
Programování v jazyku C/C++e1n%ed%20v%20jazyku%20C-C++.pdf · Borland C++ Builder Compiler...
115
1 Programování v jazyku C/C++ Programovací jazyk, zdrojový kód a překladač Prvním důležitým pojmem je zdrojový kód programu. Zdrojový kód programu není nic jiného, než hromada textových souborů, v nichž je zapsáno pomocí programovacího jazyka co má program dělat. Překladač (angl. compiler) je program, který si přečte zdrojový kód a vytvoří z něj program. Bylo vytvořeno mnoho různých programovacích jazyků a k nim samozřejmě mnoho překladačů (co jazyk, to překladač(e)). Mezi prvními programovacími jazyky byl assembler. Pomocí tohoto jazyka se přímo zapisovali instrukce procesoru. Například sečtení dvou čísel v assembleru může vypadat takto: MOV AX,a MOV BX,b ADD AX,BX MOV a,AX AX a BX je označení registrů procesoru, „a“ a „b“ jsou proměnné, které obsahují nějaká čísla. MOV je instrukce která data přesune (nejdříve data z „a“ do AX, pak z „b“ do BX ...) a ADD je instrukce, která přičte druhé číslo k prvnímu (tj. k AX přičte BX). Překladač assembleru tento zdrojový kód převede do binárního kódu (tedy programu), který je již procesoru srozumitelný. Později vznikly vyšší programovací jazyky, mezi něž patří i jazyk C, které již nepracovali přímo s instrukcemi procesoru. Předchozí kód se v jazyce C zapíše následovně: a = a+b; Přenositelnost Přenositelnost programu je pojem, který nám říká, kde všude náš program poběží. Například program pro Windows 3.11 poběží i pod Windows 95, ale nepoběží pod Linuxem. Program pro 32-bitová Windows poběží při troše štěstí i pod 64-bitovými Windows, ale ne naopak. Přenositelnost programovacího jazyka je vlastnost, která určuje, pro které platformy (operační systémy a procesory) existuje překladač. Čím více existuje překladačů pro různé procesory a OS, tím je program "přenositelnější". Překladače pro různé platformy vytvářejí různí lidé, či organizace, proto vznikají standardy jazyka, které říkají, čemu všemu musí překladač rozumět. Existuje standard ANSI C (americký standard) vytvořený organizací www.ansi.org a z něj odvozený ISO/IE 9899:1999 vytvořený organizací pro mezinárodní standard www.iso.org . Přenositelnost zdrojového kódu je dána přenositelností programovacího jazyka a dodržováním standardů. Některé překladače totiž umí „něco navíc“, co obvykle usnadňuje psaní zdrojového kódu, ale snižuje přenositelnost. Další faktor, který má vliv na přenositelnost zdrojového kódu je používání knihoven. Knihovny jsou soubory obsahující funkce, které může program využívat jejich voláním. Existují standardní knihovny, které jsou dostupné na všech podporovaných platformách, jiné jsou však dostupné jen na některých platformách. Existují knihovny pro grafické uživatelské rozhraní (angl. zkratka GUI), které jsou přenositelné například mezi Windows a Linuxem. Trocha historie C a C++ Programovací jazyk C je známý svou přenositelností a rychlostí. Byl navržen jako poměrně malý jazyk, kombinující efektivitu a výkonnost. Byl vytvořen v Bellových laboratořích AT&T Denisem Ritchiem v létech 1969 až 1973. Dále se na vzniku jazyka podíleli Brian Kernighan a Ken Thompson. Byl napsán pro snadnou přenositelnou implementaci Unixu. Postupem času vznikla ANSI (American National Standard Institute) norma jazyka C. Shodný standard definuje ISO (International Stnadards Organisation) norma. Proto se někdy uvádí spojení ANSI/ISO norma.
Transcript of Programování v jazyku C/C++e1n%ed%20v%20jazyku%20C-C++.pdf · Borland C++ Builder Compiler...

1
Programování v jazyku C/C++ Programovací jazyk, zdrojový kód a p řekladač
Prvním důležitým pojmem je zdrojový kód programu. Zdrojový kód programu není nic jiného, než hromada textových souborů, v nichž je zapsáno pomocí programovacího jazyka co má program dělat. Překlada č (angl. compiler) je program, který si přečte zdrojový kód a vytvoří z něj program. Bylo vytvořeno mnoho různých programovacích jazyků a k nim samozřejmě mnoho překladačů (co jazyk, to překladač(e)). Mezi prvními programovacími jazyky byl assembler. Pomocí tohoto jazyka se přímo zapisovali instrukce procesoru. Například sečtení dvou čísel v assembleru může vypadat takto:
MOV AX,a MOV BX,b ADD AX,BX MOV a,AX
AX a BX je označení registrů procesoru, „a“ a „b“ jsou proměnné, které obsahují nějaká čísla. MOV je instrukce která data přesune (nejdříve data z „a“ do AX, pak z „b“ do BX ...) a ADD je instrukce, která přičte druhé číslo k prvnímu (tj. k AX přičte BX). Překladač assembleru tento zdrojový kód převede do binárního kódu (tedy programu), který je již procesoru srozumitelný. Později vznikly vyšší programovací jazyky, mezi něž patří i jazyk C, které již nepracovali přímo s instrukcemi procesoru. Předchozí kód se v jazyce C zapíše následovně:
a = a+b;
Přenositelnost
Přenositelnost programu je pojem, který nám říká, kde všude náš program poběží. Například program pro Windows 3.11 poběží i pod Windows 95, ale nepoběží pod Linuxem. Program pro 32-bitová Windows poběží při troše štěstí i pod 64-bitovými Windows, ale ne naopak.
Přenositelnost programovacího jazyka je vlastnost, která určuje, pro které platformy (operační systémy a procesory) existuje překladač. Čím více existuje překladačů pro různé procesory a OS, tím je program "přenositelnější". Překladače pro různé platformy vytvářejí různí lidé, či organizace, proto vznikají standardy jazyka, které říkají, čemu všemu musí překladač rozumět. Existuje standard ANSI C (americký standard) vytvořený organizací www.ansi.org a z něj odvozený ISO/IE 9899:1999 vytvořený organizací pro mezinárodní standard www.iso.org.
Přenositelnost zdrojového kódu je dána přenositelností programovacího jazyka a dodržováním standard ů. Některé překladače totiž umí „něco navíc“, co obvykle usnadňuje psaní zdrojového kódu, ale snižuje přenositelnost. Další faktor, který má vliv na přenositelnost zdrojového kódu je používání knihoven. Knihovny jsou soubory obsahující funkce, které může program využívat jejich voláním. Existují standardní knihovny, které jsou dostupné na všech podporovaných platformách, jiné jsou však dostupné jen na některých platformách. Existují knihovny pro grafické uživatelské rozhraní (angl. zkratka GUI), které jsou přenositelné například mezi Windows a Linuxem.
Trocha historie C a C++
Programovací jazyk C je známý svou přenositelností a rychlostí. Byl navržen jako poměrně malý jazyk, kombinující efektivitu a výkonnost. Byl vytvořen v Bellových laboratořích AT&T Denisem Ritchiem v létech 1969 až 1973. Dále se na vzniku jazyka podíleli Brian Kernighan a Ken Thompson. Byl napsán pro snadnou přenositelnou implementaci Unixu. Postupem času vznikla ANSI (American National Standard Institute) norma jazyka C. Shodný standard definuje ISO (International Stnadards Organisation) norma. Proto se někdy uvádí spojení ANSI/ISO norma.

2
Jazyk C++ je pokračovatelem jazyka C. Nejdříve byl označován jako C with Classes, od roku 1983 C++. Vyvinul jej Bjarne Stroustrup v AT&T. Jazyk C++ přináší novinky, především OOP (objektově orientované programování). První oficiální norma jazyka C++ byla přijata v roce 1998.
Vývojová prost ředí a překladače
Samotný překladač umožní vytvořit ze zdrojáků program. Vývojová prost ředí (zkratka IDE = Integrated development environment) je sada nástrojů, která pomáhá s laděním programů, hledáním chyb, udržováním přehledu ve zdrojovém kódu, nápovědou k funkcím atp.
Windows API
Windows API (API = application programming interface, tj. rozhraní pro programování aplikací). Windows API není nic jiného, než sada knihoven, které lze využívat při programování k vytváření „Windowsovských“ aplikací. Do kódu se vloží pomocí příkazu
#include <windows.h>
hlavičkový soubor <windows.h> a pak je možníé používat funkce, jako například WinMain() (namísto funkce main() , nebo CreateWindow() pro vytvoření okna atd.
Překlada č pro Linux
Překladač gcc/g++ se používá v Linuxu k překladu nejčastěji. Překladač gcc je většinou již nainstalován. V Linuxu se používá k překladu většiny programů napsaných v C/C++, dokonce i k překladu samotného jádra Linuxu.
Code::Blocks
Code::Blocks je asi to nejlepší, co je zdarma. Existuje verze pro Linux i Windows. Spolupracuje s mnoha překladači (například s C++ Builder, který umí Windows API), dokáže importovat projekty z Bloodshed Dev-C++, je rozšířitelný mnoha pluginami, je přehledný a snadno se v něm tvoří multiplatformní programy (pro Linux i Windows). Instalace zabere kolem 100MB.
Bloodshed Dev-C++ a wxDev-C++
Bloodshed je (kdysi jedno z nejpopulárnějších) free vývojové prostředí, využívající k překladu minGW (což je přenesená verze linuxového gcc). Je malý, rychlý a jednoduchý. Jeho vývoj, jak se zdá, v roce 2005 umřel. Vývoj Dev-C++ převzala jiná parta programátorů, nazvala jej wxDev-C++. Více o Dev-C++
DJGPP
DJGPP je linuxový překladač gcc přenesený do prostředí Windows a je zdarma. Kromě překladače také obsahuje sadu nástrojů a knihoven, které vám pomohou vytvářet 32-bitové programy v prostředí MS-DOS/MS-Windows Lze jej používat jako gcc z příkazové řádky, nebo můžete využít vývojové prostředí RHIDE. Více o DJGPP
Visual Studio
Visual Studio je nejlepší nástroj pro vývoj aplikací pro Windows. Jedná se o tzv RAD (Rapid Applications Development) prostředí, které obsahuje vizuální pomůcky pro sestavování aplikace. Visual Studio je úzce spjato s technologií .NET.

3
Visual C++ Express Edition
Visual C++ Express Edition je takový menší bratříček Visual Studia a je zdarma. Rozhraní je totožné, jako u Visual Studia, jen toho umí méně a neobsahuje 2Gb nápovědy jako Visual Studio. Více o Visual Studiu (a C++ Express Edition)
Borland C++ Builder
C++ Builder je, obdobně jako Visual Studio, RAD vývojové prostředí od společnosti Borland. Prostředí je určeno pro jazyk C. Jinak se o něm dá napsat to samé, co o Visual Studiu.
Existuje i free prostředí s názvem Turbo C++, ale poslední verze je z roku 2006, má netušeně zastaralé požadavky na systém a po jeho instalaci se mi ani nespustil (házelo to nějaké chyby). Prostě s ním nemá smysl strácet čas.
Borland C++ Builder Compiler
Borland C++ Builder Compiler je pouze překladač pro jazyky C/C++, který můžete ovládat z příkazové řádky. Je to stejný překladač, který najdete v Borland C++ Builderu, je zdarma (musíte se jen zaregistrovat) a je bez jakéhokoliv vývojového prostředí. Lze jej používat z příkazové řádky, nebo jej může používat Code::Blocks. Stáhnout C++ Builder compiler
Eclipse
Eclipse je velice pěkné vývojové prostředí, ale především pro Javu. Do Eclipse lze pomocí pluginů zakomponovat podporu pro spoustu dalších programovacích jazyků, včetně C/C++. bohužel, nainstalovat takové pluginy a naučit se je ovládat dá dost práce. Prostředí je to vhodné především pro lidi, kteří programují v Javě, nebo pro ty, co programují v několika jazycích a chtějí používat jednotné vývojové prostředí. Eclipse existuje ve verzi pro Windows i Linux.Více o Eclipse
NetBeans
Vývojové prostředí napsané v Javě a primárně pro Javu, ale pomocí pluginu lze používat i pro C/C++. Existuje verze pro Linux i Windows a je zdarma. Toto prostředí je velkým konkurentem pro Eclipse. Více o NetBeans
Anjuta
Anjuta je Linuxové vývojové prostředí napsané pro GTK/GNOME, kdysi velmi oblíbené. Bývá součástí standardních balíčků linuxových distribucí. Více o Anjuta
Sun Studio
Sun Studio je linuxové vývojové prostředí pro C/C++ od společnosti Sun Microsystems. Od verze 11 je zdarma.Více o Sun Studio
Struktura programu První program
Následující kód lze uložit do souboru s příponou .c (např. kod.c). Přípona .c je pro některé překladače (zvláště v Linuxu) povinná. Ve jménech souboru nesmí být diakritika ani mezery!

4
1: /*------------------------------------------------* / 2: /* kod.c * / 7: #include <stdio.h> //standardni knihovna 9: int main(void) 10: { 11: printf( "Hello World\n" ); 12: return 0; 13: } 15: /*------------------------------------------------* /
Bílé znaky, jako je mezera, tabulátor nebo znak nového řádku většinou ve zdrojovém kódu jazyka C nemají žádný význam. Odsazováním program pouze získá na přehlednosti a čitelnosti. Funkci main() by jste mohli napsat do jednoho řádku, to je překladači jedno. Konce řádků jsou důležité pouze pro direktivy začínající znakem # (čti „šarp“) a u komentářů začínajících dvěma lomítky, protože jejich konec je dán právě koncem řádku.
Komentá ře
Tím nejjednodušším, co je v programu vidět, jsou komentá ře. Vše co je mezi znaky /* a */ je komentář. V jazyce C++ se navíc považuje za komentář vše za dvěma lomítky // až do konce řádku. Dobré komentá ře vám pomohou se v kódu orientovat .
Knihovny
Existují takzvané standardní knihovny, což jsou knihovny dodávané s překladačem, a uživatelské knihovny, které si vytváří programátor sám. Hlavi čkové soubory jsou soubory, v nichž jsou uloženy definice funkcí z knihovny. Jejich přípona je většinou .h, ale není povinná (stejně jako .c). Pro C++ se někdy knihovny označují příponou .hpp.
Direktiva #include říká překladači, jaký hlavičkový soubor má načíst před překladem zdrojového kódu. Pokud je jméno ve špičatých závorkách < >, pak se soubor hledá ve standardních adresářích. Které to jsou, to záleží na překladači. Pokud je jméno mezi uvozovkami, hledá se soubor v aktuálním adresáři.
Standardní knihovna stdio = standard input output (knihovna pro standardní vstup a výstup)
Funkce
V příkladu jsou v programu dvě funkce. Funkce main() a funkce printf(). Funkci main() definujeme. To znamená, že popisujeme co tato funkce bude dělat. Funkci printf() pouze „voláme“. Je to funkce definovaná v knihovně stdio.h a její definice způsobí vypsání textu.
Funkce má své jméno (main), návratovou hodnotu (int) a argumenty určené v závorkách za jménem funkce ((void)). Návratová hodnota určuje, jaká data funkce vrátí při svém skončení (např. int). Argumenty jsou data, která funkce dostává ke zpracování. Hodnota void znamená „nic“, tj. funkce main() žádné argumenty neočekává. Návratová hodnota je jen jedna a její typ se píše před jméno funkce. Argumenty se píší za jméno funkce do závorek a je-li jích více, oddělují se čárkou. Funkce printf() dostává jako argument řetězec (řetězce jsou vždy ve dvojitých uvozovkách). Znaky \n reprezentují nový řádek.
Tělo funkce je všechno to, co je ve špičatých závorkách { }. Funkce se ukončuje klíčovým slovem return za kterým je návratová hodnota funkce.
Důležité je vědět, že funkce main() je speciální funkce, která je volána v programu jako první .

5
Funkce printf()
Funkce printf() má jako první argument textový řetězec. Ten může obsahovat speciální sekvence. Sekvence \n přesune kursor na nový řádek. Za znak %s se dosadí textový řetězec, který je dalším argumentem funkce printf(). Druhý je %i, za který se dosadí celé číslo.
1: /*------------------------------------------------* / 2: /* kod2.c * / 3: #include <stdio.h> 6: int main(void) 7: { 8: printf( "1 + 1 = %i\n" , 1 + 1); 9: printf( "%i + %i = %i\n" , 1, -2, 1 + (-2)); 10: printf( "%s\n" , "Konec programu." ); 11: /* return ukonci program. */ 12: return 0; 13: printf( "Tohle se uz nezobrazi %s!\n" ); 14: } 16: /*------------------------------------------------* /
Posledního volání funkce printf() je až za příkazem return a proto k jejímu volání v programu nedojde. Navíc obsahuje chybu. V řetězci je %s , ale funkce nemá žádný další argument. Pokud by tato funkce byla volána, „sáhla“ by si kamsi do paměti pro neexistující řetězec. Buď by se vytiskly nějaké nesmysly, nebo by program skončil s chybou (neoprávněný přístup do paměti; program provedl nepovolenou operaci atp.). Na tuto chybu vás překladač nemusí upozornit, protože překladač zkontroluje jen to, že funkce printf() má mít jako první argument textový řetězec (a to má).
Datové typy, bloky, deklarace a definice Základní datové typy
Základní datové typy jazyka C
char 8 znak 'a', 'A', 'ě'
short 1) 16 krátké celé číslo 65535, -32767
int 16/32 celé číslo --||--
long 1) 32 dlouhé celé číslo --||--
long long 1) 64 ještě delší celé číslo 9223372036854775807, -9223372036854775807
enum 8/16/32 výčtový typ
float 32 racionální číslo 5.0, -5.0
double 64 racionální číslo s dvojitou přesností 5.0l, 5l, -5.0L
long double 80 velmi dlouhé racionální číslo 5.5L, 5l, -5.0l
pointer 16/32 ukazatel
Co je na jazyku C zajímavé (a za co ho někteří nemají rádi) je to, že velikost všech datových typů není standardem pevně dána. Můžete se pouze spolehnout na to, že velikost char = 8 bitů (= 1 byte) a že: sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long). Závisí to především na procesoru. Na 16-bitovém procesoru budete mít nejspíše int velikosti 16 bitů (16bitovému procesoru se s takto velkým číslem "nejlépe" pracuje).

6
Konkrétní rozsahy datových typů lze najít ve standardní knihovně <limits.h >.
Existuje ještě další způsob jak zjistit velikost datového typu. Například je zde funkce sizeof(), která vrací počet bytů datového typu (nebo proměnné). Například sizeof(char) by se vždy mělo rovnat 1.
Typy char, short, int, long a long long mohou být se znaménkem nebo bez znaménka. Určí se to pomocí klíčových slov signed (se znaménkem) nebo unsigned (beze znaménka). „signed“ je defaultní hodnota, proto jí není třeba psát.
1: /*------------------------------------------------* / 2: /* typy.c * / 4: #include <stdio.h> 5: int a; 7: int main(void) 8: { 9: /* deklarace promennych */ 10: unsigned int b; 11: float c; 13: a = 5; 14: b = 11; 15: a = a / 2; 16: c = 5.0; 17: printf( "a=%i\nb=%u\nc=%f\n" , a, b, c / 2); 19: return 0; 20: } 22: /*------------------------------------------------* / Výstup z tohoto programu bude následující: a=2 b=11 c=2.500000
Boolovské datové typy
V některých programovacích jazycích se používá datový typ bool , který může nabývat pouze hodnot true (pravda) nebo false (nepravda). Tyto hodnoty se používají ve vyhodnocování podmínek při řízení běhu programu a podmíněných operátorů. V jazyce C takovýto typ neexistuje.
V jazyce C se jako nepravda vrací 0 a jako pravda 1. A dále platí, že cokoliv nenulového se vyhodnocuje jako pravda (tj. vše kromě 0 a NULL).
V jazyce C je možné vytvářet vlastní datové typy pomocí operátoru typedef a hodnoty true a false lze tedy nadefinovat. Standard C99 (stejně jako C++) ale již přináší knihovnu přináší knihovnu <stdbool.h>.
#include <stdbool.h> bool x = true; x = false;
Bloky, deklarace a definice
Blokem se rozumí vše, co je mezi špičatými závorkami { a }. Všechny proměnné, které deklarujeme v bloku, jsou tzv. lokální proměnné a proměnné mimo blok jsou globální . Lokální proměnné platí jen v těle bloku a v blocích vnořených (jinde je překladač neuvidí).
Proměnné jsou místa kdesi v paměti počítače, které definujeme v programu. Velikost místa v paměti závisí na datovém typu proměnné. Do proměnných lze vkládat hodnoty, měnit je a číst.

7
Deklarací proměnných určujeme jaké proměnné se v programu objeví. Nejdříve se určí datový typ a za ním názvy proměnných oddělené čárkou. Deklarace se ukončí středníkem. Při deklaraci je možné do proměnné rovnou vložit hodnotu. Názvy proměnných nesmí obsahovat mezeru, národní znaky (č, ř, š atp.) a nesmí začínat číslem. Jejich maximální délka je závislá na překladači. Jazyk C rozlišuje malá a velká písmena.
unsigned int i,j,k; signed int cislo1, cislo2 = cislo3 = 25;
Dokud neurčíte jakou má proměnná hodnotu, může v ní být jakékoliv číslo. Proměnné cislo2 a cislo3 mají hodnotu 25, všechny ostatní mají náhodnou hodnotu!
Ukazatele
Ukazatele (pointry) jsou proměnné, které uchovávají adresu ukazující do paměti počítače. Při jejich deklaraci je třeba uvést, na jaký datový typ bude ukazatel ukazovat. Paměť počítače je adresována po bytech. Číslo 0 ukazuje na první bajt v paměti, číslo 1 na druhý bajt atd. Pokud máte šestnáctibitový překladač, bude velikost ukazatele 16 bitů, u 32 bitového překladače 32 bitů. Deklarace ukazatelů vypadá takto:
float *uf; // Ukazatel na float, ma velikost typu "ukazatel", nikoliv float! int *ui; void *uv;
Proměnná uf je ukazatel na typ float, ui je ukazatel na typ int a uv je tzv. prázdný ukazatel u kterého není určeno, na jaký datový typ se bude ukazovat. To překladači neumožňuje typovou kontrolu, proto je lepší jej nepoužívat, pokud to není nutné. Do všech třech proměnných lze vložit libovolné (celé) číslo, které pak bude překladačem chápáno jako adresa do paměti. K získání adresy nějaké proměnné slouží operátor &. K získání dat z adresy, která je uložena v ukazateli, slouží operátor * .
1: /*------------------------------------------------* / 2: /* ukazatel.c * / 4: #include <stdio.h> 6: int main(void) 7: { 8: int i; /* promenna int */ 9: float f, f2; 10: int *ui; /* ukazatel (na typ int) */ 11: float *uf; 13: f = 5.5; 14: uf = 50; /* v ukazateli uf je hodnota 50. Co je v pameti na 50 bajtu 15: nikdo nemuze vedet, proto se takto do ukazatele adr esa 16: nikdy (!) neprirazuje */ 17: uf = &f; /* v ukazateli uf je hodnota adresy promenne f (tak je to 18: spravne */ 19: ui = &i; 21: f2 = *uf; /* do f2 se priradi hodnota z promenne f, tedy 5.5 */ 22: *ui = 10; /* tam, kam ukazuje adresa v ui (tedy do i) se uloz i 10. 23: Hodnota promenne ui se nezmeni (je to stale adresa promenne i)*/ 26: printf( "f = %f\n" , f); /*hodnota v f se od prirazeni 5.5 nezmenila */ 27: printf( "f2 = %f\n" , f2); /* do f2 se priradila hodnota z f, na kterou 28: jsme se odkazovali pomo ci ukazatele uf */ 29: printf( "i = %i\n" , i); /* do i jsme pres ukazatel ui priradili 10 */ 31: printf( "uf = %u, *uf=%f\n" , uf, *uf); /* vytiskneme si hodnotu uf a hodnotu na teto adrese (tj. a dresu f2 a hodnotu f2) */ 34: return 0; 35: } 36: /*------------------------------------------------* /

8
Výstup z programu bude následující: f = 5.500000 f2 = 5.500000 i = 10 uf = 3221224276, *uf=5.500000
Proměnná uf obsahuje adresu paměti, na které byla proměnná f uložena. Ta se bude při každém spuštění programu lišit, neboť paměť přiřazuje programu operační systém.
V programu jsou chyby. Přímé přiřazení hodnoty do proměnné uf (uf = 50;) a pak v poslední funkci printf, kde se tiskne hodnota ukazatele uf jako celé číslo bez znaménka (unsigned int). Je možné, že vám tyto konstrukce překladač ani nedovolí přeložit!
Ukazatele (pointery) by se správně měli tisknout přes %p:
31: printf( "uf = %p, *uf=%f\n" , uf, *uf); /* vytiskneme si hodnotu uf ...
Za zmínku ještě stojí přiřazení f2 = *uf. Nejdříve se vezme hodnota z uf a z této adresy se přečte číslo dlouhé tolik bitů, kolik bitů má typ, pro který je ukazatel určen. Proměnná uf je ukazatel na typ float, který má 32 bitů. Proto se vezme 32 bitů začínajících na adrese uložené v uf a toto číslo se pak chápe jako racionální a jako takové se uloží do f2. Kdybychom deklarovali uf jako ukazatel na typ char (char *uf), pak by jsme se podívali sice na stejnou adresu, ale z ní přečetli jenom 8 bitů!
NULL
NULL je speciální znak, který znamená nic. Vložíme-li do ukazatele hodnotu NULL, pak ukazuje nikam. NULL se také často používá jako argument funkcí, když tam, kde je argument vyžadován žádný argument vložit nechceme.
NULL je definováno v knihovně <stddef.h>, která je načítána např. pomocí <stdlib.h> a <stdio.h>.
Klíčová slova, konstanty, řetězce Klíčová slova
ANSI norma jazyka C určuje následující slova jako klíčová. Tyto slova mají v jazyce C speciální význam a nelze je používat jako uživatelem definované identifikátory..
auto double int struct break else long
switch case enum register typedef char extern
return union const float short unsigned continue
for signed void default goto sizeof volatile
do if static while
Konstanty
Konstanty jsou objekty, jejichž hodnota se za chodu programu nemění. Konstanty se definují za klíčovým slovem const . Po něm následuje datový typ konstanty. Pokud ne, překladač jej chápe jako int. Dále je v definici identifikátor konstanty a za rovnítkem hodnota.
const float a = 5;

9
1: /*------------------------------------------------* / 2: /* konst.c * / 4: #include <stdio.h> 6: int main(void) 7: { 8: const a = 5; /* konstantu a vyhodnoti prekladac jako int 5 */ 9: const b = 5.9; /* konstantu b vyhodnoti prakladac jako int 5 */ 10: const float c = 5; /* konstanta c je urcena jako float,tj. 5.0 */ 11: int i = 0; 13: printf( "a/2 = %f\n" , (a / 2) * 1.0); /* celociselne deleni */ 14: printf( "b/2 = %f\n" , (b / 2) * 1.0); /* celociselne deleni */ 15: printf( "c/2 = %f\n\n" , (c / 2) * 1.0); /* deleni s des. carkou */ 17: printf( "Mala nasobilka pro cislo %i\n\n" , a); 18: printf( "%i * %i = %i\n" , a, i, i * a); 19: i = i + 1; 20: printf( "%i * %i = %i\n" , a, i, i * a); 21: i = i + 1; 22: printf( "%i * %i = %i\n" , a, i, i * a); 23: i = i + 1; 24: printf( "%i * %i = %i\n" , a, i, i * a); 25: i = i + 1; 26: printf( "%i * %i = %i\n" , a, i, i * a); 27: i = i + 1; 28: printf( "%i * %i = %i\n" , a, i, i * a); 29: i = i + 1; 30: printf( "%i * %i = %i\n" , a, i, i * a); 31: i = i + 1; 32: printf( "%i * %i = %i\n" , a, i, i * a); 33: i = i + 1; 34: printf( "%i * %i = %i\n" , a, i, i * a); 35: i = i + 1; 36: printf( "%i * %i = %i\n" , a, i, i * a); 38: return 0; 39: } 41: /*------------------------------------------------* / Výstup z programu: a/2 = 2.000000 b/2 = 2.000000 c/2 = 2.500000 Mala nasobilka pro cislo 5 5 * 1 = 5 5 * 2 = 10 5 * 3 = 15 5 * 4 = 20 5 * 5 = 25 5 * 6 = 30 5 * 7 = 35 5 * 8 = 40 5 * 9 = 45 5 * 10 = 50
Výsledkem programu je malá násobilka čísla 5. Pokud chcete malou násobilku např. čísla 4, stačí změnit konstantu a.
Řetězce
Kromě konstantních čísel lze deklarovat též konstantní znaky a řetězce:
const char pismeno = 'a';

10
Textový řetězec je tedy pole znaků (ať už se jedná o konstantní pole nebo ne). Navíc má tu zvláštnost (na rozdíl od ostatních polí), že má na konci tzv. zarážku. Je to znak, který obsahuje nulu. Tak program pozná, kde pole v paměti končí. Kde pole začíná je uloženo v ukazateli. Takto se jednoznačně určí, kde se textový řetězec nachází a co do něj patří. Zatímco znaky jsou v jednoduchých uvozovkách, textové řetězce ve dvojitých. Nulu na konci textového řetězce za vás vloží překladač sám.
const char *veta = "Toto je konstantni retezec.";
Ukazatel veta je ukazatel na typ char a ukazuje na začátek textového řetězce, tedy na písmeno T. Pokud bude program pracovat s řetězcem na který ukazatel veta ukazuje, podívá se do paměti kam ukazuje, přečte první písmeno, pak se podívá na další bajt (velikost typu char je 8 bitů) a přečte další písmeno atd. až narazí na bajt obsahující nulu a tím skončí.
V jazyce C neexistuje žádný datový typ „řetězec“. Na řetězec (obecně jakékoliv pole objektů) se můžete odkazovat pouze pomocí ukazatelů.
1: /*------------------------------------------------* / 2: /* konst2.c * / 4: #include <stdio.h> 6: int main(void) 7: { 8: const char Kpismeno = 'a'; /* konstanta */ 9: char pismeno = 'b'; 10: const char *veta = "Konstantni veta !\n" ; 11: const char *veta2 = "a" ; 12: char *ukazatel; /* ukazatel na typ char */ 14: ukazatel = &pismeno; /* ukazatel ukazuje na promennou pismeno */ 16: printf( "1: Tisknu pismena: %c %c\n" , Kpismeno, pismeno); 18: printf( "2: Tisknu vetu: %s" , veta); 19: printf( "3: Tisknu vetu: %s\n" , veta2); 21: printf( "4: Tisknu pismeno: %c\n" , *ukazatel); 23: printf( "5: Tisknu pismeno: %c\n" , *veta); 24: printf( "6: Tisknu pismeno: %c\n" , *veta2); 26: return 0; 27: printf( "7: Tisknu vetu: %s\n" , ukazatel); 28: printf( "8: Tisknu vetu: %s\n" , pismeno); 29: /* printf("9: Tisknu: %s\n",*pismeno); uplna blbost */ 30: } 32: /*------------------------------------------------* / Výstup z programu: 1: Tisknu pismena: a b 2: Tisknu vetu: Konstantni veta ! 3: Tisknu vetu: a 4: Tisknu pismeno: b 5: Tisknu pismeno: K 6: Tisknu pismeno: a
V prvním volání funkce printf() se tisknou znaky. Když funkce printf() narazí na sekvenci %c najde si další argument a ten pak vytiskne jako znak. Ve druhém volání se tiskne věta, na kterou ukazuje konstantní ukazatel veta a ve třetím volání se tiskne věta, na kterou ukazuje ukazatel veta2. Funkce printf() si ve chvíli, kdy narazí na sekvenci %s najde příslušný další argument, který bere jako adresu do paměti. Z této paměti začne po znacích číst a znaky tisknout, dokud nenarazí na nulový bajt. Věta "a" obsahuje kromě písmena 'a' také onu zarážku (nulový bajt). Ve čtvrtém volání se tiskne hodnota, na kterou ukazuje proměnná ukazatel. Jelikož proměnné veta a veta2 jsou také ukazatele, lze je použít stejným způsobem. Ukazatele veta a veta2 ukazují na začátky vět, tedy přesněji obsahují adresu paměti, na které je uloženo první písmeno věty. Proto se vytisknou v (pátém a šestém volání printf()) první znaky z věty.
11
Za příkazem return 0 se nacházejí ještě další tři volání funkce printf(). Tyto volání jsou chybné. Sedmé volání printf() se pokouší vytisknout větu, na kterou ukazuje ukazatel jménem ukazatel. Jenomže ukazatel neukazuje na větu, ale na znak v proměnné pismeno. Překladač nemůže kontrolovat kam proměnná ukazatel ukazuje (zda na řetězec nebo znak nebo jestli vůbec někam ..) a tak nepozná chybu. Pokud by došlo k takovémuto volání funkce printf(), vytiskl by se nejdříve znak v proměnné pismeno (tj. znak 'b') a pak by se tiskli další bajty v paměti počítače, dokud by se nenarazilo na nulu. Takže by se vytiskla hromada nesmyslů nebo by mohl program zkolabovat (neoprávněný přístup do paměti). Kdybychom inicializovali proměnou ukazatel např. takto: ukazatel = veta; bylo by sedmé volání printf() naprosto v pořádku. Ovšem osmé volání je už blbost. Na místo ukazatele je předán typ char. Na tuto chybu již překladač upozorní, ale přesto dokáže program přeložit. V osmém volání funkce printf() vezme znak v proměnné pismeno, použije jej jako adresu do paměti ze které se pokusí přečíst větu. V tomto případě je téměř jisté, že program zkolabuje kvůli neoprávněnému přístupu do paměti (nebo se vypíše hromada nesmyslů).
ASCII hodnota písmena 'b' je 98. Poslední volání funkce printf() by se tedy snažilo vytisknout větu začínající na 98. bajtu v paměti, kdyby toto volání překladač umožnil.
Deváté volání je opravdu nesmysl, protože proměnná pismeno není ukazatel, nelze použít operátor * (hvězdička). To by překladač odmítl přeložit.
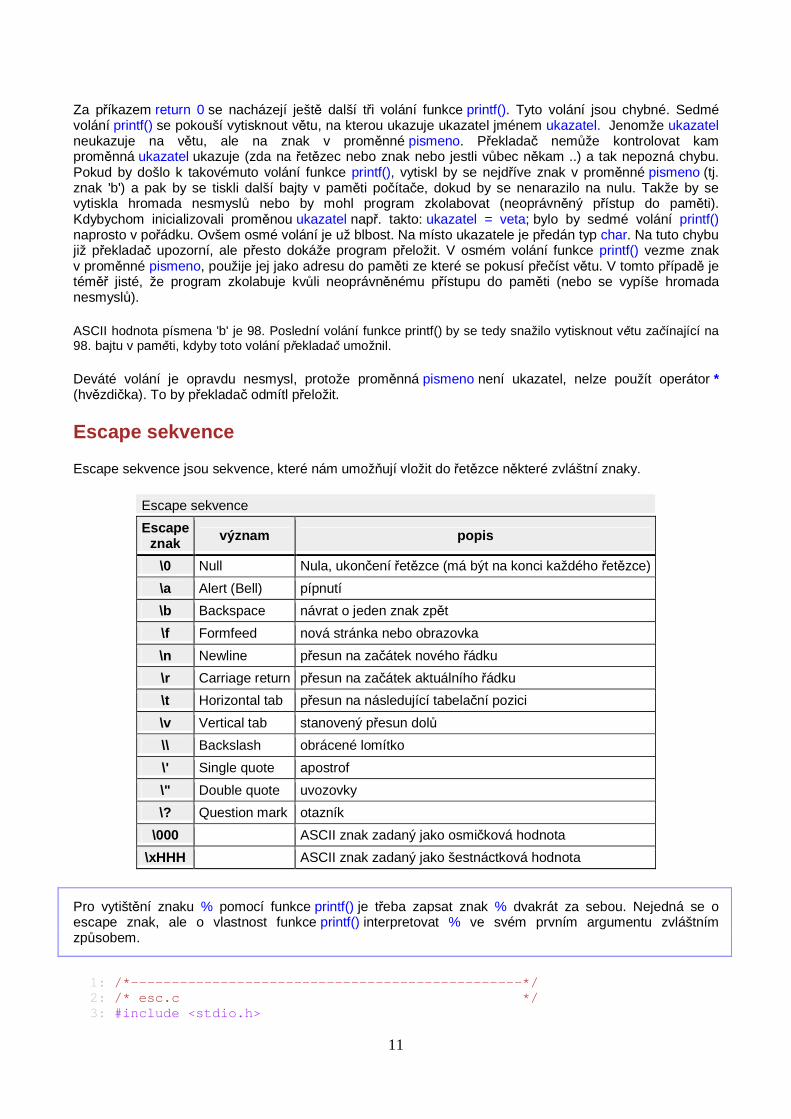
Escape sekvence
Escape sekvence jsou sekvence, které nám umožňují vložit do řetězce některé zvláštní znaky.
Escape sekvence
Escape znak význam popis
\0 Null Nula, ukončení řetězce (má být na konci každého řetězce)
\a Alert (Bell) pípnutí
\b Backspace návrat o jeden znak zpět
\f Formfeed nová stránka nebo obrazovka
\n Newline přesun na začátek nového řádku
\r Carriage return přesun na začátek aktuálního řádku
\t Horizontal tab přesun na následující tabelační pozici
\v Vertical tab stanovený přesun dolů
\\ Backslash obrácené lomítko
\' Single quote apostrof
\" Double quote uvozovky
\? Question mark otazník
\000 ASCII znak zadaný jako osmičková hodnota
\xHHH ASCII znak zadaný jako šestnáctková hodnota
Pro vytištění znaku % pomocí funkce printf() je třeba zapsat znak % dvakrát za sebou. Nejedná se o escape znak, ale o vlastnost funkce printf() interpretovat % ve svém prvním argumentu zvláštním způsobem.
1: /*------------------------------------------------* / 2: /* esc.c * / 3: #include <stdio.h>

12
5: int main(void) 6: { 7: printf( "%s %%\n" , "%" ); 8: printf( "%s\r%s\n" , "AAAAAAA", "BB" ); 9: printf( "\"\a\"\n" ); 10: printf( "\x6a\n" ); 11: return 0; 12: } 14: /*------------------------------------------------* / Výstup z programu: % % Při t řetím volání printf() BBAAAAA by se m ělo ozvat krátké pípnutí. "" j
Standardní vstup a výstup
Každý program při svém spuštění dostane od operačního systému standardní vstup (obvykle klávesnice), standardní výstup (obvykle monitor) a standardní chybový výstup (obvykle monitor). Standardní vstup se označuje jako stdin , standardní výstup jako stdout a chybový výstup je stderr . Funkce, které s těmito vstupy a výstupy pracují jsou definované v hlavičkovém souboru <stdio.h>. V OS máme možnost standardní vstupy a výstupy přesměrovat (například výstup do souboru místo na obrazovku).
Vstupní a výstupní zařízení lze rozdělit na znaková a bloková . Znaková jsou například klávesnice a monitor, bloková např. pevné disky. Rozdíl je především v možnosti získávání či vkládání dat z/do zařízení. Ke znakovým zařízením se přistupuje sekven čně tedy znak po znaku a k blokovým tzv. náhodným přístupem (random access).
Funkce printf()
Funkce printf() se používá pro formátovaný standardní výstup (do stdout). Deklarace vypadá takto:
int printf (const char * format [, arg , ...]);
Funkce printf() má návratovou hodnotu typu int. Tato hodnota je rovna počtu znaků zapsaných do výstupu, nebo speciální hodnota EOF v případě chyby zápisu. Hodnota EOF se používá jako označení konce souboru (End Of File), taktéž konce standardního vstupu a výstupu. EOF je definován v souboru <stdio.h>. Prvním argumentem je konstantní řetězec, který funkce printf() tiskne do stdout. Ten může obsahovat speciální sekvence, na jejichž místo dosazuje funkce další argumenty (začínají znakem %). Argumenty by měli mýt očekávaný datový typ, který je dán speciální sekvencí. Formát této sekvence je následující:
%[flags][width][.prec][h|l|L]type
Vše, co je uvedeno v hranatých závorkách [ ] v deklaraci může, ale nemusí být. Znak | značí „nebo“. Například [h|l|L] znamená, že v deklaraci sekvence může být h nebo l nebo L nebo ani jedna z těchto možností.
Přehled typů speciální sekvence řetězce ve funkci printf()
type význam
d, i Celé číslo se znaménkem (Zde není mezi d a i rozdíl. Rozdíl viz scanf() níže).
u Celé číslo bez znaménka.
o Číslo v osmičkové soustavě.
x, X Číslo v šestnáctkové soustavě. Písmena ABCDEF se budou tisknout jako malá při použití malého x, nebo velká při použití velkého X.
p Ukazatel (pointer)
f Racionální číslo (float, double) bez exponentu.

13
e, E Racionální číslo s exponentem, implicitně jedna pozice před desetinnou tečkou a šest za ní. Exponent uvozuje malé nebo velké E.
g, G Racionální číslo s exponentem nebo bez něj (podle absolutní hodnoty čísla). Neobsahuje desetinnou tečku, pokud nemá desetinnou část.
c Jeden znak.
s Řetězec.
Příklad:
1: /*------------------------------------------------* / 2: /* print.c * / 4: #include <stdio.h> 6: int main(void) 7: { 8: const char *COPYRIGHT = "(C)" ; 9: const int ROK = 2003; 11: printf( "%i %u %o %x %X %f %e %G\n" , -5, -5, 200, 200, 200, 10.0, 12: 10.0, 10.0); 13: printf( "%s %i\n" , COPYRIGHT, ROK); 14: return 0; 15: } 16: /*------------------------------------------------* / Výstup: -5 4294967291 310 c8 C8 10.000000 1.000000e+01 10 (C) 2003
Z čísla -5 se stalo při použití %u číslo 4294967291. To je dáno interpretací bitového zápisu, kdy se první bit zleva nepočítal jako identifikátor znaménka, ale jako součást čísla.
Položky width a .prec určují délku výstupu. Délka width určuje minimální počet znaků na výstupu. Mohou být uvozeny mezerami nebo nulami. .prec určuje maximální počet znaků na výstupu pro řetězce. Pro celá čísla je to minimum zobrazených znaků, pro racionální počet míst za desetinnou tečkou (má to tedy více významů v závislosti na typu).
Položka width může nabývat následujících hodnot:
Hodnoty width
n Vytiskne se nejméně n znaků doplněných mezerami
0n Vytiskne se nejméně n znaků doplněných nulami
* Vytiskne se nejméně n znaků, kde n je další argument funkce printf()
Položka .prec může nabývat následujících hodnot:
Hodnoty .prec
pro e, E, f nezobrazí desetinnou tečku .0
pro d, i, o, u, x nastaví standardní hodnoty
pro d, i, o, u, x minimální počet číslic
pro e, E, f počet desetinných číslic
pro g, G počet platných míst .n
pro s maximální počet znaků
.* jako přesnost bude použit následující parametr funkce printf()

14
1: /*------------------------------------------------* / 2: /* print2.c * / 4: #include <stdio.h> 6: int main(void) 7: { 8: printf( "%06i %06u %06x %6x %06f %06E %06G\n\n" , -5, -5, 200, 200, 9: 10.0, 10.0, 10.0); 11: printf( "%*s %1s %6s %%06.2G\n" , 10, "%*i" , "%06.2f" , "%06.0E" ); 13: printf( "%*i %06.2f %06.0E %06.2G\n" , 10, -5, 10.0 / 3, 10.0 / 3, 14: 10.0 / 3); 15: printf( "\n%.8s %0*.*f\n" , "Posledni vystup:" , 10, 4, 10.0 / 3); 16: return 0; 17: } 19: /*------------------------------------------------* / Výstup: -00005 4294967291 0000c8 c8 10.000000 1.000000E +01 000010 %*i %06.2f %06.0E %06.2G -5 003.33 03E+00 0003.3 Posledni 00003.3333
Do délky čísla se započítává i pozice pro znaménko. Čísla, která jsou delší než požadovaná minimální délka se nezkracují, řetězce ano.
Příznak flags může nabývat hodnot z následující tabulky:
Hodnoty flags
- výsledek je zarovnán zleva
+ u čísla bude vždy zobrazeno znaménko
mezera u kladných čísel bude místo znaménka "+" mezera
pro o, x, X výstup jako konstanty jazyka C
pro e, E, f, g, G vždy zobrazí desetinnou tečku
pro g, G ponechá nevýznamné nuly #
pro c, d, i, s, u nemá význam.
Znaky h l a L označují typ čísla. Znak h typ short (nemá smysl pro 16bitové překladače), l dlouhé celé číslo,L long double.
1: /*------------------------------------------------* / 2: /* print3.c * / 4: #include <stdio.h> 6: int main(void) 7: { 8: long int x; 9: long double y = 25.0L; 10: x = -25l; /* je mozno psat jen x = -25, protože prekladac vi, ze x je long a tak si cislo -25 prevede na -25l; 13: takhle je to vsak "cistci" a citel nejsi */ 15: printf( "%10s <%+5i> <% 5ld> <%x>\n" , "Cisla:" , 25, x, -25); 16: printf( "%-10s <%-+5i> <% 5Lf> <%#x>\n" , "Cisla:" , 25, y, -25); 17: return 0; 18: } 20: /*------------------------------------------------* / Výstup z programu: Cisla: < +25> < -25> <ffffffe7> Cisla: <+25 > < 25.000000> <0xffffffe7>
15
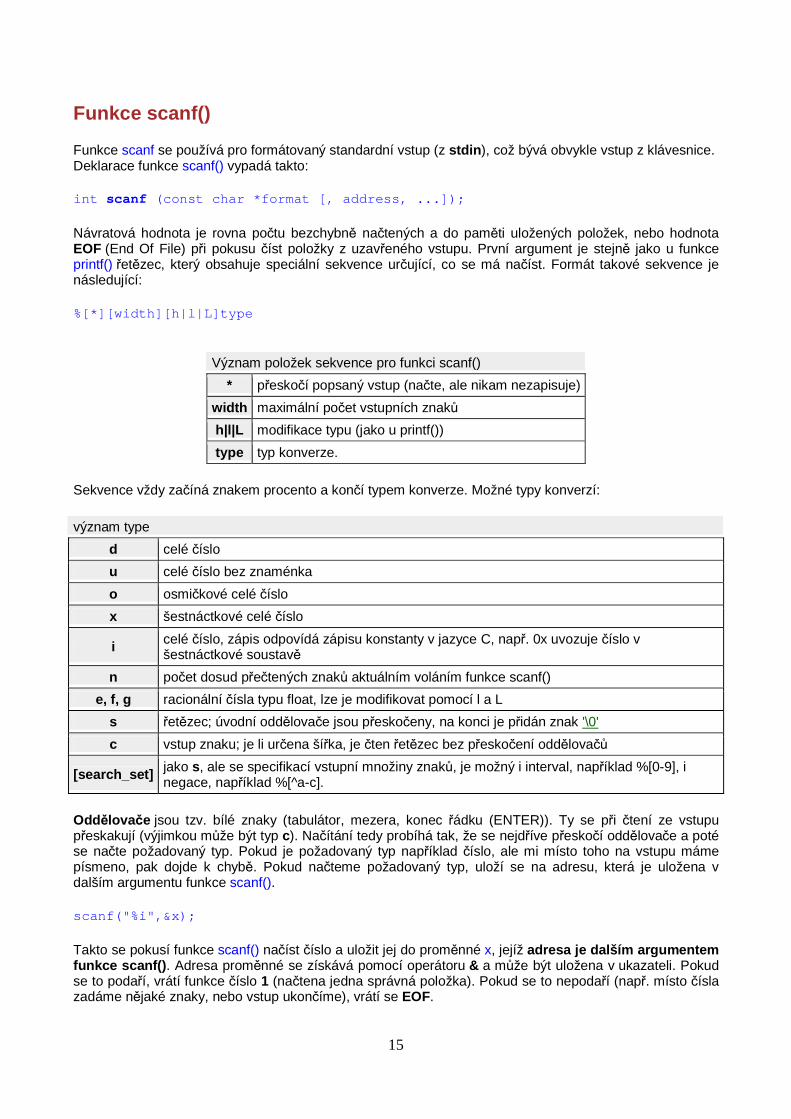
Funkce scanf()
Funkce scanf se používá pro formátovaný standardní vstup (z stdin ), což bývá obvykle vstup z klávesnice. Deklarace funkce scanf() vypadá takto:
int scanf (const char * format [, address , ...]);
Návratová hodnota je rovna počtu bezchybně načtených a do paměti uložených položek, nebo hodnota EOF (End Of File) při pokusu číst položky z uzavřeného vstupu. První argument je stejně jako u funkce printf() řetězec, který obsahuje speciální sekvence určující, co se má načíst. Formát takové sekvence je následující:
%[*][width][h|l|L]type
Význam položek sekvence pro funkci scanf()
* přeskočí popsaný vstup (načte, ale nikam nezapisuje)
width maximální počet vstupních znaků
h|l|L modifikace typu (jako u printf())
type typ konverze.
Sekvence vždy začíná znakem procento a končí typem konverze. Možné typy konverzí:
význam type
d celé číslo
u celé číslo bez znaménka
o osmičkové celé číslo
x šestnáctkové celé číslo
i celé číslo, zápis odpovídá zápisu konstanty v jazyce C, např. 0x uvozuje číslo v šestnáctkové soustavě
n počet dosud přečtených znaků aktuálním voláním funkce scanf()
e, f, g racionální čísla typu float, lze je modifikovat pomocí l a L
s řetězec; úvodní oddělovače jsou přeskočeny, na konci je přidán znak '\0'
c vstup znaku; je li určena šířka, je čten řetězec bez přeskočení oddělovačů
[search_set] jako s, ale se specifikací vstupní množiny znaků, je možný i interval, například %[0-9], i negace, například %[^a-c].
Oddělovače jsou tzv. bílé znaky (tabulátor, mezera, konec řádku (ENTER)). Ty se při čtení ze vstupu přeskakují (výjimkou může být typ c). Načítání tedy probíhá tak, že se nejdříve přeskočí oddělovače a poté se načte požadovaný typ. Pokud je požadovaný typ například číslo, ale mi místo toho na vstupu máme písmeno, pak dojde k chybě. Pokud načteme požadovaný typ, uloží se na adresu, která je uložena v dalším argumentu funkce scanf().
scanf("%i",&x);
Takto se pokusí funkce scanf() načíst číslo a uložit jej do proměnné x, jejíž adresa je dalším argumentem funkce scanf() . Adresa proměnné se získává pomocí operátoru & a může být uložena v ukazateli. Pokud se to podaří, vrátí funkce číslo 1 (načtena jedna správná položka). Pokud se to nepodaří (např. místo čísla zadáme nějaké znaky, nebo vstup ukončíme), vrátí se EOF.

16
1: /*------------------------------------------------* / 2: /* scan1.c * / 4: #include <stdio.h> 6: int main(void) 7: { 8: int x = -1; 10: printf( "Zadej cislo jako konstantu jazyka C\n" 11: "napr. 10 0x0a nebo 012: " ); 12: scanf( "%i" , &x); 13: printf( "Zadal jsi cislo %i\n" , x); 14: return 0; 15: } 17: /*------------------------------------------------* / Možné výstupy: Zadej cislo jako konstantu jazyka C napr. 10 nebo 0x0a nebo 012: -50 Zadal jsi cislo -50 Zadej cislo jako konstantu jazyka C napr. 10 nebo 0x0a nebo 012: 0xff Zadal jsi cislo 255 Zadej cislo jako konstantu jazyka C napr. 10 nebo 0x0a nebo 012: ff Zadal jsi cislo -1
Při posledním spuštění programu bylo zadáno „ff “, což není číslo ale textový řetězec, proto funkce scanf() do proměnné x nic neuložila a tak v ní zůstalo číslo -1.
Vstupní proud (stdin) můžete přerušit ve Windows a v DOSu klávesovou zkratkou CTRL+Z. V Linuxu pomocí klávesové zkratky CTRL+D.Řetězec ze standardního vstupu je ukončen oddělovačem (mezera, ENTER ).
1: /*------------------------------------------------* / 2: /* scan2.c * / 4: #include <stdio.h> 6: int main(void) 7: { 8: int x = 0; 9: double f = 0.0; 10: char znak = 'a'; 12: printf( "Zadej jeden znak a cislo max. 2 znaky dlouhe: " ); 13: scanf( "%c %2d" , &znak, &x); 14: printf( "\t--- zadal jsi %c a %i\n" , znak, x); 16: printf( "Zadej retezec a pak racionalni cislo: " ); 17: scanf( "%*s %lf" , &f); 18: printf( "\t--- zadal jsi %f\n" , f); 20: return 0; 21: } 23: /*------------------------------------------------* / Možné výstupy: Zadej jeden znak a cislo max. 2 znaky dlouhe: B 55 --- zadal jsi B a 55 Zadej retezec a pak racionalni cislo: ahoj 15.3 --- zadal jsi 15.300000 Zadej jeden znak a cislo max. 2 znaky dlouhe: B 55 ahoj 15.3 nazdar --- zadal jsi B a 55 Zadej retezec a pak racionalni cislo: --- zadal jsi 15.300000
V prvním případě bylo zadáno B 55 a ENTER. Tím byl předán nějaký vstup a funkce scanf() si prvním volání načetla nejdříve požadovaný znak a poté číslo. Při druhém volání byl vložen řetězec „ahoj “ a za ním racionální číslo. Funkce scanf() však řetězec přeskočila (%*s) a načetla číslo za ním.

17
Při druhém spuštění programu byl zadán na vstup rovnou znak, číslo, řetězec, další číslo a další řetězec. Program při prvním volání funkce scanf() načetl B a 55, spustil printf() a další volání scanf() pokračovalo v čtení vstupu tam, kde předchozí scanf() skončilo. Přeskočilo řetězec „ahoj “ a načetlo číslo 15.3.
Lze také každý vstup odesílat ENTERem jednotlivě.
Má-li být číslo dlouhé jen 2 znaky, pak každý další znak už druhé volání funkce scanf() vyhodnotí jako řetězec. Dále číslo může být chápáno též jako řetězec nebo znak. Jde jen o to, jak bude do paměti ukládáno. Číslo 5, bude uloženo jako číslo 5, znak 5 bude uložen jako číslo z ASCII tabulky odpovídající znaku 5 (což je číslo 53 ). Pokud se v prvním argumentu funkce scanf() vyskytne nějaký řetězec, znamená to, že funkce scanf() má právě tento řetězec načíst (a nikam neuložit). Pokud však takový řetězec na vstupu není, dojde k chybě.
1: /*------------------------------------------------* / 2: /* scan3.c * / 4: #include <stdio.h> 6: int main(void) 7: { 8: int zamek = 5; 9: int navrat; 11: printf( "Hodnota zamku je nyni %+5i\n" , zamek); 12: printf( "Pokud chcete hodnotu zmenit, zadejte heslo a novou hodnotu\n" 13: "a stisknete ENTER. Napriklad: heslo 25\n>> " ); 15: /* heslo je 1234567890 */ 16: navrat = scanf( "1234567890 %i" , &zamek); 18: printf( "Bylo nacteno %i spravnych polozek\n" , navrat); 19: printf( "Hodnota zamku je nyni %+5i\n" , zamek); 20: return 0; 21: } 23: /*------------------------------------------------* / Výstup z programu: Hodnota zamku je nyni +5 Pokud chcete hodnotu zmenit, zadejte heslo a novo u hodnotu a stisknete ENTER. Napriklad: heslo 25 >> 1234567890 -2345 Bylo nacteno 1 spravnych polozek Hodnota zamku je nyni -2345
Návratová hodnota funkce scanf() byla vložena do proměnné navrat.
Práce s typy dat ASCII tabulka (American Standard Code for Information Interchange)
Znak je v jazyku C typu int a v jazyku C++ typu char . Velikost char je 8 bitů, což je rozsah čísel od 0 do 255. Jakému číslu je přiřazen jaký znak, to určuje právě ASCII tabulka. Čistě textový soubor (tedy soubor obsahující jen znaky), znamená co jeden znak, to jeden bajt, bez ohledu na to, že v jazyce C je znak typu int – to je pouze „vnitřní interpretace znaku“ s kterou pracuje program. Výjimkou může být znak konec řádku, který se v DOSu a Windows reprezentuje dvojicí znaků s kódem (číselnou hodnotou) 10 a 13 (v Linuxu se zapisuje jen jeden znak – 10). Některým číslům není přidělen viditelný znak. Například kód 1 odpovídá stisku kláves CTRL+a a nemá žádný zobrazitelný ekvivalent. Interpretace číselného kódu se může měnit, v závislosti na použitém kódování (kódy 128-255). Pod těmito čísly jsou uloženy například znaky s háčky a čárky, bohužel se kódování od kódování liší (např. pro češtinu se použají kódování windows-1250 (na Windows), iso-8852-2 (ve starších verzích Linuxu) atp.).

18
Jiným typem kódování než je ASCII, je například UTF-8. To využívá k interpretaci znaku proměnlivý počet bytů. To je pro jazyk C trochu problém, protože pro jeden znak vyhrazuje vždy stejný počet bitů. Ovšem prvních 127 znaků v UTF-8 zabírá jeden bajt a jsou stejné jako v ASCII kódování.
Přetypování
Přetypování slouží ke změně datového typu objektu (proměnné, konstanty,...). Přetypování datového typu se provádí tak, že se před výraz napíše do závorky typ, na který chceme přetypovat. Nelze samozřejmě přetypovat cokoliv na cokoli, například řetězec na číslo. Přetypování je jeden z mocných nástrojů jazyka C.
1: /*------------------------------------------------* / 2: /* pretyp.c * / 4: #include <stdio.h> 6: int main(void) 7: { 8: int a, b; 9: float c, d; 10: char ch = 'x'; 12: printf( "Zadej delenec: " ); 13: scanf( "%d" , &a); 14: printf( "Zadej delitel: " ); 15: scanf( "%d" , &b); 16: c = a / b; 17: d = (float) a / b; 18: printf( "Celociselne deleni: %+5.2f\n" , c); 19: printf( "Racionalni deleni: %+5.2f\n" , d); 21: printf( "ASCII kod znaku %c je %i\n" , ch, (int) ch); 22: return 0; 23: } 25: /*------------------------------------------------* / Výstup z programu: Zadej delenec: 50 Zadej delitel: 3 Celociselne deleni: +16.00 Racionalni deleni: +16.67 ASCII kod znaku x je 120
K přetypování výrazů dochází mnohdy automaticky, například po přiřazení do proměnné typu float celočíselnou konstantu. Ta se nejprve (automaticky) převede na typ float a pak se teprve uloží do proměnné. Nebo při ukládání čísla 10 do proměnné long. Konstantu 10 překladač vyhodnotí jako int. Proto se nejdříve musí číslo 10 přetypovat na typ long. Překladač vás v takovém případě může varovat, že zde dochází k přetypování a to není hezké. Řešením je použít buďto modifikátor L ( long x = 10l; nebo float x = 10.0; místo x = 10;), nebo přetypování (long x= (long) 10;). První způsob se používá právě u konstant, druhý způsob zvláště u proměnných, protože u nich první způsob použít nelze. ( x= (long) a;).
Chyby p řetypování
Přetypovávat můžete i návratové hodnoty funkcí. Například funkce printf() vrací typ int. Návratovou hodnotu lze získat takto:
navrat = printf("Hello World");
Pokud návratovou hodnotu funkce nikam neukládáme, můžeme to překladači zdělit přetypováním návratové hodnoty na typ void takto:
(void) printf("Hello World");

19
Překladač by totiž mohl u některých funkcí (u printf() to standardně nedělá) hlásit varování, že funkce vrací návratovou hodnotu a že se nikam neukládá. Tímto přetypováním překladači dáme jasně najevo, že návratovou hodnnotu nechceme. Při přetypování však může docházet k problémům, které se těžko odhalují. Přetypování totiž neprobíhá jako zaokrouhlování, desetinná část se usekne. Malý příklad. Máme nějakou virtuální obrazovku, která obsahuje nejméně 80 sloupců, ale může jich mít i více. Počet sloupců máme uložen v proměnné COLS. Obrazovku chceme rozdělit na dvě části tak, aby jedna část obsahovala 12 sloupců plus cca 25% z toho, co je nad 80 sloupců a druhá část zbytek. Využijeme k tomu následující výpočet:
(12 + ((COLS - 80) * 0.25)); Tedy: okno1 = (12 + ((COLS-80) * 0.25)); okno2 = COLS - (12 + (COLS-80) * 0.25));
Na první pohled se může zdát, že okno1 + okno2 = COLS. Podívejme se, jak může takový výpočet interpretovat překladač pro COLS = 84 a COLS = 85:
Pro COLS = 84:
okno1 = (12 + ((84-80) *0.25)) = (12 + (4 *0.25)) = (12 + 1.0) = 13.0 okno1 = 13; okno2 = (84 - (12 + (84-80) * 0.25)) = 84 - 13.0 = 72.0 okno2 = 72;
Ale pro COLS = 85:
okno1 = (12 + ((85-80) *0.25)) = (12 + (5 *0.25)) = (12 + 1.25) = 13.25 okno1 = 13; okno2 = (85 - (12 + (85-80) * 0.25)) = 85 - 13.25 = 71.75 okno2 = 71; /* a chyba je na sv ět ě */
Řešení je jednoduché. Stačí výraz správně a včas přetypovat. Výpočet s přetypováním pro COLS = 85;
(12 + (int) ((COLS - 80) * 0.25)); okno1 = (12 + (int) ((85-80) *0.25)) = (12 + (int) (5 *0.25)) = = (12 + (int) 1.25) = 12 + 1 = 13; okno2 = (85 - (12 + (int) (85-80) * 0.25)) = 85 - ( 12 + (int) 1.25) = = 85 - (12 + 1) = 85 - 13 = 72;
Pokud překladač narazí při výpočtu na dva rozdílné typy, interpretuje oba jako ten větší (přesnější) z nich. Proto se výpočet 5 * 0.25 automaticky interpretuje jako ((float) 5) * 0.25 a ne 5 * (int) 0.25. Výsledek, který se ukládá do proměnné se do této proměnné musí vejít, proto se přetypovává vždy na typ proměnné. Při pokusu uložit do proměnné hodnotu větší, než kterou je schopna pojmout (například char ch = 256;), bude výsledkem nedefinovaná hodnota !
Pole a ukazatele Datové pole a řetězce
Řetězce jsou vlastně pole typu char zakončená nulovým znakem '\0'. Datové pole je spojité místo vyhrazené pro několik položek stejného datového typu. K tomu, abychom mohli k těmto položkám přistupovat, slouží ukazatel na onen datový typ. Pole může mít různou velikost. Kde začíná je dáno právě ukazatelem, jeho konec si však programátor musí hlídat. Konec pole nijak označen není (s výjimkou řetězců), proto se často stává ta chyba, že se program pokouší číst mimo pole a to vede ke zhroucení programu. Pole se deklaruje následovným způsobem:

20
datovy_typ nazev [rozsah];
Například:
char znaky[4]; /* pole pro 4 znaky */ int cisla[1]; /* pole pro jedno cislo */
Proměnné znaky a cisla jsou konstantní ukazatele , které ukazují na první prvek z pole. Jednotlivé položky pole se adresují od nuly pomocí hranatých závorek. (V jazyku C se indexuje od nuly, nikoliv od jedničky, jako např. v Pascalu):
cisla[0] = 5; x = cisla[0];
Číslo v hranatých závorkách při definici pole určuje jeho velikost. V jazyce C to musí být skutečné číslo, nelze použít proměnnou, ani konstantu (číslo musí překladač znát už v době překladu, aby pro pole dokázal vyhradit dostatek paměti). V jazyce C++ lze použít i konstantu (její hodnota je překladači známa, protože se nemění). Číslo v hranatých závorkách za ukazatelem při použití v kódu se nazývá index pole . Indexem pole se odkazujeme na n-tou položku pole.
Příklad používání indexu pole. char znaky[4];
ukázka uložení prázdného čtyřznakového pole v paměti
skute čná adresa ... 1535 1536 1537 1538 ...
pozice ... 0 1 2 3 ...
bity ??? ???????? ???????? ???????? ???????? ???
Momentálně pole znaky obsahuje náhodné bity. Ukazatel znaky ukazuje na adresu 1535 (to číslo je samozřejmě smyšlené). Pokud chceme vložit do pole znaky a vytvořit tak řetězec, nesmíme zapomenout na zarážku (nulový bite).
znaky[0] = 'j'; znaky[1] = 'e'; znaky[2] = '\0';
ukázka uložení dvouznakového řetězce v paměti
skute čná adresa ... 1535 1536 1537 1538 ...
pozice ... 0 1 2 3 ...
bity ??? 01101010 01100101 00000000 ???????? ???
Pokud pole rovnou inicializujeme, nemusíme uvádět jeho délku. Délka pole bude taková, kolik prvků předáme při inicializaci.
int cisla[] = { 5, -1, 3, 8}; /* pole pro 4 cisla */ char pole1[] = {'a', 'h', 'o', 'j', '\0'}; /* pole pro 5 znaku */ char pole2[] = "ahoj"; /* pole pro 5 znaku */
Inicializace pole1 a pole2 je ekvivalentní. Nyní můžeme přiřadit: pole2[4] = 'x';. Tím se však připravíme o zarážku a již nemůžeme s polem pracovat jako s řetězcem (například jej předat funkci printf(), protože by se po vytištění ahojx pokusila funkce printf() tisknout další byty z paměti za koncem pole).

21
Vícerozm ěrná pole
Jedná se o pole, jehož prvky jsou rovněž pole. Lze tak vytvářet pole libovolných dimenzí. (Je je třeba dát pozor na to, kolik takové pole zabírá místa v paměti.) Definice dvourozměrného pole a jeho uložení v paměti.
char pole[4][2] = {{0,0},{1,1},{3,4},{0xff,0xff}};
Jedná se o čtyřprvkové pole, jehož prvky jsou dvouprvkové pole.
Uložení pole 4x2 v paměti
skute čná adresa ... 1535 1536 1537 1538 1539 1540 1541 1542 ...
pozice ... [0][0] [0][1] [1][0] [1][1] [2][0] [2][1] [3][0] [3][1] ...
hodnota ??? 0 0 1 1 3 4 255 255 ???
Při putování pamětí se mění vždy nejdříve poslední index pole a pak ty předešlé.
Ukazatele a pole char *retezec1 = "Ahoj"; char retezec2[] = "Ahoj";
Rozdíl je v tom, že retezec2 je konstantní ukazatel (pole), kdežto retezec1 je ukazatel inicializovaný hodnotou adresy řetězce "Ahoj". Při obou definicích se vytvoří řetězec "Ahoj", což je pole znaků (se zarážkou '\0' na konci). V příkladu je uveden způsob jak lze adresovat jednorozměrné pole.
1: /*------------------------------------------------* / 2: /* pole1.c * / 4: #include <stdio.h> 6: int main(void) 7: { 9: float pole[] = { 5.0, 6.0, 7.0, 8.0, 9.0 }; 10: float *ukazatel; 12: ukazatel = pole; 14: /* prvni cast */ 15: printf( "%.1f " , pole[1]); 16: printf( "%.1f " , pole[1] + 10.0); 17: printf( "%.1f, " , (pole + 1)[2]); 19: /* druha cast */ 20: printf( "%.1f " , *ukazatel); 21: printf( "%.1f " , *ukazatel + 10); 22: printf( "%.1f\n" , *(ukazatel + 1)); 24: return 0; 25: } 27: /*------------------------------------------------* / Výstup z programu: 6.0 16.0 8.0, 5.0 15.0 6.0
Jazyk C zároveň pracuje chytře s aritmetikou ukazatelů. Výraz (ukazatel + 1) ukazuje na další prvek pole, přestože typ float je dlouhý hned 4 bajty a ne jeden. To je jeden z důvodů, proč se při deklaraci ukazatele určuje jeho typ. Překladač pak zvýší hodnotu ukazatele o správný počet bytů automaticky. Následující výrazy jsou ekvivalentní:
&pole[n] je totéž co (pole + n) (tj adresa n-tého prvku v paměti) pole[n] je totéž co *(pole + n) (tj hodnota n-tého prvku v paměti)

22
Ukazatele na ukazatele
V jazyku C může vytvořit ukazatel na libovolný datový typ. Ukazatel tedy může ukazovat i na ukazatel.
char **ukazatel;
Je taktéž možné vytvořit pole ukazatelů (včetně vícerozměrných polí ukazatelů...).
char *ukazatel[10]; 1: /*------------------------------------------------* / 2: /* unau1.c * / 3: #include <stdio.h> 5: int main(void) 6: { 7: int x; 8: int *ukazatel_na_int; 9: int **ukazatel_na_ukazatel; 11: int pole[] = { 5, 7, 9, 11, 13 }; 13: /* inicializace promennych */ 14: x = 25; 15: ukazatel_na_int = &x; 16: ukazatel_na_ukazatel = &ukazatel_na_int; 18: /* pristup k promenne x */ 19: printf( "%2d = %2d = %2d\n" , x, *ukazatel_na_int, 20: *(*ukazatel_na_ukazatel)); 22: /* inicializace */ 23: ukazatel_na_int = pole; 24: /* ukazatel_na_ukazatel = &ukazatel_na_int; ... to to prirazeni je o 25: * nekolik radek vyse a hodnota ukazatel_na_ukaza tel ukazuje stale na 26: * ukazatel_na_int */ 28: /* pristup k poli */ 29: printf( "%2d = %2d = %2d\n" , pole[0], *ukazatel_na_int, 30: **ukazatel_na_ukazatel); 31: printf( "%2d = %2d = %2d\n" , pole[1], *(ukazatel_na_int + 1), 32: *((*ukazatel_na_ukazatel) + 1)); 33: return 0; 34: } 36: /*------------------------------------------------* / Výstup z programu: 25 = 25 = 25 5 = 5 = 5 7 = 7 = 7
Jaké bude vyhodnocení výrazu *(*ukazatel_na_ukazatel). Závorky v tomto výrazu nejsou podstatné a jsou zde jen pro ilustraci. První, co se provede, je vyhodnocení výrazu *ukazatel_na_ukazatel. Hvězdička je dereferencí adresy , tedy hodnota proměnné, na kterou ukazuje proměnná ukazatel_na_ukazatel. V tomto případě to znamená, že *ukazatel_na_ukazatel je hodnota proměnné ukazatel_na_int (to je v příkladu adresa proměnné x). Dejme tomu, že adresa x je 123456. Potom *(*ukazatel_na_ukazatel) je *(123456) a to je hodnota, na kterou 123456 ukazuje, tedy hodnota proměnné x. Dále výraz *((*ukazatel_na_ukazatel) + 1). Dejme tomu, že pole začíná na adrese 12340. Potom ukazatel_na_int je po druhé inicializaci 12340, (*ukazatel_na_ukazatel) je tedy také 12340. A teď pozor. Výraz (*ukazatel_na_ukazatel + 1) je (12340+1*n) a výraz *((*ukazatel_na_ukazatel) + 1) je *(12340+1*n). Číslo n je počet bajtů, které zabírá typ int, protože jedničku přičítáme k ukazateli na int. Tomu se říká aritmetika ukazatel ů.
Ovšem pozor. Ukazatele a pole nelze libovolně zaměňovat. Tak například **pole1 a pole5[][5] a pole6[][6] jsou tři různé typy. S použitím vědomostí o aritmetice ukazatelů vyplývá, jaké chyby by se mohli stát při libovolných záměnách deklarací těchto proměnných. (Hlavně aplikaci pole1 na některé z dvouromzěrných polí. Správně by se mělo použít např.: int pole5[N][5]; int (*upole5)[5]; upole5 = pole5; atp.)

23
Operátory a výrazy
Operátory lze rozdělit několika způsoby. Na unární, binární, ternární (s jedním, dvěma nebo třemi operandy). Operandy jsou data (většinou čísla), se kterými operátory (např. plus) pracují. Dále se rozdělují na aritmetické, bitové, relační a logické.
Unární operátory
Operátor Význam
+, - unární plus a mínus, (určuje znaménko čísla)
& reference (získání adresy objektu)
* dereference (získání objektu dle adresy)
! logická negace
~ bitová negace
++, -- inkrementace a dekrementace hodnoty
(typ) přetypování
sizeof operátor pro získání délky objektu nebo typu
Inkrementace ++ a dekrementace -- může být zapsáno jak před výrazem, tak za ním Zvyšují, resp. snižují hodnotu čísla o jedničku. Pokud leží ++ před proměnnou, nejdříve se zvýší její hodnota a pak se proměnná použije ve výrazu (pokud v nějakém je), leží-li ++ za proměnnou, nejdříve se proměnná použije ve výrazu a pak se teprve zvýší její hodnota. Obdobně je to u dekrementace --.
Například: y = 5; x = ++y; // y se inkrementuje na 6 a poté se dosadí 6 do x x = y++; // do x se dosadí y (6) a pak se y inkrementuje (na 7)
Operátor sizeof vrací velikost datového typu nebo objektu v bytech.
float y; int x = sizeof(float); x = sizeof(y);
Priorita operátor ů
Priorita operátorů stanovuje, která část výrazu se vyhodnotí dříve, pokud to není závorkami určeno jinak. Klasickým příkladem je vyhodnocení výrazu x = 1+1*0;. Výsledkem bude samozřejmě číslo 1, protože operátor násobení má větší prioritu než operátor sčítání. Vzhledem k tomu že priorita operátorů je v jazyku C velice komplikovaná záležitost, je nejlépe používat závorky!
Binární operátory
Operátor Význam
= přiřazení
+, -,*, / plus,mínus,krát,děleno
% zbytek po celočíselném dělení (modulo)
<<, >> bitový posun vlevo, vpravo
& bitové AND
| bitové OR

24
^ bitové XOR
&& logické AND
|| logické OR
. tečka, přímý přístup ke členu struktury
-> nepřímý přístup ke členu struktury
, čárka, oddělení výrazů
< menší než
> větší než
<= menší nebo rovno
>= větší nebo rovno
== rovnost
!= nerovnost
Při bitovém posunu vlevo (vpravo) se poslední levý (pravý) bit ztrácí a zprava (zleva) je dosazena nula. Bitové operace je možné provádět jen s celočíselnými hodnotami. Při posunu čísel se znaménkem se však znaménko zachovává. Vlevo od operátoru je objekt, ve kterém se bity posouvají, vpravo od operátoru je číslo určující kolikrát se bity posunou. U logického AND a OR, výrazů >= atp. je výsledkem TRUE nebo FALSE , tedy 1 nebo 0.
Operátor přiřazení lze kombinovat s některými výpočty: +=, -=, *-, /=, <<=, >>=, &=, |=, ^=
Výraz Ekvivalent
x -= 5; x = x - 5;
x *= x; x = x * x;
x >>= 2; x = x >> 2;
Podmín ěný operátor
Podmíněný operátor ? : je ternárním operátorem (má 3 operandy). Prvním operandem je výraz, který se vyhodnotí jako logický výraz (TRUE nebo FALSE). Pokud se vyhodnotí jako TRUE, výsledkem bude druhý operand (mezi ? a :), jinak třetí operand.
printf("%s\n", (x > y) ? "x je > y" : "x je < y" );
Příklad 1: /*------------------------------------------------* / 2: /* operator.c * / 4: #include <stdio.h> 5: #include <limits.h> /* ziskame konstanty UINT_MAX a INT_MIN */ 7: int main(void) 8: { 9: int x, y, z; 10: int pole[] = { 5, -10, 15, -20, 25, -30 }; 11: unsigned int delka_pole; 12: x = y = z = 10; 14: x = y++; 15: z++; 16: printf( "%3d %3d %3d\n" , x, y, z); 17: printf( "%3d %3d %3d\n" , ++x, y++, ~z); 18: printf( "%3d %3d %3d\n" , x, y, z); 20: delka_pole = sizeof (pole) / sizeof (pole[0]);

25
21: printf( "Mate %2u bitovy prekladac.\n" , sizeof (int) * 8); 22: printf( "Pole pole[] zabira %2u bytu.\n\n" , sizeof (pole)); 24: printf( "UINT_MAX = %u = %u\n" , UINT_MAX, ~0); /* UINT_MAX = max velikost cisla v typu unsigned int */ 25: printf( "INT_MIN = %i = %i \n" , INT_MIN, 1 << (( sizeof (int) * 8) - 1)); /* posunu jednicku az do "nejlevejsiho bitu" */ 26: printf( "-51 >> 1 = %i\n\n" , -51 >> 1); 27: printf( "Zadejte index pole (od 0 do %2u): " , delka_pole - 1); 29: scanf( "%i" , &x); 30: printf( "Zadal jsi %i\n" , x); 32: /* musi se zkontrolovat platnost zadaneho indexu po le !! */ 33: x = (x < 0) ? 0 : x; 34: x = (x >= delka_pole) ? delka_pole - 1 : x; 35: printf( "pole[%u] = %i\n" , x, pole[x]); 37: return 0; 38: } 40: /*------------------------------------------------* / Výstup z programu: 10 11 11 11 11 -12 11 12 11 Mate 32 bitovy prekladac. Pole pole[] zabira 24 bytu. UINT_MAX = 4294967295 = 4294967295 INT_MIN = -2147483648 = -2147483648 -51 >> 1 = -26 Zadejte index pole (od 0 do 5): -11 Zadal jsi -11 pole[0] = 5
Protože je překladač 32 bitový, typ int zabírá 32 bitů, tj 4 bajty. Proto pole zabírá celkem 24 bajtů.
Použití NULL
Využítí hodnoty NULL, společně s podmíněným operátorem:
1: /*------------------------------------------------* / 2: /* null1.c * / 4: #include <stdio.h> 6: int main(void) 7: { 8: float *uk = NULL; 9: float p[] = { 10.2, 5.1, 0.6 }; 11: printf( "%s\n" , uk == NULL ? "Ukazatel neni inicializovan" : 12: "Ukazatel lze pouzit" ); 13: printf( "%f\n" , uk == NULL ? 0.0 : uk[0]); 15: uk = p; 17: printf( "%s\n" , uk == NULL ? "Ukazatel neni inicializovan" : 18: "Ukazatel lze pouzit" ); 19: printf( "%f\n" , uk == NULL ? 0.0 : uk[0]); 20: return 0; 21: } 23: /*------------------------------------------------* / Výstup z programu: Ukazatel neni inicializovan 0.000000 Ukazatel lze pouzit 10.200000
26
Preprocesor
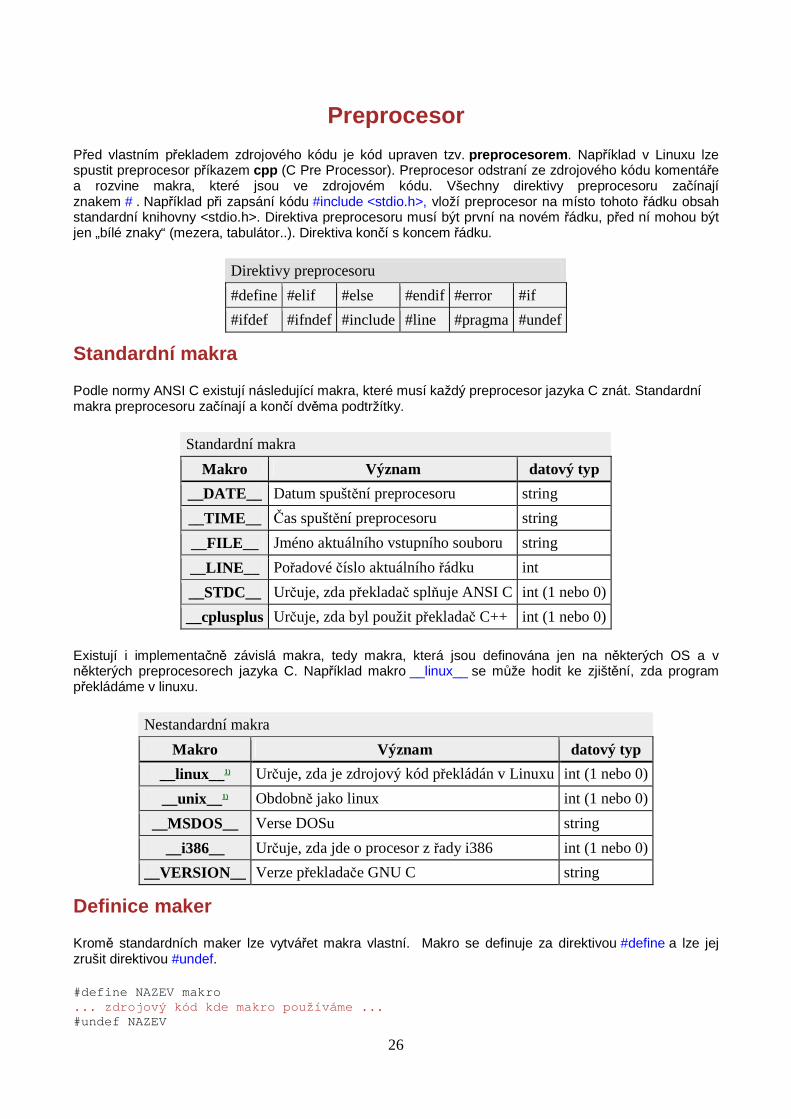
Před vlastním překladem zdrojového kódu je kód upraven tzv. preprocesorem . Například v Linuxu lze spustit preprocesor příkazem cpp (C Pre Processor). Preprocesor odstraní ze zdrojového kódu komentáře a rozvine makra, které jsou ve zdrojovém kódu. Všechny direktivy preprocesoru začínají znakem # . Například při zapsání kódu #include <stdio.h>, vloží preprocesor na místo tohoto řádku obsah standardní knihovny <stdio.h>. Direktiva preprocesoru musí být první na novém řádku, před ní mohou být jen „bílé znaky“ (mezera, tabulátor..). Direktiva končí s koncem řádku.
Direktivy preprocesoru
#define #elif #else #endif #error #if
#ifdef #ifndef #include #line #pragma #undef
Standardní makra
Podle normy ANSI C existují následující makra, které musí každý preprocesor jazyka C znát. Standardní makra preprocesoru začínají a končí dvěma podtržítky.
Standardní makra
Makro Význam datový typ
__DATE__ Datum spuštění preprocesoru string
__TIME__ Čas spuštění preprocesoru string
__FILE__ Jméno aktuálního vstupního souboru string
__LINE__ Pořadové číslo aktuálního řádku int
__STDC__ Určuje, zda překladač splňuje ANSI C int (1 nebo 0)
__cplusplus Určuje, zda byl použit překladač C++ int (1 nebo 0)
Existují i implementačně závislá makra, tedy makra, která jsou definována jen na některých OS a v některých preprocesorech jazyka C. Například makro __linux__ se může hodit ke zjištění, zda program překládáme v linuxu.
Nestandardní makra
Makro Význam datový typ
__linux__1) Určuje, zda je zdrojový kód překládán v Linuxu int (1 nebo 0)
__unix__1) Obdobně jako linux int (1 nebo 0)
__MSDOS__ Verse DOSu string
__i386__ Určuje, zda jde o procesor z řady i386 int (1 nebo 0)
__VERSION__ Verze překladače GNU C string
Definice maker
Kromě standardních maker lze vytvářet makra vlastní. Makro se definuje za direktivou #define a lze jej zrušit direktivou #undef.
#define NAZEV makro ... zdrojový kód kde makro používáme ... #undef NAZEV

27
... zde už makro není definované ...
Příklad na použití standardních i uživatelských maker. Takto vypadá zdrojový kód před zpracováním preprocesorem.
1: /*------------------------------------------------* / 2: /* makra.c * / 4: #include <stdio.h> 6: #define N 5 7: #define VERSE "1.0.0" 9: int main(void) 10: { 11: int pole[N]; 12: unsigned int x; 14: printf( "ANSI C:\t%s\t%i\n" , __STDC__ ? "ANO" : "NE " , __STDC__); 15: printf( "i386:\t%s\t%s\n" , __i386__ ? "ANO" : "NE " , __VERSION__); 16: printf( "Tento program byl prelozen %s v %s.\n" 17: "Prave jsme na radku %i.\n" , __DATE__, __TIME__, __LINE__); 19: printf( "Zadejte index pole <0,%u>: " , N - 1); 20: scanf( "%u" , &x); 22: x = x >= N ? N - 1 : x; 24: printf( "Zadejte hodnotu pole[%u]: " , x); 25: scanf( "%i" , &pole[x]); 26: printf( "verse programu %s\n" , VERSE); 28: return 0; 29: } 31: /*------------------------------------------------* /
A takto po zpracování preprocesorem před vlastním překladem. Direktiva #include <stdio.h> je nahrazena zdrojovým kódem souboru <stdio.h>. (Ten je z výpisu vypštěn - je moc dlouhý).
1: /*------------------------------------------------* / 3: int main(void) 4: { 5: int pole[5]; 6: unsigned int x; 8: printf( "ANSI C:\t%s\t%i\n" , 1 ? "ANO" : "NE " , 1); 9: printf( "i386:\t%s\t%s\n" , 1 ? "ANO" : "NE " , 10: "4.2.3 (Ubuntu 4.2.3-2ubuntu7)" ); 11: printf( "Tento program byl prelozen %s v %s.\n" 12: "Prave jsme na radku %i.\n" , "Sep 18 2008" , "10:35:06" , 17); 14: printf( "Zadejte index pole <0,%u>: " , 5 - 1); 15: scanf( "%u" , &x); 17: x = x >= 5 ? 5 - 1 : x; 19: printf( "Zadejte hodnotu pole[%u]: " , x); 20: scanf( "%i" , &pole[x]); 21: printf( "verse programu %s\n" , "1.0.0" ); 23: return 0; 24: } 26: /*------------------------------------------------* /
Teprve tento kód je předán překladači k vytvoření programu.
Výstup z programu: ANSI C: ANO 1 i386: ANO 2.95.4 20011002 (Debian prerelea se) Tento program byl prelozen Aug 10 2003 v 21:43:5 5. Prave jsme na radku 15. Zadejte index pole <0,4>: 3 Zadejte hodnotu pole[3]: 50 verse programu 1.0.0

28
Makra s argumenty
Makra mohou mít také argumenty. Jsou uzavřeny v kulatých závorkách za jménem makra a pokud je více jak jeden argument, jsou odděleny čárkou. Mezi jménem makra a závorkou obsahující argumenty nesmí být mezera.
#define NAZEV( argument1 , argument2 , ...) makro #define FOO(x) - 1 / (x) #define BAR (x) - 1 / (x)
Jejich použití ...
a = FOO(10); b = BAR;
... vyhodnocení preprocesorem:
a = - 1 / (10); b = (x) - 1 / (x);
Použití maker s argumenty má své záludnosti se kterými je třeba počítat. Vždy je třeba dát pozor na to, jakým způsobem je makro ve zdrojovém kódu rozvinuto:
#define mocnina(X) x*x #define min(X, Y) ((X) < (Y) ? (X) : (Y))
Jejich použití:
a = mocnina(3+2); b = mocnina(++n); c = min (x+y,foo(z));
Vyhodnocení preprocesorem:
a = 3+2*3+2; // tento problém lze vy řešit závorkami v makru b = ++n*++n; // prom ěnná n se inkrementuje dvakrát c = ((x+y) < (foo(z)) ? (x+y) : foo(z)); // funkce foo je volána dvakrát
Kvůli výše uvedeným problémům se nedoporučuje makry nahrazovat funkce. V jazyce C++ se od používání maker ustupuje, kde to jen jde.
Operátory # a ##
Operátory # a ## se používají v makrech s parametry. Za operátor # se dosadí řetězec, který je stejný jako argument makra. Operátor ## spojí své dva argumenty v jeden řetězec.
Definice maker:
#define VYPOCET(X,Y) printf("%s = %i\n",#X " + " #Y ,(X)+(Y)); #define SPOJENI(X,Y) printf("%i %i\n",X ## Y, cislo ## X);
Použití maker:
int cislo5 = 10; VYPOCET(5,6) SPOJENI(5,6)

29
Vyhodnocení preprocesorem:
printf("%s = %i\n", "5" " + " "6", (5)+(6)); printf("%i %i\n", 56, cislo5);
Podmín ěný p řeklad
Direktiva #if vyhodnocuje podmínku, která za ní následuje (tedy preprocesor jí vyhodnocuje). Pokud je tato podmínka vyhodnocena jako FALSE, pak vše mezi #if a #endif je ze zdrojového kódu vypuštěno. V podmínce musí být výrazy, které může vyhodnotit preprocesor (tj. nelze tam používat hodnoty proměnných atp.). Pomocí klíčového slova defined lze vyhodnocovat, zda existuje nějaké makro (zda bylo definováno). Výraz #if defined lze zkrátit výrazem #ifdef. Za podmínkou #if může být další (a další) podmínka #elif. Ta se vyhodnotí v případě, že předchozí podmínka nebyla splněna. Pokud nejsou splněny žádné podmínky, může být jako poslední direktiva #else, která již žádný výraz nevyhodnocuje a provede se právě v případě, že všechny podmínky za #if a #elif byly vyhodnoceny jako FALSE. Podmíněný překlad se ukončuje direktivou #endif. Popsaná syntaxe vypadá následovně:
#if PODMINKA1 ... zdrojovy kod pro splnenou podminku1 #elif PODMINKA2 ... zdrojovy kod pro splnenou podminku2 (kdyz podmi nka1 nebyla splnena) #elif PODMINKA3 .... zdrojovy kod pro splnenou podminku3 ... ... ... #else ... zdrojovy kod, pokud zadna z predchozich podmine k nebyla splnena ... #endif
Podmínky lze negovat pomocí operátoru ! (vykřičník).
1: /*------------------------------------------------* / 2: /* makra2.c * / 4: #include <stdio.h> 5: #define PT 6 7: int main(void) 8: { 9: #if PT > 5 10: printf( "Makro PT je vetsi jak 5\n" ); 11: #endif 13: #if defined unix && defined linux 14: printf( "Hura, ja bezim na unixovem stroji a snad pod linux em!\n" ); 15: #elif defined unix 16: printf( "Hura, ja bezim pod unixem!\n" ); 17: #else 18: printf( "Hmm, kde jsem se to kruci ocitl??\n" ); 19: #endif 21: return 0; 22: } 24: /*------------------------------------------------* /
Užití knihovny
Knihovnami (hlavičkovými soubory) v jazyce C se nazývají soubory obsahující zdrojový kód. Tyto soubory se do jiného zdrojového kódu začleňují pomocí direktivy #include. Standardní knihovny hledá překladač na standardních místech (jsou uzavřeny ve špičatých závorkách <>). Knihovny, jejichž jména jsou uzavřeny ve dvojitých uvozovkách, se hledají v aktuálním adresáři. Pokud není nalezen, hledá se ve standardních adresářích.

30
Vytvoření knihovny. Vytvoříme knihovnu s názvem "makra.h" s následujícím kódem:
1: /*------------------------------------------------* / 2: /* makra.h * / 3: #define POZDRAV "Nazdarek" 4: #define COPYRIGHT "(c) 2003" 5: #define LICENCE 6: #define TISK(a) printf( "%s\n" ,a); 7: #define SOUBOR __FILE__ 8: #define BEGIN { 9: #define END } 10: /*------------------------------------------------* /
Následné vytvoření souboru (ve stejném adresáři), do kterého je knihovnu "makra.h" začleněna.
1: /*------------------------------------------------* / 2: /* makra3.c * / 3: #include <stdio.h> 4: #include "makra.h" 6: int main(void) 7: BEGIN TISK(POZDRAV) TISK(SOUBOR) 8: #ifdef LICENCE 9: TISK(COPYRIGHT) 10: #endif 11: return 0; 12: END 13: /*------------------------------------------------* / Výstup z programu: Nazdarek makra3.c (c) 2003
Makro Licence je definováno bez toho, že by mu byla přiřazena nějakou hodnotu. Pro podmínku #ifdef stačí, že je definováno. Složené závorky lze zaměnit za BEGIN a END.
Ostatní direktivy
#pragma
Direktiva #pragma uvozuje implementačně závislé direktivy. Pokud překladač narazí na tuto direktivu a nerozumí jí, pak jí ignoruje (nezpůsobí to žádnou chybu).
Ukázka (z C++ Builderu): #pragma hdrstop
#line
Direktiva #line nastavuje hodnotu makra __LINE__ (a __FILE__).
#line N [" jméno "]
N je číslo, kterým se nastaví __LINE__ pro následující řádek a "jméno" (nepovinné) je jméno, kterým se nastaví makro __FILE__.

31
Podmínky a cykly Podmínka if-else
Podmínka if-else je velice podobná podmíněnému operátoru ? a ještě více podmíněnému překladu preprocesoru.
if ( podminka ) telo bloku else if ( podminka ) telo bloku else if ( podminka ) telo bloku else telo bloku
Podmínky musí být v kulatých závorkách. Tělo bloku může být blok , nebo jen jeden příkaz (ukončený středníkem). Podmínek else if může být konečně mnoho a nejsou povinné, stejně jako není povinná podmínka else. Vyhodnocování podmínek probíhá do té doby, než se některá vyhodnotí jako pravdivá (TRUE). Pak se provedou příkazy v bezprostředně následujícím bloku. Další podmínky se již nevyhodnocují. Pokud se žádná podmínka nevyhodnotí jako TRUE, pak se provede tělo bloku za else (pokud část else existuje). Else se umisťuje vždy na konec.
1: /*------------------------------------------------* / 2: /* ifelse.c * / 3: #include <stdio.h> 5: #define CISLO 5 6: #define MIN 0 7: #define MAX 10 9: int main(void) 10: { 11: int x = -1; 12: int navrat; 13: printf( "Na jake cislo myslim? Hadej mezi %2i a %2i: " , MIN, MAX); 15: navrat = scanf( "%i" , &x); 17: if (navrat == EOF) { 18: printf( "\ascanf nemuze cist. Je uzavren standardni vstup s tdin\n" ); 19: return 1; /* ukoncime funkci main -> konec programu */ 20: } else if (navrat != 1) { /* chceme nacist 1 polozku */ 21: printf( "\aNezadal jsi cislo!\n" ); 22: return 1; 23: } 25: if (x < MIN) 26: printf( "Tak to bylo malo trochu hochu!\n" ); 27: else if (x > MAX) 28: printf( "Tak to bylo trochu moc!\n" ); 29: else if (x == CISLO) 30: printf( "UHADNULS :-))\n" ); 31: else 32: printf( "Smula. Zkus to znovu.\n" ); 34: return 0; 35: } 37: /*------------------------------------------------* / Možný výstup: Na jake cislo myslim? Hadej mezi 0 a 10: 5 UHADNULS :-))

32
Přepínač switch
Přepínač switch obsahuje několik návěstí (case) s celočíselnou hodnotou , nebo rozmezí (např. 1 ... 5 nebo 'a' ... 'e'). Mezi třemi tečkami a hodnotami se vynechávají mezery. Na základě argumentu za klíčovým slovem switch přeskočí program na návěstí se stejnou hodnotou jakou má výraz v kulatých závorkách za switch a pokračuje vykonáváním příkazů za ním. Přepínač switch může obsahovat návěstí default, na které program skočí tehdy, když argument za klíčovým slovem switch neodpovídá hodnotě za žádným návěstím case. Default není povinné a může se použít kdekoliv (první před všemi case, mezi nimi i jako poslední).
switch ( vyraz ) { case hodnota : prikazy case hodnota : prikazy default: prikazy }
Příkaz break je speciální příkaz, který způsobí „vyskočení“ z těla příkazu switch (a také cyklů, viz dále). Program pak pokračuje ve vykonávání příkazů za blokem switch.
1: /*------------------------------------------------* / 2: /* switch.c * / 3: #include <stdio.h> 5: int main(void) 6: { 7: char znak; 9: printf( "Opravdu chcete smazat vsechna data na disku? [a/n/ k]> " ); 10: znak = (char) getchar(); 12: switch (znak) { 13: default: 14: printf( "Mel si zmacknout \'a\',\'n\' nebo \'k\' a ne \'%c\ '\n" , 15: znak); 16: case 'k': 17: return 0; 18: case 'N': 19: printf( "Stejne smazu co muzu!\n" ); 20: break ; 21: case 'n': 22: printf( "Nechcete? Smula!\n" ); 23: case 'a': 24: case 'A': 25: printf( "Data byla smazana !!!\n" ); 26: break ; 27: } 28: printf( "Ne, nebojte, to byl jenom zertik.\n" ); 29: return 0; 30: } 32: /*------------------------------------------------* / Možný výstup: Opravdu chcete smazat vsechny data na disku? [a/n/k ]> n Nechcete? Smula! Data byla smazana !!! Ne, nebojte, to byl jenom zertik.
Druhé použití break (na konci switch) je zbytečné, je tam jen pro ilustraci. Funkce getchar() z knihovny <stdio.h> vrací hodnotu datového typu int. Proto ji bylo nutno přetypovat na typ char. Tato funkce načte ze standardního vstupu znak a vrátí jej jako svou návratovou hodnotu, přičemž vrací speciální hodnotu EOF v případě uzavřeného standardního vstupu.

33
Skok goto
Použití skoku goto může velice znepřehlednit program. Proto se nepoužívá! Ostatně, ani to není nutné. Pomocí ostatních rozhodovacích příkazů se tomu lze vždy vyhnout.
Za příkazem goto je název návěští , na které má program skočit. Návěští se pak v programu určuje jednoduše tak, že se zapíše jeho jméno a za ním dvojtečka. Je možné skákat pouze na návěstí v rámci jedné funkce.
Cyklus for for ( inicializace ; podmínka ; výraz ) telo cyklu
Cyklus for provádí příkazy v těle cyklu tak dlouho, dokud platí podmínka . Tato podmínka může být jakýkoliv výraz vracející celočíselnou hodnotu. Může obsahovat konstanty, proměnné, relační operátory (==,>,|| atp.) a není povinná. V případě chyb ějící podmínky za ní p řekladač dosadí číslo jedna, což bude mít za následek v ěčné provád ění cyklu . Cyklus pak lze ukončit jen pomocí break . Pokud se hned na poprvé podmínka vyhodnotí jako FALSE, pak tělo cyklu neproběhne ani jednou. Část inicializace také není povinná. Může v ní být libovolný výraz. Tato část proběhne jen jednou (před začátkem cyklu). Poslední část v příkazu označená jako výraz se provádí po každém ukončení cyklu (před vyhodnocením podmínky) a taktéž není povinný.
1: /*------------------------------------------------* / 2: /* for.c * / 3: #include <stdio.h> 5: int main(void) 6: { 7: int x; 9: for (x = 1; x < 10; x++) { 10: if ((x % 2) != 0) 11: continue ; 12: printf( "Sude cislo: %i\n" , x); 13: } 14: printf( "\nA nebo trochu jinak:\n\n" ); 16: x = 1; 17: for (;;) { 18: if (x >= 10) 19: break ; 20: if ((x % 2) == 0) 21: printf( "Sude cislo: %i\n" , x); 22: x++; 23: } 24: return 0; 25: } 27: /*------------------------------------------------* / Výstup z programu: Sude cislo: 2 A nebo trochu jinak: Sude cislo: 4 Sude cislo: 2 Sude cislo: 6 Sude cislo: 4 Sude cislo: 8 Sude cislo: 6 Sude cislo: 8 Cyklus for se také často využívá při práci s poli. #define N 100 int x, pole [N]; for (x = 0; x <= N - 1;x++) pole[x] = 0;

34
Cykly do a while
Cyklus do má tu vlastnost, že proběhne alespoň jednou. Je ukončen klíčovým slovem while, za kterým je podmínka v kulatých závorkách a platí o ní totéž, jako u cyklu for . V cyklu lze pro řízení chodu programu využít příkazů break i continue. Tělo cyklu může být jeden příkaz nebo blok.
do telo cyklu while ( podminka );
Cyklus while je podobný, jen s tím rozdílem, že se podmínka vyhodnocuje před provedením cyklu.
while ( podminka ) telo cyklu 1: /*------------------------------------------------* / 2: /* while.c * / 3: #include <stdio.h> 5: int main(void) 6: { 7: int iterace = -1; 8: int navrat; 9: do { 10: printf( "Zadejte pocet iteraci <0,10>: " ); 11: navrat = scanf( "%i" , &iterace); 12: if (!navrat) 13: return 1; /* uzivatel nezadal cislo; navrat == 0 */ 14: if (navrat == EOF) { 15: printf( "stdin je uzavren.\n" ); 16: return 1; 17: } 18: } while ((iterace < 0) || (iterace > 10)); 20: while (iterace) { 21: printf( "%i " , iterace--); 22: } 24: printf( "\n" ); 25: return 0; 26: } 28: /*------------------------------------------------* / Možný výstup: Zadejte pocet iteraci <0,10>: -5 Zadejte pocet iteraci <0,10>: 15 Zadejte pocet iteraci <0,10>: 5 5 4 3 2 1
Funkce
Funkce jsou základním stavebním kamenem jazyka C. Při jejich volání program přeskočí do funkce a po jejím provedení se vrátí za místo, kde byla funkce volána. Opakované volání funkce šetří paměť počítače (tělo funkce je napsáno jen jednou), na druhou stranu, každé volání funkce stojí nějaký (velmi malý) čas.
for (x = 0; x < 1000; x++) { printf("Cyklus cislo: "); printf("%i\n",x); } je mnohem pomalejší než for (x = 0; x < 1000; x++) { printf("Cyklus cislo: %i\n",x); }

35
Definice funkce
Definice funkce je následující:
navratovy_typ jmeno ([ parametry ]) { telo funkce }
Jméno funkce slouží k jejímu identifikování. Při volání funkce v programu musíme uvést za funkcí kulaté závorky, a to i tehdy, když funkce nemá žádné argumenty. Samotné jméno funkce bez závorek totiž reprezentuje adresu v paměti, kde funkce začíná. Toho se dá využít v odkazech na funkci. Parametry funkce jsou očekávaná data, která bude funkce zpracovávat. Každý parametr má své jméno a musí být určen jeho datový typ. Pokud funkce nemá žádné parametry, uvádí se v závorkách slůvko void . Pokud je jich více než jeden, oddělují se čárkou. Existují i funkce s proměnlivým počtem argumentů. Parametrem může být celé nebo racionální číslo, struktura, nebo ukazatele. Nemůže to být například pole, které obsahuje x prvků, ale může to být ukazatel na začátek pole. Funkce má jednu návratovou hodnotu . Její typ se uvádí před jménem funkce. Například funkce main() má vždy návratovou hodnotu typu int. Pokud není potřeba, aby funkce vracela nějaká data, jako návratová hodnota se uvede void . Funkci lze kdykoliv ukončit příkazem return , za který se uvádí hodnota nebo výraz, jehož výsledek se stane návratovou hodnotou. Pokud funkce žádnou návratovou hodnotu nemá, uvádí se return bez hodnoty nebo výrazu. Po ukončení funkce se pokračuje v provádění kódu za místem kde byla funkce volána. Ukončením funkce main() končí program. Návratová hodnota funkce main() se vrací operačnímu systému. Zaběhnutá praxe je, že návratová hodnota 0 znamená úspěšné ukončení programu, jakákoliv jiná hodnota určuje číslo chyby.
1: /*------------------------------------------------* / 2: /* fce1.c * / 3: #include <stdio.h> 5: void tecka(int pocet) 6: { 7: if (pocet <= 0) return 12: for (; pocet > 0; pocet--) printf( ". " ); 14: } 16: int mocnina(int x) 17: { 18: return x * x; 19: } 21: int main(void) 22: { 23: tecka(10); 24: printf( "-5^2 = %i\n" , mocnina(-5)); 25: return 0; 26: } 28: /*------------------------------------------------* / Výstup programu: . . . . . . . . . . -5^2 = 25
Deklarace funkce
Při deklaraci funkce se uvádí pouze datový typ návratové hodnoty a typy argumentů. To je vše, co potřebuje překladač k tomu, aby její volání mohl do programu zapsat. Mohou se uvést i názvy argumentů, ale to není nutné. Než je funkce v programu volána, musí být deklarována . Definována může být až později. Je-li funkce rovnou definována, je definice zárove ň i deklarací . Pokud se deklarace s pozdější definicí neshodují, oznámí překladač chybu.
V následujícím programu je funkce nejdříve deklarována, použita v jiné funkci a pak teprve definována.

36
1: /*------------------------------------------------* / 2: /* deklar.c * / 3: #include <stdio.h> 6: float vypocet(int, float, float *) ; /* deklarace funkce */ 8: int main(void) 9: { 10: float a, b; 12: a = vypocet(5, 0.3, &b); 13: printf( "Soucet = %5.2f\nNasobek = %5.2f\n" , a, b); 15: return 0; 16: } 18: float vypocet(int a, float b, float *c) 19: { 20: float f; 21: *c = (float) a *b; 22: f = (float) a + b; 23: b = 55.5; /* lokalni promenna b nema s promennou b ve funkci 24: main nic spolecn eho */ 25: return f; 26: } 28: /*------------------------------------------------* / Výstup z programu: Soucet = 5.30 Nasobek = 1.50 x
Rekurzivní funkce
Pokud funkce volá ve svém těle samu sebe, nebo je volána jinou funkcí ve svém těle, hovoříme o rekurzi . Data, která jsou funkci předávána, se ukládají do takzvaného zásobníku . To je nějaké vyhrazené místo v paměti. Po skončení funkce se data ze zásobníku zase odstraní. Pokud však funkce během svého vykonávání zavolá samu sebe, pak se do zásobníku umístí další data a tak stále dokola. To je samozřejmě velice náročné na paměť a může vést až ke zhroucení programu. Použití rekurze je sice efektní, ale ne vždy efektivní. Proto je třeba mít dobrý důvod pro její použítí
1: /*------------------------------------------------* / 2: /* rekurz.c * / 3: #include <stdio.h> 5: float prvni_funkce(int, float) ; /* deklarace */ 7: float druha_funkce(int a, float f) 8: { /* definice */ 9: printf( "Vola se druha funkce\n" ); 10: return prvni_funkce(a, f * (a + 1)); 11: } 13: float prvni_funkce(int a, float f) 14: { /* definice */ 15: printf( "Prvni funkce a= %2i, f=%5.2f\n" , a, f); 16: if (a <= 0) 17: return f; 18: return druha_funkce(--a, f); 19: } 21: int main(void) 22: { 23: printf( "Vysledek je %f\n" , prvni_funkce(5, 5.0)); 24: return 0; 25: } 27: /*------------------------------------------------* / Výstup z programu: Prvni funkce a= 5, f= 5.00 Prvni funkce a= 2, f=3 00.00 Vola se druha funkce Vola se druha funkce Prvni funkce a= 4, f=25.00 Prvni funkce a= 1, f=600.00 Vola se druha funkce Vola se druha funkce Prvni funkce a= 3, f=100.00 Prvni funkce a= 0, f=600.00 Vola se druha funkce Vysledek je 600.000000

37
V příkladu se počítá jakási číselná řada. Druhá funkce zde má slouží jen k nějakému výpisu a k novému zavolání funkce prvni_funkce. Kdyby se volání return druha_funkce(--a, f); změnilo na return druha_funkce(a--,f); volala by se druha_funkce() s hodnotou proměnné a, která by nebyla snížena o jedničku. Ta by se měla snížit až po zavolání funkce. Výsledkem by byl nekonečný cyklus vzájemného volání funkcí. Na podobné problémy je potřeba dávat pozor. Klasickým příkladem na rekurzi je výpočet faktoriálu (avšak i faktoriál lze vypočítat elegantně bez rekurze).
1: /*------------------------------------------------* / 2: /* faktor.c * / 3: #include <stdio.h> 5: long double faktorial(long double x) 6: { 7: if (x == 0L) 8: return 1L; 9: return x * faktorial(x - 1L); 10: } 12: int main(void) 13: { 14: int i; 15: for (i = 0; i <= 40; i++) 16: printf( "%2i! = %040.0Lf\n" , i, faktorial(i)); 17: return 0; 18: } 20: /*------------------------------------------------* / Zkrácený výstup: 0! = 0000001 5! = 0000120 1! = 0000001 6! = 0000720 2! = 0000002 7! = 0005040 3! = 0000006 8! = 0040320 4! = 0000024
Je to smutné, ale jazyk C neumí po čítat p řesně s racionálními čísly . Je to dáno tím, jak jsou čísla v paměti uložena a jak se s nimi počítá. Po vydělení 10/3 a opětovného vynásobení výsledku třemi, vyjde 9.999...Čísla typu float mají zaru čenou p řesnost cca na 14 „nejvýznamn ějších“ míst . Vzhledem k velikosti čísla je chyba sice zanedbatelná, ovšem při použití řekněme v nějakém bankovním úřadu, by asi neměli velkou radost. Naštěstí lze přesně počítat s celočíselnými proměnnými, takže lze podobně velká čísla zpracovávat pomocí několika celočíselných proměnných (a složitých algoritmů).
Proměnlivý po čet argument ů
Funkci lze vytvořit i bez přesného počtu a typu argumentů. (Jako např. fce printf() nebo scanf(), které také mají proměnlivý počet argumentů.) Argumenty funkce se ukládají do zásobníku. Aby mohla funkce k těmto argumentům přistupovat, musíme jí předat alespoň místo, kde začít. Proto musí mít funkce s proměnlivým počtem argumentů minimáln ě jeden argument napevno daný . To, že mohou následovat další argumenty, se při definici nebo deklaraci označí pomocí tří teček (tzv. výpustka ). Pro práci s těmito nedeklarovanými argumenty existuje standardní knihovna <stdarg.h> . V ní jsou definovány tři makra:
void va_start( va_list ap, last ); type va_arg( va_list ap , type ); void va_end( va_list ap);
Výraz va_list představuje datový typ proměnné ap. Je to proměnná, která reprezentuje nedeklarované argumenty. Makro va_start inicializuje proměnnou ap pomocí poslední napevno deklarované proměnné ve funkci. Ta je předána jako druhý argument last (díky tomu získá potřebnou adresu do zásobníku s argumenty). Makro va_arg vrací hodnotu dalšího argumentu v řadě. Jakého typu má být se musí určit druhým argumentem type . Toto makro je možné volat vícekrát Maximálně však tolikrát, kolik je předáno funkci při volání nedeklarovaných argumentů. Jinak by docházelo k čtení dat, která již nepatří k argumentům funkce. Makro va_end zajišťuje bezproblémové ukončení funkce (příkazem return). Ačkoliv program poběží pravděpodobně i bez volání tohoto makra, je potřeba jej použít. V určitých kritických

38
situacích by mohlo docházet k chybám které se obtížně hledají. Je několik možností jak zjistí funkce s proměnlivým počtem argumentů, jaké jí byli argumenty předány (jakého typu) a také kolik. Například funkce printf() má vždy jako první argument řetězec (přesněji řečeno ukazatel na řetězec; řetězec je znakové pole a pole nelze předávat jako argument funkce). V tomto řetězci hledá speciální sekvence (%s,%c) a podle nich zjišťuje, že má mít další argument a také jakého typu. A tak je přesně dáno, o kolik argumentů a jakých typů si funkce řekne. Další možností je, že při deklaraci funkce je deklarován jeden parametr (minimálně jeden stejně vždy musí být), který bude obsahovat počet proměnných. Další možností je například definování nějaké zarážky. Třeba že vždy jako poslední argument bude ukazatel s hodnotou NULL , nebo číslo nula atp.
1: /*------------------------------------------------* / 2: /* fce2.c * / 3: #include <stdio.h> 4: #include <stdarg.h> 6: int maximum(const int pocet, const int znamenko, .. .) 7: { 8: va_list ap; 9: int i; 10: int maxS, dalsiS; 11: unsigned int maxU, dalsiU; 13: if (pocet <= 0) 14: return 0; 16: va_start(ap, znamenko); /* znamenko je posledni deklarovana promenna */ 18: if (znamenko) 19: maxS = va_arg(ap, int); 20: else 21: maxU = va_arg(ap, unsigned int); 23: for (i = 0; i < pocet - 1; i++) { 24: if (znamenko) { 25: dalsiS = va_arg(ap, int); 26: maxS = (maxS < dalsiS) ? dalsiS : maxS; 27: } else { 28: dalsiU = va_arg(ap, unsigned int); 29: maxU = (maxU < dalsiU) ? dalsiU : maxU; 30: } 31: } 33: va_end(ap); 34: if (znamenko) 35: return maxS; 36: else 37: return (signed int) maxU; 38: } 40: int main(void) 41: { 42: printf( "Maximum = %i\n" , maximum(3, 1, 7, 9, -2)); 43: printf( "Maximum = %x\n" , maximum(7, 1, -5, 8, -2, 5, -6, -1, 4)); 44: printf( "Maximum = %x\n" , maximum(7, 0, -5, 8, -2, 5, -6, -1, 4)); 45: return 0; 46: } 48: /*------------------------------------------------* / Výstup z programu: Maximum = 9 Maximum = 8 Maximum = ffffffff
Argumenty p říkazové řádky
Při spouštění programu z příkazové řádky (ať už v Linuxové konzoli nebo v DOSu), mu lze předávat nějaké argumenty. Argumenty příkazové řádky jsou všechna slova, zapsaná za název programu v příkazové řádce. Například v příkazu MOVE S1 S2 jsou slova S1 a S2 argumenty. Slova, která jsou od sebe oddělena mezerou nebo tabulátorem, jsou předávána zvlášť. Tvoří-li jeden argument celá věta, musí být

39
uzavřena do uvozovek. Argumenty příkazové řádky je možné číst pomocí funkce main, která je deklarována následujícím způsobem:
int main( int argc , char *argv[] );
Parametr argc představuje počet argumentů příkazové řádky a parametr argv je pole ukazatelů na argumenty příkazové řádky. Argumenty příkazové řádky jsou textové řetězce (i když je to jenom jeden znak nebo číslo) a počítá se mezi ně i název programu, který je prvním argumentem.
Například: program Zvolejte 3 krat hura
Pak argc bude mít hodnotu 5, argv[0] ukazatel na řetězec "program ", argv[1] ukazatel na řetězec "Zvolejte ", argv[2] ukazatel na řetězec "3" atd.
Příklad programu, který pracuje na základě argumentů příkazové řádky. Převede svůj druhý argument na velká nebo malá písmena podle toho, jaký je první argument. Funkci, která porovnává dva textové řetězce, vrací 1 (TRUE) v případě, že jsou schodné, jinak 0 (FALSE).
1: /*------------------------------------------------* / 2: /* argum.c * / 4: #include <stdio.h> 6: #define VELKE "velke" 7: #define MALE "male" 9: #define VAROVANI printf( "Zadejte:%s%s|%s ARGUMENT\n" ,argv[0], VELKE,MALE); 11: int shodne(char *v1, char *v2) 12: { 13: int i = 0; 14: /* pomoci zarazek '\0' zjistujeme konec retezce */ 15: while ((v1[i] != '\0') && (v2[i] != '\0')) { 16: if (v1[i] != v2[i]) 17: return 0; /* nejsou shodne; */ 18: i++; 19: } 20: if (v1[i] || v2[i]) { /* jeden retezec jeste nezkoncil, nejsou stejne */ 21: return 0; 22: } 23: return 1; /* vsechny znaky byly shodne */ 24: } 26: void velke(char *) ; 27: void male(char *) ; 29: int main(int argc, char *argv[]) 30: { 31: if (argc != 3) { 32: VAROVANI return 1; 33: } 35: if (shodne(VELKE, argv[1])) 36: velke(argv[2]); 37: else if (shodne(MALE, argv[1])) 38: male(argv[2]); 39: else { 40: VAROVANI return 1; 41: } 43: printf( "Druhy argument byl zmenen na: %s\n" , argv[2]); 44: return 0; 45: } 47: /* ve funkcich velke a male vyuzijeme vlastnosti AS CII tabulky */ 49: void velke(char *v) 50: { 51: int i = 0; 52: while (v[i]) { /* '\0' odpovida hodnote FALSE */ 53: if (v[i] >= 'a' && v[i] <= 'z') {

40
54: v[i] += ('A' - 'a'); /* rozdil v ASCII tabulce mezi 55: velkymi a m alymi pismeny */ 56: } 57: i++; 58: } /* konec while */ 59: } 61: void male(char *v) 62: { 63: int i = 0; 64: while (v[i]) { 65: if (v[i] >= 'A' && v[i] <= 'Z') { 66: v[i] += ('a' - 'A'); 67: } 68: i++; 69: } 70: } 72: /*------------------------------------------------* /
Lokální, globální a statické prom ěnné
Lokální proměnné jsou proměnné definované v těle nějakého bloku, globální mimo něj. Dále platí, že lokální proměnné mají vyšší prioritu než globální.
1: /*------------------------------------------------* / 2: /* promenne.c * / 3: #include <stdio.h> 5: int a = 0, b = 0, c = 0; /* globalni promenne */ 7: void funkce(int a, int b) 8: { 9: int a = -5; /* lokalni promenne */ 10: printf( "fce: a = %i, b = %i, c = %i\n" , a, b, c); 11: } 13: int main(void) 14: { 15: int c = 25; 17: printf( "main: a = %i, b = %i, c = %i\n" , a, b, c); 18: funkce(100, 200); 19: return 0; 20: } 22: /*------------------------------------------------* / Výstup z programu: main: a = 0, b = 0, c = 25 fce: a = -5, b = 200, c = 0
O trochu jiné jsou statické proměnné. Statické proměnné se deklarují pomocí klíčového slova static . Používají se v těle funkcí a rozdíl oproti „obyčejným“ proměnným je v tom, že se jejich hodnota po skončení průběhu funkce zachovává! Lze tak díky ní třeba zaznamenávat kolikrát byla funkce spuštěna. Oproti tomu se „obyčejná“ proměnná inicializuje při volání funkce vždy znova. Další výhodou je, že při skončení funkce máme zajištěno, že statická proměnná stále existuje a tudíž jí pomocí adresy můžeme upravovat i mimo tělo funkce, zatímco paměť pro „obyčejnou“ proměnnou může překladač v zájmu optimalizace programu využívat pro jiné účely (statickou proměnnou nemůže, a to je její nevýhoda, protože se tím sníží možná optimalizace programu).
1: /*------------------------------------------------* / 2: /* static.c * / 3: #include <stdio.h> 5: char *funkce(void) 6: { 7: static char pole[] = "Ahoj!" ; 8: static int x = 1000; 9: int y = 1000; 10: x++;

41
11: y++; 12: printf( "Funkce je volana po %i (%i)\n" , x, y); 13: return pole; 14: } 16: int main(void) 17: { 18: char *uk; 19: printf( "%s\n" , funkce()); 21: uk = funkce(); /* pomoci ukazatele zmenim statickou promennou */ 22: uk[0] = 'C'; 23: uk[1] = 'u'; 24: uk[2] = 's'; 25: uk[3] = '\0'; 27: printf( "%s\n" , funkce()); 29: return 0; 30: } 32: /*------------------------------------------------* / Výstup z programu: Funkce je volana po 1001 (1001) Ahoj! Funkce je volana po 1002 (1001) Funkce je volana po 1003 (1001) Cus
Uživatelské knihovny
Lze vytvářet knihovny (soubory mají nejčastěji příponou .h, pro jazyk C++ .hpp), v nichž jsou napsány vlastní funkce, nebo definovaná makra. Při psaní velkého programu je to nevyhnutelné.
Soubor "dos1.h": používá k pozastavení programu funkci delay() z knihovny <dos.h>.
1: /*------------------------------------------------* / 2: /* dos1.h * / 3: #include <dos.h> 5: void cekej(int cas) 6: { 7: delay(cas); 8: } 10: /*------------------------------------------------* /
Soubor "windows1.h": používá k pozastavení programu funkci Sleep() z knihovny <windows.h>.
1: /*------------------------------------------------* / 2: /* windows1.h * / 3: #include <windows.h> 5: void cekej(int cas) 6: { 7: Sleep(cas); 8: } 10: /*------------------------------------------------* /
Soubor "unix1.h": používá k pozastavení programu funkci usleep() z knihovny <unistd.h>.
1: /*------------------------------------------------* / 2: /* unix1.h * / 3: #include <unistd.h> 5: void cekej(unsigned long cas) 6: { 7: usleep(cas); 8: } 10: /*------------------------------------------------* /

42
V souboru cekej.c je třeba otestovat mnoho maker abychom zjistili, zda jsme na Windows. Různé překladače totiž používají různá makra (nejsou nikde standardizována). Nejpravděpodobněji to však bude makro __WINDOWS__ nebo __WIN32__ (a také __WIN16__ či __WIN64__ pro 16. a 64. bitové překladače). Ostatní makra, bez dvou podtržítek na začátku a na konci, jsou již zastaralá.
1: /*------------------------------------------------* / 2: /* cekej.c * / 3: #include <stdio.h> 5: #ifdef unix 6: #include "unix1.h" 7: #define VERZE "UNIX" 8: #define CEKEJ 100000ul 9: #elif defined __MSDOS__ 10: #define VERZE "MSDOS" 11: #include "dos1.h" 12: #define CEKEJ 100 13: #elif defined __WINDOWS__ ||defined _Windows ||defi ned _WINDOWS || defined __WIN32__ || defined _WIN32 || defin ed WIN32 14: #include "windows1.h" 15: #define VERZE "WINDOWS" 16: #define CEKEJ 100 17: #endif 19: int main(void) 20: { 21: int i, j; 23: for (i = 0; i <= 100; i++) { 24: printf( "\rZdrzuji: [" ); 25: for (j = 0; j < 10; j++) { 26: printf( "%c" , (j * 10 <= i) ? '.' : ' '); 27: } 28: printf( "] %3i%%" , i); 29: fflush(stdout); /* vyprazdnime standardni vystup */ 30: cekej(CEKEJ); /* implementacne zavisla funkce */ 31: } 32: printf( " OK\n" ); 33: return 0; 34: } 36: /*------------------------------------------------* /
V DOSu se k pozastavení programu používá funkce delay(), která je definována v knihovně <dos.h> a pozastaví program na zadaný počet milisekund, zatímco v Linuxu funkce usleep(), definována v knihovně <unistd.h>, pozastaví program na zadaný počet mikrosekund. Funkce fflush() pozastaví provádění programu do té doby, než se souborový proud, který je předáván jako argument, vyprázdní (tj. než se vše vypíše na obrazovku). Escape sekvence '\r' přesune kurzor na začátek řádku.
Vytváření typů
Struktury
Struktura umožňuje spojit několik datových typů do jednoho. Definice struktury:
struct [ jmeno ] { typ jmeno_polozky ; typ jmeno_polozky ; ... } [ promenne ] ;

43
Příklad struktury polozka. S definicí struktury jsou zároveň vytvořeny dvě proměnné (struktury) typu polozka.
struct polozka { unsigned int rok_narozeni; int pohlavi; char jmeno[20]; char prijmeni[20]; } Martin, Pavla;
Struktura vždy začíná klíčovým slovem struct . Poté může, ale také nemusí, být definováno jméno struktury. Pokud není definováno jméno, není možné později vytvořit další proměnné této struktury, ani ji použít jako parametr funkce. V těle struktury jsou deklarovány proměnné, které bude struktura obsahovat. Mohou to být i jiné struktury, nebo ukazatel na sebe sama. (Struktura nemůže obsahovat sebe samu). Struktury nelze sčítat, odčítat atd. U struktur lze použít pouze operátor přiřazení = . Tím se obsah jedné struktury zkopíruje do jiné. Pro přístup ke členům struktury se používají operátory . (tečka) a -> (šipka). Druhý operátor se používá v případě, že pracujeme s ukazatelem na strukturu.
polozka p, *ukazatel; ukazatel = &p; /* prirazeni 20 do casti struktury polozka pojmenov ane rok_narozeni */ p.rok_narozeni = 20; /* stejne prirazeni, jen pres ukazatel */ (*ukazatel).rok_narozeni = 20; /* stejne prirazeni pres ukazatel, jen jiny (hezci) zapis */ ukazatel->rok_narozeni = 20;
Použité závorky jsou nutné, aby bylo jasné že operátor dereference * (hvězdička) pracuje s proměnnou ukazatel. Přiřazení se šipkou je výhodnější.
Vytvořením struktury však není vytvořen nový datový typ. Struktura je obdoba datového pole, rozdíl je jen v tom, že datové pole obsahuje několik objektů stejného typu, zatímco struktura obsahuje různé datové typy. Jako není problém vytvořit pole obsahující jiné pole (vícerozměrná pole), není problém vytvořit pole obsahující strukturu. Možnosti použití struktury a také použití ukazatele typu void a aritmetiky ukazatelů:
1: /*------------------------------------------------* / 2: /* strukt.c * / 3: #include <stdio.h> 5: #define POCET 40 6: /* funkce zkopiruj kopiruje retezec v2 do retezce v 1 */ 7: void zkopiruj(char *v1, char *v2) 8: { 9: int i = 0; 10: do { 11: v1[i] = v2[i]; 12: } while (v2[i++]); 13: } 15: struct Pisen { 16: char nazev[POCET]; 17: char zpevak[POCET]; 18: char skladatel[POCET]; 19: float delka, hodnoceni; 20: } pisne[10], *ukp; 22: void vytiskni(void *str) ; /* deklarujeme funkci, 23: ktera bude tiskn out strukturu Pisen */ 25: int main(void) 26: { 27: struct Pisen pisen; 29: zkopiruj(pisen.nazev, "Twist And Shout" ); 30: zkopiruj(pisen.zpevak, "The Beatles" ); 31: zkopiruj(pisen.skladatel, "Lennon/McCartney" );

44
32: pisen.delka = 2.36; 33: pisen.hodnoceni = 1.0; 35: pisne[0] = pisen; 37: zkopiruj(pisne[1].nazev, "Eleanor Rigby" ); 38: zkopiruj(pisne[1].zpevak, "The Beatles" ); 39: zkopiruj(pisne[1].skladatel, "Lennon/McCartney" ); 40: pisne[1].delka = 2.06; 41: pisne[1].hodnoceni = 1.5; 43: ukp = &pisne[2]; /*do ukazatele ukladame adresu 3 prvku v poli pisne*/ 45: zkopiruj(ukp->nazev, "From Me To You" ); 46: zkopiruj(ukp->zpevak, "The Beatles" ); 47: zkopiruj(ukp->skladatel, "Lennon/McCartney" ); 48: ukp->delka = 1.58; 49: ukp->hodnoceni = 1.25; 51: vytiskni(&pisne[0]); 52: vytiskni(&pisne[1]); 53: vytiskni(&pisne[2]); 55: return 0; 56: } 58: void vytiskni(void *str) 59: { 60: /* str ukazuje na zacatek struktury */ 61: printf( "Nazev pisne:\t%s\n" , (char *) str); 63: str += POCET * sizeof (char); /* delka pole "nazev" ve strukture */ 64: /* str ukazuje za pole "nazev" ve strukture, tj. na 65: * zacatek pole "zpevak" */ 66: printf( "Interperet:\t%s\n" , (char *) str); 68: str += POCET * sizeof (char); 69: printf( "Skladatel(e):\t%s\n" , (char *) str); 71: str += POCET * sizeof (char); 72: printf( "Delka skladby:\t%.2f\n" , *((float *) str)); 74: str += 1 * sizeof (float); 75: printf( "Hodnoceni:\t%.2f\n\n" , *((float *) str)); 76: } 78: /*------------------------------------------------* / Výstup z programu: Nazev pisne: Twist And Shout Interperet: The Beatles Skladatel(e): Lennon/McCartney Delka skladby: 2.36 Hodnoceni: 1.00 Nazev pisne: Eleanor Rigby Interperet: The Beatles Skladatel(e): Lennon/McCartney Delka skladby: 2.06 Hodnoceni: 1.50 Nazev pisne: From Me To You Interperet: The Beatles Skladatel(e): Lennon/McCartney Delka skladby: 1.58 Hodnoceni: 1.25
Kdyby struktura Pisen neměla jméno Pisen (na řádku 15), nešlo by jí použít jako parametr funkce, vytvořit její další instanci (na řádku 27) a dokonce ani vytvořit ukazatel na tuto strukturu dále v programu. Existovali by pouze instance definované při definici struktury (na řádku 20). Zatímco textové řetězce ve funkci printf se předávají právě pomocí ukazatelů, čísla typu float je nutno předat jako hodnotu (proto ta hvězdička a závorky navíc). Aby ukazatel ukazoval do správného místa v paměti, je nutné jej postupně posouvat po položkách struktury o příslušný počet bytů (vracených operátorem sizeof .

45
Před názvem struktury je vždy nutné používat klíčové slůvko struct . Jak při deklaraci parametrů, tak při definici proměnných struktur.
void vytiskni(struct Pisen arg);
Předávání struktury jako argumentu má jednu velkou nevýhodu. Tato struktura se totiž celá zkopíruje z proměnné do zásobníku v paměti počítače (do „argumentu funkce“). Při práci s velikými strukturami, pak taková operace velice zpomaluje chod programu. Mnohem efektivnější je používat ukazatele na strukturu.
Definování typu pomocí typedef
Pomocí typedef se vytvářejí uživatelské datové typy:
typedef definice_typu identifikator ;
Definicí typu může být například struktura nebo nějaký základní typ jazyka C, identifikator je pojmenování nového datového typu:
1: /*------------------------------------------------* / 2: /* typedef2.c * / 3: #include <stdio.h> 5: typedef struct pokus { 6: int x; 7: int y; 8: char text[20]; 9: } Pokus; 11: int main(void) 12: { 13: struct pokus a = { 6, 6, "sest" }; 14: Pokus b = { 4, 5, "Ahoj" }; 16: a.x = 0; 17: b.x = 6; 18: return 0; 19: } 21: /*------------------------------------------------* /
Když už je definován datový typ Pokus, je trochu zbytečné používat strukturu pokus. Používání uživatelského typu je v mnohém příjemnější, než používání struktury jako takové:
1: /*------------------------------------------------* / 2: /* typedef3.c * / 3: #include <stdio.h> 5: /* funkce zkopiruj kopiruje retezec v2 do retezce v 1 */ 6: void zkopiruj(char *v1, char *v2) 7: { 8: int i = 0; 9: do { 10: v1[i] = v2[i]; 11: } while (v2[i++]); 12: } 14: typedef struct { 15: char nazev[40]; 16: char zpevak[40]; 17: char skladatel[40]; 18: float delka;

46
19: } Pisen; 21: typedef struct { 22: char nazev[40]; 23: int pocet_pisni; 24: float cenaSK, cenaCZ; 25: Pisen pisen[20]; 26: } CD; 28: void tiskni(CD * cd, int pocet) ; 30: int main(void) 31: { 32: CD *ualbum, alba[10], album; 33: /* inicializuji album */ 34: ualbum = &album; /* pouziti ukazatele album je tu jen pro ilustraci */ 35: zkopiruj(album.nazev, "The Beatles Songs" ); 36: album.cenaSK = 325.50; 37: ualbum->cenaCZ = 286.50; 38: album.pocet_pisni = 1; 39: /* vkladam prvni (a posledni) pisen do alba */ 40: zkopiruj(album.pisen[0].nazev, "Twist And Shout" ); 41: zkopiruj(ualbum->pisen[0].zpevak, "The Beatles" ); 42: zkopiruj(album.pisen[0].skladatel, "Lennon/McCartney" ); 43: ualbum->pisen[0].delka = 2.36; 45: /* ukazka prace z polem alba, do pole alba vkladam prvni album */ 47: alba[0] = album; 48: /* to same album vlozim jeste jednou, tentokrat prez ukazatel */ 50: alba[1] = *ualbum; 51: /* zmenim nazev a cenu ... */ 52: zkopiruj(alba[1].nazev, "Salute to The Beatles" ); 53: alba[1].cenaSK = 350.0; 54: /* ... a pridam dalsi pisen */ 55: alba[1].pocet_pisni = 2; 56: alba[1].pisen[1] = alba[1].pisen[0]; 57: zkopiruj(alba[1].pisen[1].nazev, "Eleanor Rigby" ); 58: alba[1].pisen[1].delka = 2.06; 60: tiskni(alba, 2); 61: return 0; 62: } 64: void tiskni(CD * cd, int pocet) 65: { 66: int i, j; 68: for (i = 0; i < pocet; i++) { 69: /* tisknu album "i" */ 70: printf( "%s\t%5.2fKc (%5.2fSk)\n" , cd[i].nazev, cd[i].cenaCZ, 71: cd[i].cenaSK); 72: for (j = 0; j < cd[i].pocet_pisni; j++) { 73: /* tisknu pisne z alba "i" */ 74: printf( "\t\tNazev:\t%s\n" , cd[i].pisen[j].nazev); 75: printf( "\t\tInterpret:\t%s\n" , cd[i].pisen[j].zpevak); 76: printf( "\t\tSkladatel:\t%s\n" , cd[i].pisen[j].skladatel); 77: printf( "\t\tDelka:\t%.2f\n" , cd[i].pisen[j].delka); 78: printf( "\t\t.......................\n" ); 79: } 80: printf( "------------------------------------------\n" ); 81: } 82: } 84: /*------------------------------------------------* / Výstup: The Beatles Songs 286.50Kc (325.50Sk) Nazev: Twist And Shout Interpret: The Beatles Skladatel: Lennon/McCartney Delka: 2.36 ....................... ------------------------------------------

47
Salute to The Beatles 220.00Kc (350.00Sk) Nazev: Twist And Shout Interpret: The Beatles Skladatel: Lennon/McCartney Delka: 2.36 ....................... Nazev: Eleanor Rigby Interpret: The Beatles Skladatel: Lennon/McCartney Delka: 2.06 ....................... ------------------------------------------
Výčtový typ enum
Typ enum umožňuje vytvořit proměnnou, která může obsahovat hodnoty konstant určených při deklaraci výčtového typu. Lze vytvořit buďto jen výčtový typ enum (stejně jako jenom strukturu), nebo pomocí typedef definovat nový datový typ.
enum [ jmeno ] { seznam konstant ... } [ promenne ] ;
Příklad vytvoření výčtového typu:
enum kalendar { leden = 1, unor, brezen, duben, kveten, cerven, ce rvenec, srpen, zari, rijen, listopad, prosinec } a, b; ... a = unor; ... if (b == duben) { ...
V příkladu je vytvořen výčtový typ se jménem kalendar a jsou definovány dvě proměnné a a b. Konstanty výčtového typu jsou vždy celo číselné . Pokud nemá konstanta přiřazenu hodnotu, pak má hodnotu o jednotku vyšší, než konstanta předešlá (unor tedy odpovídá číslu 2, brezen 3 atd). Pokud není definována hodnota ani konstantě první, automaticky je jí přiřazena nula. Hodnoty lze přiřadit kterékoliv konstantě ve výčtovém typu. Opět platí, že následující konstanta, pokud nemá přiřazenou hodnotu, je o jednotku větší, než předcházející konstanta. Překladač tyto konstanty chápe pouze jako čísla. Je tedy dost dobře možné je srovnávat s čísly (např if(leden == 1)),ale to by zcela postrádalo smysl. Výčtový typ se používá právě proto, aby se v programu nemusela konkrétní čísla používat. Použití výčtového typu se hodně podobá makrům preprocesoru. Jeho výhodou je právě to, že lze vytvářet proměnné výčtového typu, čímž se dá program zpřehlednit a jeho čtení je pak o něco snazší. Příkladu na použití typu enum s konstrukcí typedef.
1: /*------------------------------------------------* / 2: /* enum1.c * / 4: #include <stdio.h> 6: typedef enum { 7: vlevo, vpravo, stred, center = stred 8: } zarovnani; 11: void tiskni_znak(char ch, zarovnani zr) 12: { 13: switch (zr) { 14: case vlevo: 15: printf( "%c\n" , ch); 16: break ; 17: case vpravo: 18: printf( "%50c\n" , ch);

48
19: break ; 20: case stred: 21: printf( "%25c\n" , ch); 22: break ; 23: default: 24: printf( "%c%24c%25c\n" , '?', '?', '?'); 25: } 26: } 28: int main(void) 29: { 30: tiskni_znak('A', 50); 31: tiskni_znak('X', vlevo); 32: tiskni_znak('Y', center); 33: tiskni_znak('Z', vpravo); 34: return 0; 35: } 37: /*------------------------------------------------* / Výstup z programu: ? ? ? X Y Z
Typ union
Syntaxe typu union je stejná jako struktury, až na to, že místo klíčového slova struct se použije klíčové slovo union . Význam jednotlivých položek je stejný. Jeho použití s konstrukcí typedef také.
union [ jmeno ] { typ jmeno_polozky ; typ jmeno_polozky ; ... } [ promenne ] ;
Rozdíl tu však je. Zatímco struktura si vytvoří paměťové místo pro všechny položky, typ union zabírá v paměti jen tolik místa, kolik nejv ětší jeho položka . Z toho také vyplývá, že lze používat v jeden okamžik jen jednu položku. Kterou, to už závisí na programátorovi. Typ union tak může při programování ušetřit paměť. Navíc lze vytvořit funkci, která bude vracet různé datové typy jako typ union. Prvkem v union může být i struktura, nebo jiný typ union atp..
Funkce rand() a srand()
Funkce rand() vrací pseudonáhodné číslo v rozmezí 0 až RAND_MAX . Pseudonáhodné protože vrací čísla z číselné řady generována na základě nějakých matematických podmínek. Aby tato čísla nebyla při spuštění programu vždy stejná, nastaví se počátek této řady pomocí funkce srand() . Argumentem této funkce je číslo typu unsigned int. Dobré je předat této funkci jako argument aktuální čas.
Funkce rand() a srand() jsou definovány ve standardním hlavičkovém souboru <stdlib.h>.
1: /*------------------------------------------------* / 2: /* union.c * / 4: #include <stdio.h> 5: #include <stdlib.h> 7: typedef enum { 8: znak, cele, racionalni 9: } typ; 11: typedef union { 12: char ch; 13: unsigned int uin; 14: float fl;

49
15: } datovy_typ; 17: datovy_typ nahodne_cislo(typ t) 18: { 19: datovy_typ x; 21: switch (t) { 22: case znak: 23: x.ch = (char) (rand() % ('z' - 'a')) + 'a'; 24: break ; 25: case cele: 26: x.uin = (unsigned int) rand(); 27: break ; 28: case racionalni: 29: x.fl = (float) rand() / RAND_MAX; 30: break ; 31: } 32: return x; 33: } 35: int main(void) 36: { 37: datovy_typ un; 39: printf( "Zadej cislo: " ); 40: if (scanf( "%u" , &un.uin) == 0) 41: return 1; 43: srand(un.uin); 44: un = nahodne_cislo(racionalni); 45: printf( "float = %f\n" , un.fl); 47: un = nahodne_cislo(znak); 48: printf( "char = %c\n" , un.ch); 50: un = nahodne_cislo(cele); 51: printf( "int = %i\n" , un.uin); 53: printf( "velikost un = %u == float = %u\n" , sizeof (un), sizeof (float)); 54: return 0; 55: } 57: /*------------------------------------------------* / Možný výstup z programu: Zadej cislo: 123 float = 0.060051 char = n int = 436085873 velikost un = 4 == float = 4
Ukazatele na funkce Protože i funkce programu leží kdesi v paměti, existuje adresa, která ukazuje na začátek této funkce. Pomocí ukazatele na funkci ji lze zavolat (a to i s příslušnými argumenty). Je možné tak například napsat funkci, která bude mít jako argument ukazatel na jinou funkci, kterou pak může spustit. Deklaraci ukazatele (jmeno) na funkci, která má návratovou hodnotu „typ“. V závorce mohou být uvedené typy očekávaných argumentů funkce. typ (* jmeno )( [ typ_arg ,..] );
V následujícím příkladu je deklarován ukazatel uknf, který ukazuje na funkci bez argumentů s návratovou hodnotou „ukazatel na typ char“. Pro porovnání je hned za touto deklarací deklarace oné funkce. Závorky při deklaraci ukazatele na funkci jsou vždy nevyhnute lné . Bez nich by v tomto příkladu byla vytvořena deklarace funkce s návratovým typem „ukazatel na ukazatel na typ char“.
char *(*uknf) (void); /* deklarace ukazatele na funkci, která vrací ukaza tel */ char *uknf (void); /* deklarace funkce, která vrací ukazatel */
V příkladu použitá funkce exit() ukončí program v jakémkoliv místě s návratovou hodnotou, která je jejím argumentem. Tato funkce je definována v souboru <stdlib.h >.

50
1: /*------------------------------------------------* / 2: /* ukafce.c * / 4: #include <stdio.h> 5: #include <stdlib.h> 7: /* nejdrive vytvorime strukturu, ktera bude obsahov at nejake pojmenovani 8: * funkce pro uzivatele programu, cislo funkce, bu de zaznamenavat pocet 9: * spusteni funkce a ukazatel na funkci */ 10: typedef struct { 11: unsigned int cislo; 12: char nazev[50]; 13: unsigned int spusteno; 14: void (*ukfce) (unsigned int *, char *); 15: } robot; 17: /* nyni definujeme funkce programu, ktere budou uzi vateli nabizeny pomoci 18: * predchozi struktury */ 19: /* zobrazi pouze velka pismena */ 20: void velka_pismena(unsigned int *spusteno, char *v) 21: { 22: int i = 0; 23: (*spusteno)++; 24: do { 25: if ((v[i] >= 'A') && (v[i] <= 'Z')) { 26: printf( "%c" , v[i]); 27: } 28: } while (v[i++]); 29: printf( "\n" ); 30: } 32: /* zobrazi pouze mala pismena */ 33: void mala_pismena(unsigned int *spusteno, char *v) 34: { 35: int i = 0; 36: (*spusteno)++; 37: do { 38: if ((v[i] >= 'a') && (v[i] <= 'z')) { 39: printf( "%c" , v[i]); 40: } 41: } while (v[i++]); 42: printf( "\n" ); 43: } 45: /* zobrazi vse, co neni pismeno */ 46: void nepismena(unsigned int *spusteno, char *v) 47: { 48: int i = 0; 49: (*spusteno)++; 50: do { 51: if (!(((v[i] >= 'a') && (v[i] <= 'z')) || 52: ((v[i] >= 'A') && (v[i] <= 'Z')))) { 53: printf( "%c" , v[i]); 54: } 55: } while (v[i++]); 56: printf( "\n" ); 57: } 59: /* zobrazi text pozpatku */ 60: void obrat_text(unsigned int *spusteno, char *v) 61: { 62: int i = 0; 63: if (*spusteno >= 2) { 64: printf( "Pro dalsi pouziti teto funkce se musite registrova t!\n" ); 65: return ; 66: } 67: (*spusteno)++; 69: while (v[i++]); /* hledame konec retezce */ 71: for (i--; i >= 0; i--)

51
72: printf( "%c" , v[i]); 74: printf( "\n" ); 75: } 77: /* vlozi do textu mezery */ 78: void roztahni(unsigned int *spusteno, char *v) 79: { 80: int i = 0; 81: (*spusteno)++; 82: while (v[i]) { 83: printf( "%c " , v[i++]); 84: }; 85: printf( "\n" ); 86: } 88: /* funkce exit() ma jine parametry, nez ktere oceka va nas ukazatel, proto 89: je vytvorena funkce konec, ktera simuluje potrebu d eklarovanych argumentu */ 91: void konec(unsigned int *spusteno, char *v) 92: { 93: exit(0); /* ukonci program s navratovou hodnotou 0, ktera zn aci uspech */ 95: } 98: /*fce vlozime do pole struktury robot spolu s nazve m pro uzivatele atd. */ 99: robot *inicializuj(void) 100: { 101: /*promenna "r" je staticka, aby po skonceni funkce neprestala existovat! */ 103: static robot r[] = { {1, "Velke pismena" , 0, velka_pismena}, 104: {1, "Mala pismena" , 0, mala_pismena}, 105: {2, "Co neni pismeno" , 0, nepismena}, 106: {3, "Obraceni textu" , 0, obrat_text}, 107: {4, "Roztazeni textu" , 0, roztahni}, 108: {5, "Ukonceni" , 0, konec}, 109: {0, "" , 0, NULL} /* "zarazka", podle ktere pozname, ze jsme na konci */ 110: }; 111: return r; 112: } 115: int main(void) 116: { 117: int i, navrat; 118: robot *rb; /* ukazatel na pole struktury robot */ 119: unsigned int cislo; /* funkce jsou ve strukture ocislovany, 120: dle tohoto cisla budou vybirany */ 121: char retezec[51]; /* maximalne 50 znaku + '\0' */ 123: rb = inicializuj(); /* tato funkce vraci ukazatel na svou statickou 124: promennou. P ři opakovaném volání ukazuje stale na to same pole.* / 128: do { 129: i = 0; 130: do { 131: /* zobrazeni menu - snadne a prehledne */ 132: printf( "%2i)\t%s\t(%2i)\n" , rb[i].cislo, rb[i].nazev, 133: rb[i].spusteno); 134: } while (rb[++i].ukfce != NULL); 136: printf( "Vyber polozku dle cisla a zadejte retezec: " ); 138: /* vysledek prirazeni muzeme pouzit jako hodnotu 139: (tak ho rovnou porovname s EOF) */ 140: if ((navrat = scanf( "%u %50s" , &cislo, retezec)) == EOF) 141: break ; 142: else if (navrat != 2) { /* chybne nacteni polozek */ 143: printf( "\n Chyba vstupu (%i)!\n" , navrat); 144: /* Zrejme nebylo zadano jako prvni cislo, ale retez ec. Ten se musi nyni nacist, jinak by se jej predchozi funkc e scanf pokousela v cyklu 146: neustale nacitat jako cislo a tim by cyklus nikdy neskoncil. 147: Promenna retezec muze obsahnout maximalne 50 znak u, proto funkci scanf 148: v prvnim argumentu urcime max. delku nacitaneho r etezce. */ 151: scanf( "%50s" , retezec); 152: continue ;

52
153: } 154: i = -1; 155: while (rb[++i].ukfce != NULL) { /* hledame spravnou strukturu, dokud 156: nenarazime na na mi vytvorenou zarazku */ 157: if (rb[i].cislo == cislo) { 158: rb[i].ukfce(&rb[i].spusteno, retezec); 159: /* prochazi se cele pole, takze se spusti vsechny p olozky v 160: * poli, ktere maji rb[].cislo == c islo */ 161: /* kdyby zde byl prikaz break, provedla by se prvni nalezena 162: polozka a dale by se jiz nic neprohl edavalo */ 163: } 164: } /*nekonecny cyklus, ukonci se return, break (p ř. exit konci program)*/ 165: } while (1); 168: printf( "\nAstalavista !\n" ); 169: return 0; 170: } 172: /*------------------------------------------------* / Možný výstup z programu: 1) Velke pismena ( 0) 1) Mala pismena ( 0) 2) Co neni pismeno ( 0) 3) Obraceni textu ( 0) 4) Roztazeni textu ( 0) 5) Ukonceni ( 0) Vyber polozku dle cisla a zadejte retezec: 1 VelkaAMalaPismena VAMP elkaalaismena 1) Velke pismena ( 1) 1) Mala pismena ( 1) 2) Co neni pismeno ( 0) 3) Obraceni textu ( 0) 4) Roztazeni textu ( 0) 5) Ukonceni ( 0) Vyber polozku dle cisla a zadejte retezec: 5 konec
Program má jeden drobný nedostatek, a to, že při volání funkce k ukončení programu (je pod číslem 5) je potřeba zadat za číslo 5 ještě nějaký zbytečný řetězec. Existuje spousta možností, jak se tohoto nedostatku zbavit. Důležitější je, jak snadno se do takového programu přidá další funkce. Stačí ji jen napsat a ve funkci inicializuj() jí přidat do pole struktury robot. Nic víc se na programu měnit nemusí. Ukazatel na funkci se tak může s výhodou použít v programech, které načítají funkce z knihoven. Při vytvoření funkce stačí jen změnit nebo vytvořit novou knihovnu pro program (a ne hned překládat celý program). Program si jí načte do paměti a pak s ní může snadno pracovat pomocí ukazatele.
Přehled deklarací
typ jmeno; Proměnná určeného typu
typ *jmeno; Ukazatel na určitý typ (respektive pole daného typu)
typ jmeno[ ]; Konstantní ukazatel na pole daného typu (neznámo jak dlouhé)
typ jmeno[10]; Konstantní ukazatel na pole daného typu o velikosti 10-ti proměnných daného typu.
typ **jmeno; Ukazatel na pole ukazatelů daného typu
typ *jmeno[ ]; Konstantní ukazatel na pole ukazatelů daného typu
typ jmeno[ ][ ]; Konstantní ukazatel na pole konstantních ukazatelů na pole daného typu.
typ jmeno(); Deklarace funkce vracející typ
typ *(jmeno()); Funkce vracející ukazatel na typ. Zvýrazněné závorky jsou nadbytečné.
typ (*jmeno)() Ukazatel na funkci bez parametrů vracející typ
typ *(*jmeno)() Ukazatel na funkci bez parametrů vracející ukazatel na typ

53
Lze vytvářet i daleko složitější deklarace. Například
unsigned long *(*jmeno[5][4])(char *);
je dvojrozměrné pole obsahující ukazatele na funkci, jejíž návratová hodnota je ukazatel na typ unsigned long a argumentem této funkce je ukazatel na typ char. Rozluštit takovéto zápisy není zrovna legrace. Proto je výhodnější využívat typedef pro zjednodušení takovýchto konstrukcí. Předchozí proměnnou jmeno lze definovat takto:
typedef unsigned long *(*ukazatel_na_fci1)(char *); ukazatel_na_fci1 jmeno[5][4];
V následujícím příkladu je naprogramována „chůze opilce“. Program si přečte z příkazové řádky pravděpodobnosti, s jakými půjde opilec vpřed a vzad. Pravděpodobnost, že zůstane stát si dopočte program sám (zbytek do 100%). Jelikož na příkazové řádce jsou i čísla chápána jako text, použijeme funkci atoi() ze standardní knihovny na převod řetězce na číslo typu int. Po spuštění programu bude mít navíc uživatel možnost vybrat si z několika zobrazení opilce. Funkce pro zobrazování opilce budou v jiném souboru, než hlavní program a budou se volat pomocí ukazatele na funkce.
3: #include <dos.h> 5: void cekej(int cas) 6: { 7: delay(cas); 8: } 3: #include <windows.h> 5: void cekej(int cas) 6: { 7: Sleep(cas); 8: } 3: #include <unistd.h> 5: void cekej(unsigned long cas) 6: { 7: usleep(cas); 8: }
V souboru "define1.h" definujeme potřebné datové typy a makra. Tyto datové typy a makra se budou používat i v dalších knihovnách, proto je třeba v hlavním programu načíst tuto knihovnu (pomocí #include) jako jednu z prvních. Výčtový typ smer bude sloužit k určování směru chůze opilce, struktura pohyb bude obsahovat pravděpodobnosti, s jakou půjde opilec vpřed, vzad nebo zůstane stát a také pozici, kde opilec právě stojí. Položka stop nebude ani využita, lze jí dopočítat do 100% pomocí položek vpred a vzad . Je otázkou, zda je lepší vytvořit takovou položku, do které se hodnota jednou uloží a pak už se jen používá, nebo kdykoliv je v programu potřeba, tak se vypočte výrazem (100-vpred-vzad). Pokud by se tento výraz musel v programu vícekrát počítat (což program zpomaluje) a i tento výraz zabírá v programu místo, bylo by výhodnější položku stop použít.
1: /*------------------------------------------------* / 2: /* define1.h * / 4: #define DELKACHUZE 40 6: typedef enum { 7: dopredu, dozadu, stat 8: } smer; 10: typedef struct { 11: int vpred, vzad, stop; 12: int pozice; 13: } pohyb; 14: /*------------------------------------------------* /

54
V souboru "zobraz1.h" jsou definovány všechny funkce, kterými se zobrazuje pohyb opilce. Ukazatele na tyto funkce jsou uloženy do pole zobraz . Funkce budou volány v programu náhodně. Proto jsou tam některé záměrně vícekrát, aby byla větší pravděpodobnost, že budou vybrány.
1: /*------------------------------------------------* / 2: /* zobraz1.h * / 4: #include <stdio.h> 5: #include <stdlib.h> 7: #define TISKNIOPILCER(ZNK) printf( "\r%3i%% (%*s%*c %3i%% (%3i)" , p->vzad,\ p->pozice, ZNK, DELKACHUZE - p->pozice,')',p->vpred ,pocet); 9: #define TISKNIOPILCEN(ZNK) printf( "\n%3i%% (%*s%*c %3i%% (%3i)" , p->vzad,\ p->pozice, ZNK, DELKACHUZE - p->pozice,')',p->vpred ,pocet); 12: void zobraz_opilce1(pohyb *, const smer 1) , const int) ; 13: void zobraz_opilce2(pohyb *, const smer, const int) ; 14: void zobraz_opilce3(pohyb *, const smer, const int) ; 15: void zobraz_opilce4(pohyb *, const smer, const int) ; 17: void (*zobraz[]) (pohyb *, const smer, const int) = { 18: zobraz_opilce1,zobraz_opilce2, zobraz_opilce3, zobr az_opilce1, zobraz_opilce3}; 21: void zobraz_opilce1(pohyb * p, const smer s, const int pocet) 22: { 23: switch (s) { 24: case dopredu: 25: p->pozice++; 26: TISKNIOPILCER( "->" ) 27: break ; 28: case dozadu: 29: p->pozice--; 30: TISKNIOPILCER( "<-" ) 31: break ; 32: case stat: 33: TISKNIOPILCER( "<>" ) 34: break ; 35: }; 36: } 38: void zobraz_opilce2(pohyb * p, const smer s, const int pocet) 39: { 40: switch (s) { 41: case dopredu: 42: p->pozice++; 43: TISKNIOPILCEN( "->" ) 44: break ; 45: case dozadu: 46: p->pozice--; 47: TISKNIOPILCEN( "<-" ) 48: break ; 49: default: 50: TISKNIOPILCEN( "<>" ) 51: break ; 52: }; 53: } 55: void zobraz_opilce3(pohyb * p, const smer s, const int pocet) 56: { 57: switch (s) { 58: case dopredu: 59: p->pozice++; 60: TISKNIOPILCER( ">>" ) 61: break ; 62: case dozadu: 63: p->pozice--;

55
64: TISKNIOPILCER( "<<" ) 65: break ; 66: default: 67: TISKNIOPILCER( "><" ) 68: break ; 69: }; 70: } 72: void zobraz_opilce4(pohyb * p, const smer s, const int pocet) 73: { 74: switch (s) { 75: case dopredu: 76: p->pozice++; 77: printf( "\rPOZICE: %2i%*c" , p->pozice++, DELKACHUZE + 10, ' '); 78: break ; 79: case dozadu: 80: p->pozice--; 81: printf( "\rPOZICE: %2i%*c" , p->pozice++, DELKACHUZE + 10, ' '); 82: break ; 83: default: 84: printf( "\rPOZICE: %2i%*c" , p->pozice++, DELKACHUZE + 10, ' '); 85: break ; 86: }; 87: } 89: /*------------------------------------------------* /
A nyní srdce programu, soubor opakov1.c.
1: /*------------------------------------------------* / 2: /* opakov1.c * / 4: #include <stdio.h> 5: #include <stdlib.h> 7: #ifdef unix 8: #include "unix1.h" 9: #define VERZE "UNIX" 10: #define CEKEJ 100000ul 11: #elif defined __MSDOS__ 12: #define VERZE "MSDOS" 13: #include "dos1.h" 14: #define CEKEJ 100 15: #elif defined __WINDOWS__||defined __WIN16__||defin ed __WIN32__ || defined __WIN64__ 16: #include "windows1.h" 17: #define VERZE "WINDOWS" 18: #define CEKEJ 100 19: #endif 22: /*V souboru define1.h jsou nadefinovany datove typy, ktere se pouzivaji i v souboru zobraz1.h . Proto musi byt #include"define.h" prvni */ 26: #include "define1.h" 27: #include "zobraz1.h" 29: /*Nacteme cisla z prikazove radky a pote zkontroluj eme, zda maji 30: rozumne hodnoty. Pokud ne, program ukoncime */ 32: pohyb nacti_procenta(int argc, char *argv[]) 33: { 34: pohyb p = { 0, 0, 0, DELKACHUZE / 2 }; 35: if (argc != 3) { 36: printf( "Spatny pocet argumentu\n" 37: "Zadejte pravdepodobnost chuze vpred a vzad.\n" ); 38: exit(0); 39: } 40: p.vpred = atoi(argv[1]);

56
41: p.vzad = atoi(argv[2]); 42: p.stop = 100 - p.vpred - p.vzad; 44: if (p.stop < 0) { 45: printf( "Chybne zadane pravdepodobnosti\n" ); 46: printf( "Jejich soucet nesmi prekrocit 100\n" ); 47: exit(0); 48: } 50: if (!(p.vpred || p.vzad)) { 51: printf( "Pravdepodobnost vpred nebo vzad musi byt nenulova\ n" ); 52: exit(0); 53: } 54: if ((p.vpred < 0) || (p.vzad < 0)) { 55: printf( "Pravdepodobnosti musi byt kladne!\n" ); 56: exit(0); 57: } 58: return p; 59: } 62: smer vyber_smer(const pohyb * p) /* nahodne vybirame smer pohybu opilce */ 63: { 64: int x; 65: x = (rand() % 100); /* tj. 0 - 99 */ 66: if (x <= p->vpred) 67: return dopredu; 68: if (x <= p->vpred + p->vzad) 69: return dozadu; 70: return stat; 71: } 74: int main(int argc, char *argv[]) 75: { 76: pohyb opilec; 77: int pocet_funkci, fce, pocet; 78: opilec = nacti_procenta(argc, argv); /*Cisla inicializujeme "nenahodne",pri stejne zadan ých procentech se bude program chovat stejne. Lepe je srand inicializovat treba aktualnim casem */ 82: srand(opilec.vpred * opilec.vzad); /*NULL je ukazatel "do nikam". Ma stejnou velikost jako 84: kterykoliv ukazatel, Tj. sizeof(NULL) = sizeof(cha r *) atd. */ 86: pocet_funkci = sizeof (zobraz) / sizeof (NULL); 88: pocet = 0; 89: do { 90: pocet++; 91: fce = rand()%pocet_funkci; /*vybirame nahodne funkci na zobrazeni */ 92: zobraz[fce] (&opilec, vyber_smer(&opilec), pocet ); 93: fflush(stdout); /* vyprazdneni vystupu pred pozastavenim */ 94: cekej(CEKEJ); 95: } while ((opilec.pozice > 2) && (opilec.pozice < DELKACHUZ E - 1)); 97: printf( "\n" ); 98: return 0; 99: } 101: /*------------------------------------------------* / Možný výstup: opakov1 30 50 50% ( << ) 30% ( 8) 50% ( < - ) 30% ( 49) 50% ( >> ) 30% ( 17) 50% ( <- ) 30% ( 52) 50% ( <> ) 30% ( 24) 50% ( << ) 30% ( 64) 50% ( << ) 30% ( 27) 50% ( << ) 30% ( 70) 50% ( -> ) 30% ( 28) 50% (<- ) 30% ( 72) 50% ( << ) 30% ( 38) 50% ( <> ) 30% ( 43) 50% ( >> ) 30% ( 45)

57
Dynamická alokace paměti
Každý program lze v zásadě rozdělit na dvě části. Na část datovou, kde jsou uložena data, se kterými program pracuje (tj. proměnné) a na část programovou, která obsahuje instrukce programu. Ihned po spuštění programu jsou data která ukládáte do proměnných uložena v paměti počítače. Taková místa v paměti se nazývají statická. Takto získávaná paměť má své pro i proti. Výhodou je rychlost a zaručená dostupnost paměti. Jsou však situace, kdy dopředu nevíme, kolik paměti bude potřeba. Například třídění čísel. Jelikož dopředu nevíme, kolik čísel bude uživatel chtít setřídit, můžeme to jenom odhadnout a vytvořit si pro tato čísla pole dlouhé např. 1000 položek typu float . To už je velké pole, které zvětší velikost programu a zpomalí jeho chod, přičemž se může stát, že uživatel bude využívat v průměru třeba jen 10 položek. Na druhou stranu se také může stát, že bude potřebovat 1001 položek. Výhodnější v tomto případě je žádat o paměť pro proměnnou (nebo celá pole proměnných) za chodu programu. Tomu se říká „dynamická alokace pam ěti “. I to má však své výhody a nevýhody. Výhodou je, že program využívá právě tolik paměti, kolik potřebuje. Navíc získanou paměť můžete během programu uvolnit (je to vhodné a před ukončením programu nutné! ). Jistou nevýhodou je zvýšená pracnost s dynamickými strukturami (a časová režie při běhu programu). Proto je třeba zvážit, zda se vyplatí vytvářet dynamické data, nebo využít statických polí.
Získání a uvoln ění paměti pomocí malloc() a free()
Funkce malloc() a free() jsou obsaženy v hlavičkovém souboru <stdlib.h> , a též i datový typ size_t , používaný k určování velikosti získávané paměti. Je to celočíselný typ, definovaný pomocí typedef a je dostatečně velký na to, aby se v něm mohla uložit adresa paměti. Proto je lépe používat size_t a ne int, který nemusí být dostatečně velký na adresování celého rozsahu paměti.
void * malloc (size_t size ); void free (void * ptr );
Funkce malloc() má jako jediný argument počet bajtů paměti, které chceme od operačního systému získat. Návratová je deklarována jako ukazatel void * (s dynamicky alokovanou pamětí se pracuje pomocí ukazatelů). Paměť přidělí operační systém a funkce malloc() vrátí ukazatel na začátek této paměti. V případě, že volné paměti není dostatek, vrátí funkce malloc() hodnotu NULL . Vrácený ukazatel je třeba přetypovat na správný datový typ, který bude v alokovaném datovém poli používán. Takto získaná paměť, je souvislá oblast dlouhá size_t bajtů s nedefinovaným obsahem. Maximální velikost dynamicky alokované paměti je dána jednak fyzickými možnostmi počítače a také velikostí adresování paměti. U 32 bitových programů je možné adresovat až 4GB. Funkce free() takto alokovanou paměť opět uvolní. Její argument je ukazatel na začátek alokované paměti (tedy hodnotu, kterou vrací funkce malloc(), calloc() a realloc. Po volání funkce free() již paměť není přidělena programu a pokus o zápis do této paměti končí běhovou chybou.
Pokud program neuvolňuje nepotřebnou paměť, dochází k takzvanému „úniku pam ěti “ (memory leaks). Déle běžící aplikace si tak říká o stále více a více paměti, až nakonec spotřebuje všechnu, která je dostupná. Takovými problémy často trpí například Mozilla Firefox (ale i mnoho jiných profesionálních aplikací).
Následující program načte od uživatele číslo určující počet následujících zadávaných čísel, které se poté setřídí. Pomocí NULL je kontrolováno, zda byla dynamická paměť skutečně alokována, je přetypována návratová hodnota a určuje se velikost získávaného datového pole.
1: /*------------------------------------------------* / 2: /* dynamic1.c * / 4: #include <stdio.h> 5: #include <stdlib.h> 7: /* funkce pro setrideni pole od nejmensiho do nejve tsiho */ 8: void setrid(unsigned int delka, float pole[])

58
9: { 10: unsigned int i, j; 11: float pom; 12: if (delka <= 1) 13: return ; 15: for (j = 0; j < delka - 1; j++) { 16: i = 0; 17: do { 18: if (pole[i] > pole[i + 1]) { 19: pom = pole[i]; 20: pole[i] = pole[i + 1]; 21: pole[i + 1] = pom; 22: } 23: i++; 24: } while (i < delka - 1); 25: } 26: } 28: int main(void) 29: { 30: unsigned int i; 31: unsigned int *ui; /* ukazatel na dynamicky alokovane cislo, ktere bude urcovat delku p ole pro tridene cisla. V tomto pripade by byl o lepsi pouzit statickou promennou (jako unsi gned int i) */ 35: float *uf; /* ukazatel na dynamicky alokovane pole, do ktereho budou ulozeny tridena cisla */ 39: ui = (int *) malloc( sizeof (int)); 40: if (ui == NULL) { /* jeden mozny zpusob kontroly */ 41: printf( "Nedostatek pameti!\n" ); 42: return 0; 43: } 45: printf( "Zadejte pocet cisel: " ); 46: scanf( "%u" , ui); /* u funkce scanf by se melo kontrolovat, zda skutecne nacetla to, co mela.*/ 49: /* pozadam o tolik bytu, kolik ma typ float krat ve likost pole */ 50: if ((uf = (float *) malloc( sizeof (float) * (*ui))) == NULL) 51: /* taky zpusob kontroly :-) */ 52: { 53: printf( "Nedostatek pameti!\n" ); 54: return 0; 55: } 57: for (i = 0; i < *ui; i++) { 58: printf( "Zadejte cislo [%2u]: " , i + 1); 59: scanf( "%f" , uf + i); /* nebo uf[i] */ 60: } 62: setrid(*ui, uf); 63: for (i = 0; i < *ui; i++) { 64: printf( "%5.2f " , uf[i]); /* nebo uf + i */ 65: } 66: printf( "\n" ); 67: free(ui); 68: free(uf); 69: return 0; 70: } 72: /*------------------------------------------------* / Výstup z programu: Zadejte pocet cisel: 5 Zadejte cislo [ 4]: 2 Zadejte cislo [ 1]: 4 Zadejte cislo [ 5]: 0.5 Zadejte cislo [ 2]: 3.5 0.50 2.00 3.50 3.80 4.00 Zadejte cislo [ 3]: 3.8

59
V následujícím příkladu je dynamicky vytvořené dvourozměrné pole (s následným uvolňováním). Jeho velikost bude 100*200*sizeof(int) bajtů.
1: /*------------------------------------------------* / 2: /* dynamic2.c * / 4: #include <stdio.h> 5: #include <stdlib.h> 7: #define X 100 /* pocet radku */ 8: #define Xv1 10 /* vypis radek Xv1 az Xv2 */ 9: #define Xv2 20 11: #define Y 200 /* sloupce */ 12: #define Yv1 50 /* vypis sloupcu Yv1 az Yv2 */ 13: #define Yv2 60 15: int main(void) 16: { 17: int **ui; 18: int a, b; 20: ui = (int **) malloc(X * ( sizeof (int *))); 21: if (ui == NULL) 22: return 1; 24: for (a = 0; a < X; a++) { 25: ui[a] = (int *) malloc(Y * ( sizeof (int))); 26: if (ui[a] == NULL) 27: return 1; 28: } 30: for (a = 0; a < X; a++) 31: for (b = 0; b < Y; b++) 32: ui[a][b] = a * b; 34: printf( " " ); 35: for (b = Yv1; b <= Yv2; b++) 36: printf( "%5i " , b); 38: printf( "\n" ); 39: for (a = Xv1; a <= Xv2; a++) { 40: printf( "%3i: " , a); 41: for (b = Yv1; b <= Yv2; b++) 42: printf( "%5i " , ui[a][b]); 43: printf( "\n" ); 44: } 46: /* jak byla pamet alokovana, tak musi byt dealokova na. */ 48: for (a = 0; a < X; a++) 49: free(ui[a]); 50: free(ui); 52: return 0; 53: } 55: /*------------------------------------------------* /
V případě volání pouze free(ui), by se uvolnila jen paměť alokovaná prvním zavoláním funkce malloc(). Navíc by tak byly straceny všechny ukazatele na paměť získávanou v cyklu na řádku 25. (To by byla krásná ukázka úniku paměti.)
Získání pam ěti pro struktury pomocí calloc()
Funkce calloc() je deklarována následovně:
void * calloc (size_t nmemb, size_t size );
Funkce calloc() alokuje paměť pro nmemb položek velikosti size. Velikost položky může být například sizeof(int), počet položek rozměr požadovaného pole. Ovšem častěji se využívá pro vytvoření

60
dynamického pole struktur. Na rozdíl od funkce malloc(), vyplní alokovanou paměť nulami. Všechno ostatní je stejné (návratová hodnota, uvolňování pomocí free() atd.).
V následujícím příkladu je vytvořen seznam . Seznam obsahuje datové objekty (struktury), které jsou mezi sebou provázány ukazateli. První prvek seznamu ukazuje na druhý, druhý na třetí atd. V tomto příkladu bude prvek obsahovat, kromě ukazatele na další prvek, pole typu char , do kterého budou ukládána slova načtená od uživatele. Po skončení načítání budou slova lexikograficky seřazena. Struktura bude také obsahovat číslo určující kolikáté bylo slovo načteno. K setřídění je použita funkce strcmp(), obsažena v hlavičkovém souboru <string.h>. Tato funkce porovnává lexikograficky dva řetězce a vrací nulu, pokud jsou si rovny!
1: /*------------------------------------------------* / 2: /* dynamic3.c * / 4: #include <stdio.h> 5: #include <stdlib.h> 7: #define MAXSLOVO 20 8: #define NACTISLOVO "%20s" 10: struct veta { 11: unsigned int poradi; 12: char slovo[MAXSLOVO + 1]; 13: struct veta *dalsi; /* ukazatel na dalsi strukturu */ 14: }; 17: /* pomocna funkce na kopirovani retezce */ 18: void strcopyruj(char *cil, const char *zdroj) 19: { 20: unsigned int i = 0; 21: do { 22: cil[i] = zdroj[i]; 23: } while (zdroj[i++]); 24: } 27: /* funkce vypisujici seznam */ 28: void vypis_veta(struct veta *zacatek) 29: { 30: struct veta *dalsi; 32: dalsi = zacatek; 33: printf( "\n" ); 34: do { 35: if (strcmp(dalsi->slovo, "" )) /* prazdne slova ignoruj */ 36: printf( "%3i: %s\n" , dalsi->poradi, dalsi->slovo); 37: dalsi = dalsi->dalsi; /* prejdi na dalsi slovo */ 38: } 39: while (dalsi != NULL); 40: } 43: void setrid_seznam(struct veta *zacatek) 44: { 45: int zmena = 0; 46: struct veta *dalsi, pom; 48: dalsi = zacatek; 49: if (dalsi == NULL) 50: return ; 52: do { 53: /* jsme na koneci a nic se nezmenilo? pak mame setr ideno */ 55: if ((dalsi->dalsi == NULL) && (zmena == 0)) 56: break ; 57: else if (dalsi->dalsi == NULL) { 58: dalsi = zacatek; 59: zmena = 0; 60: } 61: if (strcmp(dalsi->slovo, dalsi->dalsi->slovo) > 0) { 62: pom = *dalsi;

61
63: strcopyruj(dalsi->slovo, dalsi->dalsi-> slovo); 64: dalsi->poradi = dalsi->dalsi->poradi; 65: strcopyruj(dalsi->dalsi->slovo, pom.slo vo); 66: dalsi->dalsi->poradi = pom.poradi; 67: zmena = 1; 68: } 69: dalsi = dalsi->dalsi; 70: } while (1); 71: } 74: /* Nasleduje funkce pro uvolneni pameti. Prvni polo zka je staticka, proto se pomoci free() neuvolnuje a take se musi jeji atribu t "dalsi" nastavit na NULL */ 78: void zabij(struct veta *zacatek) 79: { 80: struct veta *v, *pom; 82: v = zacatek->dalsi; 83: while (v != NULL) { 84: pom = v->dalsi; 85: free(v); 86: v = pom; 87: } 88: zacatek->dalsi = NULL; 89: } 91: int main(void) 92: { 93: unsigned int poradi; 94: int navrat; 95: struct veta prvni, *posledni; 97: printf( "Zadavejte slova ne delsi nez %i znaku.\n" 98: "Zadavani vet ukoncete pomoci znaku konec souboru.\ n" 99: "(tj. CTRL+D v unixech nebo CTRL+Z v DOSu a Windows )\n\n" , 100: MAXSLOVO); 102: poradi = 0; 103: posledni = &prvni; /* "prvni" je prvni prvek ze seznamu. Ukazatel 104: "posledni" ukazuje na posledn i prvek v seznamu.*/ 105: do { 106: poradi++; 107: navrat = scanf(NACTISLOVO, posledni->slovo) ; 108: posledni->poradi = poradi; 109: if ((navrat == EOF) || (navrat != 1)) { 110: /* EOF * -> konec vstupu, 111: * navrat !=1 -> nebyl nacten spravne retezec */ 112: /*dalsi prvek v seznamu jiz nebude. seznam ukon číme zarazkou NULL */ 114: posledni->dalsi = NULL; 115: break ; 116: } 117: if ((posledni->dalsi = ( struct veta *) 118: calloc(1, sizeof ( struct veta ))) == NULL) { 119: printf( "Nedostatek pameti!\n" ); 120: exit(1); 121: } 122: posledni = posledni->dalsi; 123: } while (1); 125: setrid_seznam(&prvni); 126: vypis_veta(&prvni); 127: zabij(&prvni); 129: return 0; 130: } 132: /*------------------------------------------------* /

62
Možný výstup: Zadavejte slova ne delsi nez 20 znaku. Zadavani vet ukoncete pomoci znaku kone c souboru. (tj. CTRL+D v unixech nebo CTRL+Z v DOSu a Windows) Kdyz nejde hora k Moha-Medovi, musi Moha-Med k hore . 1: Když 4: k 7: Moha-Med 8: k 5: Moha-Medovi, 6: musi 3: hora 2: nejde 9: hore.
Změna velikosti získané pam ěti pomocí realloc()
Funkce realloc() umožňuje změnit velikost alokované paměti. Deklarace funkce je následující:
void * realloc (void * ptr , size_t size );
První argument funkce, ptr (pointer) je adresa paměti, která byla alokována pomocí funkcí malloc(), calloc() nebo realloc(). Velikost tohoto paměťového bloku se zvětší (zmenší) na size bajtů. Návratovou hodnotou je ukazatel na „pře alokovanou“ paměť. To ovšem nemusí být stejné místo v paměti jako původní paměť (na kterou ukazoval argument ptr)! Proto pro volání funkce realloc() není možné přistupovat do paměti pomocí hodnoty v ukazateli ptr, ani ji uvolňovat, lze používat jen paměť na kterou ukazuje hodnota vrácená funkcí realloc(). Nově alokovaná paměť má nedefinované hodnoty, původní část přealokovné paměti, zůstává zachována. Pokud by byl argument ptr NULL , pak by bylo volání realloc() obdobné jako malloc(). Nastavení velikosti pole size na nulu dává stejný výsledek, jako volání pro ptr funkce free(). Nepodaří-li se funkci realloc() získat dostatek nové paměti, vrátí ukazatel NULL . Proto je nebezpečné používat následující konstrukci:
ukazatel = realloc(ukazatel,SIZE);
Takto by se totiž do ukazatele uložila hodnota NULL a přišli bychom o ukazatel na původní alokovanou paměť, která zůstává zachována. - V příkladu bude uživatel zadávat programu požadovanou velkost v megabajtech alokované paměti a program jí bude alokovat.
2: /* dynamic4.c * / 4: #include <stdio.h> 5: #include <stdlib.h> 7: #define MEGABAJT 1024*1024 9: int main(void) 10: { 11: unsigned long x, a; 12: char *pom, *v = NULL; 14: do { 15: printf( "Zadejte pocet megabajtu, 0 pro konec: " ); 16: scanf( "%lu" , &x); 17: pom = (char *) realloc((void *) v, x * MEGA BAJT); 18: if ((pom == NULL) && (x)) 19: printf( "Nedostatek pameti!!\n" ); 20: else { 21: v = pom; 22: /*vyplneni pameti jednickami. To pocitac trosilinku zamestna :-) */ 24: for (a = 0; a < x * MEGABAJT; a++) { 25: v[a] = '1'; 26: } 27: } 28: } while (x); 30: return 0; 31: }

63
Knihovna string.h
Obsahuje funkce pro práci s řetězci. (Datové pole obsahující znaky, které jsou zakončeny zarážkou '\0')
Výčet funkcí
Pokud funkce někam kopírují / přidávají data, nekontrolují, zda na to mají dostatek místa. To musí programátor. Jinak se může snadno stát, že program skončí kvůli „neoprávněnému přístupu do paměti“.
char *strcat ( char *dest, const char *src); Funkce připojí řetězec src k řetězci dest. Funkce vrací ukazatel na řetězec dest.
char *strncat ( char *dest, const char *src, size_t n); Jako funkce strcat, ale přidá jen n znaků z src. Tato funkce je bezpečnější z hlediska možného "přetečení" (pokus zapisovat více dat, než jakou má velikost dest).
int strcmp (const char *s1, const char *s2); Porovnává řetězce s1 a s2. Pokud je s1 < s2 pak vrací hodnotu menší než 0, pokud jsou si rovny, pak vrací 0, pokud je s1 > s2 pak vrací hodnotu větší jak 0.
int strncmp ( const char *s1, const char *s2, size_t n); Jako strcmp(), porovnává však jenom n znaků.
char *strcpy ( char *dest, const char *src); Zkopíruje řetězec src do řetězce dest. Vrací ukazatel na dest.
char *strncpy ( char *dest, const char *src, size_t n); Jako strcpy(), ale zkopíruje maximálně n znaků. (Je-li jich právně n, nepřidá zarážku).
size_t strlen ( const char *s); Vrací délku řetězce s.
char *strchr ( const char *s, int c); Vrací ukazatel na první pozici, kde se vyskytuje znak c, nebo NULL v případě, že jej nenajde. (Nenechte se zmást, že znak c je typu int a ne char, má to tak být).
char *strrchr ( const char *s, int c); To samé jako strchr(), ale hledá první výskyt zprava.
char *strstr ( const char *haystack, const char *needle); Vrací ukazatel na první výskyt řetězce needle v řetězci haystack. Pokud jej nenajde, vrací NULL.
size_t strspn ( const char *s, const char *accept); Vrací počet znaků, ve kterých se řetězec s schoduje s řetězcem accept.
size_t strcspn ( const char *s, const char *reject); Vrací počet znaků, ve kterých se řetězec s neschoduje s řetězcem reject.
Příklad použití funkcí
Díky zjištění délky prvního řetězce a velikosti pole1 jsme mohli zajistit, aby se z pole2 nezkopírovalo více znaků, než kolik se jich do pole1 vejde.
1: /*------------------------------------------------* / 2: /* retezce.c * / 4: #include <stdio.h> 5: #include <string.h> 7: int main(void) 8: { 9: char c, *ch, pole1[81], pole2[81]; 10: int x; 12: printf( "Zadejte jeden znak a stisknete ENTER: " ); 13: scanf( "%c" , &c); 14: printf( "Zadejte prvni retezec: " ); 15: scanf( "%80s" , pole1); 16: printf( "Zadejte druhy retezec: " );

64
17: scanf( "%80s" , pole2); 19: x = strcmp(pole1, pole2); 20: if (x < 0) 21: printf( "pole1 < pole2\n" ); 22: else if (x == 0) 23: printf( "pole1 = pole2\n" ); 24: else 25: printf( "pole1 > pole2\n" ); 27: printf( "Prvnich %i znaku se %s\n" , 5, 28: !strncmp(pole1, pole2, 5) ? "schoduje" : "neschoduje" ); 29: printf( "Schoduje se presne %i znaku\n" , strspn(pole1, pole2)); 31: ch = strchr(pole1, c); 32: if (ch == NULL) 33: printf( "Znak %c se v retezci \"%s\" nenachazi\n" , c, pole1); 34: else 35: printf( "pole1 od znaku %c: %s\n" , c, ch); 37: x = strlen(pole1); 38: printf( "Delka prvniho retezce: %u\n" , x); 39: strncat(pole1, pole2, sizeof (pole1) - x - 1); 40: printf( "Spojeni: %s\n" , pole1); 42: return 0; 43: } 45: /*------------------------------------------------* / Možný výstup z programu: Zadejte jeden znak a stisknete ENTER: y Zadejte prvni retezec: DlouhyRetezec Zadejte druhy retezec: Dlouze pole1 < pole2 // protoze h < z Prvnich 5 znaku se neschoduje Schoduje se presne 4 znaku pole1 od znaku y: yRetezec Delka prvniho retezce: 13 Spojeni: DlouhyRetezecDlouze
Knihovna time.h
Knihovna <time.h> umožňuje zjistit aktuální čas. Je třeba si však uvědomit, že je to je pojem relativní. V každém počítači existuje čas lokální a globální (krom toho je také letní a zimní). Globální čas se dříve označoval jako GMT (Greenwich Mean Time), dnes jako UTC (Coordinated Universal Time). Záleží na nastavení v počítači. Správně by měl být nastaven čas globální a lokální přepočítávat. Některé informace o datu a času však knihovna <time.h> neumí. Potřebné výpočty se však dají sestavit (nebo použít nějakou „nadstandardní“ knihovnu). Například funkce na zjištění přestupného roku se dá napsat takto:
1: /*---------------------------------------*/ 2: /* funkce vracejici 1 pro prestupny rok, jinak 0. * / 3: /* */ 4: int prestupny_rok(int rok) 5: { 6: return (((rok % 4 == 0) && (rok % 100 != 0)) || (rok % 40 0 == 0)); 7: } 9: /*---------------------------------------*/
Uchovávání času
Aby bylo možné čas uchovávat v co možná nejmenším počtu bitů, zaznamenává se jako počet sekund od určitého data. Například v Unixových systémech je to od 1. 1. 1970, v MS-DOSu je to 1. 1. 1980 atp. V dnešní době je to víceméně zátěž z historických důvodů. S časem uloženým v sekundách se pracuje pomocí předdefinovaného datového typu time_t . Je to celočíselný typ, například v Linuxu je to typ long.

65
Vzhledem k tomu, že program může být přeložen ve více systémech, nelze podle tohoto čísla datum a čas jednoznačně určit. Pokud však v programu zaznamenáme dvě takováto čísla, pak jejich odečtením lze zjistit, kolik sekund mezi jejich zaznamenáním uběhlo. Takovéto jednoduché odečtení však není dle normy ANSI, proto je potřeba používat funkci difftime(), která je k tomu určena (kvůli přenositelnosti na systémy, kde time_t není definován jako celé číslo). Lépe se pracuje s dalším předdefinovaným typem – tentokrát se jedná o strukturu – tm . Její definice vypadá takto:
1: struct tm { 2: int tm_sec; /* vte řiny 0-61 */ 3: int tm_min; /* minuty 0-59 */ 4: int tm_hour; /* hodiny 0-23 */ 5: int tm_mday; /* dny v m ěsíci 1-31 */ 6: int tm_mon; /* m ěsíc 0-11 */ 7: int tm_year; /* rok od 1900 */ 8: int tm_wday; /* den v týdnu 0-6, 0 je nedele */ 9: int tm_yday; /* den v roce 0-365 */ 10: int tm_isdst; /* p říznak letního času*/ 11: };
Vteřin může být opravdu 62, to není chyba tisku. Prostě to tak bylo definováno?! Příznak tm_isdst je nulový, pokud není letní čas a záporný, pokud není informace o času dostupná. Pokud je letní čas, je kladný.
Výčet funkcí char *asctime (const struct tm *timeptr);
Převede strukturu tm na řetězec ("Wed Jun 30 21:49:08 1993\n"). Návratovou hodnotou je ukazatel na tento řetězec.
char *ctime (const time_t *timep); Vrací to samé, jako asctime(localtime(timep));
double difftime (time_t time1, time_t time0); Vrací rozdíl mezi časem time0 a time1 ve vteřinách.
struct tm *gmtime (const time_t *timep); Převede čas uložený v timep (pomocí vteřin) na strukturu tm a to v čase UTC (GMT). Vrací ukazatel na tuto strukturu.
struct tm *localtime (const time_t *timep); Jako funkce gmtime(), ale vrací lokální čas (nikoliv UTC).
time_t mktime (struct tm *timeptr); Převádí strukturu na kterou odkazuje timeptr do počtu vteřin, jež jsou návratovou hodnotou.
time_t time (time_t *t); Vrací počet sekund reprezentující čas (v Unixech počet sekund od 1.1.1970). Tuto hodnotu také uloží tam, kam ukazuje ukazatel t, pokud nemá hodnotu NULL). Je to jediná funkce, která vrací aktuální čas.
size_t strftime (char *s, size_t max, const char *format, const struct tm *tm); Tato funkce převádí strukturu tm na řetězec. Tento řetězec bude uložen do pole, na které ukazuje ukazatel s. Maximálně však „max“ znaků. Co bude řetězec obsahovat, to je dáno formátovacím řetězcem format. Možnosti formátování jsou uvedeny v tabulce:
%a zkrácený název dne v týdnu %A úplný název dne v týdnu %b zkrácený název měsíce %B úplný název měsíce %c datum a čas %d den v měsíci 01-31 %H hodina 00-23

66
%I hodina ve 12-ti hodinovém formátu 01-12 %j den v roce 001-366 %m měsíc 01-12 %M minuty 00-59 %p am pro dopoledne, pm pro odpoledne %S vteřiny 00-61 %u den v týdnu 1-7, 1 = pondělí %U týden v roce 01-53 (neděle je prvním dnem v týdnu) %V týden v roce 01-53 (pondělí je prvním dnem v týdnu) %w den v týdnu 0-6 (0 = neděle) %x datum v lokálním formátu %X čas v lokálním formátu %y poslední dvě číslice roku 00-99 %Y rok %Z název časového pásma
Příklad použití funkcí I (sportka)
První příklad je spíš ukázka práce s náhodnými čísly než s časem. Čas je zde využít k inicializaci náhodných čísel (viz. funkce rand() a srand()). Příklad simuluje losování sportky.
1: /*------------------------------------------------* / 2: /* sportka.c * / 4: #include <stdio.h> 5: #include <stdlib.h> /* zde jsou definovany funkce rand() a srand() */ 6: #include <time.h> 8: #define CENA 16 /* korun za vsazeni 1 sloupce */ 10: /* funkce uhodnuto zjisti, kolik cisel z pole cisla [6] je stejnych jako prvnich 6 cisel v poli tah[7]. Posledni cislo v tomto poli je dodatkove!*/ 11: 13: unsigned int uhodnuto(unsigned int *cisla, unsigned int *tah) 14: { 15: unsigned int i, j, vyhra = 0; 17: for (j = 0; j < 6; j++) 18: for (i = 0; i < 6; i++) 19: if (cisla[j] == tah[i]) { 20: vyhra++; /* pocet uhadnutych cisel */ 21: break ; /* ukonci vnitrni cyklus */ 22: } 23: return vyhra; 24: } 26: /* funkce vyhra_sportky urci na zaklade uhodnutych cisel vyhru. 27: Pri uhodnuti 5 cisel a 6te je stejne jako dodatko ve, pak mate "druhou" */ 28: unsigned int vyhra_sportky(unsigned int uhodnute, u nsigned int *cisla, 29: unsigned int *tah) 30: { 31: unsigned int i, vyhra = 0; 32: switch (uhodnute) { 33: case 6: 34: vyhra = 1; /* mate prvni */ 35: break ; 36: case 5: 37: vyhra = 3; /* mate treti */

67
38: /* ale mozna mame druhou */ 39: for (i = 0; i < 6; i++) 40: if (cisla[i] == tah[6]) { 41: vyhra = 2; /* mame druhou */ 42: break ; 43: } 44: break ; 45: case 4: 46: vyhra = 4; 47: break ; 48: case 3: 49: vyhra = 5; /* mate patou */ 50: break ; 51: default: /* to je tu trosku zbytecne, protoze vyhra = 0 je jiz vyse, ale neni to na skodu uz kvuli srozumitelnosti kodu */ 54: vyhra = 0; /* nic jste nevyhrali */ 55: } 56: return vyhra; 57: } 59: /* tato funkce urci, kolik penez jste vyhrali */ 60: unsigned long penez(unsigned int vyhra) 61: { 62: switch (vyhra) { 63: case 5: 64: return rand() % 50 + 30; 65: case 4: 66: return rand() % 500 + 250; 67: case 3: 68: return rand() % 5000 + 1000; 69: case 2: 70: return rand() % 500000 + 50000; 71: case 1: 72: return (unsigned long) ((rand() % 1000000) + 1) * (rand() % 10) + 73: 1000000; 74: default: 75: return 0; 76: } 77: } 79: /* kontroluje, zda cislo exituje v poli zadane delk y */ 80: int existuje(unsigned int cislo, unsigned int *pole , unsigned int delka) 81: { 82: unsigned int i; 83: for (i = 0; i < delka; i++) 84: if (cislo == pole[i]) 85: return 1; 86: return 0; /* cislo se nenaslo */ 87: } 89: int main(void) 90: { 91: unsigned int i, cisla[6], tah[7], vyhra, uhodnu te, finance, vyhrano; 92: unsigned int chci_vyhrat; 93: unsigned long vyhry[] = { 0, 0, 0, 0, 0, 0 }; /* nic, prvni, druha, treti ... vyhra "nic" bude zrejme velmi casto, proto je pole typu long int */ 95: unsigned long cyklus = 0; 96: time_t cas1, cas2; 98: (void) time(&cas1); /* navratovou hodnotu ignorujeme */ 99: srand((unsigned int) time(NULL)); /* vystupni hodnotu musime z formatu time_t zkonvertovat na typ unsigned int */ 102: /* inicializace */ 103: vyhrano = 0; 105: printf( "Zadejte poradi, ktere chcete vyhrat (0,1,2,3,4,5): " ); 106: scanf( "%u" , &chci_vyhrat);

68
108: /* losovani vsazenych cisel do sportky */ 109: for (i = 0; i < 6; i++) { 110: cisla[i] = (rand() % 49) + 1; 111: if (existuje(cisla[i], cisla, i)) 112: i--; /* cislo jiz bylo vylosovano, bude se losovat znovu */ 114: } 116: /* tisk */ 117: printf( "Vsazena cisla:" ); 118: for (i = 0; i < 6; i++) 119: printf( "%3u" , cisla[i]); 120: printf( "|\n" ); 122: printf( "Cyklus :%-23s| Vyhrano Vyhry: 1 2 3 4 5 0 \n" , 123: " Vylosovane Cisla" ); 125: /* cyklus, dokud nevyhraji co chci */ 126: do { 127: /* losovani sportky */ 128: for (i = 0; i < 7; i++) { 129: tah[i] = (rand() % 49) + 1; 130: if (existuje(tah[i], tah, i)) 131: i--; /* cislo jiz bylo vylosovano, bude se losovat znovu */ 133: } 135: /* tisk vysledku */ 136: printf( "\r%8ld:" , ++cyklus); 138: for (i = 0; i < 6; i++) 139: printf( "%3u" , tah[i]); 140: printf( " /%3u" , tah[6]); /* dodatkove cislo */ 142: uhodnute = uhodnuto(cisla, tah); /* pocet uhodnutych cisel */ 143: vyhra = vyhra_sportky(uhodnute, cisla, tah) ; /* prvni,druha atp.*/ 144: finance = penez(vyhra); 145: vyhry[vyhra] += 1; /* vyhry[vyhra]++; */ 147: vyhrano += finance; 148: printf( "|%10ld[Kc] " , (unsigned long) vyhrano - cyklus * CENA); 150: for (i = 1; i < 6; i++) 151: printf( " %2ld" , vyhry[i]); 153: printf( " %2ld" , vyhry[0]); 154: /* funkce fflush() zajisti, ze program nebude pokra covat dale, dokud se 155: vystup skutecne nezobrazi v stdout (tj. na ob razovce) */ 156: fflush(stdout); 157: if (!chci_vyhrat) 158: break ; /* nechci nic vyhrat, tj. chci_vyhrat == 0 */ 159: } while ((chci_vyhrat < vyhra) || (vyhra == 0)); 161: cas2 = time(NULL); /* ziskame totez jako (void) time(&cas2); */ 162: printf( "\nZiskal jste %i - %i*%ld = %ld Kc\n" , vyhrano, CENA, cyklus, 163: vyhrano - CENA * cyklus); 164: printf( "Cele to trvalo %u vterin.\n" , 165: (unsigned int) difftime(cas2, cas1)); 167: return 0; 168: } 170: /*------------------------------------------------* / Možný výstup: Zadejte poradi, ktere chcete vyhrat (0,1,2,3,4,5): 1 Vsazena cisla: 45 30 26 25 1 3| Cyklus : Vylosovane Cisla | Vyhrano Vyhry: 1 2 3 4 5 0 4843101: 1 26 30 3 45 25 / 49| -68238394[Kc] 1 1 77 4696 85315 4753011 Ziskal jste 9251222 - 16*4843101 = -68238394 Kc Cele to trvalo 968 vterin.
Příklad použití funkcí II 1: /*------------------------------------------------* / 2: /* tm1.c * / 4: #include <stdio.h>

69
5: #include <time.h> 6: #define MAX 80 8: int main(void) 9: { 10: time_t cas; 11: /* je lhostejno pracujeme-li se strukturou tm nebo ukazatelem na ni */ 13: struct tm gtmcas; 14: struct tm *ltmcas; 15: char retezec[MAX]; 17: cas = time(NULL); 19: gtmcas = *(gmtime(&cas)); 20: ltmcas = localtime(&cas); 22: /* retezec vraceny funkcemi ctime a asctime je v an glictine a take 23: ukoncen znakem '\n' (coz je v praxi trochu neprij emne). Vyrazy LC a UTC 24: nam kvuli tomu prejdou az na dalsi radek */ 26: printf( "Je prave \"%s\" LC\n" , ctime(&cas)); 27: printf( "Je prave \"%s\" GMT\n" , asctime(>mcas)); 28: printf( "Je prave \"%s\" LC\n" , asctime(ltmcas)); 30: strftime(retezec,MAX - 1, "Je prave %A%d.%m.%Y,%I:%M %p LC" , ltmcas); 32: printf( "%s\n" , retezec); 33: printf( "Tm(LC): %02i.%02i.%04i\n" , ltmcas->tm_wday, ltmcas->tm_mon, 34: ltmcas->tm_year + 1900); 35: cas = (time_t) 0; 36: printf( "Pocatek vseho je %s" , ctime(&cas)); 38: return 0; 39: } 41: /*------------------------------------------------* / Možný výstup: Je prave "Fri Aug 29 15:31:04 2008 " LC Je prave "Fri Aug 29 13:31:04 2008 " GMT Je prave "Fri Aug 29 15:31:04 2008 " LC Je prave Friday 29.08.2008, 03:31 PM LC Tm(LC): 05.07.2008 Pocatek vseho je Thu Jan 1 01:00:00 1970
Knihovna math.h
Standardní knihovna <math.h> obsahuje spoustu funkcí, které vykonávají běžné matematické operace. Jejich parametry i návratové hodnoty jsou většinou typu double. Kromě funkcí jsou v této knihovně také užitečná makra, jako M_PI jež je hodnotou pí. V systémech UNIX bude možná potřeba překladači předat argument -lm , který zajistí použití sdílené matematické knihovny systému UNIX. Tento parametr je zkratkou pro /usr/lib/libm.a . Příkaz překladu z příkazové řádky pak může vypadat nějak takto:
gcc -o program kod.c -lm –Wall
Výčet funkcí double sin (double x);
Vrací sinus argumentu. double cos (double x);
Vrací kosinus argumentu. double tan(double x);
Vrací tangens argumentu. double asin (double x);
Vrací arcu ssinus argumentu. double acos (double x);
Vrací arkus kosinus argumentu. double atan (double x);

70
Vrací arkus tangens argumentu. double atan2 (double y, double x);
Funkce atan2() počítá arkus tangens dvou proměnných x a y. Výpočet je podobný výpočtu arkus tangens y / x, kromě toho, že znaménka obou argumentů jsou použita pro určení kvadrantu, ve kterém se nachází výsledná hodnota. Funkce atan2() vrací výsledek v radiánech, který je mezi -PI a PI včetně.
int abs(int j); Vrací absolutní hodnotu argumentu typu int . Tato funkce není kupodivu definována v <math.h> ale <stdlib.h>. Přesto paří mezi matematické.
double fabs (double j); Vrací absolutní hodnotu argumentu typu double.
double aceil (double x); Zaokrouhlí argument na nejmenší „vyšší“ celé číslo.
double floor (double x); Zaokrouhlí argument na nejbližší „nižší“ celé číslo.
double round (double x); Zaokrouhlí číslo na nejbližší celé číslo.
double exp (double x); Vrací hodnotu e (základ přirozených algoritmů) umocněnou na x.
double log (double x); Vrací hodnotu přirozeného algoritmu x.
double log10 (double x); Vrací hodnotu desítkového logaritmu x
double pow (double x, double y); Vrací hodnotu x na y (2^3=8).
double sqrt (double x); Vrací odmocninu z čísla x.
double fmod (double x, double y); Funkce fmod() počítá hodnotu zbytku podílu x děleno y. Návratová hodnota je x - n * y , kde n je podíl x / y , zaokrouhlený směrem k nule na celé číslo. Jinak řečeno, vrací celočíselný zbytek po celočíselném dělení.
double modf (double x, double *iptr); Vrátí desetinnou část x a celou část uloží tam, kam ukazuje iptr .
Použití těchto funkcí nepotřebuje žádného komentáře.
1: /*------------------------------------------------* / 2: /* matika.c * / 3: #include <stdio.h> 4: #include <math.h> 6: int main(void) 7: { 8: int ia; 9: float fa; 10: double da; 11: /* kresleni sinusove vlny */ 12: for (fa = 0.0; fa < 2.0 * M_PI; fa += M_PI / 13) { 13: ia = 40 + 20.0 * sin(fa); 14: printf( "%*c\n" , ia, '*'); 15: } 17: printf( "ceil(%f)=%f\tfloor(%f)=%f\n" , 5.9, ceil(5.9), 5.9, floor(5.9)); 18: printf( "ceil(%f)=%f\tfloor(%f)=%f\n" , 5.1, ceil(5.1), 5.1, floor(5.1)); 20: #define MODF 5.5 21: fa = modf(MODF, &da); 22: printf( "fmod(%4.2f,%4.2f)=%4.2f\nmodf(%4.2f,&y)=%4.2f --> y=%4.2f\n" , 23: 100.0, 3.0, fmod(100.0, 3.0), MODF, fa, da); 25: return 0; 26: } 28: /*------------------------------------------------* /

71
Výstup z programu: * * ceil(5.900000)=6.000000 floor(5.900000)=5.000000 ceil(5.100000)=6.000000 floor(5.100000)=5.000000 fmod(100.00,3.00)=1.00 modf(5.50,&y)=0.50 --> y=5.00
Knihovna stdlib.h
Výčet funkcí (výčet není úplný) long int strtol (const char *nptr, char **endptr, int base);
Převede řetězec nptr na číslo vzhledem k číselné soustavě base . Adresu prvního znaku, který nepatří do čísla, uloží do endptr , pokud endptr není nastaveno na NULL .
int atoi (const char *nptr); Převede řetězec nptr na číslo typu int. Tato funkce nedetekuje žádné chyby. Její chování je totožné s voláním strtol(nptr, (char **)NULL, 10);
double atof (const char *nptr); Převede řetězec nptr na číslo typu double. Tato funkce nedetekuje žádné chyby.
long atol ( const char *nptr); Převede řetězec nptr na číslo typu long int. Tato funkce nedetekuje žádné chyby.
void srand ( unsigned int seed); Inicializuje generátor pseudonáhodných čísel.
int rand ( void); Vrací pseudonáhodná čísla mezi 0 a RAND_MAX
void *calloc ( size_t nmemb, size_t size); Dynamicky alokuje paměť nmemb položek velikosti size. Do alokované paměti zapíše nuly. Vrací ukazatel na alokovanou paměť nebo NULL v případě chyby.
void *malloc ( size_t size); Dynamicky alokuje paměť velikosti size. Paměť nevynuluje. Vrací ukazatel na alokovanou paměť nebo NULL v případě chyby.
void free ( void *ptr); Uvolní dynamicky alokovanou paměť (pomocí malloc(), calloc() nebo realloc()) na kterou ukazuje ptr .
void *realloc ( void *ptr, size_t size); Změní velikost dynamicky alokované paměti ptr na velikost size.
void abort ( void); Způsobí abnormální ukončení programu. Chování funkce je implementačně závislé.
void exit ( int status); Ukončí program kdekoliv v programu. Program pak vrací hodnotu status. Všechny funkce registrované funkcemi atexit() a on_exit() jsou vyvolány v opačném pořadí jejich registrace.
int atexit ( void (* function)(void)); Přiřadí funkci do seznamu funkcí, které jsou volány při normálním ukončení programu funkcí exit nebo skončením funkce main(). Argument function je ukazatelem na funkci bez argumentů a bez návratové hodnoty. Funkce takto registrované jsou volány v opačném pořadí než jsou registrovány. Funkce atexit vrací 0 v případě úspěchu, -1 v případě chyby (např. nedostatek paměti pro registraci funkce).
int system (const char *string); Volá systémový příkaz určený řetězcem string. Například tak můžete zavolat příkaz DOSu "COPY c:\soubor1.txt c:\soubor2.txt". V Linuxu se nedoporučuje používat funkci system v programech se superuživatelskými právy. Toho by šlo totiž snadno zneužít. Nepodaří-li se spustit shell (příkazový řádek), vrací funkce system hodnotu 127, v případě jiné chyby -1. V ostatních případech vrací návratový kód příslušného příkazu.
char *getenv ( const char *name); Vyhledá hodnotu prostředí systému určenou řetězcem name . Vrátí ukazatel na tuto hodnotu, nebo NULL v případě neúspěšného hledání. Prostředí je tvořeno řetězci ve formě název=hodnota. Tuto

72
funkci budou asi využívat hlavně příznivci Linuxu, kde se jedná například o hodnoty USER, LOGNAME, HOME, PATH, SHELL, TERM apod.
int abs( int j); Vrací absolutní hodnotu argumentu typu int.
long int labs (long int j); Vrací absolutní hodnotu argumentu typu long int.
div_t div (int numer, int denom); Počítá podíl numer/denom . Podíl a zbytek po dělení vrací ve struktuře div_t . Tato struktura obsahuje složku quot , která obsahuje podíl a složku rem , která obsahuje zbytek. Obě složky jsou celočíselné. Struktura div_t je definována v <stdlib.h>
ldiv_t ldiv ( long int numer, long int denom); Jako funkce div, jenom je všechno v dlouhých celých číslech.
void qsort ( void *base, size_t nmemb, size_t size, int (*compar)(const void *, const void *)); Funkce třídí algoritmem quicksort souvislé pole libovolného typu (!), na které ukazuje base o nmemb položkách velikosti size. K třídění je použita funkce na kterou ukazuje compar . Funkci compar() budou při volání předávány jako argumenty prvky z pole base . Funkce compar() musí vracet zápornou hodnotu, pokud je první argument menší než druhý, nulovou hodnotu pokud se rovnají a kladnou hodnotu pokud je první argument větší než druhý.
Užitečná makra
Kromě těchto funkcí jsou v souboru <stdlib.h> definována i některá užitečná makra. Jejich používání zvyšuje přenositelnost programu.
EXIT_FAILURE Hodnota argumentu funkce exit pro neúspěšné ukončení programu. (nenulová hodnota)
EXIT_SUCCESS Hodnota argumentu funkce exit pro úspěšné ukončení programu. (nulová hodnota)
NULL Nulový ukazatel.
RAND_MAX Největší hodnota generovaná funkcí rand() .
Poznámky k funkcím
Funkce exit() ukončí program kdekoliv je volána. Volání této funkce je stejné, jako volání return x ve funkci main(). Hodnota x je vrácena do prostředí, ve kterém je program spuštěn, popřípadě procesu, který tento program spustil. Tuto hodnotu lze testovat třeba v dávkových souborech (.BAT) v DOSu nebo v unixových skriptech shellu. Nulová návratová hodnota se považuje za bezchybné ukončení programu. Návratovou hodnotou různých čísel lze informovat o různých příčinách konce programu. Některé návratové hodnoty však mají v různých systémech různý specifický význam. Proto, je vhodné ukončovat funkce (program) s návratovou hodnotou 0 (EXIT_SUCCESS) v případě úspěchu a 1 (EXIT_FAILURE) v případě neúspěchu.
V systémech Unix je možné zjistit návratový kód programu v systémové proměnné ?. Například příkazem echo $?.
Funkce exit() navíc před ukončením programu (stejně jako return ve funkci main()) spustí funkce registrované pomocí atexit() . Tyto registrované funkce jsou volány vždy při skončení programu, nedojde-li k jeho ukončení funkcí abort() nebo k jinému nestandardnímu konci programu. Využít se toho dá mnoha způsoby. Například lze vytvořit při spuštění programu nějaký dočasný soubor, který takto registrovaná funkce smaže. Pokud při spuštění programu soubor existuje, znamená to, že je program spuštěný vícekrát, nebo že byl nestandardně ukončen. Funkce system() udělá zhruba to, co by udělal operační systém po zadání příkazu, který je argumentem funkce system. Použití bude v příkladu. Použití funkce getenv() je

73
silně závislé na prostředí, ve kterém je program spouštěn. (viz. programování v Linuxu.) Využívá se například v souvislosti s dávkovými soubory.
Dále je ukázka definice struktury div_t . Hlavně pozor na d ělení nulou! .
1: typedef struct { 2: int quot; /* Quotient. */ 3: int rem; /* Remainder. */ 4: } div_t;
Funkce qsort() třídí prvky na základě návratové hodnoty funkce, na kterou ukazuje compar (viz ukazatele na funkce). Jelikož je tento ukazatel deklarován jako int (*compar)(const void *, const void *);, je třeba funkci která provádí porovnávání prvků z tříděného pole přetypovat To se provede následujícím způsobem.
qsort(tridene_pole, POCET_PRVKU_POLE, sizeof(prvek_ pole), (int (*) (const void *, const void *)) tridici_funkce);
V prvním příkladu je vytvořeno pole struktury cisla obsahující typ div_t a dvě čísla, jejichž podíl a zbytek po dělení bude v právě v proměnné typu div_t. Toto pole pak bude setříděno pomocí qsort(). K porovnávání prvků si slouží funkce srovnej_cislo().
1: /*------------------------------------------------* / 2: /* qsort1.c * / 4: #include <stdio.h> 5: #include <stdlib.h> 7: #define DELKAPOLE 20 9: typedef struct { 10: int x, y; 11: div_t podil; 12: } cisla; 14: int srovnej_cislo(cisla * a, cisla * b) 15: { 17: if (a->podil.rem > b->podil.rem) /* nejdrive tridime podle zbytku */ 18: return 1; 19: else if (a->podil.rem < b->podil.rem) 20: return -1; 21: /* kdyz jsou si zbytky rovny, tridime podle podilu */ 24: else if (a->podil.quot > b->podil.quot) 25: return 1; 26: else if (a->podil.quot < b->podil.quot) 27: return -1; 28: else 29: return 0; /* jsou si rovny */ 30: } 32: int main(void) 33: { 34: int i; 35: cisla pole[DELKAPOLE]; 36: for (i = 0; i < DELKAPOLE; i++) { 37: pole[i].x = i; 38: pole[i].y = 5; 39: pole[i].podil = div(pole[i].x, pole[i].y); 40: } 42: qsort(pole, sizeof (pole) / sizeof (pole[0]), sizeof (pole[0]), 43: (int (*)(const void *, const void *)) sro vnej_cislo); 45: for (i = 0; i < DELKAPOLE; i++) 46: printf( "%2i/%2i = %2i (%2i)\n" , pole[i].x, pole[i].y, 47: pole[i].podil.quot, pole[i].podil.re m); 49: return 0; 50: } 52: /*------------------------------------------------* /

74
Výstup z programu: 0/ 5 = 0 ( 0) 12/ 5 = 2 ( 2) 5/ 5 = 1 ( 0) 17/ 5 = 3 ( 2) 10/ 5 = 2 ( 0) 3/ 5 = 0 ( 3) 15/ 5 = 3 ( 0) 8/ 5 = 1 ( 3) 1/ 5 = 0 ( 1) 13/ 5 = 2 ( 3) 6/ 5 = 1 ( 1) 18/ 5 = 3 ( 3) 11/ 5 = 2 ( 1) 4/ 5 = 0 ( 4) 16/ 5 = 3 ( 1) 9/ 5 = 1 ( 4) 2/ 5 = 0 ( 2) 14/ 5 = 2 ( 4) 7/ 5 = 1 ( 2) 19/ 5 = 3 ( 4)
V následujícím příkladu jsou použity funkce exit(), abort() a atexit(). Program bude vracet hodnotu, kterou uživatel zadá z příkazové řádky.
1: /*------------------------------------------------* / 2: /* konec.c * / 4: #include <stdio.h> 5: #include <stdlib.h> 7: void koncim1(void) 8: { 9: printf( "Elektrina odpojena!\n" ); 10: } 12: void koncim2(void) 13: { 14: printf( "Systemy vypnuty!\n" ); 15: } 17: int main(int argc, char *argv[]) 18: { 20: atexit(koncim1); /* nejdrive probehne funkce koncim2 a pak koncim1, 21: atexit(koncim2); tedy v obracenem poradi nez byly registrovany */ 24: if (argc != 2) { 25: printf( "Na prikazove radce nebyla zadana navratova hodnota !\n" ); 26: abort(); 27: } 28: exit(atoi(argv[1])); 30: return 0; /* tato cast programu za exit nikdy neprobehne */ 31: } 33: /*------------------------------------------------* /
Chování programu v systému Linux.
konec // prikaz v Linuxu - spusteni programu Na prikazove radce nebyla zadana navratova hodnota! Neúspěšně ukon čen (SIGABRT) // hlaseni operacniho systemu echo $? // prikaz v Linuxu - vypis navratove hodnoty progra mu 134
V DOSu se místo „Neúspěšně ukončen (SIGABRT)“ ukáže „Abnormal program termination“. Dalším možnost spuštění (v Linuxu):
konec 5 Systemy vypnuty! Elektrina odpojena! echo $? 5
Tento program (se jménem konec ) bude využit i v následujícím příkladu (system1 ). Použita bude funkce system(), která bude program konec volat. Program konec se bude hledat ve stejném adresáři, ve kterém bude program system1 spuštěn.

75
Jména programů jsou v systému DOS a Windows samozřejmě zakončena příponou .exe, ale to na příkladu nic nemění.
Problém je však v návratové hodnotě funkce system(). V případě neúspěšného spuštění příkazového interpretu (např. bash nebo command.com) vrátí 127, v případě neúspěchu spuštění příkazu (např. příkaz neexistuje) vrátí -1. V případě, že příkaz (zadaný funkci system() jako textový řetězec) proběhne, vrátí funkce system() jeho návratový kód. Ovšem v Linuxu je tento návratový kód pozměněn a proto se musí na něj aplikovat makro WEXITSTATUS definované v souboru <sys/wait.h> . Proto je v příkladu použit podmíněný překlad a pro neunixové systémy je makro WEXITSTATUS definováno tak, že nic nedělá.
1: /*------------------------------------------------* / 2: /* system1.c * / 4: #include <stdio.h> 5: #include <stdlib.h> 7: #ifdef unix 8: #include <sys/wait.h> 9: #endif 11: #ifndef unix 12: #define WEXITSTATUS(X) X 13: #endif 15: int main(void) 16: { 17: int navrat; 19: printf( "Spoustim program> konec\n" ); 20: navrat = system( "konec" ); 21: printf( "Program skoncil s navratovou hodnotou %i\n\n" , 22: WEXITSTATUS(navrat)); 24: printf( "Spoustim program> konec 5\n" ); 25: navrat = system( "konec 5" ); 26: printf( "Program skoncil (%i)\n\n" , WEXITSTATUS(navrat)); 28: return 0; 29: } 31: /*------------------------------------------------* / Výstup z programu: Spoustim program> konec Na prikazove radce nebyla zadana navratova hodno ta! Neúsp ěšně ukon čen (SIGABRT) Program skoncil s navratovou hodnotou 134 Spoustim program> konec 5 Systemy vypnuty! Elektrina odpojena! Program skoncil (5)
Knihovny stdarg.h, limits.h a signal.h
Knihovna stdarg.h
Tato knihovna slouží k práci funkcí s proměnlivým počtem argumentů. Popis maker, které obsahuje a jejich použití je probráno v kapitole o proměnlivém počtu argumentů.
Knihovna limits.h
Knihovna <limits.h> obsahuje makra určující rozsah hodnot celočíselných datových typů. Tyto makra lze použít i v preprocesoru pro podmíněný překlad, jinak se nejčastěji používají v podmínkách programu. Hodnoty, uvedené v tabulce jsou jen orientační a v různých implementacích překladačů se liší (jinak by snad ani neměli význam). Například INT_MAX je pro 16bitové překladače 32767 a pro 32bitové 2147483647. Makra začínající písmenem U jsou pro čísla unsigned (čísla bez znaménka, např UINT_MAX.
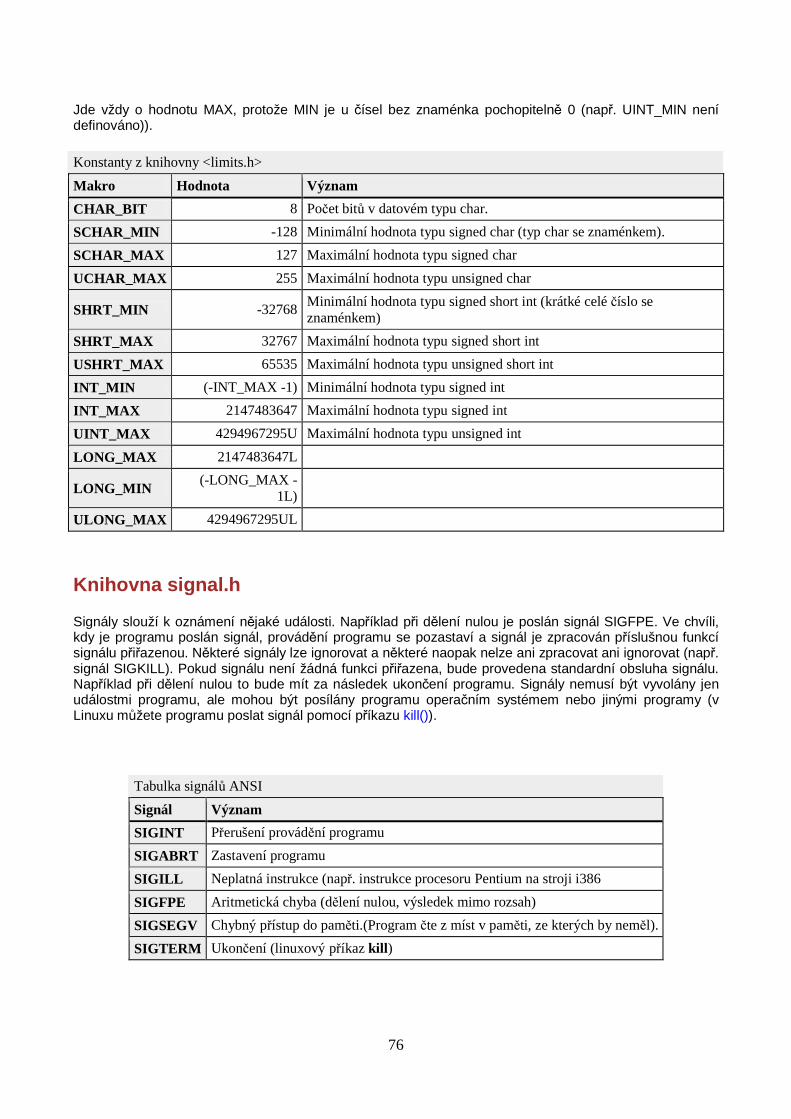
76
Jde vždy o hodnotu MAX, protože MIN je u čísel bez znaménka pochopitelně 0 (např. UINT_MIN není definováno)).
Konstanty z knihovny <limits.h>
Makro Hodnota Význam
CHAR_BIT 8 Počet bitů v datovém typu char.
SCHAR_MIN -128 Minimální hodnota typu signed char (typ char se znaménkem).
SCHAR_MAX 127 Maximální hodnota typu signed char
UCHAR_MAX 255 Maximální hodnota typu unsigned char
SHRT_MIN -32768 Minimální hodnota typu signed short int (krátké celé číslo se znaménkem)
SHRT_MAX 32767 Maximální hodnota typu signed short int
USHRT_MAX 65535 Maximální hodnota typu unsigned short int
INT_MIN (-INT_MAX -1) Minimální hodnota typu signed int
INT_MAX 2147483647 Maximální hodnota typu signed int
UINT_MAX 4294967295U Maximální hodnota typu unsigned int
LONG_MAX 2147483647L
LONG_MIN (-LONG_MAX -
1L)
ULONG_MAX 4294967295UL
Knihovna signal.h
Signály slouží k oznámení nějaké události. Například při dělení nulou je poslán signál SIGFPE. Ve chvíli, kdy je programu poslán signál, provádění programu se pozastaví a signál je zpracován příslušnou funkcí signálu přiřazenou. Některé signály lze ignorovat a některé naopak nelze ani zpracovat ani ignorovat (např. signál SIGKILL). Pokud signálu není žádná funkci přiřazena, bude provedena standardní obsluha signálu. Například při dělení nulou to bude mít za následek ukončení programu. Signály nemusí být vyvolány jen událostmi programu, ale mohou být posílány programu operačním systémem nebo jinými programy (v Linuxu můžete programu poslat signál pomocí příkazu kill()).
Tabulka signálů ANSI
Signál Význam
SIGINT Přerušení provádění programu
SIGABRT Zastavení programu
SIGILL Neplatná instrukce (např. instrukce procesoru Pentium na stroji i386
SIGFPE Aritmetická chyba (dělení nulou, výsledek mimo rozsah)
SIGSEGV Chybný přístup do paměti.(Program čte z míst v paměti, ze kterých by neměl).
SIGTERM Ukončení (linuxový příkaz kill )
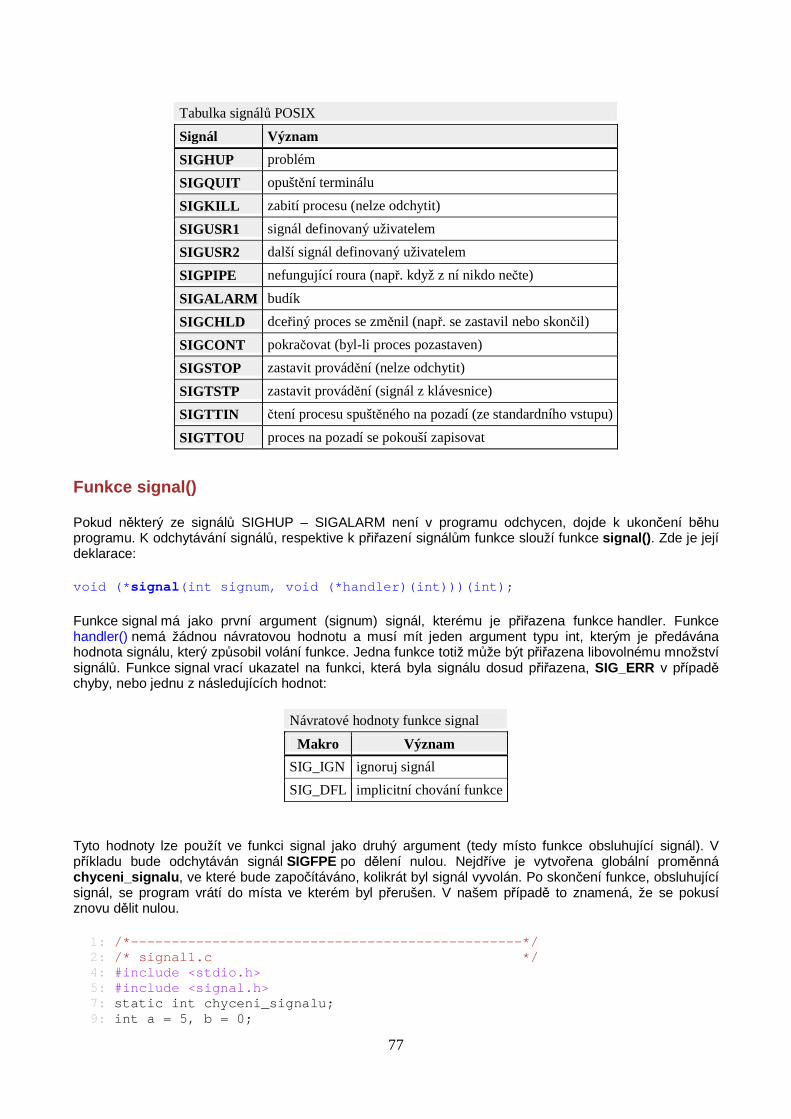
77
Tabulka signálů POSIX
Signál Význam
SIGHUP problém
SIGQUIT opuštění terminálu
SIGKILL zabití procesu (nelze odchytit)
SIGUSR1 signál definovaný uživatelem
SIGUSR2 další signál definovaný uživatelem
SIGPIPE nefungující roura (např. když z ní nikdo nečte)
SIGALARM budík
SIGCHLD dceřiný proces se změnil (např. se zastavil nebo skončil)
SIGCONT pokračovat (byl-li proces pozastaven)
SIGSTOP zastavit provádění (nelze odchytit)
SIGTSTP zastavit provádění (signál z klávesnice)
SIGTTIN čtení procesu spuštěného na pozadí (ze standardního vstupu)
SIGTTOU proces na pozadí se pokouší zapisovat
Funkce signal()
Pokud některý ze signálů SIGHUP – SIGALARM není v programu odchycen, dojde k ukončení běhu programu. K odchytávání signálů, respektive k přiřazení signálům funkce slouží funkce signal() . Zde je její deklarace:
void (* signal (int signum , void (* handler )(int)))(int);
Funkce signal má jako první argument (signum) signál, kterému je přiřazena funkce handler. Funkce handler() nemá žádnou návratovou hodnotu a musí mít jeden argument typu int, kterým je předávána hodnota signálu, který způsobil volání funkce. Jedna funkce totiž může být přiřazena libovolnému množství signálů. Funkce signal vrací ukazatel na funkci, která byla signálu dosud přiřazena, SIG_ERR v případě chyby, nebo jednu z následujících hodnot:
Návratové hodnoty funkce signal
Makro Význam
SIG_IGN ignoruj signál
SIG_DFL implicitní chování funkce
Tyto hodnoty lze použít ve funkci signal jako druhý argument (tedy místo funkce obsluhující signál). V příkladu bude odchytáván signál SIGFPE po dělení nulou. Nejdříve je vytvořena globální proměnná chyceni_signalu , ve které bude započítáváno, kolikrát byl signál vyvolán. Po skončení funkce, obsluhující signál, se program vrátí do místa ve kterém byl přerušen. V našem případě to znamená, že se pokusí znovu dělit nulou.
1: /*------------------------------------------------* / 2: /* signal1.c * / 4: #include <stdio.h> 5: #include <signal.h> 7: static int chyceni_signalu; 9: int a = 5, b = 0;

78
11: void zpracuj_signal(int cislo_signalu) 12: { 13: chyceni_signalu++; 14: switch (cislo_signalu) { 15: case SIGFPE: 16: printf 17: ( "Delit nulou se nevyplaci! a= %i, b= %i, chyceni_si gnalu= %i\n" , 18: a, b, chyceni_signalu); 19: break ; 20: default: 21: printf( "Neocekavany signal!\n" ); 22: break ; 23: } 24: if (chyceni_signalu >= 3) { 25: printf( "Uz toho mam dost!\n" ); 26: (void) signal(SIGFPE, SIG_DFL); 27: } else { 28: (void) signal(SIGFPE, zpracuj_signal); 29: } 30: } 32: int main(void) 33: { 35: void (*ukazatel_na_fci) (int); 37: ukazatel_na_fci = signal(SIGFPE, zpracuj_signal ); 38: if (ukazatel_na_fci == SIG_DFL) { 39: printf 40: ( "To je poprve, co nastavuji zpracovani signalu pro SIGFPE\n" ); 41: } 43: printf( "Zaciname: \n" ); 44: printf( "Deleni: %i/%i=%i\n" , a, b, a / b); 45: printf( "Tento text se jiz nevytiskne." ); 47: return 0; 48: } 50: /*------------------------------------------------* / Výstup v prostředí Linux: To je poprve, co nastavuji zpracovani signalu pro S IGFPE Zaciname: Delit nulou se nevyplaci! a= 5, b= 0, chycen i_signalu= 1 Delit nulou se nevyplaci! a= 5, b= 0, chycen i_signalu= 2 Delit nulou se nevyplaci! a= 5, b= 0, chycen i_signalu= 3 Uz toho mam dost! Výjimka matematického koprocesoru (SIGFPE)
Převzato z manuálových stránek k funkci signal() : Podle normy POSIX není definováno chování procesu poté, co ignoruje signál SIGFPE, SIGILL , nebo SIGSEGV, který nebyl generován funkcemi kill nebo raise . Celočíselné dělení nulou dává nedefinovaný výsledek a na některých architekturách generuje signál SIGFPE. Ignorování tohoto signálu může způsobit zacyklení procesu.
Pokud by byl v programu uveden výraz ve kterém by bylo dělení nulou přímo a ne přes proměnné jako v předchozím příkladě, pak by to překladač odhalil a buď by program nepřeložil, nebo by za výraz dosadil nulu. V takovém případě by za běhu programu k dělení nulou nedošlo.
Dnes platí, že obslužná funkce zůstává stále zaregistrována. Kvůli tomuto historickému zmatení se doporučuje místo funkce signal() používat funkci sigaction() .

79
Funkce sigaction()
Funkce signal() volá funkci sigaction() . Funkce sigaction() je o něco složitější, protože má více možností jak ovlivnit chování signálů. Zde bude ukázáno, jak tuto funkci použít namísto signal().
Funkce sigaction() odpovídá normě POSIX. To znamená, že je zaručeno, že bude definována v Unixech, ale ve Windows pravděpodobně k dispozici nebude. Ve windows si musíme vystačit s funkcí signal() (viz výše).
Deklarace funkce vypadá takto:
int sigaction (int signum , const struct sigaction * act , struct sigaction * oldact );
Návratovou hodnotou je 0 v případě úspěchu a -1 v případě chyby (v programu, ač se to správně nedělá, bude návratová hodnota ignorována). První argument je signál, který chceme odchytávat, druhý argument je struktura, která nastavuje odchytávání signálu a do třetího argumentu se uloží staré nastavení pro daný signál signum .
Definice struktury sigaction ( má stejné jméno jako funkce sigaction()).
struct sigaction { void (*sa_handler)(int); sigset_t sa_mask; int sa_flags; void (*sa_restorer)(void); }
První argument struktury sigaction je ukazatel na obslužnou funkci. Druhý argument ovlivňuje zachytávání signálů během volání obslužné funkce a pro nás je nezajímavý. Třetí argument, sa_flags, je množina příznaků, která ovlivňuje obsluhu signálu. Například SA_RESTART způsobí, že po zpracování signálu je znovu nastavena naše obsluha signálu a nikoliv implicitní akce. Poslední argument, sa_restorer, je zastaralý a již se nepoužívá.
Příklad sigaction.c dělá to samé, co příklad signal1.c
1: /*------------------------------------------------* / 2: /* sigaction.c * / 4: #include <stdio.h> 5: #include <signal.h> 7: static int chyceni_signalu; 9: int a = 5, b = 0; 11: void zpracuj_signal(int cislo_signalu) 12: { 13: chyceni_signalu++; 14: struct sigaction sa = { zpracuj_signal, 0, SA_RESTART }; 15: switch (cislo_signalu) { 16: case SIGFPE: 17: printf 18: ( "Delit nulou se nevyplaci! a= %i, b= %i, chyceni_si gnalu= %i\n" , 19: a, b, chyceni_signalu); 20: break ; 21: default: 22: printf( "Neocekavany signal!\n" ); 23: break ; 24: }

80
25: if (chyceni_signalu >= 3) { 26: printf( "Uz toho mam dost!\n" ); 27: sa.sa_handler = SIG_DFL; 28: } 29: (void) sigaction(SIGFPE, &sa, NULL); 30: } 32: int main(void) 33: { 35: void (*ukazatel_na_fci) (int); 36: struct sigaction sb, sa = { zpracuj_signal, 0, SA_RESTART }; 38: (void) sigaction(SIGFPE, &sa, &sb); 39: if (sb.sa_handler == SIG_DFL) { 40: printf 41: ( "To je poprve, co nastavuji zpracovani signalu pro SIGFPE\n" ); 42: } 44: printf( "Zaciname: \n" ); 45: printf( "Deleni: %i/%i=%i\n" , a, b, a / b); 46: printf( "Tento text se jiz nevytiskne." ); 48: return 0; 49: } 51: /*------------------------------------------------* /
Knihovna errno.h
Mnoho funkcí může z nějakého důvodu selhat. Například funkce která má otevřít soubor buď proto, že soubor neexistuje, nebo k němu program nemá přístupová práva. Nebo funkce, která má spočítat logaritmus čísla, dostane jako argument zápornou hodnotu, nebo nulu. K tomu, aby bylo možné zjistit, zda a k jaké chybě došlo, slouží knihovna <errno.h> .
Proměnná errno
Knihovna <errno.h> definuje jedinou proměnnou, a to extern int errno ;
Díky tomu se tak dá při vytváření knihovny nebo předkompilované části programu pracovat s proměnnou, která ještě nebyla nikde deklarována, takže fakticky v době překladu (knihovny, části programu, ...) ještě nemusí existovat.
Při startu programu je proměnná errno nastavena na nulu (tj. bezchybný stav). Když proběhne nějaká funkce, která umí s touto proměnnou pracovat, nastaví ji na nějakou hodnotu. Například 0, když se nic špatného nestalo. Z toho vyplývá, že pro odhalení chyby v nějaké funkci, je nutno proměnnou errno testovat ihned po ukon čení kritické funkce . (Další funkce může tuto hodnotu přepsat.) Použití errno se hodí především tam, kde funkce nemůže oznámit chybu svou návratovou hodnotou. Aby byla práce s touto proměnnou přehlednější, byla definována dvě standardní makra, která reprezentují možné chyby.
Standardní chyby definované v <errno.h>
EDOM Označuje chybu v rámci definičního oboru funkce.
ERANGE Označuje chybu v rámci oboru hodnot funkce.
Příklad využívá proměnnou errno k odhalení a určení chyby ve funkci log z knihovny <math.h>.
1: /*------------------------------------------------* / 2: /* errno1.c * / 4: #include <stdio.h> 5: #include <errno.h>

81
6: #include <math.h> 8: double logaritmus(double x) 9: { 10: double y; 11: y = log(x); 13: switch (errno) { 14: case EDOM: 15: printf( "Doslo k chybe v ramci definicniho oboru funkce!\n" ); return 0; 17: case ERANGE: 18: printf( "Doslo k chybe v ramci oboru hodnot funkce!\n" ); return 0; 20: case 0: 21: printf( "Vse je v poradku. log(%f) = %f.\n" , x, y); return y; 23: default: 24: printf( "Neocekavana chyba\n" ); return 0; 26: } 27: } 29: int main(void) 30: { 31: double x; 33: x = logaritmus(2.718281828); 34: x = logaritmus(-5); 35: x = logaritmus(9999999999); /* prilis velke cislo */ 36: x = logaritmus(0); 37: return 0; 38: } 40: /*------------------------------------------------* / Výstup z programu: Vse je v poradku. log(2.718282) = 1.000000. Doslo k chybe v ramci definicniho oboru funkce! Doslo k chybe v ramci definicniho oboru funkce! Doslo k chybe v ramci oboru hodnot funkce!
Co může obsahovat errno
Proměnná errno je typu int, takže může obsahovat celá čísla. V následující tabulce jsou uvedena některé makra převzatá z linuxového manuálu k souboru <errno.h>. Mnohé z těchto maker jsou přístupné jen pod Unixovými operačními systémy. Přesněji řečeno v systémech podporujících nejen standard ANSI C, ale i POSIX.1.
Standardní chyby definované v <errno.h>
EDOM Označuje chybu v rámci definičního oboru funkce.
ERANGE Označuje chybu v rámci oboru hodnot funkce.
E2BIG Příliš mnoho argumentů
EACCES Přístup odmítnut
EBADF Špatný deskriptor souboru
ECANCELED Operace přerušena
ECHILD Žádný podproces
EEXIST Soubor existuje
EFAULT Špatná adresa (do paměti)
EFBIG Soubor je příliš veliký
EINVAL Chybný argument
EIO Chyba vstupu/výstupu

82
EISDIR Je to adresář
EMFILE Příliš mnoho otevřených souborů
ENAMETOOLONG Příliš dlouhé jméno souboru
ENOENT Soubor nebo adresář nebyl nalezen
ENFILE Příliš mnoho otevřených souborů v systému
ENODEV Zařízení nebylo nalezeno
ENOEXEC Chyba formátu spustitelného souboru
ENOMEM Nedostatek místa (v paměti)
ENOSPC Nedostatek místa na zařízení (třeba na disku)
ENOTDIR Není adresářem
ENOTEMPTY Adresář není prázdný
EPERM Operace není přístupná
EROFS Systém je jen pro čtení (neumožňuje zápis Chyby definované v Linuxu
Chybové hlášení pomocí perror()
Všechna chybová hlášení jsou uložena v proměnné const char *sys_errlist[] ;. Počet chybových hlášení (tedy počet řetězců, na které ukazuje pole sys_errlist) je uložen v proměnné typu int, sys_nerr. Poslední chybové hlášení je tedy v:
sys_errlist[sys_nerr-1];
Proměnné sys_errlist , sys_nerr a funkce perror() jsou definovány v knihovně <stdio.h>. Deklarace :
void perror (const char * s );
Funkce perro r pošle nejdříve řetězec s, za něj přidá dvojtečku a poté chybové hlášení do standardního chybového proudu stderr (to je nejčastěji na obrazovku). Pokud má s hodnotu NULL, pak vypíše jen chybové hlášení. V případě že k žádné chybě nedošlo (errno == 0), vypíše se něco jako „Úspěch“ (Success). Díky funkci perror() lze příklad errno1.c zjednodušit. Změna je ve funkci logaritmus(), zbytek zůstane stejný.
1: /*------------------------------------------------* / 2: /* errno2.c * / 4: #include <stdio.h> 5: #include <errno.h> 6: #include <math.h> 8: double logaritmus(double x) 9: { 10: double y; 11: y = log(x); 13: switch (errno) { 14: case 0: perror(NULL); 16: printf( "log(%f) = %f.\n" , x, y); return y; 18: default: 19: perror( "Hlaseni" ); return 0; 21: } 22: } 24: int main(void) 25: { 26: double x; 28: x = logaritmus(2.718281828);

83
29: x = logaritmus(-5); 30: x = logaritmus(9999999999); /* prilis velke cislo */ 31: x = logaritmus(0); 32: return 0; 33: } 35: /*------------------------------------------------* / Možný výstup z programu: Success log(2.718282) = 1.000000. Hlaseni: Numerical argument out of domain Hlaseni: Illegal seek Hlaseni: Numerical result out of range
Žádný program by neměl ignorovat návratové hodnoty funkcí. Mezi běžné chyby patří například nedostatek místa na disku, odmítnuté internetové spojení, nedostatečná přístupová práva atp. Se všemi problémy by se programy měly umět co nejlépe vyrovnat.
Knihovna string.h II
Knihovna <string.h> obsahuje nejen funkce pracující s řetězci, ale také funkce pracující s pamětí. Tyto funkce však pracují s daty po bytech. Pokud tedy na pole typu int použijete funkci, která toto pole vyplní třeba jedničkou, pak to neznamená, že v každém prvku bude jednička, ale v každém bajtu. Pro 16bitové překladače to znamená, že typ int má velikost dvou bajtů, a číslo 1 se v něm tedy objeví dvakrát! (0000000100000001bitově = 257decimálně).
Výčet funkcí int memcmp (const void *s1, const void *s2, size_t n);
Porovná prvních n bajtů pamětí označených ukazateli s1 a s2. Vrací 0 v případě, že jsou všechny bajty stejné; větší jak 0, když s1 je větší jak s2; menší jak 0, když s1 je menší jak s2.
void *memcpy (void *dest, const void *src, size_t n); Zkopíruje n bajtů z paměti označené pomocí src do dest. Vrací ukazatel na dest. Paměti se nesmějí p řekrývat .
void *memmove (void *dest, const void *src, size_t n); Zkopíruje n bajtů z paměti označené pomocí src do dest. Vrací ukazatel na dest. Paměti se smějí překrývat . Pracuje pomaleji než memcpy().
void *memset (void *s1, int c, size_t n); Vyplní prvních n bajtů paměti označené ukazatelem s1 hodnotou c. Vrací ukazatel s1.
Je potřeba dávat si pozor, aby nemohlo dojít k pokusu o zápis mimo alokovanou paměť. Používání těchto funkcí je optimální co do rychlosti. Pokud je potřeba zkopírovat strukturu T2 do T1, je jistě nejrychlejší použít přiřazení T1 = T2;, ale jak je v příkladu ukázáno, při kopírování jen několika částí ze struktury ležících za sebou, je výhodnější použít memcpy() než přiřazovat jednu položku struktury za druhou. Obdobně se může memcpy() hodit při kopírování pole struktur.
1: /*------------------------------------------------* / 2: /* pamet1.c * / 4: #include <stdio.h> 5: #include <string.h> 7: void porovnej(const char *s1, const char *s2, const int n) 8: { 9: int x; 10: x = memcmp(s1, s2, n); 11: printf( "%2i: %s %s %s\n" , n, s1, x < 0 ? "<" : x > 0 ? ">" : "=" , s2); 12: } 14: typedef struct { 15: short int x;

84
16: char pole[10]; 17: float f; 18: } Trida; 20: void tiskni(const Trida * T) 21: { 22: unsigned int i; 23: printf( "T = {%3i,{" , T->x); 24: for (i = 0; i < sizeof (T->pole) / sizeof (T->pole[0]); i++) 25: printf( "%i," , T->pole[i]); 26: printf( "\b},{%.40f}}\n" , T->f); 27: } 29: int main(void) 30: { 31: Trida T1, T2; 32: char text1[] = "1234567890" ; 33: char text2[] = "abcdefghij" ; 35: porovnej( "aaazzzzz" , "aabaa" , 4); 36: porovnej( "aaaaa" , "aabaa" , 2); 38: tiskni((Trida *) memset(&T1, 0, sizeof (T1))); 39: tiskni((Trida *) memset(&T2, 1, sizeof (T2))); 41: /* Vyraz &T1 + n neukazuje n bajtu za adresu &T1, ale n sizeof(T1)bajtu za adresu T1. Tedy o n struktur dale. Proto je pouzit k pretypovani ukazat ele typ char, (1 bajt)a tak lze pomoci sizeof posouvat ukazatele po bajtech */ 47: memcpy((char *) &T1 + sizeof (T1.x), (char *) &T2 + sizeof (T1.x), 48: sizeof (T1) - sizeof (T1.x)); 49: tiskni(&T1); 51: printf( "text1+3: %s\n" , (char *) memcpy(text1 + 3, text2 + 6, 3)); 52: printf( "text1 : %s\n" , text1); 54: /* chybne pouziti - pameti se prekryvaji */ 55: (void) memcpy(text2 + 1, text2, 6); 56: printf( "text2+1: %s (memcpy)\n" , text2); 58: /* spravne pouziti */ 59: memcpy(text2, "abcdefghij" , 10); 60: (void) memmove(text2 + 1, text2, 6); 61: printf( "text2+1: %s (memmove)\n" , text2); 63: return 0; 64: } 66: /*------------------------------------------------* / Výstup: 4: aaazzzzz < aabaa 2: aaaaa = aabaa T = { 0,{0,0,0,0,0,0,0,0,0,0},{0.0000000000000000 000000000000}} T = {257,{1,1,1,1,1,1,1,1,1,1},{0.0000000000000000 000000000237}} T = { 0,{1,1,1,1,1,1,1,1,1,1},{0.0000000000000000 000000000237}} text1+3: ghi7890 text2+1: aabbdefhij (memcpy) text1 : 123ghi7890 text2+1: aabcdefhij (memmove)
Porovnávání struktur pomocí memcmp() je poněkud sporné co do přenositelnosti kódu. Některé platformy (ať už softwarové nebo hardwarové) mohou mezi jednotlivé části struktury vkládat bity (z jakéhosi důvodu to opravdu dělají, zvláště překladače C++). Tyto bity pak mohou mít různé hodnoty i pro struktury, jejichž obsah je stejný. Z toho důvodu může funkce memcmp() vyhodnotit stejné struktury jako různé. Jediným řešením tohoto problému je porovnávání všech složek struktur hezky jednu po druhé.
Funkce sprintf(), snprintf() a sscanf()
Tyto funkce jsou sice ze souboru <stdio.h>, jelikož však pracují také s pamětí jsou zde na závěr zařazeny.
Jejich deklarace jsou:
int sprintf (char * str , const char * format , ...); int snprintf (char * str , size_t size , const char * format ,...);

85
Funkce sprintf() zapíše formátovaný výstup stejně jako funkce printf() s tím rozdílem, že výstup jde do paměti, kam ukazuje str. Funkce snprintf() navíc zapíše pouze nanejvýš size znaků. Je tedy bezpečnější co do rizika překročení limitu alokované paměti. Funkce sprintf() by se tedy měla používat jen v případě jistoty, že formátovaný řetězec nepřekročí délku pole str.
Funkce snprintf() vrátí hodnotu -1 v případě, že se výstup musel kvůli limitu délky size zkrátit. V případě úspěchu vracejí obě funkce počet úspěšně zapsaných znaků do paměti. Na rozdíl od funkcí, které převádějí řetězce na čísla (např. atof()), se opačný převod provádí právě pomocí funkce snprintf().
1: /*------------------------------------------------* / 2: /* snpr1.c * / 4: #include <stdio.h> 5: #include <string.h> 7: int main(void) 8: { 9: char str[50]; 10: snprintf(str, 5, "%f" , 3.8); 11: printf( "Retezec %s je dlouhy %i znaku.\n" , str, strlen(str)); 12: return 0; 13: } 15: /*------------------------------------------------* / Výstup z programu: Retezec 3.80 je dlouhy 4 znaku.
Řetězec je dlouhý o jeden znak méně, než byl zadaný limit pro funkci snprintf(). Ten poslední znak je totiž vyhrazen pro označení konce řetězce '\0'.
Funkce sscanf()
Funkce sscanf() je též ze souboru stdio.h a dělá totéž co scanf, jenom místo standardního vstupu čte data z paměti, kam ukazuje str. Deklarace funkce je následující:
int sscanf (const char * str , const char * format , ...);
Knihovna stdio.h
Funkce getchar(), gets(), putchar() a puts()
Funkce getchar() načte ze standardního vstupu jeden znak a vrátí jej jako typ int. V případě chyby vrací speciální hodnotu EOF (v případě uzavřeného/chybného standardního vstupu Funkce gets() načte ze standardního vstupu řetězec do textového pole a vrátí ukazatel na toto pole. Načítá znaky, dokud nenarazí na konec řádku ('\0') nebo EOF. Tato funkce může překročit velikost pole paměti, do které řetězec ukládá a způsobit tak havárii programu! Návratovou hodnotou je ukazatel na paměť, kam řetězec ukládá (tedy návratová hodnota je rovna argumentu funkce). Funkce putchar() vytiskne jeden znak (jenž je argumentem funkce) do standardního výstupu. Vrací zapsaný znak (tedy to samé jako je argument), nebo EOF v případě chyby. Funkce puts() vytiskne řetězec, jenž je jejím argumentem, do standardního výstupu. V případě úspěchu vrací nezáporné číslo, jinak EOF. Zároveň vytiskne po řetězci ještě znak '\n' (nová řádka).
1: /*------------------------------------------------* / 2: /* gets1.c * / 4: #include <stdio.h> 5: #include <string.h> 7: int main(void) 8: { 9: char text[80]; 10: printf( "Zadejte libovolny text: " );

86
12: (void) gets(text); 13: puts(text); 14: printf( "Zadejte libovolny text: " ); 15: scanf( "%s" , text); 16: puts(text); 18: return 0; 19: } 21: /*------------------------------------------------* / Možný výstup: Zadejte libovolny text: Mam 25000 Euro. Mam 25000 Euro. Zadejte libovolny text: Mam 25000 Euro. Mam
Zatímco funkce gets() načte řetězec až do znaku nového řádku, funkce scanf() načítá řetězec k prvnímu „bílému znaku“ (mezera, tabulátor, nový řádek).
Výčet funkcí ze stdio.h FILE *fopen (const char *path, const char *mode);
Otevře souborový proud. FILE *freopen (const char *path, const char *mode, FILE *stream);
Otevře soubor se jménem path a přesměruje do něj souborový proud stream . Používá se pro přesměrování standardního vstupu stdio , nebo výstupů stdout a stderr .
int remove (const char *pathname); Smaže soubor pathname .
int rename (const char *oldpath, const char *newpath); Přejmenuje soubor oldpath na soubor newpath .
int fileno (FILE *stream); Vrací deskriptor souboru datového proudu stream.
int fflush (FILE *stream); Slouží k vyprázdnění datového proudu stream . Vrací 0 v případě úspěchu, jinak EOF.
int fclose ( FILE *stream); Uzavře (a vyprázdní) datový proud stream .
int feof (FILE *stream); Vrací kladnou nenulovou hodnotu v případě dosažení konce souboru stream, jinak 0.
int ferror (FILE *stream); V případě chyby souboru stream vrací kladnou nenulovou hodnotu, jinak 0.
void clearerr (FILE *stream); Nuluje indikátor konce souboru a chyby pro souborový proud stream.
int fseek (FILE *stream, long offset, int whence); Posune kurzor v souboru stream na pozici vzdálenou offset od místa whence .
long ftell ( FILE *stream); Vrátí aktuální pozici kurzoru souboru stream .
void rewind (FILE *stream); Posune kurzor na začátek souboru stream .
int fgetpos (FILE *stream, fpos_t *pos); Uloží aktuální pozici kurzoru do proměnné pos.
int fsetpos (FILE *stream, fpos_t *pos); Obnoví pozici kurzoru z proměnné pos.
int fgetc (FILE *stream); Načte znak ze souborového proudu stream .
char *fgets (char *s, int size, FILE *stream); Načte řetězec délky size ze souborového proudu stream .
int getc (FILE *stream); Načte znak ze souborového proudu stream .
int getchar (void); Načte a vrátí jeden znak ze standardního vstupu.
char *gets (char *s); Načte ze standardního vstupu řetězec do textového pole s a vrátí ukazatel na toto pole.

87
int ungetc (int c, FILE *stream); Vrátí znak c do proudu stream , je-li to možné. Více jak jedno vrácení znaku, před dalším čtením proudu, není garantováno. V případě úspěchu vrací znak c, jinak EOF.
int printf (const char *format, ...); Slouží k formátovanému výstupu do stdout .
int fprintf (FILE *stream, const char *format, ...); Slouží k formátovanému výstupu do souborového proudu stream .
int sprintf (char *str, const char *format, ...); Zapíše formátovaný výstup do paměti, kam ukazuje str.
int snprintf (char *str, size_t size, const char *format,...); Zapíše formátovaný výstup do paměti, kam ukazuje str, nejvýše size znaků.
int scanf (const char *format, ...); Čte data ze standardního vstupu.
int fscanf (FILE *stream, const char *format, ...); Čte data ze souborového proudu stream .
int sscanf (const char *str, const char *format, ...); Načítá formátovaný řetězec z paměti, kam ukazuje str.
int fputc (int c, FILE *stream); Tiskne znak c do souborového proud stream .
int fputs (const char *s1, FILE *stream); Tiskne řetězec s1 do souborového proud stream .
int putc (int c, FILE *stream); Tiskne řetězec c do souborového proud stream . Rozdíl mezi fputc() a putc() je zanedbatelný. Lépe je používat fputc().
int putchar (int c); Vytiskne znak c do standardního výstupu.
int puts (const char *s1); Vytiskne řetězec s1 a po něm ještě znak '\n' (nová řádka).
size_t fread (void *ptr, size_t size, size_t nmemb, FILE *stream); Načte nmemb dat o velikosti size ze souboru stream do paměti kam ukazuje ptr. Návratovou hodnotou je počet správně načtených položek.
size_t fwrite (const void *ptr, size_t size, size_t nmemb, FILE *stream); Zapíše nmemb dat o velikosti size do souboru stream z paměti kam ukazuje ptr . Návratovou hodnotou je počet správně zapsaných položek.
void perror (const char *s1); Vypíše chybové hlášení na základě proměnné errno za řetězec s1 a dvojtečku, nebo jen chybové hlášení, pokud má s1 hodnotu NULL .
Práce se soubory (a <stdio.h>)
O vstupu a výstupu
Funkce printf() a scanf() jsou typickými představiteli knihovny <stdio.h> (standard input output) . Standardní vstup a výstup se považují také za soubory (s drobnými rozdíly, například „skutečné“ soubory mají své jméno a jsou někde uloženy ...). Na rozdíl od ostatních souborů (např. textových, binárních a dalších speciálních souborů) jsou standardní vstup a výstupy otevřeny a programu přístupny automaticky při spuštění programu.
Deklarace standardního vstupu, výstupu a chybového výstupu
FILE *stdin; Standardní vstup (typicky klávesnice)
FILE *stdout; Standardní výstup (typicky obrazovka)
FILE *stderr; Standardní chybový výstup (typicky obrazovka)

88
Z tabulky je patrné, že se jedná o ukazatele na strukturu FILE. Ta je deklarovaná v souboru <stdio.h> a slouží k práci se soubory. Tato struktura je argumentem spousty funkcí ze souboru <stdio.h>.
Přístup k soubor ům
Existují dva základní způsoby jazyka C, jak přistupovat k souborům. Buďto pomocí souborového proudu , nebo pomocí přímého volání .
Souborový proud
K souborovému proudu se přistupuje pomocí struktury FILE. Díky normě ANSI je jisté, že používané funkce budou podporovány všemi („dobrými“) překladači. Proto je převážně používán tento způsob.
Přímé volání
Přímé volání má přímou vazbu na systém. Tím je zaručena maximální rychlost přístupu k souborům, ale také implementační závislost. Pro funkce s přímým voláním je nutno použít knihovny <io.h>, <sys/stat.h> a <fcntl.h>. K souboru se na rozlíl struktury FILE přistupuje pomocí manipulačního čísla tzv. deskriptoru souboru . Jedná se o datový typ int. Přímé volání není součástí normy ASCII, ale je definována normou POSIX.
Textový a binární p řístup k soubor ům
Existuje ještě jedno dělení přístupu k souborům a to na textový a binární. V textovém souboru je uložen pouze text. To umožňuje zjednodušit některé souborové operace a zlepšit tak přenositelnost mezi různými operačními systémy. Problém textových souborů spočívá ve znaku '\n'. Je to označení konce řádku. V DOSu je konec řádku dán dvěma bajty 13 a 10, zatímco v Linuxu pouze jedním (10). V jiných systémech je to pro změnu 10 a 13 (v tomto pořadí). Při textovém přístupu k souboru se načítají a zapisují textové řetězce. Přitom není nutno starat se o to, jakým způsobem je znak '\n' interpretován. Nový řádek je vnitřně reprezentován jedním znakem, který je vždy roven '\n' (při čtení/zápisu souboru dochází k automatické konverzi). Při binárním přístupu k souboru se čtou i zapisují data bajt po bajtu. V takovém případě, pokud má být soubor textový, je nutné zapsat znak '\n' v závislosti na OS. Binární přístup umožňuje tedy větší kontrolu nad zpracovávanými daty, ale práce s takovými soubory může být o něco náročnější.
Limity
Soubor <stdio.h> obsahuje i tyto makra. Pro přenositelnost programů je využití těchto maker nezbytné:
FOPEN_MAX udává maximální počet otevřených souborů. Maximum otevřených souborů omezuje operační systém, mnohdy podle aktuální konfigurace systému.
FILENAME_MAX udává maximální délku jména souboru. V systému MS-DOS je známé omezení 8+3, tj. 8 znaků, tečka a tři znaky (přípona).
Datové proudy
Otevření datového proudu FILE * fopen (const char * path , const char * mode);
Funkce fopen() vrací ukazatel na strukturu FILE. Pokud se proud nepodaří otevřít, vrací hodnotu NULL . Z jakého důvodu se nepodařilo proud uzavřít lze zjistit pomocí proměnné errno definované v souboru <errno.h>. První argument path je název souboru, který se má otevřít (samotný název pro práci s
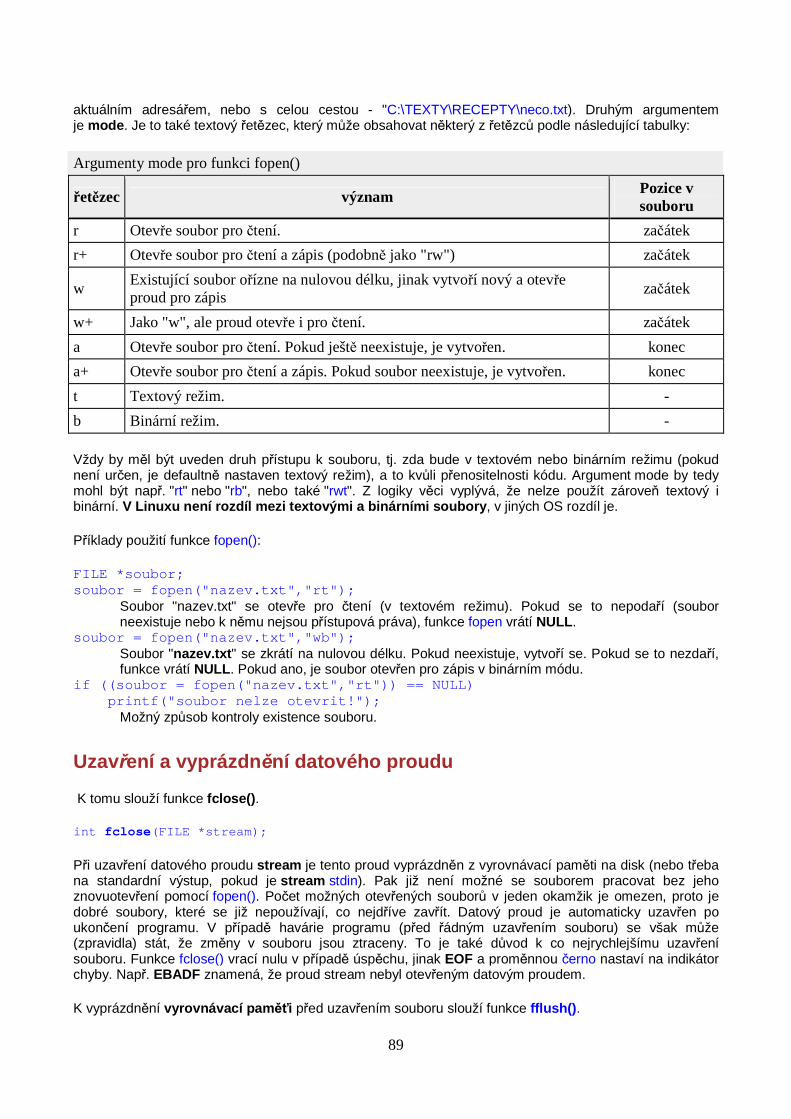
89
aktuálním adresářem, nebo s celou cestou - "C:\TEXTY\RECEPTY\neco.txt). Druhým argumentem je mode . Je to také textový řetězec, který může obsahovat některý z řetězců podle následující tabulky:
Argumenty mode pro funkci fopen()
řetězec význam Pozice v souboru
r Otevře soubor pro čtení. začátek
r+ Otevře soubor pro čtení a zápis (podobně jako "rw") začátek
w Existující soubor ořízne na nulovou délku, jinak vytvoří nový a otevře proud pro zápis
začátek
w+ Jako "w", ale proud otevře i pro čtení. začátek
a Otevře soubor pro čtení. Pokud ještě neexistuje, je vytvořen. konec
a+ Otevře soubor pro čtení a zápis. Pokud soubor neexistuje, je vytvořen. konec
t Textový režim. -
b Binární režim. -
Vždy by měl být uveden druh přístupu k souboru, tj. zda bude v textovém nebo binárním režimu (pokud není určen, je defaultně nastaven textový režim), a to kvůli přenositelnosti kódu. Argument mode by tedy mohl být např. "rt" nebo "rb", nebo také "rwt". Z logiky věci vyplývá, že nelze použít zároveň textový i binární. V Linuxu není rozdíl mezi textovými a binárními sou bory , v jiných OS rozdíl je.
Příklady použití funkce fopen():
FILE *soubor; soubor = fopen(" nazev.txt ","rt");
Soubor "nazev.txt" se otevře pro čtení (v textovém režimu). Pokud se to nepodaří (soubor neexistuje nebo k němu nejsou přístupová práva), funkce fopen vrátí NULL .
soubor = fopen(" nazev.txt ","wb"); Soubor "nazev.txt " se zkrátí na nulovou délku. Pokud neexistuje, vytvoří se. Pokud se to nezdaří, funkce vrátí NULL . Pokud ano, je soubor otevřen pro zápis v binárním módu.
if ((soubor = fopen("nazev.txt","rt")) == NULL) printf("soubor nelze otevrit!");
Možný způsob kontroly existence souboru.
Uzavření a vyprázdn ění datového proudu
K tomu slouží funkce fclose() .
int fclose (FILE * stream );
Při uzavření datového proudu stream je tento proud vyprázdněn z vyrovnávací paměti na disk (nebo třeba na standardní výstup, pokud je stream stdin). Pak již není možné se souborem pracovat bez jeho znovuotevření pomocí fopen(). Počet možných otevřených souborů v jeden okamžik je omezen, proto je dobré soubory, které se již nepoužívají, co nejdříve zavřít. Datový proud je automaticky uzavřen po ukončení programu. V případě havárie programu (před řádným uzavřením souboru) se však může (zpravidla) stát, že změny v souboru jsou ztraceny. To je také důvod k co nejrychlejšímu uzavření souboru. Funkce fclose() vrací nulu v případě úspěchu, jinak EOF a proměnnou černo nastaví na indikátor chyby. Např. EBADF znamená, že proud stream nebyl otevřeným datovým proudem.
K vyprázdnění vyrovnávací pam ěťi před uzavřením souboru slouží funkce fflush() .

90
int fflush (FILE * stream );
Argument stream je samozřejmě datovým proudem, který chcete vyprázdnit. Pokud má stream hodnotu NULL , jsou vyprázdněny všechny datové proudy, které jsou v programu otevřené. Funkce fflush() vrací 0 v případě úspěchu, jinak EOF a proměnnou errno nastaví na příslušnou chybu. Ovšem ani funkce fclose() ani fflush() nezajistí, že budou data skutečně fyzicky na disku. Mezi programem a hardwarem je totiž ještě operační systém, který také využívá vyrovnávací paměti. O tomhle je třeba vědět při psaní nějakých víceuživatelských programů (třeba databáze), kde k jednomu souboru přistupuje několik uživatelů najednou (třeba i ze vzdálených počítačů). V Unixu k reálnému zapsání dat na disk slouží funkce fsync() .
V příkladu je procvičování otevření a uzavření souboru.
1: /*------------------------------------------------* / 2: /* fopen1.c * / 4: #include <errno.h> 5: #include <stdio.h> 6: #include <string.h> 8: #define NAZEV "pokus.txt" 10: #ifndef ENOENT 11: #define ENOENT 2 12: #endif 14: /* vraci 0 pokud soubor existuje, 15: jinak cislo chyby */ 16: int SouborExistuje(char *nazev) 17: { 18: FILE *soubor; 19: if ((soubor = fopen(nazev, "rt" )) != NULL) { 20: fclose(soubor); 21: return 0; /* soubor existuje, jinak by se nesel otevrit */ 23: } 25: if (errno == ENOENT) { 26: return errno; /* soubor neexistuje */ 27: } 29: return errno; /*soubor mozna existuje, ale nepodarilo se jej otev rit*/ 30 32: } 36: int main(void) 37: { 38: FILE *soubor; 39: char text[255]; 42: printf( "Soubor %s %sexistuje.\n" , NAZEV, 43: !SouborExistuje(NAZEV) ? "" : "ne" ); 45: /*otevre se soubor pro cteni a pokud se to zdari, hned se zase zavre*/ 48: if ((soubor = fopen(NAZEV, "rt" )) == NULL) { 49: strcpy(text, "Otevreni \"rt\" souboru " ); 50: strcat(text, NAZEV); 51: perror(text); 52: } else { 53: printf( "Soubor %s se podarilo otevrit\n" , NAZEV); 54: if (fclose(soubor)) 55: perror( "Zavirani souboru" ); 56: } 59: /*otevre a zavre se pro aktualizaci, pokud neexistu je, bude vytvoren.*/ 62: if ((soubor = fopen(NAZEV, "at" )) == NULL) { 63: strcpy(text, "Otevreni \"at\" souboru " ); 64: strcat(text, NAZEV); 65: perror(text); 66: } else { 67: printf( "Soubor %s se podarilo otevrit\n" , NAZEV); 68: if (fclose(soubor)) 69: perror(NULL);

91
70: } 72: return 0; 73: } 75: /*------------------------------------------------* / Možný výstup 1 spuštění: Soubor pokus.txt neexistuje. Otevreni "rt" souboru pokus.txt: No such file or directory Soubor pokus.txt se podarilo otev řít Možný výstup 2 spuštění: Soubor pokus.txt existuje. Soubor pokus.txt se podarilo otevrit Soubor pokus.txt se podarilo otevrit
V aktuálním adresáři, by teď měl být prázdný soubor pokus.txt.
Práce s textovými soubory
Zápis do textového souboru
Pro zápis slouží funkce fprintf() . Narozdíl od funkce printf() má navíc argument stream, který určuje souborový proud. Pokud tímto souborovým proudem bude stdout , pak se chování funkce nebude lišit od funkce printf(). Další možností je zápis do standardního chybového proudu stderr , nebo do souborového proudu otevřeného funkcí fopen().
int fprintf (FILE * stream , const char * format , ...);
Kromě toho je možné také použít funkce fputs() pro tisk řetězce, fputc() a putc() pro tisk znaku. Jejich deklarace jsou následující:
int fputs (const char * s , FILE * stream ); int fputc (int c , FILE * stream ); int putc (int c , FILE * stream );
Rozdíl mezi fputc() a putc() je v tom, že fputc() je funkce, zatímco putc() je implementován jako makro (proto je lepší používat fputc() u kterého se nestane, že by byl stream vyhodnocován vícekrát).
Funkce fputc() a putc() vracejí zapsaný znak, nebo EOF v případě chyby. Funkce fputs() nezáporné číslo v případě úspěchu, při chybě EOF.
V následujícím příkladu nejsou, pro větší jednoduchost, kontrolovány návratové hodnoty funkcí (nemělo by se na to však zapomínat). Program bude zapisovat na konec souboru text zadaný od uživatele.
1: /*------------------------------------------------* / 2: /* fprintf1.c * / 4: #include <stdio.h> 5: #include <string.h> 7: #define NAZEV "textak.txt" 9: int main(void) 10: { 11: FILE *soubor; 12: char text[255]; 14: soubor = fopen(NAZEV, "a+" ); /* soubor se otevre pro aktualizaci, 15: neexistuj ici soubor se vytvori */ 16: do { 17: fputs( "Zadejte slovo, ktere chcete zapsat do souboru\n" 18: "a stisknete ENTER, nebo \"q\" pro ukonceni: " , stdout); 19: scanf( "%254s" , text); 20: if (!strcmp(text, "q" ))

92
21: break ; 22: printf( "Zapisuji >> %s <<\n" , text); 23: fprintf(soubor, ">> %s <<\n" , text); 24: } while (1); 26: fclose(soubor); 28: return 0; 29: } 31: /*------------------------------------------------* / Možný výstup: Zadejte slovo, ktere chcete zapsat do souboru a stisknete ENTER, nebo "q" pro ukonceni: jedna Zapisuji >> jedna << Zadejte slovo, ktere chcete zapsat do souboru a stisknete ENTER, nebo "q" pro ukonceni: dve Zapisuji >> dve << Zadejte slovo, ktere chcete zapsat do souboru a stisknete ENTER, nebo "q" pro ukonceni: honza jde Zapisuji >> honza << Zadejte slovo, ktere chcete zapsat do souboru a stisknete ENTER, nebo "q" pro ukonceni: Zapisuj i >> jde << Zadejte slovo, ktere chcete zapsat do souboru a stisknete ENTER, nebo "q" pro ukonceni: q
Čtení z textového souboru
Pro čtení slouží funkce fscanf() . Opět je rozdíl od funkce scanf() v argumentu stream , který určuje souborový proud. Bude-li tímto proudem stdin , je funkce shodná s scanf().
int fscanf (FILE * stream , const char * format , ...);
Kromě této funkce je možné také použít funkce fgets() pro načtení řetězce, fgetc() a getc() pro načtení znaku. Jejich deklarace jsou následující:
char * fgets (char * s , int size , FILE * stream ); int fgetc (FILE * stream ); int getc (FILE * stream );
Rozdíl mezi fgetc() a getc() je pouze v implementaci těchto funkcí překladačem. Lépe je používat fgetc().
V příkladu je otevřen nový textový soubor pro zápis. Po zápisu je soubor uzavřen, následně otevřen pro čtení, a jeho obsah načten a vypísán.
1: /*------------------------------------------------* / 2: /* fscanf1.c * / 4: #include <errno.h> 5: #include <stdio.h> 6: #include <string.h> 8: #define NAZEV "textak.txt" 10: int main(void) 11: { 12: FILE *soubor; 13: int i; 14: float x, y, z; 15: char text[255]; 16: /* nejdrive do souboru neco zapiseme */ 17: if ((soubor = fopen(NAZEV, "w" )) == NULL) { 18: fprintf(stderr, "Chyba zapisu do souboru %s\n" , NAZEV); 19: return errno; 20: } 22: fputs( "Seznam zlomku:\n" , soubor);

93
23: for (i = 1; i <= 5; i++) 24: fprintf(soubor, "%f %f %f\n" , 100.0, (float) i, 100.0 / i); 25: fclose(soubor); 26: /* a ted to zpatky nacteme */ 27: if ((soubor = fopen(NAZEV, "r" )) == NULL) { 28: fprintf(stderr, "Chyba cteni souboru %s\n" , NAZEV); 29: return errno; 30: } 32: /* prvni radek nacteme znak po znaku */ 33: do { 34: i = fgetc(soubor); 35: fputc(i, stdout); 36: } while (i != '\n'); 38: /* druhy radek (prvni radek s cisly) nacteme naraz */ 39: fgets(text, sizeof (text) - 1, soubor); 40: fputs(text, stdout); 42: /* zbytek nacteme po cislech */ 43: for (i = 1; i <= 4; i++) { 44: fscanf(soubor, "%f %f %f" , &x, &y, &z); 45: printf( "%f/%f = %f\n" , x, y, z); 46: } 48: fclose(soubor); 49: return 0; 50: } 52: /*------------------------------------------------* / Výstup z programu: Seznam zlomku: 100.000000 1.000000 100.000000 100.000000/2.000000 = 50.000000 100.000000/3.000000 = 33.333332 100.000000/4.000000 = 25.000000 100.000000/5.000000 = 20.000000
Kontrola chyb (feof(), ferror(), clearerr())
Tyto funkce pracují s datovým proudem stream a je jedno, jestli jde o textový nebo binární přístup.
int feof (FILE * stream ); void clearerr (FILE * stream ); int ferror (FILE * stream );
Funkce feof() zjišťuje konec souboru. Po dosažení konce vrací kladnou hodnotu (1) jinak 0. Funkce ferror() testuje indikátory chyb. Pokud nedošlo k chybě, vrací 0, jinak kladnou hodnotu. Funkce clearerr() dokáže jako jediná odstranit indikátor konce souboru a indikátory chyb v datovém proudu. To může být užitečné například ve chvíli, kdy se dostaneme na konec souboru, ale pak se přesuneme na jeho začátek, nebo obnovení zápisu do proudu v případě uvolnění místa na zaplněném disku.
Program v následujícím příkladu otevře soubor cisla.txt a sečte všechna čísla, v něm zapsaná.
1: /*------------------------------------------------* / 2: /* feof1.c * / 4: #include <errno.h> 5: #include <stdio.h> 6: #include <string.h> 8: #define NAZEV "cisla.txt" 10: int zavri_soubor(FILE * soubor) 11: { 12: if (fclose(soubor) == EOF) { 13: fprintf(stderr, "%s %i" , __FILE__, __LINE__); 14: perror(NULL);

94
15: return errno; 16: } 17: return 0; 18: } 20: int main(void) 21: { 22: FILE *soubor; 23: float f, suma; 25: if ((soubor = fopen(NAZEV, "rt" )) == NULL) { 26: fprintf(stderr, "%s %i:" , __FILE__, __LINE__); 27: perror(NULL); 28: return errno; 29: } 30: suma = 0.0; 31: do { 32: if (fscanf(soubor, "%f" , &f) == 1) { /* ma se nacist 1 cislo */ 33: printf( "%.1f " , f); 34: suma += f; 35: } else if (feof(soubor)) /* dosahli jsme konce souboru */ 36: break ; /*preskoci retezec, který neni cislo*/ 37: else if (fscanf(soubor, "%*s" )!= 0){ 38: fprintf(stderr, "%s %i:" , __FILE__, __LINE__); 39: perror(NULL); 40: return zavri_soubor(soubor); 41: } 42: } while (1); 44: (void) zavri_soubor(soubor); 45: printf( "\nSuma = %.3f\n" , suma); 46: return 0; 47: } 49: /*------------------------------------------------* /
Výhoda použití perror() je v tom, že lze pomocí knihovny <locale.h> nastavit jazyk, jakým na nás bude program mluvit.
Reakce, pokud cisla.txt nebude existovat. kod.c 26:No such file or direktory Nebo když nejsou přístupová práva ke čtení souboru: kod.c 26:Permission denied Soubor cisla.txt existuje a má následující obsah: text 11.257 te123xt 20.447 18.3 text 30 text ? 20 Pak je výstup: 11.3 20.4 18.3 30.0 20.0 Suma = 100.004
Práce s binárními soubory a pohyb v souborech
Čtení a zápis binárního souboru
Otevření a uzavření binárního souboru je stejné jako textového (místo příznaku t se napíše b).
Zápis pomocí fwrite()
Funkce fwrite() slouží k zápisu dat do souborového proudu. Její deklarace je následující:
size_t fwrite (const void * ptr , size_t size , size_t nmemb, FILE * stream );
Prvním argumentem je ukazatel ptr , který ukazuje na začátek místa v paměti, odkud se budou brát data pro zápis do souboru. Může to být ukazatel na strukturu, řetězec, nebo číslo atp. Druhý argument size je

95
velikost položky, kterou budeme zapisovat v bajtech (může to být např. sizeof(struktura)). Třetím argumentem je nmemb , což je počet položek, které zapíšeme. Celkem se tedy zapíše nmemb * size bajtů. A čtvrtým argumentem je datový proud stream, do kterého se data zapisují. Návratovou hodnotou je počet zapsaných položek, v ideálním případě je to rovno nmemb . V případě chyby je nastavena globální proměnná errno.
Čtení pomocí fread()
Funkce fread() slouží ke čtení dat ze souborového proudu. Její deklarace je následující:
size_t fread (void * ptr , size_t size , size_t nmemb, FILE * stream );
Funkce fread() načte nmemb dat o velikosti size ze souboru stream do paměti kam ukazuje ptr . Návratovou hodnotou je počet správně načtených položek, v ideálním případě nmemb . Pokud se nenačtou všechny požadované položky, pak došlo k chybě, nebo se funkce dostala na konec souboru. To lze zjistit pomocí funkcí feof() a ferror().
Příklad čtení a zápisu
Program zapíše do souboru strukturu data , pak ji znovu načte a vypíše.
1: /*------------------------------------------------* / 2: /* binar.c * / 4: #include <errno.h> 5: #include <stdio.h> 7: typedef struct { 8: float cisla[5]; 9: char text[100]; 10: } data; 12: #define NAZEV "bsoub.dat" 14: int main(void) 15: { 16: FILE *soubor; 17: /* pole obsahuje 5 struktur typu data */ 18: data pole[] = { {{1.1, 1.2, 1.3, 1.4, 1.5}, "prvni struktura" }, 19: {{2.1, 2.2, 2.3, 2.4, 2.5}, "druha struktura" }, 20: {{3.1, 3.2, 3.3, 3.4, 3.5}, "treti struktura" }, 21: {{4.1, 4.2, 4.3, 4.4, 4.5}, "ctvrta struktura" }, 22: {{5.1, 5.2, 5.3, 5.4, 5.5}, "pata struktura" } 23: }; 24: data xdata; 25: size_t navrat; 26: unsigned int i; 28: if ((soubor = fopen(NAZEV, "wb" )) == NULL) { 29: /* vite co znamena "w" ? */ 30: fprintf(stderr, "%s %i:" , __FILE__, __LINE__); 31: perror(NULL); 32: return errno; 33: } 35: /* zapis dat do souboru - nejdriv prvnich tri a pak zbylych dvou */ 37: navrat = fwrite(pole, sizeof (data), 3, soubor); 38: if (navrat != 3) { 39: fprintf(stderr, "%s %i:" , __FILE__, __LINE__); 40: perror(NULL); 41: if (EOF != fclose(soubor)) 42: fprintf(stderr, "S jistotou bylo zapsano %i polozek\n" , 43: navrat); 44: else 45: perror(NULL); 46: return errno;

96
47: } 49: navrat = fwrite(pole + 3, sizeof (data) * 2, 1, soubor); 50: if (navrat != 1) { 51: fprintf(stderr, "%s %i:" , __FILE__, __LINE__); 52: perror(NULL); 53: fclose(soubor); 54: fprintf(stderr, "Neni znam pocet zapsanych polozek\n" ); 55: return errno; 56: } 58: /* soubor pred ctenim uzavreme a pak zase otevreme */ 59: if (fclose(soubor) == EOF) 60: perror(NULL); 62: if ((soubor = fopen(NAZEV, "rb" )) == NULL) { 63: fprintf(stderr, "%s %i:" , __FILE__, __LINE__); 64: perror(NULL); 65: return errno; 66: } 68: /* nyni data nacteme a vypiseme */ 69: do { 70: navrat = fread(&xdata, 1, sizeof (xdata), soubor); 71: if (navrat != sizeof (xdata)) { 72: if (feof(soubor)) { 73: printf( "Konec souboru!\n" ); 74: break ; 75: } else { 76: perror(NULL); 77: fprintf(stderr, "Bylo nacteno pouze %i bajtu " 78: "z jedne polozky spravne\n" , navrat); 79: break ; 80: } 81: } 83: /* vypasni jedne struktury */ 84: for (i = 0; i < sizeof (xdata.cisla) / sizeof (xdata.cisla[0]); i++) 85: printf( "%3.1f " , xdata.cisla[i]); 86: printf( "%s\n" , xdata.text); 88: } while (!feof(soubor)); 90: if (fclose(soubor) == EOF) 91: perror(NULL); 93: return 0; 94: } 96: /*------------------------------------------------* / Výstup z programu: 1.1 1.2 1.3 1.4 1.5 prvni struktura 2.1 2.2 2.3 2.4 2.5 druha struktura 3.1 3.2 3.3 3.4 3.5 treti struktura 4.1 4.2 4.3 4.4 4.5 ctvrta struktura 5.1 5.2 5.3 5.4 5.5 pata struktura Konec souboru!
Po přečtení páté struktury ještě funkce feof() nevratcí hodnotu „true “, ale vrací ji až po pokusu načíst strukturu šestou, která již v souboru neexistuje. Příznak konce souboru je tedy nastaven až poté, co se pokoušíme na číst více dat, než je v souboru a ne ve chvíli, kdy přečteme poslední existující data ze souboru!
Pozice v souboru
Po otevření souboru pro čtení ukazuje souborový indikátor pozice (dále jen kurzor) na začátek souboru (tedy na „nultý“ bajt). Po použití libovolné funkce na přečtení určitého počtu bajtů bude kurzor automaticky ukazovat na bajt následující atd. K „ručnímu“ nastavení kurzoru na požadovanou pozici slouží následující funkce.

97
Funkce je fseek() .
int fseek (FILE * stream , long offset , int whence );
Posouvá kurzor do vzdálenosti offset (tato hodnota může být i záporná!) od místa whence . Místo whence může být SEEK_SET (relativní vzdálenost od začátku souboru), SEEK_CUR (relativní vzdálenost od aktuální pozice) nebo SEEK_END (relativní vzdálenost od konce souboru). Funkce vrací v případě úspěchu nulu.
Další funkce jsou ftell() a rewind() . long ftell (FILE * stream ); void rewind (FILE * stream );
Funkce rewind() posune kurzor na začátek souboru stream . Je to totéž, jako (void) fseek(stream, 0L, SEEK_SET). Funkce ftell() vrací hodnotu aktuální pozice kurzoru v souboru stream .
Alternativou k předešlým funkcím mohou být funkce fgetpos() a fsetpos() . Tyto funkce pracují s objektem typu fpos_t , do kterého funkce fgetpos() ukládá hodnotu aktuální pozice kurzoru a fsetpos() nastavuje pozici kurzoru podle této proměnné.
int fgetpos (FILE * stream , fpos_t * pos ); Všechny tyto funkce jsou vhodné pro používání jak v int fsetpos (FILE * stream , fpos_t * pos ); textovém, tak binárním p řístupu k souboru.
Zjišt ění velikosti souboru
Nejlepším způsobem je přesunout kurzor na konec souboru a pak funkcí ftell() zjistit aktuální pozici kurzoru. Pro jednoduchost nebudou v příkladu ošetřeny žádné chyby.
1: /*------------------------------------------------* / 2: /* ftell1.c * / 4: #include <stdio.h> 7: int main(void) 8: { 9: FILE *soubor; 10: unsigned int i; 11: char pole[100]; 12: soubor = fopen( "pokus.txt" , "w+t" ); 14: /* nejdrive zapiseme do souboru nekolik znaku 'a' * / 15: for (i = 0; i < 50; i++) 16: fputc('a', soubor); 18: /* posuneme kurzor za prvnich 5 bajtu */ 19: fseek(soubor, 5L, SEEK_SET); 20: /* zapiseme 5 znaku '-' */ 21: for (i = 0; i < 5; i++) 22: fputc('-', soubor); 24: /* posuneme se na konec souboru a zjistime jeho vel ikost */ 25: fseek(soubor, 0L, SEEK_END); 26: printf( "Velikost souboru je %lu bajtu.\n" , ftell(soubor)); 28: /* presuneme se opet na zacatek souboru a precteme jeho obsah */ 29: fseek(soubor, 0L, SEEK_SET); 30: while (!feof(soubor)) { 31: fgets(pole, sizeof (pole) / sizeof (char) - 1, soubor); 32: printf( "%s" , pole); 33: } 34: printf( "\n" ); 35: fclose(soubor); 36: return 0; 37: } 39: /*------------------------------------------------* /

98
Výstup z programu: Velikost souboru je 50 bajtu. aaaaa-----aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa aa
Adresá řová struktura
Různé operační systémy používají rozličné způsoby uchovávání dat. Například v Unixech existují ke každému souboru a adresáři přístupová práva, která je nutno při vytváření a mazání respektovat, zatímco například v DOSu nikoliv. Následující funkce se proto liší systém od systému, překladač od překladače. Příklad na konci kapitoly, byl odladěn v operačním systému Linux, v DOSovém překladači Borland C a windowsovém Dev-C++.
Aktuální adresá ř
Ke zjištění aktuálního adresáře slouží funkce getcwd() .
char * getcwd (char * buf ,size_t size );
První argument buf je ukazatel na textové pole, kam se uloží název aktuálního adresáře. Druhý argument tsize je maximální velikost, která se do pole může uložit. V případě chyby (např. jméno aktuálního adresáře je větší než size) vrátí getcwd() ukazatel NULL .
Vytvo ření adresá ře
K vytvoření adresáře se používá funkce mkdir
int mkdir (const char * pathname ); /* DOSová verze */ int mkdir (const char * pathname , mode_t mode); /* LINUXová verze */
Argument pathname je jméno adresáře, který se má vytvořit. Argument mode v deklaraci pro Unixy určuje přístupová práva. Přesněji řečeno, přístupová práva k souboru budou nastavena jako (mode & ~umask). Návratovou hodnotou je 0 v případě, že vše proběhlo bez chyby. Při chybě -1 a je nastavena globální proměnná errno na číslo chyby.
Přístupová práva
Přístupová práva k souborům a adresářům se nastavují pomocí funkce chmod() definované v hlavičkovém souboru <sys/stat.h>, <io.h>, př. jiném (záleží na prostředí, ve kterém je zdrojový kód překládán).
int chmod(const char * path , mode_t mode);
První argument je cesta k souboru nebo adresáři, jehož práva měníme. Druhý argument nastavuje přístupová práva. Funkce vrací 0 v případě úspěchu, jinak -1 a nastavuje proměnnou errno. Parametr mode lze nastavit pomocí maker definovaných v <sys/stat.h>, s přihlédnutím na to, která makra jsou pro systém dostupná. Ve Windows to může být např. S_IREAD | S_IWRITE pro právo čtení a zápisu.
Změna aktuálního adresá ře
Lze změnit pomocí funkce chdir() . Změna se projeví jen v programu, který tuto funkci spustil. (V DOSu zůstane platná i po ukončení programu.
int chdir (const char * path );
Argumentem funkce je adresář, do kterého se máme přesunout. Návratová hodnota je v případě úspěchu 0, jinak -1 a je nastavena proměnná errno.

99
Mazání soubor ů a adresá řů
Dle normy ANSI C je to funkce remove() , ale většinou je nahrazena dvěma jinými: Funkcí unlink() pro mazání souborů a funkcí rmdir() pro mazání prázdných adresářů. Funkce remove() volá funkci unlink() pro soubory a funkci rmdir() pro adresáře.
int remove (const char * pathname ); int unlink (const char * pathname ); int rmdir (const char * pathname );
Argument pathname je jméno souboru resp. adresáře, který se má smazat. Návratové hodnoty jsou v případě úspěchu 0, jinak -1 a je nastavena proměnná errno.
Přejmenování a p řesunutí soubor ů
K tomu slouží funkce rename() . Pokud bude nové jméno souboru v jiném adresáři než staré jméno, pak se soubor přesune. K tomu však dojde jedině v případě, že staré a nové jméno je na jednom disku (diskovém oddíle). Pokud bude nové jméno jméno již existujícího souboru, bude tento soubor přepsán! Deklarace funkce vypadá následovně:
int rename (const char * oldpath , const char * newpath );
Návratová hodnota v případě úspěchu je 0, jinak -1 a je nastavena proměnná errno.
Příklad 1: /*------------------------------------------------* / 2: /* adresar.c * / 4: #include <stdio.h> 5: #include <errno.h> 6: #ifdef unix 7: #include <unistd.h> 8: #include <sys/stat.h> 9: #include <sys/types.h> 10: #else 11: #include <dir.h> 12: #endif 14: #define ADRESAR "DATADIR" 15: #define SOUBOR "ahoj.txt" 17: #ifdef unix 18: #define MKDIR(X) mkdir(X,0777) 19: #else 20: #define MKDIR(X) mkdir(X) 21: #endif 23: int errkonec(void) 24: { 25: perror( "CHYBA"); 26: fprintf(stderr, "Stisknete ENTER pro ukonceni ...\n" ); 27: (void) getchar(); 28: return errno; 29: } 31: int main(void) 32: { 33: char text[255]; 34: FILE *soubor; 35: char c; 37: getcwd(text, sizeof (text) / sizeof (text[0])); 38: printf( "Vytvarim v adresari %s podadresar %s\n" , text, ADRESAR); 41: if (MKDIR(ADRESAR) != 0) {

100
42: return errkonec(); 43: } 45: printf( "Vstupuji do adresare %s\n" , ADRESAR); 46: if (chdir(ADRESAR) != 0) { 47: return errkonec(); 48: } 50: printf( "Vytvarim soubor %s\n" , SOUBOR); 52: if (!(soubor = fopen(SOUBOR, "wr" ))) 53: return errkonec(); 55: fprintf(soubor, "Ahoj" ); 56: fclose(soubor); 57: printf( "Mam zase vse smazat? [y/n] " ); 58: c = getchar(); 59: if (c == 'n') { 60: fputs( "Koncim." , stdin); 61: return 0; 62: } else if (c != 'y') { 63: fputs( "Nechapu, koncim." , stdin); 64: return 0; 65: } 67: /* mazani souboru a adresare */ 68: printf( "Mazu soubor %s\n" , SOUBOR); 69: if (unlink(SOUBOR) != 0) { 70: return errkonec(); 71: } 73: printf( "Opoustim adresar %s\n" , ADRESAR); 74: /* prechod v adresarove strukture o adresar vyse */ 75: if (chdir( ".." ) != 0) { 76: return errkonec(); 77: } 79: printf( "Mazu adresar %s\n" , ADRESAR); 80: if (rmdir(ADRESAR) != 0) { 81: return errkonec(); 82: } 84: return 0; 85: } 87: /*------------------------------------------------* /
Možný výstup:
Vytvarim v adresari /home/rimmer/public_html/rimmer /c podadresar DATADIR Vstupuji do adresare DATADIR Vytvarim soubor ahoj.txt Mam zase vse smazat? [y/n] y Mazu soubor ahoj.txt Opoustim adresar DATADIR Mazu adresar DATADIR
Přímý p řístup na disk
Tento způsob práce se soubory není v normě ANSI C (ale je součástí normy POSIX), není tedy zaručena přenositelnost. Výhodou oproti datovým proudům je rychlost. Funkce pracující s přímým přístupem na disk se chovají velice podobně jako funkce pracující s datovými proudy. Funkce jsou deklarovány v standardních knihovnách <sys/types.h>, <sys/stat.h>, <fcntl.h> a <unistd.h>.

101
Deskriptor souboru
Deskriptor souboru je kladné celé číslo, které slouží k identifikaci souboru v rámci programu. Někdy se mu také říká manipulační číslo. Toto číslo využívají všechny funkce pracující s přímým přístupem na disk. Pokud je již datový proud otevřen, pak k získání jeho deskriptoru lze použít funkci fileno() . Je deklarována v souboru <stdio.h>.
int fileno (FILE *stream);
Otevření a uzav ření souboru
Pro práci se souborem pomocí přímého přístupu na disk, je potřeba jej nejdříve „otevřít“ funkcí open() . Návratovou hodnotou je potřebný deskriptor souboru nebo -1 v případě chyby. Zde jsou dvě možné verze deklarace.
int open (const char * pathname , int flags ); int open (const char * pathname , int flags , mode_t mode);
Prvním argumentem je pathname (jméno souboru), druhým je flags , neboli příznak otevření souboru.
Příznaky flags pro open()
Příznak Otevření pro
O_RDONLY čtení
O_WRONLY zápis
O_RDWR čtení i zápis
Příznak se kombinuje pomocí bitového součtu | s některým(i) příznaky z následující tabulky. (Kromě těchto vypsaných existují další implementačně závislé.
Další příznaky flags pro funkci open()
Příznak Význam
O_CREAT Pokud soubor neexistuje, vytvoří se.
O_EXCL Používá se spolu s volbou O_CREAT. V případě, že soubor existuje, otevírání selže a funkce open() vrátí chybu.
O_TRUNC Pokud soubor existuje a je nastaven pro zápis (O_WRONLY nebo O_RDWR) je zkrácen na nulovou délku
O_APPEND Zápis bude prováděn na konec souboru.
V systému MS-DOS jsou v souboru <fcntl.h> definovány ještě dva důležité příznaky, které určují zda chceme pracovat v textovém či binárním režimu.
#define O_TEXT 0x4000 /* CR-LF translation */ #define O_BINARY 0x8000 /* no translation */
Druhá deklarace open() má navíc argument mode , který určuje přístupová práva k nově vytvářenému souboru (jinak nemá smysl). Přístupová práva v Unixech jsou pak nastavena na hodnotu mode & ~umask. Tedy obdobně jako při vytváření adresářů. Jaká přístupová práva lze použít je závislé na OS, respektive souborovém systému. V DOSu je možné nastavit S_IWRITE a S_IREAD, v Unixu jsou jiná přístupová práva, např. S_IRUSR a S_IWURS. Přístupová práva se opět kombinují pomocí bitového součtu |.

102
Dále je možné k otevření souboru s přímým přístupem na disk použít funkci creat() . Dělá to samé jako funkce open s nastaveným argumentem flags na O_CREAT|O_WRONLY|O_TRUNC .
int creat (const char * pathname , mode_t mode);
K uzavření souboru se používá funkce close() , jejímž jediným argumentem je jeho deskriptor.
int close (int fd );
Návratovou hodnotou je 0 nebo -1 v případě neúspěchu. Chceme-li mít jistotu, že po zavření souboru jsou data na disku, je nutno nejprve použít funkci sync() .
Čtení, zápis a posun
Ze souboru čteme pomocí funkce read() , do souboru zapisujeme pomocí funkce write() .
ssize_t read (int fd , void * buf , size_t count ); ssize_t write (int fd , void * buf , size_t count );
Argument fd je deskriptor otevřeného souboru, argument buf je ukazatel do paměti, kde jsou zapisovaná data, nebo kam načtená data ukládáme (argument je třeba přetypovat). Argument count je počet načítaných (zapisovaných) bajtů. Návratovou hodnotou je počet skutečně načtených (zapsaných) bajtů, nebo, v případě neúspěchu, -1. Opět - pokus načtení (zápisu) více bajtů, než je velikost paměti buf skončí běhovou chybou, a dále- jistotu vyprázdnění vyrovnávací paměti můžeme mít až po použití funkce fflush().
Pro pohyb v souboru slouží funkce lseek() .
off_t lseek (int fildes , off_t offset , int whence );
Funkce posune ukazatel deskriptoru souboru fildes o vzdálenost off_t bajtů od místa určeným argumentem whence. Tento argument může být SEEK_SET (posun od začátku), SEEK_CUR (posun od aktuální pozice) nebo SEEK_END (od konce souboru). Pokud bude ukazatel posunut za konec souboru, pak při jakémkoliv zápisu bude vzniklá mezera (mezi původním koncem souboru a nově zapsanými daty) vyplněna nulami. Návratová hodnota je v případě úspěchu pozice na kterou se deskriptor přesunul, jinak (off_t ) -1.
Následující dva programy dělají to samé. Jeden využívá přímý přístup na disk, druhý datové proudy.
1: /*------------------------------------------------* / 2: /* zapis1.c * / 4: #include <stdio.h> 5: #include <stdlib.h> 6: #include <string.h> 7: #include <sys/types.h> 8: #include <sys/stat.h> 9: #include <fcntl.h> 10: #ifdef unix 11: #include <unistd.h> 12: #else 13: #include <io.h> 14: #endif 16: #define POCET_CYKLU 1000000u 18: #ifdef unix 19: #define OPEN open( "jmeno.txt" ,O_RDWR|O_CREAT|O_TRUNC,\ 20: S_IRUSR|S_IWUSR|S_IRGRP|S_IROTH) 21: #else 22: #define OPEN open( "jmeno.txt" ,O_RDWR|O_CREAT|O_TRUNC|O_TEXT) 23: #endif 26: int main(void)

103
27: { 28: int id; 29: unsigned long i; 30: char SNO[] = "Soubor nelze otevrit\n" ; 31: char TEXT1[] = "Tenhle text budeme zapisovat do souboru\n" ; 32: char TEXT2[] = "-------------- prepsano ---------------\n" ; 34: if ((id = OPEN) <= 0) { 35: /* fprintf by bylo vhodnejsi, ale nemohl jsem si to odpustit :-} */ 36: write(fileno(stderr), SNO, strlen(SNO)); 37: exit(1); 38: } 40: for (i = 0L; i < POCET_CYKLU * 10u; i++) { 41: if (write(id, TEXT1, strlen(TEXT1)) == -1) { 42: fprintf(stderr, "Data nelze zapisovat" ); 43: exit(1); 44: } 45: } 48: lseek(id, 0, SEEK_SET); 49: for (i = 0L; i < POCET_CYKLU; i++) { 50: if (write(id, TEXT2, strlen(TEXT2)) == -1) { 51: fprintf(stderr, "Data nelze zapisovat" ); 52: exit(1); 53: } 54: #ifdef unix 55: #define clrf 0 56: #else 57: #define clrf 1 58: #endif 59: lseek(id, (strlen(TEXT1) + clrf) * 9, SEEK_ CUR); 60: #undef clrf 61: } 63: close(id); /* spravne by bylo kontrolovat navratovou hodnotu * / 64: return 0; 65: } 67: /*------------------------------------------------* /
V programu je definováno makro clrf v závislosti na operačním systému a jeho hodnota se přičítá k délce textu. Je to proto, protože v DOSu (a Windows) je znak konec řádku '\n' do souboru zapisován pomocí dvou bajtů, kdežto v Unixu pomocí jednoho. Funkce strlen() znak '\n' počítá vždy jako jeden znak. Zbytek už je otázka malé násobilky.
Druhý program využívá datové proudy.
1: /*------------------------------------------------* / 2: /* zapis2.c * / 4: #include <stdio.h> 5: #include <stdlib.h> 6: #include <string.h> 8: #define POCET_CYKLU 1000000u 10: #define OPEN fopen( "jmeno.txt" , "w+" ) 12: int main(void) 13: { 14: FILE *id; 15: unsigned long i; 16: char SNO[] = "Soubor nelze otevrit\n" ; 17: char TEXT1[] = "Tenhle text budeme zapisovat do souboru\n" ; 18: char TEXT2[] = "-------------- prepsano ---------------\n" ; 20: if ((id = OPEN) == NULL) { 21: fprintf(stderr, "%s" , SNO); 22: exit(1); 23: } 25: for (i = 0L; i < POCET_CYKLU * 10u; i++) {

104
26: if (fwrite(TEXT1, strlen(TEXT1), 1, id) != 1) { 27: fprintf(stderr, "Data nelze zapisovat" ); 28: exit(1); 29: } 30: } 32: fseek(id, 0, SEEK_SET); 33: for (i = 0L; i < (POCET_CYKLU); i++) { 34: if (fwrite(TEXT2, strlen(TEXT2), 1, id) != 1) { 35: fprintf(stderr, "Data nelze zapisovat" ); 36: exit(1); 37: } 38: #ifdef unix 39: #define clrf 0 40: #else 41: #define clrf 1 42: #endif 43: fseek(id, (strlen(TEXT1) + clrf) * 9, SEEK_ CUR); 44: #undef clrf 45: } 47: fclose(id); 48: return 0; 49: } 51: /*------------------------------------------------* /
Po spuštění obou programů vznikne na disku soubor velikosti 381Mb. Otázka je, zda zrychlení programu pomocí přímého přístupu na disk stojí za všechny ty komplikace (nižší komfort při programování a nižší přenositelnost kódu).
Spoušt ění program ů
Nejprve zdrojový kód programu mudrc , který bude v dalších programech spouštěn.
1: /*------------------------------------------------* / 2: /* mudrc.c * / 3: #include <stdio.h> 5: int main(int argc, char *argv[]) 6: { 7: int i; 8: printf( "\n***************************\n" ); 9: printf( "* mudrc rika: *\n" ); 10: switch (argc) { 11: case 1: 12: printf( "* Kdo to rusi me kruhy? *\n" ); 13: break ; 14: default: 15: printf( "* Argumenty: *\n" ); 16: /* Prvni argument je nazev programu (preskocime ho) .*/ 19: for (i = 1; i < argc; i++) { 20: printf( "* %2i) %-19s *\n" , i, argv[i]); 21: } 22: break ; 23: } 24: printf( "***************************\n\n" ); 25: return 0; 26: } 28: /*------------------------------------------------* /
Pokud nejsou programu mudrc nepředány žádné argumenty, vypíše jen hlášku „Kdo to rusi me kruhy?“, jinak vypíše zadané argumenty.

105
Funkce system()
Funkce system() je jedinná, z funkcí zde zmiňovaných, definována v normě ANSI C a zaručuje tedy největší kompatibilitu. Návratovou hodnotou je 0 v případě úspěchu, jinak -1.
int system (const char * string );
Má pouze jediný argument (textový řetězec). Je to příkaz, který se má vykonat. Příkazem může být cokoliv, co lze zadat na příkazovou řádku. Funkce system() spustí příkazový interpret a tento příkaz mu předá. Příkazový interpret příkaz vykoná a ukončí se tj. vrátí řízení programu. To, jaký příkazový interpret se spustí je ovlivněno operačním systémem. V DOSu (Windows) půjde nejpravděpodobněji o command.com MS-DOSu, v Linuxu může jít o bash, tcsh, csh atp. Spustit příkaz samotného interpretu je jednoduché. Stačí zadat jeho jméno (a za ním parametry). Například command.com obsahuje příkaz pause , který způsobí pozastavení vykonávání příkazového interpretu (a ve svém důsledku pozastavení programu, který tento příkaz pomocí system() spustil).
system("pause");
Dalším příkladem může být příkaz DIR, u kterého budeme chtít vypsat jen textové soubory.
system("dir *.txt");
Dále například i přesměrování výstupu do souboru.
system("dir *.txt > vystup.log");
Při spouštění programů je třeba zajistit, aby příkazový interpret věděl, kde se program daného jména nachází. Nejjednodušším řešením je uvést plné jméno programu. Jinak příkazový interpret hledá v aktuálním adresáři, nebo adresářích určených v systémové proměnné PATH (v DOSu se inicializace této proměnné nachází v souboru c:\autoexec.bat). Další informace o návratovém kódu a funkci system() jsou uvedeny v kapitole o knihovně <stdlib.h>, kde je tato funkce deklarována. V následujícím příkladu je spouštěn program mudrc . Je umístěn ve stejném adresáři, jako program system2 a v proměnné PATH je uveden i aktuální adresář (tj. tečka).
1: /*------------------------------------------------* / 2: /* system2.c * / 3: #include <stdlib.h> 4: #include <stdio.h> 6: #ifdef unix 7: #include <sys/wait.h> 8: #endif 10: int main(void) 11: { 12: printf( "system2: system(\"mudrc\");\n" ); 13: system( "mudrc" ); 14: printf( "system2: system(\"mudrc Jak se vede?\");\n" ); 15: system( "mudrc Jak se vede?" ); 16: printf( "system2: Konec programu.\n" ); 18: return 0; 19: } 21: /*------------------------------------------------* / Výstup: system2: system("mudrc"); ************************ *** *************************** * mudrc rika: * * mudrc rika: * * Argumenty: * * Kdo to rusi me kruhy? * * 1) Jak * *************************** * 2) se * system2: system("mudrc Jak se vede?"); * 3) vede? * *************************** system2: Konec programu.

106
Při spuštění programu system2 a přesměrování jeho výstupu do souboru se stala zvláštní věc. V souboru byly na začátku výstupy ze spuštěných programů mudrc a až na konci výstupy (z funkcí printf()) programu system2 . Došlo k tomu zřejmě tím, že spuštěný program mudrc měl ve chvíli svého vykonávání vyšší prioritu. Toto podivné chování lze brát jako další nevýhodu funkce system() oproti dále uvedeným funkcím, a i na takovéto věci si musí programátor dávat pozor.
Poznámka: Zabránit tomuto podivnému chování lze použitím funkce fflush(stdout).
Funkce exec*
Funkce exec() nahradí aktuální proces novým . Načte zadaný program do paměti a ten, který funkci spustil skončí (v případě úspěchu). Pokud se program funkcí exec() nepodaří spustit, aktuální proces poběží dál, funkce vrátí -1 a globální proměnná errno se nastaví na hodnotu chyby. Funkce exec() nespouští příkazový interpret, ale jen daný program (rychlé a účinné). Funkcí exec() existuje celá rodina, avšak nejsou součástí normy ANSI C. Z toho důvodu jejich deklaraci lze v různých systémech najít v různých hlavičkových souborech (<unistd.h>, <process.h>, <stdlib.h>), (nebo vůbec).
int execl (const char * path , const char * arg , ...); int execlp (const char * file , const char * arg , ...); int execle (const char * path , const char * arg , ..., char *const envp []); int execv (const char * path , char *const argv []); int execvp (const char * file , char *const argv []);
Všechny předchozí funkce jsou (většinou) implementovány pomocí následující funkce:
int execve (const char * file , char *const argv [], char *const envp []);
U všech funkcí je prvním argumentem název programu, který se má spustit. Funkce execlp() a execvp() se liší tím, že při hledání programu prohledávají adresáře určené systémovou proměnnou PATH (pokud není program zadán s absolutní nebo relativní cestou). Dalšími argumenty funkcí exec jsou argumenty předávané spouštěnému programu. Prvním předávaným argumentem je jméno spouštěného programu a poslední argument musí být ukazatel NULL . Funkce execle() a execve() umožňují nastavit nové systémové proměnné pro spouštěný program (pomocí argumentů envp). Rozdíl mezi funkcemi, které mají v názvu l nebo v, je jen ve způsobu předávání argumentů.
1: /*------------------------------------------------* / 2: /* exec1.c * / 4: #include <stdlib.h> 5: #include <stdio.h> 6: #ifndef unix 7: #include <process.h> 8: #else 9: #include <unistd.h> 10: #endif 11: #include <errno.h> 13: int main(void) 14: { 15: char *argv[] = { "mudrc" , "prvni" , "druhy" , "treti" , NULL }; 16: char *env[] = { "PATH=." , NULL }; 17: int navrat; 19: printf( "exec1: execl(\"nesmysl\",\"nesmysl\",\"argument1\" ,NULL);\n" ); 21: navrat = execl( "nesmysl" , "nesmysl" , "argument1" , NULL); 22: /* kdyby nesmysl existoval, nasledujici kod by jiz neprobehl */ 23: fprintf(stderr, "Navrat execl = %2i\n" , navrat); 24: perror( "CHYBA EXECL"); 26: printf( "exec1: execve(\"mudrc\", argv, env);\n" ); 27: execve( "mudrc" , argv, env); 28: /*pokud se podari spustit program mudrc, nasledujic i kod se neprovede */ 29: fprintf(stderr, "Navrat execl = %2i\n" , navrat);

107
30: perror( "CHYBA EXECVE"); 32: return 0; 33: } 35: /*------------------------------------------------* / Výstup z programu: exec1: execl("nesmysl","nesmysl","argument1",NULL); Navrat execl = -1 CHYBA EXECL: No such file or directory exec1: execve("mudrc", argv, env); *************************** * mudrc rika: * * Argumenty: * * 1) prvni * * 2) druhy * * 3) treti * ***************************
Funkce spawn*
Rodina funkcí spawn* se chová stejně jako exec* s tím rozdílem, že aktuální proces nenahradí a po svém skončení se pokračuje v jeho vykonávání. Dostupnost těchto funkcí je však ještě menší, než funkcí exec*.
V Linuxu nepřeložitelné. Jsou tu ale k dispozici funkce fork() a vfork(), jejichž použití je však náročnější.
1: /*------------------------------------------------* / 2: /* spawn1.c * / 3: #include <stdlib.h> 4: #include <stdio.h> 5: #include <process.h> 6: #include <errno.h> 8: int main(void) 9: { 11: printf ( "spawn1: spawnl(\"mudrc\",\"mudrc\",\"prvni\",\"dru hy\",\"treti\",NULL);\n" ); 13: if (spawnl(P_WAIT, "mudrc" , "mudrc" , "prvni" , "druhy" , "treti" , NULL) 14: == -1) 15: perror( "CHYBA SPAWNL"); 17: printf( "spawn1: konec.\n" ); 18: return 0; 19: } 21: /*------------------------------------------------* / Výstup: spawn1: spawnl("mudrc","mudrc","prvni","druhy","tre ti",NULL); *************************** * mudrc rika: * * Argumenty: * * 1) prvni * * 2) druhy * * 3) treti * *************************** spawn1: konec.
Algoritmy t řídění Funkce qsort()
Je nejjednodušším řešením jak setřídit data v programovacím jazyku C.

108
void qsort (void * base , size_t nmemb, size_t size , int (* compar )(const void *, const void *));
Prvním argumentem funkce qsort() je „prázdný“ ukazatel na pole, které se bude třídit. (Jelikož to bude pole typu int , přetypujeme ukazatel na ukazatel na typ int.) Druhým argumentem je počet položek (rozměr) pole, třetím argumentem je velikost jedné položky (v tomto případě počet bajtů typu int) a posledním argumentem je ukazatel na funkci (compar), podle které se budou porovnávat dva prvky z pole. Tato porovnávací funkce musí mít dva argumenty – ukazatele, kterými budou předány dvě hodnoty z pole na porovnání. Návratovou hodnotou této porovnávací funkce je typ int, podle kterého funkce qsort() pozná, který z porovnávaných prvků je větší. V případě, že větší je první prvek, musí vrátit porovnávací funkce kladnou hodnotu (1), pokud je menší vrátí hodnotu zápornou (-1) a pokud se rovnají, vrátí 0. Pokud budou návratové hodnoty v porovnávací funkci obráceny, dojde k setřídění od největšího po nejmenší.
Není zde uveden celý příklad s výstupem, jen podstatná část.
1: int pole[POLOZEK]; 3: int vetsi(int *a, int *b) 4: { 5: return *a - *b; 6: } 8: /* nezapomente nejdrive pole inicializovat nejakymi hodnotami */ 9: qsort((void *) pole, POLOZEK, sizeof (pole[0]), 10: (int (*)(const void *, const void *)) vetsi);
Buble sort
Algoritmus bublinkového třídění je poměrně jednoduchý ale ne moc efektivní. Prochází se několikrát celé pole (odzadu do předu) a porovnávají se sousední prvky. Pokud nejsou prvky správně seřazeny za sebou, jsou prohozeny. Takto nejmenší prvky „probublávají“ směrem k začátku (nebo obráceně). Po prvním průchodu je zajištěno, že nejmenší prvek probublal na začátek pole a tak s ním v dalším cyklu už nemusíme počítat.
1: /*------------------------------------------------* / 2: /* bubble.c * / 4: #include <stdio.h> 5: #include <stdlib.h> 6: #include <time.h> 8: #define ROZMER 10 10: void vypis_pole(short int cykl, unsigned int pole[] ) 11: { 12: unsigned short int i; 13: printf( "Prvky pole (%2i):\n" , cykl); 15: /* schvalne, co by se stalo, kdyby byl ROZMER lichy ? */ 16: for (i = 0; i < ROZMER / 2; i++) 17: printf( "%2u: %u\t\t%2u: %u\n" , i + 1, pole[i], i + ROZMER / 2 + 1, 18: pole[i + ROZMER / 2]); 19: /* spravna odpoved zni .... chvilka napeti ... 20: * posledni prvek z pole by se nevypsal. */ 21: } 23: int main(void) 24: { 25: unsigned int cykl, bublani; 26: unsigned int pole[ROZMER], pom; 28: /* nejdrive inicializujeme pole nahodnymi hodnotami a vypiseme jej */ 29: srand((unsigned int) time(NULL)); 31: for (cykl = 0; cykl < ROZMER; cykl++) 32: pole[cykl] = (rand() % 100) + 1; 34: printf( "Inicializace: \n" ); 35: vypis_pole(-1, pole); 37: /* ted pole setridime algoritmem bubble sort */

109
39: for (cykl = 1; cykl < ROZMER; cykl++) { 40: for (bublani = ROZMER - 1; bublani >= cykl; bublani--) { 41: printf( "." ); 42: if (pole[bublani - 1] > pole[bublani]) { 43: /* mensi cislo probubla o jeden prvek smerem k zaca tku */ 44: pom = pole[bublani - 1]; 45: pole[bublani - 1] = pole[bublani]; 46: pole[bublani] = pom; 47: } 48: } 49: /* vypiseme mezivysledek, kde "cykl" nejmensich cis el 50: * uz mame zarucene na zacatku pole */ 51: printf( "\n" ); 52: vypis_pole(cykl, pole); 53: } 55: return 0; 56: } 58: /*------------------------------------------------* / Možný výstup z programu: Inicializace: Prvky pole (-1): /* zde je inicializované a 1: 26 6: 64 zatím neset říd ěné, náhodn ě 2: 87 7: 53 vygenerované pole */ 3: 81 8: 6 4: 9 9: 23 5: 17 10: 7 ......... Prvky pole ( 1): /* po prvním "buble" cyklu nám probublalo na za čátek 1: 6 6: 17 nejmenší číslo 6. Všimn ěte si, že se nejd říve 2: 26 7: 64 snažila probublat sedmi čka. Ostatní čísla se jen 3: 87 8: 53 posunula o prvek níže. */ 4: 81 9: 7 5: 9 10: 23 ........ ...... Prvky pole ( 2): Prvky pole ( 4): 1: 6 6: 9 1: 6 6: 87 2: 7 7: 17 2: 7 7: 81 3: 26 8: 64 3: 9 8: 23 4: 87 9: 53 4: 17 9: 53 5: 81 10: 23 5: 26 10: 6 4 ....... ..... Prvky pole ( 3): Prvky pole ( 5): 1: 6 6: 81 1: 6 6: 26 2: 7 7: 17 2: 7 7: 87 3: 9 8: 23 3: 9 8: 81 4: 26 9: 64 4: 17 9: 53 5: 87 10: 53 5: 23 10: 64 .... /* Pole je se řazeno, ale buble-sort Prvky pole ( 6): o tom neví. Proto pokra čuje ve t říd ění. */ 1: 6 6: 26 .. 2: 7 7: 53 Prvky pole ( 8): 3: 9 8: 87 1: 6 6: 26 4: 17 9: 81 2: 7 7: 53 5: 23 10: 64 3: 9 8: 64 ... 4: 17 9: 81 Prvky pole ( 7): 5: 23 10: 87 1: 6 6: 26 . 2: 7 7: 53 Prvky pole ( 9): 3: 9 8: 64 1: 6 6: 26 4: 17 9: 81 4: 17 9: 87 2: 7 7: 53 5: 23 10: 87 5: 23 10: 81 3: 9 8: 64

110
Tučně zvýrazněné jsou místa v poli, kde je zaručeno, že je pole seřazeno. (Proto se vnitřní průchozí cyklus 'for' zkracuje.)
Algoritmus bubble sort má pevně daný počet operací, který závisí jen na rozměru pole. I kdyby bylo pole už seřazeno, bubble-sort by provedl stejný počet operací. Tomu lze jednoduše zabránit tak, že se bude kontrolovat, zda se při „bubble“ cyklu nějaké prvky zaměnili. Pokud ne, algoritmus se ukončí.
Quick sort
Algoritmus quick sort (nebo též „řazení dělením“) je jeden z nejefektivnějších. Princip je následující. Řazená pole se rozdělí na dvě části tak, aby v jedné části pole byla všechna čísla menší, než čísla v druhé části. Aby se to dobře programovalo, vezme se jeden prvek z pole (třeba prostřední), tzv. pivot a třídí se pole tak, že čísla z první části jsou menší a čísla z druhé části jsou větší než pivot. Na oba úseky se použije rekurzivně stejný algoritmus, a tak se pole rozděluje na menší a menší úseky, až je rozdělené na úseky délky 1, čímž je pole setříděno.
1: /*------------------------------------------------* / 2: /* quick.c * / 4: #include <stdio.h> 5: #include <stdlib.h> 6: #include <time.h> /* funkci quicks budeme volat rekurzivne, 8: #define ROZMER 10 vzdy na levou a pravou cast */ 13: void vypis_usek(const unsigned int *pole, const cha r *text, 14: const unsigned int zacatek, const u nsigned int konec) 16: { unsigned int i; 17: printf( "%-10s" , text); 18: for (i = 0; i < ROZMER; i++) { 19: if (i < zacatek || i > konec) { 20: printf( "-- " ); 21: } else { 22: printf( "%2u " , pole[i]); 23: } 24: } 25: printf( "\n" ); 26: } 28: void quicks(unsigned int *pole, const unsigned int levy_usek, 29: const unsigned int pravy_usek) 30: { 31: unsigned int levy, pravy; 32: unsigned int pivot, pom; 34: levy = levy_usek; 35: pravy = pravy_usek; 37: pivot = pole[(levy + pravy) / 2]; /* vybereme pivota */ 38: printf( "pivot: pole[%u] = %u\n" , (levy + pravy) / 2, pivot); 39: vypis_usek(pole, "Pred:" , levy_usek, pravy_usek); 41: do { 42: while (pole[levy] < pivot) 43: levy++; 44: while (pivot < pole[pravy]) 45: pravy--; 47: if (levy <= pravy) { 48: pom = pole[levy]; 49: pole[levy] = pole[pravy]; 50: pole[pravy] = pom; 51: levy++; 52: pravy--; 53: } 55: } while (levy <= pravy); 57: vypis_usek(pole, "Po:" , levy_usek, pravy_usek); 58: /*vsechna cisla od "levy_usek" k "pravy" jsou <= od "levy" po pravy_usek*/ 60: if (levy_usek < pravy)

111
61: quicks(pole, levy_usek, pravy); /* razeni leve casti */ 62: if (levy < pravy_usek) 63: quicks(pole, levy, pravy_usek); /* razeni prave casti */ 65: } 67: int main(void) 69: { unsigned int cykl; 70: unsigned int pole[] = { 74, 43, 94, 6, 89, 76, 88, 33, 52, 59 }; 72: printf( "%-10s" , "Start:" ); 74: for (cykl = 0; cykl < ROZMER; cykl++) { 75: printf( "%2u " , pole[cykl]); 76: } 77: printf( "\n" ); 79: /* ted pole setridime algoritmem quick sort */ 80: quicks(pole, 0, ROZMER - 1); 82: printf( "%-10s" , "Konec:" ); 83: for (cykl = 0; cykl < ROZMER; cykl++) { 84: printf( "%2u " , pole[cykl]); 85: } 86: printf( "\n" ); 88: return 0; 89: } 91: /*------------------------------------------------* / Start: 74 43 94 6 89 76 88 33 52 59 pivot: pole[4] = 89 Pred: 74 43 94 6 89 76 88 33 52 59 Po: 74 43 59 6 52 76 88 33 89 94 pivot: pole[3] = 6 Pred: 74 43 59 6 52 76 88 33 -- -- Po: 6 43 59 74 52 76 88 33 -- -- pivot: pole[4] = 52 Pred: -- 43 59 74 52 76 88 33 -- -- Po: -- 43 33 52 74 76 88 59 -- -- pivot: pole[2] = 33 Pred: -- 43 33 52 -- -- -- -- -- -- Po: -- 33 43 52 -- -- -- -- -- -- pivot: pole[2] = 43 Pred: -- -- 43 52 -- -- -- -- -- -- Po: -- -- 43 52 -- -- -- -- -- -- pivot: pole[5] = 76 Pred: -- -- -- -- 74 76 88 59 -- -- Po: -- -- -- -- 74 59 88 76 -- -- pivot: pole[4] = 74 Pred: -- -- -- -- 74 59 -- -- -- -- Po: -- -- -- -- 59 74 -- -- -- -- pivot: pole[6] = 88 Pred: -- -- -- -- -- -- 88 76 -- -- Po: -- -- -- -- -- -- 76 88 -- -- pivot: pole[8] = 89 Pred: -- -- -- -- -- -- -- -- 89 94 Po: -- -- -- -- -- -- -- -- 89 94 Konec: 6 33 43 52 59 74 76 88 89

112
OBSAH
Programování v jazyku C/C++ ............................................................................................................. 1 Programovací jazyk, zdrojový kód a překladač .................................................................................... 1 Přenositelnost ........................................................................................................................................ 1 Trocha historie C a C++........................................................................................................................ 1
Vývojová prostředí a překladače ......................................................................................................... 2 Windows API........................................................................................................................................ 2 Překladač pro Linux .............................................................................................................................. 2 Code::Blocks......................................................................................................................................... 2 Bloodshed Dev-C++ a wxDev-C++...................................................................................................... 2 DJGPP................................................................................................................................................... 2 Visual Studio......................................................................................................................................... 2 Visual C++ Express Edition.................................................................................................................. 3 Borland C++ Builder............................................................................................................................. 3 Borland C++ Builder Compiler ............................................................................................................ 3 Eclipse................................................................................................................................................... 3 NetBeans ............................................................................................................................................... 3 Anjuta.................................................................................................................................................... 3 Sun Studio ............................................................................................................................................. 3
Struktura programu ................................................................................................................................ 3 První program ....................................................................................................................................... 3 Komentáře............................................................................................................................................. 4 Knihovny............................................................................................................................................... 4 Funkce...................................................................................................................................................4 Funkce printf() ...................................................................................................................................... 5
Datové typy, bloky, deklarace a definice ............................................................................................ 5 Základní datové typy............................................................................................................................. 5 Boolovské datové typy.......................................................................................................................... 6 Bloky, deklarace a definice................................................................................................................... 6 Ukazatele............................................................................................................................................... 7 NULL.................................................................................................................................................... 8
Klíčová slova, konstanty, řetězce ........................................................................................................ 8 Klíčová slova......................................................................................................................................... 8 Konstanty .............................................................................................................................................. 8 Řetězce .................................................................................................................................................. 9 Escape sekvence.................................................................................................................................. 11
Standardní vstup a výstup .................................................................................................................. 12 Funkce printf() .................................................................................................................................... 12 Funkce scanf()..................................................................................................................................... 15
Práce s typy dat .................................................................................................................................... 17 ASCII tabulka ..................................................................................................................................... 17 Přetypování ......................................................................................................................................... 18
Chyby přetypování.......................................................................................................................... 18 Pole a ukazatele ................................................................................................................................... 19
Datové pole a řetězce .......................................................................................................................... 19 Vícerozměrná pole .............................................................................................................................. 21 Ukazatele a pole .................................................................................................................................. 21
Ukazatele na ukazatele.................................................................................................................... 22 Operátory a výrazy ............................................................................................................................... 23
Unární operátory ................................................................................................................................. 23

113
Priorita operátorů ................................................................................................................................ 23 Binární operátory ................................................................................................................................ 23 Podmíněný operátor ............................................................................................................................ 24
Použití NULL.................................................................................................................................. 25 Preprocesor ........................................................................................................................................... 26
Standardní makra ................................................................................................................................ 26 Definice maker.................................................................................................................................... 26
Makra s argumenty.......................................................................................................................... 28 Operátory # a ##.................................................................................................................................. 28 Podmíněný překlad ............................................................................................................................. 29 Užití knihovny..................................................................................................................................... 29 Ostatní direktivy.................................................................................................................................. 30
#pragma........................................................................................................................................... 30 #line................................................................................................................................................. 30
Podmínky a cykly.................................................................................................................................. 31 Podmínka if-else ................................................................................................................................. 31 Přepínač switch ................................................................................................................................... 32 Skok goto ............................................................................................................................................ 33 Cyklus for............................................................................................................................................ 33 Cykly do a while ................................................................................................................................. 34
Funkce.................................................................................................................................................... 34 Definice funkce ................................................................................................................................... 35 Deklarace funkce................................................................................................................................. 35 Rekurzivní funkce ............................................................................................................................... 36 Proměnlivý počet argumentů .............................................................................................................. 37 Argumenty příkazové řádky................................................................................................................ 38 Lokální, globální a statické proměnné ................................................................................................ 40 Uživatelské knihovny.......................................................................................................................... 41
Vytváření typů......................................................................................................................................... 42 Struktury.............................................................................................................................................. 42 Definování typu pomocí typedef......................................................................................................... 45 Výčtový typ enum............................................................................................................................... 47 Typ union ............................................................................................................................................ 48
Funkce rand() a srand() ................................................................................................................... 48 Ukazatele na funkce ............................................................................................................................ 49 Přehled deklarací................................................................................................................................. 52
Dynamická alokace paměti ..................................................................................................................... 57 Získání a uvolnění paměti pomocí malloc() a free()...........................................................................57 Získání paměti pro struktury pomocí calloc()..................................................................................... 59 Změna velikosti získané paměti pomocí realloc() .............................................................................. 62
Knihovna string.h.................................................................................................................................... 63 Výčet funkcí ........................................................................................................................................ 63 Příklad použití funkcí.......................................................................................................................... 63
Knihovna time.h...................................................................................................................................... 64 Uchovávání času ................................................................................................................................. 64 Výčet funkcí ........................................................................................................................................ 65 Příklad použití funkcí I (sportka) ........................................................................................................ 66 Příklad použití funkcí II ...................................................................................................................... 68
Knihovna math.h..................................................................................................................................... 69 Výčet funkcí ........................................................................................................................................ 69
Knihovna stdlib.h .................................................................................................................................... 71 Výčet funkcí (výčet není úplný).......................................................................................................... 71

114
Užitečná makra ................................................................................................................................... 72 Poznámky k funkcím .......................................................................................................................... 72
Knihovny stdarg.h, limits.h a signal.h .................................................................................................... 75 Knihovna stdarg.h ............................................................................................................................... 75 Knihovna limits.h................................................................................................................................ 75 Knihovna signal.h ............................................................................................................................... 76
Funkce signal()................................................................................................................................ 77 Funkce sigaction()........................................................................................................................... 79
Knihovna errno.h .................................................................................................................................... 80 Proměnná errno................................................................................................................................... 80 Co může obsahovat errno.................................................................................................................... 81 Chybové hlášení pomocí perror() ....................................................................................................... 82
Knihovna string.h II ................................................................................................................................ 83 Výčet funkcí ........................................................................................................................................ 83 Funkce sprintf(), snprintf() a sscanf() ................................................................................................. 84
Funkce sscanf() ............................................................................................................................... 85 Knihovna stdio.h ..................................................................................................................................... 85
Funkce getchar(), gets(), putchar() a puts()......................................................................................... 85 Výčet funkcí ze stdio.h........................................................................................................................ 86
Práce se soubory (a <stdio.h>)................................................................................................................ 87 O vstupu a výstupu.............................................................................................................................. 87 Přístup k souborům ............................................................................................................................. 88
Souborový proud............................................................................................................................. 88 Přímé volání .................................................................................................................................... 88
Textový a binární přístup k souborům ................................................................................................ 88 Limity.................................................................................................................................................. 88
Datové proudy......................................................................................................................................... 88 Otevření datového proudu................................................................................................................... 88 Uzavření a vyprázdnění datového proudu .......................................................................................... 89
Práce s textovými soubory ...................................................................................................................... 91 Zápis do textového souboru ................................................................................................................ 91 Čtení z textového souboru................................................................................................................... 92 Kontrola chyb (feof(), ferror(), clearerr()) .......................................................................................... 93
Práce s binárními soubory a pohyb v souborech..................................................................................... 94 Čtení a zápis binárního souboru.......................................................................................................... 94
Zápis pomocí fwrite()...................................................................................................................... 94 Čtení pomocí fread() ....................................................................................................................... 95 Příklad čtení a zápisu ...................................................................................................................... 95
Pozice v souboru ................................................................................................................................. 96 Zjištění velikosti souboru.................................................................................................................... 97
Adresářová struktura............................................................................................................................ 98 Aktuální adresář .................................................................................................................................. 98 Vytvoření adresáře .............................................................................................................................. 98 Přístupová práva.................................................................................................................................. 98 Změna aktuálního adresáře ................................................................................................................. 98 Mazání souborů a adresářů ................................................................................................................. 99 Přejmenování a přesunutí souborů ......................................................................................................99 Příklad ................................................................................................................................................. 99
Přímý přístup na disk ......................................................................................................................... 100 Deskriptor souboru............................................................................................................................ 101 Otevření a uzavření souboru ............................................................................................................. 101 Čtení, zápis a posun .......................................................................................................................... 102

115
Spouštění programů .......................................................................................................................... 104 Funkce system() ................................................................................................................................ 105 Funkce exec*..................................................................................................................................... 106 Funkce spawn*.................................................................................................................................. 107
Algoritmy třídění.................................................................................................................................. 107 Funkce qsort() ................................................................................................................................... 107 Buble sort .......................................................................................................................................... 108 Quick sort.......................................................................................................................................... 110
Obsah................................................................................................................................................... 112


















