
Processor Architectures and Program Mapping H. Corporaal and B. Mesman1 Platform-based Design TU/e...
36
Processor Architectures a nd Program Mapping H . Corporaal and B. Mesman 1 Platform-based Design TU/e 5kk70 Henk Corporaal Bart Mesman Digital Signal Processors
-
date post
21-Dec-2015 -
Category
Documents
-
view
228 -
download
1
Transcript of Processor Architectures and Program Mapping H. Corporaal and B. Mesman1 Platform-based Design TU/e...

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
1
Platform-based Design
TU/e 5kk70Henk Corporaal
Bart Mesman
Digital Signal Processors

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
2
flexibility
efficiency
DSP
Programmable CPU
Programmable DSP
Application specific instruction set
processor (ASIP)
Applicationspecific processor

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
3
#define NTAPS 4
int fir(int in)int i;static int state[NTAPS];static int coeff[NTAPS];int out[NTAPS];
state[NTAPS] = in;out[0] = state[0] * coeff[0];for ( i = 1; i < NTAPS+1; i++)
out[i] = out[i-1] + state[i] * coeff[i];state[i-1] = state[i];
return(out[NTAPS]);
*
Z-1
*
Z-1
*
Z-1
*
+
c3c4 c2 c1
x4 x3 x2 x1
y
Z-1
c0
x0
*
Application examples (1)

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
4
.L1000006sll $3, $2, 2 R3=R2>>2 R3=i-1addu $14, $15, $3 R14=R15+R3lw $24, 0($14) R24=load(*R14) R24=coeff[i-1]addiu $12, $6, -4 R12=R6-4addu $11, $12, $3 R11=R12+R3lw $13, 0($11) R13=load(*R11) R13=state[i-1]nopmult $24, $13 R24=R24*R13addu $25, $sp, $3 R25=sp+R3lw $9, -4($25) R9=load(R25-4) R9=out[i-1]addiu $2, $2, 1 R2=R2+1 i=i+1mflo $13 R13=move from low mpy regaddu $10, $9, $13 R10=R9+R13 R10=out[i]sw $10, 0($25) mem(*R25)=R10addu $25, $7, $3 R25=R7+R3sw $24, 0($25) mem(*R25)=R24slti $24, $2, 10bne $24, $0, .L100006addiu $15, $7, -4
Application examples (1)
19 instructions per tap!!

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
5
temp1 = input << 1temp2 = if (bit(input,7) == 1
then 29 else 0
out = temp1 exor temp2
Bit level operations:finite field arithmetic
r1 = LB input Load byter2 = SLL r1 Shift left logicalr3 = ANDI r1, mask AND immediater4 = ADDI r3, -1 ADD immediateBNE ( r4 != r0) Branch on != to nonzeronopR5 = XORI(r1, 29) Exclusive or immediateJ common Jumpnop
nonzero r5 = XOR(r1,r0) Exclusive ORcommon …
in[0] in[1] in[2] in[3] in[4] in[5] in[6] in[7]
out[0] out[1] out[2] out[3] out[4] out[5] out[6] out[7]
exor exor exor
Application examples (2)
10 instructions!!Very simple in hardware

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
6
srl $13, $2, 20andi $25, $13, 1srl $14, $2, 21andi $24, $14, 6or $15, $25, $24srl $13, $2, 22andi $14, $13, 56or $25, $15, $14sll $24, $25, 2
202223252627
source register ($2)
destination register ($24)
2 3 4 5 6 7
Bit level operations : DES example
Application examples (2)
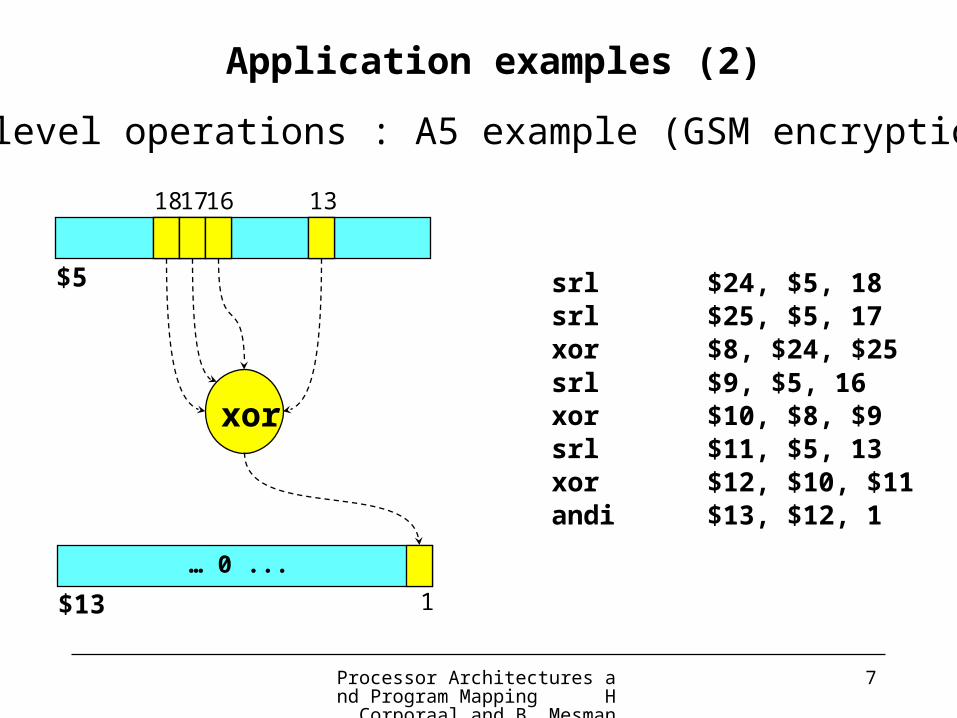
Processor Architectures and Program Mapping H. Corporaal and B. Mesman
7
srl $24, $5, 18srl $25, $5, 17xor $8, $24, $25srl $9, $5, 16xor $10, $8, $9srl $11, $5, 13xor $12, $10, $11andi $13, $12, 1
181716 13
xor
$5
1$13
… 0 ...
Bit level operations : A5 example (GSM encryption)
Application examples (2)

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
8
Application examples: conclusions
• CPUs offer flexibility, but…
• not efficient in performance
• not efficient in code size
• not efficient in power consumption

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
9
Power Consumption in microprocessorsPower consumption is (becoming) the limiting factor in
processor design
Solution in direction of• Hardware acceleration• Instruction Level Parallelism instead of clock speed• Code size efficiency
source: ISSCC2001, Patrick Gelsinger, Intel

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
10
Amdahl’s law
• Impact of an improvement on the execution time of a program depends on 2 parameters:– f = fraction of the original computation time that is
affected by the improvement– s = speedup factor (local)
• exec_time_new = exec_time_old * (1-f) + exec_time_old * f / s
• speedup_overall = exec_time_old / exec_time_new = 1 / ( 1 – f + f / s)
• if s >> 1 then speedup_overall = 1 / ( 1 – f )• Example: 40 % of program can be executed 10 x faster
speedup_overall = 1 / ( 0.6 + 0.4 / 10 ) = 1.56

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
11
• Programmable CPU cores are important for the control parts of the application. • They are well supported with tools to support the development of end-user software. ( vs. deeply embedded sw)• Keep it Simple heuristic (RISC vs. CISC)
• Make frequent cases fast and rare cases correct. • Regular (orthogonal) instruction set• No special features that match a high level language construct.• At least 16 registers to ease register allocation.
• Embedded cores are often light cores which are a compromise between performance, area and power dissipation. (vs. stand-alone CPU cores which are optimised for performance)
Conclusions

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
12
Programmable Digital Signal Processors
• real-time worst-case processing = need for more compute power sec instr cycles secprog prog instr cycle
CPI = 1• instruction level parallelism (ILP)• hardware support for loop control• attention for high level data types e.g. arrays, delaylines
(vs. scalars for CPUs)• difficult to compare architectures
• e.g. DIT, DIF, radix 2/4, FFT loop unrolling, scaling, shuffling, intialisation … can be included or forgotten
• benchmarking (Berkeley Design Technology Inc (BDTi))(compare to SpecInt benchmarks for CPs)

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
13
• architectures for programmable DSPs• multiplier-accumulator• modified Harvard architecture• extension with an ALU (decision making)• controller architectures
• examples: TI, Motorola, Philips • code generation• developments: VLIW (Very Long Instruction Word)
examples: C6 and TM
Outline

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
14
• not every signal requires 32 bits• 2 types of DSP: floating point and integer• advantages FP: most specs are in FP
(conversion to int is time consuming since the behavior may change)
• disadvantage FP: cost (area, speed, power)• integer multiplication doubles the number of bits: n * n => 2n
DSP data types

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
15
PR
ADDER
ACR
MPY(Booth,
Wallace..)
c(i) x(i)
SHIFTROUND
TRUNCATE
clockP_reg
clockP_reg
control

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
16
Prog/datamemory
EXU
Von Neumann(sequential)
progmem.
EXU
Harvard
datamem.
progmem.
EXU
datamem. 1
datamem. 2
Modified Harvard
c(i) * x(i)
Goal = 1 cycle per iteration

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
17
RAM_A RAM_B
ACU_A
AR_A
ACU_B
AR_B
MAC
DR_A DR_B
+1 PC
Interrupt address
Stack
Reset
ProgramMemory
IR
Control Bus
Rfile

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
18
*
Z-1
*
Z-1
*
Z-1
*
+
c4c5 c3 c2
x5 x4 x3 x2
y
Z-1
c1
x1
*
ci * xi
time loop
filter loop i
How updating the delayline ?
1 cycle/tap ?

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
19
Memorylocation
outputsample 1
outputsample 2
outputsample 3
outputsample 4
Outputsample 5
1 x1 x92 x2 x23 x3 x3 x34 x4 x4 x4 x45 x5 x5 x5 x5 x56 x6 x6 x6 x67 x7 x7 x78 x8 x8
Solution 2: indirect adressing
• use of a pointer to mark the begin of the delay line• problem: trashing of the whole memory• solution: modulo addressing• need for a register to store the pointer

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
20
A S
Modulo
outputto RAM
Output reg A reg SRead_A A A SRead_S S A SincA A+1 A+1 SdecA A-1 A-1 SStep A+S A+S SInc_step S+1 A S+1
Modulo can beimplemented as a mask operation if the size is 2k
16 10 00023 10 111mask=hold
ACU architecture andInstruction set

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
21
Addressing modes
• register ADD R4, R3 R[R4] = R[R4] + R[R3]• immediate ADD R4, #3 R[R4] = R[R4] + #3• direct ADD R4, (100) R[R4] = R[R4] + Mem[100]• indirect ADD R4, (R3) R[R4] = R[R4] + Mem[R[R3]]
• w. inc/dec ADD R4, (R3)± R[R4] = R[R4] + Mem[R[R3]] R[R3] = R[R3] ± 1
• indexed ADD R4, (R3±R2) R[R4] = R[R4] + Mem[R[R3]] R[R3] = R[R3] ± R[R2]
Remarks• direct = for static data• indirect = for arrays
• inc/dec = for stepping through arrays e.g. xn
• index = for stepping through arrays e.g. x2n

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
22
• 8 ARs (address or auxiliary register) available• extra indirect modes
•circular *ARn ± % post inc/dec by 1 - circular *ARn ± AR0 % post inc/dec by AR0 - circular
• bit reverse *ARn ± AR0 B post inc/dec by AR0 - bit rev.
Addressing modes: extra for DSP

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
23
+1 PC
Interrupt address
Stack
Reset
ProgramMemory
IR
ACU_A
AR_A
RAM_A
DR_A
ACU_B
AR_B
RAM_B
DR_B
MAC ALUControl Bus
Rfile

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
24
LABEL ALU MPY-ACC RAM ACUAcc = 0 init (i=0)
init counterloop incr (=i+1)
read x(i)acc(i)=acc(i-1)+x(i)*c(i)
dec counter branch to loop if counter > 0
nop
c(i) * x(i)
6 clockcycles/samplelimit pipelines in the controller
first solution
resources
time (cc)
Not showncoefficient RAM+ACU
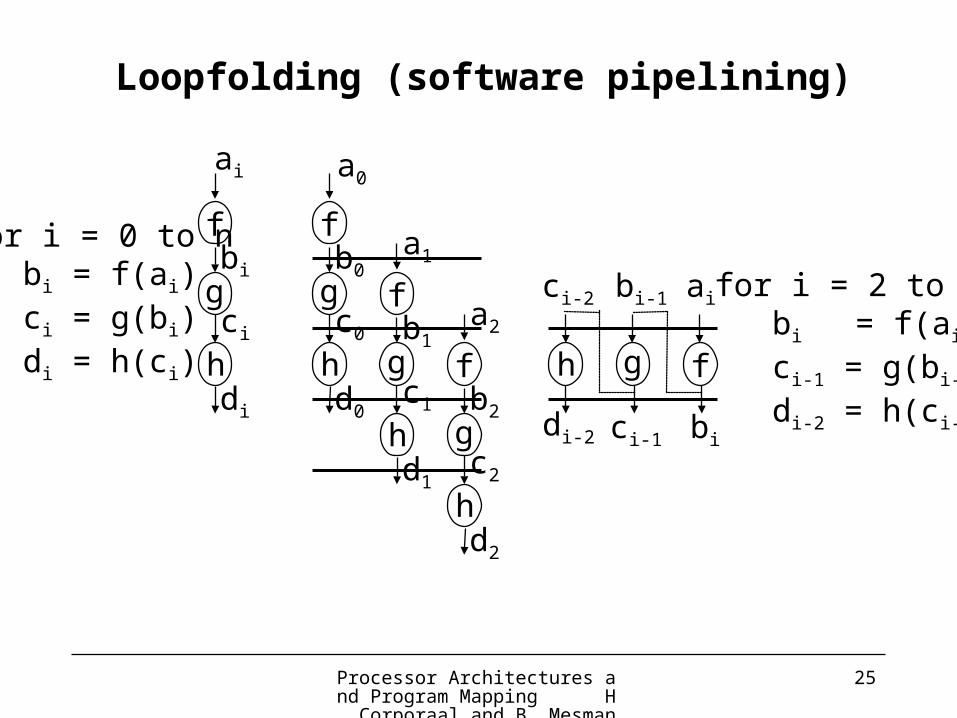
Processor Architectures and Program Mapping H. Corporaal and B. Mesman
25
f
g
h
ai
bi
ci
di
f
g
h
a0
b0
c0
d0
f
g
h
a1
b1
c1
d1
f
g
h
a2
b2
c2
d2
h g f
ai
bi
bi-1ci-2
ci-1di-2
for i = 0 to n bi = f(ai) ci = g(bi) di = h(ci)
for i = 2 to n bi = f(ai) ci-1 = g(bi-1) di-2 = h(ci-2)
Loopfolding (software pipelining)

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
26
c(i) * x(i)
Pre- and postamble4 clockcycles /sample
LABEL ALU MPY-ACC RAM ACUacc(i-1)=0 init (i=1)
init counter read x(i) inc(=i+1)loop acc(i) = acc(i-1)+x(i)*c(i) read x(i+1) incr (=i+2)
dec counterbranch to loop if counter > 0nop
acc(n-1) = acc(n-2)+x(n-1)*c(n-1) read x(n)acc(n) = acc(n-1)+x(n)*c(n)
Loopfolding (software pipelining)

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
27
Label ALU MPY-ACC RAM ACUacc(i-1=0 init (i=1)
init counter read x(i) inc(=i+1)repeat n-2 acc(i)=acc(i-1)+x(i)*c(i) read x(i+1) incr(=i+2)
acc(n-1) = acc(n-2) + x(n-1)*c(n-1) read x(n)acc(n) = acc(n-1) + x(n)*c(n)
c(i) * x(i)
hardware support for loop control
1 clockcycles/samplerepeat instruction and repeat block
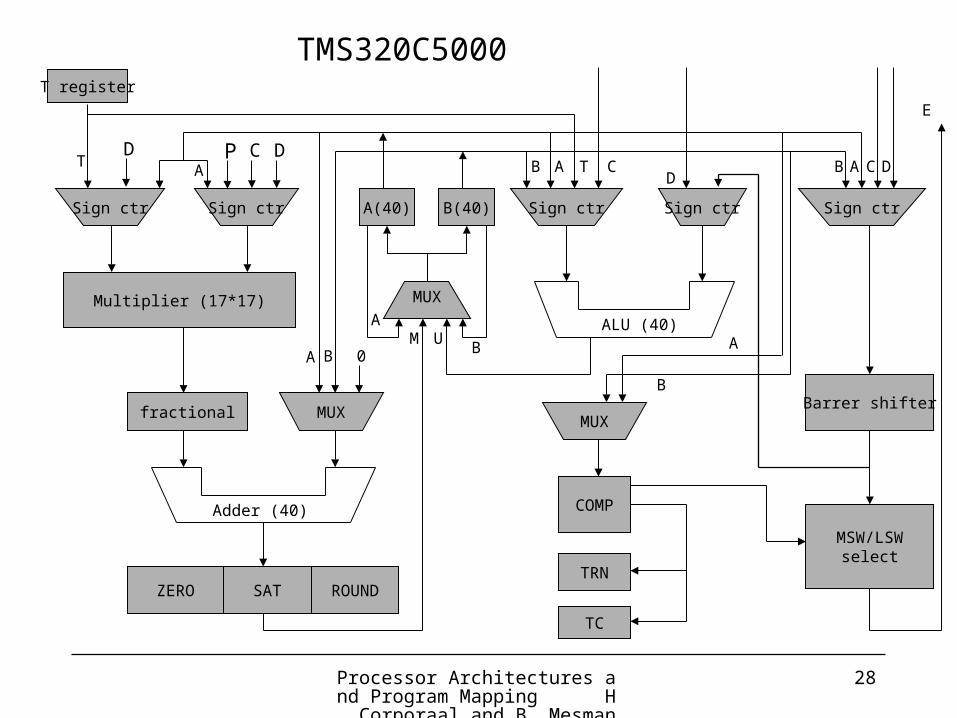
Processor Architectures and Program Mapping H. Corporaal and B. Mesman
28
T register
Sign ctr Sign ctr Sign ctr Sign ctr Sign ctr
T
Multiplier (17*17)
A(40) B(40)
MUX
A
0
A
A B
B A
fractional MUX
Adder (40)
ZERO SAT ROUND
MALU (40)
UB
MUX
TAB CD
C D
Barrer shifter
MSW/LSWselect
E
COMP
TRN
TC
B
A
P C DD
TMS320C5000

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
29
Address bus
16 bits
EXTERNALADRESS SWITCH
Y Address
Y memory256-by-24-bit
RAM256-by-24-bit
ROM
AddressALU
X memory256-by-24-bit
RAM256-by-24-bit
ROM
2,048-by-24-bitPROGRAMMEMORY
ROM
X Address
P Address
EXTERNALDATA-BUS
SWITCH
INTERNAL DATA-BUS
SWITCH
24 BITS DATA
BUS
X-DATA
Y DATA
P DATA
GLOBAL DATA
DATA ALU
24-by-24 bitMULTIPLIER-
ACCUMULATORPRODUCING
56 BIT RESULT
PROGRAM CONTROLLER
ON CHIPPERIPHERALS,
HOST,SYNCHRONOUS
SERIAL INTERFACESERIAL COMMU-
NICATIONSINTERFACE,
PROGRAMMED I/O,BUS CONTROL
2 BITS
CLOCK
3 BITS
INTERRUPT
24 BITS
I/OPORTS
7 BITS
Motorola 56K family
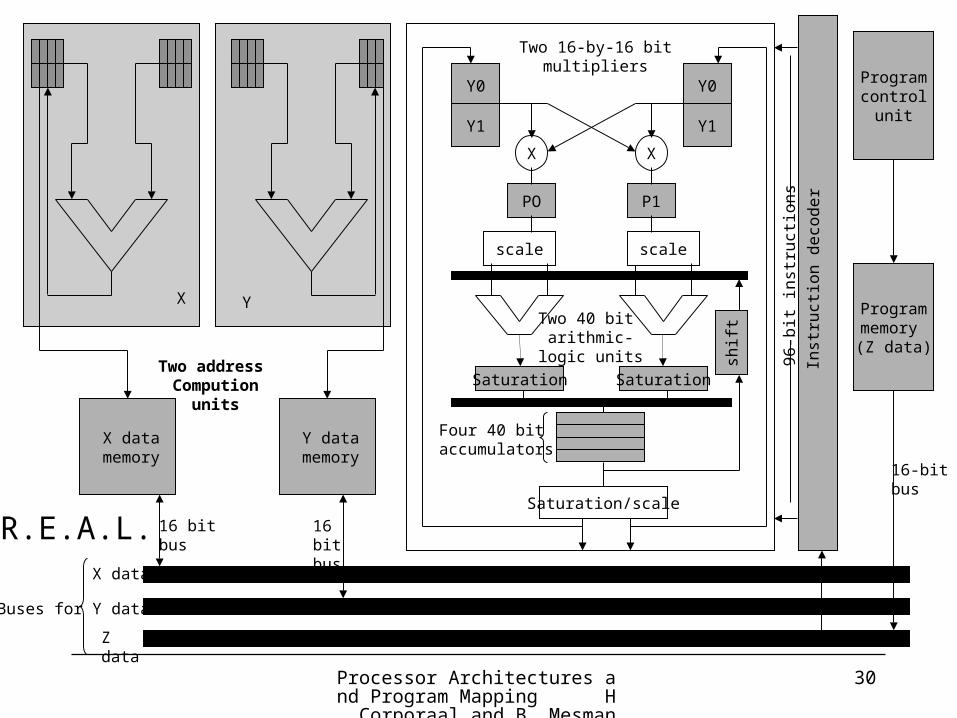
Processor Architectures and Program Mapping H. Corporaal and B. Mesman
30
X data
Y data
Z data
Buses for
X
X datamemory
16 bitbus
Y datamemory
16 bit bus
Two address Compution
units
Y
Inst
ruct
ion
d ec o
der
96-b
it in
stru
ctio
ns
Program control
unit
Programmemory (Z data)
16-bit bus
Two 16-by-16 bitmultipliers
Y0
Y1
X
Y0
Y1
X
PO P1
scale scale
Two 40 bit arithmic-logic units
SaturationSaturation
Four 40 bitaccumulators
Saturation/scale
shif
t
R.E.A.L.

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
31
lexical analysis
syntax analysis
semantic analysis
Code selection
Register allocation
scheduling
Front end
Code generation
code
source
Intermediate machine independent
representation
1 instr = // opsorder of instr

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
32
a b
*
c d
+
+
*
c t1 := a * b t2 := c + d t3 := t1 + cout := t2 * t3
t1 t2
t3
BBi
BBj BBk
Intermediate machine independent
representation
Processor Architectures and Program Mapping H. Corporaal and B. Mesman
33
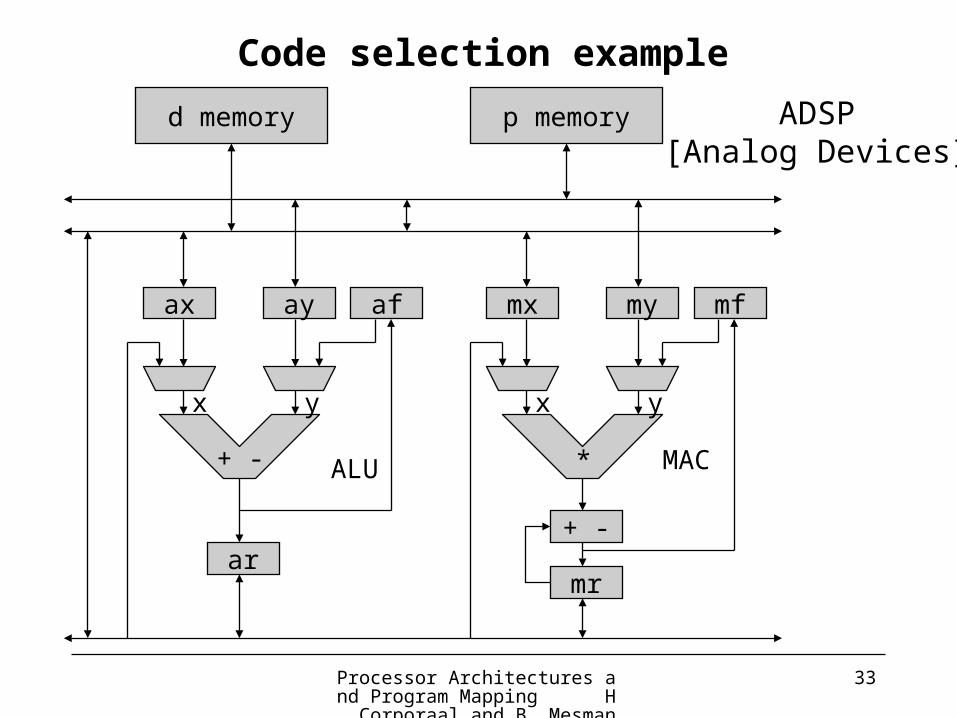
ax ay
ar
af mx my
mr
mf
+ -
x y x y
+ - *ALU MAC
d memory p memory ADSP[Analog Devices]
Code selection example
Processor Architectures and Program Mapping H. Corporaal and B. Mesman
34
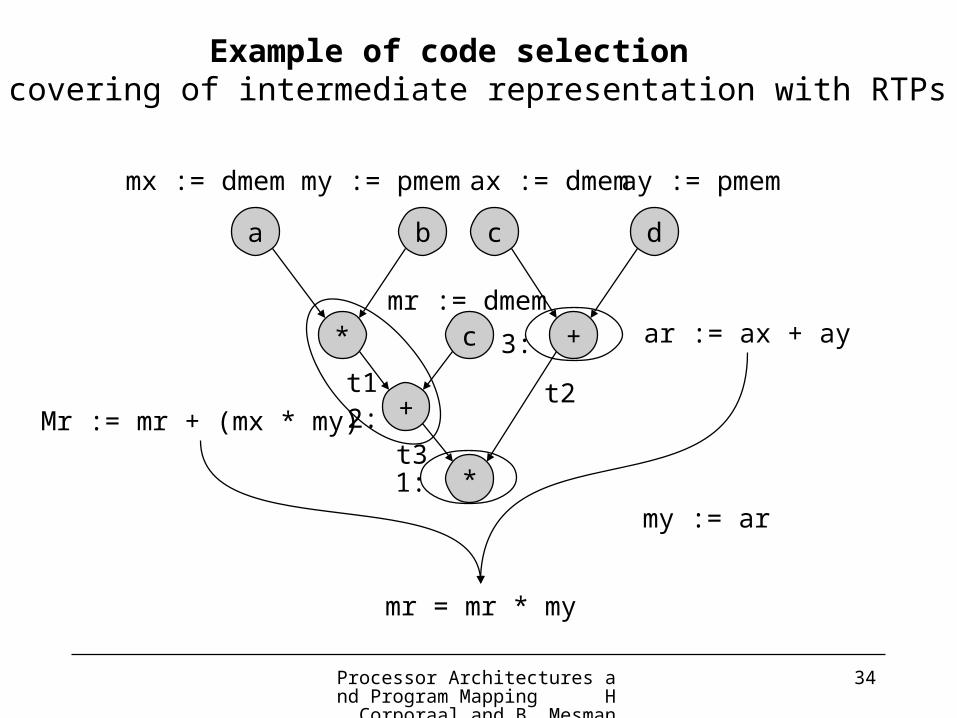
a b
*
c d
+
+
*
c
t1 t2
t3
mx := dmem my := pmem ax := dmem ay := pmem
mr := dmem
2:
1:
3: ar := ax + ay
my := ar
mr = mr * my
Mr := mr + (mx * my)
Example of code selection = covering of intermediate representation with RTPs

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
35
Problems• local decisions which have a global impact• phase coupling: example
• asap schedule• maximal freedom for scheduling• code selection during scheduling• register allocation comes afterwards• can lead to infeasible solutions

Processor Architectures and Program Mapping H. Corporaal and B. Mesman
36
Solution: 1. Solve code generation for DSPs2. Step back and rethink the architecture
develop an architecture which is still efficient but alsoa good model for building a compiler
Efficiency = exploit instruction level parallelism (ILP)compilation = systematic positioning of registers and regular interconnect= VLIW = Very Long Instruction Word
It is very difficult and almost impossible to develop robust and efficient DSP compilers. Current DSP practice = programming in assembler
phase coupling: discussion


















