
인사이트 사용자 가이드 - ADOPINSIGHT 소개 1) 소개 4 2) 특징 4 3) ... 필터 및 검색 옵션 기능 추가 ... 사이트 유입경로, 인구 통계 데이터에 대

1
인공지능 강의 노트 (2017/3/12) 서울대학교 컴퓨터공학부 장병탁 (Version 0.9 수강생용. 외부에는 아직 공개하지 말아 주세요. Thanks.) 제 2장 . 인지 에이전트 2.1 인간수준 인공지능 2.2 인지 에이전트 2.3 지각-행동-학습 사이클 2.4인지 아키텍처 2.5인공지능 로봇 2.1 인간수준 인공지능 인공지능은 인간의 마음을 연구하는 인지과학 및 뇌과학과 밀접한 관련이 있다.
인지과학의 계산주의(computationalism)와 인공지능의 기호주의(symbolism)는
기능주의(functionalism)라는 같은 철학적 기반 위에서 출발하였다. 그 후
인지과학은 뇌연구를 기반으로 하는 연결주의(connectionism), 지각과 행동을 중시하는 역동주의(dynamicism) 등 마음에 대한 새로운 패러다임을 수용하며
발전하였다. 그러나 인공지능은 뇌인지과학의 발전을 무시하고 응용 문제 풀기에
급급한 나머지 인간의 마음의 구조와 원리에 대한 중요한 요소들을 놓쳤다는
비판도 있다. 이 절에서는 인지과학과 뇌과학에서의 인간의 마음에 대한 그
동안의 연구를 살펴보고 이를 기반으로 인지적인 인공지능(cognitive AI) 그리고 더 나아가서 인간수준의 인공지능(human-level AI)을 실현하기 위한 방향을
살펴보기로 한다.
그림 2-1 에서는 인간의 마음을 연구하는 인지과학과 인간의 마음을 닮은
기계를 연구하는 인공지능이 지난 반 세기 이상 진화해 온 과정을 정리한 것이다.
인지과학은 초기에 내성주의(introspectionism)에 이어 행동주의(behaviorism)적 입장에서 과학적으로 인간을 이해하려는 연구를 하였다. 그러나 행동주의가
관측할 수 있는 것만이 과학이라는 방법론적인 새로운 입장을 제시했지만, 인간의
마음을 무시하는 오류를 범했다는 것을 알고 인간의 마음을 연구의 중심에 두는
인지과학 연구가 1950 년대에 시작된다. 인간을 닮은 지능적인 기계를 개발하려는
인공지능 연구에 이 때 같이 시작된다. 그러나 계산주의(computationalism) 관점의 인지과학과 고전적인 기호주의(symbolism) 인공지능은 마음의 근원인
뇌를 다루지 못했다는 것을 인식하고 1980 년대에 들어서는 뇌기반의 마음을
연구하기 시작한다. 이것이 인지과학에서는 연결주의(connectionism)이고
인공지능에서는 신경망(neural networks) 연구이다. 그러나 2000 년대 들어서는
뇌만으로는 인간의 마음을 모두 설명할 수 없다는 것을 인식하고 신체도 마음을 이해하는데 중요하다는 인식을 하고 체화된 인지(embodied cognition)을
인지과학이 연구하기 시작한다. 인공지능 또한 신체의 중요성을 인식하고 그 전에

2
연구하던 지능형 에이전트(소프트웨어 로봇)에서 더 나아기 진짜로 신체를 갖춘
자율주행 로봇(autonomous robots)을 연구하기 시작한다. 그런 관점에서 보면
최근에 스마트폰과 웨어러블 장치에 기반한 실세계에서의 인공지능 연구나 최근 대두되고 있는 사물인터넷 환경에서의 센서 데이터에 기반한 인공지능 연구는
자연스러운 진화과정으로 볼 수 있다. 인지과학에서는 이러한 연구를 행동
과학(action science)라고 하는 학자들도 있다.
그림 2-1. 인지과학(humans, NI)과 인공지능(machines, AI)의 공진화
아래에서는 체화된 인지과 보다 최근의 행동 과학에 대한 배경 이론을 설명할
것이다. 그리고 이를 다루기 전에 먼저 그 효시역할을 한 생태학적 발달 이론을
먼저 살펴보기로 하자. 그리고 이어서 이러한 인지과학의 이론이 인공지능
연구에서 반영되어 탄생된 인지 로보틱스에서의 연구 동향을 살펴보기로 한다.
생태학적 발달 이론 지각과 행동의 중요성을 강조하는 인지과학 연구 분야 중 하나가 생태 심리학(ecological psychology)이다. James J. Gibson 의 생태학적 발달 이론은 그
대표적인 예로서 1960 년대와 1970 년대에 제시되었다[10]. 생태 심리학은
실험실 내에서의 인공 환경에서의 실험에 반대하며 실세계에서의 행동 연구를
강조한다. Gibson 은 동물과 사람은 환경과 시스템적 생태학적인 관계에 있으며,
행동을 적절히 설명하기 위해서는 행동이 일어난 환경 즉 니치, 특히 개체와 환경을 인식론적으로 연결하는 정보를 연구하는 것을 중시한다. Gibson 은 특히
환경과 문맥의 중요성을 강조하며 내부적인 감각 보다는 외부 환경으로부터 얻는
정보가 지각의 기반이 된다고 본다. 발달과정에서 지각은 동물이나 사람으로
하여금 환경에 적응하도록 할 수 있기 때문에 중요하다. 아이들은 일상 행동에서
사용할 수 있는 사물, 사건, 틀을 기술하는 정보를 찾는 것을 학습하며 따라서
Humans (NI) and Machines (AI)
! Introspectionism - 1920
Psyche ! Behaviorism "# Cybernetics 1920 - 1950
Mind (= Computer) ! Cognitivism "# Symbolic AI 1950 - 1980
Brain ! Connectionism "# Neural Nets (ML) 1980 – 2010
Body ! Action Science "# Autonomous Robots 2010 –
Environment
36
Embodied Mind | Mind Machine ( = Smart Machine)

3
사람은 필요에 의해서 학습한다. 아이들은 세상에서 살아남고 움직이는데 필요한
정보를 수집하는 정보의 수렵채집인 (hunter-gatherer)이다.
생태학적 발달 이론에 의하면 발달은 환경적인 적합성(affordance)과 이를 지각하는 동기가 부여된 사람간의 복잡한 상호작용에 의해서 추진된다. Gibson 은
4 개의 주요 인간행동 발달 요소를 찾아내었다. 이는 (1) 주체성, (2) 전향성, (3)
질서지향성, (4) 유연성이다. 행동은 (1) 자기통제에 의해서 의도적으로 하는
것이며, (2) 예상하고 기획하며 미래지향적으로 수행하며, (3) 세상에서 뜻이
통하는 질서, 규칙성, 패턴을 찾아가는 과정이며, (4) 지각은 새로운 환경이나 신체 조건에 적응할 수 있다는 것이다. 그리고 지각은 무엇보다도 계속되는 능동적인
과정이라고 역설한다.
Gibson 의 이론은 1970 년대 말까지 발전하였으며 그당시에 대두되고 있던
구성주의적(constructivist), 정보처리 패러다임 및 인지주의적(cognitivist) 관점을
거부하였다. 즉 머릿속의 신경과학적인 기반 위에서, 외부로부터 입력되는 의미 없는 물리적인 감각으로부터 의미 있는 심적 지각을 출력 생성하는 정보 처리와
표상을 거부했다.
그림 2-2. 체화된 인지 에이전트로서의 인간.
체화된 인지 이론 기호적 인공지능 연구와 맥을 같이한 인지과학의 주 연구흐름은 인지주의였다. 즉
마음은 외부 세계에 대한내부 표상을 가지고 이 표상을 조작함으로써 인지현상을
설명할 수 있다고 보는 입장이다. 이 정보처리 모델또는 인지주의는 1960 년대
이후 인지심리학의 주류를 이루었으며 표상을 강조한 반면 환경과의 상호작용과지각 행동을 무시하는 오류를 범하였다. 이는 촘스키가 언어 이론에서
능력(competence)과 수행(performance)을 구별하면서 능력을 강조하고 언어학의
주요 연구대상으로 삼은 반면에 수행 측면은 보조적인 부차적인 문제로 치부하며

4
언어학의 핵심 연구 분야에서 배제하려고 했던 것과 통하는 관점이다. 그러나
최근 들어 이러한 형식론적 접근 방식에 대한 반론들이 제기되고 또한 특히
뇌신경과학 분야에서 새로운 증거나 나옴에 따라서 체화된 인지(embodied cognition) 또는 Grounded Cognition 에 대한 연구가 활발해 지고 있다[11].
뇌과학 분야에서 신경언어학(neurolinguistics), 체화된 언어 (embodied
language)에 대한 신경과학 연구로 나타나고 있다[12,13]. 언어학자인 Lakoff 는
대부분의 인간 인지가 감각행동 및 감정 등의 구체적이고 낮은 수준의 장치와
연결되어 있다고 주장한다[14]. 예를 들어, 색깔이나 공간관계는 신경과학적으로 지각이나 모터의 과정을 조사함으로써 이해될 수 있다는 것이다. 이는 심신
이원론에 반대하는 것이며 인간의 이성이 구현 구체성을 참조하지 않고 이해될 수
있다고 보는 주장에 반대되는 개념이다.
행동 과학 인지심리학자인 Prinz 는 지각코드와 행동코드가 연합되어 있다는
공통코딩이론(common coding theory)을 발표하였다[15]. 행동을 수행하는 것은
그에 관련된 모터 패턴과 감각 패턴간의 양방향의 연합 흔적을 남기는 것이며, 후에 감각 효과를 기대함으로써 행동을 유발할 수 있다는 것이다. 이 이론은
인지가 행동에 기반해 있다는 모터인지(motor cognition)의 핵심을 이룬다.
행동을 수행할 때 활성화 되는 뉴런들이 다른 사람이 행동을 하는 것을 관찰할
때도 활성화되는 거울 뉴런의 발견은 공통코딩이론의 증거의 하나이다[16].
유사한 맥락에서 최근에 의사결정이나 개념학습시 다중센서 큐의 결합에 관한 베이지안 모델들이 제안되고 있다[17,18]. 신경과학 분야에서 Damasio 는 의식에
있어서 감성의 중요성을 강조하면서 몸과 마음의 일체성을 주장하였고[19],
Tomasello 는 침팬지와 아이들의 언어 습득을 연구하면서 환경에 처한 상호주의
집중과 사용기반 언어습득 이론을 제시하였다[20]. 최근에는 이를 확장하여 인지
발달에 있어서 사회적, 문화적인 요소를 강조하고 있다. 심리학자 Barsalou 는 상황적 개념화 과정이 다중감각(그림 2)에 기반하고 있음을 강조하는 지각적
기호시스템(perceptual symbol system) 이론을 제시하였다. 이는 고전적인
인공지능의 기반이 되었던 Newell 의 물리적 기호시스템(physical symbol system)
가설[5]과 대조적이다.
인지 로보틱스 체화된 인지의 개념은 공학분야에서 인지 로보틱스로 발전하였다[22,23]. 초의 인공지능 로봇 중의 하나는 1960~1972 년 사이에 SRI 에서 개발된 이동로봇
Shakey 이다[24]. 이 로봇은 지각 능력이 상당히 제한되어 있기는 하였으나, 이미
카메라를 갖추고 있었으며, 계획을 필요로 하는 작업을 수행하고, 이동하며 길
찾기를 수행하고 물건을 조작하는 등 현대적인 자율이동로봇의 중요한 특징을
모두 갖추고 있었다. 1980 년대에는 전통적인 기호조작 기반의 인공지능 연구에

5
대한 반발로 행동기반 로봇 연구가 시작되었다[25-27]. 1990 년대에는 유전자
알고리즘 및 진화연산과 접목하여 진화 로봇 연구가 활발하였으며, 최근 발달
로봇, Epigenetic Robot 이 연구되고 있다. 몸과 행동을 강조한 이러한 로봇은 기존의 기호조작 기반의 인공지능 연구와는 대조되는 점에서 특이한 반면 대신
표상과 고차적인 인지정보처리 과정을 무시하는 경향이 있었다.
그림 2-3. 인지 로봇
인지로보틱스(cognitive robotics)는 로봇에게 복잡한 세계에서 복잡한 목표에
반응하여 행동하기 위해 학습하고 추론하는 처리구조를 제공함으로써 지능적인
행동을 부여하는 기술을 연구한다(그림 3). 전통적인 인지모델링 접근 방법이 세상을 묘사하는 방법으로 기호코딩 방식을 가정하였으나, 세상을 이와 같은
기호표상으로 번역하는 것은 문제가 많다는 것이 밝혀졌다. 따라서 지각과 행동
및 기호 표상의 개념은 인지로보틱스에서 다루는 핵심 주제이다.
인지로보틱스는 전통적인 인공지능 기술과는 달리 동물의 인지를
로봇정보처리 발달을 위한 출발점으로 삼는다. 목표하는 로봇 인지 능력은 지각처리, 주의 할당, 예상, 계획, 복잡한 모터 협력, 에이전트 및 자기 자신의 심리
상태에 대한 추론 등을 포함한다. 로봇 인지는 물리적인 세계(또는 시뮬레이션 된
인지 로봇에서는 가상세계)에서의 지능적인 에이전트의 행동을 체화한다.
궁극적으로 로봇은 실세계에서 행동할 수 있어야 한다. 인지 로봇은 다음과 같은
능력을 보유하여야 한다.
• 지식과 신념과 같은 정보 태도
• 선호도와 목표와 같은 동기 태도
• 심적 태도를 수정하고
• 추론, 의사결정, 계획, 관측, 통신하는 인지 능력 • 이동하고, 물체를 조작하고,
• 물체들과 안전하게 상호작용하는 물리적인 능력

6
최근에 다양한 종류의 사람을 닮은 인간형 로봇 또는 인지 로봇들이 등장하고 있다. 윌로우 가라지에서 만든 개인용 로봇 PR2, 프라운호퍼 연구소에서 개발한 Care-O-Bot 4, 알데바란에서 개발한 소프트뱅크의 Pepper 로봇 등이 있다(그림 2-5). 이들 퍼스널 로봇들은 사람 크기의 휴머노이드 로봇으로 주변 환경을 인식하여 바퀴로 이동하고 팔과 손으로 물체를 조작하거나 제스처를 하며 사람과 상호작용을 할 수 있다. 일부 로봇은 시각과 음성을 기반으로 사람과 의사 소통과 감정을 교환하는 행동을 보이기도 한다. 이러한 로봇 플랫폼에 인간수준의 지성과 감성 및 사회성을 부여하기 위한 인공지능 기술을 개발하는 것은 아주 흥미있고 유용한 일이다. 2.2 인지 에이전트 앞에서 다룬 인지과학 연구 기반의 인간수준의 인공지능에 도달하기 위해서는 보다 구체적인 인간수준의 지능체를 생각할 필요가 있다. 그러한 인간수준의 인공지능의 예로서 인지 에이전트를 정의하기로 하자. 인지 에이전트는 사람의 인지 능력을 모사하는 지능형 에이전트로 정의된다. 사람의 인지 기능은 지각, 행동, 기억, 학습, 추론, 의사결정, 언어, 시각 등을 포함하며 따라서 인지 에이전트는 환경 인식과 행동, 연상 기억, 유연한 학습과 추론, 안정적인 의사결정, 시각 및 언어 처리 능력 등을 수행한다. 고전적인 인공지능 시스템과는 달리 인지 에이전트는 센서로 환경을 지각하고 환경에 대해서 행동하며 환경과 상호작용한다는 점에서 차이가 있다. 따라서 환경으로부터 분리되어 부호화된 독립적인 정보를 처리하는 데에 초점을 맞춘 기존의 AI와는 달리, 인지 에이전트는 환경과 일체를 이루는 살아있는 동적인 시스템으로서의 인공지능을 다룬다. 요약하면 인지 에이전트는 다음과 같은 특성을 갖는다.
• 환경과 상호작용하는 열린 시스템(openendedness)
• 다양한 센서로 환경을 지각(perception)
• 환경에 영향을 주는 행동을 생성(action)
이러한 특성으로 인해서 인지 에이전트는 다음과 같은 새로운 컴퓨팅 능력을
필요로 한다.
• 실시간 동적 정보처리 능력(dynamics) • 다양한 센서데이터 통합 능력(integration)
• 순차적 행동패턴 생성 능력(generation)
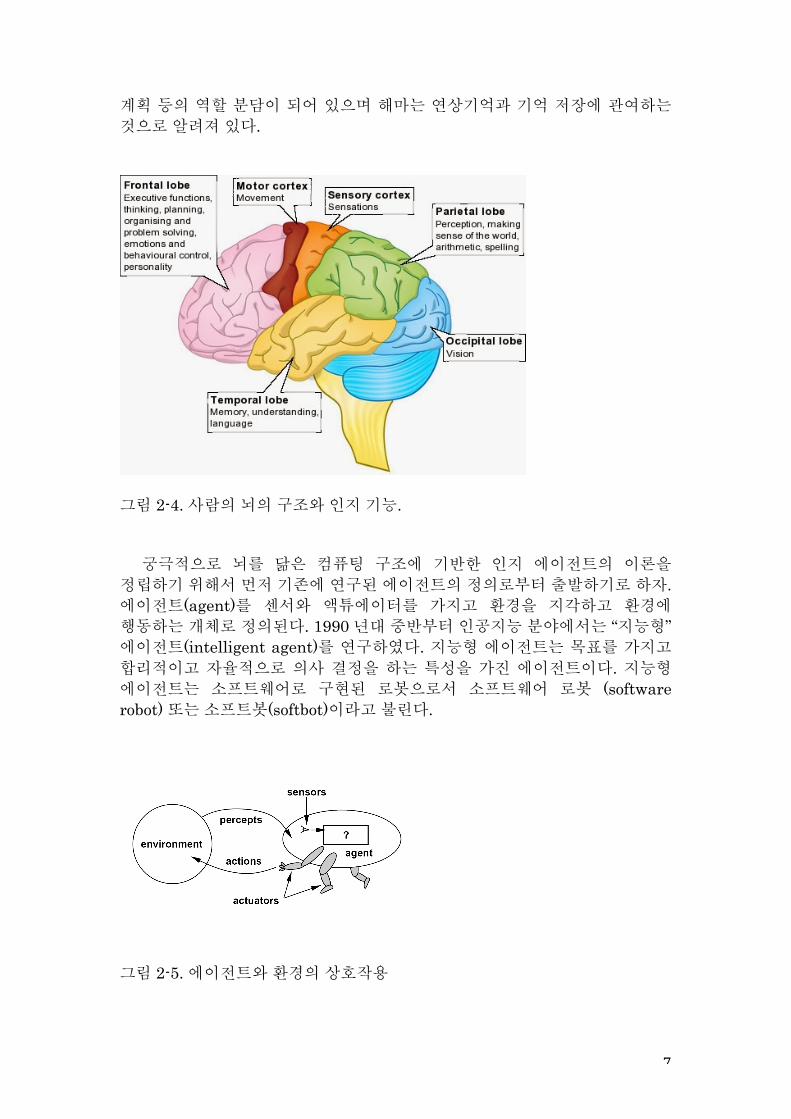
이러한 특성은 뇌를 닮은 컴퓨팅 구조가 유리한 것으로 알려져 있다. 그림 2-4는 뇌의 구조와 기능을 개략적으로 기술하고 있다. 뇌는 전체적으로 분산 표현 구조를 가지고 있고 병렬적인 정보처리를 수행하는 것으로 알려져 있다. 그러면서도 한편 영역별로 일부 특화된 정보처리를 수행한다. 대뇌피질은 특히 센서 영역과 모터 영역, 언어 영역, 시각 영역, 지각과 의미 이해, 의사결정과
7
계획 등의 역할 분담이 되어 있으며 해마는 연상기억과 기억 저장에 관여하는 것으로 알려져 있다.
그림 2-4. 사람의 뇌의 구조와 인지 기능. 궁극적으로 뇌를 닮은 컴퓨팅 구조에 기반한 인지 에이전트의 이론을 정립하기 위해서 먼저 기존에 연구된 에이전트의 정의로부터 출발하기로 하자. 에이전트(agent)를 센서와 액튜에이터를 가지고 환경을 지각하고 환경에 행동하는 개체로 정의된다. 1990년대 중반부터 인공지능 분야에서는 “지능형” 에이전트(intelligent agent)를 연구하였다. 지능형 에이전트는 목표를 가지고 합리적이고 자율적으로 의사 결정을 하는 특성을 가진 에이전트이다. 지능형 에이전트는 소프트웨어로 구현된 로봇으로서 소프트웨어 로봇 (software robot) 또는 소프트봇(softbot)이라고 불린다.
그림 2-5. 에이전트와 환경의 상호작용

8
지능형 에이전트는 보통 환경과 상호 작용을 통해서 학습하며 스스로 성능을 향상하는 학습 에이전트(learning agent)의 특성을 갖는다. 대상으로 하는 환경은 결정적일 수도 있고 확률적일 수도 있다. 결정적인 환경에서는 그 상태가 그 전 상태와 행동에 의해서 완전히 결정될 수 있으며, 확률적인 환경에서는 그 상태가 부분적으로만 관측 가능하여 불확실성이 존재한다. 지능형 에이전트가 함의하는 중요한 특성 중의 하나는 대리인(deligate)의 개념이다. 즉 지능형 에이전트는 사람을 대신해서 행동을 하며 사람을 돕는 도우미(helper) 또는 비서(assistant)의 역할을 한다. 지능형 에이전트가 처음 출현한 1990 년대에는 보통 소프트웨어로 구현되었다. 지능형 에이전트가 상용화된 사례 중 하나는 음성기반의 대화형 비서인 애플 시리이다. 시리는 스마트폰 앱으로 2009 년에 처음 등장하였으며 음성으로 질문하면 명령을 실행하여 행동으로 옮겨준다. 예를 들어, 메시지를 말하고 “문자 보내줘”라고 명령하면 문자를 자동으로 전송한다. 최근 등장하고 있는 텍스트 기반의 대화 로봇인 챗봇(chatbot)도 지능형 에이전트이다. 최근에는 몸을 갖추고 물리적인 센서와 액튜에이터를 갖는 로봇으로 진화하고 있다. 자율이동 로봇, 인지로봇, 인간형 로봇 형태의 지능형 에이전트가 그 예이다.
그림 2-6. 대화로봇 에이전트 지능형 에이전트는 다양한 종류로 나뉠 수 있다. 구현 매체에 따라서, 소프트웨어로 구현된 소프트웨어 에이전트(software agent) 또는 컴퓨터 에이전트(computational agent) 외에 사람, 동물거ㅘ 같이 유기체로 구성된 생물학적 에이전트(biological agent)와 기계 전자 장치로 된 신체를 가진 로봇 에이전트(robotic agent)도 있다(그림 2-3). 반응 시간을 기준으로 지각에 즉각적으로 반응하는 반응형 에이전트(reactive agent)와 오랜 시간 깊은 사고를 하며 행동을 선택하는 숙고형 에이전트(deliberative agent)로 나뉠 수 있다. 후자는 다시 주어진 목표를 성취하도록 행동하는 목표기반 에이전트(goal-based agent), 자신의 효용함수를 가지고 있어서 이를 최대화하는 효용기반 에이전트(utility-based agent)로 나뉠 수 있다. 지능형 에이전트는 또한 환경에서의 이동 능력이 있는지에 따라서 이동형 에이전트(mobile agent)와 고정형 에이전트(stantionary agent)가 있다.

9
물리적인 환경에서 이동하는 모바일 로봇 에이전트 뿐만 아니라 인터넷 환경에서 이동하는 모바일 에이전트도 있다. 에이전트의 용도에 따라서 인터페이스 에이전트, 인터넷 에이전트, 정보 여과 에이전트, 추천 에이전트 등으로 구분될 수도 있다(그림 2-4).
그림 2-7. 에이전트의 종류 2.3 지각-행동-학습 사이클 환경과 상호작용하는 평생학습 인지 에이전트를 생각하자. 에이전트의 목표는 환경을 계속 학습하여 환경의 변화를 예측하는 것이다. 자율 주행 자동차나 사람과 대화하는 챗봇이 이러한 예에 속한다. 예측을 위해서 에이전트는 과거 역사를 모델링하는 기억 구조를 가지고 있다. 이 기억 구조는 외부에서는 관측되지 않으며 여기서는 이를 확률분포로 표상한다(Zhang et al., 2012). 다음의 2.4 절에서는 인지과학에서 연구된 기억의 구조를 다룬다. 시간 t-‐1에서의 기억을 확률분포!!P(mt−1)로 표기하자. 에이전트는 환경에 대해서 행동
!at 을 선택하여 전이하고(행동), 새로운 상태 !st 를 관측(지각)한다. 관측치들로부터 관측되지 않는 기억구조를 추론하기 위해서(인지) 베이스 규칙을 사용할 수 있다.
그림 2-8. 에이전트의 인지 사이클

10
즉 에이전트는 t-‐1에서의 기억 즉 사전확률분포!!P(mt−1)로부터 !!P(at |mt−1)에 의해 행동을 선택하고, !!P(st |at )에 의해 새로운 상태를 지각하여, 기억상태의 우도!!P(mt |st )를 예측함으로써 사후확률분포 !!P(mt |st ,at ,mt−1)를 추정함으로써 학습한다. 이행동-지각-예측-학습의 인지 사이클은 다음과 같이 기술된다.
!!
P(mt |st ,at ,mt−1)!∝ !P(mt |st )Prediction!"# $#
P(st |at )Perception!"# $#
P(at |mt−1)Action
! "# $#
Learning! "##### $#####
보다 일반적으로, 임의의 기억상태의 사전확률분포로부터 지각과 행동 과정을 거쳐서 다음의 기억 상태로의 전이 과정을 좀 더 자세히 살펴보면 다음과 같다.
!!
P(mt |st ,at )!!=! P(mt ,mt−1 |st ,at )mt−1
∫ dmt−1
!!!!!!!!!!!!!!!!!!!!!!!!!=! P(mt |mt−1 ,st ,at )P(mt−1 |st ,at )dmt−1mt−1
∫!!!!!!!!!!!!!!!!!!!!!!!!∝ ! P(mt |mt−1 ,st ,at )P(st ,at |mt−1)P(mt−1)dmt−1
mt−1
∫ !
!!!!!!!!!!!!!!!!!!!!!!!!!=! P(mt |st )Prediction!"# $#
P(st |at )Perception!"# $#
P(at |mt−1)Action
! "# $#P(mt−1)dmt−1
mt−1
∫ !
위의 식에서 합법칙의 변형
!!P(x |z)= P(x , y |z)dy
y∫ 과 곱법칙
!!P(x , y ,z)= P(x , y |z)P(z)을 사용하였다. 또한 다음의 베이스 규칙을 사용하였다.
!!P(mt−1 |st ,at )! = !
P(st ,at |mt−1)P(mt−1)P(st ,at )
!∝ !P(st ,at |mt−1)P(mt−1)
그리고 관측 상태 !st 를 알면 은닉 상태 !mt 는 그전의 은닉 상태 !!mt−1에 무관하다는 가정 !!P(mt |mt−1 ,st ,at )= P(mt |st ) 과 !!mt−1 는 미래의 관측과 무관하다는 사실 !!P(mt−1 |st ,at )= P(mt−1)을 사용하였다. 그런데 위의 계산은 한가지 단점이 있다. 위의 식을 계산하기 위해서는 적분을 해야하는데, 대부분의 실제 환경에서는 모든 과거 상태에 대해서 적분하는 계산이 불가능하다. 적분 대신 재귀적으로 기억 상태를 순차 추정하는 방법을 생각해 보자. 이 방법은 순차적 베이지안 추정(sequential Bayesian estimation)으로 알려져 있다. 처음부터 시간 t 까지의 관측된 상태를 !!s1:t = s1s2...!st로 나타내자. 이 관측으로부터 다음의 기억 상태에 대한

11
확률 분포 즉 필터링 분포 !!P(mt |s1:t )!를 예측하는 것이 목표이다. 확률의 곱법칙
!!P(x , y)= P(x | y)P( y) 의 변형인!!P(x | y)= P(x , y)/P( y)규칙을 적용하면 다음과 같이 쓸 수 있다.
!!P(mt |s1:t )! = !
P(mt ,s1:t )P(s1:t )
! ≈ !P(mt ,st ,s1:t−1)
위 식에서 정규화를 생략하였다. 확률의 곱법칙 !!P(st ,mt )= P(st |mt )P(mt )과 합법칙 !!P(mt |s1:t−1)!= P(mt ,mt−1 |s1:t−1)mt−1
∑ 그리고 다시 곱법칙
!!P(mt ,mt−1)= P(mt |mt−1)P(mt−1)을 적용하면 다음과 같이 다시 쓸 수 있다.
!!
P(mt |s1:t )! ≈ !P(st |mt )P(mt |s1:t−1)!!!!!!!!!!!!!!!!!!!!!!!=!P(st |mt ) P(mt ,mt−1 |s1:t−1)
mt−1
∑!!!!!!!!!!!!!!!!!!!!!!=!P(st |mt ) P(mt |mt−1)P(mt−1 |s1:t−1)
mt−1
∑
시간 t에서의 기억의 필터링 분포를 !!α(mt )!라 정의하면
!!α(mt )! = !P(mt |s1:t )! 다음의 재귀식을 얻을 수 있다.
!!α(mt )! = !P(st |mt ) P(mt |mt−1)
mt−1
∑ !α(mt−1)
즉 시간 t-1에서의 기억 구조 !!α(mt−1)로부터 시간 t에서의 기억 구조!!α(mt )를 순차적으로 추정할 수 있다. 이제 여기에 상태전이에 사용되는 행동 !at을 추가하면
!!
α(mt )! = !P(st |mt ) P(mt |mt−1)mt−1
∑ !α(mt−1)
!!!!!!!!!!!!!!=! P(st ,at |mt ) P(mt |mt−1)mt−1
∑ !α(mt−1)at
∑!!!!!!!!!!!!!!=! P(st |at )
Perception!"# $#
P(at |mt )Action
!"# $#P(mt |mt−1)
Prediction! "# $#mt−1
∑ !α(mt−1)at
∑
예측, 행동, 지각의 순서로 순차적으로 계산함으로써 다음 기억 상태를 추정할 수 있다.

12
강화학습 에이전트 위에서는 관측되지 않는 은닉 상태 !mt 를 갖는 에이전트를 다루었다.
지금부터는 강화학습에서 다루는 에이전트를 다루기로 한다. 이 셋팅은 위에서
다룬 평생학습 인지 에이전트와 두 가지 다른 점이 있다.
o 모든 상태는 관측가능하다. 즉 !mt = st 이다.
o 행동에 대해서 보상치 !rt 가 주어진다.
첫번째 조건은 간소화된 것이다. 두번째 조건은 앞에서 다루지 않은 보상이라는
새로운 인자가 추가된 것이다. 먼저 상태, 행동, 보상을 정의하자(그림 2-9).
상태(state)는 환경에 대해 에이전트가 관찰할 수 있는 정보이다. 챗봇을 예로
들자면, 행동은 챗봇이 생성한 문장이고, 보상치는 챗봇이 생성한 문장에 대한
유저의 만족도로 볼수 있다. 에이전트는 시간 !t 에서 상태 !st 에 있으며 행동 !at 를
선택하여 다음 상태 !!st+1로 이전하며 이 때 보상치 !!rt+1 를 받는다. 이어서 상태 !!st+1로부터 다시 다음 행동 !!at+1 를 선택하면서 계속 순차적인 행동을 반복한다. 이
과정에서 다음 상태 !!st+1는 항상 현재 상태 !st 에만 의존적이며 그 전의 상태들에는
독립적인라는 마코프 가정을 한다.
!!P(st+1 |st ,st−1 ,...,s2 ,s1)= P(st+1 |st )
이러한 순차적 의사결정 과정을 마코프 결정 과정(Markov decision process,
MDP)이라고 한다(그림 2-10).
그림 2.9 에이전트와 환경간 상호작용의 최소 모델. 상태, 행동, 보상.

13
그림 2.10 마코프 결정 과정(MDP)
보상함수(reward function)은 다음에 받을 보상의 평균을 나타내며 다음과 같이 표시한다.
또는 전이함수(transition function)는 상태간의 전이 확률을 나타내면 다음으로 표시한다.
. 정책(policy)이란 주어진 상태에 대한 에이전트의 행동의 확률 분포이다.
에이전트가 상태 !st 에서 행동 !at 를 선택하는 함수를 정책함수라고 하며 이는 다음으로 표시된다.
또는 에이전트의 목표는 순차 행동을 통해서 받을 수 있는 보상치의 기대값을
최대화하는 것이다. 중요한 것은 이 보상이 과거가 아니라 미래에 받을
보상이라는 것이다. 미래에 받을 보상치의 합 !Rt 은 다음과 같이 정의되며
!!Rt = rt+1 +γ rt+2 +γ
2rt+3 + ...= γ krt+k+1k=0
∞
∑
여기서 γ 는 할인율이라 한다. 1 보다 작은 양수의 값을 가지며 미래에 대한
불확실성을 반영한다.
가치 함수는 상태에 대한 장기적 가치, 즉 반환을 표현한다. 이 중 상태-가치
함수 𝑉! 𝑠 는 해당 정책을 따랐을 때의 상태에 대한 평균 반환을 나타낸다.
정책의 가치 !!Vπ (s)는 상태 s 에서 정책 π 를 따라서 행동을 취할 때 미래 보상치
합 !Rt 의 기대값으로 정의된다.
1( | , )t t tR s s a+ 1 ( , )t t tr r s a+ =
1( | , )t t tT s s a+
( | )t ta sπ ( )t ta sπ=

14
!!!Vπ (s)= Eπ[Rt |st = s]
상태 s와 정책 가 주어질때, 정책 를 따르는 상태 s의 가치 는 다음과 같다.
!!V π (st )= π(at |st )
at∈A∑ T(st+1 |st ,at )
st+1∈S∑ R(st+1 |st ,at )+γV π (st+1)⎡⎣ ⎤⎦
행동-가치 함수 𝑄! 𝑠,𝑎 는 상태-가치 함수와 비슷하다. 이 함수는 해당 정책을 따랐을 때의 상태 s, 행동 a 에 대한 평균 반환
!!!Qπ (s ,a)= Eπ[Rt |st = s ,at = a]
을 나타내며 다음으로 표시된다.
!!Qπ (st ,at )= T(st+1 |st ,at )
st+1∈S∑ R(st+1 |st ,at )+γV π (st+1)⎡⎣ ⎤⎦
그림 2-11. 학습 에이전트의 구조. 수행 요소와 학습 요소로 구성. 강화학습의 근본적 목적은 가장 많은 보상을 얻는 에이전트의 행동 전략을
구하는 것이다. 이러한 보상을 가치 함수의 값으로 보아 순서를 정하였을 때, 이
함수의 최대값을 가지는 정책들이 존재하게 되며, 우리는 이것을 최적
정책(optimal policy)이라 정의 할 수 있다. 최적 정책은 𝜋∗ 로 표현한다.
수학적으로 표현하자면, 최적 상태-가치 함수는 상태에 대한 모든 정책 중 가장 큰 반환을 나타내는 값이며
!!V*(st )=maxπ
!V π (st )
π π ( )tV sπ

15
로 정의되고, 최적 행동-가치 함수는 모든 정책에 대해서 최대 행동-가치 함수의
값을 나타내며,
!!Q*(st )=maxπ
!Qπ (st ,at )
로 나타내어진다. 이에 대해 성립하는 항등식을 벨만 최적식(Bellman optimality
equation)이라 하며 다음과 같다.
!!V *(st )=maxat T(st+1 |st ,at )
st+1∈S∑ R(st+1 |st ,at )+γV *(st+1)⎡⎣ ⎤⎦
!!Q*(st ,at )= T(st+1 |st ,at )
st+1∈S∑ R(st+1 |st ,at )+γQ*(st+1 ,at+1)⎡⎣ ⎤⎦
그림 2-12. 인지 에이전트의 행동-지각-학습 사이클
벨만 최적식에 의해서 최적의 정책을 찾는 것은 상태 전이에 대한 동력학의
정확한 지식과 마코프 가정을 필요로 하고 많은 계산 시간을 요한다. 실세계
문제에서 대개 이러한 가정은 만족되지 않기 때문에 이에 대한 근사적인 해법들이
제안되었다. 한 가지 방법은 동적 프로그래밍(dynamic programming, DP)
방법이다. DP 학습법은 현재 상태 !st 에서 행동 !at 이동가능한 모든 다음 상태들
!!st+1 에서의 최적의 Q 값들의 기대치와 현재의 보상 !!r(st ,at )!의 합으로 새로운
Q 값을 수정한다.
!!Q(st ,at )!← !r(st ,at )!+ ! T(st+1 |st ,at )!maxatst+1∈S
∑ !Q(st+1 ,at+1)
Environment�
(1)-Act-(at)�
(3)-Perceive-(st+1)�(2)-Predict-(s7t+1)�
(4)-Reward-(rt+1)�
T(st+1|st,-at)� R(st+1|st,-at)�A(at|st)�
Percep?on� Learning�Ac?on�
(5)-Update-(T,-R,-A)�

16
이 방법의 단점은 환경의 동력학 모델 즉 상태 전이 함수를 가지고 있어야 한다는
것이다. 한편, 상태 전이 함수를 모를 때는 시간차 학습 방법(TD 학습)을 사용할 수 있다.
!! Q(st ,at )!← !Q(st ,at )!+ !α r(st ,at )!+ !Q(st+1 ,at+1)
Desired! "### $###
!− !Q(st ,at )Estimated!"# $#
⎡
⎣
⎢⎢
⎤
⎦
⎥⎥
위에서 시간 t+1 에서의 값 !!r(st ,at )!+ !Q(st+1 ,at+1)는 목표 함수의 역할을 하고
시간 t 에서의 값 !!Q(st ,at )는 현재의 추정치를 나타내는데 이 두 값의 차가 0 으로
수렴하면 학습이 된 것이다.
다양한 목적 함수
지금까지는 보상의 기대치를 최대화하는 것을 에이전트의 목표로 정의하였다.
그러나 경우에 따라서는 이것이 최상의 목표가 아닐 수 있다. 예를 들어서, 답의
좋은 정도 뿐만 아니라 계산 경비가 적게 드는 정책도 중요할 수도 있다. 이러한
추가 제약 조건을 고려하기 위해서 에이전트가 의사 결정을 하는데 드는 경비를 정보 경비(information cost)라 하자. 정보경비 는 정책 𝜋하에서 상태
에서 행동 을 수행하는 정보량을 나타낸다.
위에서 이다. 이제 에이전트의 목적 함수를 다음과 같이
가치 함수와 정보 경비로 구성되도록 정의할 수 있다.
즉 에이전트는 최대 보상과 최소 경비의 균형을 조절하도록 학습한다.
에이전트는 새로운 정보를 탐색할 필요가 있다. 이를 위해서 상태에 대한 관심도(Zhang, 1991a; Zhang, 1991b)나 에이전트의 호기심(Schmidhuber, 1991)을
정의할 수 있다. 탐험력이 부여된 새로운 행동 정책을 다음과 같이 정의하자.
( ; )t tI S AπtS
tA
( | )( ; ) ( ) ( | ) log
( )t t
t tt t t t t
s a t
a sI S A P s a s
P aπ ππ=∑ ∑
11 1( ) ( | ) ( ).
tt t t ts
P a a s P sπ+
+ +=∑
{ }min ( ; ) [ ( , )]t t t tI S A E Q S Aπ ππ β−
( | )t tq a s

17
흥미있는 지식을 습득하기 위해서 환경을 능동적으로 탐험하는 능력을 예측
강도(predictive power, empowerment)라 한다 (Jung et al., 2011; Still and Precup, 2012).
또한 에이전트가 행동 정책 q 를 써서 획득한 가치는 다음으로 표시된다.
위의 항들을 종합하여 에이전트의 목표를 하나의 목표함수로 다음과 같이 정의할
수 있다.
이 에이전트는 예측 강도를 최대화하고 정보 경비는 최소화하면서 전체의 보상의 기대치는 최대화한다.
2.4 인지 아키텍처 지금까지 환경과의 상호작용에 역점을 두고 에이전트 지각, 행동 및 목표를 알아보았다. 이를 구현하기 위해서는 에이전트의 내부적인 인지 구조가 중요하다. 특히 우리가 관심을 갖는 사람처럼 생각하고 사람처럼 행동하는 인지 에이전트를 만들기 위해서는 인지시스템의 구조를 어떻게 설계하는지가 중요하다. 여기에 인지과학과 뇌과학의 도움이 필요하다. 본 절에서는 인지과학에서 연구된 인지 아키텍쳐의 대표적인 사례 세 가지를 살펴본다. 이 세 개 모델의 상세한 구조는 다르지만 그 공통점이 있다. 그림 2-13은 많은 인지 구조 모델에서 발견되는 공통점을 기술한다. 두드러진 특징 중의 하나는 모두 기억 구조를 중시한다는 것이다. 인간의 기억이 단기 기억과 장기 기억으로 나뉘며, 보통 단기 기억은 작업 기억, 그리고 장기 기억은 절차 기억과 선언 기억으로 구분된다. 절차 기억은 주로 행동 선택에 관여하며 선언 기억은 지각과 이해에 관여한다. 또한 많은 인지 구조들이 학습 요소를 포함하고, 학습은 장기 기억을 변경하는 역할을 한다. 즉 학습의 결과는 기억의 변화로 나타난다. 종합하면 지각과 행동은 기억의 영향을 받으며, 이 기억은 학습을 통해서 변경된다.
{ }( )1, ;q t t tI S A Sπ+
( )tV qπ
{ }( ){ }1argmax , ; ( ) ( );q t t t t t tq
I S A S V q I S Aππ α λ+ + −

18
그림 2-13. 일반적인 인지 구조 ACT-R 인지 구조 ACT-R은 합리적인 사고의 적응적 제어 모델(Adaptive Control of Thought-Rational) 로 제안된 인지 구조이다. 인간의 마음을 가능하게 하는 기본적인 인지적 지각적 연산자를 정의하는 것을 목적으로 한다(Wikipedia). ACT-R 이론에 의하면 인간이 수행할 수 있는 과제는 이산적인 연산의 연속으로 구성된다고 본다. ACT-R 은 인간의 지식이 선언적 표상과 절차적 표상의 두 가지 종류로 구분될 수 있다고 본다. 선언적 지식은 청크(chunks)라고 하는 조각들로 표현되는데, 각 청크는 표지를 가진 슬럿으로 각각 접근이 가능한 속성들의 벡터로 표현된다. 청크는 버퍼를 통해서 유지되고 접근되며, 버퍼는 모듈들의 전단부이다. 모듈은 특화되고 비교적 독립적인 뇌의 구조를 일컷는다. 두 가지 타입의 모듈이 있다.
• 지각행동 모듈: 실세계와 또는 실세계의 시뮬레이션과 인터페이스 역할을 한다. 시각 모듈과 매뉴얼 모듈이 그 예이다.
• 메모리 모듈: 두 가지 종류의 메모리 모듈이 있다. Ø 선언 메모리: 사실로 구성된다. 케냐의 수도가 어디인지, 백두산의 높이는 얼마인지 등에 관한 지식이 그 예이다.
Ø 절차 메모리: 프로덕션으로 구성된다. 프로덕션은 무슨 조작을 할 수 있는지에 대한 지식이다. 덧셈을 하는 것이 그 예이다.

19
그림 2-14. ACT-R 인지 구조. 모듈(시각, 모터, 메모리), 버퍼, 패턴정합기로 구성되어 있다. 모든 모듈은 버퍼를 통해서 접근된다. 특정 시간의 버퍼의 내용은 그 순간의 ACT-R 의 상태를 나타낸다. 이 규칙에 대한 유일한 예외는 절차 지식을 저장하고 적용하는 절차 모듈이다. 절차 모듈은 접근가능한 버퍼가 없으며 다른 모듈의 내용을 접근하기 위해서 사용된다. 절차 지식은 프로덕션의 형태로 표현된다. 프로덕션은 신경과학적으로는 버퍼 역할을 하는 대뇌피질(cortex) 영역으로부터 대뇌기저핵(basal ganglia)으로 가고 오는 정보 흐름을 나타낸다. ACT-R 은 구현된 SW 가 존재하며 실제로 프로덕션 시스템으로 형식화된다. 내부 패턴정합기가 있어서 매 순간 버퍼의 현재 상태에 매치되는 프로덕션을 탐색한다. 한번에 오직 한개의 프로덕션만이 수행될 수 있다. 프로덕션을 수행하고 나면 버퍼를 수정하며 시스템의 상태가 변한다. 따라서 ACT-R에서는 인지 작용이 프로덕션의 발화로서 설명된다. ACT-R은 기호주의와 연결주의 논의에 있어서 기호주의를 대표하는 모델 중 하나이다. 청크와 프로덕션의 개체는 이산적이며 그 연산자는 형식적이다. 즉 표상의 의미적 내용을 참조하지 않으며 그 형식적 특성만이 계산에 참여한다. 이는 특히 청크 슬럿과 프로덕션에서의 버퍼매칭 특성에 명확히 나타나며 이는 표준적인 기호 변수로 작용한다. SOAR 인지 구조 SOAR 의 목표는 범용 지능 에이전트(general intelligent agent)에 필요한 고정된 계산학적 빌딩블록을 개발하는 것이다(Wikipedia). 여기서 범용 지능 에이전트란 사람에게서 발견할 수 있는 넓은 범위의 인지 능력(예를 들어, 의사 결정, 문제 해결 계획, 자연어 이해 등)을 실현하는 모든 종류의 지식을 표현하고 사용하고 학습할 수 있으며, 다양한 과제를 수행할 수 있는 에이전트를 일컫는다. SOAR 는 인지란 무엇인가에 대한 이론이면서도 그 이론에 대한 컴퓨터 구현이기도 하다.

20
SOAR는 일반 지능에 깔려있는 계산 구조에 대한 가정들을 구체화한다. 이러한 가정은 ACT-R이나 LIDA 등의 다른 인지 구조와 공통되는 점들이 여럿 있다. ACT-R이 인간 인지의 상세한 모델링에 더 역점을 두는데 반해서 Soar는 일반 인공지능 즉 기능성과 효율성을 강조한다. Soar의 인지 이론은 문제 공간 가설(problem space hypothesis)에 기반을 두고 있다. 이 가설은 모든 목적 지향적인 행동은 가능한 상태 공간(문제 공간)에서의 목표에 도달하기 위한 탐색으로 볼 수 있다는 것이다. 각 단계에서 하나의 연산자를 선택하고 에이전트의 현재 상태에 적용하면 이는 장기 메모리로부터 지식을 검색하거나 변경하는 내부 변화를 일으키거나, 아니면 외부 환경에서 행동으로 이어진다. Soar 라는 이름로 State, Operator, And Result 의 과정에서 유래한다. 문제 공간 가설에 내재적인 부분은 계획과 같은 복잡한 행위를 포함하는 모든 행동은 인간 행위로 볼 때 50ms 정도가 걸리는 기본 연산자들의 선택과 적용의 서열로 분할될 수 있다고 보는 것이다.
그림 2-15. SOAR 인지 구조. Soar 이론의 두번째 가설은 각 단계에서 순차적 병목 현상을 일으키는 한개의 연산자가 비록 선택되더라도 선택과 적용의 과정은 절차 지식의 문맥기반 검출을 제공하는 병렬적인 규칙 발화를 통해서 구현된다는 것이다. 세번째 가설은 선택되고 적용될 연산자에 대한 지식이 불완전하고 불확실하다면 막다른 골목이 생기고 자동적으로 하위상태가 생성된다는 것이다. 하위 상태에서는 같은 문제 해결 과정이 재귀적으로 사용되나, 이 때 의사 결정이 계속되도록 지식을 검색하고 발견하는 목표를 가지고 진행된다. 이는 계획이나 계층적 과제 분할과 같은 전통적인 문제 해결 방법에서와 같이 하위상태의 스택을 형성한다. 만약 하위상태가 만들어진 결과가 막다른 골목 문제를 해결하면 관련되는 구조는 제거된다. 이러한 방법을 범용 하위목표화(universal subgoaling)라 한다. 이러한 가정에 의하면 세 단계 수준의 정보처리를 지원하는 아키텍쳐가 된다. 가장 하위 수준에서는 상향적, 병렬적, 자동적인 정보처리가 일어난다. 다음 수준은 숙고형 수준으로서 하위 수준에서의 지식을 이용하여 하나의
SOAR�

21
행동을 제안하고, 선택하고, 적용한다. 이 두 개 수준은 빠르고, 숙련된 행동을 구현하며 개략적으로 카네만의 시스템 1 에 해당하는 처리 수준이다. 보다 복잡한 행동은 지식이 불완전하거나 불확실할 때 하위상태를 사용한 세번째 수준의 처리를 자동으로 할 때 일어나는데, 이는 개략적으로 카네만의 시스템 2에 해당한다. Soar의 네번째 가설은 기저 구조가 모듈화되어 있다는 것이다. 그런데 이 모듈화는 계획이나 언어와 같은 과제나 능력이 모듈화되어 있다는 것이 아니고 과제독립적인 모듈이 존재한다는 것이며 이는 의사결정 모듈, 메모리 모듈(단기, 공간/시각, 작업 기억; 장기 절차, 선언, 일화 메모리), 모든 장기 기억과 연관된 학습 기작, 지각과 모터 모듈 등을 말한다. 이들 기억에 대한 특성에 대한 추가의 가정도 존재하는데 학습은 온라인이고 점진적으로 일어난다는 것이다. 다섯번째의 가정은 메모리 요소가 (공간/시각 메모리 제외) 기호와 관계 구조로 표현된다는 것이다. 일반 지능을 위해서 기호 시스템이 필요하다는 가정은 물리 기호 시스템 가설(physical symbol system hypothesis)로 알려져 있다. Soar는 진화 과정에서 모든 기호 구조가 이의 검색, 유지, 학습에 영향을 주는 통계적인 메타 데이터 (사용의 최신성과 빈도수 또는 미래 보상의 기대치 등)와 연관되어 있다는 것이다. Soar 의 처리 사이클은 연산자의 선택과 적용을 지원하기 위한 절차 메모리(물체를 다루는 지식)과 작업 메모리(현재 상황의 표상)간의 상호작용으로부터 일어난다. 작업 메모리에 있는 정보는 상태를 루트로 하는 기호 그래프 구조로 표현된다. 절차 메모리에 있는 지식은 if-then 규칙 (조건과 행동의 집합)으로 표현되며 작업 메모리에 있는 내용과 계속 매칭된다. 규칙의 조건이 작업 메모리의 구조와 매치되면 발화해서 행동을 수행한다. 규칙과 작업 메모리의 결합을 프로덕션 시스템(production system)이라고 한다. 대부분의 프로덕션 시스템과 대조적으로 Soar에서는 매치되는 모든 규칙이 병렬로 발화한다. 의사 결정의 핵심이 보통 하나의 “규칙”을 선택하는 것인데 반해서 Soar의 의사 결정은 규칙에 의해서 제안, 평가, 적용되는 “연산자”를 선택하고 적용하는 것을 통해서 이루어진다. 연산자는 현재 상태를 테스트하고 작업 메모리에 있는 연산자의 표현을 생성하는 규칙이나 연산자의 선택과 적용에 대한 수용 선호도에 의해 제안된다. 추가의 규칙은 제안된 연산자와 매치되며, 제안된 다른 연산자와 비교하여 평가되는 추가의 선호도를 생성한다. 이 선호도는 결정 절차에 의해서 분석되는데 이 절차는 선호하는 연산자를 선택하고 작업 메모리에 현재의 연산자로 등록한다. 현재의 연산자와 매치되는 규칙은 발화하여 적용되고 작업 메모리를 변경한다. 작업 메모리에 대한 변경은 단순 추론, Soar 장기 의미 도는 일화 메모리로부터의 검색 질의어, 환경에서 행동을 수행하기 위한 모터 시스템에 대한 명령어, 또는 작업 메모리와 지각간의 인터페이스인 공간 시각 시스템과의 상호작용일 수 있다. 작업 메모리에 대한 이러한 변경은 새로운 연산자가 제안되고 평가되고 이어서 선택 적용되게 한다. 연산자의 우선순위가 하나의 연산자를 선택하는 것을 지정하기에 불충분하거나 또는 연산자를 적용하기에 규칙이 불충분하면, 막다른 골목에 봉착한다. 이럴 경우 문제를 해결하기 위해서 작업 메모리에서 하위상태가

22
생성된다. 하위상태에서 지식을 더 얻기 위해서 연산자를 제안하고 선택한다. 하위상태는 계층적 업무 분할, 계획, 선언적 장기 메모리 접근과 같은 현장에서 요구되는 복잡한 추론의 수단을 제공한다. 난국이 극복되면 결과를 제외한 하위 상태에 있는 모든 구조가 제거된다. Soar의 청킹 구조는 최종 결과로 이끈 하위상태에 있는 처리를 규칙으로 편집한다. 미래에는 학습된 규칙들이 비슷한 상황에서는 자동으로 발화되어 난국이 다시는 발생하지 않게 된다. 이는 복잡한 추론을 자동적이고 반응적인 처리로 점진적으로 변경하게 되기 때문이다. Soar는 추가적으로 공간 시각 시스템, 의미 메모리, 일화 메모리, 학습 등의 기능을 제공한다. LIDA 인지 구조
그림 2-16. LIDA 인지 구조 2.5 인공지능 로봇 지각행동 에이전트 이론과 인지 구조 연구는 인공지능 로봇 개발에 활용될 수 있다. 아직은 초보적인 수준이지만 최근 들어서, 물리적 환경에 놓여서 사람과 보고 듣고 대화하며 개인 비서 서비스를 제공하는 인공지능 로봇들이 등장하고 있다. 인공지능 로봇의 형태는 다양하며 신체성(몸, Body, 하드웨어)과 지능성(마음, Mind, 소프트웨어) 관점으로 구분할 수 있다(장병탁, 2016). 신체성 측면에서 볼 때, 인공지능 로봇은 센서, 모터, 팔, 손, 다리 등의 다양한 형태의 몸을 갖추고 있으며 이를 통해서 공간을 지각하고 이동하고 물건을 조작하는 능력이 있다. 한편, 지능성 관점에서는 환경에 대한 지각능력, 사람과의 상호작용 능력, 자율적인 계획과 판단에 의한 행동 능력이 중요하다. 여기서는 신체성 관점에서 최소의 신체성을 갖는 가상로봇으로부터 시작하여 점차 눈, 발, 손을 가지지만 이동은 하지 않는 고정형, 그리고 여기에 공간 이동 능력을 추가한 이동형, 그리고 주변의 물건을 조작할 수 있는 능력을 추가한 조작형의 인공지능 로봇을 순서대로 살펴보기로 한다.
LIDA�

23
그림 2-17. 인공지능 로봇의 다양한 형태. 스마트폰/웨어러블장치 기반 대화로봇과 챗봇 지난 50년 동안 인공지능 소프트웨어 기술은 눈부신 발전을 하였다. 최근 10년 사이에는 특히 인터넷과 소셜 미디어의 대중화에 힘입어 빅데이터가 쌓이고 머신러닝/딥러닝 알고리즘이 발전하고 이를 뒷받침하는 하드웨어적 컴퓨팅 파워의 증가로 인공지능 시스템의 성능이 폭발적으로 증가하고 있다. 음성인식 문제가 딥러닝 기술로 해결됨에 따라서 최근 음성대화형 비서로봇이 상용화 수준에 이르고 있다. 2011년에 스마트폰 앱으로 나온 애플 시리(Siri)를 필두로 지난 몇년 사이에 마이크로소프트의 코타나(Cortana), 페이스북의 엠(M), 구글의 나우(Now) 및 어시스턴트(Assistant) 등 대화로봇/챗들이 등장하고 있다. 최근에는 금융 서비스를 도와주는 챗봇 형태의 로보 어드바이저, 신문 기사를 써 주는 로봇 저널리스트 등 가상 로봇들의 종류와 수가 늘고 있다. 스마트폰 대신 웨어러블 디바이스 형태로 된 인공지능 로봇 서비스도 가능하다. 손목에 차는 스마트 와치나 안경 형태의 스마트 글래스를 로봇으로 볼 경우 여기에 속한다. 웨어러블 장치 특성상 이동 중에도 센싱이 되고 항상 외부 환경에 노출되어 있기 때문에 스마트폰 보다는 다양한 종류의 실세계 데이터를 수집할 수 있다. 이러한 인공지능 로봇의 예는 미래창조과학부의 소프트웨어 스타랩 프로젝트로 서울대 인지로봇인공지능센터(CRAIC)에서 진행하고 있는 ALTA 웨어러블 인지로봇이 있다.
• Personal)Assistants)(Smart)Advisors))
– Siri,)Now,)Cortana,)M,)Xiaoice)
• Wearable)Robots)(Accessories))
– )Watches,)Bands,)Glasses,)HMD.VRs.
• Tabletop)Robots)(Appliances))
– Kinect,)Echo,)Jibo,)Home,)Car)Assistants)
• Mobile)Robots)(Personal)Service)Robots))
– Buddy,)RoBoHon,)Butlr,)Pepper,)CareObot)
• Robot)Cars,)Smart)Homes,)Smart)Factories)
– Google.Cars,)Home)IoT)PlaJorm)

24
그림 2-18. 퍼스널 로봇 고정형 인공지능 대화 로봇 최근 스마트 스피커 형태의 음성기반 인공지능 서비스가 등장하고 있다. 아마존은 2014년에 처음으로 에코(Echo)라는 스마트 스피커를 출시하여 음성 언어로 명령을 주면 이를 시행하는 대화 로봇을 선보였다. 2016년에는 구글이 홈(Home)이라는 스마트 스피커 디바이스를 선보였고 국내에서도 SKT가 누구(Nugu)라는 음성기반 인공지능 스피커를 출시하였다. MIT에서 창업한 지보라는 회사에서는 시각 기능까지 가진 대화형 로봇을 개발하고 있다. 지보(Jibo)는 스피커형의 로봇 보다 한발 더 진화한 소셜로봇으로 카메라를 장착하고 고개를 돌릴 수 있어 주변 상황을 인식할 수 있다. 특별한 형태의 인지로봇은 사람과 같이 아주 미세한 얼굴 표정을 지을 수도 있다. 핸슨 로보틱스에서 만든 인간형 얼굴 로봇인 소피아(Sophia)는 눈동자, 눈썹, 입, 입술, 안면 근육 움직임을 통해서 거의 인간의 표정과 유사한 얼굴 표정을 연출할 수 있다.
• Mobile Robots – 1999 – Aibo (Sony) – 2004 – Robot Car Challenge – 2008 – Nao (Aldebaran) – 2009 – PR2 (Willow Garage) – 2010 – iCub (IIT) – 2012 – ROS Foundation
• Personal Digital Assistants – 2011 – Siri (Apple) – 2012 – Now (Google) – 2014 – Cortana (Microsoft) – 2016 – Assistant (Google)
• Personal Robots – 2014 – Echo (Amazon) – 2015 – Jibo (MIT) – 2015 – Pepper (SoftBank) – 2015 – Dash (Savioke) – 2016 – Home (Google)

25
그림 2-19. 모바일 서비스 로봇 이동형 인공지능 로봇 바퀴나 다리를 가지고 공간을 이동할 수 있는 로봇은 그 서비스의 범위가 고정형 로봇 보다 뛰어나다. 독일의 프라운호퍼 연구소에서 만든 Care-o-bot과 윌로우 가라지에서 제작한 PR2 로봇이 그러한 예이다. 일본의 소프트뱅크 로보틱스는 프랑스의 알데바란을 인수하여 이동형 소셜로봇 페퍼(Pepper)를 상용화하였다. CMU의 Cobot과 Microsoft의 안내 로봇은 입구에서 손님을 맞이하여 사무실까지 안내를 할 수 있다. 세비오키의 대쉬(Dash), 유진로봇의 터틀(Turtle), 블루 프로그의 버디(Buddy), 더블 로보틱스의 더블(Double), 써로마인드 로보틱스의 오페어(Aupair) 등 모바일 플랫폼 기반의 다양한 지능형 로봇들이 최근 등장하고 있다. 이러한 로봇은 가정, 상점, 호텔 등 넒은 공간에서 다양한 서비스를 제공할 수 있다. 시각 능력을 갖고 언어를 통해 사람들과 소셜한 대화를 수행할 수 있어 안내원 역할을 할 수도 있다. 다른 한편, 사람처럼 걷는 보행 로봇도 연구되고 있다. 일찍이 혼다에서 개발한 아시모(Asimo)는 평지와 계단에서의 이족 보행 능력을 데모하였다. 보스톤 다이나믹스에서는 이족 보행 로봇 아틀라스(Atlas)를 개발하여 눈이 쌓인 숲과 언덕을 넘어지지 않고 걸을 수 있음을 데모하였다.
Personal)Service)Robots�
PR2)(Willow)Garage))
Care9O9bot)4)(Fraunhofer)) )Pepper)(SoABank))
Buddy)(Blue)Frog))

26
그림 2-20. 인간형 인공지능 로봇. 조작형 인공지능 로봇 궁극적으로 인공지능 로봇은 팔과 손과 손가락을 가지고 물건을 잡고 조작할 수 있는 능력을 가질 것이다. 뮌헨공대와 브레멘 대학에서는 부엌에서 요리를 하는 키친로봇을 연구하고 있다. PR2와 쿠카 팔 로봇을 이용하여 쏘시지를 데워서 썰어서 아침을 서빙하거나 팝콘이나 피자를 만들어 주는 로봇을 데모하였다. 손과 손가락의 기구학적 발전과 센서 기술이 상대적으로 발전이 늦어서 아직까지 마음대로 물건을 들어 조립하거나 조작하는 것을 마음대로 할 수 있는 로봇이 많지 않다. 현재는 많은 로봇들은 물건을 잡을 때 두 개의 손가락을 밀어서 물건을 사이에 넣는다. 손가락 마디가 있어서 여러개의 손가락을 이용하여 물건을 잡는 로봇 손이 개발되고 있다. 조작은 또한 미세한 힘과 압력을 느끼는 센서 기술을 필요로 한다. 부드러운 물건을 잡을 수 있는 소프트 로봇 기술이 최근 발전하고 있다.
그림 2-21. 스마트 머신.
Life%Like'Robots'
6
Sophia''(Hanson'Robo4cs)'
Atlas''(Boston'Dynamics)'
스마트머신!
18 Mindedness'
Embodiedness'
Smart Machines

27
인공지능 로봇 기술 인공지능 로봇은 환경과 사람을 인식하고 이해하며 궁극적으로 사람처럼 생각하고 사람처럼 행동하며 개인 맞춤형 서비스를 제공할 수 있는 기계이다. 인공지능 로봇이 상용화되기 위해서는 다양한 기술을 필요로 한다. i) 사람을 이해하고 대응하는 기술, ii) 물체를 이해하고 조작하는 기술, iii) 환경을 이해하고 이동하는 기술, iv) 언어, 시각, 행동을 학습하는 기술, v) 세상에 대한 지식을 습득하는 기술 등이 필요하다. 특히 사람을 이해하기 위해서는 음성, 자연언어, 얼굴, 감성 등을 인식하고 자연스러운 대응을 할 수 있는 능력을 필요로 한다. 또한 환경내에서 이동하고 물체를 조작하는 능력이 추가된다면 사람들의 많은 작업을 대신해 줄 수 있다. 앞으로는 촉각 센서와 제스처 등을 통해서 환경과 사람을 보다 잘 인식하는 기술이 발전될 것으로 보인다. 상용화 관점에서는 이동성이 추가될 경우 고장 문제, 안전성 이슈들이 다루어져야 할 것이며, 조작성을 추가할 경우 하드웨어적인 발전을 더욱 필요로 할 것이다. 그러나 많은 인공지능 로봇의 응용은 페퍼의 예에서 볼 수 있듯이 제한된 조작과 이동성을 통해서도 상점, 호텔, 식당, 공공기관 등에서의 사람들과 상호작용하며 안내하는 개인서비스 로봇으로 활용될 수 있다. 인공지능 로봇의 미래 상자 속에 갖혀서 서비스를 제공하던 컴퓨터와는 달리 로봇은 바깥 세상으로 나와서 환경을 지각하고 환경에 행동할 수 있는 기계여서 그 응용의 범위가 훨씬 넓다. 특히 이동과 조작 능력을 가진 모바일 지능 로봇은 공장에서 고정된 작업을 하던 산업용 로봇과는 달리 미래의 연결 사회에서 새로운 제품과 서비스를 제공할 수 있다. 인공지능 로봇은 자동차, 컴퓨터, 인터넷, 스마트폰에 이은 미래 신성장동력 산업의 핵심 플랫폼이다. 왓슨이나 알파고처럼 가상세계에서의 닫힌 공간 인공지능 서비스와는 달리, 신체를 갖추고 물리세계에서의 데이터 중심의 열린 서비스가 가능하게 함으로써, 인공지능 로봇은 제4차 산업혁명 시대의 새로운 비즈니스 생태계를 열어갈 수 있다. 다른 한편 인공지능의 발전 경로에서 볼 때, 센서와 모터가 부착된 몸을 가지고 환경과 상호작용하면서 끊임없이 상호작용하며 학습하는 체화된 인지 시스템으로서의 인공지능 로봇은 인간수준의 자율지능을 실현하고 더 나아가서 감성과 자유의지를 지닌 의식을 가진 완전한 지능기계의 발명을 가져올 수도 있을 것이다.


















