fordifferent reasons.
It is important to emphasize that we arenot opposed to the concept of a search com-ponent in recognition. To the contrary, thefundamental nature of the SAM approach re-
quires that subjects may carry out an extendedsearch during recognition paradigms, if theyso desire. Furthermore, it is entirely consistentwith our approach that a sample of an imagefrom memory may occur automatically, inparallel with the evaluation of familiarity.Thus, the question is really not whether searchprocesses occur, but the degree to which suchprocesses occur. Perhaps it is surprising thatthe results reported in this article have shownthat most of the experimental findings are ex-plicable with a global familiarity model withno search component at all. This findingshould not be used to come to strong conclu-sions concerning the use of search. Becauseour global familiarity model is designed topredict many findings that are normallythought to indicate the presence of search, itis no easy matter to discriminate our purefamiliarity model from one that relies to somedegree on search.
Toward a General Model for Recalland Recognition
Regardless of the status of the data con-cerning evidence in favor of search during rec-ognition, the underlying logic of the SAMmodel requires that the subject be able to uti-lize search if he or she so chooses. We begintherefore by describing a generalization of theSAM model that incorporates a search com-ponent.
The generalized model is depicted in Figure32. As shown, there are two points at whichsearch processes can contribute: an initial,perhaps automatic, single sample of an imagethat occurs in parallel with familiarity gen-eration, and an extended search that may fol-low familiarity generation.
Next we wish to place the model in thelarger context of a general information-pro-cessing framework that covers the memorysystem from initial feature encoding to finalretrieval decisions.
On initial presentation of an item, a seriesof encoding and retrieval processes takes placewhich is largely automatic in the early stages.The general framework is depicted in Figure33. The set of automatically encoded infor-mation is termed the autofield. We use theterms encoded and retrieved interchangeablyhere, because initial encoding is a form of re-

5 »«'ll
a £.X O>
II.
!§
3 -3
I!•
I
( S T A R T J
USE TEST ITEMAND CONTEXTAS CUES
LET - FAMILIARITYVALUE
RECOVER INFORMATION FROMSAMPLED IMAGE
DECISION: HOW SHOULDINFORMATION BE UTILIZED?
USE FAMILIARITY
NO NO
1
YES
I
RESPOND "NO"
1EXTENDED MEMORY
SEARCH
J
! COMBINE SOURCES OF '! INFORMATION '
USE IMAGE INFORMATION
1rRESPOND
I 1RESPOND
21
o
70
IIOto
5

58 GARY GO,LUND AND RICHARD M. SHIFFRIN
trieval from LTS. When we say, for example,that a straight-line feature is encoded, we meanthat the system has processed the physical in-put to the point where a particular straight-line feature in LTS has been activated andmade available to the system so that furtherprocessing can take place.
The information that drives the encodingprocess includes not only the sensory inputfrom the external environment, including thecontextual surround in addition to the nom-inal stimulus defined by the experimenter, but
also internal context deriving from the sub-ject's physical state and mental activities atthe time of input. The system is assumed toact continuously to encode the changing en-vironment, but we consider only the stagesfollowing the occurrence of some event of par-ticular interest, such as the presentation of aword in a recognition experiment.
It is our view that the automatic encodingprocess produces (over a short period of time,perhaps several hundred milliseconds) a largenumber of different types of informational
I EPISODIC IMAGE |I JT
Figure 33. A framework for initial encoding according to the SAM model. (The autoficld represents theresult of automatic encoding processes, based on the test cues in the probe set. The autofield contains aregion of temporal-contextual information activated from recent episodic images. This information is usedboth for recognition decisions and as a basis for sampling images during an extended memory search.)

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 59
features, organized by content, and not by ep-isodic images. Occasionally an episodic imagemay be activated as part of the automatic en-coding process (see Figure 32), but with thisexception, the images of list items and recentevents are not in the autofield. However, con-text from these images is in the autofield, ina localized region called episodic context. It isthis episodic context, integrated together inappropriate fashion, that is used to make fa-miliarity decisions in recognition. The sameepisodic context governs search, in the follow-ing manner: An element of context is sampledat random from the contextual region of theautofield and is traced back to the image fromwhence it arose. This is the sampling processin the memory search.
Consider next the way in which the variouscodes are extracted and placed in the autofield.The typical assumption is made that process-ing takes place in an ordered sequence, thoughstrict seriality is not implied. Some of the codesthat might be retrieved are indicated in Figure33, ranging from low-level sensory features tohigh-level concepts. Of course the processingdepends on the context as well as on previousfeatures in the chain, so as upper stages arereached the features retrieved may becomebiased by the context as much as they aredetermined by the item itself. Thus one mean-ing of a word might be retrieved ahead of amore usual meaning, given the presence of abiasing word in the context. Presumably, thelater in the stage of processing, the larger isthe potential influence of context. The arrowsleading from context to the episodic imagesindicate that the similarity of the test contextto the context in the stored images causes thatcontext to be activated (in conjunction withthe extracted content features that are similarto features in the images; this other path ofactivation is indicated by the arrows leadingfrom the content features to the episodic im-ages). The arrows leading from the episodicimages to the autofield (actually to the episodiccontext area) show the genesis of the contextactivation from recent images, that serves asthe basis for both familiarity judgments andsampling. The short arrow leading from oneof the images to the autofield allows for thepossibility that one of the images may be sam-pled as part of the automatic encoding process
in parallel with the other types of encoding.When this occurs, it may be thought of as thefirst step in the search process, assuming thatan extended search is carried out.18
Why should the context from all episodicimages appear in the autofield, but not theimages themselves? The answer is based onthe associative basis by which the automaticencoding system operates. The autofield isgenerated through associations to the probecues (item and context). Because the probecues contain context, the similar context froma recent image tends to be activated and placedin the autofield. On the other hand, if a wordis presented as a distractor, so that none of itsimages is recent, then the context from its im-ages will not match that used at test, but thecontent features of the word will match manystored content features in LTS, and a varietyof physical and semantic features are placedin the autofield. When both the context andthe item in a sorted image match the test cues(i.e., a target or a similar distractor is pre-sented), then both types of information enterthe autofield, each in its appropriate region.(Occasionally, in addition, the image itself isactivated and is placed in the autofield.)
It is assumed that the subject can utilize theinformation in the autofield once it has beenretrieved and can do so according to type ofinformation, depending on the requirementsof the task. Thus a lexical decision task wouldbe accomplished through use of the lexicalinformation in the autofield, a physical matchtask through use of the low-level sensory codes,and so forth.
The possibility that our model can be usedfor tasks other than episodic recognition mighteventually prove quite important. As one ex-ample, consider the learning of categories.Suppose Nj items are input and assigned tothe rth category. At test either old or new itemsmight be given to the subject to assign to cat-egories. One approach within the SAM modelwould utilize search. The test item and the
18 Where do the episodic images in LTS come from?We propose that each image represents a sample of theinformation in the autofield that arises due to some eventoccurrence. (We make no proposal at this time concerninghow many of, and how often, these are stored.)

60 GARY GILLUND AND RICHARD M. SHIFFRIN
context would be used as cues, and some itemwould be sampled and recovered (eventually).The category of the first item recovered couldbe given as the response. This model is con-sistent with versions of the exemplar modelof Medin and Schaffer (1978) and is essentiallyisomorphic to the complete-set exemplarmodel discussed by Homa, Sterling, and Trepel(1981) and Medin, Busemeyer, and Dewey (inpress).
Of course this simple version of a SAMsearch model is not the only approach withinthe SAM framework, even if attention is re-stricted to search models only. A simple gen-eralization would let the subject attempt longersearches. For example, N samples could bemade, with a decision in favor of the categorythat is most often recovered. A further gen-eralization would have the subject use a moreintelligent decision rule, assigning a categoryto the test item on the basis of a similaritydecision that results from examining the re-covered images. (Note also that the SAMmodel is perfectly consistent with a mixed-exemplar-prototype model. If the subjectshould store a prototype separate from theindividual images, this could be found duringa memory search and could be used to generatea decision).
All of these search models for categorizationare subject to the same criticisms that wereapplied to search models for recognition. Thatis, fast, accurate, and high-confidence categoryjudgments might be difficult to explain on thebasis of search alone. One solution is availableby utilizing a variant of the familiarity modelfor recognition. For example, memory couldbe probed with three cues: context, test item,and category name. A decision in favor of amatch would be made when the total systemresponse (i.e., the denominator of the samplingfraction) exceeds some criterion.
This brief discussion of category learningis meant to provide an example of the type ofgeneralization that may be possible for thepresent model. Such generalizations are leftfor future research.
References
Allen, L. R., & Carton, R. F. (1968). The influence ofword-knowledge on the word-frequency effect in rec-ognition memory. Psychonomic Science, 10, 401-402.
Anderson, J. A. (1973). A theory for the recognition of
items from short memorized lists. Psychological Review,80, 417-438.
Anderson, J. R. (1972). FRAN: A simulation model offree recall. In G. H. Bower (Ed.), The Psychology ofLearning and Motivation (Vol. 5). New York: AcademicPress.
Anderson, J. R. (1976). Language, memory, & thought.Hillsdale, NJ: Erlbaum.
Anderson, J. R., & Bower, G. H. (1972). Recognition andretrieval processes in free recall. Psychological Review,79, 97-123.
Anderson, J. R., & Bower, G. H. (1974). A prepositionaltheory of recognition memory. Memory and Cognition,2, 406-412.
Anisfeld, M., & Knapp, M. (1968). Association, syn-onymity and directionality in false recognition. Journalof Experimental Psychology, 77, 171-179.
Antognini, J. (1975). The role of extralist associate cuesin retrieval from memory. Unpublished doctoral dis-sertation, Yale University.
Atkinson, R. C, Herrmann, D. J., & Wescourt, K. T.(1974). Search processes in recognition memory. InR. L. Solso (Ed.), Theories in cognitive psychology: TheLoyola symposium. Hillsdale, NJ: Erlbaum.
Atkinson, R. C., & Juola, J. F. (1973). Factors influencingspeed and accuracy of word recognition. In S. Kornblum(Ed.), Attention and performance (Vol. 4). New York:Academic Press.
Atkinson, R. C., & Juola, J. F. (1974). Search and decisionprocesses in recognition memory. In D. H. Krantz,R. C. Atkinson, R. D. Luce, & P. Suppes (Eds.), Con-temporary developments in mathematical psychology(Vol. 1): Learning, memory, & thinking. San Francisco:Freeman.
Atkinson, R. C., & Shiffrin, R. M., (1968). Human mem-ory: A proposed system and its control processes. InK. W. Spence & J. T. Spence (Eds.), The psychology oflearning and motivation: Advances in research and theory(Vol. 2). New York: Academic Press.
Atkinson, R. C., & Wescourt, K. T. (1975). Some remarkson a theory of memory. In P. M. A. Rabbitt & S. Domic(Eds.), Attention and performance (Vol. 5). London: Ac-ademic Press.
Balota, D. A., & Neely, J. H. (1980). Test-expectancy andword-frequency effects in recall and recognition. Journalof Experimental Psychology: Human Learning andMemory, 6, 576-587.
Birnbaum, I. M., & Parker, E. S. (Eds.) (1977). Alcoholand human memory. Hillsdale, NJ: Erlbaum. (1977).
Bower, G. H. (1972). Stimulus-sampling theory of encodingvariability. In A. W. Melton & E. Martin (Eds.), Codingprocesses in human memory. Washington, DC: Winston.
Buschke, H., & Lenon, R. (1969). Encoding homophonesand synonyms for verbal discrimination and recognition.Psychonomic Science, 14, 269-270.
Cavanagh, P. (1976). Holographic and trace strength modelsof rehearsal effects in the item recognition task. Memoryand Cognition, 4, 186-199.
Cermak, G., Schnorr, J., Buschke, H., & Atkinson, R. C.(1970). Recognition memory as influenced by differ-ential attention to semantic and acoustic properties ofwords. Psychonomic Science, 19, 79-81.
Corbett, A. T. Retrieval dynamics for rote and visual imagemnemonics. (1977). Journal of Verbal Learning andVerbal Behavior, 16, 233-246.

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 61
Cramer, P., & Eagle, M. (1972). Relationship between con-ditions of CrS presentation and the category of falserecognition errors. Journal of Experimental Psychology,94, 1-5.
Davies, G., & Cubbage, A. (1976). Attribute coding atdifferent levels of processing. Quarterly Journal of Ex-perimental Psychology, 28, 653-660.
Deese, J. (1960). Frequency of usage and number of wordsin free recall: The role of association. Psychological Re-ports, 7, 337-344.
Dosher, B. A. (1981). The effects of delay and interference:A speed-accuracy study. Cognitive Psychology, 13,551-582.
Duncan, C. P. (1974). Retrieval of low-frequency wordsfrom mixed lists. Bulletin of the Psychonomic Society,4, 137-138.
Eagle, M., & Leiter, E. (1964). Recall and recognition inintentional and incidental learning. Journal of Exper-imental Psychology, 68, 58-63.
Eagle, M., & Ortof, E. (1967). The effect of level of attentionupon "phonetic" recognition errors. Journal of VerbalLearning and Verbal Behavior, 6, 226-231.
Earhard, B. (1982). Determinants of the word-frequencyeffect in recognition memory. Memory and Cognition,10, 115-124.
Eich, J. E. (1980). The cue-dependent nature of state-dependent retrieval. Memory and Cognition, 8, 157-173.
Eich, J. M. (1982). A composite holographic associativerecall model. Psychological Review, 89, 627-661.'
Elias, C. S., & Perfetti, C. A. (1973). Encoding task andrecognition memory: The importance of semantic en-coding. Journal of Experimental Psychology, 99, 151-156.
Estes, W. K., & DaPolito, F. (1967). Independent variationof information storage and retrieval processes in paired-associate learning. Journal of Experimental Psychology,75, 18-26.
Fischler, I., & Juola, J. F. (1971). Effects of repeated testson recognition time for information in long-term mem-ory. Journal of Experimental Psychology, 91, 54-58.
Carton, R. F., & Allen, L. R. (1968). Familiarity and wordrecognition. Quarterly Journal of Experimental Psy-chology, 20, 385-389.
Gillund, G., & Shiffrin, R. M. (1981). Free recall of com-plex pictures and abstract words. Journal of VerbalLearning and Verbal Behavior, 20, 575-592.
Glanzer, M., & Bowles, N. (1976). Analysis of the wordfrequency effect in recognition memory. Journal of Ex-perimental Psychology: Human Learning and Memory,2, 21-31.
Glenberg, A., & Adams, F. (1978). Type I rehearsal andrecognition. Journal of Verbal Learning and Verbal Be-havior, 17, 455-463.
Glenberg, A., Smith, S. M., & Green, C. (1977). Type 1rehearsal: Maintenance and more. Journal of VerbalLearning and Verbal Behavior, 16, 339-352.
Glucksberg, S., & McCloskey, M. (1981). Decisions aboutignorance: Knowing that you don't know. Journal ofExperimental Psychology: Human Learning and Mem-ory, 7, 311-325.
Godden, D. R., & Baddeley, A. D. (1975). Context-de-pendent memory in two natural environments: On landand under water. British Journal of Psychology, 66, 325-331.
Godden, D. R., & Baddeley, A. D. (1980). When doescontext influence recognition memory? British Journalof Psychology, 71, 99-104.
Gorman, A. M. (1961). Recognition memory for nounsas a function of abstractness and frequency. Journal ofExperimental Psychology, 61, 23-29.
Gregg, V. H. (1976). Word frequency, recognition andrecall. In J. Brown (Ed.), Recall and recognition. London:Wiley.
Gregg, V. H., Montgomery, D. C., & Castano, D. (1980).Recall of common and uncommon words from pureand mixed lists. Journal of Verbal Learning and VerbalBehavior, 19, 240-245.
Grossman, L., & Eagle, M. (1970). Synonymity, anto-nymity, and association in false recognition responses.Journal of Experimental Psychology, 83, 244-248.
Hall, J. F. (1954). Learning as a function of word-frequency.American Journal of Psychology, 67, 138-140.
Hall, J, F. (1979). Recognition as a function of word fre-quency. American Journal of Psychology, 92, 497-505.
Hall, J. W, Grossman, L. R., & Elwood, K. D. (1976).Differences in encoding for free recall vs. recognition.Memory and Cognition, 4, 507-513.
Herrmann, D., Frisina, R. D., & Conti, G. (1978). Cat-egorization and familiarity in recognition involving awell-memorized list. Journal of Experimental Psychol-ogy: Human Learning and Memory, 4, 428-440.
Herrmann, D. G., McLaughlin, J. P., & Nelson. B. C.(1975). Visual and semantic factors in recognition fromlong-term memory. Memory and Cognition, 3, 381-384.
Hintzman, D. L. (1974). Theoretical implications of thespacing effect. In R. L. Solso (Ed.), Theories in cognitivepsychology: The Loyola symposium. Hillsdale, N.J.:Erlbaum.
Hintzman, D. L., Block, R. A., & Summers, J. J. (1973).Modality tags and memory for repetitions: Locus of thespacing effect. Journal of Verbal Learning and VerbalBehavior. 12, 229-238.
Hockley, W. E. (1982). Retrieval processes in continuousrecognition. Journal of Experimental Psychology:Learning, Memory, and Cognition, 8, 497-512.
Homa, D. (1973). Organization and long-term memorysearch. Memory and Cognition, 3, 369-379.
Homa, D., Sterling, S., & Trepel, L. (1981). Limitationsof exemplar-based generalization and the abstraction ofcategorized information. Journal of Experimental Psy-chology: Human Learning and Memory, 7, 418-439.
Humphreys, M. S. (1976). Relational information and thecontext effect in recognition memory. Memory andCognition, 4, 221-232.
Humphreys, M. S. (1978). Item and relational information:A case for context independent retrieval. Journal ofVerbal Learning and Verbal Behavior, 17, 175-187.
Humphreys, M. S., & Bain, J. D. (in press). Recognitionmemory: A cue and information analysis. Memory andCognition.
Jacoby, L. L., & Dallas, M. (1981). On the relationshipbetween autobiographical memory and perceptuallearning. Journal of Experimental Psychology: General,3, 306-340.
Juola, J. F., Fischler, I., Wood, C. T., & Atkinson, R. C.(1971). Recognition time for information stored in long-term memory. Perception & Psychophysics, 10, 8-14.
Kintsch, W. (1968). Recognition and free recall of organizedlists. Journal of Experimental Psychology, 78, 481-487.

62 GARY GILLUND AND RICHARD M. SHIFFRIN
Kintsch, W. (1970). Models for free recall and recognition.In D. A. Norman (Eds.), Models of human memory.New York: Academic Press.
Kintsch, W. (1974). The representation of meaning inmemory. Hillsdale, NJ: Erlbaum.
Light, L. L., & Carter-Sobell, L. (1970). Effects of changedsemantic context on recognition memory. Journal ofVerbal Learning and Verbal Behavior, 9, 1-11.
Link, S. W. (1975). The relative judgment theory of twochoice response time. Journal of Mathematical Psy-chology, 12, 114-135.
Luce, R. D. (1959). Individual choice behavior: A theo-retical analysis. New York: Wiley.
Maclcod, C. M., & Nelson, T. O. (1976). A nonmonotoniclag function for false alarms to associates. AmericanJournal of Psychology, 89, 127-135.
Madigan, S. A. (1969). Intrascrial repetition and codingprocesses in free recall. Journal of Verbal Learning andVerbal Behavior, 8, 828-835.
Mandler, G. (1972). Organization and recognition. In E.Tulving & W. Donaldson (Eds.), Organization of mem-ory. New York: Academic Press.
Mandler, G. (1980). Recognizing: The judgment of previousoccurrence. Psychological Review, 87, 252-271.
Mandler, G., & Bocck, W. (1974). Retrieval processes inrecognition. Memory and Cognition, 2, 613-615.
Mandler, G., Goodman, G. O., & Wilkes-Gibbs, D. L.(1982). The word-frequency paradox in recognition.Memory and Cognition, 10, 33-42.
Mandler, G., Pearlstone, Z., & Koopmans, H. J. (1969).Effects of organization and semantic similarity on recalland recognition. Journal of Verbal Learning and VerbalBehavior, 8, 410-423.
Mandler, G., Rabinowitz, J. C., & Simon, R. A. (1981).Coordinate organization: The holistic representation ofword pairs. American Journal of Psychology, 94, 209-222.
May, R. B., & Tryk, H. E. (1970). Word sequence, wordfrequency, and free recall. Canadian Journal of Psy-chology, 24, 299-304.
McCormack, P. D., & Swenson, A. L. (1972). Recognitionmemory for common and rare words. Journal of Ex-perimental Psychology, 95, 72-77.
McNicol, D., & Stewart, G. W. (1980). Reaction time andthe study of memory. In A. T. Welford (Ed.), Reaetiontimes. London: Academic Press.
Medin, D. L., Busemeyer, J. R., & Dewey, G. I. (in press).Evaluation of exemplar-based generalization and theabstraction of categorical information. Journal of Ex-perimental Psychology: Learning, Memory, and Cog-nition.
Medin, D. L., & Schaffer, M. M. (1978). Context theoryof classification learning. Psychological Review, 85, 207-238.
Mclcalfe, J., & Murdock, B. B., Jr. (1981). An encodingand retrieval model of single-trial free recall. Journalof Verbal Learning and Verbal Behavior, 20, 161-189.
Murdock, B. B., Jr. (1962). The serial position effect infree recall. Journal oj Experimental Psychology, 64, 482-488.
Murdock, B. B., Jr. (1974). Human memory: Theory anddata. Potomac, MD: Erlbaum.
Murdock, B. B., Jr. (1982). A theory for the storage andretrieval of item and associative information. Psycho-logical Review, 89, 609-626.
Murdock, B. B., Jr., & Anderson, R. E. (1975). Encoding,storage and retrieval of item information. In R. L. Solso(Ed.), Information processing and cognition: The Loyolasymposium. Hillsdale, NJ: Erlbaum.
Murdock, B. B., Jr., & Dufty, P. O. (1972). Strength theoryand recognition memory. Journal of Experimental Psy-chology, 94, 284-290.
Muter, P. (in press). Recognition and recall of words witha single meaning. Journal of Experimental Psychology:Learning, Memory, and Cognition.
Nairnc, J. S. (1983). Associative processing during roterehearsal. Journal of Experimental Psychology: Learning,Memory, and Cognition, 9, 3-20.
Neely, J. H., & Balota, D. A. (1981). Test expectancy andsemantic organization effects in recall and recognition.Memory and Cognition, 9, 283-306.
Neely, J. H., Schmidt, S. R., & Roediger, H. L. III. (1983).Inhibition from related primes in recognition memory.Journal of Experimental Psychology: Learning, Memory,and Cognition, 9, 196-211.
Nelson, D. L., & Davis, M. J. (1972). Transfer and falserecognitions based on phonetic identities of words.Journal of Experimental Psychology, 92, 347-353.
Norman, D. A., & Wickelgren, W. A. (1969). Strengththeory of decision rules and latency in short-term mem-ory. Journal of Mathematical Psychology, 6, 192-208.
Okada, R., & Burrows, D. (1973). Organizational factorsin high-speed scanning. Journal of Experimental Psy-chology, 101, 77-81.
Pachella, R. G. (1974). An interpretation of reaction timein information processing research. In B. Kantowitz(Ed.), Human information processing: Tutorials in per-formance and cognition. Hillsdale, NJ: Erlbaum.
Pike, R. (1973). Response latency models for signal de-tection. Psychological Review, 80, 53-68.
Pike, R., Dalglcish, L., & Wright, J. (1977). A multiple-observations model for response latency and the latenciesof correct and incorrect responses in recognition mem-ory. Memory and Cognition, 5, 580-589.
Raaijmakers, J. G. W., & Shiflrin, R. M. (1980). SAM:A theory of probabilistic search of associative memory.In G. H. Bower (Ed.), The psychology of learning andmotivation (Vol. 14). New York: Academic Press.
Raaijmakers, J. G. W., & Shifrrin, R. M. (1981a). Ordereffects in recall. In A. Long & A. Baddeley (Eds.), At-tention and performance(Vol. 9). Hillsdale, NJ: Erlbaum.
Raaijmakers, J. G. W., & Shiffrin, R. M. (198Ib). Searchof Associative Memory. Psychological Review, 88, 93-134.
Rabinowitz, J. C. (1978). Recognition retrieval processes:The function of category size. Unpublished doctoraldissertation, University of California, San Diego.
Rabinowitz, J. C, Mandler, G., & Barsalou, L. W. (1977).Recognition failure: Another case of retrieval failure.Journal of Verbal Learning and Verbal Behavior, 16,639-663.
Rabinowitz, J. C., Mandler, G., & Patterson, K. E. (1977).Determinants of recognition and recall: Accessibilityand generation. Journal of Experimental Psychology:General, 106, 302-329.
Rao, K. V. (1983). The word frequency effect in situationalfrequency estimation. Journal of Experimental Psy-chology: Leaning, Memory, and Cognition, 9, 73-81.
Ratcliff, R. (1978). A theory of memory retrieval. Psy-chological Review, 85, 59-108.

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 63
Ratcliff, R., & Murdock, B. B., Jr. (1976). Retrieval Pro-cesses in recognition memory. Psychological Review, 83,190-214.
Reder, L. M, Anderson, J. R., & Bjork, R. A. (1974). Asemantic interpretation of encoding specificity. Journalof Experimental Psychology, 107, 648-656.
Reed, A. V. (1973). Speed-accuracy trade-offin recognitionmemory. Science, 181, 574-576.
Reed, A. V. (1976). List length and the time course ofrecognition in immediate memory. Memory and Cog-nition, 4, 16-30.
Roberts, W. A. (1972). Free recall of word lists varyingin length and rate of presentation: A test of total-timehypotheses. Journal of Experimental Psychology, 92,365-372.
Rundus, D. (1973). Negative effects of using list items asrecall cues. Journal of Verbal Learning and Verbal Be-havior, 12, 43-50.
Salzburg, P. M. (1976). On the generality of encodingspecificity. Journal of Experimental Psychology: HumanLearning and Memory, 2, 586-596.
Schulman, A. I. (1967). Word length and rarity in rec-ognition memory. Psychonomic Science, 9, 211-212.
Schulman, A. I. (1976). Memory for rare words previouslyrated for familiarity. Journal of Experimental Psychol-ogy: Human Learning and Memory, 2, 301-307.
Schulman, A. I., & Lovelace, E. A. (1970) Recognitionmemory for words presented at a slow or rapid rate.Psychonomic Science, 21, 99-100.
Shepard, R. N. (1967). Recognition memory for words,sentences, and pictures. Journal of verbal Learning andVerbal Behavior, 6, 156-163.
Shim-in, R. M. (1970). Memory search. In D. A. Norman(Ed.), Models of human memory. New York: AcademicPress.
Shiffrin, R. M., & Schneider, W. (1977). Controlled andautomatic human information processing: 2. Perceptuallearning, automatic attending, and a general theory.Psychological Review, 84, 127-190.
Smith, S. M., Glenberg, A., & Bjork, R. A. (1978). En-vironmental context and human memory. Memory &Cognition, 6, 342-353.
Strong, E. K., Jr. (1912). The effect of length of seriesupon recognition memory. Psychological Review, 19,447-462.
Strong, E. K., Jr. (1913). The effect of time-interval uponrecognition memory. Psychological Review, 20, 339-372.
Sumby, W. H. (1963). Word frequency and serial positioneffects. Journal of Verbal Learning and Verbal Behavior,1, 443-450.
Thorndike, E. L., & Lorge, I. (1944). The teacher's wordbook of 30,000 words. New York: Columbia UniversityPress.
Todres, A. K., & Watkins, M. J. (1981). A part-set cuingeffect in recognition memory. Journal of ExperimentalPsychology: Human Learning and Memory, 7, 91-99.
Townsend, J. T. (1971). A note on the identifiability ofparallel and serial processes. Perception & Psychophysics,W, 161-163.
Tulving, E. (1968). When is recall higher than recognition?Psychonomic Science, 10, 53-54.
Tulving, E. (1974). Cue-dependent forgetting. AmericanScientist, 62, 74-82.
Tulving, E. (1976). Ecphoric processes in recall and rec-ognition. In J. Brown (Ed.), Recall and Recognition.London: Wiley.
Tulving, E. (1982a). Elements of episodic memory. Oxford:Oxford University Press.
Tulving, E. (1982b). Synergistic ecphory in recall and rec-ognition. Canadian Journal of Psychology, 36, 130-147.
Tulving, E,, & Thomson, D. M. (1971). Retrieval processesin recognition memory: Effects of associative context.Journal of Experimental Psychology, 87, 175-184.
Tulving, E., & Thomson, D. M. (1973). Encoding specificityand retrieval processes in episodic memory. Psycholog-ical Review, 80, 352-373.
Tulving, E., & Watkins, M. J. (1973). Continuity betweenrecall and recognition. American Journal of Psychology,86, 739-748.
Tulving, E., & Watkins, M. J. (1975). Structure of memorytraces. Psychological Review, 82, 261-275.
Tversky, B. (1973). Encoding processes in recognition andrecall. Cognitive Psychology, 5, 275-287.
Underwood, B. J. (1957). Interference and forgetting. Psy-chological Review, 64, 49-60.
Underwood, B. J., & Freund, J. S. (1968). Errors in rec-ognition learning and retention. Journal of ExperimentalPsychology, 78, 55-63.
Wallace, W. P., Sawyer, T. J., & Robertson, L. C, (1978).Distractors in recall, distraetor free recognition, and theword frequency effect. American Journal of Psychology,91, 295-304.
Walter, D. A. (1977). Discrete events in word encoding:The locus of elaboration. American Journal of Psy-chology, 90, 655-662.
Watkins, M. J., & Tulving, E. (1975). Episodic memory:When recognition fails. Journal of Experimental Psy-chology: General, 1, 5-29.
Wickelgren, W. A. (1977). Speed-accuracy tradeoff andinformation processing dynamics. Acta Psychologica,41, 67-85.
Wickelgren, W. A., & Corbett, A. T. (1977). Associativeinterference and retrieval dynamics in yes-no recall andrecognition. Journal of Experimental Psychology: Hu-man Learning and Memory, 3, 189-202.
Winograd, E., & Conn, C. P. (1971). Evidence from rec-ognition memory for specific encoding of unmodifiedhomographs. Journal of Verbal Learning and Verbal Be-havior, 10, 702-706.
Wiseman, S., & Tulving, E. (1975). A test of confusiontheory of encoding specificity. Journal of Verbal Learningand Verbal Behavior, 14, 370-381.
Woodward, A. E., Bjork, R. A., & Jongeward, R. H., Jr.(1973). Recall and recognition as a function of primaryrehearsal. Journal of Verbal Learning and Verbal Be-havior, 12, 608-612.
Zacks, R. T., Hasher, L., & Sanft, H. (1982). Automaticencoding of event frequency: Further findings. Journalof Experimental Psychology: Learning, Memory, andCognition, 8, 106-116.
Zechmeister, E. B., Curt, C., & Sebastian, J. A. (1978).Errors in a recognition memory task are U-shapedfunction of word-frequency. Bulletin of the PsychonomicSociety, 11, 371-373.
(Appendixes follow on next page)

64 GARY GILLUND AND RICHARD M. SHIFFRIN
Appendix A
Table A-lMeans, Criteria, Hit Rates, and False Alarm Rates for the Simulations in Sections 2 and 3
Variable
Parametera = 0.20
0.250.30
b = 0.100.200.30
c = 0.100.150.20
d = 0.0500.0750.100
v = 0.250.500.75
List length10203040
Targetmean
1.0641.3301.596
1.0331.3301.627
1.2701.3301.391
1.1451.3301.515
1.3291.3301.331
0.9971.3301.6862.067
Distractor mean
Figure 10
0.6470.8080.970
0.8080.8080.808
0.8080.8080.808
0.5390.8081.078
0.8070.8080.810
Figure 12
0.4350.8081.1761.560
Criterion
0.7790.9731.168
0.8380.9731.108
0.9460.9731.001
0.7660.9731.180
0.9720.9730.974
0.6510.9731.3021.650
Hit rate
.942
.942
.942
.861
.942
.958
.937
.942
.945
.962
.942
.915
.997
.942
.830
.916
.942
.954
.965
False alarmrate
.077
.077
.077
.385
.077
.007
.114
.077
.050
.003
.077
.244
.003
.077
.176
.007
.077
.171
.264
Figure 13 (LL = 30)
Time1 s2 s3s
Parametera = 0.23
0.250.27
Parameterb - 0.10
0.150.20
Parameterb = 0.20
0.160.12
0.6521.6863.102
c = 0.10 1.1680.15 1.3300.20 1.502
c = 0.51 1.4700.33 1.4000.15 1.330
c = 0.15 1.3300.12 1.1750.09 1.020
0.5881.1761.763
Figure 14
0.7430.8080.872
Figure 15
0.8080.8080.808
Figure 16
0.8080.8080.808
0.5641.3022.214
0.8690.9731.080
1.0361.0040.973
0.9730.9020.831
.864
.954
.975
.937
.942
.943
.848
.913
.942
.942
.921
.874
.634,171.014
.122
.077
.051
.026
.047
.077
.077
.205
.400

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 65
Table A-l (continued)
Variable
Parametera = 0.25
0.200.15
Parameter and junka = 0.25; 0
0.20; 100.1 5; 20
Parameter and junka = 0.25; 0
1020
a = 0.20; 01020
a = 0.15; 01020
Test block1234
ParameterIndividual d = 0.075
0.1000.125
Overall d = 0.0750.1000.125
Parameters b and d6H = 0.2; rfH = 0.075AL = 0.1;<4 = 0.035
Parameters b and dba = 0.2; rfH = 0-075bi. = 0.1; 4 = 0.035
Target mean
1.3301.0640.798
1.3301.4881.639
.330
.7552.170.064.488.904
0.798.222.639
1.5951.9792.3482.726
1.3301.3301.3301.3301.5151.700
Figure 23 \
1.6860.897
Figure 24
1.6860.897
Distractor mean
Figure 17
0.8080.6470.485
Figure 18
0.8081.0691.325
Figure 19
0.8081.2301.6470.6471.0691.4860.4850.9071.325
Figure 20
1.0111.3851.7602.133
Figure 22
0.8080.8220.8350.8081.0781.347
Jniform lists (LL = 30)
1.1760.549
Mixed lists (LL = 30)
1.1760.549
Criterion
0.9730.7790.584
0.9731.1631.348
0.9731.3581.7370.7791.1631.5430.5840.9691.348
1.1861.5311.8692.211
0.9730.9790.9850.9731.1801.387
1.3020.658
1.3020.658
Hit rate
.942
.942
.942
.942
.951
.948
.942
.952
.956
.942
.951
.954
.942
.947
.948
.953
.961
.965
.973
.942
.937
.934
.942
.915
.878
.954
.963
.954
.963
False alarmrate
.077
.077
.077
.077
.216
.424
.077
.179
.290
.077
.216
.350
.077
.278
.424
.081
.157
.242
.314
.077
.089
.104
.077
.244
.405
.171
.043
.171
.043
Note. Except as noted, the predictions shown are based on a list of 20 items presented at 2 s/item with the followingparameters: a - 0.25; b = 0.20; c = 0.15; d = 0.075; r = 4; v = 0.5. In each case the criterion equals the sum of thetarget and distractor means multiplied by 0.455. LL = list length.

66 GARY GILLUND AND RICHARD M. SHIFFRIN
Appendix B
Method and Procedures for an Experiment on Word Frequency and Test Type
Subjects
Subjects were 80 undergraduates from IndianaUniversity.
Materials
We selected from the Thorndike and Lorge (1944)general count, 520 HF (A or AA) and 520 LF (1-4 per million) words of between five and eight lettersin length. All stimulus generation and presentationand response collection were controlled by a PDF11/34 computer.
Design
The experiment consisted of 10 experimentaltrials, 2 trials of each type of memory test. Eachtrial contained a study list, an addition task (toclear the STS), and a memory test.
Each experimental study list consisted of 16 pairsof words. Four of each of the following combinationof words formed the pairs: HF-HF, HF-LF, LF-HF, and LF-LF. The order of presentation of thepairs was randomized for each study list.
Two recall tests and three recognition tests wereused. During the free-recall tests subjects were givena blank piece of paper and asked to write down allthe words they could remember from the previousstudy list. They were asked to write down wordstogether (on the same line) that had been presentedtogether, if they were able to do so. For the cued-recall test one word from each pair was selected tobe a cue. The subjects were asked to provide thepaired member as a response. One half of the cueswere HF words and the other half were LF words.One half of the HF cues were originally presentedin the study list as the first member of a pair, andthe other half were originally presented as the secondmember of a pair. The same selection was used forthe LF words. The order of presentation of the cueswas randomized, and the entire test list was printedon a sheet of paper for each subject.
The single-recognition test was composed of 32words. One word from each of the study pairs wasselected to form the 16 targets. Eight of the targetswere HF words, eight were LF words, eight (fourHF and four LF) words were originally presentedas the first member of a pair, and eight were orig-inally presented as the second member of a pair.In addition, eight HF words and eight LF wordsthat were never presented to that subject as studyitems were selected from the master lists to be used
as the 16 distractors. The ordering of the 32 wordswithin the test list was randomized.
The paired-recognition test was composed of 32pairs of words. Sixteen of the pairs were the original16 target pairs. The remaining pairs were neverpresented items paired as distractors. The sixteendistractor pairs were of the same frequency com-bination as the targets. The ordering of the targetand distractor pairs was randomized.
The cued-recognition test was composed of 16pairs of items. One member of each pair was des-ignated as a cue by placing an asterisk to the leftof the first member of a pair or to the right of thesecond member of a pair. Each cue was selectedfrom the study list in the same fashion that the cueswere chosen in the cued-recall task. The 16 lestitems were made up of eight targets and eight dis-tractors. Each target was paired with the cue thathad been presented with the target on the study list.One half of the targets were HF and one half, LF.For each cue-distractor combination, a HF or a LFword that had never been presented during studywas chosen at random to serve as the distractor.
Every group of four subjects received a differenttest order and a different ordering of words withina trial. Thus there were 20 different orders used inthe experiment.
Between the presentation list and the test list, anarithmetic test was given. Each arithmetic test con-sisted of the mental addition of seven single-digitnumbers, presented one at a time for 2 s each.
Procedure
Subjects were told that they would be presentedwith a series of words to study and that they wouldlater be tested. They were told that the words wouldbe presented in pairs and that they should try toassociate the pairs together using a mnemonic ofsome type. Subjects then had the procedure foreach type of test explained to them and were givenpractice trials for each type of test.
Each trial was initiated with the words GET READYprinted on the screen for 2.5 s followed by 16 pairsof words presented for 4 s each. There were 100ms of blank time between each presentation. Im-mediately after the last pair of words was presented,a series of single digits was presented to the screen,one digit at a time. Seven digits were presented for2 s each. There were 100 ms of blank time betweenthe end of one digit and the beginning of the nextdigit. After all digits were presented, WRITE THE

RETRIEVAL MODEL FOR RECOGNITION AND RECALL 67
SUM ON THE ANSWER SHEET was presented on thescreen. Subjects were then given 5 s to write theirsum on an answer booklet. The type of test thesubjects were about to receive was then indicatedon the screen and remained there for 5 s. For thefree- and cued-recall tests, subjects were given 1.5min to complete the task.
For each of the recognition tasks the single word(for the single-recognition task) or the pair of words(for the paired-recognition and the cued-recognition
tasks) was presented on the screen for 2.5 s. Foreach type of test the subjects were to respond yeson the keyboard if the test item had been studiedand no if the test item had not been studied. Subjectswere told to respond as quickly as possible withoutsacrificing accuracy, and response times were col-lected. One half of the subjects responded yes withtheir left hands and no with their right hands,whereas for the remaining subjects the order of re-sponding was reversed.
Appendix C
Statistical Analyses of the Recall-Recognition Study
A series of analyses of variance (ANOVAS) wascarried out that confirm the observations given inthe text. A separate ANOVA was completed for eachtype of test. A 2 X 2 (Frequency, HF or LF, X PairType, same or different frequency) analysis was car-ried out on the number of items correctly recalledon the cued and free-recall results, separately. Nei-ther the pair type nor the frequency main effectsnor their interaction (in all cases p > . 1) was sig-nificant. An additional ANOVA was done on the arc-sin transformations of the proportion of words cor-rectly recalled, combining the cued- and free-recalltests. The 2 X 2 X 2 (Frequency X Test X PairType) analyses revealed only one significant factor,namely test type. That is, cued-recall performancewas better than free-recall performance.
A 2 X 2 (Frequency X Pair Type) ANOVA wascompleted for the single-recognition results and onlythe main effect of frequency was significant, F( 1,79) = 100.53, p < .001. A similar analysis for thecued-recognition test showed that again only thefrequency effect was significant, F(\, 79) = 15.52,p < .001.
For the paired-recognition test a simple one-wayANOVA was completed with three levels of frequency(high, mixed, low). This was done because the HF-LF and LF-HF pairs are indistinguishable with re-gard to pair type. Therefore, they were combinedinto a single mixed-frequency point. The ANOVAagain showed that the frequency effect was signif-icant, F ( l , 79) = 15.43, p < .001.
Matched-group / tests were carried out on thedifferent types of tests to compare their overall levelof performance. As expected, the paired-test per-formance was better than the single-test perfor-mance, / (78) = 3.18, p < .005. Because of thevariability in the cued tests, the single-recognitionperformance was not significantly better than thecued-recognition performance (t = .869). We havechosen, however, to fit this difference in means be-cause the results have a logical explanation in ourmodel.
Received October 4, 1982Revision received July 29, 1983 •


















