
Optimization schemas for parallel implementation of non-deterministic languages and systems
39
SOFTWARE—PRACTICE AND EXPERIENCE Softw. Pract. Exper. 2001; 31:1143–1181 (DOI: 10.1002/spe.405) Optimization schemas for parallel implementation of non-deterministic languages and systems Gopal Gupta 1, ∗,† and Enrico Pontelli 1 1 Department of Computer Science, University of Texas at Dallas, Box 830688, EC31, Richardson, Texas 75083-0688, U.S.A. 2 Department of Computer Science, New Mexico State University, Box 300001, Dept CS, Las Cruces, New Mexico 88003, U.S.A. SUMMARY Naive parallel implementation of non-deterministic systems (such as a theorem proving system) and languages (such as logic, constraint, or concurrent constraint languages) can result in poor performance. We present three optimization schemas, based on flattening of the computation tree, procrastination of overheads, and sequentialization of computations that can be systematically applied to parallel implementations of non-deterministic systems/languages to reduce the parallel overhead and to obtain improved efficiency of parallel execution. The effectiveness of these schemas is illustrated by applying them to the ACE parallel logic programming system. The performance data presented show that considerable improvement in execution efficiency can be achieved. Copyright 2001 John Wiley & Sons, Ltd. KEY WORDS: non-deterministic languages; parallel processing; optimization principles INTRODUCTION Non-determinism arises in many areas of computer science. Artificial intelligence and constrained optimization are two such areas where non-determinism is commonly found. By non-determinism we mean the existence of multiple (potential) solutions to a problem. Search problems, generate-and-test ∗ Correspondence to: Gopal Gupta, Department of Computer Science, University of Texas at Dallas, Box 830688, EC31, Richardson, Texas 75083-0688, U.S.A. † E-mail: [email protected] Contract/grant sponsor: NSF; contract/grant number: CCR 99-00320 Contract/grant sponsor: NSF; contract/grant number: CDA-9729848 Contract/grant sponsor: NSF; contract/grant number: EIA 98-10732 Contract/grant sponsor: NSF; contract/grant number: CCR 98-20852 Contract/grant sponsor: NSF; contract/grant number: CCR 98-75279 Contract/grant sponsor: US–Spain Fullbright Program Copyright 2001 John Wiley & Sons, Ltd. Received 29 September 2000 Revised 4 June 2001 Accepted 4 June 2001
-
Upload
gopal-gupta -
Category
Documents
-
view
214 -
download
0
Transcript of Optimization schemas for parallel implementation of non-deterministic languages and systems

SOFTWARE—PRACTICE AND EXPERIENCESoftw. Pract. Exper. 2001; 31:1143–1181 (DOI: 10.1002/spe.405)
Optimization schemas forparallel implementation ofnon-deterministic languages andsystems
Gopal Gupta1,∗,† and Enrico Pontelli1
1Department of Computer Science, University of Texas at Dallas, Box 830688, EC31, Richardson,Texas 75083-0688, U.S.A.2Department of Computer Science, New Mexico State University, Box 300001, Dept CS, Las Cruces,New Mexico 88003, U.S.A.
SUMMARY
Naive parallel implementation of non-deterministic systems (such as a theorem proving system) andlanguages (such as logic, constraint, or concurrent constraint languages) can result in poor performance. Wepresent three optimization schemas, based on flattening of the computation tree, procrastination of overheads,and sequentialization of computations that can be systematically applied to parallel implementations ofnon-deterministic systems/languages to reduce the parallel overhead and to obtain improved efficiencyof parallel execution. The effectiveness of these schemas is illustrated by applying them to the ACEparallel logic programming system. The performance data presented show that considerable improvementin execution efficiency can be achieved. Copyright 2001 John Wiley & Sons, Ltd.
KEY WORDS: non-deterministic languages; parallel processing; optimization principles
INTRODUCTION
Non-determinism arises in many areas of computer science. Artificial intelligence and constrainedoptimization are two such areas where non-determinism is commonly found. By non-determinism wemean the existence of multiple (potential) solutions to a problem. Search problems, generate-and-test
∗Correspondence to: Gopal Gupta, Department of Computer Science, University of Texas at Dallas, Box 830688, EC31,Richardson, Texas 75083-0688, U.S.A.†E-mail: [email protected]
Contract/grant sponsor: NSF; contract/grant number: CCR 99-00320Contract/grant sponsor: NSF; contract/grant number: CDA-9729848Contract/grant sponsor: NSF; contract/grant number: EIA 98-10732Contract/grant sponsor: NSF; contract/grant number: CCR 98-20852Contract/grant sponsor: NSF; contract/grant number: CCR 98-75279Contract/grant sponsor: US–Spain Fullbright Program
Copyright 2001 John Wiley & Sons, Ltd.Received 29 September 2000
Revised 4 June 2001Accepted 4 June 2001

1144 G. GUPTA AND E. PONTELLI
problems, optimization problems, etc. fall in this class. Non-determinism has also been incorporatedin many programming languages: logic programming languages (e.g., Prolog [1]), constraintprogramming languages (e.g., CHIP [2]), concurrent constraint languages (e.g., AKL [3]), and rule-based languages (e.g., OPS5 [4]) being some of the salient examples.
The presence of non-determinism in a problem offers a rich source of parallelism. A problem isusually expressed as a goal to be achieved/proved/solved together with rules (or clauses) that specifyhow a given goal can be reduced into smaller subgoals. Given a (sub-)goal, there may be multiple waysof reducing it (non-determinism). On applying a rule, a (sub-)goal may reduce to a number of smaller(conjunctive) subgoals, each of which needs to be solved in order to prove the original (sub-)goal. Twoprincipal forms of parallelism can be exploited in problems that admit non-determinism.
1. Or-parallelism: the different potential solutions can be explored in parallel (i.e. given a subgoal,there may be more rules that can be used to reduce it).
2. And-parallelism: while looking for a specific solution, the different operations involved can beexecuted in parallel (i.e. conjunctive subgoals may be reduced in parallel).
Or-parallelism is a direct result of non-determinism, while and-parallelism is analogous to themore ‘traditional’ form of parallelism, commonly exploited in standard (deterministic) programminglanguages (e.g., Fortran [5]).
The solution of problems with non-determinism has been abstractly represented using and/or trees.Or-parallelism can be exploited by exploring the branches emanating from an or-node of this tree inparallel. Likewise, and-parallelism is exploited by exploring the branches emanating from and-nodesin parallel.
A system that builds an and–or tree in parallel to solve a problem with non-determinism maylook simple to implement at first, but experience shows that it is quite a difficult task. A naiveparallel implementation may lead to a slow down, or may incur a severe overhead compared to acorresponding sequential system. The parallelism present in such problems is typically very irregularand unpredictable. Consequently, parallel implementations of non-deterministic languages typicallyrely on dynamic scheduling, i.e. most of the work for partitioning and managing parallel tasks isperformed during run-time. These duties are absent from a sequential execution and represent paralleloverhead. Excessive parallel overhead may cause a naive parallel system to run many times slower onone processor compared to a similar sequential system.
This paper presents a number of general optimization schemas that can be employed byimplementors of parallel non-deterministic systems to keep the overhead incurred for exploitingparallelism low. A system builder can examine his/her design to come up with concrete optimizationsbased on the schemas proposed in this paper. It is very likely that these optimizations will helpin considerably reducing the parallel overhead, and in obtaining a more efficient system. This isindeed how we improved the efficiency of the ACE parallel logic programming system. Reductionof parallel overhead results in improved sequential efficiency (performance of the parallel system onone processor) and absolute efficiency (overall execution time) of the system. It should be noted thatthe objective of parallel execution is to obtain better absolute performance and not just better speed-ups‡. This implies that it is absolutely imperative that the sequential performance of a parallel system
‡Speedup is defined as the time taken on one processor divided by the time taken on n processors.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

OPTIMIZATION SCHEMAS 1145
be very close to that of the state-of-the-art purely sequential systems. Application of the optimizationsbased on schemas presented in this paper can take one close to this goal.
The optimization schemas presented in this paper are mainly meant for non-deterministic systemsand languages (such as parallel AI systems, theorem proving systems and implementation of logic,constraint, and concurrent languages). Our optimization schemas are in the spirit of Lampson’s ideas onsoftware system design [6], where he offers general hints for designing efficient application programs.We adopt the same perspective in this presentation. We have developed various parallel systems, andthe techniques described here have been distilled from these experiences. These techniques may not beappropriate to every situation; they should be treated as suggestions that a system designer can employto obtain a more efficient parallel implementation. In most cases we believe (and empirical evidencesuggests) that these techniques will lead to greater efficiency, but there may be cases where the costof applying an optimization may be more than the benefits that accrue from it. It is up to the systemimplementor to judge whether or not a particular optimization is going to benefit his/her system.
The optimization schemas we present are quite intuitive, and can be found scattered in the literatureas they have been applied in the past in implementations of non-deterministic systems to optimizeexecution. However, ours is the first attempt at formulating them in their general form in a singleframework, and showing through an actual example how they can be systematically applied to improveexecution performance. The optimizations inspired by these general schemes are also applicable todeterministic systems and languages; however, the benefits brought about by them are not as high asthose for non-deterministic systems, as demonstrated later. Non-deterministic systems and languagesincur a much higher overhead in their implementations—many of these overheads do not even exist inimplementations of deterministic systems.
Our aim behind presenting these optimization schemas is to develop a suite of simple and generaloptimization schemas that implementors can use to develop optimizations specialized to their ownimplementations. In fact, we show how many of the optimizations proposed in the past for variousother parallel non-deterministic systems can be explained in terms of schemas presented in this paper.We hope that this work will induce other researchers to discover more such optimization schemas andtechniques. We would like to stress the distinction that we make in this paper between the optimizationschemas and the actual optimization techniques themselves. An optimization schema can be viewedas providing general guidelines that form the underpinning of a class of specific optimizations, whereeach such specific optimization is an implementation technique for improving execution performance.
The optimization schemas we present have been used for devising actual optimizations for theACE system [7,8], a high-performance parallel Prolog system developed by the authors. Theseoptimizations have resulted in a vast improvement in performance of the ACE system. The concreteperformance improvement figures for the ACE system are presented as a testimony to the effectivenessof these schemas. The same optimizations have been applied to other parallel logic programmingimplementations (e.g., &-Prolog [9,10], Aurora [11], and Muse [12]) with consistent results. As aresult of these optimizations, in many applications the parallel overhead introduced by the ACE systemwas reduced to less than 2%, a remarkably small overhead given the enormous complexity of and–or parallel systems. The optimizations based on our schemas are intended to be applied at runtime(rather than at compile-time), therefore, the benefits accrued have to be balanced against the cost ofapplying the optimization. We believe that, in general, the benefits obtained will be more than the costof applying these optimizations; at least that is what is borne out by our experiments with the ACEsystem, where the cost of applying the optimization developed is limited to simple and inexpensive
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

1146 G. GUPTA AND E. PONTELLI
runtime checks. However, for each specific optimization that can be devised from a schema, its designerwill have to decide whether or not his/her implementation can benefit from that optimization and howit will interact with other features of the system (such as garbage collection).
It should be noted that because our schemas are for developing runtime optimizations, theseoptimizations can be triggered every time a situation where they can be applied arises. This is incontrast to applying them at compile-time, where the conditions under which they are to be triggeredcan only be approximated (e.g., determinacy of goals can be detected at compile-time only in someof the cases, however, at runtime, more precise information about the determinacy of a goal isavailable). The availability of statically determined information [13–15] regarding the execution (e.g.,types, determinacy, granularity, variable instantiations [14,16–22]), however, can lead to additionalapplications of our optimization schemas (e.g., [23] illustrates applications of some of our optimizationschemas based on the use of results from compile-time analysis).
The schemas and the accompanying optimizations presented in this paper have been investigatedin the context of shared-memory-based multiprocessor systems. Considerable research in exploitingparallelism from non-deterministic systems and languages has been done in the context of distributed-memory-based multiprocessor systems [24,25]. Many of the schemas and optimizations (such as theLast Alternative Optimization) should be applicable in a distributed-memory scenario as well, howevertheir discussion is beyond the scope of this paper.
In the rest of the paper, we take logic programming systems as representatives of non-deterministicsystems. Thus, we present our optimizations schemes and their applications in the context of logicprogramming, although we believe that they apply equally well to parallel implementations of arbitrarynon-deterministic systems (such as parallel constraint systems, concurrent systems, parallel tree-search-based artificial intelligence (AI) systems, parallel theorem provers, etc.).
And–or tree
Parallel execution of a logic program can be viewed as parallel traversal/construction of an and–ortree. An and–or tree is a tree structure containing two kind of nodes, or-nodes and and-nodes. Or-nodesare created when there are multiple ways to solve a goal. In logic programming terminology or-nodesare termed choice points. An and-node is created when a goal invokes several conjunctive subgoals.
The or- and and-nodes represent sources of parallelism, i.e., points of the execution where it ispossible to fork parallel computations. Figure 1 illustrates an and–or tree for a logic program (‘&’ in theprogram stands for parallel conjunction). Note that the and-nodes and the or-nodes may be descendentsof each other during parallel execution of the and–or tree. This results in nesting of and-parallelism andor-parallelism within each other, making the management and implementation of parallel executionenormously complex§. This complexity originates from the fact that the different kinds of nodes haveto be treated differently in order to guarantee the correct semantics of the execution. Furthermore,the complexity is exacerbated by the fact that non-deterministic systems admit backtracking¶, and
§Only a few efficient and/or-parallel implementations of Prolog have been realized.¶Note that backtracking is present even in or-parallel systems because typically there are far more alternatives than availableprocessors. Thus, multiple branches may be explored by a processor via backtracking.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

OPTIMIZATION SCHEMAS 1147
p
ab
fg i j kh
p :- c & d.a :- ...b :- f & g & h.b :- i & j & k
p :- a & b.?- p.
dc
Or-node
And-node
Figure 1. And–or parallel tree.
?- (a & b & c).
a :- ..b :- ..., d,..c :- ..d :- ..d :- ..
(a & b & c)
a
b
c’
c1 c2
c’
c1parcall frame
end marker
input marker
choice point
P1’s stack P2’s stackProcessors P1 and P2 execute the program shown above. The corresponding tree is shown above. P1 and P2’s stacks are shown to the right. Goals a and b are exectued by processor P1, and goal c (which contains a non-deterministic goal d) by processor P2. The goal a does not need an input marker as the parcall frame marks its beginning.
parcall frame
inputmarker
endmarker
choicepoint
Figure 2. Data structures for saving computation state.
incorporation of backtracking implies that a computation should be restorable to every point wherea choice was made. In the context of and–or parallelism this means saving extra information andallocation of extra data structures [8–10], so that, in the event of backtracking, the state of thecomputation can be restored. Several such extra data-structures are employed in logic programmingsystems for parallel execution (see Figure 2).
• Choice point: allocated whenever a non-deterministic goal is called; it serves as a source ofor-parallel work, as well as a description of the non-determinism present in the computation.
• Parcall frame: allocated when a parallel conjunction is called; it serves as a source of and-parallelwork [10].
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

1148 G. GUPTA AND E. PONTELLI
• Marker nodes: allocated to delimit (or mark) the segments of stacks corresponding to goals takenfrom a parallel conjunction. There are two types of marker nodes, those that mark the beginningof a goal (called input marker), and those that mark the end (called end markers) [10,26].
• Sentinel nodes: allocated to delimit segments of stacks corresponding to an alternative takenfrom a choice point [11].
These extra data structures can be quite large, and can add considerable overhead to execution.It should be emphasized that not all these data structures are needed in parallel implementation ofdeterministic systems; this is because in non-deterministic systems they are required mainly for thepurpose of recording a state so as to restore it in the event of backtracking, and deterministic systemsdo not backtrack. Additionally, some of these data structures (e.g., the Parcall frame) are needed inorder to allow dynamic scheduling of parallel tasks (note that most parallel non-deterministic systemsadopt dynamic scheduling).
Overheads of parallel exploration
Given the and–or tree for a program, its sequential execution amounts to traversing the and–or treein a pre-determined order. Parallel execution is realized by having different processors concurrentlytraverse to different parts of the and–or tree in a way consistent with the operational semantics of theprogramming language. By preservation of the operational semantics we mean that data-flow (e.g.,variables bindings) and control-flow (e.g., input/output operations) dependencies are respected duringparallel execution (similar to loop parallelization of Fortran programs, where flow dependencies haveto be preserved). Parallelism allows overlapping of exploration of different parts of the and–or tree.Nevertheless, as mentioned earlier, this does not always translate to an improvement in performance.This happens mainly because of the following reasons.
• The tree structure developed during parallel computation needs to be explicitly maintained, inorder to allow for proper management of non-determinism and backtracking—this requires theuse of additional data structures, not needed in sequential execution. Allocation and managementof these data structures represent overhead during parallel computation with respect to sequentialexecution.
• The tree structure of the computation needs to be repeatedly traversed in order to search formultiple alternatives and/or cure eventual failure of goals, and such traversal often requiressynchronization between the processors. The tree structure may be traversed more than oncebecause of backtracking, and because idle processors may have to find nodes that have workafter a failure takes place or a solution is reported (dynamic scheduling). This traversal is muchsimpler in a sequential computation, where the management of non-determinism is reduced to alinear and fast scan of the branches in a predetermined order.
Reducing overheads in and–or trees
So far we have intuitively identified the main sources of overhead in a parallel computation—management of additional data structures, and the need to traverse a complex tree structure. Basedon this we can now try to identify ways of reducing these overheads.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

OPTIMIZATION SCHEMAS 1149
Traversal of tree structure. There are various ways in which the process of traversing the complexstructure of a parallel computation can be made more efficient:
1. simplification of the computation’s structure: by reducing the complexity of the structure to betraversed it should be possible to achieve improvement in performance;
2. use of the knowledge about the computation (e.g., determinacy of goals) in order to guide thetraversal of the computation tree: information collected from the computation may suggest thepossibility of avoiding traversing certain parts of the computation tree.
Data Structure Management. Since allocating data structures is generally an expensive operation, ouraim should be to reduce the number of new data structures created. This can be achieved by:
1. reusing existing data structures whenever possible (as long as the desired execution behavior ispreserved).
2. avoiding allocation of unnecessary structures: most of the new data structures introduced in aparallel computation serve two purposes: (i) they support the management of the parallel partsof the computation; and (ii) they support the management of non-determinism.This suggests possible conditions under which we can avoid creation of additional datastructures: (i) no additional data structures are required for parts of the computation treewhich are potentially parallel but are actually explored by the same processor (i.e., potentiallyparallel but practically sequential); (ii) no additional data structures are required for parts of thecomputation that will not contribute to the non-deterministic nature of the computation (e.g.,deterministic parts of the computation).
These observations can be concretized into three optimization schemas that are presented in thefollowing sections. Note that the optimization schemas we present are not generally applicableto deterministic languages and systems because deterministic systems do not have to perform thetwo operations that we seek to eliminate: (i) repeated traversal of (parts of) an and–or tree duringbacktracking and search for work; and (ii) allocation of data structures to support parallel execution.
Before we present the optimization schemas and the optimizations that have been developed basedupon them, we give a brief overview of the ACE system. The various optimization schemas and thevarious optimizations developed based on these schemas will be concretely illustrated in the context ofthe ACE system.
The ACE system
ACE is an and–or parallel system for full Prolog developed by the authors [7,8,27,28]. The ACE systemhas been implemented by extending the SICStus Prolog system [29]. The ACE system is capable ofextracting both and-parallelism and or-parallelism from executions of standard Prolog programs.
The and-parallel component [8] executes independent goals in and-parallel, i.e., conjunctive goalsthat are determined not to influence each other’s execution at runtime are run in parallel. The enginehas also been extended to support efficient execution of dependent and-parallelism [30]. Programssupplied to the systems are automatically annotated [20,31,32] in order to make parts of the programthat can be safely run in and-parallel explicit (through the use of conditional graph expressions (CGEs)[9,33]). Note that independence is a runtime property. This annotation has to be done either manually
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

1150 G. GUPTA AND E. PONTELLI
by the programmer, or automatically by an abstract-interpretation-based parallelizing compiler (theACE system uses the latter, using an extension of the CIAO parallelizing compiler [20,34–37]). Thus,given a clause
p :- q,r,s,t.
in which r and s are determined to be independent of each other, it would be annotated as
p :- q,(r&s),t.
Observe that, in the CGE notation, ‘&’ is used to denote parallel conjunctions, while the traditional ‘,’is used to denote sequential conjunctions. Thus, operationally, a call to p will lead to q being executed,followed by goals r and s being executed in parallel with each other. Once both r and s have finished,t is executed. Upon termination of t, control moves to continuation of p.
Because not all conjunctive goals in ACE are executed in parallel, the computation structure createdis not exactly similar to the conventional and–or tree. Rather, a parallel conjunction is analogous to theand-node of an and–or tree, while a sequential conjunction is represented as a linear branch (althoughfor the rest of this paper, this distinction is not significant).
At runtime, each time a parallel conjunction (also termed parallel call or parcall) is reached, adescriptor (parcall frame) for the conjunction is allocated on the stack. The parcall frame contains oneslot for each subgoal belonging to the parallel call, where each slot contains information about thatspecific goal. At the same time, the various subgoals are made available to the other processors forparallel execution. Each processing agent (we will use the term agent and processor interchangeablyin the rest of this document) that selects a subgoal for execution will initially allocate an input markeron its control stack to indicate the beginning of a new execution; analogously, an end marker will beallocated to mark the end of the subgoal’s execution. These marker are required in order to guide thebacktracking activity on the parallel call in the case of failure (see Figure 2). The various data structuresare shown in Figure 3.
Backtracking becomes complicated in and-parallel systems because more than one goal may beexecuting in parallel, one or more of which may encounter failure and backtrack at the same time.Unlike a sequential system, there is no unique backtracking point, and the distributed nature of theexecution may require considerable synchronization activity between the different processing agents.In an and-parallel system we must ensure that the backtracking semantics is such that all solutionsare reported. One such backtracking semantics has been proposed by Hermenegildo and Nasr [38]:consider the subgoals shown below, where ‘,’ is used between sequential subgoals (because of datadependencies) and ‘&’ for parallel subgoals (no data dependencies): a,b,(c&d&e),g,h. Assumingthat all subgoals can unify with more than one rule, there are several possible cases depending uponwhich subgoal fails: If subgoal a or b fails, sequential (‘Prolog-like’) backtracking occurs. Since c,d, and e are mutually independent, if either one of them fails before finding any solution, then alimited form of intelligent backtracking can be applied and backtracking can be forced to continuedirectly from b—but see further below. If g fails, backtracking must proceed to the rightmost choicepoint within the parallel subgoals c & d & e, and recompute all goals to the right of this choicepoint (following Prolog semantics). If e were the rightmost choice point and e should subsequentlyfail, backtracking would proceed to d, and, if necessary, to c. Thus, backtracking within a set of and-parallel subgoals occurs only if initiated by a failure from outside these goals, i.e. ‘from the right’ (also
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

OPTIMIZATION SCHEMAS 1151
GOALSTACK
PF
B Goal Frame
GS
B
Choice Point
PF
Parcall Frame
PF
GS’Status
PIP# of slots# of goals to wait on# of goals still to schedule
process id. comp. status ready
process id. comp. status ready
entries for other goals
Trail EndPhysical Top
Environment
Physical Top
Trail Section
Ph.Top
ControlStack
Figure 3. Data structures needed for and-parallelism.
known as outside backtracking). If initiated from within, backtracking proceeds outside all these goals,i.e. ‘to the left’ (also known as inside backtracking). When backtracking is initiated from outside, oncea choice point is found in a subgoal p, an untried alternative is picked from it and then all the subgoalsto the right of p in the parallel conjunction are restarted (in parallel).
Independent and-parallelism with the backtracking semantics described above has beenimplemented quite efficiently by the authors in the ACE system [8]. The ACE system is builtupon the SICStus (sequential) Prolog engine which ensures good performance during sequentialexecution. ACE implementation itself is inspired by the RAPWAM [9,10]. The RAPWAM modelhas been generalized in ACE to provide a more efficient memory management scheme [8] and fasterimplementation of backtracking [23,39]. The ACE system has shown remarkable results on a varietyof benchmarks. On most of the commonly used benchmarks the system has shown excellent executiontimes and speedups—Figure 4 shows the speedups obtained on some of these benchmarks runningon an unoptimized version of ACE (data produced by running the system on a sequent symmetrymultiprocessor; analogous results have been achieved on Sun Sparc multiprocessors). ACE has beensuccessfully applied to execute in parallel large real-life Prolog applications (programs over 35 000lines long have been successfully parallelized and executed [40]). Further details regarding the structureof ACE and its performance can be found elsewhere [7,8,23].
The or-parallel component of ACE is based on a generalization of the stack-copying approach,(originally developed for the Muse or-parallel system [12]) for representing multiple environments thatarise during or-parallelism. In traditional sequential implementations only one branch of the or-paralleltree resides on the control stack at any given time. As a result, bindings for conditional variables (i.e. avariable that may receive different bindings in different branches of the or-parallel tree) can be storedin-place. These bindings are undone on backtracking with the help of the trail stack, so that if the
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

1152 G. GUPTA AND E. PONTELLI
Speedups
matr
ix-m
ult
quicksort
hano
i
Annotatortakeu
chi
boyer
No. of Agents
1.00
2.00
3.00
4.00
5.00
6.00
7.00
8.00
9.00
2.00 4.00 6.00 8.00 10.00
Spee
dup
No. of Agents
1.00
2.00
3.00
4.00
5.00
6.00
7.00
8.00
9.00
2.00 4.00 6.00 8.00 10.00
Spee
dup
(i) (ii)
simulator
Figure 4. Speedups with ACE.
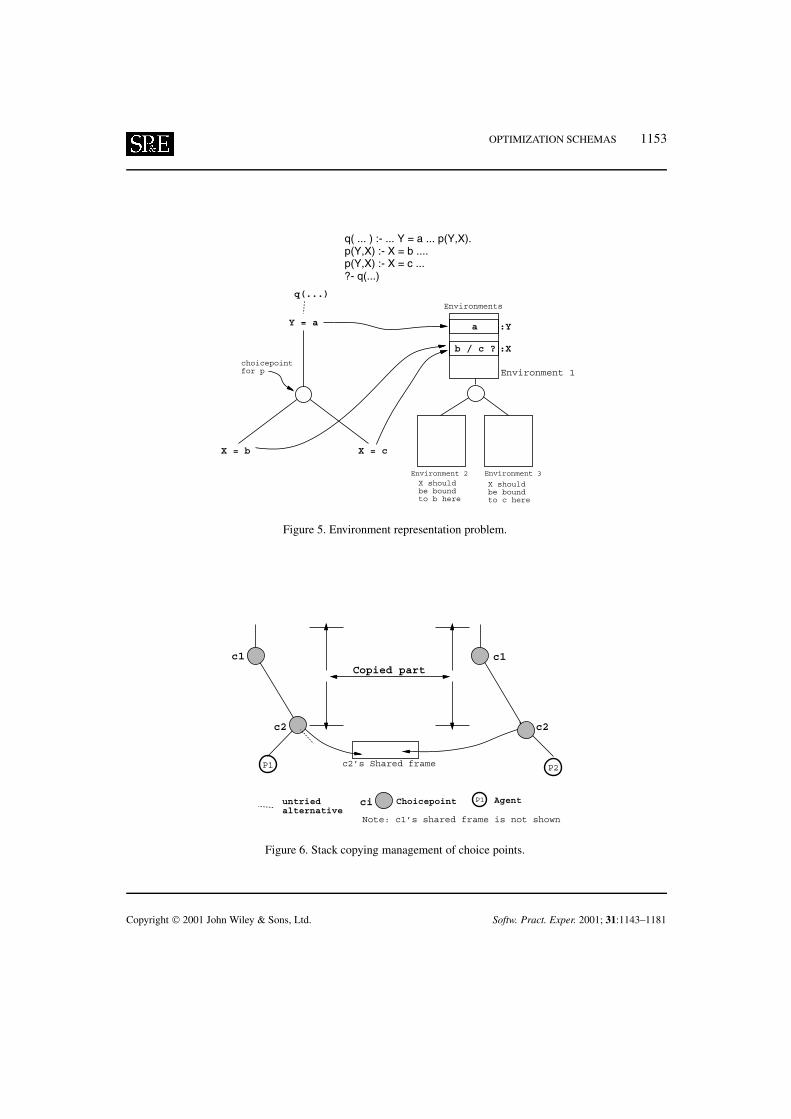
next branch also produces a binding for the conditional variable then it can be safely stored. As shownin Figure 5, in the presence of or-parallelism, alternative executions arising from a choice point maybe active simultaneously and may generate different bindings for variables allocated in environmentscreated before the branching point (the choice point where or-parallelism originated). Thus, multipleenvironments can exist at runtime, and these have to be carefully maintained so that each branch seesonly the bindings that it created.
Stack copying is based on the idea of creating different copies of the existing environments whenbranching takes place (i.e., when an idle processor selects an alternative from a choice point to starta parallel computation). Thus, in Figure 6, if processor P2 selects the second alternative from choicepoint c2, then before starting execution it will copy all choice points and environments from the rootnode up to choice pointc2 on its local stack. The existence of local copies of the ‘shared’ environmentsallows one to overcome the previously described binding management problem, since each processorwill have a local space to store the locally generated bindings.
In the stack copying model the whole state of computation is copied; this requires copying notonly the environments created before the choice point, but also the choice points themselves (andother data areas, e.g., the trail stack), in order to allow each processor to perform its execution asindependently as possible from the others. However, choice points hold control information (such asthe set of unexplored alternatives, and, thus, need to be shared data structures. Connection betweenthe different copies of the same choice point is maintained through a shared frame. The shared framecontains those parts of the choice point that are shared and that may be modified during the parallelexecution (see Figure 6). The process of selecting a choice point and copying the computation stateup to such a choice point (and creating the needed shared frames for each copied choice point) istermed a sharing operation [12]. Note that because each processor performs execution independently,implementation of various operations, e.g., garbage collection, is largely identical to that in a sequentialProlog system.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181
OPTIMIZATION SCHEMAS 1153
Y = a
X = b X = c
Environments
:X
:Ya
b / c ?
Environment 1
Environment 2 Environment 3
q( ... ) :- ... Y = a ... p(Y,X).p(Y,X) :- X = b ....p(Y,X) :- X = c ...?- q(...)
q(...)
choicepointfor p
X should be bound to b here
X should be bound to c here
Figure 5. Environment representation problem.
c2’s Shared frame
P1 AgentChoicepoint
P1 P2
Copied part
ci
Note: c1’s shared frame is not shown
untried alternative
c1
c2
c1
c2
Figure 6. Stack copying management of choice points.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

1154 G. GUPTA AND E. PONTELLI
SIMPLIFICATION OF THE COMPUTATION
As mentioned before, one of the main sources of overhead introduced during and–or parallelcomputation is due to the need to repeatedly traverse a deeply nested tree structure representing thecomputation. This traversal is related to both the management of parallel work (e.g., scheduling) andthe management of non-determinism (e.g., searching for multiple solutions). This traversal is absentin sequential systems, where the whole computation can be encoded as a simple linear structure (e.g.,sequence of choice points in a control stack [41]). In parallel systems, by contrast, the computationstructure becomes distributed across the stacks of multiple processors (Figure 2).
One way to improve the execution performance is to simplify the structure of the computation tree,in order to make its traversal cheaper and faster.
Flattening the computation tree. The first optimization schema we present is based on ‘flattening’the computation tree, and can be stated as follows. ‘Flatten the tree structure, reducing the levels ofnesting whenever possible, preserving the operational semantics.’
Recall that during parallel execution and-parallelism and or-parallelism may be nested within eachother. This complicates the management of parallelism and increases the parallel overhead. Theflattening of the tree helps in reducing the levels of nesting of and- and or-parallelism thereby reducingoverhead. Of course, the flattening of the computation tree should be done in a way such that programsemantics are unaltered—in the case of logic programming systems this means that the order in whichbacktrack literals are chosen is preserved.
The flattening scheme manifests itself in many situations, both in non-deterministic as well asdeterministic systems:
• The tail recursion optimization (and its logic programming counterpart, last call optimization[42]) is an instance of the flattening schema, where nested recursive calls become flattened intoone single call.
• The use of the unfold [43] transformation, frequently used in both sequential and parallelsystems, is another instance of the flattening scheme. In the context of logic programmingunfolding leads to merging of choice points reducing levels of their nesting. This has beenapplied to optimize or-parallel systems [44] and implementations of constraint languages [2].
• In parallel implementation of flat committed choice languages [45] the nested goals created areheld in a single large pool resulting in faster implementation. In fact, flat versions of committedchoice languages evolved so that levels of nesting of processes could be eliminated to obtainfaster implementations.
• Another limited form of flattening has been used in the ROPM system [46] and it goes under thename of distributed last call optimization. The objective of the optimization is to simplify thestructure of the computation to reduce the message flow during the execution. If a goal g calls agoal h which in turns calls p, then if p is the last call in the execution of h and h is the last callin g, the solutions produced by p can be directly communicated to g, without going through h.
• An instance of flattening has also been used for efficient implementation of nested data-paralleloperations in languages such as Paralation Lisp [47], C*, etc. Guy Blelloch was the first one toadvocate the use of flattening in implementing data-parallel languages [48]. Recently it has alsobeen incorporated in other data-parallel systems [49].
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

OPTIMIZATION SCHEMAS 1155
p & q
r & s t & u
p q
r s t u
(e,f,g,r) & s & (i,j,k,t) & u
r s t u
(ii)
e
f
g
i
j
k
i
j
k
e
f
g
(i)
Figure 7. Reusing parcall frames.
• The flattening schema is also employed in optimizing parallel code that has nested barriers.Parallel programs with nested barriers are transformed so as to merge the multiple barriers intoone, resulting in improved performance [50].
It should be noted, however, that although the flattening schema can be applied to both deterministicand non-deterministic systems, it brings about greater improvement in efficiency in non-deterministicsystems. This is because in non-deterministic systems the tree structure may become simplifiedduring the first traversal (i.e., during creation); on subsequent traversal (say, during backtracking)the tree structure is much simpler, resulting in considerably reduced overhead. For example, in thelast parallel call optimization (described next), an optimization based on the flattening schema, muchlarger efficiency gains due to flattening are observed during backward execution (backtracking) ratherthan during forward execution when the tree is first created.
We discuss next two optimizations that result from the application of flattening in the ACE system.These optimizations are termed last parallel call optimization and last alternative optimization.
Flattening: last parallel call optimization
Introduction
The last parallel call optimization (LPCO) is very similar in spirit to the last call optimization foundin sequential implementations of Prolog [42]. The intent of the LPCO is to merge, whenever possible,distinct parallel conjunctions, which are nested one inside the other. The main aim of this optimizationis to reduce the depth of nesting of parallel calls.
LPCO cannot be applied every time a nested and-parallel call arises inside another and-parallelcall, since doing so in an unrestricted way may change the operational semantics when backtrackingover parcalls. However, under certain restrictions, the operational semantics is preserved. To illustrateLPCO in the most general case, consider a parallel conjunction of the form (p&q) (See Figure 7(i)),where, as explained earlier, ‘&’ is used to denote a parallel conjunction, while ‘,’ denotes a sequentialconjunction.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

1156 G. GUPTA AND E. PONTELLI
p :- e,f,g,(r&s). q :- i,j,k,(t&u).
Recall that & denotes a parallel conjunction. LPCO will apply to p (respectively q) if:
1. there is only one (remaining) matching clause for p (respectively q), i.e. p (respectively q) isdeterminate;
2. all goals preceding the parallel conjunction in the clause—e.g., e,f,g in the case of p—for p(respectively q) are determinate;
3. the parallel call (r&s) (respectively (t&u)) is at the end of the clause for p (respectively q).
These conditions‖ can be more easily understood by considering the layout of the information onthe stacks: conditions 1 and 2 are equivalent to the absence of choice points between the current pointof execution and the logically preceding parallel call. It is important to observe that these conditionsare met in a large variety of programs (e.g., programs possessing an iterative structure), making theoptimization applicable very frequently. If these conditions are satisfied then a new descriptor for and-parallel goals—the parcall frame in ACE—is not needed for the parallel conjunction in the clause.Rather the parcall frame for (p&q) can be extended with an appropriate number of slots and executioncontinues as if clause for p was defined as p :- ((e,f,g,r)&s)∗∗, if we determine at the time ofthe parallel call (r&s) that e,f, and g are determinate. This is illustrated in Figure 7(ii). Note alsothat the conditions for LPCO do not place any restrictions on the nature of the parallel subgoals in theclause for p (respectively q). Clearly, the goals r, s, etc. can be non-deterministic.
The benefits of LPCO become even more evident when a failure causes backtracking over a parallelcall: the expensive traversal of the tree structure in search of a new alternative is replaced by a simplelinear scan of the subgoals descriptors inside a single parcall frame.
One could argue that the improved scheme described above can be accomplished simply throughcompile time transformations. However, in many cases this may not be possible. For example, if pand q are dynamic predicates or, more simply, if there is insufficient static information to detect thedeterminacy of p and q, then the compile-time analysis will not be able to trigger the application ofthe optimization. Also, for many programs the number of parallel conjunctions that can be combinedinto one will only be determined at runtime. For example, consider the following recursive clause (thatarises very frequently in real-life programs):
process_list([H|T],[Hout|Tout]) :-process(H,Hout) & process_list(T,Tout).
process_list([],[]).
This Prolog procedure applies the computationprocess to each element of the input list, and builds aresulting output list. In this case, compile time transformations cannot unfold the program to eliminatenesting of parcall frames because it will depend on the length of the input list. However, using ourruntime technique, given that the goal process list is determinate, nesting of parcall framescan be completely eliminated (Figure 8). As a result of the absence of nesting of parcall frames, ifthe process goal fails for some element of the list, then the whole conjunction will fail in one
‖In reality, these conditions can be relaxed, however this is not discussed further to keep the presentation simple [51].∗∗Although, in our case, the bindings finally generated by e,f,g should be produced before starting the execution of s.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

OPTIMIZATION SCHEMAS 1157
?- process_list([1,2,3,4]) ?- process_list([1,2,3,4])
process
process
process
process
process_list
process_list
process_list
process_list
process process process process process_list
process(1) & process_list([2,3,4])
process(3) & process_list([4])
process(2) & process_list([3,4])
process(4) & process_list([])
process(1) & process(2) & process(3) & process(4) & process_list([])
Figure 8. Reuse of parcall frames for recursive programs.
single step—while in an unoptimized execution, failure has to be sequentially propagated from thebottommost parcall frames to the ones higher up, which incurs a much greater overhead.
On applying the LPCO in a situation such as the one shown in Figure 8, control parallelism thatis deeply nested transforms itself into data parallelism resulting in improved efficiency. In fact, ourdata parallel version of Prolog [27], based on LPCO is comparable in performance to dedicated dataand-parallel Prolog systems such as Reform Prolog [52].
Implementation of LPCO
To implement LPCO, the compiler will generate a different instruction when it sees a parallel conjunctat the end of a clause. This instruction, named opt alloc parcall, behaves the same as thealloc parcall instruction (the instruction used to create parallel conjunctions) of ACE, exceptthat if the conditions for LPCO are fulfilled, LPCO will be applied.
The behavior of opt alloc parcall is quite straightforward: once it is reached, it will performa check to verify whether the conditions for the application of LPCO are met (i.e., no choice points arepresent between the current point of execution and the immediate ancestor parcall frame). If the checksucceeds, then LPCO will be applied, otherwise the instruction will proceed creating a new parcallframe (i.e. it behaves like a normal alloc parcall instruction). The above-mentioned check isimmediate and does not introduce any significant overhead—it is sufficient to check that the datastructure currently on top of the stack is a parcall frame or an input marker (and not a choice point).
To apply LPCO, the immediate ancestor parcall frame (or immediately enclosing parcall frame)will be accessed and if the current parallel conjunction has n and-parallel goals, then n new slots
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

1158 G. GUPTA AND E. PONTELLI
(ii)
(e,f,g,r) & s & (i,j,k,t) & ur s t u
i
j
k
e
f
g
p & q
p qe
f
g
i
j
k
(i)
Note that the goal q is being executedon control stack of some other processor.Also note that input markers have a directpointer to their corresponding goal slot inthe heap.
# of slots = 4# of goals to wait onptr to beginning of slots list
Other control info.
parcall frame
for (p & q) reused
efg
# of slots = 2# of goals to wait onptr to beginning of slots list
Other control info.
goal = pgoal = q
HEAP iCONTROL STACK
parcall frame
for (p & q)
p’s input marker
HEAP j
goal = tgoal = u
goal = rgoal = s
HEAP iCONTROL STACK
Figure 9. Allocating goal slots on the heap.
corresponding to these n goals will be added to it. The number of slots should be atomicallyincremented by n in the enclosing parcall frame.
Introducing the LPCO in the ACE system requires only one small change in the architecture. In theoriginal ACE (as in RAPWAM [10], DDAS [53], etc.) the slots which are used to describe the subgoalsof a parallel call are stored on the stack as part of the parcall frame itself. Given that the enclosingparcall may be allocated somewhere below in the stack, adding more slots to it may not be feasible.To enable more slots to be added later, the slots will have to be allocated on the heap and a pointer tothe beginning of the slot list stored in the parcall frame (Figure 9). The slot list can be maintained asa double linked list, simplifying the insertion/removal operations. Also, each input marker of an and-parallel goal has a pointer to its slot in the slot list for quick access (this is already part of the originalACE design). With the linked list organization, adding new slots becomes quite simple as shown inFigure 9. Note that the modification of the slot list will have to be a backtrackable atomic operation.The enclosing parcall frame becomes the parcall frame for the last parallel call, and the rest of theexecution will be similar to that in standard ACE. The garbage collection mechanisms used on theheap guarantees that as soon as we have completely backtracked over a nested parallel call (optimizedby LPCO) the space taken by the slots will be immediately recovered.
Note that changing the representation of slots from an array recorded on the stack (inside a parcallframe) to a linked list on the heap will not add any inefficiency because an and-parallel goal can access
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

OPTIMIZATION SCHEMAS 1159
Table I. Execution time in seconds (forward execution only); % improvement in parentheses.
Number of processorsBenchmarkexecuted 1 3 5 10
map2 7.14/6.39 (11%) 2.51/2.32 (8%) 1.99/1.48 (26%) 1.91/1.48 (23%)occur(5) 3.65/3.15 (14%) 1.25/1.02 (18%) 0.75/0.64 (15%) 0.43/0.35 (19%)
Table II. Execution time in seconds (LPCO with backward execution); % improvement in parentheses.
Number of processorsBenchmarkexecuted 1 3 5 10
matrix 6.30/5.36 (15%) 2.73/1.90 (30%) 2.05/1.22 (40%) 1.54/0.70 (54%)pderiv 9.49/5.61 (41%) 5.88/2.75 (53%) 5.19/2.34 (55%) 6.67/2.342 (65%)map1 24.21/14.98 (38%) 14.01/5.20 (63%) 12.24/3.23 (74%) 10.73/1.76 (84%)annotator 3.94/3.86 (2%) 1.35/1.34 (1%) 0.88/0.87 (1%) 0.49/0.47 (4%)
its corresponding slot in constant time via its input marker. All other operations for slots require a linearscanning of all the slots in the parallel call.
It is obvious that LPCO indeed leads to a saving in space as well as time during parallel execution.In fact:
• space is saved by avoiding allocation of the nested parcall frames;• some time may be saved during forward execution by avoiding creation of new data structures;
nevertheless, the time complexity of applying LPCO is often comparable to the time complexityof allocating a parcall frame;
• time is saved during backtracking, since the number of control structures to traverse isconsiderably reduced.
Performance results
The results of applying LPCO to the ACE system are shown in Tables I and II (times are in seconds).The performance figures have been obtained on a sequent symmetry multiprocessor; it must be notedthat similar results have been observed on different architectures (e.g., Sun Sparc multiprocessors andPentium-based multiprocessors). It should also be noted that different sets of benchmarks have beenused for illustrating the performance gains obtained from different optimizations presented in the paper.This is because, in general, results for only those benchmarks have been presented for a particular
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

1160 G. GUPTA AND E. PONTELLI
0 2 4 6 8 10No. of Agents
0
2
4
6
8
10
Spe
edup
LPCO (Backward Execution)
Map (no LPCO)Map (LPCO)Matrix Mult. (no LPCO)Matrix Mult. (LPCO)
0 2 4 6 8 10No. of Agents
0
2
4
6
8
10
Spe
edup
LPCO (Backward Execution)
Annotator (no LPCO)Annotator (LPCO)Deriv (no LPCO)Deriv (LPCO)
Figure 10. Speedup curves for LPCO benchmarks.
10000
20000
30000
40000
50000
Without LPCO
with LPCO
BTCluster Pderiv Occur
49%
45%
34%
Benchmarks
Hea
p a
nd
Co
ntr
ol S
tack
Usa
ge
(wo
rds)
200
400
600
800
1000
Without LPCO
with LPCO
Map MatrixMult
Benchmarks
Hea
p a
nd
Co
ntr
ol S
tack
Usa
ge
(wo
rds
x 10
^3)
48%
39%
Memory Consumption
(usage of Control Stack)
Figure 11. LPCO: improvement in control stack usage.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

OPTIMIZATION SCHEMAS 1161
optimization that have shown substantial improvement with that optimization. Improvements have beenobserved for almost all benchmarks for each optimization presented.
Table I shows the performance improvement during forward execution (where LPCO results in onlymarginal improvement if at all), while Table II shows performance improvement during backtracking,where the performance due to reduction in levels of nesting are significant. LPCO benefits thoseprograms which backtrack over deeply nested parcall frames—the deeper the nesting the better theimprovement due to LPCO. The performance improvement in terms of speedup curves are shown inFigure 10. The most noticeable is the map benchmark: without the optimization almost no speedupcan be observed (due to the heavy overhead of backtracking), while using the optimization an almostlinear speedup can be obtained. Use of LPCO also produces considerable improvement in memoryconsumption: experiments have shown that space usage in control stack decreases by almost 50% [28].This is illustrated in Figure 11, which contrasts the usage of the control stack (expressed in the numberof words used) in the unoptimized and optimized cases (this saving, however, has to be balanced againsta small increase in heap-space consumption, as the slots are now allocated on the heap and are linkedby pointers; the space savings primarily arise from the space reuse in parcall frames).
A dual optimization can be developed to improve efficiency of or-parallel executions, by mergingchoice points generated along the last alternative of each or-node. This optimization (named lastalternative optimization) has also been tested in the ACE system with excellent results [44]. The lastalternative optimization can also be used for parallelizing and optimizing constraint languages (e.g.,CHIP [2]) and is described next.
Flattening: last alternative optimization
Introduction
We illustrate the last alternative optimization (LAO) with an example. In a majority of or-parallelapplications, or-parallelism arises because a variable can be given one of many possible values. Thisis typically coded as a call to member or select predicate. For example, given a variable V, ifwe want it to assume values from the list [1,2,3,4], and for each possible value of V we want toperform some computation (almost all non-deterministic search problems and constrained optimizationproblems are programmed in this manner), then the query will look as follows:
?- member(V,[1,2,3,4]),compute(V,R).
where R will hold the result of the computation with a given value for V, and member is defined asfollows.
member(X,[X|T]).member(X,[Y|T]) :- member(X,T).
The or-parallel tree structure created is shown in Figure 12.Notice that or-parallelism will be exploited when processors move to choice points (shown as dark
circles in Figures 12 and 13) and pick the compute goals for execution. A possible scenario is shownin Figure 12 itself where processors P1, P2, P3, and P4 are exploring the four branches created forsolving compute(i,R) where 1 ≤ i ≤ 4.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

1162 G. GUPTA AND E. PONTELLI
?-member(V,[1,2,3,4]), compute(V,R)
V=1
compute(1,R)member(V,[2,3,4]),compute(V,R)
member(V,[3,4]),compute(V,R)
member(V,[4]),compute(V,R)
member(V,[ ]),compute(V,R)
fail
V=1
compute(2,R)
V=1
compute(3,R)
V=1
compute(4,R)
P3
P1
P2
P4
Figure 12. Search tree for member.
?-member(V,[1,2,3,4]), compute(V,R)
compute(1,R) member(V,[ ]),compute(V,R)
fail
compute(2,R)
V=1
compute(3,R)
V=2
compute(4,R)
P3P1 P2 P4
V=3 V=4
Figure 13. Search tree for member w/ LAO.
Note that the intent in the program is to fire off a compute goal for every element in the list[1,2,3,4]. However, because a repetitive action can be programmed in a logic programminglanguage only via recursion, we are forced to use the recursive member predicate for firing off allthe compute goals. Thus, the various calls to compute, one for each element of the list, can only begenerated in a recursive manner. Ideally, we would like to have all calls to compute generated all atonce as shown in Figure 13.
The tree structure shown in Figure 12 is nested, thus processors have to traverse larger distancesto move around the tree, and obtain work (the various compute goals). In contrast, in Figure 13 all
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

OPTIMIZATION SCHEMAS 1163
compute goals are clubbed at one choice point from where they can all be picked by processors withless traversal.
The same discussion applies to the select predicate that, like the member predicate, is alsotraditionally used to spawn or-parallelism:
select(X,[X|T],T).select(X,[Y|T],[Y|R]) :- select(X,T,R).
Several researchers have proposed ways for making the work distribution operation more efficient.For example, Smith, in his Multilog system [54,55], has proposed the addition of a disj primitive toProlog, that the programmer should place before call to member. Thus, a typical Multilog query hasthe form:
?- disj member(X,[1,2,3,4]), compute(X,R).
The disj is handled by the Multilog system in a special way: the compute predicate is iteratively calledfor each element in the list. Thus, intuitively, the list structure is converted into an array structure, onwhich a data-parallel compute call is made.
Our goal is to avoid the overhead of having to traverse the extra nesting created due to recursiveunfolding of the member function, but without requiring any help from the programmer. The solutionthus is to recognize the case in Figure 12 and somehow transform it at runtime to the situation shownin Figure 13. This is indeed what the LAO accomplishes.
This flattening can be accomplished at runtime as follows: when the last alternative in a choice pointB1, further creates a choice point B2, then there is no need to allocate this new choice point, rather B1can be updated with the information that will be stored in B2. The information in B1 is no longer neededas the last alternative has already been picked up for execution. We do assume that when processorspick work in the form of untried alternatives from a choice point, they do it in the Prolog order, i.e.,left to right, so that the rightmost alternative is always the last alternative to be selected. Of course,while reusing the existing choice point, we have to make sure that we will not change the meaning ofthe program. Thus, we have to ensure that all the alternatives have access to the correct environment,the correct arguments, etc. Note that while we have illustrated LAO with the member example, wherethe two choice points merged (B1 and B2 above) correspond to the same predicate, in the general case,they may correspond to different predicates (however, in such a case special action will be needed ifpredicates corresponding to the two choice points have a different number of arguments).
LAO can also be thought of as a generalization of the last call optimization (LCO) for or-parallelsystems. The last call optimization itself is a generalization of the familiar tail recursion optimizationfor sequential Prolog systems.
The last alternative optimization not only saves execution time but also space. Execution time issaved in two ways:
• the search tree is simplified (its depth is reduced); as a consequence, the processors have shorterpaths to traverse to get to choice points that contain work in the form of untried alternatives;
• since an existing choice point is used instead of allocating a new one, time is saved—variousfields of the older choice points can be re-used without any update.
An interesting point to note about LAO is that, although it is applicable to sequential implementationsof Prolog [56], it does not bring much benefit to sequential execution. This is because in sequential
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

1164 G. GUPTA AND E. PONTELLI
execution, when the last alternative is picked, the corresponding choice point is already deallocated(however, the fact, that some of the fields in the old choice point may be reused may bring somemarginal savings if LAO were to be applied). However, for parallel implementations of Prolog, theefficiency gains can be enormous as our performance figures indicate. Unlike a sequential system,in an or-parallel implementation when the last alternative from a choice point is picked, that choicepoint cannot be deallocated as alternatives before the last one may still be active (i.e., they are stillbeing explored by other processors). Thus, reuse of choice points can lead to considerable savings inmemory and time. Also, because of the simplification of the tree structure due to flattening, the needfor processors to synchronize with each other is reduced, resulting in not only a simple to implementmodel but also a more efficient one.
Parallel logic programming systems that incorporate or-parallelism systems will benefit considerablyfrom LAO, as the simplification of the structure of the tree leads to fewer constraints on the schedulingalgorithm, and thus to more efficient scheduling. For instance, in the DNA sequencing program of Lusket al. [57], one of the largest or-parallel programs that has been ever tried, or-parallelism is obtainedfrom the following two rules:
find_match([C|Right],Left) :-find_a_matching_pattern(C,Right,Left).
find_match([C|Right],Left) :-find_match(Right,[C|Left).
A find match query will create a right-recursive tree that is explored in parallel. Lusk et al.switch the order of rules, due to the scheduling policy used in their Aurora or-parallel system, in orderto generate a left recursive tree, so that work is more evenly distributed. With LAO such considerationsbecome moot, since all the untried alternatives become available in a single choice point. (Lusk et al.extensively discuss in their paper how to make the scheduler work the way they want it to [57]). It is ourbelief that incorporation of LAO in Aurora will considerably improve the performance of Lusk et al.’sprogram (LAO provides exactly the effect that Lusk et al. are seeking) as well as of other or-parallelprograms run on the Aurora system.
LAO will also improve the performance of programs that use failure driven loops based on Prolog’srepeat builtin. The repeat builtin (defined below) creates an infinite number of choice points fromwhere work gets picked up (a cut is usually necessary later to destroy the infinite choice points andterminate the computation). Applying LAO will merge the multiple choice points created by therecursive repeat into one single choice point.
repeat :- repeat.repeat.
An optimization for sequential systems based on flattening, which is somewhat similar to LAO, hasbeen proposed by Meier [56].
Implementation of LAO
The current implementation of LAO in ACE is quite simple. The opportunities for applying theoptimization are automatically identified. A test is performed before creation of new choice points.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

OPTIMIZATION SCHEMAS 1165
If the current execution is the rightmost alternative of the previously created choice point, and boththe previous choice point and the new one are ‘parallel’††, then no new choice point will be created.Instead the previous choice point is reused.
The ‘reuse’ of the choice point is simply realized by avoiding allocation of the new choice point andby using the fields of the old choice point to store the various state information. This gives the advantagethat certain fields of the choice point may already contain the right value and their initialization maybe avoided (e.g., pointer to the heap). Reuse of a choice point also involves attaching the alternativesof the choice point being created to the existing choice point, and storing in the same choice point therelevant state information (e.g., value of the arguments of the associated subgoal).
It is easy to include LAO in any or-parallel implementation. In the text below we sketch the changeswe had to make to accommodate LAO in the ACE system. As discussed earlier, a parallel choice pointthat has been shared in ACE actually replicates itself into (i) a number of private copies of the choicepoint (one for each processor that took work from that choice point), and (ii) the shared frame, witheach private copy having a pointer to it. Intuitively, the private copies are meant to store the ‘static’and ‘private’ parts of the state (the information that will not change between execution of the differentalternatives), while the shared frame is used to maintain the part of the state that will be modified bythe different processors during execution (and modifications performed by one processor that need tobe visible to the others) [12].
Given that implementation of LAO requires modification of certain fields of an existing choicepoint, these fields need to be transferred from the choice point to the shared frame, in order to allowcommunication of the changes to the other processors. In particular, two relevant parts of the choicepoint that need to be ‘globalized’ or transferred to the shared frame are:
• the arguments of the subgoal;• the pointer to the trail stack‡‡.
The general structure of the choice point and of the shared frame is depicted in Figure 14.The current prototypical implementation of LAO is mainly aimed at taking advantage of recursive
generators like those described in the previous examples (member, select, etc.). LAO can be easilygeneralized to situations where the choice point created along the last alternative of another choicepoint corresponds to a different predicate. The price of this generalization is the requirement of furtherglobalizing some more fields of the choice point (in particular the environment pointer needs to bemoved to the shared frame). Furthermore, the more general scheme should take care of the followingtwo situations.
1. The different procedures may have different number of arguments (see Figure 14).2. Various environments may have been allocated between the two choice points being merged. If
the alternatives of the latter choice point are promoted to the former one, then these environmentsneed to be ‘communicated’ to the other processors (otherwise they will not be able to correctly
††Note that in most or-parallel systems whether a choice point is parallel or sequential is indicated by the user. Only a parallelchoice point can give or-parallel work to other processors. Restricting the application of the LAO to parallel choice points isnecessary in order to limit the influence of the optimization on the behavior of the scheduler.‡‡The trail stack keeps track of the bindings that need to be undone on backtracking.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

1166 G. GUPTA AND E. PONTELLI
Heap Top
Environment Ptr.
Next Instruction
Work Load Info
Heap Top
Environment Ptr.
Next Instruction
Choice Point Choice Point
Shared Frame
saved arguments
X(0)X(1)
X(n)
Next Clause
Work Load Info
Note: The two choicepoints shown are copies of each other, each one of which points to the common shared frame.
Trail Info
Environment Ptr.
Figure 14. Choice points and shared frames.
Table III. Improvements using LAO (unoptimized/optimized; time in seconds).
Number of agents
Program 1 2 4 8 10
ancestors 2.460/2.706 (−10%) 1.269/1.370 (−8%) 0.669/0.629 (6%) 0.399/0.299 (25%) 0.340/0.201 (41%)maps 35.420/36.240 (−2%) 21.079/19.879 (6%) 11.620/12.189 (−10%) 9.290/8.329 (10%) 6.100/7.100 (−16%)members 8.029/8.450 (−5%) 4.021/3.731 (7%) 3.733/2.667 (29%) 3.480/2.080 (40%) 3.400/2.011 (41%)puzzle 2.939/3.001 (−2%) 1.529/1.589 (−4%) 0.890/0.809 (9%) 0.540/0.429 (21%) 0.519/0.360 (31%)
queen1 3.689/3.889 (−5%) 2.939/2.129 (28%) 1.959/1.159 (41%) 1.910/0.730 (62%) 1.909/0.629 (67%)
queen2 0.799/0.850 (−6%) 0.510/0.450 (12%) 0.320/0.240 (25%) 0.229/0.150 (34%) 0.229/0.149 (35%)
execute the new alternatives). This means that a further copying phase may be needed uponbacktracking over an optimized choice point.
Nevertheless, the savings guaranteed by LAO easily overcome the additional expenses for the aboveoverheads.
Performance results
Table III describes the results obtained by running some benchmarks on the ACE systems with andwithout LAO. Each entry in the table indicates the unoptimized execution time (in seconds), the time
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

OPTIMIZATION SCHEMAS 1167
0 2 4 6 8 10No. of Agents
0.0
2.0
4.0
6.0
8.0
10.0
Spe
edup
Speedups Using LAO
Queen 1 (LAO)Queen 1 (no LAO)Puzzle (LAO)Puzzle (no LAO)
0 2 4 6 8 10No. of Agents
0
5
10
15
Spe
edup
Speedups Using LAO
Ancestors (LAO)Ancestors (no LAO)Queen 2 (LAO)Queen 2 (no LAO)
Figure 15. Speedup curves for LAO benchmarks.
0.0 2.0 4.0 6.0 8.0 10.0No. of Agents
-20.0
0.0
20.0
40.0
60.0
80.0
Per
cent
age
of Im
prov
emen
t
Improvement using LAO(% improvement)
Queen1Queen2MembersAncestors
Figure 16. Improvement in execution time.
obtained using LAO, and the corresponding percentage of improvement. All the programs use either themember or the select predicate to generate alternative paths to the solution(s). Figure 15 comparesthe speedup curves with and without optimization, while Figure 16 represents the improvement inexecution time obtained using LAO.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

1168 G. GUPTA AND E. PONTELLI
Even though the current implementation of LAO is still a prototype, the performance figuresobserved are quite impressive. Especially with larger number of processors, the reduction in executiontime is frequently over 30%. These good results are consequence of the particularly good interactionbetween LAO and stack copying. The application of LAO allows to ‘promote’ new alternativescreated by a processor, storing them directly in a choice point that has already been copied by otherprocessors (i.e., it has already a shared frame associated with it). In this way the new alternativesbecome immediately visible to the other processors, without the need for performing further sharingactivities. As a consequence the number of sharing operations performed during execution is reducedconsiderably (in some benchmarks this number decreased from over 100 to less than 10). Consideringthat each sharing operation may be quite expensive, a good reduction in execution time can be expected.
It must be noted that, in the current implementation, the presence of LAO tends to produce a slightdegradation in execution time on a single processor (as can be observed from the execution times onone processor in Table III). This is due to the additional cost of testing, at each choice point creation,whether LAO can be applied or not. We expect to be able to considerably reduce this overhead by usinga more careful implementation of these tests and by taking advantage of the information supplied bythe compiler (e.g., distinction between sequential and parallel nodes).
In rare cases (as for the maps program, which solves the map coloring problem for a map ofWest Europe), anomalous behavior was produced, due to the experimental nature of our scheduler.We believe that the problem should disappear if more sophisticated scheduling strategies are adopted[58].
LAO for parallel constraint logic programming
A parallel constraint logic programming (CLP) system, based on finite domains [59], such as CHIP [2],SICStus [29], or CLP(FD) [60], can take substantial advantage of LAO. A typical CLP problem canbe characterized as follows: given a collection of variables, each of which ranges over a finite domain(set of values), the task is to find an assignment of values for these variables from their respectivedomains such that certain user-stated constraints are satisfied. In traditional logic programming thiswill be stated as a generate and test problem, where all possible assignments of values for the variablesfrom the domains will be considered and then tested for consistency under the given constraints. CLPover finite domains makes this process efficient, by setting up the constraints first, which significantlyprunes the domains of variables (any constraints that cannot be solved in this phase are suspended),and then performing a generate and test, where the generation phase considers values from the pruneddomain (programmed by using built-ins like labeling or indomain) and the test phase consists oftesting the assignments generated in the generate phase for the remaining suspended constraints.
The predicate indomain is nothing but a call to a member predicate, where the variable in questionis assigned successive values from the pruned domain. Most CLP systems provide efficient ways ofdoing this by providingdeleteff or labelingff [2] predicates which will first assign to variablesthat have smaller domains or are more likely to generate a failure (first-fail heuristic [2]).
In a parallel CLP system that incorporates LAO, the indomain predicate unfolds into a data-parallel call due to LAO, thus automatically improving the efficiency of parallel execution. Thus,with the incorporation of LAO, one can incorporate data parallelism automatically into a parallel CLPsystem.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

OPTIMIZATION SCHEMAS 1169
AVOIDANCE OF UNNECESSARY OPERATIONS
A general model to support parallel execution is usually designed to tackle the worst case situations.This may result in overheads even when the worst-case is not encountered. This can occur intwo situations: paying the price for supporting non-determinism in the presence of deterministiccomputations, and paying the price for supporting parallelism in the presence of sequentially executedpieces of computation. Avoiding overhead in these situations is not a straightforward task, becauseknowledge about properties of the computation (e.g. determinacy, sequentiality) can only be obtaineda posteriori, after execution.
There are two ways to avoid these worst-case induced overheads, and they can be concretized asoptimization schemas, one based on procrastination of overheads, and one based on sequentializationof computations, i.e., recognizing situations where potentially parallel computations are actuallyexecuted sequentially.
Procrastination of overheads. The optimization schema can be stated as follows. ‘The execution ofan operation that constitutes an overhead should be delayed until its effects are needed by the rest ofthe computation.’
Here again we assume that delaying will not alter the operational semantics of the language/system.The intuition is that certain operations may be delayed indefinitely, i.e. their effect may never be neededby the computation. The idea of procrastination has been repeatedly utilized in the design of theWarren Abstract Machine (WAM) [41] for efficient execution of Prolog programs; for example, inthe WAM the space for caller goal’s environment is allocated by the callee clause. Another example ofthe procrastination schema is the shallow backtracking optimization of Carlsson [61] and implementedin both sequential (SICStus) as well as or-parallel (Aurora [11] and Muse [12]) versions of Prolog.Shallow backtracking delays creation of the choice point until the head unification (and eventuallyexecution of the guard) has succeeded. If none of the head unification is successful, then backtrackingis activated without creation of any choice point (i.e. the creation of the choice point is postponedindefinitely). Carlsson reported an average speedup of 7% to 15% on a set of complex benchmarks.
The idea of procrastination has also been applied to or-parallel systems such as Muse and Aurora inthe context of choice points. Typically, in an or-parallel system the choice points have to save a largerstate than in a purely sequential system. However, if all alternatives of a choice point are explored byonly one processor, then saving this extra state is a pure overhead. In Muse and Aurora, this overheadis delayed until the scheduler explicitly declares a choice point to be parallel (in Muse and Auroraterminology, the choice point is said to have been made public [11,12]; processors can come and pickuntried alternatives only from public choice points of other processors). Thus, in Muse and Aurora,when a choice point is allocated, space is allocated for the extra part of the state that is related toparallel execution (scheduling information, value in extra registers introduced to support parallelism,etc.); however, this space is not filled in at the time of allocation. The information is filled in only laterwhen the choice point is made public by the scheduler. If a choice point is never made public, then theoverhead associated with saving the extra state is never incurred.
Procrastination has also been employed in the context of lazy evaluation of functional languages.However, our schema urges system designers to procrastinate overheads as long as the operationalsemantics are not altered. This is not the case with lazy evaluation where the overheads are not
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

1170 G. GUPTA AND E. PONTELLI
procrastinated, rather the evaluation of operations themselves in the program is procrastinated. Also,lazy evaluation alters the operational semantics of the language.
The procrastination schema can be applied to parallel logic programming systems by delaying theallocation of control data structures (e.g., choice points, markers) on the stack as much as possible.The allocation can be delayed, only up to a certain point, determined by fulfillment of some condition(otherwise the meaning of the program will change). When the condition is fulfilled the allocationcannot be delayed any further. However, if the condition is never fulfilled then the operation is delayedindefinitely. The condition is usually such that we cannot tell a priori whether it will be fulfilled or not.For example, in the case of the optimization in Muse and Aurora discussed in the previous paragraph,where saving of state data related to parallelism is procrastinated, it can be procrastinated only up tothe point when that choice point is declared public by the scheduler. Delaying it any further will causethe information to be saved to become unrecoverable. Ideally, the saving operation should have beendelayed until we are certain that the alternative at this choice point will be executed by at least twoprocessors, because it is possible that only one processor may execute all the alternatives after a choicepoint becomes public, resulting in the time spent in saving the parallel state being wasted.
Sequentialization of parallel operations. The idea of sequentializing parallel operations can be statedas follows. ‘Two consecutive branches of the same node of the computation tree executed by the samecomputing agent should incur negligible overhead.’
This schema has been implicitly used in various parallel systems. For example, many or-parallelimplementations of Prolog (like Muse [12] and Aurora [11]) allow the sequential exploitation ofconsecutive alternatives from a parallel choice point with minimal overhead (using almost standardbacktracking). The optimization in Aurora and Muse used to accomplish this, divides the or-paralleltree into public and private parts, and can be seen as an instance of the sequentialization schema. Whena processor is in the private part of the search tree, execution is exactly as in a sequential Prolog system.
Granularity control in parallel systems can also be seen as an application of this idea. Granularitycontrol attempts to break up the parallel execution into large pieces of sequential computation suchthat the total parallel overhead is insignificant compared to the execution time. Large grain sizes areobtained by taking consecutive tasks (consecutive in the sense of sequential execution) and puttingthem together for execution by one processor so that the parallel overhead associated with the smallertasks that constitute the large grain is eliminated. A similar idea has also been applied to committedchoice logic languages [45] and an improvement in performance obtained.
Like the flattening and procrastination schemas, the sequentialization schema is more relevant tonon-deterministic systems. This is because, in non-deterministic system, two pieces of computation thatare contiguous in sequential execution have to be delimited (with markers) during parallel executionin order to facilitate their parallel execution. Delimiters are needed because processors may backtrackover these computations. If two contiguous pieces of computation were anticipated to be executed inparallel, but are eventually executed by the same processor, then the overhead incurred in delimitingthese two contiguous computations can be avoided. Since backtracking is absent in deterministicsystems, and computations need not be marked as in non-deterministic systems, this schema has littleapplicability to deterministic systems. For example, during parallel execution of iterations of a Fortranloop, no overhead is saved if a processor knows, while executing the iteration with loop index k, thatthe next iteration it will execute is the next consecutive iteration with loop index k + 1. This is becauseno substantial parallel overhead is incurred in picking work (iterations) while executing Fortran DO
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

OPTIMIZATION SCHEMAS 1171
:- ... ( ... & a & b ... )
Input Marker for a
End Marker for a
Figure 17. Shallow parallelism optimization.
loops in parallel. In contrast, in non-deterministic systems substantial overhead may be incurred afterpicking work and before starting its execution because of the need to allocate markers for backtrackingpurposes.
Next we illustrate the application of procrastination and sequentialization schemas to the ACEsystem.
Procrastination: shallow parallelism optimization
During and-parallel execution a processor can pick up a goal for execution from other processors onceit becomes idle. The general model of ACE requires at this stage the allocation of a data structure onthe stack, called a (input) marker. This marker is used to indicate the point at which the executionof a subgoal was initiated, to partition the stack in sections (one for each parallel subgoal), and tomaintain the logical connections between a parallel subgoal and its parent computation. The sameconsiderations need to be applied when a subgoal is completed—a marker (end marker) needs tobe allocated to indicate the completion of a subgoal and the end of the corresponding stack section.The presence of these section markers is fundamental in order to enforce the proper behavior duringbacktracking—encountering an input marker indicates that a subgoal has been completely backtrackedover and backtracking needs to proceed in the logically preceding subgoal, while encountering anend marker indicates that we are backtracking into a parallel call. The expense incurred in allocatingthese markers is considerable, since each marker stores various information and the number of markers(O(2 × n) where n is the number of parallel subgoals) can be very high. However, if it is knownthat a subgoal is deterministic, then the presence of markers is unnecessary since there is no need tobacktrack inside these subgoals, as they do not have any untried alternatives. Thus, backtracking overdeterministic goals is a pure overhead.
Given a parallel conjunction (g1&g2&g3) if it is known that g2 is deterministic then backtrackingshould proceed directly from g3 to g1. We only have to make sure that every binding trailed duringthe execution of g2 is untrailed (undone) before backtracking moves into g1. This implies that actuallythere is no need to allocate the input marker node and the end marker node for goal g2 during forwardexecution—and this applies to every determinate and-parallel subgoal—see Figure 17.
Allocation of marker, as described above, can be avoided only if the deterministic nature of thesubgoal is known. Determinacy information is not available a priori (unless some form of compile-
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181
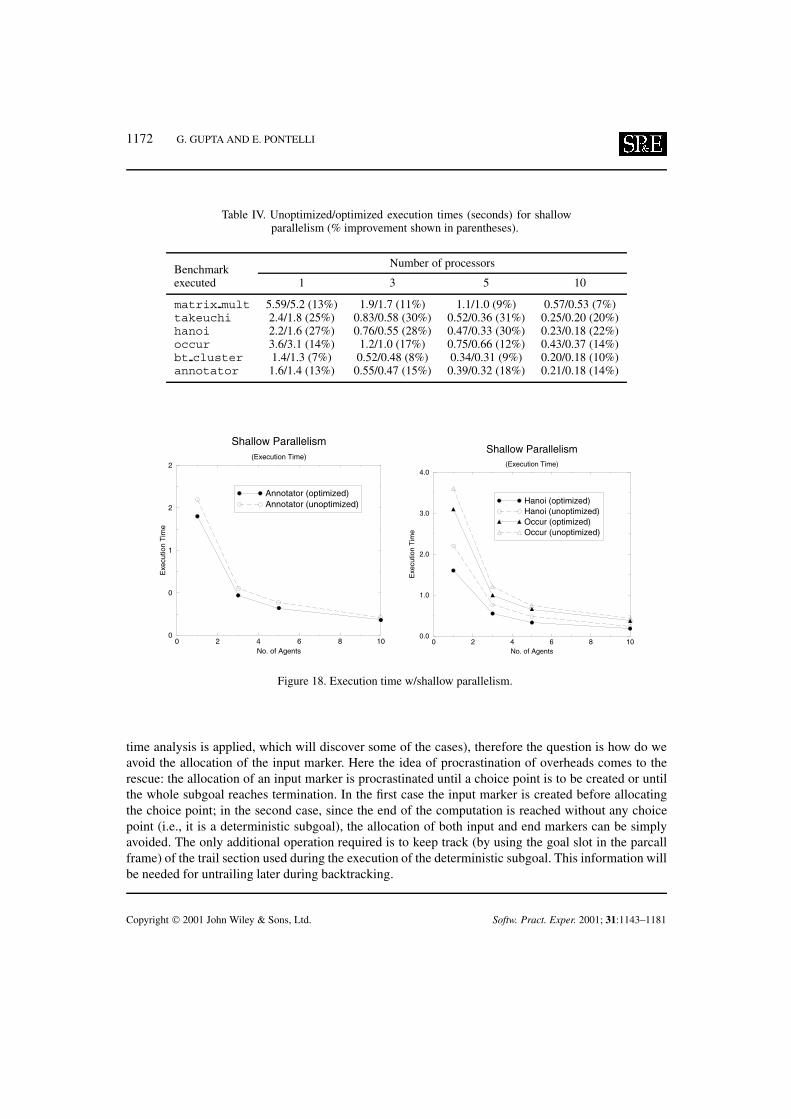
1172 G. GUPTA AND E. PONTELLI
Table IV. Unoptimized/optimized execution times (seconds) for shallowparallelism (% improvement shown in parentheses).
Number of processorsBenchmarkexecuted 1 3 5 10
matrix mult 5.59/5.2 (13%) 1.9/1.7 (11%) 1.1/1.0 (9%) 0.57/0.53 (7%)takeuchi 2.4/1.8 (25%) 0.83/0.58 (30%) 0.52/0.36 (31%) 0.25/0.20 (20%)hanoi 2.2/1.6 (27%) 0.76/0.55 (28%) 0.47/0.33 (30%) 0.23/0.18 (22%)occur 3.6/3.1 (14%) 1.2/1.0 (17%) 0.75/0.66 (12%) 0.43/0.37 (14%)bt cluster 1.4/1.3 (7%) 0.52/0.48 (8%) 0.34/0.31 (9%) 0.20/0.18 (10%)annotator 1.6/1.4 (13%) 0.55/0.47 (15%) 0.39/0.32 (18%) 0.21/0.18 (14%)
0 2 4 6 8 10No. of Agents
0
0
1
2
2
Exe
cutio
n T
ime
Shallow Parallelism(Execution Time)
Annotator (optimized)Annotator (unoptimized)
0 2 4 6 8 10No. of Agents
0.0
1.0
2.0
3.0
4.0
Exe
cutio
n T
ime
Shallow Parallelism(Execution Time)
Hanoi (optimized)Hanoi (unoptimized)Occur (optimized)Occur (unoptimized)
Figure 18. Execution time w/shallow parallelism.
time analysis is applied, which will discover some of the cases), therefore the question is how do weavoid the allocation of the input marker. Here the idea of procrastination of overheads comes to therescue: the allocation of an input marker is procrastinated until a choice point is to be created or untilthe whole subgoal reaches termination. In the first case the input marker is created before allocatingthe choice point; in the second case, since the end of the computation is reached without any choicepoint (i.e., it is a deterministic subgoal), the allocation of both input and end markers can be simplyavoided. The only additional operation required is to keep track (by using the goal slot in the parcallframe) of the trail section used during the execution of the deterministic subgoal. This information willbe needed for untrailing later during backtracking.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181
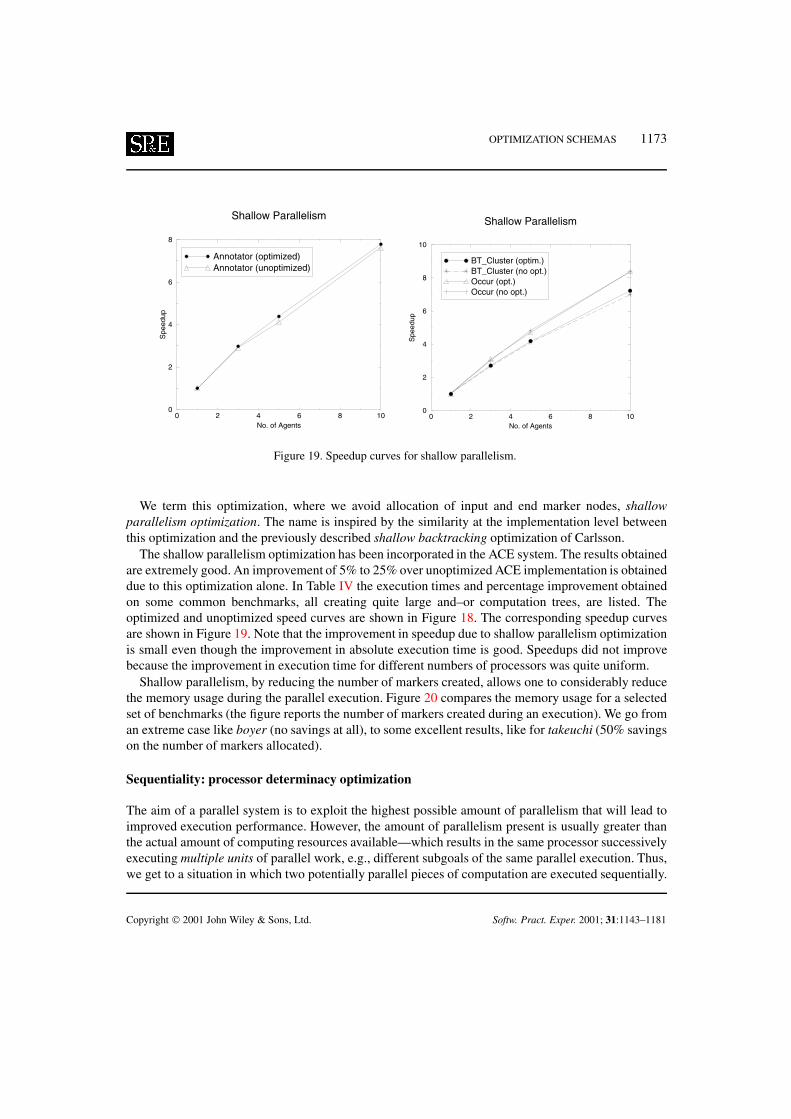
OPTIMIZATION SCHEMAS 1173
0 2 4 6 8 10No. of Agents
0
2
4
6
8
Spe
edup
Shallow Parallelism
Annotator (optimized)Annotator (unoptimized)
0 2 4 6 8 10No. of Agents
0
2
4
6
8
10
Spe
edup
Shallow Parallelism
BT_Cluster (optim.)BT_Cluster (no opt.)Occur (opt.)Occur (no opt.)
Figure 19. Speedup curves for shallow parallelism.
We term this optimization, where we avoid allocation of input and end marker nodes, shallowparallelism optimization. The name is inspired by the similarity at the implementation level betweenthis optimization and the previously described shallow backtracking optimization of Carlsson.
The shallow parallelism optimization has been incorporated in the ACE system. The results obtainedare extremely good. An improvement of 5% to 25% over unoptimized ACE implementation is obtaineddue to this optimization alone. In Table IV the execution times and percentage improvement obtainedon some common benchmarks, all creating quite large and–or computation trees, are listed. Theoptimized and unoptimized speed curves are shown in Figure 18. The corresponding speedup curvesare shown in Figure 19. Note that the improvement in speedup due to shallow parallelism optimizationis small even though the improvement in absolute execution time is good. Speedups did not improvebecause the improvement in execution time for different numbers of processors was quite uniform.
Shallow parallelism, by reducing the number of markers created, allows one to considerably reducethe memory usage during the parallel execution. Figure 20 compares the memory usage for a selectedset of benchmarks (the figure reports the number of markers created during an execution). We go froman extreme case like boyer (no savings at all), to some excellent results, like for takeuchi (50% savingson the number of markers allocated).
Sequentiality: processor determinacy optimization
The aim of a parallel system is to exploit the highest possible amount of parallelism that will lead toimproved execution performance. However, the amount of parallelism present is usually greater thanthe actual amount of computing resources available—which results in the same processor successivelyexecuting multiple units of parallel work, e.g., different subgoals of the same parallel execution. Thus,we get to a situation in which two potentially parallel pieces of computation are executed sequentially.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181
1174 G. GUPTA AND E. PONTELLI
Usage of Markers
1000
2000
3000
4000
5000
MatrixMult
BTcluster
TakeuchiAnnotator
Boyer
Occur
Benchmarks
Mar
kers
Optimized
Unoptimized
Figure 20. Shallow parallelism: number of markers allocated.
:- ... ( ... & a & b ... )
a
b
a
binput marker
end marker
Figure 21. Processor determinacy optimization.
The interesting situation occurs when the two units of work are actually executed in the same order inwhich they would be executed during a purely sequential computation; in such a case all the additionaloperations performed, related to the management of parallel execution, represent pure overhead. Thesequentialization idea can be applied in such a situation to reduce this overhead. We call the resultingoptimization the processor determinacy optimization (PDO) because it comes into affect after theprocessor that is going to execute a given goal is determined—see Figure 21.
The application of the PDO is also a posteriori. Once a situation in which the optimization can beapplied is detected, i.e., the scheduler returns (or it manages to select) a subgoal which, consideringsequential semantics, immediately follows the one just completed, we can avoid most of the overheadassociated with the second subgoal. This saving is obtained by simply avoiding allocating any markerbetween the two subgoals and—in general—treating them as a single, contiguous piece of computation.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

OPTIMIZATION SCHEMAS 1175
Table V. Unoptimized/optimized execution times in seconds (% improvement is shown in parenthesis).
Number of processors
Goals executed 1 3 5 10
matrix mult(30) 5.598/5.207 (8%) 1.954/1.765 (11%) 1.145/1.067 (7%) 0.573/0.536 (7%)quick sort(10) 1.882/1.503 (25%) 0.778/0.621 (25%) 0.548/0.443 (23%) 0.442/0.367 (20%)takeuchi(14) 2.366/1.632 (45%) 0.832/0.600 (39%) 0.521/0.388 (34%) 0.252/0.200 (26%)poccur(5) 3.651/3.104 (15%) 1.255/1.061 (18%) 0.759/0.649 (17%) 0.430/0.353 (22%)bt cluster 1.461/1.330 (10%) 0.528/0.482 (10%) 0.345/0.294 (17%) 0.202/0.165 (22%)annotator(5) 1.615/1.298 (24%) 0.556/0.454 (23%) 0.392/0.302 (30%) 0.213/0.171 (25%)
Thus, given (a&b&c) if processor executing a picks up b after finishing then the effect of thePDO will be as if the original parallel conjunction was ((a,b)&c). There are several advantagesin applying PDO: (i) memory consumption as well as execution time is reduced since allocation ofmarkers between consecutive subgoals executed on the same processor is avoided; and (ii) executiontime during backward execution is also reduced, since backtracking on the two subgoals flows directlywithout the need for performing the various actions associated with backtracking over markers.
Implementation of PDO is quite simple and requires minimal changes to the architecture: anadditional check on exit from the scheduler is needed to verify if the new subgoal can be merged withthe one previously executed. The check is immediate, at least in an architecture in which knowledge ofthe order of subgoals is maintained, which is readily available in almost all parallel logic programmingsystems that have been built. Improved results can be obtained by modifying the scheduler itself, givingpreference to selection of consecutive subgoals over other goals.
Regarding forward execution, the results obtained are extremely encouraging, as can be observedfrom Table V. For many examples the optimization manages to improve the execution time by 3% to20%. The variations in improvement depend on the number of parcall frames generated, on the effectof the marker allocation overhead on the overall execution time, and on the number of processorsavailable. For this reason we obtain considerable improvements in benchmarks like takeuchi, wherewe have deep nesting of parallel calls and the marker allocation represents the main componentof the parallel overhead. The optimization maintains its effects when we consider execution spreadacross different processors, as we can see in Figure 22, which shows the execution times of boththe optimized and the unoptimized version for some benchmarks. The improvement in absolute timetaken for execution is quite significant, however the improvements in speedup due to PDO are small.This is primarily due to the improvement in execution time for different numbers of processors beingquite uniform. Speedup curves for some benchmarks, those for which the improvement in speedups isdiscernible, are shown in Figure 23.
The advantages of PDO are even more evident in terms of memory consumption: the number ofmarkers allocated is cut in almost all the cases to half of the original value—this is because most of theexamples analyzed have parallel calls of size 2 and the optimization allows one to avoid the allocation
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

1176 G. GUPTA AND E. PONTELLI
0.0 2.0 4.0 6.0 8.0 10.0No. of Agents
0.0
500.0
1000.0
1500.0
2000.0
2500.0
Exe
cutio
n tim
e (m
s.)
Processor Determinacy Optimization
Quicksort (no PDO)Quicksort (PDO)Takeuchi (no PDO)Takeuchi (PDO)
0.0 2.0 4.0 6.0 8.0 10.0No. of Agents
0.0
1000.0
2000.0
3000.0
4000.0
Exe
cutio
n tim
e (m
s.)
Processor Determinacy Optimization
Annotator (no PDO)Annotator (PDO)Poccur (no PDO)Poccur (PDO)
Figure 22. PDO: improvement in execution time.
0.0 2.0 4.0 6.0 8.0 10.0No. of Agents
0
2
4
6
8
10
Spe
edup
s
Processor Determinacy
Annotator (opt.)Annotator (no opt.)BT_Cluster (opt.)BT_Cluster (no opt.)
0.0 2.0 4.0 6.0 8.0 10.0No. of Agents
0
2
4
6
8
10
Spe
edup
Processor Determinacy
Matrix Mult. (opt.)Matrix Mult. (no opt.)Occur (opt.)Occur (no opt.)
Figure 23. PDO: improvement in speedups.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181
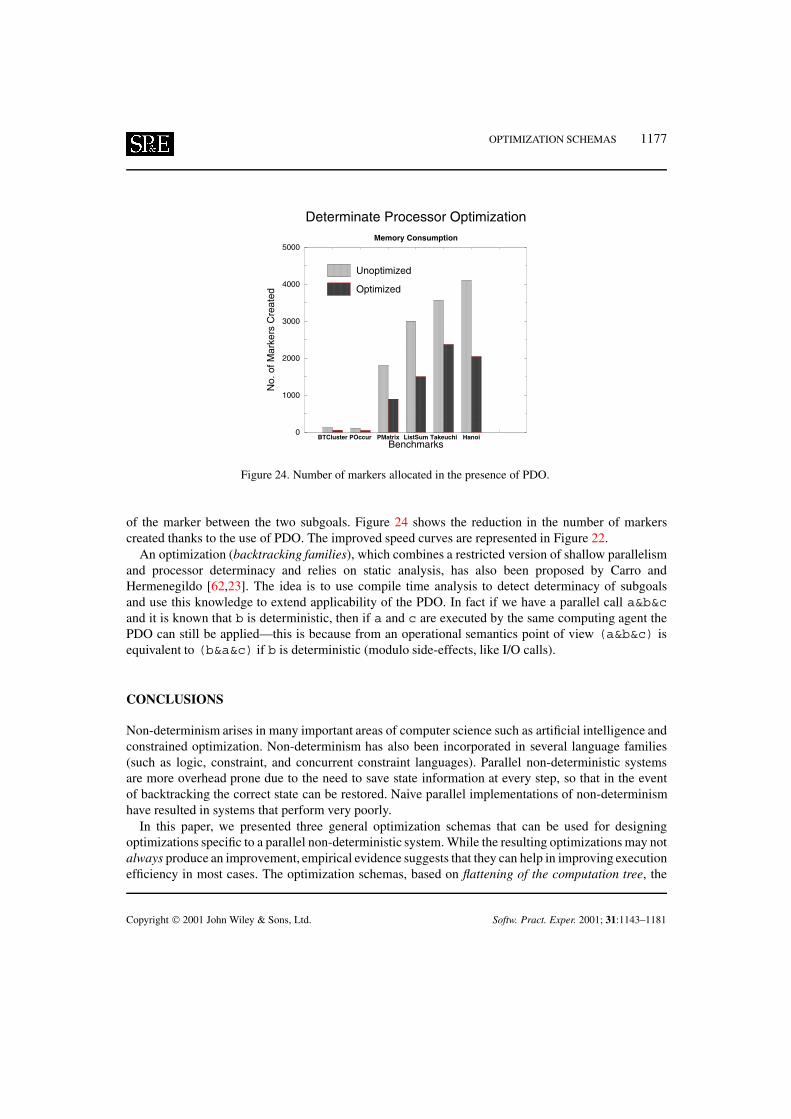
OPTIMIZATION SCHEMAS 1177
BTCluster POccur PMatrix ListSum Takeuchi HanoiBenchmarks
0
1000
2000
3000
4000
5000
No.
of M
arke
rs C
reat
ed
Determinate Processor OptimizationMemory Consumption
Unoptimized
Optimized
Figure 24. Number of markers allocated in the presence of PDO.
of the marker between the two subgoals. Figure 24 shows the reduction in the number of markerscreated thanks to the use of PDO. The improved speed curves are represented in Figure 22.
An optimization (backtracking families), which combines a restricted version of shallow parallelismand processor determinacy and relies on static analysis, has also been proposed by Carro andHermenegildo [62,23]. The idea is to use compile time analysis to detect determinacy of subgoalsand use this knowledge to extend applicability of the PDO. In fact if we have a parallel call a&b&cand it is known that b is deterministic, then if a and c are executed by the same computing agent thePDO can still be applied—this is because from an operational semantics point of view (a&b&c) isequivalent to (b&a&c) if b is deterministic (modulo side-effects, like I/O calls).
CONCLUSIONS
Non-determinism arises in many important areas of computer science such as artificial intelligence andconstrained optimization. Non-determinism has also been incorporated in several language families(such as logic, constraint, and concurrent constraint languages). Parallel non-deterministic systemsare more overhead prone due to the need to save state information at every step, so that in the eventof backtracking the correct state can be restored. Naive parallel implementations of non-determinismhave resulted in systems that perform very poorly.
In this paper, we presented three general optimization schemas that can be used for designingoptimizations specific to a parallel non-deterministic system. While the resulting optimizations may notalways produce an improvement, empirical evidence suggests that they can help in improving executionefficiency in most cases. The optimization schemas, based on flattening of the computation tree, the
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

1178 G. GUPTA AND E. PONTELLI
procrastination of overheads, and the sequentialization of computation were used to develop noveloptimizations for the ACE system, a high-performance parallel logic programming system. Applicationof optimizations based on these schemas to ACE resulted in the parallel overhead being reduced, onaverage, to less than 5% (less than 2% for many programs). The improvement in parallel executionefficiency was concretely demonstrated by presenting performance figures collected on a sequentsymmetry multiprocessor—similar improvements were observed also on Sun Sparc multiprocessors.While these schemas have been illustrated on the ACE system, they are fairly general, and can bereadily applied to other non-deterministic systems such as parallel theorem proving systems, parallelrule-based and AI systems, and parallel implementations of constraint and concurrent constraintlanguages.
Our experiments show that one can systematically improve execution performance of parallel non-deterministic systems and languages by designing optimizations based on schemas presented in thispaper. We hope this will induce other researchers to look for more such general optimization schemas,as well as to develop other useful optimizations based on schemas presented in this paper.
ACKNOWLEDGEMENTS
Thanks are due to Manuel Carro, Eduardo Correia, Vitor Santos Costa, Ines Dutra, Manuel Hermenegildo, KishShen, Fernando Silva, D. Tang, and David H. D. Warren for many stimulating discussions and suggestions.
APPENDIX A. DESCRIPTION OF BENCHMARKS
This appendix briefly describes the benchmarks used for reporting performance figures. Mostprograms are standard benchmarks used by the parallel logic programming research communityfor reporting system performance [11,12,46,52,63]. Some benchmarks are large (e.g. annotator,bt cluster, pan), while others are small. Even small programs (i.e. small in terms of number oflines) can create enormous and–or trees at runtime (e.g. Hanoi).
• ancestors: a program performing a search in a genealogical tree.• annotator: the &-Prolog compiler, an abstract interpretation-based tool used by ACE for
annotating programs with and-parallelism.• bt cluster: a clustering program developed by British Telecom, UK.• generate and test: a generic generate and test program.• hanoi: a program for towers of hanoi.• house: a program for the well-known Zebra puzzle.• listsum: a program for computing the sum of a list of integers.• map1: a program that applies a large granularity function to elements of a list.• map2: a program that applies a small granularity function to elements of a list.• matrix mult: a program for multiplying two large matrices.• members: a generate and test solution to an optimization problem.• occur: a program for searching for the occurrence of an element in a nested list.• pan: a program for generating naval flight crews.• pderiv: a program for symbolic differentiation.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

OPTIMIZATION SCHEMAS 1179
• puzzle: a solver for a crypto-arithmetic puzzle.• queens: a program for solving the N-queens problem.• queen1: a generate and test version of the queens problem.• queen2: a smarter solution to the queens problem.• takeuchi: a program that computes the Takeuchi function.
REFERENCES
1. Sterling L, Shapiro E. The Art of Prolog. MIT Press: Cambridge, MA, 1994.2. Van Hentenryck P. Constraint Satisfaction in Logic Programming. MIT Press: Cambridge, MA, 1989.3. Saraswat V. Concurrent constraint programming languages. PhD Thesis, School of Computer Science, Carnegie Mellon,
Pittsburgh, 1989.4. Brownston L. Programming Expert Systems in OPS5: An Introduction to Rule-based Programming. Addison-Wesley,
1985.5. Zima H, Chapman B. Supercompilers for Parallel and Vector Computers. ACM Press: New York, 1991.6. Lampson B. Hints for computer system design. Proceedings of the ACM Symposium on Operating Systems Principle. ACM
Press: New York, 1983.7. Gupta G, Hermenegildo M, Pontelli E, Costa VS. ACE: And/Or-parallel copying-based execution of logic programs.
Proceedings of ICLP’94. MIT Press: Cambridge, MA, 1994; 93–109.8. Pontelli E, Gupta G, Hermenegildo M. &ACE: A high-performance parallel prolog system. Proceedings of the
International Parallel Processing Symposium, April 1995. IEEE Computer Society: Santa Barbara, CA, 1995; 564–571.9. Hermenegildo M, Greene K. &-Prolog and its performance: Exploiting independent and-parallelism. Proceedings of the
International Conference on Logic Programs, June 1990. MIT Press: Cambridge, MA, 1990; 253–268.10. Hermenegildo M. An abstract machine for restricted AND-parallel execution of logic programs. Proceedings of the 3rd
ICLP (Lecture Notes in Computer Science, vol. 225). Springer: Berlin, 1986; 25–40.11. Lusk E et al. The Aurora Or-parallel Prolog system. New Generation Computing 1990; 7(2/3).12. Ali K, Karlsson R. The Muse or-parallel Prolog model and its performance. Proceedings of the 1990 North American
Conference on Logic Programs. MIT Press: Cambridge, MA, 1990; 757–776.13. Warren R, Hermenegildo M, Debray S. On the practicality of global flow analysis of logic programs. Proceedings of the
5th International Conference and Symposium on Logic Programming, August 1988. MIT Press: Cambridge, MA, 1988.14. Hermenegildo M, Bueno F, Puebla G, Lopez P. Program analysis, debugging, and optimization using the Ciao system
preprocessor. Proceedings of the International Conference on Logic Programming. MIT Press: Cambridge, MA, 1999.15. Hermenegildo M. Programming with global analysis. Proceedings of the International Logic Programming Symposium.
MIT Press: Cambridge, MA, 1997.16. Debray S, Lopez-Garcia P, Hermenegildo M. Non-failure analysis for logic programs. Proceedings of the International
Conference on Logic Programming. MIT Press: Cambridge, MA, 1997.17. Debray S, Lopez-Garcia P, Hermenegildo M, Lin N-W. Lower bound cost estimation for logic programs. Proceedings of
the International Logic Programming Symposium. MIT Press: Cambridge, MA, 1997; 291–306.18. Pfenning F. Types in Logic Programming. MIT Press: Cambridge, MA, 1992.19. Debray SK, Warren DS. Detection and optimization of functional computations in Prolog. Proceedings of the 3rd
International Conference on Logic Programming, Imperial College, July 1986 (Lecture Notes in Computer Science,vol. 225). Springer: Berlin, 1986; 490–505.
20. Pontelli E, Gupta G, Pulvirenti F, Ferro A. Automatic compile-time parallelization of prolog programs for dependentAND-parallelism. Proceedings of the International Conference on Logic Programming. MIT Press: Cambridge, MA, 1997;108–122.
21. Debray SK, Lin N-W, Hermenegilo M. Task granularity analysis in logic programs. Proceedings of the 1990 ACMConference on Programming Language Design and Implementation. ACM Press, 1990.
22. Debray SK, Warren DS. Automatic mode inference for Prolog programs. Journal of Logic Programming 1988; 5:207–229.23. Pontelli E, Gupta G, Tang D, Carro M, Hermenegildo M. Efficient implementation of independent and parallelism.
Computer Languages 1996; 22(2/3).24. Kascuk P, Wise MJ. Implementation of Distributed Prolog. Wiley: Chichester, 1992.25. Araujo L, Ruz J. A parallel Prolog system for distributed memory. Journal of Logic Programming 1997; 33(1):49–79.26. Shen K, Hermenegildo M. Divided we stand: parallel distributed stack memory management. Implementations of Logic
Programming Systems, Tick E, Succi G, (eds.). Kluwer Academic Press: Norwell, MA, 1994.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

1180 G. GUPTA AND E. PONTELLI
27. Pontelli E, Gupta G. Data and-parallel logic programming in & ACE. Proceedings of the 7th IEEE Symposium on Paralleland Distributed Processing. IEEE: Los Alamitos, CA, 1995.
28. Pontelli E, Gupta G, Tang D. Determinacy driven optimizations of parallel Prolog implementations. Proceedings of theConference on Logic Programming 95. MIT Press, 1995; 615–629.
29. Carlsson M. Sicstus Prolog User’s Manual. PO Box 1263, S-16313 Spanga, Sweden, 1988.30. Pontelli E, Gupta G. Implementation mechanisms for dependent AND-parallelism. Proceedings of the International
Conference on Logic Programming. MIT Press, 1997.31. Hermenegildo M, Warren R, Debray S. Global flow analysis as a practical compilation tool. Journal of Logic Programming
1991; 13(4):349–366.32. Muthukumar K, Bueno F, de la Banda MG, Hermenegildo M. Automatic compile-time parallelization of logic programs
for restricted, goal-level, independent and-parallelism. Journal of Logic Programming 1997; 38(2):165–218.33. DeGroot D. Restricted AND-parallelism. Proceedings of the International Conference on 5th Generation Computer
Systems, OHMSHA, Tokyo, November 1984; 471–478.34. Hermenegildo M. Towards efficient parallel implementation of concurrent constraint logic programming. Proceedings
of ICOT/NFS Workshop on Parallel Logic Programming and its Programming Environments, University of Oregon,Chikayama T, Tick E (eds.), 1994.
35. Muthukumar K, Hermenegildo M. Combined determination of sharing and freeness of program variables throughabstract interpretation. Proceedings of the 1991 International Conference on Logic Programming, June 1991. MIT Press:Cambridge, MA, 1991; 49–63.
36. Bueno F, de la Banda MG, Hermenegildo M. Effectiveness of global analysis in strict independence-based automaticprogram parallelization. Proceedings of the International Logic Programming Symposium, Bruynooghe F (ed.). MIT Press,1994.
37. Bueno F, de la Banda MG, Hermenegildo M. A comparative study of methods for automatic compile-time parallelizationof logic programs. Parallel Symbolic Computation, September 1994. World Scientific Publishing Company, 1994; 63–73.
38. Hermenegildo M, Nasr RI. Efficient management of backtracking in AND-parallelism. Proceedings of the 3rd InternationalConference on Logic Programming, Imperial College, July 1986 (Lecture Notes in Computer Science, vol. 225). Springer-Verlag. 1986; 40–55.
39. Pontelli E, Gupta G. Efficient backtracking in and-parallel implementations of non-deterministic languages. Proceedingsof the International Conference on Parallel Processing. IEEE Computer Society, 1998.
40. Pontelli E, Gupta G, Wiebe J, Farwell D. Natural language multiprocessing: a case study. Proceedings of AAAI. MIT Press:Cambridge, MA, 1998; 76–82.
41. Warren DHD. An abstract prolog instruction set. Technical Report 309, SRI International, 1983.42. Warren DHD. An improved prolog implementation which optimises tail recursion. Research Paper 156, Department of
Artificial Intelligence, University of Edinburgh.43. Pettorossi A, Proietti M. Transformation of logic programs: Foundations and techniques. Journal of Logic Programming
1994; 19/20:261–320.44. Gupta G, Pontelli E. Last alternative optimization for Or-parallel logic programming systems. Proceedings of the 8th
International Symposium on Parallel and Distributed Processing. IEEE Computer Society, 1996.45. Tick E. Concurrent logic programs a la mode. High Performance Logic Programming Systems, Tick E, Succi G (eds.).
Kluwer, 1994.46. Ramkumar B, Kale LV. Compiled execution of the reduce-OR process model on multiprocessors. Proceedings of
NACLP’89. MIT Press, 1989; 313–331.47. Sabot G. The Paralation Model: Architecture Independent Parallel Programming. MIT Press, 1988.48. Blelloch G. Vector Models for Data-parallel Computing. MIT Press, 1990.49. Palmer D, Prins J, Westfold S. Work-efficient nested data-parallelism. Frontiers of Massively Parallel Computing. McLean,
VA, 1994.50. Ramakrishnan V, Scherson I, Subramanian R. Efficient techniques for fast nested barrier synchronization. Proceedings of
the 7th ACM Symposium on Parallel Algorithms and Architectures. ACM Press: New York, 1995.51. Pontelli E, Gupta G. Nested parallel call optimization. Proceedings of the International Parallel Processing Symposium
IEEE Computer Society, 1996.52. Bevemyr J, Lindgren T, Millroth H. Reform Prolog: The language and its implementation. Proceedings of the 10th
International Conference on Logic Programming. MIT Press, 1993; 283–298.53. Shen K. Studies in And/Or parallelism in Prolog. PhD Thesis, University of Cambridge, 1992.54. Smith D. Why multi-SLD beats SLD (even on a uniprocessor). LPAR. Springer Verlag: Berlin, 1994.55. Smith D. Multilog: Data or-parallel logic programming. Proceedings of the International Conference on Logic
Programming. MIT Press, 1993.56. Meier M. Recursion vs. iteration in Prolog. Proceedings of the International Conference on Logic Programming. MIT
Press, 1991.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181

OPTIMIZATION SCHEMAS 1181
57. Lusk E, Mudambi S, Overbeek R, Szeredi P. Applications of the aurora parallel Prolog system to computational molecularbiology. Proceedings of the International Logic Programming Symposium. MIT Press, 1993.
58. Beaumont T, Warren D. Scheduling speculative work in Or-parallel Prolog systems. Proceedings of the 10th InternationalConference on Logic Programming. MIT Press, 1993; 135–149.
59. Marriott K, Stuckey P. Programming with Constraints. MIT Press: Cambridge, MA, 1998.60. Codognet P, Diaz D. A minimal extension of the WAM for clp(fd). International Conference on Logic Programming
MIT Press, 1993.61. Carlsson M. On the efficiency of optimizing shallow backtracking in compiled Prolog. Proceedings of the 6th International
Conference on Logic Programming, June 1989. MIT Press, 1989; 3–16.62. Carro M, Hermenegildo M. Backtracking families for independent and-parallelism. Technical Report, Polytechnic
University of Madrid, 1993.63. Santos Costa V, Warren D, Yang R. Andorra-I: A parallel Prolog system that transparently exploits both And- and Or-
parallelism. Proceedings of the 3rd ACM SIGPLAN PPoPP. ACM Press, 1991; 83–93.
Copyright 2001 John Wiley & Sons, Ltd. Softw. Pract. Exper. 2001; 31:1143–1181


















