
NoSql with cassandra
24
-
Upload
marek-koniew -
Category
Software
-
view
166 -
download
1
Transcript of NoSql with cassandra


NoSql with Cassandra
Marek Koniew
and a little bit of MongoDB
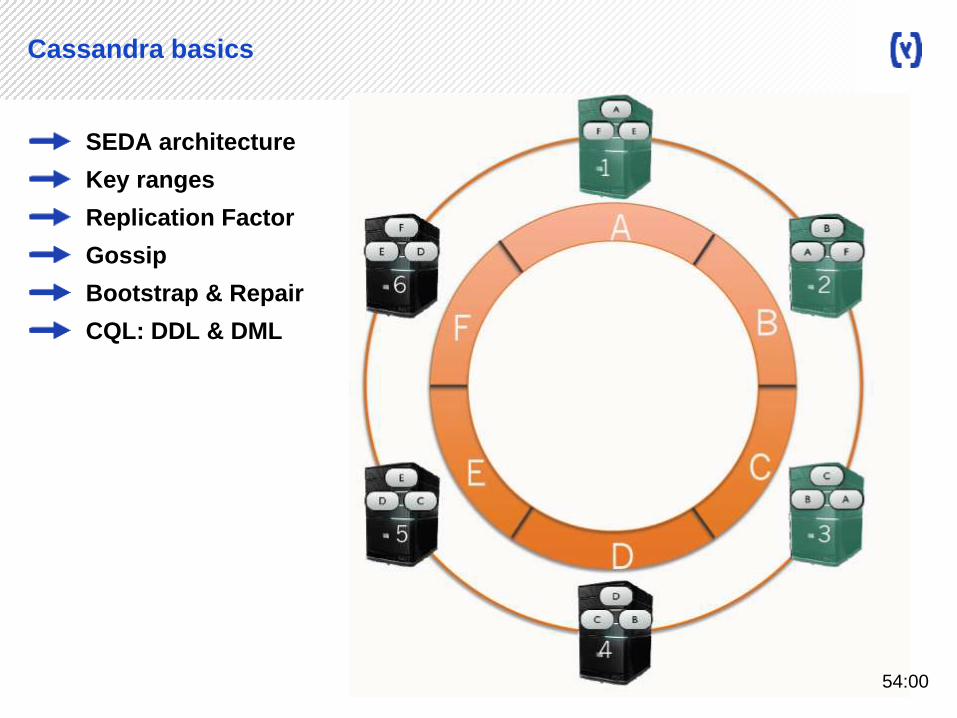
Cassandra basics
SEDA architecture
Key ranges
Replication Factor
Gossip
Bootstrap & Repair
CQL: DDL & DML
54:00
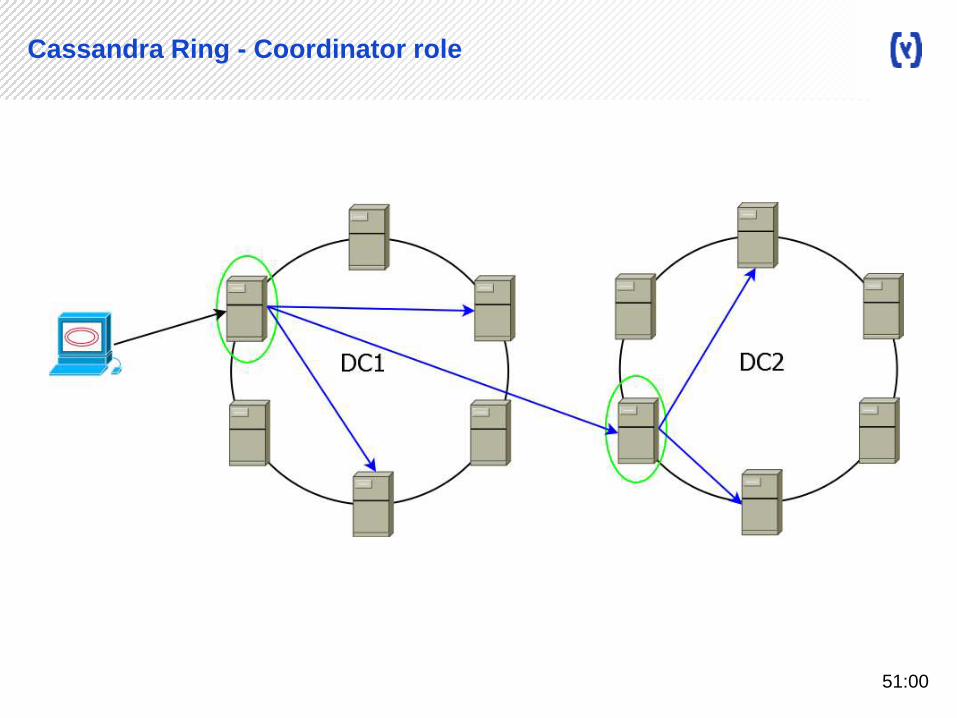
Cassandra Ring - Coordinator role
51:00
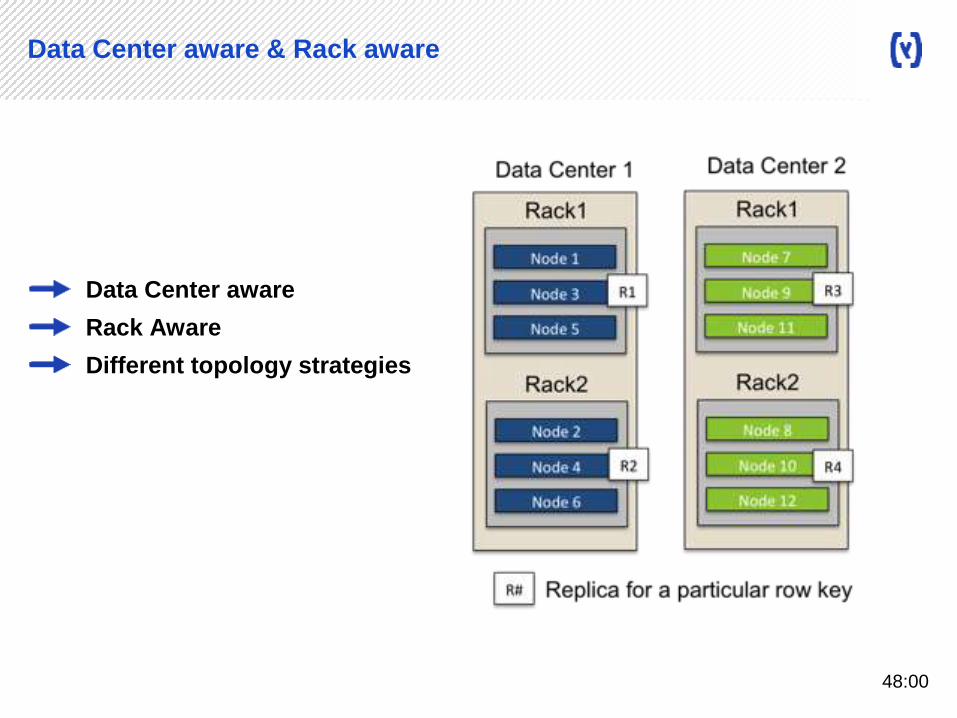
Data Center aware & Rack aware
Data Center aware
Rack Aware
Different topology strategies
48:00
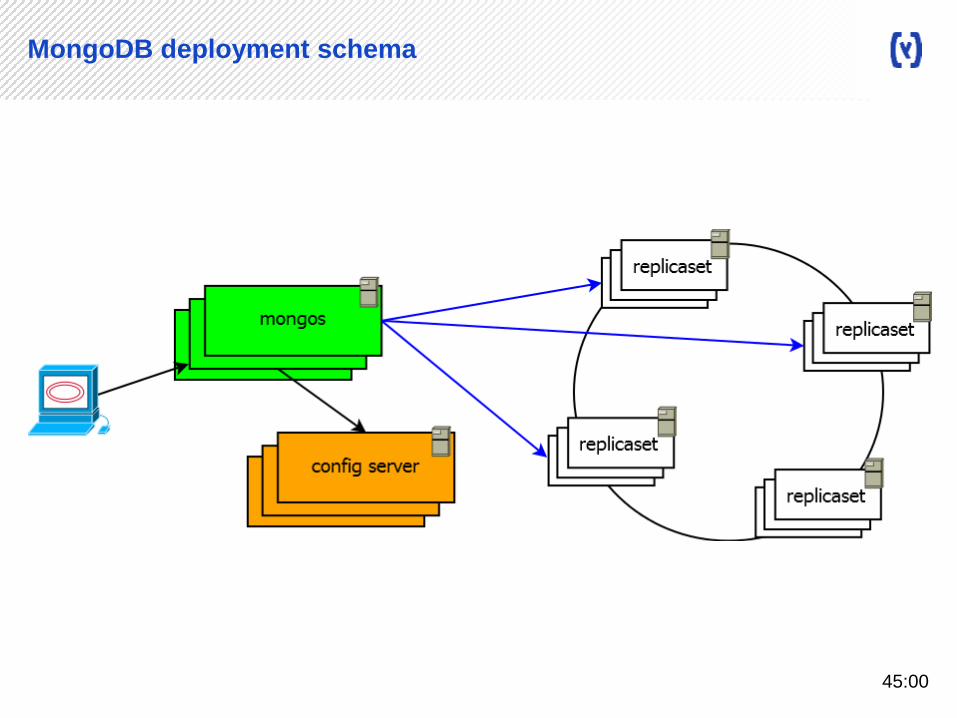
MongoDB deployment schema
45:00
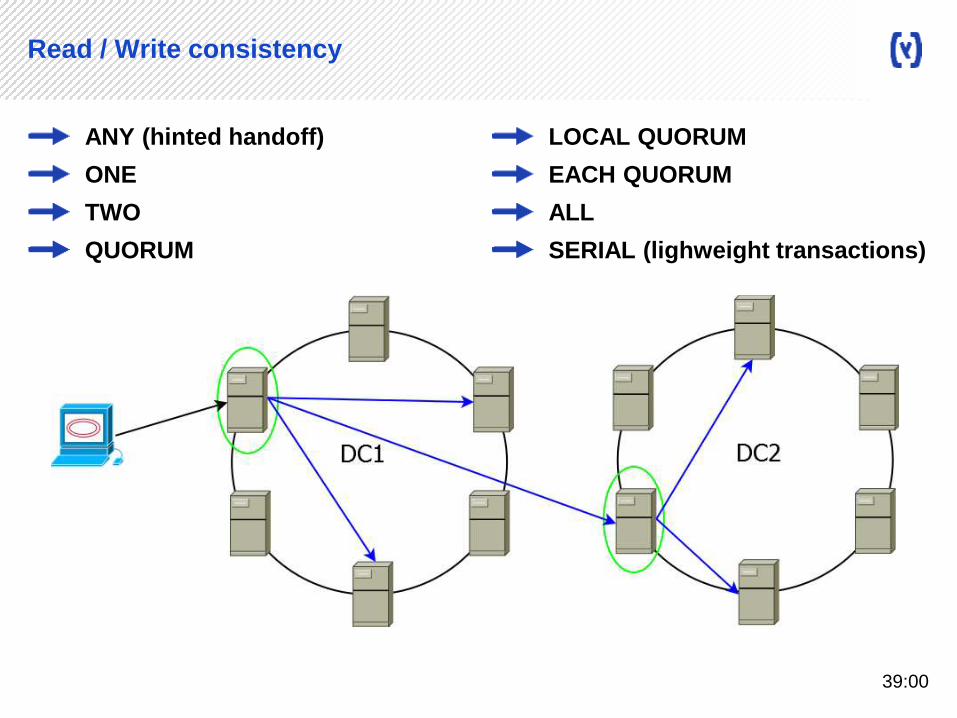
Read / Write consistency
ANY (hinted handoff)
ONE
TWO
QUORUM
LOCAL QUORUM
EACH QUORUM
ALL
SERIAL (lighweight transactions)
39:00
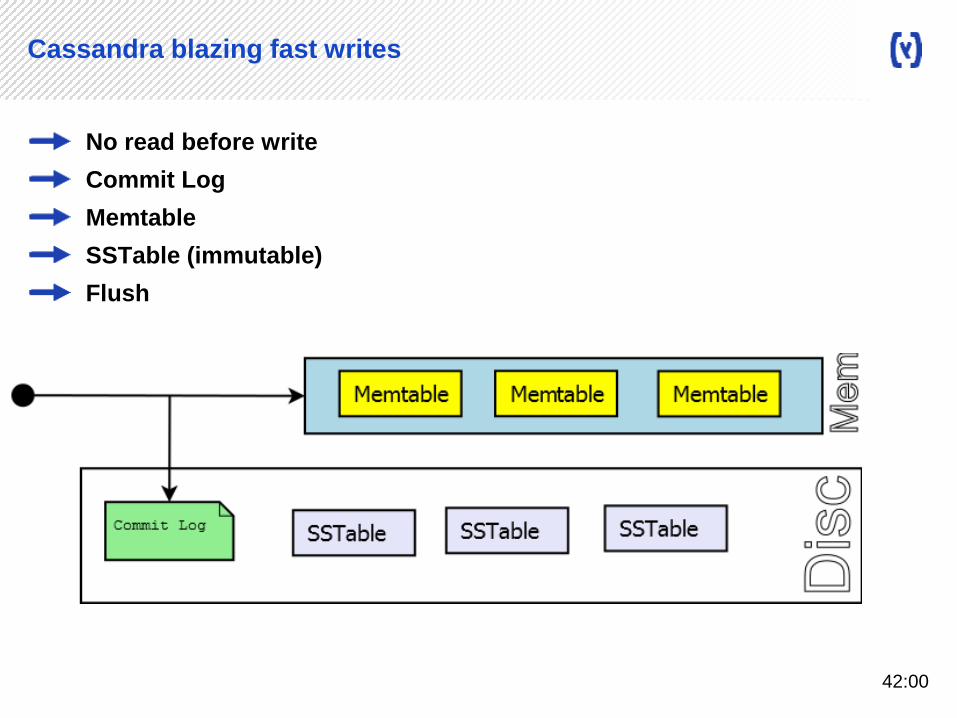
Cassandra blazing fast writes
No read before write
Commit Log
Memtable
SSTable (immutable)
Flush
42:00
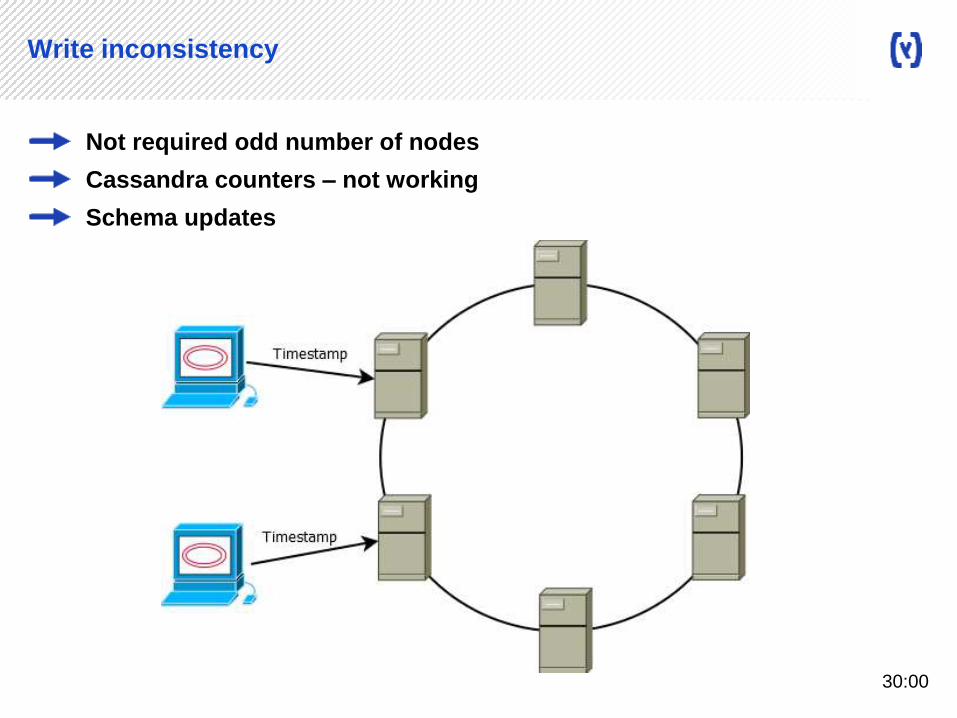
Write inconsistency
Not required odd number of nodes
Cassandra counters – not working
Schema updates
30:00
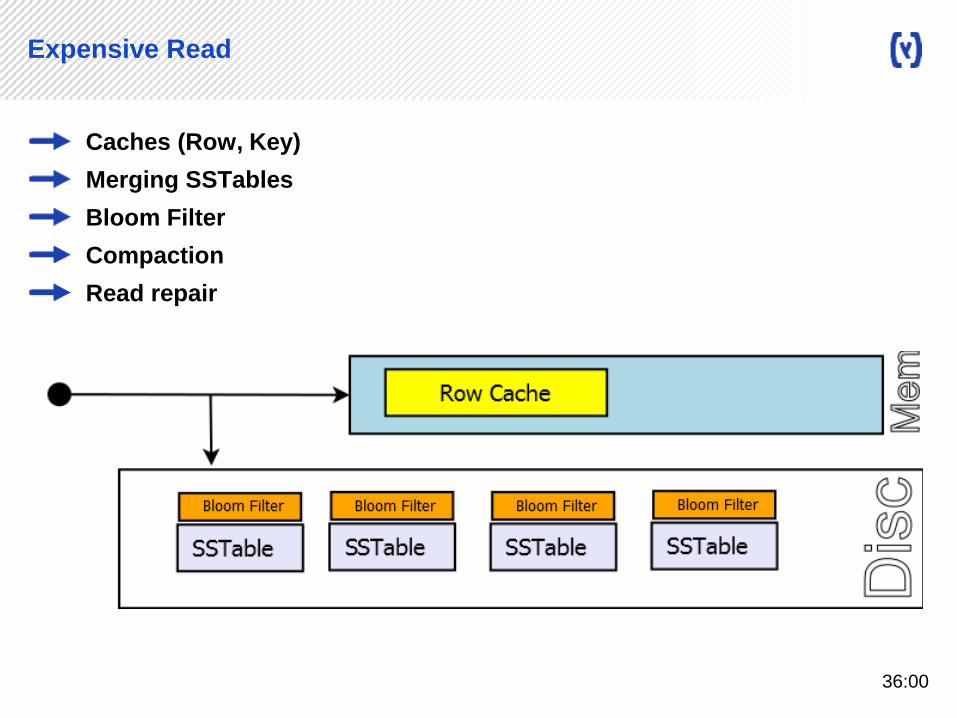
Expensive Read
Caches (Row, Key)
Merging SSTables
Bloom Filter
Compaction
Read repair
36:00
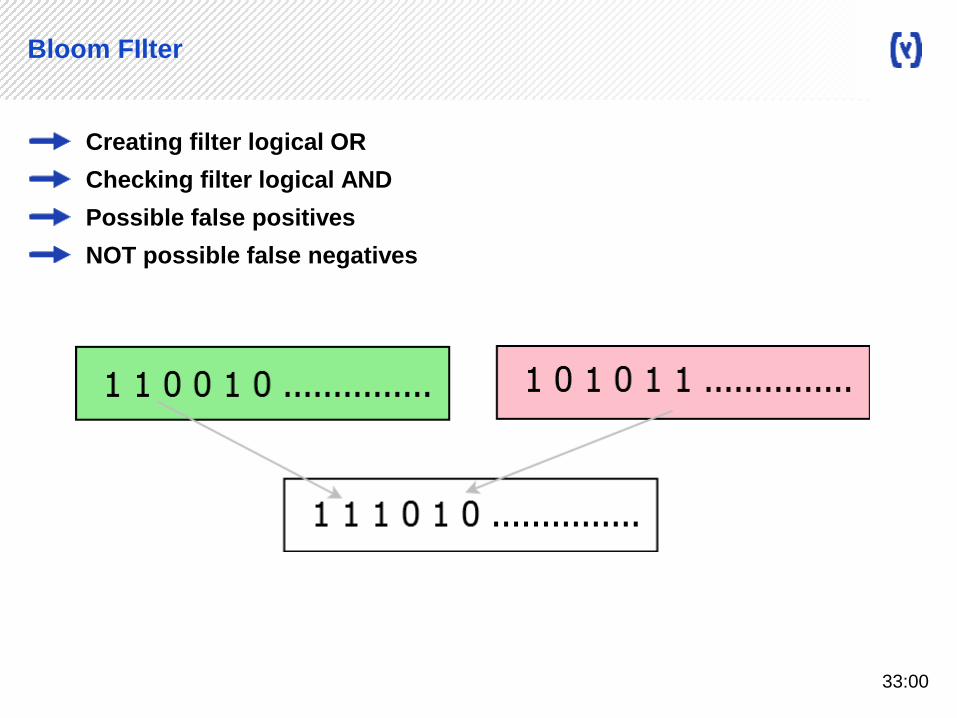
Creating filter logical OR
Checking filter logical AND
Possible false positives
NOT possible false negatives
Bloom FIlter
33:00

Atomic Operations
Cassandra „Lightweight Transactions” in 2.0 using Paxos
UPDATE usersSET reset_token = null AND password = ‘newpassword’IF reset_token = ‘some-generated-reset-token’
MongoDB atomic operations
db.runCommand( {
findAndModify: "people",
query: { name: "Tom", state: "active", rating: { $gt: 10 } },
sort: { rating: 1 },
update: { $inc: { score: 1 } }
} )
27:00
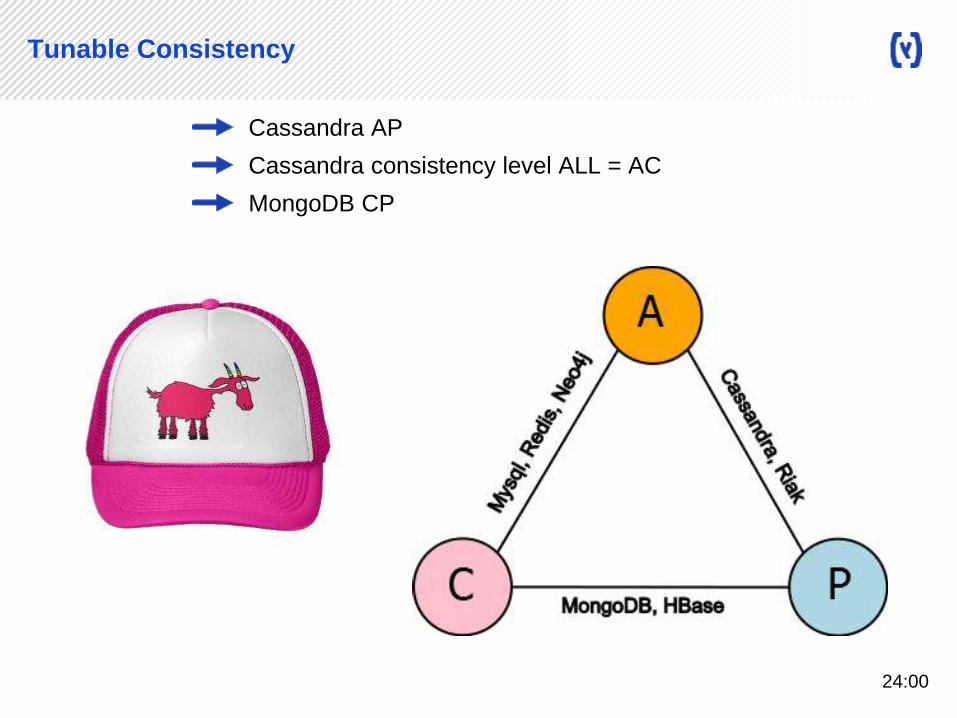
Tunable Consistency
Cassandra AP
Cassandra consistency level ALL = AC
MongoDB CP
24:00
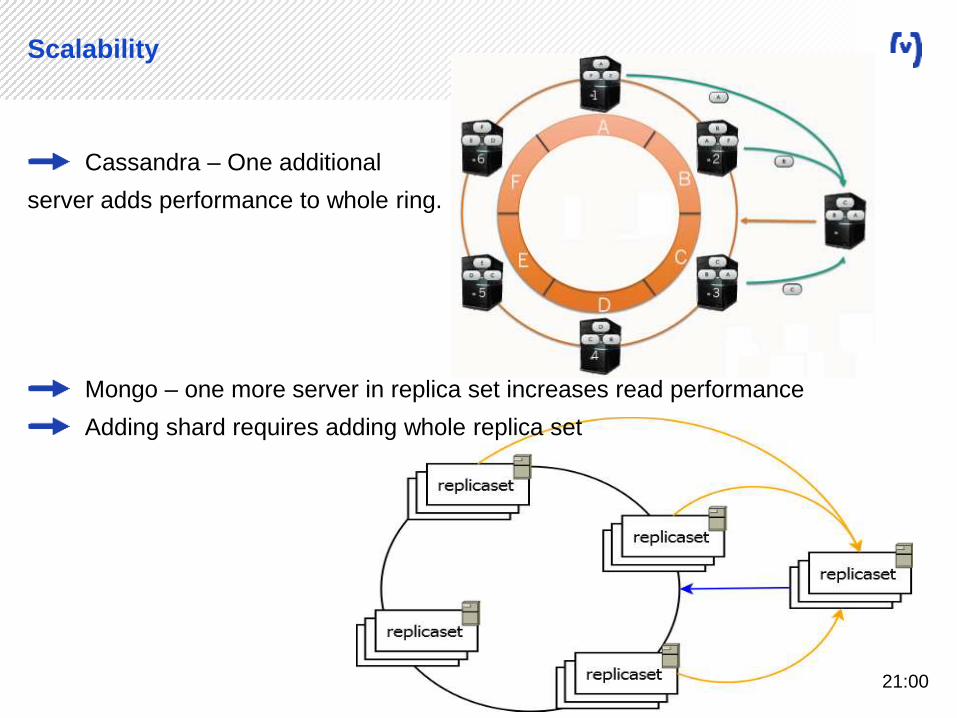
Cassandra – One additional
server adds performance to whole ring.
Mongo – one more server in replica set increases read performance
Adding shard requires adding whole replica set
Scalability
21:00
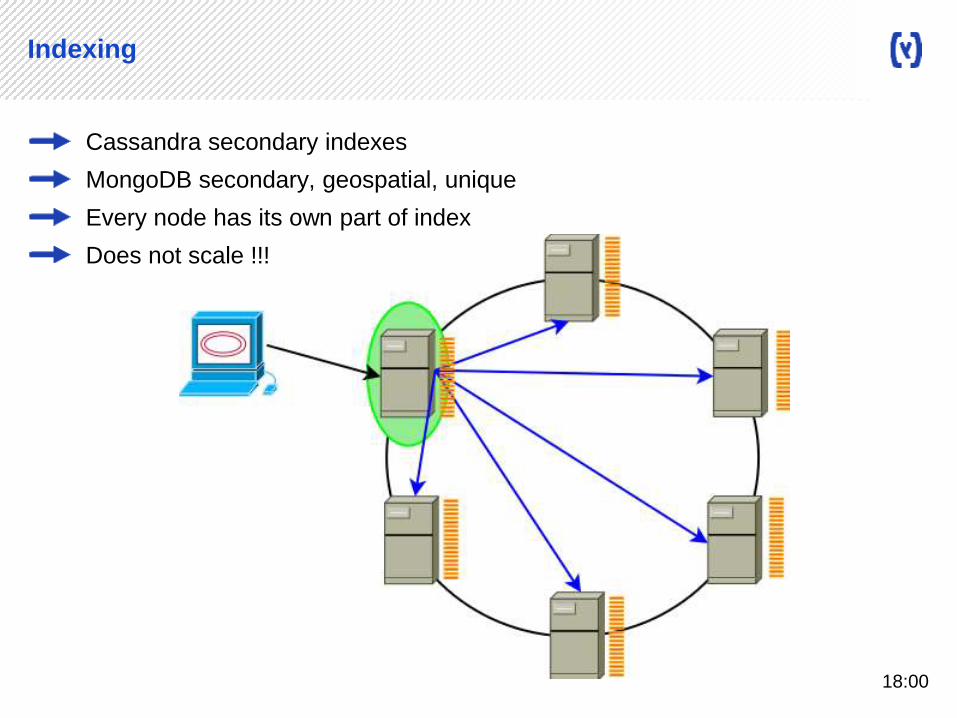
Indexing
Cassandra secondary indexes
MongoDB secondary, geospatial, unique
Every node has its own part of index
Does not scale !!!
18:00
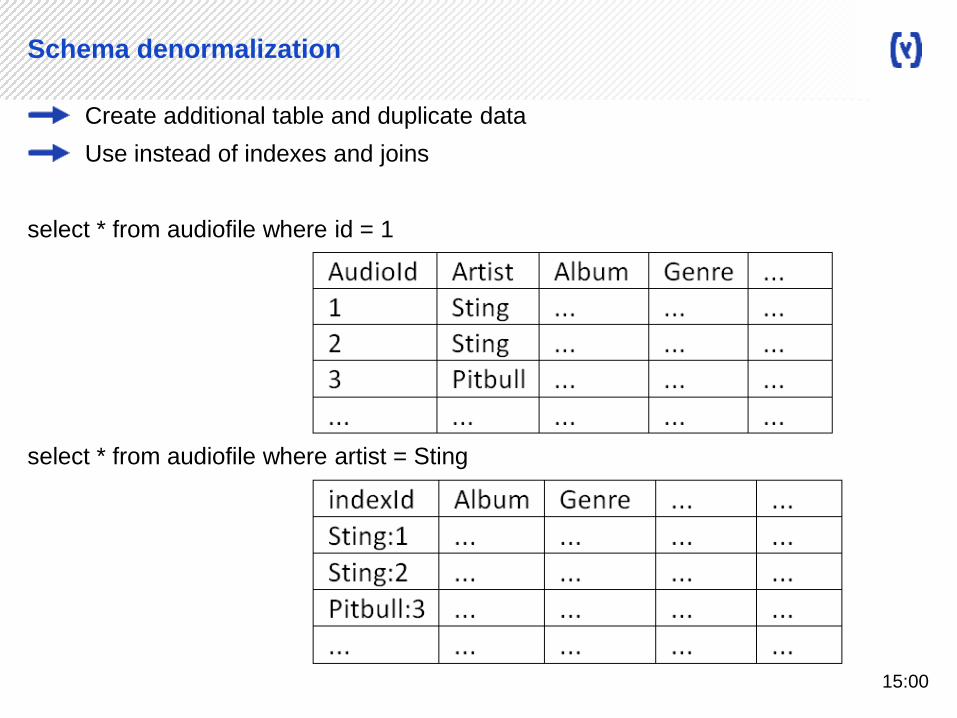
Schema denormalization
Create additional table and duplicate data
Use instead of indexes and joins
select * from audiofile where id = 1
select * from audiofile where artist = Sting
15:00

CQL: Cassandra query language (v3.1.1)
http://cassandra.apache.org/doc/cql3/CQL.html
DDL: Data definition language
DML: Data modification language
CREATE TABLE monkeySpecies (
species text PRIMARY KEY,
common_name text,
population varint,
average_size int
)
CREATE KEYSPACE Excelsior
WITH replication = {
'class':'SimpleStrategy',
'replication_factor' : 3
}
SELECT time, value
FROM events
WHERE event_type = 'myEvent'
AND time > '2011-02-03'
AND time <= '2012-01-01'
INSERT INTO NerdMovies
(movie, director, main_actor, year)
VALUES ('Serenity', 'Joss Whedon', 'Nathan Fillion',
2005)
USING TTL 86400;
12:00
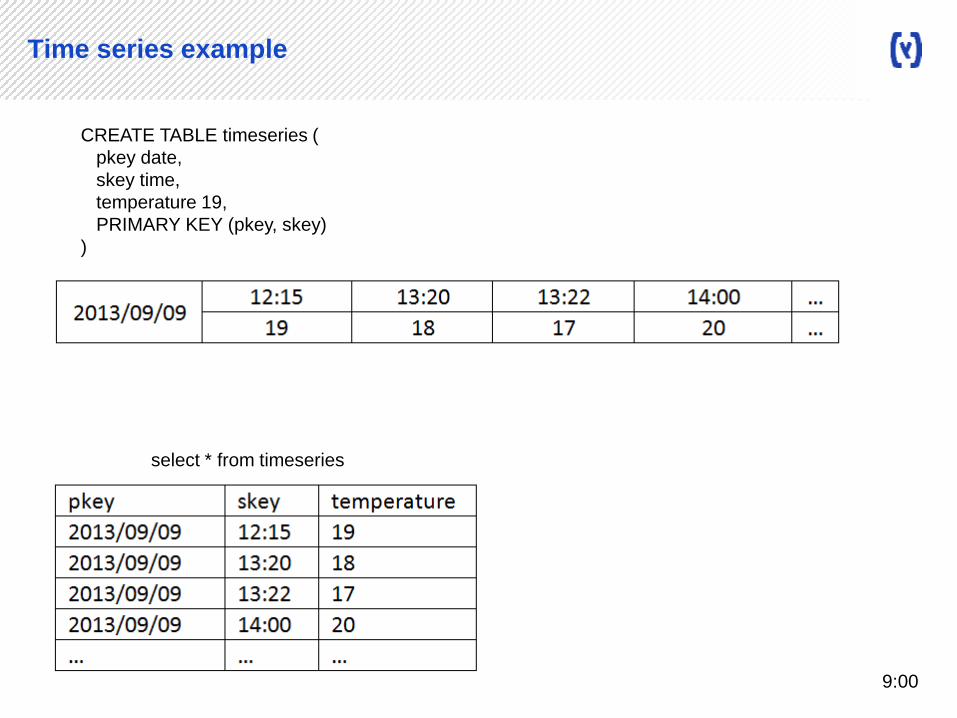
Time series example
CREATE TABLE timeseries (
pkey date,
skey time,
temperature 19,
PRIMARY KEY (pkey, skey)
)
select * from timeseries
9:00
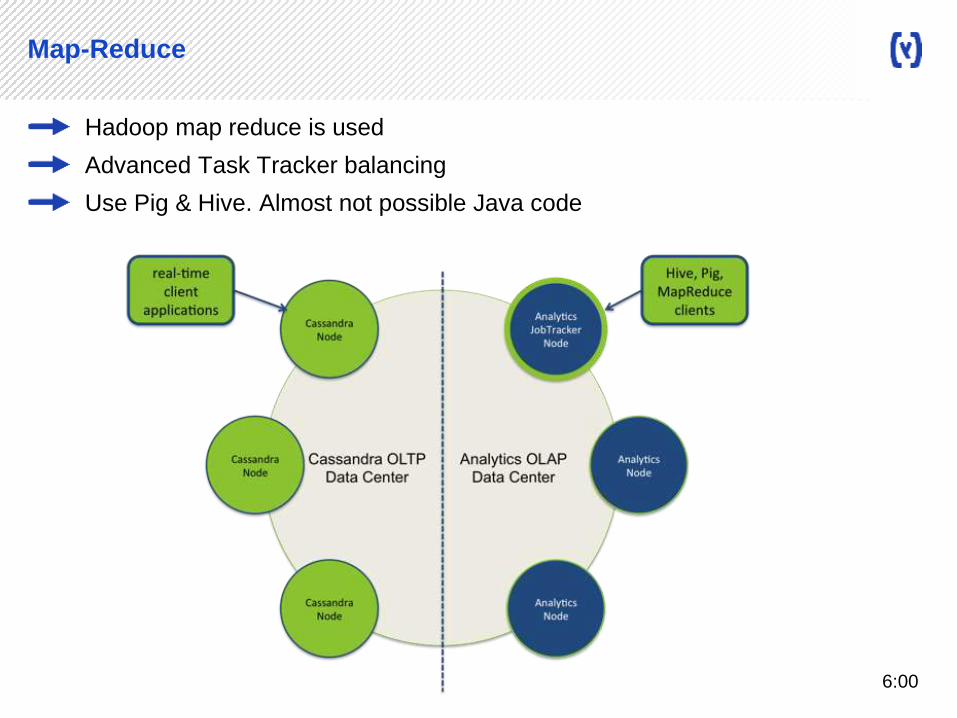
Map-Reduce
Hadoop map reduce is used
Advanced Task Tracker balancing
Use Pig & Hive. Almost not possible Java code
6:00
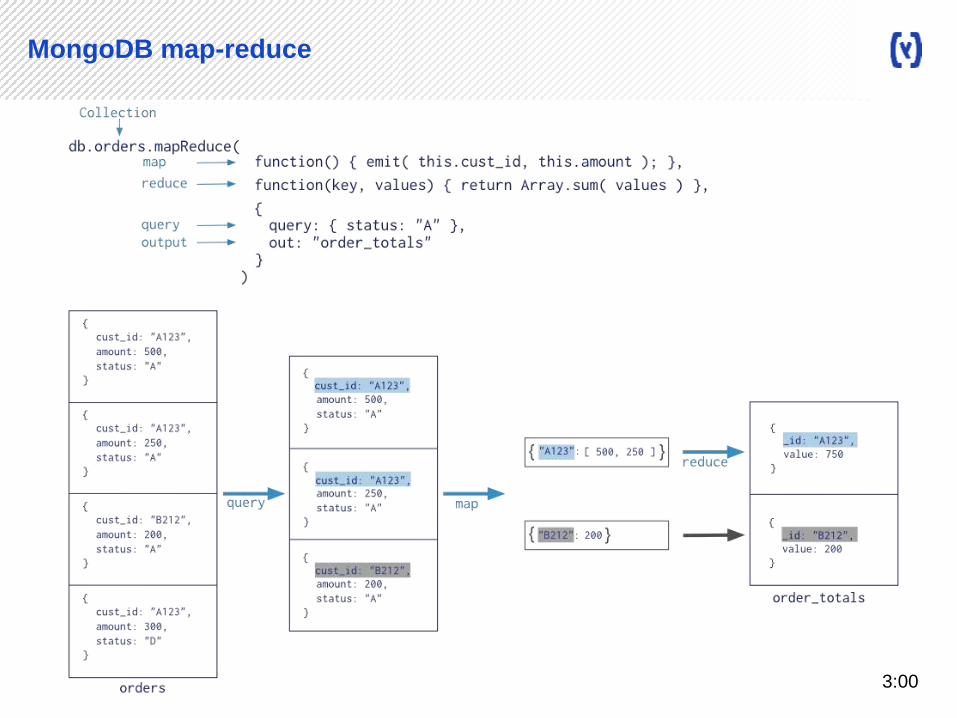
MongoDB map-reduce
3:00
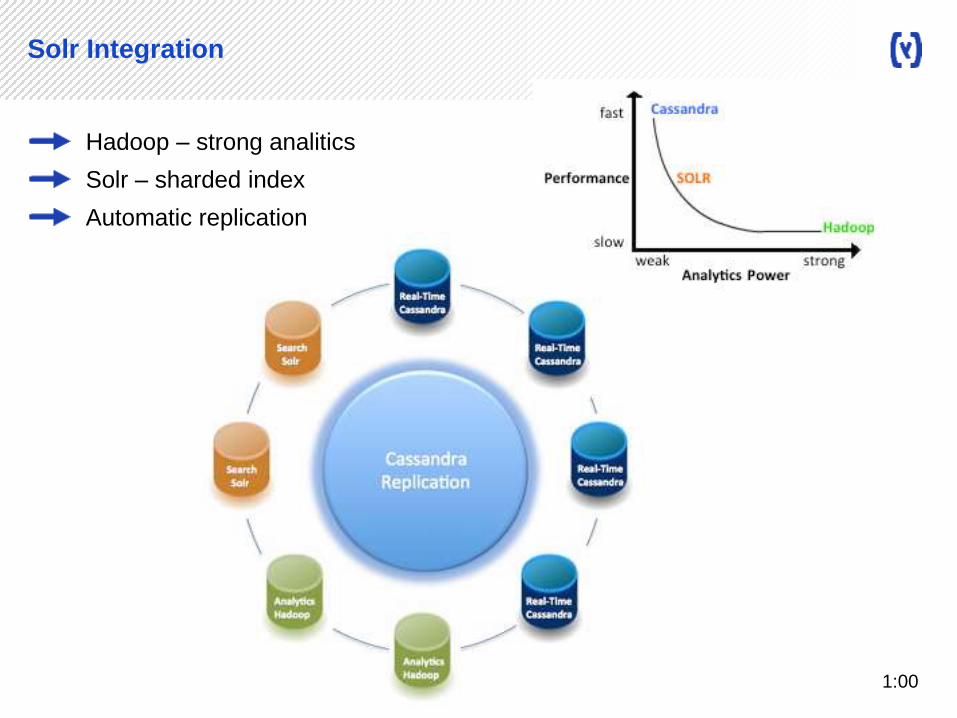
Solr Integration
Hadoop – strong analitics
Solr – sharded index
Automatic replication
1:00
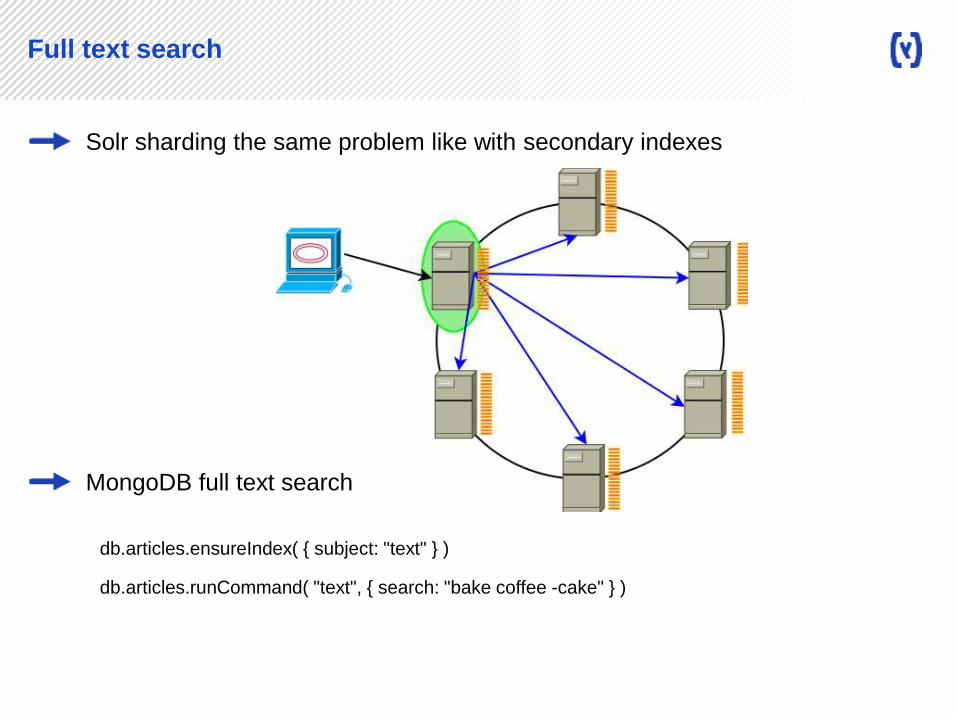
Full text search
Solr sharding the same problem like with secondary indexes
MongoDB full text search
db.articles.runCommand( "text", { search: "bake coffee -cake" } )
db.articles.ensureIndex( { subject: "text" } )

Questions



















