
On Driver Gaze Estimation: Explorations and Fusion of...
6
On Driver Gaze Estimation: Explorations and Fusion of Geometric and Data Driven Approaches Borhan Vasli, Sujitha Martin, and Mohan Manubhai Trivedi Abstract— Gaze direction is important in a number of appli- cations such as active safety and driver’s activity monitoring. However, there are challenges in estimating gaze robustly in real world driving situations. While performance of personalized gaze estimation models has improved significantly, performance improvement of universal gaze estimation is lagging behind; one reason being, learning based methods do not exploit the physical constraints of the car. In this paper, we propose a system to estimate driver’s gaze from head and eye cues projected on a multi-plane geometrical environment and a system which fuses the geometric with data driven learning method. Evaluations are conducted on naturalistic driving data containing different drivers in different vehicles in order to test the generalization of the methods. Systematic evaluations on this data set are presented for the proposed geometric based gaze estimation method and geometric plus learning based hybrid gaze estimation framework, where exploiting the geometrical constraints of the car shows promising results of generalization. Index Terms— In Cabin Activity Analysis, Human-vehicle Interaction, Gaze Estimation, Take-over, Highly Automated Vehicles. I. INTRODUCTION In 2013, on average 8 people were killed and 1,161 were injured everyday in the United States due to car accidents involving distracted drivers [1]. Distracted driving means that the driver is driving while doing another activity taking his/her attention away from driving. Distracted driving increases the chance of motor vehicle accidents. There are three major types of distraction while driving [2]: visual (eyes of the road), manual (hands of the wheel) and cognitive (mind off of driving). Early knowledge of driver behavior, in concert with the vehicle and the environment (e.g. surround- ing vehicles, pedestrians) can help to recognize and prevent dangerous situations. Driver gaze estimation is one of the key components for estimating and representing driver behavior, as seen in current research developments for driver assistance systems as well as for highly automated vehicles. In [4], Ohn-Bar et al. explored early prediction of maneuvers such as over- take and brake, where driver related cues (e.g. head, eyes) showed earlier and stronger predictive importance compared to surround and vehicle cues. On the other hand, Li et al. [6] explored the predictive importance of driver’s gaze for maneuver and secondary task detection; they exploited the findings that the duration and frequency of mirror- checking actions differed among maneuvers, secondary task performance and baseline/normal driving. Furthermore, gaze The authors are with the Laboratory for Intelligent and Safe Automobiles (LISA), University of California San Diego, La Jolla, CA 92092, USA {bvasli, scmartin, mtrivedi}@ucsd.edu Fig. 1: Gaze zones and multi-plane environment. 1: Wind- shield, 2: Right Mirror, 3: Left Mirror, 4: Infotainment Panel, 5: Rearview Mirror, and 6: Speedometer. behavior has been studied in the context of how long it takes to get the driver back into the loop when engaged in non-driving secondary task with automation in a dynamic driving simulator [7]. Therefore, estimating driver gaze and understanding gaze behavior is of increasing importance in the advancement of driver assistance and highly automated vehicles. Vision-based gaze estimation is especially desired for its non-contact, non-intrusive nature. In literature, vision based estimation works have diverged at the point of universal versus personalized models. In fact, recent works have shown impressive performance of personalized gaze estimation us- ing machine learning approaches [8] [9], while the perfor- mance of universal gaze estimation using machine learning approaches is far behind [8]. One of the disadvantages of existing learning based system is the lack of exploiting physical constraints of the car (e.g. location and relative distance between gaze zone). The question then is, can personalized systems be more generalized, with minimal effects on performance, by leveraging the geometrical con- straints of the car? This study introduces a geometric based gaze estimation method and a fusion with learning based method to raise the performance bar of universal based gaze estimation. II. RELATED WORKS In literature, vision based estimation works fall into one of two categories: learning based method or geometric methods. The work presented in [3] estimates gaze zones based on geometric methods where a 3-D car model is divided into 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC) Windsor Oceanico Hotel, Rio de Janeiro, Brazil, November 1-4, 2016 978-1-5090-1889-5/16/$31.00 ©2016 IEEE 655
Transcript of On Driver Gaze Estimation: Explorations and Fusion of...

On Driver Gaze Estimation: Explorations and Fusion of Geometric andData Driven Approaches
Borhan Vasli, Sujitha Martin, and Mohan Manubhai Trivedi
Abstract— Gaze direction is important in a number of appli-cations such as active safety and driver’s activity monitoring.However, there are challenges in estimating gaze robustly in realworld driving situations. While performance of personalizedgaze estimation models has improved significantly, performanceimprovement of universal gaze estimation is lagging behind;one reason being, learning based methods do not exploit thephysical constraints of the car. In this paper, we proposea system to estimate driver’s gaze from head and eye cuesprojected on a multi-plane geometrical environment and asystem which fuses the geometric with data driven learningmethod. Evaluations are conducted on naturalistic driving datacontaining different drivers in different vehicles in order to testthe generalization of the methods. Systematic evaluations on thisdata set are presented for the proposed geometric based gazeestimation method and geometric plus learning based hybridgaze estimation framework, where exploiting the geometricalconstraints of the car shows promising results of generalization.
Index Terms— In Cabin Activity Analysis, Human-vehicleInteraction, Gaze Estimation, Take-over, Highly AutomatedVehicles.
I. INTRODUCTION
In 2013, on average 8 people were killed and 1,161were injured everyday in the United States due to caraccidents involving distracted drivers [1]. Distracted drivingmeans that the driver is driving while doing another activitytaking his/her attention away from driving. Distracted drivingincreases the chance of motor vehicle accidents. There arethree major types of distraction while driving [2]: visual(eyes of the road), manual (hands of the wheel) and cognitive(mind off of driving). Early knowledge of driver behavior, inconcert with the vehicle and the environment (e.g. surround-ing vehicles, pedestrians) can help to recognize and preventdangerous situations.
Driver gaze estimation is one of the key componentsfor estimating and representing driver behavior, as seen incurrent research developments for driver assistance systemsas well as for highly automated vehicles. In [4], Ohn-Baret al. explored early prediction of maneuvers such as over-take and brake, where driver related cues (e.g. head, eyes)showed earlier and stronger predictive importance comparedto surround and vehicle cues. On the other hand, Li etal. [6] explored the predictive importance of driver’s gazefor maneuver and secondary task detection; they exploitedthe findings that the duration and frequency of mirror-checking actions differed among maneuvers, secondary taskperformance and baseline/normal driving. Furthermore, gaze
The authors are with the Laboratory for Intelligent and Safe Automobiles(LISA), University of California San Diego, La Jolla, CA 92092, USA{bvasli, scmartin, mtrivedi}@ucsd.edu
Fig. 1: Gaze zones and multi-plane environment. 1: Wind-shield, 2: Right Mirror, 3: Left Mirror, 4: Infotainment Panel,5: Rearview Mirror, and 6: Speedometer.
behavior has been studied in the context of how long ittakes to get the driver back into the loop when engaged innon-driving secondary task with automation in a dynamicdriving simulator [7]. Therefore, estimating driver gaze andunderstanding gaze behavior is of increasing importance inthe advancement of driver assistance and highly automatedvehicles.
Vision-based gaze estimation is especially desired for itsnon-contact, non-intrusive nature. In literature, vision basedestimation works have diverged at the point of universalversus personalized models. In fact, recent works have shownimpressive performance of personalized gaze estimation us-ing machine learning approaches [8] [9], while the perfor-mance of universal gaze estimation using machine learningapproaches is far behind [8]. One of the disadvantages ofexisting learning based system is the lack of exploitingphysical constraints of the car (e.g. location and relativedistance between gaze zone). The question then is, canpersonalized systems be more generalized, with minimaleffects on performance, by leveraging the geometrical con-straints of the car? This study introduces a geometric basedgaze estimation method and a fusion with learning basedmethod to raise the performance bar of universal based gazeestimation.
II. RELATED WORKS
In literature, vision based estimation works fall into one oftwo categories: learning based method or geometric methods.The work presented in [3] estimates gaze zones based ongeometric methods where a 3-D car model is divided into
2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC)Windsor Oceanico Hotel, Rio de Janeiro, Brazil, November 1-4, 2016
978-1-5090-1889-5/16/$31.00 ©2016 IEEE 655

different zones and 3-D gaze tracking is used to classify intogaze zones; however, no evaluations on gaze zone level isgiven. Another geometric based method, based on an earlierwork [13], is presented in [5], where the number of gazezones estimated is very limited (i.e. on-road versus off-road)and evaluations are conducted in stationary vehicles.
In terms of learning based methods, there are two prevalentworks. Tawari et al., in two separate studies, studied theimportance of head pose, head dynamics and eye cues.One of the distinguishing contributions of their work is inthe design of the features to represent observable drivercues in order to robustly estimate driver’s gaze: one is thedynamic representation of the driver’s head [12] and anotheris the representation of horizontal and vertical eye gazesurrogates [9]; evaluations in both studies were conductedwith naturalistic driving data. Another learning based methodis the work presented by Fridman et al. [8] [14] where theevaluations are commendably done on a large dataset butthe design of the features to represent the state of the headand eyes is what is causing their classifier to overfit to userbased models and causing a sharp decrease in performancefor global based models.
Our proposed method employs a geometric based methodto classify gaze into size gaze zones, which is illustratedin Fig. 1. Furthermore, we compare the performance withthe learning based method proposed in [9] and show that ahybrid of geometric and learning based methods gives betterperformance.
III. SYSTEM DESCRIPTION
The building block of the geometrical gaze estimationmethod and the existing learning based method is shownin Fig. 2. This section describes the main components ofour work which consists of the following steps: low levelfeatures, multi-plane geometric gaze estimation, learningbased gaze estimation and hybrid gaze zone estimation. Thefollowing section goes in more depth how each of the abovecomponents were implemented.
A. Low-Level Features
The gaze estimation system requires facial landmarks. Forexample position of pupil in image plane and head pose (i.e.pitch, yaw and roll). For each frame, first a face is detected[10], then facial landmarks [11] and finally iris locations[9]. Fig. 3 illustrates the landmarks for a sample frame.Moreover, head pose is calculated from landmarks such aseye corners, nose corners and nose tip as shown by yellowdots in Fig. 3. From the tracked landmarks and their relative3-D configurations, a weak perspective projection model,POS (Pose From Orthography and Scaling), determines therotation matrix and corresponding yaw, pitch and roll anglesof the head pose [12].
To compute the eye gaze with respect to the head, theproposed system requires the 3-D model of eye to get therelative position of eye contour and ultimately the pupil in3-D. We made a few assumptions in the process of the eyemodeling based on the physical and biological structure of
the eye. First assumption was that the eyeball is sphericaland has constant radius across different people. The secondwas that the eyes need to be open and pupils visible in orderto estimate the gaze vector.
Fig. 3: Facial Landmark and Head Pose. Total of 51 landmarkestimated for the face and 6 of them marked with yellow usedfor estimating the head pose
Fig. 4a illustrates the eye contour e1, e2, ..., e6 on the 3-D eye model. Since the 3-D eye model is used to find therelative position of the pupil with respect to the center ofthe eyeball P in Fig. 4b, the exact position of eye contouris not crucial. By setting the eye contour once as in Fig. 4aand we find the transformation matrix to map the 3-D pointsto the 2-D points in image plane. So for each frame, theeye contour in world coordinate can be generated from theeye landmarks in the image plane and the inverse transformmatrix.
Finally the 3-D position of the pupil can be estimatedby using the barycentric coordinate transformation to mapthe pupil from image plane to world coordinate [6]. Theadvantage of this transformation is that it preserves therelative distance of pupil to each corner, therefore the relativeposition of the pupil in 3-D will be consistent with eachimage. Fig. 4b illustrates the result.
(a) (b)
Fig. 4: 4a: the 3-D eye model with corresponding eyecontour. 4a: 2D to 3-D transformation of the pupil using thebarycoordinate transformation of the pupil. barycoordinatemaps the pupil in such a way that preserves its relativedistance each eye corner
B. Multi-plane geometric method
The ultimate goal for gaze zone estimation is to classifythe projection (intersection) of gaze vector onto multi-planeframework. The model uses Unity, which is a cross-platformgame engine, to generate a generic car model in the worldcoordinate [15]. For consistency, the origin of world’s co-ordinate is set to be the center of the driver’s head. Theplanes are defined manually for desired regions and alsoscaled to real ratios of specific car [16]. Fig. 6 shows the
656

CarConstraint
DefinePlanes
HeadPose &
LandmarksGaze Vector
Projectonof Gaze
on planesSVM Gaze Zone
HeadPose &
Landmarks
RemovedBiased
Head Pose
HorizentalGaze Angle
VerticalGaze Angle
SVM Gaze Zone
Fig. 2: Geometric based method’s block diagram on the left and learning based method’s block diagram on the right
planes in 3-D generic car model. For this paper, we define 4planes which represent windshield, right mirror, left mirrorand infotainment panel. This work can be extended to includerearview mirror and speedometer plane.
~rref
~rgaze
pupil
P
Plane: Π
θY
Z
L
Eye
Fig. 5: This figure shows the 3-D gaze estimation model.Gaze vector is connecting the center of the eyeball P and 3-D position of the pupil. θ is the relative angle of windshieldplane with respect to the driver and Lis the distance of driverfrom the windshield. These parameter can be adjust dependson the car and the user.
The gaze vector is defined as a vector that shows wherethe driver is looking with respect to world coordinate. Finalgaze vector consist of rotating the reference gaze vector(~rref ) based on three factors: head pose, eye pose andremoval of bias. Gaze vector in general is set to be thevector connecting the origin of world’s coordinate i.e. centerof eyeball, to the pupil in world’s coordinate as describedin Fig. 5. ~rref is the gaze vector when the driver is facingforward and looking forward, and normal distance from thewindshield plane. In general, the rotation matrix is based onthree angels Φx, Φy and Φz ,which determines the rotationalong each axis:
Rot(·) = Rz(Φz)Ry(Φy)Rx(Φx) (1)
Fig. 6: 3-D model of car and planes in unity environment.Planes are defined manually and their equations are used tofind the intersection points.
where,
Rx(Φx) =
1 0 00 cos(Φx) − sin(Φx)0 sin(Φx) cos(Φx)
(2)
Ry(Φy) =
cos(Φx) 0 sin(Φx)0 1 0
− sin(Φx 0 cos(Φx)
(3)
Rz(Φz) =
cos(Φz) − sin(Φz) 0− sin(Φx) cos(Φz) 0
0 0 1
(4)
~rfinal = RTBias ×REye ×RPose × ~rref (5)
As mentioned before, pose = [ΦxΦyΦz] is the yaw,pitch, and roll angels. Having the pose values one can findthe rotation matrix, Rpose, which rotate ~rref relative tothe camera. Similarly, Reye is the rotation matrix whichdescribes the movement of the pupil with respect to thehead. Lastly, the rotation Rbias is due to removing theeffect of camera placement. Pose values are with respectto the camera coordinate system, therefore different cameraplacement cause different pose and consequently differentRpose. Rbias is defined to translate any given pose withrespect to hpbias. Rbias rotation makes the pose values tobe pose = [0 0 0] when the driver is in normal distancefrom windshield, frontal face and looking forward. This stepmakes the framework independent of camera placement indifferent situation. hpbias can be obtained from the first fewframes as an initialization step. ~rfinal the final gaze vectoras computed by eq. 5.
657
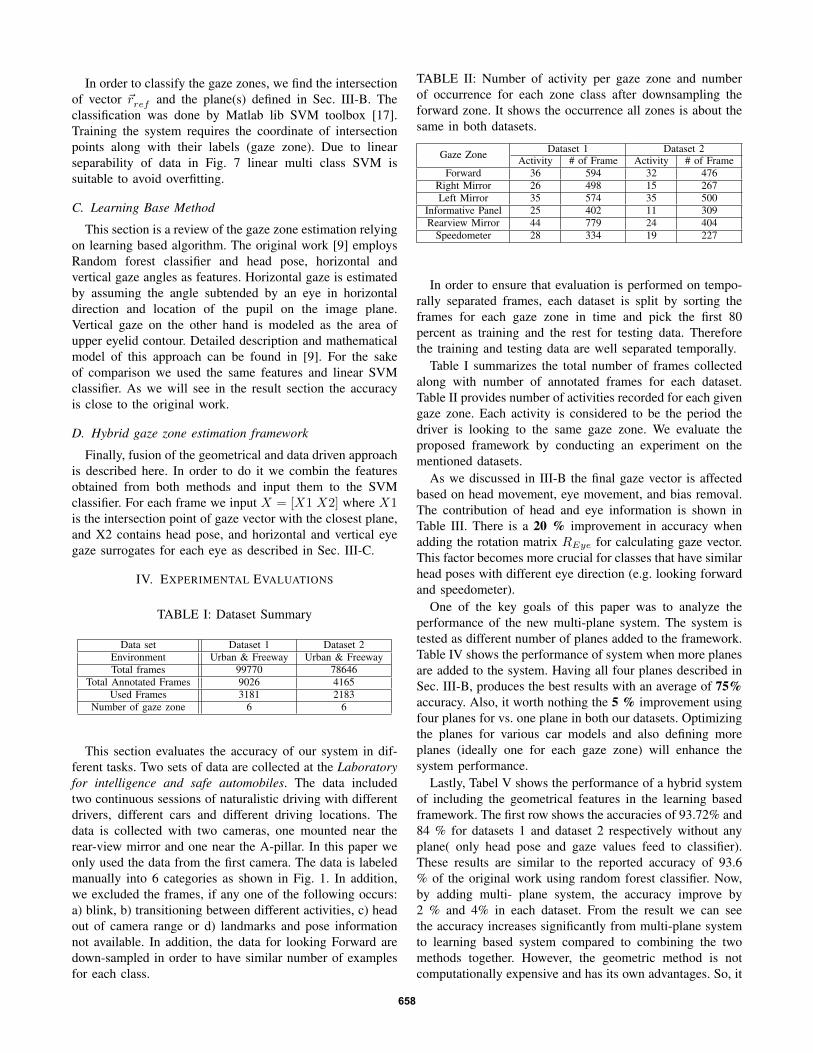
In order to classify the gaze zones, we find the intersectionof vector ~rref and the plane(s) defined in Sec. III-B. Theclassification was done by Matlab lib SVM toolbox [17].Training the system requires the coordinate of intersectionpoints along with their labels (gaze zone). Due to linearseparability of data in Fig. 7 linear multi class SVM issuitable to avoid overfitting.
C. Learning Base Method
This section is a review of the gaze zone estimation relyingon learning based algorithm. The original work [9] employsRandom forest classifier and head pose, horizontal andvertical gaze angles as features. Horizontal gaze is estimatedby assuming the angle subtended by an eye in horizontaldirection and location of the pupil on the image plane.Vertical gaze on the other hand is modeled as the area ofupper eyelid contour. Detailed description and mathematicalmodel of this approach can be found in [9]. For the sakeof comparison we used the same features and linear SVMclassifier. As we will see in the result section the accuracyis close to the original work.
D. Hybrid gaze zone estimation framework
Finally, fusion of the geometrical and data driven approachis described here. In order to do it we combin the featuresobtained from both methods and input them to the SVMclassifier. For each frame we input X = [X1 X2] where X1is the intersection point of gaze vector with the closest plane,and X2 contains head pose, and horizontal and vertical eyegaze surrogates for each eye as described in Sec. III-C.
IV. EXPERIMENTAL EVALUATIONS
TABLE I: Dataset Summary
Data set Dataset 1 Dataset 2Environment Urban & Freeway Urban & FreewayTotal frames 99770 78646
Total Annotated Frames 9026 4165Used Frames 3181 2183
Number of gaze zone 6 6
This section evaluates the accuracy of our system in dif-ferent tasks. Two sets of data are collected at the Laboratoryfor intelligence and safe automobiles. The data includedtwo continuous sessions of naturalistic driving with differentdrivers, different cars and different driving locations. Thedata is collected with two cameras, one mounted near therear-view mirror and one near the A-pillar. In this paper weonly used the data from the first camera. The data is labeledmanually into 6 categories as shown in Fig. 1. In addition,we excluded the frames, if any one of the following occurs:a) blink, b) transitioning between different activities, c) headout of camera range or d) landmarks and pose informationnot available. In addition, the data for looking Forward aredown-sampled in order to have similar number of examplesfor each class.
TABLE II: Number of activity per gaze zone and numberof occurrence for each zone class after downsampling theforward zone. It shows the occurrence all zones is about thesame in both datasets.
Gaze Zone Dataset 1 Dataset 2Activity # of Frame Activity # of Frame
Forward 36 594 32 476Right Mirror 26 498 15 267Left Mirror 35 574 35 500
Informative Panel 25 402 11 309Rearview Mirror 44 779 24 404
Speedometer 28 334 19 227
In order to ensure that evaluation is performed on tempo-rally separated frames, each dataset is split by sorting theframes for each gaze zone in time and pick the first 80percent as training and the rest for testing data. Thereforethe training and testing data are well separated temporally.
Table I summarizes the total number of frames collectedalong with number of annotated frames for each dataset.Table II provides number of activities recorded for each givengaze zone. Each activity is considered to be the period thedriver is looking to the same gaze zone. We evaluate theproposed framework by conducting an experiment on thementioned datasets.
As we discussed in III-B the final gaze vector is affectedbased on head movement, eye movement, and bias removal.The contribution of head and eye information is shown inTable III. There is a 20 % improvement in accuracy whenadding the rotation matrix REye for calculating gaze vector.This factor becomes more crucial for classes that have similarhead poses with different eye direction (e.g. looking forwardand speedometer).
One of the key goals of this paper was to analyze theperformance of the new multi-plane system. The system istested as different number of planes added to the framework.Table IV shows the performance of system when more planesare added to the system. Having all four planes described inSec. III-B, produces the best results with an average of 75%accuracy. Also, it worth nothing the 5 % improvement usingfour planes for vs. one plane in both our datasets. Optimizingthe planes for various car models and also defining moreplanes (ideally one for each gaze zone) will enhance thesystem performance.
Lastly, Tabel V shows the performance of a hybrid systemof including the geometrical features in the learning basedframework. The first row shows the accuracies of 93.72% and84 % for datasets 1 and dataset 2 respectively without anyplane( only head pose and gaze values feed to classifier).These results are similar to the reported accuracy of 93.6% of the original work using random forest classifier. Now,by adding multi- plane system, the accuracy improve by2 % and 4% in each dataset. From the result we can seethe accuracy increases significantly from multi-plane systemto learning based system compared to combining the twomethods together. However, the geometric method is notcomputationally expensive and has its own advantages. So, it
658
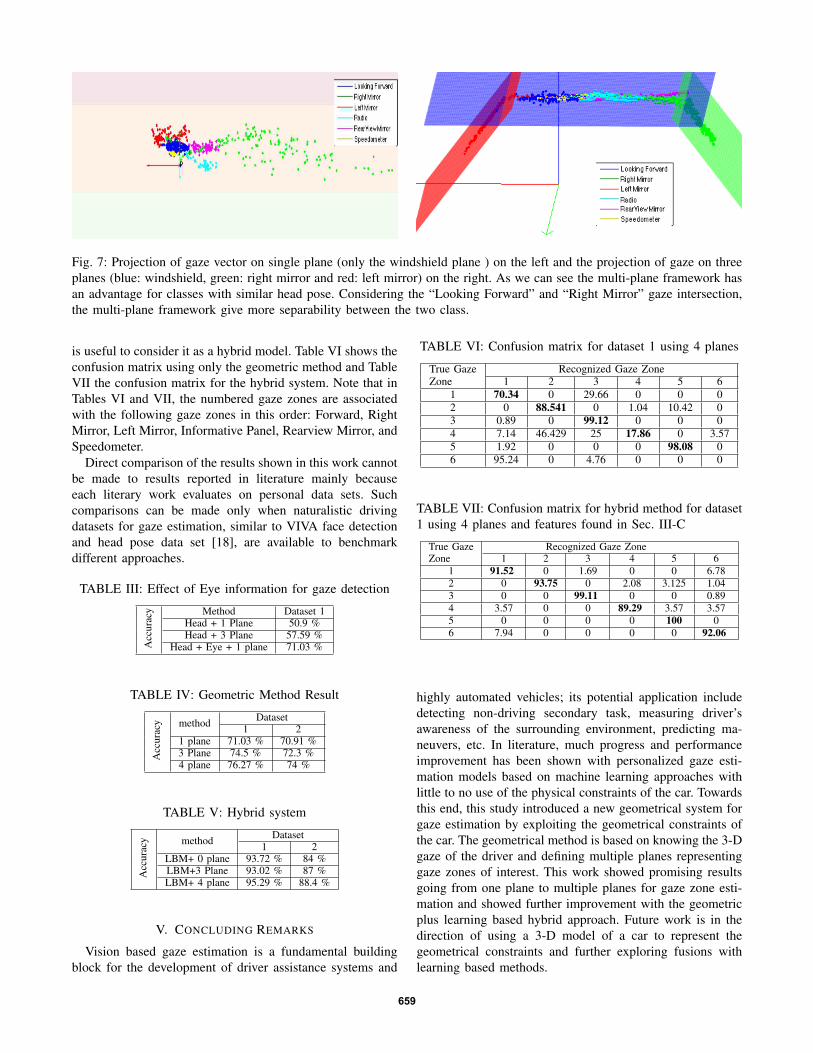
Fig. 7: Projection of gaze vector on single plane (only the windshield plane ) on the left and the projection of gaze on threeplanes (blue: windshield, green: right mirror and red: left mirror) on the right. As we can see the multi-plane framework hasan advantage for classes with similar head pose. Considering the “Looking Forward” and “Right Mirror” gaze intersection,the multi-plane framework give more separability between the two class.
is useful to consider it as a hybrid model. Table VI shows theconfusion matrix using only the geometric method and TableVII the confusion matrix for the hybrid system. Note that inTables VI and VII, the numbered gaze zones are associatedwith the following gaze zones in this order: Forward, RightMirror, Left Mirror, Informative Panel, Rearview Mirror, andSpeedometer.
Direct comparison of the results shown in this work cannotbe made to results reported in literature mainly becauseeach literary work evaluates on personal data sets. Suchcomparisons can be made only when naturalistic drivingdatasets for gaze estimation, similar to VIVA face detectionand head pose data set [18], are available to benchmarkdifferent approaches.
TABLE III: Effect of Eye information for gaze detection
Acc
urac
y Method Dataset 1Head + 1 Plane 50.9 %Head + 3 Plane 57.59 %
Head + Eye + 1 plane 71.03 %
TABLE IV: Geometric Method Result
Acc
urac
y method Dataset1 2
1 plane 71.03 % 70.91 %3 Plane 74.5 % 72.3 %4 plane 76.27 % 74 %
TABLE V: Hybrid system
Acc
urac
y method Dataset1 2
LBM+ 0 plane 93.72 % 84 %LBM+3 Plane 93.02 % 87 %LBM+ 4 plane 95.29 % 88.4 %
V. CONCLUDING REMARKS
Vision based gaze estimation is a fundamental buildingblock for the development of driver assistance systems and
TABLE VI: Confusion matrix for dataset 1 using 4 planes
True GazeZone
Recognized Gaze Zone1 2 3 4 5 6
1 70.34 0 29.66 0 0 02 0 88.541 0 1.04 10.42 03 0.89 0 99.12 0 0 04 7.14 46.429 25 17.86 0 3.575 1.92 0 0 0 98.08 06 95.24 0 4.76 0 0 0
TABLE VII: Confusion matrix for hybrid method for dataset1 using 4 planes and features found in Sec. III-C
True GazeZone
Recognized Gaze Zone1 2 3 4 5 6
1 91.52 0 1.69 0 0 6.782 0 93.75 0 2.08 3.125 1.043 0 0 99.11 0 0 0.894 3.57 0 0 89.29 3.57 3.575 0 0 0 0 100 06 7.94 0 0 0 0 92.06
highly automated vehicles; its potential application includedetecting non-driving secondary task, measuring driver’sawareness of the surrounding environment, predicting ma-neuvers, etc. In literature, much progress and performanceimprovement has been shown with personalized gaze esti-mation models based on machine learning approaches withlittle to no use of the physical constraints of the car. Towardsthis end, this study introduced a new geometrical system forgaze estimation by exploiting the geometrical constraints ofthe car. The geometrical method is based on knowing the 3-Dgaze of the driver and defining multiple planes representinggaze zones of interest. This work showed promising resultsgoing from one plane to multiple planes for gaze zone esti-mation and showed further improvement with the geometricplus learning based hybrid approach. Future work is in thedirection of using a 3-D model of a car to represent thegeometrical constraints and further exploring fusions withlearning based methods.
659

Fig. 8: Each row of images shows different activities of the driver form same datasets. From left to right : “Left Mirror”,“Right Mirror”, “Rearview mirror”, and “Radio”. It also illustrates some of the difficulties for gaze estimation such as eyeself occlusion for left mirror (first column), and pupil occlusion for radio (third column)
ACKNOWLEDGMENT
The authors would like to thank their colleagues, particu-larly Kevan Yuen for helping with the data collection processand Aida Khosroshahi for her comments and suggestionsto improve this work. The authors gratefully acknowledgesponsorship from our industry partners.
REFERENCES
[1] National Highway Traffic Safety Administration, “Distracted Driving:2013 Data, in Traffic Safety Research Notes,” April 2015.
[2] National Highway Traffic Safety Administration, “Policy Statementand Compiled FAQs on Distracted Driving,” 2014.
[3] C. Ahlstrom, K. Kircher, and A. Kircher. “A gaze-based driverdistraction warning system and its effect on visual behavior,” IEEETransactions on Intelligent Transportation Systems, 2013.
[4] E. Ohn-Bar, A. Tawari, S. Martin and Mohan M. Trivedi, “OnSurveillance for Safety Critical Events: In-Vehicle Video Networksfor Predictive Driver Assistance Systems,” Computer Vision and ImageUnderstanding, 2015.
[5] F. Vicente, Z. Huang, X. Xiong, F. Torre, W. Zhang, and D. Levi.“Driver Gaze Tracking and Eyes Off the Road Detection System.”IEEE Transactions on Intelligent Transportation Systems, 2015.
[6] N. Li, and C. Busso. “Detecting Drivers’ Mirror-Checking Actionsand Its Application to Maneuver and Secondary Task Recognition.”IEEE Transactions on Intelligent Transportation Systems, 2016.
[7] C. Gold, D. Dambock, L. Lorenz, and K. Bengler, “ “Take over!?How long does it take to get the driver back into the loop?,” HumanFactors and Ergonomics Society Annual Meeting, 2013.
[8] L.Fridman, P. Langhans, J. Lee, B. Reimer, and T. Victor, “ “Owl”and “Lizard” : Patterns of Head Pose and Eye Pose in Driver GazeClassification,” arXiv preprint arXiv, 2015.
[9] A. Tawari, K. H. Chen and M. M. Trivedi, “Where is the driver look-ing: Analysis of head, eye and iris for robust gaze zone estimation,”International IEEE Conference on Intelligent Transportation Systems,2014.
[10] K. Yuen, S. Martin and M. M. Trivedi, “On Looking at Faces in anAutomobile: Issues, Algorithms and Evaluation on Naturalistic Driv-ing Dataset,” 23rd International Conference on Pattern Recognition(ICPR), 2016.
[11] K. Yuen, S. Martin and M. M. Trivedi, “Looking at Faces in a Vehicle:A Deep CNN Based Approach and Evaluation,” IEEE Conference onIntelligent Transportation Systmes (ITSC), 2016.
[12] A. Tawari and M. M. Trivedi, “Robust and continuous estimation ofdriver gaze zone by dynamic analysis of multiple face videos,” IEEEIntelligent Vehicles Symposium Proceedings, 2014.
[13] T. Ishikawa, S. Baker, I. Matthews, and T. Kanade, “Passive drivergaze tracking with active appearance models,” 11th World CongressIntelligent Transport System, 2004.
[14] L. Fridman, P. Langhans, J. Lee, and B. Reimer, “Driver Gaze RegionEstimation without Use of Eye Movement,” IEEE Intelligent Systems,2016.
[15] “Create and Connect with Unity.” Unity. N.p., n.d. Web. 16 June 2016.[16] “Vehicle Specs Database.” FARO Technologies Inc. N.p., n.d. Web.
12 June 2016.[17] C.C. Chang and C.J. Lin. “LIBSVM : a library for support vector
machines,” ACM Transactions on Intelligent Systems and Technology,2011.
[18] S. Martin, K. Yuen and M. M. Trivedi, “Vision for Intelligent Vehiclesand Applications (VIVA): Face Detection and Head Pose Challenge,”IEEE Intelligent Vehicles Symposium (IV), 2016.
660

















