
P : Optimizing Tensor Programs with Partially Equivalent ...
19
This paper is included in the Proceedings of the 15th USENIX Symposium on Operating Systems Design and Implementation. July 14–16, 2021 978-1-939133-22-9 Open access to the Proceedings of the 15th USENIX Symposium on Operating Systems Design and Implementation is sponsored by USENIX. PET: Optimizing Tensor Programs with Partially Equivalent Transformations and Automated Corrections Haojie Wang, Jidong Zhai, Mingyu Gao, Zixuan Ma, Shizhi Tang, and Liyan Zheng, Tsinghua University; Yuanzhi Li, Carnegie Mellon University; Kaiyuan Rong and Yuanyong Chen, Tsinghua University; Zhihao Jia, Carnegie Mellon University and Facebook https://www.usenix.org/conference/osdi21/presentation/wang
Transcript of P : Optimizing Tensor Programs with Partially Equivalent ...

This paper is included in the Proceedings of the 15th USENIX Symposium on Operating Systems
Design and Implementation.July 14–16, 2021978-1-939133-22-9
Open access to the Proceedings of the 15th USENIX Symposium on Operating Systems Design and Implementation
is sponsored by USENIX.
Pet: Optimizing Tensor Programs with Partially Equivalent Transformations and
Automated CorrectionsHaojie Wang, Jidong Zhai, Mingyu Gao, Zixuan Ma, Shizhi Tang, and Liyan Zheng,
Tsinghua University; Yuanzhi Li, Carnegie Mellon University; Kaiyuan Rong and Yuanyong Chen, Tsinghua University; Zhihao Jia, Carnegie Mellon University
and Facebookhttps://www.usenix.org/conference/osdi21/presentation/wang

PET: Optimizing Tensor Programs with Partially Equivalent Transformationsand Automated Corrections
Haojie Wang Jidong Zhai Mingyu Gao Zixuan Ma Shizhi TangLiyan Zheng Yuanzhi Li† Kaiyuan Rong Yuanyong Chen Zhihao Jia†‡
Tsinghua University Carnegie Mellon University† Facebook‡
AbstractHigh-performance tensor programs are critical for effi-
ciently deploying deep neural network (DNN) models in real-world tasks. Existing frameworks optimize tensor programsby applying fully equivalent transformations, which maintainequivalence on every element of output tensors. This approachmisses possible optimization opportunities as transformationsthat only preserve equivalence on subsets of the output tensorsare excluded.
We propose PET, the first DNN framework that optimizestensor programs with partially equivalent transformations andautomated corrections. PET discovers and applies programtransformations that improve computation efficiency but onlymaintain partial functional equivalence. PET then automati-cally corrects results to restore full equivalence. We developrigorous theoretical foundations to simplify equivalence exam-ination and correction for partially equivalent transformations,and design an efficient search algorithm to quickly discoverhighly optimized programs by combining fully and partiallyequivalent optimizations at the tensor, operator, and graphlevels. Our evaluation shows that PET outperforms existingsystems by up to 2.5×, by unlocking previously missed op-portunities from partially equivalent transformations.
1 Introduction
Existing deep neural network (DNN) frameworks representDNN computations as tensor programs, which are directacyclic computation graphs describing the operations appliedto a set of tensors (i.e., n-dimensional arrays). The operatorsin tensor programs are mostly linear algebra computationssuch as matrix multiplication and convolution. Although ten-sor programs are specified based on the high-level insightsof today’s DNN algorithms, such constructions do not neces-sarily offer the best runtime performance. Current practice tooptimize tensor programs in existing DNN frameworks is toleverage program transformations, each of which identifiesa subprogram that matches a specific pattern and replaces itwith another subprogram that offers improved performance.
To preserve the statistical behavior of DNN models, exist-ing frameworks only consider fully equivalent program trans-formations, where the new subprogram is mathematicallyequivalent to the original subprogram for arbitrary inputs.For example, TensorFlow, PyTorch, TensorRT, TVM, and An-sor all use rule-based optimization strategies that directlyapply manually designed program transformations wheneverapplicable [3, 6, 26, 32, 34]. TASO automatically generatesand verifies transformations by taking operator specificationsas inputs, but is still limited to fully equivalent transforma-tions [15].
Despite the wide use of equivalent program transformationsin conventional compilers and modern DNN frameworks, theyonly exhibit limited opportunities for performance optimiza-tion, especially for tensor programs. Unlike traditional pro-grams whose primitives are scalars or simple arrays of scalars,tensor programs operate on high-dimensional tensors with upto millions of elements. Many transformations can improvethe runtime performance of a tensor program but do not pre-serve full equivalence on all elements of the output tensors.We call such transformations partially equivalent. Examplesof performance-optimizing partially equivalent transforma-tions include (1) changing the shape or linearization orderingof input tensors to improve computational efficiency, (2) re-placing less efficient operators with more optimized operatorswith similar mathematical behavior, and (3) transforming thegraph structure of a program to enable subsequent perfor-mance optimizations.
Partially equivalent transformations, despite their high po-tential, are not exploited in existing DNN frameworks due toseveral challenges. First, directly applying partially equivalenttransformations would violate the functional equivalence toan input program and potentially decrease the model accuracy.It is necessary to correct any non-equivalent regions of outputtensors, to preserve transparency to higher-level algorithms.However, quickly examining equivalence to identify theseregions and effectively generating the required correctionkernels are difficult tasks. Second, when partially equivalenttransformations are applied, the design space is substantially
USENIX Association 15th USENIX Symposium on Operating Systems Design and Implementation 37

enlarged compared to existing frameworks under equivalenceconstraint. Theoretically, any program transformation, regard-less of how different the result is from the original one, be-comes a potential candidate. The generation algorithm forpartially equivalent transformations should carefully manageits computational complexity. The optimizer must balance thebenefits and overhead and be able to combine fully and par-tially equivalent transformations to obtain performant tensorprograms.
In this paper, we explore a radically different approach tooptimize tensor programs, by exploiting partially equivalenttransformations. We develop rigorous theorems that simplifyequivalence examination and correction kernel generation,allowing us to easily restore functional equivalence and prov-ably preserve the DNN models’ statistical behavior. With asignificantly larger search space of program optimizations thatincludes both fully and partially equivalent transformations,our approach can discover highly optimized tensor programsthat existing approaches miss. Based on these techniques, wepropose PET, the first DNN framework that optimizes tensorprograms with partially equivalent transformations and auto-mated corrections. PET consists of three main components:
Mutation generator. To discover partially equivalent trans-formations automatically for an input subprogram, PET usesa mutation generator to construct potential program mutants.Each mutant takes the same input tensors as in the originalsubprogram and produces output tensors with the same shapes.This ensures that a mutant can replace the input subprogramand therefore constitutes a potential transformation.
Mutation corrector. The generated mutants of an input sub-program may produce different results on some regions of theoutput tensors, thus affecting the model accuracy. To preserveits statistical behavior, PET’s mutation corrector examinesthe equivalence between an input subprogram and its mu-tant and automatically generates correction kernels. Theseare subsequently applied to the output tensors to maintain anend-to-end equivalence to the input subprogram. To reducethe overhead and heterogeneity introduced by the correctionkernels, PET opportunistically fuses the correction kernelswith other tensor computation kernels.
Examining and correcting a partially equivalent transforma-tion is difficult, since the output tensors of a program includeup to millions of elements, and each one must be verifiedagainst a large number of input elements. A key contribu-tion of PET is a set of rigorous theoretical foundations thatsignificantly simplify this verification process. Rather thanexamining program equivalence for all positions in the outputtensors, PET needs to test only a few representative positions.
Program optimizer. PET uses a program optimizer to iden-tify mutant candidates with high performance, by effectivelybalancing the benefits from using better mutants and the over-heads of extra correction kernels. We first split an arbitrarilylarge input program into multiple small subprograms at the
positions of non-linear operators. Each subprogram then con-tains only linear operators and can be independently mutated.We support mutations on various subsets of operators in thesubprogram, and can iteratively apply mutations to obtainmutants that are more complex. Finally, we apply a series ofpost-optimizations across subprogram boundaries, includingredundancy elimination and operator fusion.
We evaluate PET on five real-world DNN models. Evenfor common and heavily optimized models in existing frame-works such as Resnet-18 [14], PET can still improve the per-formance by 1.2×. For new models such as CSRNet [20] andBERT [12], PET is up to 2.5× faster than the state-of-the-art frameworks. The significant performance improvement isenabled by combining fully and partially equivalent transfor-mations at the tensor, operator, and graph levels.
This paper makes the following contributions.• We present the first attempt in tensor program optimiza-
tion to exploit partially equivalent transformations withautomated corrections. We explore a significantly largersearch space than existing DNN frameworks.• We develop rigorous theoretical foundations that sim-
plify the equivalence examination and correction kernelgeneration, making it practical to preserve statistical be-havior even with partially equivalent transformations.• We propose efficient generation and optimization ap-
proaches to explore the large design space automaticallywith both fully and partially equivalent transformations.• We implement the above techniques into an end-to-end
framework, PET, and achieve up to 2.5× speedup com-pared to state-of-the-art frameworks.
2 Background and Motivation
To generate high-performance tensor programs, a commonform of optimization in existing DNN frameworks (e.g., Ten-sorFlow [3], TensorRT [32], and TVM [6]) is fully equivalenttransformations that improve the performance of a tensor pro-gram while preserving its mathematical equivalence. Exam-ples of current fully equivalent transformations include opera-tor fusion [2, 6], layout transformations [18], and automatedgeneration of graph substitutions [15]. Though effective atimproving performance, fully equivalent transformations ex-plore only a limited space of program optimizations.
In contrast, Figure 1 shows an example of a partially equiva-lent transformation for a convolution operator. It concatenatestwo individual images into a larger one along the width di-mension to improve performance. This is because a largerwidth, which is typically the innermost dimension for con-volution on modern accelerators like GPUs, provides moreparallelism and improves computation locality. However, thenew program after this transformation (shown in Figure 1(b))produces different results on a sub-region of the output tensoralong the boundary of the concatenation (shown as the shadedboxes in Figure 1(b)), resulting in partial non-equivalence.
38 15th USENIX Symposium on Operating Systems Design and Implementation USENIX Association

conv
T1
T2
(a) Input program.
conv
reshape & transpose
T1
T3 T4
T5
reshape & transpose
(b) A partially equivalent transformation.
T5
T2
correction
(c) Correcting results.
Figure 1: A partially equivalent transformation that improves the performance of convolution by manipulating tensor shapeand linearization. The shaded boxes in (b) highlight non-equivalent elements between two programs in the transformation. Thecorrection kernel in (c) is applied to these elements to recover the functional equivalence of the input program.
In addition to the above example that optimizes a tensor pro-gram by changing the shape and linearization of its tensors,partially equivalent transformations also include replacingless efficient operators with more optimized ones with simi-lar semantics, and modifying the graph structure of a tensorprogram to enable additional optimizations. We provide moresuch examples in §4.2 and evaluate them in §8.3.
Although partially equivalent transformations exhibit highpotential for performance improvement, they are not consid-ered in current DNN frameworks due to their possible impacton model accuracy. Manually implementing such partiallyequivalent transformations is prohibitive. First, it requiresevaluating a large amount of potential partially equivalenttransformations to discover promising ones. Second, to applypartially equivalent transformations while preserving modelaccuracy, we need correction kernels to fix the results for non-equivalent parts (see Figure 1(c)). Overall, more automatedapproaches are needed to discover performance-optimizingpartially equivalent transformations and correct the results,which are the main focus of this work.
3 Design Overview
PET is the first framework to optimize tensor programs byexploiting partially equivalent transformations and correctingtheir results automatically. To realize this, PET leverages themulti-linearity of tensor programs.
Multi-linear tensor programs (MLTPs). We first definemulti-linear tensor operators. An operator op with n inputtensors I1, . . . , In is multi-linear if op is linear to all inputs Ik:
op(I1, . . . , Ik−1,X , . . . , In)+op(I1, . . . , Ik−1,Y, . . . , In)
= op(I1, . . . , Ik−1,X +Y, . . . , In)
α ·op(I1, . . . , Ik−1,X , . . . , In) = op(I1, . . . , Ik−1,α ·X , . . . , In)
where X and Y are arbitrary tensors with the same shape asIk, and α is an arbitrary scalar. DNN computation generally
Tensor Program
Mutation Generator
Mutation Corrector
Subprogram
Subprogram
Subp
rogr
am
Optimized Tensor Program
One Subprogram
Mutant Candidates
Corrected Mutants
Subprogram
Mu
tan
tMutant
Mutant
MutantCo
rrec
tion
Kern
el
1
Sect
ion
4Se
ctio
n 5
Sect
ion
6
2
Program Partitioning
correction
Program Optimizer
Fully Equivalent Transformations
Partially Equivalent Transformations
4
3
Figure 2: PET overview.
consists of multi-linear tensor operators (e.g., matrix multipli-cation, convolution) and element-wise non-linear operators(e.g., ReLU [23] and sigmoid). The linear operators consumethe majority of the computation time, due to their high com-putational complexity. A program P is a multi-linear tensorprogram (MLTP) if all operators op ∈ P are multi-linear.
PET overview. Figure 2 shows an overview of PET. The inputto PET is a tensor program to be optimized. Similar to priorwork [6,34], PET first splits an input program into smaller sub-programs to reduce the exploration space of each subprogramwithout sacrificing performance improvement opportunities.For each subprogram, PET’s mutation generator discoverspartially equivalent transformations by generating possiblemutants for MLTPs in the subprogram. Each mutant has the
USENIX Association 15th USENIX Symposium on Operating Systems Design and Implementation 39

Table 1: Multi-linear tensor operators used in PET.Operator Description
add Element-wise additionmul Element-wise multiplicationconv Convolutiongroupconv Grouped convolutiondilatedconv Dilated convolutionbatchnorm Batch normalizationavgpool Average poolingmatmul Matrix multiplicationbatchmatmul Batch matrix multiplicationconcat Concatenate multiple tensorssplit Split a tensor into multiple tensorstranspose Transpose a tensor’s dimensionsreshape Decouple/combine a tensor’s dimensions
same input and output shapes as the original MLTPs, thusconstitutes a partially equivalent transformation (§4).
To maintain the end-to-end equivalence to an input pro-gram, PET’s mutation corrector examines the equivalencebetween a mutant and its original MLTP, and automaticallygenerates correction kernels to fix the outputs of the mutant.PET leverages rigorous theoretical foundations to simplifysuch challenging tasks (§5).
The corrected mutants are sent to PET’s program optimizer,which combines existing fully equivalent transformations withpartially equivalent ones to construct a comprehensive searchspace of program optimizations. The optimizer evaluates arich set of mutants for each subprogram and applies post-optimizations across their boundaries, in order to discoverhighly optimized candidates in the search space (§6).
4 Mutation Generator
This section describes the mutation generator in PET, whichtakes an MLTP as input and automatically generates possiblemutants to replace the input MLTP. The generation algorithmdiscovers valid mutants up to a certain size. Each generatedmutant does not necessarily preserve mathematical equiva-lence to the input program on the entire output tensors. Torestore functional equivalence, the mutation corrector (§5)automatically generates correction kernels.
4.1 Mutation Generation Algorithm
We call an MLTP P1 a mutant of another MLTP P0 if P1 andP0 have the same number of inputs (and outputs) and eachinput (and output) has the same shape. The computations ofP0 and P1 are not necessarily equivalent. Intuitively, if P0 isa subprogram in a tensor program, then replacing P0 with P1yields a valid but potentially non-equivalent tensor program.
For a given MLTP P0, PET generates potential mutants ofP0 using a given set of multi-linear operators O as the ba-
Algorithm 1 MLTP mutation generation algorithm.1: Input: A set of operators O; an input MLTP P02: Output: A set of valid program mutants M for P03: I0 = the set of input tensors in P04: M =∅5: BUILD(1, ∅, I0)6: // Depth-first search to construct mutants7: function BUILD(n, P , I )8: if P and P0 have the same input/output shapes then9: M = M +{P}
10: if n < depth then11: for op ∈ O do12: for i ∈ I and i is a valid input to op do13: Add operator op into program P14: Add the output tensors of op into I15: BUILD(n+1, P , I )16: Remove operator op from P17: Remove the output tensors of op from I18: return M
sic building blocks. Table 1 lists the operators used in ourevaluation. The list covers a variety of commonly used ten-sor operators, including compute-intensive operators (conv,matmul, etc.), element-wise operators (add, mul, etc.), andtensor manipulation (split, transpose, etc.). This set canalso be extended to include new DNN operators.
Algorithm 1 shows a depth-first search algorithm for con-structing potential mutants of an MLTP P0. PET starts froman empty program with no operator and only the set of origi-nal input tensors to P0. PET iteratively adds a new operatorto the current program P by enumerating the type of operatorfrom O and the input tensors to the operator. The input tensorscan be the initial input tensors to P0 (i.e., I0 in Algorithm 1)or the output tensors of previous operators. The depth-firstsearch algorithm enumerates all potential MLTPs up to a cer-tain size (called the mutation depth). For each mutant P , PETchecks whether P and P0 have the same number and shapesof inputs/outputs. P is a valid mutant if it passes this test.
4.2 Example Mutant CategoriesWhile the above mutation generation algorithm is generalenough to explore a sufficiently large design space, we em-phasize that several mutant categories are of particular impor-tance to PET and lead to mutants with improved performance.Note that PET does not rely on manually specified categories.Rather, these categories are discovered by PET automatically.
Reshape and transpose. It is widely known that the in-memory layouts of tensors play an important role in opti-mizing tensor programs [6]. PET leverages the reshape andtranspose operators to transform the shapes of input tensorsand the linearization ordering of tensor dimensions to gen-erate mutants with better performance. A reshape operatorchanges the shape of a tensor by decoupling a single dimen-
40 15th USENIX Symposium on Operating Systems Design and Implementation USENIX Association

sion into multiple ones or combining multiple dimensionsinto one. E.g., a reshape can transform a vector with fourelements into a 2×2 matrix. A transpose operator modifiesthe linearization ordering of a tensor’s dimensions, such asconverting a row-major matrix to a column-major one.
Reshape and transpose are generally applied jointly totransform the tensor layouts. For example, Figure 1 showsa potential mutant of a convolution operator that concate-nates two separate images (i.e., T1→ T3 in Figure 1(b)) alongthe width dimension to improve the performance of convo-lution: typically a larger width exhibits more parallelism tobe exploited on modern accelerators such as GPUs. Thisconcatenation involves a combination of three reshape andtranspose operators. First, a reshape operator splits thebatch dimension of T0 into an inner dimension that groupsevery two consecutive images, and an outer dimension thatis half the size of the original. Then, a transpose operatormoves the newly created inner dimension next to the widthdimension and updates the tensor’s linearization ordering ac-cordingly, so each row of the two images in the same groupis stored consecutively in memory. Finally, another reshapeoperator combines the two images.
The mutation generator usually fuses multiple consecu-tive reshape and transpose operators into a single com-pound operator, namely reshape & transpose. This fusionreduces the size of the generated mutants and allows for ex-ploring much larger and more sophisticated mutants.
Single-operator mutants. PET can also generate mutantsthat replace an inefficient operator in a tensor program with adifferent and more performant operator. Several standard ten-sor operators, such as convolution and matrix multiplication,have been extensively optimized either manually or automati-cally on modern hardware backends. In contrast, their variants,such as strided or dilated convolutions [20], are not as effi-ciently supported. There are performance-related benefits tomutating them into their standard counterparts with highlyoptimized kernels. As an example, Figure 3 shows a mutantthat transforms a dilated convolution into a regular convolu-tion by reorganizing the linearization ordering of the inputtensor based on the given dilation. However, the mutant is notfully equivalent to the input program and requires correctionsafterward to restore functional equivalence.
Multi-operator mutants. PET also supports substituting asubgraph of multiple operators with another more efficient setof operators. For example, a few independent convolutionswith similar tensor shapes may be combined into a singlelarger convolution to improve GPU utilization and reduce ker-nel launch overhead. This requires manipulating tensor shapesand adding proper padding (see the examples in §8.3.3).
5 Mutation Corrector
While the mutants generated by PET have potentially higherperformance than the original programs, they may producedifferent mathematical results on some regions of the out-put tensors, potentially leading to accuracy loss. To maintaintransparency at the application level, PET chooses to preservethe statistical behavior of the input program and guaranteesthe same model accuracy, with the help of a mutation cor-rector. Specifically, the mutation corrector takes as inputs anMLTP P0 and one of its mutants P , and automatically gener-ates correction kernels that are applied to the output tensorsof P to maintain functional equivalence to P0.
The goal of the mutation corrector is twofold. First, for anygiven MLTP and its mutant, the corrector analyzes the twoprograms and identifies all the regions of the output tensorson which the two programs provide identical results and there-fore do not need any correction. Second, for the remainingregions where the two outputs are different, the corrector au-tomatically generates kernels to fix the output of the mutantand preserve functional equivalence.
Designing the mutation corrector requires addressing twochallenges. First, the output tensors may be very large, involv-ing up to many millions of elements that all require equiva-lence verification. It is infeasible to verify every single ele-ment of the output tensors individually. Second, the verifica-tion of each output element may depend on a large number ofinput variables in many tensor operators. For example, eachoutput element of a matrix multiplication is the inner productof one row and one column of the two input matrices, bothwith sizes up to several thousand. Numerically enumeratingall possible values for this many input variables is impractical.
Two theorems that significantly simplify the verificationtasks are central to the PET mutation corrector. Rather thanverifying all output positions with respect to all input valuecombinations, PET only needs to verify a few representativeoutput positions with a small number of randomly generatedinput values. This dramatically reduces the verification work-load. We describe these theoretical foundations in §5.1 andintroduce our mutation correction algorithm in §5.2.
5.1 Theoretical Foundations
To simplify our analysis, we assume an input MLTP P0 and itsmutant P each has one output. Our results can be generalizedto programs with multiple outputs by sequentially analyzingeach one. Let P (I) denote the output tensor of running P onn input tensors I = (I1, ..., In). Let P (I)[~v] denote the outputvalue at position ~v, and let I j[~u] denote the input value atposition~u of I j. With these definitions, the computation for asingle output position of an MLTP P is represented as
P (I1, ..., In)[~v] = ∑~r∈R (~v)
n
∏j=1
I j[L j(~v,~r)]
USENIX Association 15th USENIX Symposium on Operating Systems Design and Implementation 41

dilated conv
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
T1
W1
T2
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
T1
reshape & transpose
1 1 1 1 2 2 2 2
1 1 1 1 2 2 2 2
1 1 1 1 2 2 2 2
1 1 1 1 2 2 2 2
3 3 3 3 4 4 4 4
3 3 3 3 4 4 4 4
3 3 3 3 4 4 4 4
3 3 3 3 4 4 4 4
T3
con
v
T4
T5
reshape & transpose
correction
T5
T2
(a) Input program.
dilated conv
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
T1
W1
T2
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
T1
reshape & transpose
1 1 1 1 2 2 2 2
1 1 1 1 2 2 2 2
1 1 1 1 2 2 2 2
1 1 1 1 2 2 2 2
3 3 3 3 4 4 4 4
3 3 3 3 4 4 4 4
3 3 3 3 4 4 4 4
3 3 3 3 4 4 4 4
T3
con
v
T4
T5
reshape & transpose
correction
T5
T2
(b) A partially equivalent transformation.
correctiondilated conv
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
T1
W1
T2
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
1 2 1 2 1 2 1 2
3 4 3 4 3 4 3 4
T1
reshape & transpose
1 1 1 1 2 2 2 2
1 1 1 1 2 2 2 2
1 1 1 1 2 2 2 2
1 1 1 1 2 2 2 2
3 3 3 3 4 4 4 4
3 3 3 3 4 4 4 4
3 3 3 3 4 4 4 4
3 3 3 3 4 4 4 4
T3
con
v
T4
T5
reshape & transpose
T5
T2
(c) Correcting results.
Figure 3: An example mutant that transforms a dilated convolution to a standard convolution. The red-shaded boxes in (b)highlight non-equivalent elements between the two programs, which are fixed by the correction kernel in (c).
where R (~v) is the summation interval of~v, which is iteratedover when computing P (I)[~v], and ~u = L j(~v,~r) is a linearmapping from (~v,~r) to a position ~u of the j-th input tensorI j. For example, a convolution with a kernel size of 3×3 andzero padding is defined as
conv(I1, I2)[c,h,w] =D−1
∑d=0
min(H−1−h,1)
∑x=max(−1,−h)
min(W−1−w,1)
∑y=max(−1,−w)
I1[d,h+ x,w+ y]× I2[d,c,x,y]
(1)
where D, H, and W refer to the number of channels, height,and width of the input image I1, respectively. The numbersbelow and above the summation symbols respectively denotethe lower and upper bounds of the summation interval. Thetwo linear mappings can be represented as L1(~v,~r) = (d,h+x,w+ y) and L2(~v,~r) = (d,c,x,y), where ~v = (c,h,w) and~r = (d,x,y).
Different positions of an output tensor may have differentsummation intervals. For the convolution operator definedabove, computing the top-left output position (i.e., h = 0,w = 0) only involves a 2×2 kernel (i.e., 0≤ x≤ 1, 0≤ y≤ 1)since that position does not have a left or top neighbor, asshown in Figure 4. We group the output positions with anidentical summation internal into a box. Formally, a box is aregion of an output tensor whose elements all have the samesummation internal. This convolution has nine boxes overall,which are depicted in Figure 4.
All output positions in the same box have an identical sum-mation internal and share similar mathematical properties,which are leveraged by PET when examining program equiv-alence. Instead of testing the equivalence of two MLTPs onall individual positions, PET only needs to verify their equiva-lence on m+1 specific positions in each box, where m is thenumber of dimensions of the output tensor.
Theorem 1 For two MLTPs P1 and P2 with an m-dimensionoutput tensor, let~e1, . . . ,~em be a set of m-dimension base vec-
conv
0 ≤ x ≤ 1-1 ≤ y ≤ 0
-1 ≤ x ≤ 1-1 ≤ y ≤ 0
-1 ≤ x ≤ 0-1 ≤ y ≤ 0
0 ≤ x ≤ 10 ≤ y ≤ 1
-1 ≤ x ≤ 10 ≤ y ≤ 1
-1 ≤ x ≤ 00 ≤ y ≤ 1
0 ≤ x ≤ 1-1 ≤ y ≤ 1
-1 ≤ x ≤ 1-1 ≤ y ≤ 1
-1 ≤ x ≤ 0-1 ≤ y ≤ 1
InputWeight
x = -1
x = 0
x = -1
y =
-1
y =
0
y =
1
Figure 4: The nine boxes of a convolution with a 3×3 kerneland zero padding, as well as their summation intervals. Aconvolution has three summation dimensions (i.e., d, x, and yin Equation (1)). The channel dimension (i.e., d) has the sameinternal in all boxes and is thus omitted.
tors. That is,~ei = (0, . . . ,0,1,0, . . . ,0) is an m-tuple with allcoordinates equal to 0 except the i-th.
Let B be a box for P1 and P2, and let~v0 be an arbitraryposition in B . Define~v j =~v0 +~e j,1 ≤ j ≤ m. If ∀I,0 ≤ i ≤m, P1(I)[~vi] = P2(I)[~vi], then ∀I,~v ∈ B, P1(I)[~v] = P2(I)[~v].
Proof sketch. The proof uses a lemma whereby if P1 and P2are equivalent for positions~v0 and~v0+~ei, then the equivalenceholds for ~v0 + k ·~ei, where k is an integer. We prove thislemma by comparing the coefficient matrices of P1 and P2with respect to the input variables. Using this lemma, we showthat P1 and P2 are equivalent for the entire box B , since any~v ∈ B can be decomposed to a linear combination of~v0 and~e0, . . . ,~em. �
Theorem 1 shows that, if P1 and P2 are equivalent for m+1specific positions in a box, identified by ~v0, ...,~vm, then theequivalence holds for all other positions in the same box.This theorem significantly reduces the verification workload:
42 15th USENIX Symposium on Operating Systems Design and Implementation USENIX Association

Table 2: Reducing verification workload in PET.
Methods Output positions Input combinations
Original all all+ Theorem 1 a few positions all+ Theorem 2 a few positions a few random inputs
instead of examining all positions of an output tensor, PETonly needs to verify m+1 specific positions in each box.
The verification of a single position remains challenging,nevertheless, as each MLTP generally involves a large numberof input variables. Proving the equivalence of two MLTPsrequires examining all possible combinations of value as-signments to these input variables. We further address thischallenge using the following theorem.
Theorem 2 For two MLTPs P1 and P2 with n input tensors,let~v be a position where P1 and P2 are not equivalent, i.e.,∃I, P1(I)[~v] 6= P2(I)[~v]. Let I′ be a randomly generated inputuniformly sampled from a finite field F. The probability thatP1(I′)[~v] = P2(I′)[~v] is at most n
p , where p is the number ofpossible values in F.
Proof sketch. This is a corollary of the Schwartz–ZippelLemma [28, 35]. �
Theorem 2 shows that if two MLTPs with n inputs arenot equivalent on a specific position ~v, then the probabilitythat they produce an identical result on this position with arandom input sampled from a finite field F is low (i.e., atmost n
p , where p is the number of possible values in F). Thistheorem shows the sufficiency and effectiveness of randomtesting for examining the equivalence of two MLTPs.
Theorem 2 relies on the fact that F is a finite field, fromwhich the random inputs are sampled, but MLTPs operate onthe infinite field of real numbers. To apply Theorem 2, wechoose F to be a field of integers modulo p, where p is a largeprime number (p = 231−1 in our evaluation). The arithmeticoperations in random testing are performed on integers andcalculated modulo the prime number p. Working with a fi-nite field provides another desirable property that applyingarithmetic operators does not involve integer overflow.
By combining Theorems 1 and 2, PET reduces the originalverification task of examining all output positions with respectto all input value combinations to a much more lightweighttask that only requires testing a few representative positionsusing several randomly generated inputs, as shown in Table 2.
5.2 Mutation Correction AlgorithmThe PET mutation correction algorithm exploits the theoremsin §5.1 to calculate which regions of the output tensors in amutant are not equivalent to the input MLTP and, therefore,need additional correction. In particular, it suffices to examinethe equivalence for each pair of overlapped boxes from the two
conv
T0
T1
(a) Input program P0.
conv
R/T
R/T
T0
T2
T3
T1
(b) A potential mutant P1.
Figure 5: Box propagation for the example in Figure 1. Thered arrows indicate the split points of each tensor dimension.
MLTPs, using a small number of random tests. The overallalgorithm works in the following three steps.
Step 1: Box propagation. First, we calculate the boxes ofa given MLTP through box propagation. The idea of boxpropagation is similar to forward and backward propagation indeep learning: we compute the boxes of an operator’s outputtensors based on the boxes of its inputs, and the computation isconducted following the operator dependencies in a program.We maintain a set of split points for each dimension of a tensorto identify the boundaries of its boxes. For a multi-linearoperator, we infer the split points of its output tensors basedon the split points of its input tensors and the operator typeand hyper-parameters. Figure 5 shows the box propagationprocedure for the mutation example in Figure 1.
Step 2: Random testing for each box pair. After obtainingall boxes of an input MLTP P1 and its mutant P2, PET lever-ages the theorems in §5.1 to examine the intersected regionsof each pair of boxes from P1 and P2. If two boxes do not haveany overlapped region, they can be skipped. For each box in-tersection, PET examines the equivalence of the two programson m+1 positions identified by Theorem 1, where m is thenumber of output tensor dimensions (e.g., m = 4 in Figure 5,since the output of a convolution has four dimensions).
For each of these m+1 positions, PET runs a set of randomtests by assigning input tensors with values uniformly sam-pled from a finite field F containing all integers between 0 andp−1, where p = 231−1 is a prime number. As a result, theprobability that two non-equivalent MLTPs produce identicaloutputs on a random input is at most n
p , where n is the numberof inputs to the MLTPs. Finally, two non-equivalent MLTPspass all tests with a probability lower than ( n
p )t , where t is the
number of test cases and a hyper-parameter in PET that servesas a tradeoff between the speed of the corrector and the errorprobability that non-equivalent MLTPs pass all random tests.
Our approach introduces an extremely small and control-lable probability of error that we have to tolerate. That is,non-equivalent programs may pass random testing with prob-ability ( n
p )t . We argue that this is an example of how random
testing can enable a tradeoff between the cost of program ver-ification and a small probability of unsoundness for verifying
USENIX Association 15th USENIX Symposium on Operating Systems Design and Implementation 43

Correction
T0 R/T-0 Conv-1 R/T-1T1 T2
W1
T3
Conv-2
T0’
T4
T3’
T0 Conv-0 T4
Mutation with correction
Fusing correction
T0 R/T-3 Conv-1-2 R/T-4T1’ T2’ T4
(a)
(b)
(c)
Figure 6: Fusing correction kernels with DNN kernels.
tensor program transformations.To further reduce the verification workload, PET includes a
caching optimization: the tests for all boxes share the same setof random inputs, and PET caches and reuses all intermediateresults to avoid redundant computations.
Step 3: Correction kernel generation. For each box failingthe random tests, PET generates correction kernels to fix itsoutputs and restore the mathematical equivalence between theoriginal MLTP and its mutant. To fix the outputs, the correc-tion kernel performs the same set of operations as the originalMLTP but only on those boxes where the two input programsare not equivalent (shown as the red shaded boxes in Figure 1).These boxes are regular cubes in the multi-dimensional spaceand can be viewed as sub-tensors of the original ones but withmuch smaller sizes. Therefore, PET directly leverages existingDNN libraries [8, 10] or kernel generation techniques [6, 34]to generate correction kernels. To reduce the correction over-head, PET opportunistically fuses the correction kernels withexisting tensor operators (§5.3).
5.3 Fusing Correction Kernels
Correction kernels may introduce non-trivial overheads dueto the cost of launching the correction kernels and their lim-ited degrees of parallelism. For example, some correctionkernels may have similar execution time compared to the cor-responding full-size tensor operators. This may eliminate theperformance gains from applying partially equivalent transfor-mations. To reduce the correction overhead, PET opportunis-tically fuses correction kernels with other tensor operators.
For example, Figure 6(b) shows the tensor program af-ter applying the partially equivalent transformation in Fig-ure 1. Conv-2 is the correction kernel for fixing the outputof Conv-1. Since the two convolution operators share thesame weights (i.e., W1), PET fuses them into a single convolu-tion, shown as Conv-1-2 in Figure 6(c). This fusion requiresconcatenating T1 and T ′0 into a single tensor and splitting theoutput of Conv-1-2 into T2 and T ′3 . The concatenation andsplit only involve direct memory copies and can be fused withthe reshape and transpose operators.
6 Program Optimizer
In this section, we describe the program optimizer in PET,which explores a large search space of program optimizations,combining fully and partially equivalent transformations, andquickly discovers highly optimized programs. The programoptimizer first splits an input program into multiple subpro-grams with smaller sizes to allow efficient mutation genera-tion (§6.1). Second, to optimize each individual subprogram,PET searches for the best mutants in a rich candidate spaceby varying both the subsets of operators to mutate togetherand the number of iterative rounds of mutation (§6.2). Finally,when stitching the optimized subprograms back together, PETapplies additional post-optimizations across the boundariesof the subprograms, including redundancy elimination andoperator fusion (§6.3). The overall program optimization al-gorithm is summarized in Algorithm 2.
Algorithm 2 Program optimization algorithm.1: Input: An input tensor program P02: Output: An optimized tensor program Popt3:4: Split P0 into a list of subprograms5: Initialize a heap H to record the top-K programs6: H .insert(P0)7: // Greedily mutate each subprogram8: for each subprogram S ∈ P0 do9: mutants = GETMUTANTS(S )
10: Initialize a new heap Hnew11: for P ∈H do12: for M ∈ mutants do13: Pnew = replace S with M in P14: Apply post-optimizations on Pnew15: Hnew.insert(Pnew)
16: H = Hnew
17: Popt = the program with the best performance in H18: return Popt19:20: function GETMUTANTS(S0)21: O = the set of mutant operators for S022: Q = {S0}, mutants = {S0}23: for r rounds do24: Qnew = {}25: for S ∈ Q do26: for each subset of operators S ′ ∈ S do27: for M ′ ∈ MUTATIONGENERATOR(O, S ′) do28: M = replace S ′ with M ′ in S29: Add M to Qnew and mutants30: Q = Qnew
31: return mutants
6.1 Program SplittingThe complexity of the mutation generation grows rapidly withthe input program size, as explained in §4. It is nearly im-
44 15th USENIX Symposium on Operating Systems Design and Implementation USENIX Association

possible to directly mutate a large tensor program with manyhundreds of operators. Instead, PET splits an input programinto multiple disjoint subprograms with smaller sizes.
It is crucial to properly select the split points for an in-put program, to effectively reduce the mutation complexitywhile still preserving most program optimization opportuni-ties. More split points lead to smaller subprograms with fewermutant candidates to be explored. As an extreme case, byconstraining each subprogram to have only a small constantnumber of operators, the overall complexity scales linearlywith the program size, rather than the naive exponential trend.However, an overly aggressive split may result in locally opti-mized mutants that are limited within subprograms, missingoptimization opportunities across subprogram boundaries.
We use non-linear operators in tensor programs as the splitpoints. First, non-linear operators such as the activation layersin DNNs are widely used in tensor programs. Typically, eachone or a few linear operators are followed by a non-linearactivation (e.g., ReLU or sigmoid). This effectively limits thesplit subprograms to the small sizes we expect. Second, as§5 explains, PET’s mutation only applies to MLTPs; any non-linear operators must be excluded from the mutation. Thismakes splitting at the points of non-linear operators a naturalchoice for the partially equivalent mutation in PET. Third, ourdesign is also motivated by an observation that most existingtensor program transformations [2, 6, 15] also do not includenon-linear operators in their substitution patterns (except forfusion, which we handle in §6.3).
PET further adjusts the subprogram sizes after splittingan input program at the non-linear operators. For multipleindividual subprograms without any data dependency, PETconsiders the possibility of combining them into a singlesubprogram using grouped or batched operators. Examplesinclude fusing the standard convolutions on different branchesof an Inception network [31] into a grouped convolution, asshown in Figure 10. On the other hand, if a subprogram is stilltoo large, PET will only query the mutation generator with asubset of operators each time (see §6.2).
6.2 Subprogram Optimization
After splitting an input program into multiple individual sub-programs, PET mutates each subprogram by querying themutation generator in §4.1 and keeps the top-K candidateswith the best estimated performance in a heap structure H , asshown from Lines 7 to 16 in Algorithm 2. A larger K allowsPET to tolerate intermediate performance decreases duringthe search but requires more memory to save all K candidatesand involves higher computation cost. At each step, each ofthe obtained mutants replaces its corresponding subprogramin each of the current candidates (i.e., P in Algorithm 2) togenerate a new candidate (i.e., Pnew), which is then applied aseries of post-optimizations (see §6.3).
PET estimates the performance of each new candidate Pnew
SG-2
SG-1
i1 w1
R/T-A R/T-B
Conv-C
R/T-D
R/T-E
ReLU-F
R/T-G
R/T-H
w2
R/T-I
o1
Conv-J
i1 w1
R/T-A R/T-B
Conv-C
ReLU-F
R/T-D
R/T-E
R/T-G
R/T-H
w2
R/T-I
o1
Conv-J
i1
w3R/T-A
Conv-ReLU-CF
R/T-DH w4
o1
Conv-J
Operator reordering Post-optimization
Inverseselimination Preprocessing
Kernel fusion
12
3
(a) (b) (c)
Figure 7: Post-optimizations applied when stitching two sub-programs SG-1 and SG-2. R/T refers to a reshape followedby a transpose. Conv and ReLU denote a convolution and aReLU operator, respectively.
using a cost model adapted from TASO [15]. The cost modelmeasures the execution time of each tensor operator oncefor each configuration (e.g., different strides and padding of aconvolution), and estimates the performance of a new programcandidate Pnew by summing up the measured execution timeof its operators. The top-K program candidates with the bestperformance thus far are kept in H .
To explore a sufficiently large space of possible mutantsfor each subprogram within reasonable time and space cost,we manage the mutation process with several key features.First, when the number of operators in a subprogram exceedsa threshold d (our evaluation uses d = 4), PET breaks thesubprogram into smaller subsets of operators by enumeratingall possible combinations with up to d operators, and onlyqueries the mutation generator on the subset, while keepingthe remaining operators unchanged (Algorithm 2 Line 26).Second, we allow iterative mutation on a subprogram for up tor rounds (Algorithm 2 Line 23), which significantly enlargesthe search space of possible mutants and allows PET to dis-cover more optimized mutants. All generated mutants in allrounds are returned to the optimizer as potential candidates.
It is worth noting that PET’s optimizer is compatible withand can incorporate existing fully equivalent transforma-tions [2, 15] besides PET’s mutations. Doing so merely re-quires enhancing the mutation generator to explore and returnfully equivalent transformations as well, which are directlyapplicable to the input subprograms in the same way as themutations. By combining fully and partially equivalent trans-formations, PET explores a significantly larger search spaceof program optimizations and discovers highly optimizedprograms that existing optimizers miss.
USENIX Association 15th USENIX Symposium on Operating Systems Design and Implementation 45

6.3 Post-Optimizations
Finally, the optimized mutants for all subprograms need to bestitched together. In addition to connecting their input and out-put tensors, we also perform several post-optimizations acrossthe subprogram boundaries to further improve the overall per-formance. We observe that the mutation generator in PETintroduces a large number of reshape and transpose (R/T)operators, especially at the beginning and the end of each sub-program. There are opportunities to fuse these R/T operatorsacross subprograms and further fuse the non-linear operatorsthat are excluded from the above subprogram optimizations.
Figure 7 shows an example with two optimized subpro-grams. To optimize the boundaries between subprograms, PETfirst groups together all R/T operators between subprogramsby reordering the R/T operators with element-wise non-linearactivations (e.g., ReLU and sigmoid), as shown in Figure 7(b).This reordering is functionally correct, since both reshapeand transpose are commutative with element-wise operators.The reordering also allows PET to fuse the non-linear activa-tions with other linear operators, such as fusing a Conv and asubsequent ReLU into a Conv-ReLU, as shown in Figure 7(c).We then apply the following three post-optimizations.
Inverses elimination. We eliminate any pairs of R/T oper-ators that can cancel out each other and therefore are equiva-lent to a no-op. We call each such pair an inverse group anddirectly remove them as part of the post-optimization. An ex-ample of an inverse group is R/T-E and R/T-G in Figure 7(b).
Operator fusion. As shown in Figure 7(c), PET fuses theremaining consecutive R/T operators into a single operator(e.g., R/T-DH) to reduce the kernel launch cost. The non-linearactivations in a tensor program are also fused with an R/T orwith other linear operators. Note that operator fusion is themost commonly used, if not the only, program optimizationfor non-linear operators. PET is able to recover most of theefficiency that was lost when splitting the tensor program.
Preprocessing. We preprocess any operator if all its inputtensors are statically known. For example, in Figure 7(b), bothR/T-B and R/T-I can be preprocessed on the convolutionweight tensors w1 and w2.
7 Implementation
PET is implemented as an end-to-end tensor program opti-mization framework, with about 13,000 lines of C++ codeand 1,000 lines of Python code. This section describes ourimplementation of the PET mutation generator and corrector.
Mutation operators. Table 1 lists the tensor operatorsincluded in the current implementation of PET. We usecuDNN [8] and cuBLAS [10] as our backend operator li-braries. PET can also be extended to include other libraries,such as TVM [6] and Ansor [34]. In our evaluation, we demon-strate this extensibility on TVM and Ansor, and show thatthey can directly benefit from PET’s partially equivalent opti-
mizations and automated corrections.Reshape and transpose are two frequently used operators
in partially equivalent transformations. Our implementationincludes a series of optimizations on them, including eliminat-ing inverse groups of R/T operators and fusing consecutiveR/T operators, as described in §6.3. Since both reshape andtranspose are multi-linear operators, PET directly uses therandom testing method introduced in §5 to examine whethera sequence of R/T operators forms an inverse group and there-fore can be eliminated.
Correction kernels. §5.2 describes a generic approach togenerate correction kernels by directly running the originalprogram on the positions with incorrect results. To reduce thecorrection overhead, PET fuses the correction kernels withother tensor operators, as described in §5.3. The correctionkernel fusion introduces additional memory copies, which arealso fused with the R/T operators during post-optimizations.
8 Evaluation
8.1 Experimental Setup
Platforms. We use a server equipped with two-socket, 28-core Intel Xeon E5-2680 v4 processors (hyper-thread en-abled), 256 GB of DRAM, and one NVIDIA Tesla V100GPU. All experiments use CUDA 10.2 and cuDNN 7.6.5except for those with TVM and Ansor, which directly use thebest kernels generated by these backends.
PET preserves an end-to-end equivalence between the orig-inal and optimized programs, same as all the baselines. PETtakes ONNX models as input. TensorRT and TASO directlysupport the ONNX format. For TensorFlow and TensorFlow-XLA, we use the onnx-tensorflow tool [25] for format conver-sion.
Workloads. We use five DNN architectures. Resnet-18 [14]is a widely used convolutional network for image classifica-tion. CSRNet [20] is a dilated convolutional network used forsemantic segmentation. Its sampling rate can be arbitrarilyadjusted to enlarge the receptive field for higher accuracy.Inception-v3 [31] is an improved version of GoogLeNet [30]with carefully designed Inception modules to improve accu-racy and computational efficiency. BERT [12] is a languagerepresentation architecture that obtains state-of-the-art accu-racy on a wide range of natural language tasks. Resnet3D-18 [13] is a 3D convolutional network for video processing.
Unless otherwise stated, in all experiments, we use CUDAevents to measure the elapsed time from launching the firstCUDA kernel in a tensor program to receiving the completionnotification of the last kernel. We set the default mutationgeneration depth to 4 (i.e., depth = 4 in Algorithm 1) and thesearch rounds to 4 (i.e., r = 4 in Algorithm 2). We furtherevaluate the scalability of the mutation generator and theprogram optimizer in §8.5.
46 15th USENIX Symposium on Operating Systems Design and Implementation USENIX Association
A B C D E012345
1.04x
Resnet-18
A B C D E0
1
2
3
2.21x
CSRNet
A B C D E0
5
10
15
20
1.24x
Inception-v3
A B C D E0
2.55
7.510
12.5
1.40x
BERT
A B C D E0
5
10
15
20
1.00x
Resnet3D-18
A B C D E0
5
10
15
1.21x
A B C D E0
2
4
6
8
2.51x
A B C D E0
20
40
60
1.44x
A B C D E0
50
100
150
1.19x
A B C D E0
50
100
150
200
1.28x
(A)TensorFlow (B)TensorFlow-XLA (C)TensorRT (D)TASO (E)PET
Exec
. tim
e (m
s)
batch_size=1
Exec
. tim
e (m
s)
batch_size=16
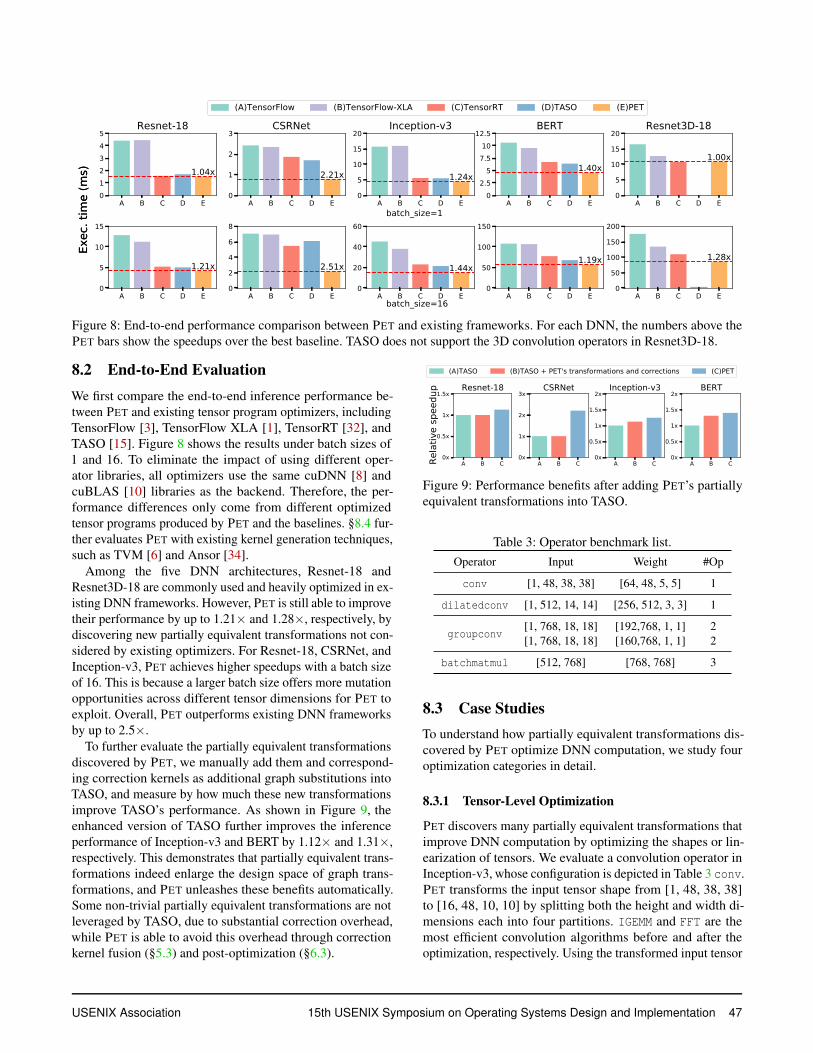
Figure 8: End-to-end performance comparison between PET and existing frameworks. For each DNN, the numbers above thePET bars show the speedups over the best baseline. TASO does not support the 3D convolution operators in Resnet3D-18.
8.2 End-to-End EvaluationWe first compare the end-to-end inference performance be-tween PET and existing tensor program optimizers, includingTensorFlow [3], TensorFlow XLA [1], TensorRT [32], andTASO [15]. Figure 8 shows the results under batch sizes of1 and 16. To eliminate the impact of using different oper-ator libraries, all optimizers use the same cuDNN [8] andcuBLAS [10] libraries as the backend. Therefore, the per-formance differences only come from different optimizedtensor programs produced by PET and the baselines. §8.4 fur-ther evaluates PET with existing kernel generation techniques,such as TVM [6] and Ansor [34].
Among the five DNN architectures, Resnet-18 andResnet3D-18 are commonly used and heavily optimized in ex-isting DNN frameworks. However, PET is still able to improvetheir performance by up to 1.21× and 1.28×, respectively, bydiscovering new partially equivalent transformations not con-sidered by existing optimizers. For Resnet-18, CSRNet, andInception-v3, PET achieves higher speedups with a batch sizeof 16. This is because a larger batch size offers more mutationopportunities across different tensor dimensions for PET toexploit. Overall, PET outperforms existing DNN frameworksby up to 2.5×.
To further evaluate the partially equivalent transformationsdiscovered by PET, we manually add them and correspond-ing correction kernels as additional graph substitutions intoTASO, and measure by how much these new transformationsimprove TASO’s performance. As shown in Figure 9, theenhanced version of TASO further improves the inferenceperformance of Inception-v3 and BERT by 1.12× and 1.31×,respectively. This demonstrates that partially equivalent trans-formations indeed enlarge the design space of graph trans-formations, and PET unleashes these benefits automatically.Some non-trivial partially equivalent transformations are notleveraged by TASO, due to substantial correction overhead,while PET is able to avoid this overhead through correctionkernel fusion (§5.3) and post-optimization (§6.3).
A B C0x
0.5x
1x
1.5xResnet-18
A B C0x
1x
2x
3xCSRNet
A B C0x
0.5x
1x
1.5x
2xInception-v3
A B C0x
0.5x
1x
1.5x
2xBERT
(A)TASO (B)TASO + PET's transformations and corrections (C)PET
Rela
tive
spee
dup
Figure 9: Performance benefits after adding PET’s partiallyequivalent transformations into TASO.
Table 3: Operator benchmark list.Operator Input Weight #Op
conv [1, 48, 38, 38] [64, 48, 5, 5] 1
dilatedconv [1, 512, 14, 14] [256, 512, 3, 3] 1
groupconv[1, 768, 18, 18] [192,768, 1, 1] 2[1, 768, 18, 18] [160,768, 1, 1] 2
batchmatmul [512, 768] [768, 768] 3
8.3 Case StudiesTo understand how partially equivalent transformations dis-covered by PET optimize DNN computation, we study fouroptimization categories in detail.
8.3.1 Tensor-Level Optimization
PET discovers many partially equivalent transformations thatimprove DNN computation by optimizing the shapes or lin-earization of tensors. We evaluate a convolution operator inInception-v3, whose configuration is depicted in Table 3 conv.PET transforms the input tensor shape from [1, 48, 38, 38]to [16, 48, 10, 10] by splitting both the height and width di-mensions each into four partitions. IGEMM and FFT are themost efficient convolution algorithms before and after theoptimization, respectively. Using the transformed input tensor
USENIX Association 15th USENIX Symposium on Operating Systems Design and Implementation 47

Table 4: Case studies on the performance of the conv anddilatedconv operators in Table 3. IGEMM, FFT, and WINO re-fer to implicit GEMM, Fast Fourier Transform, and Winogradconvolution algorithms, respectively. For conv, the optimizedprogram transforms the input tensor shape from [1, 48, 38, 38]to [16, 48, 10, 10]. For dilatedconv, the optimized programreplaces the dilatedconv with a regular convolution withthe same input and kernel sizes.
Algo Time(us)
# GPUDRAM
# GPUL2
FLOP
conv
Original IGEMM 90 1.51×104 2.80×106 2.26×108
FFT 352 1.06×108 1.15×108 8.75×107
Optimized IGEMM 90 1.52×104 1.46×106 2.46×108
FFT 51 1.09×106 7.44×106 1.26×108
dila
ted
conv
Original IGEMM 153 1.06×105 2.46×106 1.32×108
WINO N/A N/A N/A N/A
Optimized IGEMM 153 8.54×104 1.80×106 1.32×108
WINO 79 2.23×106 6.36×106 7.20×107
reduces the GPU DRAM and L2 accesses by 100× and 15×,respectively, and thus reduces the run time by 7× (Table 4).
As another example of tensor-level optimization, for convwith a stride size larger than 1 (i.e., the output tensor is adown-sample of the input tensor), PET can reorganize thelinearization of the tensors and reduce the stride size to 1,which improves the computation locality.
8.3.2 Operator-Level Optimization
For operators with less efficient implementations on specifichardware backends, PET can opportunistically replace themwith semantically similar ones with more optimized imple-mentations. We study the performance of a dilated convolu-tion in CSRNet [20], whose configuration is shown in Table 3dilatedconv. PET replaces it with a regular convolutionoperator (as shown in Figure 3) to enable more efficient al-gorithms on GPUs such as Winograd [17]. This reduces theexecution time by 1.94× (Table 4).
Other examples of operator-level optimizations includereplacing a batch matrix multiplication with a standard matrixmultiplication, a group convolution with a convolution, andan average pooling with a group convolution or a convolutionif the replacement leads to improved performance, even whenincluding the correction cost.
8.3.3 Graph-Level Optimization
PET also discovers graph-level optimizations. Figure 10shows two graph transformations discovered by PET to opti-mize Inception-v3 [31]. For two parallel conv operators withdifferent numbers of output channels, Figure 10(a) shows anon-equivalent transformation that fuses the two conv opera-tors into a groupconv by padding W2 with zeros, so that theoutput of pad has the same shape as W1. The correction splitsand discards the zeros tensor at the end (shown in red).
I1[n,c,h,w] W1[f,c,r,s] I2[n,c,h,w] W2[2f,c,r,s]
conv conv
O1[n,f,h,w] O2[n,2f,h,w]
I1[n,c,h,w] W1[f,c,r,s] I2[n,c,h,w] W2[2f,c,r,s]
O1[n,f,h,w] O2[n,2f,h,w]
concat(axis=1) concat(axis=0)
group conv (#g=3)
split(axis=1)
mutation
I1[n,c,h,w] W1[f1,c,r,s] I2[n,c,h,w] W2[f2,c,r,s]
conv conv
O1[n,f1,h,w] O2[n,f2,h,w]
W2[f2,c,r,s]
O1[n,f1,h,w] O2[n,f2,h,w]
pad
W2[f1,c,h,w]concat(axis=1)
concat(axis=0)group conv (#g=2)
split (axis=1)
zeros
mutation
I1[n,c,h,w] W1[f1,c,r,s] I2[n,c,h,w]
(a)
I1[n,c,h,w] W1[f,c,r,s] I2[n,c,h,w] W2[2f,c,r,s]
conv conv
O1[n,f,h,w] O2[n,2f,h,w]
I1[n,c,h,w] W1[f,c,r,s] I2[n,c,h,w] W2[2f,c,r,s]
O1[n,f,h,w] O2[n,2f,h,w]
concat(axis=1) concat(axis=0)
group conv (#g=3)
split(axis=1)
mutation
I1[n,c,h,w] W1[f1,c,r,s] I2[n,c,h,w] W2[f2,c,r,s]
conv conv
O1[n,f1,h,w] O2[n,f2,h,w]
W2[f2,c,r,s]
O1[n,f1,h,w] O2[n,f2,h,w]
pad
W2[f1,c,h,w]concat(axis=1)
concat(axis=0)group conv (#g=2)
split (axis=1)
zeros
mutation
I1[n,c,h,w] W1[f1,c,r,s] I2[n,c,h,w]
(b)
Figure 10: Mutants discovered by PET for Inception-v3. axisdenotes the dimension on which to perform concat andsplit.
PET also discovers fully equivalent transformations that aremissed by existing frameworks. The mutation corrector cansuccessfully verify the equivalence for all output elements, inwhich case no correction is needed. Figure 10(b) shows a newequivalent transformation discovered by PET that optimizestwo conv operators by duplicating the input tensors (i.e., I1and I2) and fusing the two conv operators into a groupconv.Note that Figure 10 shows two different mutants of the sameinput program. PET’s program optimizer can automaticallyselect a more efficient one based on the performance of thesemutants on specific devices.
8.3.4 Kernel Fusion
We use CSRNet [20] as an example to study the effective-ness of PET’s kernel fusion optimization. Figure 11(a) andFigure 11(b) show the original and optimized model archi-tectures of CSRNet. The numbers in each operator denotethe input tensor shape. To demonstrate the correction ker-nel fusion and post-optimization in PET, Figure 11(c) showsthe subprogram of a single dilated convolution before post-optimization, which contains three correction kernels and sixR/T (i.e., reshape and transpose) operators. These correc-tion kernels are fused with Conv-4, as described in §5.3. Inaddition, the multiple R/T operators between convolutions arefused into a single one during post-optimization (§6.3).
Fusing correction kernels and R/T operators is critical toPET’s performance. In an ablation study, disabling kernelfusion in PET decreases the performance of the final programby 2.9×, making it even slower than the original one.
8.4 TVM and AnsorPET improves tensor computations by generating and cor-recting partially equivalent transformations and is thereforeorthogonal to and can potentially be combined with recent ker-nel generation techniques, such as TVM [6] and Ansor [34].
We evaluate PET on TVM and Ansor with a set of com-monly used DNN operators, including conv, dilatedconv,
48 15th USENIX Symposium on Operating Systems Design and Implementation USENIX Association

T0DilatedConv-1[1,512,14,14]
ReLU-1DilatedConv-2[1,512,14,14]
ReLU-2DilatedConv-3[1,512,14,14]
ReLU-3DilatedConv-4[1,512,14,14]
ReLU-4DilatedConv-5[1,256,14,14]
ReLU-5DilatedConv-6[1,128,14,14]
ReLU-6 T6
(a) CSRNet before optimization.
T0FusedR/T-0
Conv-ReLU-1[2,512,7,15]
FusedR/T-1
Conv-ReLU-2[2,512,7,15]
FusedR/T-2
Conv-ReLU-3[2,512,7,15]
FusedR/T-3
Conv-ReLU-4[2,512,7,15]
FusedR/T-4
Conv-ReLU-5[4,256,7,7]
FusedR/T-5
Conv-ReLU-6[4,128,7,7]
FusedR/T-6
T6
(c)
(d)
(b) CSRNet after optimization.
Correction kernels
R/T-AConv-4
[2,512,7,14]R/T-F
DilatedConv-C[1,512,14,5]
T3 T4R/T-B R/T-E
DilatedConv-B[1,512,5,14]
R/T-D
Conv-A[1,512,3,14]
R/T-C TE TF ReLU-3TD
(c) DilatedConv-4’s subprogram after subprogram optimization but before post-optimization.
R/T-D R/T-E R/T-FTE
[1,256,14,14]TF
[1,256,14,14]T4
[1,256,14,14]R/T-G
TG[1,256,14,14]
R/T-HTH
[2,256,7,14]R/T-I
TI[4,256,7,7]
TD[1,256,7,15]
(d) Unfused R/T operators and corresponding tensors’ shape of F R/T-4.
Figure 11: Optimization details in PET for CSRNet.
conv dilatedconv groupconv batchmatmul0x
1x
2x
3x
4x
5x
6x
Spee
dup
over
cuD
NN/c
uBLA
S
cuDNN/cuBLAScuDNN/cuBLAS w/ PET
TVMTVM w/ PET
AnsorAnsor w/ PET
Figure 12: Performance comparison of PET on thecuDNN/cuBLAS, TVM, and Ansor backends. The perfor-mance is normalized to cuDNN/cuBLAS without PET.
groupconv, and batchmatmul, which are obtained fromResnet-18, CSRNet, Inception-v3, and BERT, respectively.Their shape configurations are listed in Table 3. To gener-ate kernels for potential mutants during the search, we allowTVM and Ansor to run 1024 trials and use the best discoveredkernels to measure the cost of the mutants.
As Figure 12 shows, when combining PET with TVM andAnsor, PET can improve the performance of the evaluatedoperators by up to 1.23× and 1.21×, respectively, comparedto directly generating kernels for these operators. Beyond suchsimple combinations, joint optimization of PET and existingkernel generation techniques would uncover more benefits,which we leave as future work.
8.5 Ablation and Sensitivity Studies
The key insight of PET is to explore partially equivalent pro-gram mutants, while state-of-the-art frameworks only capturefully equivalent transformations [15, 34]. We run several vari-ants of PET to evaluate the benefits of considering either fullyor partially equivalent program transformations, or both ofthem, as PET does. Figure 13 shows the results. When re-stricting PET to consider only equivalent transformations, itachieves similar performance gains as previous work such as
Resnet-18 CSRNet Inception-v3 BERT Resnet3D-180.0x
0.5x
1.0x
1.5x
2.0x
2.5xRe
lativ
e sp
eedu
p
W/o Opt. Equivalent Opt. Non-equivalent Opt. Joint Opt.
Figure 13: Performance comparison of tensor program opti-mizations using only (fully) equivalent transformations, onlypartially equivalent transformations, and both (as in PET).
1 2 3 4 5depth
0.95x
1.00x
1.05x
1.10x
1.15x
1.20x
1.25xResnet-18
1 2 3 4 5depth
0.8x1.0x1.2x1.4x1.6x1.8x2.0x2.2x2.4x
CSRNetrounds=2 rounds=3 rounds=4
Rela
tive
spee
dup
Figure 14: Performance comparison by using PET with differ-ent mutation depths (§4.1) and rounds (§6.2).
TASO. Partially equivalent transformations, by themselves,enable noticeable benefits but also miss significant potential.Finally, PET achieves the highest performance by jointly con-sidering both fully and partially equivalent transformations.
Finally, PET relies on several heuristic parameters to bal-ance the search time and the resultant program performance.The mutation depth in Algorithm 1 limits the maximum num-ber of operators in a program mutant; the mutation roundin Algorithm 2 specifies the maximum number of iterationsto apply mutations. Larger values of these thresholds allowlarger design spaces of potential mutants but also require
USENIX Association 15th USENIX Symposium on Operating Systems Design and Implementation 49

more time to search. Figure 14 compares the performance ofthe optimized programs under different searching depths androunds for Resnet-18 and CSRNet. The performance gainskeep increasing with larger rounds values for Resnet-18, dueto the generation of more optimized mutants, while for CSR-Net, the performance improvement mainly comes from largermutation depth. On the other hand, increasing the mutationdepth from two to three improves the performance for bothmodels significantly, since many mutations PET finds are sub-programs with three operators. In summary, the key takeawayis that PET has only moderately high search complexity yetachieves significant performance gains.
8.6 Searching TimePET uses a program optimizer to explore the search space ofpossible mutants and discover highly optimized candidates.Typically, it takes under 3 minutes (89 seconds, 88 seconds, 91seconds, and 165 seconds on Resnet-18, CSRNet, BERT, andResnet3D-18, respectively) for PET to find highly optimizedprogram mutants with a batch size of 1. However, PET spendsabout 25 minutes optimizing Inception-v3, due to the multiplebranches in the Inception modules [31]. Although their searchspaces are not directly comparable, PET’s search time is onpar with state-of-the-art DNN optimization frameworks suchas TASO [15] and Ansor [34], and is acceptable because itis a one-time cost before stable deployment. We leave anyfurther search optimizations, such as aggressive pruning andparallelization, to future work.
9 Related work
Graph-level optimizations. TensorFlow [3], TensorRT [32],TVM [6], and MetaFlow [16] optimize tensor programs by ap-plying substitutions that are manually designed by domain ex-perts. TASO [15] generates graph substitutions automaticallyfrom basic operator properties, which significantly enlargessearch space and reduces human effects. The key differencebetween PET and these frameworks is that PET can generateand correct partially equivalent transformations, enabling asignificantly larger space of program optimizations.Program mutation is a program testing technique designedto evaluate the quality of existing test cases [11]. By randomlymutating the input program and running the generated mu-tants on existing test cases, the technique can quickly estimatethe coverage of these test cases. PET generates mutants fora different purpose. Instead of testing an input tensor pro-gram, the mutants generated by PET are used for performanceoptimizations on the program.Code generation. Halide [27] is a programming languagedesigned for high-performance tensor computing, and severalworks are proposed based on its scheduling model [4, 19, 22].TVM [6,7] uses a similar scheduling language and a learning-based approach to generate highly optimized code for dif-
ferent hardware backends. Ansor [34] explores larger searchspaces than TVM and finds better optimized kernels. Ten-sorComprehensions [33] and Tiramisu [5] use polyhedralcompilation models to solve code generation problems indeep learning. As shown in §8.4, PET’s program-level op-timizations are orthogonal and can be combined with thesecode generation techniques.Data layout optimization. NeoCPU [21] optimizes CNNmodels by changing the data layout and eliminating unnec-essary layout transformations on CPUs, while Li et al. [18]explore the memory efficiency for CNNs on GPUs. Chou etal. [9] introduce a language to describe the different sparsetensor formats and automatically generate code for convert-ing data layouts. Many transformations discovered by PETalso involve layout conversions. However, the key differencesbetween PET and prior work are that PET considers morecomplicated layouts and combines tensor layout optimiza-tions with operator- and graph-level optimizations.AutoML. Recent work has proposed approaches to search foraccurate neural architectures by iteratively proposing modifi-cations to the models’ architectures and accepting proposalswith the highest accuracy gain. Examples include automaticstatistician [29] and TPOT [24]. These approaches apply non-equivalent transformations to a model architecture and rely onexpensive retraining steps to evaluate how each transforma-tion affects model accuracy. On the contrary, PET leveragesperformance optimizations in non-equivalent transformationsand applies automated corrections to preserve an end-to-endequivalence. As such, PET does not require retraining.
10 Conclusion
We present PET, the first DNN framework that optimizestensor programs with partially equivalent transformationsand automated corrections. PET discovers program trans-formations that improve DNN computations with only par-tial functional equivalence. Automated corrections are sub-sequently applied to restore full equivalence with the helpof rigorous theoretical guarantees. The results of our eval-uation show that PET outperforms existing frameworks byup to 2.5× by unlocking partially equivalent transformationsthat existing frameworks miss. PET is publicly available athttps://github.com/thu-pacman/PET.
Acknowledgments
We would like to thank the anonymous reviewers andour shepherd, Behnaz Arzani, for their valuable com-ments and suggestions. This work is partially sup-ported by National Natural Science Foundation of China(U20A20226, 62072262) and Beijing Natural Science Foun-dation (4202031). Jidong Zhai is the corresponding author ofthis paper ([email protected]).
50 15th USENIX Symposium on Operating Systems Design and Implementation USENIX Association

References
[1] Xla: Optimizing compiler for tensorflow. https://www.tensorflow.org/xla, 2017.
[2] TensorFlow Graph Transform Tool. https://github.com/tensorflow/tensorflow/tree/master/tensorflow/tools/graph_transforms,2018.
[3] Martín Abadi, Paul Barham, Jianmin Chen, ZhifengChen, Andy Davis, Jeffrey Dean, Matthieu Devin, San-jay Ghemawat, Geoffrey Irving, Michael Isard, Man-junath Kudlur, Josh Levenberg, Rajat Monga, SherryMoore, Derek G. Murray, Benoit Steiner, Paul Tucker,Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu,and Xiaoqiang Zheng. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12thUSENIX Conference on Operating Systems Design andImplementation, OSDI, 2016.
[4] Andrew Adams, Karima Ma, Luke Anderson, RiyadhBaghdadi, Tzu-Mao Li, Michaël Gharbi, Benoit Steiner,Steven Johnson, Kayvon Fatahalian, Frédo Durand, et al.Learning to optimize halide with tree search and ran-dom programs. ACM Transactions on Graphics (TOG),38(4):1–12, 2019.
[5] Riyadh Baghdadi, Jessica Ray, Malek Ben Romdhane,Emanuele Del Sozzo, Abdurrahman Akkas, YunmingZhang, Patricia Suriana, Shoaib Kamil, and Saman Ama-rasinghe. Tiramisu: A polyhedral compiler for express-ing fast and portable code. In 2019 IEEE/ACM Interna-tional Symposium on Code Generation and Optimiza-tion (CGO), pages 193–205. IEEE, 2019.
[6] Tianqi Chen, Thierry Moreau, Ziheng Jiang, HaichenShen, Eddie Q. Yan, Leyuan Wang, Yuwei Hu, LuisCeze, Carlos Guestrin, and Arvind Krishnamurthy.TVM: end-to-end optimization stack for deep learning.CoRR, abs/1802.04799, 2018.
[7] Tianqi Chen, Lianmin Zheng, Eddie Yan, Ziheng Jiang,Thierry Moreau, Luis Ceze, Carlos Guestrin, and ArvindKrishnamurthy. Learning to optimize tensor programs.In Advances in Neural Information Processing Systems31, NeurIPS’18. 2018.
[8] Sharan Chetlur, Cliff Woolley, Philippe Vandermersch,Jonathan Cohen, John Tran, Bryan Catanzaro, and EvanShelhamer. cudnn: Efficient primitives for deep learning.CoRR, abs/1410.0759, 2014.
[9] Stephen Chou, Fredrik Kjolstad, and Saman Ama-rasinghe. Automatic generation of efficient sparsetensor format conversion routines. arXiv preprintarXiv:2001.02609, 2020.
[10] Dense Linear Algebra on GPUs. https://developer.nvidia.com/cublas, 2016.
[11] Richard A DeMillo, Edward W Krauser, and Aditya PMathur. Compiler-integrated program mutation. In1991 The Fifteenth Annual International Computer Soft-ware & Applications Conference, pages 351–352. IEEEComputer Society, 1991.
[12] Jacob Devlin, Ming-Wei Chang, Kenton Lee, andKristina Toutanova. BERT: pre-training of deep bidirec-tional transformers for language understanding. CoRR,abs/1810.04805, 2018.
[13] Kensho Hara, Hirokatsu Kataoka, and Yutaka Satoh.Learning spatio-temporal features with 3d residual net-works for action recognition. In Proceedings of theIEEE International Conference on Computer VisionWorkshops, pages 3154–3160, 2017.
[14] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and JianSun. Deep residual learning for image recognition. InProceedings of the IEEE Conference on Computer Vi-sion and Pattern Recognition, CVPR, 2016.
[15] Zhihao Jia, Oded Padon, James Thomas, Todd Warsza-wski, Matei Zaharia, and Alex Aiken. Taso: optimizingdeep learning computation with automatic generationof graph substitutions. In Proceedings of the 27th ACMSymposium on Operating Systems Principles, pages 47–62, 2019.
[16] Zhihao Jia, James Thomas, Todd Warzawski, MingyuGao, Matei Zaharia, and Alex Aiken. Optimizing dnncomputation with relaxed graph substitutions. In Pro-ceedings of the 2nd Conference on Systems and MachineLearning, SysML’19, 2019.
[17] Andrew Lavin and Scott Gray. Fast algorithms for con-volutional neural networks. In Proceedings of the IEEEConference on Computer Vision and Pattern Recogni-tion, pages 4013–4021, 2016.
[18] Chao Li, Yi Yang, Min Feng, Srimat Chakradhar, andHuiyang Zhou. Optimizing memory efficiency for deepconvolutional neural networks on gpus. In SC’16: Pro-ceedings of the International Conference for High Per-formance Computing, Networking, Storage and Analysis.IEEE, 2016.
[19] Tzu-Mao Li, Michaël Gharbi, Andrew Adams, FrédoDurand, and Jonathan Ragan-Kelley. Differentiable pro-gramming for image processing and deep learning inhalide. ACM Transactions on Graphics (TOG), 37(4):1–13, 2018.
USENIX Association 15th USENIX Symposium on Operating Systems Design and Implementation 51

[20] Yuhong Li, Xiaofan Zhang, and Deming Chen. Csrnet:Dilated convolutional neural networks for understandingthe highly congested scenes. In Proceedings of the IEEEconference on computer vision and pattern recognition,pages 1091–1100, 2018.
[21] Yizhi Liu, Yao Wang, Ruofei Yu, Mu Li, Vin Sharma,and Yida Wang. Optimizing {CNN}model inference oncpus. In 2019 {USENIX} Annual Technical Conference({USENIX}{ATC} 19), pages 1025–1040, 2019.
[22] Ravi Teja Mullapudi, Andrew Adams, Dillon Sharlet,Jonathan Ragan-Kelley, and Kayvon Fatahalian. Auto-matically scheduling halide image processing pipelines.ACM Transactions on Graphics (TOG), 35(4):1–11,2016.
[23] Vinod Nair and Geoffrey E. Hinton. Rectified linearunits improve restricted boltzmann machines. In Pro-ceedings of the 27th International Conference on Inter-national Conference on Machine Learning, ICML’10,pages 807–814, USA, 2010. Omnipress.
[24] Randal S Olson and Jason H Moore. Tpot: A tree-based pipeline optimization tool for automating machinelearning. In Workshop on automatic machine learning,pages 66–74. PMLR, 2016.
[25] TensorFlow Backend for ONNX. https://github.com/onnx/onnx-tensorflow.
[26] Tensors and Dynamic neural networks in Python withstrong GPU acceleration. https://pytorch.org,2017.
[27] Jonathan Ragan-Kelley, Connelly Barnes, AndrewAdams, Sylvain Paris, Frédo Durand, and Saman Ama-rasinghe. Halide: A language and compiler for optimiz-ing parallelism, locality, and recomputation in imageprocessing pipelines. In Proceedings of the 34th ACMSIGPLAN Conference on Programming Language De-sign and Implementation, PLDI ’13, 2013.
[28] Jacob T Schwartz. Fast probabilistic algorithms forverification of polynomial identities. Journal of theACM (JACM), 27(4):701–717, 1980.
[29] Christian Steinruecken, Emma Smith, David Janz, JamesLloyd, and Zoubin Ghahramani. The automatic statisti-cian. In Automated Machine Learning, pages 161–173.Springer, Cham, 2019.
[30] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Ser-manet, Scott E. Reed, Dragomir Anguelov, Dumitru Er-han, Vincent Vanhoucke, and Andrew Rabinovich. Go-ing deeper with convolutions. CoRR, abs/1409.4842,2014.
[31] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, JonShlens, and Zbigniew Wojna. Rethinking the inceptionarchitecture for computer vision. In Proceedings ofthe IEEE Conference on Computer Vision and PatternRecognition, 2016.
[32] NVIDIA TensorRT: Programmable inference acceler-ator. https://developer.nvidia.com/tensorrt,2017.
[33] Nicolas Vasilache, Oleksandr Zinenko, TheodorosTheodoridis, Priya Goyal, Zachary DeVito, William S.Moses, Sven Verdoolaege, Andrew Adams, and AlbertCohen. Tensor comprehensions: Framework-agnostichigh-performance machine learning abstractions. CoRR,abs/1802.04730, 2018.
[34] Lianmin Zheng, Chengfan Jia, Minmin Sun, Zhao Wu,Cody Hao Yu, Ameer Haj-Ali, Yida Wang, Jun Yang,Danyang Zhuo, Koushik Sen, et al. Ansor: generatinghigh-performance tensor programs for deep learning.In 14th {USENIX} Symposium on Operating SystemsDesign and Implementation ({OSDI} 20), pages 863–879, 2020.
[35] Richard Zippel. Probabilistic algorithms for sparse poly-nomials. In International symposium on symbolic andalgebraic manipulation, pages 216–226. Springer, 1979.
52 15th USENIX Symposium on Operating Systems Design and Implementation USENIX Association

A Artifact Appendix
A.1 Abstract
This artifact appendix helps the readers reproducethe main evaluation results of the OSDI’ 21 paper:Pet: Optimizing Tensor Programs with PartiallyEquivalent Transformations and Automated Correc-tions.
A.2 Pet Usage
Pet provides C++ API to build the input tensor pro-gram, and also supports importing input tensor pro-gram from ONNX1 model. For each input tensor pro-gram, Pet generates a mathematically equivalent ex-ecutable that includes the performance optimizationsdescribed in this paper. Pet uses cuDNN/cuBLASas backend by default, but users can also export themutation subprograms with their corresponding in-put/output tensor shapes to use different backendslike TVM and Ansor.
A.3 Scope
The artifact can be used for evaluating and repro-ducing the main results of the paper, including theend-to-end evaluation, the operator-level evaluation,the performance comparison across different opti-mization policies and heuristics parameters, and thesearching time.
A.4 Contents
The artifact evaluation includes the following exper-iments:E1: An end-to-end performance comparison betweenPet and other frameworks. (Figure 8)E2: An operator-level performance comparisonon different backends, including cuDNN/cuBLAS,TVM, and Ansor. (Figure 12)E3: A performance comparison across different op-timization policies, including fully-equivalent trans-formations, partially-equivalent transformations, andjoint optimization using both. (Figure 13)
1https://onnx.ai/
E4: A performance comparison using differentheuristics. (Figure 14)E5: Searching time. (Section 8.6)
A.5 Hosting
The source code of this artifact can be foundon GitHub: https://github.com/whjthu/
pet-osdi21-ae, master branch, with commitID: 9e07cb1.
A.6 Requirements
Hardware dependencies
This artifact depends on an NVIDIA V100 GPU.
Software dependencies
This artifact depends on the following software li-braries:
• Pet uses cuDNN and cuBLAS libraries as back-end. Our evaluation uses CUDA 10.2 andcuDNN 7.6.5.
• TensorFlow, TensorRT, TASO, TVM and An-sor are used as baseline DNN frameworks in E1and E2. Our evaluation on these baseline usesTensorFlow 1.15, TensorRT 7.0.0.11, TASO withcommit ID f11782c (we add some minor fixes forTASO to support the tested models), and TVMwith commit ID 3950639.
A.7 Installation
A.7.1 Install Pet from source
• Clone code from git
• Install PET
– mkdir build; cd build; cmake ..– make -j
• Set the environment for evaluations
– export PET HOME=path to pet home
A.7.2 Install other frameworks
Please refer to the artifact evaluation instruction(README.pdf in the git repo https://github.
com/whjthu/pet-osdi21-ae) or the installation in-structions provided by the frameworks.
USENIX Association 15th USENIX Symposium on Operating Systems Design and Implementation 53

A.8 Experiments workflow
The following experiments are included in this arti-fact. All DNN benchmarks use synthetic input datain GPU device memory to remove the side effectsof data transfers between CPU and GPU. The de-tailed running instruction can be found in the artifactevaluation instruction (README.pdf in the git repohttps://github.com/whjthu/pet-osdi21-ae).
A.8.1 End-to-end performance (E1)
This experiment reproduces Figure 8 in the paper.Prerequisite: generate ONNX models
• cd $PET HOME/models-ae
• ./generate onnx.sh
TensorFlow & TensorFlow XLA. The Tensor-
Flow & TensorFlow XLA results of the 4 models areavailable in the tensorflow ae folder. The follow-ing command lines measure the inference latency ofTensorFlow and TensorFlow XLA, respectively:
• cd $PET HOME/tf-ae
• ./run.sh
TensorRT. The TensoRT results of the 4 models are
available in the tensorrt ae folder. The followingcommand lines measure the inference latency of Ten-sorRT:
• Load TensorRT environment (add library pathto LD LIBRARY PATH)
• cd $PET HOME/trt-ae
• ./run.sh
TASO. The TASO results of the 4 models are avail-
able in the taso ae folder. The following commandlines measure the inference latency of TASO:
• Load TASO environment
• cd $PET HOME/taso-ae
• ./run e2e.sh
PET. The Pet results of the 4 models are available
in the pet ae folder. The following command linesmeasure the inference latency of Pet:
• cd $PET HOME/pet-ae
• ./run e2e.sh
A.8.2 Operator-level performance (E2)
This experiment reproduces Figure 12 in the paper.The scripts are available in the operator ae folder.The experiments of TVM and Ansor will take a verylong time to search different mutation kernels.cuDNN/cuBLAS. The following command linesmeasure cuDNN/cuBLAS results for the 4 operator-level benchmarks:
• cd operator ae/cudnn
• ./run.sh
TVM & Ansor. The scripts inoperator ae/autotvm and operator ae/ansor
search the kernels for the 4 operator-level bench-marks using TVM and Ansor, respectively.
A.8.3 Different optimization policy (E3)
This experiment reproduces Figure 13 in the paper.The scripts are available in the pet-ae folder. Thefollowing command lines measure the results:
• cd $PET HOME/pet-ae
• ./run policy.sh
A.8.4 Different heuristic parameters (E4)
This experiment reproduces Figure 14 in the paper.The scripts are available in the pet-ae folder. Thefollowing command lines measure the results:
• cd $PET HOME/pet-ae
• ./run param.sh
A.8.5 Searching time (E5)
This experiment reproduces Section 8.6 in the pa-per. The scripts are available in the pet-ae folder.The same commands for Pet in E1 print the search-ing time at the same time.
• cd $PET HOME/pet-ae
• ./run e2e.sh
Note that our evaluation platform for AE has differ-ent CPUs from the platform we used for the paper sothat the searching time could be different. Neverthe-less, they should be within the same scale.
54 15th USENIX Symposium on Operating Systems Design and Implementation USENIX Association

















