
New Quasi-Newton Methods for Efficient Large-Scale …vishy/talks/LBFGS.pdf · New Quasi-Newton...
83
New Quasi-Newton Methods for Efficient Large-Scale Machine Learning S.V . N. Vishwanathan Joint work with Nic Schraudolph, Simon Günter, Jin Yu, Peter Sunehag, and Jochen Trumpf National ICT Australia and Australian National University [email protected] December 8, 2007 S.V . N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 1 / 21
Transcript of New Quasi-Newton Methods for Efficient Large-Scale …vishy/talks/LBFGS.pdf · New Quasi-Newton...

New Quasi-Newton Methods for EfficientLarge-Scale Machine Learning
S.V.N. VishwanathanJoint work with Nic Schraudolph, Simon Günter,
Jin Yu, Peter Sunehag, and Jochen Trumpf
National ICT Australia and Australian National [email protected]
December 8, 2007
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 1 / 21

Broyden, Fletcher, Goldfarb, Shanno
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 2 / 21

Standard BFGS - I
Locally Quadratic Model
mt(θ) = f (θt) +∇f (θt)>(θ − θt) +
12(θ − θt)
>Ht(θ − θt)
Ht is an n × n estimate of the Hessian
Parameter Update
θt+1 = θt − ηtBt∇f (θt)
Bt ≈ H−1t is a symmetric PSD matrix
ηt is a step size usually found via a line search
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 3 / 21

Standard BFGS - I
Locally Quadratic Model
θt+1 = argminθ
f (θt) +∇f (θt)>(θ − θt) +
12(θ − θt)
>Ht(θ − θt)
Ht is an n × n estimate of the Hessian
Parameter Update
θt+1 = θt − ηtBt∇f (θt)
Bt ≈ H−1t is a symmetric PSD matrix
ηt is a step size usually found via a line search
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 3 / 21

Standard BFGS - I
Locally Quadratic Model
θt+1 = argminθ
f (θt) +∇f (θt)>(θ − θt) +
12(θ − θt)
>Ht(θ − θt)
Ht is an n × n estimate of the Hessian
Parameter Update
θt+1 = θt − ηtBt∇f (θt)
Bt ≈ H−1t is a symmetric PSD matrix
ηt is a step size usually found via a line search
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 3 / 21

Standard BFGS - II
B Matrix Update
Update B ≈ H−1 by
Bt+1 = argminB||B − Bt ||w s.t. st = Byt
yt = ∇f (θt+1)−∇f (θt) is the difference of gradientsst = θt+1 − θt is the difference in parametersThis yields the update formula
Bt+1 =
(I −
sty>ts>t yt
)Bt
(I −
yts>ts>t yt
)+
sts>ts>t yt
Limited memory variant: use a low-rank approximation to B
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 4 / 21

Standard BFGS - II
B Matrix Update
Update B ≈ H−1 by
Bt+1 = argminB||B − Bt ||w s.t. st = Byt
yt = ∇f (θt+1)−∇f (θt) is the difference of gradientsst = θt+1 − θt is the difference in parametersThis yields the update formula
Bt+1 =
(I −
sty>ts>t yt
)Bt
(I −
yts>ts>t yt
)+
sts>ts>t yt
Limited memory variant: use a low-rank approximation to B
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 4 / 21

Standard BFGS - II
B Matrix Update
Update B ≈ H−1 by
Bt+1 = argminB||B − Bt ||w s.t. st = Byt
yt = ∇f (θt+1)−∇f (θt) is the difference of gradientsst = θt+1 − θt is the difference in parametersThis yields the update formula
Bt+1 =
(I −
sty>ts>t yt
)Bt
(I −
yts>ts>t yt
)+
sts>ts>t yt
Limited memory variant: use a low-rank approximation to B
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 4 / 21

Standard BFGS - II
B Matrix Update
Update B ≈ H−1 by
Bt+1 = argminB||B − Bt ||w s.t. st = Byt
yt = ∇f (θt+1)−∇f (θt) is the difference of gradientsst = θt+1 − θt is the difference in parametersThis yields the update formula
Bt+1 =
(I −
sty>ts>t yt
)Bt
(I −
yts>ts>t yt
)+
sts>ts>t yt
Limited memory variant: use a low-rank approximation to B
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 4 / 21

The Underlying Assumptions
Objective function is strictly convexObjectives from energy minimization methods are non-convex
Objective function is smoothRegularized risk minimization with hinge loss is not smooth
Batch gradientsProhibitively expensive on large datasets
Finite-dimensional parameter vectorKernel algorithms work in (potentially) infinite-dimensional RKHS
Aim of this Talk: Systematically relax these assumptions
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 5 / 21

The Underlying Assumptions
Objective function is strictly convexObjectives from energy minimization methods are non-convex
Objective function is smoothRegularized risk minimization with hinge loss is not smooth
Batch gradientsProhibitively expensive on large datasets
Finite-dimensional parameter vectorKernel algorithms work in (potentially) infinite-dimensional RKHS
Aim of this Talk: Systematically relax these assumptions
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 5 / 21

The Underlying Assumptions
Objective function is strictly convexObjectives from energy minimization methods are non-convex
Objective function is smoothRegularized risk minimization with hinge loss is not smooth
Batch gradientsProhibitively expensive on large datasets
Finite-dimensional parameter vectorKernel algorithms work in (potentially) infinite-dimensional RKHS
Aim of this Talk: Systematically relax these assumptions
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 5 / 21

The Underlying Assumptions
Objective function is strictly convexObjectives from energy minimization methods are non-convex
Objective function is smoothRegularized risk minimization with hinge loss is not smooth
Batch gradientsProhibitively expensive on large datasets
Finite-dimensional parameter vectorKernel algorithms work in (potentially) infinite-dimensional RKHS
Aim of this Talk: Systematically relax these assumptions
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 5 / 21

The Underlying Assumptions
Objective function is strictly convexObjectives from energy minimization methods are non-convex
Objective function is smoothRegularized risk minimization with hinge loss is not smooth
Batch gradientsProhibitively expensive on large datasets
Finite-dimensional parameter vectorKernel algorithms work in (potentially) infinite-dimensional RKHS
Aim of this Talk: Systematically relax these assumptions
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 5 / 21

The Underlying Assumptions
Objective function is strictly convexObjectives from energy minimization methods are non-convex
Objective function is smoothRegularized risk minimization with hinge loss is not smooth
Batch gradientsProhibitively expensive on large datasets
Finite-dimensional parameter vectorKernel algorithms work in (potentially) infinite-dimensional RKHS
Aim of this Talk: Systematically relax these assumptions
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 5 / 21

The Underlying Assumptions
Objective function is strictly convexObjectives from energy minimization methods are non-convex
Objective function is smoothRegularized risk minimization with hinge loss is not smooth
Batch gradientsProhibitively expensive on large datasets
Finite-dimensional parameter vectorKernel algorithms work in (potentially) infinite-dimensional RKHS
Aim of this Talk: Systematically relax these assumptions
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 5 / 21

The Underlying Assumptions
Objective function is strictly convexObjectives from energy minimization methods are non-convex
Objective function is smoothRegularized risk minimization with hinge loss is not smooth
Batch gradientsProhibitively expensive on large datasets
Finite-dimensional parameter vectorKernel algorithms work in (potentially) infinite-dimensional RKHS
Aim of this Talk: Systematically relax these assumptions
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 5 / 21

The Underlying Assumptions
Objective function is strictly convexObjectives from energy minimization methods are non-convex
Objective function is smoothRegularized risk minimization with hinge loss is not smooth
Batch gradientsProhibitively expensive on large datasets
Finite-dimensional parameter vectorKernel algorithms work in (potentially) infinite-dimensional RKHS
Aim of this Talk: Systematically relax these assumptions
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 5 / 21

Relaxing Strict Convexity
The ProblemIf obj. is not strictly convex then the Hessian has zero eigenvaluesThis can blow up our estimate B ≈ H−1
The BFGS InvariantThe BFGS update maintains the secant equation
Ht+1st = yt
B Matrix Update
Update B ≈ (H + ρI)−1 by
Bt+1 = argminB||B − Bt ||w s.t. st = Byt
yt = ∇f (θt+1)−∇f (θt) + ρst and st = θt+1 − θt .
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 6 / 21

Relaxing Strict Convexity
The ProblemIf obj. is not strictly convex then the Hessian has zero eigenvaluesThis can blow up our estimate B ≈ H−1
The BFGS InvariantThe BFGS update maintains the secant equation
Ht+1st = yt
B Matrix Update
Update B ≈ (H + ρI)−1 by
Bt+1 = argminB||B − Bt ||w s.t. st = Byt
yt = ∇f (θt+1)−∇f (θt) + ρst and st = θt+1 − θt .
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 6 / 21

Relaxing Strict Convexity
The ProblemIf obj. is not strictly convex then the Hessian has zero eigenvaluesThis can blow up our estimate B ≈ H−1
Trust Region InvariantInstead maintain the modified secant equation
(Ht+1 + ρI)st = yt
B Matrix Update
Update B ≈ (H + ρI)−1 by
Bt+1 = argminB||B − Bt ||w s.t. st = Byt
yt = ∇f (θt+1)−∇f (θt) + ρst and st = θt+1 − θt .
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 6 / 21

Relaxing Strict Convexity
The ProblemIf obj. is not strictly convex then the Hessian has zero eigenvaluesThis can blow up our estimate B ≈ H−1
Trust Region InvariantInstead maintain the modified secant equation
(Ht+1 + ρI)st = yt
B Matrix Update
Update B ≈ (H + ρI)−1 by
Bt+1 = argminB||B − Bt ||w s.t. st = Byt
yt = ∇f (θt+1)−∇f (θt) + ρst and st = θt+1 − θt .
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 6 / 21

Relaxing Convexity
The Problem
obj. not convex⇒ H has neg. eigenvalues⇒ B ≈ H−1 not PSD
Trust Region Approach
Work with B ≈ (Ht+1 + ρI)−1
Problem: may need large ρ to make B PSD, distorts curvature
Ad-Hoc Solution
Rectify curvature measurements: use |s>t yt | in update of B
PSD ApproximationsUse yt := Gtst , where Gt is a PSD curvature measure
extended Gauss-Newton approximationNatural gradient approximation (Fisher information matrix)
Efficient implementation by automatic differentiation
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 7 / 21

Relaxing Convexity
The Problem
obj. not convex⇒ H has neg. eigenvalues⇒ B ≈ H−1 not PSD
Trust Region Approach
Work with B ≈ (Ht+1 + ρI)−1
Problem: may need large ρ to make B PSD, distorts curvature
Ad-Hoc Solution
Rectify curvature measurements: use |s>t yt | in update of B
PSD ApproximationsUse yt := Gtst , where Gt is a PSD curvature measure
extended Gauss-Newton approximationNatural gradient approximation (Fisher information matrix)
Efficient implementation by automatic differentiation
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 7 / 21

Relaxing Convexity
The Problem
obj. not convex⇒ H has neg. eigenvalues⇒ B ≈ H−1 not PSD
Trust Region Approach
Work with B ≈ (Ht+1 + ρI)−1
Problem: may need large ρ to make B PSD, distorts curvature
Ad-Hoc Solution
Rectify curvature measurements: use |s>t yt | in update of B
PSD ApproximationsUse yt := Gtst , where Gt is a PSD curvature measure
extended Gauss-Newton approximationNatural gradient approximation (Fisher information matrix)
Efficient implementation by automatic differentiation
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 7 / 21

Relaxing Convexity
The Problem
obj. not convex⇒ H has neg. eigenvalues⇒ B ≈ H−1 not PSD
Trust Region Approach
Work with B ≈ (Ht+1 + ρI)−1
Problem: may need large ρ to make B PSD, distorts curvature
Ad-Hoc Solution
Rectify curvature measurements: use |s>t yt | in update of B
PSD ApproximationsUse yt := Gtst , where Gt is a PSD curvature measure
extended Gauss-Newton approximationNatural gradient approximation (Fisher information matrix)
Efficient implementation by automatic differentiation
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 7 / 21

Non-Smooth Functions
Subgradient and Subdifferentialµ is called a subgradient of f at w if, and only if,
f (w ′) ≥ f (w) +⟨w ′ − w , µ
⟩∀w ′.
The set of all subgradients, denoted ∂f (w), is the subdifferential
The Good, the Bad, and the UglyThe subdifferential is a convex set
Not every subgradient is a descent direction!
d is a descent direction if, and only if, d>µ < 0 for all µ ∈ ∂f (w)
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 8 / 21

Non-Smooth Functions
Subgradient and Subdifferentialµ is called a subgradient of f at w if, and only if,
f (w ′) ≥ f (w) +⟨w ′ − w , µ
⟩∀w ′.
The set of all subgradients, denoted ∂f (w), is the subdifferential
The Good, the Bad, and the UglyThe subdifferential is a convex set
Not every subgradient is a descent direction!
d is a descent direction if, and only if, d>µ < 0 for all µ ∈ ∂f (w)
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 8 / 21

Non-Smooth Functions
Subgradient and Subdifferentialµ is called a subgradient of f at w if, and only if,
f (w ′) ≥ f (w) +⟨w ′ − w , µ
⟩∀w ′.
The set of all subgradients, denoted ∂f (w), is the subdifferential
The Good, the Bad, and the UglyThe subdifferential is a convex set
Not every subgradient is a descent direction!
d is a descent direction if, and only if, d>µ < 0 for all µ ∈ ∂f (w)
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 8 / 21

Non-Smooth Functions
Subgradient and Subdifferentialµ is called a subgradient of f at w if, and only if,
f (w ′) ≥ f (w) +⟨w ′ − w , µ
⟩∀w ′.
The set of all subgradients, denoted ∂f (w), is the subdifferential
The Good, the Bad, and the UglyThe subdifferential is a convex set
Not every subgradient is a descent direction!
d is a descent direction if, and only if, d>µ < 0 for all µ ∈ ∂f (w)
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 8 / 21

Non-Smooth Functions
Subgradient and Subdifferentialµ is called a subgradient of f at w if, and only if,
f (w ′) ≥ f (w) +⟨w ′ − w , µ
⟩∀w ′.
The set of all subgradients, denoted ∂f (w), is the subdifferential
The Good, the Bad, and the UglyThe subdifferential is a convex set
Not every subgradient is a descent direction!
d is a descent direction if, and only if, d>µ < 0 for all µ ∈ ∂f (w)
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 8 / 21

Changing the Model
Locally Quadratic Model
mt(θ) = f (θt) +∇f (θt)>(θ − θt) +
12(θ − θt)
>Ht(θ − θt)
Parameter Update
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 9 / 21

Changing the Model
Locally (pseudo) Quadratic Model
mt(θ) = supµ∈∂f{f (θt) + µ>(θ − θt) +
12(θ − θt)
>Ht(θ − θt)}
Parameter Update
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 9 / 21

Changing the Model
Locally (pseudo) Quadratic Model
θt+1 = argminθ
supµ∈∂f{f (θt) + µ>(θ − θt) +
12(θ − θt)
>Ht(θ − θt)}
Parameter Update
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 9 / 21

Changing the Model
Locally (pseudo) Quadratic Model
θt+1 = argminθ
12(θ − θt)
>Ht(θ − θt) + ξ
s.t. f (θt) + µ>(θ − θt) ≤ ξ for all µ ∈ ∂f
Parameter Update
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 9 / 21

Changing the Model
Locally (pseudo) Quadratic Model
θkt+1 = argmin
θ
12(θ − θt)
>Ht(θ − θt) + ξ
s.t. f (θt) + µ>i (θ − θt) ≤ ξ for µ1 . . . µk ∈ ∂f
Parameter Update
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 9 / 21

Changing the Model
Locally (pseudo) Quadratic Model
Jk (d) = mind
12
d>Htd + ξ
s.t. f (θt) + µ>i d ≤ ξ for µ1 . . . µk ∈ ∂f
Parameter Update
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 9 / 21

Changing the Model
Locally (pseudo) Quadratic Model
Jk (d) = mind
12
d>Htd + ξ
s.t. f (θt) + µ>i d ≤ ξ for µ1 . . . µk ∈ ∂f
Parameter Update
θt+1 = θt − ηtBt∇f (θt)
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 9 / 21

Changing the Model
Locally (pseudo) Quadratic Model
Jk (d) = mind
12
d>Htd + ξ
s.t. f (θt) + µ>i d ≤ ξ for µ1 . . . µk ∈ ∂f
Parameter UpdateDESCENT DIRECTION BY COLUMN GENERATION(maxitr)1 k ← 1,d1 ← −Btµ1 for some arbitrary µ1 ∈ ∂f2 repeat3 µk = argsupµ∈∂f d>k µ4 if d>k µk < 0 return dk5 dk+1 = argmind Jk (d), k ← k + 16 until k ≥ maxitr
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 9 / 21

Changing the Model
Locally (pseudo) Quadratic Model
Jk (d) = mind
12
d>Htd + ξ
s.t. f (θt) + µ>i d ≤ ξ for µ1 . . . µk ∈ ∂f
Parameter UpdateDESCENT DIRECTION BY COLUMN GENERATION(maxitr)1 k ← 1,d1 ← −Btµ1 for some arbitrary µ1 ∈ ∂f2 repeat3 µk = argsupµ∈∂f d>k µ4 if d>k µk ≤ 0 return dk5 dk+1 = αdk + (1− α)(−Btµk ), k ← k + 1 Line Search in α6 until k ≥ maxitr
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 9 / 21

Changing the Model
Locally (pseudo) Quadratic Model
Jk (d) = mind
12
d>Htd + ξ
s.t. f (θt) + µ>i d ≤ ξ for µ1 . . . µk ∈ ∂f
Parameter Update
O(1/ε) rates of convergence!
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 9 / 21

Generalized Wolfe Conditions
Line SearchA BFGS line search has to satisfy the Wolfe conditions:
f (θt + ηtdt) ≤ f (θt) + c1ηt∇f (θt)>dt
∇f (θt + ηtdt)>dt ≥ c2∇f (θt)
>dt ,
where 0 < c1 < c2 < 1.
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 10 / 21

Generalized Wolfe Conditions
Line SearchFor non-smooth functions the Wolfe conditions are generalized to:
f (θt + ηtdt) ≤ f (θt) + c1ηt infµ∈∂f (θt )
(µ>dt
)
infµ′∈∂f (θt+ηt dt )
(µ′>dt
)≥ c2 sup
µ∈∂f (θt )
(µ>dt
),
where 0 < c1 < c2 < 1.
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 10 / 21

Working with the Hinge Loss
Hinge LossRegularized risk minimization with the hinge loss
f (θ) :=λ
2||θ||2 +
1n
n∑i=1
max(0,1− yi 〈θ, xi〉)
Exact Line SearchThe objective function is piecewise quadratic in any searchdirection dThis allows us to do an exact line search
Descent Direction
µk = argsupµ∈∂f d>k µ is easy to compute
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 11 / 21

Working with the Hinge Loss
Hinge LossRegularized risk minimization with the hinge loss
f (θ) :=λ
2||θ||2 +
1n
n∑i=1
max(0,1− yi 〈θ, xi〉)
Exact Line SearchThe objective function is piecewise quadratic in any searchdirection dThis allows us to do an exact line search
Descent Direction
µk = argsupµ∈∂f d>k µ is easy to compute
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 11 / 21

Working with the Hinge Loss
Hinge LossRegularized risk minimization with the hinge loss
f (θ) :=λ
2||θ||2 +
1n
n∑i=1
max(0,1− yi 〈θ, xi〉)
Exact Line SearchThe objective function is piecewise quadratic in any searchdirection dThis allows us to do an exact line search
Descent Direction
µk = argsupµ∈∂f d>k µ is easy to compute
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 11 / 21

subBFGS: Results on a Simple Problem
The Problem
f (x , y) = 100 ∗ |x |+ |y |
Particularly evil problem for BFGS!
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 12 / 21
subBFGS: Results on a Simple Problem
The Problem
f (x , y) = 100 ∗ |x |+ |y |
Particularly evil problem for BFGS!
BFGS
-1.0 -0.5 0.0 0.5 1.0x
0.0
0.2
0.4
0.6
0.8
1.0
y
-1 0 10.90
0.95
1.00
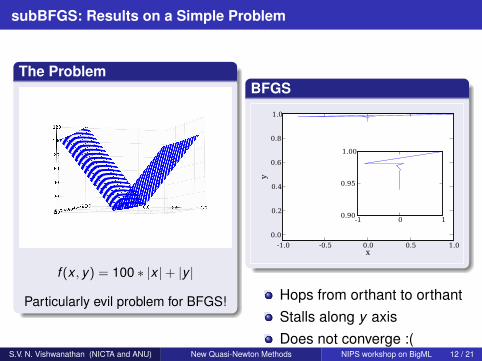
Hops from orthant to orthantStalls along y axisDoes not converge :(
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 12 / 21
subBFGS: Results on a Simple Problem
The Problem
f (x , y) = 100 ∗ |x |+ |y |
Particularly evil problem for BFGS!
BFGS’
-1.0 -0.5 0.0 0.5 1.0x
0.0
0.2
0.4
0.6
0.8
y
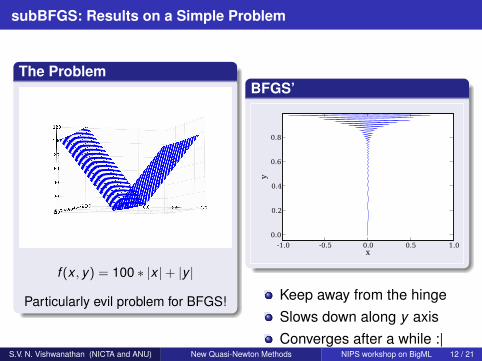
Keep away from the hingeSlows down along y axisConverges after a while :|
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 12 / 21

subBFGS: Results on a Simple Problem
The Problem
f (x , y) = 100 ∗ |x |+ |y |
Particularly evil problem for BFGS!
subBFGS
-1.0 -0.5 0.0 0.5 1.0x
0.0
0.2
0.4
0.6
0.8
1.0
y
Exact line searchConverges in 2 iterations :)
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 12 / 21
subBFGS: Results on a Simple Problem
The Problem
f (x , y) = 100 ∗ |x |+ |y |
Particularly evil problem for BFGS!
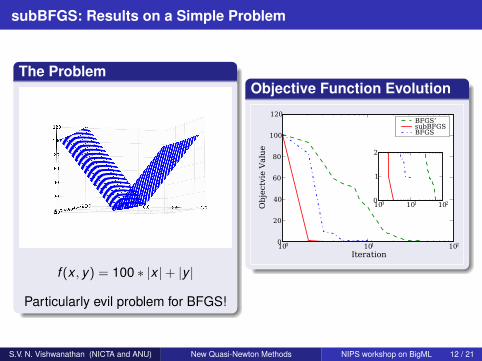
Objective Function Evolution
100 101 102
Iteration
0
20
40
60
80
100
120
Ob
jectv
ie V
alu
e
BFGS’subBFGSBFGS
100 101 1020
1
2
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 12 / 21

subBFGS: Results on Reuters
781,265 Examples 47,236 Dimensions λ = 10−6
Function Evaluations CPU time
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 13 / 21

subBFGS: Results on Reuters
781,265 Examples 47,236 Dimensions λ = 10−5
Function Evaluations CPU time
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 13 / 21
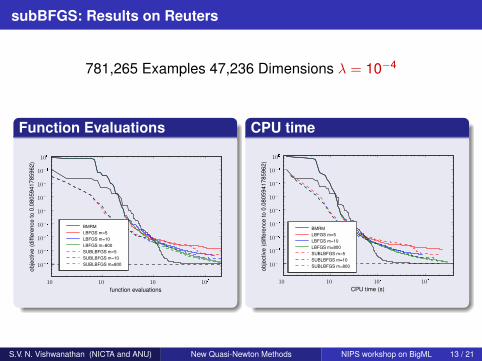
subBFGS: Results on Reuters
781,265 Examples 47,236 Dimensions λ = 10−4
Function Evaluations CPU time
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 13 / 21
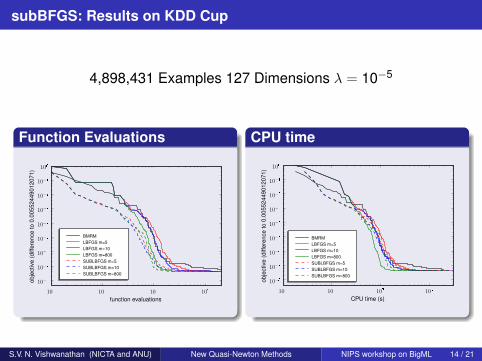
subBFGS: Results on KDD Cup
4,898,431 Examples 127 Dimensions λ = 10−5
Function Evaluations CPU time
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 14 / 21

subBFGS: Results on AstroPh
62,369 Examples 99,757 Dimensions λ = 10−7
Function Evaluations CPU time
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 15 / 21

Let’s Make Things Online
Parameter Update
θt+1 = θt − ηtBt∇f (θt)
B Matrix Update
Update formula
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 16 / 21

Let’s Make Things Online
Parameter Update
θt+1 = θt − ηtBt∇f (θt , xt)
B Matrix Update
Update formula
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 16 / 21
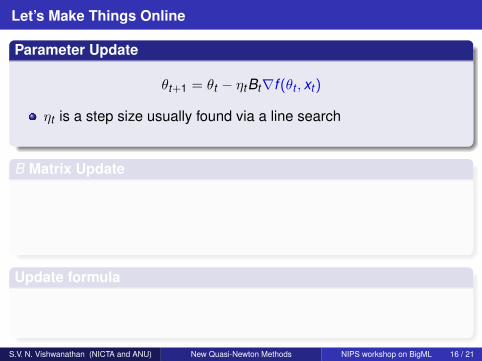
Let’s Make Things Online
Parameter Update
θt+1 = θt − ηtBt∇f (θt , xt)
ηt is a step size usually found via a line search
B Matrix Update
Update formula
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 16 / 21

Let’s Make Things Online
Parameter Update
θt+1 = θt − ηtBt∇f (θt , xt)
Replace line search with a gain schedule ηt = ττ+t η0
or online gain adaptation by stochastic meta-descent (SMD)
B Matrix Update
Update formula
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 16 / 21

Let’s Make Things Online
Parameter Update
θt+1 = θt − ηtBt∇f (θt , xt)
Replace line search with a gain schedule ηt = ττ+t η0
or online gain adaptation by stochastic meta-descent (SMD)
B Matrix Update
Update B ≈ H−1 by
Bt+1 = argmin ||B − Bt ||w s.t. st = Byt
yt := ∇f (θt+1)−∇f (θt), st := θt+1 − θt
Update formula
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 16 / 21

Let’s Make Things Online
Parameter Update
θt+1 = θt − ηtBt∇f (θt , xt)
Replace line search with a gain schedule ηt = ττ+t η0
or online gain adaptation by stochastic meta-descent (SMD)
B Matrix Update
Update B ≈ H−1 by
Bt+1 = argmin ||B − Bt ||w s.t. st = Byt
yt := ∇f (θt+1, xt+1)−∇f (θt , xt), st := θt+1 − θt
Update formula
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 16 / 21

Let’s Make Things Online
Parameter Update
θt+1 = θt − ηtBt∇f (θt , xt)
Replace line search with a gain schedule ηt = ττ+t η0
or online gain adaptation by stochastic meta-descent (SMD)
B Matrix Update
Update B ≈ H−1 by
Bt+1 = argmin ||B − Bt ||w s.t. st = Byt
yt := ∇f (θt+1, xt)−∇f (θt , xt), st := θt+1 − θt
Update formula
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 16 / 21

Let’s Make Things Online
Parameter Update
θt+1 = θt − ηtBt∇f (θt , xt)
Replace line search with a gain schedule ηt = ττ+t η0
or online gain adaptation by stochastic meta-descent (SMD)
B Matrix Update
Update B ≈ (H + ρI)−1 by
Bt+1 = argmin ||B − Bt ||w s.t. st = Byt
yt := ∇f (θt+1, xt)−∇f (θt , xt), st := θt+1 − θt
Update formula
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 16 / 21

Let’s Make Things Online
Parameter Update
θt+1 = θt − ηtBt∇f (θt , xt)
Replace line search with a gain schedule ηt = ττ+t η0
or online gain adaptation by stochastic meta-descent (SMD)
B Matrix Update
Update B ≈ (H + ρI)−1 by
Bt+1 = argmin ||B − Bt ||w s.t. st = Byt
yt := ∇f (θt+1, xt)−∇f (θt , xt) + ρst , st := θt+1 − θt
Update formula
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 16 / 21

Let’s Make Things Online
Parameter Update
θt+1 = θt − ηtBt∇f (θt , xt)
Replace line search with a gain schedule ηt = ττ+t η0
or online gain adaptation by stochastic meta-descent (SMD)
B Matrix Update
Update B ≈ (H + ρI)−1 by
Bt+1 = argmin ||B − Bt ||w s.t. st = Byt
yt := ∇f (θt+1, xt)−∇f (θt , xt) + ρst , st := θt+1 − θt
Update formula
Bt+1 =
(I −
sty>ts>t yt
)Bt
(I −
yts>ts>t yt
)+
sts>ts>t yt
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 16 / 21

Let’s Make Things Online
Parameter Update
θt+1 = θt −ηt
cBt∇f (θt , xt)
Replace line search with a gain schedule ηt = ττ+t η0
or online gain adaptation by stochastic meta-descent (SMD)
B Matrix Update
Update B ≈ (H + ρI)−1 by
Bt+1 = argmin ||B − Bt ||w s.t. st = Byt
yt := ∇f (θt+1, xt)−∇f (θt , xt) + ρst , st := θt+1 − θt
Update formula
Bt+1 =
(I −
sty>ts>t yt
)Bt
(I −
yts>ts>t yt
)+ c
sts>ts>t yt
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 16 / 21

Online BFGS (oBFGS)
Parameter Update
θt+1 = θt −ηt
cBt∇f (θt , xt)
Replace line search with a gain schedule ηt = ττ+t η0
or online gain adaptation by stochastic meta-descent (SMD)
B Matrix Update
Update B ≈ (H + ρI)−1 by
Bt+1 = argmin ||B − Bt ||w s.t. st = Byt
yt := ∇f (θt+1, xt)−∇f (θt , xt) + ρst , st := θt+1 − θt
Update formula
Bt+1 =
(I −
sty>ts>t yt
)Bt
(I −
yts>ts>t yt
)+ c
sts>ts>t yt
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 16 / 21

o(L)BFGS: Results for CRFs and SVMs
Conditional Random Fields
CoNLL-2000 Base NPChunking task
high-dim., smooth, convex
asymptotically ill-conditioned(approaches hinge loss)
Support Vector Machines
KDDCUP-99 intrusiondetection task
SVM training in the primal:convex but not smooth (hinges)
large data set: 4.9 · 106 points
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 17 / 21
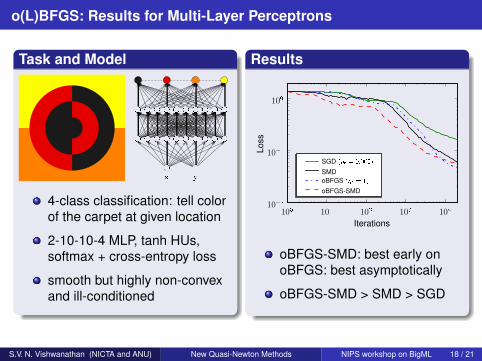
o(L)BFGS: Results for Multi-Layer Perceptrons
Task and Model
OO >>|||||||||||
66nnnnnnnnnnnnnnnnnn
44iiiiiiiiiiiiiiiiiiiiiiiiii UU++++++++
CC���������
88pppppppppppppppp
44jjjjjjjjjjjjjjjjjjjjjjjj [[777777777
II��������
::uuuuuuuuuuuuu
55kkkkkkkkkkkkkkkkkkkkk aaBBBBBBBBBBB
OO >>|||||||||||
66nnnnnnnnnnnnnnnnnn ddIIIIIIIIIIIII
UU++++++++
CC���������
88pppppppppppppppp ffNNNNNNNNNNNNNNNN
[[777777777
II��������
::uuuuuuuuuuuuu hhQQQQQQQQQQQQQQQQQQ
aaBBBBBBBBBBB
OO >>||||||||||| iiSSSSSSSSSSSSSSSSSSSSS
ddIIIIIIIIIIIII
UU++++++++
CC��������� jjTTTTTTTTTTTTTTTTTTTTTTTT
ffNNNNNNNNNNNNNNNN
[[777777777
II�������� jjUUUUUUUUUUUUUUUUUUUUUUUUUU
hhQQQQQQQQQQQQQQQQQQ
aaBBBBBBBBBBB
OO
OO II��������
CC���������
>>|||||||||||
::uuuuuuuuuuuuu
88pppppppppppppppp
66nnnnnnnnnnnnnnnnnn
55kkkkkkkkkkkkkkkkkkkkk
44jjjjjjjjjjjjjjjjjjjjjjjj
44iiiiiiiiiiiiiiiiiiiiiiiiii UU++++++++
OO II��������
CC���������
>>|||||||||||
::uuuuuuuuuuuuu
88pppppppppppppppp
66nnnnnnnnnnnnnnnnnn
55kkkkkkkkkkkkkkkkkkkkk
44jjjjjjjjjjjjjjjjjjjjjjjj [[777777777
UU++++++++
OO II��������
CC���������
>>|||||||||||
::uuuuuuuuuuuuu
88pppppppppppppppp
66nnnnnnnnnnnnnnnnnn
55kkkkkkkkkkkkkkkkkkkkk aaBBBBBBBBBBB
[[777777777
UU++++++++
OO II��������
CC���������
>>|||||||||||
::uuuuuuuuuuuuu
88pppppppppppppppp
66nnnnnnnnnnnnnnnnnn ddIIIIIIIIIIIII
aaBBBBBBBBBBB
[[777777777
UU++++++++
OO II��������
CC���������
>>|||||||||||
::uuuuuuuuuuuuu
88pppppppppppppppp ffNNNNNNNNNNNNNNNN
ddIIIIIIIIIIIII
aaBBBBBBBBBBB
[[777777777
UU++++++++
OO II��������
CC���������
>>|||||||||||
::uuuuuuuuuuuuu hhQQQQQQQQQQQQQQQQQQ
ffNNNNNNNNNNNNNNNN
ddIIIIIIIIIIIII
aaBBBBBBBBBBB
[[777777777
UU++++++++
OO II��������
CC���������
>>||||||||||| iiSSSSSSSSSSSSSSSSSSSSS
hhQQQQQQQQQQQQQQQQQQ
ffNNNNNNNNNNNNNNNN
ddIIIIIIIIIIIII
aaBBBBBBBBBBB
[[777777777
UU++++++++
OO II��������
CC��������� jjTTTTTTTTTTTTTTTTTTTTTTTT
iiSSSSSSSSSSSSSSSSSSSSS
hhQQQQQQQQQQQQQQQQQQ
ffNNNNNNNNNNNNNNNN
ddIIIIIIIIIIIII
aaBBBBBBBBBBB
[[777777777
UU++++++++
OO II�������� jjUUUUUUUUUUUUUUUUUUUUUUUUUU
jjTTTTTTTTTTTTTTTTTTTTTTTT
iiSSSSSSSSSSSSSSSSSSSSS
hhQQQQQQQQQQQQQQQQQQ
ffNNNNNNNNNNNNNNNN
ddIIIIIIIIIIIII
aaBBBBBBBBBBB
[[777777777
UU++++++++
OO
xaaBBBBBBBBBBB
[[777777777
UU++++++++
OO II��������
CC���������
>>|||||||||||
::uuuuuuuuuuuuu
88pppppppppppppppp
66nnnnnnnnnnnnnnnnnn yhhQQQQQQQQQQQQQQQQQQ
ffNNNNNNNNNNNNNNNN
ddIIIIIIIIIIIII
aaBBBBBBBBBBB
[[777777777
UU++++++++
OO II��������
CC���������
>>|||||||||||
4-class classification: tell colorof the carpet at given location
2-10-10-4 MLP, tanh HUs,softmax + cross-entropy loss
smooth but highly non-convexand ill-conditioned
Results
oBFGS-SMD: best early onoBFGS: best asymptotically
oBFGS-SMD > SMD > SGD
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 18 / 21

Let’s Lift into RKHS
LBFGSst = −ηt∇f (θt)
for i = 1, . . . , k :ai = ρt−i 〈st−i , st〉st = st − aiyt−i
st = stρt−1〈yt−1,yt−1〉
for i = k , . . . ,1:b = ρt−i 〈yt−i , st〉st = st + (ai − b)st−i
θt+1 = θt + st
yt = ∇f (θt+1)−∇f (θt)
ρt = 1〈st ,yt 〉
Maintain ring buffer of lastk values of vectors st , ytand scalar ρt
Key ObservationOnly inner products andlinear combinations usedCan be lifted to RKHS (H)
Cheap UpdatesEfficient linear-timeupdates are possible
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 19 / 21

Let’s Lift into RKHS
LBFGSst = −ηt∇f (θt)
for i = 1, . . . , k :ai = ρt−i 〈st−i , st〉st = st − aiyt−i
st = stρt−1〈yt−1,yt−1〉
for i = k , . . . ,1:b = ρt−i 〈yt−i , st〉st = st + (ai − b)st−i
θt+1 = θt + st
yt = ∇f (θt+1)−∇f (θt)
ρt = 1〈st ,yt 〉
Maintain ring buffer of lastk values of vectors st , ytand scalar ρt
Key ObservationOnly inner products andlinear combinations usedCan be lifted to RKHS (H)
Cheap UpdatesEfficient linear-timeupdates are possible
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 19 / 21

Let’s Lift into RKHS
LBFGSst = −ηt∇f (θt)
for i = 1, . . . , k :ai = ρt−i 〈st−i , st〉st = st − aiyt−i
st = stρt−1〈yt−1,yt−1〉
for i = k , . . . ,1:b = ρt−i 〈yt−i , st〉st = st + (ai − b)st−i
θt+1 = θt + st
yt = ∇f (θt+1)−∇f (θt)
ρt = 1〈st ,yt 〉
Maintain ring buffer of lastk values of vectors st , ytand scalar ρt
Key ObservationOnly inner products andlinear combinations usedCan be lifted to RKHS (H)
Cheap UpdatesEfficient linear-timeupdates are possible
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 19 / 21

Let’s Lift into RKHS
LBFGSst = −ηt∇f (θt)
for i = 1, . . . , k :ai = ρt−i 〈st−i , st〉st = st − aiyt−i
st = stρt−1〈yt−1,yt−1〉
for i = k , . . . ,1:b = ρt−i 〈yt−i , st〉st = st + (ai − b)st−i
θt+1 = θt + st
yt = ∇f (θt+1)−∇f (θt)
ρt = 1〈st ,yt 〉
Maintain ring buffer of lastk values of vectors st , ytand scalar ρt
Key ObservationOnly inner products andlinear combinations usedCan be lifted to RKHS (H)
Cheap UpdatesEfficient linear-timeupdates are possible
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 19 / 21

Let’s Lift into RKHS
LBFGSst = −ηt∇f (θt)
for i = 1, . . . , k :ai = ρt−i 〈st−i , st〉st = st − aiyt−i
st = stρt−1〈yt−1,yt−1〉
for i = k , . . . ,1:b = ρt−i 〈yt−i , st〉st = st + (ai − b)st−i
θt+1 = θt + st
yt = ∇f (θt+1)−∇f (θt)
ρt = 1〈st ,yt 〉
Maintain ring buffer of lastk values of vectors st , ytand scalar ρt
Key ObservationOnly inner products andlinear combinations usedCan be lifted to RKHS (H)
Cheap UpdatesEfficient linear-timeupdates are possible
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 19 / 21

Let’s Lift into RKHS
LBFGSst = −ηt∇f (θt)
for i = 1, . . . , k :ai = ρt−i 〈st−i , st〉st = st − aiyt−i
st = stρt−1〈yt−1,yt−1〉
for i = k , . . . ,1:b = ρt−i 〈yt−i , st〉st = st + (ai − b)st−i
θt+1 = θt + st
yt = ∇f (θt+1)−∇f (θt)
ρt = 1〈st ,yt 〉
Maintain ring buffer of lastk values of vectors st , ytand scalar ρt
Key ObservationOnly inner products andlinear combinations usedCan be lifted to RKHS (H)
Cheap UpdatesEfficient linear-timeupdates are possible
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 19 / 21

Let’s Lift into RKHS
LBFGSst = −ηt∇f (θt)
for i = 1, . . . , k :ai = ρt−i 〈st−i , st〉st = st − aiyt−i
st = stρt−1〈yt−1,yt−1〉
for i = k , . . . ,1:b = ρt−i 〈yt−i , st〉st = st + (ai − b)st−i
θt+1 = θt + st
yt = ∇f (θt+1)−∇f (θt)
ρt = 1〈st ,yt 〉
Maintain ring buffer of lastk values of vectors st , ytand scalar ρt
Key ObservationOnly inner products andlinear combinations usedCan be lifted to RKHS (H)
Cheap UpdatesEfficient linear-timeupdates are possible
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 19 / 21

Let’s Lift into RKHS
LBFGSst = −ηt∇f (θt)
for i = 1, . . . , k :ai = ρt−i 〈st−i , st〉st = st − aiyt−i
st = stρt−1〈yt−1,yt−1〉
for i = k , . . . ,1:b = ρt−i 〈yt−i , st〉st = st + (ai − b)st−i
θt+1 = θt + st
yt = ∇f (θt+1)−∇f (θt)
ρt = 1〈st ,yt 〉
Maintain ring buffer of lastk values of vectors st , ytand scalar ρt
Key ObservationOnly inner products andlinear combinations usedCan be lifted to RKHS (H)
Cheap UpdatesEfficient linear-timeupdates are possible
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 19 / 21

Let’s Lift into RKHS
LBFGS in RKHSst = −ηt∇f (θt)
for i = 1, . . . , k :ai = ρt−i 〈st−i , st〉Hst = st − aiyt−i
st = stρt−1〈yt−1,yt−1〉H
for i = k , . . . ,1:b = ρt−i 〈yt−i , st〉Hst = st + (ai − b)st−i
θt+1 = θt + st
yt = ∇f (θt+1)−∇f (θt)
ρt = 1〈st ,yt 〉H
Maintain ring buffer of lastk values of functions st , ytand scalar ρt
Key ObservationOnly inner products andlinear combinations usedCan be lifted to RKHS (H)
Cheap UpdatesEfficient linear-timeupdates are possible
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 19 / 21

Online Kernel LBFGS (okLBFGS)
Online LBFGS in RKHSst = −ηt∇f (θt , xt)
for i = 1, . . . , k :ai = ρt−i 〈st−i , st〉Hst = st − aiyt−i
st = stρt−1〈yt−1,yt−1〉H
for i = k , . . . ,1:b = ρt−i 〈yt−i , st〉Hst = st + (ai − b)st−i
θt+1 = θt + st
yt = ∇f (θt+1, xt)−∇f (θt , xt)
ρt = 1〈st ,yt 〉H
Maintain ring buffer of lastk values of functions st , ytand scalar ρt
Key ObservationOnly inner products andlinear combinations usedCan be lifted to RKHS (H)
Cheap UpdatesEfficient linear-timeupdates are possible
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 19 / 21

Online Kernel LBFGS (okLBFGS)
Online LBFGS in RKHSst = −ηt∇f (θt , xt)
for i = 1, . . . , k :ai = ρt−i 〈st−i , st〉Hst = st − aiyt−i
st = stρt−1〈yt−1,yt−1〉H
for i = k , . . . ,1:b = ρt−i 〈yt−i , st〉Hst = st + (ai − b)st−i
θt+1 = θt + st
yt = ∇f (θt+1, xt)−∇f (θt , xt)
ρt = 1〈st ,yt 〉H
Maintain ring buffer of lastk values of functions st , ytand scalar ρt
Key ObservationOnly inner products andlinear combinations usedCan be lifted to RKHS (H)
Cheap UpdatesEfficient linear-timeupdates are possible
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 19 / 21

okLBFGS: Results on MNIST
Standard
100 101 102 103 104 105
Iterations
0.00
0.05
0.10
0.15
0.20
Avera
ge E
rror
MVSenilnoDMVS
SGFBLkososageP
60 000 digits from MNIST,random presentation order
current average error duringfirst pass through the data
Counting Sequence
100 101 102 103 104 105
Iterations
0.00
0.05
0.10
0.15
0.20
0.25
0.30
Avera
ge E
rror
MVSenilno
DMVS
SGFBLko
digits rearranged into highlynon-stationary sequence:
. . .. . .
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 20 / 21

Conclusion
Systematically relaxed the underlying assumptions of BFGSExciting early results. Lots more to do.Open Problem: Can we extend subBFGS from hinge loss tostructured losses?
S.V. N. Vishwanathan (NICTA and ANU) New Quasi-Newton Methods NIPS workshop on BigML 21 / 21


















