
ONTOLOGY ENRICHMENT FROM TEXT
34
ONTOLOGY ENRICHMENT FROM TEXT Student Name: Nikhil Sachdeva Roll Number: 2016061 BTP report submitted in partial fulfillment of the requirements for the Degree of B.Tech. in Computer Science & Engineering on June 8, 2020 BTP Track: Research BTP Advisor Dr. Raghava Mutharaju Indraprastha Institute of Information Technology New Delhi
Transcript of ONTOLOGY ENRICHMENT FROM TEXT

ONTOLOGY ENRICHMENT FROM TEXT
Student Name: Nikhil SachdevaRoll Number: 2016061
BTP report submitted in partial fulfillment of the requirementsfor the Degree of B.Tech. in Computer Science & Engineering
on June 8, 2020
BTP Track: Research
BTP AdvisorDr. Raghava Mutharaju
Indraprastha Institute of Information TechnologyNew Delhi

Student’s Declaration
I hereby declare that the work presented in the report entitled Ontology Learning from Textsubmitted by me for the partial fulfillment of the requirements for the degree of Bachelor ofTechnology in Computer Science & Engineering at Indraprastha Institute of Information Tech-nology, Delhi, is an authentic record of my work carried out under guidance of Dr. RaghavaMutharaju. Due acknowledgements have been given in the report to all material used. Thiswork has not been submitted anywhere else for the reward of any other degree.
.............................. Place & Date: .............................Nikhil Sachdeva
Certificate
This is to certify that the above statement made by the candidate is correct to the best of myknowledge.
.............................. Place & Date: .............................Dr. Raghava Mutharaju
2

Abstract
Ontology Learning is the semi-automatic and automatic extraction of ontology from a naturallanguage text, using text-mining and information extraction. Each ontology primarily representssome concepts and their corresponding relationships, both of which can be extracted from a nat-ural language text. Current state-of-the-art ontology learning systems are not able to extractunion and intersection relationships between the concepts while extracting an ontology from thetext. These relationships can prove to be critical in some domains like the medical domain,where such expressive relationships can capture the missing knowledge of some concepts in thedomain. By learning such relationships and then reasoning over the learned ontology, we mightbe able to answer additional queries regarding the properties of those medical concepts. In thisproject, I have proposed an architecture to extract these types of relations from a text in themedical domain, using Semantic and Syntactic Similarity and Graph Search. In the evaluation,I enrich a Disease Ontology with union and intersection axioms that are learned from the text.I have evaluated the architecture using metrics such as Precision, Recall, and F1-scores, bycomparing the original and the learned axioms.
Keywords: Ontology Learning, Concepts, Relations, Union, Intersection, Semantic, Syntactic,Graph, Medical Domain

Acknowledgments
I would like to thank my adviser Dr. Raghava Mutharaju for guiding me, and providing me withthe insights and expertise and giving me the opportunity to pursue this project. I would alsolike to thanks Monika Jain (Ph.D Scholar at IIIT-D) for her guidance throughout the project.Finally, I would like to thank my batchmate, Gyanesh Anand, who helped me in understandingthe utility of certain tools in the medical domain.
i

Contents
1 Introduction 1
1.1 What is Ontology Learning? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Ontology Layer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2.1 Concept . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2.2 Relations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2.3 Axioms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3 What is missing? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.4 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Literature Survey 4
2.1 Techniques in Ontology Learning . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.1 Statistic-based Techniques . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.2 Linguistic-based Techniques . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.3 Logic-based Techniques . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 Related Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2.1 Entity Linking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2.2 Axiom Extraction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.3 BioWordVec . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.4 UMLS Resources . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.4.1 Metathesaurus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.4.2 Metamap . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.5 Evaluating Existing Ontology Learning Systems . . . . . . . . . . . . . . . . . . . 8
3 Proposed Architecture 12
3.1 Generalized Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.2 Proposed Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.2.1 Entity Extraction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.2.2 Training of Custom Word2Vec model . . . . . . . . . . . . . . . . . . . . . 13
3.2.3 Entity Linking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
ii

3.2.4 Ontology Modification . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.2.5 Axiom Extraction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4 Evaluations 19
4.1 Dataset . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.1.1 Ontology Pre-Processing . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.1.2 Corpus Extraction and Pre-processing . . . . . . . . . . . . . . . . . . . . 20
4.2 Evaluation of Entity Linking Module . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.3 Evaluation of Complete Model . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
5 Challenges 23
6 Future Scope 24
iii

iv

Chapter 1
Introduction
An Ontology is an explicit specification of a conceptualization, comprising a formal definition of
concepts, relations between concepts, and axioms on the relations in the domain of interest [14].
Ontologies represent the intensional aspect of a domain governing the way the corresponding
knowledge bases are populated. They have been proven useful for different applications, such
as heterogeneous data integration, information search and retrieval, question answering, and
semantic interoperability between information systems. Moreover, for advanced applications
like semantically enhanced information retrieval and question answering, there must be a clear
connection between the formal representation of the domain and the language used to express
domain meanings withing text. This task can be accomplished by producing a full-fledged
ontology for the domain of interest. This is where the challenge of ontology acquisition originates.
1.1 What is Ontology Learning?
Manually constructing ontologies is a resource-intensive and challenging task, requiring a large
amount of time and effort. The reason being the difficulty in capturing knowledge, also known as
the “knowledge acquisition bottleneck”. Much research has been going on in this challenge, re-
ferred to as Ontology Learning, which consists of automatically and semi-automatically creating
a domain ontology using unstructured textual data. The entire process of ontology construction
of a domain is depicted in Figure 1.1.
The process begins by extracting terms relevant to the domain, from the underlying text. Then,
these terms are combined with their synonyms, that can be captured from the text itself or
available lexical databases like WordNet [25], to form concepts. For relations, taxonomic and
non-taxonomic relations between the concepts are extracted from the text. Additionally, based
on the concepts and relations derived, general axiom schemata can be instantiated to extract
axioms from the text.
1

Figure 1.1: Ontology Learning Layer Cake
1.2 Ontology Layer
1.2.1 Concept
Terms extracted from the text are combined to form concepts. These concepts are labeled and
profiled to give an image to classes in ontology.
1.2.2 Relations
Taxonomic Relations
These relations represent hypernym-hyponym relations; that is, the “is a” relations between the
concepts. They are responsible for forming hierarchies in an ontology.
Non-taxonomic Relations
These relations are generated using interactions between the found concepts. A major emphasis
for these interactions is given to verbs. Relations like meronyms, that is, “part of”, roles,
attributes, possessions, etc. are covered in this category.
2

1.2.3 Axioms
Axioms are the rules for verifying the correctness of ontologies. They are identified based on
certain patterns and generalizations found among relations in the text.
1.3 What is missing?
Based on the previous section, you can see that the learning systems have extracted only those
types of relations, which either define the parent-child relationships between the concepts to
form hierarchies or to connect the concepts based on their interactions. What has not been
considered are those types of relations that may change the class definition itself. That is, rela-
tions like intersection and union relations between the concepts are different from the relations,
as mentioned earlier, as they represent a unique relationship between a concept and a group of
concepts. For instance, a context mentions, “... where a Mother is a Female and a Parent,....”.
The existing systems evaluated in Chapter 3, will identify three concepts from this context:
Mother, Female, Parent.
Moreover, they will also identify the two pairs of Subclass relations: (Female, Mother) and
(Parent, Mother). But, neither of them will be able to extract the intersection relation between
concept: Mother and group of concepts: (Parent, Female). Take another example, “ .. noise is
defined as Sound, with non-Musical features... ”, where there is again an intersection relation
between the concept Noise and group of concepts (Sound, not(Music)). Till now, all the systems
I have reviewed, have been able to extract only subclass relations, when we are talking about
taxonomic relations between the concepts. Hence, as part of my thesis, I am going to create
algorithms to extract further intersection and union relations between the identified concepts.
1.4 Motivation
Specifically in the medical domain, extracting such relations between concepts can help to iden-
tify missing properties, for example, in case of some drugs, that may belong to the intersection
or union of other drugs. One other situation can be where we are trying to identify a solution
for a disease D1 that is logically related as a union of some other diseases like D2, D3, etc. then
we can first apply those solutions that exist for D2 and D3, in the research of D1.
3

Chapter 2
Literature Survey
2.1 Techniques in Ontology Learning
Till now, many techniques from different fields like Machine Learning, Natural Language Pro-
cessing, Data Mining, Information Retrieval, Logic, and Knowledge representation have been
used to varying layers of Ontology Learning. Below are some of the techniques that are com-
monly used by many ontology learning systems to achieve greater levels of accuracy at each
layer of ontology learning.
2.1.1 Statistic-based Techniques
Statistic-based techniques are employed due to a lack of consideration for the underlying seman-
tics and relations between the components of the text. These techniques are mostly used for
term, concept, and taxonomic relation extraction.
• Term Extraction:
– C/NC Value [10]: It is used for multi-word terminology extraction, where it receives
multi-words as input and returns the score for each of them.
– Contrastive Analysis [10, 17, 28]: This technique filters out non-domain terms from
the results of term extraction based on two measures, domain consensus, and domain
relevance.
– Co-occurrence Analysis [9]: This technique scores different lexical units based on
their adjoined occurrence and gives an indirect association between various terms
and concepts.
– Clustering [9, 11]: It is an unsupervised learning technique in which similar objects
are grouped or clustered together, giving rise to many clusters.
– Term Subsumption: This technique comments on how general a word is when oc-
curring in a corpus. It is calculated between words using their inter-conditional
4

probability of occurring in the given corpora.
• Relation Extraction:
– Formal Concept Analysis [10]: It tries to use attributes of the word itself and uses
them to associate different terms together.
– Hierarchical Clustering [9]: This technique uses different similarity measures like Co-
sine Similarity, etc. to find taxonomic relations among the terms, then find similar
concepts based on clustering of those terms and finally, generate a hierarchy of con-
cepts.
– Association Rule Mining [9]: It is used to find associations between concepts at a
certain level of abstraction, clustering certain concepts under one category.
2.1.2 Linguistic-based Techniques
Linguistic-based techniques depend on the characteristics of a language and hence, use Natural
Language Processing tools in almost all of its algorithms. They are mainly used for preprocessing
of the data as well as term and relation extraction from the data.
• Preprocessing [9, 17]
– Parsing: It is a type of syntactic analysis that finds various dependencies between
words and represents in the form of a parse tree.
– POS Tagging: This technique assigns Part-of-Speech tags to different words on a
sentence level, to aide in the analysis of other algorithms.
– Seed Words: They are domain-specific words that provide a base for other algorithms
to extract similar domain-specific terms and concepts.
• Relation Extraction [9, 11,17,26]
– Lexico-syntactic parsing: It is a rule-based approach that uses regular expressions to
extract taxonomic and non-taxonomic relations from text.
– Dependency Analysis: It uses dependency paths between the terms from the parse
trees to find potential terms and relations.
– Sub-categorization Frame: In terms of words, it is the number of words of a certain
form that the word selects when appearing in a sentence. Then, this frame shapes
the kind of classes with which the word usually connects.
– Semantic Lexicons: These are already existing knowledge resources in the domain of
ontology. For instance, WordNet [25] provides a wide range of pre-defined concepts
and relations to bootstrap the process at certain levels of ontology learning.
5

2.1.3 Logic-based Techniques
These techniques are employed at the top two layers of Ontology Learning layer cake, that is,
Axiom schemata and General Axioms, which are then used to reason over the ontology for their
correctness and recall.
• Inductive Logic Programming [15, 26]: In ILP, rules are derived from existing collections
of concepts and relations using semantic lexicons and syntactic patterns, to divide the
extracted concepts and relations into positive and negative examples.
• Logical Inference: Using transitivity and inheritance rules, implicit rules are derived from
the existing ones.
2.2 Related Work
As of now, there has been no work done to extract semantically rich relations like SubClass union
and SubClass intersection between the concepts of an existing ontology, using its corresponding
text. Furthermore, I was not able to find any dataset where there exist an ontology and closely
related text. The following are the two research projects that were closely related to our project.
2.2.1 Entity Linking
[18] proposed an unsupervised approach for Entity Linking in the life sciences domain. Their
proposed method takes as input an ontology and the corresponding text and links the entity
mentions from the text with the concepts of the ontology. They have used BioNLP16 [8] word
embeddings for comparing the semantic similarity between the concept and the entity mention
and have also proposed an algorithm that re-ranks the candidate concepts generated for an
entity mention based on their syntactical structure. They find the most informative word from
the entity mention and the concept, then it again compares the semantic similarity between
that word and the candidate concept based on those headwords. Their approach only considers
the headword of either of them, when it may be possible that the complete noun phrase may
be required for more accurate meaning. The dataset they have used has been provided under
the BioNLP16 task, but in the ontology provided in that dataset, there was not a single axiom
based on the concepts.
2.2.2 Axiom Extraction
[29] proposed an approach to extract lexically expressive ontology axioms from textual defini-
tions using Formal Concept Analysis and Relational Exploration. By parsing the dependency
structure of the input text, they try to transform the dependency tree into a set of OWL axioms
using their own transformation rules. They have used these heuristics to extract the axioms from
6

simple and straightforward definitions. Their approach might not work for long and complicated
sentences, where the context is very much important.
2.3 BioWordVec
BioWordVec [32] is a set of biomedical word embeddings which are trained over 28 million
PubMed articles and 2 million MIMIC III Clinical Notes. It uses the contextual information
around a word from the unlabeled biomedical text along with the vocabulary, Medical Subject
Headings (MeSH), to generate real-valued word embeddings of 200 dimensions. Furthermore,
the model is also able to compute word embeddings for out-of-vocabulary terms. BioWordVec
has shown high evaluation scores when tested to evaluate the pre-trained word embeddings on
medical word pair similarity.
2.4 UMLS Resources
Unified Medical Learning System (UMLS) [6] is a licensed service provided by the National
Library of Medicine that provides tools and resources to integrate many health and biomed-
ical vocabularies and standards to further create more effective and interoperable biomedical
information systems.
2.4.1 Metathesaurus
The Metathesaurus [2] is the biggest component of UMLS that integrates concepts, related
meanings, and similar concepts from 200 different vocabularies into a single structured network.
Some of the widely-used vocabularies are SNOMEDCT-US, ICD-10, CDT, MeSH, Within each
source, each of the concepts is represented by a unique CUI or Concept Unique Identifier. Each
CUI represents the intended meaning of the concept. Further, each unique concept is assigned
an SUI or String Unique Identifier that represents a particular string form of that concept.
Different string forms of the same concept will be assigned different SUIs within the same
vocabulary source. Then, comes the AUI or Atom Unique Identifier, which represents every
occurrence of any string uniquely in each of the vocabularies. AUIs are the basic building blocks
of Metathesaurus.
2.4.2 Metamap
Metamap [4] is a complete tool that provides various algorithms for relating the entity mentions
of any biomedical text with the concepts of UMLS Metathesaurus. Further, it also gives out a
score for each connection, stating how good is the connection of an entity with the found con-
cept of Metathesaurus. Other features of Metamap include word sense disambiguation (WSD),
polarity detection and predicate resolution, and some other technical algorithms.
7
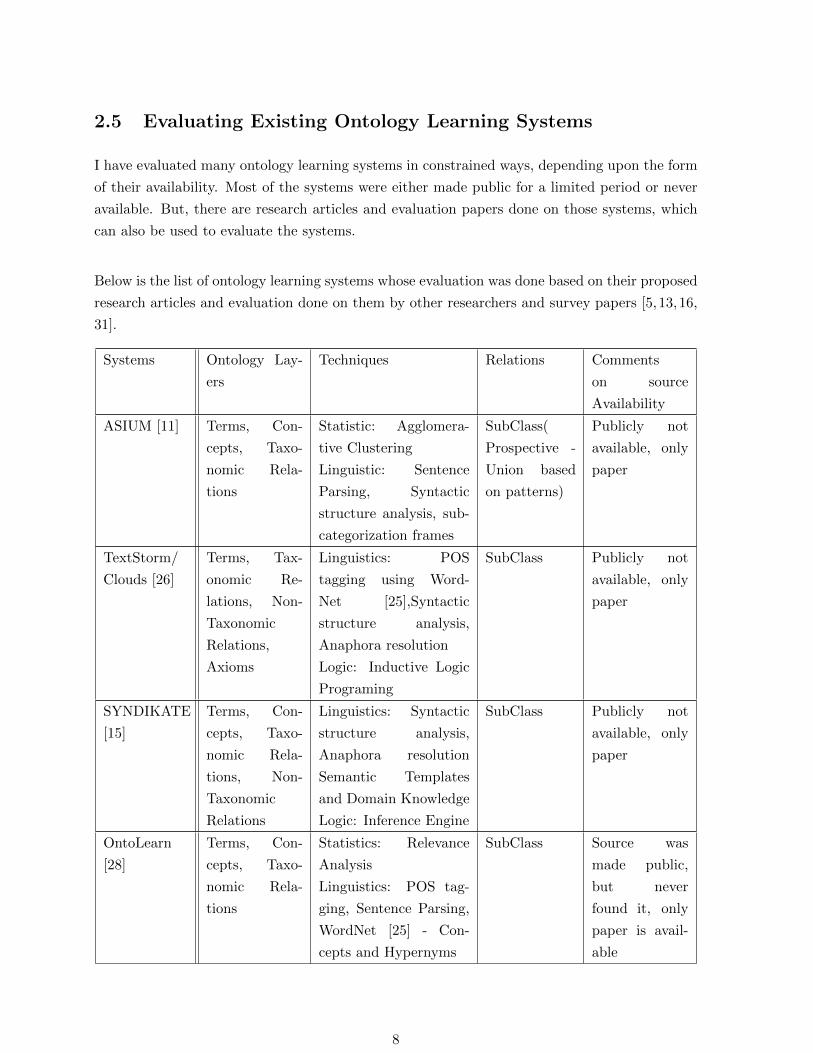
2.5 Evaluating Existing Ontology Learning Systems
I have evaluated many ontology learning systems in constrained ways, depending upon the form
of their availability. Most of the systems were either made public for a limited period or never
available. But, there are research articles and evaluation papers done on those systems, which
can also be used to evaluate the systems.
Below is the list of ontology learning systems whose evaluation was done based on their proposed
research articles and evaluation done on them by other researchers and survey papers [5,13,16,
31].
Systems Ontology Lay-
ers
Techniques Relations Comments
on source
Availability
ASIUM [11] Terms, Con-
cepts, Taxo-
nomic Rela-
tions
Statistic: Agglomera-
tive Clustering
Linguistic: Sentence
Parsing, Syntactic
structure analysis, sub-
categorization frames
SubClass(
Prospective -
Union based
on patterns)
Publicly not
available, only
paper
TextStorm/
Clouds [26]
Terms, Tax-
onomic Re-
lations, Non-
Taxonomic
Relations,
Axioms
Linguistics: POS
tagging using Word-
Net [25],Syntactic
structure analysis,
Anaphora resolution
Logic: Inductive Logic
Programing
SubClass Publicly not
available, only
paper
SYNDIKATE
[15]
Terms, Con-
cepts, Taxo-
nomic Rela-
tions, Non-
Taxonomic
Relations
Linguistics: Syntactic
structure analysis,
Anaphora resolution
Semantic Templates
and Domain Knowledge
Logic: Inference Engine
SubClass Publicly not
available, only
paper
OntoLearn
[28]
Terms, Con-
cepts, Taxo-
nomic Rela-
tions
Statistics: Relevance
Analysis
Linguistics: POS tag-
ging, Sentence Parsing,
WordNet [25] - Con-
cepts and Hypernyms
SubClass Source was
made public,
but never
found it, only
paper is avail-
able
8
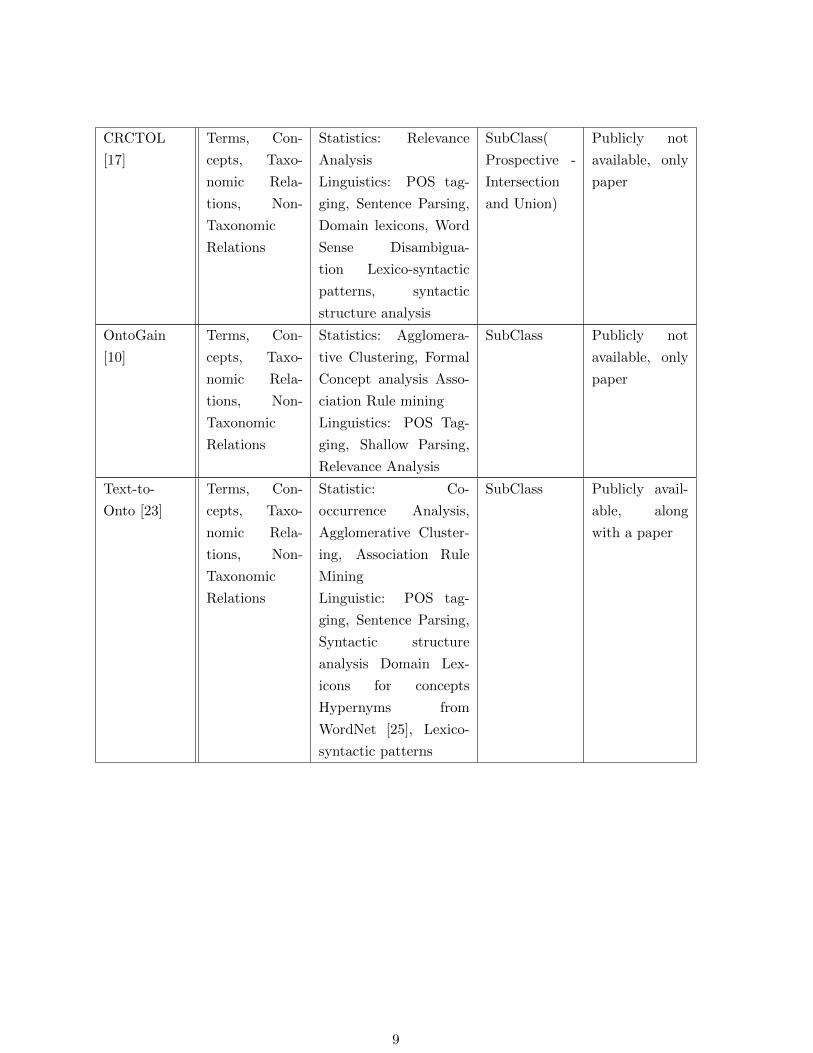
CRCTOL
[17]
Terms, Con-
cepts, Taxo-
nomic Rela-
tions, Non-
Taxonomic
Relations
Statistics: Relevance
Analysis
Linguistics: POS tag-
ging, Sentence Parsing,
Domain lexicons, Word
Sense Disambigua-
tion Lexico-syntactic
patterns, syntactic
structure analysis
SubClass(
Prospective -
Intersection
and Union)
Publicly not
available, only
paper
OntoGain
[10]
Terms, Con-
cepts, Taxo-
nomic Rela-
tions, Non-
Taxonomic
Relations
Statistics: Agglomera-
tive Clustering, Formal
Concept analysis Asso-
ciation Rule mining
Linguistics: POS Tag-
ging, Shallow Parsing,
Relevance Analysis
SubClass Publicly not
available, only
paper
Text-to-
Onto [23]
Terms, Con-
cepts, Taxo-
nomic Rela-
tions, Non-
Taxonomic
Relations
Statistic: Co-
occurrence Analysis,
Agglomerative Cluster-
ing, Association Rule
Mining
Linguistic: POS tag-
ging, Sentence Parsing,
Syntactic structure
analysis Domain Lex-
icons for concepts
Hypernyms from
WordNet [25], Lexico-
syntactic patterns
SubClass Publicly avail-
able, along
with a paper
9

Text2Onto
[9]
Terms, Con-
cepts, Taxo-
nomic Rela-
tions, Non-
Taxonomic
Relations
Statistic: Co-
occurrence Analysis,
Agglomerative Cluster-
ing, Association Rule
Mining
Linguistic: POS tag-
ging, Sentence Parsing,
Syntactic structure
analysis Domain Lex-
icons for concepts
Hypernyms from
WordNet [25], Lexico-
syntactic patterns
SubClass Publicly avail-
able, along
with a paper
T2K [22] Terms, Con-
cepts, Taxo-
nomic Rela-
tions
Statistics: Agglomera-
tive Clustering, Formal
Concept analysis, Asso-
ciation Rule mining
Linguistics: POS Tag-
ging, Sentence Parsing,
Syntactic Structure
Analysis, Relevance
Analysis
SubClass Publicly not
available, only
paper
10

Below is the list of ontology learning systems whose source codes are available, along with the
user interfaces for analysing outputs on different input text, from different domains.
Systems Ontology Layers Relations Comments
DL-Learner
[7]
Terms, Concepts,
Taxonomic Re-
lations, Non-
Taxonomic Rela-
tions, Axioms
SubClass, Intersec-
tion
Structured data is the nec-
essary component of differ-
ent layer extractions
DOME [1] Terms, Concepts,
Taxonomic Re-
lations, Non-
Taxonomic Relations
SubClass
DOG4DAG
[30]
Terms, Concepts,
Taxonomic Re-
lations, Non-
Taxonomic Relations
SubClass Domain Independent
DOODLE-
OWL [12]
Terms, Concepts,
Taxonomic Re-
lations, Non-
Taxonomic Relations
SubClass Requires Domain knowl-
edge like input keywords,
etc.
As you can see in the above table, there is not a single system that can form the SubClass
union and intersection axioms after extracting the ontology from the text. Hence, I propose my
own architecture in the subsequent section, with which we can form such relations between the
existing concepts of the ontology.
11

Chapter 3
Proposed Architecture
Before moving on to the approach, let us consider what resources we have and what will be the
end result. Initially, we have a certain article, which talks about some knowledge and definitions,
and an ontology on which that article is based on. Basically, we know that whatever entities,
named entities, relations, and concepts are mentioned in the text, will be directly related to the
concepts mentioned in the ontology.
3.1 Generalized Model
With the given text and ontology, I want to find enriching relations like union/intersection,
between the concepts of the ontology. For my thesis, I have proposed an unsupervised approach
to work in the medical domain, which may be extended to be used independently of the working
domain. The core basis of my approach is based on the semantic and syntactic similarity between
the concepts and the entity mentions in the text. As you can see in Figure 3.1, it is the most
generalized model for my approach. The only module that can be improved is the “Entity
Linking” Module in the given approach. The rest of the modules are pre-processing and factual
algorithms, that can remain the same but maybe changed when computational resources are
concerned.
Figure 3.1: Generalized Model
12

Figure 3.2: Proposed Model
3.2 Proposed Model
As for the Entity Linking Module of the model (Figure 3.2) used in this paper, I have used the
following approach for which I have given a detailed explanation in the subsequent sections: (i)
comparing the real-valued vector representations of the entity and the candidate concept, using
the pre-trained word embedding model BioWordVec [32], (ii) comparing the real-valued vector
representations of the entity and the candidate concept using a custom word2vec model trained
on the text in which the entities are mentioned, and (iii) comparing the entity and the candidate
concept using the tree-search algorithm on UMLS Metathesaurus [2].
3.2.1 Entity Extraction
First is the entity extraction module, where we will extract all such entities which are relevant
to the medical domain. All these entity mentions that appear in the text can either be a noun
or a noun phrase or a verb or a verb phrase. We will extract all such entity mentions using
the python library SciSpacy, which is based on the widely-used Spacy library. SciSpacy has
provided many pre-trained models for extracting medically-relevant entities, of which I have
used “en core sci lg”.
After the first module, we now have the list of entity mentions (E) from the text and list of
concepts (C) from the ontology.
3.2.2 Training of Custom Word2Vec model
Before moving on to the entity linking module, we will be needing a custom word2vec model
that will be trained on the text corpus given as input. The reason being, the word embeddings
generated based on this model will capture the context around the target word for which the
word embedding is calculated.
Using the Gensim python library, I have trained a custom word2vec model using the input text
13

corpus that will generate embeddings of 200 dimensions. Furthermore, while training the model,
I have considered the context window of 5 around the target word (for example, Pneumonia:
W1 W2 W3 W4 W5 pneumonia W6 W7 W8 W9 W10
where Wi are the contextual words around the target word Pneumonia.
3.2.3 Entity Linking
In this second module, we want to find those candidate concepts that can act as a parent class of
each of the entity mentions found in the text, i.e., if that entity can be the type of the candidate
concept. For every entity mention, we will iterate over all the candidate concepts and pass the
concept-entity (c-e) pair through the 3 modules of Entity Linking module sequentially.
BioWordVec based comparison
Using the BioWordVec [32], we will generate the real-valued word embeddings for both candidate
concept and entity mention, WE(c), and WE(e) respectively. After generating the embeddings,
we will compare their cosine similarity and if:
cosine(WE(c),WE(e)) > 0.75 (3.1)
is passed, the candidate-concept pair will be passed onto the second module. The value 0.75 is
completely experimental basis and can vary based on the modules used in combination with it.
Custom Word2Vec based comparison
Using the custom Word2Vec model, we will generate the real-valued word embeddings for both
candidate concept and entity mention, WE(c), and WE(e) respectively. After generating the
embeddings, we will compare their cosine similarity and if:
cosine(WE(c),WE(e)) > 0.55 (3.2)
is passed, the candidate-concept pair will be passed onto the second module. Again, the value
0.55 is completely experimental basis and can vary based on the modules used in combination
with it.
UMLS Metathesurus Search
After passing the 2 modules of Entity Linking module, we will finally compare if the candidate
concept can be good to be the parent class of the entity mention based on tree search on UMLS
Metathesaurus [2]. While searching the tree, the concept-entity connection can be based on
14

Figure 3.3: Scenario-1: Where the entity men-tion is found directly under the sub-tree of thecandidate concept.
Figure 3.4: Scenario-2: Where there exists aNearest common ancestor of both the conceptand entity menion.
two scenarios. If the pair is found to be valid pair based on scenario-1, then it will be directly
added as concept-instance pair into the ontology. If it fails in scenario-1, it will be checked for
scenario-2. Finally, based on scenario-2, a decision will be made if there is a quality connection
between the concept and the entity mention. Now, I will explain both the scenarios.
Scenario 1: For the first scenario, we will extract all the descendants of the candidate
concept from UMLS Metathesaurus across all the relevant sources. All the descendants that are
returned will be represented by their unique CUI or SUI or AUI across the sources. We will
iterate over this list of descendants and check if the concerned entity is present directly under
the sub-tree of the candidate concept. That can be achieved by just comparing the target entity
with each of the listed descendants. Now, do note that we have to extract the descendants of
the concept from each of the source vocabularies.
In Figure 3.3, considering that “Pneumonia” is the candidate concept and “Congenital Bac-
terial Pneumonia” is the entity mention, we can see that “Congenital Bacterial Pneu-
monia” comes directly in the descendants of the concept “Pneumonia”. So, after this com-
parison, “Congenital Bacterial Pneumonia” will be directly added as an instance of the
concept “Pneumonia”.
Now, consider another example, where the candidate concept is “Infective Pneumonia” and
the entity mention is “Basal Pneumonia”. After searching through the descendants of “In-
fective Pneumonia”, we found that “Basal Pneumonia” does not match with any of the
listed descendants across all the sources. So, this pair will now be considered for Scenario-2.
Scenario 2: For the second scenario, we will compare the ancestors of both the candidate
concept and the entity mention. In the Figure 3.4, considering the latter example under Scenario-
15

Figure 3.5: Results of Ancestors of Infective Pneumonia and Basal Pneumonia
1, we will compare the ancestors of “Infective Pneumonia” and “Basal Pneumonia” and
locate the Least Common Ancestor using the recursive algorithm. If you can see in Figure 3.5,
after running the algorithm, we found that “Respiratory Finding” is the lowest common
ancestor of “Infective Pneumonia” and “Basal Pneumonia”.
After we have located the Lowest Common Ancestor “Respiratory Finding”, we will now com-
pare the scores of pairs (“Respiratory Finding”, “Infective Pneumonia”) and (“Respiratory
Finding”, “Basal Pneumonia”), which is generated when we put both the pairs appended in
two individual sentences and pass those sentences into Metamap [4]. Metamap returns a score
for the pair and if:
m1 = Metamap(“Infective Pneumonia, a Respiratory Finding”)
m2 = Metamap(“Basal Pneumonia, a Respiratory Finding”)
(m1 + m2)/2 > 0.85 (3.3)
then the entity mention “Basal Pneumonia” will be added as an instance of the candidate
concept “Infective Pneumonia”. Otherwise, the pair is ignored.
3.2.4 Ontology Modification
Whenever we find a connection between an entity mention and a candidate concept, the same
entity mention is also added as an instance of all the subsequent parent class of the candidate
concept. The reason being, all those parent concepts act as a more generalized representation
of the same entity mention. So, they need to be connected with the entity mention.
After running the complete model for each of the entity mentions and candidate concepts, we
will have the following dictionary of concepts, D, where:
D = {C1, C2, C3, C4, .....}
16

where
D[C1] = [I1, I2, I3, I4, .....]
D[C2] = [I2, I5, I6, .....]
D[C3] = [I3, I4, I5, .....]
........................
3.2.5 Axiom Extraction
To form all the axioms based on a list of concepts, we will just find union and intersection
between them, using a dynamic programming paradigm.
At Phase 1, we will find SubClass union and SubClass intersection between each pair of concepts
and if the corresponding set is not empty and matches with the set of 3rd concept, then for each
type of axiom, we will add the axioms in the following way:
We will compare two types of axioms: SubClass union and SubClass intersection, which can be
described as the following:
A v B t C (3.4)
where A, B, C are different concepts and A is a SubClass of the union of B, and C; and
W v X u Y (3.5)
where W, X, Y are different concepts and X is a SubClass of the intersection of X, and Y.
Consider the union axiom 3.4. The left hand side of the axiom will become the key and the
right-hand side will become the value of list of concepts that form the relation,:
Union[“A”] = [“B”, “C”]
When another union axiom is found, with “A” being on the left-hand side, they will be just
appended to the existing list of “A” as:
A v E tD (3.6)
Considering 3.6 axiom is found after 3.4, then the dictionary will be updated as:
Union[“A”] = [“B”, “C”, “D”, “E”]
Now, consider intersection axiom 3.5. There can be multiple intersections that can exist on a
single target concept, so they will be stored as separate list of hyphenated strings in following
way:
17

Intersection[“W”] = [“X-Y-Z”]
When another intersection axiom is found, with “W” being on the left-hand side, it will be
added as a separate axiom to the existing list of “A” just like before as:
W v P u Z (3.7)
Considering 3.7 axiom is found after 3.5, then the dictionary will be updated as:
Intersection[“W”] = [“X-Y-Z”, “P-Z”]
At Phase 2, we will check if there are any axioms formed using a combination of 3 concepts.
That can be done by comparing the original list of concepts and the dictionaries of axioms
formed at Phase 1.
At Phase 3, we will check if there are any axioms formed using a combination of 4 concepts.
That can be done by comparing the original list of concepts and the dictionaries of axioms
formed at Phase 2 and comparing each dictionary with itself, which were formed at Phase 1.
This will be done until Phase 6 because most of the existing axioms had a logical meaning
at most Phase 6. Furthermore, the phase limit was also decided on an experimental basis,
comparing the F-1 scores obtained when restricting to each phase.
18

Chapter 4
Evaluations
4.1 Dataset
While working in the medical domain, I was not able to find any corpora whose corresponding
ontology (axioms and instances included) existed. Finding an ontology rich in axioms and
connected instances was the main issue. To tackle the same problem, I found an ontology, the
Disease Ontology [19], which consisted of many axioms between their concepts, but still there
were no instances that were connected to any of the concept. So, first I had to pre-process the
ontology and then, extract many such articles which were related to each of the instances and
concepts.
4.1.1 Ontology Pre-Processing
As you can see in the Figure 4.1 of the Disease Ontology, there no instances connected to
any concept. Basically, by connection, I mean no instance has been shown as a type of any
concept mentioned in the ontology. But, if you can see here, the lowermost leaf-child concept,
for example, “external ear basal cell carcinoma” can act as an instance of the directly connected
parent class “external ear carcinoma”. Subsequently, it can also be connected as an instance
of all the subsequent parent classes in the hierarchy (red underlined). Furthermore, some class
axioms are connected with these newly formed instances (in Figure 4.2). These class axioms
(SubClass Axioms) are resolved by just connecting the newly-formed instance, for example,
“external ear basal cell carcinoma” with the mentioned class names, which in this case, are
“basal cell carcinoma” and “external ear carcinoma”. This process will be executed for all the
newly-formed instances. Finally, we have a total of 10085 concepts and 7875 instances. Total
number of pairs (concept-instance) are 42511.
19

Figure 4.1: Scenario-1: The Disease Ontology Representation.
Figure 4.2: Scenario-2:Axioms related to thenewly-formed instance“external ear basal cellcarcinoma”.
4.1.2 Corpus Extraction and Pre-processing
After Ontology Pre-processing, we have received all the newly formed instances. We will extract
all the publicly available pubmed abstracts, which are based on these instances. While extracting
the articles, these instances and their subsequent parent classes will be fed as keywords. Using
EntrezPy python library, we can extract top 4-5 articles which are majorly based on the inputted
keywords. After extraction, we have a total of 739 articles.
4.2 Evaluation of Entity Linking Module
After executing the Ontology Pre-processing, we can extract all the concept-instance pairs and
store them in a dictionary where the key is a string literal comprising of hyphenated concept-
instance pairs and the value is ‘1’. For example, since there is a connection between “external
ear carcinoma” and “external ear basal cell carcinoma”, so it will be added into the dictionary
as:
d[“external ear carcinoma-external ear basal cell carcinoma”] = 1
Consider this dictionary as PrePairs, with all those pairs that actually existed in the Ontology
before running the Entity Linking module. After running the module, we have found new
connections between the existing concepts and instances. Consider PostPairs as a separate
dictionary of such pairs that were found between the existing concepts and instances after
running the module. Now, after comparing the pairs in both the dictionaries, I got following
metrics: Recall of 47.8 and Precision of 9.58. The final F1-score is 15.97.
20
As you can see, the F1-score is hugely impacted because of the low Precision. Reason being,
a huge number of new connections (False Positives) were found between the existing concepts
and instances. As we do not have a dataset where an ontology and text are very much closely-
related, many connections were found in the ontology based on the extracted abstracts. This
resulted in a very low F1-score.
4.3 Evaluation of Complete Model
To evaluate the complete model, we will just compare the axioms that initially existed in the
ontology and newly-formed axioms, after running the recursive algorithm on the generated
concept-instance pairs. Total number of SubClass axioms that initially existed in the ontology,
are 10085 intersection axioms and 323 union axioms.
Consider two dictionaries: PreUnion and PreIntersection, of axioms that originally existed in
the Disease Ontology. After running the complete model and calculating the axioms based on
the last module of the model, the newly formed axioms will be stored in the corresponding
dictionaries: PostUnion and PostIntersection. Some of the extracted examples are shown in
Table 4.1.
Axiom Type Actual Axiom Extracted Axiom
SubClass
Intersection
Ampulla of Vater Carcinoma sub-
ClassOf Ampulla of Vater Cancer
and Carcinoma and Disease and
Cancer
Ampulla of Vater Carcinoma sub-
ClassOf Ampulla of Vater Cancer
and Ampulla of Vater Neoplasm and
Carcinoma and Biliary Tract Benign
Neoplasm and Benign Neoplasm and
Disease and Cancer
SubClass
Intersection
Duodenal Obstruction subClassOf
Duodenal Disease and Disease
Duodenal Obstruction subClassOf
Duodenal Disease and Disease
SubClass
Intersection
Histiocytosis subClassOf Lym-
phatic System Disease and Disease
Histiocytosis subClassOf Lym-
phatic System Disease and Disease
SubClass
Intersection
Lymph Node Cancer subClassOf
Lymph Node Disease and Lymphatic
System Cancer and Disease and
Cancer
Lymph Node Cancer subClassOf
Lymph Node Disease and Lym-
phedema and Lymphatic System
Cancer and Lymphatic System Dis-
ease and Disease and Cancer
21

SubClass
Union
Prader-Willi Syndrome sub-
ClassOf Paternal variant or
Chromosomnal deletion or
Loss of function variant or Chro-
mosomnal translocation or Mater-
nal uniparental disomy
Prader-Willi Syndrome sub-
ClassOf Paternal variant or
Chromosomnal deletion or
Loss of function variant or Chro-
mosomnal translocation or Chro-
mosomnal transposition or Chro-
mosomnal structure variation or
Maternal uniparental disomy
Table 4.1: Examples of actual SubClass axioms and respectively extracted axioms.
As you can see in the above table, simpler axioms were being extracted accurately, but as we
increase the complexity of the axiom, more new concepts start getting connected as part of the
subClass axioms. Finally, comparing both the pairs of dictionaries, (PreIntersection and PostIn-
tersection) and (PreUnion and PostUnion), we got the corresponding F1-scores as: SubClass
Intersection = 19.08 and SubClass Union = 14.2. Considering the metrics we obtained
from the evaluation of entity linking module, a lot of false positive pairs were generated, and
hence, we got many new axioms in the case of SubClass union axioms. As for SubClass inter-
section ones, many news axioms were formed based on the existing EquivalentClass intersection
axioms. Hence, the Precision and corresponding F1-scores decreased.
22

Chapter 5
Challenges
At the beginning of this semester, we started by discussing the approach for the general domain.
While working in the general domain, initially I tried to extend the work of [29], using NLP
Stanford Parser [24] for parsing the dependency structure and transformation rules for creating
the DL axioms, but as I mentioned earlier, this could only work for simple sentences that
basically give a definition or functional aspect of some concept. I tried to capture the context
within long paragraphs but after applying the transformation rules, the generated axioms were
meaningless long sentences.
While working in the general domain, I researched over some Entity Linking methods, where they
try to link the entity mentions in the text corpora with a curated list of concepts. Furthermore,
these methods have used existing word embedding models like Glove [27] and Word2Vec [3] for
the semantic similarity between the entity mentions and the concepts. In combination with
these models, I tried to compare the entity and concept based on their relational connections,
i.e., what type of relations do the concept and entity exhibit. This required relational extraction
from text, but again required very rich text corpus and ontology, which I could not find in the
general domain.
Finally, after shifting to the medical domain, as I have shown you in earlier sections, that there
does not exist any ontology with instances connected to the concepts and axioms based on
the concepts. Furthermore, as I was able to process the Disease Ontology according to my
requirements, there was another missing component, the text corpora based on the Disease
Ontology. That is why I was not able to extract decent enough results through my proposed
architecture.
23

Chapter 6
Future Scope
As I mentioned earlier, the only module that can be improved in the above model is the Entity
Linking module. For this paper, I have used real-valued word embeddings and graph-based
algorithms to find the linking between a concept and an entity mention. Instead of using these
modules, we can also the neural models like Albert [20] or BioBert [21] that have shown very
promising results when normalizing the entity mentions using character-level embeddings. I was
not able to incorporate this model because of time constraints and little knowledge about the
fine-tuning of such models.
Apart from Entity Linking approaches, other approaches like pattern-matching can also replace
the Entity Linking Module. As of now, we have the heuristic rules for extracting hyponyms and
hypernyms, but we do not have such rules to extract union and intersection relations between
the same entity mentions in the text. Some of these rules can include some phrases like “as well
as”, “can also be”, etc. But, again it needs deep understanding and research for the syntactical
rules of the English language.
Lastly, [29]’s work can also be extended if we concentrate more on the transformation rules,
which creates DL axioms based on the syntactic structure of the dependency tree. Examining
the dependency structure of more complex English sentences in a recursive manner and applying
the transformation rule in the appropriate manner may give way for more complex DL axioms.
24

Bibliography
[1] Dome, http://dome.sourceforge.net/.
[2] Metathesaurus. National Library of Medicine (US), Sep 2009.
[3] Google Code Archive - Long-term storage for Google Code Project Hosting., Jun 2020.
[Online; accessed 6. Jun. 2020].
[4] Aronson, A. R., and Lang, F.-M. An overview of MetaMap: historical perspective and
recent advances. J. Am. Med. Inform. Assoc. 17, 3 (May 2010), 229.
[5] Asim, M. N., Wasim, M., Khan, M. U. G., Mahmood, W., and Abbasi, H. M. A
survey of ontology learning techniques and applications. Database 2018 (10 2018). bay101.
[6] Bodenreider, O. The Unified Medical Language System (UMLS): integrating biomedical
terminology. Nucleic Acids Res. 32, Database (Jan 2004), D267.
[7] Buhmann, L., Lehmann, J., and Westphal, P. Dl-learner - a framework for inductive
learning on the semantic web. Web Semantics: Science, Services and Agents on the World
Wide Web 39 (2016), 15 – 24.
[8] Chiu, B., Crichton, G., Korhonen, A., and Pyysalo, S. How to train good word
embeddings for biomedical NLP. In Proceedings of the 15th Workshop on Biomedical Nat-
ural Language Processing (Berlin, Germany, Aug. 2016), Association for Computational
Linguistics, pp. 166–174.
[9] Cimiano, P., and Volker, J. Text2onto. In Natural Language Processing and Infor-
mation Systems (Berlin, Heidelberg, 2005), A. Montoyo, R. Munoz, and E. Metais, Eds.,
Springer Berlin Heidelberg, pp. 227–238.
[10] Drymonas, E., Zervanou, K., and Petrakis, E. G. M. Unsupervised ontology acqui-
sition from plain texts: The ontogain system. In Natural Language Processing and Infor-
mation Systems (Berlin, Heidelberg, 2010), C. J. Hopfe, Y. Rezgui, E. Metais, A. Preece,
and H. Li, Eds., Springer Berlin Heidelberg, pp. 277–287.
[11] Faure, D. Acquisition of semantic knowledge using machine learning methods: The system
”asium.
25

[12] Fukuta, N., Yamaguchi, T., Morita, T., and Izumi, N. Doddle-owl: Interactive
domain ontology development with open source software in java. IEICE Transactions on
Information and Systems E91D (04 2008).
[13] Ghosh, M., Naja, H., Abdulrab, H., and Khalil, M. Ontology learning process as a
bottom-up strategy for building domain-specific ontology from legal texts. pp. 473–480.
[14] Guarino, N., Oberle, D., and Staab, S. What is an ontology? In Handbook on
Ontologies, S. Staab and R. Studer, Eds., International Handbooks on Information Systems.
Springer, 2009, pp. 1–17.
[15] Hahn, U., and Romacker, M. The syndikate text knowledge base generator. In Pro-
ceedings of the First International Conference on Human Language Technology Research
(2001).
[16] Hatala, M., GasIŒevicI, D., Siadaty, M., Jovanovic, J., and Torniai, C. Ontol-
ogy extraction tools: An empirical study with educators. IEEE Transactions on Learning
Technologies 5, 03 (jul 2012), 275–289.
[17] Jiang, X., and Tan, A.-H. Crctol: A semantic-based domain ontology learning system.
Journal of the American Society for Information Science and Technology 61, 1 (2010),
150–168.
[18] Karadeniz, I., and Ozgur, A. Linking entities through an ontology using word embed-
dings and syntactic re-ranking. BMC Bioinf. 20, 1 (Dec 2019), 1–12.
[19] Kibbe, W. A., Arze, C., Felix, V., Mitraka, E., Bolton, E., Fu, G., Mungall,
C. J., Binder, J. X., Malone, J., Vasant, D., Parkinson, H., Schriml, L. M.,
Kibbe, W. A., Arze, C., Felix, V., Mitraka, E., Bolton, E., Fu, G., Mungall,
C. J., Binder, J. X., Malone, J., Vasant, D., Parkinson, H., and Schriml, L. M.
Disease Ontology 2015 Update: An Expanded and Updated Database of Human Diseases
for Linking Biomedical Knowledge Through Disease Data. Nucleic Acids Res. 43, Database
(Jan 2015), issue.
[20] Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., and Soricut, R.
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv
(Sep 2019).
[21] Lee, J., Yoon, W., Kim, S., Kim, D., Kim, S., So, C. H., and Kang, J. BioBERT:
a pre-trained biomedical language representation model for biomedical text mining. arXiv
(Jan 2019).
[22] Lenci, A., Montemagni, S., Pirrelli, V., and Venturi, G. Ontology learning from
italian legal texts. In Proceedings of the 2009 Conference on Law, Ontologies and the
Semantic Web: Channelling the Legal Information Flood (Amsterdam, The Netherlands,
The Netherlands, 2009), IOS Press, pp. 75–94.
26

[23] Maedche, A., Maedche, E., and Staab, S. The text-to-onto ontology learning envi-
ronment. In Software Demonstration at ICCS-2000 - Eight International Conference on
Conceptual Structures (2000).
[24] Marneffe, M.-C., MacCartney, B., and Manning, C. Generating typed dependency
parses from phrase structure parses. vol. 6.
[25] Miller, G. A. Wordnet: A lexical database for english. Commun. ACM 38, 11 (Nov.
1995), 39–41.
[26] Oliveira, A., Pereira, F. C., and Cardoso, A. Automatic reading and learning from
text, 2001.
[27] Pennington, J., Socher, R., and Manning, C. GloVe: Global vectors for word
representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural
Language Processing (EMNLP) (Doha, Qatar, Oct. 2014), Association for Computational
Linguistics, pp. 1532–1543.
[28] Velardi, P., Faralli, S., and Navigli, R. Ontolearn reloaded: A graph-based algo-
rithm for taxonomy induction. Computational Linguistics 39 (09 2013), 665–707.
[29] Volker, J., and Rudolph, S. Lexico-logical acquisition of owl dl axioms: an integrated
approach to ontology refinement. pp. 62–77.
[30] Wachter, T., Fabian, G., and Schroeder, M. Dog4dag: Semi-automated ontology
generation in obo-edit and protEgE. In Proceedings of the 4th International Workshop on
Semantic Web Applications and Tools for the Life Sciences (New York, NY, USA, 2012),
SWAT4LS ’11, ACM, pp. 119–120.
[31] Wong, W., Liu, W., and Bennamoun, M. Ontology learning from text: A look back
and into the future. ACM Comput. Surv. 44 (2012), 20:1–20:36.
[32] Zhang, Y., Chen, Q., Yang, Z., Lin, H., and Lu, Z. BioWordVec, improving biomed-
ical word embeddings with subword information and MeSH. Sci. Data 6, 52 (May 2019),
1–9.
27


















