
On necessary and sufficient cryptographic assumptions: the case of memory checking Lecture 3 :...
48
On necessary and sufficient cryptographic assumptions: the case of memory checking Lecture 3 : Memory Checking, Consecutive Messages Protocols and Learning Distributions Lecturer: Moni Naor Weizmann Institute of Science Web site of lectures: www.wisdom.weizmann.ac.il/~naor/COURSE/ens.html
-
Upload
reynard-sutton -
Category
Documents
-
view
222 -
download
1
Transcript of On necessary and sufficient cryptographic assumptions: the case of memory checking Lecture 3 :...

On necessary and sufficient cryptographic assumptions: the case of memory checking
Lecture 3 : Memory Checking, Consecutive
Messages Protocols and Learning Distributions
Lecturer: Moni Naor
Weizmann Institute of ScienceWeb site of lectures: www.wisdom.weizmann.ac.il/~naor/COURSE/ens.html

Recap of Lecture 2• The authentication problem• Authentication use universal hash functions• The Sub-linear authentication problem
– A pretty good authenticator based on one-way functions• Communication complexity• Deterministic and Probabilistic protocols
– The equality function• Simultaneous Message Protocols
– Tight ( sqrt(n)) bound for equality

public encodingpx
Authenticators for a large and unreliable memory
• Encoding Algorithm E:– Receives a vector x 2 {0,1}n, encodes:
• a public encoding px
• a small secret encoding sx. Space complexity: s(n)• Decoding Algorithm D:
– Receives a public encoding p and decodes it into a vector x {0,1}n
• Consistency Verifier V:– Receives public px’ and secret sx encodings, verifies whether decoder output = encoder input– Makes few queries to public encoding: query complexity: t(n)
• An adversary sees (only) the public encodings and can change them
E
secret encoding sx
V
Dpublic encodingpy
acceptreject
x {0,1}n xy
s(n) bits
t(n) bits

Pretty Good Authenticator• Idea: encode X using a good error correcting code C
– Actually erasures are more relevant– As long as a certain fraction of the symbols of C(X) is available, can decode X– Good example: Reed Solomon code
• Add to each symbol a tag Fk(a,i), a function of • secret information k 2 {0,1}s, • symbol a 2 • location i
• Verifiers picks random location i reads symbol ’a’ and tag t – Check whether t=Fk(a,i) and rejects if not
• Decoding process removes all inappropriate tags and uses the decoding procedure of C

The Complexity of Authentication
• V works many times– The adversary can modify the public encoding only
between activations of V• Want both the space complexity s(n) and the
query complexity t(n) to be small– Much smaller than the file size n
For the pretty good authenticator s(n)¢t(n) ¿ n
Online Memory Checking
• Example: Verify information in your GMail account.Download the entire 2GB to verify a message?
• Don’t verify the entire 2GB, just what you read:– How much of the file do you read per bit that you retrieve
and authenticate?How large a fingerprint do you need?
– Online memory checkers

Memory CheckersHow to check a large and unreliable memory
• Store and retrieve requests to large adversarial memory – a vector in {0,1}n
• Detects whether the answer to any retrieve was different than the last store
• Uses small, secret, reliable memory: space complexity s(n)• Makes its own store and retrieve requests:
query complexity t(n)
C memory checkerU
userP
public memoryS
secret memorys(n) bits
t(n) bits

Types of Checkers
When are errors detected?
Offline vs. Online detection:
– Offline: at the end of a (long) series of requests, the checkers detects whether there was an error at some point
– Online: errors are detected whenever they occurWhen a retrieve gave a different value than the last store

Computational assumptions and memory checkers• For offline memory checkers no computational
assumptions are needed:Probability of detecting errors: εQuery complexity: t(n)=O(1) (amortized)
Space complexity: s(n)=O(log n + log 1/ε) [Blum, Evans, Gemmel, Kannan and Naor 1991]
• For online memory checkers with computational assumptions, good schemes are known:Query complexity t(n)=O(log n) Space complexity s(n)=n (for any > 0)Probability of not detecting errors: negligible
Are they necessary?!
Next lecture: yes computational assumptions are necessary

Memory Checker Authenticator
If there exists an online memory checker with– space complexity s(n) – query complexity t(n)
then there exists an authenticator with– space complexity O(s(n)) – query complexity O(t(n))
Idea: Use a high-distance code

An Upper Bound
An online memory checker:• Divide the n-bit file into chunks of size t(n)• Use a hash function from an almost-universal family
h: {0,1}t(n){0,1}c
(size: O(log n) bits)• Save in private memory a hash of each chunk• Query Complexity: t(n)• Space Complexity: s(n) = O(n/t(n))

Improve the Upper Bound?
• For Memory Checkers:What about Locally Decodable Codes?
• For Authenticators:What about PCPs of proximity?

An offline memory checker
Idea: reduce to the string/set comparison problem• The two string
– The bits read define RR– The bits written define WWHave to make sure that under normal circumstances R R = WW
• Read position before each write• Read the full string at the end • For each position in memory• Add timestamps
– Need a hash function h that can be computed `on the fly’

Using inner product• Define R R and WW as long vectors• Add time stamps since locations change
– for each 1· i · n – for each possible time t– For each possible value v
• Have a bit position in R R and W W vectors are sparse
• The function h defines a long vector Vh
h(RR) = Vh ¢ R R
The vector Vh should be such– If R R ≠ W W then Vh ¢ R R ≠ Vh ¢WW– Possible to evaluate Vh(i,v,t) easily
1 0 00 1
1 1 11 1
1 1 1 1 1 1 1 1 1 1 10 0 0 0 0 0 0 0 0 1 11 110 0 0 0

Small bias probability spacesLet be a probability space
– with N random variables x1, x2,… xN obtaining values in {0,1}. We say that it is -biased if for any subset S µ {1…N}
|Pr[ ©i 2 S xi =1] - Pr[ ©i2 S xi =0]| ·
A probability space is 0-biased iff it is the uniform distribution on x1, x2, …, xN – Size 2N
Much smaller spaces exist for >0Description of a point can be O(log(K/)) Want an efficient way to compute xi from the representation of the point
in the sample space. Should be polynomial in log i and the representation of the sample point

A construction based on quadratic residuousity
Let P be a large primeMust be À N
Each h is defined by 0 · a · P-1 ha(x) quadratic character of x+a mod P
This is a random shift of the character string
Property: the resulting probability space is -biased for =N2/PAnalysis based on Weil’s Theorem
The down side: computationally expensiveeach such function discovers error with probability at most ½
The probability that the Xor of the subset corresponding R-WR-W is 1Are we done?
Possible to come up with contsruction of size
O(log n + log t+log 1/}

A slightly different look: multi-sets• Define R R and WW as sets
– RR={(i,t,v)| location i was read with value v and timestamp t}– WW={(i,t,v)| location i was written with value v at time t}
• To check that two multi-set are the same:• Define the polynomial pS of the set S
pS = a 2 S (x-a)
Can compute the polynomial pS on the fly in any order S is given no polynomials of two different (multi) sets agree on more than their size many points
Choose a random r and compare pRR(r) and pWW(r)Probability they are equal if R R ≠ W W is at mot |T|/Size of Field
Are we done?

Problem: replay attack
• What happens if the adversary gives the reader the correct values in the wrong order?
• Luckily: time progresses. Add a check that the time stamp is not larger than the current
time

The Checker
On Read of address i at current time t– Get the value v and timestamp t’– Check that t’ is less than t – Update the hash function h(RR)
Using the multi-set approach over GF[p3] with random r:
multiply current register by vp2+vpi+t-r
– Write value v and timestamp t at address i
– Update the hash function h(WW) with value (v,a,t)
On Write to address i with value v at current time t– Get the value v’ and timestamp t’– Check that t’ is less than t– Update the hash function h(RR)
– Write new value v and timestamp t at address i
– Update the hash function h(WW) with value (v,a,t)
At the end: checkers reads all the memory cells and updates h(RR) accordingly compares h(WW) with h(RR)
Initialization: set WW=RR= and h(WW) = h(RR) = 0
flag

AnalysisLemma: if the RAM malfunctions and no flag raised, then R R ≠
W W A malfunction occurs if the (v,t) the checker reads from an address are
different from (v,t) of the corresponding writeLet (v,t,i) be the triple with the highest value t with a corresponding
errant read
Claim: no other read operation returns (v,t,i) value – no read after t can return (v,t,i), since then there is a higher
timestamp than t with an errant read– no read before t can return (v,t,i), since then it would be flagged
From the lemma and the properties of h we have that a malfunctioning RAM is caught with probability at least 1-

Invasive Memory Checkers • A memory checker is called invasive if it changes
anything in the main memory
Ajtai [2003]: Even an offline memory checker must be invasive must be for any non-trivial result
Main point: handling replay attacks Proof technique: reduction to element distinctness

On-line memory checkers• Idea add tags as in the pretty good authenticator
Fk(v,i)– Fk is a pseudo random function
• Problem: replay attacks• Solution: tree of tags
– leaves correspond to entries in the memory • Store in each internal node the sum of the value of its two
children– Plus an authentication
• Verification of a leaf: access all node on the path from root – plus their siblings
s(n) is the key size
t(n) is log n x tag size
Recall: one-way functions exist iff pseudo-random functions exist

Tree of tags
U1 U2 U5 U6 U7 U8U3 U4
U9=U1+U2, Fk(U9)
U10 U11 U12
U13U14
U15

An alternative construction
• Use a tree of hashes• Store in secret memory the root of the tree
– Does not need to be secret – only reliable
• What property should the hash function have?• What complexity assumption is needed?

Possible definitions
• A function g:{0,1}2k → {0,1}k where it is hard to find m’ ≠ m but g(m)=g(m’)
• Problems: – not good for non-uniform models– hard to connect to other assumptions
• Want a family of functions from which one is selected
• Use the advantage we have: the target is known

Possible definitions• A family of functions
G={g|g:{0,1}k → {0,1}h(k)}Such that• Easy to sample g from G and g G has succinct description• Given (k, g, x) easy to compute g(x) • h(k) < k
• Hard to find collisions: Alternative 1 – any collision– Given k and g G hard to find x, x’ {0,1}k where
x ≠ x’ but g(x)=g(x’) – Sometimes called collision intractable– hard to connect to other assumptionsAlternative 2 – target collision– Given (k,g,x) hard to find x’ {0,1}k where
x ≠ x’ but g(x)=g(x’)

Universal One-Way Hash functionsUOWHFs
• When/how is the target x chosen?• Independently of g but want to work for any possible x
– First x is selected by adversary, then g G is selected at random• Technical point: let ℓ1 , ℓ2 :{0,1}* → {0,1}* be functions mapping n to input and
output sizes. We assume – ℓ1 (n) > ℓ2 (n) and – both are bounded by polynomials in n
Definition: A family of functions G= ⋃n=1∞ Gn where Gn ={g|g:{0,1}ℓ1(n)
→{0,1}}ℓ2(n)} is called (ℓ1, ℓ2 )-universal one-way hash if:• Given n easy to sample random g from Gn and g Gn has description polynomial in
n• Given (n, g, x) easy to compute g(x) • Hard to find target collisions: no polynomial time adversary can on input n
– generate x {0,1}ℓ1(n)
– given a random g Gn find x’ {0,1}ℓ1(n) wherex ≠ x’ but g(x) = g(x’)
succeed with non-negligible probability for sufficiently large n

Pair-wise independent permutations Definition: a family of permutations (1-1 functions)
H= {h| h: {0,1}n → {0,1}n } is called Strongly Universal2 or pair-wise independent if:
– for all x1, x2 {0,1}n and y1, y2 {0,1}n where x1 ≠ x2 wand y1 ≠ y2 we have
Prob[h(x1) = y1 and h(x2) = y2 ] = 1/2n ∙ 1/(2n-1)Where the probability is over a randomly chosen h H
The same as in truly random permutations
In particular Prob[h(x2) = y2 | h(x1) = y1 ] = 1/(2n-1)
Construction: let F be a finite field F (e.g. GF[2n])H= {ha,b(x) = a∙x + b | a, b F, a ≠ 0 }

Constructing (n, n-1)-UOWHFs • Idea: Combine one-way with universal
– Want to match each image of the one-way functions with another random image
• Let f :{0,1}n → {0,1}n be a one-way permutation• Let H = {h|h:{0,1}n → {0,1}n} be a Strongly
Universal2 family of permutations • Let chopn-1 :{0,1}n → {0,1}n-1 be a 2-to-1
function– E.g. chopping last bit of input
Consider the (n, n-1)-family G where each g G is
defined by h H
g(x) = chopn-1(h(f(x)))
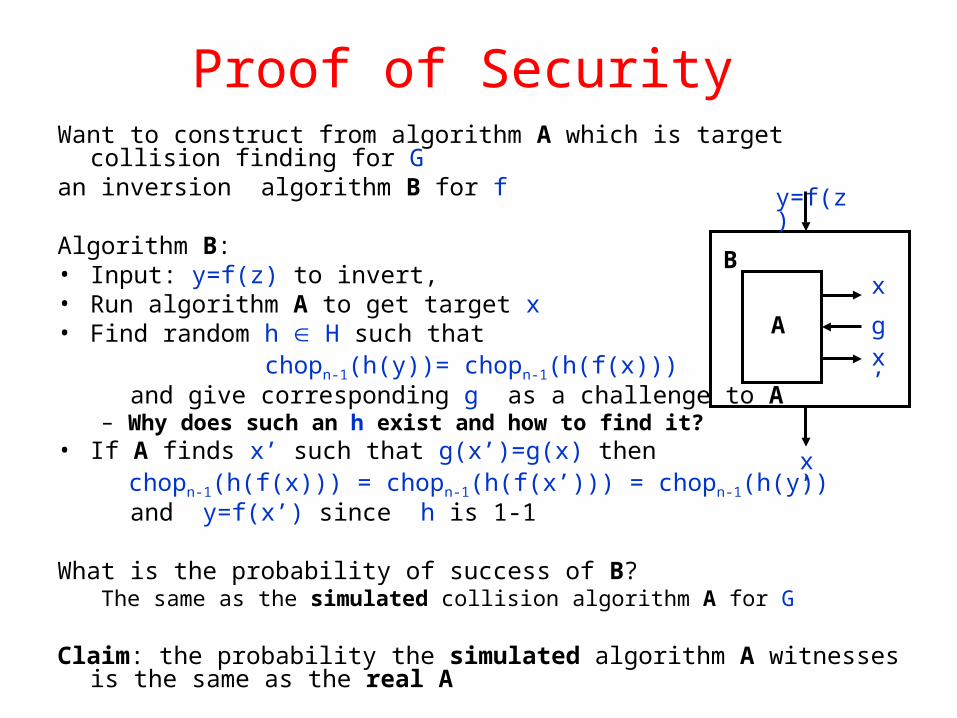
Proof of Security Want to construct from algorithm A which is target collision finding for G an inversion algorithm B for f
Algorithm B:• Input: y=f(z) to invert, • Run algorithm A to get target x• Find random h H such that
chopn-1(h(y))= chopn-1(h(f(x))) and give corresponding g as a challenge to A
– Why does such an h exist and how to find it?• If A finds x’ such that g(x’)=g(x) then
chopn-1(h(f(x))) = chopn-1(h(f(x’))) = chopn-1(h(y)) and y=f(x’) since h is 1-1
What is the probability of success of B?The same as the simulated collision algorithm A for G
Claim: the probability the simulated algorithm A witnesses is the same as the real A
x
gx’
y=f(z)
B
A
x’

Why does such an h exist and how to find it? chopn-1(h(y))= chopn-1(h(f(x)))
• Choose random w{0,1}n
• let w’ be such that chopn-1(w)=chopn-1(w’)• Want h(y)=w and h(f(x))=w’• Such an h should exist from pair-wise independence• Easy to find and unique for
H= {ha,b(x) = a∙x + b | a, b F, a ≠ 0 }
• Open problem(?): what happens to the security of the construction if H does not have the property

Distribution of simulated A vs. real A
The difference between the simulated and real A:• Real A gets g defined by random hH• Simulated A chooses x and gets g defined by
– Choosing random z{0,1}n and computing y=f(z) • y is uniform in {0,1}n from f being a permutation
– Choosing random w{0,1}n and finding random hH such that h(y)=w and h(f(x))=w’
– Since both random y and random w are random the result is a random hH
Simulated A and real A witness the same distributionThe probability that B inverts is the same as A finding a
collision

What about the reverse combination• Let f :{0,1}n → {0,1}n be a one-way permutation• Let H = {h|h:{0,1}n → {0,1}n} be a Strongly Universal2 family of
permutations Consider the (n, n-1)-family G where each g G is defined by h H
g(x) = chopn-1(f(h(x)))
Is it a UOWHF?
Not necessarily: if • h is easy to invert and • f does not affect the last bit
– not contradictory to either being one-way or a permutationThen easy to find collisions: any x the that x’ collides under h will also collide under
g

From (n, n-1)-UOWHFs to (n, n/2)-UOWHFs
• Idea: composition.• What happens to the security of the scheme?
– The probability of inverting f given a collision finding algorithm for H may be small by a factor of 2/n

The Tree Construction
g1
g2
g3
Let n= 2 ∙ l ∙ k. and t= log n/k. Each gi is chosen independently from G. The result is a family of functions {0,1}n → {0,1}k which is (n,k)-UOWHF Size of representation: t log |G| where t is the number of levels in the tree
m
Let G be a (2k,k)-UOWHF

General construction (n, k)-UOWHFs
• Use tree composition• Description length: k log (n/k) (n, n/2)-
descriptions of hash function– 2k bits in the example
Can use the same tree for memory checking
Access pattern as before
UOWHF exist iff one-way functions exist

Checking other Data Structures
• Checking queues • Checking stacks
– Can even be done in an online manner!
• Application: certificate revocation– Have to check a look-up table

Conclusions
• If one-way functions exist, then on-line memory checking is possible with
t(n) ¢ s(n) ¿ n
• Major open problem: obtain a more efficient solution – break the log n factor

Simultaneous Messages Protocols
• Suggested by Yao 1979
mA
mB
f(x,y)
x {0,1}n
y {0,1}n
ALICE
BOB
CAROL

The simultaneous messages model:• Alice receives x and Bob who receives inputs y • They simultaneously send a message to a referee Carol
who initially get no input • Carol should compute f(x,y)Several possible models:• Deterministic: all lower bounds for deterministic protocols
for f(x,y) are applicable here • Shared (Public) random coins:
– Equality has a good protocol • Consider public string as hash functions h, • Alice sends h(x) Bob sends h(y) and Charlie compares the outcome• The complexity can be as little as O(1) is after constant probability of error
Provided the random bits are chosen independently than the inputs

Simultaneous Messages Protocols• For the equality function:• There exists a protocol where
– |mA| x |mB| = O(n) – Let C be a good error correcting code– Alice and bob arrange C(x) and
C(y) in an |mA| x |mB| rectangle• Alice sends a random row• Bob send a random columns• Carol compares the intersection

Simultaneous Messages Protocols• Lower bounds for the equality function:
– |mA| + |mB| = (√n) [Newman Szegedy 1996]
– |mA| x |mB| = (n) [Babai Kimmel 1997]
• Idea: for each x 2 {0,1}n find a `typical’ multiset of messages Tx = {w1, w2,…,wt} where
t 2 O(|mB|)
Each wi is a message in the original protocol, |mA| bits
Property: for each message mB the behavior on Tx approximates the real behavior
Average behavior of Carol on w1, w2,…,wt is close to its average response during protocol
Over random i, and randomness of Carol
Over randomness of Alice and Carol

Simultaneous Messages ProtocolsHow to find for each x 2 {0,1}n such a `typical’ Tx of size t
• Claim: a random choice of wi’s is goodProof by Chernoff
– Need to `take care’ of every mB (2|mB| possibilities )
• Claim: for x x’ we have Tx Tx’– Otherwise behaves the same when y = x for x and x’
• Let Sx be the mB’s for which protocol mostly says ’1’ • Let Wx be the mB’s for which protocol mostly says ’0’• Then for y=x the distribution should be mostly on Sx
• Conclusion: t ¢ |mA| ¸ n and we get|mA| x |mB| = (n) [Babai Kimmel 1997]

General issue
• What do combinatorial lower bounds men when complexity issues are involved?
• What happens to the pigeon-hole principal when one-way functions (one-way hashing) are involved?
• Does the simultaneous message lower bound hold when one-way functions exist– Issue is complicated by the model– Can define Consecutive Message Protocol model with
iff results

Consecutive Messages Protocols
Theorem For any CM protocol that computes the equality function,If |mP| ≤ n/100 then |mA| x |mB| = (n)
f(x,y)
x {0,1}n
y {0,1}n
ALICE
CAROL
BOB
mA
mP
mB
Proof: along the Babai Kimmel liness(n
)t(n)
rp

Complexity considerations• Suppose that
– One-way functions exist– All parties are polynomial time
• Including the adversary– Then sublinear CM protocols for equality exist
• The CM protocol:Let H be a UOWHF– Alice’s chooses h 2R H
Sends mA=h(x)– Alice mp to deliver h– Bob Sends mB=h(x)– Carol accepts iff mA = mB
Easy to translate an adversary for the CM protocol to an adversary to the UOWHFness of H

Sublinear CM protocols imply one-way function
Theorem: a CM protocol for equality where – all parties are polynomial time – t(n) ¢ s(n) 2 o(n) and |mp| 2 o(n) exists iff one-way function exist
Proof: Consider the function
ff(x,rA,rp,rB1,rB
2, …, rBk) = (rp,mp,rB
1,rB2, …, rB
k ,mB1,mB
2, …, mB
k) Where
• mp = M Mpp(x,rA,rP)• mB
i =MB(x,rBi,mp,rP)
Main Lemma: the function f f is distributionally one-way
Mp is the function that maps Alice’s input to the public message mp
MB is the function that maps Bob’s input to the private message mB

CM protocol implies one-way functions• Adversary selects a random x for Alice• Alice sends public information mp, rpub
• Adversary generates a multiset Tx of s(n) Bob-messagesClaim: W.h.p., for every Alice message, Tx approximates Carol’s
output
• Adversary randomly inverts the function f and w.h.p. finds x’x s.t. Tx characterizes Carol when Bob’s input is both x and x’
Why? Tx is of length much smaller than n since s(n) ¢ t(n) + |mp| is not too large!
• Since on x and x’ where x’ x Carol’s behavior is similar in both cases, the protocol cannot have high success probability


















