
Proteomic Profiling of the Planarian Schmidtea mediterranea and its
66
Proteomic Profiling of the Planarian Schmidtea mediterranea and its mucous reveals similarities with human secretions and those predicted for parasitic flatworms by Donald Gerald Bocchinfuso A thesis submitted in conformity with the requirements for the degree of Master of Science Department of Molecular Genetics University of Toronto © Copyright by Donald Gerald Bocchinfuso 2012
Transcript of Proteomic Profiling of the Planarian Schmidtea mediterranea and its

Proteomic Profiling of the Planarian Schmidtea mediterranea and its mucous reveals similarities with
human secretions and those predicted for parasitic flatworms
by
Donald Gerald Bocchinfuso
A thesis submitted in conformity with the requirements for the degree of Master of Science
Department of Molecular Genetics University of Toronto
© Copyright by Donald Gerald Bocchinfuso 2012

ii
Proteomic Profiling of the Planarian Schmidtea mediterranea and
its mucous reveals similarities with human secretions and those
predicted for parasitic flatworms
Donald Gerald Bocchinfuso
Master of Science
Department of Molecular Genetics University of Toronto
2012
Abstract
The freshwater planarian Schmidtea mediterranea has been used in research for over 100 years,
and is an emerging stem cell model. Exteriorly, planarians are covered in mucous secretions of
unknown composition. While the planarian genome has been sequenced, it remains mostly
unannotated. The goal my master’s research was to annotate the planarian proteome and mucous
sub-proteome. Using a proteogenomics approach, I elucidated the proteome and mucous sub-
proteome via mass spectrometry together with an in silico translated transcript database. I
identified 1604 proteins, which were annotated using the Swiss-Prot BLAST algorithm and Gene
Ontology analysis. The S. mediterranea proteome is highly similar to that predicted for the
trematode Schistosoma mansoni associated with schistosomiasis. Remarkably, orthologs of 119
planarian mucous proteins are present in human mucosal secretions and tear fluid. I suggest
planarians have potential to be a model system for parasitic worms and diseases underlined by
mucous aberrancies.

iii
Acknowledgments
Throughout my master’s tenure, I have had the privilege of working with and learning from
gifted and inspiring scientists, all of whom have contributed invaluably to my graduate training.
Primarily, I would like to thank my supervisor Dr. Michael Moran for providing me with the
opportunity to study in his laboratory. I am immensely grateful for his great patience and
leadership, under which I have significantly grown and progressed as a scientist.
Moreover, I would also like to thank all my fellow Moran lab members whose positive attitudes
made me look forward to each and every day in the lab. I am especially thankful to Dr. Jiefei
Tong and Mr. Paul Taylor, for without their help and expertise I would not have been able to
successfully complete my graduate project. As well, I would like to acknowledge Mr. Eric Ross
whose work greatly enhanced the breadth and relevance of my study, proving imperative in its
publication. To my supervisory committee members, Drs. Lori Frappier and Bret Pearson, your
guidance and insights were vital in directing my work and graduate training.
Finally, I am forever indebted to my family and friends for all of their love and support, and
without whom I could not have earned my master’s degree. I would like to thank all my
classmates at the University of Toronto who greatly enriched my experience as a graduate
student and who were a constant source of camaraderie and exuberance. I thank my close friends,
in particular my girlfriend Rachel who have unconditionally supported me throughout my
master’s tenure and in all my endeavors. Last but not least, to my beloved parents Paul and
Wendy, thank-you for everything; your continued motivation and encouragement have always
driven me to strive for the best.
Donald G. Bocchinfuso
June 2012, Toronto, ON.

iv
Table of Contents
Acknowledgments.......................................................................................................................... iii
Table of Contents ........................................................................................................................... iv
List of Tables ................................................................................................................................. vi
List of Figures ............................................................................................................................... vii
List of Appendices ....................................................................................................................... viii
List of Abbreviations ..................................................................................................................... ix
Chapter 1 Introduction .................................................................................................................... 1
1 Introduction ................................................................................................................................ 1
1.1 Proteomic Profiling of Model Organisms........................................................................... 1
1.2 Planarian Biology and Contemporary Planarian Research ................................................. 2
1.3 Experimental Challenges in Planarian Research – The Need for an Annotated Planarian Profile.................................................................................................................. 3
1.4 Overview of Protein Mass Spectrometry............................................................................ 5
1.5 Analyzing Mass Spectrometry Data ................................................................................... 7
1.6 Annotating Mass Spectrometry Data .................................................................................. 8
1.7 Transcriptomic Database Creation using Modern Sequencing Technologies .................... 9
1.8 Developing Planarians as a Model Organism................................................................... 10
1.9 Planarian Mucous and its Potential as a Mucous Model .................................................. 11
1.10 Proteomic Mucous Profiling using Mass Spectrometry ................................................... 12
1.11 Outline and Rationale for Thesis Research....................................................................... 13
Chapter 2 Materials and Methods ................................................................................................. 16
2 Materials and Methods............................................................................................................. 16
2.1 Preparation of Worm Lysates ........................................................................................... 16
2.2 Liquid Chromatography and Mass Spectrometry Analysis .............................................. 17
2.3 Database Creation ............................................................................................................. 18

v
2.4 Criteria for Peptide and Protein Identification and Protein Grouping .............................. 18
2.5 Gene Ontology Analysis ................................................................................................... 19
Chapter 3 Results .......................................................................................................................... 20
3 Results ...................................................................................................................................... 20
3.1 Mass Spectrometry Analysis............................................................................................. 20
3.2 Annotating Identified Proteins.......................................................................................... 22
3.3 Comparing Planarian Proteins to Published Proteomes.................................................... 25
3.4 Gene Ontology Annotation ............................................................................................... 30
Chapter 4 Discussion and Conclusions......................................................................................... 33
4 Discussion and Conclusions..................................................................................................... 33
4.1 Analyzing Mass Spectrometry Data ................................................................................. 33
4.2 Interpreting Mass Spectrometry Analyses ........................................................................ 34
4.3 Examining Protein Annotations........................................................................................ 35
4.4 Planarian Mucous as a Disease Model.............................................................................. 36
4.5 Planarians as a Model to Study Parasitic Worms ............................................................. 37
4.6 Conclusions and Future Directions ................................................................................... 39
Bibliography ................................................................................................................................. 41

vi
List of Tables
Table 1: Mucous Protein Overlap……………………………………………………………25

vii
List of Figures
Figure 1: Experiment Overview…….……………………………………………………………13
Figure 2: Representative MS/MS Acquisition...…………………………………………………19
Figure 3: Protein Overlap Among Analyzed Fractions.…………………………………………22
Figure 4: GO Analysis Results……………......…………………………………………………29

viii
List of Appendices
Electronic Appendix A: Peptide and Protein Reports…………………………………...CD-ROM
Electronic Appendix B: Protein Annotations……………………………………………CD-ROM
Electronic Appendix C: S. mansoni Protein Overlap……….…………………………...CD-ROM

ix
List of Abbreviations
4-(2-hydroxyethyl)-1-piperazineethanesulfonic acid HEPES
Base pair bp
Basic local alignment search tool BLAST
Complementary DNA cDNA
Expectation value E-value
False-discovery rate FDR
Gene ontology GO
Glutathione S-transferase GST
Kilodalton kDa
Laeonereis acuta L. acuta
Linear trap quadruple LTQ
Liquid chromatography LC
Mass spectrometry MS
Multidimensional protein identification technology MudPIT
N-acetylcysteine NAC
Phosphate-buffered saline PBS
Schistosoma haematobium S. haematobium
Schistosoma japonicum S. japonicum
Schistosoma mansoni S. mansoni

x
Schmidtea mediterranea S. mediterranea
Signal peptide SP
Strong cation exchange SCX
Tandem mass spectrometry MS/MS

1
Chapter 1 Introduction
1 Introduction
1.1 Proteomic Profiling of Model Organisms
One of the cornerstones of modern molecular biology, proteomics involves the wide-scale
characterization of the expression, structure, and function of all proteins in a cell, tissue, or
organism (1, 2). This complete set of proteins, known as the proteome (3), is both larger and
more complex than the genome; an entity’s set of genetic information in its entirety (4).
Proteomics based approaches aimed at elucidating the proteome of cells, tissues, or organisms
are becoming ever more prevalent in the post-genomic era. Perhaps some of the most noteworthy
proteomics projects involve the characterization of the proteomes of model organisms used in
clinical and research settings. These non-human species play a fundamental role in the
investigations of the biological activities of numerous species, forming much of the core of
modern biological knowledge (5). Accordingly, the common descent and conservation of genetic
information amongst all living organisms over the course of evolution allows data generated
from the study of model organisms to be extrapolated and applied to other species (6).
Model organisms are especially useful in the study of human disease, as human experimentation
is often unfeasible or unethical (7). As such, many protein databases for model species used in
the exploration of human biological phenomena have already been compiled, including
noteworthy species such as mouse, yeast, Caenorhabditis elegans, and Drosophila melanogaster
(8). That being said, many species lack significant proteomic characterization, with an
incomplete or non-existent protein database. Since proteins participate in virtually every cellular
process (9), such a lack of knowledge greatly impedes both genomic and proteomic analyses,
establishing a need for the proteomic profiling of poorly studied species.
As the field of molecular biology continues to grow, researchers have begun to look at new
model species in solving their broad spectrum of biological questions. Species such as the
flowering plant Arabidopsis thaliana, the zebrafish Danio rerio, and the frog Xenopus laevis
have proven beneficial and are now commonplace in the research setting. One such novel model
species is the freshwater planarian Schmidtea mediterranea (herein referred to as planarians)

2
which has recently found great accolade in the area of stem cell biology. In truth, planarians are
not new to biological research, having made their debut nearly 200 years ago in the laboratories
of J.G. Dalyell (1814), J.R. Johnson (1822) (10), and later Harriet Randolph (1892), and the
famous drosophila biologist T.H. Morgan (1898) (11).
1.2 Planarian Biology and Contemporary Planarian Research
Planarians are hallmarked by a remarkable ability to regenerate large portions of missing body
parts (12, 13), making them the ideal model to study stem cell biology. It was this striking
phenomenon which fuelled the curiosity of Morgan and his contemporaries, leading them to
begin elucidating the underlying mechanisms governing planarian regeneration. Experimentation
led Randolph in 1892 to attribute planarian regeneration to a “neoblast” population of cells,
believed to give rise to the mesoderm cell layer (14). While the term neoblast remained,
Randolph’s observations were somewhat mistaken in that while planarians’ regenerative ability
is derived from neoblasts, the cells are in fact pluripotent, capable of differentiating into all cell
types in planarian (15-18). Indeed, neoblasts are somatic stem cells which represent the only
proliferating cells in adult planarians (19), stimulated to proliferate to regenerate lost body parts
during times on injury or amputation to regenerate lost body parts (20).
While regeneration establishes planarians as a functional model organism, planarians harbour
many other traits which further legitimize their model organism status. Planarians are one of the
simplest metazoans, and are very easy to culture in a laboratory setting (11, 21). Modern research
innovations have made the planarian easy to manipulate using various experimental techniques
(22, 23), making them amenable to studying gene function (23, 24), developmental plasticity (25,
26), and various other phenomena (27, 28). More explicitly, planarian-specific protocols
involving RNA interference and in situ hybridization have been developed specifically for
planarian experimentation. Additionally, planarians are a bona fide model to study cilia and cilia-
driven motility, as planarian undersides consist of a monostratified ciliated epithelium,
fundamental for planarian motility (26).

3
Externally, planarians are covered in a mucous secretion of unknown composition, implicated in
numerous biological processes essential for planarian survival (29, 30). During locomotion, a
planarian secretes generous amounts of mucous to create a low-friction surface on which to
propel itself via ciliary gliding (26, 31). This is important not only for predator evasion, but
during exposure to light, as planarians are strongly photophobic (32). Moreover, these mucosal
secretions have been implicated in innate immunity and in the maintenance of an exterior
osmotic balance (30, 33). As planarian mucous represents a substantial barrier against external
large molecules, it obstructs hybridization approaches such as in situ hybridization and
immunohistochemistry, prompting removal prior to experimentation using mucolytic agents such
as N-acetylcysteine (NAC) (34, 35).
Despite the availability of numerous planarian species, S. mediterranea remains the preferred
species for biological study in molecular research (11). Most other planarian species such as
Girardia tigrina (36) and Dugesia japonica (37) possess mixoploidy or polyploidy genomes,
with cells having multiple sets of chromosomes. This greatly challenges both the sequencing and
assembly of contiguous DNA segments using traditional methods, making difficult the
generation of an accurately sequenced genome (38). Comparatively, S. mediterranea has a
recently sequenced (39) diploid genome (40), consisting of approximately 4.8x108 basepairs
(25). This allows for high-throughout experimentation on the genome-wide scale, lending an
additional utility to the use of planarians as a model organism.
1.3 Experimental Challenges in Planarian Research – The Need for an Annotated Planarian Profile
With new advances in sequencing technology, fully sequenced genomes are becoming available
at an increasing rate (41, 42), causing not genome sequencing, but annotation to bottleneck
modern genomic studies (43). Without sufficient characterization, the generation of such copious
amounts of data is rendered virtually useless due to the difficulty of making significant
interpretations on unannotated data (42, 44). Thus, annotating the genomes of model organisms
is especially important, given their widespread significance to the greater research community
(45). In addition to annotation, genes predicted by genome sequencing must be validated through
comparative analysis with protein expression data (46). This is especially important for

4
eukaryotic genomes, which contain added complexities derived from the presence of introns and
varying rates of alternative splicing (47, 48). Proteomic data, such as peptide identifications from
mass spectrometry (MS), can provide such information to directly verify genes predicted from
sequencing projects (49), ascertaining the quality of sequence databases (50).
In analyzing sequences on a genome-wide scale, a complete protein profile of the species at hand
is a common source of proteomic data used for gene validation. Such datasets include data on
hundreds of proteins, providing a representative look at overall protein expression. A protein
profile is also crucial for analyzing and interpreting experimental data made on protein
identifications and characterizations, allowing both qualitative and quantitative measurements to
be made on protein expression (51). Protein profiles are an especially useful resource for model
organisms, given their widespread use as human disease models. Through comparative analysis
of proteomic datasets, proteins found in model organisms which are homologous to medically
relevant human proteins can be identified. Homologous proteins are those which have evolved
from a common ancestor and share similar functions (52), making them ideal subjects in the
study of their human counterparts.
While the planarian genome is sequenced, it remains largely unannotated lacking extensive
information on gene identifications and functions. Indeed, planarian studies hitherto have largely
centered on genomic analyses examining neoblast biology and the functions of select genes. This
lack of annotation impedes planarian’s efficacy as a model system, not only for human biology,
but potentially to serve as a model for other worm species as well. Proteomic-based approaches
on the other hand have only been recently used to study planarians (50, 53), with a complete
proteome profile yet to be created. Consequently, planarian genomic sequences have not been
extensively validated, with minimal proteomics having been done thus far (50). Given their
model organism status, there exists a substantial need for a planarian protein profile to be
completed.

5
1.4 Overview of Protein Mass Spectrometry
Although completing a protein profile of a species with an unannotated genome is both
experimentally and bioinformatically challenging, modern approaches involving protein mass
spectrometry have substantially assuaged the process (41, 54). Mass spectrometry is a technique
used to characterize molecules through accurate measurement of the mass-to-charge ratio of
charged particles using electromagnetic fields. This information can in turn be used to decipher
the identity of the analyte constituents. In addition to determining the masses and identifies of
particles, mass spectrometry is used to elucidate the elemental composition and chemical
structure of molecules, and is particularly useful for analyzing protein-based samples (55).
Historically, identification of proteins was limited to de novo methods (56, 57), most notably
Edman degradation which individually sequences amino acids in a peptide using chemical
fractionation (58). However, de novo methods are limited both in their overall throughput and
adaptability when working with chemically modified peptides, pressuring the implementation of
novel strategies. While mass spectrometry was known to be ideally suited to generating data on
which protein identifications could be made, it was not until the advent of the laser desorption
method of ionization in 1985 that mass spectrometry could be used to analyze macromolecules
such as proteins (59, 60). As mass spectrometry instruments function under vacuum conditions
to minimize extraneous contaminats such as air molecules, analyte samples are required to be in
a gaseous state prior to analysis. Macromolecules are particularly sensitive to degradation during
gas-phase ionization, thus preventing their analysis by mass spectrometry prior to the
development of the laser desorption method.
Currently, the most common method for placing proteins into the gaseous stage is electrospray
ionization, a technique first described in 1989 which garnered a Nobel Prize in 2002 (61, 62).
Following dissolution in an organic solvent, the protein analyte is pumped through a narrow
capillary tube whose terminal end is maintained at a high potential difference. Once the analyte
is pumped across this area of high voltage, it disperses into a fine aerosol due to Coulombic
repulsion, evaporating the solvent and rendering the analyte in gaseous form (63). The analyte
becomes charged due to the protonation of amino acid residues containing basic side chains such
as arginine, histidine, and lysine, and enters the mass spectrometer for analysis (64).

6
Discovery-centered proteomics, aimed at identifying as many proteins as possible in a given
sample such as in the compilation of a protein profile, most often adapts a “bottom-up” or
“shotgun” approach (65, 66). In this method, proteins are first subject to proteolytic digestion
with an enzyme such as trypsin, creating a complex mixture of peptides. The peptide mixture is
then separated using offline approaches such as gel electrophoresis, or by online liquid
chromatography (LC) methods. Complex preparations used in protein profiling most often adopt
the latter approach (65), using capillary-based high-performance liquid chromatography
instruments. As discussed above, this setup is ideal for placing peptides into the gaseous phase
using electrospray ionization, largely accounting for the technique’s widespread use in modern
proteomics.
Optimal chromatographic separation of peptides is crucial, as increased separation allows the
mass spectrometer to analyze a greater number of peptide species, leading to an increased
number of protein identifications. For this reason, online two-dimensional chromatography
methods have recently been developed which separates peptides using two chromatographic
phases (67, 68). Known as multidimensional protein identification technology (MudPIT) (68),
this method first separates peptides by ionic separation based on positive charge (strong-cation
exchange), followed by hydrophobicity (reversed-phase). Peptides are bound first by negatively
charged cationic exchange resin, and are eluted into second phase using a salt solution. Similarly,
peptides are bound by reversed-phase resin, a hydrophobic chain of carbon atoms, and eluted
using an organic solvent (69, 70). The process is repeated in a gradient fashion, with increasing
salt and organic solution concentrations.
Finally, peptides are ionized into the gaseous phase and injected into the mass spectrometer,
where their masses are first determined by the instrument’s mass analyzer. The peptides are then
further fragmented via collision with inert gases or high-energy resonant excitation to analyze
their amino acid sequences and potential modifications (71). This sequential analysis, known as
tandem mass spectrometry (MS/MS), is fundamental in modern proteomics and has been
implemented in a wide range of mass spectrometry instruments (60).

7
1.5 Analyzing Mass Spectrometry Data
While mass spectrometers are able to produce an abundance of information, identifying
thousands of peptides in a single experiment, reconstructing peptides back into their constituent
proteins requires offline computer interpretation. Several search algorithms capable of
correlating raw mass spectrometry data with protein sequence databases have been developed
(60). Most contemporary search algorithms are based on refinements to the principle of peptide
mass mapping, which holds that the mass of a peptide derived from an enzymatically cleaved
protein can be used to link that peptide back to the protein from which it originated (72-74). With
the development of MS/MS, modern search algorithms are capable of making more confident
peptide matches by using the m/z data of peptide fragment to support initial alignments made by
whole peptide data alone (75, 76). Thus, protein search algorithms compare identified peptides
with a protein sequence database constructed from the same species as the analyzed sample.
For species like planarian for which no protein database exists, nucleic acid sequences may be
substituted for algorithm-based peptide searches (60). Using a simple computer script, genomic
sequences can be in silico translated into all six protein reading frames to generate sequences of
amino acids. The efficacy of this technique was first demonstrated using known protein (54), and
has since been used with larger genomes (77-80), including full genome translations (41). Mass
spectrometry centered on genomic sequences provides information both on the proteomic and
genomic levels, aiding in protein identification and validation of existing genome annotations
(81-83).
Subsequent to the correlation of mass spectrometry data with a sequence database using a search
algorithm, an accepted list of protein identifications must be compiled within certain threshold
criteria. For small datasets, protein identifications can be subject to manual verification by the
researcher to individually verify each peptide assignment (84). Evidently, this practice cannot be
applied to large datasets, such as protein profiles where hundreds of proteins are identified.
Instead, statistical models applied through automated computer algorithms are used to assess and
critique peptide assignments made by search algorithms (84, 85). Protein identifications are
accepted only if they can be made above a given certainty, or within a specified false-discovery
rate (FDR), limiting total protein identifications to a final, high-confidence dataset.

8
1.6 Annotating Mass Spectrometry Data
Following the processing of mass spectrometry data by search and identification critiquing
algorithms, protein identifications can be subject to various bioinformatical analyses which
provide annotation to identified proteins. For established species, protein annotations are usually
coupled to their respective sequences in the databases used for peptide mass mapping. This
simplifies the annotation process, as proteins can be both identified and annotated in a single run
by a search algorithm. Conversely, species which have not been well characterized often lack
annotated sequence databases, as is the case with planarians. Working with data derived from
such species requires alternate annotation strategies, ranging from manual annotation to large-
scale automated methods.
Although manual protein annotation provides the most accurate view of a protein’s structural and
functional characteristics, it normally requires extensive experimentation and is unpractical for
large datasets. Currently, numerous automated approaches are available which are capable of
efficiently annotating large datasets. Many of these tools utilize existing protein annotations from
well characterized species to annotate query proteins on the basis of sequence homology (86-88).
Homologus sequences derived from protein homologs share a high degree of similarity (52, 89),
a feature easily exploitable by computer software.
One of the most widely used tools for comparing sequences based on homology is the basic local
alignment search tool (BLAST) (87). Unlike other alignment tools (86), BLAST prioritizes speed
over sensitivity, making it amenable to analyzing large datasets (90). With BLAST, query
sequences are compared to a database containing sequences from numerous species, and
database constituents resembling the query sequences are identified. These annotations
accompanying these identified sequences can be used as annotation for the query sequence,
creating a rapid way to annotate data from poorly characterized species.
In addition to the fundamental functional annotations provided by BLAST and similar alignment
tools, identified proteins can also be more generally characterized, providing additional levels of
annotation information. A commonly used resource to provide such alternate annotation is Gene
Ontology (GO), a bioinformatics endeavour which classifies genes and proteins using both
functional and physical annotations (91). The GO database contains information on many

9
commonly used model species, and is continuously updated making it widely used in modern
bioinformatical analyses (92).
1.7 Transcriptomic Database Creation using Modern Sequencing Technologies
As previously mentioned, fully-sequenced genomes are becoming available at a rapid rate thanks
to advances in nucleic acid sequencing technologies. In truth, it is not only the genomes of
organisms which are being sequenced, but their transcriptomes as well. Perhaps even more
useful than a fully sequenced genome, a transcriptome represents all of the RNA molecules
expressed in a given cell, tissue, or organism (93). A fully sequenced transcriptome provides an
additional level of information not realized in genomic sequences in that it shows the
transcriptional structure of genes, as it represents only transcribed DNA. However, like their
genomic cousins, transcriptomes also benefit from validation using a protein profile, identifying
erroneous transcripts resulting from imperfections in the sequencing process.
Genomic and transcriptomic sequences are generated using relatively the same method, differing
only in the initial isolation of each respective nucleic acid species. Mainly, in the generation of a
transcriptome, RNA is isolated and reversed transcribed to its complementary DNA, known as
cDNA (93). In general, two approaches may be used in the sequencing of nucleic acids. The first
approach involves hybridization techniques which make use of microarray or tiling array
technologies (94-97). Hybridization approaches while high-throughout and relatively
inexpensive, are subject to high background levels resulting from cross-hybridization amongst
sequences, causing sequencing errors (98, 99). On the other hand, sequence-based methods
directly deduce sequences using a variety of tactics. Traditionally, sequencing was accomplished
using the Sanger method, a chain-termination approach hallmarked by its relative ease and
reliability (100, 101). DNA-sequencing methods have been continuously improved upon, with
newer technologies having replaced the Sanger method as the contemporary sequencing
standard.
Collectively called “next-generation sequencing”, these newer methods such as Illumina SDS
(102), Applied Biosystems SOLiD (103), and the Roche 454 System (104) are high-throughput

10
approaches which have significantly lowered sequencing costs (105). Next-generation
sequencing is now being used in large-scale sequencing projects, having already been applied to
several species, including human (106-108). Offering high reproducibility while minimizing
background noise levels, next-generation sequencing approaches are especially useful in the
sequencing of large, complex transcriptomes (103, 106).
1.8 Developing Planarians as a Model Organism
Having already demonstrated their suitability as a model organism, the potential of planarians as
a model system should not be limited to the regeneration and cilia fields. Given their simplistic
biology, planarians have the capacity to be used as a model system to study not only human
phenomena, but other invertebrate species relevant to human health (22, 109, 110). Accordingly,
the planarian transcriptome was recently fully sequenced using the Illumina method, generating a
database containing over 25,000 transcripts. In line with other next-generation sequencing
technologies, the Illumina method is a high-throughput approach commonly used in large-scale
sequencing projects (111, 112). Starting with an initial amplification step, DNA fragments are
sequenced via a synthesis process using chemically blocked nucleotides such to isolate each
nucleotide incorporation. Each of the four nucleotides carries a unique fluorescent tag, allowing
incorporations to be unambiguously identified by the Illumina instrument. Following analysis of
a new incorporation, the chemical block is removed and synthesis proceeds with another round
of incorporations.
As transcriptomes more accurately represent genes and gene structure than genomic sequences,
the planarian transcriptome sequence will undoubtedly help to further planarians as a model
species. The planarian transcriptome will be helpful in performing comparative analyses with
other genomes and proteomes, making it possible to accurately identify planarian genes which
have been conserved across species. Researchers have already postulated planarians use a model
to study other invertebrate species such as the parasitic flatworm Schistosoma mansoni. Serving
as one of the leading causes of the Schistosomiasis, S. masoni is a human parasite which also
infects other animals (113). Worldwide, over 200 million people suffer from schistosomiasis, a
disease which causes chronic illness in both adults and children (114).

11
Infection of S. mansoni and related species occurs in aqueous environment, when larval forms of
the parasites penetrate the skin of the infected individual. Following initial infection, parasite
larvae are transported via hepatic portal circulation to the liver, where they mature and mate.
Adult worms then migrate to different areas of the body, including the bladder and intestines
where they deposit eggs (113, 115). Long-term schistosomiasis is extremely detrimental, having
the ability to cause liver fibrosis, calcification of the bladder, and impaired cognitive
development in children (116). Given their dependence on a free living host, laboratory
cultivation of schistosomes like S. mansoni harbours many challenges, necessitating the need for
a free-living model.
1.9 Planarian Mucous and its Potential as a Mucous Model
Planarian mucous also holds the ability to diversify planarians as a model species, given the
array of mucosal and secretion based diseases. In Schistosomiasis, schistosomes and their eggs
secrete numerous molecules into the host environment (117), some of which are immunogenic
and promote illness (115). Immune reactions typified by granuloma formation in areas of egg
deposition are caused by egg secretory products (118, 119), which have been correlated with an
increased risk of bladder cancer in chronic schistosomiasis (120). Moreover, mature
schistosomes secrete numerous proteins necessary for worm survival, propagating infection
whilst damaging host tissues. Targeted therapeutic strategies aimed at exploiting schistosome
secretory products have demonstrated middling efficacy (121), with a mucosal model being of
prospective benefit for future studies.
Diseases associated with mucous pathology are prevalent in humans and other animals (122),
and may benefit from research based on mucous models. One of the most common diseases
driven by a mucosal aberrancy is cystic fibrosis, an autosomal recessive disorder which affects
the lungs, pancreas, liver, and intestine (123). A deletion mutation which causes misfolding of
the CFTR protein causes abnormal transport of chloride and sodium across epithelial cells,
producing viscous mucous which causes breathing difficulties (124, 125). In addition, patients
suffer from pancreatic cyst formation, impaired growth, and are prone to frequent bacterial
infections, significantly shortening overall life span (125, 126).

12
Likewise, mucous hypersecretion is a disease in which an over abundance of mucous is
generated and secreted from airways into their respective lumens (127). Patients suffer from
acute asthma attacks, and the disease is correlated with an increased mortality in lung disease.
Although numerous therapies for treatment of mucous hypersecretion are available, many of
these remain unproven in a clinical setting, establishing the need for relevant research models
(127). With further characterization, planarian mucous has the potential to be used in research
aimed at examining the phenomena associated with mucosal diseases, as well as in the
development of therapeutics.
1.10 Proteomic Mucous Profiling using Mass Spectrometry
A plethora of mucosal substances from humans and other organisms have been characterized
using protein mass spectrometry. These datasets are fundamental in understanding mucous
biology and distinguishing mucousopathies, not only for humans but for other species as well.
The high protein content of mucous establishes mass spectrometry as the premier technology for
analyzing mucosal fractions, as evidenced by an increasing number of such focused publications.
Protein profiles for many different types of human mucosa have been completed, ranging from
nasal and epithelial secretions (128-130) to cervical mucous (131) and even human tear fluid.
Likewise, mucosal secretions from non-human species have also been profiled, such as those
from various species of fish (132, 133).
As mucous functions ubiquitously throughout the body and across species as a protective and
immunological barrier, it can be reasonably postulated that the protein content of mucous is quite
similar among different fractions. Protein overlap across mucous proteomes have already been
examined for various human secretions (134), with abundant protein overlap among fractions
having been observed. Presently, mucous protein overlap between human and non-human
fractions has not been examined, leaving unknown whether any protein overlap exists across
diverse species. Performing such analyses may prove beneficial, as non-human species may have
the potential to serve as models for mucous-based diseases should a significant overlap exist
among mucosal fractions.

13
While some non-human mucous proteomes have been profiled, there exists a general deficit of
high-content datasets, especially for model organism species. Numerous studies were completed
prior to the advent of mass spectrometry approaches which are capable of identifying hundreds
of proteins in a single sample. These studies have focused on a few select proteins, and have
provided only a glimpse into how proteins govern mucous function. Conclusively, additional
mass spectrometry centered profiling exercises will greatly benefit future studies aimed at
comparing human and non-human mucosal fractions.
1.11 Outline and Rationale for Thesis Research
Planarians’ standing as a significant model organism in contemporary search, in tandem with
their potential and anticipated employment as a novel model for established systems necessitates
their need for extensive proteomic investigation. The absence of a complete planarian profile
encumbers both genomic and proteomic analyses, limiting their efficacy as a model system. That
being said, the goal of my master’s research was to further develop planarians as a model
organism by creation of an annotated planarian protein profile and characterization of the
planarian mucous proteome using high resolution mass spectrometry.
Prior to experimentation, a searchable protein database was constructed from sequenced
planarian transcripts assembled from next-generation sequencing reads. Using an in silico
algorithm, transcripts were translated into all six possible reading frames to generate a protein
sequence database. In total, 1604 proteins were identified, with 452 proteins being identified in
three different mucosal fractions. The Swiss-Prot BLAST was used to annotate planarian
proteins based on their similarity with known proteins in other organisms, allowing comparative
analyses to be performed.
Following BLAST annotation, planarian proteins were further annotated by GO analysis, which
identified an enrichment of extracellularly defined proteins in each of the mucosal fractions.
Planarian mucous proteins were compared to proteins from human secretions, revealing striking
similarities between the two species. Moreover, identified planarian proteins were systematically
compared to the parasite S. mansoni (135), demonstrating a high overlap between the planarian
and S. mansoni proteomes (Fig. 1). These observations further establish planarians as a model

14
organism, possibly opening new avenues for the study of parasitic infections and
mucousopathies such as asthma, various lung diseases, and cystic fibrosis.
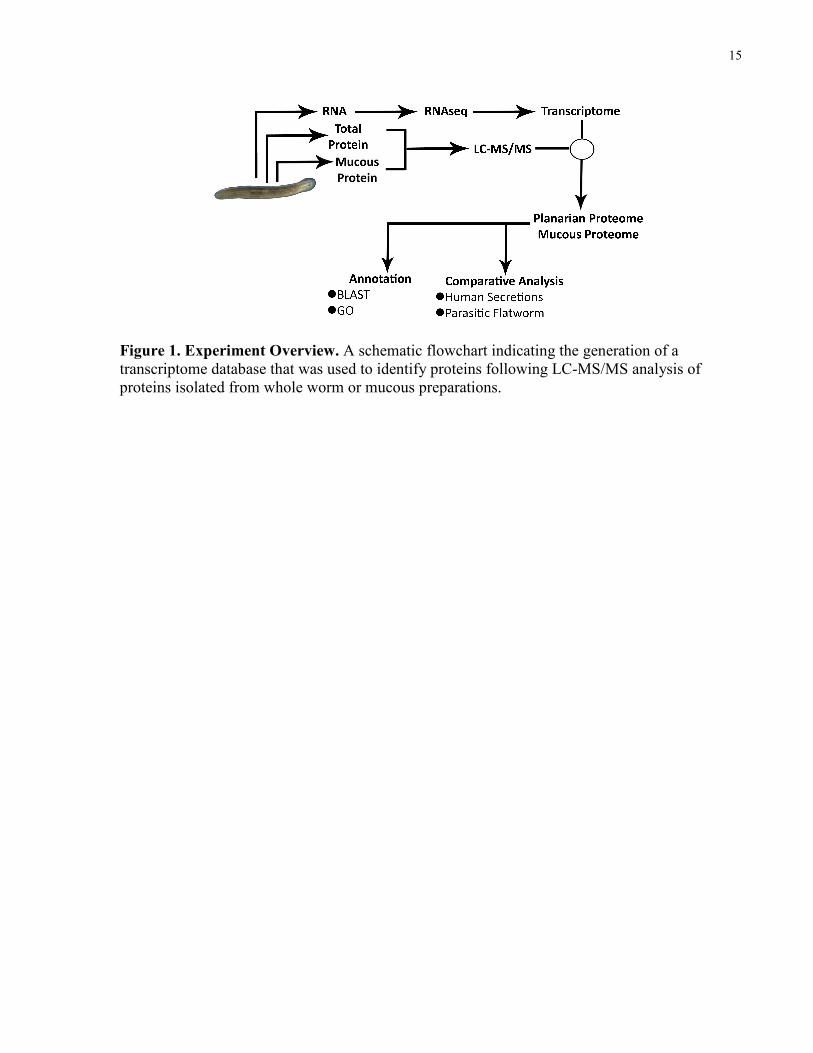
15
Figure 1. Experiment Overview. A schematic flowchart indicating the generation of a transcriptome database that was used to identify proteins following LC-MS/MS analysis of proteins isolated from whole worm or mucous preparations.

16
Chapter 2 Materials and Methods
2 Materials and Methods
2.1 Preparation of Worm Lysates
Lysates were generated from whole organisms of the CIW4 clonal strain of asexual Schmidtea
mediterranea, sized matched to 2 – 4 mm, using a tissue homogenizer and lysis buffer containing
20 mM HEPES buffer (4-(2-hydroxyethyl)-1-piperazineethanesulfonic acid) (Cell Signaling
Technology, Boston, MA, USA) 8 M urea (EMD Chemicals, Darmstadt, Germany), 1 mM
sodium orthovanadate (BioShop Canada Inc., Burlington, ON, Canada), 2.5 mM sodium
pyrophosphate (Cell Signaling Technology), and 1 mM β-glycerophosphate (Cell Signaling
Technology). Whole organisms were also treated with 5% NAC (Sigma-Aldrich, St. Louis, MO,
USA) in 1X phosphate-buffered saline (PBS) (BioShop) for 8 min to remove their mucous
coating (35), and subsequently lysed as described above. Lysates were subsequently sonicated on
continuous mode using three 30 s pulses with a sonic dismembrator (model 100; Fisher
Scientific, Pittsburgh, PA, USA). Mucosal extracts were generated by incubating whole
organisms with 5% NAC in 3.3 mg/mL sodium bicarbonate (EMD) (136) as described above,
and the NAC/mucous solution was extracted by pipetting. The extracted solution was
concentrated using a 3 kilodalton (kDa) molecular weight cut-off centrifugal filter (Millipore
Ireland Ltd., Carrigtwohill, Ireland), and incubated with 20% acetone (Sigma-Aldrich) at -20°C
overnight to precipitate proteins. Precipitated proteins were pelleted by centrifugation at 15,000 x
g for 10 min, and the resultant pellet was resuspended in 100 mM ammonium biocarbonate
(BioShop) containing 8 M urea. Alternatively, a mucous fraction was generated by placing
planarians and water (40 mL) into 15 cm polystyrene Petri dishes (Sarstedt Inc., Newton, NC,
USA). Planarians were exposed to visible light for 3 h to induce motility, after which planarians
were removed from the dishes. All water was collected, and the surface of each dish was washed
vigorously with a solution of 8 M urea in 100 mM ammonium bicarbonate. The water and urea
fractions were combined, and the resultant mixture was concentrated. All samples were reduced
by using 45 mM dithiothreitol (Cell Signaling Technology) for 20 min at 60°C and subsequently
alkylated by using 100 mM iodoacetamide (BioShop) for 15 min at 23°C in the dark. Lysates
were digested overnight at 23°C with trypsin (Thermo Scientific, Waltham, MA, USA) in

17
HEPES buffer containing tosyl phenylalanyl chloromethyl ketone protease inhibitor, and
proteolysis was quenched with 1% trifluoroacetic acid (EMD).
2.2 Liquid Chromatography and Mass Spectrometry Analysis
An integrated nano-LC system (Easy-nLC; Thermo Fisher Scientific, Odense, Denmark) was
used to perform a fully automated 9-cycle MudPIT analysis (69) on peptide samples from whole
and NAC treated worms using inline strong cation exchange (SCX) and reversed-phase
chromatography (70). Peptides from mucous extracts and the water/urea mixture were analyzed
using only reversed-phase chromatography. LC was performed as described in Taylor 2009 (70).
Briefly, samples analyzed by MudPIT were loaded onto a 100 µm fused silica microcapillary
column packed with 5 µm Magic C18 100 Å reversed-phase material (Michrom Bioresources
Inc., Auburn, CA, USA) and Luna 5 µm SCX 100 Å strong cation exchange resin (Phenomenex,
Torrance, CA, USA). A high-performance liquid chromatography gradient was established
consisting of 0%, 10%, 20%, 25%, 30%, 35%, 40%, 60%, and 100% ammonium acetate salt
bumps, followed by a water/acetonitrile gradient. Samples analyzed using only reversed-phase
chromatography were loaded onto an identical column packed only with reversed-phase resin,
and subject to a water/acetonitrile gradient. Eluted peptides from both column setups were
electrosprayed directly into a linear ion trap-Orbitrap Fourier transform mass spectrometer
(LTQ-Orbitrap Classic; Thermo Fisher Scientific, Bremen, Germany) using a nanoelectrospray
ion source (Proxeon Biosystems A/S, Odense, Denmark). MS spectra were obtained using a
method which consisted of one MS full scan (400-1500 m/z) in the Orbitrap mass analyzer, an
automatic gain control target of 500,000 with a maximum ion injection of 500 ms, one
microscan, and a resolution of 60,000 (full-width half-maximum). MS/MS spectra were obtained
in the linear ion trap analyzer using the six most intense ions at 35% normalized collision energy.
Automatic gain control targets were 10,000 with a maximum ion injection time of 100 ms. A
minimum ion intensity of 1000 was required to trigger an MS/MS spectrum. Dynamic exclusion
was applied using a maximum exclusion list of 500 with one repeat count, with an exclusion
duration of 40 s.

18
2.3 Database Creation
Transcripts were assembled from 206 million 100 base pair (bp) pairs reads from an
IlluminaHiseq, 85 million 100 bp pairs of reads from an IlluminaGAxII and ~233 million 40 bp
single end reads for an IlluminaGAxII. Each set of reads was assembled independently using the
Trinity Assembly (137) pipeline with default parameters. The resulting transcriptome assemblies
were then trimmed and assembled together using the Velvet implementation available in
Geneious (138) with default parameters. The resultant transcripts were filtered for contaminates
(i.e. did not match genomic sequence) and transcripts which did not encode an open-reading
frame of >100 amino acids (300 bp) were discarded. Finally, we compared our transcripts to de
novo transcriptome assemblies from published datasets (45, 50, 139). Transcripts present in these
assemblies which were missing from our assembly were added to our final transcriptome dataset.
2.4 Criteria for Peptide and Protein Identification and Protein Grouping
The complete method used for identification of peptides and proteins is described in Gortzak-
Uzan et al. (85). Briefly MS/MS data were analyzed by using the search engine X!Tandem
(CYCLONE 2010.12.01.2) (www.thegpm.org). Search analyses were performed assuming
trypsin digestion allowing one missed cleavage, with a fragment ion mass tolerance error of 0.4
Da and precursor ion mass tolerance of 20 ppm. The iodoacetamide derivative of cysteine was
specified as a fixed modification, while the oxidized form of methionine and N-terminal
glutamate to pyroglutamate acid conversion were specified as variable modifications. Using a
Python (version 2.6.2)-based tool a false-positive rate was calculated on the peptide level by
using a scrambled version of the same database as used for initial searching. Peptides were
binned into three charge states (+2, +3, +4), and X!Tandem expectation values were calculated to
minimize peptides matching to decoy sequences for each charge state. The total value of reverse
spectra to total forward spectra was set at 0.2%, resulting in a low number of decoy sequences in
the final protein list (<0.5%). In generating a final list of proteins, only proteins identified with
≥2 unique peptides and ≥7 amino acids were accepted. Using a database grouping algorithm
designed to minimize protein interference, proteins were grouped favouring parsimonious
clustering (140, 141). Identified proteins were annotated with the entire UniProtKB/Swiss-Prot

19
(519,348 entries) and UniProtKB/TrEMBL (11,636,205 entries) databases (release 2010_09),
using the Swiss-Prot BLAST algorithm. BLAST homology was determined by using the best
BLAST match, regardless of species, with an expectation value (E-value) inclusion threshold of
0.001. Complete information on all peptide and protein identifications, including identification
probabilities and sequence coverage can be found in Electronic Appendix A.
2.5 Gene Ontology Analysis
Gene Ontology analysis was performed with Swiss-Prot accession numbers by using the
ProteinCenter software suite (version 3.8.2014, Thermo Fisher Scientific, Odense, Denmark) on
March 16, 2012. Proteins were searched using the entire Ensembl human protein database as
background at a FDR of 5%.

20
Chapter 3 Results
3 Results
3.1 Mass Spectrometry Analysis
First, I homogenized and lysed whole planarians and subjected their proteins to an in-solution
trypsin digestion as described in Materials and Methods. The resultant peptide solutions I
analyzed by a MudPIT method combining SCX and reversed-phase LC. Eluted peptides were
ionized by electrospray and injected into an LTQ-Orbitrap instrument. I performed an identical
analysis on whole worms following treatment with NAC to remove the external mucous coating.
The neutral pH NAC mucous extract which I generated, far less complex than the whole worm
preparations, was analyzed by one-dimensional reversed-phase chromatography prior to MS/MS.
Another solitary mucous fraction, the mucous trail, I produced by allowing planarians to migrate
freely across the surface of a 15 cm Petri dish. After removing planarians from the dish, I
harvested surface-adhered mucous for MS/MS analysis (see Materials and Methods). Shown in
Figure 2 is a representative example of an MS/MS acquisition and identification for ion
817.39(m/z) corresponding to the mucous peptide HGGIDLGFNMPSFGGK.
It should be noted that I also produced a mucous extract by using an acidic NAC solution (pH 2),
which is commonly used during the preparation of worms for staining and microscopic imaging.
This approach was abandoned since I suspected that it resulted in the release of membrane and/or
internal proteins as an artifact of the harsh nature of the method, which rendered worms
immobile and flat as a consequence of the immediate lethality of the treatment. By contrast, the
bicarbonate-buffered NAC protocol allowed me to collect mucous while worms remained viable
as evidenced by their continued motility including slow contraction of the dorsal muscles during
NAC treatment, causing them to assume a bent, crescent shape.
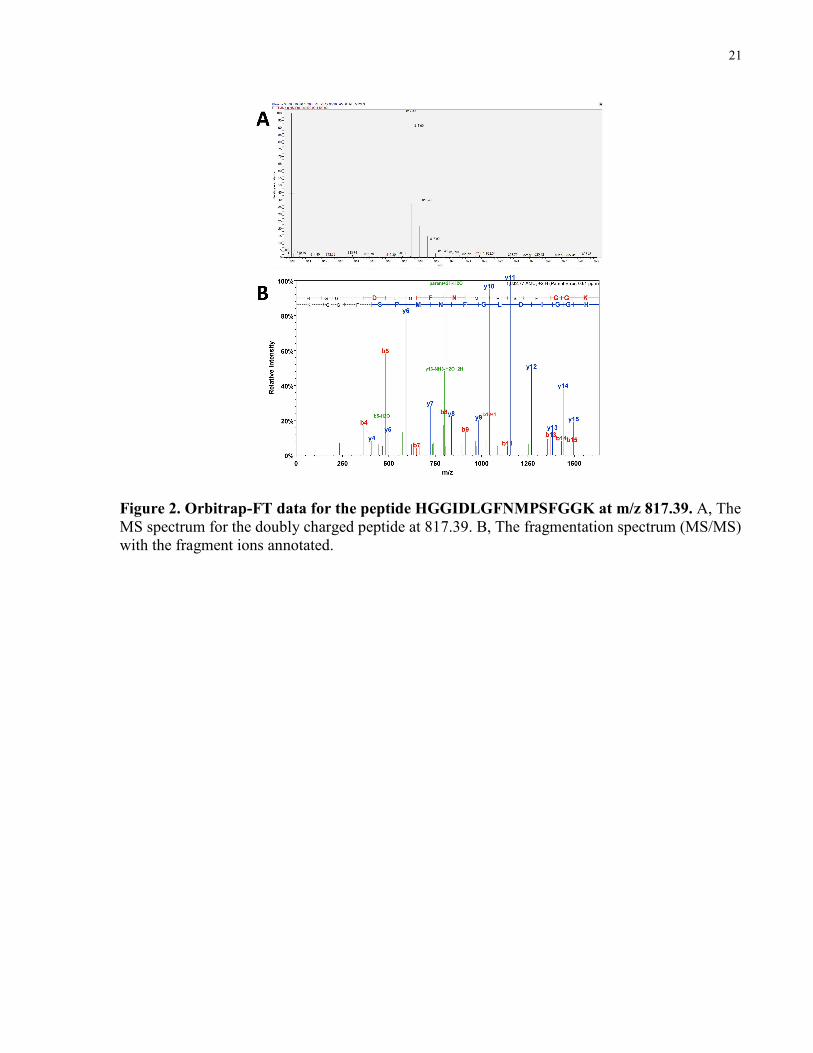
21
Figure 2. Orbitrap-FT data for the peptide HGGIDLGFNMPSFGGK at m/z 817.39. A, The MS spectrum for the doubly charged peptide at 817.39. B, The fragmentation spectrum (MS/MS) with the fragment ions annotated.

22
3.2 Annotating Identified Proteins
Our collaborators (Bret J. Pearson – University of Toronto, Eric Ross - Stowers Institute for
Medical Research) created a planarian transcriptome database containing greater than 25,000
planarian transcripts, I created a protein sequence database by using an algorithm designed to
translate the transcriptome into all six possible reading frames. A six-frame translation of the
database was necessary because our collaborators assembled it by using hundreds of millions of
short sequencing reads without direction, making unknown which direction/reading frame
transcripts were in. This approach is commonly used in searching mass spectrometry data with
sequences in which the correct reading frame for translation is unknown (54, 142).
Subsequently, I used the translated database to analyze my MS data with the search engine
X!Tandem, as described in Materials and Methods. Our collaborators from the Kislinger lab
(University of Toronto) then assembled a final list of protein identifications at a false-discovery
rate of <0.5%. A total of 1604 planarian proteins, each identified by at least two unique peptides
were identified (Electronic Appendix A). The complete list of identified proteins with annotation
is available in Electronic Appendix B. This dataset contains the transcript accession number, the
Swiss-Prot protein description, accession number, E-value, and the number of identified peptides
for each protein.
Initially, I differentially assessed the mucous proteome by comparing whole worms to worms
that had been treated with NAC to remove their mucous. From this analysis, I observed 236
NAC-sensitive proteins that were unique to whole, untreated planarians, and 7 unique to the
NAC-treated worms (Fig. 3A, Electronic Appendix B). The MS analysis of the buffered NAC
extract which I performed revealed 249 proteins (Electronic Appendix B). The majority of NAC
extract proteins (247) were detected in whole worms, and a fewer number (227) were found in
the NAC-treated worms (Fig. 3A). Collectively, 452 non redundant proteins were implicated as
mucous proteins by their presence in the NAC extract, mucous trail fraction, or NAC-sensitive
worm association.
Proteins which I identified by MS were annotated by our collaborator (Eric Ross) by comparing
identified protein sequences to characterized proteins from all available species using the Swiss-
Prot BLAST algorithm (Electronic Appendix B). The top BLAST entry corresponding to each
identified protein was used to annotate protein hits, with an E-value inclusion threshold of 0.001.

23
In total, 1252 identified proteins were matched to a BLAST entry, whereas 352 had no BLAST
match. Of the 249 proteins identified in the buffered NAC extract, 189 had a corresponding
BLAST match, as did 22 of the 35 mucous trail fraction proteins. Twenty-two mucous trail
proteins were also found in the buffered NAC extract, while 34 mucous trail proteins were also
identified in untreated planarians. In total, out of all 452 candidate mucous proteins I identified,
299 had a corresponding BLAST match.

24
Figure 3. Venn diagrams depicting overlap in non-redundant proteins among analyzed
fractions. A, Overlap between whole worm, NAC-treated worms, and NAC extract samples. B, Overlap between NAC extract and mucous trail samples.

25
3.3 Comparing Planarian Proteins to Published Proteomes
I compared the planarian mucous proteins which I Identified to member proteins of published
secretomes, from human mucous (129-131), and human tear fluid (143). Strikingly, 119
planarian mucous proteins, which group into 70 related protein families, appeared to be
orthologs or very similar to proteins identified in these characterized secretomes. Table 1 shows
the overlap between identified NAC extract, mucous trail, and NAC-sensitive proteins with
proteins from published secretomes described above. Comparatively, nasal mucous shared 8
proteins with the NAC extract, 2 NAC-sensitive proteins, and 2 proteins with mucous trail.
Olfactory cleft mucous shared 7 proteins with mucous trail, 31 proteins with the NAC extract,
and 7 similar to NAC-sensitive proteins. Cervical mucous shared 2 proteins with mucous trail, 35
proteins with the NAC extract, and 13 NAC-sensitive proteins. Tear fluid shared 8 proteins with
mucous trail, 77 proteins with the NAC extract, and had 34 NAC-sensitive proteins. Collectively,
this represents a 7%, 40%, 47%, and 20% overlap for nasal mucous, olfactory cleft mucous,
cervical mucous, and tear fluid respectively.
To assess whether planarians could be used as a model system to study parasitic worm species,
our collaborator (Eric Ross) systematically compared the proteins I identified to an S. mansoni
gene database, annotated with proteins similar to S. mansoni queries using the Swiss-Prot
BLAST algorithm (135). Of the 1604 S. mediterranea, proteins I identified, 1369 were also
found in the S. mansoni proteome, representing an overlap of 85%. Interestingly, the mucous
proteins I identified in the three mucous fractions (NAC extract; trail mucous; NAC-sensitive)
were also similar to proteins in the S. mansoni parasite, with overlap exceeding 75% (82%, 77%,
78%, respectively) (Electronic Appendix C).
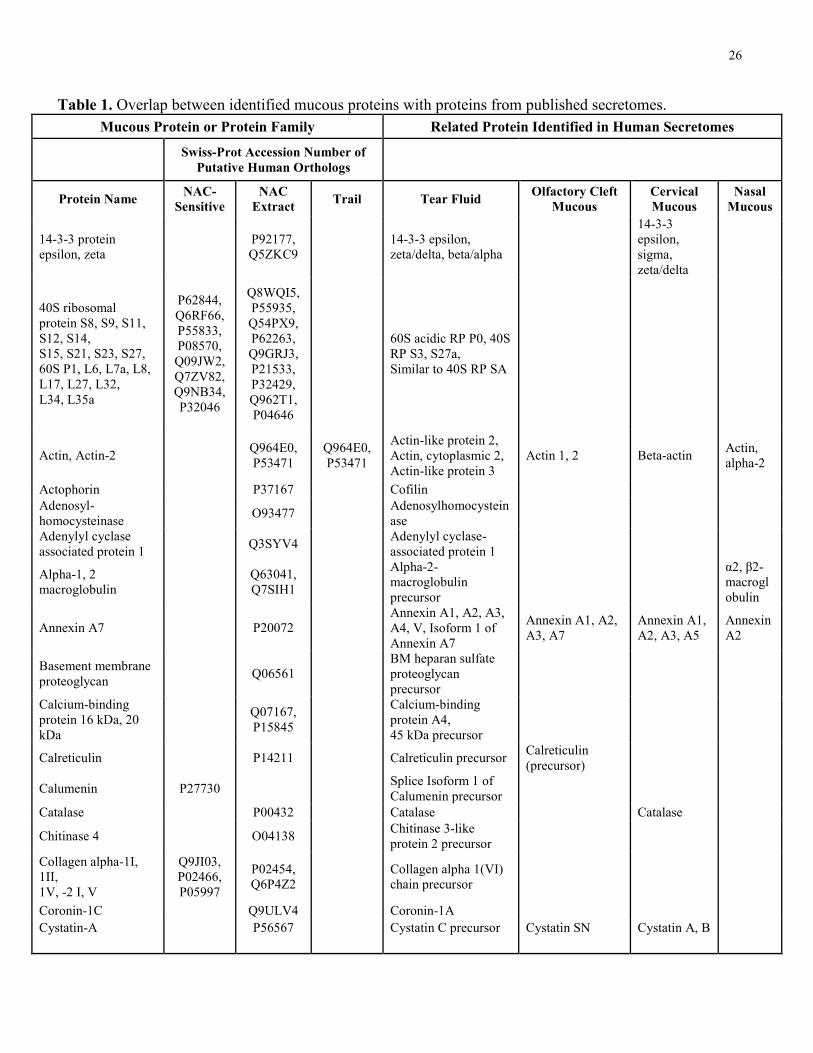
26
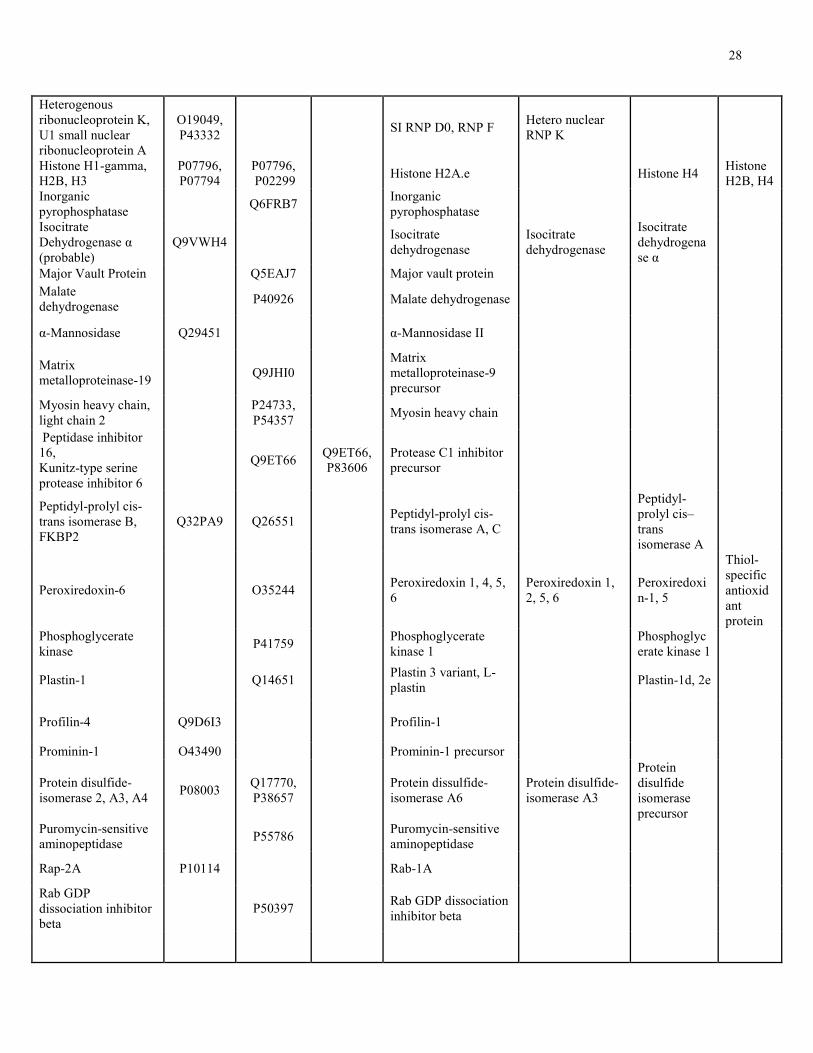
Table 1. Overlap between identified mucous proteins with proteins from published secretomes.
Mucous Protein or Protein Family Related Protein Identified in Human Secretomes
Swiss-Prot Accession Number of
Putative Human Orthologs
Protein Name NAC-
Sensitive
NAC
Extract Trail Tear Fluid
Olfactory Cleft
Mucous
Cervical
Mucous
Nasal
Mucous
14-3-3 protein epsilon, zeta
P92177, Q5ZKC9
14-3-3 epsilon, zeta/delta, beta/alpha
14-3-3 epsilon, sigma, zeta/delta
40S ribosomal protein S8, S9, S11, S12, S14, S15, S21, S23, S27, 60S P1, L6, L7a, L8, L17, L27, L32, L34, L35a
P62844, Q6RF66, P55833, P08570, Q09JW2, Q7ZV82, Q9NB34, P32046
Q8WQI5, P55935, Q54PX9, P62263, Q9GRJ3, P21533, P32429, Q962T1, P04646
60S acidic RP P0, 40S RP S3, S27a, Similar to 40S RP SA
Actin, Actin-2 Q964E0, P53471
Q964E0, P53471
Actin-like protein 2, Actin, cytoplasmic 2, Actin-like protein 3
Actin 1, 2 Beta-actin Actin, alpha-2
Actophorin P37167 Cofilin Adenosyl- homocysteinase
O93477 Adenosylhomocysteinase
Adenylyl cyclase associated protein 1
Q3SYV4 Adenylyl cyclase-associated protein 1
Alpha-1, 2 macroglobulin
Q63041, Q7SIH1
Alpha-2-macroglobulin precursor
α2, β2-macroglobulin
Annexin A7 P20072 Annexin A1, A2, A3, A4, V, Isoform 1 of Annexin A7
Annexin A1, A2, A3, A7
Annexin A1, A2, A3, A5
Annexin A2
Basement membrane proteoglycan
Q06561 BM heparan sulfate proteoglycan precursor
Calcium-binding protein 16 kDa, 20 kDa
Q07167, P15845
Calcium-binding protein A4, 45 kDa precursor
Calreticulin P14211 Calreticulin precursor Calreticulin (precursor)
Calumenin P27730 Splice Isoform 1 of Calumenin precursor
Catalase P00432 Catalase Catalase
Chitinase 4 O04138 Chitinase 3-like protein 2 precursor
Collagen alpha-1I, 1II, 1V, -2 I, V
Q9JI03, P02466, P05997
P02454, Q6P4Z2
Collagen alpha 1(VI) chain precursor
Coronin-1C Q9ULV4 Coronin-1A Cystatin-A P56567 Cystatin C precursor Cystatin SN Cystatin A, B
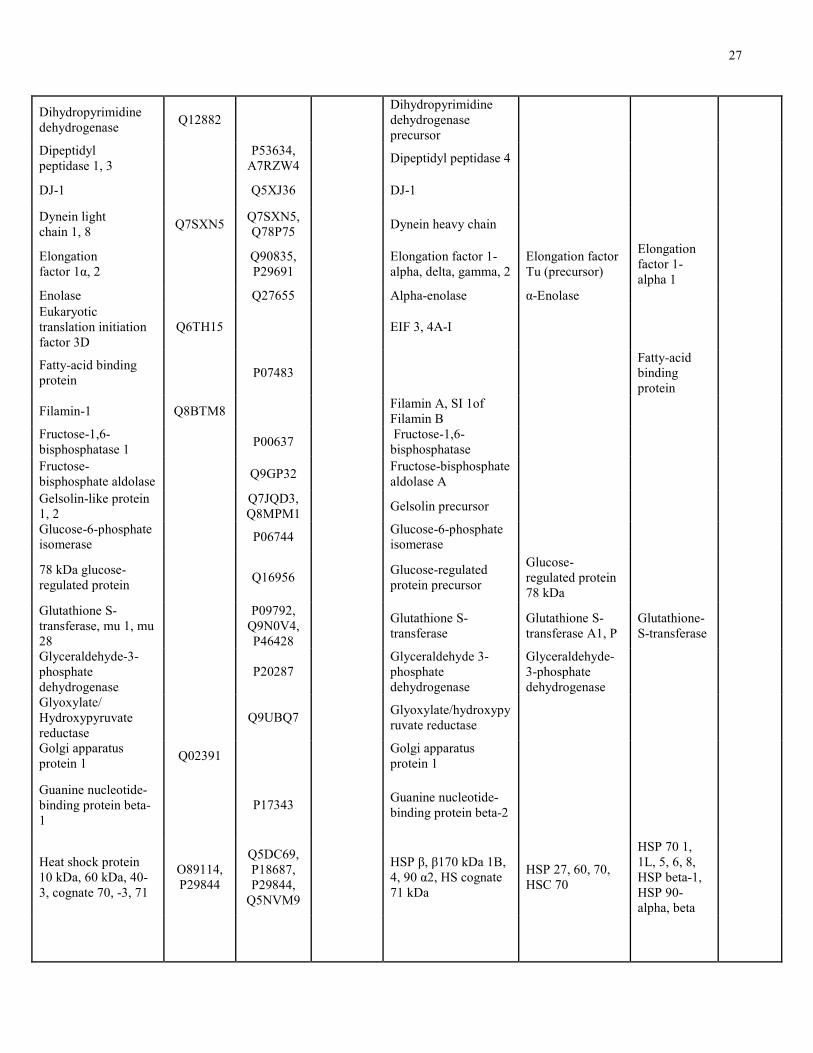
27
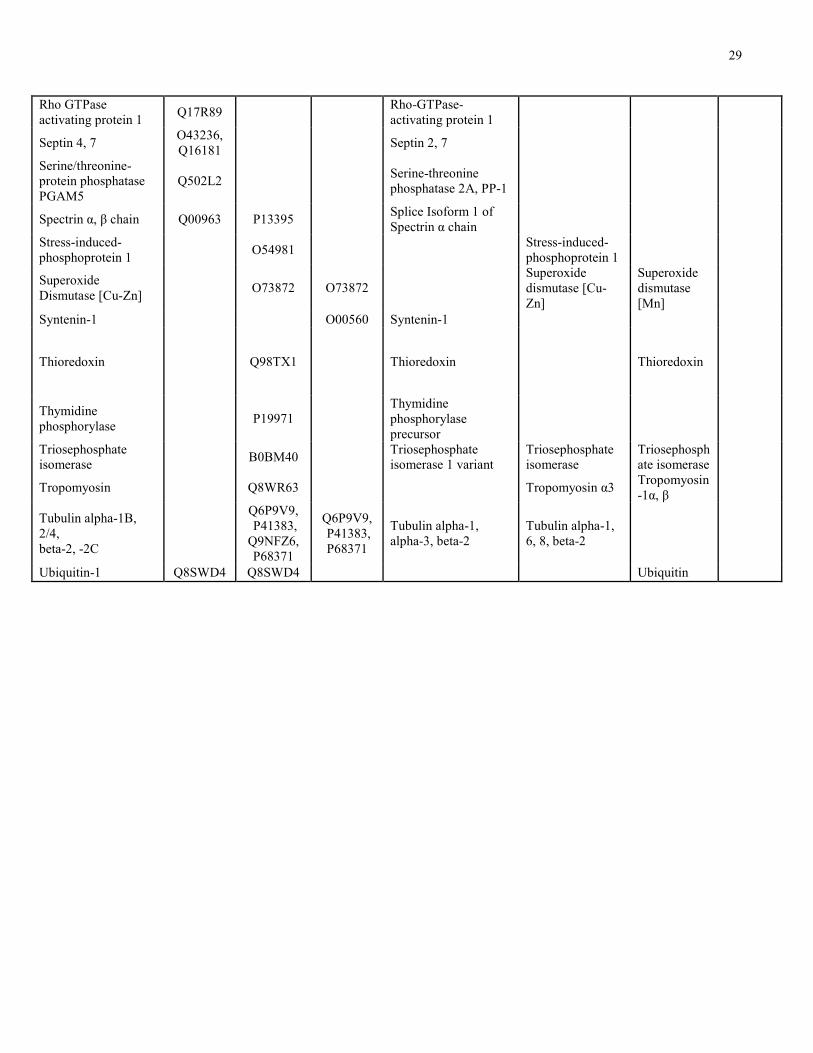
Dihydropyrimidine dehydrogenase
Q12882 Dihydropyrimidine dehydrogenase precursor
Dipeptidyl peptidase 1, 3
P53634,
A7RZW4 Dipeptidyl peptidase 4
DJ-1 Q5XJ36 DJ-1
Dynein light chain 1, 8
Q7SXN5 Q7SXN5, Q78P75
Dynein heavy chain
Elongation factor 1α, 2
Q90835, P29691
Elongation factor 1-alpha, delta, gamma, 2
Elongation factor Tu (precursor)
Elongation factor 1-alpha 1
Enolase Q27655 Alpha-enolase α-Enolase Eukaryotic translation initiation factor 3D
Q6TH15 EIF 3, 4A-I
Fatty-acid binding protein
P07483 Fatty-acid binding protein
Filamin-1 Q8BTM8 Filamin A, SI 1of Filamin B
Fructose-1,6-bisphosphatase 1
P00637 Fructose-1,6-bisphosphatase
Fructose-bisphosphate aldolase
Q9GP32 Fructose-bisphosphate aldolase A
Gelsolin-like protein 1, 2
Q7JQD3, Q8MPM1
Gelsolin precursor
Glucose-6-phosphate isomerase
P06744 Glucose-6-phosphate isomerase
78 kDa glucose-regulated protein
Q16956 Glucose-regulated protein precursor
Glucose-regulated protein 78 kDa
Glutathione S-transferase, mu 1, mu 28
P09792,
Q9N0V4, P46428
Glutathione S-transferase
Glutathione S-transferase A1, P
Glutathione-S-transferase
Glyceraldehyde-3-phosphate dehydrogenase
P20287 Glyceraldehyde 3-phosphate dehydrogenase
Glyceraldehyde-3-phosphate dehydrogenase
Glyoxylate/ Hydroxypyruvate reductase
Q9UBQ7 Glyoxylate/hydroxypyruvate reductase
Golgi apparatus protein 1
Q02391 Golgi apparatus protein 1
Guanine nucleotide- binding protein beta-1
P17343 Guanine nucleotide-binding protein beta-2
Heat shock protein 10 kDa, 60 kDa, 40-3, cognate 70, -3, 71
O89114, P29844
Q5DC69, P18687, P29844,
Q5NVM9
HSP β, β170 kDa 1B, 4, 90 α2, HS cognate 71 kDa
HSP 27, 60, 70, HSC 70
HSP 70 1, 1L, 5, 6, 8, HSP beta-1, HSP 90-alpha, beta
28
Heterogenous ribonucleoprotein K, U1 small nuclear ribonucleoprotein A
O19049, P43332
SI RNP D0, RNP F Hetero nuclear RNP K
Histone H1-gamma, H2B, H3
P07796, P07794
P07796, P02299
Histone H2A.e Histone H4 Histone H2B, H4
Inorganic pyrophosphatase
Q6FRB7 Inorganic pyrophosphatase
Isocitrate Dehydrogenase α (probable)
Q9VWH4 Isocitrate dehydrogenase
Isocitrate dehydrogenase
Isocitrate dehydrogenase α
Major Vault Protein Q5EAJ7 Major vault protein
Malate dehydrogenase
P40926 Malate dehydrogenase
α-Mannosidase Q29451 α-Mannosidase II
Matrix metalloproteinase-19
Q9JHI0 Matrix metalloproteinase-9 precursor
Myosin heavy chain, light chain 2
P24733, P54357
Myosin heavy chain
Peptidase inhibitor 16, Kunitz-type serine protease inhibitor 6
Q9ET66 Q9ET66, P83606
Protease C1 inhibitor precursor
Peptidyl-prolyl cis-trans isomerase B, FKBP2
Q32PA9 Q26551 Peptidyl-prolyl cis-trans isomerase A, C
Peptidyl-prolyl cis–trans isomerase A
Peroxiredoxin-6 O35244 Peroxiredoxin 1, 4, 5, 6
Peroxiredoxin 1, 2, 5, 6
Peroxiredoxin-1, 5
Thiol-specific antioxidant protein
Phosphoglycerate kinase
P41759 Phosphoglycerate kinase 1
Phosphoglycerate kinase 1
Plastin-1 Q14651 Plastin 3 variant, L-plastin
Plastin-1d, 2e
Profilin-4 Q9D6I3 Profilin-1
Prominin-1 O43490 Prominin-1 precursor
Protein disulfide- isomerase 2, A3, A4
P08003 Q17770, P38657
Protein dissulfide-isomerase A6
Protein disulfide-isomerase A3
Protein disulfide isomerase precursor
Puromycin-sensitive aminopeptidase
P55786 Puromycin-sensitive aminopeptidase
Rap-2A P10114 Rab-1A
Rab GDP dissociation inhibitor beta
P50397 Rab GDP dissociation inhibitor beta
29
Rho GTPase activating protein 1
Q17R89 Rho-GTPase-activating protein 1
Septin 4, 7 O43236, Q16181
Septin 2, 7
Serine/threonine-protein phosphatase PGAM5
Q502L2 Serine-threonine phosphatase 2A, PP-1
Spectrin α, β chain Q00963 P13395 Splice Isoform 1 of Spectrin α chain
Stress-induced-phosphoprotein 1
O54981 Stress-induced-phosphoprotein 1
Superoxide Dismutase [Cu-Zn]
O73872 O73872 Superoxide dismutase [Cu-Zn]
Superoxide dismutase [Mn]
Syntenin-1 O00560 Syntenin-1
Thioredoxin Q98TX1 Thioredoxin Thioredoxin
Thymidine phosphorylase
P19971 Thymidine phosphorylase precursor
Triosephosphate isomerase
B0BM40 Triosephosphate isomerase 1 variant
Triosephosphate isomerase
Triosephosphate isomerase
Tropomyosin Q8WR63 Tropomyosin α3 Tropomyosin-1α, β
Tubulin alpha-1B, 2/4, beta-2, -2C
Q6P9V9, P41383, Q9NFZ6, P68371
Q6P9V9, P41383, P68371
Tubulin alpha-1, alpha-3, beta-2
Tubulin alpha-1, 6, 8, beta-2
Ubiquitin-1 Q8SWD4 Q8SWD4 Ubiquitin

30
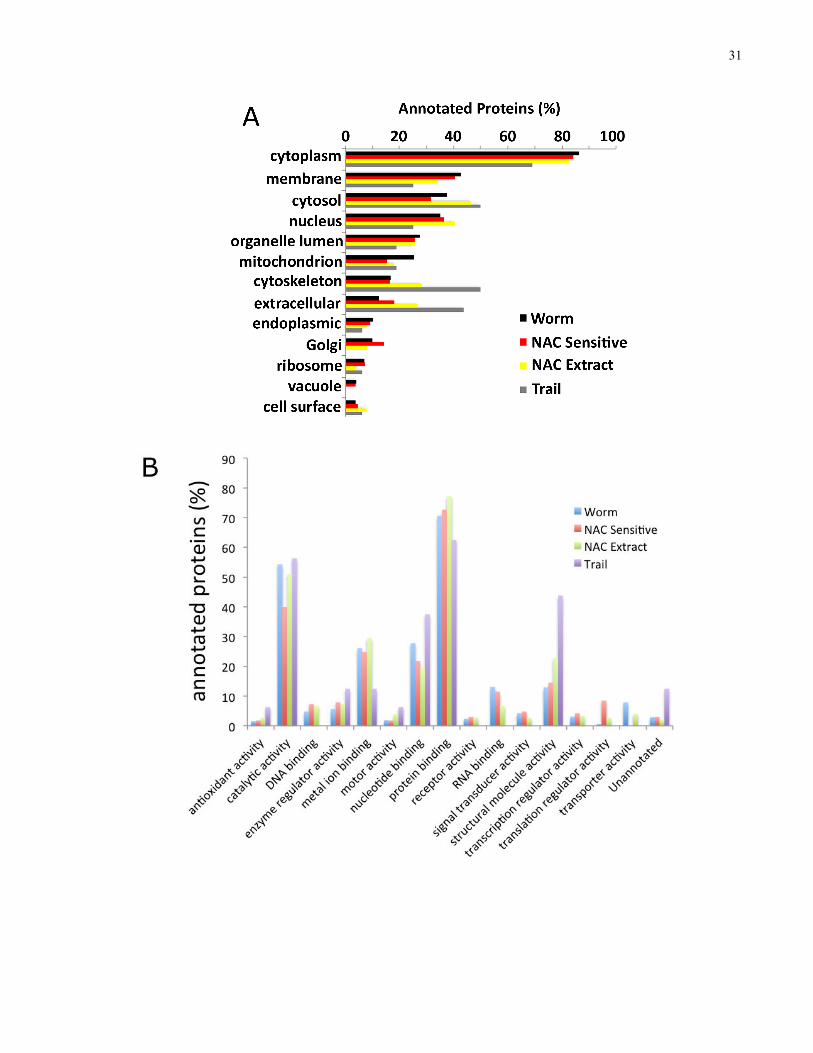
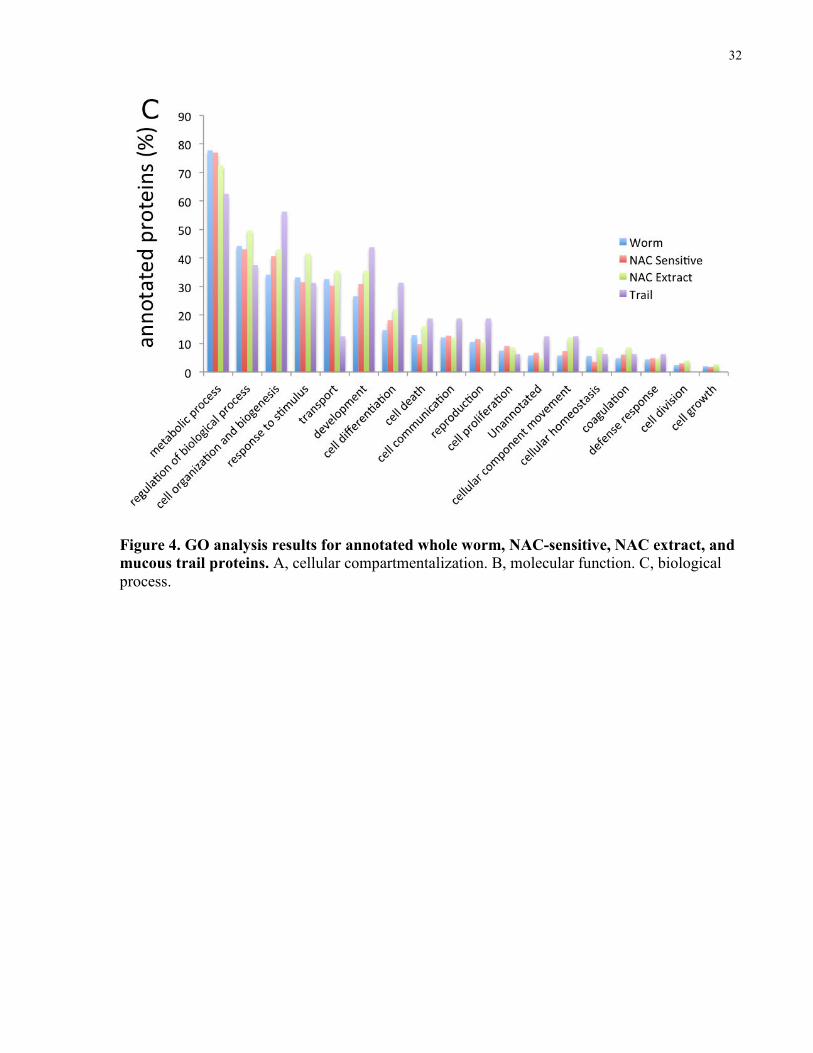
3.4 Gene Ontology Annotation
In order to perform GO analyses (91), our collaborator (Eric Ross) annotated identified planarian
proteins with homologous human matches (Eric Ross), using the Swiss-Prot BLAST algorithm. I
performed GO analysis on all identified planarian proteins with a human BLAST match,
including individual analyses for NAC-sensitive, the NAC extract, and the mucous trail
fractions. Using the ProteinCenter software suite (Thermo Fisher Scientific), I performed
statistical analyses on the GO classifications of cellular compartmentalization (Fig. 4A),
molecular function (Fig. 4B), and biological process (Fig. 4C).
Upon examination of the cellular compartmentalization classification analysis, I observed an
enrichment for extracellular proteins in each of the mucosal extracts, in comparison to the entire
planarian proteome. While 12% of proteins in the entire planarian proteome were classified as
having an extracellular localization, 18% (43/236) of the NAC-sensitive set of proteins, more
than a quarter (27%; 67/249) of the NAC extract proteins, and greater than 40% (15/35) of the
mucous trail proteins were annotated as extracellular, with an overrepresentation of extracellular
proteins over the background Ensembl human protein database.
Additionally, I also analyzed the signal peptide (SP) sequence content of the mucosal proteins
which I identified, reinforcing the conclusion that the mucous fractions were enriched for
secreted/extracellular proteins. While the whole planarian proteome is comprised of 13% SP-
containing proteins, the NAC extract had 18% SP proteins, and 20% of the set of NAC-sensitive
proteins contained an SP sequence. The mucous trail fraction showed the greatest enrichment for
SP-containing proteins at 30%.
31
32
Figure 4. GO analysis results for annotated whole worm, NAC-sensitive, NAC extract, and mucous trail proteins. A, cellular compartmentalization. B, molecular function. C, biological process.

33
Chapter 4 Discussion and Conclusions
4 Discussion and Conclusions
4.1 Analyzing Mass Spectrometry Data
The six-frame translation approach I adapted to generate a planarian protein sequence database
has been widely used to analyze mass spectrometry data. As described in the Introduction, the
efficacy of using nucleic acid sequences to search mass spectrometry data was first shown in a
proof-of-principle study using known proteins (54). More recently, this aptly named
“proteogenomics” method (144) has since been used with larger genomes (77-80), including full
genome translations (41, 145). Integrating transcriptomic sequences with proteomic data
provides an additional level of information not realized with genomic sequences in that genes
can be validated on the transcriptional level, as transcriptomic sequences represent only
transcribed DNA (93).
While generating a protein sequence database was relatively straightforward, assembling a final
list of protein identifications from database search results was inherently more challenging.
Commonly, peptide assignments made by database search algorithms such as X!Tandem are
critiqued statistically by using algorithms such as “Peptide Prophet” (84). Following this initial
critiquing, peptide assignments which can be confidently made to a given statistical threshold are
assembled into their corresponding proteins using grouping algorithms like “Protein Prophet”
(146). Protein grouping is especially important when analyzing multiple samples, as grouping
algorithms ultimately determine the protein content of each analyzed sample. Collectively, these
algorithms work to verify peptide and protein identifications by assessing individual assignment
probabilities on the peptide and protein levels.
While statistical verification methods are extensively used in modern proteomics (147-150),
alternative strategies are also used. Initially, I subjected my MS data to statistical critiquing by
the Peptide and Protein Prophet algorithms, which are part of the more comprehensive software
package “Scaffold 3”. Following analysis of the critiquing results, I determined that protein
grouping had not been optimally executed, as evidenced by a minimal protein overlap amongst

34
mucosal fractions. To resolve this, I decided to adopt an alternate peptide and protein critiquing
scheme originally described in Gortzak-Uzan 2007 (85).
This approach was initially developed by our collaborators in the Kislinger lab, and employs a
peptide level FDR to resolve protein identifications. The algorithm ascertains peptide
assignments by comparing identified peptides to a “decoy” version of the same database used for
initial searching, which in my case involved the use of a randomly scrambled version of my
translated planarian database. Prior to analysis, I combined data from all my respective mass
spectrometry experiments into a single entity, in order to reduce false-negative identifications.
Accepted proteins were grouped by using an algorithm favouring parsimonious clustering, which
accurately grouped proteins amongst samples, in particular between whole and NAC treated
worms. This clustering more accurately defined NAC-sensitive proteins, indicated by an
increased overlap between the protein content of NAC-sensitive and NAC extract fractions.
4.2 Interpreting Mass Spectrometry Analyses
From the differential analysis I performed which identified 236 NAC-sensitive proteins, it is
evident that NAC-treated worms had fewer proteins due to the effective removal of their mucous
fraction. Nonetheless, I identified 7 proteins as being unique to NAC-treated worms which
suggests that, due to the sampling nature of the MS/MS protocol, the recorded protein lists I have
constructed have not fully accounted for the entire worm proteome. The majority of the 247
NAC extract proteins which I identified were detected in whole worms, while 227 were found in
NAC treated worms. This suggests the NAC treatment was enriched for mucous proteins, but
also that many mucous proteins may not reside exclusively in the mucous compartment. In
support of this, the GO analysis I performed on the cellular compartmentalization classification
indicated that many mucosal proteins had multiple localization annotations. Indeed, many
proteins were annotated as being both cytoplasmically and extracellularly localized.
The mucous fraction recovered from Petri dishes previously inhabited by planarians was found
to contain only 35 proteins, significantly fewer than the NAC-sensitive and NAC extract
fractions, and may represent a distinct “trail” subset of the planarian mucous proteome.
Consistent with my observation is the literature finding that some mucous-producing species are

35
known to display bilateral secretion, secreting biochemically different mucosal fractions (151,
152). These fractions function independently of one another, consisting of a “trail” left behind
during locomotion, and a portion more closely associated to the animal’s exterior used in times
of inactivity. The trail portion in many species is used not only to permit the locomotion of the
trail-producing individual, but to allow others to travel on the same trail, communally reducing
energy expenditures (153, 154). In gastropods, this “inactive” portion contains up to 2.7 times
more protein by mass than the trail portion (151), varying in composition among gastropod
species (155).
4.3 Examining Protein Annotations
The GO analyses which I performed demonstrated a clear enrichment for extracellular proteins
in planarian mucous, as is expected for an extracellular fraction. While GO analysis often yields
broad and overlapping annotations, it remains an effective method to analyze previously
unexamined proteomes (143), as is the case with planarian. Not all identified planarian mucous
proteins hold GO annotations for the extracellular region, which is true for other published
secretomes. This raises questions about the mechanism by which these proteins enter the
extracellular compartment, and may also be an indication, that my fractionation methodology
was not perfected. GO analysis of the NAC extract revealed an underrepresentation of
membrane-associated proteins, as referenced against the Ensembl human protein database. The
low level of membrane-localized proteins supports the conclusion that the NAC treatment did
not significantly disrupt membrane-associated proteins, causing them to partition into the NAC
fraction as artifacts.
The SP enrichment analysis which I completed verified that each of the three mucous fractions I
generated was enriched for SP sequence-containing proteins. As SPs target proteins through the
secretory pathway (156), enrichment for SP-containing proteins serves to validate the identified
proteins as bona fide mucous proteome constituents. Although not all the identified mucous
proteins are predicted to contain an SP, this alone does not affect their legitimacy as extracellular
constituents, as not all extracellular proteins contain this feature (157, 158). Many proteins are
extracellularly secreted by non-traditional mechanisms which circumvent the standard
endoplasmic reticulum-Golgi apparatus pathway of secretion (159, 160). Indeed, protein

36
secretion has been shown to proceed by a variety of mechanisms ranging from ionophore-
stimulated mechanisms (160), to the exocytosis of intracellular membranes (159, 161).
4.4 Planarian Mucous as a Disease Model
Given its significant overlap with proteins found in human secretions, the planarian mucous
proteome may prove to be a useful model in human disease studies. As described in Results, I
showed that 119 planarian proteins appeared to be orthologs or very similar to proteins identified
in characterized human secretomes. This not only provided validation to my annotation of
planarian mucous proteins, but to the best of my knowledge for the first time revealed mucous
proteins conserved across diverse species.
Some overlapping proteins most likely play specific roles within the mucous environment. For
example, collagen which is present in different isoforms in both planaria mucous and tear fluid,
is hygroscopic in nature, consequently serving as an external emollient (162). Peroxiredoxins
which serve as antioxidants in mucous (163) are both found in planarian mucous and other
secretomes (Table 1). In other worm species, such as the annelid Laeonereis acuta, antioxidant
proteins play a substantial role in protecting the worm against environmental reactive oxygen
species (12). Specifically, L. acuta secrete large amounts of mucous which contains the
antioxidant species catalase, superoxide dismutase, and glutathione peroxidase. These enzymes
intercept or degrade environmental peroxyl and hydroxyl radicals originating from organic
matter in their aqueous environments (164). Likewise, the antioxidant activity of the mucosa
covering respiratory tract epithelial cells in humans has been shown to be crucial for protecting
against radical damage from environmental pollutants and bodily microorganisms (165).
Diseases associated with mucous pathology are prevalent in humans and other animals (122) and
may benefit from research based on mucous models, especially in the development and testing of
therapeutic agents. In the treatment of mucous hypersecretion, a condition correlated with asthma
and poor prognosis in lung disease (166), practitioners sometimes rely on the use of unproven
products which would benefit from testing in a model system (127). The use of mucous models
is also important in the development of drugs which pass through mucosal layers, but do not
necessarily target the mucous itself. Many drugs bind to and interact with mucous, affecting drug

37
uptake, release, and overall efficacy (167). This is perhaps especially important in cystic fibrosis,
a disease hallmarked by thick, dense mucous which impedes drug delivery and diffusion (168).
Mucous models hold therapeutic importance in oral health care, where the protective and
emollient properties of mucous are of particular interest. This is primarily evident in the
treatment of mouth dryness, a common condition for which contemporary therapies do not
sufficiently emulate natural saliva (169). The biochemical properties of mucous are also of
commercial interest, as mucosal substances are used in coating biomaterials for low friction
coefficient implants (170). Such commercial applications may not only benefit from planarians
as a mucous model, but from planarian mucous or synthetic derivatives.
The planarian mucous proteome shares many proteins with tear fluid, making planarian a
pertinent model for studying tear fluid in addition to mucous. Tear models hold practical for
studying both the physical and chemical properties of tears, something which has shown to be
important in the research and development of many commercial applications (171). Disease
studies can also benefit from a proteomics-defined tear fluid model, as many ocular diseases
result from irregularities in the tear fluid proteome. Specifically, conditions such as diabetic dry
eye disease have been linked to decreased reactive oxygen species protection (172), resulting
from changes to protective proteins such as peroxiredoxins, found in both human tear fluid (173)
and planarian mucous.
4.5 Planarians as a Model to Study Parasitic Worms
The high overlap between the S. mediterranea and S. mansoni proteomes further establishes
planarians as a model to study S. mansoni and other parasitic flatworms such as Schistosoma
japonicum, which themselves present numerous experimental challenges (22). Specifically,
parasitic species rely on free-living hosts for survival and propagation, requiring elaborate
culturing methods to maintain them in a laboratory setting (174, 175). Culturing of schistosome
species for example usually entails maintenance of a living colony of freshwater snails (174),
such as Biomphalaria genus members for S. mansoni (176), and Bulinus genus members for
Schistosoma haematobium (177). These snail populations are necessary for the large-scale
production of both the parasites and their eggs, as they serve as intermediate parasite hosts (178).

38
The extensive overlap between S. mansoni gene products and planarian mucous proteins is also
noteworthy given that the pathogenicity of some parasitic worm species is driven by secretory
products released into the host environment (179). Some of these proteins, such as serine and
metallo proteases, and nucleoside diphosphate kinase were also found in planarian mucous. In
humans, schistosomes release proteases which aid in skin penetration during initial infection by
disrupting epithelial basement membranes (180-182). Multiple proteases which I identified in my
planarian mucous fractions were found to overlap with predicted S. mansoni proteins, including
aminopeptidases and metalloproteinases. S. mansoni proteases have the potential to serve as
therapeutic targets in the treatment of schistosome infection, and having already been the subject
of targeted research aimed at interfering with their activity (183).
Following successful invasion into the host, immature worms circulate and mature into adults,
laying eggs in various tissues throughout the body (184, 185). Deposited eggs secrete proteins
which elicit the production of host anti-inflammatory cytokines (186, 187), allowing them to
evade host immune responses (188). These secreted egg antigens have been thoroughly studied
(189, 190), and have been the subject of vaccine-based therapeutics centered on their
exploitation (191). Interestingly, I identified a planarian protein which was identified by BLAST
annotation as being one of these egg antigen proteins. The protein, which was BLAST-matched
to the S. mansoni major egg antigen protein, was found in whole worms and may prove useful in
studies directed at furthering characterizing schistosoma egg antigens.
In addition to being used to drive initial infection, schistosomes secrete proteases to degrade host
erythrocytes to obtain hemoglobin which they use to acquire essential amino acids (192-194).
Multiple schistosome proteases have been implicated in erythrocyte degradation (195), including
members of the cathepsin family which I identified in planarians. As is the case with the other
various schistosome proteins I have discussed, the cathepsins and related proteases implicated in
erythrocyte degradation have been proposed to be druggable targets for anti-schistosome
therapies (196, 197). Once again, this lends further significance to the high overlap I observed
between the planarian proteins I identified and the S. mansoni proteome.
Another protein important to schistosome survival and fecundity are the glutathione s-transferase
(GST) family of enzymes (198). The GST family is comprised of numerous isoenzymes which
catalyze the conjugation of the tripeptide glutathione to a multitude of substrates, functioning in

39
the detoxification of foreign compounds (199, 200). Accordingly, GST members have been
investigated as potential therapeutic targets in schistosomes, particularly in S. mansoni. In my
planarian fractions I identified multiple GST family members, including a protein homologously
matched to a 28 kDa GST which has been implicated in targeted therapeutics. Mainly,
approaches which used monoclonal antibodies against the 28 kDa GST member were shown to
reduce both fecundity and egg viability during in vivo S. mansoni infections (201). Not only did I
demonstrate the presence of GST members in planarians, these proteins were shown to overlap
with S. mansoni GSTs in the comparative analysis which was performed. This creates the
possibility that planarians may be used as a model in the development of future strategies which
target GSTs in S. mansoni.
4.6 Conclusions and Future Directions
My master’s work has provided annotation for the planarian proteome and mucous sub-
proteome, broadening the potential of an already established model system. Annotation of the
mucous proteome creates abundant possibilities for examining both the physiological and
biochemical functions of mucosal proteins within the context of the mucous environment. Given
the wide range of functions of planarian mucous, from locomotion and substrate adhesion, to
predation and innate immunity, it is quite possible that mucosal proteins carry out these
responsibilities as a function of previously undocumented mechanisms and properties.
Furthermore, as I have discussed extensively throughout my thesis, I propose that planarians may
be used to identify and validate conserved schistosome proteins as targets against which new
drugs or therapeutic modalities may be developed.
As many identified planarian proteins which I identified by MS share no significant BLAST
match, there exists the need for further genome and proteome annotation and functional
characterization. The proteins unmatched to a homologous mate by BLAST analysis will require
individual assessments by manual annotation, and may prove especially interesting if they are
associated with tissue regeneration or other biological properties that distinguish planarians as a
model system. MS experimentation also has the ability to facilitate analysis of these proteins, as
de novo peptide sequencing strategies may be used to elucidate their amino acid sequences.
Furthermore, the three-dimensional structure of proteins can be studied by MS analysis,

40
supplementing more traditional approaches to analyzing molecular structures such as nuclear
magnetic resonance spectroscopy and X-ray crystallography (202).
In order to further the potential of planarians as a model to study schistosomes, the planarian
proteins which I have identified and annotated should be compared to other schistosome species.
In addition to S. mansoni, several schistosome species are responsible for causing
schistosomiasis in humans, including S. japonicum and S. haematobium (203). For species like S.
japonicum which have fully sequenced genomes (204), such comparative analyses are relatively
straightforward, and hold immense benefit.
As I have demonstrated, my experimental pipeline combining high-resolution mass spectrometry
and automated protein annotation is suitable for analyzing the proteomes of understudied model
organisms. Other model species which have not been proteomically defined or have just recently
emerged as novel model system can also benefit from this pipeline, making it amenable to many
fields of biology. MS instruments are continuously being improved, benefitting from ever-
increasing mass resolutions, allowing them to identify significantly more proteins than their
predecessors. Consequently, future protein profiling exercises promise to yield a much greater
wealth of information, perhaps being able to decipher an entire proteome in a single MS analysis.

41
Bibliography
1. Wilkins, M. R., Pasquali, C., Appel, R. D., Ou, K., Golaz, O., Sanchez, J.-C., Yan, J. X., Gooley, A. A., Hughes, G., Humphery-Smith, I., Williams, K. L., and Hochstrasser, D. F. (1996) From Proteins to Proteomes: Large Scale Protein Identification by Two-Dimensional Electrophoresis and Arnino Acid Analysis. Nat Biotech 14, 61-65.
2. Anderson, N. L., and Anderson, N. G. (1998) Proteome and proteomics: New technologies, new concepts, and new words. ELECTROPHORESIS 19, 1853-1861.
3. Wilkins, M. (2009) Proteomics data mining. Expert Review of Proteomics 6, 599-603.
4. Harrison, P. M., Kumar, A., Lang, N., Snyder, M., and Gerstein, M. (2002) A question of size: the eukaryotic proteome and the problems in defining it. Nucleic Acids Research 30, 1083-1090.
5. Hedges, S. B. (2002) The origin and evolution of model organisms. Nat Rev Genet 3, 838-849.
6. McGuire, M. T. (1986) The Case for Animal Experimentation: An Evolutionary and Ethical Perspective. JAMA: The Journal of the American Medical Association 256, 1054-1055.
7. Fields, S., and Johnston, M. (2005) Whither Model Organism Research? Science 307, 1885-1886.
8. Auerbach, D., Thaminy, S., Hottiger, M. O., and Stagljar, I. (2002) The post-genomic era of interactive proteomics: Facts and perspectives. PROTEOMICS 2, 611-623.
9. Taylor, R. D., Jewsbury, P. J., and Essex, J. W. (2002) A review of protein-small molecule docking methods. Journal of Computer-Aided Molecular Design 16, 151-166.
10. Brøndsted, H. V. (1969) Planarian Regeneration, Pergamon Press, London.
11. Newmark, P. A., and Alvarado, A. S. (2002) Not your father's planarian: a classic model enters the era of functional genomics. Nat Rev Genet 3, 210-219.
12. Moraes, T. B., Ribas Ferreira, J. L., da Rosa, C. E., Sandrini, J. Z., Votto, A. P., Trindade, G. S., Geracitano, L. A., Abreu, P. C., and Monserrat, J. M. (2006) Antioxidant properties of the mucus secreted by Laeonereis acuta (Polychaeta, Nereididae): A defense against environmental pro-oxidants? Comparative Biochemistry and Physiology Part C: Toxicology & Pharmacology 142, 293-300.
13. Randolph, H. (1897) Observations and experiments on regeneration in Planarians. Development Genes and Evolution 5, 352-372.
14. Randolph, H. (1892) The regeneration of the tail in lumbriculus. Journal of Morphology 7, 317-344.

42
15. Baguñà, J., Salo, E., and Auladell, C. (1989) Regeneration and pattern formation in planarians III. Evidence that neoblasts are totipotent stem cells and the source of blastema cells. Development 107, 77-86.
16. Ladurner, P., Rieger, R., and Baguñà, J. (2000) Spatial Distribution and Differentiation Potential of Stem Cells in Hatchlings and Adults in the Marine Platyhelminth Macrostomum sp.: A Bromodeoxyuridine Analysis. Developmental Biology 226, 231-241.
17. Newmark, P. A., and Sánchez Alvarado, A. (2000) Bromodeoxyuridine Specifically Labels the Regenerative Stem Cells of Planarians. Developmental Biology 220, 142-153.
18. Wagner, D. E., Wang, I. E., and Reddien, P. W. (2011) Clonogenic Neoblasts Are Pluripotent Adult Stem Cells That Underlie Planarian Regeneration. Science 332, 811-816.
19. Baguñà, J. (1976) Mitosis in the intact and regenerating planarian Dugesia mediterranea n.sp. I. Mitotic studies during growth, feeding and starvation. Journal of Experimental Zoology 195, 53-64.
20. Baguñà, J. (1976) Mitosis in the intact and regenerating planarian Dugesia mediterranea n.sp. II. Mitotic studies during regeneration, and a possible mechanism of blastema formation. Journal of Experimental Zoology 195, 65-79.
21. Alvarado, A. S. (2004) Regeneration and the need for simpler model organisms. Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences 359, 759-763.
22. Alvarado, A. S., Newmark, P. A., Robb, S. M. C., and Juste, R. j. (2002) The Schmidtea mediterranea database as a molecular resource for studying platyhelminthes, stem cells and regeneration. Development 129, 5659-5665.
23. Newmark, P. A., Reddien, P. W., Cebrià , F., and Alvarado, A. S. n. (2003) Ingestion of bacterially expressed double-stranded RNA inhibits gene expression in planarians. Proceedings of the National Academy of Sciences of the United States of America 100, 11861-11865.
24. Alvarado, A. S., and Newmark, P. A. (1999) Double-stranded RNA specifically disrupts gene expression during planarian regeneration. Proceedings of the National Academy of Sciences 96, 5049-5054.
25. Alvarado, A. S. (2003) The freshwater planarian Schmidtea mediterranea: embryogenesis, stem cells and regeneration. Current Opinion in Genetics & Development 13, 438-444.
26. Rompolas, P., Patel-King, R. S., King, S. M., Stephen, M. K., and Gregory, J. P. (2009) Schmidtea mediterranea: A Model System for Analysis of Motile Cilia. Methods in Cell Biology 93, 81-98.
27. Robb, S. M. C., and Alvarado, A. S. (2002) Identification of immunological reagents for use in the study of freshwater planarians by means of whole-mount immunofluorescence and confocal microscopy. genesis 32, 293-298.

43
28. Oviedo, N. J., Newmark, P. A., and Sánchez Alvarado, A. (2003) Allometric scaling and proportion regulation in the freshwater planarian Schmidtea mediterranea. Developmental Dynamics 226, 326-333.
29. Pedersen, K. J. (1959) Some features of the fine structure and histochemistry of planarian subepidermal gland cells. Cell and Tissue Research 50, 121-142.
30. Pedersen, K. J. (1963) Slime-Secreting Cells of Planarians. Annals of the New York Academy of Sciences 106, 424-443.
31. Martin, G. G. (1978) A new function of rhabdites: Mucus production for ciliary gliding. Zoomorphology 91, 235-248.
32. Stevenson, C. G., and Beane, W. S. (2010) A Low Percent Ethanol Method for Immobilizing Planarians. PLoS ONE 5, e15310.
33. Hyman, L. (1951) The invertebrates: platyhelminthes and rhynchocoela, McGraw-Hill Book Company, Inc., New York.
34. Umesono, Y., Watanabe, K., and Agata, K. (1997) A planarian orthopedia homolog is specifically expressed in the branch region of both the mature and regenerating brain. Development, Growth & Differentiation 39, 723-727.
35. Pearson, B. J., Eisenhoffer, G. T., Gurley, K. A., Rink, J. C., Miller, D. E., and Sánchez Alvarado, A. (2009) Formaldehyde-based whole-mount in situ hybridization method for planarians. Developmental Dynamics 238, 443-450.
36. Bayascas, J. R., Castillo, E., Munoz-Marmol, A. M., and Salo, E. (1997) Planarian Hox genes: novel patterns of expression during regeneration. Development 124, 141-148.
37. Orii, H., Kato, K., Umesono, Y., Sakurai, T., Agata, K., and Watanabe, K. (1999) The Planarian HOM/HOX Homeobox Genes (Plox) Expressed along the Anteroposterior Axis. Developmental Biology 210, 456-468.
38. Griffin, P., Robin, C., and Hoffmann, A. (2011) A next-generation sequencing method for overcoming the multiple gene copy problem in polyploid phylogenetics, applied to Poa grasses. BMC Biology 9, 19.
39. Robb, S. M. C., Ross, E., and Alvarado, A. S. n. (2008) SmedGD: the Schmidtea mediterranea genome database. Nucleic Acids Research 36, D599-D606.
40. Baguñà, J., Carranza, S., Pala, M., Ribera, C., Giribet, G., Arnedo, M. A., Ribas, M., and Riutort, M. (1999) From morphology and karyology to molecules. New methods for taxonomical identification of asexual populations of freshwater planarians. A tribute to Professor Mario Benazzi. Italian Journal of Zoology 66, 207-214.
41. Smith, J. C., Northey, J. G. B., Garg, J., Pearlman, R. E., and Siu, K. W. M. (2005) Robust Method for Proteome Analysis by MS/MS Using an Entire Translated Genome:

44
Demonstration on the Ciliome of Tetrahymena thermophila. Journal of Proteome Research 4, 909-919.
42. Reeves, G. A., Talavera, D., and Thornton, J. M. (2009) Genome and proteome annotation: organization, interpretation and integration. Journal of The Royal Society Interface 6, 129-147.
43. Pagani, I., Liolios, K., Jansson, J., Chen, I.-M. A., Smirnova, T., Nosrat, B., Markowitz, V. M., and Kyrpides, N. C. (2012) The Genomes OnLine Database (GOLD) v.4: status of genomic and metagenomic projects and their associated metadata. Nucleic Acids Research 40, D571-D579.
44. O'Donovan, C., Apweiler, R., and Bairoch, A. (2001) The human proteomics initiative (HPI). Trends in Biotechnology 19, 178-181.
45. Cantarel, B., Korf, I., Robb, S., Parra, G., Ross, E., Moore, B., Holt, C., Sánchez Alvarado, A., and Yandell, M. (2008) MAKER: An easy-to-use annotation pipeline designed for emerging model organism genomes. Genome Research 18, 188-196.
46. Ansong, C., Purvine, S. O., Adkins, J. N., Lipton, M. S., and Smith, R. D. (2008) Proteogenomics: needs and roles to be filled by proteomics in genome annotation. Briefings in Functional Genomics & Proteomics 7, 50-62.
47. Kan, Z., Rouchka, E. C., Gish, W. R., and States, D. J. (2001) Gene Structure Prediction and Alternative Splicing Analysis Using Genomically Aligned ESTs. Genome Research 11, 889-900.
48. Modrek, B., Resch, A., Grasso, C., and Lee, C. (2001) Genome-wide detection of alternative splicing in expressed sequences of human genes. Nucleic Acids Research 29, 2850-2859.
49. Wright, J., Sugden, D., Francis-McIntyre, S., Riba-Garcia, I., Gaskell, S., Grigoriev, I., Baker, S., Beynon, R., and Hubbard, S. (2009) Exploiting proteomic data for genome annotation and gene model validation in Aspergillus niger. BMC Genomics 10, 61.
50. Adamidi, C., Wang, Y., Gruen, D., Mastrobuoni, G., You, X., Tolle, D., Dodt, M., Mackowiak, S. D., Gogol-Doering, A., Oenal, P., Rybak, A., Ross, E., Alvarado, A. S. n., Kempa, S., Dieterich, C., Rajewsky, N., and Chen, W. (2011) De novo assembly and validation of planaria transcriptome by massive parallel sequencing and shotgun proteomics. Genome Research 21, 1193-1200
51. Schmidt, A., Bisle, B., Kislinger, T., Lipton, M. S., and Paša-Tolic, L. (2009) Quantitative Peptide and Protein Profiling by Mass Spectrometry: Mass Spectrometry of Proteins and Peptides. pp. 21-38, Humana Press.
52. Fitch, W. M. (1970) Distinguishing Homologous from Analogous Proteins. Systematic Biology 19, 99-113.

45
53. Fernandez-Taboada, E., Rodriguez-Esteban, G., Salo, E., and Abril, J. (2011) A proteomics approach to decipher the molecular nature of planarian stem cells. BMC Genomics 12, 133.
54. Yates III, J. R., Eng, J. K., and McCormack, A. L. (1995) Mining Genomes: Correlating Tandem Mass Spectra of Modified and Unmodified Peptides to Sequences in Nucleotide Databases. Analytical Chemistry 67, 3202-3210.
55. de Hoffmann, E. (2000) Mass Spectrometry. Kirk-Othmer Encyclopedia of Chemical Technology, John Wiley & Sons, Inc.
56. Hewick, R. M., Hunkapiller, M. W., Hood, L. E., and Dreyer, W. J. (1981) A gas-liquid solid phase peptide and protein sequenator. Journal of Biological Chemistry 256, 7990-7997.
57. Aebersold, R. H., Leavitt, J., Saavedra, R. A., Hood, L. E., and Kent, S. B. (1987) Internal amino acid sequence analysis of proteins separated by one- or two-dimensional gel electrophoresis after in situ protease digestion on nitrocellulose. Proceedings of the National Academy of Sciences 84, 6970-6974.
58. Edman, P. (1949) A method for the determination of amino acid sequence in peptides. Archives of biochemistry 22.
59. Karas, M., Bachmann, D., and Hillenkamp, F. (1985) Influence of the wavelength in high-irradiance ultraviolet laser desorption mass spectrometry of organic molecules. Analytical Chemistry 57, 2935-2939.
60. Aebersold, R., and Goodlett, D. R. (2001) Mass Spectrometry in Proteomics. Chemical Reviews 101, 269-296.
61. Fenn, J., Mann, M., Meng, C., Wong, S., and Whitehouse, C. (1989) Electrospray ionization for mass spectrometry of large biomolecules. Science 246, 64-71.
62. Fenn, J. B. (2003) Electrospray Wings for Molecular Elephants (Nobel Lecture). Angewandte Chemie International Edition 42, 3871-3894.
63. Gu, W., Heil, P. E., Choi, H., and Kim, K. (2007) Comprehensive model for fine Coulomb fission of liquid droplets charged to Rayleigh limit. Applied Physics Letters 91, 064104-064103.
64. Voet, D., Voet, J.G., Pratt, C.W. (2008) Fundamentals of Biochemistry: Life at the Molecular Level (Third Edition), Third Ed., John Wiley & Sons, Inc.
65. Aebersold, R., and Mann, M. (2003) Mass spectrometry-based proteomics. Nature 422, 198-207.
66. Chait, B. T. (2006) Mass Spectrometry: Bottom-Up or Top-Down? Science 314, 65-66.

46
67. Link, A. J., Eng, J., Schieltz, D. M., Carmack, E., Mize, G. J., Morris, D. R., Garvik, B. M., and Yates, J. R. (1999) Direct analysis of protein complexes using mass spectrometry. Nat Biotech 17, 676-682.
68. Delahunty, C., and Yates, J. R. (2003) Identification of Proteins in Complex Mixtures Using Liquid Chromatography and Mass Spectrometry. Current Protocols in Cell Biology, John Wiley & Sons, Inc.
69. Delahunty, C. M., J.R. Yates (2007) MudPIT: multidimensional protein identification technology. Biotechniques 43, 563, 565, 567.
70. Taylor, P., Nielsen, P. A., Trelle, M. B., Hørning, O. B., Andersen, M. B., Vorm, O., Moran, M. F., and Kislinger, T. (2009) Automated 2D Peptide Separation on a 1D Nano-LC-MS System. Journal of Proteome Research 8, 1610-1616.
71. McAlister, G. C., Phanstiel, D. H., Westphall, M. S., and Coon, J. J. (2011) Higher-energy collision-activated dissociation without a dedicated collision cell. Molecular & Cellular Proteomics.
72. Henzel, W. J., Billeci, T. M., Stults, J. T., Wong, S. C., Grimley, C., and Watanabe, C. (1993) Identifying proteins from two-dimensional gels by molecular mass searching of peptide fragments in protein sequence databases. Proceedings of the National Academy of Sciences 90, 5011-5015.
73. Yates III, J. R., Speicher, S., Griffin, P. R., and Hunkapiller, T. (1993) Peptide Mass Maps: A Highly Informative Approach to Protein Identification. Analytical Biochemistry 214, 397-408.
74. Patterson, S. D., and Aebersold, R. (1995) Mass spectrometric approaches for the identification of gel-separated proteins. ELECTROPHORESIS 16, 1791-1814.
75. Craig, R., and Beavis, R. C. (2004) TANDEM: matching proteins with tandem mass spectra. Bioinformatics 20, 1466-1467.
76. Perkins, D. N., Pappin, D. J. C., Creasy, D. M., and Cottrell, J. S. (1999) Probability-based protein identification by searching sequence databases using mass spectrometry data. ELECTROPHORESIS 20, 3551-3567.
77. Choudhary, J. S., Blackstock, W. P., Creasy, D. M., and Cottrell, J. S. (2001) Interrogating the human genome using uninterpreted mass spectrometry data. PROTEOMICS 1, 651-667.
78. Küster, B., Mortensen, P., Andersen, J. S., and Mann, M. (2001) Mass spectrometry allows direct identification of proteins in large genomes. PROTEOMICS 1, 641-650.
79. Giddings, M. C., Shah, A. A., Gesteland, R., and Moore, B. (2003) Genome-based peptide fingerprint scanning. Proceedings of the National Academy of Sciences 100, 20-25.

47
80. Kalume, D., Peri, S., Reddy, R., Zhong, J., Okulate, M., Kumar, N., and Pandey, A. (2005) Genome annotation of Anopheles gambiae using mass spectrometry-derived data. BMC Genomics 6, 128.
81. Ishino, Y., Okada, H., Ikeuchi, M., and Taniguchi, H. (2007) Mass spectrometry-based prokaryote gene annotation. PROTEOMICS 7, 4053-4065.
82. Merrihew, G. E., Davis, C., Ewing, B., Williams, G., Käll, L., Frewen, B. E., Noble, W. S., Green, P., Thomas, J. H., and MacCoss, M. J. (2008) Use of shotgun proteomics for the identification, confirmation, and correction of C. elegans gene annotations. Genome Research 18, 1660-1669.
83. Lamontagne, J., Beland, M., Forest, A., Cote-Martin, A., Nassif, N., Tomaki, F., Moriyon, I., Moreno, E., and Paramithiotis, E. (2010) Proteomics-based confirmation of protein expression and correction of annotation errors in the Brucella abortus genome. BMC Genomics 11, 300.
84. Keller, A., Nesvizhskii, A. I., Kolker, E., and Aebersold, R. (2002) Empirical Statistical Model To Estimate the Accuracy of Peptide Identifications Made by MS/MS and Database Search. Analytical Chemistry 74, 5383-5392.
85. Gortzak-Uzan, L., Ignatchenko, A., Evangelou, A. I., Agochiya, M., Brown, K. A., St.Onge, P., Kireeva, I., Schmitt-Ulms, G., Brown, T. J., Murphy, J., Rosen, B., Shaw, P., Jurisica, I., and Kislinger, T. (2007) A Proteome Resource of Ovarian Cancer Ascites: Integrated Proteomic and Bioinformatic Analyses To Identify Putative Biomarkers. Journal of Proteome Research 7, 339-351.
86. Smith, T. F., and Waterman, M. S. (1981) Identification of common molecular subsequences. Journal of molecular biology 147, 195-197.
87. Altschul, S. F., Gish, W., Miller, W., Myers, E. W., and Lipman, D. J. (1990) Basic local alignment search tool. Journal of molecular biology 215, 403-410.
88. Curwen, V., Eyras, E., Andrews, T. D., Clarke, L., Mongin, E., Searle, S. M. J., and Clamp, M. (2004) The Ensembl Automatic Gene Annotation System. Genome Research 14, 942-950.
89. Koonin, E. V. (2005) Orthologs, Paralogs, and Evolutionary Genomics. Annual Review of Genetics 39, 309-338.
90. McGinnis, S., and Madden, T. L. (2004) BLAST: at the core of a powerful and diverse set of sequence analysis tools. Nucleic Acids Research 32, W20-W25.
91. Ashburner, M., Ball, C. A., Blake, J. A., Botstein, D., Butler, H., Cherry, J. M., Davis, A. P., Dolinski, K., Dwight, S. S., Eppig, J. T., Harris, M. A., Hill, D. P., Issel-Tarver, L., Kasarskis, A., Lewis, S., Matese, J. C., Richardson, J. E., Ringwald, M., Rubin, G. M., and Sherlock, G. (2000) Gene Ontology: tool for the unification of biology. Nat Genet 25, 25-29.

48
92. Diehl, A. D., Lee, J. A., Scheuermann, R. H., and Blake, J. A. (2007) Ontology development for biological systems: immunology. Bioinformatics 23, 913-915.
93. Wang, Z., Gerstein, M., and Snyder, M. (2009) RNA-Seq: a revolutionary tool for transcriptomics. Nat Rev Genet 10, 57-63.
94. Clark, T. A., Sugnet, C. W., and Ares, M. (2002) Genomewide Analysis of mRNA Processing in Yeast Using Splicing-Specific Microarrays. Science 296, 907-910.
95. Yamada, K., Lim, J., Dale, J. M., Chen, H., Shinn, P., Palm, C. J., Southwick, A. M., Wu, H. C., Kim, C., Nguyen, M., Pham, P., Cheuk, R., Karlin-Newmann, G., Liu, S. X., Lam, B., Sakano, H., Wu, T., Yu, G., Miranda, M., Quach, H. L., Tripp, M., Chang, C. H., Lee, J. M., Toriumi, M., Chan, M. M. H., Tang, C. C., Onodera, C. S., Deng, J. M., Akiyama, K., Ansari, Y., Arakawa, T., Banh, J., Banno, F., Bowser, L., Brooks, S., Carninci, P., Chao, Q., Choy, N., Enju, A., Goldsmith, A. D., Gurjal, M., Hansen, N. F., Hayashizaki, Y., Johnson-Hopson, C., Hsuan, V. W., Iida, K., Karnes, M., Khan, S., Koesema, E., Ishida, J., Jiang, P. X., Jones, T., Kawai, J., Kamiya, A., Meyers, C., Nakajima, M., Narusaka, M., Seki, M., Sakurai, T., Satou, M., Tamse, R., Vaysberg, M., Wallender, E. K., Wong, C., Yamamura, Y., Yuan, S., Shinozaki, K., Davis, R. W., Theologis, A., and Ecker, J. R. (2003) Empirical Analysis of Transcriptional Activity in the Arabidopsis Genome. Science 302, 842-846.
96. Bertone, P., Stolc, V., Royce, T. E., Rozowsky, J. S., Urban, A. E., Zhu, X., Rinn, J. L., Tongprasit, W., Samanta, M., Weissman, S., Gerstein, M., and Snyder, M. (2004) Global Identification of Human Transcribed Sequences with Genome Tiling Arrays. Science 306, 2242-2246.
97. David, L., Huber, W., Granovskaia, M., Toedling, J., Palm, C. J., Bofkin, L., Jones, T., Davis, R. W., and Steinmetz, L. M. (2006) A high-resolution map of transcription in the yeast genome. Proceedings of the National Academy of Sciences 103, 5320-5325.
98. Okoniewski, M., and Miller, C. (2006) Hybridization interactions between probesets in short oligo microarrays lead to spurious correlations. BMC Bioinformatics 7, 276.
99. Royce, T. E., Rozowsky, J. S., and Gerstein, M. B. (2007) Toward a universal microarray: prediction of gene expression through nearest-neighbor probe sequence identification. Nucleic Acids Research 35, e99.
100. Sanger, F., and Coulson, A. R. (1975) A rapid method for determining sequences in DNA by primed synthesis with DNA polymerase. Journal of molecular biology 94, 441-448.
101. Sanger, F., Nicklen, S., and Coulson, A. R. (1977) DNA sequencing with chain-terminating inhibitors. Proceedings of the National Academy of Sciences 74, 5463-5467.
102. Chiang, C., Jacobsen, J. C., Ernst, C., Hanscom, C., Heilbut, A., Blumenthal, I., Mills, R. E., Kirby, A., Lindgren, A. M., Rudiger, S. R., McLaughlan, C. J., Bawden, C. S., Reid, S. J., Faull, R. L. M., Snell, R. G., Hall, I. M., Shen, Y., Ohsumi, T. K., Borowsky, M. L., Daly, M. J., Lee, C., Morton, C. C., MacDonald, M. E., Gusella, J. F., and Talkowski, M. E. (2012) Complex reorganization and predominant non-homologous repair following chromosomal breakage in

49
karyotypically balanced germline rearrangements and transgenic integration. Nat Genet 44, 390-397.
103. Cloonan, N., Forrest, A. R. R., Kolle, G., Gardiner, B. B. A., Faulkner, G. J., Brown, M. K., Taylor, D. F., Steptoe, A. L., Wani, S., Bethel, G., Robertson, A. J., Perkins, A. C., Bruce, S. J., Lee, C. C., Ranade, S. S., Peckham, H. E., Manning, J. M., McKernan, K. J., and Grimmond, S. M. (2008) Stem cell transcriptome profiling via massive-scale mRNA sequencing. Nat Meth 5, 613-619.
104. Vera, J. C., Wheat, C. W., Fescemyer, H. W., Frilander, M. J., Crawford, D. L., Hanski, I., and Marden, J. H. (2008) Rapid transcriptome characterization for a nonmodel organism using 454 pyrosequencing. Molecular Ecology 17, 1636-1647.
105. Schuster, S. C. (2008) Next-generation sequencing transforms today's biology. Nature methods 5, 16-18.
106. Nagalakshmi, U., Wang, Z., Waern, K., Shou, C., Raha, D., Gerstein, M., and Snyder, M. (2008) The Transcriptional Landscape of the Yeast Genome Defined by RNA Sequencing. Science 320, 1344-1349.
107. Marioni, J. C., Mason, C. E., Mane, S. M., Stephens, M., and Gilad, Y. (2008) RNA-seq: An assessment of technical reproducibility and comparison with gene expression arrays. Genome Research 18, 1509-1517.
108. Mortazavi, A., Williams, B. A., McCue, K., Schaeffer, L., and Wold, B. (2008) Mapping and quantifying mammalian transcriptomes by RNA-Seq. Nat Meth 5, 621-628.
109. Schaeffer, D. J. (1993) Planarians as a Model System for in Vivo Tumorigenesis Studies. Ecotoxicology and Environmental Safety 25, 1-18.
110. Walker, A. (2011) Insights into the functional biology of schistosomes. Parasites & Vectors 4, 1-6.
111. Bentley, D. R. (2006) Whole-genome re-sequencing. Current Opinion in Genetics & Development 16, 545-552.
112. Mardis, E. R. (2008) Next-generation DNA sequencing methods. Annual review of genomics and human genetics 9, 387-402.
113. Chitsulo, L., Loverde, P., and Engels, D. (2004) Focus: Schistosomiasis. Nat Rev Micro 2, 12-13.
114. Wang, L., Utzinger, J., and Zhou, X.-N. (2008) Schistosomiasis control: experiences and lessons from China. The Lancet 372, 1793-1795.
115. Hang, L. M., Warren, K. S., and Boros, D. L. (1974) Schistosoma mansoni: Antigenic secretions and the etiology of egg granulomas in mice. Experimental Parasitology 35, 288-298.

50
116. King, C. H., and Dangerfield-Cha, M. (2008) The unacknowledged impact of chronic schistosomiasis. Chronic Illness 4, 65-79.
117. Sung, C. K., and Dresden, M. H. (1986) Cysteinyl proteinases of Schistosoma mansoni eggs: purification and partial characterization. The Journal of parasitology 72, 891-900.
118. Doenhoff, M. J., Hassounah, O., Murare, H., Bain, J., and Lucas, S. (1986) The schistosome egg granuloma: immunopathology in the cause of host protection or parasite survival? Transactions of the Royal Society of Tropical Medicine and Hygiene 80, 503-514.
119. Karanja, D. M. S., Colley, D. G., Nahlen, B. L., Ouma, J. H., and Secor, W. E. (1997) Studies on Schistosomiasis in Western Kenya: I. Evidence for Immune-Facilitated Excretion of Schistosome Eggs from Patients with Schistosoma mansoni and Human Immunodeficiency Virus Coinfections. The American Journal of Tropical Medicine and Hygiene 56, 515-521.
120. Mostafa, M. H., Sheweita, S. A., and O'Connor, P. J. (1999) Relationship between Schistosomiasis and Bladder Cancer. Clinical Microbiology Reviews 12, 97-111.
121. McManus, D. P., and Loukas, A. (2008) Current Status of Vaccines for Schistosomiasis. Clinical Microbiology Reviews 21, 225-242.
122. Speare, D. J., and Mirsalimi, S. M. (1992) Pathology of the mucous coat of trout skin during an erosive bacterial dermatitis: A technical advance in mucous coat stabilization for ultrastructural examination. Journal of Comparative Pathology 106, 201-211.
123. Strausbaugh, S. D., and Davis, P. B. (2007) Cystic Fibrosis: A Review of Epidemiology and Pathobiology. Clinics in Chest Medicine 28, 279-288.
124. Yankaskas, J. R., Marshall, B. C., Sufian, B., Simon, R. H., and Rodman, D. (2004) Cystic Fibrosis Adult Care: Consensus Conference Report Chest 125, 1S-39S.
125. Andersen, D. H. (1938) Cystic Fibrosis of the Pancreas and Its Relation to Celiac Disease: A Clinical and Pathologic Study. Am J Dis Child 56, 344-399.
126. Rana, M., Munns, C. F., Selvadurai, H., Donaghue, K. C., and Craig, M. E. (2010) Cystic fibrosis-related diabetes in children-gaps in the evidence? Nat Rev Endocrinol 6, 371-378.
127. Baraniuk, J. N., and Zheng, Y. (2010) Treatment of mucous hypersecretion. Clinical & Experimental Allergy Reviews 10, 12-19.
128. Ali, M., Lillehoj, E., Park, Y., Kyo, Y., and Kim, K. (2011) Analysis of the proteome of human airway epithelial secretions. Proteome Science 9, 4.
129. Débat, H., Eloit, C., Blon, F., Sarazin, B. t., Henry, C. l., Huet, J.-C., Trotier, D., and Pernollet, J.-C. (2007) Identification of Human Olfactory Cleft Mucus Proteins Using Proteomic Analysis. Journal of Proteome Research 6, 1985-1996.
130. Casado, B., Pannell, L. K., Iadarola, P., and Baraniuk, J. N. (2005) Identification of human nasal mucous proteins using proteomics. PROTEOMICS 5, 2949-2959.

51
131. Panicker, G., Ye, Y., Wang, D., and Unger, E. (2010) Characterization of the Human Cervical Mucous Proteome. Clinical Proteomics 6, 18-28.
132. Rajan, B., Fernandes, J. M. O., Caipang, C. M. A., Kiron, V., Rombout, J. H. W. M., and Brinchmann, M. F. (2011) Proteome reference map of the skin mucus of Atlantic cod (Gadus morhua) revealing immune competent molecules. Fish Shellfish Immun. 31, 224-231.
133. Chong, K., Joshi, S., Jin, L. T., and Shu-Chien, A. C. (2006) Proteomics profiling of epidermal mucus secretion of a cichlid (Symphysodon aequifasciata) demonstrating parental care behavior. Proteomics 6, 2251-2258.
134. Li, S.-J., Peng, M., Li, H., Liu, B.-S., Wang, C., Wu, J.-R., Li, Y.-X., and Zeng, R. (2009) Sys-BodyFluid: a systematical database for human body fluid proteome research. Nucleic Acids Research 37, D907-D912.
135. Berriman, M., Haas, B. J., LoVerde, P. T., Wilson, R. A., Dillon, G. P., Cerqueira, G. C., Mashiyama, S. T., Al-Lazikani, B., Andrade, L. F., Ashton, P. D., Aslett, M. A., Bartholomeu, D. C., Blandin, G., Caffrey, C. R., Coghlan, A., Coulson, R., Day, T. A., Delcher, A., DeMarco, R., Djikeng, A., Eyre, T., Gamble, J. A., Ghedin, E., Gu, Y., Hertz-Fowler, C., Hirai, H., Hirai, Y., Houston, R., Ivens, A., Johnston, D. A., Lacerda, D., Macedo, C. D., McVeigh, P., Ning, Z., Oliveira, G., Overington, J. P., Parkhill, J., Pertea, M., Pierce, R. J., Protasio, A. V., Quail, M. A., Rajandream, M.-A., Rogers, J., Sajid, M., Salzberg, S. L., Stanke, M., Tivey, A. R., White, O., Williams, D. L., Wortman, J., Wu, W., Zamanian, M., Zerlotini, A., Fraser-Liggett, C. M., Barrell, B. G., and El-Sayed, N. M. (2009) The genome of the blood fluke Schistosoma mansoni. Nature 460, 352-358.
136. Oeda, T., Henkel, T., Ohmori, H., Schill W.B. (1997) Scavenging effect of N-acetyl-L-cysteine against reactive oxygen species in human semen: a possible therapeutic modality for male factor infertility? Andrologia 29, 125-131.
137. Grabherr, M. G., Haas, B. J., Yassour, M., Levin, J. Z., Thompson, D. A., Amit, I., Adiconis, X., Fan, L., Raychowdhury, R., Zeng, Q., Chen, Z., Mauceli, E., Hacohen, N., Gnirke, A., Rhind, N., di Palma, F., Birren, B. W., Nusbaum, C., Lindblad-Toh, K., Friedman, N., and Regev, A. (2011) Full-length transcriptome assembly from RNA-Seq data without a reference genome. Nat Biotech 29, 644-652.
138. Drummond, A. J., Ashton, B., Buxton, S., Cheung, M., Cooper, A., Duran, C., Field, M., Heled, J., Kearse, M., Markowitz, S., Moir, R., Stones-Havas, S., Sturrock, S., Thierer, T., Wilson, A. (2011) Geneious v5.4. http://www.geneious.com/.
139. Sandmann, T., Vogg, M., Owlarn, S., Boutros, M., and Bartscherer, K. (2011) The head-regeneration transcriptome of the planarian Schmidtea mediterranea. Genome Biology 12, 1-19.
140. Adachi, J., Kumar, C., Zhang, Y., and Mann, M. (2007) In-depth Analysis of the Adipocyte Proteome by Mass Spectrometry and Bioinformatics. Molecular & Cellular Proteomics 6, 1257-1273.

52
141. Adamski, M., Blackwell, T., Menon, R., Martens, L., Hermjakob, H., Taylor, C., Omenn, G. S., and States, D. J. (2005) Data management and preliminary data analysis in the pilot phase of the HUPO Plasma Proteome Project. PROTEOMICS 5, 3246-3261.
142. Pandey, A., and Lewitter, F. (1999) Nucleotide sequence databases: a gold mine for biologists. Trends in Biochemical Sciences 24, 276-280.
143. de Souza, G., de Godoy, L., and Mann, M. (2006) Identification of 491 proteins in the tear fluid proteome reveals a large number of proteases and protease inhibitors. Genome Biology 7, R72.
144. Renuse, S., Chaerkady, R., and Pandey, A. (2011) Proteogenomics. PROTEOMICS 11, 620-630.
145. Pawar, H., Sahasrabuddhe, N. A., Renuse, S., Keerthikumar, S., Sharma, J., Kumar, G. S. S., Venugopal, A., Sekhar, N. R., Kelkar, D. S., Nemade, H., Khobragade, S. N., Muthusamy, B., Kandasamy, K., Harsha, H. C., Chaerkady, R., Patole, M. S., Pandey A. (2011) A Proteogenomic approach to map the proteome of an unsequenced pathogen - Leishmania donovani. PROTEOMICS In Press.
146. Nesvizhskii, A. I., Keller, A., Kolker, E., and Aebersold, R. (2003) A Statistical Model for Identifying Proteins by Tandem Mass Spectrometry. Analytical Chemistry 75, 4646-4658.
147. Rush, J., Moritz, A., Lee, K. A., Guo, A., Goss, V. L., Spek, E. J., Zhang, H., Zha, X.-M., Polakiewicz, R. D., and Comb, M. J. (2005) Immunoaffinity profiling of tyrosine phosphorylation in cancer cells. Nat Biotech 23, 94-101.
148. Atwood, J. A., Weatherly, D. B., Minning, T. A., Bundy, B., Cavola, C., Opperdoes, F. R., Orlando, R., and Tarleton, R. L. (2005) The Trypanosoma cruzi Proteome. Science 309, 473-476.
149. Haas, W., Faherty, B. K., Gerber, S. A., Elias, J. E., Beausoleil, S. A., Bakalarski, C. E., Li, X., Villén, J., and Gygi, S. P. (2006) Optimization and Use of Peptide Mass Measurement Accuracy in Shotgun Proteomics. Molecular & Cellular Proteomics 5, 1326-1337.
150. Dávalos, A., Fernández-Hernando, C., Sowa, G., Derakhshan, B., Lin, M. I., Lee, J. Y., Zhao, H., Luo, R., Colangelo, C., and Sessa, W. C. (2010) Quantitative Proteomics of Caveolin-1-regulated Proteins. Molecular & Cellular Proteomics 9, 2109-2124.
151. Smith, A. M., and Morin, M. C. (2002) Biochemical Differences Between Trail Mucus and Adhesive Mucus From Marsh Periwinkle Snails. The Biological Bulletin 203, 338-346.
152. Smith, A. M., Quick, T. J., and St. Peter, R. L. (1999) Differences in the Composition of Adhesive and Non-Adhesive Mucus From the Limpet Lottia limatula. The Biological Bulletin 196, 34-44.
153. Davies, M. S., and Beckwith, P. (1999) Role of mucus trails and trail-following in the behaviour and nutrition of the periwinkle Littorina littorea. Marine Ecology Progress Series 179, 247-257.

53
154. Davies, M. S., and Blackwell, J. (2007) Energy saving through trail following in a marine snail. Proceedings of the Royal Society B: Biological Sciences 274, 1233-1236.
155. Bretz, D. D., and Dimock Jr, R. V. (1993) Behaviorally important characteristics of the mucous trail of the marine gastropod Ilyanassa Obsoleta (Say). Journal of Experimental Marine Biology and Ecology 71, 181-191.
156. von Heijne, G. (1990) The signal peptide. Journal of Membrane Biology 115, 195-201.
157. Antelmann, H., Tjalsma, H., Voigt, B., Ohlmeier, S., Bron, S., van Dijl, J. M., and Hecker, M. (2001) A Proteomic View on Genome-Based Signal Peptide Predictions. Genome Research 11, 1484-1502.
158. Delepelaire, P., and Wandersman, C. (1989) Protease secretion by Erwinia chrysanthemi. Proteases B and C are synthesized and secreted as zymogens without a signal peptide. Journal of Biological Chemistry 264, 9083-9089.
159. Rubartelli, A., Cozzolino, F., Talio, M., and Sitia, R. (1990) A novel secretory pathway for interleukin-1 beta, a protein lacking a signal sequence. The EMBO journal 9, 1503-1510.
160. Mignatti, P., Morimoto, T., and Rifkin, D. B. (1992) Basic fibroblast growth factor, a protein devoid of secretory signal sequence, is released by cells via a pathway independent of the endoplasmic reticulum-Golgi complex. Journal of Cellular Physiology 151, 81-93.
161. Gardella, S., Andrei, C., Ferrera, D., Lotti, L. V., Torrisi, M. R., Bianchi, M. E., and Rubartelli, A. (2002) The nuclear protein HMGB1 is secreted by monocytes via a non-classical, vesicle-mediated secretory pathway. EMBO reports 3, 995-1001.
162. Venus, M., Waterman, J., and McNab, I. (2010) Basic physiology of the skin. Surgery (Oxford) 28, 469-472.
163. Rahman, I., Biswas, S. K., and Kode, A. (2006) Oxidant and antioxidant balance in the airways and airway diseases. European Journal of Pharmacology 533, 222-239.
164. Regan, E. A., Mazur, W., Meoni, E., Toljamo, T., Millar, J., Vuopala, K., Bowler, R. P., Rahman, I., Nicks, M. E., Crapo, J. D., and Kinnula, V. L. (2011) Smoking and COPD increase sputum levels of extracellular superoxide dismutase. Free Radical Biology and Medicine 51, 726-732.
165. Cross, C., Halliwell, B., and Allen, A. (1984) Antioxidant Protection: A Function of Tracheobronchial and Gastrointestinal Mucus. The Lancet 323, 1328-1330.
166. Ryu, J.-H., Kim, C.-H., and Yoon, J.-H. (2010) Innate immune responses of the airway epithelium. Molecules and Cells 30, 173-183.
167. Svensson, O., Lindh, L., Cárdenas, M., and Arnebrant, T. (2006) Layer-by-layer assembly of mucin and chitosan--Influence of surface properties, concentration and type of mucin. Journal of Colloid and Interface Science 299, 608-616.

54
168. Bhat, P. G., Flanagan, D. R., and Donovan, M. D. (1996) Drug diffusion through cystic fibrotic mucus: Steady-state permeation, rheologic properties, and glycoprotein morphology. Journal of Pharmaceutical Sciences 85, 624-630.
169. Christersson, C. E., Lindh, L., and Arnebrant, T. (2000) Film-forming properties and viscosities of saliva substitutes and human whole saliva. European Journal of Oral Sciences 108, 418-425.
170. Burke, S. E., and Barrett, C. J. (2003) pH-responsive properties of multilayered poly(L-lysine)/hyaluronic acid surfaces. Biomacromolecules 4, 1773-1783.
171. Bright, A. M., and Tighe, B. J. (1993) The composition and interfacial properties of tears, tear substitutes and tear models. Journal of The British Contact Lens Association 16, 57-66.
172. Augustin, A. J., Spitznas, M., Kaviani, N., Meller, D., Koch, F. H. J., Grus, F., and Göbbels, M. J. (1995) Oxidative reactions in the tear fluid of patients suffering from dry eyes. Graefe's Archive for Clinical and Experimental Ophthalmology 233, 694-698.
173. Zhou, L., Beuerman, R. W., Chan, C. M., Zhao, S. Z., Li, X. R., Yang, H., Tong, L., Liu, S., Stern, M. E., and Tan, D. (2009) Identification of Tear Fluid Biomarkers in Dry Eye Syndrome Using iTRAQ Quantitative Proteomics. Journal of Proteome Research 8, 4889-4905.
174. Lee, C.-L., and Lewert, R. M. (1956) The Maintenance of Schistosoma Mansoni in the Laboratory. Journal of Infectious Diseases 99, 15-20.
175. Holliman, R. B., Wasserman, B. M., and Davis, W. R. (1972) Studies on Centrifugation and Hatching of Schistosoma mansoni Eggs. American Midland Naturalist 87, 251-253.
176. Crompton, D. W. T. (1999) How Much Human Helminthiasis Is There in the World? The Journal of parasitology 85, 397-403.
177. Kane, R. A., Stothard, J. R., Emery, A. M., and Rollinson, D. (2008) Molecular characterization of freshwater snails in the genus Bulinus: a role for barcodes? Parasites & Vectors 1, 15.
178. Gatlin, M. R., Black, C. L., Mwinzi, P. N., Secor, W. E., Karanja, D. M., and Colley, D. G. (2009) Association of the Gene Polymorphisms IFN-γ +874, IL-13 -1055 and IL-4 -590 with Patterns of Reinfection with Schistosoma mansoni. PLoS Negl Trop Dis 3, e375.
179. Yatsuda, A. P., Krijgsveld, J., Cornelissen, A. W. C. A., Heck, A. J. R., and de Vries, E. (2003) Comprehensive Analysis of the Secreted Proteins of the Parasite Haemonchus contortus Reveals Extensive Sequence Variation and Differential Immune Recognition. Journal of Biological Chemistry 278, 16941-16951.
180. Landsperger, W. J., Stirewalt, M. A., and Dresden, M. H. (1982) Purification and properties of a proteolytic enzyme from the cercariae of the human trematode parasite Schistosoma mansoni. The Biochemical journal 201, 137-144.

55
181. McKerrow, J. H., Pino-Heiss, S., Lindquist, R., and Werb, Z. (1985) Purification and characterization of an elastinolytic proteinase secreted by cercariae of Schistosoma mansoni. Journal of Biological Chemistry 260, 3703-3707.
182. McKerrow, J. H., and Doenhoff, M. J. (1988) Schistosome proteases. Parasitology today (Personal ed.) 4, 334-340.
183. Abdulla, M. H., Lim, K. C., Sajid, M., McKerrow, J. H., and Caffrey, C. R. (2007) Schistosomiasis mansoni: novel chemotherapy using a cysteine protease inhibitor. PLoS medicine 4, e14.
184. Wynn, T., Eltoum, I., Cheever, A., Lewis, F., Gause, W., and Sher, A. (1993) Analysis of cytokine mRNA expression during primary granuloma formation induced by eggs of Schistosoma mansoni. The Journal of Immunology 151, 1430-1440.
185. Cheever, A., Williams, M., Wynn, T., Finkelman, F., Seder, R., Cox, T., Hieny, S., Caspar, P., and Sher, A. (1994) Anti-IL-4 treatment of Schistosoma mansoni-infected mice inhibits development of T cells and non-B, non-T cells expressing Th2 cytokines while decreasing egg-induced hepatic fibrosis. The Journal of Immunology 153, 753-759.
186. Grzych, J., Pearce, E., Cheever, A., Caulada, Z., Caspar, P., Heiny, S., Lewis, F., and Sher, A. (1991) Egg deposition is the major stimulus for the production of Th2 cytokines in murine schistosomiasis mansoni. The Journal of Immunology 146, 1322-1327.
187. Kaplan, M. H., Whitfield, J. R., Boros, D. L., and Grusby, M. J. (1998) Th2 Cells Are Required for the Schistosoma mansoni Egg-Induced Granulomatous Response. The Journal of Immunology 160, 1850-1856.
188. Ramaswamy, K., Salafsky, B., Potluri, S., He, Y. X., Li, J. W., and Shibuya, T. (1995) Secretion of an anti-inflammatory, immunomodulatory factor by Schistosomulae of Schistosoma mansoni. Journal of inflammation 46, 13-22.
189. Stein, L. D., and David, J. R. (1986) Cloning of a developmentally regulated tegument antigen of Schistosoma mansoni. Molecular and Biochemical Parasitology 20, 253-264.
190. Jeffs, S. A., Hagan, P., Allen, R., Correa-Oliveira, R., Smithers, S. R., and Simpson, A. J. G. (1991) Molecular cloning and characterisation of the 22-kilodalton adult Schistosoma mansoni antigen recognised by antibodies from mice protectively vaccinated with isolated tegumental surface membranes. Molecular and Biochemical Parasitology 46, 159-167.
191. El-Ahwany, E., Bauiomy, I.R., Nagy, F., Zalat, R., Mahmoud, O., Zada, S. (T Regulatory Cell Responses to Immunization with a Soluble Egg Antigen in Schistosoma mansoni-Infected Mice) 2012. Korean J Parasitol 50, 29-35.
192. Kasschau, M. R., and Dresden, M. H. (1986) Schistosoma mansoni: Characterization of hemolytic activity from adult worms. Experimental Parasitology 61, 201-209.
193. Chappell, C. L., and Dresden, M. H. (1987) Purification of cysteine proteinases from adult Schistosoma mansoni. Archives of Biochemistry and Biophysics 256, 560-568.

56
194. Chappell, C. L., and Dresden, M. H. (1986) Schistosoma mansoni: Proteinase activity of hemoglobinase from the digestive tract of adult worms. Experimental Parasitology 61, 160-167.
195. Brindley, P. J., Kalinna, B. H., Dalton, J. P., Day, S. R., Wong, J. Y. M., Smythe, M. L., and McManus, D. P. (1997) Proteolytic degradation of host hemoglobin by schistosomes. Molecular and Biochemical Parasitology 89, 1-9.
196. Ring, C. S., Sun, E., McKerrow, J. H., Lee, G. K., Rosenthal, P. J., Kuntz, I. D., and Cohen, F. E. (1993) Structure-based inhibitor design by using protein models for the development of antiparasitic agents. Proceedings of the National Academy of Sciences 90, 3583-3587.
197. Wasilewski, M. M., Lim, K. C., Phillips, J., and McKerrow, J. H. (1996) Cysteine protease inhibitors block schistosome hemoglobin degradation in vitro and decrease worm burden and egg production in vivo. Molecular and Biochemical Parasitology 81, 179-189.
198. Brophy, P. M., and Barrett, J. (1990) Glutathione transferase in helminths. Parasitology 100, 345-349.
199. Ketterer, B., Meyer, D.J., Clark, A.G., ed. (1989) Soluble glutathione transferase isozymes, Academic Press, London.
200. Mannervik, B., Alin, P., Guthenberg, C., Jensson, H., Tahir, M. K., Warholm, M., and Jörnvall, H. (1985) Identification of three classes of cytosolic glutathione transferase common to several mammalian species: correlation between structural data and enzymatic properties. Proceedings of the National Academy of Sciences 82, 7202-7206.
201. Xu, C.-B., Verwaerde, C., Grzych, J.-M., Fontaine, J., and Capron, A. (1991) A monoclonal antibody blocking the Schistosoma mansoni 28-kDa glutathione S-transferase activity reduces female worm fecundity and egg viability. European Journal of Immunology 21, 1801-1807.
202. Smith, D. L., and Zhang, Z. (1994) Probing noncovalent structural features of proteins by mass spectrometry. Mass Spectrometry Reviews 13, 411-429.
203. Pearce, E. J., and MacDonald, A. S. (2002) The immunobiology of schistosomiasis. Nature reviews. Immunology 2, 499-511.
204. The Schistosoma japonicum Genome Sequencing and Functional Analysis Consortium. (2009) The Schistosoma japonicum genome reveals features of host-parasite interplay. Nature 460, 345-351.


















