
Nick McKeown Spring 2012 Lecture 2,3 Output Queueing EE384x Packet Switch Architectures.
35
Nick McKeown Spring 2012 Lecture 2,3 Output Queueing EE384x Packet Switch Architectures
-
Upload
winifred-nicholson -
Category
Documents
-
view
217 -
download
0
Transcript of Nick McKeown Spring 2012 Lecture 2,3 Output Queueing EE384x Packet Switch Architectures.

Nick McKeown
Spring 2012
Lecture 2,3
Output Queueing
EE384xPacket Switch Architectures

Outline
1. Output Queued Switches
2. Rate and Delay guarantees

Output queued switch
Link 1
Link 2
Link 3
Link 4
Link 1, ingress Link 1, egress
Link 2, ingress Link 2, egress
Link 3, ingress Link 3, egress
Link 4, ingress Link 4, egress
Link rate, R
R
R
R
Link rate, R
R
R
R

CharacteristicsArriving packets immediately written to output queue.
Isolation: Packets unaffected by packets to other outputs.
Work conserving: an output line is always busy when there is a packet in the switch for it.
Throughput: Maximized.
Average delay: Minimized.
We can control the rate of individual flows, and the delay of individual packets

The shared memory switch
Link 1, ingress Link 1, egress
Link 2, ingress Link 2, egress
Link 3, ingress Link 3, egress
Link N, ingress Link N, egress
A single pool of memory
R
R
R
R
R
R

Questions
• Is a shared memory switch work conserving?
• How does average packet delay compare to an output queued switch?
• Packet loss?

Memory bandwidth
OQ switchPer output: (N+1)R
Switch total: NR(N+1) N2R
Shared Memory Switch:Switch total: 2NR

Capacity of shared memory switches
SharedMemory
64 byte bus
2ns SRAM
1
2
N
Assume:1.2ns random access SRAM2.500MHz bus; separate read and write3.64byte wide bus4.Smallest packet size = 64bytes
500MHz * 64bytes * 8~= 256Gb/s

Outline
1. Output Queued Switches
2. Rate and Delay guarantees

Rate Guarantees
Problem #1: In a FIFO queue, all packets and flows receive the same service rate.
Solution: Place each flow in its own output queue; serve each queue at a different rate.
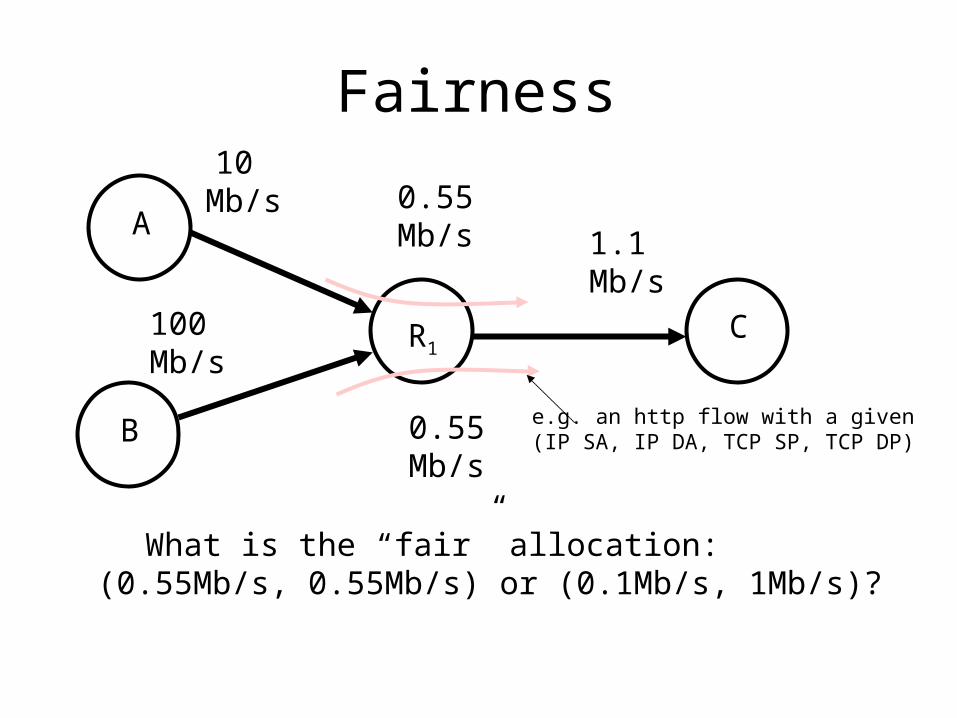
Fairness
1.1 Mb/s
10 Mb/s
100 Mb/s
A
B
R1C
0.55Mb/s
0.55Mb/s
What is the “fair” allocation: (0.55Mb/s, 0.55Mb/s) or (0.1Mb/s, 1Mb/s)?
e.g. an http flow with a given(IP SA, IP DA, TCP SP, TCP DP)

Fairness
1.1 Mb/s
10 Mb/s
100 Mb/s
A
B
R1 D
What is the “fair” allocation?0.2 Mb/sC

Max-Min FairnessA common way to allocate flows
N flows share a link of rate C. Flow f wishes to send at rate W(f), and is allocated rate R(f).
• Pick the flow, f, with the smallest requested rate.
• If W(f) < C/N, then set R(f) = W(f). • If W(f) > C/N, then set R(f) = C/N.• Set N = N – 1. C = C – R(f).• If N>0 goto 1.

1W(f1) = 0.1
W(f3) = 10R1
C
W(f4) = 5
W(f2) = 0.5
Max-Min FairnessAn example
Round 1: Set R(f1) = 0.1
Round 2: Set R(f2) = 0.9/3 = 0.3
Round 3: Set R(f4) = 0.6/2 = 0.3
Round 4: Set R(f3) = 0.3/1 = 0.3

Max-Min Fairness
How can a router “allocate” different rates to different flows?
First, let’s see how a router can allocate the “same” rate to different flows…
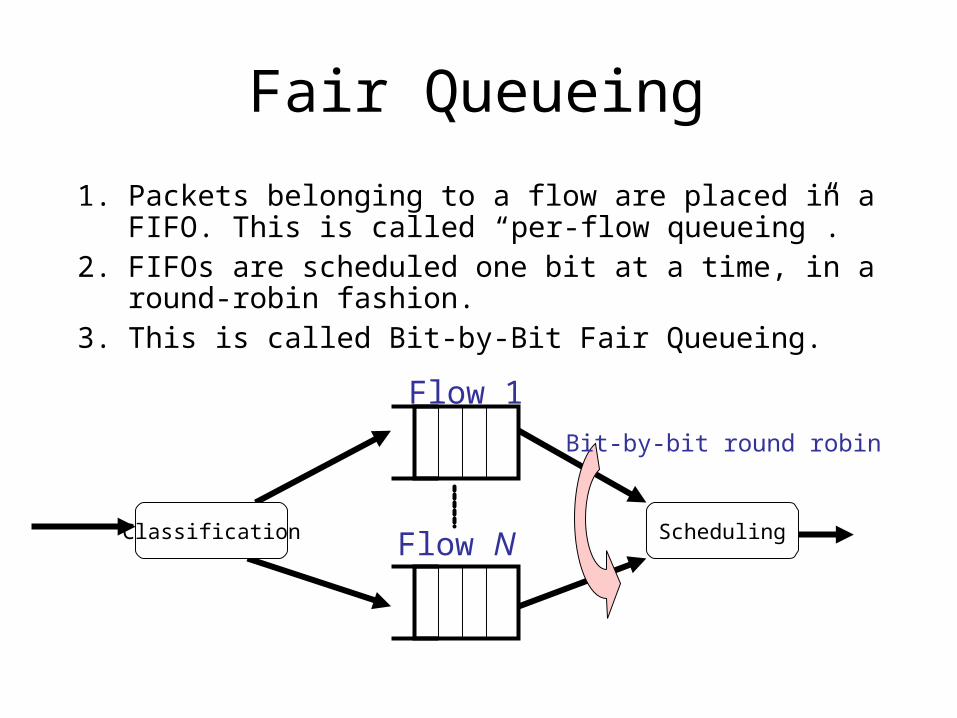
Fair Queueing
1. Packets belonging to a flow are placed in a FIFO. This is called “per-flow queueing”.
2. FIFOs are scheduled one bit at a time, in a round-robin fashion.
3. This is called Bit-by-Bit Fair Queueing.Flow 1
Flow NClassification Scheduling
Bit-by-bit round robin

Weighted Bit-by-Bit Fair Queueing
Likewise, flows can be allocated different rates by servicing a different number of bits for each flow during each round.
1R(f1) = 0.1
R(f3) = 0.3R1
C
R(f4) = 0.3
R(f2) = 0.3
Order of service for the four queues:
… f1, f2, f2, f2, f3, f3, f3, f4, f4, f4, f1,…
Also called “Generalized Processor Sharing (GPS)”

Packetized Weighted Fair Queueing (WFQ)
Problem: We need to serve a whole packet at a time.
Solution: 1. Determine what time a packet, p, would complete if we served flows
bit-by-bit. Call this the packet’s finishing time, F.
2. Serve packets in the order of increasing finishing time.
Theorem: Packet p will depart before F + TRANSPmax
Also called “Packetized Generalized Processor Sharing (PGPS)”

Intuition behind Packetized WFQ
1. Consider packet p that arrives and immediately enters service under WFQ.
2. Potentially, there are packets Q = {q, r, …} that arrive after p that would have completed service before p under bit-by-bit WFQ. These packets are delayed by the duration of p’s service.
3. Because the amount of data in Q that could have departed before p must be less than or equal to the length of p, their ordering is simply changed.
4. Packets in Q are delayed by the maximum duration of p.
(Detailed proof in Parekh and Gallager)

Calculating F
• Assume that at time t there are N(t) active (non-empty) queues.
• Let R(t) be the number of rounds in a round-robin service discipline of the active queues, in [0,t].
• A P bit long packet entering service at t0 will complete service in round R(t) = R(t0) + P.
• 1, max( , ( )), and where: time that -th
packet starts service. i i i i i i iF S P S F R t S i

An example of calculating F
Flow 1
Flow i
Flow N
Calculate Si and Fi
& Enqueue
Pick packet withsmallest Fi
& Send
In both cases, Fi = Si + Pi
R(t) is monotonically increasing with t, therefore same departure order in R(t) as in t.
Case 1: If packet arrives to non-empty queue, then Si = Fi-1
Case 2: If packet arrives at t0 to empty queue, then Si = R(t0)
R(t)

WFQ is complex
1. There may be hundreds to millions of flows; the linecard needs to manage a FIFO per flow.
2. The finishing time must be calculated for each arriving packet,3. Packets must be sorted by their departure time. Naively, with m
packets, the sorting time is O(logm).4. In practice, this can be made to be O(logN), for N active flows:
1
2
3
N
Packets arriving to egress linecard
CalculateFp
Find Smallest Fp
Departing packet
Egress linecard

Delay Guarantees
Problem #2: In a FIFO queue, the delay of a packet is determined by the number of packets ahead of it (from other flows).
Solution: Control the departure time of each packet.
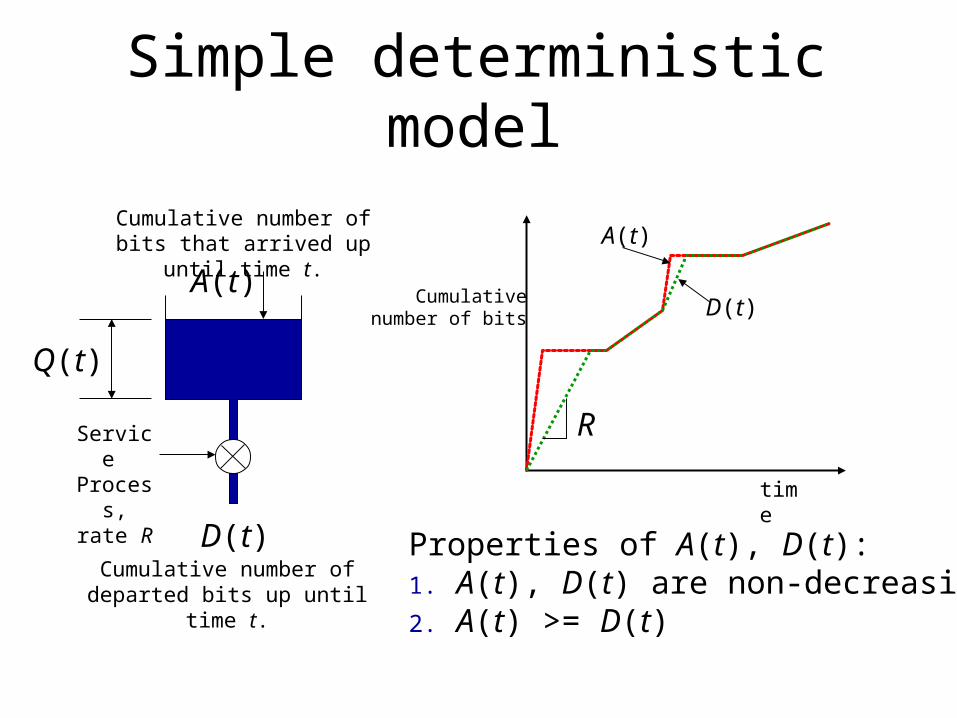
Simple deterministic model
A(t)
D(t)Cumulative number of
departed bits up until time t.
time
Service Process, rate R
Cumulativenumber of bits
Cumulative number of bits that arrived up until time t.
R
A(t)
D(t)
Q(t)
Properties of A(t), D(t):1. A(t), D(t) are non-decreasing2. A(t) >= D(t)

D(t)
A(t)
time
Q(t)
d(t)
Queue occupancy: Q(t) = A(t) - D(t).
Queueing delay, d(t), is the time spent in the queue by a bit that arrived at time t, (assuming that the queue is served FCFS/FIFO).
Simple Deterministic Model
Cumulativenumber of bits
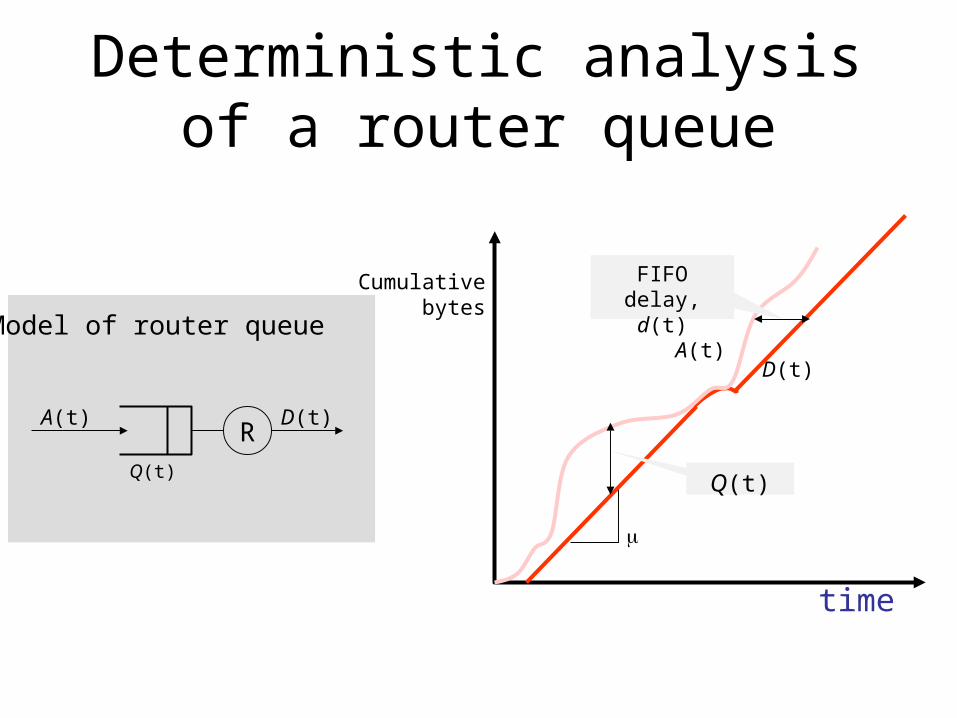
time
Cumulativebytes
A(t)D(t)
Q(t)
Deterministic analysis of a router queue
FIFO delay, d(t)
RA(t) D(t)
Model of router queue
Q(t)

So how can we control the delay of packets?
Assume continuous time, bit-by-bit flows for a moment…
1. Let’s say we know the arrival process, Af(t), of flow f to a router.
2. Let’s say we know the rate, R(f) that is allocated to flow f.
3. Then, in the usual way, we can determine the delay of packets in f, and the buffer occupancy.

Flow 1
Flow NClassificationWFQ
Scheduler
A1(t)
AN(t)
R(f1), D1(t)
R(fN), DN(t)
time
Cumulativebytes
A1(t) D1(t)
R(f1)
Key idea: In general, we don’t
know the arrival process. So let’s
constrain it.

One way to bound the arrival process
time
Cumulativebytes
t
Number of bytes that can arrive in any period of length t
is bounded by:
This is called “() regulation”
A1(t)

() Constrained Arrivals and Minimum Service Rate
time
Cumulativebytes
A1(t) D1(t)
R(f1)
dmax
Bmax
Theorem [Parekh,Gallager]: If flows are leaky-bucket constrained,and routers use WFQ, then end-to-end delay guarantees are possible.
1 1
.
( ) , ( ) / ( ).
For no packet loss,
I f then
B
R f d t R f

The leaky bucket “()” regulator
Tokensat rate,
Token bucket
size,
Packet buffer
Packets Packets
One byte (or packet) per token

How the user/flow can conform to the () regulationLeaky bucket as a “shaper”
Tokensat rate,
Token bucketsize
Variable bit-ratecompression
To network
time
bytes
time
bytes
time
bytes
C
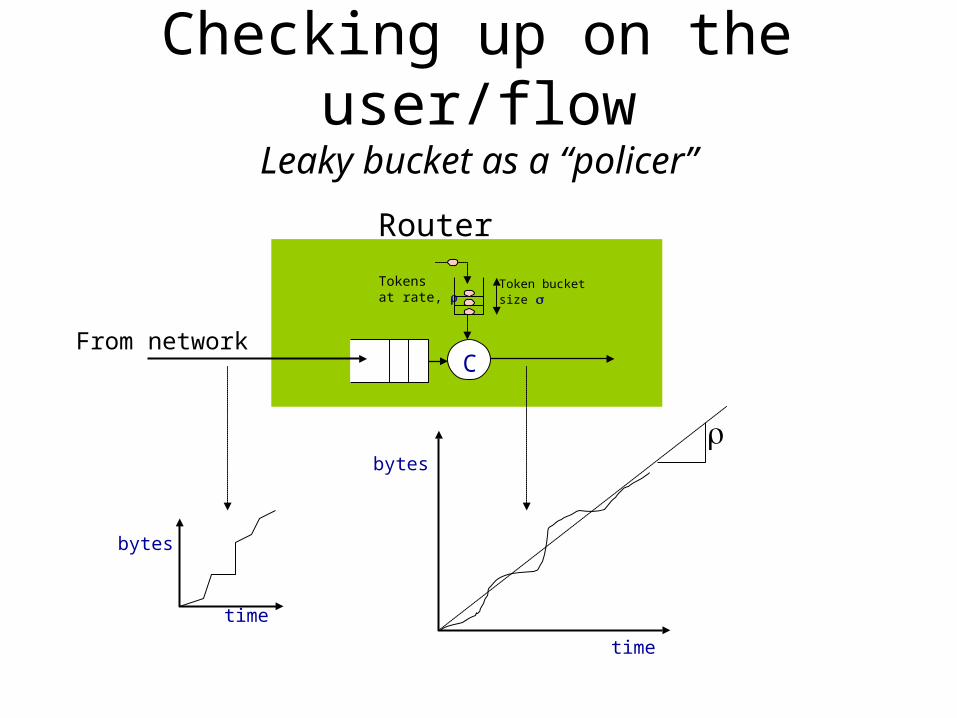
Checking up on the user/flowLeaky bucket as a “policer”
Tokensat rate,
Token bucketsize
time
bytes
time
bytes
C
Router
From network

Packet switch with QoS
Policer
Policer
Classifier
Policer
Policer
Classifier
Per-flow Queue
Scheduler
Per-flow Queue
Per-flow Queue
Scheduler
Per-flow Queue
Questions: These results assume an OQ switch1. Why?2. What happens if it is not?

References
1. Abhay K. Parekh and R. Gallager“A Generalized Processor Sharing Approach to Flow Control in Integrated Services Networks: The Single Node Case” IEEE Transactions on Networking, June 1993.
2. M. Shreedhar and G. Varghese“Efficient Fair Queueing using Deficit Round Robin”, ACM Sigcomm, 1995.


















