
On Generalizing Driver Gaze Zone Estimation Using...
6
On Generalizing Driver Gaze Zone Estimation using Convolutional Neural Networks Sourabh Vora, Akshay Rangesh and Mohan M. Trivedi Abstract— The knowledge of driver distraction will be im- portant for self driving cars in the near future to determine the handoff time to the driver. Driver’s gaze direction has been previously shown as an important cue in understanding distraction. While there has been a significant improvement in personalized driver gaze zone estimation systems, a generalized gaze zone estimation system which is invariant to different subjects, perspective and scale is still lagging behind. We take a step towards the generalized system using a Convolutional Neural Network (CNN). For evaluating our system, we collect large naturalistic driving data of 11 drives, driven by 10 subjects in two different cars and label gaze zones for 47515 frames. We train our CNN on 7 subjects and test on the other 3 subjects. Our best performing model achieves an accuracy of 93.36% showing good generalization capability. I. I NTRODUCTION According to a recent study [1] on ’Takeover time’ in driverless cars, drivers engaged in secondary tasks exhibit larger variance and slower responses to requests to resume control. It is also well known that driver inattention is the leading cause of vehicular accidents. According to another study [2], 80% of crashes and 65% of near crashes involve driver distraction. Surveys on automotive collisions [3], [4] demonstrated that drivers were less likely (30%-43%) to cause an injury related collision when they had one or more passengers who could alert them to unseen hazards. It is therefore essential for Advanced Driver Assistance Systems (ADAS) to capture these distractions so that the humans inside the car [5] can be alerted or guided in case of dangerous situations. This will ensure that the handover process between the driver and the self driving car is smooth and safe. Driver gaze activity is an important cue to recognize driver distraction. In a study on the effects of performing secondary tasks in a highly automated driving simulator [6], it was found that the frequency and duration of mirror-checking reduced during secondary task performance versus normal, baseline driving. Alternatively, Ahlstrom et al. [7] developed a rule based 2-second ’attention buffer’ framework which depleted when the driver looked away from the field relevant to driving (FRD); and it starts filling up when the gaze direction is redirected towards FRD. Driver gaze activity can also be used to predict driver behavior [8]. Martin et al. [9] developed a framework for modeling driver behavior and maneuver prediction from gaze fixations and transitions. The authors are with the Laboratory for Intelligent and Safe Au- tomobiles, University of California, San Diego, CA 92092, USA. email - sovora, arangesh, [email protected] Fig. 1: Where is the driver looking? Can a universal machine vision based system be trained to be invariant to drivers, perspective, scale, etc.? Thus, there exists a need for a continuous driver gaze zone estimation system. While there has been a lot of research in improving person- alized driver gaze zone estimation systems, there hasn’t been a lot of progress in generalizing this task across different drivers, cars, perspectives and scale. We make an attempt in that direction using Convolutional Neural Networks (CNNs). CNNs have shown tremendous promise in the fields of image classification, object detection and recognition. We study their effectiveness in generalizing driver gaze estimation systems through a large naturalistic driving dataset of 10 drivers consisting of 47515 frames. Data are captured in two different cars with different camera settings of field of view (Fig 1). The main contributions of this work are: a) A systematic analysis of CNNs on generalizing driver gaze zone estimation systems b) Comparison of the CNN based model with some other state of the art approaches and, c) A large naturalistic driving dataset of 11 drivers with extensive variability to evaluate the two methods. 2017 IEEE Intelligent Vehicles Symposium (IV) June 11-14, 2017, Redondo Beach, CA, USA 978-1-5090-4803-8/17/$31.00 ©2017 IEEE 849
Transcript of On Generalizing Driver Gaze Zone Estimation Using...

On Generalizing Driver Gaze Zone Estimation using ConvolutionalNeural Networks
Sourabh Vora, Akshay Rangesh and Mohan M. Trivedi
Abstract— The knowledge of driver distraction will be im-portant for self driving cars in the near future to determinethe handoff time to the driver. Driver’s gaze direction hasbeen previously shown as an important cue in understandingdistraction. While there has been a significant improvement inpersonalized driver gaze zone estimation systems, a generalizedgaze zone estimation system which is invariant to differentsubjects, perspective and scale is still lagging behind. We takea step towards the generalized system using a ConvolutionalNeural Network (CNN). For evaluating our system, we collectlarge naturalistic driving data of 11 drives, driven by 10 subjectsin two different cars and label gaze zones for 47515 frames. Wetrain our CNN on 7 subjects and test on the other 3 subjects.Our best performing model achieves an accuracy of 93.36%showing good generalization capability.
I. INTRODUCTION
According to a recent study [1] on ’Takeover time’ indriverless cars, drivers engaged in secondary tasks exhibitlarger variance and slower responses to requests to resumecontrol. It is also well known that driver inattention is theleading cause of vehicular accidents. According to anotherstudy [2], 80% of crashes and 65% of near crashes involvedriver distraction.
Surveys on automotive collisions [3], [4] demonstratedthat drivers were less likely (30%-43%) to cause an injuryrelated collision when they had one or more passengers whocould alert them to unseen hazards. It is therefore essentialfor Advanced Driver Assistance Systems (ADAS) to capturethese distractions so that the humans inside the car [5] canbe alerted or guided in case of dangerous situations. Thiswill ensure that the handover process between the driver andthe self driving car is smooth and safe.
Driver gaze activity is an important cue to recognize driverdistraction. In a study on the effects of performing secondarytasks in a highly automated driving simulator [6], it wasfound that the frequency and duration of mirror-checkingreduced during secondary task performance versus normal,baseline driving. Alternatively, Ahlstrom et al. [7] developeda rule based 2-second ’attention buffer’ framework whichdepleted when the driver looked away from the field relevantto driving (FRD); and it starts filling up when the gazedirection is redirected towards FRD. Driver gaze activitycan also be used to predict driver behavior [8]. Martin etal. [9] developed a framework for modeling driver behaviorand maneuver prediction from gaze fixations and transitions.
The authors are with the Laboratory for Intelligent and Safe Au-tomobiles, University of California, San Diego, CA 92092, USA.email - sovora, arangesh, [email protected]
Fig. 1: Where is the driver looking? Can a universal machinevision based system be trained to be invariant to drivers,perspective, scale, etc.?
Thus, there exists a need for a continuous driver gaze zoneestimation system.
While there has been a lot of research in improving person-alized driver gaze zone estimation systems, there hasn’t beena lot of progress in generalizing this task across differentdrivers, cars, perspectives and scale. We make an attempt inthat direction using Convolutional Neural Networks (CNNs).CNNs have shown tremendous promise in the fields of imageclassification, object detection and recognition. We studytheir effectiveness in generalizing driver gaze estimationsystems through a large naturalistic driving dataset of 10drivers consisting of 47515 frames. Data are captured in twodifferent cars with different camera settings of field of view(Fig 1).
The main contributions of this work are: a) A systematicanalysis of CNNs on generalizing driver gaze zone estimationsystems b) Comparison of the CNN based model with someother state of the art approaches and, c) A large naturalisticdriving dataset of 11 drivers with extensive variability toevaluate the two methods.
2017 IEEE Intelligent Vehicles Symposium (IV)June 11-14, 2017, Redondo Beach, CA, USA
978-1-5090-4803-8/17/$31.00 ©2017 IEEE 849
II. RELATED RESEARCH
Driver monitoring has been a long standing researchproblem in Computer Vision. For an overview on driverinattention monitoring systems, readers are encouraged torefer to a review by Dong et al. [10].
A prominent approach for driver gaze zone estimationis remote eye tracking. However, remote eye tracking isstill a very challenging task in the outdoor environment.These systems [11], [12], [13], [14] rely on near-infrared(IR) illuminators to generate the bright pupil effect. Thismakes them susceptible to outdoor lighting conditions. Ad-ditionally, the hardware necessary to generate the bright eyeeffect hinders the system integration into the car dashboard.These specialized hardware also require a lengthy calibrationprocedure which is expensive to maintain due to the constantvibrations and jolts during driving.
Due to the above mentioned problems, vision based sys-tems appear to be an attractive solution for gaze zone esti-mation. These systems can be grouped into two categories:Techniques that only use the head pose [15], [16] and thosethat use the driver’s head pose as well as gaze [17], [18],[19], [20]. Driver head pose provides a decent estimate of thecoarse gaze direction. For a good overview of vision basedhead pose estimation systems, readers are encouraged to referto a survey by Murphy-Chutorian and Trivedi [21]. However,methods which rely on head pose alone fail to discriminatebetween adjacent zones separated by subtle eye movement,like front windshield and speedometer. Using a combinationof gaze and head pose was shown to provide a more robustestimate of gaze zones by Tawari et al. [17] for personalizedgaze zone estimation systems. Fridman et al. [22], [23] take astep towards generalized gaze zone estimation by performingthe analysis on a huge dataset of 40 drivers and doingcross driver testing. However, they employ a high confidencedecision pruning of 10 i.e. they only make a decision whenthe ratio of the highest probability predicted by the classifierto the second highest probability is greater than 10. Becauseof the pruning step as well as missed frames due to inaccuratedetection of facial landmarks and pupil, the decision makingability of their model is limited to 1.3 frames per second (fps)in a 30 fps video. A system with a low decision rate wouldmiss several glances for mirror checks making it unusablefor driver attention monitoring. Thus, there exists a need fora better system which generalizes well to different driversfor the gaze zone estimation task.
We take a step towards that direction using CNNs. Therehasn’t been many research studies which use CNNs forpredicting driver’s gaze. Choi et al’ [24] use a five layeredCNN to classify driver’s gaze in 9 zones. However, to thebest of our knowledge, they don’t do cross driver testing. Inthis study, we further systematize this approach by havingseparate subjects in train and test sets. Cross driver testingis particularly important as it better resembles the real worldconditions where the system will need to run on subjectswhich it has not seen during training. We also evaluate ourmodel across variations in camera position and field of view.
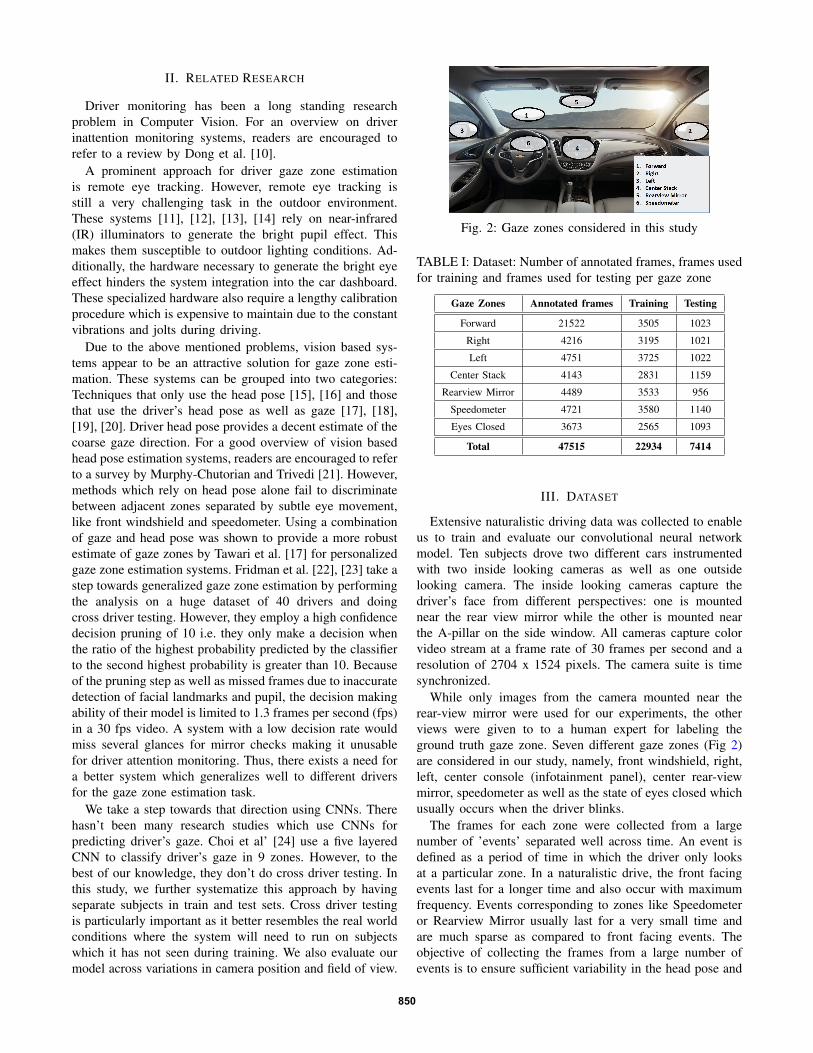
Fig. 2: Gaze zones considered in this study
TABLE I: Dataset: Number of annotated frames, frames usedfor training and frames used for testing per gaze zone
Gaze Zones Annotated frames Training Testing
Forward 21522 3505 1023
Right 4216 3195 1021
Left 4751 3725 1022
Center Stack 4143 2831 1159
Rearview Mirror 4489 3533 956
Speedometer 4721 3580 1140
Eyes Closed 3673 2565 1093
Total 47515 22934 7414
III. DATASET
Extensive naturalistic driving data was collected to enableus to train and evaluate our convolutional neural networkmodel. Ten subjects drove two different cars instrumentedwith two inside looking cameras as well as one outsidelooking camera. The inside looking cameras capture thedriver’s face from different perspectives: one is mountednear the rear view mirror while the other is mounted nearthe A-pillar on the side window. All cameras capture colorvideo stream at a frame rate of 30 frames per second and aresolution of 2704 x 1524 pixels. The camera suite is timesynchronized.
While only images from the camera mounted near therear-view mirror were used for our experiments, the otherviews were given to to a human expert for labeling theground truth gaze zone. Seven different gaze zones (Fig 2)are considered in our study, namely, front windshield, right,left, center console (infotainment panel), center rear-viewmirror, speedometer as well as the state of eyes closed whichusually occurs when the driver blinks.
The frames for each zone were collected from a largenumber of ’events’ separated well across time. An event isdefined as a period of time in which the driver only looksat a particular zone. In a naturalistic drive, the front facingevents last for a longer time and also occur with maximumfrequency. Events corresponding to zones like Speedometeror Rearview Mirror usually last for a very small time andare much sparse as compared to front facing events. Theobjective of collecting the frames from a large number ofevents is to ensure sufficient variability in the head pose and
850

Fig. 3: An overview of the proposed pipeline. It consistsof two major blocks namely the Input Pre-processing Blockand the Network Finetuning Block. One of the three regioncrops and one of the two networks are chosen for trainingand testing.
pupil location in the frames as well as to obtain highly variedillumination conditions.
Fig 1 shows some sample instances of drivers looking atdifferent gaze zones. The videos were deliberately capturedfor different drives in different settings of fields of view (wideangle vs normal). The subjects also adjusted the seat positionaccording to their comfort. We believe that all such variationsin the dataset are necessary to build a robust model thatgeneralizes well.
Since the forward facing frames dominate the dataset, theyare sub sampled so as to create a balanced dataset. Further,the dataset is divided such that the drives from 7 subjects areused for training while the drives from 3 subjects are usedfor testing our model. Table I shows the number of framesper zone finally used in our train and test datasets.
IV. METHODOLOGY
CNNs are good at transfer learning. Oquab et al. [25]showed that image representations learned with CNNs onlarge-scale annotated datasets can be efficiently transferred toother visual recognition tasks with limited amount of trainingdata. We attempt to finetune two CNNs originally trainedon the ImageNet dataset [26]. We consider the followingoptions: a) AlexNet [27] and b) VGG with 16 layers [28].
Fig. 3 describes the block diagram of our completesystem. It consists of two major blocks namely: a) Inputpre-processing block and, b) Network finetuning block. Theinput pre-processing block extracts the portions of the rawinput image that are most relevant to gaze zone estimation.The network fine tuning block then finetunes the ImageNettrained CNNs using the sub images output by the input pre-processing block. Both blocks are described in greater detailin sections IV-A and IV-B.
A. Training
We remove the last layer of the network (which has1000 neurons) from both architectures and add a new fullyconnected layer with 7 neurons and a softmax layer on top
(a) Top half of the face (b) Face
(c) Face and Context
Fig. 4: Preprocessed inputs to the CNNs (before subtractingthe mean) for training and testing
of it. We initialize the newly added layer using the methodproposed by He et al. [29]. We fine tune the entire networkusing our training data. Since the networks are pre-trainedon a very large dataset, we use a low learning rate. For bothnetworks, we start with a hundredth of the learning rate usedto train the respective networks and observe the training andvalidation loss and accuracy. If the loss function oscillates,we further decrease the learning rate. It was found that alearning rate of 10−4 works well with both the networks. Thenetworks were fine tuned for a duration of 5 epochs withmini batch gradient descent using adaptive learning rates.Based on GPU memory constraints, batch sizes of 64 and32 were used for training AlexNet and VGG16 respectively.The Adam optimization algorithm, introduced by Kingmaand Ba [30], was used.
B. Input to the CNNs
We choose three different approaches for prepocessingthe inputs to the CNNs. In the first case (Fig 4b), driver’sface was detected and used as an input. The face detectorpresented by Yuen et al. [31] was used. In the second case,some context was added to driver’s face by extending the facebounding box in all directions (Fig 4c). Context has given aboost in performance in several computer vision problemsand this input strategy will help us determine whetheradding context to the face bounding box will improve theperformance of the CNN. In the third case, only the top halfof the face was used as an input (Fig 4a). The cropped imageswere all resized to 224x224 or 227x227 according to thenetwork requirements and finally, the mean was subtracted.
V. EXPERIMENTAL ANALYSIS & DISCUSSION
The evaluation of the experiments performed in IV arepresented using three metrics. The first two forms of eval-uation metrics are the weighted and unweighted accuracy.
851
TABLE II: Weighted accuracy for both networks whenpresented with different image region crops. Cross drivertesting was performed for each experiment; drives by 7subjects were used for training while drives by 3 differentsubjects were used for testing.
Half Face Face Face+Context
AlexNet 88.91 82.08 75.56
VGG16 93.36 92.74 91.21
They are calculated as:
Weighted Accuracy =1N
N
∑i=1
(True positive)i
(Total Population)i(1)
Unweighted Accuracy =∑
Ni=1(True positive)i
∑Ni=1(Total Population)i
(2)
where, N = Number of gaze zones.The third evaluation metric is the N class confusion matrixwhere each row represents true gaze zone and each columnrepresents estimated gaze zone.
A. Analysis of the networks and face bounding box size
Table II presents the weighted accuracy obtained on thetest set for different combinations of networks and input pre-processing. Our best performing model achieves an accuracyof 93.36% clearly demonstrating the generalization capabil-ities of the features learned through CNN. Two trends areclearly observable based on the results. First, the perfor-mance of both the networks increases as the face boundingbox size is reduced. Second, finetuned VGG16 outperformsfinetuned AlexNet for all input pre-processing forms.
The low performance of AlexNet can be attributed to largekernel size (11×11) and a stride of 4 in the first convolutionlayer. The gaze zones change with very slight movement ofthe pupil or eyelid. This fine discriminating information ofthe eye is missed out in the first layer due to convolution withlarge kernel size and a stride of 4. In our experiments, wefound that the network easily classifies zones with large headmovement (left and right) whereas it struggles to classifyzones with slight eye movement (Eg. Front, Speedometerand Eyes Closed). The large increase in accuracy when onlythe top half of the face is provided as an input as compared towhen the large Face+Context sub image is provided furtherconfirms the fact.
VGG16 is composed of convolution layers that perform3×3 convolutions with a stride of 1. These small convolutionkernels coupled with the larger depth of the network allowsfor discriminating gaze zones with even slight movementsof the pupil or eyelid. The advantage of small 3×3 kernelsize is clearly visible when we evaluate the performanceof both the networks fine tuned on Face+Context images.While the performance of AlexNet decreases significantly to75.56% from 88.9% when trained on Face+Context imagesas compared to when trained on HalfFace images, this is not
TABLE III: Confusion matrix for 7 gaze zones using fine-tuned VGG16 trained on images containing upper half ofthe face. Drives by 7 subjects were used for training whiledrives by 3 different subjects were used for testing.
True Zone Recognized Gaze Zone
Forward 95.31 0.2 1.56 0 1.76 1.08 0.1
Right 0 99.51 0 0 0.1 0 0.39
Left 1.96 0 85.71 0 0 0.1 12.23
Center Stack 0.17 6.56 0.35 87.58 0.26 4.92 0.17
Rearview Mirror 0 0.21 0 0 99.48 0 0.31
Speedometer 1.49 0.61 0 5.27 0 90.87 1.76
Eyes Clsoed 0.91 0.82 0.18 0.73 0.09 2.2 95.06
Weighted Accuracy = 93.36%Unweighted Accuracy = 93.17%
TABLE IV: Confusion matrix for 7 gaze zones using theRandom Forest model. Drives by 7 subjects were used fortraining while drives by 3 different subjects were used fortesting.
True Zone Recognized Gaze Zone
Forward 84.16 0 7.72 0.68 1.47 5.38 0.59
Right 0 99.12 0 0 0.39 0 0.49
Left 6.17 0 71.17 0.33 0.67 1.83 19.83
Center Stack 0.78 8.57 0 32.55 15.41 0 42.68
Rearview Mirror 0 0.84 0 0.21 98.74 0 0.21
Speedometer 27.81 0 6.84 2.89 0 40.96 21.49
Eyes Closed 6.99 4.56 11.36 10.87 7.18 4.37 54.66
Weighted Accuracy = 68.76%Unweighted Accuracy = 67.15%
the case with VGG16. For VGG16, there is only a slightdrop from 93.36% to 91.21%. This shows that small 3× 3kernels help preserve the fine discriminating features of theeye, even when the eyes are such a small part of the image.
B. Comparison of our CNN based model with some currentstate of the art models
In this section, we compare our best performing model(VGG16 trained on upper half of face images) with someother recent gaze zone estimation studies. The techniquepresented by Tawari et al. [17] was implemented on ourdataset so as to enable a fair comparison. They use a RandomForest classifier with hand crafted features of head pose andgaze surrogates which are calculated using facial landmarks.
Table III presents the confusion matrix obtained by testingour VGG16 model while Table IV presents the confusion
852

matrix obtained by the Random Forest Model.We see that our CNN based model clearly outperforms
the Random Forest model by a substantial margin of 24.6%.There are several factors responsible for the low performanceof the Random Forest model. The biggest ones are the posi-tion and orientation of the driver with respect to the camera.The Random Forest model relies on the head pose and gazeangles to discriminate between different gaze zones and theseangles are not robust to the position and orientation of thedriver with respect to the camera. Further, for determiningthe eye openness, the area of the upper eyelid was used as afeature which also changes with different subjects, differentseat position and camera settings. All these factors combinedlimit the Random Forest model with hand crafted features togeneralize as shown by the results on our dataset. Further,the accuracy of 68.76% was calculated when only the frameswhich pass the landmarks and pupil detection steps wereconsidered. Because the classifier cannot make a predictionfor frames which do not pass the above mentioned steps,these frames should ideally be considered as misclassifica-tions. The weighted accuracy of the Random Forest modelwhen calculated using this scheme further drops down to64.1%. Inaccurate estimation of these intermediate taskswas also seen to seriously limit the performance in [22],[23]. In our CNN based approach there is no dependencyon accurate facial landmark estimation and pupil detectionwhich is another huge advantage over the Random Forestapproaches.
We also compare our work with Choi et al. [24]. Theytrained a truncated version of AlexNet and achieved a highaccuracy of 95% on their dataset. However, to the best of ourknowledge, they don’t do cross driver testing and divide eachdrive temporally. The first 70% frames for each drive wereused for training, next 15% frames were used for validationand the last 15% were used for testing. In our experiments,we show that AlexNet does not perform very well ascompared to VGG16. We replicated their experimental setupby dividing our drives temporally and achieve a very highaccuracy of 98.5% using AlexNet trained on face images.This clearly shows that the network is learning driver specificfeatures and therefore overfits to the subjects.
Finally, to further evaluate the generalization ability ofour CNNs, tests were also performed for subjects wearingglasses in a leave-one-subject-out fashion. The accuracyobtained by both the networks was only slightly less (lessthan 3%) than the accuracy seen when the networks weretested on subjects not wearing glasses (Table II). Theseresults are very promising as the traditional approach offirst detecting landmarks and pupil seriously suffer when thesubjects are wearing glasses. Extensive analysis still needs tobe performed as there were only two subjects in our datasetwho wore glasses. We plan to do that in the future.
VI. CONCLUDING REMARKS
Correct classification of driver’s gaze is important as alert-ing the driver at the ’correct time’ can prevent several roadaccidents. It will also help autonomous vehicles to determine
driver distraction so as to calculate the appropriate takeovertime. In literature, a large progress has been made towardspersonalized gaze zone estimation systems but not towardssystems which can generalize to different drivers, cars, per-spective and scale. Towards this end, this research study usesCNNs to classify driver’s gaze into seven zones. The modelwas evaluated on a large naturalistic driving dataset (NDS)of 11 drives, driven by 10 subjects in 2 separate cars. Twoseparate CNNs (AlexNet and VGG16) were fine tuned onthe collected NDS using three different input pre processingtechniques. VGG16 was seen to outperform AlexNet becauseof the small kernel size (3 × 3) in the convolution layer.Further, it was seen that the input strategy of using only theupper half of the face works better as compared to whenthe entire face or face+context images were used. Our bestperforming model (VGG16 finetuned on Half Face images)achieves an accuracy of 93.36% which shows tremendousimprovement when compared to some recent state of theart techniques. Future work in this direction will be towardsadding more zones and utilizing temporal context.
VII. ACKNOWLEDGMENTS
The authors would like to specially thank Dr. SujithaMartin, Kevan Yuen and Nachiket Deo for their suggestionsto improve this work. The authors would also like to thankour sponsors and our colleagues at Laboratory of Intelligentand Safe Automobiles (LISA) for their massive help in datacollection.
REFERENCES
[1] A. Eriksson and N. Stanton, “Take-over time in highly automatedvehicles: non-critical transitions to and from manual control,” HumanFactors, 2016.
[2] G. M. Fitch, S. A. Soccolich, F. Guo, J. McClafferty, Y. Fang, R. L.Olson, M. A. Perez, R. J. Hanowski, J. M. Hankey, and T. A. Dingus,“The impact of hand-held and hands-free cell phone use on drivingperformance and safety-critical event risk,” Tech. Rep., 2013.
[3] T. Rueda-Domingo, P. Lardelli-Claret, J. de Dios Luna-del Castillo,J. J. Jimenez-Moleon, M. Garcıa-Martın, and A. Bueno-Cavanillas,“The influence of passengers on the risk of the driver causing a carcollision in spain: Analysis of collisions from 1990 to 1999,” AccidentAnalysis & Prevention, vol. 36, no. 3, pp. 481–489, 2004.
[4] K. A. Braitman, N. K. Chaudhary, and A. T. McCartt, “Effect ofpassenger presence on older drivers risk of fatal crash involvement,”Traffic injury prevention, vol. 15, no. 5, pp. 451–456, 2014.
[5] E. Ohn-Bar and M. M. Trivedi, “Looking at humans in the age ofself-driving and highly automated vehicles,” IEEE Transactions onIntelligent Vehicles, vol. 1, no. 1, pp. 90–104, 2016.
[6] N. Li and C. Busso, “Detecting drivers’ mirror-checking actions andits application to maneuver and secondary task recognition,” IEEETransactions on Intelligent Transportation Systems, vol. 17, no. 4, pp.980–992, 2016.
[7] C. Ahlstrom, K. Kircher, and A. Kircher, “A gaze-based driverdistraction warning system and its effect on visual behavior,” IEEETransactions on Intelligent Transportation Systems, vol. 14, no. 2, pp.965–973, 2013.
[8] A. Doshi and M. M. Trivedi, “Tactical driver behavior predictionand intent inference: A review,” in Intelligent Transportation Systems(ITSC), 2011 14th International IEEE Conference on. IEEE, 2011,pp. 1892–1897.
[9] S. Martin and M. M. Trivedi, “Gaze fixations and dynamics forbehavior modeling and prediction of on-road driving maneuvers,” inIntelligent Vehicles Symposium Proceedings, 2017 IEEE. IEEE, 2017.
853

[10] Y. Dong, Z. Hu, K. Uchimura, and N. Murayama, “Driver inattentionmonitoring system for intelligent vehicles: A review,” IEEE transac-tions on intelligent transportation systems, vol. 12, no. 2, pp. 596–614,2011.
[11] L. M. Bergasa, J. Nuevo, M. A. Sotelo, R. Barea, and M. E. Lopez,“Real-time system for monitoring driver vigilance,” IEEE Transactionson Intelligent Transportation Systems, vol. 7, no. 1, pp. 63–77, 2006.
[12] Q. Ji and X. Yang, “Real time visual cues extraction for monitoringdriver vigilance,” in International Conference on Computer VisionSystems. Springer, 2001, pp. 107–124.
[13] ——, “Real-time eye, gaze, and face pose tracking for monitoringdriver vigilance,” Real-Time Imaging, vol. 8, no. 5, pp. 357–377, 2002.
[14] C. H. Morimoto, D. Koons, A. Amir, and M. Flickner, “Pupil de-tection and tracking using multiple light sources,” Image and visioncomputing, vol. 18, no. 4, pp. 331–335, 2000.
[15] A. Tawari and M. M. Trivedi, “Robust and continuous estimation ofdriver gaze zone by dynamic analysis of multiple face videos,” inIntelligent Vehicles Symposium Proceedings, 2014 IEEE. IEEE, 2014,pp. 344–349.
[16] S. J. Lee, J. Jo, H. G. Jung, K. R. Park, and J. Kim, “Real-timegaze estimator based on driver’s head orientation for forward collisionwarning system,” IEEE Transactions on Intelligent TransportationSystems, vol. 12, no. 1, pp. 254–267, 2011.
[17] A. Tawari, K. H. Chen, and M. M. Trivedi, “Where is the driverlooking: Analysis of head, eye and iris for robust gaze zone estima-tion,” in Intelligent Transportation Systems (ITSC), 2014 IEEE 17thInternational Conference. IEEE, 2014, pp. 988–994.
[18] T. Ishikawa, “Passive driver gaze tracking with active appearancemodels,” 2004.
[19] P. Smith, M. Shah, and N. da Vitoria Lobo, “Determining drivervisual attention with one camera,” IEEE transactions on intelligenttransportation systems, vol. 4, no. 4, pp. 205–218, 2003.
[20] B. Vasli, S. Martin, and M. M. Trivedi, “On driver gaze estimation:Explorations and fusion of geometric and data driven approaches,” inIntelligent Transportation Systems (ITSC), 2016 IEEE 19th Interna-tional Conference on. IEEE, 2016, pp. 655–660.
[21] E. Murphy-Chutorian and M. M. Trivedi, “Head pose estimation incomputer vision: A survey,” IEEE transactions on pattern analysisand machine intelligence, vol. 31, no. 4, pp. 607–626, 2009.
[22] L. Fridman, J. Lee, B. Reimer, and T. Victor, “owland lizard: patternsof head pose and eye pose in driver gaze classification,” IET ComputerVision, vol. 10, no. 4, pp. 308–313, 2016.
[23] L. Fridman, P. Langhans, J. Lee, and B. Reimer, “Driver gazeregion estimation without using eye movement,” arXiv preprintarXiv:1507.04760, 2015.
[24] I.-H. Choi, S. K. Hong, and Y.-G. Kim, “Real-time categorization ofdriver’s gaze zone using the deep learning techniques,” in Big Dataand Smart Computing (BigComp), 2016 International Conference on.IEEE, 2016, pp. 143–148.
[25] M. Oquab, L. Bottou, I. Laptev, and J. Sivic, “Learning and trans-ferring mid-level image representations using convolutional neuralnetworks,” in Proceedings of the IEEE conference on computer visionand pattern recognition, 2014, pp. 1717–1724.
[26] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei,“Imagenet: A large-scale hierarchical image database,” in ComputerVision and Pattern Recognition, 2009. CVPR 2009. IEEE Conferenceon. IEEE, 2009, pp. 248–255.
[27] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classificationwith deep convolutional neural networks,” in Advances in neuralinformation processing systems, 2012, pp. 1097–1105.
[28] K. Simonyan and A. Zisserman, “Very deep convolutional networksfor large-scale image recognition,” CoRR, vol. abs/1409.1556, 2014.
[29] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers:Surpassing human-level performance on imagenet classification,” inProceedings of the IEEE international conference on computer vision,2015, pp. 1026–1034.
[30] D. Kingma and J. Ba, “Adam: A method for stochastic optimization,”arXiv preprint arXiv:1412.6980, 2014.
[31] K. Yuen, S. Martin, and M. M. Trivedi, “Looking at faces in a vehicle:A deep cnn based approach and evaluation,” in Intelligent Transporta-tion Systems (ITSC), 2016 IEEE 19th International Conference on.IEEE, 2016, pp. 649–654.
854


















