NGS/IBM: April2002PPL-Dept of Computer Science, UIUC Programming Environment and Performance...
34
NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC Programming Environment and Performance Modeling for million-processor machines Laxmikant (Sanjay) Kale Parallel Programming Laboratory Department of Computer Science University of Illinois at Urbana-Champaign Http://charm.Cs.uiuc.edu
-
Upload
lorena-grant -
Category
Documents
-
view
219 -
download
0
description
NGS/IBM: April2002PPL-Dept of Computer Science, UIUC Project Objective and Overview Focus on extremely large parallel machines –Exemplified by Blue Gene/Cyclops Issues: –Programming Environment: Objects, threads, compiler support –Runtime performance adaptation –Performance modeling Coarse grained models Fine grained models Hybrid –Applications: Unstructured Meshes (FEM/Crack Propagation),.. David Padua Sanjay Kale Sarita Adve Phillipe Geubelle
Transcript of NGS/IBM: April2002PPL-Dept of Computer Science, UIUC Programming Environment and Performance...

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Programming Environment and Performance Modeling for
million-processor machines
Laxmikant (Sanjay) KaleParallel Programming Laboratory
Department of Computer ScienceUniversity of Illinois at Urbana-Champaign
Http://charm.Cs.uiuc.edu

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Context: Group Mission and Approach• To enhance Performance and Productivity in
programming complex parallel applications– Performance: scalable to very large number of processors– Productivity: of human programmers– Complex: irregular structure, dynamic variations
• Approach: Application Oriented yet CS centered research– Develop enabling technology, for a wide collection of apps.– Develop, use and test it in the context of real applications– Develop standard library of reusable parallel components

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Project Objective and Overview• Focus on extremely large parallel machines
– Exemplified by Blue Gene/Cyclops• Issues:
– Programming Environment:• Objects, threads, compiler support
– Runtime performance adaptation– Performance modeling
• Coarse grained models• Fine grained models• Hybrid
– Applications: • Unstructured Meshes (FEM/Crack Propagation), ..
David Padua
Sanjay Kale
Sarita Adve
Phillipe Geubelle

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Project Objective and Overview
• Focus on extremely large parallel machines– Exemplified by Blue Gene/Cyclops
• Issues:– Programming Environment– Runtime performance adaptation– Performance modeling
• Coarse grained models• Fine grained models• Hybrid
– Applications: • Unstructured Meshes (FEM/Crack
Propagation), ..
David Padua
Sanjay Kale
Sarita Adve
Phillipe Geubelle

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Multi-partition Decomposition
• Idea: divide the computation into a large number of pieces– Independent of number of processors– Typically larger than number of processors– Let the system map entities to processors
• Optimal division of labor between “system” and programmer:
• Decomposition done by programmer, • Everything else automated

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Object-based Parallelization
User View
System implementationUser is only concerned with interaction between objects

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Charm++
• Parallel C++ with Data Driven Objects• Object Arrays/ Object Collections• Object Groups:
– Global object with a “representative” on each PE• Asynchronous method invocation• Prioritized scheduling• Information sharing abstractions: readonly, tables,..• Mature, robust, portable• http://charm.cs.uiuc.edu

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Data driven execution
Scheduler Scheduler
Message Q Message Q

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Load Balancing Framework
• Based on object migration – Partitions implemented as objects (or threads) are
mapped to available processors by LB framework• Measurement based load balancers:
– Principle of persistence• Computational loads and communication patterns
– Runtime system measures actual computation times of every partition, as well as communication patterns
• Variety of “plug-in” LB strategies available– Scalable to a few thousand processors– Including those for situations when principle of
persistence does not apply

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Building on Object-based Parallelism
• Application induced load imbalances• Environment induced performance issues:
– Dealing with extraneous loads on shared m/cs– Vacating workstations– Heterogeneous clusters– Shrinking and Expanding jobs to available Pes
• Object “migration”: novel uses– Automatic checkpointing– Automatic prefetching for out-of-core execution
• Reuse: object based components

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Applications
• Charm++ developed in the context of real applications
• Current applications we are involved with:– Molecular dynamics– Crack propagation– Rocket simulation: fluid dynamics + structures +– QM/MM: Material properties via quantum mech– Cosmology simulations: parallel analysis+viz– Cosmology: gravitational with multiple timestepping

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Molecular Dynamics
• Collection of [charged] atoms, with bonds• Newtonian mechanics• At each time-step
– Calculate forces on each atom • Bonds:• Non-bonded: electrostatic and van der Waal’s
– Calculate velocities and advance positions• 1 femtosecond time-step, millions needed!• Thousands of atoms (1,000 - 100,000)

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Object Based Parallelization for MD

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Performance Data: SC2000
Speedup on ASCI Red: BC1 (200k atoms)
0
200
400
600
800
1000
1200
1400
0 500 1000 1500 2000 2500
Processors
Spee
dup

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Charm++ Is a Good Match for M-PIM
• Encapsulation : objects• Cost model:
– Object data, read-only data, remote data• Migration and resource management: automatic• One sided communication: since the beginning• Asynchronous global operations (reductions, ..)• Modularity:
– see 1996 paper for why DD Objects enable modularity• Acceptability:
– C++– Now also: AMPI on top of charm++

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Higher-level Models
• Do programmers find Charm++/AMPI easy/good– We think so – Certainly a good intermediate level model
• Higher level abstractions can be built on it• But what kinds of abstractions?• We think domain-specific ones

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Specialization
MPIexpression
Scheduling
Mapping
Decomposition
HPFCharm++
Domain specific
frameworks
/AMPI

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Further Match With MPIM
• Ability to predict:– Which data is going to be needed and– Which code will execute– Based on the ready queue of object method
invocations– So, we can:
• Prefetch data accurately• Prefetch code if needed
S SQ Q

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
So, What Are We Doing About It?
• How to develop any programming environment for a machine that isn’t built yet
• Blue Gene/C emulator using charm++– Completed last year– Implememnts low level BG/C API
• Packet sends, extract packet from comm buffers– Emulation runs on machines with hundreds of
“normal” processors• Charm++ on blue Gene /C Emulator

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Structure of the Emulators
Blue Gene/CLow-level API
Charm++
Converse
Converse
Charm++
BG/C low level API
Charm++

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Emulation on a Parallel Machine
Simulating (Host) Processor
BG/C Nodes
Hardware thread

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Extensions to Charm++ for BG/C
• Microtasks:– Objects may fire microtasks that can be
executed by any thread on the same node– Increases parallelism– Overhead: sub-microsecond
• Issue:– Object affinity: map to thread or node?
• Thread, currently.• Microtasks alleviate load balancing within a node

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Emulation efficiency
• How much time does it take to run an emulation?– 8 Million processors being emulated on 100– In addition, lower cache performance– Lots of tiny messages
• On a Linux cluster:– Emulation shows good speedup

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Emulation efficiencyEmulation Time on Linux Cluster
0
2
4
6
8
10
12
14
0 10 20 30 40 50 60 70
Num of processors
Tim
e (S
ecs)
1000 BG/C nodes (10x10x10)
Each with 200 threads
(total of 200,000 user-level threads)
But Data is preliminary, based on
one simulation

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Emulator to Simulator
• Step 1: Coarse grained simulation– Simulation: performance prediction capability– Models contention for processor/thread– Also models communication delay based on distance– Doesn’t model memory access on chip, or network– How to do this in spite of out-of-order message
delivery?• Rely on determinism of Charm++ programs• Time stamped messages and threads• Parallel time-stamp correction algorithm

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
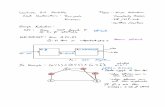
Timestamp correction
• Basic execution: – Timestamped messages
• Correction needed when:– A message arrives with an earlier timestamp
than other messages “processed” already• Cases:
– Messages to Handlers or simple objects– MPI style threads, without wildcard or irecvs– Charm++ with dependence expressed via
structured dagger

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
M8
M1 M7M6M5M4M3M2
RecvTime
ExecutionTimeLine
Timestamps Correction

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
M8M1 M7M6M5M4M3M2
RecvTime
ExecutionTimeLine
Timestamps Correction

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
M1 M7M6M5M4M3M2
RecvTime
ExecutionTimeLine
M8
ExecutionTimeLineM1 M7M6M5M4M3M2 M8
RecvTime
Correction Message
Timestamps Correction

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
M1 M7M6M5M4M3M2
RecvTime
ExecutionTimeLine
Correction Message (M4)
M4
Correction Message (M4)
M4
M1 M7M4M3M2
RecvTime
ExecutionTimeLineM5 M6
Correction Message
M1 M7M6M4 M3M2
RecvTime
ExecutionTimeLineM5
Correction Message
Timestamps Correction

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Applications on the current system
• Using BG Charm++ • LeanMD:
– Research quality Molecular Dyanmics– Version 0: only electrostatics + van der Vaal
• Simple AMR kernel– Adaptive tree to generate millions of objects
• Each holding a 3D array– Communication with “neighbors”
• Tree makes it harder to find nbrs, but Charm makes it easy

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Emulator to Simulator
• Step 2: Add fine grained procesor simulation– Sarita Adve: RSIM based simulation of a node
• SMP node simulation: completed– Also: simulation of interconnection network– Millions of thread units/caches to simulate in detail?
• Step 3: Hybrid simulation– Instead: use detailed simulation to build model– Drive coarse simulation using model behavior– Further help from compiler and RTS

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Modeling layers
Applications
Libraries/RTS
Chip Architecture Network model
For each: need a detailed simulation and a simpler
(e.g. table-driven) “model”
And methods for combining
them

NGS/IBM: April2002 PPL-Dept of Computer Science, UIUC
Summary
• Charm++ (data-driven migratable objects)– is a well-matched candidate programming model for
M-PIMs• We have developed an Emulator/Simulator
– For BG/C– Runs on parallel machines
• We have Implemented multi-million object applications using Charm++– And tested on emulated Blue Gene/C
• More info: http://charm.cs.uiuc.edu– Emulator is available for download, along with Charm