
OPTIMIZING AND ENHANCING PARALLEL MULTI … AND ENHANCING PARALLEL MULTI STORAGE BACKUP COMPRESSION...
12
OPTIMIZING AND ENHANCING PARALLEL MULTI STORAGE BACKUP COMPRESSION FOR REAL-TIME DATABASE SYSTEMS 1. M. Muthukumar 2. Dr.T.Ravichandran Research Scholar, Principal, Karpagam University, Hindusthan Institute of Technology, Coimbatore, Coimbatore, Tamilnadu, India. Tamilnadu, India. [email protected] ABSTRACT One of the big challenges in the world was the amount of data being stored, especially in Data Warehouses. Data stored in databases keep growing as a result of businesses requirements for more information. A big portion of the cost of keeping large amounts of data is in the cost of disk systems, and the resources utilized in managing the data. Backup Compression field in the database systems has tremendously revolutionized in the past few decades. Most existing work presented attribute-level compression methods but the main contribution of such work had been on the numerical attributes compression alone, in which it employed to reduce the length of integers, dates and floating point numbers. Nevertheless, the existing work has not evolved the process of compressing string- valued attributes. To improve the existing work issues, in this work, we study how to construct compressed database systems that provides better in performance than traditional techniques and to store the database backups to multiple storages. The compression of database systems for real time environment is developed with our proposed Hierarchical Iterative Row- Attribute Compression (HIRAC) algorithm, provides good compression, while allowing access even at attribute level. HIRAC algorithm repeatedly increases the compression ratio at each scan of the database systems. The quantity of compression can be computed based on the number of iterations on the rows. After compressing the real time database systems, it allows database backups to be stored at multiple devices in parallel. Extensive experiments were conducted to estimate the performance of the proposed parallel multi- storage backup compression (PMBC) using HIRAC algorithm with respect to previously known tehniques, such as attribute-level compression methods. Keywords: Backup Compression, Parallel Multistorage, Large Database, Compression Techniques 1. INTRODUCTION Database compression has been a very familiar topic in the research, and there has been a requirement of amount of work on this subject. Data available in a database are highly valuable. Commercially available real time database systems have not heavily utilized compression techniques on data stored in relational tables. One reason is that the trade-off between time and space for compression is not always attractive for real time databases. A typical compression technique may offer space savings, but only at a cost of much increased query time against the data. Furthermore, many of the standard M Muthukumar et al ,Int.J.Computer Technology & Applications,Vol 3 (4), 1406-1417 IJCTA | July-August 2012 Available [email protected] 1406 ISSN:2229-6093
Transcript of OPTIMIZING AND ENHANCING PARALLEL MULTI … AND ENHANCING PARALLEL MULTI STORAGE BACKUP COMPRESSION...

OPTIMIZING AND ENHANCING PARALLEL MULTI STORAGE
BACKUP COMPRESSION FOR REAL-TIME DATABASE SYSTEMS
1. M. Muthukumar 2. Dr.T.Ravichandran
Research Scholar, Principal,
Karpagam University, Hindusthan Institute of Technology,
Coimbatore, Coimbatore,
Tamilnadu, India. Tamilnadu, India.
ABSTRACT
One of the big challenges in the world was the
amount of data being stored, especially in
Data Warehouses. Data stored in databases
keep growing as a result of businesses
requirements for more information. A big
portion of the cost of keeping large amounts of
data is in the cost of disk systems, and the
resources utilized in managing the data.
Backup Compression field in the database
systems has tremendously revolutionized in
the past few decades.
Most existing work presented attribute-level
compression methods but the main
contribution of such work had been on the
numerical attributes compression alone, in
which it employed to reduce the length of
integers, dates and floating point numbers.
Nevertheless, the existing work has not
evolved the process of compressing string-
valued attributes. To improve the existing
work issues, in this work, we study how to
construct compressed database systems that
provides better in performance than
traditional techniques and to store the
database backups to multiple storages.
The compression of database systems for real
time environment is developed with our
proposed Hierarchical Iterative Row-
Attribute Compression (HIRAC) algorithm,
provides good compression, while allowing
access even at attribute level. HIRAC
algorithm repeatedly increases the
compression ratio at each scan of the
database systems. The quantity of
compression can be computed based on the
number of iterations on the rows. After
compressing the real time database systems, it
allows database backups to be stored at
multiple devices in parallel. Extensive
experiments were conducted to estimate the
performance of the proposed parallel multi-
storage backup compression (PMBC) using
HIRAC algorithm with respect to previously
known tehniques, such as attribute-level
compression methods.
Keywords: Backup Compression, Parallel
Multistorage, Large Database,
Compression Techniques
1. INTRODUCTION
Database compression has been a very
familiar topic in the research, and there has
been a requirement of amount of work on this
subject. Data available in a database are
highly valuable. Commercially available real
time database systems have not heavily
utilized compression techniques on data stored
in relational tables. One reason is that the
trade-off between time and space for
compression is not always attractive for real
time databases. A typical compression
technique may offer space savings, but only at
a cost of much increased query time against
the data. Furthermore, many of the standard
M Muthukumar et al ,Int.J.Computer Technology & Applications,Vol 3 (4), 1406-1417
IJCTA | July-August 2012 Available [email protected]
1406
ISSN:2229-6093

techniques do not even guarantee that data
size does not increase after compression.
Global domains like banking, insurance,
finance, railway, and many other government
sectors will have a million and billions of
transaction on day-by-day. All these
transactions should be recorded on the
database for future reference. Such a domain
database will be grown GBs and TBs of data
during daily activities. Global domain
provider used to take the backup of their
database multiple times in a day also once in
few hours. This daily activities will be
consuming considerable time on every day.
This research will provides a solution to
compress the very large scale databases
(VLSDB‟s) more effectively, reduce the
storage requirements, costs and increase the
speed of backup. VLSDB‟s has a
distinguished role because it would otherwise
be very difficult to compress or store these
databases on the available disk. The cost of
storage, retrieval, and transmission of data
within a VLSDB‟s database system is greatly
reduced by database compression.
Over the last decades, enhancements in CPU
speed have outperfomed improvements in disk
access rates by providing an orders of
magnitude. For instance, the CPU speed has
been enhanced by about one thousand fold,
whereas disk bandwidth and latency have
been enhanced by nearly forty fold
correspondingly. The hardware posses‟ drastic
challenges to database system performance, as
database applications are frequently disk-
bound or memory-bound. This research
examines the uses of compression and backup
techniques to identify the reduced disk I/O and
memory access against additional CPU
overhead. In a compressed database system,
data are accumulated in compressed type on
disk and are decompressed with query
processing.
Information technology has met with several
advances for the production of massive high-
dimensional database systems applicable for
new applications such as corporate data
warehouses, bio-informatics and
networktraffic monitoring. Normally, the sizes
in the datbase systems are in the range of
terabytes, hence it is a challenging purpose to
protect them efficiently. Several techniques
are available to diminish the distinct sizes of
such tables, but the process of using
conventional data compression method is
stationary or dictionary-based. Such strategies
are „syntactic‟ in nature because they
overview the table as a large byte string and
worked at the byte level. More precisly,
compression techniques, which obtain
semantics of the table in the database systems
are taken into consideration at the time of
compression, have obtained necessiate
attention. In particular, these algorithms first
starts to present a descriptive model M, of the
database systems by taking the semantics of
the attributes present in the tables and then
divide them into the three groups with respect
to M:
a. Data values that can be obtained
from model.
b. Data values necessary for obtaining
the data values using M.
c. Data values that do not fit M.
By accumulating only the M combined with
the groups of data values, compression is
mainatined because typically takes up less
storage space contrast to the original database.
The advantages over compression are analysis
of data is complex, fast retrieval of data,
enhancement of query.
To compress data based on the attrbiutes
presence, the complex issue is to select a
appropriate set of representative rows. For this
reason, in this work, we present an algorithm
called HIRAC algorithm which repeatedly
enhances the set of selected representative
M Muthukumar et al ,Int.J.Computer Technology & Applications,Vol 3 (4), 1406-1417
IJCTA | July-August 2012 Available [email protected]
1407
ISSN:2229-6093

rows. From one step to the next, new
representative rows may be chosen, and old
ones are retarded. Although the representative
rows are changing continuosly, each steps
monotonically enhances the universal quality.
For a smaller number of iterations taken over
with the database systems, it is necessary to
present proficient compression performance.
In addition to this, each steps involved in the
algorithm needs only a single scan over the
database systems, leading to a fast
compression strategy.
2. LITERATURE REVIEW
An authentic datasets are regularly huge
enough to demand data compression.
Conventional data compression strategies care
for the table as a huge byte string and run at
the byte level. A semantic compression
algorithm [1] called ItCompress ITerative
Compression, which attains fine density while
authorizing contact even at attribute stage
without need of the decompression of a
superior unit.
Database compression has been a much
admired subject in the examine literature and
there is a huge quantity of work on this
subject. The most evident motivation to
believe compression in a database background
is to diminish the space essential in the disk.
The paper [2] proposed the firmness of data in
Relational Database Management Systems
(RDBMS) using offered content compression
algorithms. Information theory habitually
compacts with “usual data,” be it textual data,
image, or video data. Nevertheless, databases
of different sorts have appear into survival in
current years for accumulating “alternative
data” counting social data, biological data,
topographical maps, web data, and medical
data. In compressing such data, one must
reflect on two types of information [3] with
lossy compression techniques [4]. A system of
lossy compression of distinct memory less
sources for constricting the sources supported
on bounded distortion measure [5].
Planning at
enhancing compression presentation,
an iterative algorithm [6] is planned to
discover the best separation of a frame with
computation of compression ratio [7]. The
sequential processing utilized by
mainly compression algorithms, signify that
these long-range replication are not noticed
[8]. In order to assemble the confronts of
important storage and application
development, as well as condensed
backup [10] windows and restricted IT
resources, more and more association hold
Hierarchical Storage Management (HSM) [9]
supported on network environment [11].
Run-length encoding (RLE), where repeats of
the same element are expressed as pairs, is an
attractive approach for compressing sorted
data in a column store [12]. The task of string
matching to find the most effective phrase
[13] for replacement in the input stream is not
a simple one. Real-time database compression
algorithm must provide high compression
radio to realize large numbers of data storage
in real-time database [14].
In this work, HIRAC compression algorithm
is used for compressing the database and
allowed the compressed database at multiple
storages in parallel based on row-attribute
iterative compression.
3. PARALLEL MULTI STORAGE
BACKUP COMPRESSION FOR REAL-
TIME DATABASE SYSTEMS The proposed work is efficeintly desgined and
developed for a backup compression process
for real-time database systems using HIRAC
algorithm and can allow the compressed
backups to store it in multiple storages in
parallel. The proposed HIRAC with parallel
multi-storage backup for real time database
M Muthukumar et al ,Int.J.Computer Technology & Applications,Vol 3 (4), 1406-1417
IJCTA | July-August 2012 Available [email protected]
1408
ISSN:2229-6093

systems comprises of three operations. The
first operation is to identify and analyze the
entire database, the next step is to compress
the database systems to take up as backups
and the last step is to store the compressed
backups in multiple storages in parallel. The
architecture diagram of the proposed HIRAC
based Parallel Multi-Storage Backup model
for real time database systems are shown in
fig 3.1.
The first phase is to analyze the database
based on the environment in which it creates.
At forst, the attributes/tuples present in the
database sytems are analyzed and identify the
goal of the database creation and maintain a
set of attributes and tables maintained in the
database systems.
The second phase describes the process of
taking the backup of database system by
compressing the database using Hierarchical
Iterative Row-Attribute Compression
(HIRAC). The HIRAC algorithm is used to
provide a good compression techniques by
allowing access to the database level and
enhances the compression ratio for a ease
backup of database systems.
The third phase describes the process
of storing the compressed backups at different
levels of storages in paralell. Since it has been
stored at multi-storage devices, the copy of
compressed backups are always available at
any system, there is less chance of database
systems to be lost and can easily be recovered.
Fig 3.1 Architecture diagram of proposed PMBC for real time database systems
From the above figure (Fig 3.1), the process
of parallel multi-storage backup
compression comprises of three steps.
a. Analyzing the entire database
b. Implementing the HIRAC algorithm
c. Copying the data from the database
files into backup devices at parallel.
The compressing techniques have been used
in this work efficiently to compress the
M Muthukumar et al ,Int.J.Computer Technology & Applications,Vol 3 (4), 1406-1417
IJCTA | July-August 2012 Available [email protected]
1409
ISSN:2229-6093

database systems in an iterative procedures
and process of the compression algorithm is
describes under subsections.
3.1 Analyzing the entire database
Database analysis is apprehensive
with the environment and use of data. It
engages the classification of the data
elements which are desired to sustain the
data dealing out system of the organization,
the introduction of these elements into
rational groups and the description of the
relations among the resulting groups. The
prologue of Database Management Systems
(DBMS) has optimized a superior stage of
analysis, where the data elements are
definite by a rational model or `schema'
(conceptual schema). When conversing the
schema in the context of a DBMS, the things
of substitute designs on the effectiveness or
ease of completion is measured, i.e. the
examination is still somewhat achievement
reliant. The figure below describes the
database analysis life cycle.
Fig 3.2 Database Analysis lifecycle
The progress of strategies of data
analysis has assisted to recognize the
structure and meaning of data in
organizations. Data analysis strategies can
be utilized as the first step of extrapolating
the difficulties of the genuine world into a
form that can be detained on a computer and
be contacted by many users. The data can be
collected by conservative methods.
3.2 Implementing HIRAC algorithm
To compress database, an algorithm
is presented here called HIRAC algorithm
which iteratively enhances the collection of
selected representative rows. From one step
to the next, new representative rows may be
chosen, and old ones discarded. The
algorithm below (fig 3.3) describes the
process of implementing the HIRAC
algorithm.
M Muthukumar et al ,Int.J.Computer Technology & Applications,Vol 3 (4), 1406-1417
IJCTA | July-August 2012 Available [email protected]
1410
ISSN:2229-6093

Fig 3.3 Algorithm for implementing Database Compression
The algorithm begins by identifying the arbitrary set of rows from the table. It then repeatedly
enhances with the aim of enhancing the total coverage over the table to be compressed. There are
two phases in each iteration:
Phase1 : In this phase, each row R in D is assigned to a representative row Pmax (R) and the
G(Pi) indicates the set of rows that are implied to a representative row [step 3]
Phase2 : In this phase, it identifies the number of occurrences of the categorical attribute
obtained in the table. [step 4 to 6]
The table below describes the parameters used in the algorithm:
Parameter Description
D Database
T Set of tables
R Set of rows
P Set of representative rows
Pi[xj] Value of attribute X for representative row Pi
Pmax (R) Representative row that best matches with R
G(Pi) set of rows which have Pi as the best match
Table 1 Constraints Description
Input: Database D, Set of tables T, rows R
Output: Compressed database with a set of representative rows P = {P1, P2, …, Pk}
Identify an arbitrary set of rows
If total count of (D, T) increases, do
For each T in D
Assign id of each row
Find Pmax (R)
Recompute each Pi in P as folloes
{
For each attribute
Pi[xj] = fv(xj, G(Pi))
End For
End For
End If
M Muthukumar et al ,Int.J.Computer Technology & Applications,Vol 3 (4), 1406-1417
IJCTA | July-August 2012 Available [email protected]
1411
ISSN:2229-6093

HIRAC algorithm which is discussed above
on the other hand assumes an effortless
viewpoint of “direct optimization”. Since the
endeavor of a compression algorithm is to
decrease the storage constraint for a
database, Compression openly utilize this as
an optimization principle and guarantee that
only patterns which progress the
compression are established in each step of
its iterations. Though the optimization
problem is hard in an existing compression
algorithms case as well, the heuristic used in
this simple. HIRAC algorithm approach
provides much lower time complexity
contrast to an existing technique.
3.3 Parallel storage
Creating and storing backups compressed
database is the same as creating and storing
backups with a single device. The only
difference is to specify al, the backup
devices which are ready to store the backup
data are involved in the operation. The
diagram (fig 3.4) below describes the
process of parallel storage mechanisms.
Fig 3.4 Process of Parallel Multi Storage
Using several backup devices used for backup of the compressed database utilized in parallel in
terms of enhancing the speed of backup and restore operations. Each backup device was
processed from the similar time like other backup devices. The main concern over parallel multi-
storage backup devices is data security. Since the compressed database systems are backup in
several storage devices in parallel, no need to worry about the database system to get lost. Each
storage devices which holds compressed database systems are involved in operations.
4. EXPERIMENTAL EVALUATION
The proposed backup compression process for real-time database systems using HIRAC
algorithm with parallel multi-storage process is implemented in oracle java and used housing
data set derived from UCI repository. The housing dataset consists of 506 instances with 14
attributes, but here we have taken 10 set of attributes.
In this work, we have how the compressed housing database systems using HIRAC algorithm by
identifying the set of representative rows and columns for real time environments. The
implementation of the proposed backup compression process
M Muthukumar et al ,Int.J.Computer Technology & Applications,Vol 3 (4), 1406-1417
IJCTA | July-August 2012 Available [email protected]
1412
ISSN:2229-6093

for real-time database systems using HIRAC algorithm with parallel multi-storage process in
Java, and it allowed out a series of performance experiments in order to examine the efficiency
of the proposed backup compression process for real-time database systems using HIRAC
algorithm with parallel multi-storage process. The experiments were run on an Intel P-IV
machine with 4 GB memory and 2GHz dual processor CPU. The proposed HIRAC based
Parallel backup model for real time environment is efficiently designed for compression and
taking backup compressed data with the database systems. The performance of the proposed
backup compression process for real-time database systems using HIRAC algorithm with
parallel multi-storage process is measured in terms of
i) Compression ratio
ii) back up time
iii) Throughput
Compression ratio is the ratio of size of the compressed database system with the original size
of the uncompressed database systems.
edsizeUncompresssizeCompressednratioCompressio :
……………. (eqn 1)
Backup time is the time taken to take the backup of compressed database systems.
Throughput defines the system rate of storing the compressed backups in multiple storages at
parallel.
5. RESULTS AND DISCUSSION
In this work, we have seen how the database is efficiently compressed with the proposed backup
compression process for real-time database systems using HIRAC algorithm with parallel multi-
storage process and compared the results with an existing attribute-level compression methods
written in mainstream languages such as Java. We used a real time database for an
experimentation to examine the efficiency of the proposed backup compression process for real-
time database systems using HIRAC algorithm with parallel multi-storage process. The below
table and graph described the performance evaluation of the proposed backup compression
process for real-time database systems using HIRAC algorithm with parallel multi-storage
process.
No. of Data in Database Compression Ratio (gb)
HIRAC Algorithm Existing Attribute
Level Methods
25 1.3 2.9
50 1.9 3.6
75 2.3 4.5
100 3 6.9
125 3.9 5.9
Table 5.1 No. of Data in Database vs Compression Ratio
M Muthukumar et al ,Int.J.Computer Technology & Applications,Vol 3 (4), 1406-1417
IJCTA | July-August 2012 Available [email protected]
1413
ISSN:2229-6093
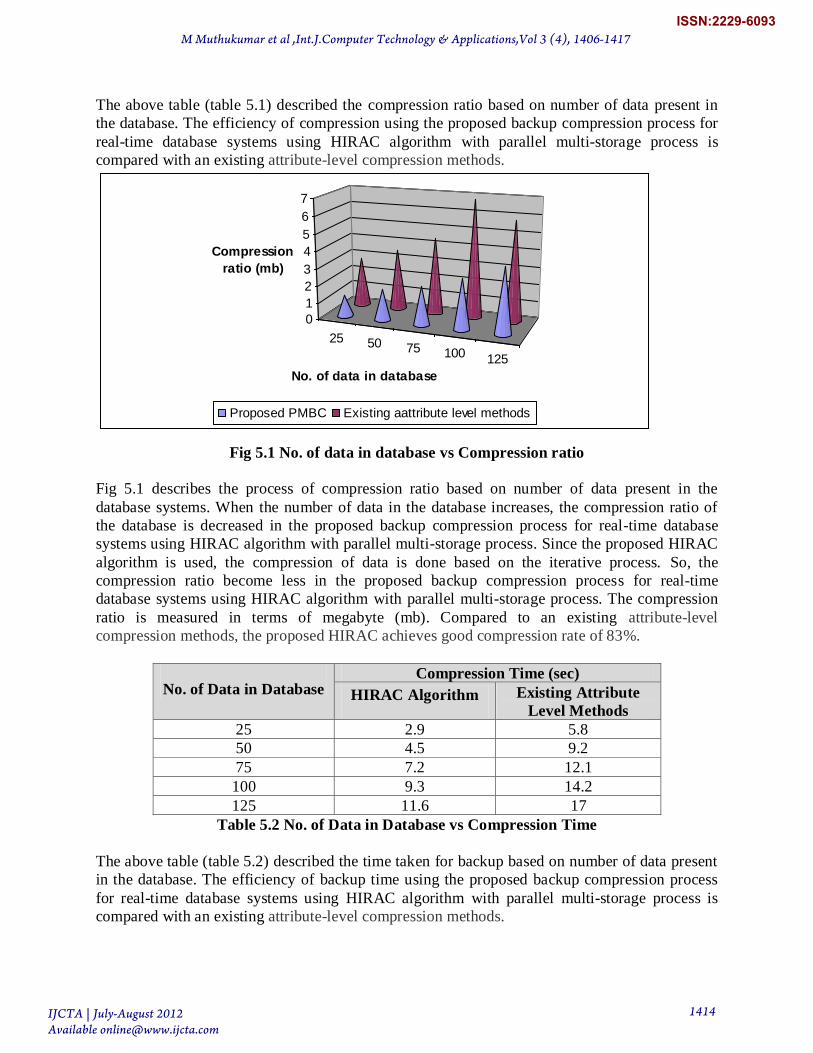
The above table (table 5.1) described the compression ratio based on number of data present in
the database. The efficiency of compression using the proposed backup compression process for
real-time database systems using HIRAC algorithm with parallel multi-storage process is
compared with an existing attribute-level compression methods.
25 50 75 100 125
0
1
2
3
4
5
6
7
Compression
ratio (mb)
No. of data in database
Proposed PMBC Existing aattribute level methods
Fig 5.1 No. of data in database vs Compression ratio
Fig 5.1 describes the process of compression ratio based on number of data present in the
database systems. When the number of data in the database increases, the compression ratio of
the database is decreased in the proposed backup compression process for real-time database
systems using HIRAC algorithm with parallel multi-storage process. Since the proposed HIRAC
algorithm is used, the compression of data is done based on the iterative process. So, the
compression ratio become less in the proposed backup compression process for real-time
database systems using HIRAC algorithm with parallel multi-storage process. The compression
ratio is measured in terms of megabyte (mb). Compared to an existing attribute-level
compression methods, the proposed HIRAC achieves good compression rate of 83%.
No. of Data in Database Compression Time (sec)
HIRAC Algorithm Existing Attribute
Level Methods
25 2.9 5.8
50 4.5 9.2
75 7.2 12.1
100 9.3 14.2
125 11.6 17
Table 5.2 No. of Data in Database vs Compression Time
The above table (table 5.2) described the time taken for backup based on number of data present
in the database. The efficiency of backup time using the proposed backup compression process
for real-time database systems using HIRAC algorithm with parallel multi-storage process is
compared with an existing attribute-level compression methods.
M Muthukumar et al ,Int.J.Computer Technology & Applications,Vol 3 (4), 1406-1417
IJCTA | July-August 2012 Available [email protected]
1414
ISSN:2229-6093

25 50 75 100 125
0
5
10
15
20
Backup time
(sec)
No. of data in database
Proposed PMBC Existing aattribute level methods
Fig 5.2 No. of data in database vs. Compression time
Fig 5.2 describes the process of time taken for backup based on number of data present in the
database systems. When the number of data in the database increases, the time taken for backup
for the database is decreased in the proposed backup compression process for real-time database
systems using HIRAC algorithm with parallel multi-storage process. Since the proposed HIRAC
algorithm is used, the compression of data is done based on the iterative process. So, the backup
become less in the proposed backup compression process for real-time database systems using
HIRAC algorithm with parallel multi-storage process. The backup time is measured in terms of
seconds (secs). Compared to an existing attribute-level compression methods, the proposed
HIRAC based parallel backup achieves less backup time and the variance would be 70% better.
No. of Location used
for PMBC
Throughput (%)
Proposed HIRAC
based Parallel Backup
Existing Attribute
Level Methods
1 12 5
2 20 10
3 25 15
4 32 19
5 40 22
Table 5.3 No. of Storage Location vs Throughput
The above table (table 5.3) described the throughput based on number of devices used for
parallel storage mechanism. The throughput obtained using the proposed backup compression
process for real-time database systems using HIRAC algorithm with parallel multi-storage
process is compared with an existing attribute-level compression method.
M Muthukumar et al ,Int.J.Computer Technology & Applications,Vol 3 (4), 1406-1417
IJCTA | July-August 2012 Available [email protected]
1415
ISSN:2229-6093
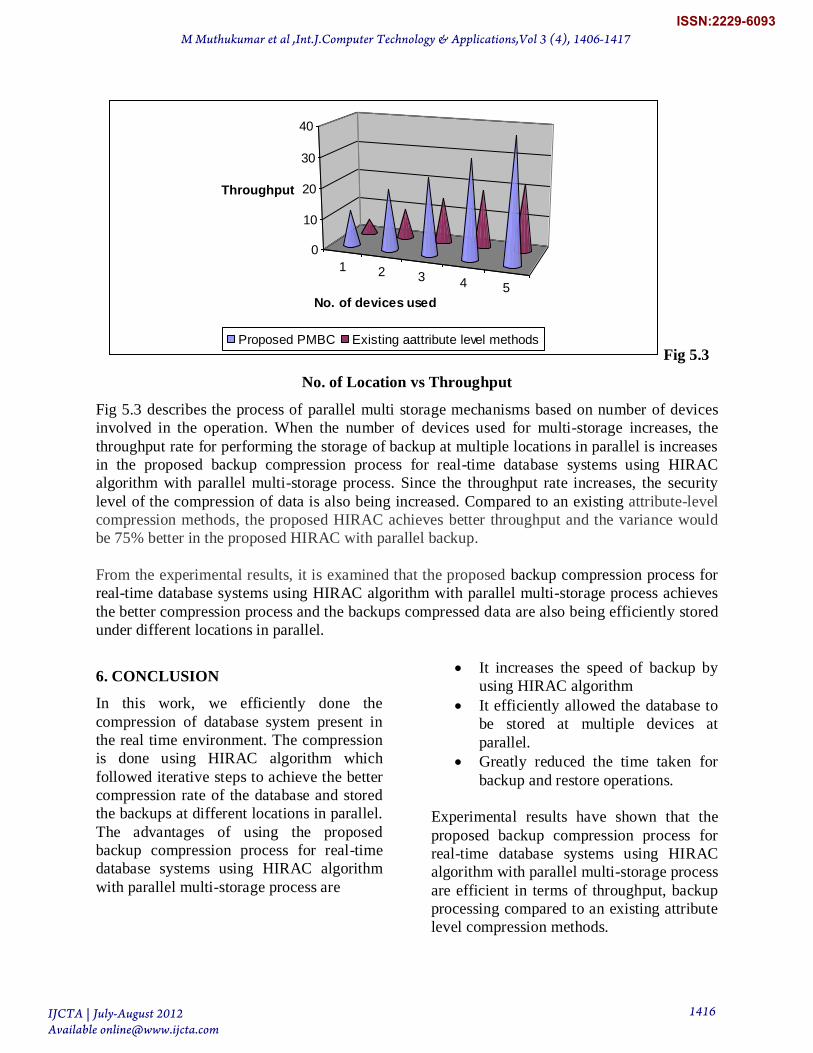
1 2 3 4 5
0
10
20
30
40
Throughput
No. of devices used
Proposed PMBC Existing aattribute level methods
Fig 5.3
No. of Location vs Throughput
Fig 5.3 describes the process of parallel multi storage mechanisms based on number of devices
involved in the operation. When the number of devices used for multi-storage increases, the
throughput rate for performing the storage of backup at multiple locations in parallel is increases
in the proposed backup compression process for real-time database systems using HIRAC
algorithm with parallel multi-storage process. Since the throughput rate increases, the security
level of the compression of data is also being increased. Compared to an existing attribute-level
compression methods, the proposed HIRAC achieves better throughput and the variance would
be 75% better in the proposed HIRAC with parallel backup.
From the experimental results, it is examined that the proposed backup compression process for
real-time database systems using HIRAC algorithm with parallel multi-storage process achieves
the better compression process and the backups compressed data are also being efficiently stored
under different locations in parallel.
6. CONCLUSION
In this work, we efficiently done the
compression of database system present in
the real time environment. The compression
is done using HIRAC algorithm which
followed iterative steps to achieve the better
compression rate of the database and stored
the backups at different locations in parallel.
The advantages of using the proposed
backup compression process for real-time
database systems using HIRAC algorithm
with parallel multi-storage process are
It increases the speed of backup by
using HIRAC algorithm
It efficiently allowed the database to
be stored at multiple devices at
parallel.
Greatly reduced the time taken for
backup and restore operations.
Experimental results have shown that the
proposed backup compression process for
real-time database systems using HIRAC
algorithm with parallel multi-storage process
are efficient in terms of throughput, backup
processing compared to an existing attribute
level compression methods.
M Muthukumar et al ,Int.J.Computer Technology & Applications,Vol 3 (4), 1406-1417
IJCTA | July-August 2012 Available [email protected]
1416
ISSN:2229-6093

7. AUTHORS PROFILE
Mr.M.Muthukumar is pursing Ph.D in
Database Compression. He received the
B.Sc degree from Madras University,
Tamilnadu, India in 1997, M.C.A degree
from the Bharathidasan University,
Tamilnadu, India in 2000 and M.Phil from
Manonmaniam Sundaranar University,
Tamilnadu, India in 2003. He is currently
working as Technical Lead in Department of
Application Delivery, MphasisS Limited,
Bangalore, Karnadaka, India. Before
Mphasis Limited he was working as IT
Analyst, in Department of Application and
Software Development, IBM India Private
Limited, Bangalore, Karnadaka, India.
Professor Dr.T.Ravichandran received the
B.E degrees from Bharathiar University,
Tamilnadu, India and M.E degrees from
Madurai Kamaraj University, Tamilnadu,
India in 1994 and 1997, respectively, and
PhD degree from the Periyar University,
Salem, India, in 2007. He is currently the
Principal of Hindustan Institute of
Technology, Coimbatore Tamilnadu, India.
Before joining Hindustan Institute of
Technology, Professor Ravichandran has
been a Professor and Vice Principal in
Vellalar College of Engineering &
Technology, Erode, Tamilnadu, India. His
research interests include theory and
practical issues of building distributed
systems, Internet computing and security,
mobile computing, performance evaluation,
and fault tolerant computing. Professor
Ravichandran is a member of the IEEE, CSI
and ISTE. Professor Ravichandran has
published more than 80 papers in refereed
international journals and refereed
international conferences proceedings.
REFERENCES
[1] H. V. Jagadish , Raymond T. Ng et. Al., “ItCompress: An iterative semantic compression algorithm”, proceedings
in 20th international conference on data engineering 2004
[2] Jorge Vieira, Jorge Bernardino, Henrique Madeira ,
“Efficient compression of text attributes of data warehouse dimensions”, Proceeding on the 7th international conference
on Data warehousing and Knowledge discovery, 2005
[3] Yongwook Choi et. Al., “Compression of Graphical
Structures: Fundamental Limits, Algorithms, and Experiments”, Information Theory, IEEE Transactions on,
Feb. 2012
[4] Wainwright, M.J. et. Al., “Lossy Source Compression
Using Low-Density Generator Matrix Codes: Analysis and Algorithms”, Information Theory, IEEE Transactions on,
Volume: 56 , Issue: 3 , March 2010
[5] Gupta, A. et. Al., “Nonlinear Sparse-Graph Codes for
Lossy Compression”, Information Theory, IEEE Transactions on, Volume: 55 , Issue: 5, May 2009
[6] Limin Liu et. Al., “A low-complexity iterative mode
selection algorithm Forwyner-Ziv video compression”,
ICIP 2008. 15th IEEE International Conference on Image Processing, 2008.
[7] Matsushita, R. et. Al., “Critical compression ratio of
iterative re-weighted l1 minimization for compressed
sensing”, IEEE on Information Theory Workshop (ITW), 2011
[8] Kuruppu, S. et. Al., “Iterative Dictionary Construction
for Compression of Large DNA DataSets”, IEEE/ACM
Transactions on Computational Biology and Bioinformatics, feb 2012
[9] Hongyuan Ma et. Al., “Experiences with Hierarchical
Storage Management Support in Blue Whale File System”,
2010 International Conference on Parallel and Distributed Computing, Applications and Technologies (PDCAT),
[10] Hongfei Yin et. Al., “”Verification-Based Multi-
backup Firmware Architecture, an Assurance of Trusted
Boot Process for the Embedded Systems”, 2011 IEEE 10th International Conference on Trust,
Security and Privacy in Computing and Communications
(TrustCom),
[11] Seong Hoon Kim et. Al., “A configuration management system for multi-hop zigbeenetworks”, ICCE
'09. Digest of Technical Papers International Conference on
Consumer Electronics, 2009.
[12] Sushila Aghav., “Database compression techniques for performance optimization”, ICCET, 2010 2nd International
Conference, 2010.
[13] Adam Cannane Hugh E. Williams., “A Compression
Scheme for Large Databases”, Database Conference 2010. [14] Wenjun Huang, Weimin Wang, Hui Xu., “A Lossless
Data Compression Algorithm for Real-time Database”,
WCICA 2006, The Sixth World Congress 2006.
[15] W. P. Cockshott, D. McGregor, N. Kotsis, J. Wilson., “Data Compression in Database Systems”, Ninth
International Workshop, 1998.
M Muthukumar et al ,Int.J.Computer Technology & Applications,Vol 3 (4), 1406-1417
IJCTA | July-August 2012 Available [email protected]
1417
ISSN:2229-6093


















