PowerPoint Presentation - Research | Department...
1
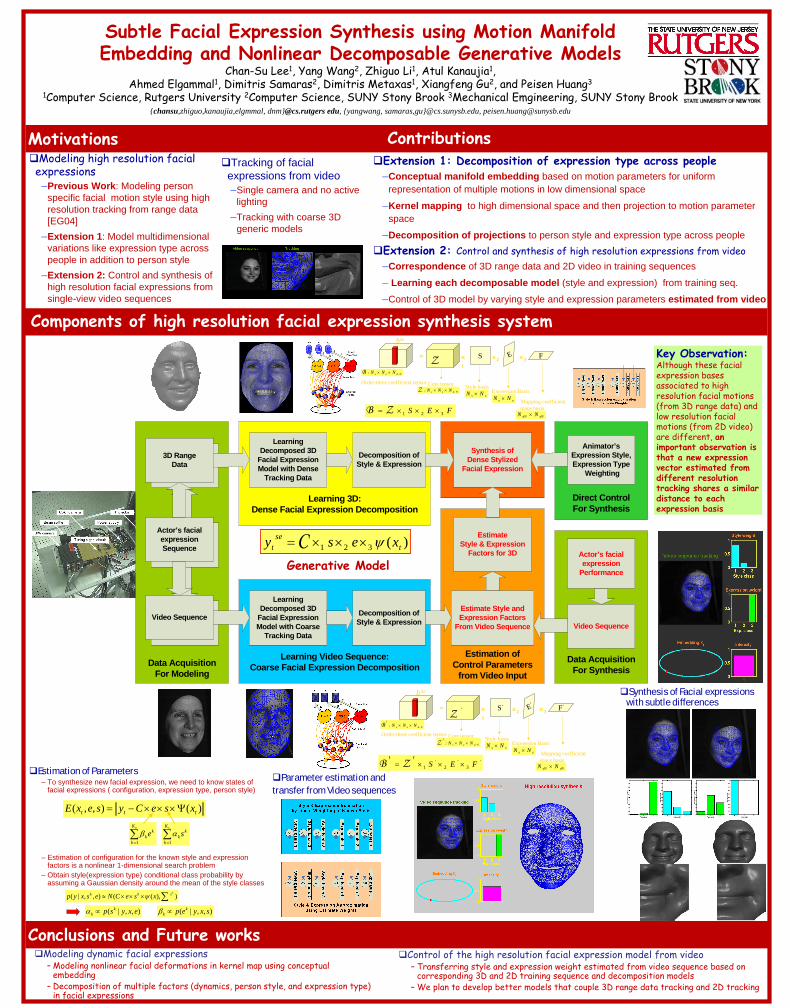
Subtle Facial Expression Synthesis using Motion Manifold Embedding and Nonlinear Decomposable Generative Models Chan-Su Lee 1 , Yang Wang 2 , Zhiguo Li 1 , Atul Kanaujia 1 , Ahmed Elgammal 1 , Dimitris Samaras 2 , Dimitris Metaxas 1 , Xiangfeng Gu 2 , and Peisen Huang 3 1 Computer Science, Rutgers University 2 Computer Science, SUNY Stony Brook 3 Mechanical Emgineering, SUNY Stony Brook {chansu,zhiguo,kanaujia,elgmmal, dnm}@cs.rutgers edu, {yangwang, samaras,gu}@cs.sunysb.edu, [email protected] Motivations Modeling high resolution facial expressions –Previous Work: Modeling person specific facial motion style using high resolution tracking from range data [EG04] –Extension 1: Model multidimensional variations like expression type across people in addition to person style –Extension 2: Control and synthesis of high resolution facial expressions from single-view video sequences Estimation of Parameters – To synthesize new facial expression, we need to know states of facial expressions ( configuration, expression type, person style) – Estimation of configuration for the known style and expression factors is a nonlinear 1-dimensional search problem – Obtain style(expression type) conditional class probability by assuming a Gaussian density around the mean of the style classes Conclusions and Future works Modeling dynamic facial expressions – Modeling nonlinear facial deformations in kernel map using conceptual embedding – Decomposition of multiple factors (dynamics, person style, and expression type) in facial expressions Control of the high resolution facial expression model from video – Transferring style and expression weight estimated from video sequence based on corresponding 3D and 2D training sequence and decomposition models – We plan to develop better models that couple 3D range data tracking and 2D tracking Tracking of facial expressions from video –Single camera and no active lighting –Tracking with coarse 3D generic models Components of high resolution facial expression synthesis system N d e s N N N ⋅ × × : ' B b ’se Order-three coefficient tensor = S ’ F ’ E ’ ' Z × 1 × 2 × 3 Core tensor Style basis Expression Basis Mapping coefficient space basis ' 3 ' 2 ' 1 F E S × × × = ' Ζ ' B s s N N × e e N N × dN dN N N × N d e s N N N ⋅ × × : ' Z ) ( 3 2 1 t se t x e s y ψ × × × = C Generative Model N d e s N N N ⋅ × × : B b se Order-three coefficient tensor = S F E Z × 1 × 2 × 3 Core tensor Style basis Expression Basis Mapping coefficient space basis F E S 3 2 1 × × × = Ζ B s s N N × e e N N × dN dN N N × N d e s N N N ⋅ × × : Z ) ( ) , , ( t t t x s e C y s e x E Ψ × × × − = ∑ = e K k k k e 1 β ∑ = s K k k k s 1 α ) ), ( ( ) , , | ( ∑ × × × ≈ k s k k x s e C N e s x y p ψ ) , , | ( e x y s p k k ∝ α ) , , | ( s x y e p k k ∝ β Parameter estimation and transfer from Video sequences Synthesis of Facial expressions with subtle differences Extension 1: Decomposition of expression type across people –Conceptual manifold embedding based on motion parameters for uniform representation of multiple motions in low dimensional space –Kernel mapping to high dimensional space and then projection to motion parameter space –Decomposition of projections to person style and expression type across people Extension 2: Control and synthesis of high resolution expressions from video –Correspondence of 3D range data and 2D video in training sequences – Learning each decomposable model (style and expression) from training seq. –Control of 3D model by varying style and expression parameters estimated from video Contributions Direct Control For Synthesis Data Acquisition For Modeling Learning Video Sequence: Coarse Facial Expression Decomposition Estimation of Control Parameters from Video Input Learning 3D: Dense Facial Expression Decomposition Learning Decomposed 3D Facial Expression Model with Dense Tracking Data Learning Decomposed 3D Facial Expression Model with Coarse Tracking Data Decomposition of Style & Expression Decomposition of Style & Expression Estimate Style & Expression Factors for 3D Estimate Style and Expression Factors From Video Sequence Synthesis of Dense Stylized Facial Expression Actor’s facial expression Sequence 3D Range Data Video Sequence Data Acquisition For Synthesis Actor’s facial expression Performance Video Sequence Animator’s Expression Style, Expression Type Weighting Key Observation: Although these facial expression bases associated to high resolution facial motions (from 3D range data) and low resolution facial motions (from 2D video) are different, an important observation is that a new expression vector estimated from different resolution tracking shares a similar distance to each expression basis
-
Upload
hoangthuan -
Category
Documents
-
view
214 -
download
0
Transcript of PowerPoint Presentation - Research | Department...
Subtle Facial Expression Synthesis using Motion ManifoldEmbedding and Nonlinear Decomposable Generative Models
Chan-Su Lee1, Yang Wang2, Zhiguo Li1, Atul Kanaujia1, Ahmed Elgammal1, Dimitris Samaras2, Dimitris Metaxas1, Xiangfeng Gu2, and Peisen Huang3
1Computer Science, Rutgers University 2Computer Science, SUNY Stony Brook 3Mechanical Emgineering, SUNY Stony Brook{chansu,zhiguo,kanaujia,elgmmal, dnm}@cs.rutgers edu, {yangwang, samaras,gu}@cs.sunysb.edu, [email protected]
MotivationsModeling high resolution facial
expressions–Previous Work: Modeling person
specific facial motion style using high resolution tracking from range data [EG04]
–Extension 1: Model multidimensional variations like expression type across people in addition to person style
–Extension 2: Control and synthesis of high resolution facial expressions from single-view video sequences
Estimation of Parameters– To synthesize new facial expression, we need to know states of
facial expressions ( configuration, expression type, person style)
– Estimation of configuration for the known style and expression factors is a nonlinear 1-dimensional search problem
– Obtain style(expression type) conditional class probability by assuming a Gaussian density around the mean of the style classes
Conclusions and Future worksModeling dynamic facial expressions – Modeling nonlinear facial deformations in kernel map using conceptual
embedding– Decomposition of multiple factors (dynamics, person style, and expression type)
in facial expressions
Control of the high resolution facial expression model from video– Transferring style and expression weight estimated from video sequence based on
corresponding 3D and 2D training sequence and decomposition models– We plan to develop better models that couple 3D range data tracking and 2D tracking
Tracking of facial expressions from video–Single camera and no active
lighting –Tracking with coarse 3D
generic models
Components of high resolution facial expression synthesis system
Ndes NNN ⋅×× : 'B
b’se
Order-three coefficient tensor
= S’ F’E’'Z ×
1
×2 ×3
Core tensor Style basisExpression Basis
Mapping coefficient space basis'
3'
2'
1 FES ×××= 'Ζ'Bss NN ×
ee NN ×
dNdN NN ×
Ndes NNN ⋅×× : 'Z
)(321 tse
t xesy ψ×××=CGenerative Model
Ndes NNN ⋅×× : B
bse
Order-three coefficient tensor
= S FEZ ×1
×2 ×3
Core tensor Style basisExpression Basis
Mapping coefficient space basisFES 321 ×××= ΖB
ss NN ×ee NN ×
dNdN NN ×
Ndes NNN ⋅×× : Z
)(),,( ttt xseCysexE Ψ×××−=
∑=
eK
k
kke
1
β ∑=
sK
k
kk s
1
α
)),((),,|( ∑×××≈kskk xseCNesxyp ψ
),,|( exysp kk ∝α ),,|( sxyep k
k ∝β
Parameter estimation and transfer from Video sequences
Synthesis of Facial expressions with subtle differences
Extension 1: Decomposition of expression type across people–Conceptual manifold embedding based on motion parameters for uniform
representation of multiple motions in low dimensional space
–Kernel mapping to high dimensional space and then projection to motion parameter space
–Decomposition of projections to person style and expression type across peopleExtension 2: Control and synthesis of high resolution expressions from video–Correspondence of 3D range data and 2D video in training sequences
– Learning each decomposable model (style and expression) from training seq.
–Control of 3D model by varying style and expression parameters estimated from video
Contributions
Direct ControlFor Synthesis
Data Acquisition For Modeling
Learning Video Sequence:Coarse Facial Expression Decomposition
Estimation of Control Parameters
from Video Input
Learning 3D:Dense Facial Expression Decomposition
Learning Decomposed 3D
Facial Expression Model with Dense
Tracking Data
Learning Decomposed 3D
Facial Expression Model with Coarse
Tracking Data
Decomposition of Style & Expression
Decomposition of Style & Expression
Estimate Style & Expression
Factors for 3D
Estimate Style and Expression Factors
From Video Sequence
Synthesis of Dense Stylized
Facial Expression
Actor’s facial expressionSequence
Actor’s facial expressionSequence
3D RangeData
3D RangeData
Video SequenceVideo Sequence
Data Acquisition For Synthesis
Actor’s facial expression
Performance
Video Sequence
Animator’sExpression Style, Expression Type
Weighting
Key Observation:Although these facial expression bases associated to high resolution facial motions (from 3D range data) and low resolution facial motions (from 2D video) are different, an important observation is that a new expression vector estimated from different resolution tracking shares a similar distance to each expression basis






![A Threefold Recognition in Complex Industrial …research.cs.rutgers.edu/~dk598/downloads/mulproc/ieeemult12/final.pdfRecognition in Complex Industrial Environments ... [3B2-9] mmu2012030042.3d](https://static.fdocuments.net/doc/165x107/5aea46277f8b9ac3618d905c/a-threefold-recognition-in-complex-industrial-dk598downloadsmulprocieeemult12finalpdfrecognition.jpg)


![a arXiv:1503.06813v2 [cs.CV] 13 Apr 2015 · tgaaly@cs.rutgers.edu (Tarek El-Gaaly), elgammal@cs.rutgers.edu (Ahmed Elgammal), jiangzg@buaa.edu.cn (Zhiguo Jiang) Accepted in Computer](https://static.fdocuments.net/doc/165x107/5f52e6395067e32266202638/a-arxiv150306813v2-cscv-13-apr-2015-tgaalycs-tarek-el-gaaly-elgammalcs.jpg)
![Facial Expression Analysis using Nonlinear Decomposable ...elgammal/pub/LeeAMFG05FacialExpres… · e.g. [17,19]. Nonlinear dimensionalityreduction has been recently exploited to](https://static.fdocuments.net/doc/165x107/5fa3095e43c38c17ba423eac/facial-expression-analysis-using-nonlinear-decomposable-elgammalpubleeamfg05facialexpres.jpg)