
Overview of Extreme-Scale Software Research in China
73
Overview of Extreme- Scale Software Research in China Depei Qian Sino-German Joint Software Institute (JSI) Beihang University China-USA Computer Software Workshop Sep. 27, 2011
-
Upload
micah-love -
Category
Documents
-
view
22 -
download
5
description
Overview of Extreme-Scale Software Research in China. Depei Qian Sino-German Joint Software Institute (JSI) Beihang University China-USA Computer Software Workshop Sep. 27, 2011. Outline. Related R&D efforts in China Algorithms and Computational Methods HPC and e-Infrastructure - PowerPoint PPT Presentation
Transcript of Overview of Extreme-Scale Software Research in China

Overview of Extreme-Scale Software Research in China
Depei Qian
Sino-German Joint Software Institute (JSI)
Beihang University
China-USA Computer Software Workshop Sep. 27, 2011

Outline Related R&D efforts in China Algorithms and Computational Methods HPC and e-Infrastructure Parallel programming frameworks Programming heterogeneous systems Advanced compiler technology Tools Domain specific programming support

Related R&D efforts in China NSFC
Basic algorithms and computable modeling for high performance scientific computing
Network based research environment Many-core parallel programming
863 program High productivity computer and Grid service environment Multicore/many-core programming support HPC software for earth system modeling
973 program Parallel algorithms for large scale scientific computing Virtual computing environment

Algorithms and Computational Methods

NSFC’s Key Initiative on Algorithm and Modeling
Basic algorithms and computable modeling for high performance scientific computing
8-year, launched in 2011 180 million Yuan funding Focused on
Novel computational methods and basic parallel algorithms
Computable modeling for selected domains Implementation and verification of parallel
algorithms by simulation

HPC & e-Infrastructure

863’s key projects on HPC and Grid
“High productivity Computer and Grid Service Environment” Period: 2006-2010 940 million Yuan from the MOST and more than
1B Yuan matching money from other sources
Major R&D activities Developing PFlops computers Building up a grid service environment--CNGrid Developing Grid and HPC applications in
selected areas

CNGrid GOS Architecture
Tomcat(Apache)+Axis, GT4, gLite, OMII
Dynamic DeployService
CA Service
System Mgmt Portal
Hosting Environment
Core
System
Tool/App
Message Service
Agora
User Mgmt Res MgmtAgora Mgmt
Naming
HPCG App & Mgmt Portal
GSML Browser
ServiceControllerOther
RController
BatchJob mgmt
MetaScheduleAccount mgmt
File mgmt
metainfo mgmt
HPCG Backend
Resource Space
GOS System Call (Resource mgmt,Agora mgmt, User mgmt, Grip mgmt, etc)GOS Library (Batch, Message, File, etc)
Other Domain Specific Applications
Grip Runtime
Grip Instance MgmtSecurity
Res AC & Sharing
Other 3rd software &
tools
Java J2SE
GridWorkflowDataGrid
IDE Compiler
GSML Composer
GSML Workshop.
Debugger
Grip
Gsh & cmd tools
VegaSSH
Cmd Line Tools
DB ServiceWork Flow
Engine
Grid Portal, Gsh+CLI, GSML Workshop and Grid Apps
OS (Linux/Unix/Windows)
PC Server (Grid Server)
J2SE(1.4.2_07, 1.5.0_07)
Tomcat(5.0.28) +Axis(1.2 rc2)
Axis Handlers for Message Level Security
Core, System and App Level Services

Abstractions
Grid community: Agora persistent information storage and
organization Grid process: Grip
runtime control

CNGrid GOS deployment
CNGrid GOS deployed on 11 sites and some application Grids
Support heterogeneous HPCs: Galaxy, Dawning, DeepComp
Support multiple platforms Unix, Linux, Windows
Using public network connection, enable only HTTP port
Flexible client Web browser Special client GSML client

IAPCM: 1TFlops, 4.9TB storage, 10 applications, 138 users, IPv4/v6 access
CNIC: 150TFlops, 1.4PB storage , 30 applications, 269 users all over the country, IPv4/v6 access
Shandong University 10TFlops, 18TB storage, 7 applications, 60+ users, IPv4/v6 access
SSC: 200TFlops, 600TB storage, 15 applications, 286 users, IPv4/v6 access
USTC: 1TFlops, 15TB storage, 18 applications, 60+ users, IPv4/v6 access
HKU: 20TFlops, 80+ users, IPv4/v6 access
SIAT: 10TFlops, 17.6TB storage, IPv4v6 access
Tsinghua University: 1.33TFlops, 158TB storage, 29 applications, 100+ users. IPV4/V6 access
XJTU: 4TFlops, 25TB storage, 14 applications, 120+ users, IPv4/v6 access
HUST: 1.7TFlops, 15TB storage, IPv4/v6 access
GSCC: 40TFlops, 40TB, 6 applications, 45 users , IPv4/v6 access

CNGrid: resources
11 sites >450TFlops 2900TB storage Three PF-scale
sites will be integrated into CNGrid soon

CNGrid : services and users
230 services >1400 users
China commercial Aircraft Corp
Bao Steel automobile institutes of CAS universities ……

CNGrid : applications
Supporting >700 projects 973, 863, NSFC, CAS Innovative, and
Engineering projects

Parallel programming frameworks
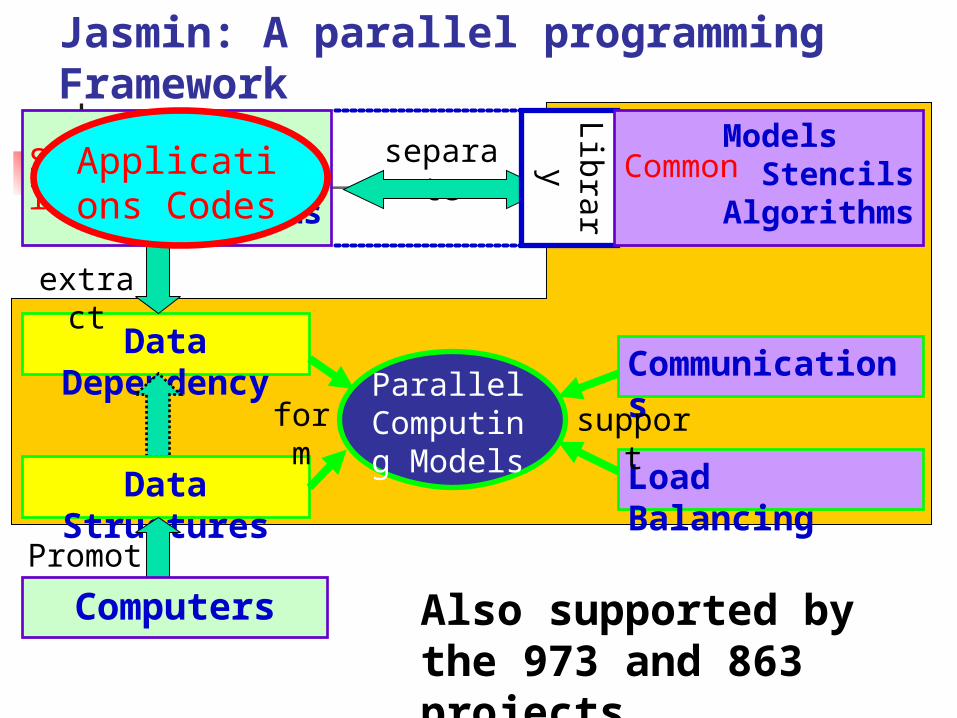
Data Dependency
extract
Data Structures
Promote
Communications
Load Balancing
supportParallel
Computing Models
form
separate Models Stencils
Algorithms
Special
Library
Models Stencils
Algorithms
Common
Also supported by the 973 and 863 projects
Applications Codes
Computers
Jasmin: A parallel programming Framework

Basic ideas Hide the complexity of programming millons
of cores
Integrate the efficient implementations of parallel fast numerical algorithms
Provide efficient data structures and solver libraries
Support software engineering for code extensibility.

Personal Computer
Serial Programming
TeraFlops Cluster
PetaFlops MPP
Scale up usin
g Infra
structu
res
Applications Codes
Basic Ideas

Unstructured Grid
Structured Grid
Inertial Confinement Fusion
Global Climate Modeling
CFD
Material Simulations
……
Particle Simulation
JASMIN
http:://www.iapcm.ac.cn/jasmin , 2010SR050446
2003-now
J parallel Adaptive Structured Mesh INfrastructure
JASMIN

Architecture : Multilayered, Modularized, Object-oriented ; Codes: C++/C/F90/F77 + MPI/OpenMP , 500,000 lines ;Installation: Personal computers, Cluster, MPP.
JASMIN
V. 2.0
User provides: physics, parameters, numerical methods, expert experiences, special algorithms, etc.
HPC implementations( thousands of CPUs) : data structures, parallelization, load balancing, adaptivity, visualization, restart, memory, etc.
Numerical Algorithms : geometry, fast solvers, mature numerical methods, time integrators, etc.
User Interfaces : Components based Parallel Programming models. ( C++ classes)
JASMIN

Codes# CPU cores
Codes# CPU cores
LARED-S 32,768 RH2D 1,024
LARED-P 72,000 HIME3D 3,600
LAP3D 16,384 PDD3D 4,096
MEPH3D 38,400 LARED-R 512
MD3D 80,000LARED Integration
128
RT3D 1,000
Simulation duration : several hours to tens of hours.
Numerical simulations on TianHe-1A

Programming heterogeneous systems

GPU programming support
Source to source translation Runtime optimization Mixed programming model for
multi-GPU systems

S2S translation for GPU
A source-to-source translator, GPU-
S2S, for GPU programming
Facilitate the development of
parallel programs on GPU by
combining automatic mapping and
static compilation

S2S translation for GPU (con’d)
Insert directives into the source program Guide implicit call of CUDA runtime libraries
Enable the user to control the mapping from the
homogeneous CPU platform to GPU’s streaming
platform
Optimization based on runtime profiling Take full advantage of GPU according to the
application characteristics by collecting runtime
dynamic information.

The GPU-S2S architecture
GPU-S2S
GPU supporti ng l i brary
User standard l i brary
Runni ng- t i me performance col l ecti on
Operati ng system
GPU pl atform
Layer of performance di scover
Cal l i ng shared l i brary
Profi l ei nformati on
Pthread thread model
MPI message transfer modelLayer of sof tware
producti vi ty
PGAS programmi ng model

Program translation by GPU-S2S
homogeneous platform code
with directives
Computing function called by homogeneos platform code
Templates library of optimized computing intensive applications
Profile libray
Kernel program of
GPU according templates
Control program of CPU
General purpose
computing interface
GPU-S2S
Calling shared libaryUser defined part
Source code before translation (homogeneous platform program framework)
Source code after translation (GPU streaming architecture platform program framework)
User standard library Calling shared libary
Templates library of optimized computing intensive applications
Profile library

C l anguage compi l er
homogeneous pl atform
code
*. c、*. h Pretreatment
Second l evel dynami c i nstrumentati on
GPU-S2S
Extract profi l e i nformati on:computi ng kernel
Fi rst l evel dynami c i nstrumentati on
Automati cal l y i nserti ng di recti ves
Compi l e and run
Compi l e and run
Extract profi l e i nformati on:Data bl ock si ze, Share memory confi gurati on parameters, J udge whether can use stream
Thi rd l evel dynami c i nstrumentati on i n
CUDA code
Generate CUDA code
usi ng stream
Extract profi l e i nformati on:Number of stream, Data si ze of every stream
Generate CUDA code contai ni ng opti mi zed
kernel Need to opti mi ze
further
Don’ t need to opti mi ze further Termi nati on
Compi l e and run
Fi rst Level Profi l e
Second Level Profi l e
Thi rd Level Profi l e
CUDA code
*. h、*. cu、
*. cCUDA
Compi l er tool
Executabl e code on
GPU
*. o
Runtime optimization based on profiling
First level profiling (function level)
Second level profiling (memory access and kernel improvement )
Third level profiling (data partition)

First level profiling
Identify computing kernels Instrument the scan
source code, get the execution time of every function, and identify computing kernel
Homogeneous pl atform codeAl l ocate address
space i ni t i al i zati on
functi on0
Free address space
Source- to-source compi l er
i nstrumentati on0
functi on1
functi onN
...
i nstrumentati on0
i nstrumentati o1
i nstrumentati on1
i nstrumentati onN
i nstrumentati onN

Second level profiling
Identify the memory access pattern and improve the kernels Instrument the
computing kernels extract and analyze
the profile information, optimize according to the feature of application, and finally generate the CUDA code with optimized kernel
Homogeneous pl atform code
Source- to-sourcecompi l er
i nstrumentati on
i nstrumentati on
i nstrumentati on
Computi ng kernel 1
Computi ng kernel 2
Computi ng kernel 3
...
...

Third level profiling
Optimization by improve data partition Get copy time and
computing time by instrumentation
Compute the number of streams and data size of each stream
Generate the optimized CUDA code with stream
CUDA control codeAl l ocate address
space
functi on0- -copyi n
Free address space
Source- to-source compi l er
i nstrumentati oni
...
i ni t i al i zati on
Al l ocate gl obal address space
functi on0- -kernel
functi on0- -copyout
i nstrumentati oni
i nstrumentati onk
i nstrumentati onk
i nstrumentati ono
i nstrumentati ono

Matrix multiplication Performance comparison before and after profile
Execution performance comparison on different platform
The CUDA code with three
level profiling optimization
achieves 31% improvement
over the CUDA code with
only memory access
optimization, and 91%
improvement over the
CUDA code using only
global memory for
computing .
0
2000000
4000000
6000000
8000000
10000000
1024 2048 4096 8192
di ff erent si ze of i nputdata
time
ms
() three l evel
profi l eopt i mi zat i onCPU
0
100
200
300
400
500
600
700
800
1024 2048di ff erent si ze of i nput data
time
ms(
)
memoryaccessopt i mi zat i on
onl y usi nggl obalmemory
second l evelprofi l eopt i mi zat i on
thi rd l evelprofi l eopt i mi zat i on
05000
10000150002000025000
300003500040000
4500050000
4096 8192
di ff erent si ze of i nput data
time
ms(
)
memoryaccessopt i mi zat i on
onl y usi nggl obalmemory
second l evelprofi l eopt i mi zat i on
thi rd l evelprofi l eopt i mi zat i on

FFT(1048576 points) Performance comparison before and after profile
FFT(1048576 points ) execution performance comparison on different platform
The CUDA code after
three level profile
optimization achieves
38% improvement over
the CUDA code with
memory access
optimization, and 77%
improvement over the
CUDA code using only
global memory for
computing .
0
200
400
600
800
1000
1200
1400
1600
1800
15 30 45 60 number of Batch
time
ms
()
memory accessopt i mi zat i on
second l evelprofi l eopt i mi zat i onthi rd l evelprofi l eopt i mi zat i ononl y usi nggl obal memory
0
10000
20000
30000
40000
50000
15 30 45 60
di ff erent si ze of i nput data
time
ms
() three l evel
profi l eopt i mi zat i onCPU

The memory of the CPU+GPU system are both distributed and shared. So it is feasible to use MPI and PGAS programming model for this new kind of system.
MPI PGAS
Using message passing or shared data for communication between parallel tasks or GPUs
CPU
Mai nMemMessage
data
CPU
Mai nMem Share space
Pri vate space
Devi ceMem
GPU
Devi ceMem
GPU
Devi ceMem
GPU
Devi ceMem
GPU
Share data
Programming Multi-GPU systems

Mixed Programming Model
CPUDevi ce choosi ngProgram i ni t i al
Mai n MM Devi ce MM
Computi ng start cal l computi ng
Mai n MM Devi ce MM
GPU
Host Devi ce
Source data copy i n
Resul t data copy out
CUDA program execution
CUDA runti me
Program start
MPI / UPC runti me
CPU
GPU
CPU
CPU
GPU
CPU
CPU
GPU
CPU cudaMemCopy
Communi cati on between tasks
(communi cati on i nterface of upper programi ng model )
Paral l elTask
Computi ng kernel
end
NVIDIA GPU —— CUDATraditional Programming model —— MPI/UPC
MPI+CUDA/UPC+CUDA

MPI+CUDA experiment
Platform 2 NF5588 server, equipped with
1 Xeon CPU (2.27GHz), 12GB MM 2 NVIDIA Tesla C1060 GPU(GT200
architecture , 4GB deviceMM) 1Gbt Ethernet RedHatLinux5.3 CUDA Toolkit 2.3 and CUDA SDK OpenMPI 1.3 BerkeleyUPC 2.1

MPI+CUDA experiment (con’d)
Matrix Multiplication program Using block matrix multiply for UPC programming. Data spread on each UPC thread. The computing kernel carries out the multiplication of two
blocks at one time, using CUDA to implement. The total time of execution :
Tsum=Tcom+Tcuda=Tcom+Tcopy+Tkernel
Tcom: UPC thread communication time
Tcuda: CUDA program execution time Tcopy: Data transmission time between host and device Tkernel: GPU computing time

MPI+CUDA experiment (con’d)
For 4094*4096 , the speedup of 1 MPI+CUDA task ( using 1 GPU for
computing) is 184x of the case with 8 MPI task.
For small scale data , such as 256 , 512 , the execution time of using 2
GPUs is even longer than using 1 GPUs
the computing scale is too small , the communication between two tasks
overwhelm the reduction of computing time.
2 server , 8 MPI task most 1 server with 2 GPUs

PKU Manycore Software Research Group Software tool development for GPU
clusters Unified multicore/manycore/clustering
programming Resilience technology for very-large GPU
clusters Software porting service
Joint project, <3k-line Code, supporting Tianhe Advanced training program

PKU-Tianhe Turbulence Simulation
Reach a scale 43 times higher than that of the Earth Simulator did
7168 nodes / 14336 CPUs / 7168 GPUs
FFT speed: 1.6X of Jaguar
Proof of feasibility of GPU speed up for large scale systems
Jaguar
PKUFFT ( using GPUs )
MKL ( not using GPUs )

Advanced Compiler Technology

Advanced Compiler Technology (ACT) Group at the ICT, CAS
ACT’s Current research Parallel programming languages and models Optimized compilers and tools for HPC (Dawning) and multi-
core processors (Loongson) Will lead the new multicore/many-core programming
support project

PTA: Process-based TAsk parallel programming model
new process-based task construct With properties of isolation, atomicity and deterministic submission
Annotate a loop into two parts, prologue and task segment
#pragma pta parallel [clauses]#pragma pta task#pragma pta propagate (varlist)
Suitable for expressing coarse-grained, irregular parallelism on loops
Implementation and performance PTA compiler, runtime system and assistant tool (help writing correct
programs) Speedup: 4.62 to 43.98 (average 27.58 on 48 cores); 3.08 to 7.83
(average 6.72 on 8 cores) Code changes is within 10 lines, much smaller than OpenMP

UPC-H : A Parallel Programming Model for Deep Parallel Hierarchies
Hierarchical UPC Provide multi-level data distribution Implicit and explicit hierarchical loop parallelism
Hybrid execution model: SPMD with fork-join Multi-dimensional data distribution and super-pipelining
Implementations on CUDA clusters and Dawning 6000 cluster Based on Berkeley UPC
Enhance optimizations as localization and communication optimization Support SIMD intrinsics
CUDA cluster : 72% of hand-tuned version’s performance, code reduction to 68%
Multi-core cluster: better process mapping and cache reuse than UPC

OpenMP and Runtime Support for Heterogeneous Platforms
Heterogeneous platforms consisting of CPUs and GPUs Multiple GPUs, or CPU-GPU cooperation brings extra data transfer
hurting the performance gain Programmers need unified data management system
OpenMP extension Specify partitioning ratio to optimize data transfer globally Specify heterogeneous blocking sizes to reduce false sharing among
computing devices Runtime support
DSM system based on the blocking size specified Intelligent runtime prefetching with the help of compiler analysis
Implementation and results On OpenUH compiler Gains 1.6X speedup through prefetching on NPB/SP (class C)

Analyzers based on Compiling Techniques for MPI programs
Communication slicing and process mapping tool Compiler part
PDG Graph Building and slicing generation Iteration Set Transformation for approximation
Optimized mapping tool Weighted graph, Hardware characteristic Graph partitioning and feedback-based evaluation
Memory bandwidth measuring tool for MPI programs Detect the burst of bandwidth requirements
Enhance the performance of MPI error checking Redundant error checking removal by dynamically turning on/off the global
error checking With the help of compiler analysis on communicators Integrated with a model checking tool (ISP) and a runtime checking tool
(MARMOT)

LoongCC: An Optimizing Compiler for Loongson Multicore Processors
Based on Open64-4.2 and supporting C/C++/Fortran Open source at http://svn.open64.net/svnroot/open64/trunk/
Powerful optimizer and analyzer with better performances
SIMD intrinsic support Memory locality optimization Data layout optimization Data prefetching Load/store grouping for 128-bit memory access instructions
Integrated with Aggressive Auto Parallelization Optimization (AAPO) module
Dynamic privatization Parallel model with dynamic alias optimization Array reduction optimization

Tools

Testing and evaluation of HPC systems
A center led by Tsinghua University (Prof. Wenguang Chen)
Developing accurate and efficient testing and evaluation tools
Developing benchmarks for HPC evaluation
Provide services to HPC developers and users
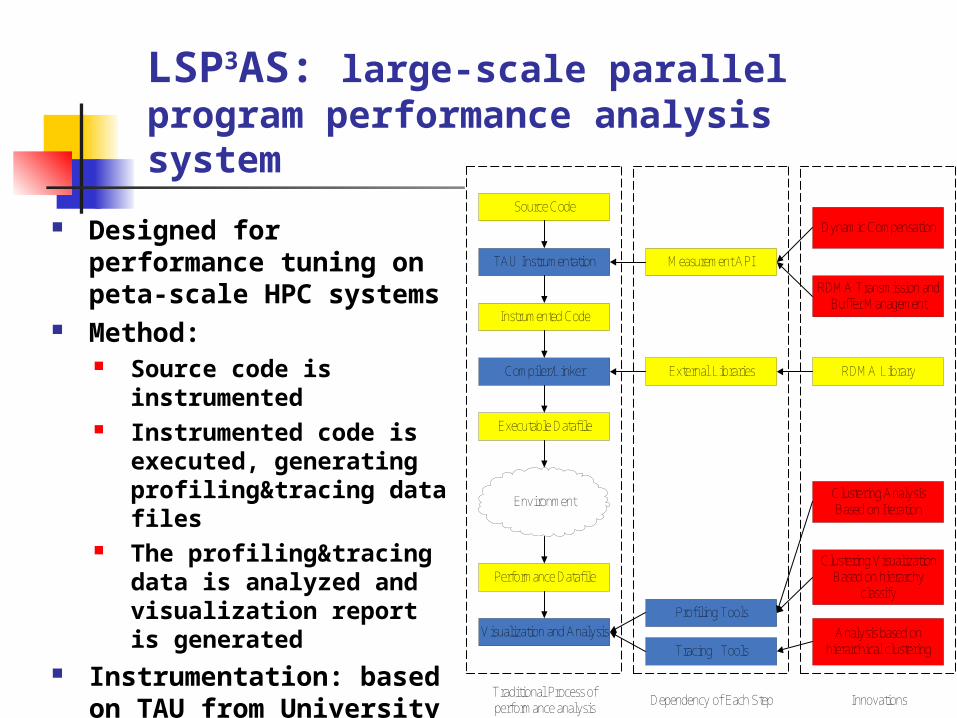
LSP3AS: large-scale parallel program performance analysis system
Source Code
TAU Instrumentation Measurement API
Instrumented Code
Compiler/Linker External Libraries
Executable Datafile
Environment
Visualization and Analysis
Performance Datafile
Profiling Tools
Tracing Tools
Dynamic Compensation
RDMA Transmission and Buffer Management
RDMA Library
Clustering AnalysisBased on Iteration
Clustering VisualizationBased on hierarchy
classify
Traditional Process of performance analysis
Dependency of Each Step Innovations
Analysis based on hierarchical clustering
Designed for performance tuning on peta-scale HPC systems
Method: Source code is
instrumented Instrumented code is
executed, generating profiling&tracing data files
The profiling&tracing data is analyzed and visualization report is generated
Instrumentation: based on TAU from University of Oregon

Compute node ……
Storage system
IO node
Sender
User process
Shared Memory
Receiver
Lustre ClientOr GFS
User process
Compute node
Sender
User process
Shared Memory
User process
Compute node ……Sender
User process
Shared Memory
User process
Compute node
Sender
User process
Shared Memory
User process
IO node
Receiver
Lustre ClientOr GFS
Thread Thread
LSP3AS: large-scale parallel program performance analysis system
Scalable performance data collection
Distributed data collection and transmission: eliminate bottlenecks in network and data processing
Dynamic Compensation: reduce the influence of performance data volume
Efficient Data Transmission: use Remote Direct Memory Access (RDMA) to achieve high bandwidth and low latency
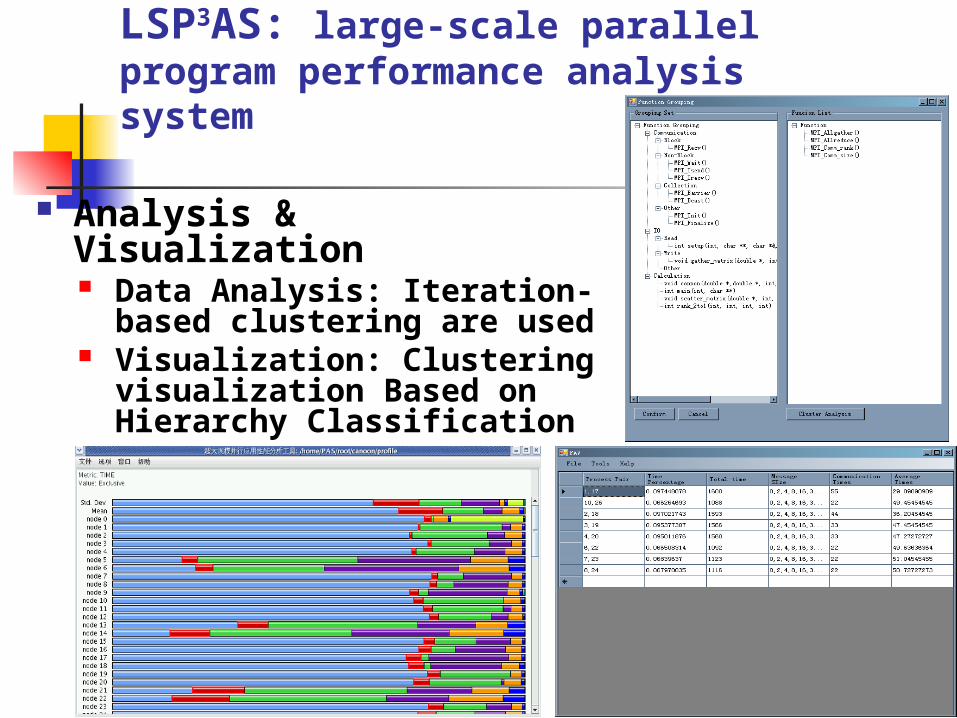
Analysis & Visualization Data Analysis: Iteration-based
clustering are used Visualization: Clustering
visualization Based on Hierarchy Classification
LSP3AS: large-scale parallel program performance analysis system

SimHPC: Parallel Simulator
Challenge for HPC Simulation: performance Target system: >1,000 nodes and processors Difficult for traditional architecture simulators
e.g. Simics Our solution
Parallel simulation Using cluster to simulate cluster
Use same node in host system with the target Advantage: no need to model and simulate detailed components,
such as pipeline in processors and cache Execution-driven, Full-system simulation, support execution of
Linux and applications include benchmarks (e.g. Linpack)

SimHPC: Parallel Simulator (con’d) Analysis
Execution time of a process in target system is composed of:
process run IO readyT T T T
− Trun: execution time of instruction sequences− TIO: I/O blocking time, such as r/w files, send/recv
msgs− Tready: waiting time in ready-state
equal to hostcan be obtained in Linux kernel
needed to be simulated
So, Our simulator needs to:①Capture system events
• process scheduling• I/O operations: read/write files, MPI send()/recv()
②Simulate I/O and interconnection network subsystems③Synchronize timing of each application process
unequal to hostneeded to be re-calculated

SimHPC: Parallel Simulator (con’d)
System Architecture Application processes of multiple target nodes
allocated to one host node number of host nodes << number of target nodes
Events captured on host node while application is running
Events sent to the central node for time analysis, synchronization, and simulation
……
Architecture Simulation
Analysis & Time-axis Sychronize
Interconnection Network
Event Capture
Host node
Control
Event Capture
Host node
Event Capture
Host node
Event Collection
Disk I/O
Simulation Results
Parallel applications
Process ...
Target ...
……Simulator
Host Linux
Host Hardware Platform
Host
Process Process ...
Target
Process Process ...
Target ...
Simulator
Host Linux
Host Hardware Platform
Host
Process Process ...
Target
Process

SimHPC: Parallel Simulator (con’d)
Simulation Slowdown
• Experiment Results– Host: 5 IBM Blade HS21 (2-way Xeon)– Target: 32 – 1024 nodes– OS: Linux– App: Linpack HPL
Linpack performance for Fat-tree and 2D-mesh Interconnection
networks
Communication time for Fat-tree and 2D-mesh Interconnection
networks
Simulation Error Test

System-level Power Management
Power-aware Job Scheduling algorithmSuspend a node if its idle-time > thresholdWakeup nodes if there is no enough nodes to execute jobs, whileAvoid node thrashing between busy and suspend state
The algorithm is integrated into OpenPBS

System-level Power Management (con’d)
Power Management Tool Monitor the power-related status of the system Reduce runtime power consumption of the
machine Multiple power management policies
Manual-control On-demand control Suspend-enable …
Layers of Power Management
Node sleep/wakeup
Node On/Off
CPU Freq. control
Fan speed control
Power control of I/O equipments
...Node Level
Power Management Software / Interfaces
Power Management Policies
Power Management Agent in Node
Management/Interface
Level
Policy Level

Power management test for different Task Load
(Compared to no power management)
• Power Management Test– On 5 IBM HS21 blades Power Mesurement
Power
Control & Monitor
Commands
Status Power data
System
Task Load(tasks per
hour)
Power Management
Policy
Task Exec. Time(s)
Power Consumption
(J)
Comparison
Performance
slowdown
Power Saving
20On-demand 3.55 1778077 5.15% -1.66%
Suspend 3.60 1632521 9.76% -12.74%
200On-demand 3.55 1831432 4.62% -3.84%
Suspend 3.65 1683161 10.61% -10.78%
800On-demand 3.55 2132947 3.55% -7.05%
Suspend 3.66 2123577 11.25% -9.34%
System-level Power Management (con’d)

Domain specific programming support

Joint work Shanghai Astronomical Observatory, CAS (SHAO), Institute of Software, CAS (ISCAS) Shanghai Supercomputer Center (SSC)
Build a high performance parallel computing software platform for astrophysics research, focusing on the planetary fluid dynamics and N-body problems
New parallel computing models and parallel algorithms studied, validated and adopted to achieve high performance.
Parallel Computing Platform for Astrophysics

Architecture
Physical and Mathematic
al Model
Physical and Mathematic
al Model
Parallel Computing
Model
Parallel Computing
Model
Numerical Methods
Numerical Methods
MPIMPI OpenMPOpenMP FortranFortran CC
100T Supercomputer
PETScPETSc AztecAztec
Software Platform for AstrophysicsSoftware Platform for Astrophysics
Web Portal on CNGridWeb Portal on CNGrid
Fluid Dynamics N-body Problem
Improved Preconditioner
Improved Preconditioner
Improved Lib. for Collective Comunication
Improved Lib. for Collective Comunication
SpMVSpMV
FFTWFFTW GSLGSL
LustreLustre
Software Developme
nt
Software Developme
nt
Data Processing Scientific Visualiztion
Data Processing Scientific Visualiztion
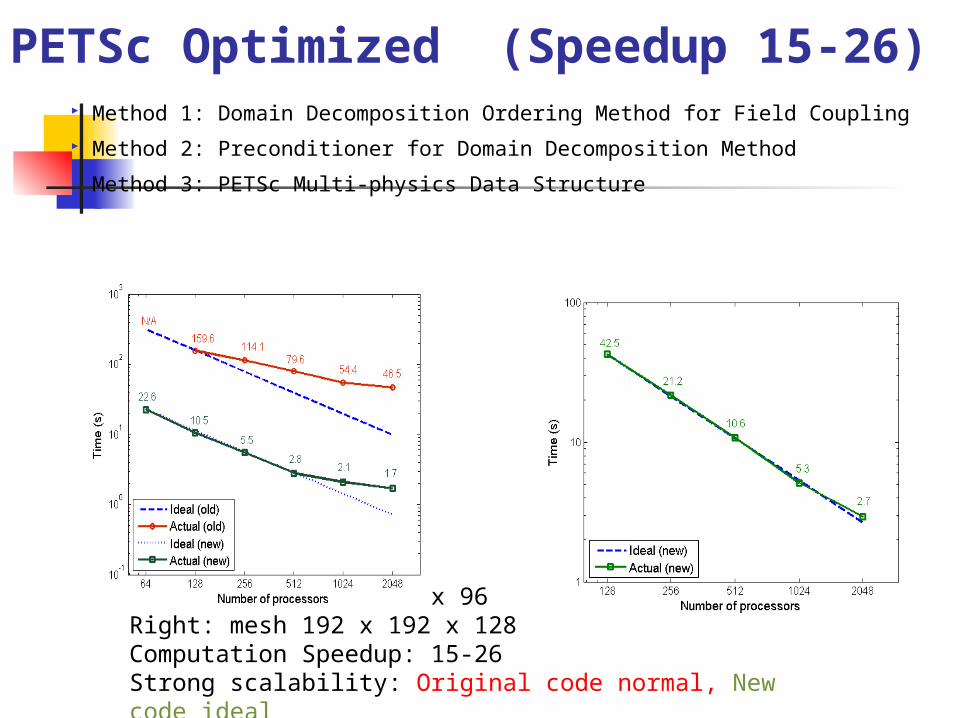
Method 1: Domain Decomposition Ordering Method for Field Coupling Method 2: Preconditioner for Domain Decomposition Method Method 3: PETSc Multi-physics Data Structure
PETSc Optimized (Speedup 15-26)
Left: mesh 128 x 128 x 96 Right: mesh 192 x 192 x 128 Computation Speedup: 15-26Strong scalability: Original code normal, New code idealTest environment: BlueGene/L at NCAR (HPCA2009)

23/4/19
Strong Scalability on TianHe-1A

CLeXML Math Library
CPUCPUComputationa
l ModelComputationa
l Model
BLASBLAS FFTFFT
Self Adaptive Tunning, Instruction
Reordering, Software
Pipelining…
Self Adaptive Tunning, Instruction
Reordering, Software
Pipelining…
LAPACKLAPACK
Task Parallel
Task Parallel Iterative SolverIterative Solver
Self Adaptive Tunning
Multi-core parallel
Self Adaptive Tunning
Multi-core parallel

BLAS2 Performance: MKL vs. CLeXML

HPC Software support for Earth System Modeling
Led by Tsinghua University Tsinghua Beihang University Jiangnan Computing Institute Peking University …
Part of the national effort on climate change study
67

Source Code
Executable
Standard Data Set
Result Evaluation
Result Visualization
Algorithm(Parallel)
Earth System Model
Development Wizard and
Editor
Compiler/Debugger/Optimizer
Computation Output
Initial Field and Boundary Condition
Running Environment
Data Visualization and Analysis
Tools
Data Management Subsystem
Other Data
Earth System ModelDevelopment Workflow
68

Major research activities
Efficient integration and management of massive heterogeneous data
Subprojet I
Fast visualization of massive data analysis and diagnosis of model data
Subproject II
MPMD program debugging,analysis and high-availability technologies
Subproject III
Integrated development environment(IDE) and Demonstrative applications for earth system model
Subproject IV
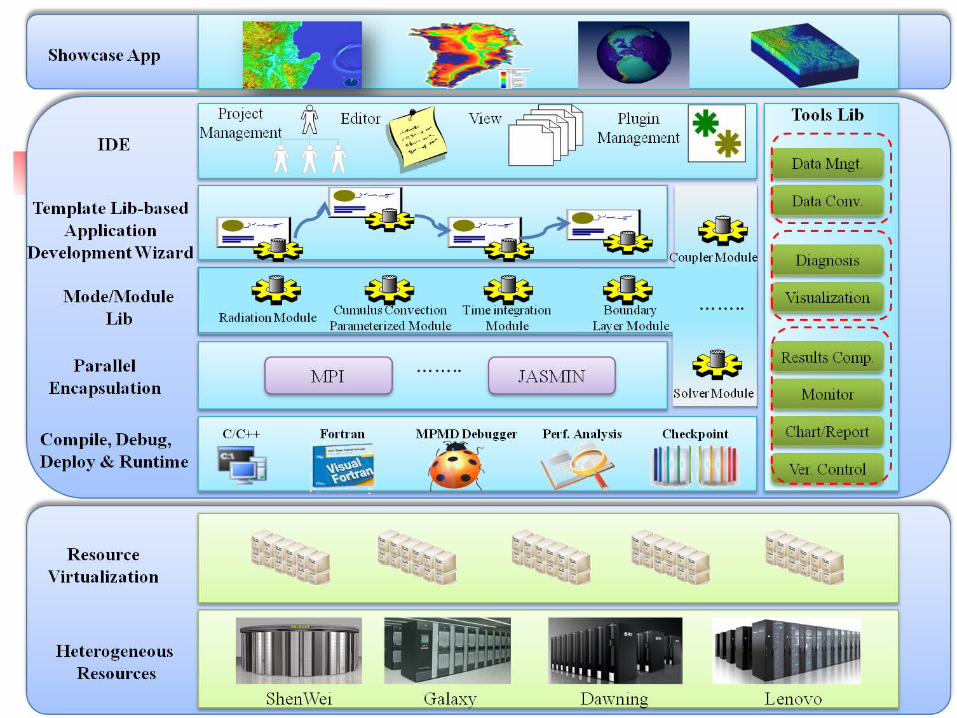

71
Expected Results
integrated high performance computing environment for
earth system model
integrated high performance computing environment for
earth system model
model application systems
Demonstrative Applications
research on global change
Existing tools: compiler
system monitorversion control
editor
development tools:
data conversiondiagnosisdebugging
performance analysishigh availability
template librarymodule library
high performance computers in China
software standards international
resources

Potential cooperation areas Software for exa-scale computer systems
Power Performance Programmability resilience
CPU/GPU hybrid programming Parallel algorithms and parallel program
frameworks Large scale parallel applications support
Applications requiring ExaFlops computers

Thank you!


















