
Pokročilé architektury počítačů -...
26
Pokročilé architektury počítačů Superpočítače a paralelní počítání Tutoriál 4 Martin Milata
Transcript of Pokročilé architektury počítačů -...

Pokročilé architektury počítačů
Superpočítače a paralelní počítání
Tutoriál 4
Martin Milata


Dvě třídy MIMD multiprocesorů
● Třídy se odvíjí od počtu procesorů, který v důsledku definuje organizaci paměti a propojovací strategii
● Architektura s centralizovanou sdílenou pamětí● Menší počet procesorů (méně než 100) umožňuje sdílení jedné
centralizované paměti
● Použití cache pamětí per procesor
● Sdílená paměť dělená do banků (větší propustnost)– Pro všechny procesory zůstává zachována stejná (uniformní) přístupová
doba – Uniform Memory Access (UMA) se Symmetric (shared-memory) Multiprocessors (SMPs)
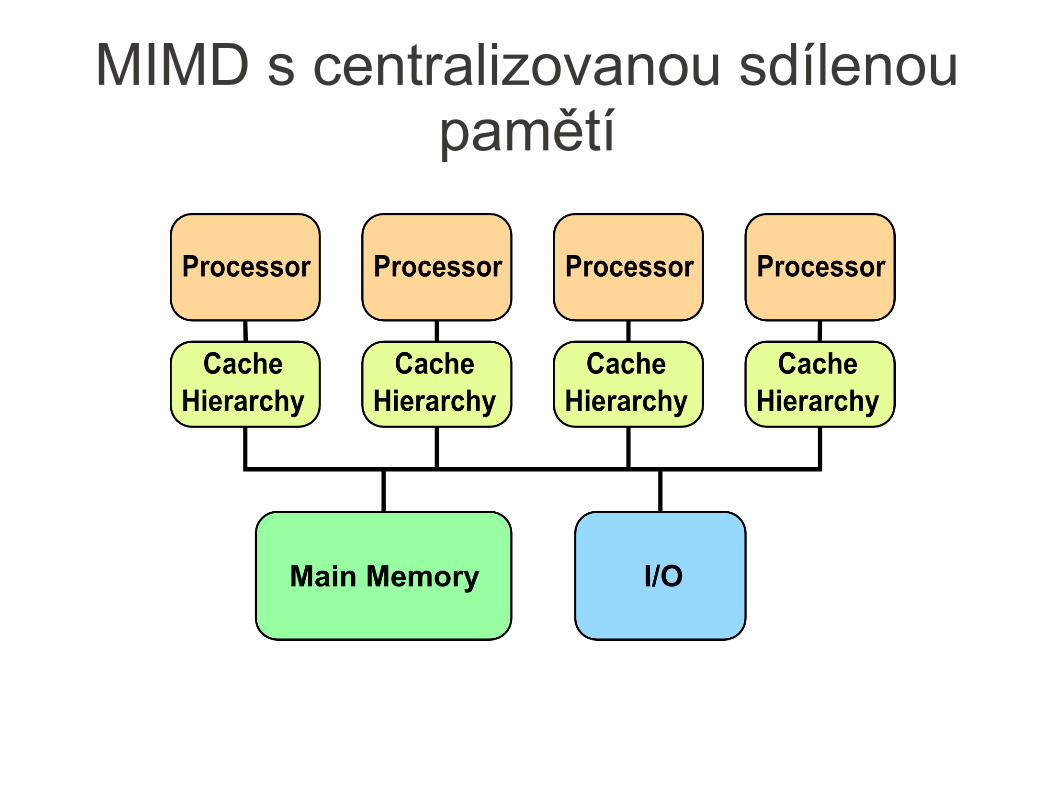
MIMD s centralizovanou sdílenou pamětí

Dvě třídy MIMD multiprocesorů
● Architektura multiprocesorů s fyzicky distribuovanou pamětí● Umožňuje použití většího počtu procesoru v klasteru v
porovnání s architekturou se sdílenou pamětí
● Lepší škálovatelnost - cenově dostupnější řešení složené z většího počtu levnějších pamětí
● Větší šířka pásma – každý uzel přispívá šířkou lokální směrnice k její celkové velikosti
● Redukce latence přístupu do paměti - většina přístupu řešena lokálně v rámci jednoho uzlu
● Komplikovaný a pomalý přístup do pamětí jiných uzlů (vzdálený přístup)– Jednotlivé uzly musejí být propojeny vhodnou propojovací sítí (obousměrná
přepínaná síť, vedlejší multidimenzionální síť)
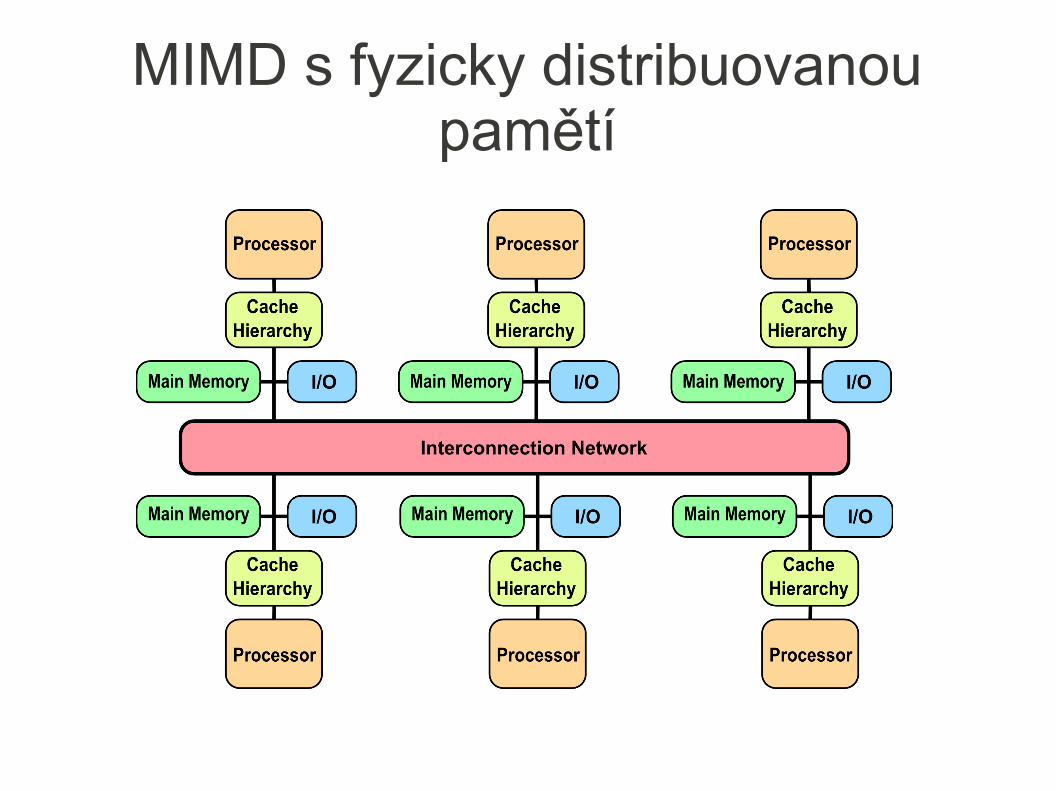
MIMD s fyzicky distribuovanou pamětí

Modely přístupu k paměti
Na základě modelu adresního prostoru sdílené paměti rozlišujeme dva přístupy
● Sdílený adresní prostor● Adresní prostor je rozprostřen přes všechny uzly resp. části
distribuované paměti
● Vytváří tím jeden logický sdílený adresní prostor
– Pomocí něj může být adresována libovolná paměťová buňka kdekoliv v distribuované soustavě
– Model se nazývá Distributed shared-memory (DSM)
● Přístupová doba v rámci celého prostoru není jednotná
– Přístup k lokální částí distribuované paměti je výrazně kratší ve srovnání s latencí vzdáleného přístupu
– Nonuniform memory access (NUMAs)
● Stejná fyzická adresa vždy ukazuje na stejnou paměťovou buňku

Modely přístupu k paměti
● Per uzel privátní adresní prostor● Každý uzel disponuje vlastním adresním prostorem
– Uzel lze chápat jako samostatný počítač (Obvykle je samostatným počítačem).
● Procesor nemá přímou možnost adresovat paměť jiného uzlu
● Stejná fyzická adresa na různých uzlech reprezentuje různé paměťové buňky
● Preferovaný paměťový model pro dnešní klasterová řešení
● Přístup k paměti cizích uzlů● Sdílený adresní prostor
– Load a Store instrukce, jejichž implementace počítá s možným přístupem mimo lokální paměť
● Privátní adresní prostory
– Metoda explicitního zasílání zpráv mezi procesory
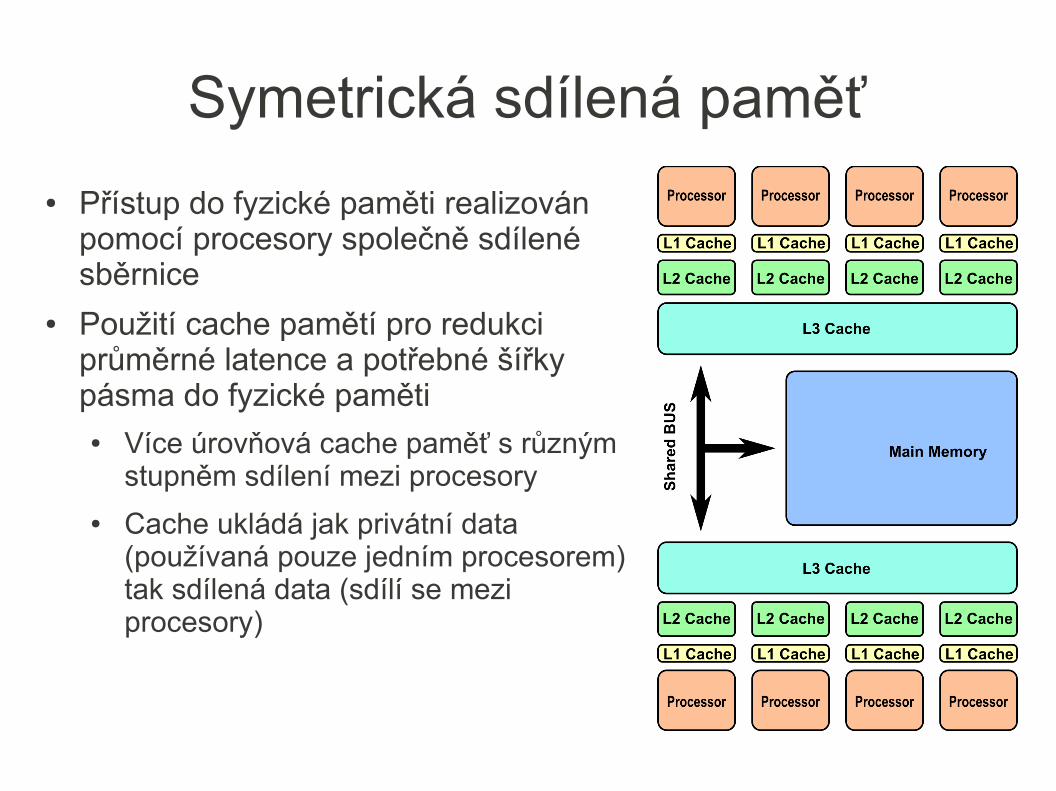
Symetrická sdílená paměť
● Přístup do fyzické paměti realizován pomocí procesory společně sdílené sběrnice
● Použití cache pamětí pro redukci průměrné latence a potřebné šířky pásma do fyzické paměti● Více úrovňová cache paměť s různým
stupněm sdílení mezi procesory
● Cache ukládá jak privátní data (používaná pouze jedním procesorem) tak sdílená data (sdílí se mezi procesory)

Cache paměť a multi-procesory
● Uložení sdílených dat v cache paměti● Redukuje přístupovou latenci a potřebnou šířku pásma pro přístup
do fyzické paměti
● Způsobuje replikaci a dočasné uložení informace na více místech a to i v rámci stejného stupně cache hierarchie– Cache přiřazená každému procesoru může obsahovat vlastní kopii dat
– Tím umožňuje paralelní přístup k datům bez vyvolání konfliktu na společné sběrnici
● Přináší problém cache koherence– Potřeba zajistit, aby každé čtení datové položky obsažené v cache pamětích
vrátilo pro něj aktuální zapsanou hodnotu
● Přináší problém konzistence– Definice pořadí read a write požadavků na sdílenou datovou položku

Schémata zajištění koherence
● Pro multiprocesorové systémy s menším počtem procesorů je obvykle protokol zajištění cache koherence implementován v HW● Jeho realizace je založena na sledování datových bloků na sdílené
sběrnici mezi procesory a fyzickou pamětí
● Dvě základní třídy protokolu pro zajištění cache koherence● Directory based - Stav sdílení bloku fyzické paměti je udržován na jednom
místě (directory). Přináší vyšší implementační režii než sooping. Výhodou je možnost použití s větším počtem procesorů
● Snooping – Stav bloků neuchovává centralizovaně. Podmínkou nasazení je možnost zaslání broadcast zprávy, kterou zaregistrují všechny cache kontroléry. Změny aktualizace obsahu bloků v cache se provádí na základně odposlouchávání komunikace jiných procesorů
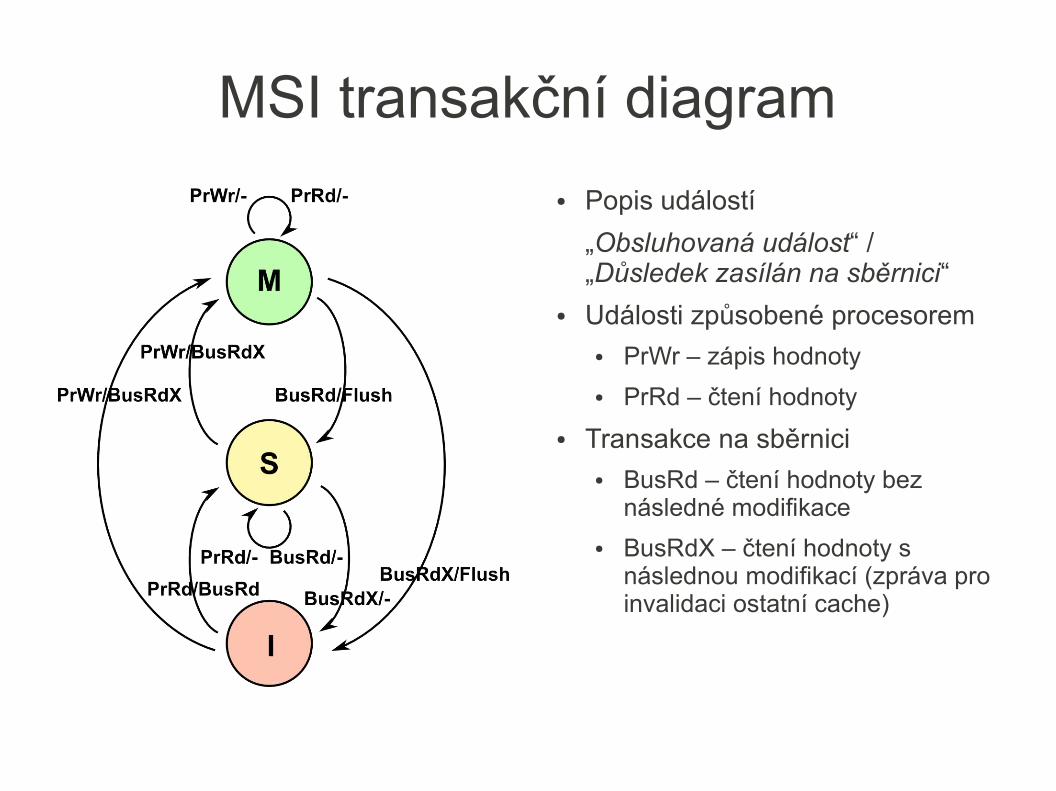
MSI transakční diagram
● Popis událostí
„Obsluhovaná událost“ / „Důsledek zasílán na sběrnici“
● Události způsobené procesorem● PrWr – zápis hodnoty
● PrRd – čtení hodnoty
● Transakce na sběrnici● BusRd – čtení hodnoty bez
následné modifikace
● BusRdX – čtení hodnoty s následnou modifikací (zpráva pro invalidaci ostatní cache)

Propojovací sítě paralelního počítače – taxonomie
● Komponenty propojovací sítě● Linka (drát, optika)
● Přepínač – význam závislý na použité technologii
● Výpočetní uzel
● Topologie● Statická síť – spojení realizováno p2p pevnými linkami (přímé propojení)
● Dynamická síť – propoj tvořen přepínanou sítí (nepřímé propojení – přepínačem zprostředkované)
● Povaha sítě● Blokující – existují takové cesty mezi různými uzly p, q a r, s pro něž
platí, že komunikace nemůže probíhat současně (konfliktní cesty)
● Neblokující – plně nezávislé cesty mezi všemi propojenými uzly
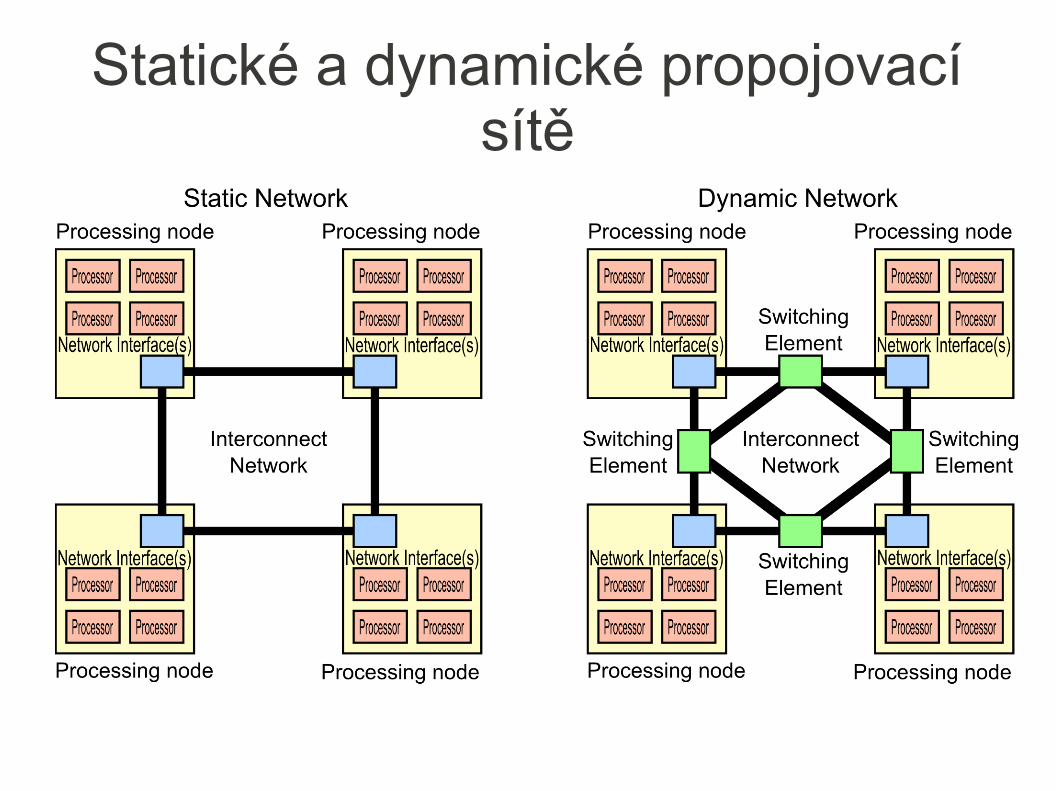
Statické a dynamické propojovací sítě

Vlastností propojovací sítě
● Síťové rozhraní● Zodpovídá za přípravu paketů, výpočet směrovací informace (obvykle
se nepohybujeme v prostředí IP sítí) a dočasné ukládání odesílaných resp. přijímaných dat (I/O buffering)
● Můžeme rozlišit na– I/O Bus (karty různých technologií nepříklad pro PCI, PCI Expres sloty)
– Memory Bus (Intel QuickPath Interconnect, AMD HyperTransport)
● Síťová topologie● Stupeň (uzlu) – počet linek na uzel
● Diametr (sítě) – nejkratší cesta mezi nejvzdálenějšími uzly sítě
● Bisekční šířka (Bisection Width) – minimální počat hran dělící síť na dvě části
● Cena – počet linek nebo přepínačů
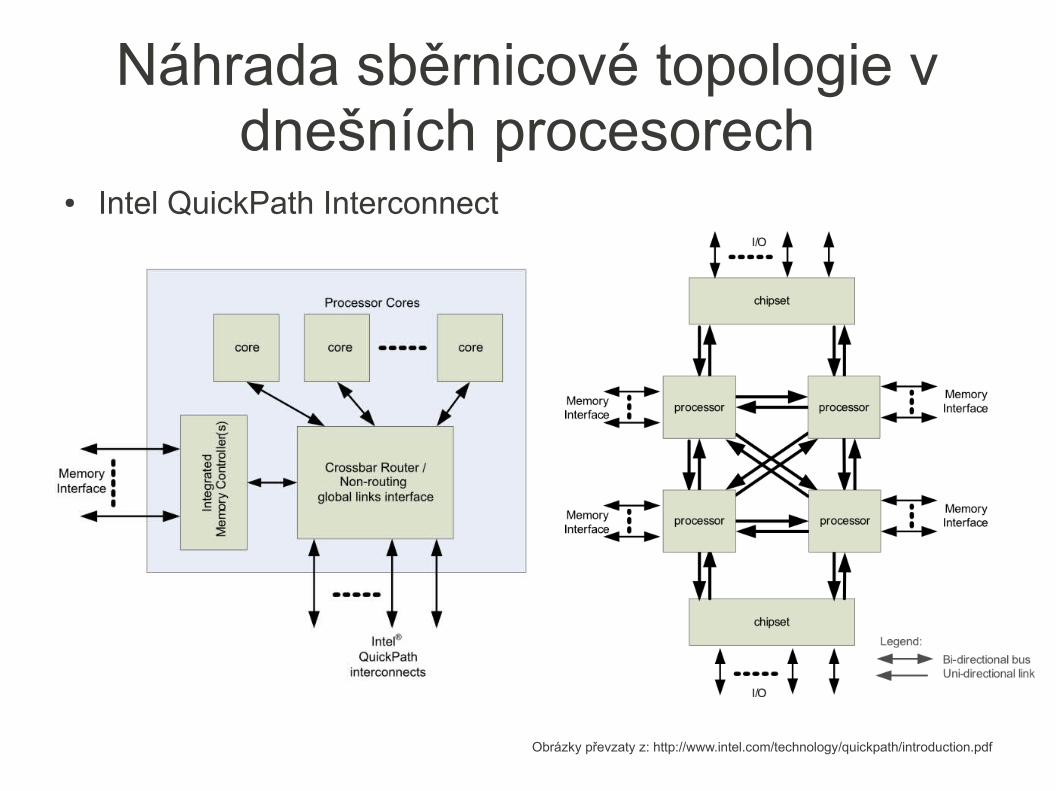
Náhrada sběrnicové topologie v dnešních procesorech
● Intel QuickPath Interconnect
Obrázky převzaty z: http://www.intel.com/technology/quickpath/introduction.pdf

Topologiepropojovacích sítí paralelních počítačů
● Nepřímé propojovací sítě● Sběrnice (Bus-Based Networks)
● Plně přepínaná síť (Crossbar Networks)
● Víceúrovňové sítě (Multistage Networks)
● Přímé propojovací sítě (modely)● Plně propojená síť (Full Mesh Networks)
● Síť s hvězdicovou topologií (Star-Connected Networks)
● k-dimenzionální mesh sítě (k-dim mesh Networks)
● Sítě se stromovou strukturou

Model topologie propojovací sítěStatické toroidní sítě
● Statické topologie s toroidním uspořádáním● n – rozměrný torus (1 – rozměrný torus resp. kruh, 2,3 – rozměrný
torus)
● 3D torus je často používaná topologie pro mnoha uzlové systémy

Fyzická versus logická topologie
● Fyzická organizace uzlů často nevyhovuje požadavkům na propojení prováděného výpočtu
● Nad fyzickou topologií se buduje logická s pomocí mapování výpočetních uzlů (vrcholů) logického uspořádání na fyzické● Pomocí logického přemapování topologie je možné realizovat
výpočet na superpočítačích s rozdílným fyzickým uspořádáním
● Metriky pro mapování mezi topologiemi G(V, E) na G'(V', E')● Congestion (Zahlcení)
– maximální počet hran z E mapovaný na hranu z E'
● Dilation (Roztažení)– maximální počet hran z E' mapovaný na jednu hranu z E
● Expansion (Rozšíření)– Četnost množiny V / četnost množiny V'
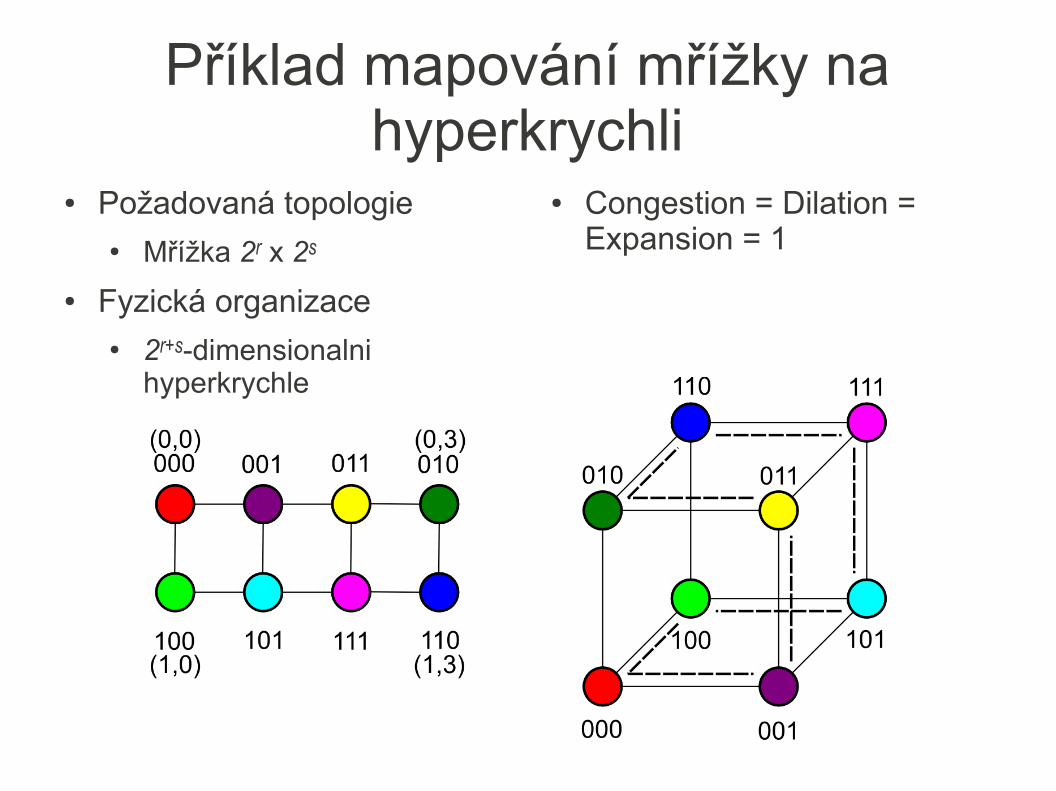
Příklad mapování mřížky na hyperkrychli
● Požadovaná topologie ● Mřížka 2r x 2s
● Fyzická organizace● 2r+s-dimensionalni
hyperkrychle
● Congestion = Dilation = Expansion = 1
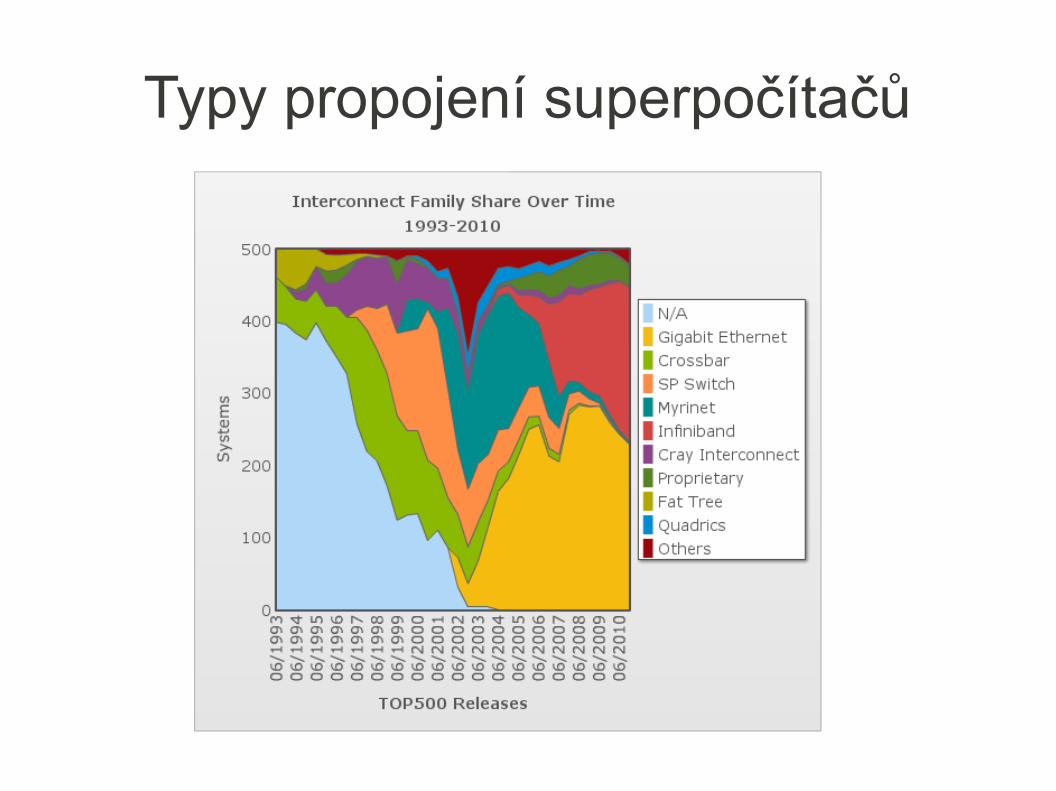
Typy propojení superpočítačů

Klastr
● Sestava vzájemně propojených počítačů (výpočetních uzlů)● Většinou homogenní (uzly stejné HW konfigurace)
● Uzly dokáží efektivně řešit paralelní algoritmy s pomocí vzájemné spolupráce (nestačí počítače propojit, musejí být schopny na úloze spolupracovat)
● Spolupráce uzlů a tím i paralelizace založena na zasílání zpráv (message-passing – MPI)● Obtížnější paralelizace ve srovnání s MPP
● Potřeba propojů mezi uzly s nízkou latencí a vysokou propustností– InfiniBand, kombinovaná a proprietární řešení
● Obtížnější správa ● Jedná se o samostatné počítače s více či méně nezávislými OS
– Distribuované souborové systémy, ...
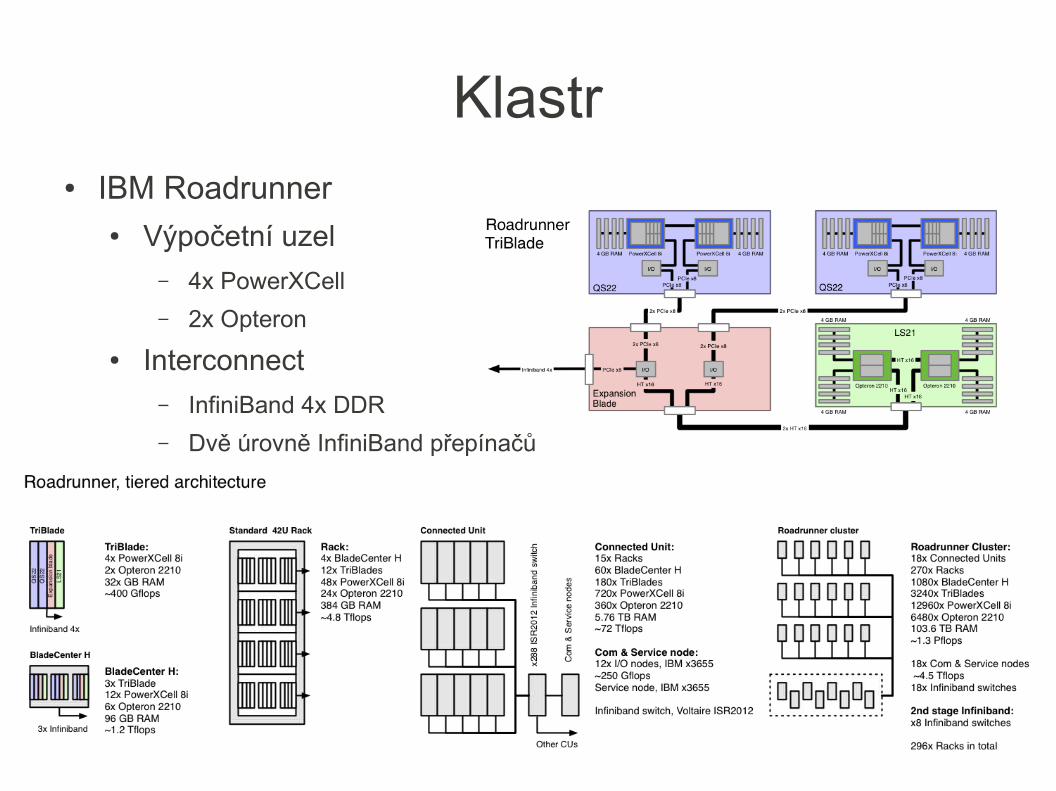
Klastr● IBM Roadrunner
● Výpočetní uzel– 4x PowerXCell
– 2x Opteron
● Interconnect– InfiniBand 4x DDR
– Dvě úrovně InfiniBand přepínačů

Literatura
● John L. Hennessy, David A. Patterson, Computer Architecture: A Quantitative Approach (4th Edition)
● Ananth Grama, Anshul Gupta, George Karypis, Vipin Kumar: Introduction to Parallel Computing, 2003
● Filip Staněk: Superpočítače dnes a zítra (aneb krátký náhled na SC)
● D. Goldenberg: InfiniBand Technology Overview● J. M. Crummey: Parallel Computing Platforms (Routing, Network
Embedding)● T. Shanley, J. Winkles: InfiniBand network architecture● Internetové zdroje
● www.wikipedia.org

Superpočítání a plánovač Torque
● Skript pro stažení a automatický import hlavního a výpočetních uzlů clustery
wget http://158.196.141.74/cluster/cluster.sh -O /tmp/cluster.sh● Importují se dva virtuální počítače
– HeadNode – řídící uzel klastru
– CN1 – výpočetní uzel klastru
● Druhý výpočetní uzel lze importovat stažením souborů a jejich následným importem do VirtualBoxu
wget http://158.196.141.74/cluster/CN2.vmdk -O /tmp/CN2.vmdk
wget http://158.196.141.74/cluster/cn2.ovf -O /tmp/cn2.ovf

Přístup k výpočetním uzlům
● Pro všechny uzly jsou platné dva přístupové účty ● root / pap
● pap / pap
● Práce s Torque● Výpis stavu konfigurovaných uzlů
pbsnodes -a
● Výpis konfigurace Torque na HeadNode
cat /var/spool/torque/server_priv/nodes
● Výpis fronty úloh
qstat
● Zařazení interaktivní úlohy (nelze jako root – su pap)
qsub -I
















