
Propagazione degli errori di sensibilit awebusers.fis.uniroma3.it/liquidsgroup/didattica/Analisi dei...
22
Propagazione degli errori di sensibilit` a Esercitazione 10 ottobre 2003 1 Dimensione e unit` a di misura di una grandezza I valori assunti da una grandezza fisica sono specificati da un numero e da un’unit` a di misura. L’unit` a di misura corrisponde alla dimensione 2 (indicata con [ ]) della grandezza 3 . Ad esempio [p(pressione)] = h F (forza) S(superficie) i = MLT -2 L 2 = ML -1 T -2 Pa = N m 2 = kg m s -2 m 2 = kg m -1 s-2 Spesso vengono usati multipli o sottomultipli (che possono agevolmente essere scritti in termini delle unit` a del S.I. attraverso la notazione scientifica 4 ) (1 GPa= 10 6 Pa 1 μPa= 10 -6 Pa) o unit` a diverse (1 atm=1.012 · 10 5 Pa 1 mmHg= 1 760 atm= 1.33 · 10 -3 Pa). Misure dirette e indirette Una grandezza y ` e misurata indirettamente se si pu` o esprimere in funzione di quantit` a x 1 ,x 2 ,x 3 ,...,x n misurate direttamente 5 : y = f (x 1 x 2 ,x 3 ,...,x n ). (1) Esempio 1 n =2 x1 = M (massa) x2 = ag (accelerazione di gravit` a) y = Fp (forza peso) Fp = f (M,ag )= M · ag Se M =1.0mg ag =9.8ms -2 ⇒ Fp =9.8 · 10 -6 ms -2 kg =9.8N . Propagazione degli errori di sensibilt` a Le grandezze misurate direttamente sono affette da errori di sensibilit` a, dovuti alla sensibilit` a e alla risoluzione dello strumento di misura. M = (1.000 ± 0.001) mg ag = (9.81 ± 0.01)ms -2 . Come questi errori determinano l’errore di sensibilit` a sulla misura indiretta? Si ricordi che la variazione di una funzione rispetto alla variazione di un suo argomento ` e, per definizione, la derivata parziale rispetto a quella variabile (vedi Tab. 1 per le regole di calcolo delle derivate) dy |{z} variazione di y = ∂f ∂x 1 x 2 ...xncost | {z } come varia y rispetto a x 1 , se x 2 ...x n non variano dx 1 |{z} variazione di x 1 + ∂f ∂x 2 x 1 ,x 3 ...xncost dx 2 +···+ ∂f ∂x n x 1 ,x 2 ...x n-1 cost dx n 1 Per segnalazioni di errori, critiche e suggerimenti, scrivere a mancinelli@fis.uniroma3.it . 2 Esistono grandezze adimensionali come gli angoli che hanno comunque un’unit` a di misura (i radianti sono il rapporto tra lunghezze, un grado ` e la 360esima parte di un angolo giro (2π radianti)). E’ sempre adimensionale l’argomento di funzioni trigonometriche, esponenziali, logaritmiche. 3 M=massa, L=lunghezza, T =tempo 4 In potenze positive o negative di 10. 5 In linguaggio matemetico y ` e chiamata variabile dipendente, x 1 ...xn variabili indipendenti.
Transcript of Propagazione degli errori di sensibilit awebusers.fis.uniroma3.it/liquidsgroup/didattica/Analisi dei...

1
Propagazione degli errori di sensibilitaEsercitazione 10 ottobre 20031
Dimensione e unita di misura di una grandezzaI valori assunti da una grandezza fisica sono specificati da un numero e da un’unita
di misura. L’unita di misura corrisponde alla dimensione2 (indicata con [ ]) dellagrandezza3.
Ad esempio
[p(pressione)] =[
F(forza)S(superficie)
]= MLT−2
L2 = ML−1T−2
Pa = Nm2 = kg m s−2
m2 = kg m−1 s−2
Spesso vengono usati multipli o sottomultipli (che possono agevolmente esserescritti in termini delle unita del S.I. attraverso la notazione scientifica4)
(1 GPa= 106 Pa 1 µPa= 10−6 Pa)
o unita diverse(1 atm=1.012 · 105 Pa 1 mmHg= 1
760atm= 1.33 · 10−3 Pa).
Misure dirette e indiretteUna grandezza y e misurata indirettamente se si puo esprimere in funzione di
quantita x1, x2, x3, . . . , xn misurate direttamente5:
y = f(x1x2, x3, . . . , xn). (1)
Esempio 1
n = 2 x1 = M (massa) x2 = ag (accelerazione di gravita) y = Fp (forza peso)
Fp = f(M,ag) = M · ag
Se M = 1.0mg ag = 9.8ms−2 ⇒ Fp = 9.8 · 10−6ms−2kg = 9.8N.
Propagazione degli errori di sensibiltaLe grandezze misurate direttamente sono affette da errori di sensibilita, dovuti
alla sensibilita e alla risoluzione dello strumento di misura.M = (1.000± 0.001) mg ag = (9.81± 0.01)ms−2.
Come questi errori determinano l’errore di sensibilita sulla misura indiretta?
Si ricordi che la variazione di una funzione rispetto alla variazione di un suoargomento e, per definizione, la derivata parziale rispetto a quella variabile (vediTab. 1 per le regole di calcolo delle derivate)
dy︸︷︷︸variazione
di y
=∂f
∂x1
∣∣∣∣x2...xncost︸ ︷︷ ︸
come varia y rispetto a x1,se x2 . . . xn non variano
dx1︸︷︷︸variazione
di x1
+∂f
∂x2
∣∣∣∣x1,x3...xncost
dx2+· · ·+ ∂f
∂xn
∣∣∣∣x1,x2...xn−1cost
dxn
1Per segnalazioni di errori, critiche e suggerimenti, scrivere a [email protected] .2Esistono grandezze adimensionali come gli angoli che hanno comunque un’unita di misura (i radianti sono il
rapporto tra lunghezze, un grado e la 360esima parte di un angolo giro (2π radianti)). E’ sempre adimensionalel’argomento di funzioni trigonometriche, esponenziali, logaritmiche.
3M=massa, L=lunghezza, T=tempo4In potenze positive o negative di 10.5In linguaggio matemetico y e chiamata variabile dipendente, x1 . . . xn variabili indipendenti.

2
funzione f(x) derivata df(x)dx
xα α reale αxα−1
log x 1x
expx expxcosx − sinxsinx cosxtanx 1
(cos x)2
f(g(x)) f ′(g(x)) · g′(x)
d
dx(f · g) =
df
dxg +
dg
dxf
d
dx
(f
g
)=f ′g − fg′
g2
Tabella 1: Le piu frequenti derivate e regola di derivazione del prodotto e del quoziente di duefunzioni.
Supponendo gli errori di sensibilita “piccoli”, e naturale definire l’errore assoluto
sulla grandezza misurata indirettamente come
∆y =∣∣∣ ∂f∂x1
∣∣∣∆x1 +∣∣∣ ∂f∂x2
∣∣∣∆x2 + · · ·+∣∣∣ ∂f∂xn
∣∣∣∆xn
dove si prendono i valori assoluti delle derivate in quanto la variabilita di f ri-spetto a un suo argomento non puo che accrescere l’errore.
Tornando all’esempio 1: Fp = M · ag si ha
∆Fp = ∆M · ag +M ·∆ag.
Se M = (1.000± 0.001)mg ag = (9.81± 0.01)ms−2,
∆Fp = 10−9kg · 9.81ms−2 + 10−6kg · 0.01ms−2 = 2 10−8ms−2kg
da cui Fp = (9.81± 0.02)10−6ms−2kg.
L’errore relativo (o percentuale)6 di una grandezza x
∆x
|x|consente di valutare l’accuratezza di una misura e di compararla con quella di altremisure (cioe a prescindere dalle dimensioni delle varie misure).
Nell’esempio 1, non ha senso comparare ∆M = 0.001mg con ag = 0.01ms−2, ma dal calcolo
degli errori relativi∆M
M=
0.001
1.000= 0.1%
∆agag
=0.01
9.81' 0.1%
risulta che le due misure hanno lo stesso grado di accuratezza.
6E’ ovviamente una quantita adimensionale.

3
E’ utile ragionare in termini di errori relativi quando occorre valutare l’errore diuna grandezza misurata indirettamente, che si esprime come prodotto o quozientedi altre grandezze.
Infatti, se
y = xα11 x
α22 . . . xαnn
si ha7
∆y|y| = |α1|∆x1
|x1| + |α2|∆x2
|x2| + · · ·+ |αn|∆xn|xn|
Nell’esempio 1 si poteva procedere usando la formula sugli errori relativi (con α1 = 1 e α2 = 1)∆FpFp
= ∆MM
+∆agag
= 0.0011.000
+ 0.019.81
= 0.2%, Fp = 9.81 · 10−6ms−2kg ⇒ ∆Fp = 0.02 10−6ms−2kg
N.b.: il numero delle cifre significative negli errori di sensibilita e sempre uno(e il valore assunto dalla grandezza deve essere scritto in base all’errore).
Non avrebbe senso scrivere ∆Fp = 0.0198 10−6ms−2kg oppure Fp = (9.8100± 0.02)N!
Esempio 2Determinare con quale precisione occorre specificare π (π = 3.141592654..),affinche, dato il raggio di una sfera all’1%, la misura della superficie
della sfera sia affetta da un errore < 5%.
Soluzione.
S = 4πR2 =⇒ ∆S
S=
∆π
π+ 2
∆R
R
∆π
π+ 2 · 1% < 5% =⇒ ∆π
π< 3%, ∆π = 0.09.
∆π = 0.09 determina il numero di cifre significative di π, cioe π = 3.14 ± 0.09; taleprecisione e pertanto sufficiente per ottenere che la misura della superficie della sfera siaaffetta da un errore < 5%.
7Per la proprieta dei logaritmi log (xα11 xα2
2 ) = α1 log x1 + α2 log x2, valida per x1, x2 positivi e per ogni α1, α2
reali,dy
y= d log y = d log (xα1
1 xα22 ) = d(α1 log x1 + α2 log x2) = α1
dx1
x1+ α2
dx2
x2

4
Esempio 3La legge oraria di un oscillatore armonico e
x = x0 cos (ωt+ φ).
Sia ω =√
km
dove k = (5.0±0.1)10−1N/m e la costante elastica e m = (200± 4)hg
e la massa dell’oscillatore. Se φ = π6e x0 = (10.0 ± 0.2)cm con quale
sensibilita occorre misurare il tempo t ' 10s affinche x sia affetto da
un errore relativo del 15%? Quale valore assumono x e ∆x nel S.I.?
Soluzione.
Nel S.I. m = (20.0± 0.4)kg x0 = (1.00± 0.02)10−1m
ω = k0.5m−0.5 ⇒ ∆ω
ω= 0.5
∆k
k+0.5
∆m
m= 0.5
1
50+0.5
4
200= 2% ⇒ ω = (0.50±0.01)s−1
∆x
x=
∆x0
x0
+∆ cos (ωt+ φ)
| cos (ωt+ φ)| =∆x0
x0
+| sin (ωt+ φ)(t∆ω + ω∆t)|
| cos (ωt+ φ)|Essendo t,∆t, ω,∆ω positivi | sin (ωt+ φ)(t∆ω +ω∆t)| = | sin (ωt+ φ)|(t∆ω +ω∆t)e
∆x
x=
∆x0
x0
+ | tan (ωt+ φ)|(t∆ω + ω∆t)
15% =0.2
10+| tan (0.5 · 10 + π/6)|·10·0.01+| tan (0.5 · 10 + π/6)|·0.5·∆t ⇒ ∆t = 0.7s
x = 0.1m cos (0.50 · 10 + π/6) ' 0.0725m ⇒ ∆x = 0.01m ⇒ x = (7±1)10−2m
Esercizio 1Un escursionista scala una montagna percorrendo, in base alla difficolta
del territorio, dai 250 ai 350 m l’ora. Determinare la durata della sua
escursione se la vetta e a 2170m e al punto di partenza il suo altimetro
segna una quota di (1400± 10)m.
(Ris. t = 2h30′ ± 30′)
Esercizio 2Una popolazione di batteri cresce secondo una legge
N = N0 exp (t
τ).
Se il numero iniziale di batteri e (1.00±0.02)106 e τ = (20±5)min, quanto
tempo occorre aspettare affinche il loro numero sia di (1.0± 0.1)108?
(Ris. t = (90± 30)min)

5
Distribuzioni discreteEsercitazione 14 novembre 20038
Distribuzione binomiale
Si fa un esperimento (o prova): puo manifestarsi un certo evento A con probabilitap oppure no (con probabilita q = 1 − p). La distribuzione binomiale descrive laprobabilita che su N prove indipendenti si ottenga x volte l’evento A e percio:
PN,p(x) =
(Nx
)px(1− p)N−x.
Il valor medio della distribuzione, cioe il numero medio di eventi di tipo A, e
µ = E(x) =∑
x
xPN,p(x) = Np.
La deviazione standard, che da una misura dell’errore statistico, e
σ2 = E((x− µ)2) = Np(1− p).
Si dice che si stima9 il valor medio al x% se√σ2
µ= x%.
Poiche nel caso della distribuzione binomiale√σ2
µ=√NpqNp
=√
Npq(Np)2 = q√
Np, se N ↗
la stima si fa sempre piu precisa.
Esempio 1 (equivalenza tra metodo ‘‘classico’’ e prescrizione binomiale)
Qual’e la probabilita che in 3 lanci di una moneta esca due volte croce?
Le possibili terne sono 23: TTT TTC TCT TCC CTT CTC CCC CCT, avendo indicato conC croce e con T testa.Di queste 3 contengono la coppia CC: TCC CTC CCT. La probabilita richiesta e pertanto
casi favorevoli
casi possibili=
3
23.
Analogamente si puo procedere con la formula della distribuzione binomiale. In questo esempiol’esperimento (o prova) e il lancio, l’evento A e l’uscita di croce (C), N = 3, x = 2 e la probabilita passociata ad A e 1
2 . L’evento complementare, cioe testa, T, ha la stessa probabilita, q = p. Usandola formula della distribuzione binomiale, la probabilita richiesta e
P3, 12(2) =
(32
)(1
2
)2(1
2
)1
.
8Per segnalazioni di errori, critiche e suggerimenti, scrivere a [email protected] .9Nota che la stima e l’equivalente statistico dell’errore relativo.

6
Esempio 2 (fortuna e pregiudizio)
Si gioca con un dado, che e stato truccato a nostra insaputafaccia 1 2 3 4 5 6
probabilta 0.2 0.1 0.2 0.1 0.1 0.3Qual’e la probabilita di vincere almeno una volta su 3 scommesse, puntando sempre sul
6? Come posso rendermi conto di essere stato truffato (anche se a mio favore)?
La probabilta che esca 6 e p = 0.3, che non esca q = 0.7. Posso vincere una, due o tre volte sutre scommesse, la probabilita di tale evento (disgiunzione di eventi indipendenti) e
P3,0.3(1) + P3,0.3(2) + P3,0.3(3) =
(31
)0.310.72 +
(32
)0.320.71 +
(33
)0.330.70 = 0.657
Se il dado non fosse stato truccato tale probabilita sarebbe stata
P3, 16(1)+P3, 16
(2)+P3, 16(3) =
(31
)0.16710.8332+
(32
)0.16720.8331+
(33
)0.16730.8330 = 0.422
Alla fine delle tre scommesse, forse, potro dire di essere stato fortunato, ma non che il dado etruccato perche su tre prove c’e, chiaramente, un disaccordo tra frequenze sperimentali e probabilitateoriche (la situazione piu “equa” sarebbe, comunque, che uscissero tre facce diverse, allora questetre avrebbero frequenza 1/3 e le altre tre frequenza 0?!), cioe potro avanzare sospetti solo dopo unnumero consistente di scommesse (e non e detto che, in generale, mi convenga!).
Osservazione Cosa significa numero consistente di prove? Sara molto probabile che, per N sufficien-temente grande, il numero medio di volte in cui e uscito 6 sia nell’intervallo [µ −
√σ2, µ +
√σ2]. Se per
il dado truccato p∗ = 0.3 e quindi µ∗ = Np∗ e σ∗2 = Np∗(1 − p∗), per il dado “regolare” p = 0.167 eµ = Np e σ2 = Np(1 − p). I due intervalli in cui puo cadere il numero medio di 6 sono, rispettivamente,[µ∗−
√σ∗2, µ∗+
√σ∗2] e [µ−
√σ2, µ+
√σ2]. Se i due intervalli sono disgiunti (e lo diventeranno al crescere
di N in quanto il valor medio e stimato con precisione via via maggiore) allora sara ragionevole dire che ildado e truccato. Questo corrisponde alla condizione
µ+√σ2 < µ∗ −
√σ∗2 =⇒ N >
(√pq +
√p∗q∗
p− q
)2
.
Nel caso in esame se N > 40.

7
Distribuzione poissoniana
Esistono fenomeni in cui non si possono numerare le prove e testare se in ognunasi e verificato un certo evento o meno. L’unica informazione data e un qualchenumero medio di eventi (in un certo intervallo di tempo) m. Pensate ad esempioal decadimento del carbonio 14 di cui si conosce solo la vita media e non ha sensoparlare ne di numero di prove N ne di probabilita p. m e percio l’unico parametroda cui puo dipendere la distribuzione di probabilita associata a questa categoria difenomeni.
La distribuzione poissoniana descrive la probabilita che, dato m numero mediodi eventi di un certo tipo, se ne verifichino x di quel tipo e
Pm(x) = e−mmx
x!.
In questo caso il valor medio e, per ipotesi, µ = E(x) =∑
x xPm(x) = m,la deviazione standard e σ2 = E((x− µ)2) = m.Puo darsi sia dato il numero medio di eventi in un certo periodo T e vengano richiesteinformazioni relative ad un altro periodo di tempo T’. Occorre allora passare per ilflusso (numero di eventi nell’unita di tempo) φ, che e legato a m dalla mT = µT =σ2T = φT da cui φ = mT
T, da cui mT ′ = µT ′ = σ2
T ′ = φT ′ = mTT ′T
. Se T ′ > T allorala stima al tempo T ′ sara migliore di quella al tempo T:
√σ2T
µT=
1√φT
>1√φT ′
=
√σ2T ′
µT ′.
Esempio 3
Il numero di telefonate che ricevo in 12 mesi e il numero di quelle in cui hanno sbagliato
a digitare il numero e:
mesi GEN FEB MAR APR MAG GIU LUG AGO SET OTT NOV DIC
n◦ telefonate 101 95 88 99 93 80 112 67 114 87 92 108
n◦ t. sbagliate 1 1 0 1 2 0 3 0 1 1 0 2Quante telefonate sbagliate mi aspetto di ricevere in un mese di 31 giorni? Qual’e
la probabilita di ricevere non piu di 2 telefonate sbagliate in una settimana?
Ricevo nei 12 mesi 1136 telefonate di cui 12 sbagliate. Il numero medio di telefonate sbagliatein un mese di 31 giorni e percio n31 = 12
36531 = 1.02Il numero medio di telefonate sbagliate in una settimana e m = 12
3657 = 0.23. La probabilita diricevere non piu di 2 telefonate sbagliate in una settimana e dunque:
Pr{0 t.sb} + Pr{1 t.sb} + Pr{2 t.sb} = e−.23
(1 + 0.23 +
0.232
2
)= 0.998

8
Esempio 4
Una sorgente emette un flusso φ di 40.5 particelle al minuto. Quanti minuti devo aspettare
per conoscere il numero di particelle all’1%?
Il numero medio di particelle emesse in t minuti e Nt = tφ. Il rapporto tra deviazione standard
e numero medio di particelle e√NtNt
= 1√Nt
. Quindi t = 1φ(1%)2 = 247min.
Esempio 5
Se conosco al 2% il numero medio di incidenti in un mese dopo 12 mesi di osservazioni,
per quanti mesi devo registrarne il numero per avere una stima all’1%?
Il rapporto tra deviazione standard e numero medio di incidenti al mese m1 nei 12 mesi e1√
m112 mesi= 2%, da cui m1 = 1
0.02212 . Dopo x mesi si raggiunge una stima all’1% se 1√m1x mesi
=
1%, da cui x = 10.012m1
. Sostituendo in quest’ultima m1 si ottiene x = 48 mesi = 4 anni.

9
Approssimazione di una binomiale con una poissoniana
Si considerino N prove indipendenti in cui puo verificarsi un certo evento A conprobabilita p. Il numero totale di eventi A, detto x, su N prove e distribuito secondo
la legge binomiale PN,p(x) =
(Nx
)px(1− p)N−x.
Si dimostra che, nel limite di N → ∞ e p → 0, con m = Np finito e non nullo, ladistribuzione binomiale tende ad una distribuzione poissoniana di parametro m eargomento x:
PN,p(x) −→ Pm(x) = e−mmx
x!.
Esempio 6
In media 2 provette su 100 prodotte da una fabbrica di vetri risultano fallate. Per
i 10 studenti di una classe di laboratorio, l’universita ne acquista 12. Qual’e la
probabilita che tutti gli studenti ne abbiano una?
Tutti gli studenti ne hanno una se al massimo 2 sono rotte, quindi la probabilita e:
Pr(2rotte)+Pr(1rotta)+Pr(0rotte) =
(122
)0.0220.9810+
(121
)0.0210.9811+
(120
)0.0200.9812 = 0.99846
Proviamo ad approssimare con la distribuzione poissoniana. Il numero medio di provette rotte su12 e
m = Np = 2%12 = 0.24.
In questo schema
Pr(2rotte) + Pr(1rotta) + Pr(0rotte) =0.242e−0.24
2!+
0.241e−0.24
1!+
0.240e−0.24
0!= 0.99807,
ovvero l’approssimazione e molto buona.
Cio che si vede in generale e che l’approssimazione funziona se:
p� 0.1 e m = pN � 5.
Osservazione Data una distribuzione poissoniana, specificata da un parametrom, e vicersa impossibile
individuare univocamente N e p tali che m = Np e fare una trattazione binomiale del problema.
Per illustrare un possibile errore torniamo all’esempio 3, che NON si puo trattare con una distribuzione
binomiale. Non ha senso pensare: la probabilita di ricevere una telefonata sbagliata in un giorno e p =12365
; in 7 giorni posso ricevere 0,1 o, al massimo, 2 telefonate sbagliate, quindi la probabilita richiesta e(70
)p0(1 − p)7 +
(71
)p1(1 − p)6 +
(72
)p2(1 − p)5, perche tale procedimento funzionerebbe solo
qualora sapessi di ricevere 7 telefonate nei 7 giorni, e questo non e specificato nel testo.

10
Esercizio 1
Un passaggio a livello si abbassa ogni 30 minuti per 5 minuti. Qual’e la probabilita
di trovarlo abbassato sempre, transitandovi una volta a giorno per 15 giorni? E di
trovarlo abbassato per 5 giorni consecutivi almeno una volta al giorno, passandovi
due volte al giorno? Perche non e possibile risolvere l’esercizio usando la distribuzione
poissoniana?[R. 2 · 10−13. 0.6%. Perche p > 0.1.]
Esercizio 2
Una comitiva di 4 persone va ad una sala da booling dove ci sono 8 piste. Il n◦ medio
di piste occupate a quell’ora e 6. Qual’e la probabilita che debbano aspettare? E
se le piste occupate fossero in media 8 e le comitive 2, quale sarebbe la probabilita
che entrambe debbano aspettare?[R. 10.3%.19.5%.]
Esercizio 3
In una popolazione, la percentuale di portatori sani di una certa caratteristica genetica
e 0.8%. Su un campione di 10000 individui, qual’e la probabilita che almeno 2 siano
portatori?[R.1− (P80(0) + P80(1)) ' 1.]

11
Distribuzioni discrete (II parte)Esercitazione 27 novembre 200310
Esempio 7
Su 1060 clienti di un ipermercato 53 si sono rivolti all’ufficio reclami. In un emporio,
su 257 acquirenti il 95% si e detto soddisfatto. Dove conviene acquistare? Perche?
In entrambi i casi, il 95% e soddisfatto (q = 0.95), il 5% no (p = 0.05). Ma, dato il maggiornumero di clienti (Niper = 1060), la stima e migliore nel caso dell’ipermercato. Infatti la stima e
data al √σ2
µ=
√q√Np
=
{13.4% per l’ipermercato27.2% per l’emporio
.
Esempio 8
In un certo comune, il numero di bambini nati nel 2002 supera del 20% quello delle
bambine. Se la stima e fatta all’incirca all’1.6%, determinare il numero di bambini
(maschi e femmine) nati nel 2002 e la probabilita che, considerando 4 famiglie con
due figli ciascuna, in almeno una siano piu bambine che bambini.
Se p e la probabilita che nasca un bambino e q quella che nasca una bambina
{p+ q = 1p− q = 0.2
da cui p = 0.6 e q = 0.4.
Essendo√q√Np
= 1.6% si ha N = q2
(1.6%)2p = 2604.
Relativamente ad una famiglia dividiamo i casi in: 2F (2 bambine), 1F 1M (1 bambina e 1bambino), 2M (due bambini). L’evento 2F, che e quello di riferimento, cioe che, in una famiglia,“ci sono piu bambine” ha probabilita
pFF =
(2
2
)0.420.60 = 0.16
l’evento complementare ha probabililita
qFF = 1− pFF = 0.84
ovvero
pMF + pMM =
(2
1
)0.410.61 +
(2
0
)0.400.62 = 0.84.
La probabilita che in almeno una delle 4 famiglie ci siano piu bambine e uguale alla probabilitadell’evento complementare a: “in tutte le famiglie ci sono o piu bambini o lo stesso numero dibambini e bambine”, cioe:
1−(
4
0
)0.1600.844 = 50.2%.
Analogo risulato se si calcola la somma della probabilita degli eventi disgiunti: “in 1 famiglia piubambine”, “in 2 famiglie piu bambine”, “in 3 famiglie piu bambine”, “in 4 famiglie piu bambine”
(4
1
)0.1610.843 +
(4
2
)0.1620.842 +
(4
3
)0.1630.841 +
(4
4
)0.1640.840 = 50.2%.
10Per segnalazioni di errori, critiche e suggerimenti, scrivere a [email protected] .

12
Esempio 9
Durante l’ora di religione mi assento in media 1 volta su 10. Il corso e di 60 ore
e il preside supplisce l’insegnante 1 volta ogni 6 ore. Qual’e la probabilita di essere
espulsa alla seconda assenza ingiustificata? Quale sarebbe stata la probabilita se
avessi saputo (anziche che il preside sostituisce l’insegnante 1 volta ogni 6 ore)
che la probabilita che il preside sostituisca l’insegnante e 16?
In 6 ore la probabilita che ci sia il preside e: 166 = 1 (cioe l’evento e certo); che io sia assente
(almeno una volta nei 6 giorni): 1− e−0.6 (essendo µ6 = 1106 il numero medio delle ore in cui sono
assente in 6 ore). L’evento congiunto ha probabilita p6 = 1 − e−0.6. Non verro espulsa solo seil preside mi trovera sempre nelle 60 ore o al piu una volta non mi trovera una volta; quindi laprobabilita di essere espulsa e:
1−(
10
0
)p0
6(1− p6)10 −(
10
1
)p1
6(1− p6)9
Se si fosse avuta, invece, l’informazione che la probabilita che ci sia il preside e 16 , la probabilita
di un’assenza ingiustificata in un’ora sarebbe stata p1 = 1 − e−0.6 · 16 , e la probabilita di essere
espulsa sarebbe stata
1−(
60
0
)p0
1(1− p1)60 −(
60
1
)p1
1(1− p1)59,
cioe molto piu alta.D’altra parte nel primo caso e piu prevedibile la venuta del preside (esattamente una volta ogni 6ore)!
Esempio 10
In un condominio ci sono 12 appartamenti di 70 m2. La probabilita di trovare una
formica e del 5% per m2. Qual’e la probabilita di trovare in 2 appartamenti un numero
di formiche pari al numero atteso? Qual’e la probabilita che in almeno un appartamento
del condominio non vi siano formiche?
Il numero atteso di formiche in due appartamenti e: 5% · 70 · 2 = 7. La probabilita di trovare
un numero di formiche pari al numero atteso e P7(7) = e−7 77
7! = 14.9%.Dobbiamo ora calcolare la probabilita dell’evento complementare di “in tutti e 12 gli apparta-
menti c’e almeno una formica”.La probabilita che in un appartamento ci sia almeno una formica e
a = 1− e−3.5 (poiche e−3.5 3.50
0! e la probabilita che non ce ne sia nessuna). La probabilita che “in
tutti e 12 gli appartamenti ci sia almeno una formica” e b =(
1212
)a12(1− a)0. Quindi la probabilita
che in almeno un appartamento non ci siano formiche e 1− (1− e−3.5)12 = 30.8%.

13
Da Schaum’s- “Probabilita e statistica”Esercizio 4
Determinare la probabilita che, in un lancio di 6 monete truccate, si verifichi 2 o
piu volte ‘‘testa’’; meno di 4 volte ‘‘croce’’. [R. 5764;
2132]
Esercizio 5
Se il 3% di elettrodomestici costruiti da una fabbrica sono difettosi, determinare
la probabilita che in un campione di 100 elettrodomestici (a) piu di 5; (b) tra 1 e
3; (c) 2 o meno di 2 elettrodomestici siano difettosi[R.8.4%, 59.7%, 42.3%]
Esercizio 6
Di 800 famiglie con 5 figli quante in media avranno (a) 3 figli maschi; (b) 5 figlie
femmine; (c) 2 o 3 maschi? (Si assuma che la probabilita di maschi e femmine sia la
stessa) [R. 250, 25, 500]
Esercizio 7
Determinare la probabilita di rispondere correttamente almeno 6 volte su 10 di un esame
‘‘si o no’’.[R. 193512]
Esercizio 8
Un’urna contiene 1 pallina rossa e 7 bianche. Si estrae una pallina, si vede il colore
e si rimette nell’urna. Determinare che in 8 estrazioni si scelga 3 volte la rossa.
Si puo utilizzare la distribuzione binomiale? Perche?[R. 6%]
Per riflettere...da G. Lolli “Il riso di Talete” -Bollati Boringhieri
Esercizio 9
Un test per diagnosticare un’allergia, la cui incidenza sulla popolazione e di 1/1000,
ha un tasso di risposte false positive pari al 5% (e nessuna risposta falsa negativa);
qual’e la probabilita che una persona, che e risultata positiva a tale test, abbia
effettivamente la malattia diagnosticata?[R.1/51]
Esercizio 10
Se in una popolazione di insetti, la percentuale di maschi(M) e leggermente maggiore
di quelle delle femmine(F), qual’e la sequenza piu probabile in un campione di 6 elementi
scelti a caso: MMMMMM FFFFFF FMMFFFM?

14
Errata corrige Nel file “Distribuzioni discrete1.pdf” a pag.1 (nel periodo prima dell’esempio 1)
c’e un errore nel calcolo della stima nella binomiale: occorre correggere√σ2
µ =√q√Np
con√σ2
µ =√q√Np
.
Soluzioni esercizi dall’1. al 3. (testi in “Distribuzioni discrete1.pdf”)1. p = 5/35 = 14.3%, N = 15, P (15) = 0.14315 ' 2 · 10−3
Lo trovo abbassato 1 o 2 volte al giorno con probabilita:
pr =
(2
1
)pq +
(2
2
)p2q0 = 0.27.
Cio succede per 5 giorni consecutivi tra 15 in 10 modi
10pr5(1− pr)10 = 0.6%.
Non si puo usare la distribuzione binomiale perche p > 0.1.
2. m = 6 quindi e−6 86
8!Il secondo quesito non si puo risolvere usando la distribuzione binomiale.
3. m = 0.8%10000 = 80 La probabilita richiesta e percio 1− e−80( 800
0! + 801
1! ) ' 1.

15
Propagazione degli errori statistici.
Test del χ2 per la bonta di adattamento.Metodo dei minimi quadrati.
Esercitazione 14 gennaio 200411
Propagazione degli errori casualiSiano B1, . . . , BN delle variabili casuali con valori attesi µB1 , . . . , µBN e deviazioni
standard σB1 , . . . , σBN . Si ricordi che gli errori statistici sono dati con due cifresignificative e il troncamento su un valore atteso deve essere operato con un numerodi cifre decimali uguale a quello dell’errore statistico corrispondente.
Sia A una variabile definita in funzione di B1 . . . BN :
A = V (B1, . . . , BN).
Da semplici calcoli, risulta che il valore aspettato di A e:
µA = V (µB1 , . . . , µBN ) +12
∑x=B1,...,BN
∂2V∂x2
∣∣∣µB1
,...,µBN
σ2x
e la deviazione standard:
σA =
√∑
x=B1,...,BN
(∂V∂x
∣∣µB1
,...,µBN
)2
σ2x
Il secondo addendo a destra nella formula del valore aspettato e correttivo rispettoal primo addendo. Pertanto nei calcoli e spesso trascurato.
Esempio
Siano B = 22.35m, C = 876cm, D = 323s e σB = 0.15m, σC = 11cm, σD =22s. Si determinino il valore aspettato e la deviazione standard di
A =3(B − C)
D2.
R. Si calcolano le derivate parziali:∂A∂B
= 3D2
∂A∂C
= − 3D2
∂A∂D
= −6(B−C)D3
∂2A∂B2 = 0 ∂2A
∂C2 = 0 ∂2A∂D2 =
18(B−C)D4 , da cui:
µA =3(µB − µC)
µ2D
+1
2
18(µB − µC)
µ4D
σ2D = 3.91 · 10−4m
s2
σA =
√9
D4(σ2
B + σ2C) +
36(B − C)2
D6σ2D = 0.54 · 10−4m
s2.
Si noti che 12
18(µB−µC)
µ4D
σ2D = 5.44 10−6 m
s2� 3(µB−µC)
µ2D
= 3.91 · 10−4 ms2, percio
µA ' 3(µB−µC)
µ2D
.
11Per segnalazioni di errori, critiche e suggerimenti, scrivere a [email protected] .
16
Test del χ2
La variabile chi quadro χ2
Siano z1 . . . zν variabili gaussiane standardizzate12. Si definisce
χ2 =
ν∑
i=1
z2i .
Risulta che la funzione di distribuzione di χ2 e
f(χ2) =1
Γ( ν2 )
(χ2
2
) ν2−1
e−χ2
21
2.
2 4 6 8 10 12 14 16 18 20
f(χ2
)
χ2
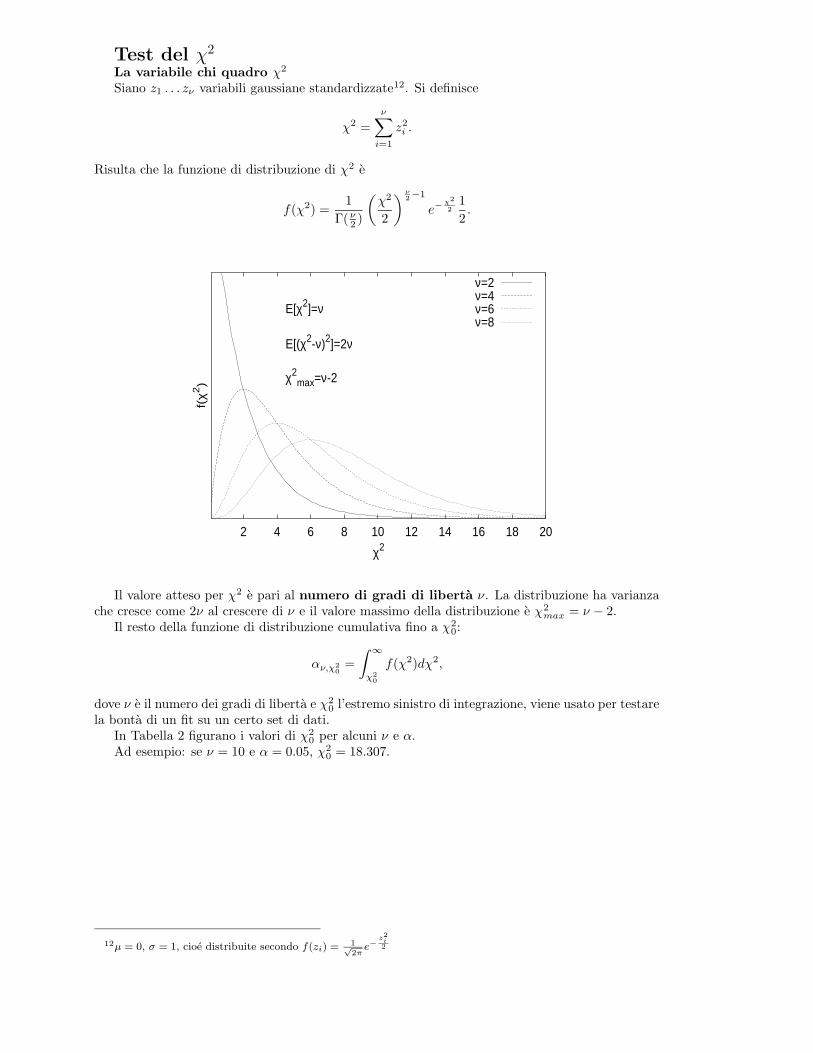
E[χ2]=ν
E[(χ2-ν)2]=2ν
χ2max=ν-2
ν=2ν=4ν=6ν=8
Il valore atteso per χ2 e pari al numero di gradi di liberta ν. La distribuzione ha varianzache cresce come 2ν al crescere di ν e il valore massimo della distribuzione e χ2
max = ν − 2.Il resto della funzione di distribuzione cumulativa fino a χ2
0:
αν,χ20
=
∫ ∞
χ20
f(χ2)dχ2,
dove ν e il numero dei gradi di liberta e χ20 l’estremo sinistro di integrazione, viene usato per testare
la bonta di un fit su un certo set di dati.In Tabella 2 figurano i valori di χ2
0 per alcuni ν e α.Ad esempio: se ν = 10 e α = 0.05, χ2
0 = 18.307.
12µ = 0, σ = 1, cioe distribuite secondo f(zi) = 1√2πe−
z2i2
17
0
0.02
0.04
0.06
0.08
0.1
0.12
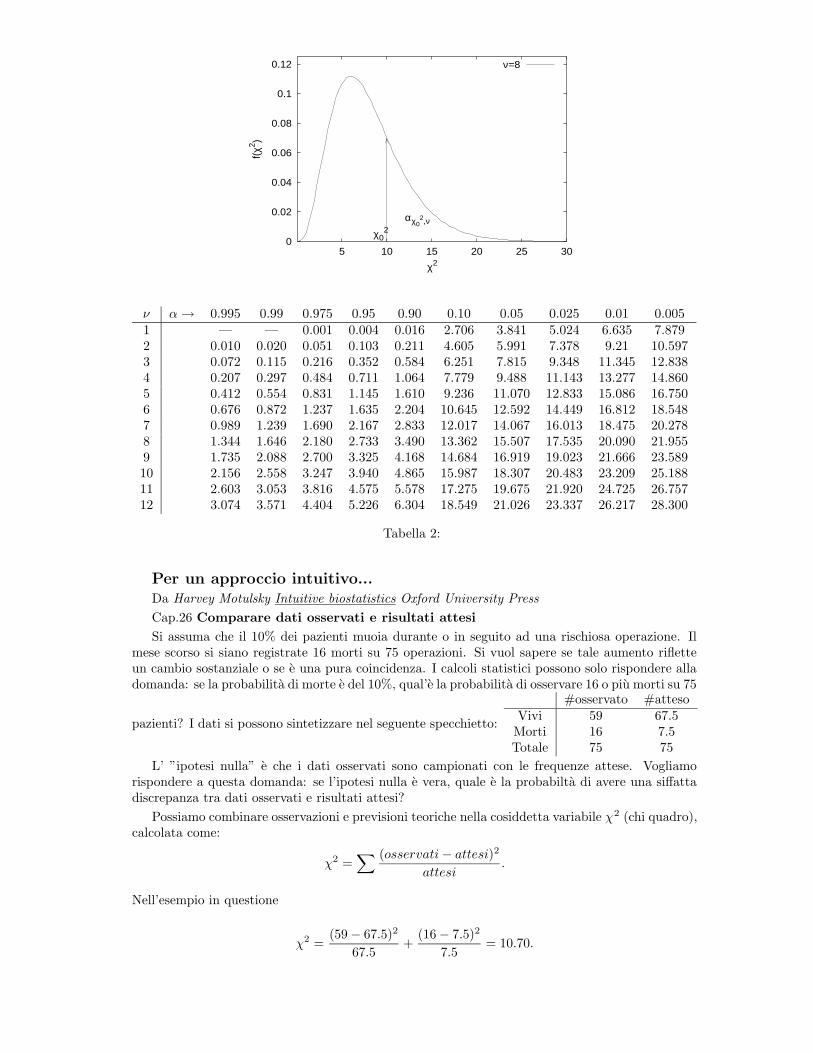
5 10 15 20 25 30f(
χ2 )χ2
χ02
αχ02,ν
ν=8
ν α→ 0.995 0.99 0.975 0.95 0.90 0.10 0.05 0.025 0.01 0.0051 — — 0.001 0.004 0.016 2.706 3.841 5.024 6.635 7.8792 0.010 0.020 0.051 0.103 0.211 4.605 5.991 7.378 9.21 10.5973 0.072 0.115 0.216 0.352 0.584 6.251 7.815 9.348 11.345 12.8384 0.207 0.297 0.484 0.711 1.064 7.779 9.488 11.143 13.277 14.8605 0.412 0.554 0.831 1.145 1.610 9.236 11.070 12.833 15.086 16.7506 0.676 0.872 1.237 1.635 2.204 10.645 12.592 14.449 16.812 18.5487 0.989 1.239 1.690 2.167 2.833 12.017 14.067 16.013 18.475 20.2788 1.344 1.646 2.180 2.733 3.490 13.362 15.507 17.535 20.090 21.9559 1.735 2.088 2.700 3.325 4.168 14.684 16.919 19.023 21.666 23.58910 2.156 2.558 3.247 3.940 4.865 15.987 18.307 20.483 23.209 25.18811 2.603 3.053 3.816 4.575 5.578 17.275 19.675 21.920 24.725 26.75712 3.074 3.571 4.404 5.226 6.304 18.549 21.026 23.337 26.217 28.300
Tabella 2:
Per un approccio intuitivo...Da Harvey Motulsky Intuitive biostatistics Oxford University Press
Cap.26 Comparare dati osservati e risultati attesi
Si assuma che il 10% dei pazienti muoia durante o in seguito ad una rischiosa operazione. Ilmese scorso si siano registrate 16 morti su 75 operazioni. Si vuol sapere se tale aumento rifletteun cambio sostanziale o se e una pura coincidenza. I calcoli statistici possono solo rispondere alladomanda: se la probabilita di morte e del 10%, qual’e la probabilita di osservare 16 o piu morti su 75
pazienti? I dati si possono sintetizzare nel seguente specchietto:
#osservato #attesoVivi 59 67.5
Morti 16 7.5Totale 75 75
L’ ”ipotesi nulla” e che i dati osservati sono campionati con le frequenze attese. Vogliamorispondere a questa domanda: se l’ipotesi nulla e vera, quale e la probabilta di avere una siffattadiscrepanza tra dati osservati e risultati attesi?
Possiamo combinare osservazioni e previsioni teoriche nella cosiddetta variabile χ2 (chi quadro),calcolata come:
χ2 =∑ (osservati− attesi)2
attesi.
Nell’esempio in questione
χ2 =(59− 67.5)2
67.5+
(16− 7.5)2
7.5= 10.70.

18
Per intuire la base della definizione del χ2, e utile vederla nella forma
χ2 =∑(
osservati− attesi√attesi
)2
.
Il rapporto tra dato sperimentale meno valore teorico corrispondente e l’errore statistico previsto(pari, nella statistica di Poisson alla radice quadrata del valore aspettato, cioe del valore teorico)e una variabile a media nulla e varianza pari a uno. La somma su tutti i dati di tali valori da unastima della bonta di adattamento della distribuzione teorica ai dati sperimentali.
Il valore di χ2 tende a crescere al crescere del numero di categorie. Il numero dei gradi di libertae, nell’esempio, pari al numero di categorie (2) meno 1 (e il vincolo che, una volta noto il numerototale di pazienti e quello di pazienti morti, si sa automaticamente quello dei pazienti vivi).
Dalla Tabella 2 (pag.17), che impareremo a leggere tra poco, risulta che la probabilita cheχ2 > 7.879 e < 5%. Tale risultato si induce a rigettare l’ipotesi nulla.
Si supponga che una certa serie di dati provenga da una certa distribuzione.
• Si stimano13, se necessario, i parametri della distribuzione teorica a partire daidati.
• Si confrontano le frequenze sperimentali con quelle previste dalla distribuzioneteorica attraverso le proprieta della variabile χ2.
1. Test del χ2 per distribuzioni discrete Siano x1 . . . xN i valori assunti confrequenze sperimentali f exp1 . . . f expN .Si fa un’ipotesi sulla distribuzione seguita. Ad esempio:-per un dado non truccato si assume p = 1/6;-oppure si stima il valore medio m di una poissoniana.Si calcolano le frequenze attese dalla distribuzione teorica f teo1 . . . f teoN .
Si costruisce lo schema:
x f exp f teo
x1 f exp1 f teo1
x2 f exp2 f teo2
.. .. ..xN f expN f teoN
e si calcola
χ2 =∑N
i=1(fexpi −f teoi )2
f teoi
χ2 segue approssimativamente14 la funzione di distribuzione del χ2 con unnumero di gradi di liberta pari a
ν = N − 1− v
dove N e il numero dei dati sperimentali, v e il numero dei parametri delladistribuzione teorica stimati a partire dai dati sperimentali, 1 corrisponde alvincolo della normalizzazione delle probabilita15.
13Si ricordi che la media x =∑Ni=1 xiN
e una stima incondizionata di µ e la varianza campionaria s2 =∑Ni=1(xi−x)2
N−1
di σ2.14La frequenza e per definizione una variabile binomiale; nel limite di un gran numero N di prove tende ad una
poissoniana con valore aspettato e varianza m = Np = f teo. La variabile(fexpi −fteoi )2
fteoitende percio ad essere una
variabile gaussiana standardizzata.15La probabilita e il rapporto frequenza diviso numero totale di eventi.

19
Si sceglie ora il livello di confidenza α (ad esempio il 5%), che significa dareuna misura di quanto si vuole che il test sia severo. Si ricava dalla Tabella 2χ2
0 tale che α = Pr{χ2 > χ20}. Se χ2 > χ2
0 il test e negativo.
Ad esempio: se ν = 5 e α = 0.05 χ20 = 11.070.
ν α→ 0.995 0.99 0.975 0.95 0.90 0.10 0.05 0.025 0.01 0.005
1 — — 0.001 0.004 0.016 2.706 3.841 5.024 6.635 7.8792 0.010 0.020 0.051 0.103 0.211 4.605 5.991 7.378 9.21 10.597.. .. .. .. .. .. .. .. .. .. ..
5 0.412 0.554 0.831 1.145 1.610 9.236 11.070 12.833 15.086 16.750
6 0.676 0.872 1.237 1.635 2.204 10.645 12.592 14.449 16.812 18.548.. .. .. .. .. .. .. .. .. .. ..
Esempio 1 (Schaum)
In 200 lanci di una moneta escono 115 teste e 85 croci. Si sottoponga
a test l’ipotesi che la moneta non e truccata, usando un livello di
significativita dello 0.05.
R.
x f exp(x) f teo(x)T 115 100
C 85 100
χ2 = (100−115)2
100+ (100−85)2
100= 4.50
Il numero dei gradi di liberta e ν = 2 − 1 = 1. Dalla Tabella 1
leggo: Pr{χ2 > 3.84} = 0.05, ma χ2 > 3.84 per cui, al livello di
confidenza stabilito, non si puo affermare che la moneta non sia truccata.
Esempio 2 (distribuzione poissoniana)
Un gruppo di galline allevate male viene osservato per 50 giorni consecutivi
trovando# uova deposte 0 1 2 3 4 5
# giorni 10 13 13 8 4 2. Puo tale distribuzione
essere descritta con una poissoniana con un livello di confidenza del
5%?
R.Calcolo il numero medio di uova al giorno
m = µ =0 · 10 + 1 · 13 + 2 · 13 + 3 · 8 + 4 · 4 + 5 · 2
50= 1.78.
Il numero teorico di giorni su 50 in cui vengono prodotte x uova e
percio 50 · f(x) = 50 · e−1.78 1.78x
x!.
# uova deposte 0 1 2 3 4 ≥ 5
# giorni 10 13 13 8 4 2
# teorico di giorni 8.43 15.01 13.36 7.93 3.53 1.74Si noti che # teorico di giorni in cui sono state deposte ≥ 5 uova
=50− (8.43 + 15.01 + · · ·+ 3.53).
χ2 = 0.67. Il numero dei gradi di liberta e ν = 6−1−1 = 4. Risulta
χ2 = (10.83−8.43)2
8.43+ (13−15.01)2
15.01+ · · · = 0.67 < χ2
ν=4,α=0.05 ' 9.49, percio la
distribuzione si adatta ai dati nel livello di confidenza stabilito.

20
Esercizio
Nella tabella seguente sono riportati dati relativi a colture batteriche,
analizzati dividendo in quadrati il campo visivo. Si voglia stabilire
se i batteri sono distribuiti a caso (cioe secondo una statistica poissoniana)
o in aggregati di tipo organizzato. n(x) e il numero di quadrati in
cui compaiono x batteri.x 0 1 2 3 4 ≥5nexp(x) 8 16 18 15 9 7
R. N◦ quadrati=73 N◦ batteri= 168, m = 2.30, nteo(x) = 73 · e−2.3 2.3x
x!,
χ2 = 0.356, ν = 5, Pr{χ2ν=4 ≥ 11.07} = 0.05 Test ok.
Esercizio
Nell’intervallo x=0-2 e stato costruito l’istogramma di frequenze di
una serie di N = 60 dati, forniti da un estrattore di numeri con
distribuzione uniforme. Le frequenze sperimentali sono riportate in
tabella. Verificare utilizzando il test del χ2, che la distribuzione
dei dati sia effettivamente uniforme.x 0.0-0.2 0.2-0.4 0.4-0.6 0.6-0.8 0.8-1.0 1.0-1.2 1.2-1.4 1.4-1.6 1.6-1.8 1.8-2.0
Nf(x) 5 6 6 8 5 6 4 7 7 6
R. pteo(x) = 0.1 ∀x, N = 60, χ2 = 2, ν = 9, Pr{χ2ν=9 ≥ 16.919} = 0.05
Test ok.
2. Metodo dei minimi quadrati e test del χ2 per fit lineari
Si abbia una serie di dati {(xi, yi)}i=1,...,N con errori statistici ∆xi = 0 e ∆yi =σi. Si vogliano interpolare tali dati sperimentali con una retta di equazione y =
mx+q, determinata minimizzando rispetto a m e q la somma∑N
i=1(yi−(mxi+q))
2
σ2i
(di qui il nome di “metodo dei minimi quadrati”). Si assuma l’ipotesi che σi = σper ogni i.
Si parte da una tabella di dati sperimentali a due entratex y.. .... ..
(1) Si calcola x =∑Ni=1 xiN
e(2) si inserisce una terza colonna di ξ = x− x.
(3) Quindi si trova y =∑Ni=1 yiN
.
(4) Si compila una quarta colonna yξ, da cui (5) si trova ξy =∑Ni=1 ξi·yiN
, e (6)
una quinta colonna ξ2, da cui (7) si determina ξ2 =∑Ni=1 ξ
2
N.
La retta di equazione y = aξ + b che minimizza∑N
i=1 (yi − (aξi + b))2 ha16
b = y
a = yξ
ξ2
16Nel caso generale in cui le σi sono diverse, ad essere minimizzato e∑Ni=1
(yi−(aξi+b))2
σ2i
e le medie seguenti
devono essere interpretate come medie pesate con pesi 1σ2i
.

21
Gli errori statistici associati sono
σb = σ√N
σa = σ√ξ2·N
Tornando alle variabili x, y il coefficiente angolare risulta
m = a con σm = σa
e il termine noto e17
q = b− ax con σq =√σ2b + σ2
a(x)2
Si inseriscono a questo punto (8) i valori teorici delle y in una sesta colonna:x y (2) ξ (4) yξ (6) ξ2 (8) yteor
.. .. .. .. .. ..
.. .. .. .. .. ..
.. .. .. .. .. ..
.. .. .. .. .. ..
(1) x (3) y (5) yξ (7) ξ2
Per verificare la bonta del fit lineare cosı ottenuto, si opera il test del χ2 apartire dal chi quadro sperimentale
χ2 =∑Ni=1(yi−yteoi )2
σ2
dove yteoi = aξi + b, con un numero di gradi di liberta pari a
ν = N − 2
essendo stati stimati 2 parametri (m e q), a partire dai dati18.
Scelto un intervallo di confidenza α, si procede con un test a due code, vale adire: si determinano χ2
1 e χ22 tali che α1 = 1− α
2e α2 = α
2, da cui Pr{χ2 ≤ χ2
1
o χ2 ≥ χ22} = (1− (1− α
2)) + α
2= α.
Nel caso di fit, il test puo fallire per un χ2 troppo grande oppure, se si ottieneun χ2 troppo piccolo, possono essere stati sovrastimati gli errori statistici 19 σio il numero di parametri necessari per il fit20.
Ad esempio: se ν = 5 e α = 0.05, χ21 = 0.831 e χ2
2 = 12.833.
Se χ2 < χ21 o χ2 > χ2
2 il test risulta negativo.
Viceversa, se χ21 ≤ χ2 ≤ χ2
2, il test e positivo.
ν α→ 0.995 0.99 0.975 0.95 0.90 0.10 0.05 0.025 0.01 0.005
1 — — 0.001 0.004 0.016 2.706 3.841 5.024 6.635 7.8792 0.010 0.020 0.051 0.103 0.211 4.605 5.991 7.378 9.21 10.597.. .. .. .. .. .. .. .. .. .. ..
5 0.412 0.554 0.831 1.145 1.610 9.236 11.070 12.833 15.086 16.750
6 0.676 0.872 1.237 1.635 2.204 10.645 12.592 14.449 16.812 18.548.. .. .. .. .. .. .. .. .. .. ..
17Si dimostri la formula su σq attraverso la teoria della propagazione dell’errore statistico.18Qui, chiaramente, non c’e nessun vincolo di normalizzazione.19A denominatore nei termini.20Che, in generale, non e detto sia lineare.

22
Esempio
Determinare i parametri della miglior retta passante per i punti sperimentali
riportati nella tabella seguente, nell’ipotesi che gli errori sulle
y siano tutti pari a 0.10N. Effettuare il test del χ2.x(cm) 1 2 3 4 5 6 7
y(N) 2.80 5.50 8.00 10.80 13.70 16.00 19.00
R. Procedendo come sopra, si ottiene il seguente schemax(cm) y(N) (2) ξ(cm) (4) yξ(N cm) (6) ξ2(cm2) (8) yteo (N)
1 2.80 -3 -8.40 9 2.762
2 5.50 -2 -11.00 4 5.451
3 8.00 -1 -8.00 1 8.140
4 10.80 0 0.00 0 10.829
5 13.70 1 13.70 1 13.518
6 16.00 2 32.00 4 16.207
7 19.00 3 57.0 9 18.896
(1) (3) (5) (7)
x = 4 cm y = 10.829 N yξ = 10.757Ncm ξ2 = 4cm2
da cui si ricavano
b = 10.829N σb = 0.038N
a = 2.689N
cmσa = 0.019
N
cm.
Di qui m = (2.689± 0.019) Ncm
e q = (0.0730± 0.0072)N.
Il chi quadro risulta χ2 = 0.1110.102 = 11.11. Il numero dei gradi di liberta
e ν = 7 − 2 = 5. Fissando un livello di confidenza dello 0.05 si
scopre dalla Tabella 1 che Pr{0.831 < χ2 < 12.832} = 0.95.
Poiche 0.831 < χ2 < 12.832 il fit risulta accettabile.
Esercizio
Applicare il metodo dei minimi quadrati alla seguente tabella di dati,
assumendo ∆y = 0.025 cmps
e effettuare il test del χ2 sul fit ottenuto.
x (cm) 2.55 4.05 5.55 7.05 8.55 10.05 11.55
y (cm/ ps) 8.500 11.200 13.700 16.500 19.400 21.700 24.700
R. m = (1.793± 0.019)ps−1, q = (3.89± 0.15) cmps, χ2 = 9.28,ν = 5,Pr{χ2 ≤
0.83 o χ2 ≥ 12.83} = 0.05. Test ok.


















