

NoSQL vs SQL Christian Gross Individual [email protected].
42
-
Upload
aileen-shepherd -
Category
Documents
-
view
217 -
download
0
Transcript of NoSQL vs SQL Christian Gross Individual [email protected].

Who Am I?• I have consulted companies on how to manage
software development– Mostly Internet based systems (eg web services, web
sites, etc)• Last 7 years worked as a developer quant/algo
developer• Now I manage my own money and write my own
algos– I code each and every day as I do quantitative analysis– I crunch HUGE amounts of data (sometimes in the
billions on billions of records)

Agenda
• This is a talk that abstracts my experiences into a number of observations– It is not meant to cover all bases
• It is about SQL and NoSQL, though I assume you already know quite a bit about SQL

My Problem Set
• Work on algo’s that trade and research the market• Problem sets are large where one algo needs 15
years on a single core to make a decisions– Yet decision needs to be within 30 seconds
• Data need to be sliced and diced (tweets, rss, etc)• Balance sheets need to be processed– Financial statements vary from company to company

NoSQL or SQL, etc What they Solve
• It is about persistence of information that will be retrieved at some later point in time
• All you are interested in is the ability to store and retrieve data in unique ways
• The question is how do you persist? What strategies do you use?

Understanding the Problem
• It is not just about storing data• It is about being efficient in the storage of data– This means one solution might not fit all problems
• With smaller sets of data (eg millions of records) it is pretty easy to do the right thing– Once things get into the billions of records then
things become complicated– You are fighting software and hardware at the same
time

NoSQL Definitionhttp://nosql-database.org/
• NoSQL DEFINITION: Next Generation Databases mostly addressing some of the points: being non-relational, distributed, open-source and horizontal scalable. The original intention has been modern web-scale databases. The movement began early 2009 and is growing rapidly. Often more characteristics apply as: schema-free, easy replication support, simple API, eventually consistent /BASE (not ACID), a huge data amount, and more. So the misleading term "nosql" (the community now translates it mostly with "not only sql") should be seen as an alias to something like the definition above.

There is not JUST one NoSQL…
• There are literally dozens of leading NoSQL implementations
• There are multiple NoSQL implementation types– I am not referring to programming language as that
is another complexity– I am referring to how the underlying data is
represented
• Best overview is nosql-database.org

Software is Not Your Only Problem
• Hardware is very important and will have an impact on your system as most likely you will have a cluster of computers– Is the network fast enough?– Are the hard disks fast enough?– Can the processor(s) handle the data?

Choosing Hardware
• You don’t choose the hardware first, and then the software
• You decide on the software, and then make sure you buy the best hardware for your budget– A slow piece of hardware will not be improved by
awesome software– For example Redis needs large amounts of RAM, but
very little hard disk space and a very fast network

A Controversial Suggestion
• In this world of software I prefer Open Source because of the ramifications of not choosing Open Source– Your data is your life and bloodline of the algorithm, and
potentially business
• Open source does have its problems in that you might need to either hire specific programmers, or companies– It is not going to save you that much money as talent might
be more expensive
• Closed source companies can mean that you might have to live with problems, data corruption, or forced upgrades

Problem Of Data
• It is extremely difficult if not impossible to rebuild data from zero– A rebuild without any base data means data might be lost
• Moving data from one db instance to another is problematic– How do you know your data is copied properly?– Problem is that it can be difficult to ensure data at A is data at B
• Need hashing, etc
• This is why I made the Open Source comment as I am in control of my data

Choosing the Software is Simpler by the Problem
• Instead of saying I use this technology, I suggest you try to figure out the persistence algorithm you are going to use
• Algo’s I have abstracted– Needle in a haystack– Data based on a set of limitations– Transformed data– Complex unknown data– Temporary intermediary data

Algo: Needle in haystack
• You are looking for a specific piece of information– EG on a social network it means an individual user and the
relations to other individual users
• You are looking for a subset of data and general speaking it is a graph based approach with a simple key used to navigate
• A special case where the result set is independent of the other persisted results– EG my tweets that I edit will not be edited by another person– Allows for many optimizations (eg concurrency, state)

Algo: Data Based on a set of limitations
• You are choosing data based on a set of criteria– It is usually a much larger dataset literally millions of
records in a database of billions
• The criteria often is time based– Side note: There are time based databases
• You are sifting through very large number of records to get some information
• The data is not independent of each other– Eg an edit will change the state of the criteria

Algo: Transformed Data
• It is data that has a view or transformation based on some original data– Important to realize that the transformation is
data in its own right
• While the transformation is not captured data, the underlying source of the transformation is captured data– Financial bars (Open, High, Low, Close, Time size)
are a transformation of the ticks

Algo: Complex or Unknown Data
• This is the most complicated and difficult data to store and process
• You don’t know what it is, or what it will look like, or what you can do with it
• The persistence layer is sometimes blind, but may offer you a data representation that allows for unknown data

Temporary or Intermediary Data
• Typically data where the storage itself is needed to optimize another calculation
• It is data that will be constructed, deleted, and reconstructed again
• This data is noisy and very problematic because it is neither read mostly, nor write mostly– It might have an index associated with it or not
• Derivatives are a transformation of various underlying pieces of information

Client side access technology
• When accessing the database you might use a host of different technologies;– Thrift, proprietary, JSON, BSON, XML, etc
• BEWARE: Do not go for client access technologies that tend to “abstract” and “simplify” as they might slow down and make your client less efficient
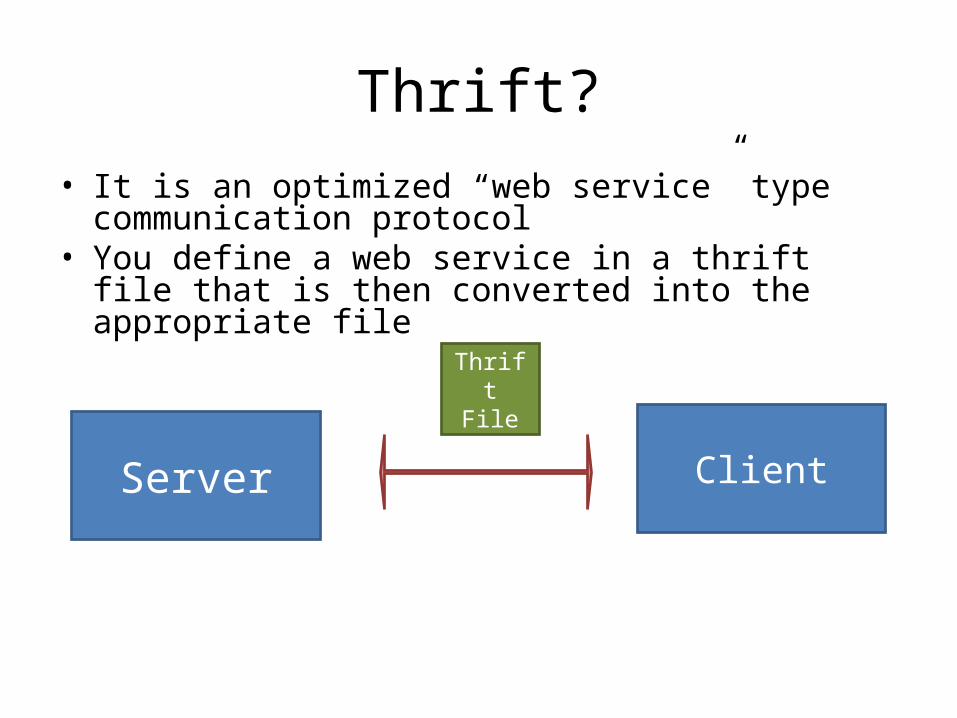
Thrift?• It is an optimized “web service” type communication
protocol• You define a web service in a thrift file that is then
converted into the appropriate file
Server Client
Thrift File

Thrift Example
Python

ACID
• Next topic…
Sorry, but most NoSQL have no ACID

Security
• Next topic
Sorry but most NoSQL databases expect you to add a layer in front, or have extremely rudimentary security

Classifying of Databases
• A Distributed database has specific features and it can be described using the CAP Theorem or Brewers Theorem

Visual Guide To NoSQL (or SQL)http://blog.nahurst.com/visual-guide-to-nosql-systems

SQL (eg PostgreSQL)
• I will not say much since, we already know this one quite well
• Uses the SQL langauge• Uses tables, columns and rows• Transactions are popular

SQL and its Algo Application
• Needle in a haystack– Requires optimization, but that optimization can cause inserts, etc to
be extremely slow
• Data based on a set of limitations– Superb and this is what SQL is really intended for
• Transformed data– Simplistic and complicated transformations are a pain in the butt
• Complex unknown data– Forget about it
• Temporary intermediary data– Can be very good as deleting and rebuilding is very quick, though a
caveat are the indices

Key Value (eg Redis) http://www.dotkam.com/2009/08/30/key-value-store-list/
• All your data is referenced via a key
• The data is manipulated using Get, Put, and Delete
• You can sort the keys• Joins are not supported and
need to be implemented via code

Key Value and its Algo Application
• Needle in a haystack– Superb
• Data based on a set of limitations– Forget about it since you will need to manually go through the
data
• Transformed data– Way too complicated
• Complex unknown data– Way to complicated
• Temporary intermediary data– Can be awesome if you use something like Redis

Document Oriented (eg MongoDB)elasticsearch.org
• Data is stored as “documents” – We are not talking about Word
documents• It means mostly schema free
structured data– Can be queried
• Is easily mapped to OO systems
• No join need to implement via programming

Document and its Algo Application
• Needle in a haystack– Can be very good
• Data based on a set of limitations– Maybe, and it is very much an implementation detail
• Transformed data– Can be very good since you can use a Map-Reduce type
functionality
• Complex unknown data– Superb
• Temporary intermediary data– Problematic as the indices and implementation could wreck havoc

Column Oriented http://arxtecture.com/column-oriented-database-what-databeast-is-this/

Column Oriented http://en.wikipedia.org/wiki/Column-oriented_DBMS
• It takes the SQL row idea and turns it on its head– You store columns and they reference row id’s• Eg a column value could reference multiple rows
• Makes it very easy to extract a subset of data as it is a very quick reference– Therein lies the rub, if you want a row of data
then things become more complicated as you need to perform quite a few more look ups

Column Oriented and its Algo Application
• Needle in a haystack– Can be very good
• Data based on a set of limitations– Not really, and it is very much an implementation detail and reduced
data set
• Transformed data– Can be very good since you can use a Map-Reduce type functionality
• Complex unknown data– Acceptable
• Temporary intermediary data– Acceptable

Some NoSQL Ideas…
• Now I want to focus on some very unique NoSQL implementation details
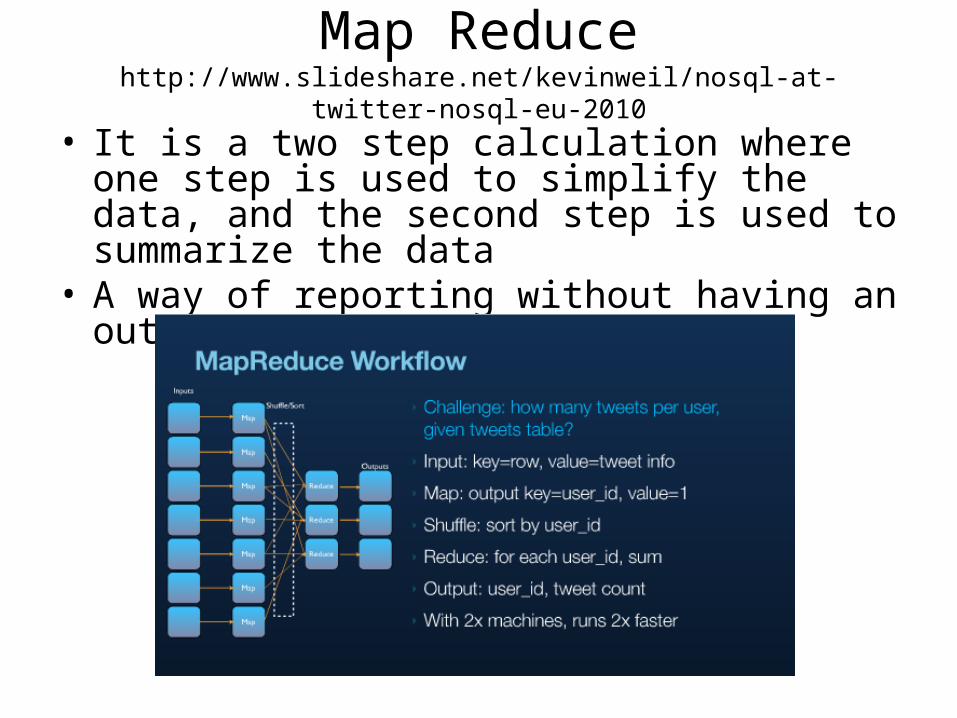
Map Reducehttp://www.slideshare.net/kevinweil/nosql-at-twitter-nosql-eu-2010
• It is a two step calculation where one step is used to simplify the data, and the second step is used to summarize the data
• A way of reporting without having an output

Map Reduce
Ex 1Mongo DB

Sharding• Used to partition the database across multiple
physical computers– ad-hoc– consistent hashing– range based
• Think of glass shards where each shard is a piece of the complete glass
• Sharding is built into NoSQL databases– The question is which algorithm is used
• Often works in conjunction with object replication or instead of

Sharding MongoDB(range, or hash key based partitioning)
Shard Key

Why Do You Care About Sharding?• It impacts failover, and consistency• Because NoSQL consistency is eventual (mostly)• Querying can either be fast or slow
– Local query, or global query• It is very very specific to the NoSQL
implementation used– You need to understand it if you want optimal
performance• It needs to be thought out because a bad data
model will shard poorly and scale poorly

How To Approach The Problem
• I am sorry that I have not simplified your life and pointed you at a single solution
• I gave you a set of guidelines– Figure out the algo you are to use– Figure out your hardware budget– Figure out which technology approach best suits your needs– Based on that decide on the software
• It might involve multiple technologies– I use Redis, MySQL, and MongoDB (just for my trading algos)

Conclusions• NoSQL is not “NO SQL”, but “not only SQL”
– A bit of a misnomer• NoSQL is above solving some specific use cases in a
very efficient manner• NoSQL does not mean don’t use SQL• You use whatever you need for the problem space
you are confronted with


















