
Programação dinâmica em tempo real para Processos de Decisão Markovianos com Probabilidades...
64
Programação dinâmica em tempo real para Processos de Decisão Markovianos com Probabilidades Imprecisas 28 de novembro de 2014 - IME/USP Daniel Baptista Dias Orientadora: Karina Valdivia Delgado 1
-
Upload
daniel-dias -
Category
Science
-
view
218 -
download
2
Transcript of Programação dinâmica em tempo real para Processos de Decisão Markovianos com Probabilidades...

Programação dinâmica em tempo real
para Processos de Decisão Markovianos
com Probabilidades Imprecisas
28 de novembro de 2014 - IME/USP
Daniel Baptista Dias
Orientadora: Karina Valdivia Delgado
1

Agenda
Introdução
Introdução
Motivação / Objetivos
Stochastic Shortest Path MDP (SSP MDP)
Definições formais
Soluções para SSP MDP
Stochastic Shortest Path MDP-IP (SSP MDP-IP)
Definições formais
Soluções síncronas para SSP MDP-IP
Algoritmos assíncronos para SSP MDP-IPs
Experimentos e Resultados
Conclusões
2

Introdução
Os Processos de Decisão Markovianos (MDPs) tem sido
usados como um arcabouço padrão para problemas de
planejamento probabilístico.
Eles modelam a interação de um agente em um ambiente,
que executam ações com efeitos probabilísticos que
podem levar o agente a diferentes estados.
3

Introdução
Exemplo: Navegação de robôs
𝟎, 𝟗
𝟎, 𝟏
4

Introdução
Entretanto, pode ser difícil obter as medidas precisas das
probabilidades de transição
𝒑𝟏
𝒑𝟐 Em que: 𝟎, 𝟕 ≤ 𝒑𝟏 ≤ 𝟎, 𝟗
𝟎, 𝟏 ≤ 𝒑𝟐 ≤ 𝟎, 𝟑 5

Introdução
Processos de Decisão Markovianos com Probabilidades Imprecisas (MDP-IPs) As probabilidades imprecisas são dadas através de parâmetros nas
transições de estados restritas por um conjunto de inequações
Geralmente modelados de duas maneiras: MDP-IP enumerativo: estados com informações autocontidas
MDP-IP fatorado: estados representados por variáveis de estado
Solução para MDP-IPs fatorados: SPUDD-IP Algoritmo de programação dinâmica síncrona fatorada
Supera o algoritmo clássico enumerativo Iteração de Valor em duas ordens de magnitude
6

Introdução
Stochastic Shortest Path MDPs (SSP MDPs)
Apresentados por Bertsekas e Tsitsiklis (1991)
Considera um estado inicial e um conjunto de estados meta
Soluções comuns para SSP MDPs
Algoritmos de programação dinâmica assíncrona
Exploram a informação de um estado inicial do problema
Obtêm uma política ótima parcial
Algoritmos conhecidos: RTDP e SSiPP
Short Sighted SSP MDPs (Trevizan, 2013)
São problemas menores criados a partir de SSP MDP
7

Introdução
estados
iniciais
estados
meta
Estados estados alcançáveis
Exemplo de atualizações assíncronas no espaço de estados
8

Motivação
Nunca foram propostos algoritmos de programação dinâmica
assíncrona para SSP MDP-IPs com restrições gerais
Deve-se adaptar algumas características do (L)RTDP e (L)SSiPP
para se criar estes algoritmos para SSP MDP-IPs
As principais são:
Como garantir a convergência de soluções de programação dinâmica
assíncrona para SSP MDP-IPs?
Como amostrar o próximo estado no trial dadas as probabilidades
imprecisas?
Como criar os Short-Sighted SSP MDP-IPs a partir de SSP MDP-IPs?
9

Objetivos
O objetivo deste trabalho de mestrado é:
Propor novos algoritmos assíncronos para resolver SSP MDP-IPs
enumerativos e fatorados, estendendo os algoritmos (L)RTDP e
(L)SSiPP para lidar com um conjunto de probabilidades no lugar
de probabilidades precisas.
10

Agenda
Introdução
Introdução
Motivação / Objetivos
Stochastic Shortest Path MDP (SSP MDP)
Definições formais
Soluções para SSP MDP
Stochastic Shortest Path MDP-IP (SSP MDP-IP)
Definições formais
Soluções síncronas para SSP MDP-IP
Algoritmos assíncronos para SSP MDP-IPs
Experimentos e Resultados
Conclusões
11

SSP MDPs – Definição formal
Um SSP MDP (Bertsekas e Tsitsiklis, 1991), é uma tupla S, 𝐴, 𝐶, 𝑃, 𝐺, 𝑠0 em que:
𝑆 é um conjunto finito de estados
𝐴 é um conjunto finito de ações
𝐶 ∶ 𝑆 × 𝐴 → ℛ+ é uma função de custo
𝑃(𝑠′|𝑠, 𝑎) define a probabilidade de transição de se alcançar um estado 𝑠′ ∈ 𝑆 a partir de um estado 𝑠 ∈ 𝑆, executando a ação 𝑎 ∈ 𝐴
𝐺 ⊆ 𝑆 é um conjunto de estados meta, definidos como estados de absorção. Para cada 𝑠 ∈ 𝐺, 𝑃(𝑠|𝑠, 𝑎) = 1 e 𝐶(𝑠, 𝑎) = 0 para todo 𝑎 ∈ 𝐴
𝑠0 ∈ 𝑆 é o estado inicial
12

SSP MDPs – Definição formal
Este modelo assume dois pressupostos (Bertsekas e
Tsitsiklis, 1991):
Política apropriada: Cada 𝑠 ∈ 𝑆 deve ter ao menos uma
política apropriada, i.e., uma política que garante que um estado
meta é alcançado com probabilidade 1.
Política imprópria: Cada política imprópria deve ter custo
∞ em todos os estados que não podem alcançar a meta com
probabilidade 1.
13
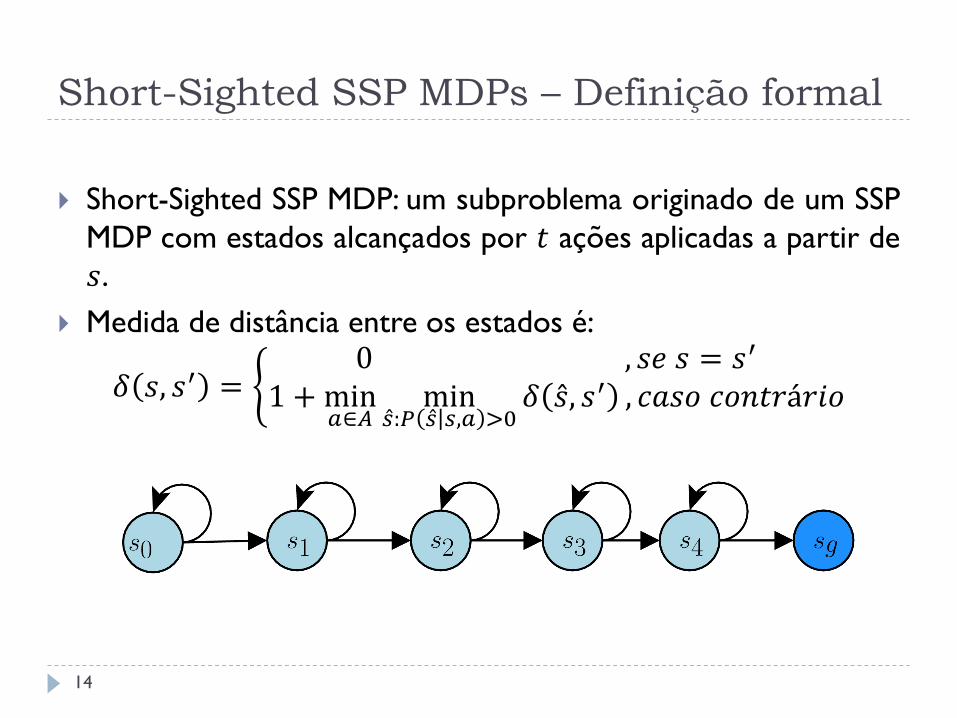
Short-Sighted SSP MDPs – Definição formal
Short-Sighted SSP MDP: um subproblema originado de um SSP
MDP com estados alcançados por 𝑡 ações aplicadas a partir de
𝑠.
Medida de distância entre os estados é:
𝛿 𝑠, 𝑠′ = 0 , 𝑠𝑒 𝑠 = 𝑠′
1 + min𝑎∈𝐴
min𝑠 :𝑃 𝑠 𝑠,𝑎 >0
𝛿 𝑠 , 𝑠′ , 𝑐𝑎𝑠𝑜 𝑐𝑜𝑛𝑡𝑟á𝑟𝑖𝑜
14

Short-Sighted SSP MDPs – Definição formal
Short-Sighted SSP MDP: um subproblema originado de um SSP
MDP com estados alcançados por 𝑡 ações aplicadas a partir de
𝑠.
Medida de distância entre os estados é:
𝛿 𝑠, 𝑠′ = 0 , 𝑠𝑒 𝑠 = 𝑠′
1 + min𝑎∈𝐴
min𝑠 :𝑃 𝑠 𝑠,𝑎 >0
𝛿 𝑠 , 𝑠′ , 𝑐𝑎𝑠𝑜 𝑐𝑜𝑛𝑡𝑟á𝑟𝑖𝑜
Exemplo de um Short-Sighted SSP MDP enraizado em 𝑠0 com 𝑡 = 2
15

Short-Sighted SSP MDPs – Definição formal
Um Short-Sighted SSP MDP enraizado em 𝑠 ∈ 𝑆 e com
profundidade 𝑡 ∈ 𝒩+é uma tupla 𝑆𝑠,𝑡 , 𝐴, 𝐶𝑠,𝑡 , 𝑃, 𝐺𝑠,𝑡 , 𝑠 , onde:
𝐴 e 𝑃 são definidos como em SSP MDPs;
𝑆𝑠,𝑡 = {𝑠′ ∈ 𝑆|𝛿 𝑠, 𝑠′ ≤ 𝑡}
𝐺𝑠,𝑡 = 𝑠′ ∈ 𝑆 𝛿 𝑠, 𝑠′ = 𝑡 ∪ 𝐺 ∩ 𝑆𝑠,𝑡
𝐶𝑠,𝑡 𝑠′, 𝑎, 𝑠′′ = 𝐶 𝑠′, 𝑎, 𝑠′′ +𝐻(𝑠′′)
𝐶 𝑠′, 𝑎, 𝑠′′𝑠𝑒 𝑠′′∈𝐺𝑠,𝑡\G
𝑐𝑎𝑠𝑜 𝑐𝑜𝑛𝑡𝑟á𝑟𝑖𝑜
Onde 𝐻(𝑠) é uma heurística definida para o estado 𝑠
Neste trabalho o custo será considerado dependente apenas
de 𝑠 e 𝑎, i.e., 𝐶(𝑠′, 𝑎) e 𝐻 𝑠′′ = 0
16

SSP MDPs – IV
Para resolver um SSP MDP é usado equação de Bellman:
𝑉∗(𝑠) = 𝑚𝑖𝑛𝑎∈𝐴 𝐶 𝑠, 𝑎 + 𝑃 𝑠′ 𝑠, 𝑎 𝑉∗(𝑠′)
𝑠′∈𝑆
Iteração de Valor: algoritmo de programação dinâmica
síncrona
𝑉𝑡+1 𝑠 = 𝐵𝑉𝑡 𝑠 = min𝑎∈𝐴
𝑄𝑡+1(𝑠, 𝑎)
𝑄𝑡+1(𝑠, 𝑎) = 𝐶(𝑠, 𝑎) + 𝑃 𝑠′ 𝑠, 𝑎 𝑉𝑡(𝑠′)
𝑠′∈ 𝑆
17

SSP MDPs – RTDP
Programação dinâmica em tempo real, proposto por
Barto et al (1995)
Solução de programação dinâmica assíncrona:
Simula uma política gulosa a partir do estado inicial (trial)
A cada visita de estado, seu valor é atualizado usando a
equação de Bellman e uma simulação da execução da melhor
ação é feita a fim de visitar outro estado
18

SSP MDPs – RTDP
O trial é interrompido quando o algoritmo encontra um
determinado estado meta
A convergência do algoritmo pode demorar
Estados visitados com menos frequência sofrem poucas atualizações
19

SSP MDPs – LRTDP
Extensão do RTDP, proposta por Bonet e Geffner (2003)
Melhora a convergência através da rotulação dos estados que convergiram
Características:
Os trials são interrompidos quando um estado rotulado é encontrado
Ao final de um trial, os estados visitados são atualizados se necessário e a convergência dos mesmos é verificada (através do procedimento CheckSolved)
20
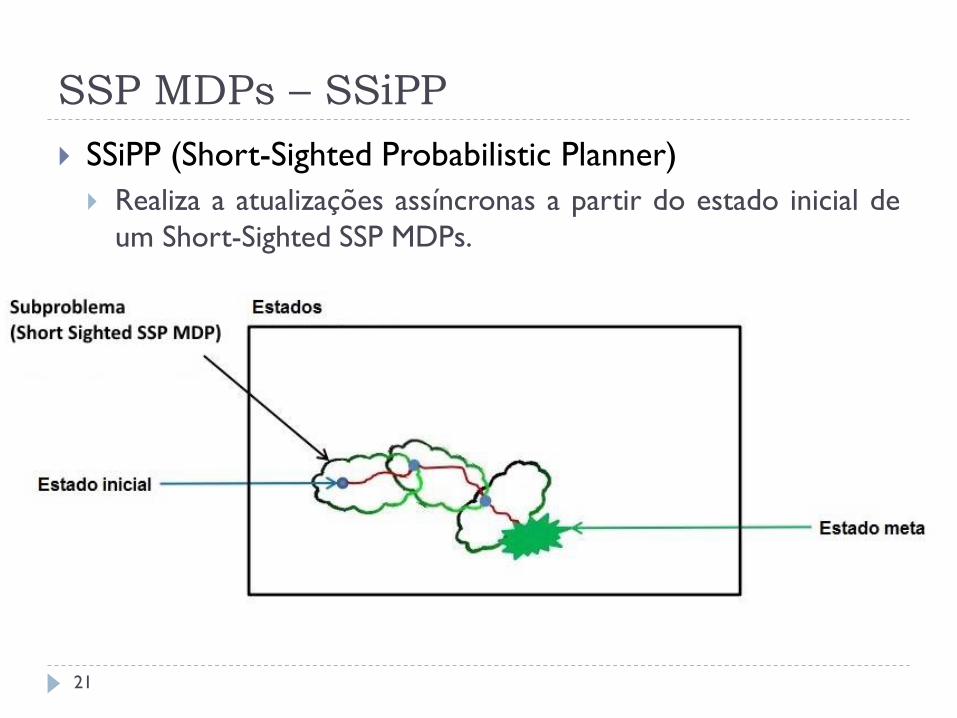
SSP MDPs – SSiPP
SSiPP (Short-Sighted Probabilistic Planner)
Realiza a atualizações assíncronas a partir do estado inicial de
um Short-Sighted SSP MDPs.
21

Agenda
Introdução
Introdução
Motivação / Objetivos
Stochastic Shortest Path MDP (SSP MDP)
Definições formais
Soluções para SSP MDP
Stochastic Shortest Path MDP-IP (SSP MDP-IP)
Definições formais
Soluções síncronas para SSP MDP-IP
Algoritmos assíncronos para SSP MDP-IPs
Experimentos e Resultados
Conclusões
22

SSP MDP-IPs – Definição formal
Definido por uma tupla 𝑆, 𝐴, 𝐶,𝒦, 𝐺, 𝑠0 onde:
𝑆, 𝐴, 𝐶, 𝐺 e 𝑠0 são definidos como qualquer SSP MDP; e
𝒦 é um conjunto de conjuntos credais de transição, onde um
conjunto credal de transição 𝐾 é definido para cada par de
estado-ação, i.e., 𝒦 ≤ 𝒦 𝑚𝑎𝑥= S × A .
São assumidos os pressupostos de políticas apropriadas e
impróprias.
23

SSP MDP-IPs – Definição formal
24

SSP MDP-IPs – Conjunto credal
25

SSP MDP-IPs – Critérios de escolha
Abordagem baseada em jogos
Utilizada para definir o valor de uma política
Assume-se que existe outro agente no sistema, a Natureza
Ela escolherá uma distribuição de probabilidades em um
conjunto credal assumindo algum critério
Critério minimax
O agente seleciona as ações que minimizam o custo futuro
A Natureza escolhe a probabilidade que maximiza o custo
esperado do agente (i.e., a Natureza é adversária)
26

SSP MDP-IPs – Critérios de escolha
Assim, a equação de Bellman para SSP MDP-IPs é:
𝑉∗ 𝑠 = min 𝑎∈ 𝐴
max𝑃∈ 𝐾
𝐶(𝑠, 𝑎) + 𝑃 𝑠′ 𝑠, 𝑎 𝑉∗(𝑠′)
𝑠′∈ 𝑆
Existe de valor de equilíbrio para um SSP game alternado
(Patek e Bertsekas, 1999)
Este valor pode ser calculado para SSP MDP-IPs com a
equação de Bellman
27

SSP MDP-IPs – Iteração de Valor
Iteração de Valor para SSP MDP-IPs:
𝑉𝑡+1(𝑠) = (𝑇𝑉𝑡)(𝑠) = 𝑚𝑖𝑛𝑎∈𝐴 𝑄𝑡+1(𝑠, 𝑎)
𝑄𝑡+1 𝑠, 𝑎 = 𝐶 𝑠, 𝑎 + max𝑃∈ 𝐾
𝑃(𝑠′|𝑠, 𝑎)
𝑠′∈ S
𝑉𝑡(𝑠′)
28

Short-Sighted SSP MDP-IPs
Um Short-Sighted SSP MDP-IP tem as mesmas definições
que os Short-Sighted SSP MDP, com uma tupla
𝑆𝑠,𝑡 , 𝐴, 𝐶𝑠,𝑡 , 𝑃, 𝐺𝑠,𝑡 , 𝑠 .
Porém 𝑆𝑠,𝑡 e 𝐺𝑠,𝑡 ao invés de ser definido por 𝛿 𝑠, 𝑠′ ,
será definido pela função 𝛿𝐼𝑃 𝑠, 𝑠′ :
𝛿𝐼𝑃 𝑠, 𝑠′ = 0 , 𝑠𝑒 𝑠 = 𝑠′
1 + min𝑎∈𝐴
min𝑠 :𝑃 𝑠 𝑠,𝑎 >0∀𝑃∈𝐾(⋅|𝑠,𝑎)
𝛿𝐼𝑃 𝑠 , 𝑠′ , 𝑐𝑎𝑠𝑜 𝑐𝑜𝑛𝑡𝑟á𝑟𝑖𝑜
29

SSP MDP-IPs fatorado – definição formal
Um SSP MDP-IP fatorado é um SSP MDP-IP em que:
Os estados 𝑥 são especificados como uma atribuição conjunta
para um vetor 𝑋 de 𝑛 variáveis de estado (𝑋1, … , 𝑋𝑛)
As redes credais dinâmicas (Cozman, 2000, 2005 , Delgado et al,
2011) são utilizadas para representar a função de transição
Os PADDs (Delgado et al, 2011) podem ser usados para
representar a função de transição
30

SSP MDP-IPs fatorado – SPUDD-IP
O SPUDD-IP (Delgado et al, 2011) atualiza os estados
com as seguintes equações:
𝑉𝐷𝐷𝑡+1 𝑋 = 𝑚𝑖𝑛𝑎∈𝐴 𝑄𝐷𝐷
𝑡+1(𝑋 , 𝑎)
𝑄𝐷𝐷𝑡+1 𝑋 , 𝑎 = 𝐶𝐷𝐷 𝑋 , 𝑎 ⊕
max𝑝 ∈𝐾𝑎
⊗𝑖=1𝑛 (𝑃𝐷𝐷(𝑋𝑖
′|𝑝𝑎𝑎 𝑋1′ , 𝑎) ⊗ 𝑉𝐷𝐷
𝑡 (𝑋 ′)
𝑥1′ ,⋅,𝑥𝑛
′
31

Conversão de SSP MDP-IP fatorados
Um SSP MDP-IP enumerativo pode ser criado através de
um fatorado pelo cálculo da probabilidades de transição
conjunta:
𝑃 𝑥 ′ 𝑥 , 𝑎 = 𝑃(𝑥𝑖′|𝑝𝑎𝑎 𝑋𝑖
′ , 𝑎)
𝑛
𝑖=1
As probabilidades de transição deste novo SSP MDP-IP
enumerativo não serão mais lineares, pois podem
envolver multiplicação de parâmetros
32

Agenda
Introdução
Introdução
Motivação / Objetivos
Stochastic Shortest Path MDP (SSP MDP)
Definições formais
Soluções para SSP MDP
Stochastic Shortest Path MDP-IP (SSP MDP-IP)
Definições formais
Soluções síncronas para SSP MDP-IP
Algoritmos assíncronos para SSP MDP-IPs
Experimentos e Resultados
Conclusões
33

Algoritmos assíncronos para SSP MDP-IPs
Neste trabalho foram desenvolvidos os seguintes
algoritmos para SSP MDP-IPs:
RTDP-IP
factRTDP-IP
SSiPP-IP
LRTDP-IP
factLRTDP-IP
LSSiPP-IP
34

RTDP-IP
Utiliza as mesmas estratégias do algoritmo RTDP, com as
seguintes alterações:
O Bellman backup para o estado atual visitado é
executado considerando o critério minimax
A escolha do próximo estado é feita considerando as
probabilidades imprecisas, isto é, dado uma ação gulosa,
primeiro os valores para cada 𝑝𝑖 são escolhidos, sujeitos ao
conjunto de restrições 𝜑, para depois realizar a escolha real
35

RTDP-IP – Bellman Backup
36

RTDP-IP
Utiliza as mesmas estratégias do algoritmo para SSP
MDPs, com as seguintes alterações:
O Bellman backup para o estado atual visitado é executado
considerando o critério minimax
A escolha do próximo estado é feita considerando as
probabilidades imprecisas, isto é, dado uma ação
gulosa, primeiro os valores para cada 𝒑𝒊 são escolhidos,
sujeitos ao conjunto de restrições 𝝋 , para depois
realizar a escolha real
37

RTDP-IP – Escolha do próximo estado
38

RTDP-IP – Escolha do próximo estado
A escolha do valor das probabilidades imprecisas pode
ser feita de três formas:
Utilizando o mesmo valor computado pelo Bellman update
(método minimax_parameter_choice)
Calculando um valor aleatório válido a cada visita de um
estado durante o trial (método rand_parameter_choice)
Calculando um valor válido pré determinado apenas uma vez
no início do algoritmo (método predefined_parameter_choice)
39

RTDP-IP – Escolha do próximo estado
Para os métodos:
rand_parameter_choice
predefined_parameter_choice
Procedimento:
Os vértices 𝑢𝑗 do conjunto credal 𝐾(⋅ |𝑠, 𝑎) são enumerados através do
software LRS;
Um ponto aleatório é amostrado como uma combinação linear de 𝑢𝑗 (Devroye, 1986) como:
𝑝 = 𝑤𝑗 × 𝑢𝑗
𝑙
𝑗=0
40

RTDP-IP – Prova de convergência
Considera a prova de Buffet e Aberdeen (2005)
Que por sua vez estende a prova de Barto et al. (1999)
Os seguintes pontos são provados para garantir a convergência do RTDP-IP:
O operador 𝑇 (Bellman Backup) é uma contração (Patek e Bertsekas, 1999)
A admissibilidade da função valor é mantida durante a execução do algoritmo
Ao realizar repetidos trials nos estados relevantes utilizando qualquer método de amostragem do próximo estado, o RTDP-IP converge.
41

LRTDP-IP
Semelhante ao RTDP-IP, com as seguintes diferenças:
O critério de parada do algoritmo e parada do trial são
idênticos ao LRTDP
No fim de cada trial é verificado se o estado pode ser rotulado
como resolvido através do método CheckSolved-IP
Ao se buscar os estados sucessores no CheckSolved-IP,
considera-se todas as transições parametrizadas diferentes de
0 (zero)
42

factRTDP-IP e factLRTDP-IP
Baseado no algoritmo factRTDP (Holguin, 2013), que atualiza um estado por vez
Implementa o Bellman Update e a seleção do próximo estado de forma fatorada
𝑉𝐷𝐷𝑡+1 𝑥 = 𝑚𝑖𝑛𝑎∈𝐴 𝑄𝐷𝐷
𝑡+1(𝑥 , 𝑎)
𝑄𝐷𝐷𝑡+1 𝑥 , 𝑎 = 𝐸𝑣𝑎𝑙𝑃𝐴𝐷𝐷(𝐶𝐷𝐷 𝑋, 𝑎 , 𝑥 ) ⊕
max𝑝 ∈𝐾𝑎
⊗𝑖=1𝑛 (𝑝𝐸𝑣𝑎𝑙𝑃𝐴𝐷𝐷(𝑃𝐷𝐷(𝑋𝑖
′|𝑝𝑎𝑎 𝑋1′ , 𝑎), 𝑥 ) ⊗ 𝑉𝐷𝐷
𝑡 (𝑋′)
𝑥1′ ,⋅,𝑥𝑛
′
O factLRTDP-IP também realiza as operações de forma fatorada, porém com chamadas ao método factCheckSolved-IP
43

SSiPP-IP e LSSiPP-IP
Modifica o SSiPP nos seguintes pontos:
Ao segmentar um SSP MDP-IP ele gera um Short-Sighted SSP
MDP-IP e chama um solver para SSP MDP-IPs para resolvê-lo
Ao simular a política devolvida pelo solver, ele leva em
consideração os métodos de amostragem de próximo estado
apresentados no RTDP-IP
O LSSiPP-IP considera os mesmos pontos e também
utiliza o método CheckSolved-IP para rotular os estados
resolvidos, considerando as probabilidades imprecisas.
44

Agenda
Introdução
Introdução
Motivação / Objetivos
Stochastic Shortest Path MDP (SSP MDP)
Definições formais
Soluções para SSP MDP
Stochastic Shortest Path MDP-IP (SSP MDP-IP)
Definições formais
Soluções síncronas para SSP MDP-IP
Algoritmos assíncronos para SSP MDP-IPs
Experimentos e Resultados
Conclusões
45

Experimentos realizados
Dois experimentos foram realizados:
Um comparando os algoritmos assíncronos RTDP-IP, LRTDP-IP, factRTDP-IP e factLRTDP-IP com o algoritmo síncrono estado-da-arte SPUDD-IP
Outro comparando os algoritmos assíncronos LRTDP-IP e LSSiPP-IP
Todos os algoritmos foram comparados em relação a:
Tempo de Convergência
Taxa de Convergência
Chamadas ao Solver
46

Experimentos realizados
O primeiro experimento foi realizado considerando os domínios:
Navigation (IPPC-2011)
Relaxed Triangle Tireworld (IPPC-2005)
SysAdmin, topologia Uniring (Guestrin et al, 2003)
Todos os domínios foram adaptados para SSP MDP-IPs, a partir do RDDL e do PPDDL.
Em domínios com deadends, todos os algoritmos tem tratamento para detectá-los.
47

Experimento 1 – Tempo de convergência
48
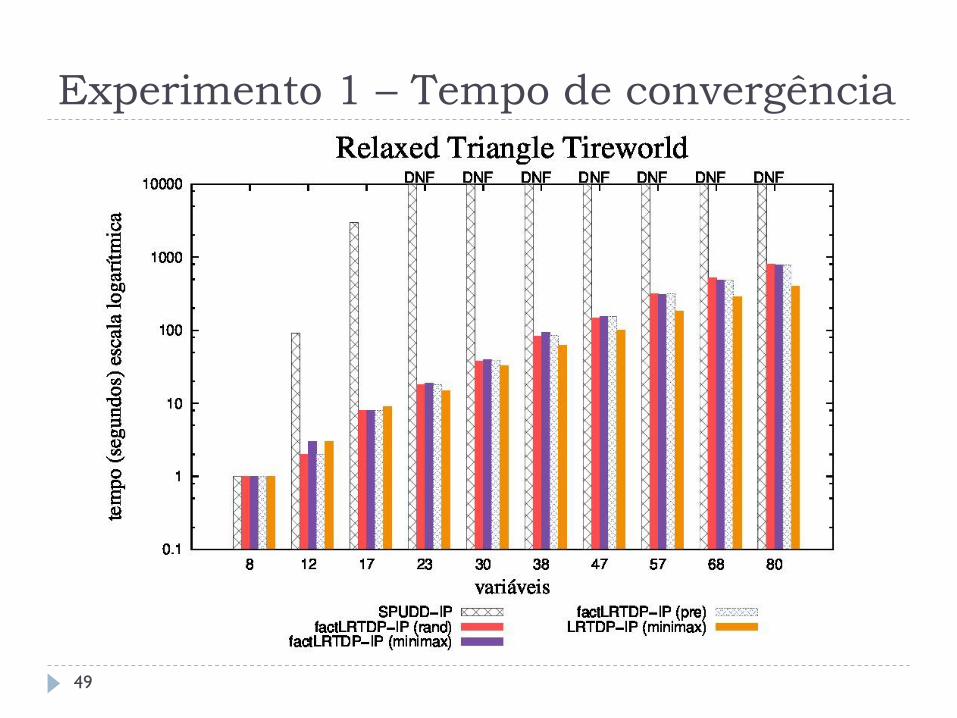
Experimento 1 – Tempo de convergência
49

Experimento 1 – Tempo de convergência
50

Experimento 1 – Taxa de convergência
51

Experimento 1 – Taxa de convergência
52

Experimento 1 – Chamadas ao Solver
53

Experimentos realizados
O segundo experimento foi realizado considerando os
domínios:
Navigation (IPPC-2011)
Relaxed Triangle Tireworld (IPPC-2005)
NoRelaxed Triangle Tireworld (IPPC-2005)
A execução do LSSiPP-IP é feita com 𝑡 = 1, 3, 5 .
Os algoritmos utilizam o minimax_parameter_choice.
A detecção de deadends é realizada da mesma forma que
no experimento anterior.
54
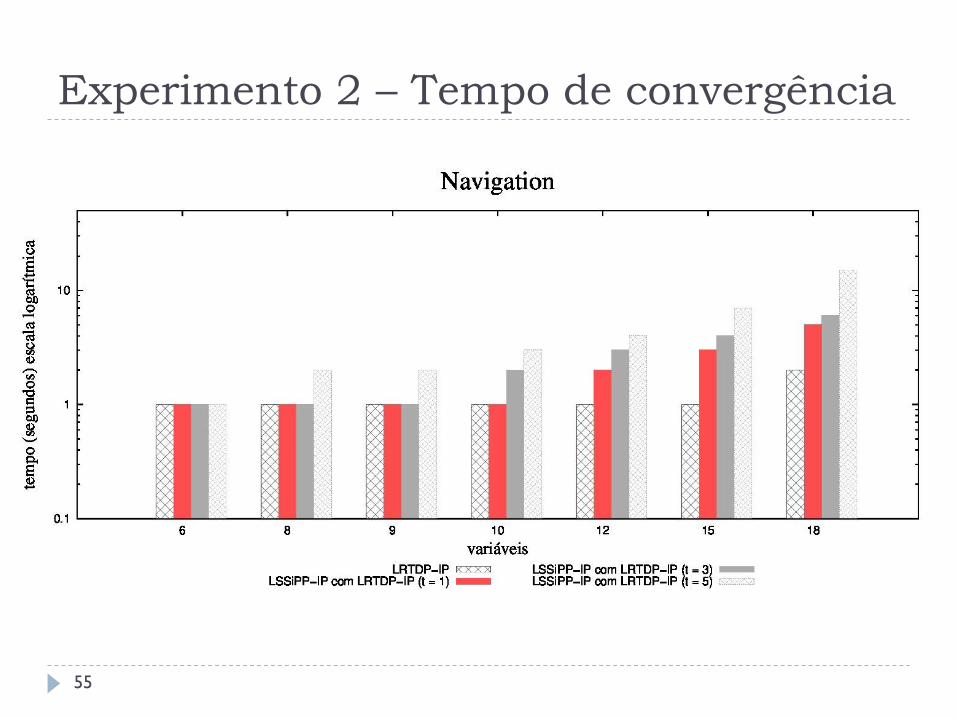
Experimento 2 – Tempo de convergência
55

Experimento 2 – Convergência x Solver
56

Agenda
Introdução
Introdução
Motivação / Objetivos
Stochastic Shortest Path MDP (SSP MDP)
Definições formais
Soluções para SSP MDP
Stochastic Shortest Path MDP-IP (SSP MDP-IP)
Definições formais
Soluções síncronas para SSP MDP-IP
Algoritmos assíncronos para SSP MDP-IPs
Experimentos e Resultados
Conclusões
57

Contribuições
Algoritmos de programação dinâmica assíncrona
enumerativos e fatorados para SSP MDP-IPs
Criação de métodos de amostragem para o próximo
estado
Algoritmos de programação dinâmica assíncrona para
Short-Sighted SSP MDP-IP
58

Conclusões
O (L)RTDP-IP e o fact(L)RTDP-IP se mostraram melhor que o SPUDD-IP em até três ordens, resolvendo problemas com até 120 variáveis
Esta melhoria não se aplica em domínios densos
Os diferentes métodos de amostragem não interferem no tempo de execução dos algoritmos
O LSSiPP-IP não consegue ser melhor que o LRTDP-IP, não reproduzindo o comportamento observado em SSP MDPs
59

Trabalhos futuros
Adaptação dos algoritmos para considerar deadends genéricos (Kolobov et al, 2010)
Propor novas funções valor admissíveis para Short-Sighted SSP MDP-IPs
Adaptar outros algoritmos assíncronos de SSP MDPs para os SSP MDP-IPs
Investigar abordagens Bayesianas para SSP MDP-IPs
60

Bibliografia Barto et al.(1995) Andrew G. Barto, Steven J. Bradtke e Satinder P.
Singh. Learning to act using real-time dynamic programming. Artificial Intelligence, 72:81 - 138. ISSN 0004-3702.
Bertsekas e Tsitsiklis(1991) Dimitri P. Bertsekas e John N. Tsitsiklis. An analysis of stochastic shortest path problems. Math. Oper. Res., 16(3):580 - 595. ISSN 0364-765X.
Bonet e Geffner(2003) B. Bonet e H. Geffner. Labeled RTDP: Improving the convergence of real-time dynamic programming. Proceedings of 2003 International Conference on Automated Planning and Scheduling, páginas 12-21.
Buffet e Aberdeen(2005) Olivier Buffet e Douglas Aberdeen. Robust planning with LRTDP. Em Proceedings of 2005 International Joint Conference on Artificial Intelligence, páginas 1214-1219.
61

Bibliografia
Cozman(2000) F. G. Cozman. Credal networks. Artificial Intelligence, 120:199-233.
Cozman(2005) F. G. Cozman. Graphical models for imprecise probabilities. International Journal of Approximate Reasoning, 39(2-3):167-184.
Delgado et al.(2011) Karina Valdivia Delgado, Scott Sanner e Leliane Nunes de Barros. Efficient solutions to factored MDPs with imprecise transition probabilities. Artificial Intelligence, 175:1498 - 1527. ISSN 0004-3702
Devroye(1986) Luc Devroye. Non-Uniform Random Variate Generation. Springer-Verlag.
62

Bibliografia
Guestrin et al.(2003) Carlos Guestrin, Daphne Koller, Ronald Parr e Shobha Venkataraman. Efficient solution algorithms for factored MDPs. Journal of Artificial Intelligence Research, 19:399-468.
Holguin(2013) Mijail Gamarra Holguin. Planejamento probabilístico usando programação dinâmica assíncrona e fatorada. Dissertação de Mestrado, IME-USP.
Patek e Bertsekas(1999) Stephen D Patek e Dimitri P Bertsekas. Stochastic shortest path games. SIAM Journal on Control and Optimization, 37(3):804-824.
Trevizan(2013) Felipe W Trevizan. Short-sighted Probabilistic Planning. Tese de Doutorado, Carnegie Melon.
63

Obrigado !
64


















