
Phrase-based Rāga Recognition using Vector Space...
71
Phrase-based R āga Recognition using Vector Space Modeling Sankalp Gulati * , Joan Serrà ^ , Vignesh Ishwar * , Sertan Şentürk * and Xavier Serra * e 41 st IEEE International Conference on Acoustics, Speech and Signal Processing Shanghai, China, 2016 * Music Technology Group, Universitat Pompeu Fabra, Barcelona, Spain ^ Telefonica Research, Barcelona, Spain
Transcript of Phrase-based Rāga Recognition using Vector Space...

Phrase-based Rāga Recognition using Vector Space Modeling
Sankalp Gulati*, Joan Serrà^, Vignesh Ishwar*, Sertan Şentürk* and Xavier Serra*
The 41st IEEE International Conference on Acoustics, Speech and Signal Processing Shanghai, China, 2016
*Music Technology Group, Universitat Pompeu Fabra, Barcelona, Spain ^Telefonica Research, Barcelona, Spain

Indian Art Music
Indian Art Music
Indian subcontinent: India, Pakistan, Bangladesh, Srilanka, Nepal and Bhutan

Indian Art Music

Indian Art Music: Hindustani music

Indian Art Music: Carnatic music

Rāga: melodic framework q Grammar for improvisation and composition
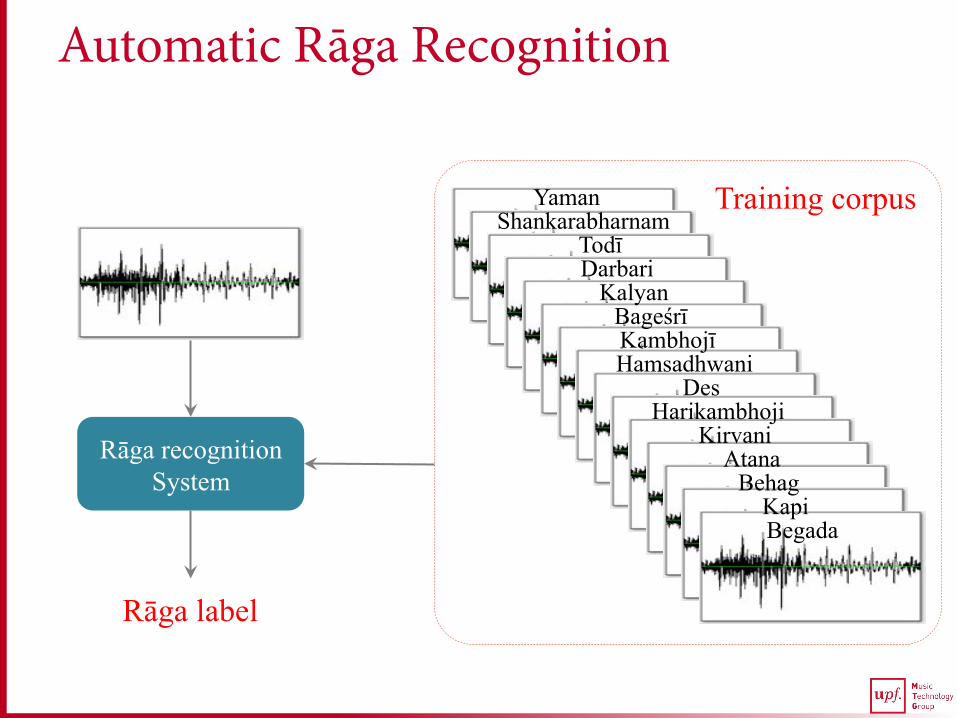
Automatic Rāga Recognition
Training corpus
Rāga recognition System
Rāga label
Yaman Shankarabharnam
Todī Darbari
Kalyan Bageśrī Kambhojī Hamsadhwani
Des Harikambhoji
Kirvani Atana
Behag Kapi Begada
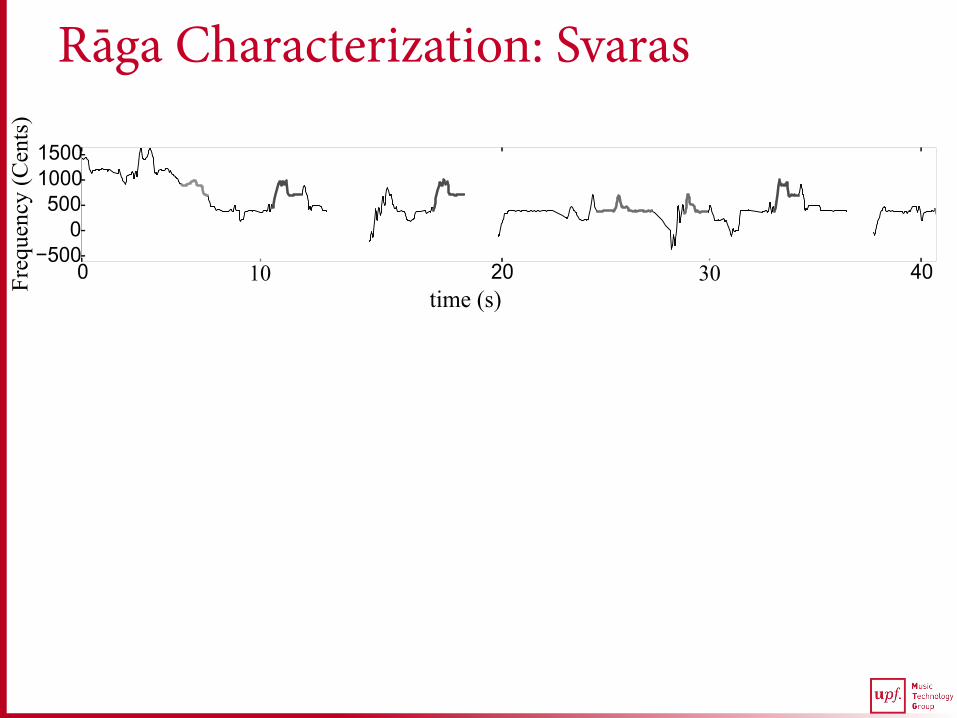
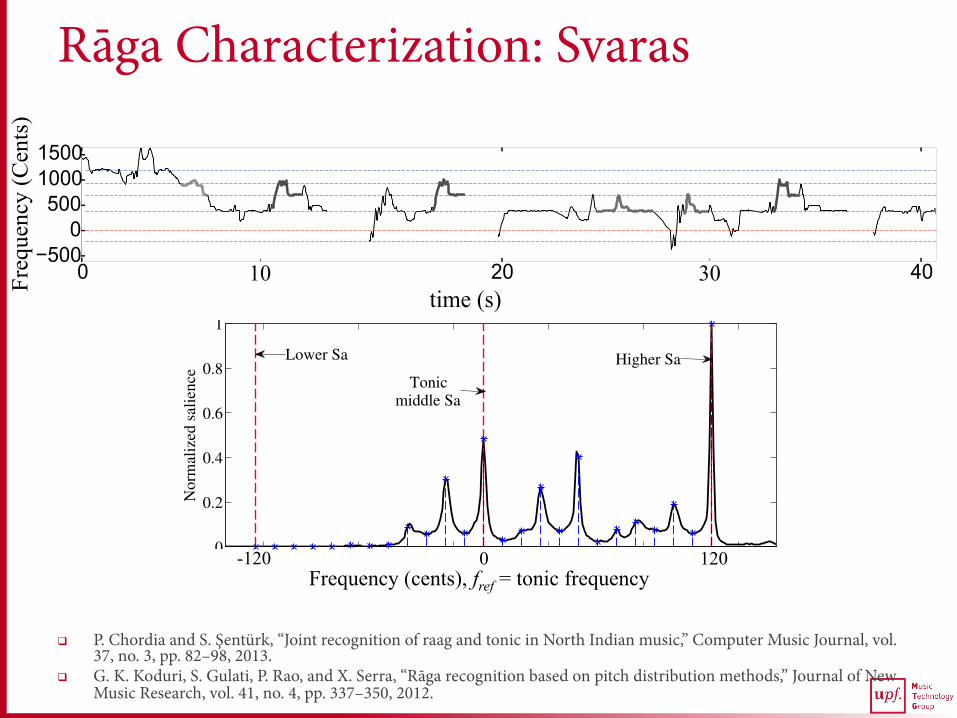
Rāga Characterization: Svaras
time (s) 10 30
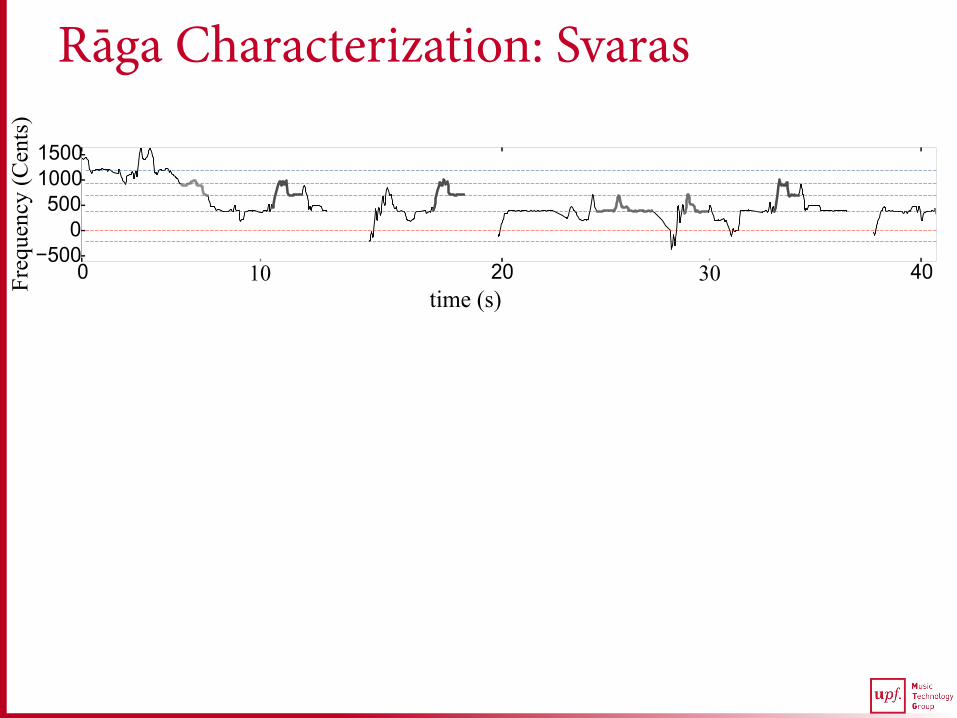
Rāga Characterization: Svaras
time (s) 10 30
Rāga Characterization: Svaras
50 100 150 200 250 3000
0.2
0.4
0.6
0.8
1
Frequency (bins), 1 bin = 10 Cents, Ref = 55 Hz
Norm
aliz
ed s
alie
nce
Lower Sa
Tonicmiddle Sa
Higher Sa
Frequency (cents), fref = tonic frequency
0 120 -120
q P. Chordia and S. Şentürk, “Joint recognition of raag and tonic in North Indian music,” Computer Music Journal, vol. 37, no. 3, pp. 82–98, 2013.
q G. K. Koduri, S. Gulati, P. Rao, and X. Serra, “Rāga recognition based on pitch distribution methods,” Journal of New Music Research, vol. 41, no. 4, pp. 337–350, 2012.
time (s) 10 30
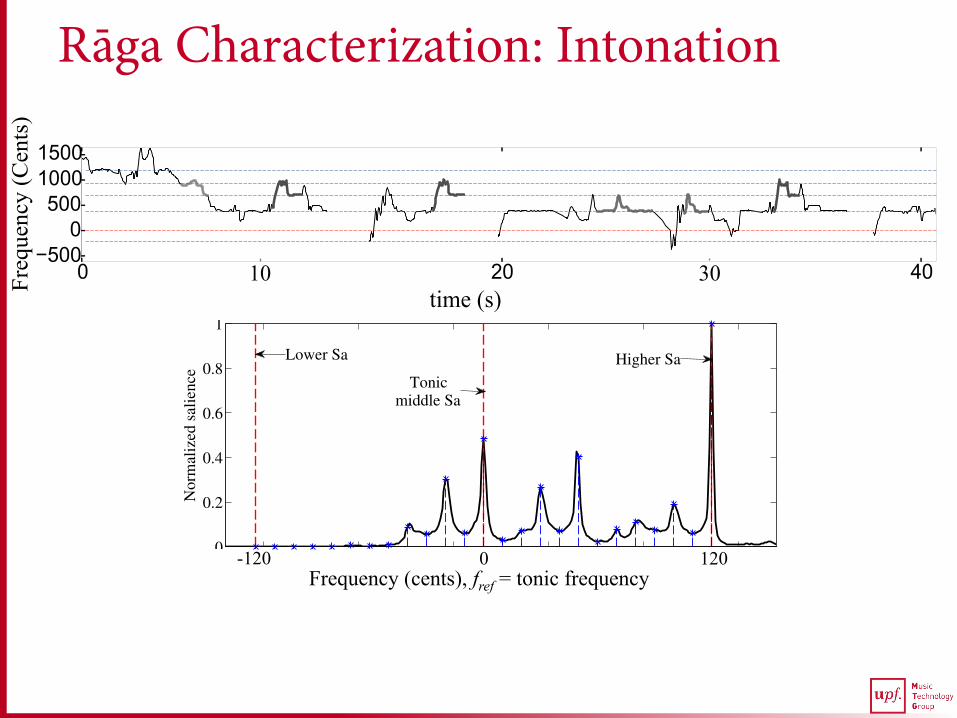
Rāga Characterization: Intonation
50 100 150 200 250 3000
0.2
0.4
0.6
0.8
1
Frequency (bins), 1 bin = 10 Cents, Ref = 55 Hz
Norm
aliz
ed s
alie
nce
Lower Sa
Tonicmiddle Sa
Higher Sa
Frequency (cents), fref = tonic frequency
0 120 -120
time (s) 10 30
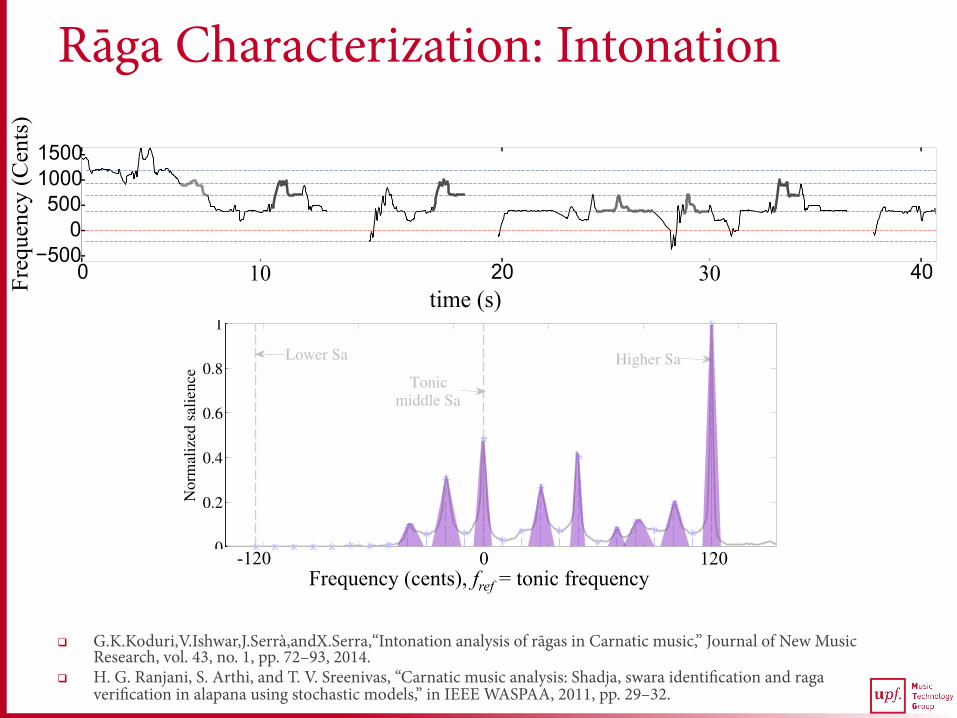
Rāga Characterization: Intonation
50 100 150 200 250 3000
0.2
0.4
0.6
0.8
1
Frequency (bins), 1 bin = 10 Cents, Ref = 55 Hz
Norm
aliz
ed s
alie
nce
Lower Sa
Tonicmiddle Sa
Higher Sa
Frequency (cents), fref = tonic frequency
0 120 -120
q G.K.Koduri,V.Ishwar,J.Serrà,andX.Serra,“Intonation analysis of rāgas in Carnatic music,” Journal of New Music Research, vol. 43, no. 1, pp. 72–93, 2014.
q H. G. Ranjani, S. Arthi, and T. V. Sreenivas, “Carnatic music analysis: Shadja, swara identification and raga verification in alapana using stochastic models,” in IEEE WASPAA, 2011, pp. 29–32.
time (s) 10 30
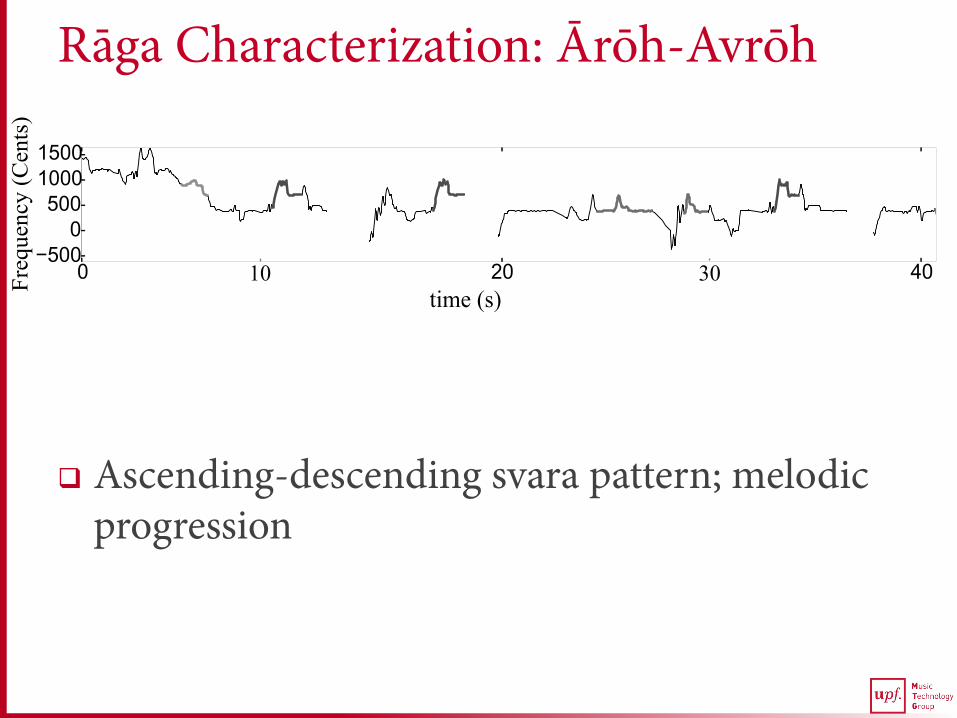
Rāga Characterization: Ārōh-Avrōh
q Ascending-descending svara pattern; melodic progression
time (s) 10 30
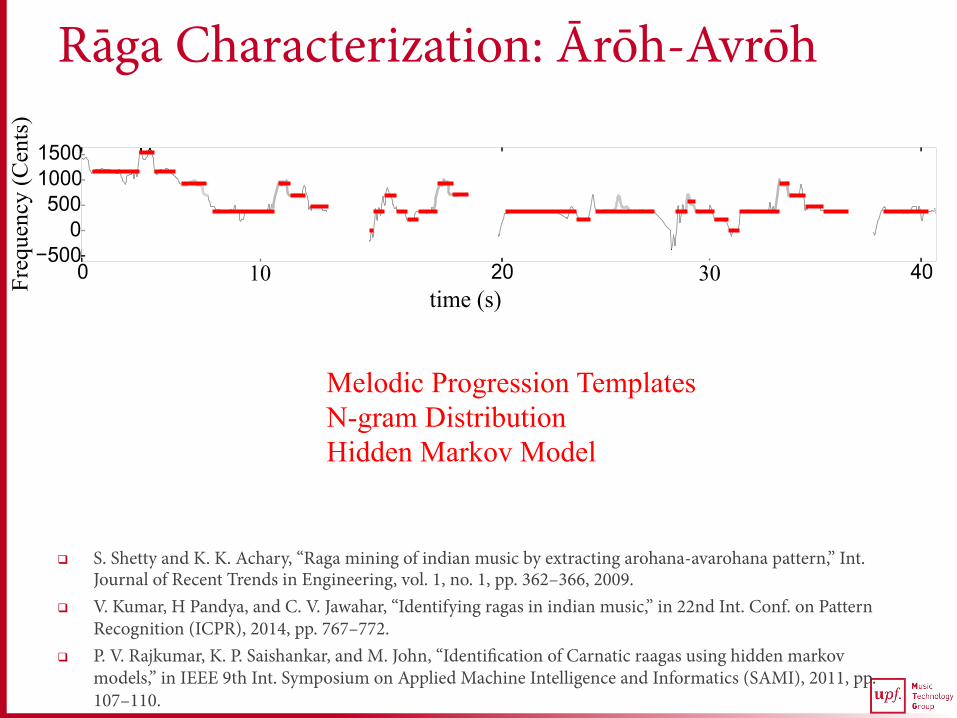
time (s) 10 30
Rāga Characterization: Ārōh-Avrōh
q S. Shetty and K. K. Achary, “Raga mining of indian music by extracting arohana-avarohana pattern,” Int. Journal of Recent Trends in Engineering, vol. 1, no. 1, pp. 362–366, 2009.
q V. Kumar, H Pandya, and C. V. Jawahar, “Identifying ragas in indian music,” in 22nd Int. Conf. on Pattern Recognition (ICPR), 2014, pp. 767–772.
q P. V. Rajkumar, K. P. Saishankar, and M. John, “Identification of Carnatic raagas using hidden markov models,” in IEEE 9th Int. Symposium on Applied Machine Intelligence and Informatics (SAMI), 2011, pp. 107–110.
Melodic Progression Templates N-gram Distribution Hidden Markov Model
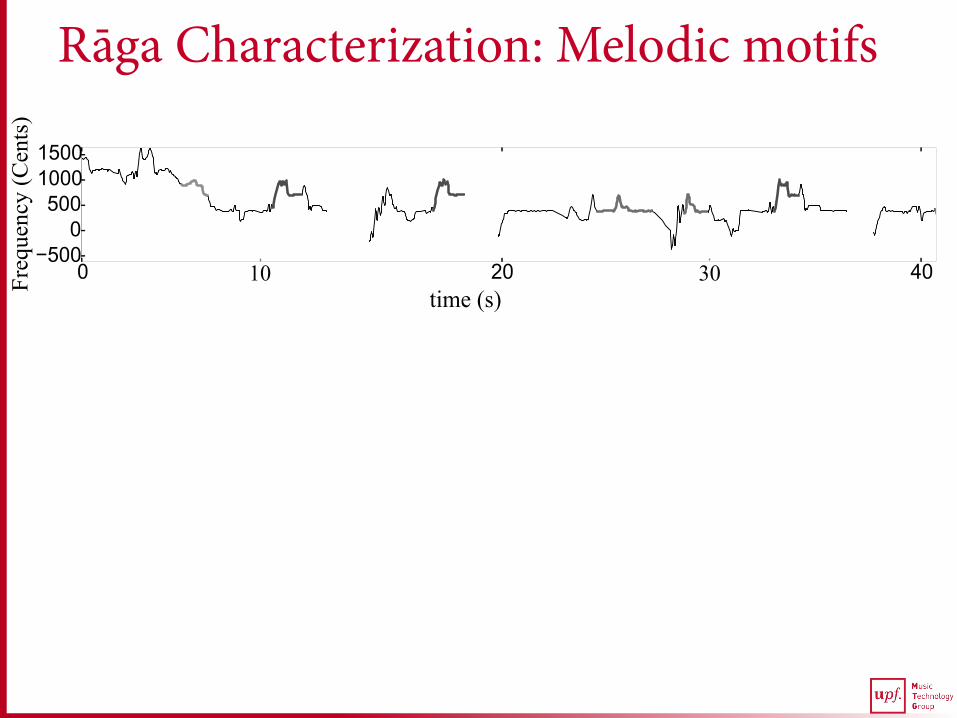
Rāga Characterization: Melodic motifs
time (s) 10 30
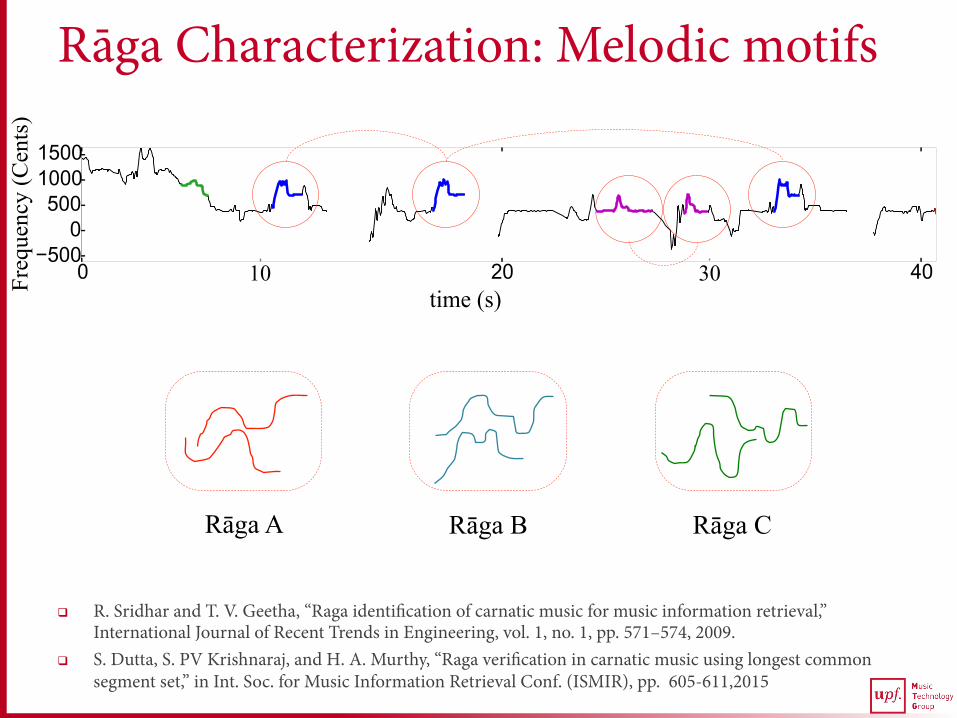
time (s) 10 30
Rāga Characterization: Melodic motifs
q R. Sridhar and T. V. Geetha, “Raga identification of carnatic music for music information retrieval,” International Journal of Recent Trends in Engineering, vol. 1, no. 1, pp. 571–574, 2009.
q S. Dutta, S. PV Krishnaraj, and H. A. Murthy, “Raga verification in carnatic music using longest common segment set,” in Int. Soc. for Music Information Retrieval Conf. (ISMIR), pp. 605-611,2015
Rāga A Rāga B Rāga C
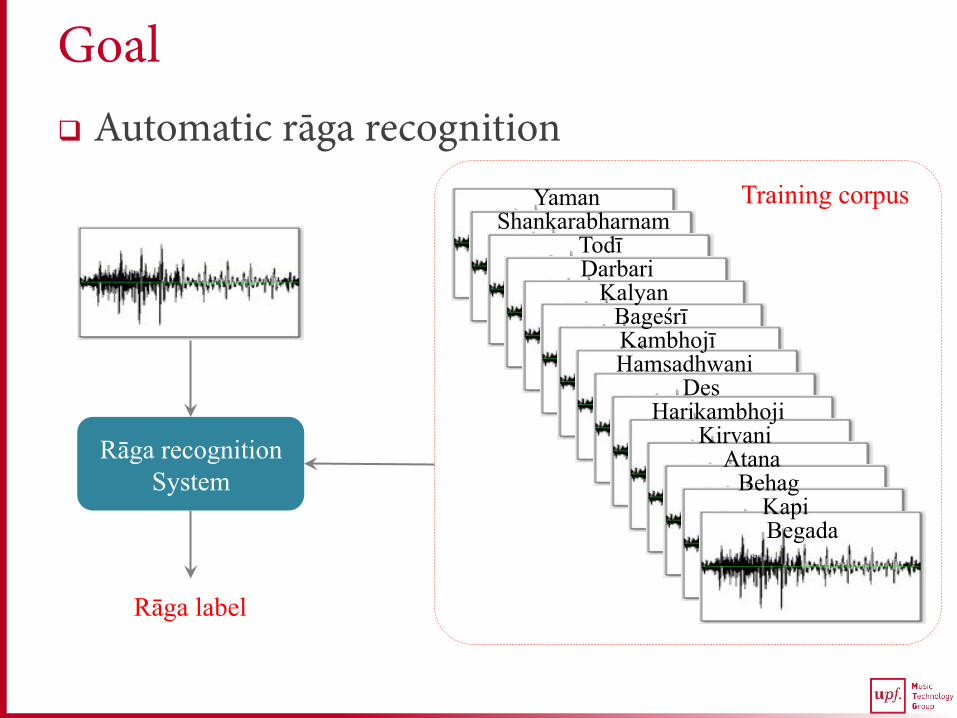
Goal q Automatic rāga recognition
Training corpus
Rāga recognition System
Rāga label
Yaman Shankarabharnam
Todī Darbari
Kalyan Bageśrī Kambhojī Hamsadhwani
Des Harikambhoji
Kirvani Atana
Behag Kapi Begada
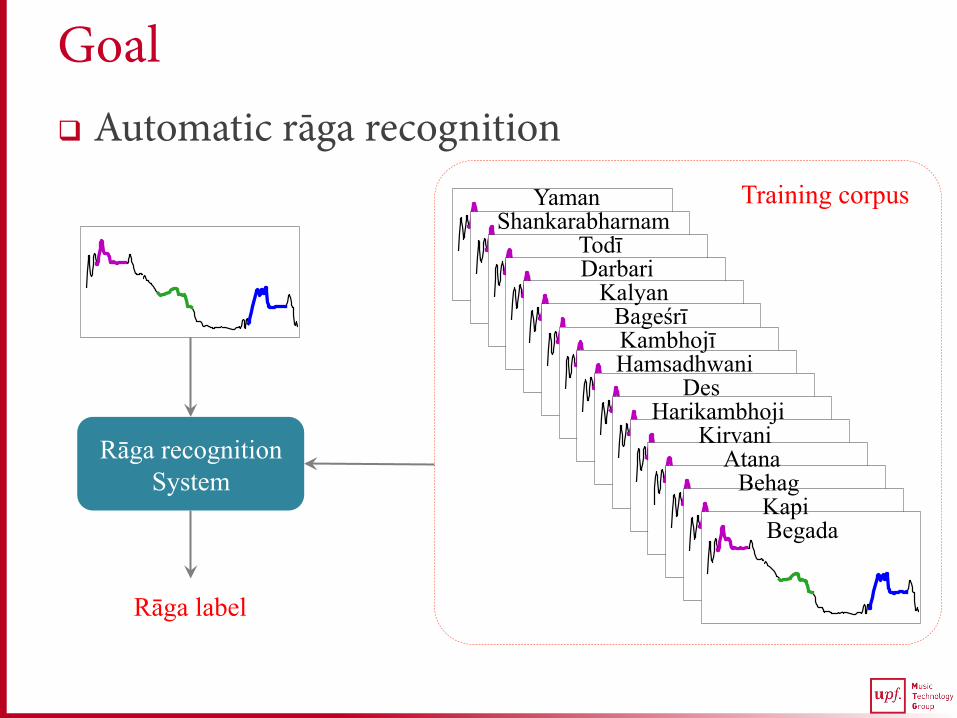
Goal q Automatic rāga recognition
Training corpus
Rāga recognition System
Rāga label
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
time (s) 10 30
Yaman Shankarabharnam
Todī Darbari
Kalyan Bageśrī Kambhojī Hamsadhwani
Des Harikambhoji
Kirvani Atana
Behag Kapi Begada
time (s) 10 30
time (s) 10 30
time (s) 10 30
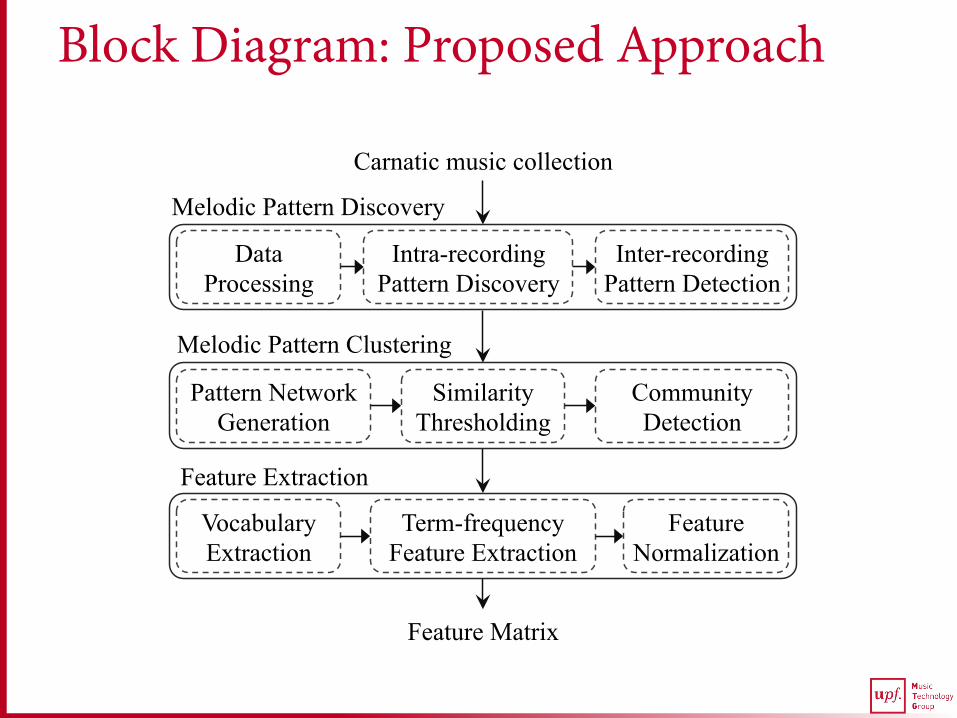
Block Diagram: Proposed Approach
Inter-recording Pattern Detection
Intra-recording Pattern Discovery
Data Processing
Pattern Network Generation
Similarity Thresholding
Community Detection
Carnatic music collection
Melodic Pattern Discovery
Melodic Pattern Clustering
Vocabulary Extraction
Term-frequency Feature Extraction
Feature Normalization
Feature Extraction
Feature Matrix
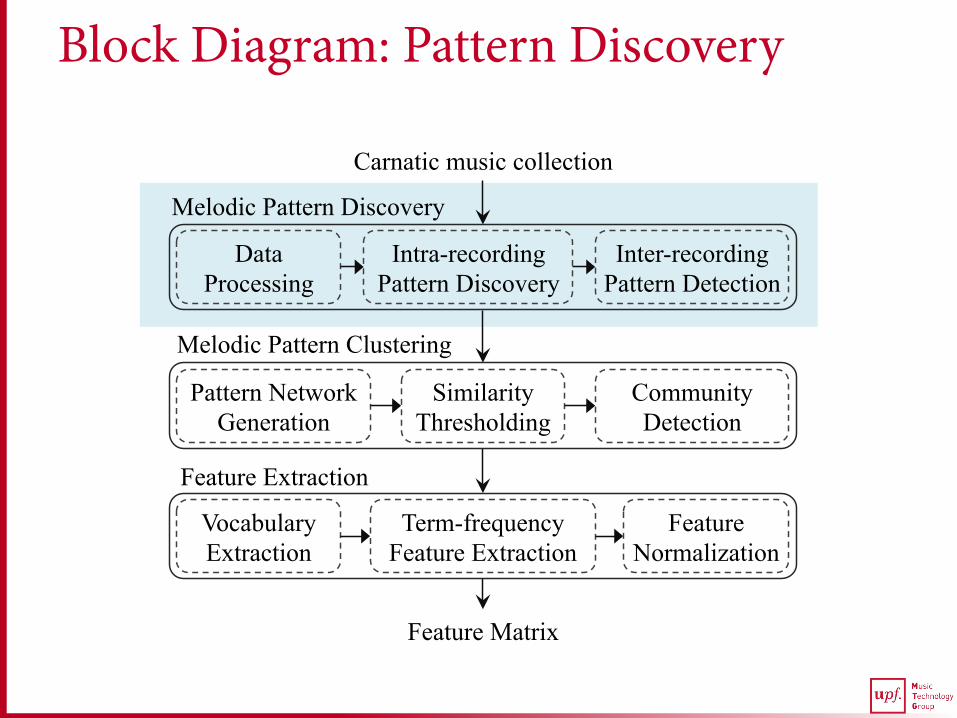
Block Diagram: Pattern Discovery
Inter-recording Pattern Detection
Intra-recording Pattern Discovery
Data Processing
Pattern Network Generation
Similarity Thresholding
Community Detection
Carnatic music collection
Melodic Pattern Discovery
Melodic Pattern Clustering
Vocabulary Extraction
Term-frequency Feature Extraction
Feature Normalization
Feature Extraction
Feature Matrix
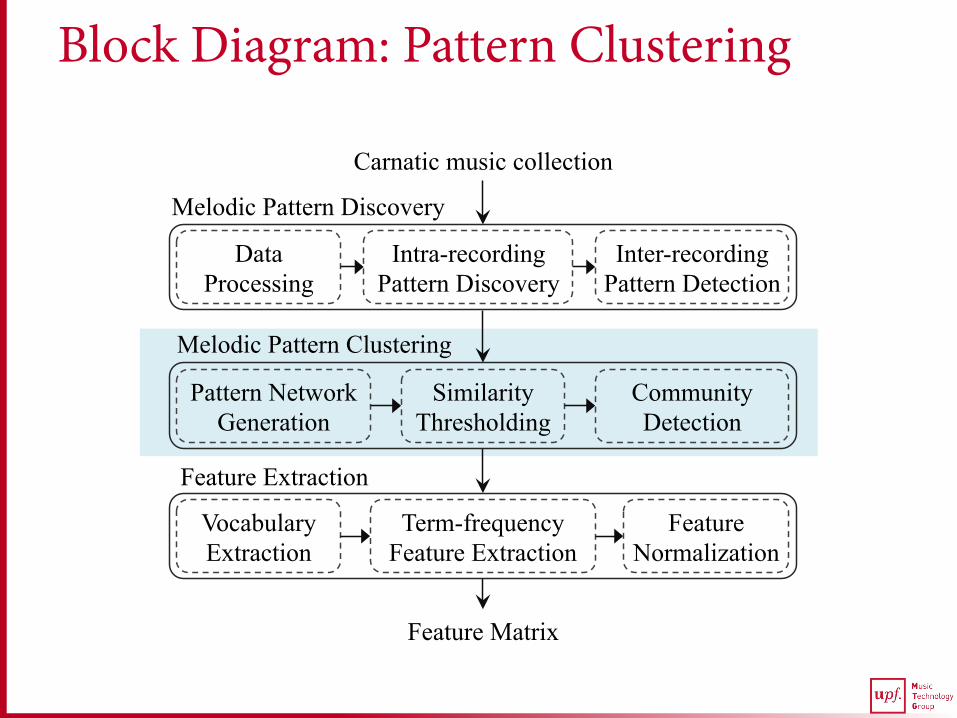
Block Diagram: Pattern Clustering
Inter-recording Pattern Detection
Intra-recording Pattern Discovery
Data Processing
Pattern Network Generation
Similarity Thresholding
Community Detection
Carnatic music collection
Melodic Pattern Discovery
Melodic Pattern Clustering
Vocabulary Extraction
Term-frequency Feature Extraction
Feature Normalization
Feature Extraction
Feature Matrix
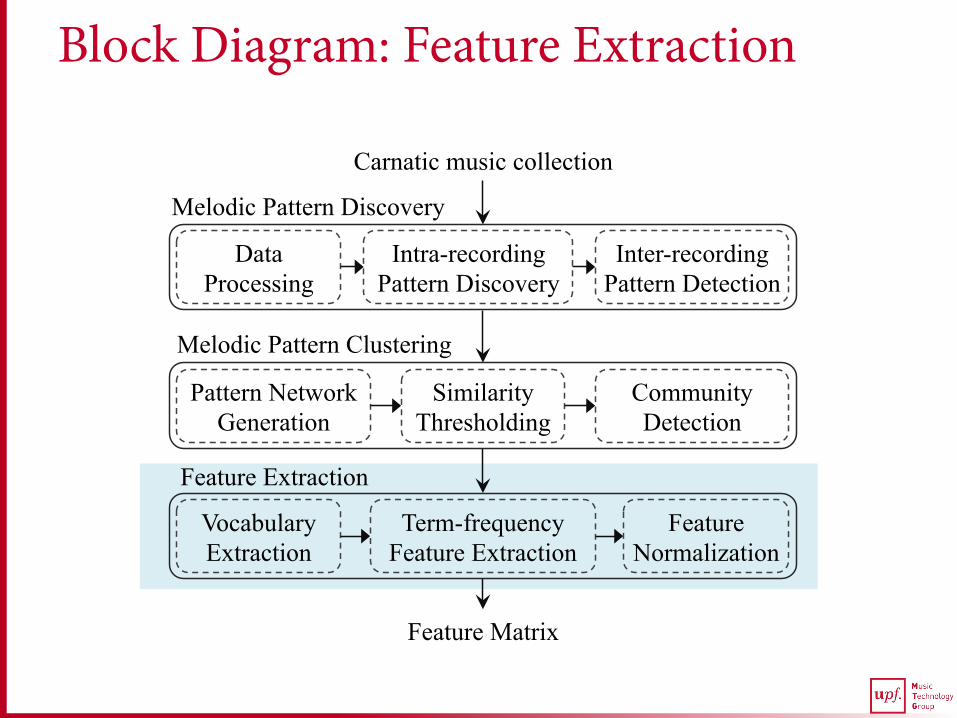
Block Diagram: Feature Extraction
Inter-recording Pattern Detection
Intra-recording Pattern Discovery
Data Processing
Pattern Network Generation
Similarity Thresholding
Community Detection
Carnatic music collection
Melodic Pattern Discovery
Melodic Pattern Clustering
Vocabulary Extraction
Term-frequency Feature Extraction
Feature Normalization
Feature Extraction
Feature Matrix
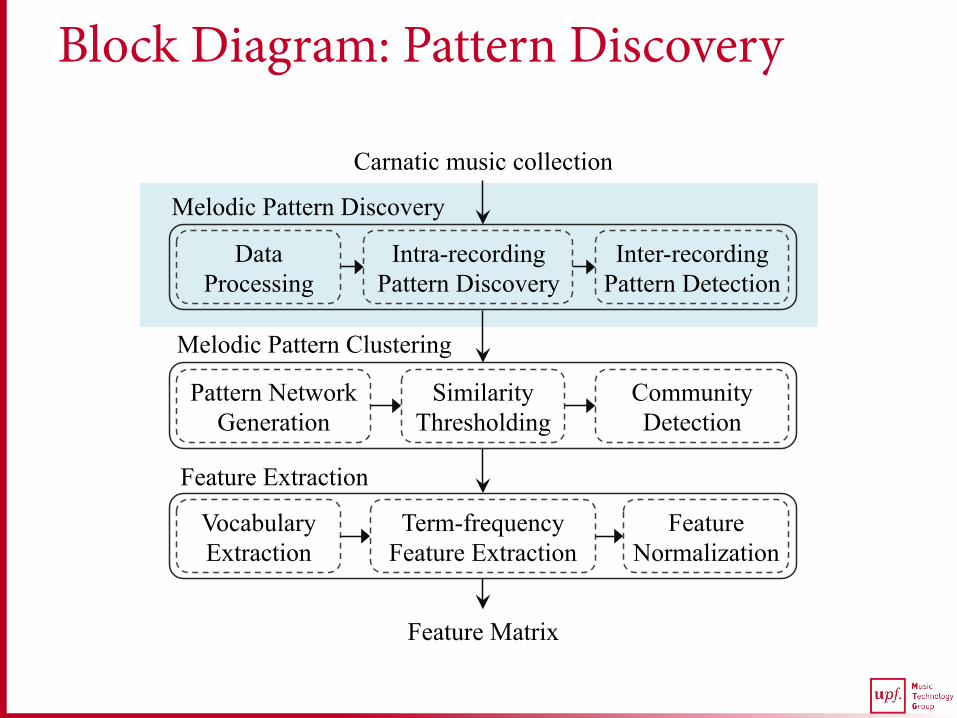
Block Diagram: Pattern Discovery
Inter-recording Pattern Detection
Intra-recording Pattern Discovery
Data Processing
Pattern Network Generation
Similarity Thresholding
Community Detection
Carnatic music collection
Melodic Pattern Discovery
Melodic Pattern Clustering
Vocabulary Extraction
Term-frequency Feature Extraction
Feature Normalization
Feature Extraction
Feature Matrix

Block Diagram: Pattern Discovery
Inter-recording Pattern Detection
Intra-recording Pattern Discovery
Data Processing
Pattern Network Generation
Similarity Thresholding
Community Detection
Carnatic music collection
Melodic Pattern Discovery
Melodic Pattern Clustering
Vocabulary Extraction
Term-frequency Feature Extraction
Feature Normalization
Feature Extraction
Feature Matrix
S. Gulati, J. Serrà, V. Ishwar, and X. Serra, “Mining melodic patterns in large audio collections of Indian art music,” in Int. Conf. on Signal Image Technology & Internet Based Systems - MIRA, Marrakesh, Morocco, 2014, pp. 264–271.
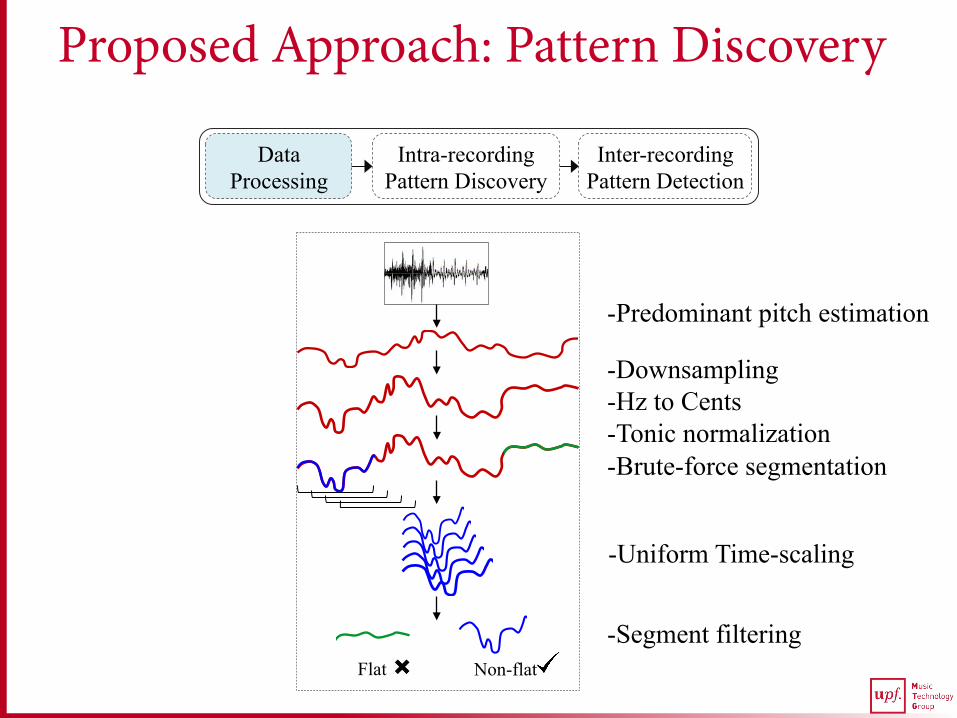
Proposed Approach: Pattern Discovery
-Predominant pitch estimation
-Downsampling -Hz to Cents -Tonic normalization -Brute-force segmentation
-Segment filtering
-Uniform Time-scaling
Flat Non-flat
Inter-recording Pattern Detection
Intra-recording Pattern Discovery
Data Processing
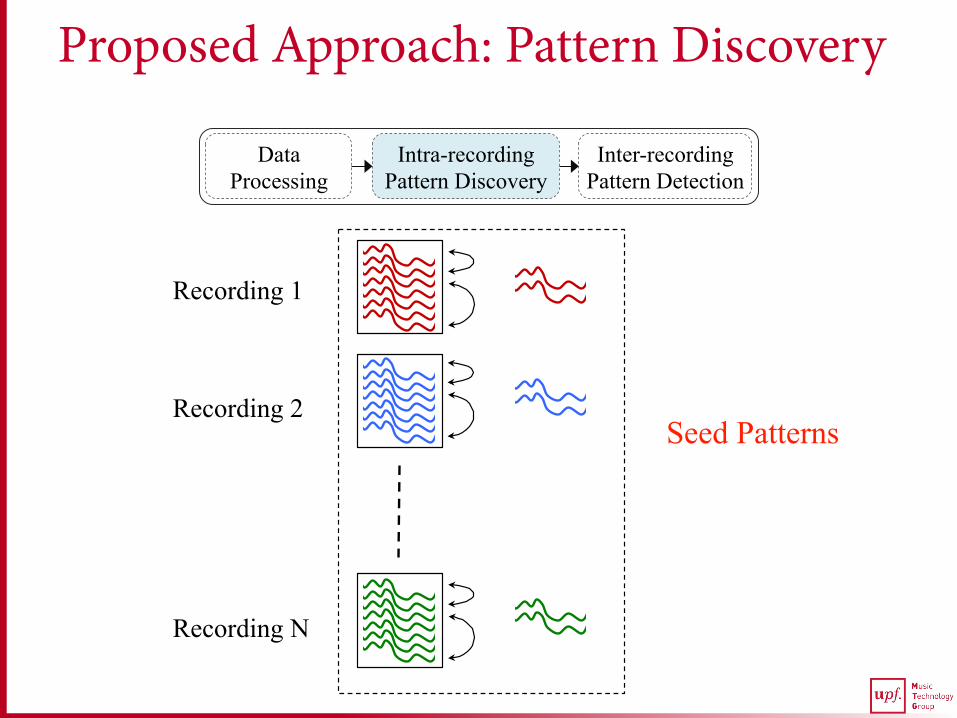
Proposed Approach: Pattern Discovery
Inter-recording Pattern Detection
Intra-recording Pattern Discovery
Data Processing
Seed Patterns
Recording 1
Recording 2
Recording N
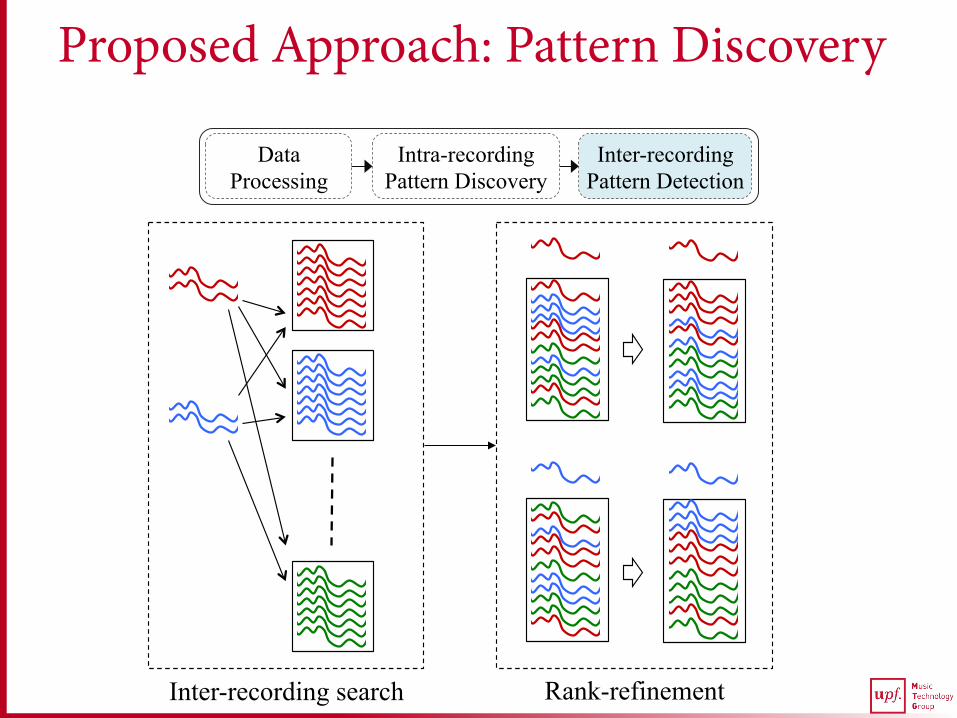
Proposed Approach: Pattern Discovery
Inter-recording Pattern Detection
Intra-recording Pattern Discovery
Data Processing
Inter-recording search Rank-refinement
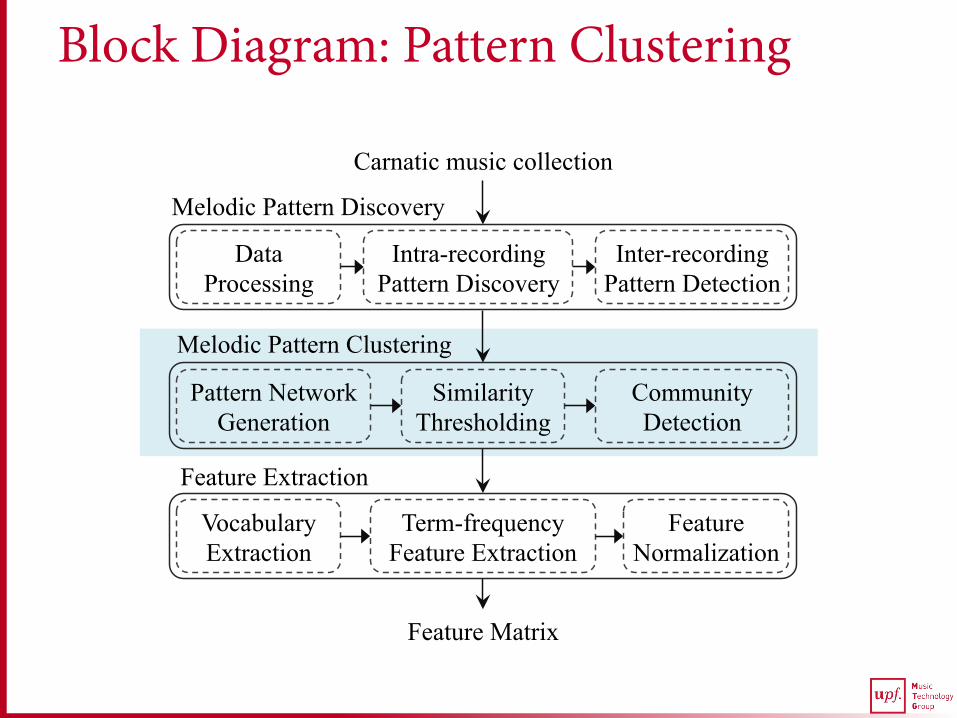
Block Diagram: Pattern Clustering
Inter-recording Pattern Detection
Intra-recording Pattern Discovery
Data Processing
Pattern Network Generation
Similarity Thresholding
Community Detection
Carnatic music collection
Melodic Pattern Discovery
Melodic Pattern Clustering
Vocabulary Extraction
Term-frequency Feature Extraction
Feature Normalization
Feature Extraction
Feature Matrix
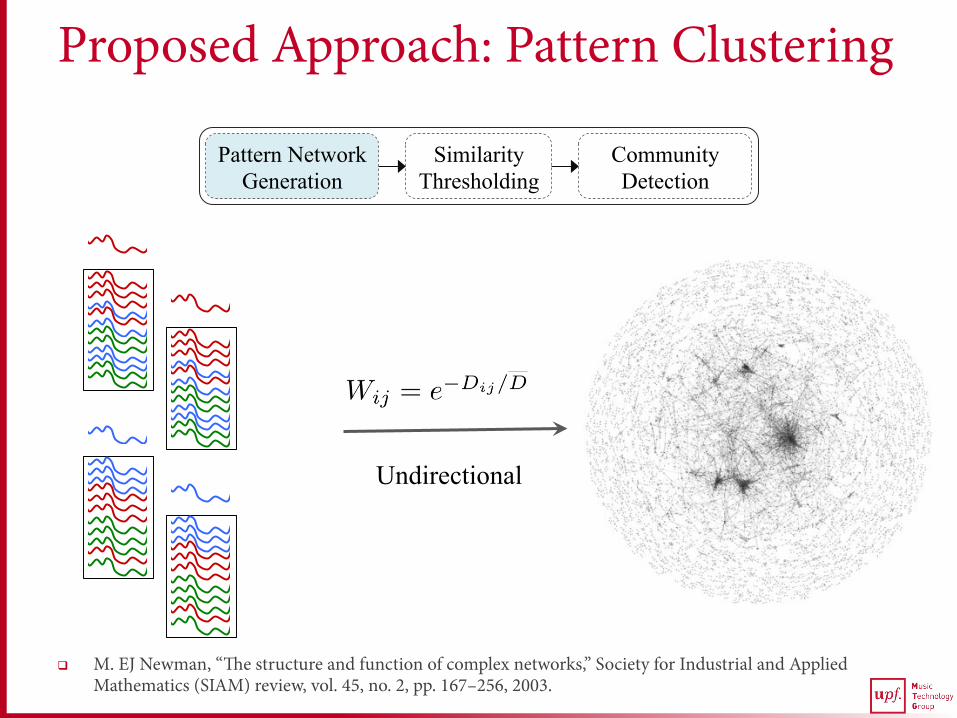
Proposed Approach: Pattern Clustering
q M. EJ Newman, “The structure and function of complex networks,” Society for Industrial and Applied Mathematics (SIAM) review, vol. 45, no. 2, pp. 167–256, 2003.
Pattern Network Generation
Similarity Thresholding
Community Detection
Undirectional
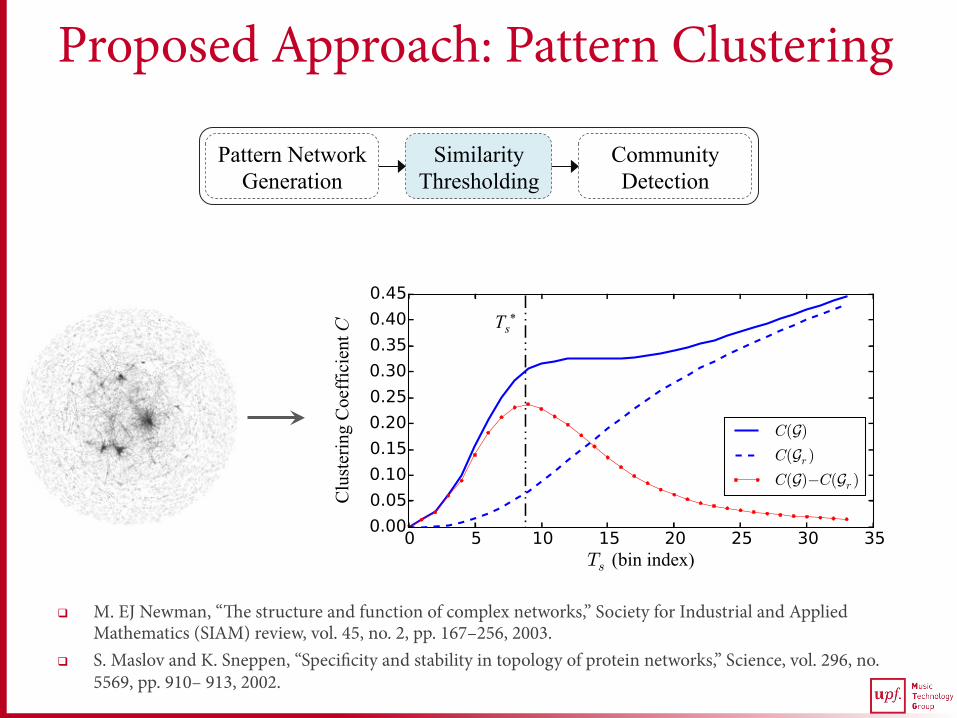
Proposed Approach: Pattern Clustering
q M. EJ Newman, “The structure and function of complex networks,” Society for Industrial and Applied Mathematics (SIAM) review, vol. 45, no. 2, pp. 167–256, 2003.
q S. Maslov and K. Sneppen, “Specificity and stability in topology of protein networks,” Science, vol. 296, no. 5569, pp. 910– 913, 2002.
Pattern Network Generation
Similarity Thresholding
Community Detection
Ts*
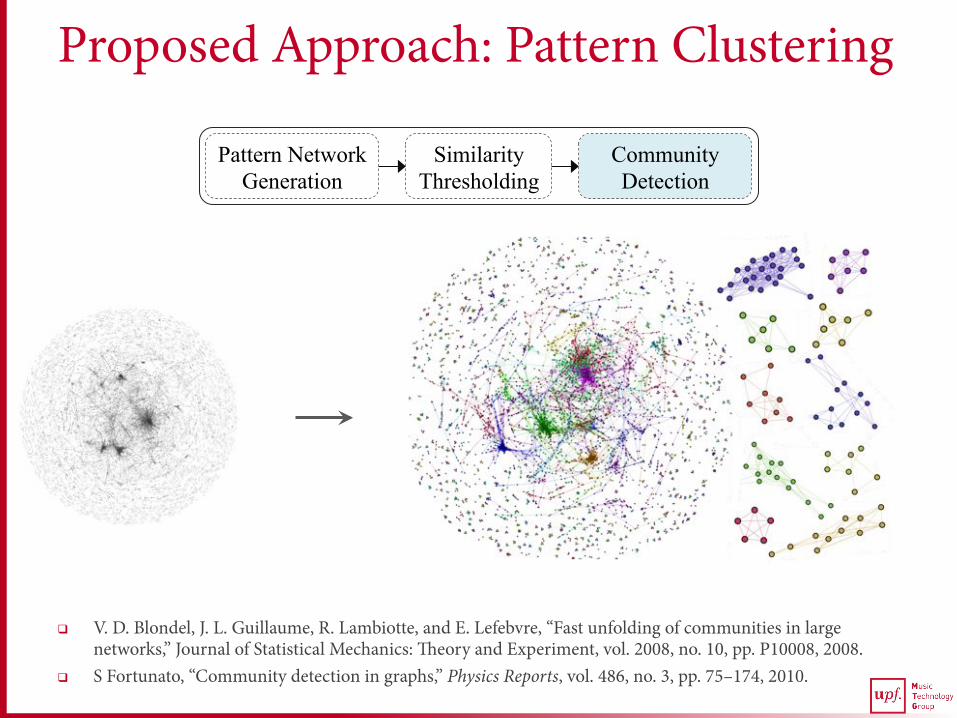
Proposed Approach: Pattern Clustering
q V. D. Blondel, J. L. Guillaume, R. Lambiotte, and E. Lefebvre, “Fast unfolding of communities in large networks,” Journal of Statistical Mechanics: Theory and Experiment, vol. 2008, no. 10, pp. P10008, 2008.
q S Fortunato, “Community detection in graphs,” Physics Reports, vol. 486, no. 3, pp. 75–174, 2010.
Pattern Network Generation
Similarity Thresholding
Community Detection
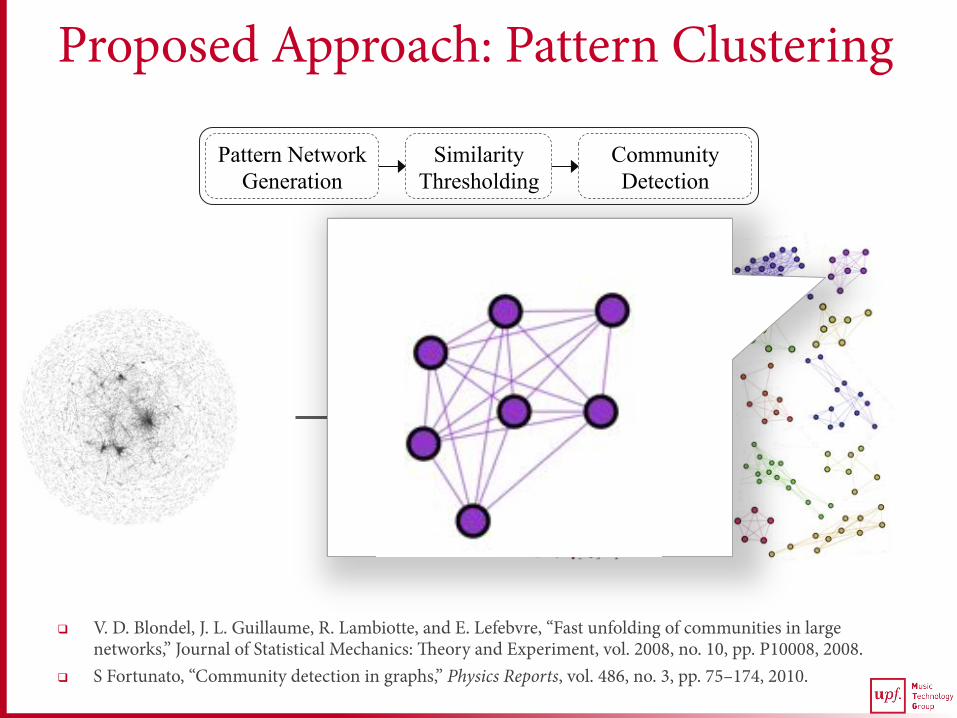
Proposed Approach: Pattern Clustering
Pattern Network Generation
Similarity Thresholding
Community Detection
q V. D. Blondel, J. L. Guillaume, R. Lambiotte, and E. Lefebvre, “Fast unfolding of communities in large networks,” Journal of Statistical Mechanics: Theory and Experiment, vol. 2008, no. 10, pp. P10008, 2008.
q S Fortunato, “Community detection in graphs,” Physics Reports, vol. 486, no. 3, pp. 75–174, 2010.
Block Diagram: Feature Extraction
Inter-recording Pattern Detection
Intra-recording Pattern Discovery
Data Processing
Pattern Network Generation
Similarity Thresholding
Community Detection
Carnatic music collection
Melodic Pattern Discovery
Melodic Pattern Clustering
Vocabulary Extraction
Term-frequency Feature Extraction
Feature Normalization
Feature Extraction
Feature Matrix

Proposed Approach: Feature Extraction

Proposed Approach: Feature Extraction
Text/document classification
Phrases Rāga
Recordings
Words Topic Documents

Proposed Approach: Feature Extraction
Text/document classification
Term Frequency Inverse Document Frequency (TF-IDF)
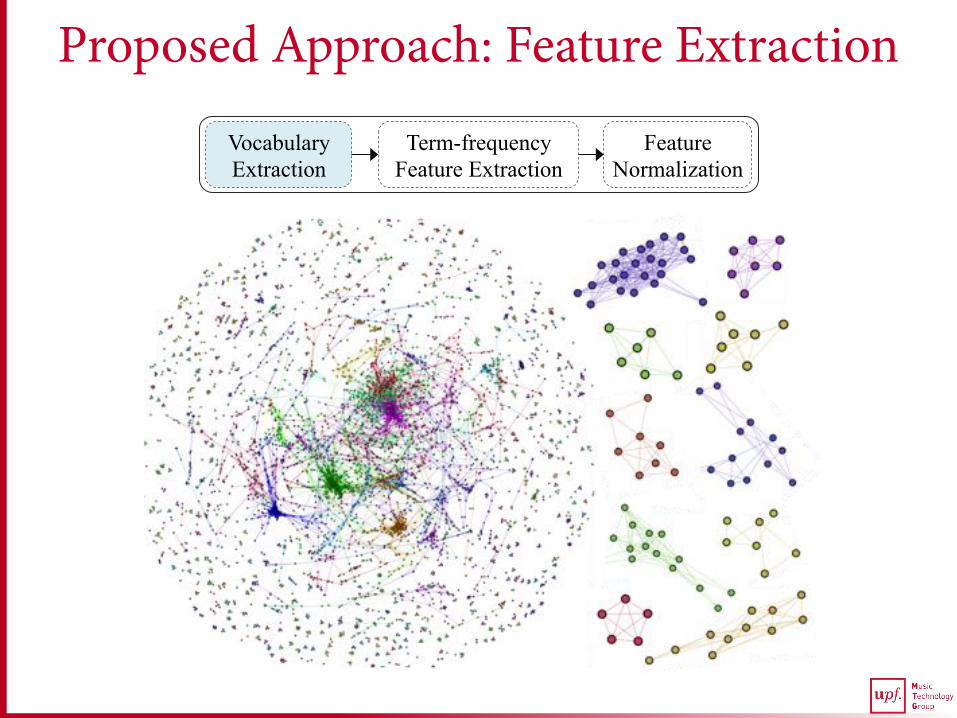
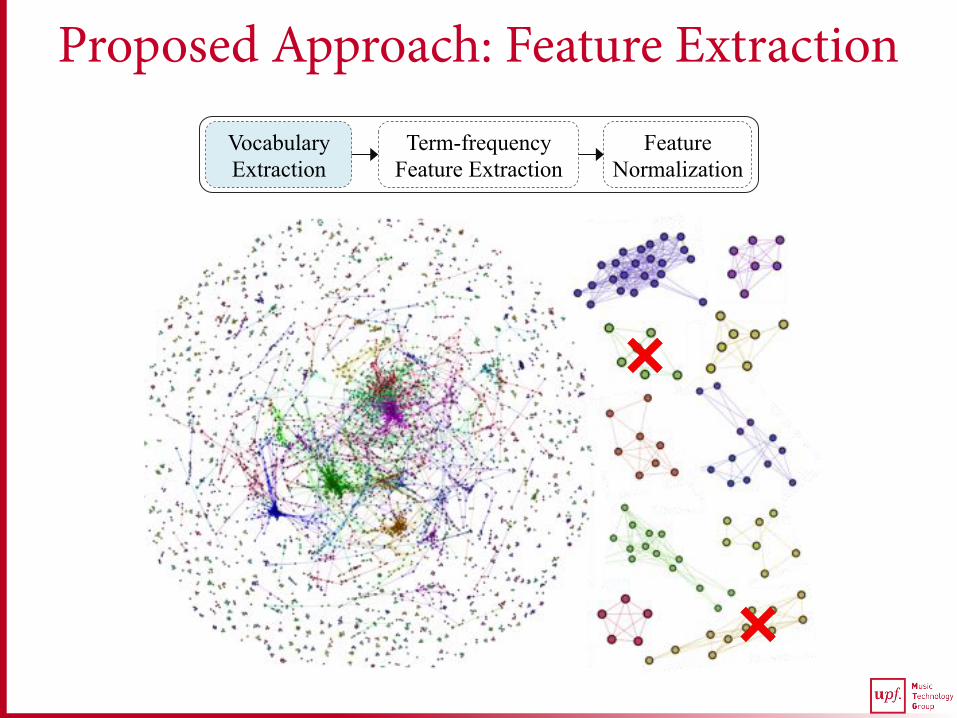
Proposed Approach: Feature Extraction Vocabulary Extraction
Term-frequency Feature Extraction
Feature Normalization
Proposed Approach: Feature Extraction Vocabulary Extraction
Term-frequency Feature Extraction
Feature Normalization

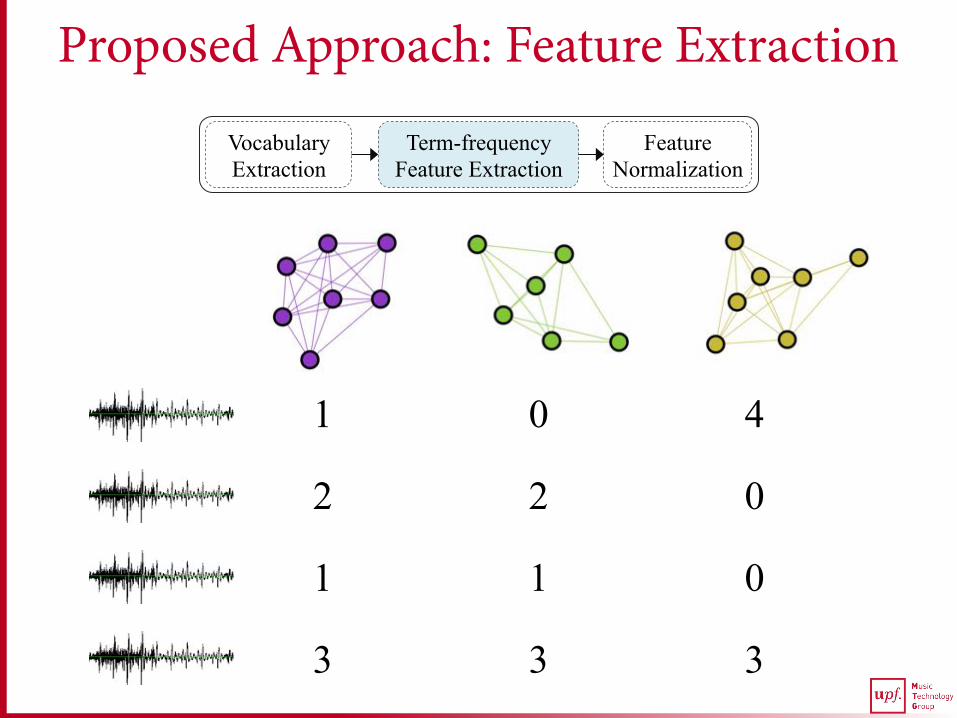
Proposed Approach: Feature Extraction Vocabulary Extraction
Term-frequency Feature Extraction
Feature Normalization
Proposed Approach: Feature Extraction
1 0 4
2 2 0
1 1 0
3 3 3
Vocabulary Extraction
Term-frequency Feature Extraction
Feature Normalization

Proposed Approach: Feature Extraction Vocabulary Extraction
Term-frequency Feature Extraction
Feature Normalization

Proposed Approach: Feature Extraction Vocabulary Extraction
Term-frequency Feature Extraction
Feature Normalization
F1(p, r) =
!
1, if f(p, r) > 0
0, otherwise(1)
F2(p, r) = f(p, r) (2)
F3(p, r) = f(p, r)× irf(p,R) (3)
irf(p,R) = log
"
N
|{r ∈ R : p ∈ r}|
#
(4)

Proposed Approach: Feature Extraction Vocabulary Extraction
Term-frequency Feature Extraction
Feature Normalization
F1(p, r) =
!
1, if f(p, r) > 0
0, otherwise(1)
F2(p, r) = f(p, r) (2)
F3(p, r) = f(p, r)× irf(p,R) (3)
irf(p,R) = log
"
N
|{r ∈ R : p ∈ r}|
#
(4)
F1(p, r) =
!
1, if f(p, r) > 0
0, otherwise(1)
F2(p, r) = f(p, r) (2)
F3(p, r) = f(p, r)× irf(p,R) (3)
irf(p,R) = log
"
N
|{r ∈ R : p ∈ r}|
#
(4)

Proposed Approach: Feature Extraction Vocabulary Extraction
Term-frequency Feature Extraction
Feature Normalization
F1(p, r) =
!
1, if f(p, r) > 0
0, otherwise(1)
F2(p, r) = f(p, r) (2)
F3(p, r) = f(p, r)× irf(p,R) (3)
irf(p,R) = log
"
N
|{r ∈ R : p ∈ r}|
#
(4)
F1(p, r) =
!
1, if f(p, r) > 0
0, otherwise(1)
F2(p, r) = f(p, r) (2)
F3(p, r) = f(p, r)× irf(p,R) (3)
irf(p,R) = log
"
N
|{r ∈ R : p ∈ r}|
#
(4)
F1(p, r) =
!
1, if f(p, r) > 0
0, otherwise(1)
F2(p, r) = f(p, r) (2)
F3(p, r) = f(p, r)× irf(p,R) (3)
irf(p,R) = log
"
N
|{r ∈ R : p ∈ r}|
#
(4)
F1(p, r) =
!
1, if f(p, r) > 0
0, otherwise(1)
F2(p, r) = f(p, r) (2)
F3(p, r) = f(p, r)× irf(p,R) (3)
irf(p,R) = log
"
N
|{r ∈ R : p ∈ r}|
#
(4)

Evaluation: Music Collection

Evaluation: Music Collection q Corpus: CompMusic Carnatic music
§ Commercial released music (~325) CDs § Metadata available in Musicbrainz
MusicBrainz

Evaluation: Music Collection q Corpus: CompMusic Carnatic music
§ Commercial released music (~325) CDs § Metadata available in Musicbrainz
q Datasets: subsets of corpus § DB40rāga
¨ 480 audio recordings, 124 hours of music ¨ 40 diverse set of rāgas ¨ 310 compositions, 62 unique artists
§ DB10rāga ¨ 10 rāga subset of DB40rāga
MusicBrainz

Evaluation: Music Collection q Corpus: CompMusic Carnatic music
§ Commercial released music (~325) CDs § Metadata available in Musicbrainz
q Datasets: subsets of corpus § DB40rāga
¨ 480 audio recordings, 124 hours of music ¨ 40 diverse set of rāgas ¨ 310 compositions, 62 unique artists
§ DB10rāga ¨ 10 rāga subset of DB40rāga
MusicBrainz
h#p://compmusic.upf.edu/node/278

Evaluation: Classification methodology q Experimental setup
§ Stratified 12-fold cross validation (balanced) § Repeat experiment 20 times § Evaluation measure: mean classification accuracy

Evaluation: Classification methodology q Experimental setup
§ Stratified 12-fold cross validation (balanced) § Repeat experiment 20 times § Evaluation measure: mean classification accuracy
q Classifiers § Multinomial, Gaussian and Bernoulli naive Bayes
(NBM, NBG and NBB) § SVM with a linear and RBF-kernel, and with a
SGD learning (SVML, SVMR and SGD) § logistic regression (LR) and random forest (RF)

Evaluation: Classification methodology q Statistical significance
§ Mann-Whitney U test (p < 0.01) § Multiple comparisons: Holm Bonferroni method
q H. B. Mann and D. R. Whitney, “On a test of whether one of two random variables is stochastically larger than the other,” The annals of mathematical statistics, vol. 18, no. 1, pp. 50–60, 1947.
q S. Holm, “A simple sequentially rejective multiple test procedure,” Scandinavian journal of statistics, vol. 6, no. 2, pp. 65–70, 1979.

Evaluation: Classification methodology q Statistical significance
§ Mann-Whitney U test (p < 0.01) § Multiple comparisons: Holm Bonferroni method
q Comparison with the state-of-the-art § S1: Pitch-class-distribution (PCD)-based method
(PCD120, PCDfull) § S2: Parameterized (PCD)-based method (PCDparam)
q H. B. Mann and D. R. Whitney, “On a test of whether one of two random variables is stochastically larger than the other,” The annals of mathematical statistics, vol. 18, no. 1, pp. 50–60, 1947.
q S. Holm, “A simple sequentially rejective multiple test procedure,” Scandinavian journal of statistics, vol. 6, no. 2, pp. 65–70, 1979.
q P. Chordia and S. Şentürk, “Joint recognition of raag and tonic in North Indian music,” Computer Music Journal, vol. 37, no. 3, pp. 82–98, 2013.
q G.K.Koduri,V.Ishwar,J.Serrà,andX.Serra,“Intonation analysis of rāgas in Carnatic music,” Journal of New Music Research, vol. 43, no. 1, pp. 72–93, 2014.
Results
where, f(p, r) denotes the raw frequency of occurrence of phrasep in recording r. F1 only considers the presence or absence of aphrase in a recording. In order to investigate if the frequency of oc-currence of melodic phrases is relevant for characterizing ragas, wetake F2(p, r) = f(p, r). As mentioned, the melodic phrases thatoccur across different ragas and in several recordings are futile forraga recognition. Therefore, to reduce their effect in the feature vec-tor we employ a weighting scheme, similar to the inverse documentfrequency (idf) weighting in text retrieval.
F3(p, r) = f(p, r)⇥ irf(p,R) (2)
irf(p,R) = log
✓N
|{r 2 R : p 2 r}|
◆(3)
where, |{r 2 R : p 2 r}| is the number of recordings where themelodic phrase p is present, that is f(p, r) 6= 0 for these recordings.We denote our proposed method by M
3. EVALUATION
3.1. Music Collection
The music collection used in this study is compiled as a part of theCompMusic project [26–28]. The collection comprises 124 hours ofcommercially available audio recordings of Carnatic music belong-ing to 40 ragas. For each raga, there are 12 music pieces, whichamounts to a total of 480 recordings. All the editorial metadata foreach audio recording is publicly available in Musicbrainz3, an open-source metadata repository. The music collection primarily consistsof vocal performances of 62 different artists. There are a total of 310different compositions belonging to diverse forms in Carnatic music(for example kirtana, varnam, virtuttam). The chosen ragas containdiverse set of svaras (note), both in terms of the number of svaras andtheir pitch-classes (svarasthanas). To facilitate comparative studiesand promote reproducible research we make this music collectionpublicly available online4.
From this music collection we build two datasets, which we de-note by DB40raga and DB10raga. DB40raga comprises the entiremusic collection and DB10raga comprises a subset of 10 ragas. Weuse DB10raga to make our results more comparable to studies wherethe evaluations are performed on similar number of ragas.
3.2. Classification and Evaluation Methodology
The features obtained above are used to train a classifier. In orderto assess the relevance of these features for raga recognition, we ex-periment with different algorithms exploiting diverse classificationstrategies [29]: Multinomial, Gaussian and Bernoulli naive Bayes(NBM, NBG and NBB, respectively), support vector machines witha linear and a radial basis function kernel, and with a stochastic gra-dient descent learning (SVML, SVMR and SGD, respectively), lo-gistic regression (LR) and random forest (RF). We use the imple-mentation of these classifiers available in scikit-learn toolkit [30],version 0.15.1. Since in this study, our focus is to extract a musicallyrelevant set of features based on melodic phrases, we use the defaultparameter settings for the classifiers available in scikit-learn.
We use a stratified 12-fold cross-validation methodology forevaluations. The folds are generated such that every fold comprisesequal number of feature instances per raga. We repeat the entireexperiment 20 times, and report the mean classification accuracy as
3https://musicbrainz.org4http://compmusic.upf.edu/node/278
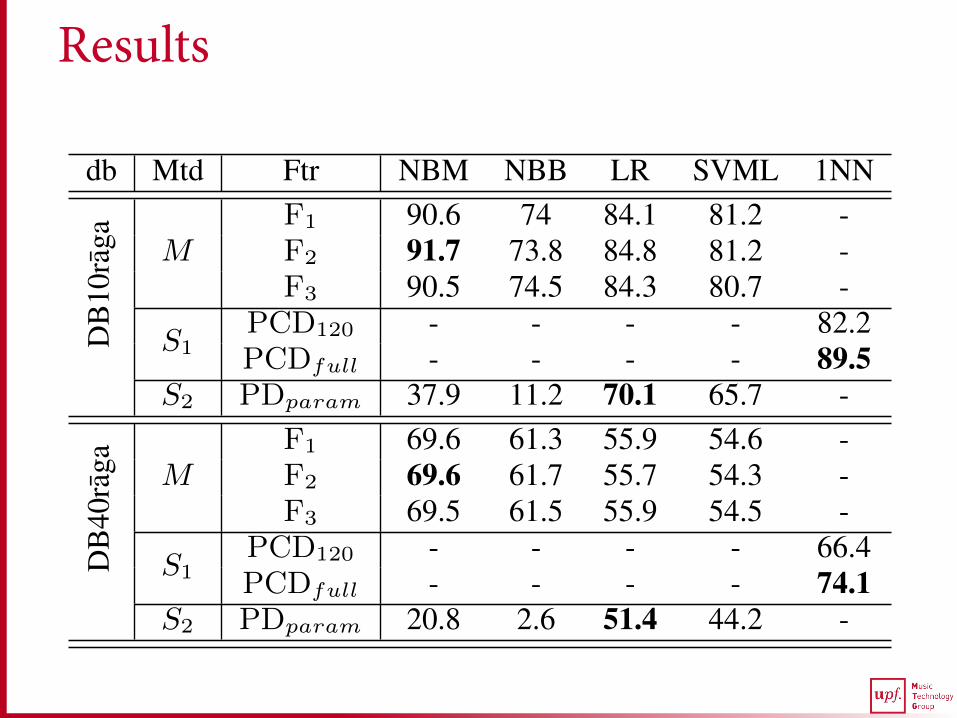
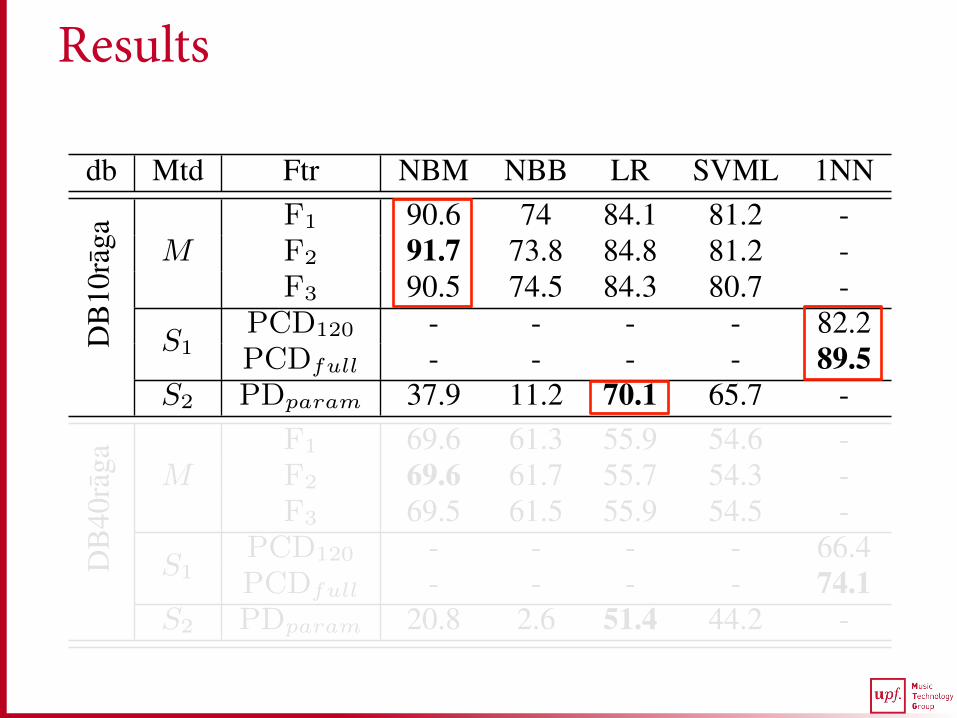
db Mtd Ftr NBM NBB LR SVML 1NN
DB
10ra
ga MF1 90.6 74 84.1 81.2 -F2 91.7 73.8 84.8 81.2 -F3 90.5 74.5 84.3 80.7 -
S1PCD120 - - - - 82.2PCDfull - - - - 89.5
S2 PDparam 37.9 11.2 70.1 65.7 -
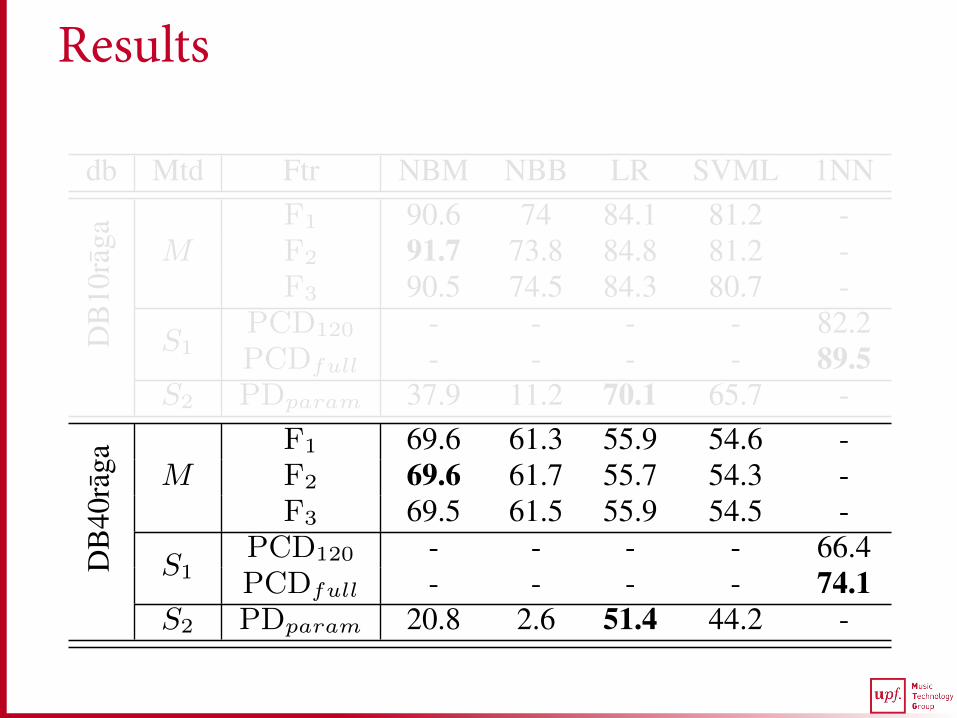
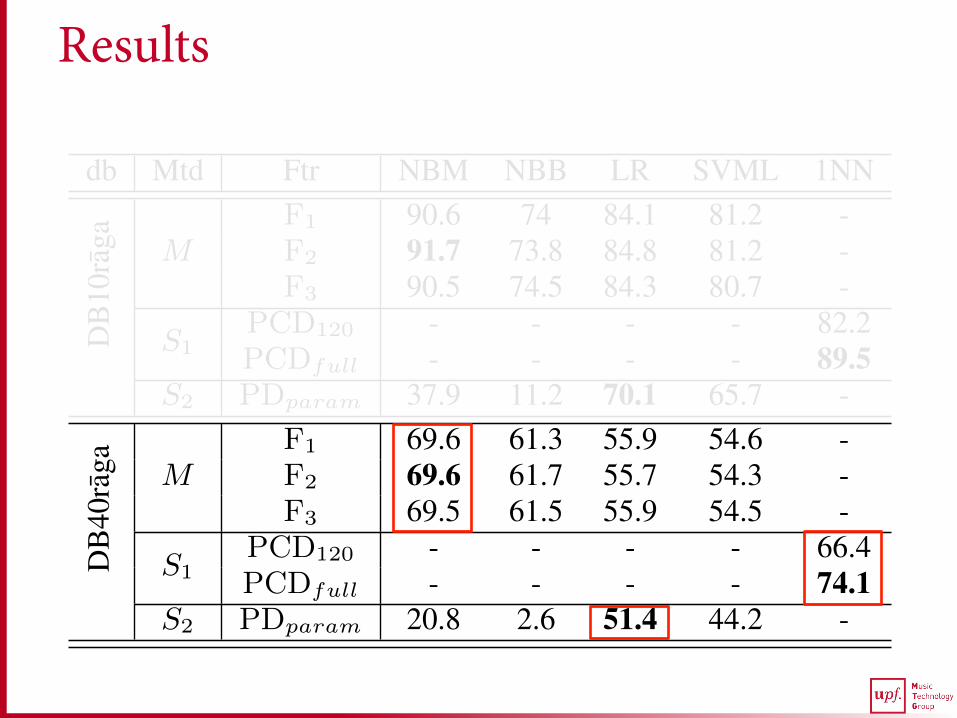
DB
40ra
ga MF1 69.6 61.3 55.9 54.6 -F2 69.6 61.7 55.7 54.3 -F3 69.5 61.5 55.9 54.5 -
S1PCD120 - - - - 66.4PCDfull - - - - 74.1
S2 PDparam 20.8 2.6 51.4 44.2 -
Table 1. Accuracy (in percentage) of different methods (Mtd) fortwo datasets (db) using different classifiers and features (Ftr).
the evaluation measure. In order to assess if the difference in theperformance of any two methods is statistically significant, we usethe Mann-Whitney U test [31] with p = 0.01. In addition, to com-pensate for multiple comparisons, we apply the Holm-Bonferronimethod [32].
3.3. Comparison with the state of the art
We compare our results with two state of the art methods proposedin [7] and [12]. As an input to these methods, we use the samepredominant melody and tonic as used in our method. The methodin [7] uses smoothened pitch-class distribution (PCD) as the tonalfeature and employs 1-nearest neighbor classifier (1NN) using Bhat-tacharyya distance for predicting raga label. We denote this methodby S1. The authors in [7] report a window size of 120 s as an opti-mal duration for computing PCDs (denoted here by PCD120). How-ever, we also experiment with PCDs computed over the entire audiorecording (denoted here by PCDfull). Note that in [7] the authorsdo not experiment with a window size larger than 120 s.
The method proposed in [12] also uses features based on pitchdistribution. However, unlike in [7], the authors use parameterizedpitch distribution of individual svaras as features (denoted here byPDparam). We denote this method by S2. The authors of both thesepapers courteously ran the experiments on our dataset using the orig-inal implementations of the methods.
4. RESULTS AND DISCUSSION
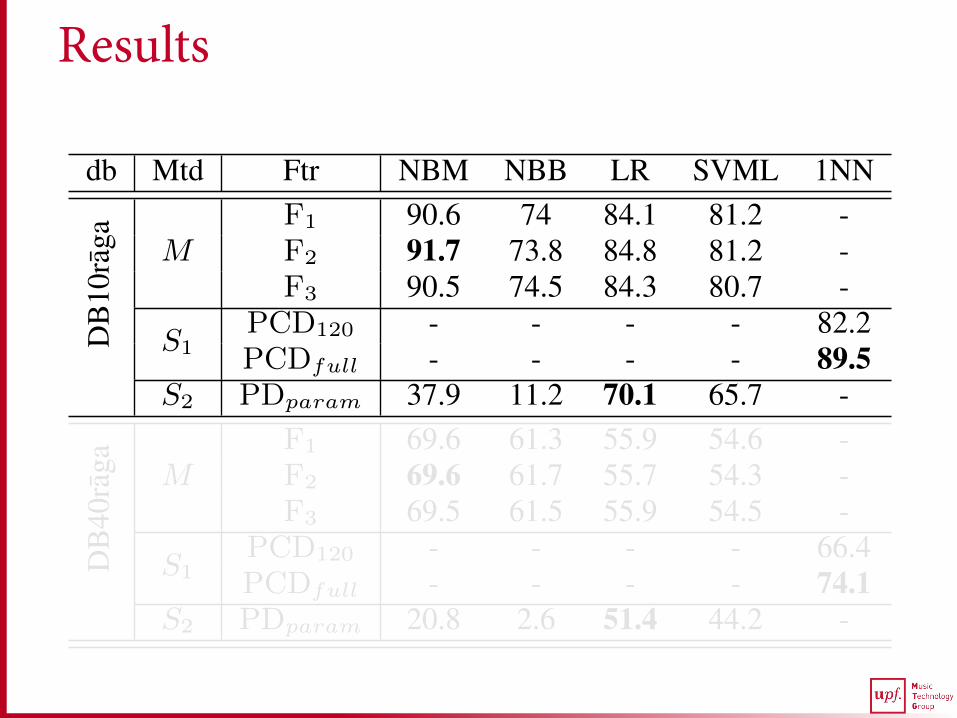
In Table 1, we present the results of our proposed method M and thetwo state of the art methods S1 and S2 for the two datasets DB10ragaand DB40raga. The highest accuracy for every method is highlightedin bold for both the datasets. Due to lack of space we present resultsonly for the best performing classifiers.
We start by analyzing the results of the variants of M . From Ta-ble 1, we see that the highest accuracy obtained by M for DB10ragais 91.7%. Compared to DB10raga, there is a significant drop in theperformance of every variant of M for DB40raga. The best perform-ing variant in the latter achieves 69.6% accuracy. We also see thatfor both the datasets, the accuracy obtained by M across the featuresets is nearly the same for each classifier, with no statistically sig-nificant difference. This suggests that, considering just the presenceor the absence of a melodic phrase, irrespective of its frequency ofoccurrence, is sufficient for raga recognition. Interestingly, this find-ing is consistent with the fact that characteristic melodic phrases are
Results
where, f(p, r) denotes the raw frequency of occurrence of phrasep in recording r. F1 only considers the presence or absence of aphrase in a recording. In order to investigate if the frequency of oc-currence of melodic phrases is relevant for characterizing ragas, wetake F2(p, r) = f(p, r). As mentioned, the melodic phrases thatoccur across different ragas and in several recordings are futile forraga recognition. Therefore, to reduce their effect in the feature vec-tor we employ a weighting scheme, similar to the inverse documentfrequency (idf) weighting in text retrieval.
F3(p, r) = f(p, r)⇥ irf(p,R) (2)
irf(p,R) = log
✓N
|{r 2 R : p 2 r}|
◆(3)
where, |{r 2 R : p 2 r}| is the number of recordings where themelodic phrase p is present, that is f(p, r) 6= 0 for these recordings.We denote our proposed method by M
3. EVALUATION
3.1. Music Collection
The music collection used in this study is compiled as a part of theCompMusic project [26–28]. The collection comprises 124 hours ofcommercially available audio recordings of Carnatic music belong-ing to 40 ragas. For each raga, there are 12 music pieces, whichamounts to a total of 480 recordings. All the editorial metadata foreach audio recording is publicly available in Musicbrainz3, an open-source metadata repository. The music collection primarily consistsof vocal performances of 62 different artists. There are a total of 310different compositions belonging to diverse forms in Carnatic music(for example kirtana, varnam, virtuttam). The chosen ragas containdiverse set of svaras (note), both in terms of the number of svaras andtheir pitch-classes (svarasthanas). To facilitate comparative studiesand promote reproducible research we make this music collectionpublicly available online4.
From this music collection we build two datasets, which we de-note by DB40raga and DB10raga. DB40raga comprises the entiremusic collection and DB10raga comprises a subset of 10 ragas. Weuse DB10raga to make our results more comparable to studies wherethe evaluations are performed on similar number of ragas.
3.2. Classification and Evaluation Methodology
The features obtained above are used to train a classifier. In orderto assess the relevance of these features for raga recognition, we ex-periment with different algorithms exploiting diverse classificationstrategies [29]: Multinomial, Gaussian and Bernoulli naive Bayes(NBM, NBG and NBB, respectively), support vector machines witha linear and a radial basis function kernel, and with a stochastic gra-dient descent learning (SVML, SVMR and SGD, respectively), lo-gistic regression (LR) and random forest (RF). We use the imple-mentation of these classifiers available in scikit-learn toolkit [30],version 0.15.1. Since in this study, our focus is to extract a musicallyrelevant set of features based on melodic phrases, we use the defaultparameter settings for the classifiers available in scikit-learn.
We use a stratified 12-fold cross-validation methodology forevaluations. The folds are generated such that every fold comprisesequal number of feature instances per raga. We repeat the entireexperiment 20 times, and report the mean classification accuracy as
3https://musicbrainz.org4http://compmusic.upf.edu/node/278
db Mtd Ftr NBM NBB LR SVML 1NN
DB
10ra
ga MF1 90.6 74 84.1 81.2 -F2 91.7 73.8 84.8 81.2 -F3 90.5 74.5 84.3 80.7 -
S1PCD120 - - - - 82.2PCDfull - - - - 89.5
S2 PDparam 37.9 11.2 70.1 65.7 -
DB
40ra
ga MF1 69.6 61.3 55.9 54.6 -F2 69.6 61.7 55.7 54.3 -F3 69.5 61.5 55.9 54.5 -
S1PCD120 - - - - 66.4PCDfull - - - - 74.1
S2 PDparam 20.8 2.6 51.4 44.2 -
Table 1. Accuracy (in percentage) of different methods (Mtd) fortwo datasets (db) using different classifiers and features (Ftr).
the evaluation measure. In order to assess if the difference in theperformance of any two methods is statistically significant, we usethe Mann-Whitney U test [31] with p = 0.01. In addition, to com-pensate for multiple comparisons, we apply the Holm-Bonferronimethod [32].
3.3. Comparison with the state of the art
We compare our results with two state of the art methods proposedin [7] and [12]. As an input to these methods, we use the samepredominant melody and tonic as used in our method. The methodin [7] uses smoothened pitch-class distribution (PCD) as the tonalfeature and employs 1-nearest neighbor classifier (1NN) using Bhat-tacharyya distance for predicting raga label. We denote this methodby S1. The authors in [7] report a window size of 120 s as an opti-mal duration for computing PCDs (denoted here by PCD120). How-ever, we also experiment with PCDs computed over the entire audiorecording (denoted here by PCDfull). Note that in [7] the authorsdo not experiment with a window size larger than 120 s.
The method proposed in [12] also uses features based on pitchdistribution. However, unlike in [7], the authors use parameterizedpitch distribution of individual svaras as features (denoted here byPDparam). We denote this method by S2. The authors of both thesepapers courteously ran the experiments on our dataset using the orig-inal implementations of the methods.
4. RESULTS AND DISCUSSION
In Table 1, we present the results of our proposed method M and thetwo state of the art methods S1 and S2 for the two datasets DB10ragaand DB40raga. The highest accuracy for every method is highlightedin bold for both the datasets. Due to lack of space we present resultsonly for the best performing classifiers.
We start by analyzing the results of the variants of M . From Ta-ble 1, we see that the highest accuracy obtained by M for DB10ragais 91.7%. Compared to DB10raga, there is a significant drop in theperformance of every variant of M for DB40raga. The best perform-ing variant in the latter achieves 69.6% accuracy. We also see thatfor both the datasets, the accuracy obtained by M across the featuresets is nearly the same for each classifier, with no statistically sig-nificant difference. This suggests that, considering just the presenceor the absence of a melodic phrase, irrespective of its frequency ofoccurrence, is sufficient for raga recognition. Interestingly, this find-ing is consistent with the fact that characteristic melodic phrases are
Results
where, f(p, r) denotes the raw frequency of occurrence of phrasep in recording r. F1 only considers the presence or absence of aphrase in a recording. In order to investigate if the frequency of oc-currence of melodic phrases is relevant for characterizing ragas, wetake F2(p, r) = f(p, r). As mentioned, the melodic phrases thatoccur across different ragas and in several recordings are futile forraga recognition. Therefore, to reduce their effect in the feature vec-tor we employ a weighting scheme, similar to the inverse documentfrequency (idf) weighting in text retrieval.
F3(p, r) = f(p, r)⇥ irf(p,R) (2)
irf(p,R) = log
✓N
|{r 2 R : p 2 r}|
◆(3)
where, |{r 2 R : p 2 r}| is the number of recordings where themelodic phrase p is present, that is f(p, r) 6= 0 for these recordings.We denote our proposed method by M
3. EVALUATION
3.1. Music Collection
The music collection used in this study is compiled as a part of theCompMusic project [26–28]. The collection comprises 124 hours ofcommercially available audio recordings of Carnatic music belong-ing to 40 ragas. For each raga, there are 12 music pieces, whichamounts to a total of 480 recordings. All the editorial metadata foreach audio recording is publicly available in Musicbrainz3, an open-source metadata repository. The music collection primarily consistsof vocal performances of 62 different artists. There are a total of 310different compositions belonging to diverse forms in Carnatic music(for example kirtana, varnam, virtuttam). The chosen ragas containdiverse set of svaras (note), both in terms of the number of svaras andtheir pitch-classes (svarasthanas). To facilitate comparative studiesand promote reproducible research we make this music collectionpublicly available online4.
From this music collection we build two datasets, which we de-note by DB40raga and DB10raga. DB40raga comprises the entiremusic collection and DB10raga comprises a subset of 10 ragas. Weuse DB10raga to make our results more comparable to studies wherethe evaluations are performed on similar number of ragas.
3.2. Classification and Evaluation Methodology
The features obtained above are used to train a classifier. In orderto assess the relevance of these features for raga recognition, we ex-periment with different algorithms exploiting diverse classificationstrategies [29]: Multinomial, Gaussian and Bernoulli naive Bayes(NBM, NBG and NBB, respectively), support vector machines witha linear and a radial basis function kernel, and with a stochastic gra-dient descent learning (SVML, SVMR and SGD, respectively), lo-gistic regression (LR) and random forest (RF). We use the imple-mentation of these classifiers available in scikit-learn toolkit [30],version 0.15.1. Since in this study, our focus is to extract a musicallyrelevant set of features based on melodic phrases, we use the defaultparameter settings for the classifiers available in scikit-learn.
We use a stratified 12-fold cross-validation methodology forevaluations. The folds are generated such that every fold comprisesequal number of feature instances per raga. We repeat the entireexperiment 20 times, and report the mean classification accuracy as
3https://musicbrainz.org4http://compmusic.upf.edu/node/278
db Mtd Ftr NBM NBB LR SVML 1NN
DB
10ra
ga MF1 90.6 74 84.1 81.2 -F2 91.7 73.8 84.8 81.2 -F3 90.5 74.5 84.3 80.7 -
S1PCD120 - - - - 82.2PCDfull - - - - 89.5
S2 PDparam 37.9 11.2 70.1 65.7 -
DB
40ra
ga MF1 69.6 61.3 55.9 54.6 -F2 69.6 61.7 55.7 54.3 -F3 69.5 61.5 55.9 54.5 -
S1PCD120 - - - - 66.4PCDfull - - - - 74.1
S2 PDparam 20.8 2.6 51.4 44.2 -
Table 1. Accuracy (in percentage) of different methods (Mtd) fortwo datasets (db) using different classifiers and features (Ftr).
the evaluation measure. In order to assess if the difference in theperformance of any two methods is statistically significant, we usethe Mann-Whitney U test [31] with p = 0.01. In addition, to com-pensate for multiple comparisons, we apply the Holm-Bonferronimethod [32].
3.3. Comparison with the state of the art
We compare our results with two state of the art methods proposedin [7] and [12]. As an input to these methods, we use the samepredominant melody and tonic as used in our method. The methodin [7] uses smoothened pitch-class distribution (PCD) as the tonalfeature and employs 1-nearest neighbor classifier (1NN) using Bhat-tacharyya distance for predicting raga label. We denote this methodby S1. The authors in [7] report a window size of 120 s as an opti-mal duration for computing PCDs (denoted here by PCD120). How-ever, we also experiment with PCDs computed over the entire audiorecording (denoted here by PCDfull). Note that in [7] the authorsdo not experiment with a window size larger than 120 s.
The method proposed in [12] also uses features based on pitchdistribution. However, unlike in [7], the authors use parameterizedpitch distribution of individual svaras as features (denoted here byPDparam). We denote this method by S2. The authors of both thesepapers courteously ran the experiments on our dataset using the orig-inal implementations of the methods.
4. RESULTS AND DISCUSSION
In Table 1, we present the results of our proposed method M and thetwo state of the art methods S1 and S2 for the two datasets DB10ragaand DB40raga. The highest accuracy for every method is highlightedin bold for both the datasets. Due to lack of space we present resultsonly for the best performing classifiers.
We start by analyzing the results of the variants of M . From Ta-ble 1, we see that the highest accuracy obtained by M for DB10ragais 91.7%. Compared to DB10raga, there is a significant drop in theperformance of every variant of M for DB40raga. The best perform-ing variant in the latter achieves 69.6% accuracy. We also see thatfor both the datasets, the accuracy obtained by M across the featuresets is nearly the same for each classifier, with no statistically sig-nificant difference. This suggests that, considering just the presenceor the absence of a melodic phrase, irrespective of its frequency ofoccurrence, is sufficient for raga recognition. Interestingly, this find-ing is consistent with the fact that characteristic melodic phrases are
Results
where, f(p, r) denotes the raw frequency of occurrence of phrasep in recording r. F1 only considers the presence or absence of aphrase in a recording. In order to investigate if the frequency of oc-currence of melodic phrases is relevant for characterizing ragas, wetake F2(p, r) = f(p, r). As mentioned, the melodic phrases thatoccur across different ragas and in several recordings are futile forraga recognition. Therefore, to reduce their effect in the feature vec-tor we employ a weighting scheme, similar to the inverse documentfrequency (idf) weighting in text retrieval.
F3(p, r) = f(p, r)⇥ irf(p,R) (2)
irf(p,R) = log
✓N
|{r 2 R : p 2 r}|
◆(3)
where, |{r 2 R : p 2 r}| is the number of recordings where themelodic phrase p is present, that is f(p, r) 6= 0 for these recordings.We denote our proposed method by M
3. EVALUATION
3.1. Music Collection
The music collection used in this study is compiled as a part of theCompMusic project [26–28]. The collection comprises 124 hours ofcommercially available audio recordings of Carnatic music belong-ing to 40 ragas. For each raga, there are 12 music pieces, whichamounts to a total of 480 recordings. All the editorial metadata foreach audio recording is publicly available in Musicbrainz3, an open-source metadata repository. The music collection primarily consistsof vocal performances of 62 different artists. There are a total of 310different compositions belonging to diverse forms in Carnatic music(for example kirtana, varnam, virtuttam). The chosen ragas containdiverse set of svaras (note), both in terms of the number of svaras andtheir pitch-classes (svarasthanas). To facilitate comparative studiesand promote reproducible research we make this music collectionpublicly available online4.
From this music collection we build two datasets, which we de-note by DB40raga and DB10raga. DB40raga comprises the entiremusic collection and DB10raga comprises a subset of 10 ragas. Weuse DB10raga to make our results more comparable to studies wherethe evaluations are performed on similar number of ragas.
3.2. Classification and Evaluation Methodology
The features obtained above are used to train a classifier. In orderto assess the relevance of these features for raga recognition, we ex-periment with different algorithms exploiting diverse classificationstrategies [29]: Multinomial, Gaussian and Bernoulli naive Bayes(NBM, NBG and NBB, respectively), support vector machines witha linear and a radial basis function kernel, and with a stochastic gra-dient descent learning (SVML, SVMR and SGD, respectively), lo-gistic regression (LR) and random forest (RF). We use the imple-mentation of these classifiers available in scikit-learn toolkit [30],version 0.15.1. Since in this study, our focus is to extract a musicallyrelevant set of features based on melodic phrases, we use the defaultparameter settings for the classifiers available in scikit-learn.
We use a stratified 12-fold cross-validation methodology forevaluations. The folds are generated such that every fold comprisesequal number of feature instances per raga. We repeat the entireexperiment 20 times, and report the mean classification accuracy as
3https://musicbrainz.org4http://compmusic.upf.edu/node/278
db Mtd Ftr NBM NBB LR SVML 1NN
DB
10ra
ga MF1 90.6 74 84.1 81.2 -F2 91.7 73.8 84.8 81.2 -F3 90.5 74.5 84.3 80.7 -
S1PCD120 - - - - 82.2PCDfull - - - - 89.5
S2 PDparam 37.9 11.2 70.1 65.7 -
DB
40ra
ga MF1 69.6 61.3 55.9 54.6 -F2 69.6 61.7 55.7 54.3 -F3 69.5 61.5 55.9 54.5 -
S1PCD120 - - - - 66.4PCDfull - - - - 74.1
S2 PDparam 20.8 2.6 51.4 44.2 -
Table 1. Accuracy (in percentage) of different methods (Mtd) fortwo datasets (db) using different classifiers and features (Ftr).
the evaluation measure. In order to assess if the difference in theperformance of any two methods is statistically significant, we usethe Mann-Whitney U test [31] with p = 0.01. In addition, to com-pensate for multiple comparisons, we apply the Holm-Bonferronimethod [32].
3.3. Comparison with the state of the art
We compare our results with two state of the art methods proposedin [7] and [12]. As an input to these methods, we use the samepredominant melody and tonic as used in our method. The methodin [7] uses smoothened pitch-class distribution (PCD) as the tonalfeature and employs 1-nearest neighbor classifier (1NN) using Bhat-tacharyya distance for predicting raga label. We denote this methodby S1. The authors in [7] report a window size of 120 s as an opti-mal duration for computing PCDs (denoted here by PCD120). How-ever, we also experiment with PCDs computed over the entire audiorecording (denoted here by PCDfull). Note that in [7] the authorsdo not experiment with a window size larger than 120 s.
The method proposed in [12] also uses features based on pitchdistribution. However, unlike in [7], the authors use parameterizedpitch distribution of individual svaras as features (denoted here byPDparam). We denote this method by S2. The authors of both thesepapers courteously ran the experiments on our dataset using the orig-inal implementations of the methods.
4. RESULTS AND DISCUSSION
In Table 1, we present the results of our proposed method M and thetwo state of the art methods S1 and S2 for the two datasets DB10ragaand DB40raga. The highest accuracy for every method is highlightedin bold for both the datasets. Due to lack of space we present resultsonly for the best performing classifiers.
We start by analyzing the results of the variants of M . From Ta-ble 1, we see that the highest accuracy obtained by M for DB10ragais 91.7%. Compared to DB10raga, there is a significant drop in theperformance of every variant of M for DB40raga. The best perform-ing variant in the latter achieves 69.6% accuracy. We also see thatfor both the datasets, the accuracy obtained by M across the featuresets is nearly the same for each classifier, with no statistically sig-nificant difference. This suggests that, considering just the presenceor the absence of a melodic phrase, irrespective of its frequency ofoccurrence, is sufficient for raga recognition. Interestingly, this find-ing is consistent with the fact that characteristic melodic phrases are
Results
where, f(p, r) denotes the raw frequency of occurrence of phrasep in recording r. F1 only considers the presence or absence of aphrase in a recording. In order to investigate if the frequency of oc-currence of melodic phrases is relevant for characterizing ragas, wetake F2(p, r) = f(p, r). As mentioned, the melodic phrases thatoccur across different ragas and in several recordings are futile forraga recognition. Therefore, to reduce their effect in the feature vec-tor we employ a weighting scheme, similar to the inverse documentfrequency (idf) weighting in text retrieval.
F3(p, r) = f(p, r)⇥ irf(p,R) (2)
irf(p,R) = log
✓N
|{r 2 R : p 2 r}|
◆(3)
where, |{r 2 R : p 2 r}| is the number of recordings where themelodic phrase p is present, that is f(p, r) 6= 0 for these recordings.We denote our proposed method by M
3. EVALUATION
3.1. Music Collection
The music collection used in this study is compiled as a part of theCompMusic project [26–28]. The collection comprises 124 hours ofcommercially available audio recordings of Carnatic music belong-ing to 40 ragas. For each raga, there are 12 music pieces, whichamounts to a total of 480 recordings. All the editorial metadata foreach audio recording is publicly available in Musicbrainz3, an open-source metadata repository. The music collection primarily consistsof vocal performances of 62 different artists. There are a total of 310different compositions belonging to diverse forms in Carnatic music(for example kirtana, varnam, virtuttam). The chosen ragas containdiverse set of svaras (note), both in terms of the number of svaras andtheir pitch-classes (svarasthanas). To facilitate comparative studiesand promote reproducible research we make this music collectionpublicly available online4.
From this music collection we build two datasets, which we de-note by DB40raga and DB10raga. DB40raga comprises the entiremusic collection and DB10raga comprises a subset of 10 ragas. Weuse DB10raga to make our results more comparable to studies wherethe evaluations are performed on similar number of ragas.
3.2. Classification and Evaluation Methodology
The features obtained above are used to train a classifier. In orderto assess the relevance of these features for raga recognition, we ex-periment with different algorithms exploiting diverse classificationstrategies [29]: Multinomial, Gaussian and Bernoulli naive Bayes(NBM, NBG and NBB, respectively), support vector machines witha linear and a radial basis function kernel, and with a stochastic gra-dient descent learning (SVML, SVMR and SGD, respectively), lo-gistic regression (LR) and random forest (RF). We use the imple-mentation of these classifiers available in scikit-learn toolkit [30],version 0.15.1. Since in this study, our focus is to extract a musicallyrelevant set of features based on melodic phrases, we use the defaultparameter settings for the classifiers available in scikit-learn.
We use a stratified 12-fold cross-validation methodology forevaluations. The folds are generated such that every fold comprisesequal number of feature instances per raga. We repeat the entireexperiment 20 times, and report the mean classification accuracy as
3https://musicbrainz.org4http://compmusic.upf.edu/node/278
db Mtd Ftr NBM NBB LR SVML 1NN
DB
10ra
ga MF1 90.6 74 84.1 81.2 -F2 91.7 73.8 84.8 81.2 -F3 90.5 74.5 84.3 80.7 -
S1PCD120 - - - - 82.2PCDfull - - - - 89.5
S2 PDparam 37.9 11.2 70.1 65.7 -
DB
40ra
ga MF1 69.6 61.3 55.9 54.6 -F2 69.6 61.7 55.7 54.3 -F3 69.5 61.5 55.9 54.5 -
S1PCD120 - - - - 66.4PCDfull - - - - 74.1
S2 PDparam 20.8 2.6 51.4 44.2 -
Table 1. Accuracy (in percentage) of different methods (Mtd) fortwo datasets (db) using different classifiers and features (Ftr).
the evaluation measure. In order to assess if the difference in theperformance of any two methods is statistically significant, we usethe Mann-Whitney U test [31] with p = 0.01. In addition, to com-pensate for multiple comparisons, we apply the Holm-Bonferronimethod [32].
3.3. Comparison with the state of the art
We compare our results with two state of the art methods proposedin [7] and [12]. As an input to these methods, we use the samepredominant melody and tonic as used in our method. The methodin [7] uses smoothened pitch-class distribution (PCD) as the tonalfeature and employs 1-nearest neighbor classifier (1NN) using Bhat-tacharyya distance for predicting raga label. We denote this methodby S1. The authors in [7] report a window size of 120 s as an opti-mal duration for computing PCDs (denoted here by PCD120). How-ever, we also experiment with PCDs computed over the entire audiorecording (denoted here by PCDfull). Note that in [7] the authorsdo not experiment with a window size larger than 120 s.
The method proposed in [12] also uses features based on pitchdistribution. However, unlike in [7], the authors use parameterizedpitch distribution of individual svaras as features (denoted here byPDparam). We denote this method by S2. The authors of both thesepapers courteously ran the experiments on our dataset using the orig-inal implementations of the methods.
4. RESULTS AND DISCUSSION
In Table 1, we present the results of our proposed method M and thetwo state of the art methods S1 and S2 for the two datasets DB10ragaand DB40raga. The highest accuracy for every method is highlightedin bold for both the datasets. Due to lack of space we present resultsonly for the best performing classifiers.
We start by analyzing the results of the variants of M . From Ta-ble 1, we see that the highest accuracy obtained by M for DB10ragais 91.7%. Compared to DB10raga, there is a significant drop in theperformance of every variant of M for DB40raga. The best perform-ing variant in the latter achieves 69.6% accuracy. We also see thatfor both the datasets, the accuracy obtained by M across the featuresets is nearly the same for each classifier, with no statistically sig-nificant difference. This suggests that, considering just the presenceor the absence of a melodic phrase, irrespective of its frequency ofoccurrence, is sufficient for raga recognition. Interestingly, this find-ing is consistent with the fact that characteristic melodic phrases are
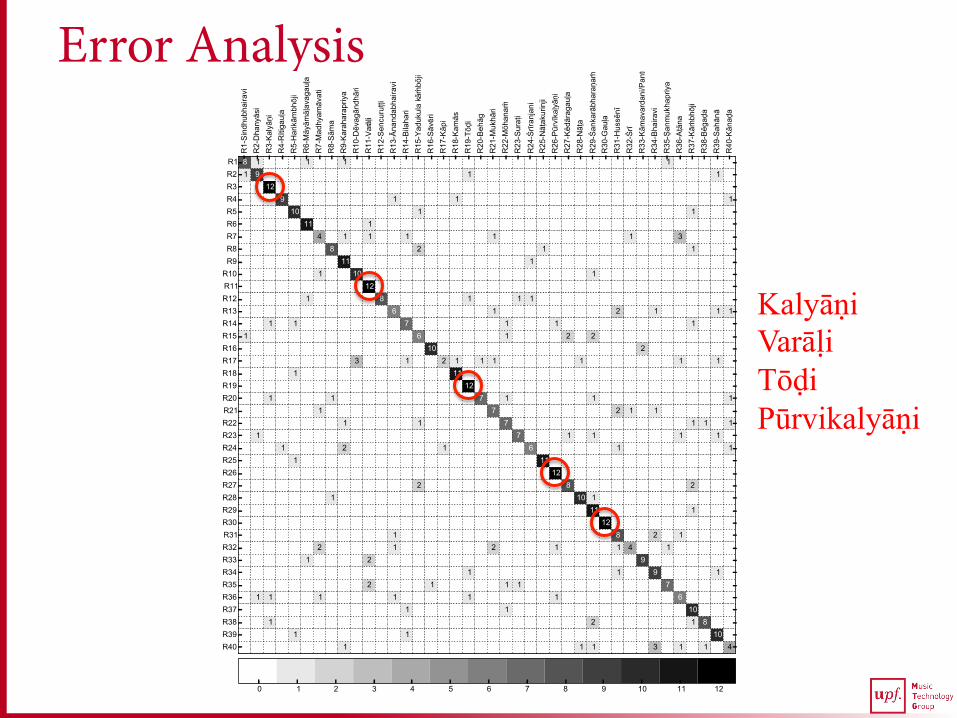
Error Analysis
Kalyāṇi Varāḷi Tōḍi Pūrvikalyāṇi
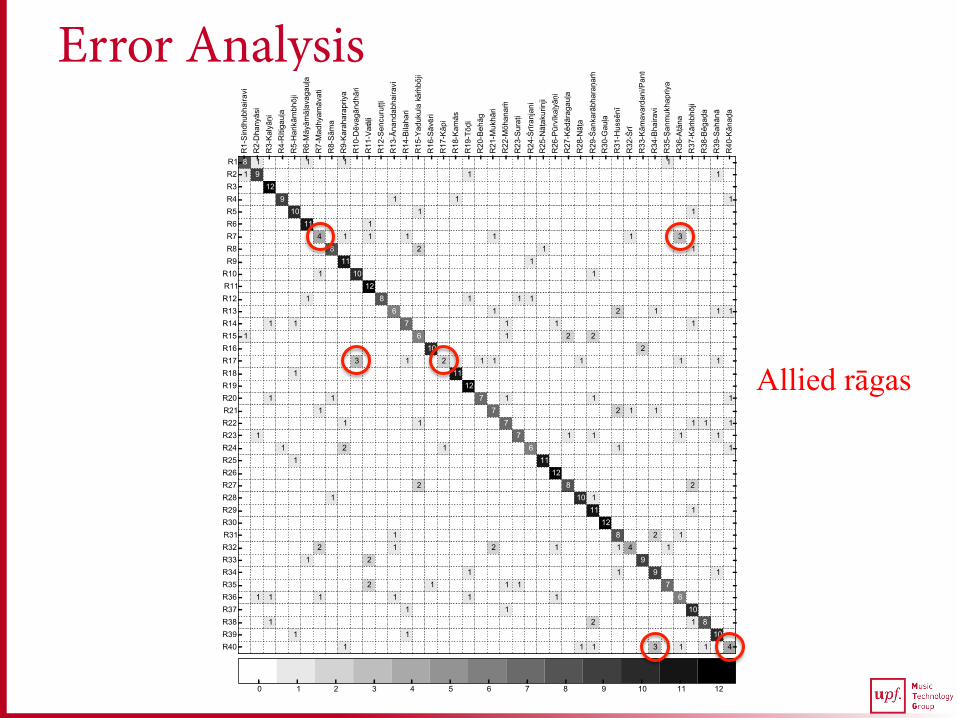
Error Analysis
Allied rāgas
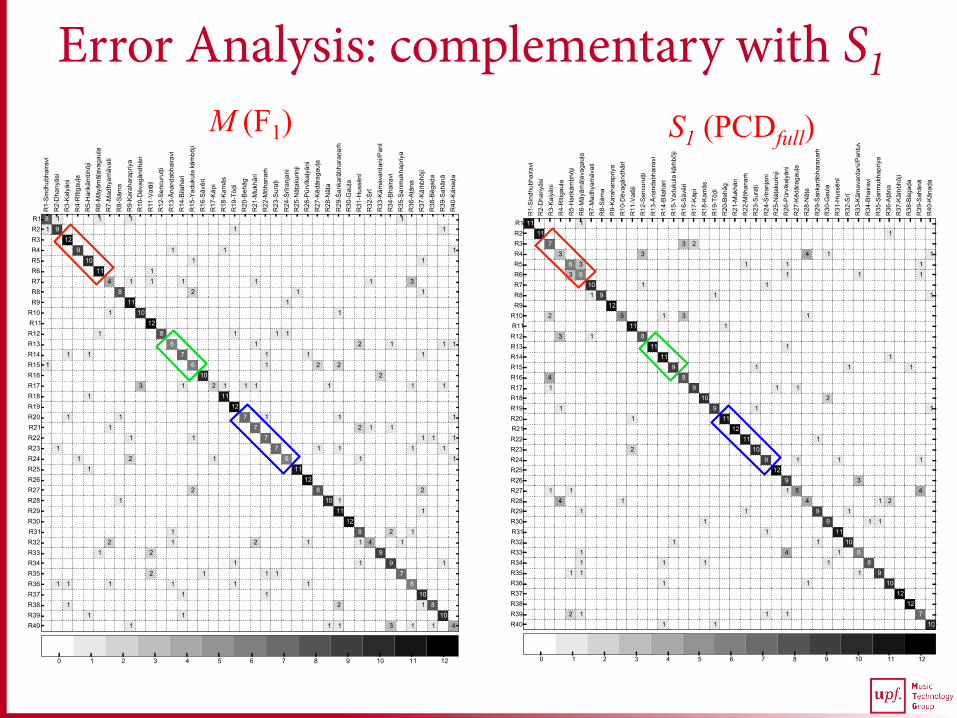
Error Analysis: complementary with S1 M (F1) S1 (PCDfull)

Summary

Summary q Phrase-based rāga recognition using VSM is a
successful strategy

Summary q Phrase-based rāga recognition using VSM is a
successful strategy q Mere presence/absence of melodic phrases is
enough to recognize rāga

Summary q Phrase-based rāga recognition using VSM is a
successful strategy q Mere presence/absence of melodic phrases
enough to recognize rāga q Multinomial Naive Bayes classifier outperforms
the rest

Summary q Phrase-based rāga recognition using VSM is a
successful strategy q Mere presence/absence of melodic phrases
enough to recognize rāga q Multinomial Naive Bayes classifier outperforms
the rest q Topological properties of network - similarity
threshold

Summary q Phrase-based rāga recognition using VSM is a
successful strategy q Mere presence/absence of melodic phrases
enough to recognize rāga q Multinomial Naive Bayes classifier outperforms
the rest q Topological properties of network - similarity
threshold q Complementary errors in prediction compared
to PCD-based methods (Future Work)
Resources q Rāga dataset:
§ http://compmusic.upf.edu/node/278
q Demo: § http://dunya.compmusic.upf.edu/pattern_network/
q CompMusic: § http://compmusic.upf.edu/
q Related datasets: § http://compmusic.upf.edu/datasets
Resources q Rāga dataset:
§ http://compmusic.upf.edu/node/278
q Demo: § http://dunya.compmusic.upf.edu/pattern_network/
q CompMusic: § http://compmusic.upf.edu/
q Related datasets: § http://compmusic.upf.edu/datasets
Resources q Rāga dataset:
§ http://compmusic.upf.edu/node/278
q Demo: § http://dunya.compmusic.upf.edu/pattern_network/
q CompMusic (Project): § http://compmusic.upf.edu/
q Related datasets: § http://compmusic.upf.edu/datasets

Phrase-based Rāga Recognition using Vector Space Modeling
Sankalp Gulati*, Joan Serrà^, Vignesh Ishwar*, Sertan Şentürk* and Xavier Serra*
The 41st IEEE International Conference on Acoustics, Speech and Signal Processing Shanghai, China, 2016
*Music Technology Group, Universitat Pompeu Fabra, Barcelona, Spain ^Telefonica Research, Barcelona, Spain


















