
Optimierungen bei C und C++ 385 - mathematik.uni-ulm.de · •C und C++ gehen davon aus, dass...
36
Optimierungen bei C und C++ 385 ◮ Was können optimierende Übersetzer erreichen? ◮ Wie lassen sich optimierende Übersetzer unterstützen? ◮ Welche Fallen können sich durch den Einsatz von optimierenden Übersetzer eröffnen?
Transcript of Optimierungen bei C und C++ 385 - mathematik.uni-ulm.de · •C und C++ gehen davon aus, dass...

Optimierungen bei C und C++ 385
◮ Was können optimierende Übersetzer erreichen?
◮ Wie lassen sich optimierende Übersetzer unterstützen?
◮ Welche Fallen können sich durch den Einsatz von optimierendenÜbersetzer eröffnen?

Was wird optimiert? 386
Es gibt zwei teilweise gegensätzliche Ziele der Optimierung:
◮ Minimierung der Länge des erzeugten Maschinencodes.
◮ Minimierung der Ausführungszeit.
Es ist relativ leicht, sich dem ersten Ziel zu nähern. Die zweite
Problemstellung ist in ihrer allgemeinen Form nicht vorbestimmbar
(wegen potentiell unterschiedlicher Eingaben) bzw. in seiner allgemeinen
Form nicht berechenbar.

Minimierung des erzeugten Maschinencodes 387
• Die Problemstellung ist grundsätzlich für sehr kleine Sequenzen lösbar.
• Bei größeren Sequenzen wird zwar nicht das Minimum erreicht,dennoch sind die Ergebnisse beachtlich, wenn alle bekanntenTechniken konsequent eingesetzt werden.

GNU-Superoptimizer 388
• Der GNU-Superoptimizer generiert sukzessive alle möglichenInstruktionssequenzen, bis eine gefunden wird, die die gewünschteFunktionalität umsetzt.
• Die Überprüfung erfolgt durch umfangreiche Tests, ist aber keinBeweis, dass die gefundene Sequenz äquivalent zur gewünschtenFunktion ist. In der Praxis sind jedoch noch keine falschen Lösungengeliefert worden.
• Der Aufwand des GNU-Superoptimizers liegt bei O((mn)2n), wobei m
die Zahl der zur Verfügung stehenden Instruktionen ist und n dieLänge der kürzesten Sequenz.
• Siehe http://ftp.gnu.org/gnu/superopt/(ist von 1995 und lässt sich leider mit modernen C-Übersetzern nichtmehr übersetzen)
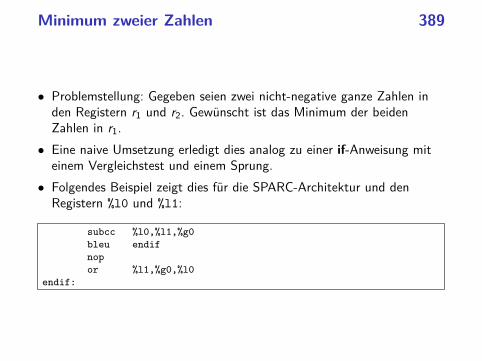
Minimum zweier Zahlen 389
• Problemstellung: Gegeben seien zwei nicht-negative ganze Zahlen inden Registern r1 und r2. Gewünscht ist das Minimum der beidenZahlen in r1.
• Eine naive Umsetzung erledigt dies analog zu einer if-Anweisung miteinem Vergleichstest und einem Sprung.
• Folgendes Beispiel zeigt dies für die SPARC-Architektur und denRegistern %l0 und %l1:
subcc %l0,%l1,%g0
bleu endif
nop
or %l1,%g0,%l0
endif:

Minimum zweier Zahlen 390
subcc %l1,%l0,%g1
subx %g0,%g0,%g2
and %g2,%g1,%l1
addcc %l1,%l0,%l0
• Der Superoptimizer benötigt (auf Thales) weniger als 5 Sekunden, um28 Sequenzen mit jeweils 4 Instruktionen vorzuschlagen, die allesamtdas Minimum bestimmen, ohne einen Sprung zu benötigen. Dies isteine der gefundenen Varianten.
• Die Instruktionen entsprechen folgendem Pseudo-Code:
%g1 = %l1 - %l0
carry = %l0 > %l1? 1: 0
%g2 = -carry
%l1 = %g2 & %g1
%l0 = %l1 + %l0
• Generell ist die Vermeidung bedingter Sprünge ein Gewinn, da diesedas Pipelining erschweren.

Pipelining 391
• Moderne Prozessoren arbeiten nach dem Fließbandprinzip: Über dasFließband kommen laufend neue Instruktionen hinzu und jedeInstruktion wird nacheinander von verschiedenen Fließbandarbeiternbearbeitet.
• Dies parallelisiert die Ausführung, da unter günstigen Umständen alleFließbandarbeiter gleichzeitig etwas tun können.
• Eine der ersten Pipelining-Architekturen war die IBM 7094 aus derMitte der 60er-Jahre mit zwei Stationen am Fließband. DieUltraSPARC-IV-Architektur hat 14 Stationen.
• Die RISC-Architekturen (RISC = reduced instruction set computer)wurden speziell entwickelt, um das Potential für Pipelining zuvergrößern.
• Bei der Pentium-Architektur werden im Rahmen des Pipelinings dieInstruktionen zuerst intern in RISC-Instruktionen konvertiert, so dasssie ebenfalls von diesem Potential profitieren kann.

Typische Instruktionen auf Maschinenebene 392
Um zu verstehen, was alles innerhalb einer Pipeline zu erledigen ist, hilftein Blick auf die möglichen Typen von Instruktionen:
◮ Operationen, die nur auf Registern angewendet werden und die dasErgebnis in einem Register ablegen (wie etwa subcc in denBeispielen).
◮ Instruktionen mit Speicherzugriff. Hier wird eine Speicheradresseberechnet und dann erfolgt entweder eine Lese- oder eineSchreiboperation.
◮ Sprünge.
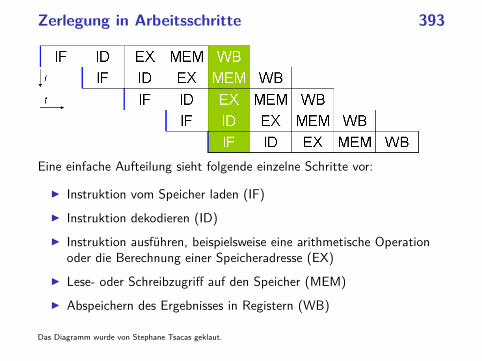
Zerlegung in Arbeitsschritte 393
Eine einfache Aufteilung sieht folgende einzelne Schritte vor:
◮ Instruktion vom Speicher laden (IF)
◮ Instruktion dekodieren (ID)
◮ Instruktion ausführen, beispielsweise eine arithmetische Operationoder die Berechnung einer Speicheradresse (EX)
◮ Lese- oder Schreibzugriff auf den Speicher (MEM)
◮ Abspeichern des Ergebnisses in Registern (WB)
Das Diagramm wurde von Stephane Tsacas geklaut.

Branch Prediction 394
• Bedingte Sprünge sind ein Problem für das Pipelining, da unklar ist,wie gesprungen wird, bevor es zur Ausführungsphase kommt.
• RISC-Maschinen führen typischerweise die Instruktion unmittelbarnach einem bedingten Sprung immer mit aus, selbst wenn der Sprunggenommen wird. Dies mildert etwas den negativen Effekt für diePipeline.
• Im übrigen gibt es die Technik der branch prediction, bei der einErgebnis angenommen wird und dann das Fließband auf den Verdachthin weiterarbeitet, dass die Vorhersage zutrifft. Im Falle einesMisserfolgs muss dann u.U. recht viel rückgängig gemacht werden.
• Das ist machbar, solange nur Register verändert werden. MancheArchitekturen verfolgen die Alternativen sogar parallel und haben fürjedes abstrakte Register mehrere implementierte Register, die dieWerte für die einzelnen Fälle enthalten.
• Die Vorhersage wird vom Übersetzer generiert. Typisch istbeispielsweise, dass bei Schleifen eine Fortsetzung der Schleifevorhergesagt wird.

Sprungvermeidung am Beispiel einer while-Schleife 395
int a[10];
int main() {
int i = 0;
while (i < 10 && a[i] != 0) ++i;
}
• Eine triviale Umsetzung erzeugt zwei Sprünge: Zwei bedingte Sprüngein der Auswertung der Schleifenbedingung und einen unbedingtenSprung am Ende der Schleife:
while:
mov %i5,%o2
subcc %o2,10,%g0
bge endwhile
nop
sethi %hi(a),%o1
or %o1,%lo(a),%o1
sll %o2,2,%o0
ld [%o1+%o0],%o0
subcc %o0,0.%g0
be endwhile
nop
ba while
add %o2,1,%i5
endwhile:

Sprungvermeidung am Beispiel einer while-Schleife 396
ba whilecond
nop
whilebody:
add %l0,1,%l0
whilecond:
subcc %l0,10,%g0
bge endwhile
nop
sethi %hi(a),%i0
sll %l0,2,%i1
add %i0,%i1,%i0
ld [%i0+%lo(a)],%i0
subcc %i0,%g0,%g0
bne whilecond
nop
endwhile:
• Die Auswertung der Sprungbedingung erfolgt nun am Ende derSchleife, so dass pro Schleifendurchlauf nur zwei bedingte Sprüngeausgeführt werden. Dafür ist ein zusätzlicher Sprung am Anfang derwhile-Schleife notwendig.

Typische Techniken zur Minimierung desMaschinencodes 397
• Lokale Variablen und Parameter soweit wie möglich in Registernhalten. Dies spart Lade- und Speicherinstruktionen.
• Vereinfachung von Blattfunktionen. Das sind Funktionen, die keineweitere Funktionen aufrufen.
• Auswerten von konstanten Ausdrücken während der Übersetzzeit(constant folding).
• Vermeidung von Sprüngen.
• Vermeidung von Multiplikationen, wenn einer der Operanden konstantist.
• Elimination mehrfach vorkommender Teilausdrücke.Beispiel: a[i + j] = 3 * a[i + j] + 1;
• Konvertierung absoluter Adressberechnungen in relative.Beispiel: for (int i = 0; i < 10; ++i) a[i] = 0;
• Datenflussanalyse und Eliminierung unbenötigten Programmtexts

Lokale Variablen in Registern 398
• Ein Übersetzer kann lokale Variablen nur dann permanent in einemRegister unterbringen, wenn zu keinem Zeitpunkt eine Speicheradressebenötigt wird.
• Sobald der Adress-Operator & zum Einsatz kommt, muss dieseVariable zwingend im Speicher gehalten werden.
• Das gleiche gilt, wenn Referenzen auf die Variable existieren.
• Zwar kann der Übersetzer den Wert dieser Variablen ggf. in einemRegister vorhalten. Jedoch muss in verschiedenen Situationen der Wertneu geladen werden, z.B. wenn ein weiterer Funktionsaufruf erfolgt, beidem ein Zugriff über den Zeiger bzw. die Referenz erfolgen könnte.

Lokale Variablen in Registern 399
int index;
while (std::cin >> index) {
a[index] = f(a[index]);
a[index] += g(a[index]);
}
• In diesem Beispiel wird eine Referenz auf index an den >>-Operatorübergeben. Der Übersetzer weiß nicht, ob diese Adresse überirgendwelche Datenstrukturen so abgelegt wird, dass die Funktionen f
und g darauf zugreifen. Entsprechend wird der Übersetzer genötigt,immer wieder den Wert von index aus dem Speicher zu laden.
• Deswegen ist es ggf. hilfreich, explizit eine weitere lokale Variablen zuverwenden, die eine Kopie des Werts erhält und von der keine Adressegenommen wird:
int index;
while (std::cin >> index) {
int i = index;
a[i] = f(a[i]);
a[i] += g(a[i]);
}

Lokale Variablen in Registern 400
bool find(int* a, int len, int& index) {
while (index < len) {
if (a[index] == 0) return true;
++index;
}
return false;
}
• Referenzparameter sollten bei häufiger Nutzung in ausschließlich lokalgenutzte Variablen kopiert werden, um einen externen Einflussauszuschließen.
bool find(int* a, int len, int& index) {
for (int i = index; i < len; ++i) {
if (a[index] == 0) {
index = i; return true;
}
}
index = len;
return false;
}

Alias-Problematik 401
void f(int* i, int* j) {
*i = 1;
*j = 2;
// value of *i?
}
• Wenn mehrere Zeiger oder Referenzen gleichzeitig verwendet werden,unterbleiben Optimierungen, wenn nicht ausgeschlossen werden kann,dass mehrere davon auf das gleiche Objekt zeigen.
• Wenn der Wert von *i verändert wird, dann ist unklar, ob sich auch*j verändert. Sollte anschließend auf *j zugegriffen werden, muss derWert erneut geladen werden.
• In C (noch nicht in C++) gibt es die Möglichkeit, mit Hilfe desSchlüsselworts restrict Aliasse auszuschließen:
void f(int* restrict i, int* restrict j) {
*i = 1;
*j = 2;
// *i == 1 still assumed
}

Datenflussanalyse 402
• Mit der Datenflussanalyse werden Abhängigkeitsgraphen erstellt, diefeststellen, welche Variablen unter Umständen in Abhängigkeit welcheranderer Variablen verändert werden können.
• Im einfachsten Falle kann dies auch zur Propagation von Konstantengenutzt werden.Beispiel: Nach int a = 7; int b = a; ist bekannt, dass b den Wert7 hat.
• Die Datenflussanalyse kann für eine Variable recht umfassenddurchgeführt werden, wenn sie lokal ist und ihre Adresse nieweitergegeben wurde.

Elimination unbenötigten Programmtexts 403
void loopingsleep(int count) {
for (int i = 0; i < count; ++i)
;
}
• Mit Hilfe der Datenflussanalyse lässt sich untersuchen, welche Teileeiner Funktion Einfluss haben auf den return-Wert oder die außerhalbder Funktion sichtbaren Datenstrukturen.
• Anweisungen, die nichts von außen sichtbares verändern, könneneliminiert werden.
• Auf diese Weise verschwindet die for-Schleife im obigen Beispiel.
• Der erwünschte Verzögerungseffekt lässt sich retten, indem in derSchleife unter Verwendung der Schleifenvariablen eine externeFunktion aufgerufen wird. (Das funktioniert, weil normalerweise keineglobale Datenflussanalyse stattfindet.)

Datenflussanalyse bei globalen Variablen 404
• Globale Variablen können ebenso in die Datenflussanalyse einbezogenwerden.
• C und C++ gehen davon aus, dass globale Variablen sich nichtüberraschend ändern, solange keine Alias-Problematik vorliegt undkeine unbekannten Funktionen aufgerufen werden.
• Das ist problematisch, wenn Threads oder Signalbehandlerunsynchronisiert auf globale Variablen zugreifen.
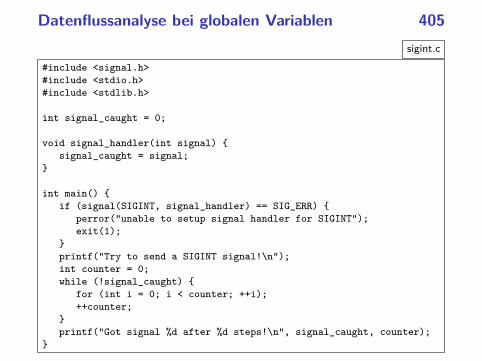
Datenflussanalyse bei globalen Variablen 405
sigint.c
#include <signal.h>
#include <stdio.h>
#include <stdlib.h>
int signal_caught = 0;
void signal_handler(int signal) {
signal_caught = signal;
}
int main() {
if (signal(SIGINT, signal_handler) == SIG_ERR) {
perror("unable to setup signal handler for SIGINT");
exit(1);
}
printf("Try to send a SIGINT signal!\n");
int counter = 0;
while (!signal_caught) {
for (int i = 0; i < counter; ++i);
++counter;
}
printf("Got signal %d after %d steps!\n", signal_caught, counter);
}

Datenflussanalyse bei globalen Variablen 406
sigint.c
int counter = 0;
while (!signal_caught) {
for (int i = 0; i < counter; ++i);
++counter;
}
• Hier sieht der Übersetzer nicht, dass sich die globale Variablesignal_caught innerhalb eines Schleifendurchlaufs verändern könnte.
• Der optimierte Code testet deswegen die Variable signal_caught nurein einziges Mal beim Schleifenantritt und danach nicht mehr.Entsprechend gibt es keinen Schleifenabbruch, wenn derSignalbehandler aktiv wird.
dairinis$ gcc -o sigint -std=c99 sigint.c
dairinis$ sigint
Try to send a SIGINT signal!
^CGot signal 2 after 24178 steps!
dairinis$ gcc -o sigint -O -std=c99 sigint.c
dairinis$ sigint
Try to send a SIGINT signal!
^C^Cdairinis$

Datenflussanalyse bei globalen Variablen 407
volatile sig_atomic_t signal_caught = 0;
• Mit dem Schlüsselwort volatile können globale Variablengekennzeichnet werden, die sich überraschend ändern können.
• Zusätzlich wurde hier noch korrekterweise der Datentyp sig_atomic_t
anstelle von int verwendet, um die Atomizität eines Schreibzugriffssicherzustellen.
• C und C++ garantieren, dass Zuweisungen an volatile-Objekte in derAusführungsreihenfolge erfolgen. (Das ist bei anderen Objekten nichtzwangsläufig der Fall.)
• Beispiel: a = 2; a = 3;
Hier würde normalerweise a = 2 wegoptimiert werden. Wenn a jedocheine volatile-Variable ist, wird ihr zuerst 2 zugewiesen und danach die3.
• Wenn notwendige volatile-Auszeichnungen vergessen werden, könnenProgramme bei eingeschaltetem Optimierer ein fehlerhaftes Verhaltenaufweisen.

Optimierungsstufen 408
Optimierende Übersetzer bieten typischerweise Stufen an. Recht typischist dabei folgende Aufteilung des gcc:
Stufe Option Vorteile0 schnelle Übersetzung, mehr Transparenz beim De-
bugging1 -O1 lokale Peephole-Optimierungen2 -O2 Minimierung des Umfangs des generierten Codes3 -O3 Minimierung der Laufzeit mit ggf. umfangreicheren
Code

Typische Techniken zur Minimierung der Laufzeit 409
Bei der (oder den) höchsten Optimierungsstufe(n) wird teilweise eineerhebliche Expansion des generierten Codes in Kauf genommen, umLaufzeitvorteile zu erreichen. Die wichtigsten Techniken:
• Loop unrolling
• Instruction scheduling
• Function inlining

Loop unrolling 410
for (int i = 0; i < 100; ++i) {
a[i] = i;
}
• Diese Technik reduziert deutlich die Zahl der bedingten Sprünge,indem mehrere Schleifendurchläufe in einem Zug erledigt werden.
• Das geht nur, wenn die einzelnen Schleifendurchläufe unabhängigvoneinander erfolgen können, d.h. kein Schleifendurchlauf von denErgebnissen der früheren Durchgänge abhängt.
• Dies wird mit Hilfe der Datenflussanalyse überprüft, wobei sich derÜbersetzer auf die Fälle beschränkt, bei denen er sich sicher sein kann.D.h. nicht jede für diese Technik geeignete Schleife wird auchtatsächlich entsprechend optimiert.
for (int i = 0; i < 100; i += 4) {
a[i] = i;
a[i+1] = i + 1;
a[i+2] = i + 2;
a[i+3] = i + 3;
}

Speicherzugriffe einer CPU 411
• Zugriffe einer CPU auf den primären Hauptspeicher sindvergleichsweise langsam. Obwohl Hauptspeicher generell schnellerwurde, behielten die CPUs ihren Geschwindigkeitsvorsprung.
• Grundsätzlich ist Speicher direkt auf einer CPU deutlich schneller.Jedoch lässt sich Speicher auf einem CPU-Chip aus Komplexitäts-,Produktions- und Kostengründen nicht beliebig ausbauen.
• Deswegen arbeiten moderne Architekturen mit einer Kettehintereinander geschalteter Speicher. Zur Einschätzung derGrößenordnung sind hier die Angaben für die Theseus, die mitProzessoren des Typs UltraSPARC IV+ ausgestattet ist:
Cache Kapazität TaktzyklenRegister 1L1-Cache 64 KiB 2-3L2-Cache 2 MiB um 10L3-Cache 32 MiB um 60Hauptspeicher 32 GiB um 250
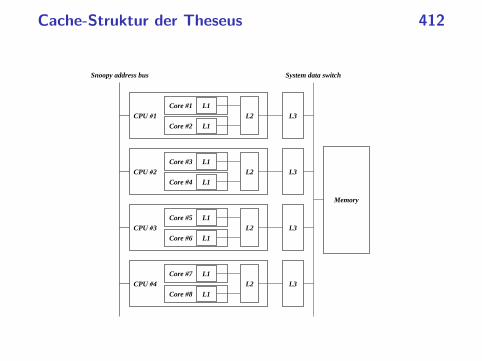
Cache-Struktur der Theseus 412
L1
L1
L1
L1
L1
L1
L1
L1
Memory
Core #1
Core #2
L2CPU #1 L3
Core #3
Core #4
L2CPU #2 L3
Core #5
Core #6
L2CPU #3 L3
Core #7
Core #8
L2CPU #4 L3
Snoopy address bus System data switch
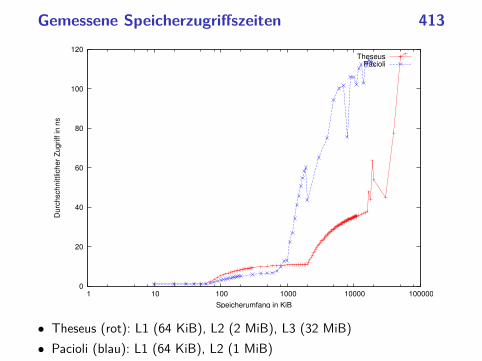
Gemessene Speicherzugriffszeiten 413
0
20
40
60
80
100
120
1 10 100 1000 10000 100000
Durc
hschnittlic
her
Zugriff in n
s
Speicherumfang in KiB
TheseusPacioli
• Theseus (rot): L1 (64 KiB), L2 (2 MiB), L3 (32 MiB)
• Pacioli (blau): L1 (64 KiB), L2 (1 MiB)

Cache lines 414
• Ein Cache ist in sogenannten cache lines organisiert, d.h. eine cache
line ist die Einheit, die vom Hauptspeicher geladen oderzurückgeschrieben wird.
• Jede der cache lines umfasst – je nach Architektur – 32 - 128 Bytes.Auf der Theseus sind es beispielsweise 64 Bytes.
• Jede der cache lines kann unabhängig voneinander gefüllt werden undeinem Abschnitt im Hauptspeicher entsprechen.
• Das bedeutet, dass bei einem Zugriff auf a[i] mit recht hoherWahrscheinlichkeit auch a[i+1] zur Verfügung steht.

Instruction scheduling 415
• Diese Technik bemüht sich darum, die Instruktionen (soweit diesentsprechend der Datenflussanalyse möglich ist) so anzuordnen, dass inder Prozessor-Pipeline keine Stockungen auftreten.
• Das lässt sich nur in Abhängigkeit des konkret verwendeten Prozessorsoptimieren, da nicht selten verschiedene Prozessoren der gleichenArchitektur mit unterschiedlichen Pipelines arbeiten.
• Ein recht großer Gewinn wird erzielt, wenn ein vom Speicher geladenerWert erst sehr viel später genutzt wird.
• Beispiel: x = a[i] + 5; y = b[i] + 3;
Hier ist es sinnvoll, zuerst die Ladebefehle für a[i] und b[i] zugenerieren und erst danach die beiden Additionen durchzuführen undam Ende die beiden Zuweisungen.

Fallbeispiel: Vektoraddition 416
axpy.c
// y = y + alpha * x
void axpy(int n, double alpha, const double* x, double* y) {
for (int i = 0; i < n; ++i) {
y[i] += alpha * x[i];
}
}
• Dies ist eine kleine Blattfunktion, die eine Vektoraddition umsetzt. DieLänge der beiden Vektoren ist durch n gegeben, x und y zeigen auf diebeiden Vektoren.
• Aufrufkonvention:
Variable Registern %o0
alpha %o1 und %o2
x %o3
y %o4
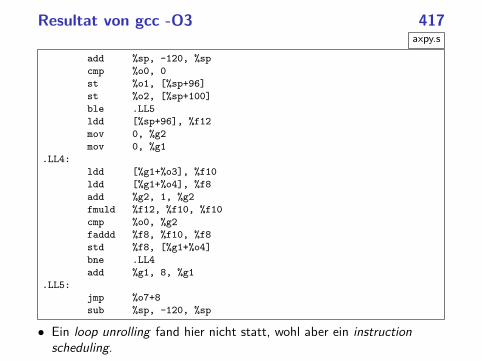
Resultat von gcc -O3 417axpy.s
add %sp, -120, %sp
cmp %o0, 0
st %o1, [%sp+96]
st %o2, [%sp+100]
ble .LL5
ldd [%sp+96], %f12
mov 0, %g2
mov 0, %g1
.LL4:
ldd [%g1+%o3], %f10
ldd [%g1+%o4], %f8
add %g2, 1, %g2
fmuld %f12, %f10, %f10
cmp %o0, %g2
faddd %f8, %f10, %f8
std %f8, [%g1+%o4]
bne .LL4
add %g1, 8, %g1
.LL5:
jmp %o7+8
sub %sp, -120, %sp
• Ein loop unrolling fand hier nicht statt, wohl aber ein instruction
scheduling.

Resultat von cc -fast 418
• Der C-Compiler von Sun generiert für die gleiche Funktion 241Instruktionen (im Vergleich zu den 19 Instruktionen beim gcc).
• Der innere Schleifenkern mit 81 Instruktionen behandelt 8 Iterationengleichzeitig. Das orientiert sich exakt an der Größe der cache lines derArchitektur: 8 ∗ sizeof(double)== 64.
• Mit Hilfe der prefetch-Instruktion wird dabei jeweils noch zusätzlichdem Cache der Hinweis gegeben, die jeweils nächsten 8 Werte bei x
und y zu laden.
• Der Code ist deswegen so umfangreich, weil
◮ die Randfälle berücksichtigt werden müssen, wenn n nicht durch8 teilbar ist und
◮ die Vorbereitung recht umfangreich ist, da der Schleifenkern vonzahlreichen bereits geladenen Registern ausgeht.

gcc -funroll-loops 419
• Der gcc kann mit der Option „-funroll-loops“ ebenfalls dazu überredetwerden, Schleifen zu expandieren.
• Bei diesem Beispiel werden dann ebenfalls 8 Iterationen gleichzeitigbehandelt.
• Der innere Schleifenkern besteht beim gcc nur aus 51 Instruktionen –ein prefetch entfällt und das Laden aus dem Speicher wird nicht anden Schleifenanfang vorgezogen. Entsprechend wird hier dasOptimierungspotential noch nicht ausgereizt.

Function inlining 420
• Hierbei wird auf den Aufruf einer Funktion verzichtet. Stattdessen wirdder Inhalt der Funktion genau dort expandiert, wo sie aufgerufen wird.
• Das läuft so ähnlich ab wie bei der Verwendung von Makros, nurgelten weiterhin die bekannten Regeln.
• Das kann jedoch nur gelingen, wenn der Programmtext deraufzurufenden Funktion bekannt ist.
• Das klappt bei Funktionen, die in der gleichen Übersetzungseinheitenthalten sind und in C++ bei Templates, bei denen der benötigteProgrammtext in der entsprechenden Headerdatei zur Verfügung steht.
• Letzteres wird in C++ intensiv (etwa bei der STL oder deriostreams-Bibliothek) genutzt, was teilweise erheblicheÜbersetzungszeiten mit sich bringt.


















