
Part 1: Biological Networks 1.Protein-protein interaction networks 2.Regulatory networks...
48
Part 1: Biological Networks 1. Protein-protein interaction networks 2. Regulatory networks 3. Expression networks 4. Metabolic networks 5. … more biological networks 6. Other types of networks
-
Upload
shona-price -
Category
Documents
-
view
221 -
download
1
Transcript of Part 1: Biological Networks 1.Protein-protein interaction networks 2.Regulatory networks...

Part 1: Biological Networks
1. Protein-protein interaction networks
2. Regulatory networks
3. Expression networks
4. Metabolic networks
5. … more biological networks
6. Other types of networks

[Qian, et al, J. Mol. Bio., 314:1053-1066]
Expression networks

Regulatory networks
[Horak, et al, Genes & Development, 16:3017-3033]

Expression networksRegulatory networks

Expression networksRegulatory networks
Interaction networks

Metabolic networks
[DeRisi, Iyer, and Brown, Science, 278:680-686]

Expression networksRegulatory networks
Interaction networks
Metabolic networks

... more biological networks
All of SCOP entries
1Oxido-
reductases
3Hydrolases
1.1Acting on CH-OH
1.1.1.1 Alcohol dehydrogenase
ENZYME
1.1.1NAD and
NADP acceptor
NON-ENZYME
3.1Acting on
ester bonds
1 Meta-bolism
1.1 Carb.
metab.
3.8 Extracel.
matrix
3.8.2 Extracel.
matrixglyco-protein
1.1.1 Polysach.
metab.
3.8.2.1 Fibro-nectin
General similarity Functional class similarityPrecise functional similarity
3 Cell
structure
1.5Acting on
CH-NH
3.4Acting on
peptide bonds
1.1.1.3Homoserine
dehydrogenase
1.2Nucleotide
metab.
3.1 Nucleus
3.8.2.2Tenascin
1.1.1.1 Glycogenmetab.
1.1.1.2 Starchmetab.
3.1.1.1 Carboxylesterase
3.1.1Carboxylic
ester hydro-lases
3.1.1.8 Cholineesterase
Hierarchies & DAGs [Enzyme, Bairoch; GO, Ashburner; MIPS, Mewes, Frishman]

Neural networks[Cajal]
Gene order networks Genetic interaction networks[Boone]
... more biological networks

Other types of networks
Disease Spread
[Krebs]
Social Network
Food Web
ElectronicCircuit
Internet[Burch & Cheswick]

Part 2: Graphs, Networks
• Graph definition• Topological properties of graphs
- Degree of a node
- Clustering coefficient
- Characteristic path length
• Random networks• Small World networks• Scale Free networks

• Graph: a pair of sets G={P,E} where P is a set of nodes, and E is a set of edges that connect 2 elements of P.
• Directed, undirected graphs
• Large, complex networks are ubiquitous in the world:
- Genetic networks- Nervous system- Social interactions- World Wide Web

• Degree of a node: the number of edges incident on the node
i
Degree of node i = 5

Clustering coefficient LOCAL property
• The clustering coefficient of node i is the ratio of the number of edges that exist among its neighbours, over the number of edges that could exist
iE
Clustering coefficient of node i = 1/6
• The clustering coefficient for the entire network C is the average of all the
iC

Characteristic path length GLOBAL property
• is the number of edges in the shortest path between vertices i and j
( , )i jL
• The characteristic path length L of a graph is the average of the for every possible pair (i,j)
( , )i jL
( , ) 2i jL
i
j
Networks with small values of L are said to have the “small world property”

Models for networks of complex topology
• Erdos-Renyi (1960)• Watts-Strogatz (1998)• Barabasi-Albert (1999)

The Erdős-Rényi [ER] model (1960)
• Start with N vertices and no edges• Connect each pair of vertices with probability PER
Important result: many properties in these graphs appear quite suddenly, at a threshold value of PER(N)
-If PER~c/N with c<1, then almost all vertices belong to isolated trees-Cycles of all orders appear at PER ~ 1/N

The Watts-Strogatz [WS] model (1998)
• Start with a regular network with N vertices• Rewire each edge with probability p
For p=0 (Regular Networks): •high clustering coefficient •high characteristic path length
For p=1 (Random Networks): •low clustering coefficient•low characteristic path length
QUESTION: What happens for intermediate values of p?

1) There is a broad interval of p for which L is small but C remains large
2) Small world networks are common :

The Barabási-Albert [BA] model (1999)
ER Model
Look at the distribution of degrees
ER Model WS Model actors power grid www
The probability of finding a highly connected node decreases exponentially with k
( ) ~P K K

• GROWTH: starting with a small number of vertices m0 at every timestep add a new vertex with m ≤ m0
• PREFERENTIAL ATTACHMENT: the probability Π that a new vertex will be connected to vertex i depends on the connectivity of that vertex:
● two problems with the previous models:
1. N does not vary
2. the probability that two vertices are connected is uniform
( ) ii
jj
kk
k

a) Connectivity distribution with N = m0+t=300000 and m0=m=1(circles), m0=m=3 (squares), and m0=m=5 (diamons) and m0=m=7 (triangles)
b) P(k) for m0=m=5 and system size N=100000 (circles), N=150000 (squares) and N=200000 (diamonds)
Scale Free Networks

Part 3: Machine Learning
• Artificial Intelligence/Machine Learning• Definition of Learning• 3 types of learning
1. Supervised learning2. Unsupervised learning3. Reinforcement Learning
• Classification problems, regression problems• Occam’s razor• Estimating generalization • Some important topics:
1. Naïve Bayes2. Probability density estimation3. Linear discriminants4. Non-linear discriminants (Decision Trees, Support Vector
Machines)




Bayes’ Rule: minimum classification error is achieved by selecting the class with largest posterior probability
PROBLEM: we are given and we have to decide whether it is an a or a b
1( , , )Tdx xx
Classification Problems

Regression Problems
PROBLEM: we are only given the red points, and we would like approximate the blue curve (e.g. with polynomial functions)
QUESTION: which solution should I pick? And why?




Naïve Bayes
F 1 F 2 F 3 … F n TARGET
Gene 1 1 1.34 1 … 2.23 1
Gene 2 0 4.24 44 … 2.3 1
Gene 3 1 3.59 34 … 34.42 0
Gene 4 1 0.001 64 … 24.3 0
Gene 5 0 6.87 6 … 6.5 0
… … … … … … …
Gene n 1 4.56 72 … 5.3 1
Example: given a set of features for each gene, predict whether it is essential

( | )( | ) k k
k
p C P CP C
p
xx
x
Bayes Rule: select the class with the highest posterior probability
For a problem with two classes this becomes:
0Cotherwise, choose class
1 1
0 0
( | )1
( | )
p C P C
p C P C
x
x 1C then choose class if

1
0
( | )
( | )i
ii
p x CL
p x Cwhere and are called Likelihood Ratio for feature i.
1 2 1 2| , ,..., | | | |i n i i i n ip C p x x x C p x C p x C p x C x
Naïve Bayes approximation:
1 1 2 1 1 1
1 0 2 0 0 0
01 2
1
( | ) ( | ) ( | )1
( | ) ( | ) ( | )n
n
n
p x C p x C p x C P C
p x C p x C p x C P C
P CL L L
P C
For a two classes problem:

Probability density estimation
• Assume a certain probabilistic model for each class • Learn the parameters for each model (EM algorithm)
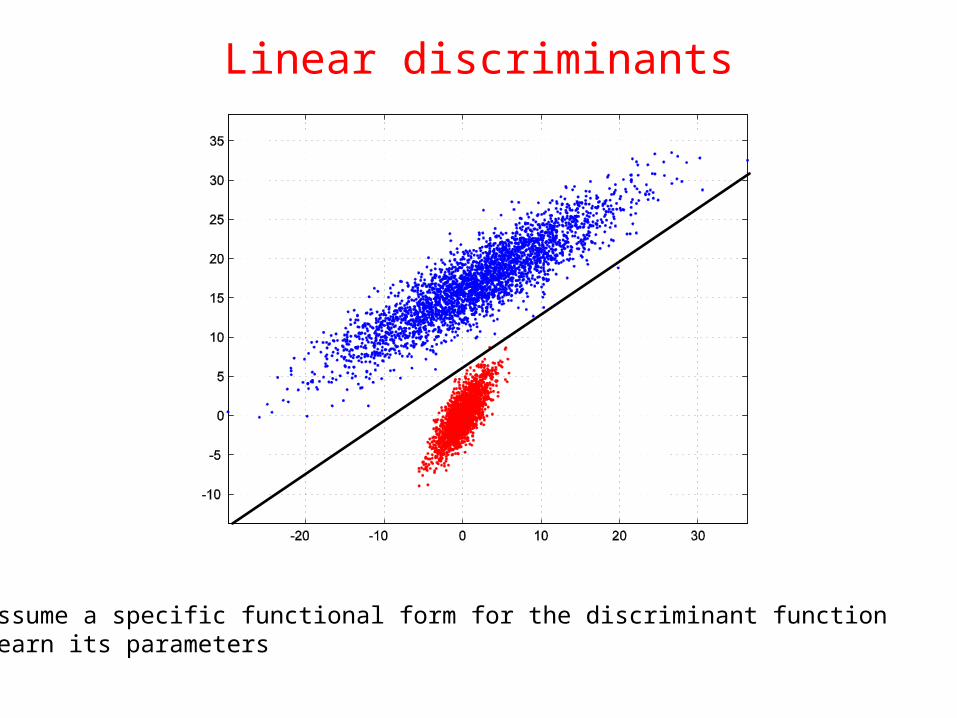
Linear discriminants
• assume a specific functional form for the discriminant function• learn its parameters

Decision Trees (C4.5, CART)
ISSUES: • how to choose the “best” attribute• how to prune the tree
Trees can be converted into rules !

Part 4: Networks Predictions
• Naïve Bayes for inferring Protein-Protein Interactions

Network Gold-Standards
The data
[Jansen, Yu, et al., Science; Yu, et al., Genome Res.]
Feature 2, e.g. same functionFeature 1, e.g. co-expression
Gold-standard +Gold-standard –

Network Gold-Standards
( | )
( | )i
ii
p xL
p x
Likelihood Ratio for Feature i:
Feature 2, e.g. same functionFeature 1, e.g. co-expression
Gold-standard +Gold-standard –

Feature 2, e.g. same functionFeature 1, e.g. co-expression
Gold-standard +Gold-standard –
Network Gold-Standards
L1 = (4/4)/(3/6) =2( | )
( | )i
ii
p xL
p x
Likelihood Ratio for Feature i:

Feature 2, e.g. same functionFeature 1, e.g. co-expression
Gold-standard +Gold-standard –
Network Gold-Standards
L1 = (4/4)/(3/6) =2( | )
( | )i
ii
p xL
p x
Likelihood Ratio for Feature i:

Feature 2, e.g. same functionFeature 1, e.g. co-expression
Gold-standard +Gold-standard –
Network Gold-Standards
L1 = (4/4)/(3/6) =2( | )
( | )i
ii
p xL
p x
Likelihood Ratio for Feature i:

Feature 2, e.g. same functionFeature 1, e.g. co-expression
Gold-standard +Gold-standard –
Network Gold-Standards
L1 = (4/4)/(3/6) =2( | )
( | )i
ii
p xL
p x
Likelihood Ratio for Feature i:

Feature 2, e.g. same functionFeature 1, e.g. co-expression
Gold-standard +Gold-standard –
Network Gold-Standards
( | )
( | )i
ii
p xL
p x
Likelihood Ratio for Feature i: L1 = (4/4)/(3/6) =2

Feature 2, e.g. same functionFeature 1, e.g. co-expression
Gold-standard +Gold-standard –
Network Gold-StandardsL1 = (4/4)/(3/6) =2L2 = (3/4)/(3/6) =1.5
For each protein pair:LR = L1 L2log(LR) = log(L1) + log(L2)
( | )
( | )i
ii
p xL
p x
Likelihood Ratio for Feature i:

Feature 2, e.g. same functionFeature 1, e.g. co-expression
Gold-standard +Gold-standard –
Network Gold-StandardsL1 = (4/4)/(3/6) =2L2 = (3/4)/(3/6) =1.5
For each protein pair:LR = L1 L2log(LR) = log(L1) + log(L2)
( | )
( | )i
ii
p xL
p x
Likelihood Ratio for Feature i:

1. Individual features are weak predictors,
LR ~ 10;
2. Bayesian integration is much more powerful,
LRcutoff = 600 ~9000 interactions
1 3.632 0.583 0.53
1 124.932 85.503 87.974 67.365 26.466 9.877 4.338 1.679 0.70
10 0.2511 0.1412 0.1113 0.0514 0.0415 0.0916 0.0017 0.0018 0.0019 0.00
1 25.502 22.533 8.634 21.285 0.06
1 9.222 14.363 4.384 3.055 0.76
Functional similarity: MIPS
Functional similarity: GO
Essentiality
Co-expression


















